



1. INTRODUCTION
En français, les groupes consonantiques constitués d’une consonne obstruante (/p, b, t, d, k, g, f, v/) suivie d’une liquide (/l, ʁ/) en position finale de mot, comme dans les mots découvre [de.kuvʁʁ] ou terrible [te.ʁʁibl], ont un statut phonologique particulier. Sur l’échelle de sonorité, les liquides sont en effet situées entre les voyelles et les obstruantes. De fait, si une liquide est contenue dans la même syllabe que l’obstruante qu’elle suit, le principe de sonorité séquentielle (Sonority Sequencing Principle, v. Selkirk, Reference Selkirk1984), qui stipule qu’une syllabe doit présenter une courbe croissante puis décroissante de sonorité, est violé (Dell, Reference Dell1985; Côté, Reference Côté2004). En pratique, il existe trois stratégies pour que la courbe de sonorité idéale soit conservée lors de la prononciation de mots français comme découvre ou terrible dans la parole continue. La première n’est applicable que si l’item cible est suivi d’un mot à initiale vocalique : le cluster de consonnes final est alors resyllabé avec la voyelle initiale du mot suivant ([te.ʁibl.e.pʁœv] > [te.ʁi.ble.pʁœv] pour terrible épreuve). La seconde stratégie consiste en la réalisation d’un schwa après la liquide, ce qui a pour conséquence, comme pour la première stratégie, que le groupe obstruante + liquide passe de la position de coda ([de.kuvʁ], [te.ʁibl]) à la position d’attaque ([de.ku.vʁə], [te.ʁi.blə]). La troisième stratégie consiste en l’élision de la consonne liquide, ce qui n’entraîne aucune restructuration syllabique et permet du même coup que le pic de sonorité ne remonte pas sur l’obstruante après avoir décru ([de.kuv], [te.ʁib]). C’est à la découverte des facteurs qui déclenchent l’application de cette dernière stratégie par les locuteurs du français d’Europe que le présent article est consacré.
L’articulation d’un schwa dans ces contextes entraînant quasi-obligatoirement l’articulation de la liquide,Footnote 1 on peut facilement comprendre pourquoi dans les recherches antérieures, le comportement des liquides finales post-obstruantes (désormais LFPO) a surtout été abordé sous l’angle de l’application de la troisième stratégie. D’un point de vue sociolinguistique, ce n’est pas la prononciation de la liquide qui est un phénomène saillant, mais bien sa non-prononciation. Comme l’articulation d’une nasale alvéolaire (/n/) au lieu d’une nasale vélaire (/ŋ/) dans les clusters se terminant par -ing en anglais (Labov, Reference Labov1966; Trudgill, Reference Trudgill1974), phénomène auquel la chute des LFPO a été comparée (Armstrong, Reference Armstrong2001; Boughton, Reference Boughton2015), le phénomène a en effet longtemps été perçu comme un marqueur propre au français ‘populaire’ (Guiraud, Reference Guiraud1965 : 101) ou ‘ordinaire’ (Gadet, Reference Gadet1989 : 102),Footnote 2 surtout quand le mot qui suit commence par une voyelle (de Cornulier, Reference de Cornulier, de Cornulier and Dell1978; Tranel, Reference Tranel1987). Partant, rien d’étonnant à ce qu’il constitue une variable de premier choix sur laquelle les auditeurs s’appuient pour juger du caractère plus ou moins naturel ou approprié d’extraits de parole, qu’ils soient produits par un synthétiseur (Brognaux et Drugman, Reference Brognaux and Drugman2014) ou par un humain (dans une tâche psycholinguistique d’identification lexicale p. ex., Peperkamp et Iturralde Zurita, Reference Peperkamp and Iturralde Zurita2019).Footnote 3
De façon générale, si les facteurs linguistiques et extralinguistiques qui motivent l’élision des LFPO sont relativement bien étudiés, les mécanismes qui régissent leurs interactions demeurent encore largement méconnus à l’heure actuelle (§2).Footnote 4 Dans cet article, nous proposons de faire avancer nos connaissances en regard de ce problème, en reportant les résultats d’une analyse conduite à partir de l’analyse de plus de 2500 items extraits d’un corpus de 13 heures, annoté semi-automatiquement à différents niveaux linguistiques, et échantillonné de manière à tenir compte de la variation diatopique et diaphasique en français européen (§3). L’analyse des données est réalisée en deux temps. En ce qui concerne les mots grammaticaux, peu nombreux, les statistiques sont essentiellement descriptives. En ce qui concerne les mots lexicaux, des modèles linéaires généralisés à effets mixtes, qui permettent de considérer plusieurs variables dans un même modèle tout en tenant compte de la variation intra- et interlocuteur, ont été réalisés. Et il ressort que sur plus d’une dizaine de prédicteurs testés, seule la moitié d’entre eux s’avèrent jouer effectivement un rôle sur le comportement des LFPO (§4). Ces résultats sont discutés à la lumière d’études antérieures sur la variation sociophonétique en français (§5).
2. ÉTAT DE LA QUESTION
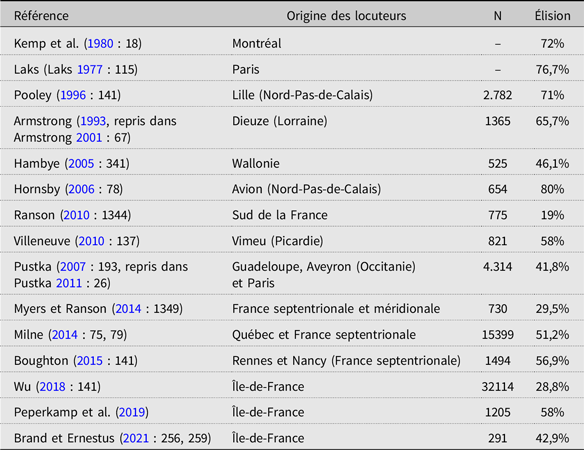
Si l’on considère l’ensemble des études sur corpus relatives aux LFPO en français conduites depuis le début des années 80, on peut estimer qu’en moyenne, un mot sur deux contenant une LFPO est prononcé sans sa liquide en parole continue :
Considérés en l’état, les chiffres reportés dans le Tableau 1 ne veulent toutefois pas dire grand-chose, tant il est vrai que le taux d’élision des LFPO varie drastiquement selon les différents facteurs (extra)linguistiques que les uns et les autres prennent (ou non) en compte lors de leurs calculs. En nous basant sur les travaux susmentionnés et d’autres, nous en avons isolé six grands types.
Tableau 1. Inventaire des études portant sur l’élision des LFPO en français, avec origine des locuteurs, nombre d’observations et pourcentage d’élision.Footnote 5
2.1. Facteurs articulatoires
Sur le plan articulatoire, la (non-)réalisation d’une LFPO a été évaluée de façons différentes. D’aucuns se sont concentrés sur le mode d’articulation de la liquide (/l/ vs /ʁ/) : selon Armstrong (Reference Armstrong1993, Reference Armstrong2001) et Pooley (Reference Pooley1996), les clusters contenant un /ʁ/ seraient plus souvent simplifiés que les clusters comprenant un /l/; selon Pustka (Reference Pustka2007, Reference Pustka2011) et Villeneuve (Reference Villeneuve2010), ce trait n’aurait aucune incidence sur le comportement de la liquide. D’autres ont examiné le mode et le lieu d’articulation de l’obstruante. D’après les observations de Pooley (Reference Pooley1996), Pustka (Reference Pustka2007, Reference Pustka2011) et Villeneuve (Reference Villeneuve2010), les consonnes fricatives (/f/ et /v/) entraînent plutôt la non-prononciation de la LFPO, alors que les occlusives ont plutôt tendance à en favoriser la prononciation. Finalement, un troisième groupe de chercheurs ont abordé la question en tenant compte des combinaisons possibles entre obstruantes et liquides. Ainsi, Pooley (Reference Pooley1996), Hornsby (Reference Hornsby2006), Pustka (Reference Pustka2007, Reference Pustka2011) de même que Myers et Ranson (Reference Myers and Ranson2014) observent des différences selon les combinaisons : dans les clusters <gl> et <kr>, les liquides seraient plus souvent articulées que dans les clusters <fr> ou <pl>, notamment.
2.2. Facteurs phonotactiques
Un second facteur concerne la nature du contexte droit du cluster (pause, voyelle ou consonne) : Gadet (Reference Gadet1989) stipule que la non-prononciation de la LFPO est plus fréquente quand le mot est suivi d’une consonne que quand il est suivi d’une pause, et quand il est suivi d’une pause que quand il est suivi d’une voyelle. Pooley (Reference Pooley1996) et Hambye (Reference Hambye2005) présentent des faits allant dans le même sens. Pourtant, Kemp et al. (Reference Kemp, Pupier, Yaeger, Shuy and Shnukal1980), Chevrot et al. (Reference Chevrot, Beaud and Varga2000), Hornsby (Reference Hornsby2006), Villeneuve (Reference Villeneuve2010), Boughton (Reference Boughton, Jones and Hornsby2013, Reference Boughton2015), Myers et Ranson (Reference Myers and Ranson2014) mais aussi Milne (Reference Milne2014), Wu (Reference Wu2018) ainsi que Peperkamp et al. (Reference Peperkamp, Hegde and Carbajal2019), sont mitigés quant à cette assertion. Tous observent que si la non-prononciation de la liquide est plus fréquente devant consonne que devant pause ou voyelle, ils ne trouvent pas forcément de différence entre ces deux derniers contextes.
Dans le cas où la LFPO était suivie par un mot à initiale consonantique, certains chercheurs ont pensé à coder le type de consonne. Myers et Ranson (Reference Myers and Ranson2014) rapportent que si la consonne initiale du mot suivant est similaire à l’obstruante en termes de lieux et modes, la non-prononciation de la liquide est favorisée. Wu (Reference Wu2018) observe que la liquide est davantage élidée si la consonne du mot suivant est une obstruante par rapport à une nasale ou une liquide.
2.3. Facteurs lexicaux
La catégorie grammaticale du mot hébergeant la LFPO a également été considérée comme un facteur susceptible d’avoir un rôle sur le comportement des LFPO. Selon Gadet (Reference Gadet1989), la non-prononciation de /ʁ/ serait plus systématique dans les mots lexicaux (noms et verbes) que dans les mots grammaticaux (prépositions, cardinaux), alors que pour la liquide /l/, ce serait l’inverse : la non-prononciation serait plus fréquente dans les mots grammaticaux (pronoms) que dans les mots lexicaux (noms et verbes). L’importance des catégories grammaticales est également soulignée par Kemp et al. (Reference Kemp, Pupier, Yaeger, Shuy and Shnukal1980) ainsi que Myers et Ranson (Reference Myers and Ranson2014). Elle est toutefois contestée par Pooley (Reference Pooley1996), qui remarque à la suite de l’analyse de ses données que la nature du mot (grammatical ou lexical) ne joue pas de rôle sur la prononciation ou la non-prononciation de LFPO (tout du moins s’il s’agit d’un /ʁ/).
Un autre facteur lexical touche à la fréquence du mot hébergeant la LFPO (Laks, Reference Laks1977; Kemp et al., Reference Kemp, Pupier, Yaeger, Shuy and Shnukal1980; Armstrong, Reference Armstrong2001; Brand et Ernestus, Reference Brand and Ernestus2021). Selon une hypothèse communément admise, plus un mot est fréquent, plus il aurait tendance à être prononcé de façon « réduite » (v. notamment Wang, Reference Wang1969; Bybee, Reference Bybee2002). Ainsi, Pooley (Reference Pooley1996) remarque que les adverbes fréquents comme peut-être ou par contre sont plus souvent prononcés sans leur LFPO que des prépositions comme entre et contre, dont l’usage est moins fréquent. Dans la même veine, Ranson (Reference Ranson2010), Myers et Ranson (Reference Myers and Ranson2014) ou encore Villeneuve (Reference Villeneuve2010) observent d’intéressantes corrélations positives entre la fréquence du mot et la non-prononciation des LFPO : plus un mot est fréquent, plus sa LFPO a tendance à ne pas être prononcée. Des observations que nuance toutefois Pustka (Reference Pustka2007, Reference Pustka2011). L’auteure remarque en effet que des mots rares comme astre, pègre, ténèbres ou encore oindre sont rarement prononcés sans leur LFPO. Mais elle ne trouve toutefois pas de corrélations significatives entre le taux de non-prononciation des LFPO et la fréquence des mots contenant ce genre de cluster dans son corpus.
