



1. Introduction
Cable-driven manipulators (CDMs) are a novel class of robots. Similar to snake robots [Reference Li, Zhang, Xiu, Deng, Zhang, Tong, Law, Zhu, Wu and Zhu1], they can move flexibly in confined environments due to their slender bodies and a large number of degrees of freedom (DOFs) [Reference Robert and Bryan2]. Unlike snake robots, CDMs have separate driving systems and all DOFs can be independently controlled. This makes them more suitable than snake robots for executing dangerous tasks such as operating in nuclear facilities and intricate industrial devices [Reference Li, Ma, Li, Wang and Wang3, Reference Peng, Zhang, Meng and Liang4].
In the past decades, many hyper-redundant manipulators were designed, which can be roughly classified into two categories: rigid-backbone and continuum-backbone manipulators [Reference Walker, Choset, Chirikjian, Siciliano and Khatib5, Reference Dong, Raffles, Cobos-Guzman, Axinte and Kell6]. As a main form of these robots, a rigid-backbone robot is connected by a number of joints and links. As a pioneer, Shigeo designs a multi-segment manipulator [Reference Shigeo, Peter and Charles7]. Several commercial manipulators of this structure are developed by OC robotics [Reference Buckingham, Chitrakaran, Conkie, Ferguson, Graham, Lazell, Lichon, Parry, Pollard, Kayani, Redman, Summers and Green8]. Kang and Dai designed a pneumatic muscle-based continuum robot with embedded tendons in ref. [Reference Kang, Guo, Chen, Branson and Dai9] and a novel continuum robot with shape memory alloy initiated variable stiffness in [Reference Yang, Geng, Walker, Branson, Liu, Dai and Kang10]. In refs. [Reference Dong, Axinte, Palmer, Cobos, Raffles, Rabani and Kell11, Reference Mohammad, Russo, Fang, Dong, Axinte and Kell12], mechanism and control of a manipulator that can coil and uncoil are investigated. Such robots as the hyper-redundant manipulator developed by OC Robotics [Reference Buckingham and Graham13] and a collaborative continuous robot system developed by Dong [Reference Dong, Wang, Mohammad, Ba, Russo, Norton, Kell and Axinte14] are used in challenging environments.
Since CDMs execute tasks in confined spaces with multi-obstacle, they require high performances in terms of safety and precision. However, it is difficult to control them due to their hyper-redundancy DOFs, nonlinear and multi-level relationships among motors, joints and end effectors [Reference Lau, Oetomo and Halgamuge15]. To solve these problems, several motion control methods including path following and path planning of CDMs were proposed in the past years.
Path following of CDMs is to control their slender bodies to track desired paths without collision. Since high DOFs of CDMs, their path following is usually solved by using an iterative Jacobian-based method [Reference Tang, Ji, Zhu and Gu16]. Conkur computes link’s position relative to a given B-spline curve path by using a numerical approach [Reference Conkur17]. To control a snake arm robot following desired trajectories with minimal errors, Palmer et al. propose a tip-following approach by using a sequential quadratic programing optimization method [Reference Palmer, Cobos-Guzman and Axinte18]. In ref. [Reference Wang, Tang, Gu and Zhu19], a tip-following method is proposed for CDMs and its performance is analyzed. A path-following method with prediction lookup and interpolation algorithms is investigated for CDMs working in confined spaces [Reference Tang, Zhu, Zhu and Gu20]. With these methods, CDMs can move along desired paths accurately. However, these paths are given by operators according to constraints of tasks and CDMs. When they are required to automatically execute special tasks in multi-obstacle environments, their path planning is essential.
