



Impact Statement
Acute surface-level ozone events have a multitude of negative health consequences. Meteorology plays a major role in the development and intensification of these events; therefore, better understanding the complex interplay between meteorology and surface-level ozone is paramount. For this purpose, in this work, we develop a methodology to model the relationship between vertical temperature profiles and high quantiles of surface-level ozone. We find that acute surface-level ozone events are associated with air temperature inversions over much of the US Southwest in the summer; however, hot weather conditions look to be the primary driver over the Sierra Nevada Mountains and in far Northern California.
1. Introduction
Surface-level ozone (O3) has negative health consequences that may be further magnified when it reaches its highest levels. The elderly and those with complicating health conditions, such as asthma, may be even more vulnerable to the impacts of surface-level O3. O3 is formed via a chemical reaction between NOx and volatile organic compounds (VOCs) in the presence of sunlight. Therefore, emissions play a role in characterizing O3 levels on the surface. However, it is not uncommon for 2 days with identical NOx and VOCs emissions to have drastically different surface-level O3 amounts. It is well established that local and regional meteorological conditions account for a large portion of this discrepancy (Jacob and Winner, Reference Jacob and Winner2009; Tai et al., Reference Tai, Mickley and Jacob2010; Liu and Cui, Reference Liu and Cui2014; Porter et al., Reference Porter, Heald, Cooley and Russell2015). Broadly speaking, these works conclude that meteorological variables such as surface-level air temperature, circulation, and stagnation are related to surface-level air pollution; however, there are often several approaches for characterizing these meteorological conditions.
One way to capture these types of meteorological conditions is by considering atmospheric profile variables (APVs). An APV is considered to be a function mapping the altitude above a location on Earth’s surface to a scalar measurement. The vertical temperature profile (VTP), which reports the temperature of the air at increasing altitude is an important APV in climate sciences. Modeling surface-level air pollution as a function of APVs has been considered previously (Du et al., Reference Du, Liu, Yu, Li, Chen, Peng, Dong, Dong and Wang2013; Rendón et al., Reference Rendón, Salazar, Palacio, Wirth and Brötz2014 Wolf et al., Reference Wolf, Esau and Reuder2014; Russell et al., Reference Russell, Wang and McMahan2017; Russell and Porter, Reference Russell and Porter2021), but has received much less attention in the literature in comparison to approaches that consider surface-level (scalar) covariates exclusively. In this work, we investigate the association between the VTP and high levels of surface-level O3 through the use of methods developed within the framework of functional data analysis (FDA). In FDA, some or all observations are taken to be functions, as opposed to scalars and/or vectors. To this end, in this work, we consider the VTP to be a functional covariate.
Modeling a scalar response variable as a function of a functional covariate is often done via the use of the functional linear model Horváth and Kokoszka (Reference Horváth and Kokoszka2012). As in a standard linear regression model, a functional linear model (with a scalar response) estimates the conditional mean response given the functional covariate. If one is interested in higher quantiles of the response distribution, a functional quantile regression model may be of use. Along these lines, Russell and Dyer (Reference Russell and Dyer2017) suggest a penalized functional quantile regression model to investigate the impact of APVs on surface-level air pollution at locations in South Carolina and Florida. These authors conclude that surface-level air pollution is related to APVs at different pressure levels, and that these associations differ by location and season. As acute levels of surface-level O3 may have a disproportionately higher impact on human health outcomes, we focus on modeling higher conditional quantiles of the O3 response in this work.
The last 10 or 15 years have seen the proliferation of gridded data products, which offer climate and air pollution data over large spatial domains with excellent temporal coverage and no missing values. By its nature, the grid utilized in a gridded data product could be thought of as a regular spatial lattice. Others have considered approaches for analysis of data in these contexts (Huang et al., Reference Huang, Hsu, Theobald and Breidt2010; Zhu et al., Reference Zhu, Huang and Reyes2010; Zheng and Zhu, Reference Zheng and Zhu2012; Reyes et al., Reference Reyes, Giraldo and Mateu2015), although our research objectives and methods differ from these works. We emphasize that our primary goal is to better understand the relationship between the VTP and high surface-level O3 in the summer in the US Southwest based on output from a gridded data product. That is, our objective is to model the relationship between a functional covariate and conditional quantiles of a scalar response at points on a regular lattice.
A simple analysis approach would be to fit independent functional linear regression models at each point on the lattice. Unfortunately, such an approach would likely be difficult to interpret due to the presence of excess noise. For our data, we believe that it is reasonable to assume that the functional regression relationships at adjacent points on the lattice are similar. For this reason, we consider an approach that institutes a penalty for the dissimilarity between estimated coefficient functions at adjacent locations on the lattice. This approach helps us with our objective of better understanding the relationship between VTP and key quantiles of surface-level O3 at all points on the lattice.
