


MACHINE LEARNING IN ARCHAEOLOGY
Machine learning (ML) is gaining prominence in the media and in the academic literature. This review briefly describes what ML is, how it is being used in archaeology today, and where it might be used in the future for archaeological purposes. The rapid growth in the use of ML, due in large part to the increasing accessibility and capability of the algorithms, has meant that the number of publications far outpaces any attempt to cover this in a short article. The selected publications mentioned here demonstrate how diverse, vibrant, and innovative this research has become. This research also demonstrates some of the challenges of using ML, ranging from managing the sparse and complex datasets to systemic biases that can influence the results.
Machine learning describes the study and programming of algorithms allowing computers to learn from data and then make predictions from those data (see, for example, Shalev-Shwartz and Ben-David Reference Shalev-Shwartz and Ben-David2014). Broadly, ML uses statistical techniques to analyze a set of categorized “training” data to derive a series of mathematical classifiers (“descriptors” or “feature vectors”) for each data category. The resulting classification system ideally means that objects in each category are mathematically identifiable as distinct from objects in all other categories. This trained classification model finds the best set of mathematical “features” to reliably identify examples for the categories. In other words, the computer can use math to classify quantifiable objects into distinct groups (Figure 1).
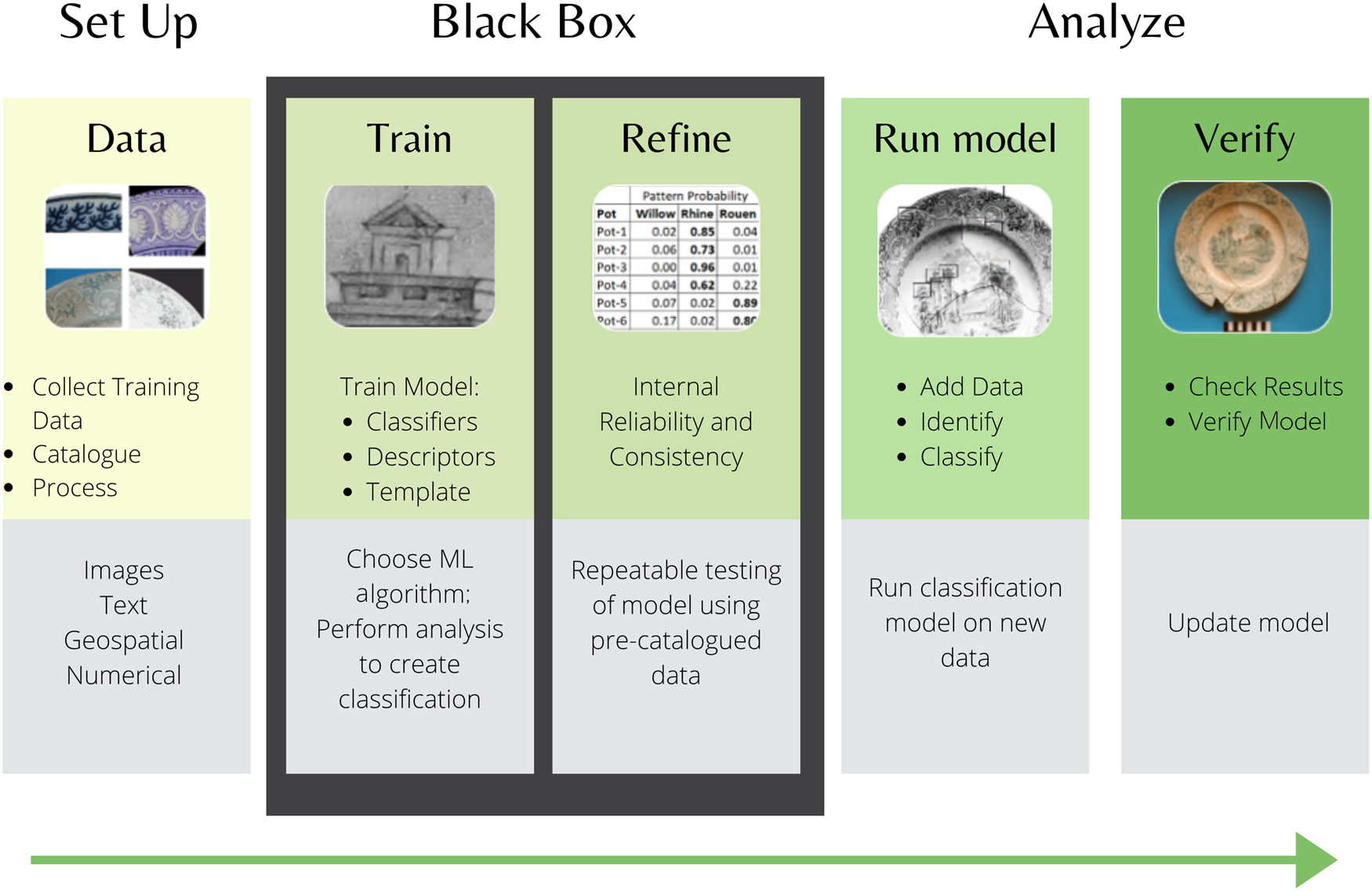
FIGURE 1. Schematic overview of the process of machine learning applied to archaeological data, showing an example of matching decorative patterns on historical ceramics.
Dunnell's (Reference Dunnell1971) Systematics in Prehistory was prescribed reading for many students, and it has long cemented classification as a central focus for archaeologists. ML takes many of the relatively familiar statistical techniques of classification—such as factor, discriminant, and cluster analyses—to another level. It does this by closing the loop on the construction of a classification schema based on a “known”—and large—set of data to test and tune the model. This makes the classification as internally consistent as possible. Less familiar algorithms, such as those associated with neural networks, add other methods to manage noise in the data, reliability, and efficiency in the models.
