


1. Introduction
Children’s gestures are very informative about their language learning (Goldin-Meadow, Reference Goldin-Meadow2005; Iverson & Goldin-Meadow, Reference Iverson and Goldin-Meadow2005; Özçalışkan & Goldin-Meadow, Reference Özçalışkan and Goldin-Meadow2009). This is true not just for the acquisition of words and syntax, but also appears to be true of children’s ability to tell a well-structured story (that is, a story structured around sequences of goals, attempts, and outcomes: Demir, Levine, & Goldin-Meadow, Reference Demir, Levine and Goldin-Meadow2014). Demir and colleagues (2014) found that, when telling a story, five-year-old children who spontaneously gestured from the point of view of a character produced more cohesive and coherent narratives at later ages, or had better narrative structure. In their study, children were asked to retell a story at four different ages, beginning at age five and ending at age eight. The authors explored which factors best predicted narrative structure at later ages. They found that gestures from the point of view of a character predicted well-structured narratives. Demir and colleagues’ work suggests an intriguing possibility: If children who spontaneously gesture from the point of view of a character tell better stories later on, does asking children to produce such gestures improve their storytelling? In the present study, we ask whether children who are instructed to gesture from the point of view of a character when telling stories display better narrative structure in those stories. Before describing the study, we briefly discuss the relevance of narrative structure to language and literacy development in later years, summarize relevant research on narrative structure and narrative development, and discuss the relationship between gesture, perspective taking, and cognition.
Narrative abilities have important implications for children’s literacy, as they are considered a bridge between earlier developing oral language skills and later developing reading skills. Individual differences in narrative skill relate to children’s later reading success (Feagans & Short, Reference Feagans and Short1984; Gillam & Johnston, Reference Gillam and Johnston1992; Griffin, Hemphill, Camp, & Palmer Wolf, Reference Griffin, Hemphill, Camp and Palmer Wolf2004). Given the importance of narrative for later reading success, promoting narrative skills is a major focus in research on early literacy. While results thus far have been mixed, it does seem possible to design interventions that promote narrative development in young children (Petersen, Reference Petersen2011; Peterson, Jesso, & McCabe, Reference Peterson, Jesso and McCabe1999).
Children start referring to past events and mentioning future events at two years of age (McCabe & Peterson, Reference McCabe and Peterson1991). By ages five to six, children begin to produce their own independent narratives organized around goals and attempts of characters, and they reliably and frequently refer to the main components of narrative structure (initial orientation, complication, and resolution: Berman & Slobin, Reference Berman and Slobin1994). These ages constitute significant transitional years where children’s narrative skills vary greatly (Berman & Slobin, Reference Berman and Slobin1994; Colletta, Reference Colletta2009; Reilly, Reference Reilly1992). Children’s narrative structure continues to develop during the school years, extending into adolescence (Applebee, Reference Applebee1978; Berman & Slobin, Reference Berman and Slobin1994; Warden, Reference Warden1976).
Narratives are structured at both the micro- and macro-levels (Ninio & Snow, Reference Ninio and Snow1996). Cohesion (organization at the micro-level) refers to the linguistic, local relations that tie the span of idea units in the narrative together and create a text (Halliday & Hasan, Reference Halliday and Hasan1979; Karmiloff-Smith, Reference Karmiloff-Smith1979). For example, anaphoric pronouns like it create cohesion by tying two nominal elements together. The focus of the current paper is on narrative structure at the macro-level. Coherence (organization at the macro-level) refers to elements that give narrative content a schematic organization and tie the different parts of the narrative to each other in a meaningful way (Bamberg & Marchman, Reference Bamberg and Marchman1990; Berman & Slobin, Reference Berman and Slobin1994). For instance, we might use general world knowledge, context, and inference to fill in gaps when interpreting a narrative, as well as using the linguistic features that give rise to cohesion (Brown & Yule, Reference Brown and Yule1983). Of course, micro- and macro-level structure are not separable, as many of the elements that create cohesion also create coherence (Dancygier, Reference Dancygier2012). Macro-level narrative structure has been defined in the literature in different ways; commonalities among different definitions are that well-structured narratives are organized around the goals and attempts of the story’s characters, and that a particularly salient feature of well-structured narratives is that they conform to a hierarchical story schema with various episodes. Each episode consists of an initiating event that leads to the creation of a goal by the character, an attempt to achieve the goal, failure or success in achieving the goal, and reactions of the character to the consequence. The components that make up episodes are temporally or causally related (Berman & Slobin, Reference Berman and Slobin1994; Labov & Waletzky, Reference Labov and Waletzky1997; Stein & Glenn, Reference Stein, Glenn and Freedle1979).
The literature on narrative development has focused primarily on children’s speech, but children often produce gestures along with their narratives (Alibali, Evans, Hostetter, Ryan, & Mainela-Arnold, Reference Alibali, Evans, Hostetter, Ryan and Mainela-Arnold2009; Colletta et al., Reference Colletta, Guidetti, Kunene, Capirci, Cristilli, Demir and Levine2015; McNeill, Reference McNeill1992). These gestures have the potential to serve as a unique window into children’s narrative development (Cassell & McNeill, Reference Cassell and McNeill1991). Berman and Slobin (Reference Berman and Slobin1994) and Reilly (Reference Reilly1992) suggest that young children might express their early representations through extralinguistic means (such as gesture) before they become adept at telling a story. Being asked to gesture in particular ways has been shown to promote language skills for earlier-developing aspects of language, such as vocabulary (LeBarton, Raudenbush, & Goldin-Meadow, Reference LeBarton, Raudenbush and Goldin-Meadow2015). Might being instructed to gesture from the point of view of a character promote the creation of narrative structure?
As noted already, another aspect of gesture that has important implications for both narrative structure and cognition is viewpoint. Viewpoint in gesture has been shown to correlate with particular discourse contexts (Debreslioska, Özyürek, Gullberg, & Perniss, Reference Debreslioska, Özyürek, Gullberg and Perniss2013; Parrill, Reference Parrill2010). Character viewpoint (hereafter CVPT) gestures occur at particularly central moments in a discourse, so asking participants to produce those kinds of gestures might encourage the mention of central events. More specifically, Demir and colleagues hypothesized that CVPT gesture indicates that a child is imagining the event from the perspective of the character. In their 2014 study, children’s narratives and gestures were studied at ages five through eight. While children who produced CVPT gestures at age five did not have better narrative structure at that time, they did produce better-structured narratives at ages six, seven, and eight. Children’s OVPT (observer viewpoint) gestures did not predict narrative structure at later ages. Thus, Demir and colleagues argue that there is something special about CVPT gesture. They speculate that imagining the event from the perspective of the character results in greater focus on that character’s goals and attempts.
