


Introduction
Algorithms are playing an increasingly important role in the modern economy and, more recently, civic life. Online search engines, digital media, and e-commerce websites have long made use of recommendation systems to filter, sort, and suggest the products and media we consume on the internet. However, with the rise of social media and scientific developments in artificial intelligence research, algorithms have started to impact how decisions are made in entirely new domains. The influence of algorithms can be found in the structure of our social networks, whom we marry, what news articles we see, and what jobs we get.
As algorithmic suggestions and decisions have proliferated, so too has an awareness – and, increasingly, wariness – about the impact that algorithms are having on society. This has included specific concerns about racial disparities in the predictive accuracy of recidivism prediction instruments (Reference Angwin, Larson, Mattu and KirchnerAngwin et al. 2016), gender bias in how digital job advertisements are placed (Reference Lambrecht and TuckerLambrecht and Tucker 2016), the ability of dynamic pricing algorithms to discriminate indiscriminately (Reference Miller and HosanagarMiller and Hosanagar 2019), the role of news-filtering algorithms in polarizing our political discussions (Reference PariserPariser 2014), and a general concern about the ethics of using the unprecedented power of artificial intelligence for private and governmental surveillance (Reference TufekciTufekci 2017; Reference ZuboffZuboff 2019). All of this attention has led to an increased scrutiny of not just the institutions behind these technologies, but also the mathematics of the specific algorithms driving these systems and the decisions of the people engineering them.
As such, articulating and understanding the roles that algorithms play in shaping our society is no longer an academic exercise. In April 2019, a group of US Senators proposed the “Algorithmic Accountability Act” (AAA), in which they raised concern about the potential for “automated decision systems” to exhibit bias and discrimination (among concerns such as privacy and security) (Reference BookerBooker 2019). Their proposed remedy would require firms to conduct “impact assessments” of their internal algorithms and security systems. Despite the inherent complexities involved in assessing the impact of algorithmic social systems, this process may soon be a legally required undertaking for many organizations. As we begin to debate, study, legislate, and influence the role of algorithms in our society, it is essential to have a common (and commonsense) characterization of how algorithmic social systems function. What are the inputs of these systems? What influence do these inputs have on outcomes of interest?Footnote 1 What properties, rules, or dynamics of these systems generalize across different contexts?
In this chapter, we introduce a framework for understanding and modeling the complexities of algorithmic social systems. While some commentators have directly implicated “algorithms,” “machines,” “software,” and “math” as the primary source of concern in many systems, we believe this language masks what are sometimes the most important dynamics for determining outcomes in these systems (Reference EubanksEubanks 2018; Reference KnightKnight 2017; Reference O’NeilO’Neil 2017). Algorithms do not emerge out of thin air; their impact is driven by not just the mathematics behind them, but also the data that feed them, and the systems they interact with. We use this framework to propose a description of algorithmic systems being comprised of three fundamental factors: The underlying data on which they are trained, the logic of the algorithms themselves, and the way in which human beings interact with these systems (see Figure 4.1). Each of the individual factors in these systems plays an important role and can, in various circumstances, have the largest responsibility in determining outcomes. Furthermore, as we will demonstrate concretely, the interactions between the various components can also have significant impact, making targeted interventions difficult to evaluate ex ante and cross-context comparisons difficult to generalize between different circumstances.

Figure 3: The results of algorithmic systems can be attributed to their underlying data, the mathematical logic of the algorithms, and the way people interact with these factors.
As researchers attempt to study algorithmic social systems and lawmakers get closer to drafting legislation that regulates the inputs and outputs of these systems, we believe it is important to consider the challenges of ascribing blame, liability, and responsibility in the many circumstances in which automated decisions play a significant role. Our framework provides a scaffolding on which analysis of any algorithmic social system can be conducted. While we advocate for nuance and rigor in the assessment of algorithmic systems, we are not suggesting that such systems are simply too complex to understand, analyze, or influence. Indeed, the purpose of our framework is to encourage researchers, policymakers, and critics to (first) identify each of three components – data, algorithms, and people – when discussing the prospect of intervening in an algorithmic social system and (second) ensure the responsibilities and intended consequences of such interventions are well-articulated for each of the system’s components. This framework provides a principled starting point for modeling the key factors involved with complex algorithmic systems.
Case Study: Filter Bubble
To illustrate the utility of our framework for understanding the impact of algorithms in a particular context, we focus our attention on a hotly debated topic in the social sciences in recent years: The phenomenon of “filter bubbles” and the role that algorithms have played in creating them.Footnote 2 In the United States,Footnote 3 social media and search engines are increasingly prominent sources of news, with up to two-thirds of Americans relying on social media for news in their daily lives (Reference MoonMoon 2017). However, many commentators have raised concerns about the way in which these news platforms fragment our social fabric: Because psychometric algorithms at large tech companies are able to learn users’ preferences over time, the more people use these tools, the less likely it is that they will come across articles from perspectives that are different from their own (Reference PariserPariser 2014; The Economist 2017). The Obama Administration raised concern about this phenomenon in their 2016 White House Report on “Big Data”, in which they specifically referred to algorithms “that narrow instead of expand user options” as being a “hard-to-detect flaw” in the design of personalized services (Obama 2016). Especially given the scholarship on the increase in political polarization in the United States over the last several decades, we are at a moment when shared values and information environments are already under threat (Reference SunsteinSunstein 1999; Reference Achenbach and ClementAchenbach and Clement 2016). Any role that algorithms and technology platforms play in increasing social fragmentation – for example, by exclusively serving conservative news to conservative users and liberal news to liberal users – is worth investigating and understanding.
Such an understanding will be necessary if our goals – as individuals, scholars, activists, and policymakers – are to mitigate the negative consequences of online filter bubbles. The importance of developing a clear understanding of online platforms’ roles in the filter bubble phenomenon is underscored by a recent legislative proposal, introduced on the floor of the United States Senate in November 2019, named the “Filter Bubble Transparency Act” (FBTA). Separate from the Algorithmic Accountability Act, and designed specifically with the consumers of social media and political news in mind, this legislation has a stated purpose of guaranteeing Americans the right to “engage with a [media] platform without being manipulated by algorithms driven by user-specific data” (US Senate 2019).
In their attempts to legislate the use of personal data by internet platforms, the authors of the bill distinguish between two types of “user-specific” data: That which were “expressly provided by the user to the platform” for the purpose of an “algorithmic ranking system,” and that which were not. The bill specifies that platforms are allowed to use the list of accounts that someone subscribes to on social media to determine what content they will see. However, any filtering, ordering, or ranking of someone’s content feed – outside of chronological ordering – would require that platforms show “a prominently placed icon” near their content feeds. This icon would serve two primary purposes: (1) inform users that their feeds are being filtered based on their user-specific behavioral data and (2) allow users to select between an algorithmically ranked feed and a chronological feed.Footnote 4
Given the name of the bill itself, the implicit assumption of these regulations is that requiring platforms to be more transparent and giving users the option to avoid algorithmic filtering will alleviate some problems associated with digital filter bubbles. But to what extent are these assumptions true? In an effort to enrich our understanding of how this and other potential interventions might affect users’ online browsing behaviors, we review relevant research on the roles of people, data, and algorithms in determining filter bubble effects on social media and content aggregation platforms.
Review of Related Literature
We review several empirical studies that attempted directly to compare the effects between different factors in our framework applied to digital media platforms. These studies give us some insight into how significant each of the factors are in determining the extent of the filter bubble effect by attempting to quantify the political diversity of internet users’ media consumption.
We begin by considering research on users of Facebook, the largest social media network in the world and often the focus of discussions about digital filter bubbles. While much of the platform’s data are kept proprietary, researchers at Facebook published a large-scale study of real-user behavior in 2015 (Reference Bakshy, Messing and AdamicBakshy, Messing, and Adamic 2015). By looking at the behavior of 10.1 million active Facebook users in the US who self-reported their political ideology (“conservative,” “moderate,” and “liberal”), the researchers analyzed how the social network influences its users’ exposure to diverse perspectives. The researchers then calculated what proportion of the news stories in these users’ newsfeeds was crosscutting, defined as sharing a perspective other than their own (for example, a liberal reading a news story with a primarily conservative perspective).
To evaluate the impact of Facebook’s newsfeed algorithm, the researchers identified three factors that influence the extent to which we see crosscutting news. First, who our friends are and what news stories they share; second, among all the news stories shared by friends, which ones are displayed by the newsfeed algorithm; and third, which of the displayed news stories we actually click on. Note that this systematic approach to decomposing the impact of the newsfeed algorithm is similar to the data-algorithm-people framework we proposed earlier. In the context of a social media newsfeed, the primary data that feed into Facebook’s algorithm are the articles shared by one’s network. The algorithm then chooses which articles to display, from which individual users select a subsample of articles to click on and read. Each of these steps interacts in a dynamic process that determines the intensity of our ideological segregation.
By systematically comparing the extent to which exposure to crosscutting news is affected by each step in this filtering process, the researchers were able to quantify how much each factor affected the ideological diversity of news consumption on Facebook. If the second step – the newsfeed algorithm itself – is the primary driver of the echo chamber, this would suggest that Facebook’s design choices and the specific logic of its filtering algorithms play a significant role in driving online polarization. By way of contrast, if the first or third steps are more responsible for the filter bubble, it would suggest that the data and ways we interact with algorithmic suggestions are more significant than the algorithms themselves. Of course, this would not absolve Facebook from all responsibility in the development of filter bubbles, but it would suggest that focusing on algorithms specifically as the primary driver of polarization would be a parochial way of understanding the problem.
Interestingly, it is this latter hypothesis that was borne out by Facebook’s study. The researchers found that if users acquired their news from a randomly selected group of Facebook users, nearly 45 percent of stories seen by liberals and 40 percent seen by conservatives on Facebook would be crosscutting. However, because users come across stories from their self-selected network of friends, the researchers found that only 24 percent of news stories shared by liberals’ friends were crosscutting and about 35 percent of stories shared by conservatives’ friends were crosscutting. The friends people choose to associate with on Facebook play a dramatic role in reducing the diversity of news we see on the platform (relative to what is shared by the broader US population). Because we are more likely to be connected to friends with interests similar to our own (a phenomenon known as “homophily”), the news items those friends share are more likely to agree with our preexisting ideological positions than a random sample of news items across Facebook (Reference McPherson, Smith-Lovin and CookMcPherson et al. 2001).
The study also found that the newsfeed algorithm did reduce the proportion of crosscutting news stories (to 22 percent for liberals and 34 percent for conservatives). However, the magnitude of this reduction was significantly smaller than that attributable to the self-selection process in the first step. Facebook’s algorithm does exacerbate the filter bubble, but not by much. The last step in the filtering process – the extent to which we actually click on crosscutting news stories – further reduces the ideological diversity of our news. But again, the magnitude of this effect is modest: The final proportion of crosscutting news stories we click on is 21 percent for liberals and 30 percent for conservatives (see Figure 4.2).