Unlike path following, path-planning methods are rarely researched. In the recent years, path planning for CDMs has emerged as a prominent research area. In ref. [Reference LaValle21], bilevel optimization and genetic algorithms are used to plan paths for redundant manipulators. It maximizes the manipulability of the robot but fails to consider smoothness of the planned paths. In ref. [Reference Luo, Li, Zhang, Tan and Liang22], a motion planning method that considers constraints of joint limits and environments is designed for a novel coiled CDM. However, this motion planning method depends on the kinematic model. Wei et al. propose a specialized rapidly exploring random tree (RRT) path-planning method for achieving a follow-the-leader motion of CDMs [Reference Wei, Zheng and Gu23]. A CDM controlled by this method can move in porous plate environments. Jia et al. propose an MDA + RRT path-planning approach for CDMs that considers the maximum deflection angle of joints [Reference Jia, Huang, Chen, Guo, Yin and Chen24]. To quickly plan suitable paths for CDMs, an RRT-A* method is proposed and verified in ref. [Reference Zhang, Gai, Ju, Miao and Lao25]. Yang et al. designed an ellipsoid-shaped RRT*-based path-planning method for CDMs with angle limitations [Reference Ji, Xie, Wang and Yang26]. The mentioned methods are based on research conducted on accurate models of CDMs. In reality, it is difficult to establish such accurate models because of their complex mechanisms and coupling relationships.
Different from these model-based methods, reinforcement learning (RL) algorithm can plan suitable paths without depending on any models [Reference Sangiovanni, Rendiniello, Incremona, Ferrara and Piastra27, Reference Hua, Wang, Xu and Chen28]. In ref. [Reference Sangiovanni, Rendiniello, Incremona, Ferrara and Piastra27], Sangiovanni et al. propose a collision avoidance method for a 6-DOF manipulator based on a deep RL algorithm. The manipulator can complete tasks with an unpredictable obstacle invasive its workspace. To plan collision-free path in duct-entry space for an 8-DOF manipulator, an RL-based collision-free path planner is designed [Reference Hua, Wang, Xu and Chen28]. The generality of the planner is not enough for different ducts. This work is significant for control manipulators. However, their manipulators’ DOF is lesser than CDMs’ and their environments are not complex enough. Driven by this work, it is valuable to research RL-based path-planning methods for hyper-redundant CDMs in multi-obstacle environments.
In this paper, path planning of CDMs in multi-obstacle environments is tackled with a deep deterministic policy gradient (DDPG) algorithm. To meet pose constraints of hyper-redundant CDMs, DDPG is modified according to CDMs’ features. A specialized reward function considering smoothness, arrival time and distance is designed to improve the adaptability of planned paths. A tip-following method is used to control CDMs to move along a planned path. Extensive simulations and experiments about path planning and following a 17-DOF CDM are conducted. To the best of our knowledge, there has been little research on using DDPG for path planning of CDM.
The rest of this paper is organized as follows: design and kinematics of CDM are described in Section 2. A DDPG-based path planning and tip-following methods are given in Section 3. Simulations and experiments are conducted to verify its efficiency in Section 4. Section 5 concludes the paper.
2. Design and mathematical model of CDM
As shown in Fig. 1, a CDM with 17 DOFs is designed. It consists of a robotic manipulator and an actuation system. The manipulator is connected by 8 rotational sections. Each section is driven by 3 cables and it can rotate in pitch and yaw directions through coupling control of corresponding cables. There are 24 groups of motors and driving modules arranged circularly on a pedestal. In order to expand the robot’s workspace, the pedestal is fixed on a platform that can move forward and backward.
2.1. Kinematics analysis of CDM
In order to control CDM, we establish and analyze its kinematics model and mapping relationships by using a product of exponentials (POEs) formula method. As shown in Fig. 1(d), the robotic manipulator has 8 sections. Each section is composed of a link and a universal joint. Mathematical symbols used in this paper are listed in Table I.
Table I. Mathematical notation.


Figure 1. Design and model of a 17-degree of freedom cable-driven manipulator (CDM). (a) The designed hyper-redundant CDM. (b) A simplified geometric model of the CDM. (c) Model of a joint. (d) Geometric model.
The kinematics analysis of CDM includes relationships among task space, joint space and driving space. Since the focus of this work is path planning of CDM, we mainly derive kinematics between task space and joint one. For the task-joint kinematics, a mutual transformation between rotational joints’ angles and end effector’s posture is necessary.