2.4. Facteurs prosodiques
Pooley (Reference Pooley1996) et Pustka (Reference Pustka2007, Reference Pustka2011) remarquent que les LFPO sont moins souvent prononcées quand elles sont en position accentuable (c’est-à-dire en position finale de groupe clitique, pour reprendre les termes de Garde, Reference Garde1965). En pratique, cela veut dire que les mots intonés dans le même groupe accentuel que le mot qu’ils précèdent voient leur LFPO ‘protégée’, alors que les LFPO des mots qui se trouvent en bord droit de groupe accentuel ont plus de chances de ne pas être prononcées. P. ex., selon cette hypothèse, il est plus probable que la LFPO du lexème centre dans le syntagme le centre du pays soit prononcée si le mot est phrasé dans un groupe accentuel différent que le mot qu’il suit (/l(ə)ˈɑ̃tʁ(ə) | dypɛˈi/) que s’il ne l’est pas (/l(ə)(ə)sɑ̃tdypɛˈi/).
Dans l’étude de Brand et Ernestus (2021), deux critères comparables à ce dernier sont pris en compte : la position du mot dans l’énoncé (au début, au milieu ou à la fin) et le nombre de syllabes dans le mot. En se basant sur de tels critères, les chercheuses remarquent que lorsque le mot contenant une LFPO est au milieu d’un énoncé, la liquide a plus de chance de ne pas être prononcée que si le mot est dans une autre position. Elles observent également que la liquide est plus souvent prononcée sur les mots courts que sur les mots longs.
Dans la même veine, Myers et Ranson (Reference Myers and Ranson2014) observent des effets significatifs de la position du mot dans l’énoncé, ce qui va dans le même sens que dans l’étude précédente. D’après leurs résultats, l’élision de la LFPO est favorisée dans un mot placé à l’intérieur d’un énoncé autre que dans une position prénominale et par rapport à un mot placé en position finale.
Enfin, d’autres travaux ont pris en compte la vitesse d’articulation, calculée comme la durée relative des syllabes du groupe dans lequel s’insère le mot avec une LFPO. Ce facteur s’est avéré significatif aussi bien dans l’étude de Milne (Reference Milne2014) que dans celles de Myers et Ranson (Reference Myers and Ranson2014) et de Brand et Ernestus (Reference Brand and Ernestus2021). Les uns comme les autres montrent que plus la durée syllabique est courte (donc plus les locuteurs articulent rapidement), plus la tendance à ne pas prononcer la LFPO est grande.
2.5. Facteurs liés à la situation de parole
En ce qui concerne le rôle de la situation de parole (ou le degré de formalité du contexte de communication), le consensus entre les auteurs est plus grand. Laks (Reference Laks1977) et Armstrong (Reference Armstrong1993, Reference Armstrong2001) observent que la chute des LFPO est moins fréquente dans les productions où l’enquêteur est présent (l’enquêteur joue le rôle d’interlocuteur) que dans les productions où l’interlocuteur est absent (la conversation se fait entre pairs uniquement). Sur la base de la comparaison de trois corpus alignés automatiquement,Footnote 6 Wu (Reference Wu2018) formule une conclusion similaire : plus la situation de parole est informelle, moins les LFPO sont réalisées. Enfin, Hambye (Reference Hambye2005), Milne (Reference Milne2014) et Boughton (Reference Boughton2015), remarquent tous que les locuteurs de leurs corpus prononcent davantage de LFPO lors d’une tâche de lecture (qui génère de la parole plus contrôlée) qu’en conversation (où la parole est moins contrôlée).
2.6. Facteurs relatifs au locuteur
Le dernier ensemble de variables ayant été discutées dans les études consacrées au comportement des LFPO en français sont relatives au profil socioéconomique des locuteurs. Laks (Reference Laks1977) a notamment constaté une corrélation marquée entre le profil socioéconomique des participants et leur propension à prononcer ou non les LFPO. D’après ses résultats, il ressort que plus les participants sont socialement ‘défavorisés’, plus ils ont tendance à ne pas prononcer les LFPO, et vice-versa (les taux d’élision allant de 30% pour les locuteurs en haut de l’échelle sociale à près de 100% pour les participants en bas de cette échelle). Des observations analogues ont été faites par Kemp et al. (Reference Kemp, Pupier, Yaeger, Shuy and Shnukal1980) sur un corpus de français québécois.
Souvent, on observe que le profil socioéconomique interagit avec deux autres variables, à savoir le sexe et l’âge des locuteurs. Dans deux études faisant intervenir des groupes de locuteurs de différents âges, Pooley (Reference Pooley1996) et Hornsby (Reference Hornsby2006) ont mis au jour des liens intéressants entre la non-prononciation des LFPO, l’âge, le sexe et le niveau socio-éducatif des locuteurs (les locuteurs de sexe masculin, moins éduqués et âgés de plus de 45 ans produiraient davantage de clusters sans LFPO que les autres). Villeneuve (Reference Villeneuve2010) ne signale aucun effet de sexe dans son étude, mais remarque que les locuteurs aînés (55 ans et plus) réalisent moins de LFPO que les locuteurs plus jeunes (25–54 ans). Quant à Boughton (Reference Boughton2015), elle observe que les locuteurs de classe ouvrière prononcent moins souvent les LFPO que les locuteurs de classe moyenne; que les locuteurs masculins prononcent moins souvent la LFPO que les femmes (ce qui coïncide avec ce que disent Pooley, Reference Pooley1996 et Hornsby, Reference Hornsby2006). En revanche, l’auteure remarque que l’âge n’a aucun effet sur le comportement des LFPO, les jeunes locuteurs de son corpus (16–25 ans) présentant un taux de non-prononciation presque identique aux locuteurs plus âgés (40–60 ans).
Enfin, il convient de signaler que l’origine géographique du locuteur a été étudiée par certains auteurs. Milne (Reference Milne2014) a ainsi comparé le français canadien et le français standard européen, et a trouvé un taux de non-prononciation plus important dans la variété américaine que dans la variété européenne. Hambye (Reference Hambye2005) trouve également des différences entre des locuteurs originaires de Tournai (ville proche de Lille, située sur la frontière franco-belge, et où le français qui y est parlé est généralement considéré comme plus proche de la variété de référence du français, Bardiaux, Reference Bardiaux2014) et des locuteurs de Gembloux et de Liège (deux variétés fortement marquées régionalement). D’après les comptages de Hambye (Reference Hambye2005), il ressort en effet que les locuteurs de Liège et de Gembloux prononcent moins de LFPO que les locuteurs de Tournai. Pustka (Reference Pustka2007, Reference Pustka2011) a comparé les productions de cinq groupes de locuteurs : des locuteurs de Paris, de Guadeloupe et du Midi de la France (département de l’Aveyron); des locuteurs originaires de Guadeloupe et d’Aveyron résidant à Paris. En pratique, elle constate que les locuteurs de Guadeloupe prononcent moins souvent les LFPO que les locuteurs de Paris, qui se comportent à leur tour différemment des immigrants aveyronnais, ces derniers présentant des pourcentages de non-prononciation légèrement supérieurs à ceux des locuteurs de l’Aveyron mais inférieurs à ceux des Parisiens. Quant à Boughton (2013), elle a comparé les productions des locuteurs de Rennes et de Nancy (deux villes à égale distance de Paris, situées à l’Ouest et à l’Est de la France), et a constaté des différences entre les locuteurs de ces variétés, les locuteurs de Nancy étant plus enclins à prononcer les LFPO que ceux de Rennes. Enfin, Myers et Ranson (Reference Myers and Ranson2014) comparent les productions de locutrices du sud de la France et du nord de la France : elles observent que dans les productions méridionales, le taux de non-prononciation des LFPO est plus bas que dans l’autre groupe, en raison de la propension plus importante à la prononciation du schwa dans cette région.
2.7. Synthèse et problématique
Les facteurs ayant un impact sur la (non-)prononciation des LFPO en français sont nombreux, mais le consensus qui se dégage quant à leur rôle respectif dans la communauté des chercheurs est mitigé. On a vu que des facteurs comme le mode d’articulation de la LFPO, la fréquence lexicale, la catégorie grammaticale, l’âge et le sexe des locuteurs étaient des critères qui ne faisaient pas l’unanimité. On a vu aussi que s’il y a accord sur le fait que le contexte droit (consonne, pause ou voyelle) permet d’expliquer le comportement de la LFPO, il est difficile de savoir dans quel sens ce facteur fonctionne, certains auteurs considérant le contexte préconsonantique comme défavorisant la prononciation de la LFPO au même titre que le contexte pré-pausal, d’autres ne trouvant pas de différences entre ces deux contextes. Le rôle du mode et du lieu d’articulation de l’obstruante, l’origine géographique des locuteurs et le statut prosodique du mot hébergeant le cluster prêtent moins à débat, mais ces variables n’ont pas été testées par la majorité des auteurs. Au final, seuls deux éléments semblent faire consensus : le style de parole (la parole préparée/lue étant plus encline à l’articulation de LFPO que la parole non-préparée/non-lue), le profil socioéconomique des locuteurs (les locuteurs présentant un profil social moins prestigieux socialement font chuter dans une plus grande proportion les LFPO que les locuteurs présentant un profil social plus prestigieux).
Comment expliquer l’existence de ces discordances ? Selon nous, l’une des principales raisons provient du fait que la majorité des auteurs considèrent les facteurs susceptibles d’influencer le comportement des LFPO de façon indépendante, alors qu’il est clair qu’ils doivent être considérés les uns par rapport aux autres, comme cela a été montré par ceux qui ont croisé différents facteurs dans leur analyse. À cet égard, Armstrong (Reference Armstrong2001) affirme que le comportement des LFPO est davantage influencé par le style de parole que par le sexe et les facteurs de niveau socio-économique. Hambye (Reference Hambye2005) conclut que les intervenants de son corpus ne se comportent pas de la même façon en ce qui concerne leur niveau socio-éducatif et le style de parole, les écarts entre les différentes catégories socio-éducatives des locuteurs étant plus marqués en lecture qu’en conversation. Pustka (Reference Pustka2007, Reference Pustka2011) trouve aussi une influence substantielle de la combinaison entre l’origine du locuteur et le contexte droit du cluster LFPO : les locuteurs de la Guadeloupe présentent un taux de non-prononciation plus élevé avant voyelle par rapport aux locuteurs originaires d’autres régions. Dans la même lignée, Villeneuve (Reference Villeneuve2010) rapporte que dans la position prévocalique, la non-prononciation de la LFPO est plus fréquente dans les productions des locuteurs âgés que dans les productions des locuteurs jeunes. Autre exemple : dans l’étude de Wu (Reference Wu2018), il y a une différence entre hommes et femmes dans les corpus de parole journalistique, mais pas en parole spontanée. Dans le travail de Milne (Reference Milne2014), il ressort que l’effet de vitesse d’articulation n’est pas aussi important en parole lue qu’en parole spontanée. Quant aux résultats de Boughton (Reference Boughton, Jones and Hornsby2013), ils montrent que le contexte ne joue pas toujours le même rôle selon le profil socio-économique, l’âge et le sexe des locuteurs :
Middle-class speakers and females prefer the standard variant [LFPO prononcée] in all contexts, though we observe the greatest shift between groups in the behavior of the two classes in prevocalic/prepausal context, where deletion rates are 30% lower for middle-class speakers. This result is mirrored in the difference between males and females, where the gap in prevocalic/prepausal context nears 20%, almost double that for preconsonantal context (Boughton, Reference Boughton, Jones and Hornsby2013 : 13).
