



No CrossRef data available.
Article contents
Stochastic linearized generalized alternating direction method of multipliers: Expected convergence rates and large deviation properties
Published online by Cambridge University Press: 14 March 2023
Abstract
Alternating direction method of multipliers (ADMM) receives much attention in the field of optimization and computer science, etc. The generalized ADMM (G-ADMM) proposed by Eckstein and Bertsekas incorporates an acceleration factor and is more efficient than the original ADMM. However, G-ADMM is not applicable in some models where the objective function value (or its gradient) is computationally costly or even impossible to compute. In this paper, we consider the two-block separable convex optimization problem with linear constraints, where only noisy estimations of the gradient of the objective function are accessible. Under this setting, we propose a stochastic linearized generalized ADMM (called SLG-ADMM) where two subproblems are approximated by some linearization strategies. And in theory, we analyze the expected convergence rates and large deviation properties of SLG-ADMM. In particular, we show that the worst-case expected convergence rates of SLG-ADMM are 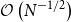 $\mathcal{O}\left( {{N}^{-1/2}}\right)$ and
$\mathcal{O}\left( {{N}^{-1/2}}\right)$ and 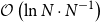 $\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has
$\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has 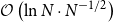 $\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and
$\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and 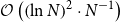 $\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
$\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
Keywords
- Type
- Special Issue: TAMC 2022
- Information
- Mathematical Structures in Computer Science , Volume 34 , Special Issue 3: Theory and Applications of Models of Computation , March 2024 , pp. 162 - 179
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press
References
Deng, W. and Yin, W. (2016). On the global and linear convergence of the generalized alternating direction method of multipliers. Journal of Scientific Computing 66 (3) 889–916.CrossRefGoogle Scholar
Eckstein, J. and Bertsekas, D. P. (1992). On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Mathematical Programming 55 (1) 293–318.CrossRefGoogle Scholar
Fang, E. X., He, B., Liu, H. and Yuan, X. (2015). Generalized alternating direction method of multipliers: new theoretical insights and applications. Mathematical Programming Computation 7 (2) 149–187.CrossRefGoogle ScholarPubMed
Gabay, D. and Mercier, B. (1976). A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Computers & Mathematics with Applications 2 (1) 17–40.CrossRefGoogle Scholar
Gao, X., Jiang, B. and Zhang, S. (2018). On the information-adaptive variants of the ADMM: an iteration complexity perspective. Journal of Scientific Computing 76 (1) 327–363.CrossRefGoogle Scholar
Ghadimi, S. and Lan, G. (2013). Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM Journal on Optimization 23 (4) 2341–2368.CrossRefGoogle Scholar
Ghadimi, S. and Lan, G. (2012). Accelerated gradient methods for nonconvex nonlinear and stochastic programming. Mathematical Programming 156 (1) 59–99.CrossRefGoogle Scholar
Ghadimi, S., Lan, G. and Zhang, H. (2016). Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization. Mathematical Programming 155 (1) 267–305.CrossRefGoogle Scholar
Glowinski, R. (2014). On alternating direction methods of multipliers: a historical perspective. In: Modeling, Simulation and Optimization for Science and Technology, pp 59–82. Dordrecht: Springer.CrossRefGoogle Scholar
Glowinski, R. and Marroco, A. (1975). Sur l’approximation, par éléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problèmes de Dirichlet non linéaires. Revue Française d’automatique, Informatique, Recherche Opérationnelle. Analyse Numérique 9 (R2) 41–76.CrossRefGoogle Scholar
