



Introduction
Type 2 diabetes mellitus (T2DM) is a chronic metabolic disorder associated with numerous complications, which can affect multiple organ systems(Reference Papatheodorou, Banach and Bekiari1). T2DM is also recognised as a serious, worldwide public health concern and will continue to pose a major challenge for healthcare systems and the individual, since its prevalence is expected to almost double by 2030, mainly due to unhealthy lifestyles(Reference Forouhi and Wareham2). According to the International Diabetes Federation, there will be approximately 580 million people with T2DM by the year 2030(Reference Saeedi, Petersohn and Salpea3).
Researchers over the past decades have used a variety of techniques in order to build numerous predictive models for the risk of T2DM, mainly because the majority of T2DM cases occur years before the clinical diagnosis(Reference Fraser, Twombly and Zhu4) and also because T2DM is associated with multiple complications when left untreated. Most of these predictive models include socio-demographic, clinical and genetic data as the predictive variables, yielding high values of area under the receiver operating characteristic (ROC) curve (AUC) ranging from 0⋅60 to 0⋅91(Reference Noble, Mathur and Dent5). Moreover, over the past two decades, the issue of the importance of dietary habits in the prevention and management of T2DM has received considerable critical attention(Reference Ley, Hamdy and Mohan6), concluding that dietary changes, combined with lifestyle changes, can significantly reduce the incidence of T2DM(Reference Guess7). However, the literature to date has not focused on incorporating food intake variables in predictive models for the risk of T2DM, which may increase the accuracy of these models considerably.
We, therefore, developed a new predictive model of T2DM, including only food intake variables, using cross-sectional data from the Cooperative Health Research in the Region of Augsburg (KORA) FF4 study population. The major objective of the present study was to determine the performance measures of this model.
Methods
Study population
The KORA FF4 study (2013–14) is the second follow-up examination of the population-based KORA S4 health survey, conducted in the city of Augsburg and two surrounding counties in Southern Germany between 1999 and 2001. Of all 4261 individuals included in the S4 baseline study, 2279 individuals also participated in the KORA FF4 study. The participation rate for KORA FF4 has been described previously(Reference Kowall, Rathmann and Stang8). Of the total 2279 participants, 668 were excluded from the analyses due to missing dietary intake data, resulting in 1591 individuals with complete data (Fig. 1).

Fig. 1. Flow diagram of study participants and exclusions in the Cooperative Health Research in the Augsburg Region (KORA) FF4 study.
The present study was carried out according to the Declaration of Helsinki. All examinations were approved by the ethics committee of the Bavarian Chamber of Physicians, Munich. Written informed consent was obtained from all participants.
Assessment of habitual dietary intake
KORA FF4 dietary intake data was collected through one food frequency questionnaire (FFQ) and up to three 24-h food lists (24HFL). The FFQ was based on the German version of the multilingual European Food Propensity Questionnaire(Reference Illner, Harttig and Tognon9) and assessed how frequently and in what amount 148 food items were consumed over the previous 12 months. The 24HFL are structured questionnaires, which encompass more than 300 food items and are used to assess the type of food consumed during the last 24 h. Details regarding the 24HFL have been published elsewhere(Reference Freese, Feller and Harttig10). The participants in KORA FF4 were asked to complete the first 24HFL at the study centre and the other two at home, preferably web-based in order to attenuate the presence of incomplete data; otherwise, a paper questionnaire could be provided. Finally, dietary intake data were available for 1591 participants who completed at least one 24HFL and one FFQ.