Dans un autre ordre d’idée, Putska (Pustka Reference Pustka2011 : 28) s’interroge sur le fait que certains clusters obstruante + liquide, en plus d’être rares, n’apparaissent que dans certains mots diatopiquement distribués. Elle donne l’exemple de la séquence <gr>, qui n’apparaît que dans le mot nègre, un mot qui n’est prononcé que dans la bouche de locuteurs de Guadeloupe, où il n’a pas la même connotation péjorative qu’en Europe. Et de conclure : « La nature du groupe OL [obstruante + liquide] peut donc s’avérer être une variable parasite, derrière laquelle se cache une variation diatopique ou lexicale. »Footnote 7 Enfin, Myers et Ranson (Reference Myers and Ranson2014) soulignent l’importance de croiser le facteur régional avec le facteur de fréquence lexicale, certains mots étant raccourcis plus souvent que d’autres dans une région mais pas dans l’autre.
Un second problème concerne le choix des méthodes pour évaluer l’effet de certains facteurs sur la variable à l’étude. Par exemple, Pustka (Reference Pustka2007 : 208) remarque que « la liquide tombe plus souvent après une plosive (45%) qu’après une fricative (33%) », mais ne fournit pas d’analyse statistique pour s’assurer que cette différence n’est pas due au hasard, ou à l’influence d’un autre prédicteur qui n’aurait pas été contrôlé. Même imprudence chez Boughton (Reference Boughton, Jones and Hornsby2013 : 128), quand elle observe que « Rennes participants consistently delete more liquids than Nancy speakers » en raison d’une « difference of over 20 percentage points between the two locations », mais sans avoir observé l’influence d’autres facteurs sur ces résultats. Dans certains cas toutefois, des analyses statistiques viennent appuyer les conclusions : on retrouve des tests d’indépendance (χ2 ) chez Pooley (Reference Pooley1996), chez Hambye (Reference Hambye2005) et des tests d’analyse de variance (Anova) chez Armstrong (Reference Armstrong2001). Pourtant, ces tests ne permettent pas de prendre en compte plusieurs facteurs en même temps, et ne peuvent donc que confirmer ou infirmer l’existence de différences significatives quant à une variable isolée (ou entre des groupes de sous-corpus).
Villeneuve (Reference Villeneuve2010) est la première à proposer une analyse multifactorielle du problème. L’approche est toutefois discutable, et ce pour au moins deux raisons : d’abord, parce que l’auteure ne tient pas compte des interactions entre les variables entrées dans le modèle (ni du fait que ces variables soient éventuellement corrélées); ensuite, parce que rien n’indique dans son modèle qu’elle a pris soin de tenir compte de la variation intra- et interlocuteur.Footnote 8 Dans ce contexte, il est possible que les effets observés soient dus au comportement de certains locuteurs, qui produiraient certains items plus souvent que d’autres – nonobstant la fréquence de ces items dans le corpus ou dans l’absolu; v. les remarques de Pustka (Reference Pustka2011) au sujet du mot nègre reportées supra.
Dans les études récentes, des analyses statistiques plus complexes, à base de régressions, avec ou sans effets mixtes, ont été proposées. Le problème est que dans ces travaux, seuls quelques facteurs explicatifs sont testés dans un même modèle. Dans Milne (Reference Milne2014), les facteurs pris en compte comprennent la variation régionale (comparaison entre des locuteurs originaires du Québec et de la France septentrionale), le style de parole (lecture et spontanée), le contexte droit (devant pause, consonne ou voyelle) et la vitesse d’articulation. Des facteurs importants relatifs aux caractéristiques articulatoires des clusters, aux catégories de mots (grammaticaux ou lexicaux), à leur position dans la chaîne, sans parler des critères externes relatifs aux locuteurs (âge, sexe et profil socio-économique), sont laissés de côté. Wu (Reference Wu2018), qui travaille sur l’articulation de /ʁ/ seulement, ne considère que le style de parole, le sexe et le contexte droit (devant pause, consonne ou voyelle), en laissant de côté des paramètres pourtant tout aussi importants, à savoir la vitesse d’articulation et le nombre de syllabes dans le mot, de même que la catégorie grammaticale et la fréquence lexicale. Brand et Ernestus (Reference Brand and Ernestus2021) abordent le problème de la chute des LFPO dans le cadre d’une recherche sur la réduction phonétique.Footnote 9 Ce sont elles qui proposent le modèle le plus complet. Toutefois, comme c’est le cas de Wu, leur corpus n’est pas taillé pour tenir compte de facteurs variationnels qui touchent à l’âge, au niveau social ou à l’origine des locuteurs.
Au final, on l’aura compris : on ne sait toujours pas quels sont les mécanismes qui motivent la (non-)prononciation des LFPO en français à l’heure actuelle. Du travail reste donc à fournir pour aboutir à une meilleure compréhension du problème.
3. MÉTHODE
3.1. Participants
Les matériaux que nous utilisons dans cette étude ont été extraits de la base Phonologie du Français Contemporain (PFC, Durand, Laks et Lyche, Reference Durand, Laks and Lyche2009). Plus précisément, le corpus de travail comprend les productions de locuteurs originaires de 15 régions de la francophonie d’Europe : 5 localités de la partie septentrionale de la France (Béthune, Brécey, Lyon, Paris et Ogéviller), 5 localités de Suisse romande (Fribourg, Genève, Martigny, Neuchâtel et Nyon) et 5 localités de Belgique (Bruxelles, Gembloux, Liège, Marche-en-Famenne et Tournai). La localisation de ces points d’enquête peut être visualisée sur la Figure 1.
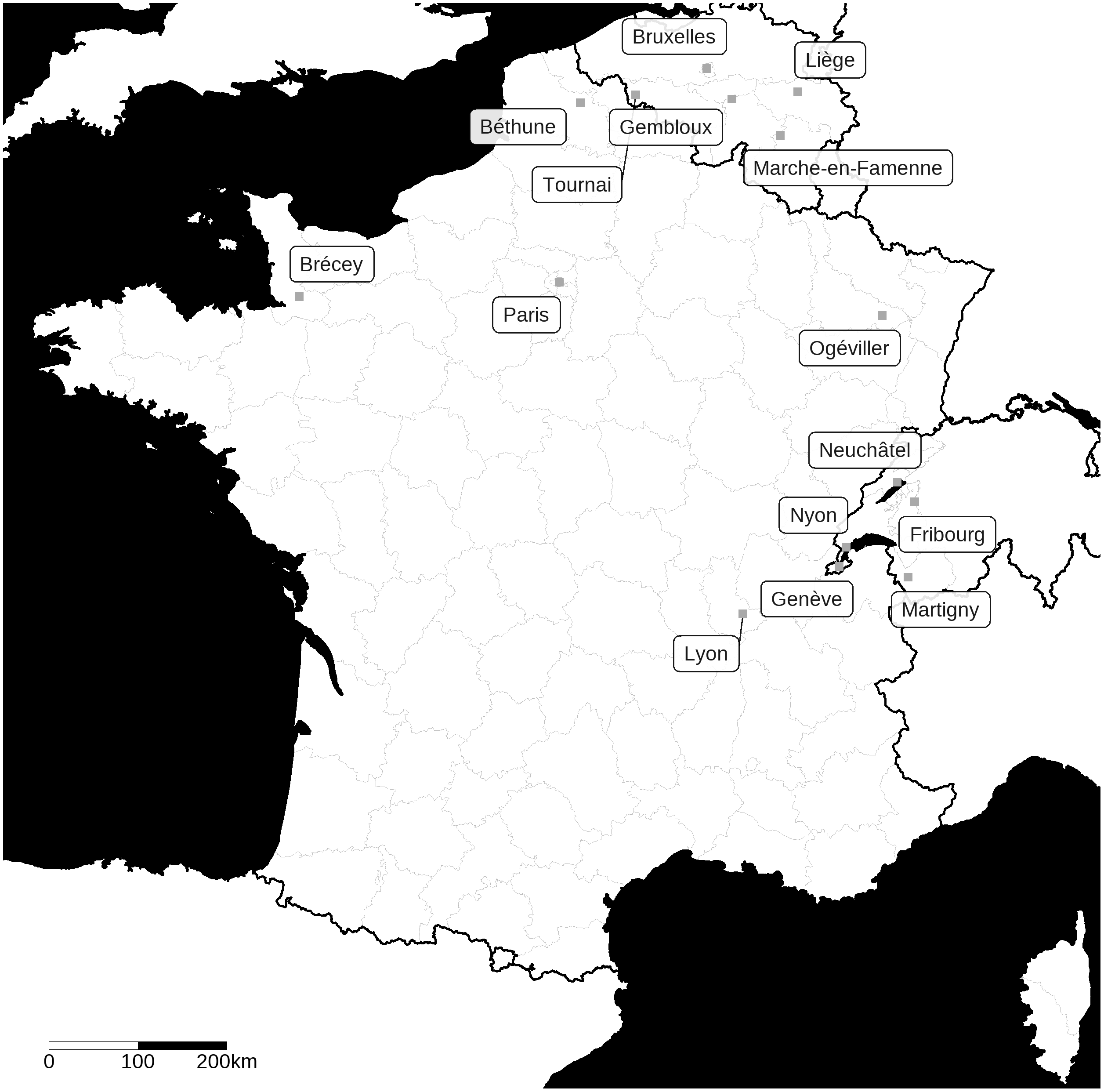
Figure 1. Carte de la francophonie d’Europe, avec localisation des 15 points d’enquêtes. Les lignes épaisses signalent des frontières entre pays, les lignes plus fines des divisions internes aux provinces en Belgique, des départements en France et des cantons francophones en Suisse.
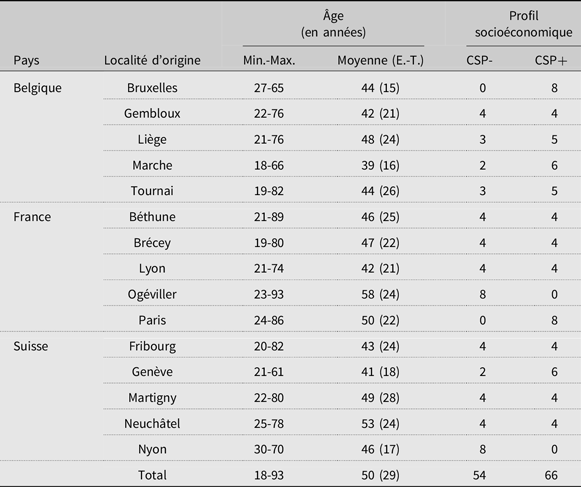
Pour chacun des 15 points d’enquête, 4 hommes et 4 femmes ayant passé la plus grande partie de leur vie et étant bien ancrés dans lesdites localités ont été sélectionnés. Les 120 locuteurs présentent des âges et des profils socioéconomiques comparables entre eux et entre les régions. Le tableau 2 résume l’ensemble des informations y relatives.Footnote 10
Tableau 2. Origine (pays et points d’enquête) des locuteurs, âge (en années, avec min., max., moyenne et écart-type) et nombre de locuteurs par profil socio-économique pour chaque groupe au moment de l’enregistrement
Chacun des 120 participants a été enregistré dans deux contextes de parole : dans une tâche de lecture et dans le cadre d’un entretien plus ou moins libre.Footnote 11
3.2. Annotations
La totalité du texte lu (398 mots) ainsi que 3 minutes de conversation ont été annotés semi-automatiquement entre 2013 et 2016, dans le cadre d’un projet sur la variation prosodique régionale du français européen (Avanzi Reference Avanzi2014). À un premier niveau, le corpus comprend une segmentation en phonèmes, syllabes et mots graphiques, réalisée à l’aide du plugin EasyAlign (Goldman, Reference Goldman2011) qui fonctionne sous Praat (Boersma Reference Boersma2001). Les alignements ont tous été vérifiés et corrigés manuellement par différents collaborateurs, qui se sont basés sur l’écoute des fichiers audio mais aussi sur le spectrogramme en vue de réajuster, ajouter ou supprimer des frontières de phonèmes, avec une attention spéciale aux phénomènes phonotactiques qui posent le plus problème aux aligneurs (schwas, liaison, élision, etc.). Sur la base du découpage en mots graphiques, une lemmatisation a été effectuée avec le logiciel Dismo (Christodoulides, Avanzi et Goldman, Reference Christodoulides, Avanzi and Goldman2014), et cet étiquetage a également été révisé manuellement. Le corpus contient également une tire d’annotation où sont identifiées différentes informations relatives aux disfluences (Christodoulides et Avanzi, Reference Christodoulides and Avanzi2015), ainsi que les unités inter-pausales (Schwab et Avanzi, Reference Schwab and Avanzi2015).