As defined in our previous work [Reference Ju, Zhang, Xu, Yuan, Miao, Zhou and Cao29],
 $f_1$
and
$f_1$
and
 $f_{1}^{-1}$
are the forward and inverse kinematics between task space and joint space, respectively. We have:
$f_{1}^{-1}$
are the forward and inverse kinematics between task space and joint space, respectively. We have:
 \begin{equation} f_1= T_{\mathbb{S},\mathbb{E}}= T_{\mathbb{S},\mathbb{B}}(dB)T_{ \mathbb{B},\mathbb{E}}(\theta _1,\theta _2,\theta _3,\ldots,\theta _{16}). \end{equation}
\begin{equation} f_1= T_{\mathbb{S},\mathbb{E}}= T_{\mathbb{S},\mathbb{B}}(dB)T_{ \mathbb{B},\mathbb{E}}(\theta _1,\theta _2,\theta _3,\ldots,\theta _{16}). \end{equation}
The twist
 $\hat{\xi }_{i}$
can be obtained from:
$\hat{\xi }_{i}$
can be obtained from:
 \begin{equation} \hat{\xi }_{i}={ \left [ \begin{array}{cc} \hat{\omega }_{i}&\nu _{i}\\ 0&0\\ \end{array} \right ]}\in SE(3), \end{equation}
\begin{equation} \hat{\xi }_{i}={ \left [ \begin{array}{cc} \hat{\omega }_{i}&\nu _{i}\\ 0&0\\ \end{array} \right ]}\in SE(3), \end{equation}
where
 $\hat{\omega }_{i}$
is a skew symmetric matrix of
$\hat{\omega }_{i}$
is a skew symmetric matrix of
 $\omega _{i}$
,
$\omega _{i}$
,
 $\xi _{i}=[\nu ^{T}_{i}, \omega ^{T}_{i}]^{T}$
,
$\xi _{i}=[\nu ^{T}_{i}, \omega ^{T}_{i}]^{T}$
,
 $\nu _{i}=-\omega _{i}\times q_{i}$
,
$\nu _{i}=-\omega _{i}\times q_{i}$
,
 $\omega _{i}$
and
$\omega _{i}$
and
 $q_{i}$
are set as Table II.
$q_{i}$
are set as Table II.
Table II. Product of exponential parameters of cable-driven manipulator.

In a POE formula method, a rotation motion of CDM can be described in the form of an exponential product as:
 \begin{equation} e^{\hat{\xi }\theta }={ \left [ \begin{array}{cc} R&\rho \\ 0&1\\ \end{array} \right ]}\in SE(3), \end{equation}
\begin{equation} e^{\hat{\xi }\theta }={ \left [ \begin{array}{cc} R&\rho \\ 0&1\\ \end{array} \right ]}\in SE(3), \end{equation}
where
 $R=I+\sin \theta \hat{\omega }+(1-\cos \theta )\hat{\omega }^{2}$
,
$R=I+\sin \theta \hat{\omega }+(1-\cos \theta )\hat{\omega }^{2}$
,
 $\rho =(I\theta +(1-\cos \theta )\hat{\omega }+(\theta -\sin \theta )\hat{\omega }^{2})\nu$
and
$\rho =(I\theta +(1-\cos \theta )\hat{\omega }+(\theta -\sin \theta )\hat{\omega }^{2})\nu$
and
 $I\in R^{3\times 3}$
is an identity matrix. The posture of the end effector is:
$I\in R^{3\times 3}$
is an identity matrix. The posture of the end effector is:
 \begin{equation} T_{\mathbb{B},\mathbb{E}}(\theta _{1},\theta _{2},\ldots,\theta _{16})=e^{\hat{\xi }_{1}\theta _{1}}e^{\hat{\xi }_{2}\theta _{2}}\ldots e^{\hat{\xi }_{16}\theta _{16}}T_{\mathbb{B},\mathbb{E}}(0), \end{equation}
\begin{equation} T_{\mathbb{B},\mathbb{E}}(\theta _{1},\theta _{2},\ldots,\theta _{16})=e^{\hat{\xi }_{1}\theta _{1}}e^{\hat{\xi }_{2}\theta _{2}}\ldots e^{\hat{\xi }_{16}\theta _{16}}T_{\mathbb{B},\mathbb{E}}(0), \end{equation}
where
 $T_{\mathbb{B},\mathbb{E}}(0)$
is an initial end posture of CDM.
$T_{\mathbb{B},\mathbb{E}}(0)$
is an initial end posture of CDM.
