



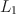
Introduction
Full Information Item factor analysis (IFA), known as factor analysis of ordered categorical (such as binary) item-level data, has been a useful tool to explore the latent structure underlying educational and psychological tests (Bock, Gibbons, & Muraki, Reference Bock, Gibbons and Muraki1988). IFA provides a wealth of information regarding the characteristics of the items and tests, which are important to ensure reliability and validity of a measure. As IFA deals with item-level responses, it is also considered as multidimensional item response theory (MIRT) (Embretson & Reise, Reference Embretson and Reise2000; Reckase, Reference Reckase2009)
The widely used multidimensional 2-parameter logistic (M2PL) model assumes item response function of the ith individual to the jth item as

where there are N subjects who respond to J items independently with binary response variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij},$$\end{document}
 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\dots ,N$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\dots ,N$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\dots ,J$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\dots ,J$$\end{document}
 .
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 denotes a K-dimensional vector of item discrimination parameters for the jth item and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
denotes a K-dimensional vector of item discrimination parameters for the jth item and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
 denotes the corresponding item difficulty parameter.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
denotes the corresponding item difficulty parameter.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
 denotes the K-dimensional vector of latent ability for student i.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
denotes the K-dimensional vector of latent ability for student i.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 may contain structural 0’s implying that item j does not measure (hence not load on) certain factors. When both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
may contain structural 0’s implying that item j does not measure (hence not load on) certain factors. When both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
 are unidimensional, the 2PL model and one-factor categorical factor analysis model are mathematically equivalent (Takane & De Leeuw, Reference Takane and De Leeuw1987; Wirth & Edwards, Reference Wirth and Edwards2007). Another popular MIRT model that is often suitable for multiple-choice binary response items is the multidimensional 3-parameter logistic (M3PL) model. It includes an additional parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
are unidimensional, the 2PL model and one-factor categorical factor analysis model are mathematically equivalent (Takane & De Leeuw, Reference Takane and De Leeuw1987; Wirth & Edwards, Reference Wirth and Edwards2007). Another popular MIRT model that is often suitable for multiple-choice binary response items is the multidimensional 3-parameter logistic (M3PL) model. It includes an additional parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
 to quantify guessing probability of the jth item. Hence, the item response function is expressed as
to quantify guessing probability of the jth item. Hence, the item response function is expressed as

Although the inclusion of the guessing parameter makes the model more flexible, it no longer belongs to the exponential family and its estimation becomes much more challenging (Thissen & Wainer, Reference Thissen and Wainer1982; Yen, Reference Yen1987).
In an exploratory IFA, the item factor loading structure that is reflected by the systematic 0’s in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 is unknown. Identifying the loading structure, which is equivalent to the sparsity structure of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
is unknown. Identifying the loading structure, which is equivalent to the sparsity structure of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 , is crucial not only for accurate calibration of item parameters and recovery of individual latent traits, but also for understanding the construct validity of a measure. Traditional approaches for identifying item factor loading structure proceed in two steps: (1) allowing all item factor loadings to be freely estimated, subject to identifiability constraints; and (2) conducting a post-hoc rotation (Browne, Reference Browne2001a). Most software packages use varimax (Kaiser, Reference Kaiser1958) for orthogonal rotation or promax (Hendrickson & White,Reference Hendrickson and White1966) for oblique rotation by default. Other popular methods include, for instance, the CF-Quartimax rotation (Browne, Reference Browne2001a). While these rotation methods intend to produce a near-simple structure, an arbitrary cutoff for the rotated factor loadings is often needed. Rotation methods that encourage sparse solutions have also been developed in Jennrich (Reference Jennrich2004; Reference Jennrich2006) using the component loss functions for orthogonal and oblique rotations.
, is crucial not only for accurate calibration of item parameters and recovery of individual latent traits, but also for understanding the construct validity of a measure. Traditional approaches for identifying item factor loading structure proceed in two steps: (1) allowing all item factor loadings to be freely estimated, subject to identifiability constraints; and (2) conducting a post-hoc rotation (Browne, Reference Browne2001a). Most software packages use varimax (Kaiser, Reference Kaiser1958) for orthogonal rotation or promax (Hendrickson & White,Reference Hendrickson and White1966) for oblique rotation by default. Other popular methods include, for instance, the CF-Quartimax rotation (Browne, Reference Browne2001a). While these rotation methods intend to produce a near-simple structure, an arbitrary cutoff for the rotated factor loadings is often needed. Rotation methods that encourage sparse solutions have also been developed in Jennrich (Reference Jennrich2004; Reference Jennrich2006) using the component loss functions for orthogonal and oblique rotations.
To avoid setting subjective cutoffs, Sun, Chen, Liu, Ying, and Xin (Reference Sun, Chen, Liu, Ying and Xin2016) recently proposed to formulate the problem of estimating the loading structure in MIRT as a latent variable selection problem. Specifically, for each item, a set of latent traits influencing the distribution of the responses are selected by the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_1$$\end{document}
 -regularized regression. The
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_1$$\end{document}
-regularized regression. The
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_1$$\end{document}
 -regularized regression, also known as the constrained least absolute shrinkage and selection operator (Lasso) (Tibshirani, Reference Tibshirani1996), has received much attention for solving variable selection problems for both linear and generalized linear models (Friedman, Hastie, & Tibshirani, Reference Friedman, Hastie and Tibshirani2010). The principle idea is to penalize the factor loadings toward zero if the corresponding latent traits are not associated with an item. This leads to correctly estimating an optimal nonzero factor loading structure, instead of setting subjective cutoffs. This approach also has the advantage over the information criterion-based model selection methods in terms of the computational cost because it simultaneously estimates both loading structure and model parameters. Despite its appeal, the computation is still quite challenging in MIRT model due to its intractable marginal likelihood function that involves high-dimensional integration. For parameter estimation, Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) used direct numerical approximation of the likelihood in the iterative expectation-maximization (EM) procedure, which can be computationally inefficient especially in higher dimensions. Specifically, they showed that the computation time for the latent variable selection with dimension
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3$$\end{document}
-regularized regression, also known as the constrained least absolute shrinkage and selection operator (Lasso) (Tibshirani, Reference Tibshirani1996), has received much attention for solving variable selection problems for both linear and generalized linear models (Friedman, Hastie, & Tibshirani, Reference Friedman, Hastie and Tibshirani2010). The principle idea is to penalize the factor loadings toward zero if the corresponding latent traits are not associated with an item. This leads to correctly estimating an optimal nonzero factor loading structure, instead of setting subjective cutoffs. This approach also has the advantage over the information criterion-based model selection methods in terms of the computational cost because it simultaneously estimates both loading structure and model parameters. Despite its appeal, the computation is still quite challenging in MIRT model due to its intractable marginal likelihood function that involves high-dimensional integration. For parameter estimation, Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) used direct numerical approximation of the likelihood in the iterative expectation-maximization (EM) procedure, which can be computationally inefficient especially in higher dimensions. Specifically, they showed that the computation time for the latent variable selection with dimension
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3$$\end{document}
 is about 30 minutes for the first penalization tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
is about 30 minutes for the first penalization tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 and additional 10 minutes for the subsequent
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
and additional 10 minutes for the subsequent
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 s. Considering that multiple
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
s. Considering that multiple
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 s have to be used for the latent variable selection via regularization, it can take a few hours to estimate a test structure for a single dataset with high dimensions.
s have to be used for the latent variable selection via regularization, it can take a few hours to estimate a test structure for a single dataset with high dimensions.
Indeed, developing efficient estimation algorithms for MIRT parameter estimation has always been a productive research topic. A number of methods have been proposed to deal with the computational challenge (Rabe-Hesketh, Skrondal, & Pickles, Reference Rabe-Hesketh, Skrondal and Pickles2005; von Davier & Sinharay, Reference von Davier and Sinharay2010). The first one is the adaptive Gaussian quadrature method. Although the number of quadrature points per dimension could be small, the total number of quadrature points still increases exponentially with the number of dimensions. Moreover, an extra step is needed to compute the posterior mode and variance of latent factors in each iteration, which adds additional computation costs (Pinheiro & Bates, Reference Pinheiro and Bates1995). The second one is the Monte Carlo techniques. This family of methods include, for instance, the Monte Carlo EM algorithm (McCulloch, Reference McCulloch1997; C. Wang & Xu, Reference Wang and Xu2015), stochastic EM algorithm (von Davier & Sinharay, Reference von Davier and Sinharay2010; S. Zhang, Chen, & Liu, Reference Zhang, Chen and Liu2020), or Metropolis-Hastings Robbins-Monro algorithm (Cai, Reference Cai2010b; Reference Caia). These methods circumvent intractable integrations by sampling from the posterior distributions; however, they may be still computationally intensive for complicated high-dimensional models, as a large Monte Carlo sample size is typically needed and the posterior distributions usually do not have a closed form. Fully Bayesian estimation methods, such as Markov chain Monte Carlo (MCMC) (Albert, Reference Albert1992; Patz & Junker, Reference Patz and Junker1999), is equally computationally intensive, even though it is preferable with smaller sample sizes. It usually needs a long chain to converge for complex models. In addition, Chen, Li, and Zhang (Reference Chen, Li and Zhang2019) and H. Zhang, Chen, and Li (Reference Zhang, Chen and Li2020) studied the joint maximum likelihood estimation by treating the latent abilities as fixed effect parameters instead of random variables; though computationally efficient, such joint likelihood based estimation approaches may be less statistically efficient than the marginal likelihood estimation (e.g., Cho, Wang, Zhang, and Xu (Reference Cho, Wang, Zhang and Xu2021)).
Most recently, a variational approximation approach to the marginal likelihood was proposed, namely the Gaussian Variational EM (GVEM) algorithm (Cho et al., Reference Cho, Wang, Zhang and Xu2021). GVEM adopts a variational lower bound of the intractable likelihood within the EM framework. The carefully constructed variational lower bound allows one to derive closed-form updates for all model parameters in the iterative EM steps, making the algorithm computationally efficient. Cho et al. (Reference Cho, Wang, Zhang and Xu2021) also proposed a stochastic version of GVEM to further improve its computational efficiency when both the number of subjects, N, and the number of test items, J, are large. The idea is to stochastically optimize the variational approximation in the E step, i.e., subsample data to form noisy estimate of the variational lower bound and iteratively update the estimate with a decreasing step size (Hoffman, Blei, Wang, & Paisley, Reference Hoffman, Blei, Wang and Paisley2013). The combined advantage of having simple closed-form updates and stochastic optimization makes the GVEM algorithm appealing to high-dimensional MIRT models. Additionally, it was shown that GVEM works well in complex M3PL models compared to the existing methods.
In this paper, we propose to extend the GVEM algorithm by adding a regularization penalty to simultaneously estimate item factor loading structure and model parameters. Our study differs from Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016)’s in the following aspects: (1) we use GVEM as the estimation algorithm instead of the quadrature-based EM algorithm, hence the new method is more suitable to tackle high-dimensional challenge; (2) we consider both Lasso and adaptive Lasso (Zou, Reference Zou2006), the latter of which produces more accurate loading structure recovery; (3) we apply the new method to both the M2PL and M3PL models.
The rest of the paper is organized as follows. Section 2 briefly introduces the GVEM algorithm for the MIRT models. Section 3 presents the general regularized variational algorithm. Sections 4 and 5 illustrate the performance of the proposed methods with simulation studies and real data analysis, respectively. Section 6 discusses potential future studies, and the supplementary material includes the derivations of the estimation procedures and additional data analysis results.
Variational Estimation for MIRT
In this section, we will briefly present the key idea of variational approximation discussed in Cho et al. (Reference Cho, Wang, Zhang and Xu2021). The exposition will be based on the M3PL model, but it can be easily simplified to the M2PL model. For conciseness, let us denote the model parameters for the MIRT models by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}=\{{\varvec{\alpha }}_j,j=1,\dots ,J\}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}} =\{b_j, j=1,\dots ,J\}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}} =\{b_j, j=1,\dots ,J\}$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ {\varvec{C}} =\{c_j, j=1,\dots ,J\}$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ {\varvec{C}} =\{c_j, j=1,\dots ,J\}$$\end{document}
 . Also, denote the responses
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{Y}} = \{Y_i, i=1, \dots , N\}$$\end{document}
. Also, denote the responses
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{Y}} = \{Y_i, i=1, \dots , N\}$$\end{document}
 where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_i = \{Y_{ij}, j=1,\dots ,J\}$$\end{document}
where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_i = \{Y_{ij}, j=1,\dots ,J\}$$\end{document}
 is the ith subject’s response vector. Due to the typical local independence assumption in IRT, the log-marginal likelihood of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
is the ith subject’s response vector. Due to the typical local independence assumption in IRT, the log-marginal likelihood of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{C}}$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{C}}$$\end{document}
 in M3PL model given the responses
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {Y}}$$\end{document}
in M3PL model given the responses
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {Y}}$$\end{document}
 is
is