2. Pointwise Functional Quantile Regression Modeling
For the random process
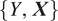 $ \left\{Y,\boldsymbol{X}\right\} $
with iid copies
$ \left\{Y,\boldsymbol{X}\right\} $
with iid copies
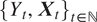 $ {\left\{{Y}_t,{\boldsymbol{X}}_t\right\}}_{t\in \mathrm{\mathbb{N}}} $
, assume the response variable of interest is
$ {\left\{{Y}_t,{\boldsymbol{X}}_t\right\}}_{t\in \mathrm{\mathbb{N}}} $
, assume the response variable of interest is
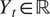 $ {Y}_t\in \mathrm{\mathbb{R}} $
, and
$ {Y}_t\in \mathrm{\mathbb{R}} $
, and
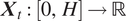 $ {\boldsymbol{X}}_t:\left[0,H\right]\to \mathrm{\mathbb{R}} $
is a functional covariate. Further, assume that
$ {\boldsymbol{X}}_t:\left[0,H\right]\to \mathrm{\mathbb{R}} $
is a functional covariate. Further, assume that
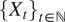 $ {\left\{{X}_t\right\}}_{t\in \mathrm{\mathbb{N}}} $
are in
$ {\left\{{X}_t\right\}}_{t\in \mathrm{\mathbb{N}}} $
are in
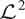 $ {\mathrm{\mathcal{L}}}^2 $
, the separable Hilbert space determined by the set of measurable real-valued square-integrable functions on [0,H]. Given the value of the functional covariate, we directly model
$ {\mathrm{\mathcal{L}}}^2 $
, the separable Hilbert space determined by the set of measurable real-valued square-integrable functions on [0,H]. Given the value of the functional covariate, we directly model
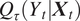 $ {Q}_{\tau}\left({Y}_t|{\boldsymbol{X}}_t\right) $
, the conditional
$ {Q}_{\tau}\left({Y}_t|{\boldsymbol{X}}_t\right) $
, the conditional
 $ \tau $
th quantile of the scalar response variable for some
$ \tau $
th quantile of the scalar response variable for some
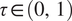 $ \tau \in \left(0,1\right) $
, via
$ \tau \in \left(0,1\right) $
, via
 $$ {Q}_{\tau}\left({Y}_t|{\boldsymbol{X}}_t\right)\hskip0.35em =\hskip0.35em {\alpha}_{\tau }+{\int}_0^H{\boldsymbol{X}}_t^c(s){\boldsymbol{\beta}}_{\tau }(s) ds. $$
$$ {Q}_{\tau}\left({Y}_t|{\boldsymbol{X}}_t\right)\hskip0.35em =\hskip0.35em {\alpha}_{\tau }+{\int}_0^H{\boldsymbol{X}}_t^c(s){\boldsymbol{\beta}}_{\tau }(s) ds. $$
We note that the intercept
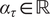 $ {\alpha}_{\tau}\in \mathrm{\mathbb{R}} $
, and we call
$ {\alpha}_{\tau}\in \mathrm{\mathbb{R}} $
, and we call
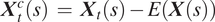 $ {\boldsymbol{X}}_t^c(s)\hskip0.35em =\hskip0.35em {\boldsymbol{X}}_t(s)-E\left(\boldsymbol{X}(s)\right) $
the centered covariate function. Additionally, the twice differentiable function
$ {\boldsymbol{X}}_t^c(s)\hskip0.35em =\hskip0.35em {\boldsymbol{X}}_t(s)-E\left(\boldsymbol{X}(s)\right) $
the centered covariate function. Additionally, the twice differentiable function
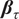 $ {\boldsymbol{\beta}}_{\tau } $
is called the coefficient function for the
$ {\boldsymbol{\beta}}_{\tau } $
is called the coefficient function for the
 $ \tau $
th quantile. In a typical analysis, estimation and inference regarding
$ \tau $
th quantile. In a typical analysis, estimation and inference regarding
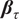 $ {\boldsymbol{\beta}}_{\tau } $
in equation (1) is a primary aim, as portions of
$ {\boldsymbol{\beta}}_{\tau } $
in equation (1) is a primary aim, as portions of
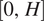 $ \left[0,H\right] $
over which the coefficient function is positive (negative), imply a positive (negative) relationship with that conditional quantile of the response. Additionally, we assume that
$ \left[0,H\right] $
over which the coefficient function is positive (negative), imply a positive (negative) relationship with that conditional quantile of the response. Additionally, we assume that
 $ {\boldsymbol{\beta}}_{\tau}^{\prime \prime}\in {\mathrm{\mathcal{L}}}^2 $
, and that
$ {\boldsymbol{\beta}}_{\tau}^{\prime \prime}\in {\mathrm{\mathcal{L}}}^2 $
, and that
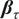 $ {\boldsymbol{\beta}}_{\tau } $
and
$ {\boldsymbol{\beta}}_{\tau } $
and
 $ {\boldsymbol{\beta}}_{\tau}^{\prime } $
are both absolutely continuous.
$ {\boldsymbol{\beta}}_{\tau}^{\prime } $
are both absolutely continuous.
As this is commonly done in FDA, we assume that
 $ {\boldsymbol{\beta}}_{\tau } $
can be approximated by a linear combination of a finite set of known basis functions,
$ {\boldsymbol{\beta}}_{\tau } $
can be approximated by a linear combination of a finite set of known basis functions,
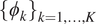 $ {\left\{{\phi}_k\right\}}_{k=1,\dots, K} $
. This implies
$ {\left\{{\phi}_k\right\}}_{k=1,\dots, K} $
. This implies
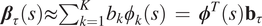 $ {\boldsymbol{\beta}}_{\tau }(s)\approx {\sum}_{k=1}^K{b}_k{\phi}_k(s)\hskip0.35em =\hskip0.35em {\boldsymbol{\phi}}^T(s){\mathbf{b}}_{\tau } $
. In reality, functional covariates
$ {\boldsymbol{\beta}}_{\tau }(s)\approx {\sum}_{k=1}^K{b}_k{\phi}_k(s)\hskip0.35em =\hskip0.35em {\boldsymbol{\phi}}^T(s){\mathbf{b}}_{\tau } $
. In reality, functional covariates
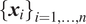 $ {\left\{{\boldsymbol{x}}_i\right\}}_{i=1,\dots, n} $
are infinite dimensional and therefore not fully be observed. Instead, the analyst observes
$ {\left\{{\boldsymbol{x}}_i\right\}}_{i=1,\dots, n} $