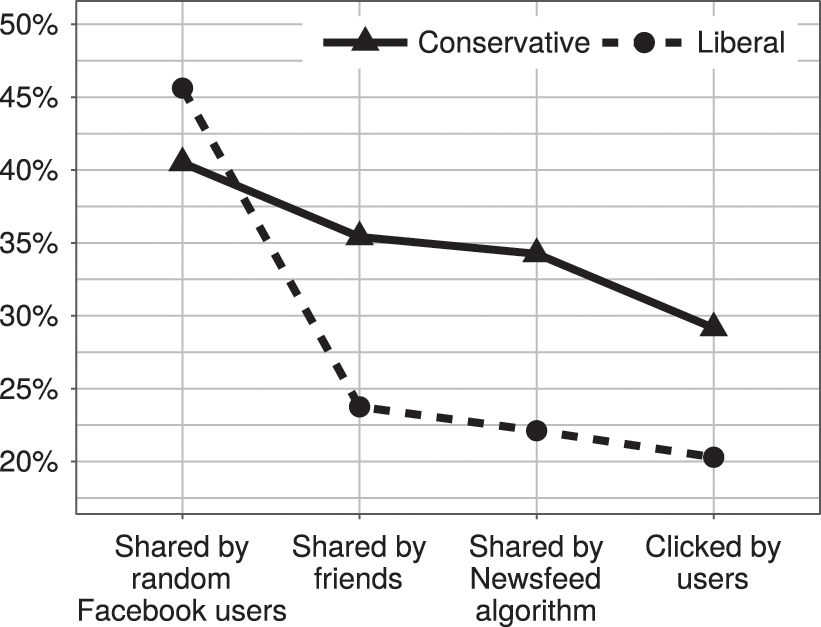
Figure 4: Summarized results of “Exposure to ideologically diverse news and opinion on Facebook” (based on data presented in Science, 2015).
Given that the research cited above was conducted in-house by Facebook social scientists, critics may be skeptical of these findings. However, the results described above are consistent with another recent study on the topic of filter bubbles. Using an independently gathered dataset on web-browsing behavior, Reference Flaxman, Goel and RaoFlaxman, Goel, and Rao (2016) were able to isolate the impact of social media on news consumption patterns relative to other channels, such as news aggregators, search engines, and direct referrals (e.g., through bookmarks or typing specific websites into the browser’s address bar).
While this cross-channel comparison is different from the specific filtering effects of Facebook’s newsfeed analyzed by Bakshy et al., there are important similarities in the high-level findings. Flaxman et al. compare ideological exposure between four different channels of online news consumption, with varying levels of algorithmic influence: direct referrals (visits to self-selected news sites, with mostly editorial curation), news aggregators (whose recommendations are almost entirely driven by algorithmic selection), and search engines and social media (both of which are influenced by users’ choices themselves – what they search for and who they befriend – and algorithmic curation). In this research, the authors find interesting nuances around the differences between news and opinion articles and the importance of defining what metrics we use to quantify ideological polarization. But among their primary findings is that “the vast majority of online news consumption is accounted for by individuals simply visiting the home pages of their favorite, typically mainstream news outlets.”
While it is not possible to disentangle the specific effects of algorithmic selection vs. the effects of homophily in social networks in this study, we can compare the researchers’ findings between pure algorithmic curation (on news aggregators) and self-initiated browsing behaviors (through direct referrals). It turns out that, particularly for “hard news,” the algorithmically curated news feeds had content that was less ideologically polarized, resulting in users being exposed to more crosscutting content on these platforms than their personal browsing behaviors. As before, this research suggests that individuals’ own ideological preferences – and how those preferences translate into behavior in social networks and online browsing behaviors – play a larger role in the filter bubble effect than the results of algorithmic curation.
Another related set of studies, from our research group in 2010 and 2014, evaluated media consumption patterns of more than 1,700 iTunes users (Reference Fleder, Hosanagar and BujaFleder et al. 2010; Reference Hosanagar, Fleder, Lee and BujaHosanagar et al. 2014). We measured the overlap in media consumed by users – in other words, the extent to which two randomly selected users listened to any overlapping set of songs. If users were fragmenting due to algorithmic recommendations, the overlap in consumption across users would decrease after they start receiving recommendations. However, in our findings, we found that recommendation algorithms increased the average overlap of digital media consumption. This increase occurred for two reasons. First, users simply consumed more media when an algorithm found relevant media for them. If two users consumed twice as much media, then the chance of them consuming common content also increased. Second, algorithmic recommendations helped users explore and branch into new interests. While one might be concerned that these new interests were fragmented across many genres, our evidence suggests recommendation algorithms systematically push users toward more similar content. This is partially due to the fact that these algorithms exhibit a popularity bias, whereby products that are already popular are more likely to be recommended (Reference Fleder and HosanagarFleder and Hosanagar 2009). Because algorithms tend to push different people toward the same content, even after controlling for the volume-effect of recommendations, the algorithm had the effect of increasing consumption overlap among users. In aggregate, this means that algorithms increase the probability that you share a musical interest with another random user in the system. That the effects of algorithms can appear to increase fragmentation in one context (social media) and decrease it in another (digital media) suggests we need to be careful about making cross-context generalizations in this discussion. We will revisit (and attempt to provide insight into) this observation in a simulation analysis below, but we now discuss several recent studies that address an important limitation of research discussed thus far.
While all of the aforementioned studies are useful for illuminating the empirics of media consumption patterns on the internet, their research questions are, fundamentally, ones that compare the effects of data, people, and algorithms on fragmentation. This is different from asking what the effects would be if we were to counterfactually manipulate these factors (while attempting to hold others constant). In particular, an important component of these systems not explicitly discussed yet is that the design, logic, and mathematics of recommendation algorithms can have significant effects on fragmentation. This is demonstrated by Reference Garimella, De Francisci Morales, Gionis and MathioudakisGarimella et al. (2017), who designed an algorithm specifically to reduce users’ political polarity by exposing them to diverse content. Further, recent game-theoretic work on the digital filter bubbles – which models the dynamics of network formation, the economic incentives of content producers, and horizontal differentiation among user preferences – also suggests that different algorithm designs can both enhance and mitigate filter bubble effects in different contexts (Reference Berman and KatonaBerman and Katona 2019).
Despite their insights, a limitation of these studies is that they were not able to study how their proposed interventions behave in the wild. However, there are some studies in which the specific roles of different recommendation algorithms are evaluated in close-to-real-world environments. Reference Graells-Garrido, Lalmas and Baeza-Yates.Graells-Garrido et al. (2016) experimentally changed the graphical interface of a Chilean Twitter service designed to surface and recommend new content for its users to read. The authors randomly assigned users to different variations of the site’s graphical interface and different versions of the service’s recommendation algorithm. Interestingly, while the algorithm the authors designed to increase users’ network diversity was successful in exposing users to more politically diverse accounts, it performed worse than a (homophilic) baseline algorithm in getting users to accept its recommendations. This finding points to the importance of considering the downstream effects on all components of this algorithmic social system; simply changing one factor (algorithm design) may be offset by the differential way that other factors respond (e.g., people’s uptake of a new algorithm’s recommendations).
This point is also demonstrated by a study that attempted not to change the algorithms used on social media platforms, but rather by directly increasing the political diversity of users’ social graph (an intervention on the data component in our framework). In this work, researchers incentivized Twitter users to follow a bot account that reshared posts from accounts of elected officials and opinion leaders of the political party opposite from their own (Reference Bail, Argyle, Brown, Bumpus, Chen and Fallin Hunzaker et alBail et al. 2018). While this intervention expanded the political diversity the accounts users followed, this exposure to opposing opinions actually reinforced users’ original political identities, causing liberals to hold more liberal views and conservatives to have more conservative views.
We have so far looked at studies that have counterfactually changed users’ recommendation algorithms and network structures, but what about the effects of attempting to change people’s behaviors directly? Indeed, implicit in the transparency requirement proposed in the FBTA is the assumption that the behavior of the people using social media and content platforms would be different if they had more information. Informing users that their feeds are being algorithmically filtered might cause them to become more aware of the things they click, like, and react to, or opt to use a different (perhaps purely chronological) type of content filtering.
While we know little about the targeted effects of this specific type of transparency on social media users’ browsing behavior, we can look at some research that has attempted similar behavioral interventions. In Reference Gillani, Yuan, Saveski, Vosoughi and RoyGillani et al. (2018), researchers recruited Twitter users to use a “social mirror” application that was designed to reveal the structure and partisanship of each participant’s social network. By being made aware of the homogeneity of their network, the authors hypothesized that they could “motivate more diverse content-sharing and information-seeking behaviors.” Unfortunately, the results of the study were largely null, indicating that even behavioral interventions specifically designed to mitigate filter bubble effects have limited effects. If nothing else, this research points to the likelihood that the transparency component of the FBTA’s proposal will have little effect on changing consumer behavior on digital content platforms.
The Interaction Between Algorithms and Data
Taken together, the research discussed above demonstrates that the algorithms, underlying data, and human behaviors all have roles to play in the fragmentation debate. Especially when analyzing individual aspects of a single algorithmic social system, our three-factor framework provides useful context for understanding the dynamics at play between users, their data, and the algorithms they interact with. However, the juxtaposition of findings from the two separate contexts analyzed in this research – digital music and political news – highlights an important phenomenon: In some contexts, algorithmic recommendations can (modestly) increase fragmentation, while in other contexts, algorithms decrease fragmentation. This is not necessarily the understanding portrayed in some popular press, which has suggested that algorithms are a (if not the) primary culprit to blame for filter bubbles (Reference GuptaGupta 2019; Reference HernHern 2017; Reference LazerLazer 2015). There are many factors varying across the studies cited above, but this simple observation about the apparent heterogeneity in algorithmic effects suggests that discussions of digital filter bubbles without systematic and contextual nuance may lead us to make simplistic conclusions.
In line with this observation, we wish to highlight the need for rigor and caution in applying policy changes or recommendations across different contexts. As US legislators edge closer to directly intervening in the way online platforms recommend and curate digital media, it is important to recognize the challenges associated with crafting regulations that accomplish their intended goals. To illustrate these complexities, we will show specifically how the interactions between the various factors in algorithmic systems can play significant roles in system outcomes. In particular, we will show how applying the same (relatively minor) changes to the underlying logic of a recommendation algorithm in different contexts can have dramatically different results on the users’ emergent level of fragmentation. In addition to contextualizing the seemingly contradictory findings of the research cited earlier, this analysis demonstrates that, especially when several factors are changing simultaneously between contexts, one-size-fits-all approaches for addressing concerns about the digital filter bubble will likely fail.
Simulation Analysis
The research cited above suggests that complex interactions between the factors in an algorithmic social system may exist, but the contexts are too disparate for any systematic analysis. Ideally, we would like to experimentally vary the nature of the data, people, and algorithms in these environments to understand how they may interact. This motivates the development of a simulation framework, which we outline below. To make our rhetorical case for the importance of interaction effects across different contexts, we will only have to vary two of the three factors (the specific mathematics of the algorithms that determine which media are recommended and the underlying data that serve as inputs to the algorithms). But we emphasize how in between most real-world systems, all three factors will vary simultaneously, only adding to the complexities involved in making any unilateral policy recommendations across contexts.