where N is the total number of respondents and J is the total number of items in the test. Similarly this holds for the M2PL model with model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
 . Here,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\phi $$\end{document}
. Here,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\phi $$\end{document}
 denotes the K-dimensional Gaussian distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}$$\end{document}
denotes the K-dimensional Gaussian distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}$$\end{document}
 with mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{0}}$$\end{document}
with mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{0}}$$\end{document}
 and covariance
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
and covariance
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
 . The maximum likelihood estimators of the model parameters are then obtained from maximizing the marginal likelihood function, which is often intractable under MIRT.
. The maximum likelihood estimators of the model parameters are then obtained from maximizing the marginal likelihood function, which is often intractable under MIRT.
From here onwards,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$M_p$$\end{document}
 is used to denote all model parameters for simplicity. Following Cho et al. (Reference Cho, Wang, Zhang and Xu2021), the variational approximation of (3) can be derived as follows. First, for any arbitrary probability density function
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i(\cdot )$$\end{document}
is used to denote all model parameters for simplicity. Following Cho et al. (Reference Cho, Wang, Zhang and Xu2021), the variational approximation of (3) can be derived as follows. First, for any arbitrary probability density function
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i(\cdot )$$\end{document}
 , we can rewrite the log-marginal likelihood in Eq. 3 as
, we can rewrite the log-marginal likelihood in Eq. 3 as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ KL\{q_i({\varvec{\theta }}_i) \Vert P({\varvec{\theta }}_i \mid Y_i,M_p)\} =\int _{{\varvec{\theta }}_i} \log \frac{q_i({\varvec{\theta }}_i)}{P({\varvec{\theta }}_i\mid Y_i,M_p)} \times q_i({\varvec{\theta }}_i)d{\varvec{\theta }}_i $$\end{document}
 denotes the Kullback–Leibler (KL) distance between the distributions
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
denotes the Kullback–Leibler (KL) distance between the distributions
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 . Then, since
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$KL\{q_i({\varvec{\theta }}_i) \Vert P({\varvec{\theta }}_i \mid Y_i,M_p)\} \ge 0$$\end{document}
. Then, since
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$KL\{q_i({\varvec{\theta }}_i) \Vert P({\varvec{\theta }}_i \mid Y_i,M_p)\} \ge 0$$\end{document}
 , we have a lower bound of the marginal likelihood as
, we have a lower bound of the marginal likelihood as

Note that the equality in (4) holds if and only if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)=P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\dots ,N$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\dots ,N$$\end{document}
 . Thus, to use the lower bound in (4) to approximate the marginal likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$l(M_p;{\mathbf {Y}})$$\end{document}
. Thus, to use the lower bound in (4) to approximate the marginal likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$l(M_p;{\mathbf {Y}})$$\end{document}
 , the posterior distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
, the posterior distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 gives the best choice of the variational distribution function
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
gives the best choice of the variational distribution function
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 . However, such a choice of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
. However, such a choice of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 is not practically applicable as the posterior distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
is not practically applicable as the posterior distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 is unknown. Alternatively, we could choose
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
is unknown. Alternatively, we could choose
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 as a tractable approximation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
as a tractable approximation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 . One example is the EM algorithm, which can be viewed as choosing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
. One example is the EM algorithm, which can be viewed as choosing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 as the estimated posterior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,{{\hat{M}}}_p)$$\end{document}
as the estimated posterior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,{{\hat{M}}}_p)$$\end{document}
 with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\hat{M}}}_p$$\end{document}
with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\hat{M}}}_p$$\end{document}
 from a previous EM step estimate. However, in the MIRT model, it is known that the expectation in E-step with respect to the posterior distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
from a previous EM step estimate. However, in the MIRT model, it is known that the expectation in E-step with respect to the posterior distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
 , i.e., the first term in (4) with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
, i.e., the first term in (4) with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 being the estimated posterior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,{{\hat{M}}}_p)$$\end{document}
being the estimated posterior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,{{\hat{M}}}_p)$$\end{document}
 , does not have an explicit form and often is challenging to compute.
, does not have an explicit form and often is challenging to compute.
Different from the EM algorithm, the variational inference method uses alternative choices of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 ’s to have a computationally more efficient estimation of the lower bound in (4). Since the posterior distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
’s to have a computationally more efficient estimation of the lower bound in (4). Since the posterior distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 for the MIRT model can be well approximated by a Gaussian distribution as the number of items J increases, following (Cho et al. Reference Cho, Wang, Zhang and Xu2021), we choose
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
for the MIRT model can be well approximated by a Gaussian distribution as the number of items J increases, following (Cho et al. Reference Cho, Wang, Zhang and Xu2021), we choose
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 from a family of Gaussian distributions and estimate the model parameters by the GVEM algorithm. In particular, in the E-step,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
from a family of Gaussian distributions and estimate the model parameters by the GVEM algorithm. In particular, in the E-step,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
 is estimated within the Gaussian family to minimize the KL distance between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
is estimated within the Gaussian family to minimize the KL distance between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\varvec{\theta }}_i\mid Y_i,M_p)$$\end{document}
 , and we then evaluate the expectation of the likelihood lower bound with respect to the estimated
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
, and we then evaluate the expectation of the likelihood lower bound with respect to the estimated
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i({\varvec{\theta }}_i)$$\end{document}
 . In the M-step, the expectation is maximized to update all model parameters. Carefully chosen
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
. In the M-step, the expectation is maximized to update all model parameters. Carefully chosen
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
 yield closed-form updates for all model parameters (Cho et al., Reference Cho, Wang, Zhang and Xu2021), making the algorithm computationally efficient.
yield closed-form updates for all model parameters (Cho et al., Reference Cho, Wang, Zhang and Xu2021), making the algorithm computationally efficient.
Regularized Estimation of Loading Structure
In this paper, our main interest is to estimate a sparse loading structure, denoted as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_{A} = (q_{jk})$$\end{document}
 where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_{jk} = I({\varvec{\alpha }}_{jk} \ne 0)$$\end{document}
where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_{jk} = I({\varvec{\alpha }}_{jk} \ne 0)$$\end{document}
 . Similar to Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we cast the problem of sparsity estimation as a latent variable selection problem and solve it using the regularized regression via
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_1$$\end{document}
. Similar to Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we cast the problem of sparsity estimation as a latent variable selection problem and solve it using the regularized regression via
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_1$$\end{document}
 –type penalization. One main contribution is to apply variational approach to avoid directly calculating intractable marginal likelihood while solving the regularization problem.
–type penalization. One main contribution is to apply variational approach to avoid directly calculating intractable marginal likelihood while solving the regularization problem.
Although Lasso regularization is a popular technique for simultaneous model estimation and efficient variable selection, there has been some arguments against the Lasso oracle statement. For instance, Zou (Reference Zou2006) argued that there exist nontrivial conditions for the Lasso variable selection to be consistent and thus Lasso rarely enjoys oracle properties. Although the computational efficiency of Lasso is appealing for the estimation problems in high-dimensional MIRT models, the bias of the Lasso may prevent consistent variable selection and model estimation. On the other hand, adaptive Lasso is shown to enjoy oracle properties if the regularization parameters are chosen to be data-dependent (Zou, Reference Zou2006). Since it is a convex optimization problem, its global optimizer can be efficiently solved. Additionally, adaptive Lasso is a simple extension of Lasso, which makes it easy to implement with the existing algorithm for the Lasso and is computationally efficient as well. Hence, adaptive Lasso is a good candidate as a penalization method for identifying item factor loading structure in MIRT. Specifically for parameter estimation, we solve the following optimization problem;

where

with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\hat{w}}}_{jk} = {1}/{|{\hat{\alpha }}^{(0)}_{jk}|^\gamma }$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk}$$\end{document}
 an initial estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
an initial estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
 without the regularization penalty, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma >0$$\end{document}
without the regularization penalty, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma >0$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda >0$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda >0$$\end{document}
 the tuning parameters. In the adaptive Lasso penalization, we use adaptive penalization weights for each parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
the tuning parameters. In the adaptive Lasso penalization, we use adaptive penalization weights for each parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
 , instead of a constant penalization parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
, instead of a constant penalization parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 as in Lasso. The penalization weight for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
as in Lasso. The penalization weight for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
 is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda {{\hat{w}}}_{jk} = {\lambda }/{|{\hat{\alpha }}^{(0)}_{jk}|^\gamma }$$\end{document}
is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda {{\hat{w}}}_{jk} = {\lambda }/{|{\hat{\alpha }}^{(0)}_{jk}|^\gamma }$$\end{document}
 . Thus,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk} < 1$$\end{document}
. Thus,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk} < 1$$\end{document}
 will get penalized more than the bigger values such as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk} > 1$$\end{document}
will get penalized more than the bigger values such as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk} > 1$$\end{document}
 . The weight is chosen to be dependent on data to satisfy the regulatory conditions discussed in Zou (Reference Zou2006). Particularly, Zou (2006) recommended three values, 0.5, 1, and 2, for the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
. The weight is chosen to be dependent on data to satisfy the regulatory conditions discussed in Zou (Reference Zou2006). Particularly, Zou (2006) recommended three values, 0.5, 1, and 2, for the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
 parameter, and the selection of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
parameter, and the selection of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 parameter will be discussed in Sect. 3.2.
parameter will be discussed in Sect. 3.2.
To ensure identifiability, we impose certain constraints on the a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K\times K$$\end{document}
 sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 . For the remaining part of the A matrix, we do not assume any pre-specified zero structure but instead, the appropriate penalization is imposed to shrink
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_{jk}$$\end{document}
. For the remaining part of the A matrix, we do not assume any pre-specified zero structure but instead, the appropriate penalization is imposed to shrink
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_{jk}$$\end{document}
 ’s to recover the true zero structure,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q^*_A$$\end{document}
’s to recover the true zero structure,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q^*_A$$\end{document}
 . Below are two different constraints on the A matrix. Note that the second constraint is more flexible; hence, it is more challenging estimation wise. Except for adding constraints on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
. Below are two different constraints on the A matrix. Note that the second constraint is more flexible; hence, it is more challenging estimation wise. Except for adding constraints on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 , we also fix the diagonals of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
, we also fix the diagonals of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
 at 1. Similar to Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we will compare the performance of these two constraint settings in the simulation study.
at 1. Similar to Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we will compare the performance of these two constraint settings in the simulation study.
Constraint 1 To ensure identifiability, we designate one item for each latent factor and this item is associated with only that factor. That is, we set a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K\times K$$\end{document}
 sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 to be an identity matrix,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$I_K$$\end{document}
to be an identity matrix,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$I_K$$\end{document}
 . Together with the constraints on the variance of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
. Together with the constraints on the variance of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
 , we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K^2$$\end{document}
, we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K^2$$\end{document}
 constraints in total.
constraints in total.
Constraint 2 Instead of setting all off-diagonals of a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K\times K$$\end{document}
 sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 to be zero, we keep the sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
to be zero, we keep the sub-matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 to be a triangular matrix with the diagonal being ones. That is, there are test items associated with each factor for sure and they may be associated with other factors as well. Nonzero entries except for the diagonal entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
to be a triangular matrix with the diagonal being ones. That is, there are test items associated with each factor for sure and they may be associated with other factors as well. Nonzero entries except for the diagonal entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 are penalized during the estimation procedure. Although this constraint is much weaker than the Constraint 1, it still ensures empirical identifiability when proper regularized likelihood such as (5) is used for the model estimation (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016).
are penalized during the estimation procedure. Although this constraint is much weaker than the Constraint 1, it still ensures empirical identifiability when proper regularized likelihood such as (5) is used for the model estimation (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016).
Additional Penalty for M3PL
The parameter estimation for M3PL in practice often gets more challenging due to the inclusion of guessing parameters. To tackle this challenge and improve the accuracy of the parameter estimation in M3PL, we propose to impose additional constraints on the model parameters,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {B}}= \{b_j; j=1, \dots , J\}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}= \{c_j; j=1,\dots , J\}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}= \{c_j; j=1,\dots , J\}$$\end{document}
 in addition to the parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {A}}$$\end{document}
in addition to the parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {A}}$$\end{document}
 . Specifically for parameter estimation, we solve the following optimization problem where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\cdot )$$\end{document}
. Specifically for parameter estimation, we solve the following optimization problem where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P(\cdot )$$\end{document}
 denotes a penalty function on model parameters:
denotes a penalty function on model parameters:

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\mathbf {B}}) = \sum _{j=1}^J\log N(b_j|\mu _b,\sigma _b^2)$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\mathbf {C}}) = \sum _{j=1}^J\log Beta(c_j|\alpha _c, \beta _c)$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P({\mathbf {C}}) = \sum _{j=1}^J\log Beta(c_j|\alpha _c, \beta _c)$$\end{document}
 for some distribution parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _b$$\end{document}
for some distribution parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _b$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma _b^2$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma _b^2$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _c$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _c$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta _c$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta _c$$\end{document}
 . These penalty functions are chosen to satisfy the ranges of values on which the parameters are defined. For instance, since the guessing parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
. These penalty functions are chosen to satisfy the ranges of values on which the parameters are defined. For instance, since the guessing parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
 naturally satisfy the constraint
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\{0< c_j < 1; j=1,\dots ,J\}$$\end{document}
naturally satisfy the constraint
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\{0< c_j < 1; j=1,\dots ,J\}$$\end{document}
 , we can assume a “prior” distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j \sim Beta(\alpha _c,\beta _c)$$\end{document}
, we can assume a “prior” distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j \sim Beta(\alpha _c,\beta _c)$$\end{document}
 . Similarly, we can assume a “prior” distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j \sim N(\mu _b,\sigma ^2_b)$$\end{document}
. Similarly, we can assume a “prior” distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j \sim N(\mu _b,\sigma ^2_b)$$\end{document}
 . The penalty on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
. The penalty on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
 are essentially a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_2$$\end{document}
are essentially a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$L_2$$\end{document}
 -type and Laplace penalization, respectively. By imposing these additional penalties on model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {B}}$$\end{document}
-type and Laplace penalization, respectively. By imposing these additional penalties on model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {B}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
 , the parameter estimation becomes more stable and robust.
, the parameter estimation becomes more stable and robust.
The approach of imposing additional penalty on model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {B}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
 with the chosen distributions is similar to the Bayes modal estimation presented by Tierney and Kadane (Reference Tierney and Kadane1986). That is, an augmented optimization objective is employed that includes the likelihood and some prior beliefs on the item parameters. These priors can be used to prevent deviant parameter estimates and help the algorithm to produce more accurate estimation in complex M3PL models. Essentially, Bayes modal estimation can be seen as a regularization on maximum likelihood estimation where maximum likelihood estimation is a special case of Bayes model estimation that assumes uniform prior distributions.
with the chosen distributions is similar to the Bayes modal estimation presented by Tierney and Kadane (Reference Tierney and Kadane1986). That is, an augmented optimization objective is employed that includes the likelihood and some prior beliefs on the item parameters. These priors can be used to prevent deviant parameter estimates and help the algorithm to produce more accurate estimation in complex M3PL models. Essentially, Bayes modal estimation can be seen as a regularization on maximum likelihood estimation where maximum likelihood estimation is a special case of Bayes model estimation that assumes uniform prior distributions.
The amount of penalization can be flexibly controlled using the distribution parameters. For instance, one can use non-informative priors on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {C}}$$\end{document}
 such as Beta(1, 1), which is equivalent to flat uniform distribution on [0, 1]. Additionally, one can similarly choose non-informative normal prior with high variance
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma _b$$\end{document}
such as Beta(1, 1), which is equivalent to flat uniform distribution on [0, 1]. Additionally, one can similarly choose non-informative normal prior with high variance
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma _b$$\end{document}
 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {B}}$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {B}}$$\end{document}
 . This suggests that although additional penalization functions are added, the algorithm also allows the flexible estimation with essentially no penalty with the choice of non-informative distributions. The advantage of this is that practitioners can adjust the amount of prior knowledge they would like to impose on the model. The less prior knowledge one uses, the more flexible the estimation is and the results will be based more on the observed data. With these prior-like penalties, our algorithm yields more precise parameter estimates for the M3PL model.
. This suggests that although additional penalization functions are added, the algorithm also allows the flexible estimation with essentially no penalty with the choice of non-informative distributions. The advantage of this is that practitioners can adjust the amount of prior knowledge they would like to impose on the model. The less prior knowledge one uses, the more flexible the estimation is and the results will be based more on the observed data. With these prior-like penalties, our algorithm yields more precise parameter estimates for the M3PL model.
Computation via GVEM
This section introduces the main estimation algorithm to obtain the estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({\hat{A}}_{\lambda }, {\hat{B}}_{\lambda }, {\hat{C}}_{\lambda })$$\end{document}
 via (6) using GVEM algorithm. As introduced in Sect. 2, we will use a variational lower bound to approximate the intractable marginal log-likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$l({\mathbf {A}},{\mathbf {B}},{\mathbf {C}}; {\mathbf {Y}})$$\end{document}
via (6) using GVEM algorithm. As introduced in Sect. 2, we will use a variational lower bound to approximate the intractable marginal log-likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$l({\mathbf {A}},{\mathbf {B}},{\mathbf {C}}; {\mathbf {Y}})$$\end{document}
 in (6).
in (6).
To derive a lower bound for easy estimation of the M3PL parameters, instead of directly working with (4), we employ an equivalent representation of the M3PL model with auxiliary latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}$$\end{document}
 , which is an indicator function of whether the ith individual answers the jth item based on the latent ability or guesses it correctly (von Davier, Reference von Davier2009). Specifically
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}=1$$\end{document}
, which is an indicator function of whether the ith individual answers the jth item based on the latent ability or guesses it correctly (von Davier, Reference von Davier2009). Specifically
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}=1$$\end{document}
 if the ith individual solves item j based on his/her ability, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij} = 0$$\end{document}
if the ith individual solves item j based on his/her ability, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij} = 0$$\end{document}
 if he/she guesses item j correctly. The distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij}$$\end{document}
if he/she guesses item j correctly. The distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij}$$\end{document}
 given the latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
given the latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}$$\end{document}
 is then
is then

where we define
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$0^0=1$$\end{document}
 , and it can be seen that this new model with auxiliary variable Z is equivalent to the M3PL model (von Davier, Reference von Davier2009, Cho et al., Reference Cho, Wang, Zhang and Xu2021). Denote
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{Z}}_i = \{Z_{i1}, Z_{i2}, \dots , Z_{iJ} \}$$\end{document}
, and it can be seen that this new model with auxiliary variable Z is equivalent to the M3PL model (von Davier, Reference von Davier2009, Cho et al., Reference Cho, Wang, Zhang and Xu2021). Denote
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{Z}}_i = \{Z_{i1}, Z_{i2}, \dots , Z_{iJ} \}$$\end{document}
 and its distribution as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({\varvec{Z}}_i) = \prod _{j=1}^J p(Z_{ij})$$\end{document}
and its distribution as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({\varvec{Z}}_i) = \prod _{j=1}^J p(Z_{ij})$$\end{document}
 . Then the complete data likelihood of the ith subject can be written as
. Then the complete data likelihood of the ith subject can be written as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\phi $$\end{document}
 denotes the normal probability density function for latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}$$\end{document}
denotes the normal probability density function for latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}$$\end{document}
 . Here, without loss of generality, we focus on the ith subject’s likelihood function due to the independence of different subjects.
. Here, without loss of generality, we focus on the ith subject’s likelihood function due to the independence of different subjects.
With the above representation, for any variational distribution functions
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}$$\end{document}
 (to be estimated later) of the latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
(to be estimated later) of the latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}_i$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij}$$\end{document}
 , similar to the derivation in Sect. 2, we have the following variational lower bound, which generalizes (4),
, similar to the derivation in Sect. 2, we have the following variational lower bound, which generalizes (4),


where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_i({\varvec{Z}}_i) = \prod _{j=1}^J r_{ij}(Z_{ij})$$\end{document}
 . Since (9) doesn’t depend on parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
. Since (9) doesn’t depend on parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{C}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{C}}$$\end{document}
 , we focus on (8) for the derivation of the lower bound. For (8), note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\log P(Y_{i},{\varvec{\theta }}_i, {\varvec{Z}}_i\mid {\varvec{A}},{\varvec{B}},{\varvec{C}})$$\end{document}
, we focus on (8) for the derivation of the lower bound. For (8), note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\log P(Y_{i},{\varvec{\theta }}_i, {\varvec{Z}}_i\mid {\varvec{A}},{\varvec{B}},{\varvec{C}})$$\end{document}
 takes the form of (7). To obtain a closed form lower bound expression for (8), we further use a local variational method (Bishop, Reference Bishop2006; Jordan, Ghahramani, Jaakkola, & Saul, Reference Jordan, Ghahramani, Jaakkola and Saul1999). Particularly, define
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\xi _{i,j}$$\end{document}
takes the form of (7). To obtain a closed form lower bound expression for (8), we further use a local variational method (Bishop, Reference Bishop2006; Jordan, Ghahramani, Jaakkola, & Saul, Reference Jordan, Ghahramani, Jaakkola and Saul1999). Particularly, define
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\xi _{i,j}$$\end{document}
 as a variational parameter indexed by i and j, and let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ \eta ({\xi _{i,j}})= (2{\xi _{i,j}})^{-1}[ {e^{\xi _{i,j}}}/{(1+e^{\xi _{i,j}})}-{1}/{2} ]. $$\end{document}
as a variational parameter indexed by i and j, and let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ \eta ({\xi _{i,j}})= (2{\xi _{i,j}})^{-1}[ {e^{\xi _{i,j}}}/{(1+e^{\xi _{i,j}})}-{1}/{2} ]. $$\end{document}
 Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\xi }_i = (\xi _{i,j}, j=1,\cdots , J)$$\end{document}
Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\xi }_i = (\xi _{i,j}, j=1,\cdots , J)$$\end{document}
 denote the ith subject’s variational parameters for the J items. Then following the local variational method (Bishop, Reference Bishop2006), we have
denote the ith subject’s variational parameters for the J items. Then following the local variational method (Bishop, Reference Bishop2006), we have

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$l({\varvec{A}}, {\varvec{B}},{\varvec{C}}, \varvec{\xi }_i ; Y_i,{\varvec{\theta }}_i,{\varvec{Z}}_{i})$$\end{document}
 is defined as
is defined as

and it gives a lower bound of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\log P(Y_i,{\varvec{\theta }}_i, {\varvec{Z}}_{i} \mid {\varvec{A}}, {\varvec{B}}, {\varvec{C}})$$\end{document}
 in (8). We then have the following expression for the variational lower bound of the marginal likelihood of all observed responses in (6),
in (8). We then have the following expression for the variational lower bound of the marginal likelihood of all observed responses in (6),

with the lower bound
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E({\varvec{A}},{\varvec{B}},{\varvec{C}}, \varvec{\xi })$$\end{document}
 defined as
defined as