3.3. Sélection des items
Grâce à des scripts, nous avons pu extraire de ce corpus toutes les unités séparées par des blancs graphiques (tokens) se terminant par les graphèmes <t, d, p, b, g, k, c, f, v>, suivis de <r> ou <l> et de <e> (plus éventuellement de <s> et <nt>), soit 2801 items au total.Footnote 12 Pour travailler sur un corpus aussi homogène que possible, nous avons dû exclure un certain nombre de cas.
Nous avons d’abord écarté les mots prononcés à l’anglaise (jingle, N=1), les régionalismes (encouble,Footnote 13 N=1) et les noms propres (Londres, Alexandre, N=21).Footnote 14 Nous avons également laissé de côté les items qui constituent le premier membre d’un mot composé (quatre-vingts, quatre mille, N=11) et les items suivis d’un mot commençant par la même liquide que la consonne initiale du mot précédent (avec <l>, par exemple l’année prochaine, N = 8; avec <r> notre référence, N=10), en raison des ambiguïtés d’interprétation qu’ils génèrent.Footnote 15 Nous avons aussi isolé tous les mots suivis d’un euh d’hésitation (prendre euh, des êtres euh, N=59) ou associés à une disfluence (de notre # Footnote 16 liberté, montrer pattre blanche euh patte blanche, N=97).
3.4. Variables considérées
Les annotations que comporte le corpus nous ont permis de juger du rôle de plus d’une douzaine de prédicteurs sur le comportement des LFPO des mots lexicaux de notre corpus, soit la quasi-totalité des paramètres généralement mentionnés dans la bibliographie sur le sujet (S§2). Un premier facteur concerne (i) le contexte droit de l’item hôte : est-il suivi d’une pause (N=633), d’un mot à initiale consonantique (N=1472) ou d’un mot à initiale vocalique (N=488) ? Les facteurs suivants concernent les caractéristiques phonétiques du groupe obstruante + liquide. Nous avons codé le (ii) la continuance de la consonne (occlusive, N=2370; fricative, N=223), (iii) le lieu d’articulation de cette consonne (labiodental, N=70; dorsal, N=77; bilabial, N=297; dental, N=2067) et (iv) la nature de la liquide (<l>, N=281; <r>, N=2312). Ensuite, nous avons calculé (v) la fréquence lexicale de l’item hôte dans le corpus Lexique3 (New et al., Reference New, Pallier, Ferrand and Matos2001), par million de mots.Footnote 17 Les mots les moins fréquents (rectangle, admissible, cadastre, etc.) reçoivent un score de 0,50 à 0,60, alors que le plus fréquent (le verbe être) obtient un score de 32236,5).Footnote 18 Dans un autre temps, nous avons calculé (vi) le nombre de syllabes dans l’item hôte (1 syllabe, N=1342; 2 syllabes, N=1201; 3 syllabes et plus, N=50Footnote 19 ; moyenne=1,5, E.T.=0,5). Par ailleurs, puisque l’on sait que la vitesse à laquelle on parle influence la réalisation des segments, nous avons calculé la durée syllabique moyenne de l’unité inter-pause dans laquelle l’item hôte a été prononcé, obtenant ainsi (vii) la vitesse d’articulation locale pour ledit segment en ms (min.=73,4, max.=706,8, moyenne=219,7 et E.T.=61,8). De plus, nous avons codé (viii) le statut prosodique du mot, en différenciant les mots intonés dans le même groupe accentuel que le mot qu’ils précèdent (N=716) des mots intonés dans un groupe accentuel différent (N=1877), ce qui nous a permis de tenir compte du facteur intono-syntaxique (l’idée étant que si le mot appartient au même groupe accentuel que le mot qui le suit, il est plus ‘lié’ que s’il est phrasé dans une unité prosodique différente, Delais-Roussarie et al., Reference Delais-Roussarie, Nespor and Smith1996, Avanzi Reference Avanzi2013). En ce qui concerne les informations relatives aux locuteurs, nous avons entré dans le modèle (ix) le pays d’où ils sont originaires (Belgique, N=855; France, N=871; Suisse, N=867), (x) leur âge (min.=18, max.=93, moyenne=45,9 et E.T.=21,2), (xi) leur genre (femme, N=1305; homme, N=1288) et (xii) leur profil socioéconomique (CSP-, N=1181; CSP+, N=1412). Enfin, nous avons codé la variable (xiii) style de parole (lecture, N=1780; conversation, N=813).
3.5. Statistiques
Les statistiques ont été conduites dans le logiciel R (version 4.2, R Development Core Team, 2013), à l’aide de la fonction glmmTMB de la librairie éponyme (Brooks et al., Reference Brooks, Kristensen, Benthem, Magnusson, Berg and Nielsen2017). Les données ont été analysées à l’aide de modèles linéaires généralisés à effets mixtes (GLMM, v. McCulloch et Neuhaus, Reference McCulloch and Neuhaus2001), avec une fonction logit (transformation logistique et distribution binomiale) et une inflation nulle supposée constante dans l’ensemble de données (ziformula=∼1).Footnote 20 La réalisation de la liquide (oui/non) a été entrée comme variable dépendante, les 13 prédicteurs présentés ci-dessus (§3.4) ont été entrés comme des variables indépendantes,Footnote 21 les items et les locuteurs comme des variables aléatoires. Les valeurs de p ont été obtenues au moyen de la fonction drop1 de la librairie stats. Les tests post-hoc ont été effectués au moyen de la fonction emmeans de la librairie emmeans (Lenth, Reference Lenth2016).
4. RÉSULTATS
Sur les 2593 observables valides du corpus,Footnote 22 il est apparu que les mots grammaticaux étaient nettement moins nombreux que les mots lexicaux (N=238 contre N=2355, respectivement) et que la distribution de ces derniers en regard des variables présentées à la section 3.4. ne permettait pas l’utilisation de modèles statistiques tels que ceux décrits à la section 3.5. Les mots grammaticaux sont donc traités avec des outils de statistique descriptive uniquement (§4.1); les modèles statistiques inférentiels (présentés en 3.5) seront appliqués aux mots lexicaux dans un second temps (§4.2).
4.1. Mots grammaticaux
Sur les 238 mots grammaticaux du corpus, la moitié (N=120) sont prononcés lors de la lecture du texte. 116 impliquent le possessif notre (dans le SN notre liberté)Footnote 23 et 4 occurrences la préposition entre (dans l’expression entre parenthèses). Toutes les occurrences d’entre sont prononcées avec leur liquide assortie d’un schwa (/ɑ̃.tʁə.pa.ʁɑ̃.tɛz/). Sur ces 116 occurrences restantes de notre, la liquide est prononcée 102 fois (dont 82 occurrences comportant un schwa), ce qui veut dire que la liquide n’est élidée que dans 12,1% des cas (N=14).Footnote 24
En parole conversationnelle, la distribution des 118 items peut être résumée au moyen de la Figure 2. On peut voir que seulement quatre lexèmes sont concernés.Footnote 25 Trois d’entre eux (notre, votre et entre) ne sont jamais suivis d’une pause, et quand ils précèdent un mot à initiale consonantique, la liquide est soit majoritairement supprimée (notre, votre), soit majoritairement réalisée, auquel cas elle est assortie d’un schwa (23/27 occurrences d’entre). Suivie d’un mot à initiale vocalique, la liquide est systématiquement maintenue dans ces trois mots. Quant au cardinal quatre, on constate que la liquide est toujours prononcée devant voyelle (N=23), et majoritairement élidée devant pause (4/6 cas). Devant consonne, le /ʁ/ n’est guère prononcé (16/20 cas).
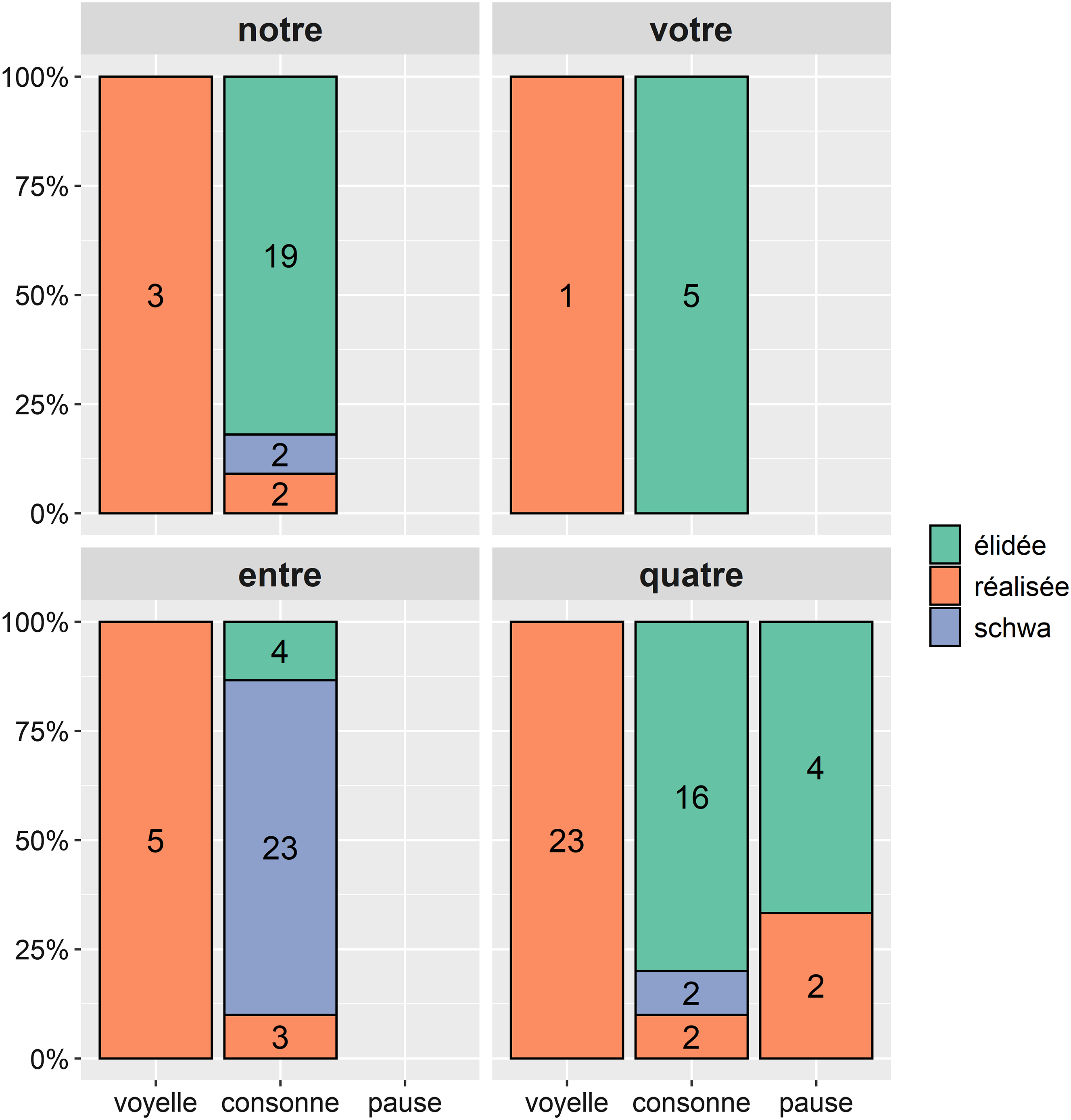
Figure 2. Distribution (en %) des liquides pour chacun des quatre mots grammaticaux (notre, votre, entre et quatre) dans le corpus de conversation, en fonction de leur comportement (élidées, réalisées ou suivies d’un schwa) et du contexte droit (suivies d’un mot qui commence par une voyelle ou une consonne, suivies d’une pause).