Our framework is designed to capture many of the most important dynamics of how recommendation algorithms and consumers interact through time. In particular, we will model a set of consumers with idiosyncratic preferences, interacting with an online media platform in which their consumption patterns are influenced by the platform’s recommendations (similar to how news is recommended on Facebook or books and movies are recommended on Amazon). As with recommendation algorithms in real life, the recommendations one user receives in our simulation are also influenced by the consumption patterns of other users on the platform. This introduces a complex set of dynamics that make it difficult to predict a priori how one algorithm will affect system outcomes compared to another. As mentioned, we will study how this system evolves under different assumptions about the internal logic of the recommendation algorithm and the nature of the data on which these algorithms are trained.Footnote 5 We will specifically compare how two different recommendation algorithms affect fragmentation in environments that are more or less polarized. While there are many ways to describe “fragmentation,” in this setting we use a measure of “overlap” between users’ media consumption patterns. In our context, overlap will measure the extent to which a user in one ideological group consumes the same content as users from an alternative ideological group (roughly based on the conservative-liberal dichotomy in American politics). We discuss precisely how our simulation works in more detail below.
Simulation Setup
Our simulation is built around a two-dimensional “ideal point model” (Reference Kamakura and RajendraKamakura 1986). The two dimensions represent two abstract product attributes in this market. To capture the notion of political polarity, we will think of the X-dimension in our analysis as being analogous to one’s location on a scale from progressive to conservative. The Y-dimension can then be thought of as representing an abstract auxiliary attribute associated with digital media. (In the real world, these may be target age group, degree of sensationalization, writing style, etc.) An example of the data that serve as input to this model is shown in Figure 4.3. The preference of an individual consumer is represented by their position in this space (their “ideal point”); the products available for consumption in this market are also characterized by their coordinates in attribute space. This system allows us to model consumer utility as a function of the distance between their ideal point and the item they consume. In this model, users probabilistically consume items that are closer to them with a higher chance than they consume items that are further away.Footnote 6
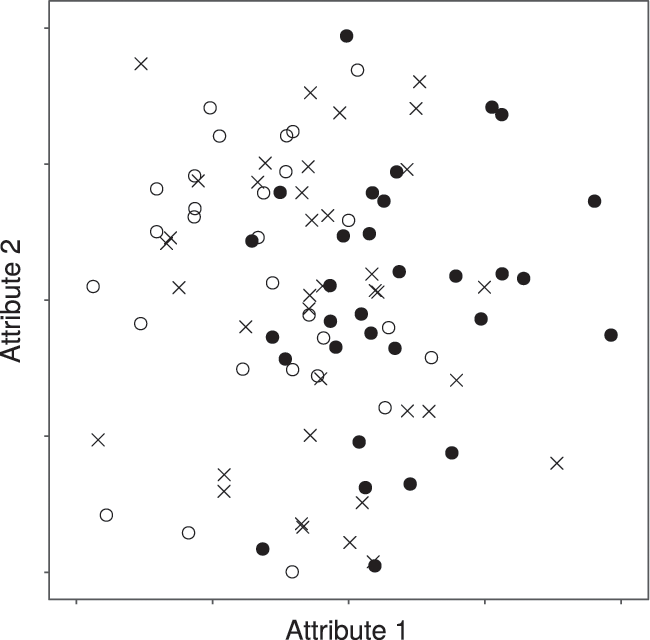
Figure 5: Sample draw of consumers and items
We first describe how we manipulate the ambient data-generating process for our simulation. In particular, we will vary the degree of underlying polarization present in the political environment. This manipulation is designed to account for the fact that some forms of media (like political news) may be inherently more fragmented/clustered along item attributes than others. To model this in our simulation, we first divide consumers into two nominal groups: White and black. In one set of simulations, we will assume that there is very little difference in political preferences among these two groups; but in another set of simulations, we will assume that these two groups’ preferences follow a bimodal distribution, with white congregating around one extreme and black congregating around the opposite extreme. We label these initial conditions as “overlapping” and “polarized”, respectively (see Figure 4.4). Effectively, these two different preference distributions help create two very different input datasets of media preferences for training our system’s recommendation algorithms.
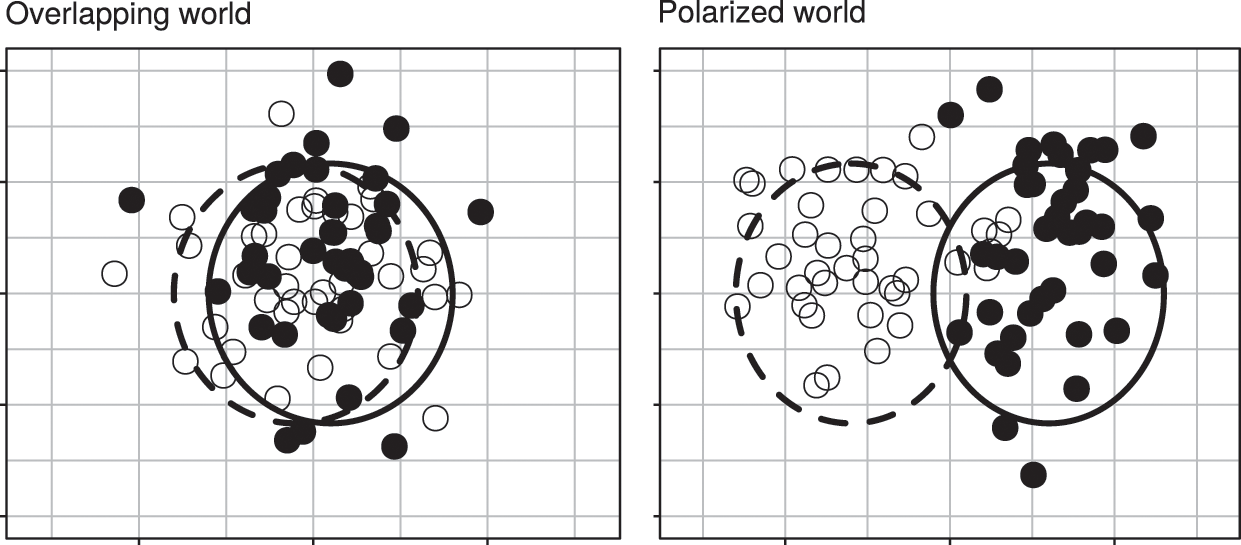
Figure 6: Sample draws of consumer ideal points in overlapping (left) and polarized (right) contexts
One of the primary motivations for the use of recommendation systems in practice is that it is not possible for consumers to perform an exhaustive search of the item space. This means that – at least initially – consumers should only be aware of a subset of products in the market. We capture this in our model by only allowing consumers to purchase products in their “awareness set.” Initially, this set includes only products that are either close to the consumer in attribute space or close to the origin. This reflects the notion that consumers are likely to be aware of items in their own “neighborhood” and those that are most popular in the market overall.Footnote 7 Because consumers are not aware of all items in the market, we will use a recommendation algorithm to add items into each consumer’s consideration set over time.
Importantly, by performing this analysis via simulation, we can vary the both the ambient data environment of different contexts and the nature of an algorithm’s internal logic. Further, we can do this in more systematic ways than the empirical studies described earlier were able to do. The first algorithm we will use is the classic, nearest-neighbor collaborative filter (“people like you also bought X”). This is a deterministic algorithm that first selects the ten “most similar” users to a particular focal user (using mathematical definitions of “similarity” based on historical purchases), and then recommends the most popular item among this set of neighbors. We will then use an extension of the collaborative filter that uses stochastic item selection: Rather than recommending the most popular item in each neighborhood, as is done by the classical method, the stochastic algorithm recommends each item with a probability that is proportional to its popularity among a user’s most similar neighbors. This algorithm is designed to mitigate the problem of “popularity bias” in collaborative filters alluded to earlier; for our purposes, the stochastic collaborative filter provides a small twist on the classical algorithm that allows us to investigate how different algorithms behave in and interact with different contexts.
In keeping with our interest in analyzing polarization in digital media consumption, we will use this simulation framework to measure how each combination of empirical context and algorithm logic affects aggregate measures of fragmentation between white and black consumer types. We do this by operationalizing the notion of “commonality” or “overlap” by first constructing a network in which each consumer is a node and edges are added between two nodes whenever two users consume the same item (see Figure 4.5). Thus, users who consume similar items will have stronger ties in this network than users who do not share any mutually consumed items. Our final quantitative measure of overlap will be the percentage of edges in the entire network that are between users of different types (i.e., we count the number of connections between white and black users, and divide this by the total number of connections in the network).Footnote 8
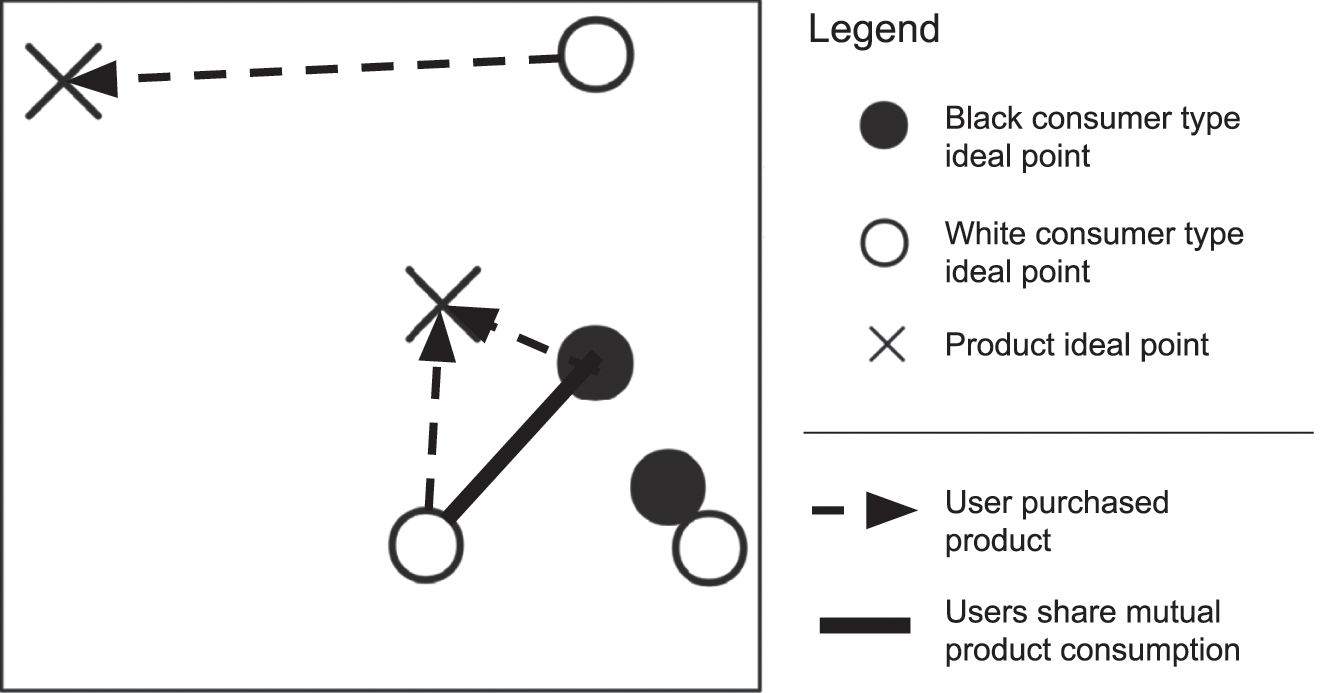
Figure 7: When two users consume the same item, we add a network connection between them. We measure the number and proportion of edges between users of different types.