Support for the claim that taking a character (or actor) viewpoint changes encoding can also be found in the work of Brunyé and colleagues (Brunyé, Ditman, Mahoney, Augustyn, & Taylor, Reference Brunyé, Ditman, Mahoney, Augustyn and Taylor2009; Brunyé, Ditman, Mahoney, & Taylor, Reference Brunyé, Ditman, Mahoney and Taylor2011, Ditman, Brunyé, Mahoney, & Taylor, Reference Ditman, Brunyé, Mahoney and Taylor2010). In several studies, these researchers found that people can be prompted to take an actor’s viewpoint on an event, and that doing so changes encoding in ways that are parallel to experiencing the event as an actor. After reading narratives containing second person pronouns (you are …), participants were faster to recognize pictures of actions depicted from the point of view of an actor, as compared to pictures showing an observer’s view of the action (Brunyé et al., Reference Brunyé, Ditman, Mahoney, Augustyn and Taylor2009). Being presented with an action from the point of view of an actor also led to better memory for that action (Ditman et al., Reference Ditman, Brunyé, Mahoney and Taylor2010). Further, reading about negative events from a you perspective (leading to a first person imagining of the event) also changed participants’ mood (Brunyé et al., 2011). In these studies, linguistic cues were used to encourage first person encoding of events, and this appeared to be effective in changing encoding. These studies focus on speech, but other work has found re-enacting gesture from CVPT to benefit recall (Wesson & Salmon, Reference Wesson and Salmon2001). This finding has to be disentangled from a general benefit of being asked to gesture on recall (Cook, Duffy, & Fenn, Reference Cook, Duffy and Fenn2013; Novack, Congdon, Hemani-Lopez, & Goldin-Meadow, Reference Novack, Congdon, Hemani-Lopez and Goldin-Meadow2014, Stevanoni & Salmon, Reference Stevanoni and Salmon2005). However, if CVPT gesture does boost recall, this might help to explain why it predicted better narrative structure at later ages. That is, children instructed to gesture from the point of view of a character might imagine the cartoon from an agent’s point of view, and therefore have better recall for details of the stories, as well as better narrative structure.
The inter-relationships hypothesized by Demir and colleagues (2014) can be schematized as in Figure 1. For whatever reason, possibly better perspective-taking ability, some children imagine certain events from a first person point of view. This results in the production of CVPT gesture, and also in better encoding of the event (better focus on goals and actions). Only after the maturation of narrative ability (linguistic competence, short-term memory capacity) does this difference result in better-structured narratives.
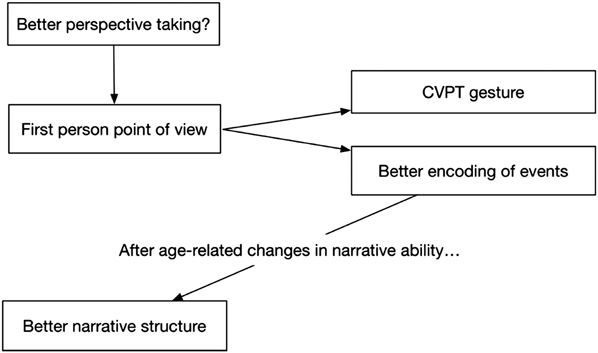
Fig. 1. Possible relationships among first person point of view, CVPT gesture, encoding, and narrative structure.
However, there is no direct evidence that CVPT gesture can be used to infer a first person point of view. Perhaps the closest is a study by Parrill and Stec (Reference Parrill and Stec2018). In this study, participants read stories containing either second person pronouns (you are …) or third person pronouns (she is …), and then narrated the stories. Participants who read the second person versions produced first person speech. They did not produce more CVPT gestures compared to participants who received third person descriptions. Because being prompted to produce first person speech did not change gesture, the question of what exactly CVPT gesture means about a person’s conceptualization remains open.
The current study attempts to tease apart some of the relationships schematized in Figure 1. We asked children to produce CVPT gesture in order to see if this instruction impacts narrative structure scores. If asking children to produce CVPT gesture causes them to take a first person point of view, this instruction could result in better encoding for the events. Better encoding could in turn lead to better narrative structure and better recall. This account (schematized in Figure 2) argues that being prompted to gesture from a particular point of view changes how children conceptualize the event in a way that also improves narrative structure and recall.
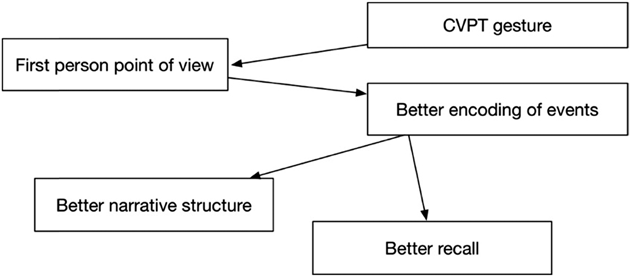
Fig. 2. Hypothesized effects of CVPT gesture on encoding, narrative structure, and recall.
If children who are asked to produce more CVPT gestures do not have better narrative structure and recall, there are several possible explanations. It may be that simply producing CVPT gesture does not result in a first person point of view. It may be that producing CVPT gestures does result in a first person point of view, but the first person point of view does not lead to better encoding. It may also be that further development of narrative ability is necessary, and that gestural intervention cannot impact children of this age.
In summary, this study attempts to ‘reverse the arrow’ between first person point of view and CVPT gesture that is shown in Figure 1. Addressing the relationship between character viewpoint gesture and narrative ability can shed light on the conceptual processes that underlie them both. In addition, improving children’s narrative skills is of educational importance, given the strong relationships between early narrative skills and later reading success (Feagans & Short, Reference Feagans and Short1984; Gillam & Johnston, Reference Gillam and Johnston1992; Griffin et al., Reference Griffin, Hemphill, Camp and Palmer Wolf2004). The improvement of narrative structure thus has important implications for developing literacy skills later on. Our main research questions are: Compared to other kinds of gestures or a no instruction control, does asking children to gesture from the point of view of a character (1) improve their narrative structure immediately, (2) improve their narrative structure after a one-week delay, and (3) lead to better recall?