Au total, les faits examinés relatifs aux mots grammaticaux peuvent être résumés de la façon suivante. Dans le corpus de lecture, le mot notre est très majoritairement prononcé avec sa consonne liquide finale. Dans le corpus de conversation, pour les quatre mots répertoriés, la liquide est systématiquement prononcée devant voyelle; elle est majoritairement élidée devant consonne, sauf en ce qui concerne la préposition entre, majoritairement prononcée [ɑ̃tʁə]. Devant pause, la tendance est à la non-prononciation.
4.2. Mots lexicaux
4.2.1. Aperçu de la distribution des données
Avant de présenter les résultats des modèles statistiques examinant l’impact de différents prédicteurs sur la réalisation ou non d’une LFPO, il nous a paru intéressant de donner un aperçu de la distribution du comportement des 2355 LFPO de mots lexicaux dans les volets du corpus lecture et conversation du corpus.
Sur la Figure 3, on peut voir que l’application des trois stratégies varie fortement d’un style à l’autre. En moyenne, 39% des LFPO ne sont pas prononcées en conversation, contre 10% en lecture. On observe également une différence importante quand on croise le style et le contexte, notamment en ce qui concerne les items suivant un mot à initiale consonantique : en lecture, 57,6% des liquides sont suivies d’un schwa, contre 16,3% seulement en conversation. On remarque également que dans l’un et l’autre style, les schwas ne sont jamais ou presque produits avant voyelle.
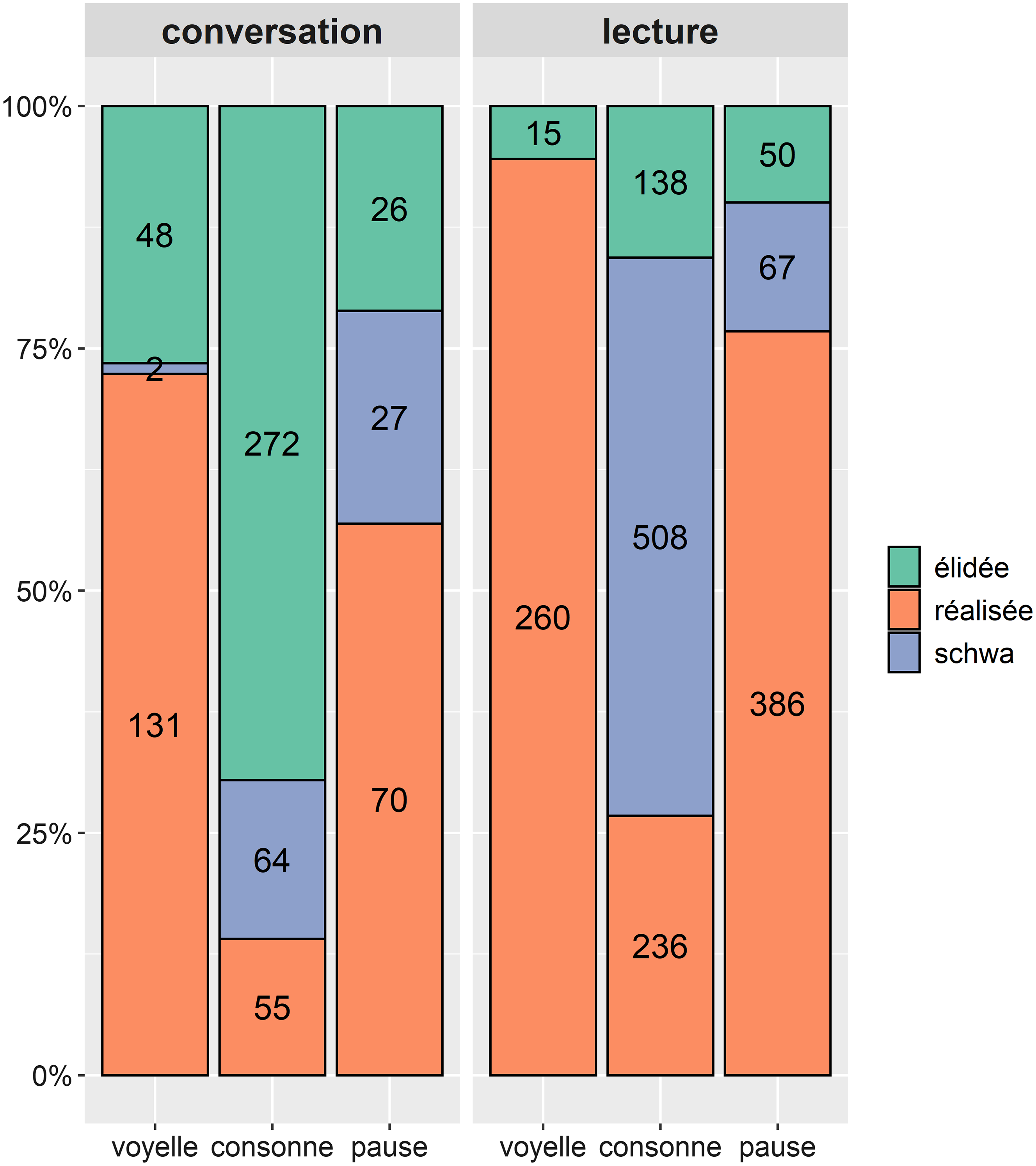
Figure 3. Distribution (en %) des liquides dans le corpus de conversation (à gauche) et dans le corpus de lecture (à droite), en fonction de leur comportement (élidée, réalisée ou suivie d’un schwa) et du contexte droit (suivies d’un mot qui commence par une voyelle ou une consonne, suivies d’une pause).
Compte tenu du fait que nous nous intéressons, dans cet article, à la présence ou l’absence d’une liquide indépendamment de la réalisation d’un schwa, les analyses qui suivent ont été conduites sur l’ensemble des clusters où aucun schwa n’avait été produit, soit sur 1687 unités lexicales.
4.2.2. Sélection du modèle statistique
Pour définir le meilleur modèle explicatif, nous avons dans un premier temps entré les 13 facteurs potentiellement pertinents présentés ci-dessus (§3.4) dans un seul et même modèle, sans tenir compte des interactions possibles entre les prédicteurs. Nous avons alors testé le degré de multicolinéarité de ces 13 prédicteurs au moyen de la fonction check_collinearity de la librairie performance de R (Lüdecke et al., Reference Lüdecke, Ben-Shachar, Patil, Waggoner and Makowski2021). Les valeurs de VIF (Variable Inflation Factors, « facteurs d’inflation variable ») étant toutes très faibles sauf pour le prédicteur lieu d’articulation de l’obstruante (72,14),Footnote 26 ce prédicteur a dû être écarté de l’analyse.Footnote 27 Nous avons donc effectué un nouveau modèle avec les 12 prédicteurs restants, mais cette fois-ci en tenant compte d’une dizaine d’interactions impliquant la nature de la liquide et : (i) le contexte droit, (ii) la constituance de l’obstruante, (iii) le profil socioéconomique; (iv) le contexte droit et le style; le pays et : (v) la vitesse d’articulation, (vi) le style; l’âge et : (viii) la vitesse d’articulation, (ix) le pays, (x) le style; (xi) le style et la vitesse d’articulation. Nous avons enfin mis de côté tous les prédicteurs non-significatifs dans un nouveau modèle en ne retenant que ceux qui présentaient des valeurs de p<0,01. Nous avons alors examiné la structure des résidus du nouveau modèle ainsi mis au point. Afin de valider formellement la spécification de ce modèle final, nous avons effectué un test diagnostic des résidus à l’aide de la librairie DHARMa (Hartig, Reference Hartig2020). Cette procédure a permis de montrer que les résidus suivaient une distribution statistiquement uniforme (ce que confirme le test de Kolmogov-Smirnov), comme on peut le lire sur la Figure 4.
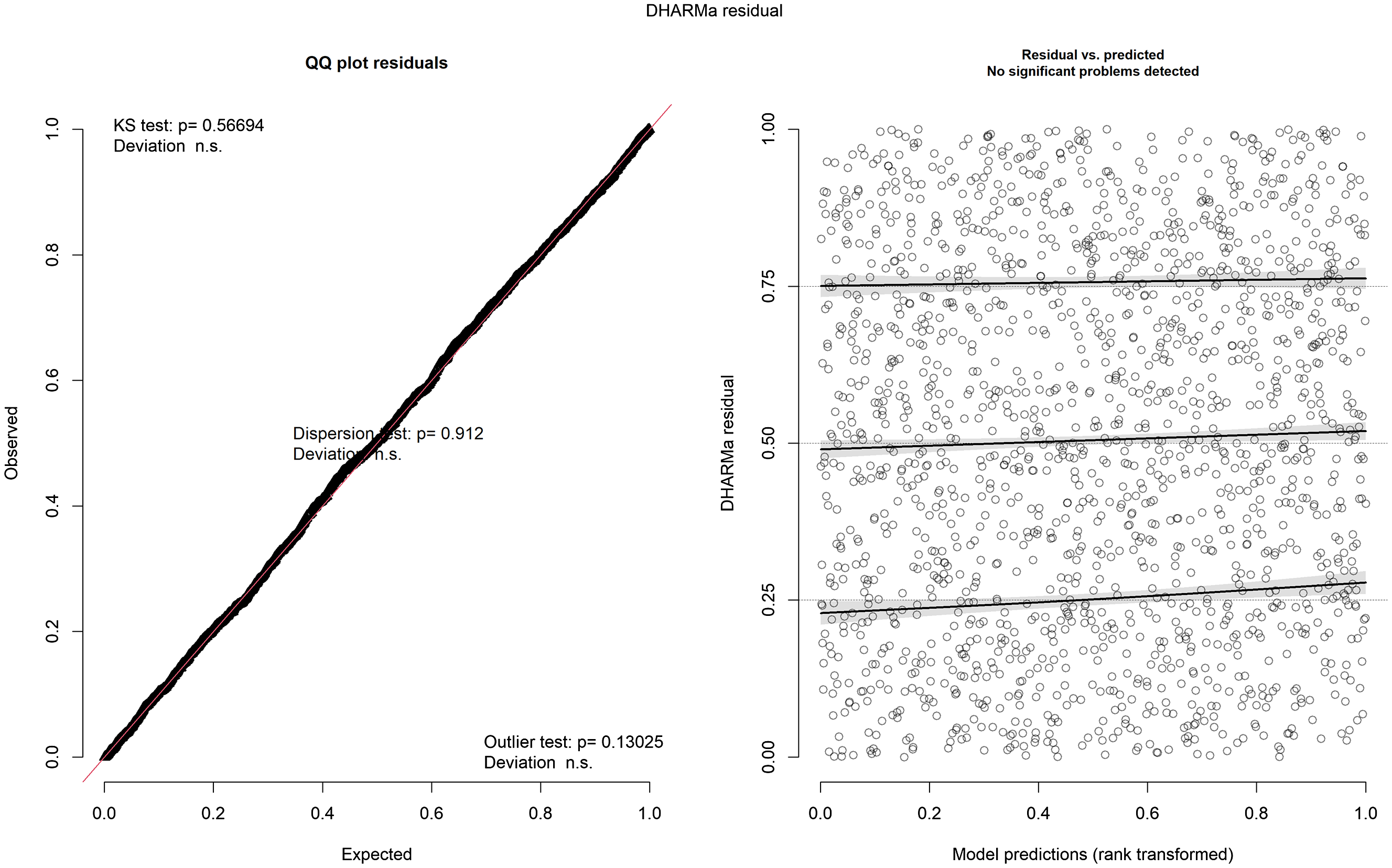
Figure 4. Distribution des résidus du modèle final, avec distribution attendue (expected) et distribution observée (observed). Les valeurs des différents tests statistiques sont affichées de part et d’autre du graphe de gauche (avec KS : Kolmogorov-Smirnov).