In summary, we have a 2-by-2 experimental setup (overlapping vs. polarized context; classical vs. stochastic collaborative filter) that we carry out according to the following procedure:
1. Overlapping vs. polarized preference distribution chosen.
2. Deterministic vs. stochastic collaborative filtering algorithm chosen.
3. Consumer and item positions drawn in attribute space (according to assumption about preference distribution made in step 1).
4. Consumers initially made aware of small subset of items.
5. Each user is recommended an item by adding it to their awareness set (recommended items are selected based on each users’ consumption history, according to the algorithm selected in step 2).
6. Each user probabilistically selects one item to consume from their awareness set, with higher weights given to those items that are closer to the user in attribute space.
7. Recommendation algorithm updates nearest neighbor calculations based on new consumption data.
8. Steps 5–7 repeat for 500 iterations.
9. Polarization metrics calculated for co-consumption network between consumers.
Simulation Results and Discussion
We have plotted the numeric results of our simulations in Figure 4.6, in which we have graphed the proportion of cross-type edges (our measure of overlap/commonality) for each of the four experimental conditions.
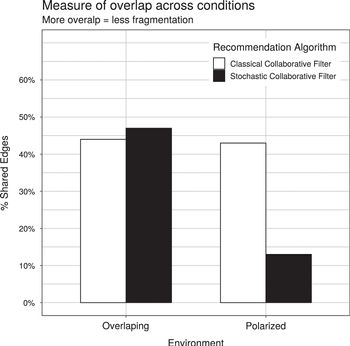
Figure 8: Proportion of cross-type edges (measure of overlap) in 2-by-2 simulation experiment
First, note how moving from a classical to stochastic collaborative filter (comparing colors within groups) has differential effects depending on the underlying data distribution. In the polarized world, the stochastic algorithm decreases commonality among dissimilar users (the proportion of cross-type edges goes from 43 percent to 13 percent), whereas this same change in the world with overlapping groups increases commonality (the proportion of cross-type edges goes from 44 percent to 47 percent). Similarly, when we hold the algorithm constant (comparing across groups for the same colors), moving from the polarized world to the overlapping world has a marginal effect on commonality when the classical algorithm is used, but this shift has a substantial effect on commonality when the stochastic algorithm is used.
These observations demonstrate that understanding the impact of either data or algorithms requires us to consider their effects jointly, with a focus on how they interact with one another. While this is a simple simulation in a microenvironment with several artificial assumptions, the implications of these results should inform our macro-discussion about echo chambers (and algorithmic systems) generally. Indeed, even in this simplistic, simulated world in which only a small number factors are varying, we observe complex interactions between data and algorithms. In real-world environments, the algorithms are more opaque, the data are more massive, and users exhibit more complex patterns of behavior. All of these factors only increase the complexity of the social system and suggest a need for an even greater appreciation of the intricacies associated with the interactions between all factors involved. On the whole, we believe these results suggest that, if policymakers are not careful about recognizing the distinct dynamics at play in different media contexts, they run the risk of exacerbating problems in one context while attempting to fix them in another.
While these interactions may indeed be complex, our framework provides a basis for understanding how the same changes in one context can have opposing effects in a different context (as we observed in the previously discussed studies on newsfeed and digital music fragmentation). We hope our simulation highlights both the importance of using a systematic framework for understanding algorithmic effects and – due to the presence of potentially significant interactions between factors in algorithmic systems – the importance of not overgeneralizing findings from one context or implementing policies that indiscriminately affect systems with differing characteristics.
Conclusion
In sum, the framework we propose here provides a way to decompose and contextualize current concerns around the negative impacts of algorithmic suggestions and decisions. We apply the framework to look at the growing concerns that social newsfeed algorithms are driving increased political polarization. We find that algorithms can play a role but focusing exclusively on them while ignoring the manner in which data, algorithms and people interact can paint an incomplete, and even misleading, picture when attempting to understand the effects of each component across different contexts. By systematically decomposing the causes of filter bubbles, we are able to provide a more complete characterization of the problem and facilitate the development of meaningful policy changes for moving forward.
As we attempt to engineer our algorithmic systems, the algorithms themselves certainly deserve a high degree of scrutiny. But it is important to not forget the role of other components of the system. As our analysis has shown, the same algorithm can have dramatically different effects depending on the context in which it is applied, and the same input data can have varying results depending on the algorithm that is acting on the data.
We conclude by suggesting that adding more context – both sociological and technological – to these discussions provides the most meaningful way forward for ensuring algorithms have a positive effect on society. By decomposing, quantifying, and ultimately understanding the complex dynamics that exist between humans and algorithms, we will be able to more efficiently diagnose, inform, and improve these systems. In this chapter, we have suggested a starting place for this process, which is for researchers to focus on both the individual roles of and the interactions between people, data, and algorithms in algorithmic social systems. We argue that, if we are to successfully steer these systems toward socially beneficial outcomes, it will be critical to appreciate the complexities between these systems and to avoid reaching for simplistic generalizations about the dynamics at play within them.
A century and a half ago, Karl Marx wrote about markets becoming concentrated over time – the fundamental genetic defect that would eventually lead to capitalism’s demise and spur the proletarian revolution.Footnote 1 Today, his dire prediction seems to ring true. While business dynamism has been stagnant for years, a few firms grow fast, amass astonishing profits, and capture a huge share of the market.Footnote 2
Just in the fall of 2017, Apple – already the world’s most valuable company by market capitalization – announced an increase in profits of 19 percent. Google/Alphabet’s profits grew by an even stronger 33 percent, and Facebook topped both with an increase in profits of 79 percent. Each of these three has also cornered an enormous portion of a market. Apple is the world’s largest smartphone producer by revenue, Google dominates online search with a market share of well over 80 percent globally, and Facebook rules the social media platform market, with over 2 billion users worldwide in 2017.
They are not the only ones. Digital markets, in particular, seem to move swiftly towards concentration. The market for domain names is cornered by GoDaddy, Netflix controls more than 75 percent of the US video streaming market, and Amazon accounts for 43 percent of US online retail sales.Footnote 3
Unsurprisingly, a growing number of commentators has called for strengthening existing antitrust and competition laws to ensure that the concentration process is slowed, or at the very least does not lead to uncompetitive behavior by market-dominating firms.Footnote 4
In this chapter, I suggest that these concerns are well-warranted, but that the remedies proposed are ill-suited to address the challenge we face. This is because while we see market concentration, the reason for that concentration has shifted, rendering much of the existing regulatory toolkit to ensure competitive markets essentially ineffective. In its place, I suggest a novel regulatory measure – the progressive data-sharing mandate – that is specifically designed to tackle the very concentration dynamic we witness.
The first part of this chapter describes the concentration process in greater detail, and how the dynamic is fueled by a new driver. I then explain why this novel driver – the feedback effect – cripples market competition differently than existing drivers, and thus requires novel regulatory measures. In the second part, I put forward such a measure, carefully tailored to address the crippling dynamic that leads to market concentration, and map out the consequences of such a measure should it be enacted.Footnote 5
A Closer Look at Market Concentration
Markets become concentrated when one or a small number of market participants enjoy a significant cost differential in offering products or services. There are many drivers for such a concentration dynamic, but the most prominent and well-analyzed are so-called scale effects. Scale effects signify the downward slope of marginal costs to produce or sell a particular good the more a particular actor sells.
Scale effects manifest themselves in various forms. For instance, buyers of large volumes can often negotiate discounts and thus get better deals than those purchasing smaller quantities. Fixed costs, too, are less onerous when they are spread across many goods rather than just a few. That’s why it is costlier per good sold for Microsoft to operate its retail stores than for Apple. Many scale effects aren’t consumed once a company has reached a certain size, but continue to be present as they grow and deliver improvements to a company’s bottom line. As Ford Model Ts came off the assembly line almost a century ago and sales increased steadily over time, Ford was able to continue to lower cost year after year, largely because of the focus on exploiting scale effects in every aspect of manufacturing and sales.
Because smaller competitors do not reap similar benefits of scale, they have to produce at higher cost. This provides large players with an advantage in the market that they can convert into higher profits or, through lower prices, an increase in demand and thus market share. The resulting dynamic, at least in principle, is that through scale effects bigger players grow bigger, while smaller competitors wither away.
Of course, this theory does not always pan out in practice. Some large players are badly managed, become complacent, and lose their ability to produce the goods the market wants. Large firms have the scale advantage, but it often comes with a lack of flexibility and an inability to adjust swiftly to changes in the marketplace. In general, however, scale effects do lead to market concentration. Economists have been worrying about the negative effects for competitive markets for decades.
More recently, a further effect has led to much discussion. Termed the network effect, it is present whenever additional customers joining a particular service increase the utility of that service to everyone else using it.Footnote 6 It is often associated with digital networks and the Internet. Every additional person using Facebook, for example, improves the utility Facebook has for other users as they can reach more people through the service. But network effects are not an invention of the digital age. They already were a key driver leading to the consolidation of telephone networks (and thus concentration of network operators) in the early twentieth century, and even before that in the concentration of railroad networks.Footnote 7
Network effects are particularly beneficial for the companies that provide the respective service, because apart from accommodating additional users, they need not actively do anything for the utility of their service to improve. Unlike with scale effects, for instance, firms do not have to renegotiate sourcing contracts to reap the benefits.
Network effects offer another advantage to scale effects, at least in theory: They grow more quickly with an increase in size than the often more linear scale effects. This is true even though in practice the increases in utility are not evenly spread, and certainly do not simply grow by the square of the number of users, as a particularly popular formulation of a certain type of network effect, “Metcalfe’s law” seems to suggest.Footnote 8
These qualities have made network effects the focus of many startups, and an important driver for substantial entrepreneurial successes. Particularly social network services, such as Facebook, Twitter, and LinkedIn have greatly benefitted from them, much as in the 1990s telecom providers and mobile phone equipment producers profited from the network effects of the GSM mobile phone standard. This has propelled network effects into public prominence.
Scale and network effects are not exclusive. In digital markets, often both of them are at play. Amazon profits from scale effects thanks to the huge volume of orders it fulfills, but also from network effects as it offers its customers a community to review and share information about products. Google can spread its indexing cost for its search engine across billions of users every day, but its shared document standards and interfaces (e.g., Google Docs) also create a sticky global network of activity.
For consumers, scale and network effects often have positive consequences. In competitive markets, lowering the cost of production per unit will result in lower prices, saving consumers a bundle. And an improving utility of a particular service, thanks to network effects, is a benefit for all of its customers.
Unfortunately, scale and network effects also help companies to increase their market shares, as they can produce more cheaply than smaller competitors or, thanks to network effects, offer a superior service. Combined, scale and network effects have facilitated a concentration process in countless markets around the world, reducing, at times even eliminating robust competition. Without sufficient competition, large firms can extract extra rents from customers.
Over time, this dynamic would cripple markets if there weren’t a powerful counterforce that enabled new entrants to successfully compete with large incumbents and at times even to topple them. This counterforce is innovation.