The usual dietary intake of all food times was calculated using a two-step approach, based on a combination of the National Cancer Institute method(Reference Tooze, Kipnis and Buckman11) and the Multiple Source Method(Reference Haubrock, Nothlings and Volatier12). In the first step, the individuals’ consumption probability for each food item was calculated based on 24HFL dietary intake data, with logistic mixed models adjusted for age, sex, body mass index (BMI), physical activity, smoking, education and food consumption frequency calculated from the FFQ. In the second step, 24-h dietary recall data from the Bavarian Food Consumption Survey II(Reference Himmerich, Gedrich and Karg13) were analysed in order to calculate the consumption amount of each food item, since the 24HFL do not assess portion sizes. Mixed models containing the same covariates as in the first step were used, and the usual consumption amount of each food item was predicted from the β-estimates of these models. The product of the estimated consumption probability and estimated consumption amount of each food item provided the usual dietary intake of all food items on a consumption day. Finally, the dietary intake data were divided into sixteen food groups based on the European Prospective Investigation into Cancer and Nutrition Soft classification system(Reference Slimani, Deharveng and Charrondiere14). Data from the German Food Composition Database were used to estimate nutrient intakes (Bundeslebensmittelschlüssel BLS3.02). In total, 193 dietary intake variables were included in the analysis after the removal of the food variables that were registered as ‘other and unclassified’.
Ascertainment of T2DM, age and sex
In addition to the habitual food intake variables, age, sex, BMI and T2DM status were included in the analysis. T2DM was assessed through self-reports of the participants and also by the current use of antidiabetic medication, both of which were verified by the individuals’ treating physician. The age and sex of participants were assessed through questionnaires and a computer-assisted personal interview. The BMI of participants was calculated by trained staff performing anthropometric measurements of height and weight.
Statistical analysis
We compared the sixteen main groups of food intake variables among study participants with and without diabetes using percentage values for categorical variables and medians (25th and 75th percentile) for continuous variables.
We constructed a predictive model of T2DM status using the elastic net penalised multivariate regression method(Reference Zou and Hastie15), which combines the methods of lasso and ridge regression. We used the R package ‘glmnet’, where the elastic net algorithm is implemented in order to build our model(Reference Friedman, Hastie and Tibshirani16). This method is suitable for creating predictive models using datasets where collinear predictors are present, like in our case. The elastic net model requires two parameters (α and λ) to be specified and also needs its variables to be scaled. α indicates the ratio of the two penalties (L 1 and L 2), while λ is the shrinkage parameter. The optimal value of the λ parameter was selected using 5-fold cross-validation. After fitting the elastic net regression model in the training dataset, the model is fitted in the test dataset in order to calculate the performance of the model by the AUC. This process is repeated five times until every subset of the dataset has been a test dataset. In this way, the optimal value of λ, which produces the model with the highest AUC, can be calculated. Since a function to calculate the optimal value of the α parameter is not implemented in the ‘glmnet’ package, we calculated the optimal value of the λ parameter at six fixed different values of α: 0, 0⋅2, 0⋅4, 0⋅6, 0⋅8 and 1, respectively.
To identify the significant regression coefficients of the food intake variables, we used Bunea et al.'s approach(Reference Bunea, She and Ombao17), by implementing bootstrapping in our analysis. We created 5000 bootstrap samples, by sampling our dataset with replacement 5000 times. Then, we built a predictive model for each bootstrap sample, and hence, the percentage of times each predictor was non-zero was calculated, which is called the variable inclusion probability (VIP). We used the open-source R code that is annotated in the study of Abram et al. (Reference Abram, Helwig and Moodie18) in order to make the analysis and produce the graph with the selected variables at different thresholds of the VIP.
Finally, after selecting the food intake variables with standardised regression coefficients which were non-zero in more than 95 % of all bootstraps, we fitted a logistic regression model with these predictors and calculated its value of the AUC. We also calculated the values of specific performance measures of our model: sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV) and accuracy. P-values <0⋅05 were considered statistically significant. All analyses were carried out using the statistical software R (version 3.5.1, Foundation for Statistical Computing, Vienna, Austria).
Results
From a total number of 1591 participants, 139 (8⋅7 %) were diagnosed with T2DM. Individuals with T2DM were more likely to be older, to be male, to have higher BMI and to have a higher intake of potatoes and meat products and a lower intake of vegetables, pulse, dairy products, sweets and non-alcoholic drinks (Table 1).