In short, given a known set of classified data, ML algorithms are “trained” to understand the mathematical rules underpinning that classification, which are then used to extract, classify, sort, and draw conclusions from a new set of related data. The data that can be analyzed includes all kinds of numeric and textual information, images, and spatial-temporal datasets. Digital data is all numbers to a computer!
MACHINE LEARNING FOR ARCHAEOLOGICAL DATA
Archaeological data is also probably better described as “slow data” (see, for example, Heitman et al. Reference Heitman, Worthy and Plog2017; Kansa and Kansa Reference Kansa and Kansa2016). Whereas “Big Data” approaches focus on managing data flowing in on a continuous or near-continuous basis, archaeological data can be very slow to create—sometimes taking years or decades—and is delivered in large “lumps” of complex contextualized information. ML provides the opportunity to process such “lumps” of data, create models from those data, and then use that analysis to interpret subsequent data. These methods enable not only the sorting and management of new data but also learning from the new data and the reincorporation of the results into more robust interpretations. ML works best on highly structured and large datasets, but there are ways of using it to explore the sparse and messy datasets archaeologists often obtain.
Although ML can be applied to a range of digital data, to date, archaeologists have broadly focused on the following types:
• Numerical and/or categorical data
• Textual data
• Images
• Geospatial data
As noted earlier, ML algorithms on numerical and categorical data are very much extensions of the traditional statistical techniques (Hörr et al. Reference Hörr, Lindinger and Brunnett2014). For example, the ML analysis of chemical data for provenience studies that rely on cluster and factor analysis can be less influenced by the statistical requirements of those algorithms and can be refined as new data becomes available (Hazenfratz Marks et al. Reference Hazenfratz Marks, Munita and Neves2017). Similarly, ML has been used for pattern classification of pottery styles (Bickler Reference Bickler2018a; Chetouani et al. Reference Chetouani, Treuillet, Exbrayat and Jesset2020; Romanengo et al. Reference Romanengo, Biasotti and Falcidieno2020).
Textual data have also been analyzed using ML, including the analysis of archaeological records to extract key information or develop more consistent data (Brandsen et al. Reference Brandsen, Verberne, Wansleeben, Lambers, Calzolari, Béchet, Blache, Choukri, Cieri, Declerck, Goggi, Isahara, Maegaard, Mariani, Mazo, Moreno, Odijk and Piperidis2020; Davis Reference Davis2020; Felicetti Reference Felicetti2017). More dramatically, ML techniques offer the possibility of automating the translation of ancient languages such as Egyptian hieroglyphs (e.g., FabriciusFootnote 1; Sanders Reference Sanders2018).