Three quarters of a century ago, economist Joseph Schumpeter emphasized the disruptive force of innovation – of new products or production processes (or markets).Footnote 9 Innovative companies with ground-breaking ideas are able to overtake existing players, and in doing so preserve competition in the marketplace. Economies of scale, as well as network effects, are kept in check by the might of innovation, resulting in a dynamic balance that enhances consumer welfare.
Even (or perhaps particularly) in the context of digital markets, there is ample evidence that innovation has been the key driver that enabled new entrants to unseat dominating incumbents. 3G and LTE pushed aside GSM, Facebook dethroned MySpace, Google replaced Yahoo! as the online search champion, and Apple’s operating system now runs on more digital devices than Microsoft’s Windows. In our digital economy, too, innovation has provided the much needed antidote to market concentration.
Schumpeter feared that eventually innovation would become concentrated in a few large companies, because of their ability to attract talent and create a suitable environment for stimulating and bringing to market new ideas.Footnote 10 So far, fortunately, this has not happened. Quite the contrary: Large companies often become unwieldy, with many hierarchies and entrenched processes that are difficult to adapt, and with ossified structures that stunt innovation and scare away talent, leaving new entrants with ample opportunities to compete against established players.Footnote 11
Quite obviously, the counterforce of innovation is strongest in sectors that experience quick and substantial technical change. Unsurprisingly therefore, the Internet seemed to usher in an especially disruptive phase of innovation, with lowered cost of entry and an amazing variety of new ideas. Unlike Henry Ford, new data startups do not require huge amounts of capital to build factories, neither do they today even need huge server farms (as Google and Amazon did) to build out a new innovative idea. Digital disruptors can use digital platforms and infrastructures available to them often at commodity price. Until 2010, Twitter was renting cloud assets for its service rather than having built its own. And Uber, Lyft, and Didi Chuxing did not have to design and build digital devices to connect their drivers to their services; they are smartly piggybacking on existing smart phone infrastructure.Footnote 12
Away from the realm of the digital economy, however, the innovation story has become a bit less impressive in recent years. Innovation economists have been pointing to the great deceleration in business dynamism outside of a small number of high-tech fields as an indication that our ability to disrupt through innovation in many sectors is actually stalling.Footnote 13 But at least in high-tech, encompassing an ever-increasing share of the economy, the innovation engine seemed as capable of disruption as ever. Unfortunately, and dramatically, this is changing, and the change is linked to a shift in the nature of innovation.
Since the beginning of humanity, innovation has been tied to the inventiveness of the human spirit. The ability to innovate rested on new ideas generated by human creativity and ingenuity – ideas that could then be translated into superior products and services or production processes. The romantic image of the single idea that changes the world overnight might rarely have been true, but persistent entrepreneurs have been able to shape markets and society. Because, at least in principle, such novel and valuable ideas can come from any human being, the capacity to innovate is not limited to large organizations with deep pockets. Sometimes, the tinkerer in the garage outsmarts armies of corporate researchers, whose preconceived notions of what works and how may cloud their ability to – in the words of Steve Jobs – see the world differently.
The story of innovation has been tied to human originality, and – at least in more recent decades – to the small startup Davids upending slow and stodgy Goliaths. Although this narrative may be mythical and naïve, innovation unquestionably has acted as a powerful counterforce to scale-based concentration effects. But innovation’s positive role in ensuring competitiveness hinges on it being equally available (at least in principle) to organizations and players of any size.
The world is abuzz with talk about artificial intelligence and machine learning. The labels may conjure up alarming visions of humanoid robots roaming the world. The reality, however, is more sanguine – and more troubling. What is termed AI or machine learning isn’t a system that acquires abstract knowledge by being fed general rules. Machine learning denotes the ability to analyze massive amounts of data and uncover statistical patterns in them, devising algorithms that capture and replicate these patterns. Importantly, as new data points become available, the analysis is redone, and the resulting algorithm adjusted. Incrementally, the system “learns.” It captures an ever more comprehensive slice of reality, and thus more accurately reflects the essence of the phenomenon in question.
We already see such systems popping up everywhere in the digital realm. Google’s services – from online search and spell-check to language translation, from voice recognition all the way to autonomous driving – are continuously improving because of the gigantic stream of data available to Google. And Google isn’t alone. Apple’s Siri and Amazon’s Alexa are improving because of data-driven machine learning, and so are the music recommendations presented by Spotify and the products recommended on Alibaba. Every additional data point so gathered is an opportunity to automatically learn from and adapt the system. And the more data points gathered the faster machines learn, producing innovation.
Whether it is a data-driven system defeating some of the world’s best poker players, or a system diagnosing skin cancer with precision equal or better than the average dermatologist, the principle is always the same: Automated learning from the analysis of huge amounts of training and feedback data.Footnote 14 As the ability of machines to collect and analyze data comprehensively and increasingly unsupervised has grown dramatically, the source of innovation has been shifting from humans to systems of data and software. Yesterday’s innovator was a human with bold ideas; tomorrow’s equivalent are those capturing and feeding the most data into their learning systems.
Of course, humans will continue to invent, and human-based innovation is far from over. But data-driven innovation offers a few advantages that human innovation can’t easily replicate. It scales well, while human innovation doesn’t so easily. It can be formalized and thus incorporated in organizational processes while standardizing the human innovation process is far more difficult; human ingenuity is unpredictable. And, arguably most importantly, data-driven machine-based innovation is less inhibited by human imagination – by the questions we humans ask as much as by the questions we don’t ask; by the tensions we sense, and by what we seem deaf to.
Of course, the data that AI systems use to learn from isn’t devoid of biases and errors, leading to biased decisions.Footnote 15 But the hope is that with comprehensive data from diverse sources, some of these distortions are flattened out.Footnote 16 At the very least, they are less constraining than the biases of a small number of humans in a conventional innovation lab, subject to “group-think.”Footnote 17 With fewer constraints due to human preconceptions, data-driven machine-based innovation is less encumbered by traditional thinking and conventional beliefs. This is not to suggest that data-driven innovation is always better than human innovation; only that in the future human innovation will no longer be always the most relevant game in town.
As the source of innovation shifts at least partially from human ingenuity to data analyzed by machine learning systems, those with access to much data have most of the raw material to translate into innovative insights. Here, too, having the raw material does not necessarily equate with the ability to employ it successfully. Some companies will fail in the innovation drive despite having all the data, because of their shortcomings in setting up and maintaining appropriate systems and processes to learn from it.Footnote 18 But the reverse is even more true: Without data, even the best AI company will falter. In short, having access to data is the crucial (albeit not sufficient) condition for innovative success in the data age.
Due to this change in the nature of innovation, the emerging market dynamic pits large incumbent companies with substantial scale economies and network effects on the one hand against smaller startups with needs for lots of data to learn from. This in itself is already problematic: Companies with lots of data will hardly let entrepreneurs have access to their data troves, when they realize that access to data is a source of innovation (and thus competitive success). This likely inhibits small startups to turn themselves into disruptive innovators. The result is a market that may still be competitive and innovative among the larger firms, but no longer easy to enter for newer, smaller players.
The situation is far more damning, however, when we look at the kind of data that will lead to innovation advantages. Most of the digital superstar firms aren’t conventional manufacturing behemoths, neither are they exploiters or traders of natural resources. They are data-rich marketplaces with smart recommendation and other decision-assistance systems to aid market participants in their transaction decisions.Footnote 19 For these marketplaces, innovation lies in the ability to better match transaction partners: to help them in discovery and selection, as well as the process of decision making. If these companies want to innovate a better decision assistant, they need not any kind of data, but data about preferences and transactions – precisely the kind of data available to these digital superstars. It is data that offers feedback to the superstars about market activities from which to learn. Amazon’s recommendation engine is getting better and better with each additional data point collected through a customer’s interaction on Amazon’s website. Spotify’s choice of music gets better with each feedback from one of its listeners, much as each time you let Siri proceed with what she understood to be your request, Siri’s underlying voice recognition system learns to understand human speech.
Not simply any kind of data, but feedback data is the raw material that lets these superstar companies innovate and offers customers a superior experience on their marketplaces. It’s no surprise that eBay, a major long-established marketplace, is investing heavily into data and machine learning, because it, too, needs to tap into the innovative power of the feedback data streams it has access to if it wants to compete successfully against the other superstars.Footnote 20 Neither is it astonishing that shopping curation service Stitch Fix, one of the latest digital unicorns, employs many dozens of data analysts to mature its machine-learning systems that translate rich feedback data from multiple channels, including through photos posted online, into its innovative curation service.Footnote 21
These digital superstars are innovating, but such innovation is no longer acting as a counterforce to market concentration. Instead, it’s fed by valuable feedback data that only large data-rich markets collect in huge quantities. This makes firms that operate data-rich marketplaces and smart decision assistants (and who already benefit from scale and network effects) the most innovative as well. The feedback effect aligns innovation with market concentration, and shapes markets and the economy much as scale and network effects already do. The result is an unprecedented impulse towards larger and more powerful firms that could lead to a dramatic restructuring of our economy.
But the feedback effect isn’t only pushing market concentration, undermining competition, and ultimately leading to higher prices and dangerously powerful oligopolies. It, perhaps surprisingly, also makes the superstar firms that use the feedback effect extensively for innovation, as well as their customers, shockingly vulnerable to systemic failure. As AI systems learn from data and get better and better in assisting participants in a superstar’s marketplace, more and more customers will be attracted to such a market. As a result, everyone may be using the same decision assistant. In such a context, any hidden errors and biases in the decision assistant will affect and potentially cripple every participant’s decision making. It’s akin to the danger of a brake in one’s car malfunctioning due to a manufacturing defect – and the realization that everyone else’s car uses the same faulty brake, too. This single point of failure undermines decentralized decision making, the very quality of markets that makes them so resilient and successful. In turn, this structural defect in the marketplace will make the superstar firm that runs the marketplace deeply vulnerable as well, because an error in decision assistance may now bring down the entire company.
Thus, superstar firms utilizing data-driven machine learning find themselves in a highly uncomfortable position. On the one hand, their exploitation of the feedback effect creates a unique and dangerous vulnerability. On the other hand, without data-driven innovation they will no longer be able to compete. Faced with the imminent threat of competition versus the potential danger of a systemic vulnerability, most firms will likely opt to tackle the former rather than focus on the later. Long-term, this will lead to a problematic situation, not just for their customers but for the companies as well.
Policy Responses
Market concentrations aren’t new. By themselves, in most instances they aren’t seen as problematic, at least from a consumer welfare perspective. As long as players even with very high market share don’t exploit their position – for example by raising prices beyond what would be acceptable in a competitive market – regulatory measures are usually deemed unnecessary. Consequently, in competition law, the focus in recent years has been on constraining anticompetitive behavior.Footnote 22
This poses a unique challenge in the context of the feedback effect. Companies exploiting the feedback effect, especially as detailed in the previous section, aren’t behaving illicitly as defined by conventional competition regulation. They are simply utilizing the resources available to them, in the form of feedback data, to advance innovation. Companies have no obligation under existing competition law to make it easy for their rivals – large or small, established or new – to compete against them. Only when they cross a red line into illegal behavior will they be stopped. Hence, one could argue that feedback effects even if resulting in market concentration aren’t problematic in themselves, and do not require regulatory attention.