2. Method
2.1. participants
Forty-four kindergarten students from a private school in the northeastern US participated in the study (23 females, mean age at the time of the session six years, one month, range 5;3–6;9). Parents signed a consent document indicating their willingness to have the child participate, and also filled out a demographic questionnaire. Demographic data are included in the ‘Appendix’. The child was also asked to give oral consent at the start of the study. No compensation was provided to parent or child for participating. Each child participated in two sessions, a narrative session and a recall session one week later. Both sessions were videotaped.
2.2. materials
Children watched three training cartoon video clips and four experimental cartoon video clips. Clips came from cartoons, a common way to elicit gesture data for both children and adults (see, e.g., Demir et al., Reference Demir, Levine and Goldin-Meadow2014; McNeill, Reference McNeill1992). While they have drawbacks (e.g., anthropomorphized animals might not be a good data source for our understanding of human mental representations), they also have significant strengths. For instance, they involve actions and movements that can be easily schematized in gesture, and participants tend to find them engaging. We used cartoon video clips for this study because they tend to elicit iconic gesture (gesture that closely correlates to the semantic content of speech), and specifically gestures from the point of view of a character (CVPT), and an observer (OVPT). As noted by Parrill (Reference Parrill2010), not all events can be gestured from both a character and an observer point of view. For example, a person holding a newspaper is very likely to evoke a CVPT gesture showing the hands holding an object, and is unlikely to be gestured from OVPT. A gesture showing a complex trajectory (e.g., a character running down a mountain) is more likely to evoke an OVPT gesture. Some events have the potential to evoke both types of gesture. A character swinging through space on a rope can be gestured by showing the character’s hands holding the rope and moving (CPVT), or by showing the path the character took by tracing it (OVPT). For both the training and experimental session we used video clips that contained multiple events that could be gestured from either point of view. Because we were exploring narrative structure, we also made sure that all videos used in the experimental trials contained multiple goal–attempt–outcome sequences.
2.3. procedure: training
Children participated individually. When they entered the experiment room, the experimenter introduced a ‘story-telling circle’ (see Figure 3) by saying, You probably noticed there’s this circle on the floor. This is a special spot we’re going to use to tell stories. Let me show you. She then stepped into the circle and told a brief story during which she produced unscripted gestures (no effort was made to keep them the same every time for this introduction, though the story itself was the same). The story-telling circle helped ensure that children stood in the same place for each trial, while having the experimenter model story-telling helped them feel more comfortable and helped them get a sense of what was going to happen in the study. The experimenter then asked for oral consent from the child by saying, I brought some of my favorite cartoons to show you. Do you want to watch them? Do you want to ask any questions before we watch them?

Fig. 3. Experiment set-up.
Following consent, the child participated in three training trials. The training and experimental procedure used a between-participants design, so that each child was in one condition throughout. During the three training trials, the experimenter and child watched a five-second video clip together; the experimenter described the clip in a way that differed across conditions, then the child was prompted to describe the clip according to specific instructions that differed by condition. The training video clips were segments from videos not used in the experimental portion of the study. Differences across conditions are as follows:
1. Character viewpoint condition (tell, show, and pretend). After watching the clip, the experimenter said Now I’m going to tell you and show you what happened and I’m going to pretend I’m the [character, e.g., mouse, cat]. The experimenter acted out two specific events from the clip, each paired with a specific character viewpoint gesture. An example is provided in Table 1. The experimenter then prompted the child to produce a description by saying: Now can you tell me and show me what happened and pretend you’re the [character]?
2. Observer viewpoint condition (tell and show). After watching the clip, the experimenter said, Now I’m going to tell you and show you what happened. The experimenter acted out two specific events from the clip, each paired with an observer viewpoint gesture (see Table 1). The experimenter prompted the child to produce a description by saying: Now can you tell me and show me what happened?
3. Control condition (tell). After watching the clip, the experimenter said, Now I’m going to tell you what happened. The experimenter repeated the verbal descriptions from the same two specific events from the clip, this time with no gesture. The experimenter prompted the child to produce a description by saying: Now can you tell me what happened?
table 1. Narrative structure scoring (Demir et al., Reference Demir, Levine and Goldin-Meadow2014)
In summary, the children were first trained with three training trials. In the character viewpoint condition, children were prompted to gesture (show me), and to take on the role of the character (pretend you are the …), and character viewpoint gestures were modeled for them. In the observer viewpoint condition, children were prompted to gesture (show me), but they were not prompted to take on the role of the character, and observer viewpoint gestures were modeled for them. In the control condition, children were not prompted to gesture (tell me …), though they could still choose to do so. The gestures performed by the experimenter were a character viewpoint variant and an observer viewpoint variant of the same event across the gesture conditions, and were always performed the same way within conditions. An example is given in the ‘Appendix’.
In the character and observer viewpoint conditions, if the child produced a gesture of the correct type (character in the character viewpoint condition, observer in the observer viewpoint condition), the experimenter said That was great! and moved on to the next training trial. If the child produced gesture but no speech, the experimenter prompted her or him with I like how you showed me, but can you tell me? If the child produced speech but did not produce the correct type of gesture in one of the gesture conditions, the experimenter prompted the child again, using the respective prompts for each condition, as provided in the ‘Appendix’. After the child’s second attempt, the experimenter moved on to the next training trial regardless of whether or not the child produced the correct kind of gesture. It should be noted that the narrations children produced during training were not part of the analysis.
2.4. procedure: experimental task
After the child completed the three training trials, the experimenter moved on to the experimental task, again using a between-participants design in which the child received prompts that were the same as during training. In this task, the child watched four one-minute video clips. While these short video clips did not allow for very extended narratives, each contained multiple goal–attempt–outcome sequences, and were appropriate for use with young children. After watching each clip, the children were prompted to describe the clip to the experimenter. The experimenter did not produce any gestures during the experimental task. Prompts began by asking the child if he or she noticed the main character: There was an [animal] in the story! Did you see the [animal]? The experimenter clarified if necessary. Following this, the prompt used varied by condition.
1. Character viewpoint condition description prompt. Can you tell me and show me what happened and pretend you’re the [animal]?
2. Observer viewpoint condition description prompt. Can you tell me and show me what happened?
3. Control condition description prompt. Can you tell me what happened?
If the child produced a very incomplete narration (e.g., there was a dog) the experimenter prompted once with and then what happened? The number of children in the three conditions were as follows: character viewpoint: 15, observer viewpoint: 15, control: 14.