Table 1. Characteristics of the study population by type 2 diabetes statusa
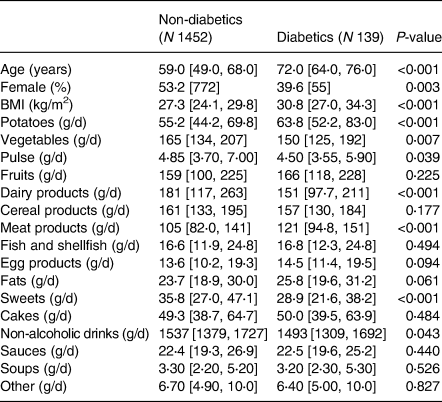
a Medians and 25th and 75th percentiles for continuous variables; percentages and counts for categorical variables.
Supplementary Fig. S1 of Supplementary material displays the boxplots of the 5000 calculated AUC values, derived from the 5-fold cross-validation procedure, for each α value. The mean values of the AUC values remain relatively stable across the six fixed α values, so we chose the lasso model which is the most parsimonious (α = 1). In Supplementary Fig. S2 of Supplementary material, significance thresholds are plotted, at which each of the 193 food intake variables is declared significant using the VIP approach. The grey bar of each predictor specifies the maximum value of the significance threshold that will result in the inclusion of each predictor in the final model. In simpler words, the grey bar indicates the percentage of non-zero coefficient values in the 5000 samples, for each predictor. It is also clear from the plot that when the elastic net model with α 0 is fitted (ridge regression), all the coefficients are present at every bootstrap sample, since ridge regression does not zero out any coefficients.
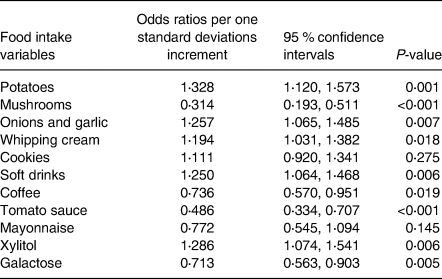
By applying the VIP threshold of 95 %, eleven food intake variables were selected. After fitting a logistic regression model with the selected variables, the AUC was 0⋅792 (95 % CI 0⋅756, 0⋅826) (Fig. 2), and the values of its performance measures at different sensitivity thresholds are listed in Table 2. The variables, which had the strongest positive effect on the odds of having T2DM, were potatoes, xylitol, onions and garlic, and soft drinks, while the strongest negative effect was exerted from tomato sauce and mushrooms. Specifically, one standard deviation increases in potatoes, xylitol, onions and garlic, and soft drinks were related with 32⋅8 % (95 % CI 12⋅0 %, 57⋅3 %), 28⋅6 % (95 % CI 7⋅4 %, 54⋅1 %), 25⋅7 % (95 % CI 6⋅5 %, 48⋅5 %) and 25⋅0 % (95 % CI 6⋅4 %, 46⋅8 %), respectively, higher odds of T2DM, whereas one standard deviation increases in tomato sauce and mushrooms were related with 51⋅4 % (95 % CI 29⋅3 %, 66⋅6 %) and 68⋅6 % (95 % CI 48⋅9 %, 80⋅7 %), respectively, lower odds of T2DM.