are infinite dimensional and therefore not fully be observed. Instead, the analyst observes
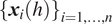 $ {\left\{{\boldsymbol{x}}_i(h)\right\}}_{i=1,\dots, n} $
for
$ {\left\{{\boldsymbol{x}}_i(h)\right\}}_{i=1,\dots, n} $
for
 $ h\in \left\{{h}_1,\dots, {h}_U\right\} $
such that
$ h\in \left\{{h}_1,\dots, {h}_U\right\} $
such that
 $ 0<{h}_1<\cdots <{h}_U\le H $
. We further assume that we are able to identify
$ 0<{h}_1<\cdots <{h}_U\le H $
. We further assume that we are able to identify
 $ {\boldsymbol{a}}_i\in {\mathrm{\mathbb{R}}}^M $
such that
$ {\boldsymbol{a}}_i\in {\mathrm{\mathbb{R}}}^M $
such that
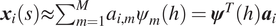 $ {\boldsymbol{x}}_i(s)\approx {\sum}_{m=1}^M{a}_{i,m}{\psi}_m(h)={\boldsymbol{\psi}}^T(h){\boldsymbol{a}}_i $
, where
$ {\boldsymbol{x}}_i(s)\approx {\sum}_{m=1}^M{a}_{i,m}{\psi}_m(h)={\boldsymbol{\psi}}^T(h){\boldsymbol{a}}_i $
, where
 $ {\left\{{\psi}_m\right\}}_{m=1,\dots, M} $
is another set of known basis functions. Therefore, the conditional quantile in equation (1) can be expressed via
$ {\left\{{\psi}_m\right\}}_{m=1,\dots, M} $
is another set of known basis functions. Therefore, the conditional quantile in equation (1) can be expressed via
 $$ {Q}_{\tau}\left({Y}_t|{\boldsymbol{X}}_t\right)\hskip0.35em \approx \hskip0.35em {\alpha}_{\tau }+{\int}_0^H\left({\boldsymbol{a}}_t^T\boldsymbol{\psi} (h)\right)\left({\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{\tau}\right) dh\hskip0.35em =\hskip0.35em {\alpha}_{\tau }+{\boldsymbol{a}}_t^T{\boldsymbol{Jb}}_{\tau }. $$
$$ {Q}_{\tau}\left({Y}_t|{\boldsymbol{X}}_t\right)\hskip0.35em \approx \hskip0.35em {\alpha}_{\tau }+{\int}_0^H\left({\boldsymbol{a}}_t^T\boldsymbol{\psi} (h)\right)\left({\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{\tau}\right) dh\hskip0.35em =\hskip0.35em {\alpha}_{\tau }+{\boldsymbol{a}}_t^T{\boldsymbol{Jb}}_{\tau }. $$
Here, the
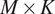 $ M\times K $
dimensional matrix
$ M\times K $
dimensional matrix
 $ \boldsymbol{J} $
is constructed such that the entry in the
$ \boldsymbol{J} $
is constructed such that the entry in the
 $ m $
th row and
$ m $
th row and
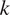 $ k $
th column is
$ k $
th column is
 $ {\int}_0^H{\psi}_m(h){\phi}_k(h) dh $
. We estimate
$ {\int}_0^H{\psi}_m(h){\phi}_k(h) dh $
. We estimate
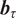 $ {\boldsymbol{b}}_{\tau } $
and
$ {\boldsymbol{b}}_{\tau } $
and
 $ {\alpha}_{\tau } $
via
$ {\alpha}_{\tau } $
via
 $$ {\left({\hat{\alpha}}_{\tau },{\hat{\boldsymbol{b}}}_{\tau}\right)}^T=\underset{\boldsymbol{b}\in {\mathrm{\mathbb{R}}}^K,\alpha \in \mathrm{\mathbb{R}}}{\mathrm{argmin}}\sum \limits_{t=1}^n{\rho}_{\tau}\left({y}_t-\alpha -{\boldsymbol{a}}_t^T\boldsymbol{Jb}\right), $$
$$ {\left({\hat{\alpha}}_{\tau },{\hat{\boldsymbol{b}}}_{\tau}\right)}^T=\underset{\boldsymbol{b}\in {\mathrm{\mathbb{R}}}^K,\alpha \in \mathrm{\mathbb{R}}}{\mathrm{argmin}}\sum \limits_{t=1}^n{\rho}_{\tau}\left({y}_t-\alpha -{\boldsymbol{a}}_t^T\boldsymbol{Jb}\right), $$
where
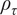 $ {\rho}_{\tau } $
is the check-loss function commonly used in quantile regression (Koenker and Bassett Jr., Reference Koenker and Bassett1978). The resulting optimum from equation (3) leads to the coefficient function estimator via the relationship
$ {\rho}_{\tau } $
is the check-loss function commonly used in quantile regression (Koenker and Bassett Jr., Reference Koenker and Bassett1978). The resulting optimum from equation (3) leads to the coefficient function estimator via the relationship
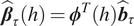 $ {\hat{\boldsymbol{\beta}}}_{\tau }(h)={\boldsymbol{\phi}}^T(h){\hat{\boldsymbol{b}}}_{\tau } $
.
$ {\hat{\boldsymbol{\beta}}}_{\tau }(h)={\boldsymbol{\phi}}^T(h){\hat{\boldsymbol{b}}}_{\tau } $
.
3. Functional Quantile Regression Modeling on a Grid
Climate scientists often make use of gridded data products, which can be thought of as producing output over the points on a regular spatial lattice. Assume that
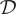 $ \mathcal{D} $
is a spatial domain of interest, and that we observe data over the set of points on a regular lattice
$ \mathcal{D} $
is a spatial domain of interest, and that we observe data over the set of points on a regular lattice
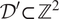 $ {\mathcal{D}}^{\prime}\subset {\mathrm{\mathbb{Z}}}^2 $
, such that
$ {\mathcal{D}}^{\prime}\subset {\mathrm{\mathbb{Z}}}^2 $
, such that
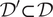 $ {\mathcal{D}}^{\prime}\subset \mathcal{D} $
. Despite the fact that the primary objective is to describe the association between the functional covariate and a key quantile of the scalar response everywhere in
$ {\mathcal{D}}^{\prime}\subset \mathcal{D} $
. Despite the fact that the primary objective is to describe the association between the functional covariate and a key quantile of the scalar response everywhere in
 $ \mathcal{D} $
, we assume that modeling this relationship
$ \mathcal{D} $
, we assume that modeling this relationship
 $ \mathrm{\forall}\ \mathbf{s}\in {\mathcal{D}}^{\mathrm{\prime}} $
will be useful. Additionally, we assume that the true coefficient functions at nearby locations are similar, which makes the approach of borrowing information from nearby cells a potentially promising way to improve coefficient function estimates.