2.2. Kinematics analysis of a joint
As shown in Fig. 1
(c), position and orientation of each section are determined by rotation of its joints. Rotation angles are controlled by corresponding three cables. To analyze the relationship between cable lengths and rotation angles of joints, a geometric model of a joint is simplified as shown in Fig. 1
(d). In the schematic diagram of the first universal joint,
 $i=1$
, the transformation relationship between coordinate systems is:
$i=1$
, the transformation relationship between coordinate systems is:
 \begin{equation} \begin{split} _{O}^{M}T=Trans\left ( 0,0,h \right ) Rot\left ( X,\theta _{2} \right ) \end{split}, \end{equation}
\begin{equation} \begin{split} _{O}^{M}T=Trans\left ( 0,0,h \right ) Rot\left ( X,\theta _{2} \right ) \end{split}, \end{equation}
 \begin{equation} \begin{split} _{N}^{O}T=Rot\left ( Y,\theta _{1} \right ) Trans\left ( 0,0,h \right ) \end{split}. \end{equation}
\begin{equation} \begin{split} _{N}^{O}T=Rot\left ( Y,\theta _{1} \right ) Trans\left ( 0,0,h \right ) \end{split}. \end{equation}
The transformation relationship between
 $\{M\}$
and
$\{M\}$
and
 $\{N\}$
is:
$\{N\}$
is:
 \begin{equation} \begin{split} _{M}^{N}T=_{N}^{O}T_{O}^{M}T =\left [ \begin{matrix} C_{\beta _i}& S_{\alpha _i}S_{\beta _i}& C_{\alpha _i}S_{\beta _i}& 2S_{\beta _i}h\\ 0& C_{\alpha _i}& -S_{\alpha _i}& 0\\ -S_{\beta _i}& C_{\beta _i}S_{\alpha _i}& C_{\alpha _i}C_{\beta _i}& 2C_{\beta _i}h\\ 0& 0& 0& 1\\ \end{matrix} \right ] \end{split}. \end{equation}
\begin{equation} \begin{split} _{M}^{N}T=_{N}^{O}T_{O}^{M}T =\left [ \begin{matrix} C_{\beta _i}& S_{\alpha _i}S_{\beta _i}& C_{\alpha _i}S_{\beta _i}& 2S_{\beta _i}h\\ 0& C_{\alpha _i}& -S_{\alpha _i}& 0\\ -S_{\beta _i}& C_{\beta _i}S_{\alpha _i}& C_{\alpha _i}C_{\beta _i}& 2C_{\beta _i}h\\ 0& 0& 0& 1\\ \end{matrix} \right ] \end{split}. \end{equation}
In addition, coordinates of cables’ holes in the corresponding disk can be computed.
The driven cables of the first joint can be computed as:
 \begin{equation} \begin{split} L_{c,j}=\left [\begin{array}{c} 2hS_{\theta _{1}}-r C_{\varphi +(j-1)\frac{2\pi }{3}}+rC_{\varphi +(j-1)\frac{2\pi }{3}}C_{\theta _{1}}+rS_{\theta _{2}}S_{\theta _{1}}S_{\varphi +(j-1)\frac{2\pi }{3}}\\[5pt] r C_{\theta _{2}}S_{\varphi +(j-1)\frac{2\pi }{3}}-rS_{\varphi +(j-1)\frac{2\pi }{3}}\\[5pt] 2hC_{\theta _{1}}-rC_{\varphi +(j-1)\frac{2\pi }{3}}S_{\theta _{1}}+rC_{\theta _{1}}S_{\theta _{2}}S_{\varphi +(j-1)\frac{2\pi }{3}}\\[5pt] 0\\ \end{array} \right ] \mathcal{} \end{split},\ j=1,2,3. \end{equation}
\begin{equation} \begin{split} L_{c,j}=\left [\begin{array}{c} 2hS_{\theta _{1}}-r C_{\varphi +(j-1)\frac{2\pi }{3}}+rC_{\varphi +(j-1)\frac{2\pi }{3}}C_{\theta _{1}}+rS_{\theta _{2}}S_{\theta _{1}}S_{\varphi +(j-1)\frac{2\pi }{3}}\\[5pt] r C_{\theta _{2}}S_{\varphi +(j-1)\frac{2\pi }{3}}-rS_{\varphi +(j-1)\frac{2\pi }{3}}\\[5pt] 2hC_{\theta _{1}}-rC_{\varphi +(j-1)\frac{2\pi }{3}}S_{\theta _{1}}+rC_{\theta _{1}}S_{\theta _{2}}S_{\varphi +(j-1)\frac{2\pi }{3}}\\[5pt] 0\\ \end{array} \right ] \mathcal{} \end{split},\ j=1,2,3. \end{equation}