After each description, children were asked a set of comprehension questions (shown in the ‘Appendix’). The purpose of these questions was to assess whether the children’s basic understanding of the events in the stories was the same across conditions. The prompt for the comprehension questions was always: That was a great story! I’m going to ask you some questions about the [animal]. After completing all four trials (description followed by comprehension questions), the experimenter told the child: Okay, I’m going to see you again in a week and we’re going to do some other stuff, but that’s it for today! Thank you so much for watching these cartoons with me!
The training and experimental trials were presented using Superlab (Cedrus Corporation) experiment software, presented on a laptop. The children stood to watch the videos while the experimenter sat next to them, they then moved to the story-telling circle while the experimenter sat next to it, as shown in Figure 3.
2.5. procedure: recall session
In the recall session, each child did the following:
1. a free recall session. The child was prompted to remember the four experimental videos with the following prompt: Last time I saw you we watched a cartoon about a [animal]. Tell me what happened in that cartoon and tell me everything you can remember.
2. a cued recall session. The child was prompted to recall the four experimental videos with the following prompt: Here’s a picture from one of the cartoons we watched. [The child was shown a still image of the main character in the story engaged in an event from the story.] Tell me again: What happened in the cartoon, and tell me everything you can remember.
3. a syntax comprehension task. The experimenter administered a picture-matching syntax comprehension task (Huttenlocher, Vasilyeva, Cymerman, & Levine, Reference Huttenlocher, Vasilyeva, Cymerman and Levine2002). Details and a sample item can be found in the ‘Appendix’. This task provides a measure of spoken language comprehension.
4. a spatial measure. The experimenter administered the short form (16 trials) of the Thurstone Primary Mental Abilities Spatial Relations Subtest (Thurstone, Reference Thurstone1974), a basic measure of spatial ability. Details and a sample item can be found in the ‘Appendix’. We explored spatial skill because of suggestions that high spatial skill is associated with higher gesture rate (especially when combined with low ability to quickly produce words – phonemic fluency; Hostetter & Alibali, Reference Hostetter and Alibali2007). As with the narrative session, the recall still images and the syntax comprehension pictures were presented using Superlab experiment software, presented on a laptop. The story-telling circle was also used for the recall tasks (see Figure 3). The spatial measure was done on paper.
2.6. coding: narrative session
2.6.1. Speech and gesture
Speech and gesture coding was carried out in ELAN (Crasborn & Sloetjes, Reference Crasborn, Sloetjes, Crasborn, Hanke, Efthimiou, Zwitserlood and Thoutenhoofd2008; ELAN is an annotation software program created by the Max Planck Institute for Psycholinguistics, The Language Archive, Nijmegen, the Netherlands; see <http://tla.mpi.nl/tools/tla-tools/elan/>). Speech was transcribed and divided into clauses. We defined a clause as an expression of a single situation, typically containing a subject (which may have been unexpressed syntactically) and a predicate. We averaged over the stories to obtain mean number of clauses for each child.
All gestures produced by the children were transcribed and sorted into the following categories (after McNeill, Reference McNeill1992): concrete iconic (features of the hand or body action map onto features of the stimulus event), or other. ‘Other’ included gestures that depict abstract content such as ideas or emotions (often called metaphoric gestures), deictic (gestures that point or locate objects in space), and beats (rhythmic gestures with little additional semantic content). Because of our specific research questions, we did not include other gestures in our analysis.
Concrete iconic gestures were then coded for viewpoint. Gestures in which children took on the role of the character, using their bodies as the character’s body, were identified as character viewpoint gestures (CVPT), as shown in Figure 4a. Gestures in which children used the hand or arm to reflect the character as a whole, as though showing the scene as an observer, were identified as observer viewpoint gestures (OVPT), as shown in Figure 4b.

Fig. 4. Character and observer viewpoint gestures.
We averaged over the stories to obtain mean number of gestures, and mean proportion of CVPT and OVPT for each child. We also calculated gesture rate for each child as the mean number of gestures divided by the mean number of clauses.
2.6.2. Narrative structure score (NSS)
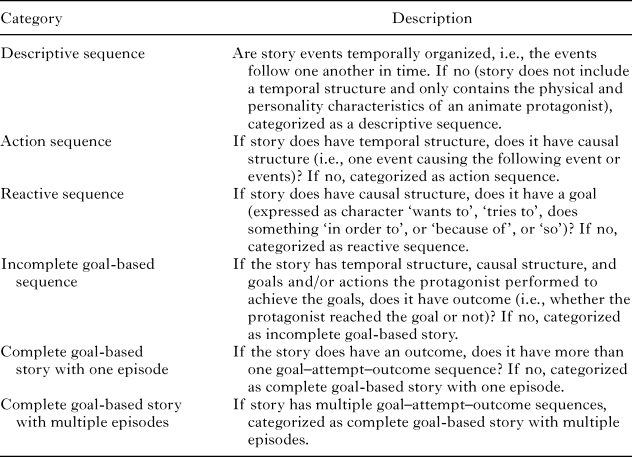
Using an ELAN output transcript of each child’s speech, narrative structure was coded using the process described by Demir and colleagues (2014, p. 667). Their scheme comes from Stein and Glenn (Reference Stein, Glenn and Freedle1979). This scheme is shown in Table 1.
It should be noted that there are multiple ways to measure narrative complexity or strength. For example, some researchers (Nicoladis, Marentette, & Navarro, Reference Nicoladis, Marentette and Navarro2016) focus on the use of clausal connectors (e.g., and, or, so, when) as a measure of narrative complexity. Others focus on number of clauses, uses of connectors, and also on anaphoric expressions (Colletta, Reference Colletta2009). We used a narrative structure scoring system that is organized around goal, attempt, and outcome sequences because we wanted to extend the findings of the previous study that made use of this scheme (Demir et al., Reference Demir, Levine and Goldin-Meadow2014), not because we regard it as the most definitive scheme. However, it also important to note that there are common elements to the schemes used by researchers studying multimodal language, particularly the use of clausal connectors (because, when) that indicate temporal and causal relationships.
Stories received a numerical score based on which category they were placed in. A story categorized as a descriptive sequence received a 1, a story categorized as an action sequence received a 2, and so on. The highest score a story could receive was therefore a 5. However, despite the fact that videos contained multiple goal sequences, in our case no stories were scored as 5. Because children narrated four stories, we averaged their narrative structure scores across the stories to yield a mean narrative structure score. Examples of each category of story are presented in the ‘Appendix’.