$ \mathrm{\forall}\ \mathbf{s}\in {\mathcal{D}}^{\mathrm{\prime}} $
will be useful. Additionally, we assume that the true coefficient functions at nearby locations are similar, which makes the approach of borrowing information from nearby cells a potentially promising way to improve coefficient function estimates.
Assume that at time
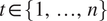 $ t\in \left\{1,\dots, n\right\} $
, we observe realizations of a functional covariate and scalar response at locations
$ t\in \left\{1,\dots, n\right\} $
, we observe realizations of a functional covariate and scalar response at locations
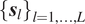 $ {\left\{{\boldsymbol{s}}_l\right\}}_{l=1,\dots, L} $
such that
$ {\left\{{\boldsymbol{s}}_l\right\}}_{l=1,\dots, L} $
such that
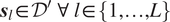 $ {\boldsymbol{s}}_l\in {\mathcal{D}}^{\mathrm{\prime}}\ \mathrm{\forall}\ l\in \{1,\dots, L\} $
, at a sequence of pressure levels
$ {\boldsymbol{s}}_l\in {\mathcal{D}}^{\mathrm{\prime}}\ \mathrm{\forall}\ l\in \{1,\dots, L\} $
, at a sequence of pressure levels
 $ 0<{h}_1<\cdots <{h}_U\hskip0.35em \le \hskip0.35em H $
. We propose a procedure to simultaneously estimate all
$ 0<{h}_1<\cdots <{h}_U\hskip0.35em \le \hskip0.35em H $
. We propose a procedure to simultaneously estimate all
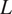 $ L $
coefficient functions
$ L $
coefficient functions
 $ {\left\{{\boldsymbol{\beta}}_{\tau, l}\right\}}_{l=1,\dots, L} $
, under the assumptions described above. We again assume that the true coefficient function at
$ {\left\{{\boldsymbol{\beta}}_{\tau, l}\right\}}_{l=1,\dots, L} $
, under the assumptions described above. We again assume that the true coefficient function at
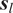 $ {\boldsymbol{s}}_l $
is well approximated by a finite linear combination of known basis functions, giving
$ {\boldsymbol{s}}_l $
is well approximated by a finite linear combination of known basis functions, giving
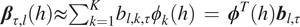 $ {\boldsymbol{\beta}}_{\tau, l}(h)\approx {\sum}_{k=1}^K{b}_{l,k,\tau }{\phi}_k(h)\hskip0.35em =\hskip0.35em {\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l,\tau } $
. Observations from the functional covariate are denoted by
$ {\boldsymbol{\beta}}_{\tau, l}(h)\approx {\sum}_{k=1}^K{b}_{l,k,\tau }{\phi}_k(h)\hskip0.35em =\hskip0.35em {\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l,\tau } $
. Observations from the functional covariate are denoted by
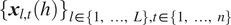 $ {\left\{{\boldsymbol{x}}_{l,t}(h)\right\}}_{l\in \left\{1,\dots, L\right\},t\in \left\{1,\dots, n\right\}} $
, and assume further that there exists
$ {\left\{{\boldsymbol{x}}_{l,t}(h)\right\}}_{l\in \left\{1,\dots, L\right\},t\in \left\{1,\dots, n\right\}} $
, and assume further that there exists
 $ {\boldsymbol{a}}_{l,t}\in {\mathrm{\mathbb{R}}}^M $
such that
$ {\boldsymbol{a}}_{l,t}\in {\mathrm{\mathbb{R}}}^M $
such that
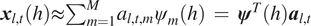 $ {\boldsymbol{x}}_{l,t}(h)\approx {\sum}_{m=1}^M{a}_{l,t,m}{\psi}_m(h)\hskip0.35em =\hskip0.35em {\boldsymbol{\psi}}^T(h){\boldsymbol{a}}_{l,t} $
. We then approximate the conditional
$ {\boldsymbol{x}}_{l,t}(h)\approx {\sum}_{m=1}^M{a}_{l,t,m}{\psi}_m(h)\hskip0.35em =\hskip0.35em {\boldsymbol{\psi}}^T(h){\boldsymbol{a}}_{l,t} $
. We then approximate the conditional
 $ \tau $
th quantile of the response at time
$ \tau $
th quantile of the response at time
 $ t $
and location
$ t $
and location
 $ {\boldsymbol{s}}_l $
by
$ {\boldsymbol{s}}_l $
by
 $$ {Q}_{\tau}\left({Y}_{l,t}|{\boldsymbol{X}}_{l,t}\right)\hskip0.35em \approx \hskip0.35em {\alpha}_{l,\tau }+{\int}_0^H\left({\boldsymbol{a}}_{l,t}^T\boldsymbol{\psi} (h)\right)\left({\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l,\tau}\right) dh\hskip0.35em =\hskip0.35em {\alpha}_{l,\tau }+{\boldsymbol{a}}_{l,t}^T{\boldsymbol{Jb}}_{l,\tau }. $$
$$ {Q}_{\tau}\left({Y}_{l,t}|{\boldsymbol{X}}_{l,t}\right)\hskip0.35em \approx \hskip0.35em {\alpha}_{l,\tau }+{\int}_0^H\left({\boldsymbol{a}}_{l,t}^T\boldsymbol{\psi} (h)\right)\left({\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l,\tau}\right) dh\hskip0.35em =\hskip0.35em {\alpha}_{l,\tau }+{\boldsymbol{a}}_{l,t}^T{\boldsymbol{Jb}}_{l,\tau }. $$
One could consider the estimator
 $$ {\left({\tilde{\boldsymbol{A}}}_{\tau}^T,{\tilde{\boldsymbol{B}}}_{\tau}^T\right)}^T=\underset{\boldsymbol{B}\in {\mathrm{\mathbb{R}}}^{KL},\boldsymbol{A}\in {\mathrm{\mathbb{R}}}^L}{\mathrm{argmin}}{\Lambda}_{\tau}\left({\boldsymbol{A}}_{\tau },{\boldsymbol{B}}_{\tau}\right), $$