The processing of images using ML has been one of the most productive areas to date for archaeologists. The forms of the images vary from photographs to stylized drawings of archaeological objects. Typically, ML has been used to identify “objects” within images, describe rock art and structural elements of buildings (Kogou et al. Reference Kogou, Shahtahmassebi, Lucian, Liang, Shui, Zhang, Su and van Schaik2020; Prasomphan and Jung Reference Prasomphan and Jung2017; Tsigkas et al. Reference Tsigkas, Sfikas, Pasialis, Vlachopoulos and Nikou2020), and analyze designs as well as tool and vessel forms (e.g., Bevan et al. Reference Bevan, Li, Martinon-Torres, Green, Xia, Zhao, Zhao, Ma, Cao and Rehren2014; Gualandi et al. Reference Gualandi, Gattiglia and Anichini2021; Nash and Prewitt Reference Nash and Prewitt2016; Pawlowicz et al. Reference Pawlowicz, Downum and Terlep2017); to identify shell or animal bone (Bickler Reference Bickler2018b; Huffer and Graham Reference Huffer and Graham2018); and to document use wear and damage on tools and ecofacts (Byeon et al. Reference Byeon, Dominguez-Rodrigo, Arampatzis, Baquedano, Yravedra, González and Koumoutsakos2019; Cifuentes-Alcobendas and Domínguez-Rodrigo Reference Cifuentes-Alcobendas and Domínguez-Rodrigo2019; Grove and Blinkhorn Reference Grove and Blinkhorn2020).
ML processing roles therefore range from sorting and filtering archaeological images to improving the management or accessibility of image data for analysis (e.g., Engel et al. Reference Engel, Mangiafico, Issavi and Lukas2019) through to the creation of automated or semiautomated processes (where expert oversight is used alongside the ML algorithms) for classification of form, taphonomy, and function (e.g., Gualandi et al. Reference Gualandi, Gattiglia and Anichini2021). ML also can be used in the reconstruction of vessels based on pattern matching of shapes and decoration or as jigsaw-puzzle solvers (Cintas et al. Reference Cintas, Lucena, Fuertes, Delrieux, Navarro, González-José and Molinos2020; Felicetti et al. Reference Felicetti, Paolanti, Zingaretti, Pierdicca and Malinverni2021; Ostertag and Beurton-Aimar Reference Ostertag and Beurton-Aimar2020).
Another benefit of the ML approach is that multiple algorithms can automatically be applied to the same dataset at the same time to form competing classifications. In this way, the “best” algorithm, with appropriate parameters, can be determined. Such automated machine learning can be advantageous because most archaeologists will tend to use a limited range of statistical algorithms with which they are familiar rather than pick and choose from those that suit specific datasets.
The difficulties of creating models with limited training material available from archaeological situations can be mitigated using “transfer learning.” Pretrained models that extract relevant features from a general set of nonarchaeological images can be supplemented with a smaller library of preclassified images relevant to the specific task. This allows the model to create the most relevant descriptors for distinguishing archaeological features from each other (see Horton and Paunic Reference Horton and Paunic2017). Such “transfer learning” is likely to become a dominant way of building useful ML models for archaeology.