2.6.3. Perspective in speech
As in Demir and colleagues (2014), we coded direct and indirect quotations. We also identified expressions of cognition and emotion in children’s speech, both of which indicate that the child is taking the point of view of the character. We used the scheme of Langdon, Michie, Ward, McConaghy, Catts, and Coltheart (Reference Langdon, Michie, Ward, McConaghy, Catts and Coltheart1997) and identified any lexical terms describing perception (e.g., see), desire (e.g., want), emotion (e.g., feel), and cognition (e.g., think) (Langdon et al., Reference Langdon, Michie, Ward, McConaghy, Catts and Coltheart1997, p. 176).
This coding was done for each clause, and a single clause could have more than one of these categories present. A child’s count was then totaled across these categories (direct quotes, indirect quotes, perception/cognition verbs), and averaged over stories to yield a measure indicating mean number of instances of first person perspective in speech.
2.6.4. Comprehension question scoring
Each question was scored as correct or incorrect. This score was then divided by number of questions for proportion correct.
2.7. coding: recall session
Four children (two control, two CVPT) were not used in the recall session because video data were corrupted or lost after a hard disk failure. Speech, gesture, narrative structure score, and first person speech for the recall session were coded as described above. To measure recall, we used the method of Stevanoni and Salmon (Reference Stevanoni and Salmon2005), which was itself adapted from Jones and Pipe (Reference Jones and Pipe2002). Children got a point for every core action and core object mentioned. For example, in describing a scene where the coyote puts on a bib, if the child says the coyote puts on a bib, he or she would get a point for core action (put on) and a point for core object (bib). We also counted the number of distortions or intrusions (child incorrectly mentions a core action or an object). For example, if in describing a scene where the coyote picks up a fork and knife the child says the coyote picked up a spoon, this would be scored as a distortion of the core objects knife/fork. If the child said the coyote threw a fork, this would be scored as a distortion of the core action pick up. We did not count a description as an error if the child simply didn’t know how to describe it (e.g., the roadrunner was described as bird). For the cued recall scoring, the child got a point only for any new core action or core object mentioned, or for new distortions/intrusions. Because we have no hypotheses about cued versus free recall, we collapsed over these parts of the session to create total recall measures for actions/objects and distortions/intrusions. Finally, to create a single measure of recall, we subtracted distortions/intrusions from actions/objects recalled.
2.7.1. Syntax comprehension scoring and PMA Spatial Relations Subtest scoring
For both the syntax comprehension and the spatial relations test, children received a score indicating percent correct (number correct divided by number of questions).
2.8. reliability
We randomly selected seven children from the completed dataset (15% of the data) and a second coder coded both narrative and recall data to establish reliability of coding for gesture type (97% agreement), narrative structure (100% agreement), perspective in speech (96% agreement), and correct recall (94% agreement).
3. Results
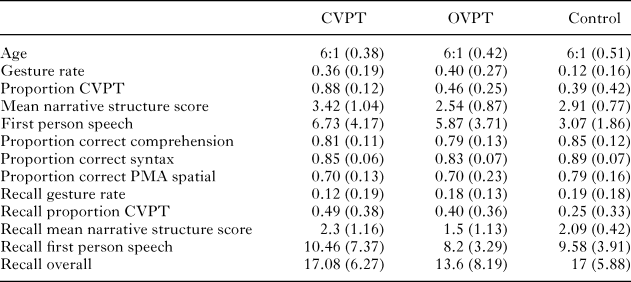
We present results for the narrative session first, followed by results for the recall session. We discuss our reasons for using particular statistical procedures and other statistical detail in the ‘Appendix’. Data are available via the Open Science Framework <https://osf.io/6ds5k/>. A table with descriptive statistics for all measures can be found in the ‘Appendix’.
3.1. narrative session
Our key research questions are whether training impacted children’s gestures, and whether training impacted narrative structure scores. That is, was there an effect of the training condition on gesture and on narrative structure score? Figure 5a shows the mean proportion CVPT gesture by condition (recall that proportion CVPT + proportion OVPT = 100%). Figure 5b shows mean narrative structure scores by condition.
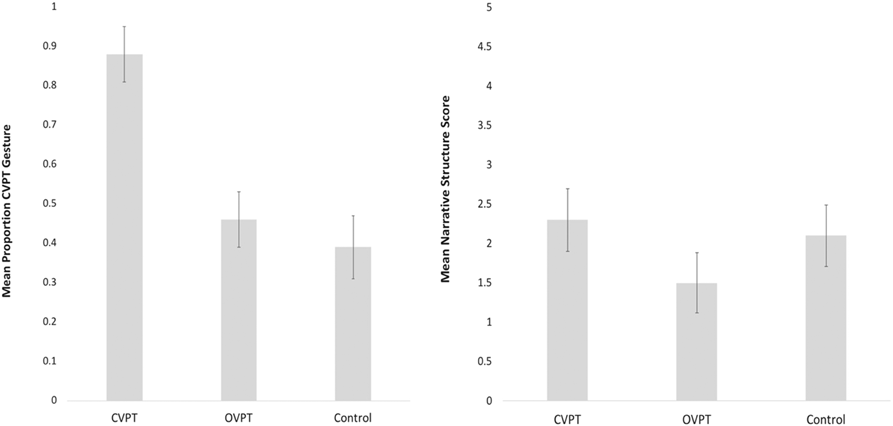
Fig. 5. Mean proportion CVPT gesture (left) and mean narrative structure score (right) by condition; error bars show standard error of the mean.
Because we are interested in the effect of the training condition on two outcome variables, we used a one factor (condition) MANOVA with proportion CVPT and mean narrative structure score as outcome variables to analyze our results. We found a statistically significant effect of condition (F(4,82) = 5.8, p = .001, ηp2 = .22). Tests of between subjects effects showed a significant difference across conditions for both proportion CVPT (F(2,41) = 12.98, p = .001, ηp2 = .39) and narrative structure score (F(2,41) = 3.52, p = .001, ηp2 = .15). Planned post-hoc comparisons were conducted for both dependent variables using Scheffé’s test (because of unequal group sizes). For CVPT gesture production, the CVPT condition differed significantly from both the OVPT (mean difference = 0.42, 95% CI [0.15, 0.68]) and the control (mean difference = 0.42, 95% CI [0.22, 0.76], while OVPT and control did not differ from each other: mean difference = 0.06, 95% CI [–0.20, 0.34]. For narrative structure score, the CVPT condition differed significantly from the OVPT (mean difference = 0.87, 95% CI [0.03, 1.7]), but not the control (mean difference = 0.50, 95% CI [–0.35, 1.3]). OVPT and control did not differ from each other: mean difference = 0.36, 95% CI [–0.49, 1.2].