$$ {\left({\tilde{\boldsymbol{A}}}_{\tau}^T,{\tilde{\boldsymbol{B}}}_{\tau}^T\right)}^T=\underset{\boldsymbol{B}\in {\mathrm{\mathbb{R}}}^{KL},\boldsymbol{A}\in {\mathrm{\mathbb{R}}}^L}{\mathrm{argmin}}{\Lambda}_{\tau}\left({\boldsymbol{A}}_{\tau },{\boldsymbol{B}}_{\tau}\right), $$
for
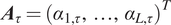 $ {\boldsymbol{A}}_{\tau }={\left({\alpha}_{1,\tau },\dots, {\alpha}_{L,\tau}\right)}^T $
and
$ {\boldsymbol{A}}_{\tau }={\left({\alpha}_{1,\tau },\dots, {\alpha}_{L,\tau}\right)}^T $
and
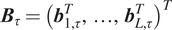 $ {\boldsymbol{B}}_{\tau }={\left({\boldsymbol{b}}_{1,\tau}^T,\dots, {\boldsymbol{b}}_{L,\tau}^T\right)}^T $
, where
$ {\boldsymbol{B}}_{\tau }={\left({\boldsymbol{b}}_{1,\tau}^T,\dots, {\boldsymbol{b}}_{L,\tau}^T\right)}^T $
, where
 $$ {\Lambda}_{\tau}\left({\boldsymbol{A}}_{\tau },{\boldsymbol{B}}_{\tau}\right)=\sum \limits_{l=1}^L\left(\sum \limits_{t=1}^n{\rho}_{\tau}\left({y}_{tl}-{\alpha}_{l,\tau }-{\boldsymbol{a}}_{l,t}^T{\boldsymbol{Jb}}_{l,\tau}\right)\right). $$
$$ {\Lambda}_{\tau}\left({\boldsymbol{A}}_{\tau },{\boldsymbol{B}}_{\tau}\right)=\sum \limits_{l=1}^L\left(\sum \limits_{t=1}^n{\rho}_{\tau}\left({y}_{tl}-{\alpha}_{l,\tau }-{\boldsymbol{a}}_{l,t}^T{\boldsymbol{Jb}}_{l,\tau}\right)\right). $$
The estimator in equation (5) does not incorporate any sort of penalty for dissimilarity between neighboring estimated coefficient functions. As we believe that nearby coefficient functions exhibit similarity in our data application, we supplement the loss function in equation (5) by an additional penalty term.
3.1. Penalizing spatial dissimilarity
Our spatial region of interest is composed of lush forests, arid deserts, coastal regions, and high mountain terrain. Because of this geographical heterogeneity, some pairs of neighboring cells on the lattice may exhibit a higher (or lower) degree of spatial similarity in terms of their true underlying coefficient functions. For this reason, for neighboring locations
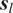 $ {\boldsymbol{s}}_l $
and
$ {\boldsymbol{s}}_l $
and
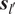 $ {\boldsymbol{s}}_{l^{\prime }} $
(
$ {\boldsymbol{s}}_{l^{\prime }} $
(
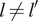 $ l\ne {l}^{\prime } $
), we propose the weighting function
$ l\ne {l}^{\prime } $
), we propose the weighting function
 $$ {w}_{\theta, \gamma}\left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right)=\theta \exp \left(-\gamma \delta \left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right)\right), $$
$$ {w}_{\theta, \gamma}\left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right)=\theta \exp \left(-\gamma \delta \left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right)\right), $$
where
 $ \theta >0 $
and
$ \theta >0 $
and
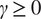 $ \gamma \hskip0.35em \ge \hskip0.35em 0 $
are unknown parameters and the function
$ \gamma \hskip0.35em \ge \hskip0.35em 0 $
are unknown parameters and the function
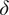 $ \delta $
models geographic and or climatological dissimilarity between two locations. We propose the penalized estimator
$ \delta $
models geographic and or climatological dissimilarity between two locations. We propose the penalized estimator
 $$ {\left({\hat{\boldsymbol{A}}}_{\tau}^T,{\hat{\boldsymbol{B}}}_{\tau}^T\right)}^T=\underset{\boldsymbol{B}\in {\mathrm{\mathbb{R}}}^{KL},\boldsymbol{A}\in {\mathrm{\mathbb{R}}}^L}{\mathrm{argmin}}{\Lambda}_{\tau}\left(\boldsymbol{A},\boldsymbol{B}\right)+{\Lambda}_{\mathrm{spat}}\left(\boldsymbol{A},\boldsymbol{B},\theta, \gamma, \tau \right), $$
$$ {\left({\hat{\boldsymbol{A}}}_{\tau}^T,{\hat{\boldsymbol{B}}}_{\tau}^T\right)}^T=\underset{\boldsymbol{B}\in {\mathrm{\mathbb{R}}}^{KL},\boldsymbol{A}\in {\mathrm{\mathbb{R}}}^L}{\mathrm{argmin}}{\Lambda}_{\tau}\left(\boldsymbol{A},\boldsymbol{B}\right)+{\Lambda}_{\mathrm{spat}}\left(\boldsymbol{A},\boldsymbol{B},\theta, \gamma, \tau \right), $$
where
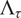 $ {\Lambda}_{\tau } $
is defined in equation (6) and
$ {\Lambda}_{\tau } $
is defined in equation (6) and
 $$ {\Lambda}_{\mathrm{spat}}\left(\boldsymbol{A},\boldsymbol{B},\theta, \gamma, \tau \right)=\sum \limits_{1\le l<{l}^{\prime}\le L}{w}_{\theta, \gamma}\left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right){\int}_0^H\mid {\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l,\tau }-{\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l^{\prime },\tau}\mid dh\hskip0.35em \unicode{x1D540}\left\{{\boldsymbol{s}}_l\sim {\boldsymbol{s}}_{l^{\prime }}\right\}. $$
$$ {\Lambda}_{\mathrm{spat}}\left(\boldsymbol{A},\boldsymbol{B},\theta, \gamma, \tau \right)=\sum \limits_{1\le l<{l}^{\prime}\le L}{w}_{\theta, \gamma}\left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right){\int}_0^H\mid {\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l,\tau }-{\boldsymbol{\phi}}^T(h){\boldsymbol{b}}_{l^{\prime },\tau}\mid dh\hskip0.35em \unicode{x1D540}\left\{{\boldsymbol{s}}_l\sim {\boldsymbol{s}}_{l^{\prime }}\right\}. $$