4.2.3. Résultats
Les résultats du modèle décrit ci-dessus sont présentés dans le Tableau 3.
Tableau 3. Résumé du modèle linéaire généralisé à effets mixtes relatif au comportement de la liquide (prononciation vs élision) pour les items lexicaux du corpus de conversation
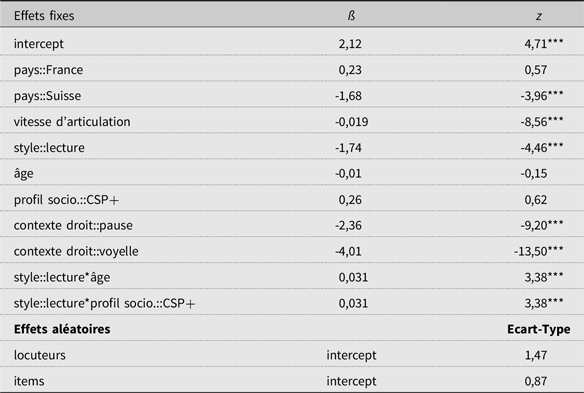
Note: *** indique que la probabilité (p) est inférieure à 0,001.
En premier lieu, comme on aurait pu s’y attendre à la lecture de la Figure 3 plus haut et comme on le voit sur la Figure 5, on peut voir que le contexte droit a une influence sur le comportement de la LFPO : celle-ci est significativement moins souvent prononcée devant consonne (58,5%) que devant voyelle (13,8%, avec p<0,001) ou devant pause (14,3%, avec p<0,001). Le modèle ne fait pas ressortir pas de différence entre les contextes de pause et de voyelle.
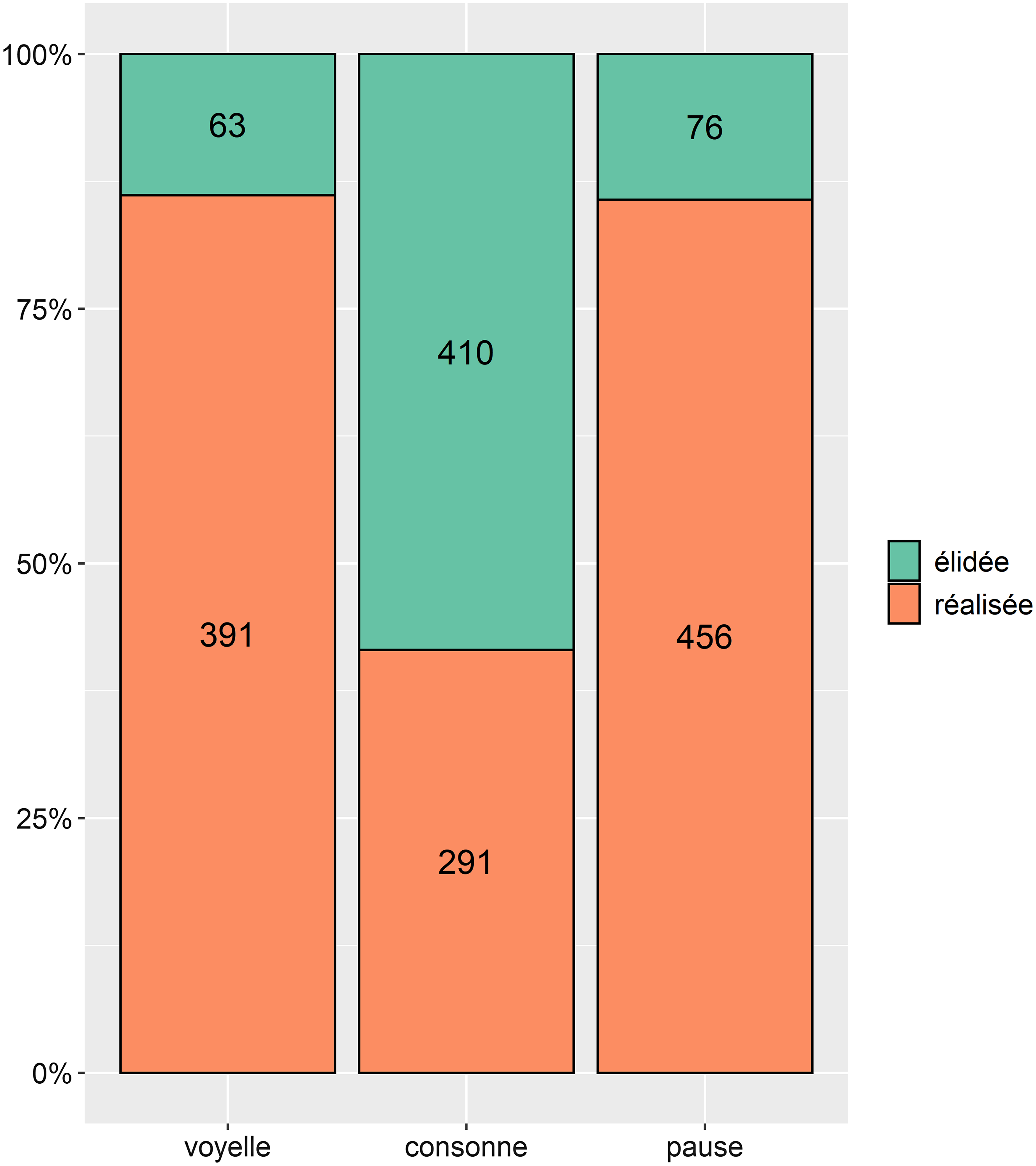
Figure 5. Distribution (en %) des liquides dans le corpus, en fonction de leur comportement (élidée ou réalisée) et du contexte droit (suivies d’un mot qui commence par une voyelle ou une consonne, suivies d’une pause).
Ensuite, on observe un effet de la vitesse d’articulation sur la variable dépendante. Comme on peut le voir sur la Figure 6, plus la durée syllabique augmente (donc que la vitesse d’articulation ralentit), plus les chances que la liquide soit prononcée sont élevées.
En ce qui concerne les variables extralinguistiques, on note un effet du pays d’origine des participants (Figure 7). Avec seulement 20,9% d’élision, les Suisses se démarquent significativement (p<0,001) des Belges (39% d’élision) et des Français (41%), qui ne se distinguent pas entre eux.
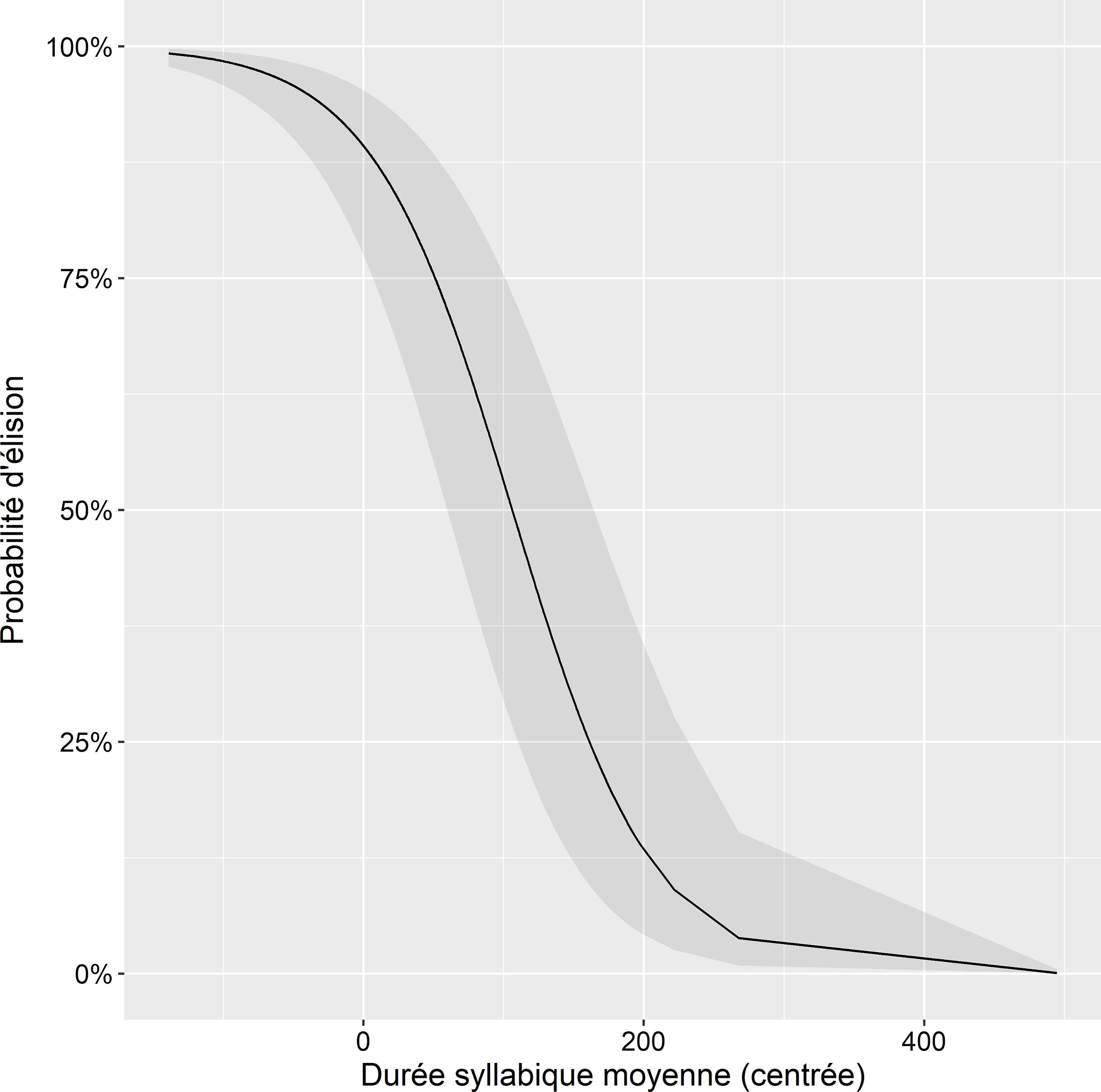
Figure 6. Probabilité d’élision de la liquide dans le corpus en fonction de la vitesse d’articulation (en ms, les valeurs sont ici centrées); la zone grisée rend compte de l’écart-type.