THE SEARCH FOR SITES
Perhaps the most active area for archaeologists using ML relates to geospatial data. Rarely does archaeology generate the large quantities of systematically coded data at a pace that makes ML so effective in commercial environments. The increasing availability of large-scale lidar, satellite, and aerial imagery on local, regional, and national scales, however, is transforming archaeology around the globe—particularly the searching and mapping of archaeological sites (Figure 2). ML algorithms can be used to process the geospatial data in the search for sites in diverse environments (Bonhage et al. Reference Bonhage, Eltaher, Raab, Breuß, Raab and Schneider2021; Caspari and Crespo Reference Caspari and Crespo2019; Davis Reference Davis2019; Davis, DiNapoli, et al. Reference Davis, DiNapoli and Douglass2020; Davis, Seeber, et al. Reference Davis, Seeber and Sanger2020; Evans and Hofer Reference Evans and Hofer2019; Guyot et al. Reference Guyot, Hubert-Moy and Lorho2018, Reference Guyot, Lennon, Lorho and Hubert-Moy2021; Orengo et al. Reference Orengo, Conesa, Garcia, Green, Madella and Petrie2020; Soroush et al. Reference Soroush, Mehrtash, Khazraee and Ur2020; Thabeng et al. Reference Thabeng, Merlo and Adam2019; Trier et al. Reference Trier, Salberg, Pilø, Matsumoto and Uleberg2018, Reference Trier, Cowley and Waldeland2019; Verschoof-van der Vaart and Lambers Reference Vaart, Wouter and Lambers2019; Verschoof-van der Vaart et al. Reference Vaart, Wouter, Lambers, Kowalczyk and Bourgeois2020).

FIGURE 2. An illustrative fictional example of how machine learning may be applied to feature identification in geospatial data and the reconstruction of a site.
The construction of the ML models can help to identify the contribution of different variables that are useful predictors of where sites are found across landscapes (Sharafi et al. Reference Sharafi, Fouladvand, Simpson and Alvarez2016; Zheng et al. Reference Zheng, Tang, Ogundiran and Yang2020). The different scales in which these models can operate empower archaeologists when cataloguing heritage by thematic choices, morphology, and environmental context, which in turn makes for both better heritage management (e.g., Castiello and Tonini Reference Castiello and Tonini2019; Davis, Seeber, et al. Reference Davis, Seeber and Sanger2020; Jones and Bickler Reference Jones and Bickler2017) and more detailed research around the world (e.g., Caspari and Crespo Reference Caspari and Crespo2019; Freeland et al. Reference Freeland, Heung, Burley, Clark and Knudby2016).
These ML approaches to heritage landscapes can be used to assist in mitigating some of the difficulties of predictive modeling for cultural resource management (see, for example, Dore and Wandsnider Reference Dore, Wandsnider, Mehrer and Westcott2006). This includes methods to test the internal consistency of the ML predictions and to explore in more detail the relevant factors that contribute to the presence and absence of archaeological sites in a landscape. This can be critical in areas where physical access or visibility of archaeological sites is difficult.
BLACK BOXES
The complexity of the ML algorithms is significant and the amount of work to create new models is substantial. The result of this complexity, however, is often a “black box” approach that relies on a previously created classification model and a need to accept the applicability to new data without getting too concerned over the mathematics and its possible limitations (Figure 1).
For many archaeological applications where the ML is an assistant to more detailed work, such analysis may be more than adequate. Where the objectives might be to identify a range of new possibilities for the location of sites or to assist in sorting artifact types, the benefits of machine-assisted classification, checked by additional archaeological investigation such as fieldwork, can be significant.
Byeon and colleagues (Reference Byeon, Dominguez-Rodrigo, Arampatzis, Baquedano, Yravedra, González and Koumoutsakos2019:41), for example, in their analysis of cut marks on bones suggest that their model is more reliable than manual systems. Most ML models of archaeological data, however, are likely to be less reliable than those of expert traditional methodologies because they are as yet unable to manage the range of variation and inconsistencies of archaeological data. This may be offset by major time-saving and scalability benefits, which allow the experts to focus on the more difficult or contentious examples.
Typically, the most significant hurdle to constructing good ML models is that they work best when built on large databases of information, such as thousands of catalogued images or reliably sourced material, which can be difficult to achieve, especially on archaeological budgets and with the diversity of data that may be available. The nature of archaeologically recovered samples, with poor preservation, makes the task even more difficult because fragmentation and surface state (including erosion, patina, and vegetation coverage, for example) can affect the success of identification. Specialists can typically identify material with which ML models trained on idealized collections would struggle.