We note that equation (9) gives the sum of the spatial dissimilarity penalties over all pairs of adjacent cells in
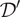 $ {\mathcal{D}}^{\prime } $
. Here,
$ {\mathcal{D}}^{\prime } $
. Here,
 $ \unicode{x1D540}\left\{\cdot \right\} $
denotes the indicator function, and
$ \unicode{x1D540}\left\{\cdot \right\} $
denotes the indicator function, and
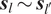 $ {\boldsymbol{s}}_l\sim {\boldsymbol{s}}_{l^{\prime }} $
implies that
$ {\boldsymbol{s}}_l\sim {\boldsymbol{s}}_{l^{\prime }} $
implies that
 $ {\boldsymbol{s}}_l $
and
$ {\boldsymbol{s}}_l $
and
 $ {\boldsymbol{s}}_{l^{\prime }} $
are adjacent. The definition of adjacency is flexible and can be selected in a way that makes sense for a specific data application. Importantly, the
$ {\boldsymbol{s}}_{l^{\prime }} $
are adjacent. The definition of adjacency is flexible and can be selected in a way that makes sense for a specific data application. Importantly, the
 $ {\hat{\boldsymbol{B}}}_{\tau }={\left({\hat{\boldsymbol{b}}}_{{\boldsymbol{s}}_1,\tau}^T,\dots, {\hat{\boldsymbol{b}}}_{{\boldsymbol{s}}_L,\tau}^T\right)}^T $
that minimizes (8) leads to the coefficient functions estimates
$ {\hat{\boldsymbol{B}}}_{\tau }={\left({\hat{\boldsymbol{b}}}_{{\boldsymbol{s}}_1,\tau}^T,\dots, {\hat{\boldsymbol{b}}}_{{\boldsymbol{s}}_L,\tau}^T\right)}^T $
that minimizes (8) leads to the coefficient functions estimates
 $ {\left\{{\hat{\boldsymbol{\beta}}}_{\tau, l}\right\}}_{l=1,\dots, L} $
. The absolute loss penalty in equation (9) is used, because the absolute value function can be expressed in terms of the check-loss function, as seen in equation (10). This makes it straightforward to implement the penalty by augmenting the quantile regression design matrix.
$ {\left\{{\hat{\boldsymbol{\beta}}}_{\tau, l}\right\}}_{l=1,\dots, L} $
. The absolute loss penalty in equation (9) is used, because the absolute value function can be expressed in terms of the check-loss function, as seen in equation (10). This makes it straightforward to implement the penalty by augmenting the quantile regression design matrix.
4. Analysis of Surface-Level Ozone in the US Southwest
The primary research objective in this work is to gain a better level of understanding regarding the effects of VTP on acute daily surface-level O3 events over the US Southwest. The O3 and VTP data come from the GEOS-Chem model version 12.2.1 (Bey et al., Reference Bey, Jacob, Yantosca, Logan, Field, Fiore, Li, Liu, Mickley and Schultz2001), run for the period of late summer (July/August) 2016. Importantly, GEOS-Chem obtains meteorological variables from the Modern-Era Retrospective Analysis for Research and Applications, Version 2 (Gelaro et al., Reference Gelaro, McCarty, Suąrez, Todling, Molod, Takacs, Randles, Darmenov, Bosilovich, Reichle, Wargan, Coy, Cullather, Draper, Akella, Buchard, Conaty, da Silva, Gu, Kim, Koster, Lucchesi, Merkova, Nielsen, Partyka, Pawson, Putman, Rienecker, Schubert, Sienkiewicz and Zhao2017). For illustrative purposes, we plot surface-level O
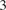 $ {}_3 $
levels (in ppb) for all US Southwest grid cells on July 30, 2016, in the left panel of Figure 1. On this day, surface-level O3 is fairly high over much of the region. The right panel of Figure 1 plots the VTP for the grid cell containing Riverside, CA on this day. For reference, Riverside, CA is plotted on the map in the left panel. Typically, the temperature of the air warms at lower altitudes; however, we see that this is not the case on this day. This plot of the VTP indicates the presence of a temperature inversion, where cooler air at the surface is trapped under warmer air. The high levels of surface-level O3 in Riverside may be due in part to the presence of this inversion.
$ {}_3 $
levels (in ppb) for all US Southwest grid cells on July 30, 2016, in the left panel of Figure 1. On this day, surface-level O3 is fairly high over much of the region. The right panel of Figure 1 plots the VTP for the grid cell containing Riverside, CA on this day. For reference, Riverside, CA is plotted on the map in the left panel. Typically, the temperature of the air warms at lower altitudes; however, we see that this is not the case on this day. This plot of the VTP indicates the presence of a temperature inversion, where cooler air at the surface is trapped under warmer air. The high levels of surface-level O3 in Riverside may be due in part to the presence of this inversion.