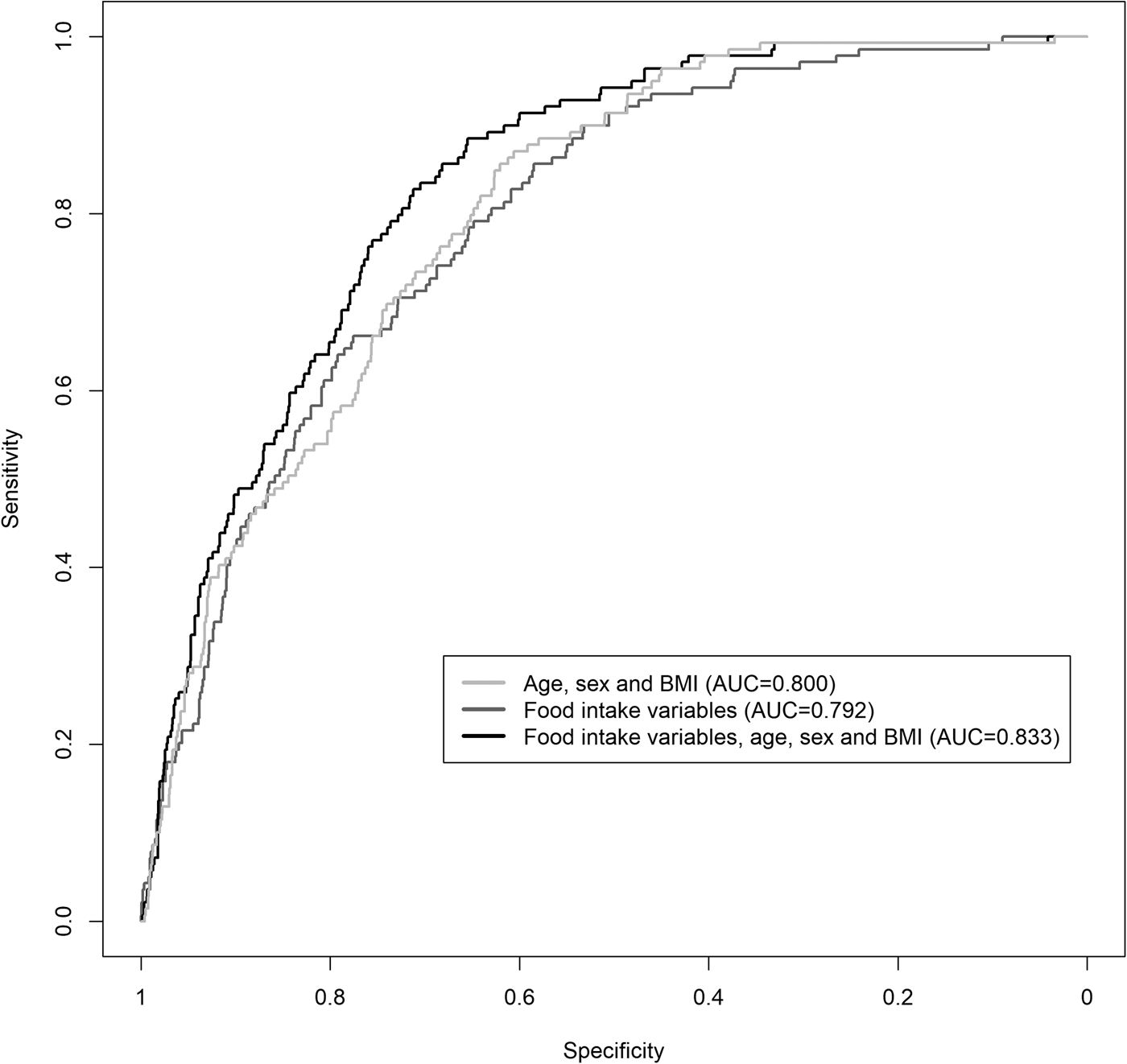
Fig. 2. ROC curves of the predictive logistic regression models of T2DM using food intake variables, age, sex and BMI. AUC: area under the ROC curve; T2DM, type 2 diabetes mellitus.
Table 2. Performance measures of the predictive model for the risk of type 2 diabetes at different sensitivity thresholdsa
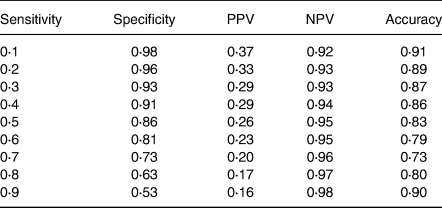
a Only food intake variables are included in the model as predictive variables.