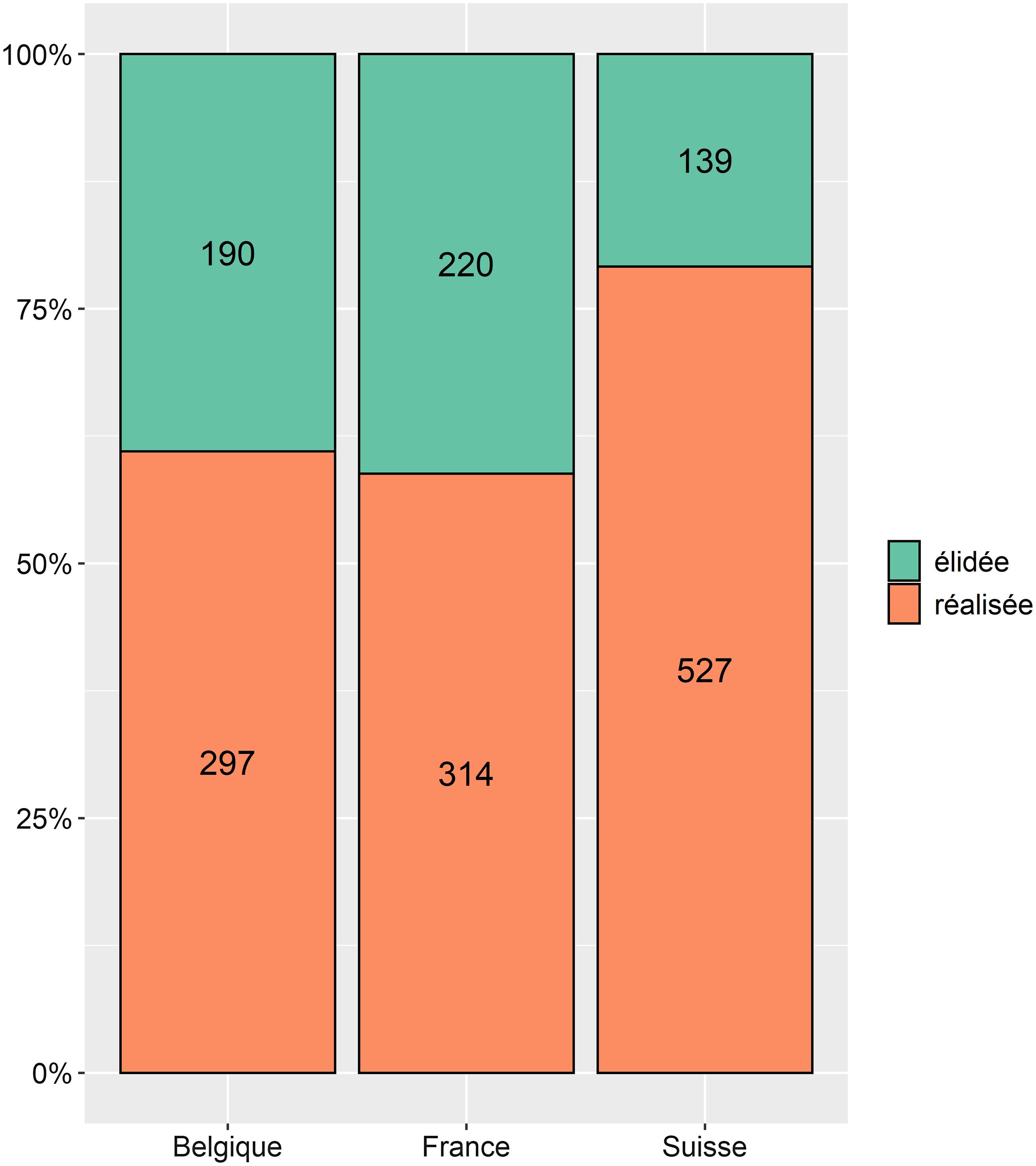
Figure 7. Distribution (en %) des liquides dans le corpus en fonction de leur réalisation (élidée ou réalisée) et du pays d’origine des participants.
On observe également un effet du style de parole sur le comportement de la variable dépendante : comme on l’a entraperçu sur la Figure 3 déjà commentée, en lecture, les liquides sont globalement plus souvent prononcées qu’en conversation (81,2% vs 42,5% d’élision). De façon intéressante, on observe toutefois que cet effet de style interagit avec l’âge des locuteurs. La Figure 8 montre que dans la tâche de lecture, plus les participants sont âgés, plus ils ont tendance à prononcer la liquide finale. En conversation à l’inverse, l’âge n’a strictement aucun impact sur le comportement de la variable à l’étude : le taux d’élision reste stable à travers les générations.
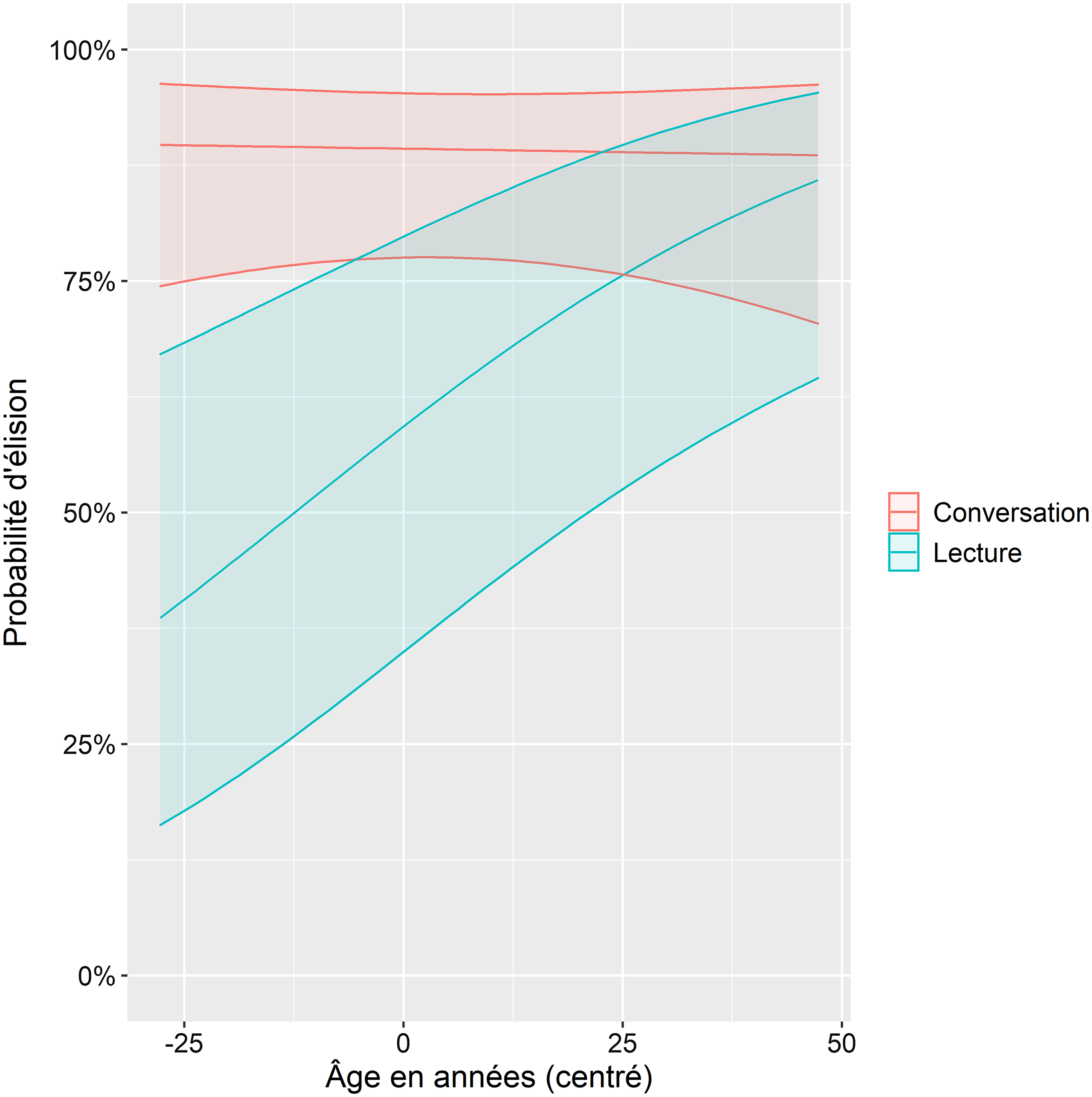
Figure 8. Probabilité d’élision de la liquide dans le corpus en fonction de l’âge des participants (en années, les valeurs sont ici centrées) et du style de parole (conversation ou lecture); les liserais autour des lignes rendent compte de l’écart-type.

Figure 9. Distribution (en %) des liquides dans le corpus de conversation (à gauche) et dans le corpus de lecture (à droite), en fonction de leur comportement (élidée ou réalisée) et du profil socio-économique des participants (CSP- ou CSP+).
Dans le même ordre d’idée, le modèle fait ressortir l’existence d’une interaction significative entre le style et le profil socioéconomique des locuteurs. En conversation, avec respectivement 52,2% et 61,7% d’élision, les locuteurs CSP+ et CSP- ne se comportent pas différemment les uns des autres. En lecture en revanche, avec respectivement 12,5% et 25,1% d’élision, les CSP- produisent significativement moins de liquides que les CSP+ (p<0,001) (Figure 9).
5. DISCUSSION
Sur la base d’un corpus comportant plus de 2500 unités analysées, nous avons pu dégager quelques grandes tendances permettant d’expliquer le comportement des liquides finales post-obstruantes en français.
En ce qui concerne les mots grammaticaux, nos analyses sont restées descriptives, compte tenu de la rareté des occurrences dans le corpus analysé (238 items), si bien qu’il est difficile de tirer des conclusions fermes quant à leur comportement.
Pour les mots lexicaux en revanche, le corpus a permis dans un premier temps de comptabiliser la fréquence des différentes stratégies à disposition des locuteurs lorsqu’ils étaient confrontés à la violation du principe de sonorité séquentielle. Il est apparu que l’articulation d’un schwa ne se faisait jamais ou presque devant voyelle, et qu’elle semblait plus fréquente devant consonne en lecture qu’en conversation. L’articulation d’un schwa reposant sur des contraintes qui lui sont propres, nous avons préféré laisser de côté ce phénomène pour nous concentrer sur les variables linguistiques et extralinguistiques qui peuvent expliquer la non-prononciation d’une liquide après une consonne obstruante en fin de mot.
Pour ce faire, nous avons conduit une analyse statistique au moyen de modèles généralisés à effets mixtes, qui permettaient de prendre en compte plus d’une douzaine de prédicteurs, ceux-là même qui ont été relevés dans la littérature. En pratique, nous avons examiné le rôle de prédicteurs relatifs aux propriétés phonétiques des LFPO (lieu et mode d’articulation des consonnes, types de cluster), à leur contexte (vitesse d’articulation, statut prosodique du mot hôte, contexte droit) et aux axes de la diavariation (diastratique, diatopique, diagénérationnelle, diagénique et diaphasique).
Du modèle effectué, il ressort que sur l’ensemble des prédicteurs analysés, la moitié d’entre eux se sont avérés jouer un rôle sur le comportement de la variable.
En ce qui concerne le contexte droit, on a vu qu’il n’y avait pas de différence entre les contextes vocalique et pausal, et que ce sont toujours les mots suivis par un mot à initiale consonantique qui se différencient des mots suivis par une voyelle ou par une pause. Ces résultats sont cohérents avec ce qui a été observé dans les recherches antérieures, la plupart des auteurs ayant conclu à l’importance d’une initiale consonantique par rapport à une initiale vocalique ou une pause dans le contexte droit de l’item hébergeant une LFPO (§2.2). En lecture comme en conversation, si la présence d’un mot à initiale vocalique favorise grandement l’articulation d’une liquide, on peut penser que c’est en raison de la possibilité de resyllabation qu’offre ce contexte (le syntagme centre informatique étant préférentiellement syllabé /sɑ̃.tʁɛ̃.fɔʁ.ma.tik/ que /sɑ̃tʁ.ɛ̃.fɔʁ.ma.tik/. Quant aux contextes de pauses, ils s’avèrent coïncider avec les frontières droites des constituants les plus hauts dans la hiérarchie prosodique (constituants qu’on appelle ‘syntagmes intonatifs’, v. Nespor et Vogel, Reference Nespor and Vogel1986; Delais-Roussarie, Reference Delais-Roussarie, Nespor and Smith1996). Or, on sait que dans ces contextes, les segments sont plus souvent mieux articulés qu’ailleurs (Fougeron, Reference Fougeron2001). Sur le plan perceptif, on comprend qu’il s’agit d’un contexte crucial, où l’absence d’une liquide se remarque davantage. Compte tenu du caractère profondément marqué socialement de l’élision des LFPO, cela explique sans doute pourquoi les contextes pré-pausaux favorisent autant l’articulation des liquides que les voyelles.