Figure 1. We plot surface-level O3 (in ppb) at all US Southwest grid cells on July 30, 2016 (left), and the VTP for the grid cell containing Riverside, CA on this day (right). Riverside, CA is plotted on the map in the left panel.
In order to more effectively penalize the dissimilarity between adjacent grid cells, we seek to identify a data product that is able to assess the degree to which two adjacent grid cells are similar from a geographical and climatological perspective. For this purpose, we use the PRISM data product (Daly et al., Reference Daly, Taylor and Gibson1997) as it explicitly incorporates information about rainfall and implicitly incorporates information about geographical features such as elevation. Denote the 30-year average annual precipitation totals for PRISM cell
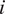 $ i $
$ i $
 $ \left(i\hskip0.35em =\hskip0.35em 1,\dots, {N}_{\mathrm{Prism}}\right) $
via
$ \left(i\hskip0.35em =\hskip0.35em 1,\dots, {N}_{\mathrm{Prism}}\right) $
via
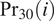 $ {\Pr}_{30}(i) $
. We define
$ {\Pr}_{30}(i) $
. We define
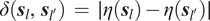 $ \delta \left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right)\hskip0.35em =\hskip0.35em \mid \eta \left({\boldsymbol{s}}_l\right)-\eta \left({\boldsymbol{s}}_{l^{\prime }}\right)\mid $
, where
$ \delta \left({\boldsymbol{s}}_l,{\boldsymbol{s}}_{l^{\prime }}\right)\hskip0.35em =\hskip0.35em \mid \eta \left({\boldsymbol{s}}_l\right)-\eta \left({\boldsymbol{s}}_{l^{\prime }}\right)\mid $
, where
 $ \eta \left({\mathbf{s}}_l\right)={\sum}_{i=1}^{N_{\mathrm{Prism}}}\left({\Pr}_{30}(i)\unicode{x1D540}\left\{i\in l\right\}\right)/{\sum}_{i=1}^{N_{\mathrm{Prism}}}\unicode{x1D540}\left\{i\in l\right\} $
, and
$ \eta \left({\mathbf{s}}_l\right)={\sum}_{i=1}^{N_{\mathrm{Prism}}}\left({\Pr}_{30}(i)\unicode{x1D540}\left\{i\in l\right\}\right)/{\sum}_{i=1}^{N_{\mathrm{Prism}}}\unicode{x1D540}\left\{i\in l\right\} $
, and
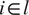 $ i\in l $
is the event that the midpoint of PRISM cell
$ i\in l $
is the event that the midpoint of PRISM cell
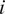 $ i $
is contained in cell
$ i $
is contained in cell
 $ l $
. Essentially,
$ l $
. Essentially,
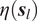 $ \eta \left({\boldsymbol{s}}_l\right) $
is the average of all PRISM 30-year annual precipitation totals for all PRISM locations in the grid cell
$ \eta \left({\boldsymbol{s}}_l\right) $
is the average of all PRISM 30-year annual precipitation totals for all PRISM locations in the grid cell
 $ l $
. The PRISM data product takes both geographical and climatological information into account, and therefore we find it useful to leverage it for this purpose. We implement our analysis procedure using B-spline basis functions to represent both the coefficient function as well as the functional covariates. We utilize 7 B-spline basis functions of order 4 with equally spaced interior knots to represent the functional covariates and estimated coefficient functions. The parameters
$ l $
. The PRISM data product takes both geographical and climatological information into account, and therefore we find it useful to leverage it for this purpose. We implement our analysis procedure using B-spline basis functions to represent both the coefficient function as well as the functional covariates. We utilize 7 B-spline basis functions of order 4 with equally spaced interior knots to represent the functional covariates and estimated coefficient functions. The parameters
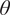 $ \theta $
and
$ \theta $
and
 $ \gamma $
are estimated via a two-dimensional grid search using Bayesian information criterion (BIC) as the model comparison criterion. In keeping with our objective of modeling acute surface-level O3, we take
$ \gamma $
are estimated via a two-dimensional grid search using Bayesian information criterion (BIC) as the model comparison criterion. In keeping with our objective of modeling acute surface-level O3, we take
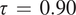 $ \tau \hskip0.35em =\hskip0.35em 0.90 $
.
$ \tau \hskip0.35em =\hskip0.35em 0.90 $
.
Figure 2 plots the resulting coefficient function estimates at all locations in the spatial domain for a sequence of eight equally spaced pressure levels: 825, 850, …, 975, 1,000. Recall that a pressure level of approximately 1,000 corresponds with the Earth’s surface. At higher pressure levels (above 925 or 950), warmer temperatures are associated with larger high O3 events. Around the pressure level 950, we begin to see this relationship disappear over large portions of this region. Instead, as we go lower in the atmosphere, larger high O3 events are associated with cooler air over Nevada, Southern Utah, and Arizona, as well as coastal California. Interestingly, we see the opposite over the high mountains of California and in the far northern part of the state. This implies that air temperature inversions are associated with acute surface-level O3 events over the majority of the US Southwest; in contrast, warmer air at the surface is linked to these types of air pollution events over the Sierra Nevada Mountains and in Northern California.

Figure 2. For a sequence of eight pressure levels, we plot the resulting coefficient function estimates for all cells on our spatial grid.