These initial analyses suggest that being asked to gesture from the point of view of the character did have an effect on CVPT gesture and narrative structure scores. However, it is also possible that differences in overall gesture rate explain the patterns we see. To address this possibility, we carried out a one factor ANOVA (condition) with gesture rate (number of gestures / number of clauses) as the dependent variable. There was a significant difference in gesture rate across conditions (F(2,41) = 6.97, p = .002, ηp2 = .25). Planned post-hoc comparisons showed that the CVPT condition children had a higher gesture rate than control (mean difference = 0.23, 95% CI [0.03, 0.44]), but not OVPT (mean difference = –0.04, 95% CI [–0.25, 0.16]). OVPT children also had a higher gesture rate than control children (mean difference = 0.28, 95% CI [0.07, 0.48]). This pattern suggests that explicitly asking children to gesture (show) increased gesture rate relative to the no instruction control.
A second explanation for the patterns we observed is that children in the three conditions differed in age, story comprehension, or performance on the verbal or spatial measures, despite assignment to condition being random. These individual differences may have been responsible for differences in CVPT gesture or narrative structure score. Because of our relatively small sample size, we elected to group particular variables for analysis rather than attempting to account for all at once (see ‘Appendix’). A one factor (condition) ANOVA with age as the dependent variable showed no relationship between age and condition (F(2,41) = 0.01, p = .98). A one factor (condition) ANOVA showed no relationship between condition and mean proportion correct on the comprehension questions (F(2,41) = 81, p = .45). Finally, a one factor (condition) MANOVA with proportion correct on the syntax and spatial measures as the dependent variables showed no effect of condition on these measures (F(4,82) = 1.66, p = .18).
The final piece of the picture we wanted to explore was whether differences in first person speech also occurred across conditions. That is, did asking children to pretend to be a character also result in changes in the extent to which they used the first person to describe the events? A one factor (condition) ANOVA with first person speech as the dependent variable showed an effect of condition on first person speech (F(2,41) = 4.47, p = .02, ηp2 = .18). Planned post-hoc comparisons showed that the CVPT children had higher rates of first person speech compared to control (mean difference = 3.66, 95% CI [0.42, 6.89]), but not OVPT (mean difference = 0.86, 95% CI [–2.3, 4.05]). OVTP and control also did not differ statistically (mean difference = 2.79, 95% CI [–0.43, 6.03]).
3.2. recall session
As noted in the ‘Method’ section, recall data were lost for four children (two control, two CVPT) due to hard disk failure. Because all recall values were missing for these children, they are not included in the analysis. Our key research question is whether the training received in the narrative session impacted children’s gestures and narrative structure scores in the recall session. That is, did the training condition have an effect on gesture and on narrative structure scores in the recall session? Figures 6a and 6b show the proportion CVPT gesture and the mean narrative structure scores for the recall session.
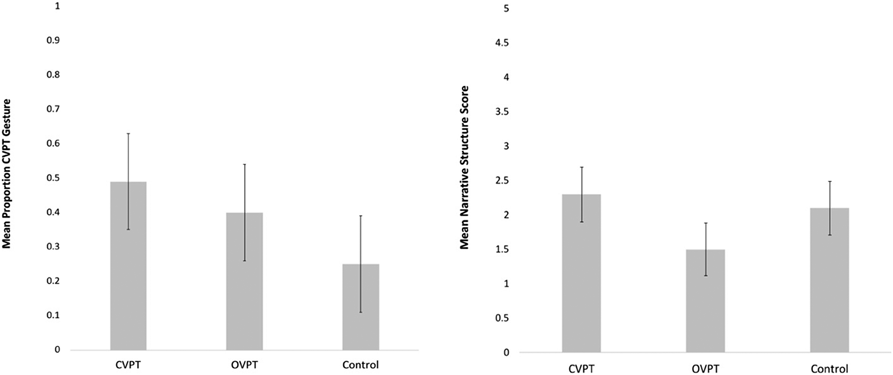
Fig. 6. Recall proportion CVPT gesture (left) and mean narrative structure score (right) by condition; error bars show standard error of the mean.
We used a one factor (condition) MANOVA with proportion CVPT and mean narrative structure score as outcome variables to explore these results. We found no effect of condition (F(4,74) = 2.1, p = .09). We next carried out a one factor ANOVA (condition) with recall gesture rate (number of gestures / number of clauses) as the dependent variable to see if differences in overall gesture rate varied. There was no significant difference in gesture rate across conditions (F(2,37) = 1.04, p = .36). Analyses for the narrative session had already established that age, story comprehension, and verbal and spatial skills did not differ across conditions. A one factor (condition) ANOVA with first person speech as the dependent variable showed no effect of condition on first person speech (F(2,37) = 0.69, p = .50). The last question to address is whether the training condition affected the number of details recalled correctly. A one factor (condition) ANOVA with overall recall as the dependent variable showed no effect of condition on recall (F(2,37) = 1.14, p = .33). In summary, these analyses indicate that the training received in the narrative session did not impact children’s behavior in the recall session.
4. Discussion
Our key findings are that children who received training asking them to tell, show, and pretend to be a character produced more CVPT gestures. They also had higher narrative structure scores, though only relative to children who received the OVPT training (tell and show). Children who received training asking them to gesture (both CVPT and OVPT conditions) produced higher rates of gesture, but only those asked to ‘pretend’ (CVPT) had higher rates of CVPT gesture, and higher narrative structure scores. They also had higher rates of first person speech. Gesture rate, age, comprehension of stories, and performance on a language and spatial measure did not differ by condition. After a week’s delay, the training did not impact gestural behavior, narrative structure scores, first person speech rates, or recall.