Han, D. R. (2022). A survey on some recent developments of alternating direction method of multipliers. Journal of the Operations Research Society of China 10 (1) 1–52.CrossRefGoogle Scholar
Han, D., Sun, D. and Zhang, L. (2018). Linear rate convergence of the alternating direction method of multipliers for convex composite programming. Mathematics of Operations Research 43 (2) 622–637.CrossRefGoogle Scholar
He, B. S. (2017). On the convergence properties of alternating direction method of multipliers. Numerical Mathematics, a Journal of Chinese Universities(Chinese Series) 39 81–96.Google Scholar
He, B. and Yuan, X. (2012). On the
 $O(1/n)$
convergence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis 50 (2) 700–709.CrossRefGoogle Scholar
$O(1/n)$
convergence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis 50 (2) 700–709.CrossRefGoogle Scholar
 $O(1/n)$
convergence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis 50 (2) 700–709.CrossRefGoogle Scholar
$O(1/n)$
convergence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis 50 (2) 700–709.CrossRefGoogle ScholarHe, B. and Yuan, X. (2015). On non-ergodic convergence rate of Douglas-Rachford alternating direction method of multipliers. Numerische Mathematik 130 (3) 567–577.CrossRefGoogle Scholar
Jiang, B., Lin, T., Ma, S. and Zhang, S. (2019). Structured nonconvex and nonsmooth optimization: algorithms and iteration complexity analysis. Computational Optimization and Applications 72 (1) 115–157.CrossRefGoogle Scholar
Lan, G. (2012). An optimal method for stochastic composite optimization. Mathematical Programming 133 (1) 365–397.CrossRefGoogle Scholar
Lan, G. (2020). First-order and stochastic optimization methods for machine learning. New York: Springer.CrossRefGoogle Scholar
Li, G. and Pong, T. K. (2015). Global convergence of splitting methods for nonconvex composite optimization. SIAM Journal on Optimization 25 (4) 2434–2460.CrossRefGoogle Scholar
Monteiro, R. D. C. and Svaiter, B. F. (2013). Iteration-complexity of block-decomposition algorithms and the alternating direction method of multipliers. SIAM Journal on Optimization 23 (1) 475–507.CrossRefGoogle Scholar
Nemirovski, A., Juditsky, A., Lan, G. and Shapiro, A. (2009). Robust stochastic approximation approach to stochastic programming. SIAM Journal on Optimization 19 (4) 1574–1609.CrossRefGoogle Scholar
Ouyang, H., He, N., Tran, L. and Gray, A. (2013). Stochastic alternating direction method of multipliers. In: Proceedings of the 30th International Conference on Machine Learning, pp. 80–88. Atlanta: PMLR.Google Scholar
Robbins, H. and Monro, S. (1951). A stochastic approximation method. The Annals of Mathematical Statistics 22 (3) 400–407.CrossRefGoogle Scholar
Suzuki, T. (2013). Dual averaging and proximal gradient descent for online alternating direction multiplier method. In: Proceedings of the 30th International Conference on Machine Learning, pp. 392–400. Atlanta: PMLR.Google Scholar
Suzuki, T. (2014). Stochastic dual coordinate ascent with alternating direction method of multipliers. In: Proceedings of the 31th International Conference on Machine Learning, pp. 736–744. Beijing: PMLR.Google Scholar
Wang, Y., Yin, W. and Zeng, J. (2019). Global convergence of ADMM in nonconvex nonsmooth optimization. Journal of Scientific Computing 78 (1) 29–63.CrossRefGoogle Scholar
Yang, W. H. and Han, D. (2016). Linear convergence of the alternating direction method of multipliers for a class of convex optimization problems. SIAM Journal on Numerical Analysis 54 (2) 625–640.CrossRefGoogle Scholar
Zhang, J., Luo, Z. Q. (2020). A proximal alternating direction method of multiplier for linearly constrained nonconvex minimization. SIAM Journal on Optimization 30 (3) 2272–2302.CrossRefGoogle Scholar
Zhao, P., Yang, J., Zhang, T. and Li, P. (2015). Adaptive stochastic alternating direction method of multipliers. In: Proceedings of the 32th International Conference on Machine Learning, pp. 69–77. Lille: PMLR.Google Scholar