Un second paramètre s’étant avéré significatif concerne la vitesse d’articulation. Là aussi, ces résultats ne sont pas surprenants, dans la mesure où il a été prouvé, dans toutes les études précédentes sur les LFPO qui en ont tenu compte, que plus les locuteurs parlent vite et moins ils ont tendance à articuler les LFPO. Ce résultat confirme donc ce qui a été montré dans les recherches récentes sur la LFPO (§2.4), mais aussi que le comportement des LFPO ne diffère pas fondamentalement des autres phénomènes phonotactiques phares de la phonologie, comme le schwa (Bürki et al., Reference Bürki, Ernestus, Gendrot, Fougeron and Frauenfelder2011) et la liaison (Adda-Decker et al., Reference Adda-Decker, Delais-Roussarie, Fougeron, Gendrot and Lamel2012), tout aussi sensibles à ce paramètre.
Troisièmement, nos analyses ont fait ressortir un effet du pays d’origine des locuteurs. On savait que les locuteurs antillais et québécois avaient davantage tendance à simplifier les mots comportant une LFPO par rapport aux locuteurs de la partie septentrionale de la France (Pustka, Reference Pustka2007, Reference Pustka2011; Milne, Reference Milne2014), en raison pour les uns de l’influence du contact avec le créole, pour les autres de la distance plus grande qu’ils entretiennent avec la norme hexagonale. On savait aussi que les locuteurs du sud de la France, parce qu’ils produisent davantage de schwas, faisaient beaucoup moins chuter les LFPO que ceux de la partie septentrionale de la France (Pustka, Reference Pustka2007, Reference Pustka2011; Myers et Ranson, Reference Myers and Ranson2014). Notre étude permet de compléter nos connaissances du comportement des LFPO à l’échelle de la francophonie. Plus spécifiquement, il en ressort que les Suisses produisent davantage de LFPO que les Belges et les Français. On aurait pu penser que cette singularité des locuteurs suisses puisse être expliquée en raison d’un autre paramètre, la vitesse d’articulation, l’idée étant que les Suisses parlent plus lentement que les Français et les Belges (comme le montrent Schwab et Avanzi, Reference Schwab and Avanzi2015, qui ont travaillé sur le même corpus que nous avons utilisé dans cet article), et donc qu’ils articulent davantage de segments. L’absence d’interaction significative entre le pays et la vitesse d’articulation nous enjoint pourtant à exclure cette hypothèse. Une autre explication consisterait à dire que les Suisses se surveillent plus, par rapport aux Belges ou aux Français, quand ils parlent. Mais cela reste encore à prouver. Une comparaison avec les productions de locuteurs originaires de France voisine (Savoie, Franche-Comté) permettrait sans doute également d’y voir plus clair, et de confirmer que la tendance à articuler davantage les liquides post-obstruante est un marqueur phonétique propre au français de Suisse romande.
Enfin, on a vu que s’il existait des différences entre la lecture et la conversation, celles-ci dépendaient également du profil socioéconomique des locuteurs. À nos yeux, le résultat n’est pas si surprenant, car les locuteurs que nous avons catégorisés comme des CSP- ont a priori une moins bonne connaissance des normes de la lecture à voix haute par rapport aux locuteurs CSP+. Les CSP+ étant plus habitués à la pratique de la langue écrite, ils ont produit des enregistrements plus soignés et mieux articulés que les autres. Quant à savoir pourquoi cette différence ne se retrouve pas en conversation, c’est plus problématique en regard de ce qui avait été observé dans les travaux antérieurs. Nous proposerons deux explications, pas forcément incompatibles l’une avec l’autre. La première explication est que l’écart entre les CSP- et les CSP+ dans notre corpus n’est pas assez marqué, en d’autres termes que les différences sociales entre les locuteurs ne sont pas assez nettes. La seconde réside dans le fait que l’élision des liquides n’est peut-être pas un marqueur sociolinguistique de classe aussi puissant que l’on n’aurait pu le croire en conversation, du moins dans les situations d’entretiens du corpus PFC, ceux-ci élicitant une parole relativement finalement peut-être plus contrôlée ? Il serait utile, pour trancher en faveur de cette seconde interprétation, de tester le comportement d’autres marqueurs sociolinguistiques, morpho-phoniques (liaisons, chutes de <l> dans les pronoms sujets il et ils, absence du ne de négation, etc., v. Léon et Tennant, Reference Léon and Tennant1990, inter alia) dans le corpus.
Enfin, on a vu que les différences que l’on observe entre la conversation et la lecture ne sont pas les mêmes selon l’âge des locuteurs. Pour mémoire, il est apparu qu’en lecture, plus les participants étaient âgés, plus ils tendaient à articuler leurs liquides, alors qu’en conversation, aucun effet d’âge ne se faisait sentir sur la (non-)prononciation de la liquide. Ici encore, on ne peut pas invoquer la vitesse d’articulation pour expliquer cette différence. D’une part, on n’observe pas d’interaction entre le style et la vitesse d’articulation dans notre modèle. D’autre part, on sait que les francophones âgés articulent moins vite que les plus jeunes, mais que le style de parole n’a pas d’influence sur ce paramètre : en d’autres termes, la différence entre les participants âgés et les participants plus jeunes est stable entre la lecture et la conversation (Schwab et Avanzi, Reference Schwab and Avanzi2015). On serait donc tenté de voir ici un changement en cours dans les habitudes de lecture des francophones. De nos jours, les jeunes liraient moins soigneusement que les plus âgés.
Quant aux autres prédicteurs souvent invoqués dans la bibliographie sur le sujet, bon nombre ne sont pas ressortis comme pertinents pour décrire la variable à l’étude. Le fait d’avoir exclu de l’analyse les mots grammaticaux, qui se placent majoritairement dans le même groupe accentuel que le mot qu’ils précèdent, a sans doute permis de faire ressortir le caractère non pertinent de ce paramètre (ce qui n’est guère étonnant finalement, les frontières de groupes accentuels ne bloquant pas forcément les phénomènes de sandhis comme la liaison ou l’enchaînement, v. Avanzi et al., Reference Avanzi, Bordal and Obin2011). Pour les autres paramètres, les différences entre notre méthode et celles que d’autres ont suivies peuvent expliquer les différences. Dans notre étude, nous avons travaillé à partir de données alignées et vérifiées manuellement, ce qui n’est pas forcément le cas de nombreux chercheurs ayant publié avant les années 2010 (la technologie n’étant pas forcément aussi accessible qu’aujourd’hui). Or, quand on connaît la difficulté à identifier avec précision la présence ou non d’un segment dans la chaîne parlée, ce détail a son importance. Par ailleurs, l’utilisation de modèles statistiques élaborés, permettant de prendre en compte un grand nombre de paramètres dans un seul et même modèle, en ayant pris soin de tester auparavant le degré de multicolinéarité des facteurs, permet d’expliquer également les différences entre les résultats de recherches antérieures et les nôtres. Une explication, au sujet de l’absence de significativité de la fréquence lexicale, réside dans le format des modèles que nous avons utilisés. Ces modèles qui contiennent des effets ‘mixtes’ permettent de tenir compte aussi bien de la variation intra- et interlocuteurs que de la distribution des items dans le corpus. De fait, si ce paramètre de fréquence lexicale a pu ressortir comme significatif dans d’autres études, c’est parce que lesdites études ne tenaient pas compte du fait que certains locuteurs produisent plus de mots que d’autres, et que certains mots fréquents sont aussi plus souvent élidés que d’autres (v. Burki et al., 2011 pour des conclusions similaires en regard du schwa).
Enfin, pour terminer, signalons que cette étude comporte un certain nombre de limitations. Malgré la taille de notre corpus et le soin apporté à la sélection des items analysés, celui-ci n’a pas permis de faire de statistiques sur les mots grammaticaux. Or la non-prononciation des liquides finales post-obstruantes semble plus fréquente sur ce genre de mot : l’examen de ce genre de données doit être réalisé pour compléter les résultats présentés ici. Par ailleurs, le nombre de locuteurs (8 par point d’enquête) ne nous a pas permis de comparer plus finement les effets de région, certains auteurs ayant trouvé des différences entre l’est et l’ouest de la partie septentrionale de la France (Boughton, Reference Boughton, Jones and Hornsby2013) ou à l’intérieur de la Wallonie (Hambye, Reference Hambye2005). Un autre problème est que nous avons abordé la question du comportement comme une variable binaire (élision/articulation), alors qu’il est clair que le problème doit également tenir compte des phénomènes de réduction à l’œuvre dans la parole continue. Comme le montrent Burki et al. (Reference Bürki, Ernestus, Gendrot, Fougeron and Frauenfelder2011) sur le schwa, et plus récemment Brand & Ernestus (Reference Brand and Ernestus2021) sur les liquides, quand un segment est présent, il n’est pas toujours réalisé de la même façon, certaines formes étant plus raccourcies que d’autres. Reste également la question du schwa, stratégie alternative qui semble davantage utilisée en lecture qu’en conversation. L’analyse de ce paramètre, au moyen des mêmes prédicteurs pris en compte dans ce travail, devra être entreprise.
5. Conclusion
En conclusion, nous avons présenté dans cet article une analyse multifactorielle de la non-prononciation des liquides post-obstruantes finales de mot en français, un phénomène par lequel un <l> ou <r> final dans la transcription orthographique d’un mot tombe dans le flux de la parole, comme dans les items découvre et terrible, prononcés /dekuv/ et /teʁib/ et non /dekuvʁ/ et /teʁibl/. Plus de 2500 items contenant un cluster obstruante+liquide en fin de mot ont été extraits d’un corpus de parole de 13 heures, étiqueté à différents niveaux et comprenant des productions de 120 locuteurs originaires de 3 pays francophones (Belgique, France et Suisse) et enregistrés en deux tâches différentes (lecture et conversation). Les résultats obtenus ont permis de porter un regard nouveau sur les paramètres qui motivent l’élision des liquides post-obstruantes finales de mots. Nous avons pu voir que parmi les variables phonotactiques, lexicales, prosodiques, sociolinguistiques et stylistiques, le contexte droit (mot suivi d’une consonne, d’une voyelle ou d’une pause), la vitesse d’articulation, l’origine géographique et le profil socioéconomique, tout comme le style de parole (lecture vs conversation) permettaient d’expliquer en grande partie les phénomènes d’élision de LFPO en français. L’étude a laissé de côté un certain nombre de faits, comme le caractère binaire ou graduel des phénomènes de facilité de prononciation ou la présence d’un schwa. Ces facteurs devront être pris en compte dans le futur.
Remerciements
Nous sommes très reconnaissants envers Sandrine Brognaux, George Christodoulides, François Delafontaine, Jean-Philippe Goldman et Sandra Schwab pour leur aide précieuse dans la transcription, le codage et l’extraction des données. Nous tenons également à remercier chaleureusement les trois évaluateurs de la revue pour leurs commentaires constructifs sur une version antérieure de cet article. Leur expertise a été d’une grande aide pour améliorer la qualité de notre travail.
Competing interests
The author declares none.
Conflits d’intérêts
L’auteurs n’en déclare aucun.













 Open access
Open access