The implications of this are that managing the ML models’ misclassification, resulting in either targets being wrongly classified or not classified at all, should be part of the strategy for their use in archaeological situations. The algorithms usually offer a range of ways of establishing their mathematical robustness, but archaeologists still need to ensure that the results stand up to scrutiny in the real world.
AVOIDING BIAS
Another aspect of ML is that the models are very much a product of the data from which they are built. As a result, the models tend to classify according to the categories they know about, which makes them susceptible to (at least) two major forms of bias.
The first relates to a form of lumping an assemblage into previously determined categories. This means that rare and unusual objects can easily be missed by being grouped with a more common type. A ceramic vessel of similar shape to one of the modeled forms, for example, may look “normal” but could have an unusual surface treatment that would immediately be noted by an archaeologist.
A second form of bias, and probably the most common, is that the models cannot fully incorporate the variability of the features being classified. ML analyses are susceptible to missing the “forest for the trees” because the data used to train the models are often stripped of contextual information (especially in the case of images) or operate on a limited set of prechosen variables that may not include sufficient information to distinguish between important (that is, archaeologically relevant) classes.
ML techniques do have ways of checking “performance,” but these still rely on internal mathematical measures and require attention from archaeological research to ensure that they are delivering good results. Difficulties with ML have repeatedly been encountered outside of archaeology including exacerbating race and gender biases in commercial situations (Gebru Reference Gebru, Dubber, Pasquale and Das2020).
This sort of bias is of particular concern for archaeologists using ML on data associated with Indigenous communities. Optimization techniques, such as least-cost analysis, generally result in outcomes that are based on behavioral elements such as “energy” efficiencies. “Success” is therefore measured in terms of purportedly “scientific” measures. Archaeologists engaging with Indigenous communities that are using models based on acultural—or ethnocentric—assumptions can create interpretations that are stripped of cultural context and meaning. Increasingly, those assumptions are being challenged as measures of success, especially as Indigenous forms of inquiry focus on behaviors and outcomes rooted in cultural value systems (see, for example, Davis, DiNapoli, et al. Reference Davis, DiNapoli and Douglass2020; Douglass et al. Reference Douglass, Morales, Manahira, Fenomanana, Samba, Lahiniriko, Chrisostome, Vavisoa, Soafiavy, Justome, Leonce, Hubertine, Pierre, Tahirisoa, Colomb, Lovanirina, Andriankaja and Robison2019). Archaeologists bear the responsibility of ensuring that their research contributes to descendant cultures (e.g., Allen and Phillips Reference Allen, Phillips, Phillips and Allen2010; Solomon and Forbes Reference Solomon, Forbes, Phillips and Allen2010).
EVOLUTION OR REVOLUTION
Archaeologists are not likely to be replaced in the foreseeable future by an insurrection of archaeological robots. Harari (Reference Harari2017) has given us a 97% chance of keeping our jobs! The real revolution for archaeologists is less about ML and more about the fact that ML, along with other forms of analysis, will allow for the use of a larger—and rapidly expanding—corpus of archaeological data. This transformation is shifting both academic and cultural resource management inquiry. Many of its applications are evolutionary, greatly improving the types, scale, and complexity of analytic tools that archaeologists already use.
There is no doubt that ML can significantly aid identification of archaeological samples with the potential to draw upon an ever-improving and ever-expanding library of data. This makes sharing data from projects much more important. The reward for this is making identification of new data easier and more reliable, which offers advantages for not only research objectives but also cultural heritage, where improvements can have significant financial benefits. The revolution will be in integrating these outcomes into both academic and cultural resource management frameworks, which is a significant challenge given that archaeologists will have to become competent in managing this much richer and more diverse information (Kansa and Kansa Reference Kansa and Kansa2021).
Acknowledgments
I would like to thank Peter J. Cobb for providing me with the opportunity to write this article and for discussions. Dorothy Brown helped sort out the text and references, for which I am most grateful. My thanks to University of Hong Kong undergraduate student Agnes Pui Yee Sung for redrawing Figure 1. Thomas MacDiarmid built the 3D model for Figure 2 based on precolonial Māori archaeological sites. I acknowledge the incorporation of mātauranga Māori (Indigenous knowledge) in that work.