The flaw in this argument is the focus on consumer welfare, narrowly defined. Until now, competition law could be focused on such a narrow scope of consumer welfare, because innovation, which acted as a crucial counterforce to scale and network effects, was founded on human ingenuity. Nobody, not even the largest player in the market, could hope to have a monopoly on the human mind to have new ideas. At least in theory, therefore, the biggest incumbent could be dethroned by an innovative startup with an ingenious idea, so long as the incumbent did not engage in deliberately anticompetitive manipulation of the market. In practice, of course, large players have been able to use their market power to capture a disproportionate slice of human talent. But that has not precluded others from having great ideas, and bringing them to market, at least in sectors with relatively low barriers to entry.
Therefore, policymakers have not felt the need to worry about market concentration inhibiting innovation, at least not in the highly dynamic sector of digital technologies with its fast pace of innovation and comparatively low barriers to entry. With data-driven machine learning turning into a prime engine for innovation, this is no longer the case. Those with access to data in general, and feedback data in particular, now enjoy a massive advantage over others. This concentrates innovative activity among the largest players in a market and reduces the breadth and diversity of innovation.
Some may argue that a concentration of innovation activity isn’t bad in itself. High-tech areas such as chip manufacturing, despite being highly concentrated, have been subject to continued innovation in recent years. The truth is, however, that low barriers to entry have always been the hallmark of strong and sustained innovation. It may be true that chip manufacturing is concentrated, but the advances in computer chips over the past two decades (if not longer) do not primarily stem from advances in chip manufacturing coming from the few remaining large chip fabs, but from innovation in tooling for chip manufacturing, and even more importantly from chip design – a far less concentrated area with far lower financial barriers to entry. A similar argument could be made for the innovation dynamic in biotech, and the crucial role of CRISPR in enabling genetic engineering at relatively low cost.Footnote 23 As it turns out, the most recent trajectories of high-tech innovation offer ample evidence for diversity and against concentration.
There is a decisive further reason for being concerned about the concentration of innovative activity. As detailed in the previous section, feedback-data-driven machine learning concentrates innovation among superstar firms that operate data-rich markets and offer smart decision assistance. The resulting single points of failure create vulnerabilities for the entire market, including market participants. Just consider a failure of the recommendation system in an app store market for one of the two big smart phone ecosystems: It could prompt hundreds of millions of consumers worldwide to download apps they don’t need or want, and that perhaps are even nefarious, irrespective of any illegal or uncompetitive behavior of the market provider.
Massive market failures and the resulting potential for huge losses in consumer welfare, could, perhaps should turn into a valid concern for policymakers. But because this dynamic involves no illicit behavior by market participants, current competition law fails to protect against it.Footnote 24 Worse, even if competition law were triggered by data-driven innovation, it offers no suitable remedies. Behavioral remedies fail when the problem lies in the very dynamic of data-driven innovation. For instance, prohibiting or greatly constraining data-rich companies to utilize their data troves to gain novel insights, makes little sense: it would stifle innovation, limit the insights gleaned from data, and reduce data’s overall utility, which likely translates into a reduction in overall consumer welfare and market efficiency.
In light of the limitations of behavioral remedies and the huge power of the most well-known superstar firms, the so-called GAFA – Google (technically a unit of the holding company Alphabet), Amazon, Facebook, and Apple – some have suggested that these firms should be broken up, much like AT&T, to prevent their controlling such large shares of the market.Footnote 25 This seems a blunt and draconian remedy, and it’s unclear how such a remedy could be anything more than a temporary fix. Given the underlying drivers of market power (scale, network, and feedback effects), market concentration after such a breakup would likely continue anew.
This calls for different and novel policy measures – both new triggers for regulatory action, and new remedies – that are more carefully crafted to address the root cause of the problem: the shift in the source of innovation. Expanding on work by Jens Prüfer and colleagues on search engines, I suggest a progressive data-sharing mandate.Footnote 26
The principle of such a mandate is straightforward: Every company with a share above a certain threshold – for instance 10 percent – in a market has to let other market participants have access to a subset of the data it has collected and uses in its data-driven machine learning systems. The higher the market share of a particular company, the larger the slice of the data that it has to share.Footnote 27
Data would be depersonalized to avoid any undue privacy risksFootnote 28 and the data shared would be chosen randomly from the full dataset.Footnote 29 Technically, access would happen through an appropriate API – and without a regulator in the middle to eliminate any unnecessary slowdown.Footnote 30 The task of the regulator would be to ensure and enforce compliance, and to categorize companies based on market share.
Importantly, every competitor would be granted access to the appropriate slice of the data. For instance, in a market with two large players commanding 30 and 40 percent of the market and many small players below the 10 percent threshold, not only the small players would get access to a slice of the data of the big players. Each of the big players would be entitled to access a slice of the other big player.
This setup has a number of advantages. Every market participant could continue to utilize the data available to it; unlike a monetary redistribution through a tax, the progressive data-sharing mandate does not “rob” the large players of the ability to innovate. But by granting access to other especially smaller players, it enables these smaller players to amass large enough data sets to use in data-driven machine learning, and thus to stay innovative. It also facilitates competition in the market by helping smaller players without inhibiting the ability of large players to utilize data as well. Every player benefits from access to data, but smaller players benefit more so – relatively speaking – than larger players. In short, the idea builds on the unique quality of data to be used multiple times by different parties without losing its value.
The progressive data-sharing mandate is also narrowly tailored to tackle the problem in question. If the challenge is the shift in the source of innovation to data, enabling access to data spreads the raw material of innovation. The policy also does not negate the effort expended by large data collectors, as competitors gain access to only a randomly chosen subset of the data trove and not all of it. Crucially, this measure protects not only market competition, it also ensures a diversity of players based on a diversity of data sets. As the data subset provided to competitors is randomly selected, each player will have a somewhat different data source to learn from. This means that, for instance, not only multiple recommendation engines will be possible, but that the data used to train each such engine differs from one another, preventing the likelihood of systemic weaknesses.
Won’t the large data-using superstars battle such a mandate, thereby dooming its chance for legislative success? Not necessarily. To be innovative in the context of data-rich markets will require access to lots of relevant feedback data. But even though data is the prime component for success, it is not the only one. Google’s chief economist Hal Varian has said as much, when he highlighted the differentiating power of algorithms, especially regarding the most appropriate machine learning tools.Footnote 31 This suggests that large companies that have superb data analytics and machine learning capabilities continue to be well-placed to extract innovation out of data. Hence, they may see giving data access to smaller competitors as less of a ruinous threat, especially compared with some of the regulatory alternatives – like breakups – being discussed.
Moreover, mandating data sharing isn’t an entirely novel policy measure. Its principle of enabling data access is embedded in a number of regulatory measures that have been enacted around the world. In the US and the European Union for instance, the legal right of phone subscribers to keep their phone numbers as they switch operators essentially disappropriated phone companies from valuable assets in the name of lowering switching cost.Footnote 32 It resulted in an increase in competition in the phone markets, and improved consumer welfare. Perhaps emboldened by this success, the European Union later passed legislation to let bank customers get access to their bank account data in machine-readable form.Footnote 33 This was intended not only to lower switching cost (and enhance competition in the banking sector), but also to create a wide stream of informational raw material that innovative fintechs can avail themselves of to enter the market. The goal is a diverse and innovative ecosystem of financial insight driven by drastically enhanced access to data. And finally and most dramatically, the EU’s General Data Protection RegulationFootnote 34, which came into force in 2018, explicitly mandates “data portability” – the right of individuals to get all personal data from a data processor in machine-readable form.Footnote 35 It’s phone number portability and bank account portability spread across the board and applied to all personal data.
There is an important difference, however, between data portability and the progressive data-sharing mandate. Data portability’s immediate aim is a rebalancing of informational power away from large data processors and towards individuals. Only if individuals then make their “portable data” accessible to other processors can the market concentration process be halted. The health of market competition thus hinges on the behavior of individuals, who do not all have strong incentives to share their data.Footnote 36 Moreover, because their data contains personal identifiers – it’s the unaltered personal dataset – individuals have to trust data processors each time they share their data with them. This puts an unfair burden on individuals and results in an unfortunate disincentive for data sharing.
Data portability is simply not predictable and sustainable enough a policy measure to ensure competition and diversity in markets. But it is, no doubt, a powerful case in point that even legislative mandates that constrain the power of large data processors can get enacted – and in this case even on a pan-European level. This bodes well for the chances of a progressive data-sharing mandate.
Conclusions
In the past, markets have remained competitive in significant part because scale and network effects have been counterbalanced by innovation. Competition law could thus be focused on uncompetitive behavior, and not on market concentration in general. As the source of innovation shifts from human ingenuity to data-driven machine learning, behavioral constraints are no longer sufficient to protect competition.
The situation is exacerbated when the raw material of innovation in digital decision assistance is feedback data, collected and used by the providers of both markets and digital assistants. Then, in addition to worries about a concentration of innovation, we may also face a single point of failure, exposing the market itself to a structural vulnerability.
The progressive data-sharing mandate is the policy measure I propose to address this unique situation. It is narrowly tailored to spread access to the raw material of innovation, with incentives for data utilization and renewed competition based on the ability to tease valuable insights from the raw data. While novel as a competition measure, it is based on principles of lowering switching cost and enhancing competition that are well-rooted in existing policy practices. If enacted, the progressive data-sharing mandate will act as a powerful antidote to market concentration, foster broad innovation, and prevent systemic vulnerabilities of online markets.Footnote 37
Introduction
Offering a “barously brief” distillation of Marshall McLuhan’s writings, John M. Culkin expanded on one of McLuhan’s five postulates, Art Imitates Life, with the now-famous line, We shape our tools and thereafter they shape us.Footnote 1 This fear of being shaped and controlled by tools, rather than autonomously wielding them, lies at the heart of current concerns with machine learning and artificial intelligence systems (ML/AI systems). Stories recounting the actual or potential bad outcomes of seemingly blind deference and overreliance on ML/AI systems crowd the popular press. Whether it is Facebook’s algorithms allowing Russian operatives to unleash a weapon of mass manipulation, trained on troves of personal data, on electorates in the US and other countries; inequitable algorithmic bail decisions placing people of color behind bars while whites with similar profiles are sent home to await trial; cars in autonomous mode driving their inattentive could-be-drivers to their death; or algorithms assisting Volkswagen in routing around air quality regulations, there is a growing sense that our tools, if left unchecked, will undermine our choices, our values, and our public policies.
If we fail to grapple with the significant challenges posed by ML/AI systems designed to automate tasks or aid decision making, things may get much worse. At risk are potential decreases in human agency and skill,Footnote 2 both over- and under-reliance on decision support systems,Footnote 3 confusion about responsibility,Footnote 4 and diminished accountability.Footnote 5 Relatedly, as technology reconfigures work practices, it also shifts power in ways that may misalign with liability frameworks, diminishing humans’ agency and control but still leaving them to bear the blame for system failures.Footnote 6 Automation bias, power dynamics, belief in the objectivity and infallibility of data, and distrust of professional knowledge and diminished respect for expertise – all coupled with the growing availability of ML/AI systems and services – portend a potential future in which we are ruled by our tools.