Their lengths are:
 \begin{equation} \begin{split} |L_{c,j}|&=((rC_{\varphi +(j-1)\frac{2\pi }{3}}(C_{\theta _{1}}-1)+2h S_{\theta _{1}}C_{\theta _{2}} +r S_{\varphi +(j-1)\frac{2\pi }{3}}S_{\theta _{1}}S_{\theta _{2}})^{2}\\[5pt] &\quad +(2h(C_{\theta _{1}}C_{\theta _{2}}+1)-rC_{\varphi +(j-1)\frac{2\pi }{3}}S_{\theta _{1}} +r S_{\varphi +(j-1)\frac{2\pi }{3}}C_{\theta _{1}}S_{\theta _{2}})^{2} \quad \quad j=1,2,3.\\[5pt] &\qquad \qquad \qquad\qquad\quad +(r S_{\varphi +(j-1)\frac{2\pi }{3}}(C_{\theta _{2}}-1)-2hS_{\theta _{2}})^{2})^{1/2} \end{split} \end{equation}
\begin{equation} \begin{split} |L_{c,j}|&=((rC_{\varphi +(j-1)\frac{2\pi }{3}}(C_{\theta _{1}}-1)+2h S_{\theta _{1}}C_{\theta _{2}} +r S_{\varphi +(j-1)\frac{2\pi }{3}}S_{\theta _{1}}S_{\theta _{2}})^{2}\\[5pt] &\quad +(2h(C_{\theta _{1}}C_{\theta _{2}}+1)-rC_{\varphi +(j-1)\frac{2\pi }{3}}S_{\theta _{1}} +r S_{\varphi +(j-1)\frac{2\pi }{3}}C_{\theta _{1}}S_{\theta _{2}})^{2} \quad \quad j=1,2,3.\\[5pt] &\qquad \qquad \qquad\qquad\quad +(r S_{\varphi +(j-1)\frac{2\pi }{3}}(C_{\theta _{2}}-1)-2hS_{\theta _{2}})^{2})^{1/2} \end{split} \end{equation}
where
 $r$
is radius of the circle where the holes are distributed on the disk.
$r$
is radius of the circle where the holes are distributed on the disk.
Using above kinematics model, desired motion of other section can be realized with given pitch and yaw angles
 $\theta _{2i-1}$
and
$\theta _{2i-1}$
and
 $\theta _{2i}$
.
$\theta _{2i}$
.
3. Path planning based on DDPG
Path planning is important for CDMs to move in complex environments with multiple obstacles. Objectives of CDM path planning can be presented as:
-
• Followed ability: The curvature of a planned path should be within the limitation of CDM joints.
-
• Path performances: The planned path should be shorter and smoother.
-
• Efficiency: Passable paths should be planned rapidly in different environments.
For the path planning of CDMs, the states of CDMs at a certain moment only depend on the previous states and actions. They are independent of the previous states and actions. Due to this feature, path planning of CDM can be modeled as a Markov decision problem. RL is particularly suitable for solving MDPs due to its advantages, such as model independence, exploration-exploitation balance, dynamic decision-making ability and reward-driven learning. Compared with other DRL algorithms, DDPG performs better in processing continuous action spaces, expressing deep learning, as well as algorithm stability and convergence, making it suitable for solving MDPs. In this work, a DDPG-based method is investigated to solve path planning of CDM.
3.1. DDPG
DDPG is a model-free algorithm that can learn competitive policies for many tasks by using same hyper-parameters and network structures [Reference Lillicrap, Hunt, Pritzel, Heess, Erez, Tassa, Silver and Wierstra30]. It is illustrated in Fig. 2 and realized in Algorithm 1.
Algorithm 1: The DDPG Algorithm.