NPV, negative predictive value; PPV, positive predictive value.
By adding age, sex and BMI together with the food intake variables in our predictive model, the AUC increased slightly to 0⋅833 (95 % CI 0⋅801, 0⋅862) (Fig. 2). The odds ratio per one standard deviation increment for the selected food intake variables with their corresponding 95 % CI is shown in Table 3.
Table 3. Results of the multivariate logistic regression analysis with the selected food intake variables as predictors of type 2 diabetes
Discussion
The present study was set out with the aim of assessing the importance of nutrition data in predictive modelling for the risk of T2DM. Thus, we incorporated various food variables in a predictive model for T2DM and calculated its performance measures. In our analysis, using the population-based cross-sectional data from the KORA FF4 study, we built a predictive model for the risk of T2DM, which yielded an AUC of 0⋅792.
A considerable amount of literature has been published on prediction models for T2DM. There was an exponential upward trend in the number of studies introducing new prediction models from 2006 and onwards(Reference Noble, Mathur and Dent5), providing good estimates on the risk of having or developing T2DM in the future. A wide set of techniques was used in order to build these models, including also in the last years’ methods developed from the computer science field, like neural networks(Reference Jahani and Mahdavi19), which have been shown to increase the prediction accuracy of these models. Moreover, all these predictive models presented in the current literature were based on socio-demographic, clinical and/or genetic data, with the latter influencing slightly the performance of the models(Reference Noble, Mathur and Dent5,Reference Collins, Mallett and Omar20) . The most commonly used predictors for the risk of T2DM are age, family history of diabetes, BMI, hypertension, waist circumference, sex, ethnicity and smoking status(Reference Collins, Mallett and Omar20).
Despite the constant increase in developing new predictive models for T2DM within the last years, there have been reported only a few studies involving nutrition data in their analysis in the form of T2DM risk scores(Reference Schulze, Hoffmann and Boeing21–Reference Halton, Liu and Manson23). Over the past two decades, numerous studies highlighted the importance of lifestyle factors, including physical activity, weight loss, nutrition and smoking, in the prevention and management of T2DM(Reference Galaviz, Weber and Straus24–Reference Sheng, Cao and Pang26). With regard to nutrition, it has been found that specific dietary behaviours reduce significantly the incidence of T2DM(Reference Sheng, Cao and Pang26,Reference Qian, Liu and Hu27) and others can increase it(Reference Schwingshackl, Hoffmann and Lampousi28), and so including nutrition data into the T2DM risk prediction models could improve their performance. The present results, and specifically the performance measures of our model, highlight the important role that nutrition can play in identifying individuals with an increased risk for T2DM.
There are several possible explanations for these results. First of all, specific dietary patterns may influence the individuals’ risk of T2DM, since they can have a significant role in the pathogenesis of this chronic disease. For example, plant-based diets have been reported to reduce the risk of T2DM by jointly improving insulin sensitivity, controlling weight gain, resulting in weight loss and lowering systemic inflammation(Reference Qian, Liu and Hu27). On the other hand, specific food groups, like red and processed meat, are related to increased T2DM risk(Reference Schwingshackl, Hoffmann and Lampousi28), possibly due to high haem iron and dietary cholesterol concentration(Reference Micha, Michas and Mozaffarian29). Second, specific food intake variables can be related to clinical and socio-demographic factors, like BMI, age and sex(Reference Hausman, Johnson and Davey30,Reference Tugault-Lafleur and Black31) , which have been previously reported to act as strong predictors of the T2DM risk. This can also explain the similar values of AUC between the predictive model of T2DM status with only food intake variables included and the one with only age, sex and BMI (Fig. 2). The cross-sectional study design may have also been partly responsible for this small difference, since the real performance measures of our predictive model can be validated only under a longitudinal design. However, given the increasing prevalence of T2DM(Reference Saeedi, Petersohn and Salpea3), even small improvements on the AUC of T2DM predictive models may have a significant effect on the amount of people that could eventually be identified from these models as high risk for developing T2DM. Third, certain diet patterns have been found to have an effect on the control and management of T2DM(Reference Papamichou, Panagiotakos and Itsiopoulos32). So, owning to the cross-sectional nature of our data, it may also be possible that specific food intake variables can be strong predictors of T2DM, because diabetic individuals may have formed different dietary habits from non-diabetics, as a part of their disease management. The reverse association between T2DM and food intake variables can also explain some of the association estimates in the present study. For example, garlic supplement has been found to control blood glucose in T2DM patients(Reference Wang, Zhang and Lan33) and may be part of the T2DM therapy for many of them. However, the association estimate of garlic intake with T2DM was positive in the present study, which could have been due to a probable reverse association of T2DM with garlic intake and the predictive and not causal nature of our statistical model. In these ways mentioned earlier, the performance of our predictive model can be explained.