Designing a future in which our tools help us reason and act more effectively, efficiently, and in ways aligned with our social values – i.e., creating the tools that help us act responsibly – requires attention to system design and governance models. ML/AI systems that support us, rather than control us, require designs that foster in-the-moment human engagement with the knowledge and actions systems produce, and governance models that support ongoing critical engagement with ML/AI processes and outputs. Expert decision-support systems are a useful case study to consider the system properties that could maintain human engagement and the governance choices that could ensure they emerge.
We begin by describing three new challenges – design by data, opacity to designer, and dynamic and variable features – posed by the use of predictive algorithmic systems in professional, expert domains. Concerns about inscrutable bureaucratic rules and privatization of public policy making (and the specific opacity that technology can bring to either) apply to predictive machine learning systems generally, but we suggest there are distinctive challenges posed by such predictive systems. We then briefly explore transparency and explainability, two policy objectives that current scholarship suggests are antidotes to such challenges. We show how conceptions of transparency and explainability differ along disciplinary lines (e.g., law, computer science, social sciences) and identify limitations of each concept for addressing the challenges posed by algorithmic systems in expert domains.
We then introduce the concept of contestability and explain the particular benefits of contestable ML/AI systems in the professional context over and above transparent or explainable systems. This approach can be valuable for an algorithmic handoff in a highly professionalized domain, such as the use of predictive coding software – a particular e-discovery tool – by lawyers during litigation. Current governance frameworks around the use of predictive coding in the form of professional norms and codified rules and regulations have their limitations. We argue that an approach centered around contestability would better promote attorneys’ continued, active engagement with these algorithmic systems without relying so heavily on retrospective, case-specific, and costly legal remedies.
The Limitations of Existing Approaches to Protecting Values
Technical systems containing algorithms are shaping and displacing human decision making in a variety of fields, such as criminal justice,Footnote 7 medicine,Footnote 8 product recommendations,Footnote 9 and the practice of law.Footnote 10 Such decision-making handoffs have been met with calls for greater transparency and explainability about system-level and algorithmic processes. The delegation of professional decision making to predictive algorithms – models that predict or estimate an output based on a given inputFootnote 11 – creates additional issues with respect to opacity in machine learningFootnote 12 and to more general concerns with bureaucratic inscrutabilityFootnote 13 and privatization of public power.Footnote 14
Three Challenges Facing Algorithmic Systems in Expert Domains
We identify three challenges facing the use of predictive algorithms in expert systems. First, such predictive algorithms are not designed by technologists in the traditional sense. Whereas engineers of traditional expert systems explicitly program in a set of rules, ideally from the domain knowledge of adept individuals, predictive algorithms supplant this expert wisdom by deriving a set of decision rules from data.
Predictive algorithms can be partitioned into two categories: (1) those focused on outcomes that do not rely too heavily on professional judgment (e.g., was an individual readmitted to the hospital within thirty days of their visit?) versus (2) those focused on outcomes that are more tailored toward emulating the decisions made by professionals with specific domain expertise (e.g., does this patient have pneumonia?). Specifically, the first example can be deemed either true or false simply via observation of admit logs, regardless of professional training. The second example, by way of contrast, is distinct from the first in that it requires medical expertise to make such a diagnosis. In the strictest sense, expert systems fall into the second category,Footnote 15 and as such, inferences of such rules via predictive algorithms create unique challenges for the transfer of expertise from both individuals to the algorithm, and from the algorithm to individuals.
The second challenge is one of opacity. In many ways, this issue is induced by the first. While certain classes of predictive algorithms lend themselves to ease of understanding (such as logistic regression and shallow decision trees), other classes of model make it difficult to understand the rules inferred from the data (such as neural networks and ensemble methods). Unlike expert systems, where domain professionals can review and interrogate the internal rules, the opacity of certain algorithms prevents explicit examination of these decision rules, leaving experts to infer the model’s underlying reasoning from input–output relationships.
Last, these algorithms are case-specific and evolving. They will not necessarily make the same decision about two distinct people in the same way at the same point in time, neither will they necessarily make the same decision about the same individual at varying points in time. This plasticity creates challenges for understanding and interrogating a model’s behavior, as input–output behavior can vary from case to case and can vary over time.
Transparency: Perspectives and Limitations
Due to the challenges described above, algorithmic handoffs have been met with calls for greater transparency.Footnote 16 At a fundamental level, transparency refers to some notion of openness or access, with the goal of becoming informed about the system. However, the word “transparency” lends itself to the question: What is being made transparent?
Given the growing role that algorithmically driven systems are poised to play across government and the private sector, we should exercise care in choosing policy objectives for transparency. A trio of federal laws – two adopted in the 1970s due to fears that the federal government was amassing data about citizens – exemplify three policy approaches to transparency relevant to algorithmic systems. Together, the laws aim to ensure citizens “know what their Government is up to,”Footnote 17 that “all federal data banks be fully and accurately reported to the Congress and the American people,”Footnote 18 that individuals have access to information about themselves held in such data banks, and that privacy considerations inform the adoption of new technologies that manage personal information. These approaches can be summarized as relating to (1) scope of a system, (2) the decision rules of a process, and (3) the outputs.
The Privacy Act of 1974,Footnote 19 which requires notices to be published in the Federal Register prior to the creation of a new federal record-keeping system, and section 208 of the E-Government Act of 2002,Footnote 20 which requires the completion of privacy impact assessments, exemplify the scope perspective. These laws provide notice about the existence and purpose of data-collection systems and the technology that supports them. For example, the Privacy Act of 1974 requires public notice that a system is being created and additional information about the system, including its name and location, the categories of individual and record maintained in the system, the use and purpose of records in the system, agency procedures regarding storage, retrieval, and disposal of the records, etc.Footnote 21 The first tenet of the Code of Fair Information Practices, first set out in a 1973 HEW (Health, Education, Welfare) ReportFootnote 22 and represented in the Privacy Act of 1974 and data-protection laws the world over, stipulates in part that “there must be no personal-data record-keeping systems whose very existence is secret.”Footnote 23 With the Privacy Act of 1974, the transparency theory is one of public notice and scope. Returning to our previous question of “what is being made transparent,” in this approach to transparency, it is precisely the existence and scope being made available.
Unlike the scope aspect of transparency, the decision-rules aspect is not concerned with whether or not such a system exists. Rather, this view of transparency refers to tools to extract information about how these systems function. As an example, consider the Freedom of Information Act (FOIA), a law that grants individuals the ability to access information and documents controlled by the federal government.Footnote 24 The transparency theory here is that the public has a vested interest in accessing such information. But instead of disclosing the information upfront, it sets up a mechanism to meet the public’s demand for it. As such, FOIA allows for individuals to gain access to the decisional rules of these systems and processes. Similarly, the privacy impact assessment requirement of the E-Government Act of 2002 provides transparency around agencies’ consideration of new technologies, as well as their ultimate design choices.
Last, several privacy laws allow individuals to examine the inputs and outputs of systems that make decisions about them. Under this perspective, transparency is not the end goal itself. Rather, transparency supports the twin goals of ensuring fair inputs and understanding the rationale for the outputs by way of pertinent information about the inputs and reasoning. The laws all entitle individuals to access information used about them and to correct or amend data. Some of the privacy laws in this area also entitle individuals to receive information about the reasons behind negative outcomes.Footnote 25 For example, under the Equal Credit Opportunity Act, if a candidate’s credit application is rejected, the credit bureau must provide the key reasons for the decision.Footnote 26 Thus, this type of transparency refers to notice of how a particular decision was reached. These forms of transparency are aimed at individual, rather than collective, understanding; they provide, to a limited extent, insight into the data and the reasoning – or functioning – of systems.
Within the computer science literature, transparency is similar to the functional and outputs perspective presented in law. That is, transparency often refers to some notion of openness around either the internals of a model or system, or around the outputs. Typically, less focus is given to disclosing the subjective choices that were invoked during the system design and engineering process or to system inputs.
The social sciences and statistics, however, take a more comprehensive perspective on transparency. Transparency in these disciplines not only captures the ideas from law and computer science, but also means disclosures about how the data was gathered, how it was cleaned and normalized, the methods used in the analysis, the choice of hyperparameters and other thresholds, etc., often in line with the goals of reproducibility.Footnote 27 The sweep of transparency reflects an understanding that these choices contribute to the methodological design and analysis. This more holistic approach to transparency acknowledges the effect that humans have in this process (reflected in decisions about data, as well as behaviors captured in the data), which is particularly pertinent for predictive algorithms.
Current policy debates, and scientific research, center around explainability and interpretability. Transparency is being reframed, particularly in the computer science research agenda, as an instrumental rather than final objective of regulation and system design. The goal is not to lay bare the workings of the machine, but rather to ensure that users understand how the machines are making decisions – whether those decisions be offering predictions to inform human action or acting independently. This reflects both growing recognition of the inability of humans to understand how some algorithms work even with full access to code and data, but also an emphasis on the overall system – rather than solely the algorithm – as the artifact to be known.
Explainability: Perspectives and Limitations
Explainability is an additional design goal for machine-learning systems. Driven in part by growing recognition of the limits of transparency to foster human understanding of algorithmic systems, and in part by pursuit of other goals such as safety and human compatibility, researchers and regulators are shifting their focus to techniques and incentives to produce machine-learning systems that can explain themselves to their human users. Such desires are well-founded in the abstract. For the purposes of decision making or collaboration, explanations can act as an interface between an end-user and the computer system, with the purpose of keeping a human in the loop for safety and discretion. Hence, explanations invite questioning of AI models and systems to understand limits, build trust, and prevent harm. As with transparency, different disciplines have responded to this call to action by operationalizing both explanations and explainability in differing ways.
One notable use of explanations and explainability comes from the social sciences. MillerFootnote 28 performed a comprehensive literature review of over 200 articles from the social sciences and found that explanations are causal, contrastive, selective, and social. What is pertinent from this categorization is how well the paradigms invoked in predictive algorithms (machine learning, artificial intelligence, etc.) fall within social understandings of explanations. Machine learning raises difficulties for all four of Miller’s attributes of explanations.
For concreteness and clarity, imagine we have a predictive algorithm that classifies a patient’s risk for breast cancer as either low risk, medium risk, or high risk. In this scenario, a causal explanation would answer the question: “Why was the patient classified as high risk?” Alternatively, a contrastive explanation would answer questions of the form, “Why was the patient classified as high risk as opposed to low risk or medium risk?” As such, explanations of the causal type require singular scope on the outcome, whereas contrastive explanations examine not only the predicted outcome, but other candidate alternatives as well.
With respect to machine learning, this distinction is important and suggestive. Machine learning is itself a correlation box. As such, the output itself should not be interpreted as causal. However, when individuals ask for causal explanations of predictive algorithms, they are not necessarily assuming that the underlying data mechanism is causal. Rather, the notion of causality is seeking to understand what caused the algorithm to decide that the patient was high risk, not what caused the patient to be high risk in actuality. Thus, causal explanations can be given of a model built on correlation. However, the fact that they can be produced doesn’t mean that causal explanations further meaningful understanding of the system.