Why did being asked to pretend result in better narrative structure scores? One possibility is that the instruction (e.g., Pretend to be the rabbit) encouraged children to make the character the focus of the narration. Thus, the higher narrative structure scores might be a function of focusing the narrative on a particular actor. However, we think this is unlikely, as children in all conditions were prompted to pay attention to a specific character before describing the story. Alternatively, children who were asked to pretend may simply have been having more fun, and greater motivation or engagement might account for their higher scores. We cannot eliminate this possibility with the measures we collected. The more theoretically interesting possibility is that gesturing from the point of view of a character may have improved narrative structure because of something special about CVPT gestures. If CVPT gesture can be used to infer that the child is imagining the event from the perspective of the character, this actor perspective may result in greater focus on that character’s goals and attempts. We schematized this relationship in Figure 2. In this model, greater focus on goals and attempts is the cause of higher narrative structure scores. We did see higher rates of first person speech in the CVPT condition, which offers some support for the argument that children are taking the point of view of a character. However, the better narrative structure scores we observed were only in comparison to the OVPT condition, not the no instruction control. This means it would be equally valid to conclude that OVPT gesture decreases narrative structure. The claim that CVPT gesture reflects a first person conceptualization is difficult to test. Our results offer some support, but it is indirect. A next step could be to examine different types of CVPT gesture. CVPT gestures are not all equivalent (Parrill & Stec, Reference Parrill and Stec2018). A gesture with an actor’s handshape is usually considered sufficient to code a gesture CVPT, but this handshape may reflect minimal perspective taking. A child who not only uses the same handshape as the character, but who also enacts the character’s gaze and posture, mimics the character’s intonation, and uses the personal pronouns and tense (e.g., first person, present tense) of the original event could be expected to have truly taken the character’s point of view.
Why did we not find that CVPT gesture benefited recall a week later? Brunyé and colleagues (Brunyé et al., Reference Brunyé, Ditman, Mahoney, Augustyn and Taylor2009; Brunyé et al., Reference Brunyé, Ditman, Mahoney and Taylor2011, Ditman et al., Reference Ditman, Brunyé, Mahoney and Taylor2010) did find that a first person encoding enhanced recall (or affected mood). Of course, they did not study gesture, but others have found gesture to benefit recall. This discrepancy may be related to an important difference between our approach and those used in previous studies. Stevanoni and Salmon (Reference Stevanoni and Salmon2005) found that children who were instructed to gesture at the time of recall remembered more, whereas we instructed our children to gesture at the time of encoding. On the other hand, Cook, Yip, and Goldin-Meadow (Reference Cook, Yip and Goldin-Meadow2010) instructed participants to gesture at the time of encoding, and did find a beneficial effect on recall. Their participants were adults, so for children in this age group, it may simply be that the brief intervention was not sufficient to boost recall.
We also wonder whether intervening in children’s spontaneous gesture production (by training them to produce particular kinds of gesture) might have a different effect than simply asking them to gesture, as some previous ‘gesture instruction’ studies have done. While being asked to gesture in particular ways can promote learning (Broaders, Cook, Mitchell, & Goldin-Meadow, Reference Broaders, Cook, Mitchell and Goldin-Meadow2007; Cook & Goldin-Meadow, Reference Cook and Goldin-Meadow2006; Goldin-Meadow, Reference Goldin-Meadow2007; Goldin-Meadow & Alibali, Reference Goldin-Meadow, Alibali and Medin1995; Goldin-Meadow, Levine, Zinchenko, Yip, Hemani, & Factor, Reference Goldin-Meadow, Levine, Zinchenko, Yip, Hemani and Factor2012; LeBarton et al., Reference LeBarton, Raudenbush and Goldin-Meadow2015; Novack et al., Reference Novack, Congdon, Hemani-Lopez and Goldin-Meadow2014; Ping & Goldin-Meadow, Reference Ping and Goldin-Meadow2008; Singer & Goldin-Meadow, Reference Singer and Goldin-Meadow2005), previous studies have examined the acquisition of principles such as mathematical equivalency and mental rotation. These concepts may not resemble the acquisition of complex narrative skills, which rely on memory, attention, linguistic ability, etc. (Berman & Slobin, Reference Berman and Slobin1994; Colletta, Reference Colletta2009; Demir et al., Reference Demir, Levine and Goldin-Meadow2014).
What role did first person speech play in increasing narrative structure scores? The Demir et al. (Reference Demir, Levine and Goldin-Meadow2014) longitudinal study suggested that using first person speech at age five did not predict better narrative structure at later ages, whereas using CVPT gesture did. We did see higher rates of first person speech in the CVPT condition, but it is important to note that children were only trained to gesture from the point of view of a character, not to adopt that character’s linguistic point of view.
The role of CVPT gestures might be specific to the developmental stage we focused on. We studied kindergarteners, who are in a transitional stage in narrative development. With age, the nature of children’s iconic gestures changes. Younger children produce more CVPT gestures than adults, and fewer dual viewpoint gestures (McNeill, Reference McNeill1992) than adults (Reig Alamillo, Colletta, & Guidetti, Reference Reig Alamillo, Colletta and Guidetti2013). With age, CVPT gestures decrease, and OVPT and dual viewpoint gestures increase. Another open question is whether and how the possible facilitating role of CVPT gestures changes with age.
Whatever the underlying causes, this brief intervention did boost narrative skill. This finding might have educational implications. Prior studies aiming to improve narrative skills in children have focused primarily on children’s speech. Focusing on speech reveals only a limited view of children’s understanding of narratives. More extended interventions or instructions that target children’s gestures as well as their speech might meet with greater success. This intervention is relatively easy to incorporate into a kindergarten curriculum. It is possible that pretending simply increases motivation rather than changing how children conceptualized the event, but an increase in motivation is hardly problematic if it leads to better narrative structure.
5. Conclusions
If children who spontaneously produce CVPT gestures at age five go on to tell better structured stories at later ages, does asking children to produce CVPT gestures improve their narrative structure immediately after? If so, the effect of embodying a character while describing its actions may change encoding in ways that have effects on narrative structure, and as has been previously stated, could subsequently facilitate literacy skills at later ages. Our study found some support for a causal role of CVPT gesture: children trained to produce CVPT gestures produced more of those gestures and had higher narrative structure scores. We take the results to indicate that gesturing from the point of view of a character promotes perspective taking. Gesture provides a crucial window into the cognitive processes that give rise to language, and these findings suggest that asking a child to take the point of view of a character can impact macro-level narrative structure. While we did not find any lasting effects on narrative structure scores, or any benefit of gestural training on recall, this was a very brief one-time intervention. Training children in CVPT story-telling repeatedly could potentially show a stronger effect. This is a relatively easy classroom intervention to conduct, and thus has real practical value. Our study adds to the body of literature showing that speech and gesture inter-relate and develop in tightly coordinated ways, and showcases how gesture can be used as a tool to impact cognition and learning.