Appropriate choices of the variational distributions will lead to a closed form expression of the lower bound in (11). Particularly, following the derivations in Cho et al. (Reference Cho, Wang, Zhang and Xu2021), the above likelihood function implies that an optimal choice of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
 is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ q_i({\varvec{\theta }}_i) \sim N({\varvec{\theta }}_i \mid \mu _i,\Sigma _i )$$\end{document}
is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ q_i({\varvec{\theta }}_i) \sim N({\varvec{\theta }}_i \mid \mu _i,\Sigma _i )$$\end{document}
 where the mean and covariance are
where the mean and covariance are


and the variational distributions
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}(Z_{ij})$$\end{document}
 are
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}(Z_{ij}) \sim Bernoulli(s_{ij})$$\end{document}
are
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}(Z_{ij}) \sim Bernoulli(s_{ij})$$\end{document}
 , where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = 1$$\end{document}
, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = 1$$\end{document}
 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij} = 0$$\end{document}
if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij} = 0$$\end{document}
 , and otherwise
, and otherwise

With the above chosen
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q_i$$\end{document}
 ’s and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}$$\end{document}
’s and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_{ij}$$\end{document}
 ’s, we aim to estimate model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
’s, we aim to estimate model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{A}}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{B}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{C}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{C}}$$\end{document}
 , together with the introduced local variational parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\xi }$$\end{document}
, together with the introduced local variational parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\xi }$$\end{document}
 , by maximizing the variational lower bound of the marginal likelihood,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E({\varvec{A}},{\varvec{B}},{\varvec{C}}, \varvec{\xi })$$\end{document}
, by maximizing the variational lower bound of the marginal likelihood,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E({\varvec{A}},{\varvec{B}},{\varvec{C}}, \varvec{\xi })$$\end{document}
 in (11), with the proposed penalties in (6), that is,
in (11), with the proposed penalties in (6), that is,

The corresponding solution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({\hat{{\mathbf {A}}}}_{\lambda }, {\hat{{\mathbf {B}}}}_{\lambda }, {\hat{{\mathbf {C}}}}_{\lambda })$$\end{document}
 gives the our GVEM estimators for the penalized likelihood in (6).
gives the our GVEM estimators for the penalized likelihood in (6).
To estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({\varvec{A}}, {\mathbf {B}}, {\mathbf {C}})$$\end{document}
 , we use the coordinate descent algorithm (Friedman, Hastie, Höfling, & Tibshirani, Reference Friedman, Hastie, Höfling and Tibshirani2007; Friedman et al., Reference Friedman, Hastie and Tibshirani2010), which solves the target optimization problem by successively minimizing along each coordinate direction of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({\varvec{A}}, {\mathbf {B}}, {\mathbf {C}})$$\end{document}
, we use the coordinate descent algorithm (Friedman, Hastie, Höfling, & Tibshirani, Reference Friedman, Hastie, Höfling and Tibshirani2007; Friedman et al., Reference Friedman, Hastie and Tibshirani2010), which solves the target optimization problem by successively minimizing along each coordinate direction of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({\varvec{A}}, {\mathbf {B}}, {\mathbf {C}})$$\end{document}
 . For each item j, there are one difficulty parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
. For each item j, there are one difficulty parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
 , one guessing parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
, one guessing parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
 , and K discrimination parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
, and K discrimination parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 . The coordinate descent algorithm updates each of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K+2$$\end{document}
. The coordinate descent algorithm updates each of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K+2$$\end{document}
 variables according to the following updating rule. (Please see Appendix for a detailed derivation of the updating rule.) Note that the derivation of the below soft-thresholding update rule of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$a_{jk}$$\end{document}
variables according to the following updating rule. (Please see Appendix for a detailed derivation of the updating rule.) Note that the derivation of the below soft-thresholding update rule of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$a_{jk}$$\end{document}
 can be viewed as from the proximal gradient descent algorithm (Beck & Teboulle, Reference Beck and Teboulle2009). Define a function S to be a soft threshold operator such that
can be viewed as from the proximal gradient descent algorithm (Beck & Teboulle, Reference Beck and Teboulle2009). Define a function S to be a soft threshold operator such that

where for any real number x, sign(x) denotes the sign of x and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_+$$\end{document}
 denotes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\max \{0,x\}$$\end{document}
denotes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\max \{0,x\}$$\end{document}
 . The model parameters,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
. The model parameters,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}_j$$\end{document}
 ’s,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
’s,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b_j$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c_j$$\end{document}
 are updated using Equations (17), (18), and (19), respectively,
are updated using Equations (17), (18), and (19), respectively,



where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\alpha }}^{(0)}_{jk}$$\end{document}
 is the initial estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
is the initial estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{jk}$$\end{document}
 by the GVEM algorithm without including the penalty terms in (15). Additionally, the variational parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\xi $$\end{document}
by the GVEM algorithm without including the penalty terms in (15). Additionally, the variational parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\xi $$\end{document}
 ’s are updated as
’s are updated as

and the covariance can be updated as

To choose the constant sparsity parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 , we can apply popular information criteria, such as Akaike Information Criterion (AIC), Bayesian information criterion (BIC) and generalized information criterion (GIC) (Nishii, Reference Nishii1984; Y. Fan & Tang, Reference Fan and Tang2013). We estimate the information criteria by substituting the log-likelihood with the variational lower bound from the GVEM algorithm. The sparsity parameter that minimizes these information criteria will be considered optimal. Our pilot study shows that the GIC method proposed for high-dimensional model selection in Y. Fan and Tang (Reference Fan and Tang2013) performs better than AIC and BIC, and hence GIC is used throughout the study.
, we can apply popular information criteria, such as Akaike Information Criterion (AIC), Bayesian information criterion (BIC) and generalized information criterion (GIC) (Nishii, Reference Nishii1984; Y. Fan & Tang, Reference Fan and Tang2013). We estimate the information criteria by substituting the log-likelihood with the variational lower bound from the GVEM algorithm. The sparsity parameter that minimizes these information criteria will be considered optimal. Our pilot study shows that the GIC method proposed for high-dimensional model selection in Y. Fan and Tang (Reference Fan and Tang2013) performs better than AIC and BIC, and hence GIC is used throughout the study.
The detailed algorithm of the regularized estimation of the loading structure via adaptive Lasso penalization is illustrated in Algorithm 1.


Remark 1
In addition to our choice of adaptive Lasso for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$P_\lambda ({\mathbf {A}})$$\end{document}
 in (6), there are generally other methods of penalization. For instance, J. Fan and Li (Reference Fan and Li2001) showed that the Lasso penalization problem is suboptimal to their proposed method called smoothly clipped absolute deviation (SCAD) penalty as Lasso produces biased estimates for the large coefficients. They showed that the SCAD penalization enjoys asymptotic normality and oracle properties with proper choice of regularization parameters. Due to its solid theoretical properties, SCAD has been widely applied in variable selection problems (T. Wang, Xu, & Zhu Reference Wang, Xu and Zhu2012; Liu, Yao, & Li, Reference Liu, Yao and Li2016; Breheny & Huang Reference Breheny and Huang2011). Additionally, Minimax Concave Penalty (MCP) has been presented as a fast, continuous and nearly unbiased method of penalization and hence claimed to be a good alternative to Lasso (C. H. Zhang Reference Zhang2010). Truncated Lasso is also another popular penalization method (Shen, Pan, & Zhu, Reference Shen, Pan and Zhu2012; Xu & Shang, Reference Xu and Shang2018); however, penalty function for these methods is non-convex and it makes local solutions to be nonunique in general, which is computationally challenging to solve as well. On the other hand, adaptive Lasso uses a convex penalty and it is computationally efficient, which makes it a good candidate for regularization problem under complex MIRT models. Hence, we choose adaptive Lasso for solving our regularized problem.
in (6), there are generally other methods of penalization. For instance, J. Fan and Li (Reference Fan and Li2001) showed that the Lasso penalization problem is suboptimal to their proposed method called smoothly clipped absolute deviation (SCAD) penalty as Lasso produces biased estimates for the large coefficients. They showed that the SCAD penalization enjoys asymptotic normality and oracle properties with proper choice of regularization parameters. Due to its solid theoretical properties, SCAD has been widely applied in variable selection problems (T. Wang, Xu, & Zhu Reference Wang, Xu and Zhu2012; Liu, Yao, & Li, Reference Liu, Yao and Li2016; Breheny & Huang Reference Breheny and Huang2011). Additionally, Minimax Concave Penalty (MCP) has been presented as a fast, continuous and nearly unbiased method of penalization and hence claimed to be a good alternative to Lasso (C. H. Zhang Reference Zhang2010). Truncated Lasso is also another popular penalization method (Shen, Pan, & Zhu, Reference Shen, Pan and Zhu2012; Xu & Shang, Reference Xu and Shang2018); however, penalty function for these methods is non-convex and it makes local solutions to be nonunique in general, which is computationally challenging to solve as well. On the other hand, adaptive Lasso uses a convex penalty and it is computationally efficient, which makes it a good candidate for regularization problem under complex MIRT models. Hence, we choose adaptive Lasso for solving our regularized problem.
Simulation Study
Design
A simulation study was conducted to evaluate the performance of the regularized GVEM algorithm in identifying true item factor loading structure with both M2PL and M3PL models. Three manipulated factors were considered: (1) the number of dimensions was fixed at 3 and 5 (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K = 3, 5$$\end{document}
 ); (2) the correlations among factors were fixed at either 0.1, 0.3, or 0.7; and (3) both between-item and within-item multidimensional structures were considered. The sample size was fixed at 2000 (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 2000$$\end{document}
); (2) the correlations among factors were fixed at either 0.1, 0.3, or 0.7; and (3) both between-item and within-item multidimensional structures were considered. The sample size was fixed at 2000 (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 2000$$\end{document}
 ) and 100 replications were run.Footnote 1
) and 100 replications were run.Footnote 1
For the between-item MIRT model, the test length was 45, with 15 items loaded onto each factor. The true item parameters were selected from the 2013 NAEP item bank (combined national and state assessments) for grade 8. For the within-item MIRT, the true item discrimination parameters were simulated from Unif(0.75, 2), and the difficulty parameters were drawn from the standard normal distribution. Additionally in M3PL, the guessing parameters were fixed at 0.2. The generated item parameters resemble the item parameters in Table 6.1 of (Reckase, Reference Reckase2009) closely. When the dimension was 3, about
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$60\%$$\end{document}
 of the items were loaded onto one factor, about
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$25\%$$\end{document}
of the items were loaded onto one factor, about
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$25\%$$\end{document}
 were loaded onto two factors, and the rest were loaded onto all three factors, whereas for the 5-dimension conditions, about
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$60\%$$\end{document}
were loaded onto two factors, and the rest were loaded onto all three factors, whereas for the 5-dimension conditions, about
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$60\%$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$20\%$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$20\%$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$20\%$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$20\%$$\end{document}
 of the items were loaded onto one, two, and three factors, respectively. In all cases, the latent traits
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}$$\end{document}
of the items were loaded onto one, two, and three factors, respectively. In all cases, the latent traits
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\theta }}$$\end{document}
 were simulated from
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$MVN(0,\Sigma _{\varvec{\theta }})$$\end{document}
were simulated from
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$MVN(0,\Sigma _{\varvec{\theta }})$$\end{document}
 with variance 1, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r= 0.1, 0.3$$\end{document}
with variance 1, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r= 0.1, 0.3$$\end{document}
 or 0.7.
or 0.7.
Six methods were compared in the study, and they are (1) traditional exploratory item factor analysis followed by the CF-Quartimax rotation. This method is denoted as “Rotation” in all results. For this method, during estimation, we did not assume any constraint on the item discrimination parameter but fixed the population covariance matrix to an identity matrix, i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Sigma }_{\varvec{\theta }}={\varvec{I}}$$\end{document}
 . The GVEM algorithm was used for model estimation. The final discrimination parameters were transformed to standardized factor loadings, the value of which was compared to 0.3 (Henson & Roberts, Reference Henson and Roberts2006; Costello & Osborne, Reference Costello and Osborne2005). We used
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\psi }_j={{\varvec{U}}}^{-1}\varvec{\alpha }_j$$\end{document}
. The GVEM algorithm was used for model estimation. The final discrimination parameters were transformed to standardized factor loadings, the value of which was compared to 0.3 (Henson & Roberts, Reference Henson and Roberts2006; Costello & Osborne, Reference Costello and Osborne2005). We used
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\psi }_j={{\varvec{U}}}^{-1}\varvec{\alpha }_j$$\end{document}
 , where
, where
![]() to obtain the standardized factor loadings. If
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$|\psi _{jk}|$$\end{document}
to obtain the standardized factor loadings. If
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$|\psi _{jk}|$$\end{document}
 exceeds 0.3, the item is assumed to load on the corresponding factor. This transformation function worked for all simulated conditions except for the within-item structure,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, K=3$$\end{document}
exceeds 0.3, the item is assumed to load on the corresponding factor. This transformation function worked for all simulated conditions except for the within-item structure,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, K=3$$\end{document}
 , M2PL and M3PL. In these two conditions, we transformed the true discrimination parameters to standardized factor loadings, and found some values were smaller than 0.3. Under these two conditions, we set the cutoff values as 0.75 instead, as the true values were generated from Unif(0.75, 2). Setting a different cutoff will certainly affect the results, and this, to some extent, implies the subjectivity in the traditional EFA rotation method. (2) Exploratory item factor analysis with fixed anchors, and it is denoted as “Fixed Anchors” in all results. For this method, we imposed constraint 1 on the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
, M2PL and M3PL. In these two conditions, we transformed the true discrimination parameters to standardized factor loadings, and found some values were smaller than 0.3. Under these two conditions, we set the cutoff values as 0.75 instead, as the true values were generated from Unif(0.75, 2). Setting a different cutoff will certainly affect the results, and this, to some extent, implies the subjectivity in the traditional EFA rotation method. (2) Exploratory item factor analysis with fixed anchors, and it is denoted as “Fixed Anchors” in all results. For this method, we imposed constraint 1 on the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Q_A$$\end{document}
 such that post-hoc rotation is no longer needed. We used the same transformation formula to calculate standardized factor loadings. This method was considered to ensure a direct and fair comparison to the regularization methods. (3) Lasso with constraint 1 and 2; and (4) adaptive Lasso with constraint 1 and 2. For the regularization methods, the tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
such that post-hoc rotation is no longer needed. We used the same transformation formula to calculate standardized factor loadings. This method was considered to ensure a direct and fair comparison to the regularization methods. (3) Lasso with constraint 1 and 2; and (4) adaptive Lasso with constraint 1 and 2. For the regularization methods, the tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 was chosen by GIC. The GIC was computed as follows:
was chosen by GIC. The GIC was computed as follows:

where N refers to the sample size, k refers to the number of parameters estimated by the model,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E({\varvec{A}},{\varvec{B}},{\varvec{C}}, \varvec{\xi })$$\end{document}
 refers to the lower bound.
refers to the lower bound.
In additional to the two constraints for the model ability, we truncated
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{{\varvec{\alpha }}}}_{jk}$$\end{document}
 to 0 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$|{\hat{{\varvec{\alpha }}}}_{jk}| < 0.001$$\end{document}
to 0 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$|{\hat{{\varvec{\alpha }}}}_{jk}| < 0.001$$\end{document}
 . As to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
. As to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
 in adaptive Lasso, Zou (2006) recommended three values, 0.5, 1, and 2. A few pilot trials were conducted to decide on the optimal
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
in adaptive Lasso, Zou (2006) recommended three values, 0.5, 1, and 2. A few pilot trials were conducted to decide on the optimal
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =2$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =2$$\end{document}
 was used for all conditions except a few conditions in which case
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =1$$\end{document}
was used for all conditions except a few conditions in which case
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =1$$\end{document}
 was used. These conditions are within-item M2PL,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, k=5$$\end{document}
was used. These conditions are within-item M2PL,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, k=5$$\end{document}
 , constraint 1 and 2, as well as between-item M2PL,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, k=5$$\end{document}
, constraint 1 and 2, as well as between-item M2PL,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, k=5$$\end{document}
 , constraint 2 only.
, constraint 2 only.
As the main objective of this section is to estimate relationship between test items and latent traits, we used the correct estimation rate of A matrix (eq. (22)). It measures how well the sparsity of the A matrix is estimated by the regularized estimation. Notice that we only calculated correct rate for entries excluding the first K by K sub-matrix since we fixed this part to have identity matrix as a zero structure to ensure identifiability.

We also compared the performance of Lasso and adaptive Lasso penalization using two measures: sensitivity and specificity. In our context, sensitivity is the probability of correctly identifying nonzero entries among true nonzero entries. Specificity is the probability of correctly identifying zero entries among true zero entries. In other words, sensitivity measures the true negative rate, while specificity illustrates the true positive rate. Naturally, a test with both high sensitivity and high specificity is desired, although there is always a trade-off.
Other criteria include the average relative bias and root mean squared error (RMSE). The parameter recovery for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
 is calculated by taking differences between each freely estimated entries of the true
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
is calculated by taking differences between each freely estimated entries of the true
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{\varvec{\theta }}$$\end{document}
 and estimated
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\Sigma }}_{\varvec{\theta }}$$\end{document}
and estimated
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\Sigma }}_{\varvec{\theta }}$$\end{document}
 . Relative bias and RMSE were obtained for each nonzero model parameter across all items within a condition first and then averaged over 100 replications.
. Relative bias and RMSE were obtained for each nonzero model parameter across all items within a condition first and then averaged over 100 replications.
Simulation Results
In this section, we first present the simulation results under various settings in M2PL and M3PL with boxplots to show the distribution of correct estimation rates, sensitivities, and specificities. Among the three information criteria, GIC showed the best performance at selecting the optimal result as it favors the models that penalizes more on the number of parameters; thus, we present the simulation results with GIC selection criteria in figures in this section.
Figures 1 and 2 show the recovery of item factor loading structure in terms of correct rates, sensitivity and specificity under M2PL and M3PL, respectively. All six methods were presented in the same order under each manipulated condition in Figures 1, 2, 3, 4, 5, 6. For M2PL, the adaptive Lasso method is consistently the best-performing method under all conditions, except when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.1, K=5$$\end{document}
 , item structure is within-item M2PL, and when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.3, K=5$$\end{document}
, item structure is within-item M2PL, and when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.3, K=5$$\end{document}
 , item structure is between-item M2PL. Under these two conditions, EFA rotation method performs slightly better than the adaptive Lasso method. The EFA with fixed anchors and Lasso regularization methods, on the other hand, performs a lot worse. When
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3$$\end{document}
, item structure is between-item M2PL. Under these two conditions, EFA rotation method performs slightly better than the adaptive Lasso method. The EFA with fixed anchors and Lasso regularization methods, on the other hand, performs a lot worse. When
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3$$\end{document}
 , and within-item M2PL is used, EFA rotation method performs considerably worse than EFA with fixed anchors and adaptive Lasso methods. Between the two constraint settings, constraint 2 yields more free parameters and hence it is harder to handle than constraint 1. Therefore, it is not surprising that adaptive Lasso with constraint 1 performs slightly better than with constraint 2 in more challenging scenarios (i.e., higher correlation, larger K, and within-item multidimensionality), whereas the difference between the two types is almost negligible in simpler scenarios.
, and within-item M2PL is used, EFA rotation method performs considerably worse than EFA with fixed anchors and adaptive Lasso methods. Between the two constraint settings, constraint 2 yields more free parameters and hence it is harder to handle than constraint 1. Therefore, it is not surprising that adaptive Lasso with constraint 1 performs slightly better than with constraint 2 in more challenging scenarios (i.e., higher correlation, larger K, and within-item multidimensionality), whereas the difference between the two types is almost negligible in simpler scenarios.
When M3PL is the data generating model, the recovery of item factor loading structure is generally worse than that from M2PL, with a decrement of correct rate, sensitivity, and specificity in the range of 5% to 20%. The general trend of the manipulated factors on the results stay the same as compared to M2PL. That is, increasing factor correlation or allowing item cross-loadings makes the recovery of factor structure harder, although adaptive Lasso still performs the best among the six methods in all conditions except when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=5$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=5$$\end{document}
 and test exhibits between-item multidimensional structure. In this case, EFA rotation method tends to excel.
and test exhibits between-item multidimensional structure. In this case, EFA rotation method tends to excel.

Figure. 1 Correct estimation rates of item factor loading structure under M2PL.

Figure. 2 Correct estimation rates of item factor loading structure under M3PL.
Figure 3 presents the relative bias of model parameters under M2PL. When the test has 5 latent factors and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.1$$\end{document}
 or 0.3, although relative bias vary slightly differently for different parameters, the results from the six methods are almost indistinguishable. In a between-item structure with 3 factors, the relative bias for b has more variability across replications. It is because the true parameters of some items are close to 0. The relative bias vary more for the within-item condition in general. In a within-item structure, the two regularization methods appear to produce less bias than the EFA rotation method especially for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
or 0.3, although relative bias vary slightly differently for different parameters, the results from the six methods are almost indistinguishable. In a between-item structure with 3 factors, the relative bias for b has more variability across replications. It is because the true parameters of some items are close to 0. The relative bias vary more for the within-item condition in general. In a within-item structure, the two regularization methods appear to produce less bias than the EFA rotation method especially for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
 . Under
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3, r=0.1$$\end{document}
. Under
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3, r=0.1$$\end{document}
 or 0.7, within-item M2PL conditions, the relative bias values for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
or 0.7, within-item M2PL conditions, the relative bias values for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
 estimated by EFA rotation fall outside of the range. Figure 4 presents the RMSE of model parameters under M2PL. Again, all six methods produce comparable RMSE when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.1$$\end{document}
estimated by EFA rotation fall outside of the range. Figure 4 presents the RMSE of model parameters under M2PL. Again, all six methods produce comparable RMSE when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.1$$\end{document}
 under between-item condition. When the factor correlation increases, the EFA rotation method generates larger RMSE for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha $$\end{document}
under between-item condition. When the factor correlation increases, the EFA rotation method generates larger RMSE for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha $$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
 . The same trend holds under the within-item M2PL conditions, although adaptive Lasso method seems to generate large RMSE for some conditions. Under the most difficult condition of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, K=5$$\end{document}
. The same trend holds under the within-item M2PL conditions, although adaptive Lasso method seems to generate large RMSE for some conditions. Under the most difficult condition of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, K=5$$\end{document}
 , one can see a lot of variability of RMSE across replications. In this case, the two Lasso methods seem to produce smaller median RMSE for majority of the parameters than EFA rotation method and EFA with fixed anchors method. The better performance of Lasso methods compared to adaptive Lasso may be because of two reasons: (1) we computed bias and RMSE only on those parameters whose true values were nonzero. Hence, even if the Lasso method fails to shrink some true zero loadings to zero, they will not count toward bias or RMSE. (2) Initial values play an important role in adaptive Lasso to determine an adaptive penalty weight. We used the results from EFA rotation methods as initial values, and other better initial values could be explored in the future, such as the SVD method in H. Zhang et al. (Reference Zhang, Chen and Li2020).
, one can see a lot of variability of RMSE across replications. In this case, the two Lasso methods seem to produce smaller median RMSE for majority of the parameters than EFA rotation method and EFA with fixed anchors method. The better performance of Lasso methods compared to adaptive Lasso may be because of two reasons: (1) we computed bias and RMSE only on those parameters whose true values were nonzero. Hence, even if the Lasso method fails to shrink some true zero loadings to zero, they will not count toward bias or RMSE. (2) Initial values play an important role in adaptive Lasso to determine an adaptive penalty weight. We used the results from EFA rotation methods as initial values, and other better initial values could be explored in the future, such as the SVD method in H. Zhang et al. (Reference Zhang, Chen and Li2020).