5. Discussion
In this work, at each location on a spatial lattice, we estimate the relationship between the VTP and high daily surface-level O3 events during the summer in the US Southwest states of California, Nevada, Arizona, and Utah. We take a functional quantile regression approach, and as we believe that nearby coefficient functions are similar, we estimate at all points on the lattice simultaneously and penalize the spatial dissimilarity. In this work, we model acute surface-level O3 events by estimating the conditional 0.90 quantile of the response distribution. Because of the geographic heterogeneity of this diverse region, we weight differences between coefficient function estimates at neighboring cells more if they are similar geographically and/or climatologically. Our analysis concludes that temperature inversions are a primary driver of acute O3 events over Arizona, Utah, Nevada, and coastal California. In contrast, higher temperatures are associated with acute O3 events over far Northern California and the Sierra Nevada Mountains.
We determine two cells on the grid to be adjacent if they are connected to the N, S, E, or W. In the future, we hope to expand this definition to further outlying cells. Doing so would complicate estimation, but may improve estimates. Also, the model developed in this work does not incorporate temporal dependence. Although we believe that the results presented here would not change greatly, we hope to refine the modeling approach to account for temporal dependence in the future. We would also like to further refine our methodology to simultaneously consider other quantiles of interest, and to investigate the impact of alternative weighting functions. In the future, we believe that it would be interesting to consider combinations of other regions and seasons, to compare and contrast the results presented here. Similarly, it would be interesting to consider models other than GEOS-Chem model version 12.2.1. Other extensions to our modeling procedure include developing modeling procedures that are able to incorporate both gridded model output and in situ observations (O3 and VTP). We hope to consider these ideas in future work.
We note that equation (9), with its absolute value penalty terms written in terms of finite differences, can also be expressed via the check-loss function, relying on the fact that
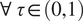 $ \mathrm{\forall}\ \tau \in (0,1) $
and
$ \mathrm{\forall}\ \tau \in (0,1) $
and
 $ u\in \mathrm{\mathbb{R}} $
:
$ u\in \mathrm{\mathbb{R}} $
:
 $$ {\displaystyle \begin{array}{l}\mid u\mid \hskip0.35em =\hskip0.35em \mid u\mid \unicode{x1D540}\left\{u>0\right\}\tau +\mid u\mid \unicode{x1D540}\left\{u>0\right\}\left(1-\tau \right)\\ {}\hskip3.6em +\hskip0.35em \mid u\mid \unicode{x1D540}\left\{u<0\right\}\tau +\mid u\mid \unicode{x1D540}\left\{u<0\right\}\left(1-\tau \right)\\ {}\hskip2em =\hskip0.35em \mid 0--u\mid \unicode{x1D540}\left\{0--u>0\right\}\tau +\mid 0-u\mid \unicode{x1D540}\left\{0-u<0\right\}\left(1-\tau \right)\\ {}\hskip3.5em +\mid 0-u\mid \unicode{x1D540}\left\{0-u>0\right\}\tau +\mid 0--u\mid \unicode{x1D540}\left\{0--u<0\right\}\left(1-\tau \right)\\ {}\hskip2em =\hskip0.35em {\rho}_{\tau}\left(0-u\right)+{\rho}_{\tau}\left(0--u\right).\end{array}} $$
$$ {\displaystyle \begin{array}{l}\mid u\mid \hskip0.35em =\hskip0.35em \mid u\mid \unicode{x1D540}\left\{u>0\right\}\tau +\mid u\mid \unicode{x1D540}\left\{u>0\right\}\left(1-\tau \right)\\ {}\hskip3.6em +\hskip0.35em \mid u\mid \unicode{x1D540}\left\{u<0\right\}\tau +\mid u\mid \unicode{x1D540}\left\{u<0\right\}\left(1-\tau \right)\\ {}\hskip2em =\hskip0.35em \mid 0--u\mid \unicode{x1D540}\left\{0--u>0\right\}\tau +\mid 0-u\mid \unicode{x1D540}\left\{0-u<0\right\}\left(1-\tau \right)\\ {}\hskip3.5em +\mid 0-u\mid \unicode{x1D540}\left\{0-u>0\right\}\tau +\mid 0--u\mid \unicode{x1D540}\left\{0--u<0\right\}\left(1-\tau \right)\\ {}\hskip2em =\hskip0.35em {\rho}_{\tau}\left(0-u\right)+{\rho}_{\tau}\left(0--u\right).\end{array}} $$
Therefore, in practice, the optimization in equation (8) can be performed in a computationally efficient manner by constructing the design matrix determined by the loss function in equation (6), and augmenting it with the design matrix determined by the penalty
 $ {\Lambda}_{\mathrm{spat}} $
in equation (9), relying on the relationship in equation (10)). For this reason, functions designed for quantile regression with scalar covariates, such as R’s quantreg package, may be utilized for optimization. With a large number of adjacent cells, the resulting design matrix will be very large, but also very sparse. This sparsity can be leveraged to make estimation reasonable.
$ {\Lambda}_{\mathrm{spat}} $
in equation (9), relying on the relationship in equation (10)). For this reason, functions designed for quantile regression with scalar covariates, such as R’s quantreg package, may be utilized for optimization. With a large number of adjacent cells, the resulting design matrix will be very large, but also very sparse. This sparsity can be leveraged to make estimation reasonable.
Acknowledgments
We acknowledge two reviewers, whose comments and suggestions helped to improve this manuscript.
Author Contributions
Conceptualization: both authors; Data curation: W.P.; Formal analysis: B.R.; Methodology: B.R.; Software: B.R.; Writing—original draft: B.R.; Writing—review and editing: both authors. Both authors approved the final submitted draft.
Competing Interests
The authors declare none.
Data Availability Statement
The ozone data and atmospheric profile variables data are available upon reasonable request from the corresponding author. The PRISM 30-year precipitation averages are available at https://prism.oregonstate.edu/normals/.
Funding Statement
This work received no specific grant from any funding agency, commercial or not-for-profit sectors.
Provenance
This article is part of the Climate Informatics 2022 proceedings and was accepted in Environmental Data Science on the basis of the Climate Informatics peer review process.
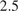



 Open access
Open access