Contrastive explanations are a better fit for machine learning. The very paradigm of machine learning – classification models – are built in a contrastive manner. These models are trained to learn to pick the “best” output given a set of inputs – or equivalently stated, the model is taught to discern an answer to a series of input questions based on the fixed set of alternatives available. Combining these insights, it follows that requiring causal explanations for classification models is inappropriate for determining why a model predicted the value it did. Contrastive explanations, which provide insight into the counterfactual alternatives that the model rejected as viable, transfer more knowledge about the system, than causal ones.
Regardless of whether the type of explanation is causal or contrastive, Miller argued that explanations in the social sciences were selective. That is, explanations tend to highlight a few key justifications rather than being completely exhaustive. Consider the case of a doctor performing a breast cancer-screening test in the absence of a predictive algorithm. When relaying the rationale of their diagnosis to a patient, a doctor would provide sufficient reasons for their decision to justify their answer. Now, consider the state of the world where a handoff has been made to the predictive model. Suppose the model being used relies on 500 features. When explaining why the model predicted the outcome it did, it is indeed unreasonable to assume that providing information about all 500 features would practically relay any information about why the model made the choice it did. As such, requiring explanations of predictive models requires honing into the relevant features of a decision problem, which may differ from patient to patient and may vary over time.
On the aspect of explanations being social, Miller noted that explanations are meant to transfer knowledge from one individual to another. In the example above, where the doctor performs the breast cancer-screening test, this was the point of having the doctor justify their diagnosis to the patients – to inform the patient about their breast cancer-risk level. When applied to technical systems, the goal is to transfer knowledge about the internal logic of how the system reached its conclusion to some individual (or class of individuals). In the case of our breast cancer-risk prediction, this would manifest itself as a way to justify why the algorithm predicted high risk as opposed to low risk. It is worth noting that for predictive algorithms, it is often difficult to truly achieve the social goal of explanations. Certain qualities of algorithms – such as their functional form (e.g., nonlinear, containing interaction terms), their input data, and other characteristics – make it particularly difficult to assess the internal logic of the algorithm itself, or for the system to even explain what it is doing. It is therefore difficult for these machine systems to transfer knowledge to individuals in the form of an explanation that is either causal or contrastive. To the extent that explanations are aimed at improving human understanding of the logic of algorithms, the qualities of some algorithms may be incompatible with this means of transferring knowledge. It may be that the knowledge transfer must come the other way around, from the human to the machine, which is then bound to particular way or ways of knowing.Footnote 29
Thus, there are tensions between the paradigms of predictive algorithms and those characteristics laid out by Miller. As such, the discussion above suggests that our target is off. That is, to actually fully and critically engage with predictive algorithms, this suggests that we require something stronger than transparency and explainability. Enter contestability – the ability to challenge machine predictions.
Toward Contestability as a Feature of Expert Decision-Support Systems
Contestability fosters engagement rather than passivity, questioning rather than acquiescence. As such, contestability is a particularly important system quality where the goal is for predictive algorithms to enhance and support human reasoning, such as decision-support systems. Contestability is one way “to enable responsibility in knowing”Footnote 30 as the production of knowledge is spread across humans and machines. Contestability can support critical, generative, and responsible engagement between users and algorithms, users and system designers, and ideally between users and those subject to decisions (when they are not the users), as well as the public.
Efforts to make algorithmic systems knowable respond to the individual need to understand the tools one uses, as well as the social need to ensure that new tools are fit for purpose. Contestability is a design intervention that can contribute to both.Footnote 31 However, our focus here is on its potential contribution to the creation of governance models that “support epistemically responsible behavior”Footnote 32 and support shared reasoning about the appropriateness of algorithmic systems behavior.Footnote 33
Contestability, the ability to contest decisions, is at the heart of legal rights that afford individuals access to personal data and insight into the decision-making processes used to classify them,Footnote 34 and it is one of the interests that transparency serves. Contestability as a design goal, however, is more ambitious and far-reaching. A system designed for contestability would protect the ability to contest a specific outcome, consistent with privacy and consumer protection law. It would also facilitate generative engagement between humans and algorithms throughout the use of the machine-learning system and support the interests and rights of a broader range of stakeholders – users, designers, as well as decision subjects – in shaping its performance.
Hirsch et al. set out contestability as a design objective to address myriad ethical risks posed by the potential reworking of relationships and redistribution of power caused by the introduction of machine-learning systems.Footnote 35 Based on their experience designing a machine-learning system for psychotherapy, Hirsch et al. offer three lower-level design principles to support contestability: (1) improving accuracy through phased and iterative deployment with expert users in environments that encourage feedback; (2) heightening legibility through mechanisms that “unpack aggregate measures” and “trac[e] system predictions all the way down” so that “users can follow, and if necessary, contest the reasoning behind each prediction”; and relatedly, in an effort to identify and vigilantly prevent system misuse and implicit bias, (3) identifying “aggregate effects” that may imperil vulnerable users through mechanisms that allow “users to ask questions and record disagreements with system behavior” and engage the system in self-monitoring.Footnote 36 Together, these design principles can drive active, critical, real-time engagement with the reasoning of machine-learning system inputs, outputs, and models.
This sort of deep engagement and ongoing challenge and recalibration of the reasoning of algorithms is essential to yield the benefits of humans and machines reasoning together. Concerns that engineers will stealthily usurp or undermine the decision-making logics and processes of other domains have been an ongoing and legitimate complaint about decision support and other computer systems.Footnote 37 Encouraging human users to engage and reflect on algorithmic processes can reduce the risk of stealthy displacement of professional and organizational logics by the logics of software developers and their employers. Where an approach based on explanations imagines questioning and challenging as out-of-band activities – exception handling, appeals processes, etc. – contestable systems are designed to foster critical engagement within the system. Such systems use that engagement to iteratively identify and embed domain knowledge and contextual values, as decision making becomes a collaborative effort within a sociotechnical system.
In the context of decision-support systems, increasing system explainability and interpretability is viewed as a strategy to address errors that stem from automation bias and to improve trust.Footnote 38 Researchers have examined the impact of various forms of explanatory material, including confidence scores, and comprehensive and selective lists of important inputs, on the accuracy of decisions, deviation from system recommendations, and trust.Footnote 39 The relationship between explanations and correct decision making is not conclusive.Footnote 40
Policy debates, like the majority of research on interpretable systems, envision explanations as static.Footnote 41 Yet, the responsive and dynamic tailoring at which machine learning and AI systems excel could allow explanations to respond to the expertise and other context-specific needs of the user, yielding decisions that leverage, and iteratively learn from, the situated knowledge and professional expertise of users.
The human engagement contestable systems invite would align well with regulatory and liability rules that seek to keep humans in the loop. For example, the Food and Drug Administration is directed to exclude from the definition of “device” those clinical decision support systems whose software function is intended for the purpose of:
supporting or providing recommendations to a health care professional about prevention, diagnosis, or treatment of a disease or condition; and enabling [providers] to independently review the basis for such recommendations … so that it is not the intent that such [provider] rely primarily on any of such recommendations to make a clinical diagnosis or treatment decision regarding an individual patient.Footnote 42
By excluding systems that prioritize human discretion from onerous medical-device approval processes, Congress shows its preference for human expert reasoning. Similarly, where courts have found professionals exhibiting overreliance on tools, they have structured liability to foster professional engagement and responsibility.Footnote 43 Systems designed for contestability invite engagement rather than delegation of responsibility. They can do so through both the provision of different kinds of information and an interactive design that encourages exploration and querying.
Professionals appropriate technologies differently, employing them in everyday work practice, as informed by routines, habits, norms, values and ideas and obligations of professional identity. Drawing attention to the structures that shape the adoption of technological systems opens up new opportunities for intervention. Appropriate handoffs to, and collaborations with, decision-support systems demand that they reflect professional logics and provide users with the ability to understand, contest, and oversee decision making. Professionals are a potential source of governance for such systems, and policy should seek to exploit and empower them, as they are well-positioned to ensure ongoing attention to values in handoffs and collaborations with machine-learning systems.
Regulatory approaches should seek to put professionals and decision support systems in conversation, not position professionals as passive recipients of system wisdom who must rely on out-of-system mechanisms to challenge them. For these reasons, calls for explainability fall short and should be replaced by regulatory approaches that drive contestable design. This requires attention to both the information demands of professionals – what they need to know such as training data, inputs, decisional rules, etc. – and processes of interaction that elicit professional expertise and allow professionals to learn about and shape machine decision making.
Contestable Design Directions
Contestable design is a research agenda, not a suite of settled techniques to deploy. The question of what information and interactions will prompt appropriate engagement and shaping of a predictive coding system by professionals is likely to be both domain- and context-specific. However, there are systems in use and under development that support real-time questioning, curiosity, and scrutiny of machine learning systems’ reasoning. First, Google’s People and AI Research (PAIR) Initiative’s “What-if Tool” is an actual tool that allows users to explore a machine-learning model. For example, users can see how changes in aspects of a dataset influence the learned model, understand how different models perform on the same dataset, compare counterfactuals, and test particular operational constraints related to fairness.Footnote 44 Second, LIME (Local Interpretable Model-agnostic Explanations), which generates locally interpretable models to explain the outputs of predictive systems, and SP-LIME, which builds on LIME to provide insight into the model (rather than a given prediction) by identifying and explaining a set of representative instances of the model’s performance, offer information that, if presented to users, could inform their interaction with the model.Footnote 45 While the tools themselves focus only on surfacing information about decisions and models, if integrated with an interactive user interface, they could promote the explorations of predictions and models necessary for sound use of predictive systems to inform professional judgement.
Other research is exploring the ways in which structured interaction between domain experts and predictive models can improve performance.Footnote 46 There are two distinct approaches. One approach enables interaction during the development process. Here, the machine-learning training process is reframed as an HCI task, allowing a set of users the ability to iteratively refine a model during its conception.Footnote 47 In contrast to interaction during the development process, the second approach has focused on ways in which subject matter experts, with domain-specific knowledge, can interact with predictive systems that have already been developed in real time to invoke collaboration, exploration of data, and introspection.Footnote 48 At the very least, ensuring that decisions about things such as thresholds are decided by professionals in the context of use (and remain visible to those using the system), rather than set as defaults, can support greater engagement with predictive systems.
Conclusion
Contestability allows professionals, not just data, to train systems. In doing so, contestability transfers knowledge about how the machine is reasoning to the professional, and it allows the professional to collaborate, critique, and correct the predictive algorithm. While relevant professional norms, ethical obligations, and laws are necessary, design has a role to play in promoting responsible introduction of predictive ML/AI systems in professional, expert domains. Such systems must be designed with contestability in mind from the outset. Designing for contestability has some specific advantages compared to rules and laws. Opportunities to reflect on the inputs and assumptions that shape systems can avert disasters where they misalign with the conditions or understandings of professional users. Reminders of professional responsibilities and potential risks of not complying with them can prompt engagement before undesirable outcomes occur. Contestable design can confer training benefits allowing users to learn through use. Finally, it can be used to signal the distribution of responsibility from the start rather than relying solely on litigation to retrospectively mete it out in light of failures. Contestability can foster professional engagement with tools rather than deferential reliance. To the extent the goal is to yield the best of human-machine knowledge production, designing for contestability can promote the responsible production of knowledge with machine learning tools within professional contexts.







 Open access
Open access