The present results have some important implications for public health practice and clinicians. The implementation of nutrition data into new predictive models for T2DM may create new risk scores that will be able to identify early people who will develop T2DM and so suggest them medical consultation. Moreover, the assessment of patients’ nutrition based on self-report is relatively easy to be done. Hence, although the incorporation of a predictive model into clinical practice is usually hard and influenced by multiple contextual factors, including nutrition data into predictive models may be feasible.
Strengths of the present study include its population-based design, large sample size, objective assessment of T2DM and assessment of a full range of food items. However, several limitations need to be taken into consideration. First, we were not able to assess the temporal ordering of the consumption of the food variables and T2DM because of the cross-sectional study design. Second, the assessment of the food intake variables was based on self-report, so measurement error cannot be excluded. Third, we have not validated our prediction model in an external dataset. Lastly, we did not include important predictors, and the most commonly used, for the risk of T2DM include family history of diabetes, physical inactivity, history of hyperglycaemia and use of anti-hypertensives(Reference Collins, Mallett and Omar20) and we tried, instead, to focus mainly on the predictive performance of food intake variables. Despite having probably undermined the performance measures of our model by excluding such important predictors of T2DM, food intake variables alone in our predictive model yielded a high AUC and similar to that of the predictive model with only age, sex and BMI included. Thus, we believe that furtherly examining the predictive and causal effect of food intake variable under explanatory studies could help us manage T2DM in a better way, regarding the screening, prevention and treatment of T2DM patients, and that was the main reason for building a predictive model with only food intake variables.
In conclusion, we found that building a predictive model of T2DM risk with including only food intake variables can yield high-performance measures. Implementing nutrition data into predictive models that will be used by clinicians and public health practitioners may be feasible. However, further population-based longitudinal studies, which will take these variables into account, are needed to confirm the present results.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/jns.2021.36.
Acknowledgements
Dietary assessment in the KORA FF4 was supported by iMED, a research alliance within the Helmholtz Association, Germany. This work was funded by grants of the German Federal Ministry for Education and Research (FK 01EA1409E) and the German Research Foundation (FL 776/6-1). The KORA study was initiated and financed by the Helmholtz Zentrum München – German Research Center for Environmental Health, which is funded by the BMBF and by the State of Bavaria. Furthermore, KORA research was supported within the Munich Center of Health Sciences (MC Health), Ludwig-Maximilians-Universität, as part of LMUinnovativ. The funding agencies had no role in the design, analysis or writing of this article.
The authors’ responsibilities were as follows. A. K. and A. F. designed the research, wrote this paper and had primary responsibility for the final content. A. K. analysed the data. A. F. and K. S. provided essential materials. All authors critically revised the manuscript. All authors read and approved the final manuscript.
The authors declare that they have no conflicts of interest.








 Open access
Open access