Figure. 3 Relative bias of model parameter estimates under M2PL.

Figure. 4 RMSE of model parameter estimates under M2PL.

Figure. 5 Relative bias of model parameter estimates under M3PL.

Figure. 6 RMSE of model parameter estimates under M3PL.
Figures 5 and 6 show the relative bias and RMSE of model parameters under M3PL. The inclusion of the guessing parameter, unsurprisingly, makes the model parameter recovery much harder, as shown in larger bias and RMSE as well as more variability across replications. The overall pattern observed from M2PL results continued to hold. That is, increasing factor correlation and using within-item factor structure not only increase relative bias and RMSE, but also yield more instability across replications. The EFA rotation method produces the largest average absolute bias and mean RMSE in almost all conditions, followed by EFA with fixed anchors method, although results from regularization methods seem to have more variability when the factor correlation is high.
In summary, the adaptive Lasso method outperforms EFA rotation method under almost all conditions regarding item factor loading structure recovery. There are only 3 exceptions: when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.1, K=5$$\end{document}
 , item structure is within-item M2PL, when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.3, K=5$$\end{document}
, item structure is within-item M2PL, when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.3, K=5$$\end{document}
 , item structure is between-item M2PL, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, K=5$$\end{document}
, item structure is between-item M2PL, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r=0.7, K=5$$\end{document}
 , item structure is between-item M3PL. In these three conditions, EFA rotation method performs better than the adaptive Lasso method by a small margin. Under some simple scenarios (i.e., low-correlation or medium-correlation and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3$$\end{document}
, item structure is between-item M3PL. In these three conditions, EFA rotation method performs better than the adaptive Lasso method by a small margin. Under some simple scenarios (i.e., low-correlation or medium-correlation and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$K=3$$\end{document}
 , item structure is between-item M2PL), there is no appreciable difference between the EFA rotation method and the adaptive Lasso method with either type of constraints. As for item parameter recovery, the adaptive Lasso method outperforms EFA rotation method for all of the high-correlation scenarios in M2PL. For small-correlation, between-item M2PL conditions, the results of adaptive Lasso and EFA rotation method appear to be indistinguishable. In M3PL, the adaptive Lasso method produces more accurate results compared to EFA rotation method under all conditions. Only under between-item M3PL conditions, EFA rotation generates smaller RMSE values and relative bias with less variability for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
, item structure is between-item M2PL), there is no appreciable difference between the EFA rotation method and the adaptive Lasso method with either type of constraints. As for item parameter recovery, the adaptive Lasso method outperforms EFA rotation method for all of the high-correlation scenarios in M2PL. For small-correlation, between-item M2PL conditions, the results of adaptive Lasso and EFA rotation method appear to be indistinguishable. In M3PL, the adaptive Lasso method produces more accurate results compared to EFA rotation method under all conditions. Only under between-item M3PL conditions, EFA rotation generates smaller RMSE values and relative bias with less variability for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _\theta $$\end{document}
 , but it produces larger RMSE and relative bias for other parameters.
, but it produces larger RMSE and relative bias for other parameters.
Real Data Analysis
In this section, the proposed regularization method was applied to the National Education Longitudinal Study of 1988 (NELS:88) data, and results were compared with those from EFA rotation method. NELS:88 was collected from a nationally representative sample of students whose performance on different cognitive batteries were tracked from 8th to 12th grade (the first three studies) in years 1988, 1990, and 1992. In this study, we focused on the science and mathematics test data where the multidimensional factorial structure has been previously investigated (e.g, Kupermintz & Snow, Reference Kupermintz and Snow1997; Nussbaum, Hamilton, & Snow, Reference Nussbaum, Hamilton and Snow1997). Table 1 shows an example of the content of the questions in science test. For the science subject, there are 25 items and four factors were found from the data collected in 1988: “Elementary science (ES)”, “Chemistry knowledge (CK)”, “Scientific reasoning (SR)” and “Reasoning with knowledge (RK)”. For the math subject, there are 40 items in 1988 and two factors emerged. They are “Mathematical reasoning (MR)” and “Mathematical knowledge (MK)”. We pooled together data from both domains, resulting in 65 items and a complete sample size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N=13,488$$\end{document}
 .
.
In the previous analysis of NELS:88 by Cho et al. (2020), the GVEM approach was used to empirically estimate the optimal number of latent traits from this data set. The result suggests there exists six latent traits measured by NELS:88. This finding is consistent with what the previous literature implies (e.g, Kupermintz & Snow, Reference Kupermintz and Snow1997; Nussbaum et al., Reference Nussbaum, Hamilton and Snow1997). Thus, we fix the dimension of latent factors as six for this analysis. Also, Kupermintz and Snow (Reference Kupermintz and Snow1997) and Nussbaum et al. (Reference Nussbaum, Hamilton and Snow1997) analyzed the latent traits required by each test item based on the content of the questions. Based on their findings, we chose 6 questions that only associate with each one of latent factors and performed our proposed regularized estimation under Constraint 1.
Table 1 NELS:88 science items and descriptions were adopted from Rock et al. (Reference Rock, Pollack, Owings and Hafner1991).
| Item | 8th grade | 10th grade | Description |
|---|---|---|---|
| S01 | 1 | Infer geologic history from facts about limestone deposits | |
| S02 | 2 | Identify components of solar system | |
| S03 | 3 | 2 | Read a graph depicting solubility of chemicals |
| S04 | 4 | 3 | Choose an improvement for an experiment on mice |
| S05 | 5 | 4 | Choose a statement about source of moon’s light |
| S06 | 6 | 5 | Identify the example of a simple reflex |
| S07 | 7 | Choose viable way of communicating on moon | |
| S08 | 8 | Select statement about position of sun, moon, earth in diagram | |
| S09 | 9 | Identify source of oxygen in ocean water | |
| S10 | 10 | 1 | Choose the property used to classify a list of substances |
| S11 | 11 | Explain lower freezing temperature of ocean water | |
| S12 | 12 | 6 | Answer question about the earth’s orbit |
| S13 | 13 | Infer use of oxygen from description of condition of aquarium | |
| S14 | 14 | 7 | Estimate temperature of a mixture |
| S15 | 15 | 8 | Select a statement about the process of respiration |
| S16 | 16 | 9 | Read a graph depicting digestion of a protein by an enzyme |
| S17 | 17 | 10 | Explain location of marine algae |
| S18 | 18 | 11 | Choose best indication of an approaching storm |
| S19 | 19 | 12 | Choose the alternative that is not a chemical change |
| S20 | 20 | 13 | Infer statement from results of an experiment using a filter |
| S21 | 21 | 14 | Explain reason for late afternoon breeze from the ocean |
| S22 | 22 | 15 | Select basis for a statement about a food chain |
| S23 | 23 | 16 | Interpret symbols describing a chemical reaction |
| S24 | 24 | 17 | Differentiate statements based on a model or an observation |
| S25 | 25 | 18 | Describe color of offspring from a guinea-pig cross |
| S26 | 19 | Calculate a mass given density and dimensions | |
| S27 | 20 | Locate the balance point of a weighted lever | |
| S28 | 21 | Interpret a contour map | |
| S29 | 22 | Identify diagram depicting path of light through camera lens | |
| S30 | 23 | Calculate grams of a substance given its half life | |
| S31 | 24 | Read population graph; identify equilibrium point | |
| S32 | 25 | Identify cause of fire from overloaded circuit |
S stands for Science items, and item descriptions were adopted from.
Both the EFA rotation (with the CF-Quartimax rotation) and adaptive Lasso methods with M2PL and M3PL were fitted to the data set. EFA rotation assumed all items load on all factors. For the adaptive Lasso method, we assumed all items load on all factors and hence penalty is added on every element in the loading matrix except for the constraints. Note that we also consider another version of adaptive Lasso which assumes math items only load on the two math factors, and science items only load on the four science factors, hence there are structural 0’s in the loading matrix that we neither estimate nor add penalty on. The results of this version are reported in the online supplementary materials to save space. Given the large sample size and test length (65 items in total), stochastic version of GVEM algorithm was used for M3PL. Specifically we used a stochastic sampling of 200 at each iteration and initially sampled 3000 for more stable convergence. For models with penalty, only adaptive Lasso was considered at it was shown to perform better than Lasso penalty under majority conditions in the simulation studies. The penalty parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
 was fixed at 3 in adaptive Lasso. This is because the item factor loading structure is more complex (as compared to simulation study), hence, heavier penalization (i.e., higher
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
was fixed at 3 in adaptive Lasso. This is because the item factor loading structure is more complex (as compared to simulation study), hence, heavier penalization (i.e., higher
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
 ) was used to produce a nicer sparse structure. Table 2 shows that the M2PL in general yields smaller GIC than M3PL. For the same model, adaptive Lasso produces the smaller GIC compared to the EFA rotation method. The fact that M2PL is preferred over M3PL implies that guessing may not play a big role on the performance in NELS:88 math and science assessments. Moreover, larger GIC from EFA rotation method implies that the factor loading structure obtained from it may not reflect the true item factor relationship as closely as the adaptive Lasso method.
) was used to produce a nicer sparse structure. Table 2 shows that the M2PL in general yields smaller GIC than M3PL. For the same model, adaptive Lasso produces the smaller GIC compared to the EFA rotation method. The fact that M2PL is preferred over M3PL implies that guessing may not play a big role on the performance in NELS:88 math and science assessments. Moreover, larger GIC from EFA rotation method implies that the factor loading structure obtained from it may not reflect the true item factor relationship as closely as the adaptive Lasso method.
Table 2 GIC comparison from two methods and two models (AL stands for adaptive Lasso).
| M2PL | M3PL | ||
|---|---|---|---|
| EFA | AL | EFA | AL |
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$1.20\times 10^6$$\end{document}

|
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$0.73\times 10^6$$\end{document}

|
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$1.28\times 10^6$$\end{document}

|
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$1.81\times 10^6$$\end{document}