Appendix
Materials: cartoons used
Baseball Bugs (Bugs Bunny, Freleng, 1946), Fast and Furrious (Wile E Coyote, Jones, 1949), For Scent-imental Reasons (Pepe Le Pew, Jones, 1949), and Feed the Kitty (Marc Antony, Jones, 1952)

Syntax comprehension task
In the syntax comprehension task (Huttenlocher et al., Reference Huttenlocher, Vasilyeva, Cymerman and Levine2002), the experimenter reads 54 sentences to the child, each describing a single or multi-clause event. Sentences increase in complexity over the course of the task (e.g., sentence 1: The boy is eating pizza; sentence 54: A girl who is standing next to the boy is holding at kite). Children see a set of pictures and have to choose the picture that matches the sentence. Figure A1 shows the pictures paired with sentence 54 (the example given above). For questions 11–55, one picture was intended as a ‘foil’, that is, it could be interpreted as correct if the child did not attend carefully to the syntax (the middle picture in Figure A1). This task is a basic measure of oral language.
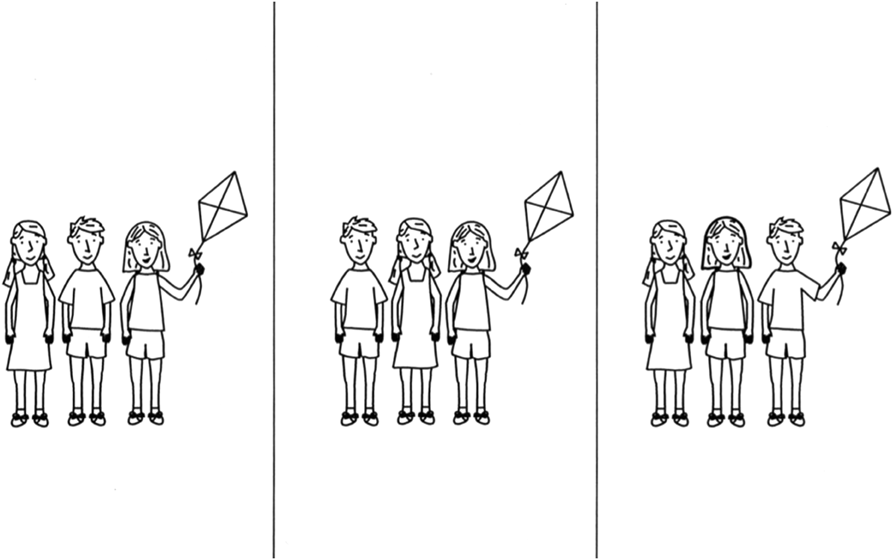
Fig. A1. Syntax comprehension sample item.
Spatial measure task
In the Thurstone Primary Mental Abilities Spatial Relations Subtest (Thurstone, Reference Thurstone1974), children see a square with a shape missing and must choose which of four possibilities would complete the square. This subtest was done with paper and pencil. Figure A2 shows a sample item.

Fig. A2. Spatial test sample item.
Training: prompts for gesture conditions
When children did not produce the correct gesture, the experimenter followed this set of prompts:
1. character viewpoint condition. I like how you told me, but you forgot to pretend you were the [character]! Remember when I said [repeat second speech–gesture pair from training]. I was pretending to be the [character]! Now can you tell me and show me what happened and pretend you’re the [character]?
2. observer viewpoint condition. I like how you told me, but you forgot to show me! Remember when I said [repeat second speech–gesture pair from training]? I was showing you what happened! Now can you tell me and show me what happened?
Comprehension questions
What did the rabbit hit?
Why did the rabbit ride a bus?
Did the rabbit ride on an elevator?
Who was the skunk following?
Why was skunk following that animal?
Did the skunk run upstairs?
What kind of an animal did the dog bring home?
Why did the dog try to hide the animal?
Did the dog climb on top of a ball?
What did the coyote have around his neck?
Why did the coyote have a knife and fork?
Did the coyote chase a mouse?
Narrative structure scoring examples
Descriptive sequence (1): The skunk wanted to give the cat love. Scored as descriptive due to lack of temporal organization.
Action sequence (2): The dog set up a cat thing and it ran into the person. The kitty was on a boot. That’s all I have to tell. Scored as action sequence because had temporal but no causal structure.
Reactive sequence (3): What happened was um his dad chased him. And then he went inside the room and then he pushed the window out to see and then he said hello. Scored as reactive because had causal structure, but no goal.
Incomplete goal-based sequence (4): What happened was he climbed up and then he throwed his glove to catch the ball. Scored as incomplete because had goal but no outcome.
Complete goal-based story with one episode (5): There was a coyote chasing the ostrich and the ostrich got away because it was too fast and the wolf the um coyote was too tired. Scored as complete: had both goal and outcome.

Descriptive statistics
See Table A3.
table a3. Descriptive statistics for variables of interest (SDs in parentheses)
Statistical analyses
Analyses were carried out using IMB SPSS Statistics version 24. The number of participants in this study is small, while the number of outcome variables is large, limiting the kinds of analyses we could perform. Our goal was to perform the simplest analyses that would answer our main research questions and explore obvious alternative explanations, were we to find an effect of training on our key outcome variables. We sometimes conducted ANOVA rather than MANOVA in order to preserve the ability to detect differences. Grouping of variables was guided by conceptual considerations rather than by inter-correlations (Huberty & Morris, Reference Huberty and Morris1989).
Assumption testing for (M)ANOVA
Sample size rules of thumb vary – we used the guideline that the number of observations should be larger than number of levels multiplied by number of dependent variables. We also choose not to analyze more than two dependent variables at the same time to avoid violating sample size rules of thumb. Extreme values were assessed using stem and leaf plots or Mahalanobis distances. Maximum Mahalanobis distances did not exceed the critical value in any case. There were indeed extreme values, and we verified the scoring on all to ensure there were no errors in the data. These extreme values represent real variability on some of these measures (e.g., particularly high or low spatial scores). Multivariate normality was assessed using the Shapiro–Wilk statistic. This assumption was not always met. In cases where all assumptions were met, the statistics reported use Wilks’ Lambda, and when not met, Pillai’s trace. Linear relationships among dependent variables were assessed using scatterplots. Homogeneity of variance was tested using Levene’s test of equality of error and non-significant results occurred in all cases. Homogeneity of covariance was tested using Box’s test of equality of covariance matrices. Box’s M values exceeded the cut-off value of .001 in all cases. Multicollinearity was assessed using bivariate correlations. In all cases, we found a relationship that exceeded the minimum (using a .2 cut-off) and did not exceed the maximum (using a .8 cut-off). Planned post-hoc comparisons used Scheffés test because of unequal group sizes and robustness to non-normality.