|
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Next, using M2PL with adaptive Lasso, Tables 3 and 4 illustrate the estimated sparse test structure from math and science test, respectively, and Tables 5 and 6 present the results from the EFA rotation method. Note the order of the latent traits for the EFA rotation method is arbitrary. As shown, for the EFA rotation method, before using 0.3 as the cutoff, we observe more cross-loadings, but after standardizing the factor loadings and using 0.3 as the cutoff, the EFA rotation method yields more spare and close to simple structure compared to the adaptive Lasso method. However, it appears that, in the EFA rotation method, both math and science items load dominantly on a single factor, which contracts with the findings that 2 and 4 best reflect the underlying factor structure. On the other hand, item factor loadings obtained from adaptive Lasso method, although they are less sparse and contain more cross loadings, appear to be more reasonable.
Tables 7 and 8 present the estimated factor correlations for two methods. Factor correlations obtained from EFA are in the range of 0.01 to 0.73, which are much lower than those from the regularization method. Adaptive Lasso estimated the correlations between latent factors in the range of 0.81 to 0.99. Such discrepancy could be explained from simulation findings. That is, the simulation results indicate EFA rotation method appears to underestimate the factor correlation especially when the true correlation is high and the number of factors is large. Also, GIC favors the regularization method which implies that high factor correlations are likely present in the data. The observed high correlation also appears to be consistent with decades of research on NELS data that treats math and science as unitary constructs.
Table 3 Estimated sparse test structure for math test in NELS:88 (adaptive Lasso).
| Factor | MR | MK | ES | SR | CK | RK |
|---|---|---|---|---|---|---|
| M1 | 0 | 0.768 | 0.923 | 0 | 0 | 0 |
| M2 | 0 | 0.645 | 0.500 | 0 | 0 | 0 |
| M3 | 0.899 | 0 | 0 | 0 | 0.940 | 0 |
| M4 | 0.470 | 1.009 | 0 | 0 | 0 | 0 |
| M5 | 0 | 1.484 | 0 | 0 | 0 | 0 |
| M6 | 1.149 | 0 | 0 | 0 | 0.812 | 0 |
| M7 | 1.016 | 0 | 0 | 0 | 0.263 | 0 |
| M8 | 0 | 1.009 | 0 | 0 | 0.041 | 0 |
| M9 | 1.373 | 0 | 0 | 0 | 1.255 | 0 |
| M10 | 0 | 0 | 0 | 0 | 6.625 | 0 |
| M11 | 1.182 | 0 | 0 | 0 | 1.361 | 0 |
| M12 | 0 | 0 | 0 | 0 | 6.259 | 0 |
| M13 | 1.466 | 0 | 0 | 0 | 0 | 0 |
| M14 | 0 | 1.154 | 0 | 0 | 0 | 0 |
| M15 | 3.535 | 0 | 1.345 | 0 | 0 | 0 |
| M16 | 1.573 | 0 | 0 | 0 | 0 | 0 |
| M17 | 0 | 0 | 0 | 0 | 5.784 | 0 |
| M18 | 0.867 | 0 | 0 | 0 | 0 | 0 |
| M19 | 1.459 | 0 | 0 | 0 | 0 | 0 |
| M20 | 1.021 | 0 | 0 | 0 | 0 | 0 |
| M21 | 1.521 | 0 | 0 | 0 | 0 | 0 |
| M22 | 1.709 | 0 | 0.821 | 0 | 0 | 0 |
| M23 | 0.449 | 0 | 0.496 | 0 | 0 | 0 |
| M24 | 0.412 | 0 | 0.466 | 0 | 0 | 0 |
| M25 | 1.456 | 0 | 0 | 0 | 0 | 0 |
| M26 | 0.954 | 0 | 0.390 | 0 | 0 | 0 |
| M27 | 0 | 0.463 | 0 | 0 | 0 | 0 |
| M28 | 0.758 | 0 | 0.328 | 0 | 0 | 0 |
| M29 | 0 | 0 | 2.903 | 0 | 0 | 0 |
| M30 | 1.299 | 0 | 0 | 0 | 1.689 | 0 |
| M31 | 0 | 0.855 | 0.715 | 0 | 0 | 0 |
| M32 | 1.222 | 0 | 0 | 0 | 1.186 | 0 |
| M33 | 0.423 | 0 | 0 | 0.099 | 0 | 0 |
| M34 | 1.046 | 0 | 0 | 0 | 0.292 | 0 |
| M35 | 0 | 0.706 | 0.147 | 0 | 0 | 0 |
| M36 | 1.120 | 0 | 0 | 0 | 1.887 | 0 |
| M37 | 0.727 | 0 | 1.049 | 0 | 0 | 0 |
| M38 | 0 | 1.765 | 0 | 0 | 0 | 0 |
| M39 | 0 | 0.475 | 1.460 | 0 | 0 | 0 |
| M40 | 1.447 | 0 | 0 | 0 | 0.640 | 0 |
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Table 4 Estimated sparse test structure for science test in NELS:88 (adaptive Lasso).
| Factor | MR | MK | ES | SR | CK | RK |
|---|---|---|---|---|---|---|
| S1 | 0 | 0 | 0 | 0 | 0.992 | 0 |
| S2 | 0 | 0 | 0.822 | 0 | 0 | 0 |
| S3 | 0.175 | 0 | 0.629 | 0 | 0 | 0 |
| S4 | 0 | 0 | 0.695 | 0 | 0 | 0 |
| S5 | 0 | 0 | 1.483 | 0 | 0 | 0 |
| S6 | 0 | 0 | 1.338 | 0 | 0 | 0 |
| S7 | 0 | 0 | 0 | 0.966 | 0 | 0 |
| S8 | 0 | 0 | 0 | 0.741 | 0 | 0 |
| S9 | 0 | 0 | 2.469 | 0 | 0 | 0 |
| S10 | 0.238 | 0 | 0 | 0 | 0.715 | 0 |
| S11 | 0 | 0 | 0 | 0.542 | 0 | 0 |
| S12 | 0 | 0.441 | 0 | 0.787 | 0 | 0 |
| S13 | 0 | 0 | 0.900 | 0 | 0 | 0 |
| S14 | 0 | 0.988 | 0 | 0 | 0.614 | 0 |
| S15 | 0 | 0 | 0 | 0 | 0 | 0.65 |
| S16 | 0.351 | 0 | 0 | 0 | 0.313 | 0 |
| S17 | 0 | 0 | 0.899 | 0 | 0 | 0 |
| S18 | 0 | 0 | 0 | 0.056 | 1.093 | 0 |
| S19 | 0 | 0 | 0 | 0 | 1.491 | 0 |
| S20 | 0.164 | 0 | 0 | 0 | 0.368 | 0 |
| S21 | 0 | 0 | 0 | 0 | 0.535 | 0 |
| S22 | 0 | 0 | 0.563 | 0 | 0 | 0 |
| S23 | 0 | 0 | 0 | 0 | 1.620 | 0 |
| S24 | 0 | 0 | 0 | 0 | 0.960 | 0 |
| S25 | 0.154 | 0 | 0 | 0 | 0.404 | 0 |
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Table 5 Estimated sparse test structure for math test in NELS:88 (EFA rotation Method).
| Estimated item discrimination parameters | Estimated standardized factor loadings | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Factor | F1 | F2 | F3 | F4 | F5 | F6 | F1 | F2 | F3 | F4 | F5 | F6 |
| M1 | 0.700 | 0.288 | 0.167 | 0.053 | 0.097 | 0.106 | 0.536 | 0 | 0 | 0 | 0 | 0 |
| M2 | 0.671 | 0.252 | 0.091 | 0.187 | 0.087 | 0.147 | 0.528 | 0 | 0 | 0 | 0 | 0 |
| M3 | 1.001 | 0.134 | 0.162 | 0 | 0.017 | 0.146 | 0.685 | 0 | 0 | 0 | 0 | 0 |
| M4 | 1.454 | 0.135 | 0 | 0.168 | 0 | 0 | 0.816 | 0 | 0 | 0 | 0 | 0 |
| M5 | 1.238 | 0.135 | 0.062 | 0.269 | 0.071 | 0.035 | 0.767 | 0 | 0 | 0 | 0 | 0 |
| M6 | 1.162 | 0 | 0.114 | 0 | 0.015 | 0.044 | 0.751 | 0 | 0 | 0 | 0 | 0 |
| M7 | 0.954 | 0.074 | 0.169 | 0.017 | 0.127 | 0.051 | 0.672 | 0 | 0 | 0 | 0 | 0 |
| M8 | 0.783 | 0.163 | 0.084 | 0.07 | 0.088 | 0.036 | 0.603 | 0 | 0 | 0 | 0 | 0 |
| M9 | 1.315 | 0 | 0.074 | 0 | 0.167 | 0.056 | 0.781 | 0 | 0 | 0 | 0 | 0 |
| M10 | 0.392 | 0.127 | 0.919 | 0 | 0.174 | 0.137 | 0 | 0 | 0.679 | 0 | 0 | 0 |
| M11 | 1.087 | 0 | 0.023 | 0 | 0.18 | 0 | 0.711 | 0 | 0 | 0 | 0 | 0 |
| M12 | 0.610 | 0.053 | 0.917 | 0 | 0.163 | 0.111 | 0.301 | 0 | 0.693 | 0 | 0 | 0 |
| M13 | 1.362 | 0 | 0.094 | 0 | 0 | 0.042 | 0.793 | 0 | 0 | 0 | 0 | 0 |
| M14 | 1.107 | 0.024 | 0.082 | 0.221 | 0 | 0.022 | 0.734 | 0 | 0 | 0 | 0 | 0 |
| M15 | 0.340 | 0.166 | 0 | 0 | 0.164 | 0.116 | 0 | 0 | 0 | 0 | 0 | 0 |
| M16 | 1.733 | 0 | 0 | 0 | 0 | 0.002 | 0.860 | 0 | 0 | 0 | 0 | 0 |
| M17 | 0.225 | 0.124 | 0.832 | 0.004 | 0.215 | 0.169 | 0 | 0 | 0.628 | 0 | 0 | 0 |
| M18 | 0.710 | 0.019 | 0.01 | 0 | 0.220 | 0 | 0.562 | 0 | 0 | 0 | 0 | 0 |
| M19 | 1.421 | 0 | 0 | 0.006 | 0 | 0 | 0.800 | 0 | 0 | 0 | 0 | 0 |
| M20 | 1.071 | 0.017 | 0 | 0 | 0.039 | 0 | 0.728 | 0 | 0 | 0 | 0 | 0 |
| M21 | 1.588 | 0 | 0 | 0 | 0.022 | 0.063 | 0.837 | 0 | 0 | 0 | 0 | 0 |
| M22 | 0.847 | 0.257 | 0 | 0 | 0 | 0.206 | 0.602 | 0 | 0 | 0 | 0 | 0 |
| M23 | 0.600 | 0.246 | 0.003 | 0 | 0 | 0.221 | 0.485 | 0 | 0 | 0 | 0 | 0 |
| M24 | 0.513 | 0.307 | 0.043 | 0 | 0.018 | 0.112 | 0.431 | 0 | 0 | 0 | 0 | 0 |
| M25 | 1.315 | 0.003 | 0.111 | 0 | 0.091 | 0 | 0.788 | 0 | 0 | 0 | 0 | 0 |
| M26 | 0.999 | 0.201 | 0.082 | 0 | 0 | 0.208 | 0.678 | 0 | 0 | 0 | 0 | 0 |
| M27 | 0.454 | 0.106 | 0.037 | 0.162 | 0 | 0 | 0.407 | 0 | 0 | 0 | 0 | 0 |
| M28 | 0.882 | 0.147 | 0.029 | 0.030 | 0 | 0.103 | 0.651 | 0 | 0 | 0 | 0 | 0 |
| M29 | 0.577 | 0.378 | 0.155 | 0 | 0 | 0.148 | 0.448 | 0.348 | 0 | 0 | 0 | 0 |
| M30 | 1.460 | 0 | 0.214 | 0 | 0.115 | 0 | 0.802 | 0 | 0 | 0 | 0 | 0 |
| M31 | 0.779 | 0.296 | 0.172 | 0.175 | 0.239 | 0.289 | 0.536 | 0 | 0 | 0 | 0 | 0 |
| M32 | 1.244 | 0 | 0.173 | 0 | 0.096 | 0 | 0.759 | 0 | 0 | 0 | 0 | 0 |
| M33 | 0.601 | 0.059 | 0 | 0.006 | 0.241 | 0 | 0.470 | 0 | 0 | 0 | 0 | 0 |
| M34 | 1.053 | 0.050 | 0.117 | 0.093 | 0.207 | 0 | 0.704 | 0 | 0 | 0 | 0 | 0 |
| M35 | 0.734 | 0.290 | 0 | 0.121 | 0 | 0 | 0.566 | 0 | 0 | 0 | 0 | 0 |
| M36 | 1.355 | 0.079 | 0.316 | 0 | 0.062 | 0.229 | 0.751 | 0 | 0.304 | 0 | 0 | 0 |
| M37 | 0.923 | 0.344 | 0.156 | 0.040 | 0.087 | 0.453 | 0.574 | 0 | 0 | 0 | 0 | 0.422 |
| M38 | 1.542 | 0.132 | 0 | 0.205 | 0.011 | 0.142 | 0.827 | 0 | 0 | 0 | 0 | 0 |
| M39 | 0.532 | 0.132 | 0.056 | 0.213 | 0 | 0.202 | 0.438 | 0 | 0 | 0 | 0 | 0 |
| M40 | 1.539 | 0.147 | 0.182 | 0.085 | 0.161 | 0.186 | 0.803 | 0 | 0 | 0 | 0 | 0 |
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Table 6 Estimated sparse test structure for science test in NELS:88 (Rotation Method).
| Estimated item discrimination parameters | Estimated standardized factor loadings | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Factor | F1 | F2 | F3 | F4 | F5 | F6 | F1 | F2 | F3 | F4 | F5 | F6 |
| S1 | 0.135 | 0.145 | 0.116 | 0.101 | 0.370 | 0.426 | 0 | 0 | 0 | 0 | 0.321 | 0.393 |
| S2 | 0.092 | 0.145 | 0.096 | 0.093 | 0.235 | 0.399 | 0 | 0 | 0 | 0 | 0 | 0.371 |
| S3 | 0.276 | 0.063 | 0.022 | 0 | 0.114 | 0.456 | 0 | 0 | 0 | 0 | 0 | 0.416 |
| S4 | 0 | 0.245 | 0.103 | 0 | 0.164 | 0.322 | 0 | 0 | 0 | 0 | 0 | 0.307 |
| S5 | 0.284 | 0.307 | 0.109 | 0.107 | 0.303 | 0.727 | 0 | 0 | 0 | 0 | 0 | 0.598 |
| S6 | 0.280 | 0.271 | 0.153 | 0.060 | 0.287 | 0.613 | 0 | 0 | 0 | 0 | 0 | 0.529 |
| S7 | 0 | 0.138 | 0 | 0.117 | 0.254 | 0.602 | 0 | 0 | 0 | 0 | 0 | 0.519 |
| S8 | 0.014 | 0.144 | 0 | 0.073 | 0.336 | 0.388 | 0 | 0 | 0 | 0 | 0 | 0.363 |
| S9 | 0.136 | 0.193 | 0 | 0.017 | 0.006 | 0.573 | 0 | 0 | 0 | 0 | 0 | 0.499 |
| S10 | 0.310 | 0.132 | 0.094 | 0.043 | 0.377 | 0.215 | 0 | 0 | 0 | 0 | 0.347 | 0 |
| S11 | 0.056 | 0.04 | 0 | 0.058 | 0.309 | 0.237 | 0 | 0 | 0 | 0 | 0 | 0 |
| S12 | 0.426 | 0.168 | 0.027 | 0.198 | 0.301 | 0.420 | 0.325 | 0 | 0 | 0 | 0 | 0.391 |
| S13 | 0.055 | 0.23 | 0.215 | 0.06 | 0.067 | 0.515 | 0 | 0 | 0 | 0 | 0 | 0.459 |
| S14 | 1.007 | 0.159 | 0.091 | 0.303 | 0.307 | 0.170 | 0.656 | 0 | 0 | 0 | 0 | 0 |
| S15 | 0.124 | 0 | 0.087 | 0.019 | 0 | 0.645 | 0 | 0 | 0 | 0 | 0 | 0.543 |
| S16 | 0.273 | 0.248 | 0.040 | 0 | 0.332 | 0 | 0 | 0 | 0 | 0 | 0.315 | 0 |
| S17 | 0.219 | 0 | 0 | 0.104 | 0.494 | 0.279 | 0 | 0 | 0 | 0 | 0.430 | 0 |
| S18 | 0.278 | 0 | 0 | 0.193 | 0.507 | 0.311 | 0 | 0 | 0 | 0 | 0.436 | 0 |
| S19 | 0.206 | 0.002 | 0.059 | 0.095 | 0.422 | 0.291 | 0 | 0 | 0 | 0 | 0.375 | 0 |
| S20 | 0.196 | 0 | 0 | 0 | 0.392 | 0.114 | 0 | 0 | 0 | 0 | 0.363 | 0 |
| S21 | 0.072 | 0.170 | 0 | 0.01 | 0.538 | 0 | 0 | 0 | 0 | 0 | 0.474 | 0 |
| S22 | 0.045 | 0.099 | 0 | 0 | 0.158 | 0.358 | 0 | 0 | 0 | 0 | 0 | 0.337 |
| S23 | 0 | 0.278 | 0.094 | 0 | 0.399 | 0 | 0 | 0 | 0 | 0 | 0.362 | 0 |
| S24 | 0.160 | 0.061 | 0.101 | 0.082 | 0.290 | 0.523 | 0 | 0 | 0 | 0 | 0 | 0.465 |
| S25 | 0.167 | 0.114 | 0.073 | 0 | 0.126 | 0.199 | 0 | 0 | 0 | 0 | 0 | 0 |
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Table 7 Estimated Correlation between latent factors (Adaptive Lasso).
| MR | MK | ES | SR | CK | RK | |
|---|---|---|---|---|---|---|
| MR | 1.0000 | 0.9808 | 0.8465 | 0.7740 | 0.8646 | 0.8328 |
| MK | 0.9808 | 1.0000 | 0.9242 | 0.8684 | 0.9364 | 0.9119 |
| ES | 0.8465 | 0.9242 | 1.0000 | 0.9901 | 0.9968 | 0.9931 |
| SR | 0.7740 | 0.8684 | 0.9901 | 1.0000 | 0.9822 | 0.9807 |
| CK | 0.8646 | 0.9364 | 0.9968 | 0.9822 | 1.0000 | 0.9873 |
| RK | 0.8328 | 0.9119 | 0.9931 | 0.9807 | 0.9873 | 1.0000 |
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Table 8 Estimated Correlation between latent factors (EFA Rotation).
| F1 | F2 | F3 | F4 | F5 | F6 | |
|---|---|---|---|---|---|---|
| F1 | 1.0000 | 0.5784 | 0.7344 | 0.0848 | 0.6897 | 0.6780 |
| F2 | 0.5784 | 1.0000 | 0.3224 | 0.3783 | 0.4007 | 0.7268 |
| F3 | 0.7344 | 0.3224 | 1.0000 | 0.0067 | 0.4671 | 0.4186 |
| F4 | 0.0848 | 0.3783 | 0.0067 | 1.0000 | 0.1829 | 0.2630 |
| F5 | 0.6897 | 0.4007 | 0.4671 | 0.1829 | 1.0000 | 0.5051 |
| F6 | 0.6780 | 0.7268 | 0.4186 | 0.2630 | 0.5051 | 1.0000 |
SOURCE: U.S. Department of Education, National Center for Education Statistics, National Education Longitudinal Study of 1988 (NELS: 88), “Base Year Through Second Follow-up”.
Discussions
Exploratory factor analysis (EFA) is a popular statistical tool to gain insight into latent structures underlying the observed data (Gorsuch, Reference Gorsuch1988; Fabrigar & Wegener, Reference Fabrigar and Wegener2011). Exploratory item factor analysis is a subset of EFA methods that deals with categorical observed data. In exploratory IFA, the relationship among observed item responses are explained by a few number of common factors. The naming of the common factors can be inferred from the content of the items that load on those factors, and hence, a simple structure with items loading exclusively on a single factor is usually preferred.
In this paper, a Gaussian variational regularization method is proposed for the estimation of the sparse item-trait relationship in M2PL and M3PL models. This computationally efficient method estimates both item factor loading structure and model parameters simultaneously. Both Lasso and adaptive Lasso penalties are considered, and simulation studies demonstrate that they perform well in correctly estimating the sparse item-trait structure for both M2PL and M3PL models. Adaptive Lasso penalization is preferred between the two. With adaptive Lasso penalization, GIC is used to choose the tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 , whereas the tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
, whereas the tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma $$\end{document}
 takes one of the three suggested values by Zou (2006). Adaptive lasso also outperforms traditional EFA rotation method in most of the simulation conditions, and the two methods are almost indistinguishable for simpler scenarios such as lower factor correlation and lower dimensions. Since a user specified cutoff is needed to decide “significant” factor loadings, future studies could consider sparsity-encouraging rotation (e.g., Jennrich, 2006) to avoid arbitrarily truncating the rotated factor loadings.
takes one of the three suggested values by Zou (2006). Adaptive lasso also outperforms traditional EFA rotation method in most of the simulation conditions, and the two methods are almost indistinguishable for simpler scenarios such as lower factor correlation and lower dimensions. Since a user specified cutoff is needed to decide “significant” factor loadings, future studies could consider sparsity-encouraging rotation (e.g., Jennrich, 2006) to avoid arbitrarily truncating the rotated factor loadings.
The current study can also be expanded in the following directions. First, we assume the total number of factors, K, is known in advance. However, this assumption may be freed by varying K and use GIC as the model selection criterion to select the optimal K. This approach is in contrast to the family of criteria based on eigenvalues of the sample tetrachoric or polychoric correlation matrix of the observed data. Examples of this latter approach include the scree test (Cattell, Reference Cattell1966), the parallel analysis (Horn, Reference Horn1965), among others. Future studies on evaluating the relative performance of these two approaches are worth pursuing. Note that because K is usually defined as the minimum number of latent common factors that is needed to describe the statistical dependencies in data, challenges may arise when there are additional nuisance factors, such as a bi-factor structure.
Second, the proposed method may be generalized to other types of MIRT models, such as the non-compensatory models (e.g., C. Wang & Nydick, Reference Wang and Nydick2015), which is essentially a nonlinear item factor model. While the adaptive Lasso idea can be directly applied, more work is needed to derive a suitable variational lower bound to enable the GVEM algorithm.
Third, it is of interest to further study the theoretical properties of the estimation and the model selection consistency for the proposed method. As shown in Cho et al. (Reference Cho, Wang, Zhang and Xu2021), the GVEM algorithm (without additional penalty) can consistently estimate the model parameters of the 2-parameter MIRT model under a global Frobenius norm evaluation and the asymptotic regime when both N and J increase to infinity. With the additional adaptive Lasso penalty, it is expected that a similar global consistency result would hold when the tuning parameter is properly chosen. For instance, with the tuning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda =0$$\end{document}
 , the proposed estimator becomes that in Cho et al. (Reference Cho, Wang, Zhang and Xu2021) and the consistency result then follows. Moreover, it would also be of interest to study the variable selection consistency as well as the oracle properties as in Zou (Reference Zou2006) under the MIRT setting. However, such a problem is much more challenging due to several reasons. First, additional work is still needed to derive the entry-wise consistency and convergence rate results under the double asymptotic regime with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N, J\rightarrow \infty $$\end{document}
, the proposed estimator becomes that in Cho et al. (Reference Cho, Wang, Zhang and Xu2021) and the consistency result then follows. Moreover, it would also be of interest to study the variable selection consistency as well as the oracle properties as in Zou (Reference Zou2006) under the MIRT setting. However, such a problem is much more challenging due to several reasons. First, additional work is still needed to derive the entry-wise consistency and convergence rate results under the double asymptotic regime with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N, J\rightarrow \infty $$\end{document}
 . In particular, to show the oracle properties, we would need a sharp characterization of the entry-wise convergence rate of the GVEM estimators, which, however, is a challenging problem in the high-dimensional MIRT model. Second, the theoretical analysis of adaptive Lasso (or other penalties) is more challenging under the high-dimensional latent variable models, such as MIRT, and the variational approximation further complicates the problem. In fact, the frequentist consistency properties of many variational approximation methods remain unaddressed in the current literature. For such reasons, we would leave this interesting problem for future study.
. In particular, to show the oracle properties, we would need a sharp characterization of the entry-wise convergence rate of the GVEM estimators, which, however, is a challenging problem in the high-dimensional MIRT model. Second, the theoretical analysis of adaptive Lasso (or other penalties) is more challenging under the high-dimensional latent variable models, such as MIRT, and the variational approximation further complicates the problem. In fact, the frequentist consistency properties of many variational approximation methods remain unaddressed in the current literature. For such reasons, we would leave this interesting problem for future study.
Finally, it is interesting to obtain standard errors of the proposed regularized estimators. For variational approximations, the commonly used de-biasing technique in high-dimensional statistics may not be directly applicable, due to the additional approximation bias induced by the variational method. One way to reduce such a variational bias is to perform an importance sampling based reweighing after the variational estimation so that the likelihood function can be better approximated (Domke & Sheldon, Reference Domke and Sheldon2018); then a de-biasing step for the regularized estimation could be used to obtain the standard error estimates. Another approach is to use the bootstrap method to obtain the standard errors. As the setting of variational estimation for MIRT differs from many of the existing works on de-biasing estimation or bootstrap, the theoretical consistency properties of these methods are challenging and remain open problems in the literature. We therefore leave this interesting problem for future study.