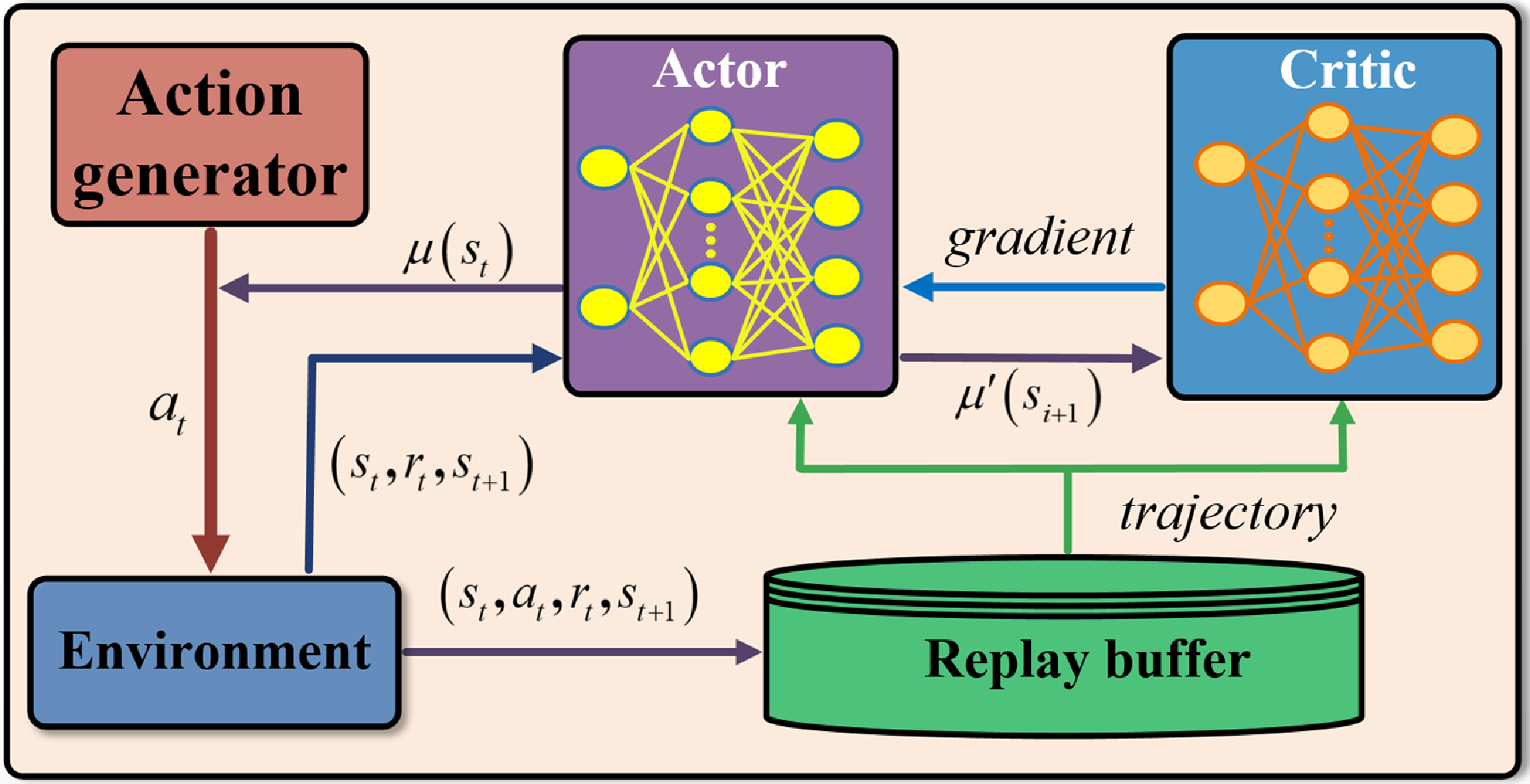
Figure 2. The deep deterministic policy gradient path-planning algorithm.
DDPG maintains a parameterized actor function
 $\mu (s\mid \theta ^{\mu })$
that specifies the current policy by deterministically mapping states to a specific action. A critic
$\mu (s\mid \theta ^{\mu })$
that specifies the current policy by deterministically mapping states to a specific action. A critic
 $Q(s, a)$
is learned by using a Bellman equation. An actor is updated by using a chain rule to an expected return from a start distribution
$Q(s, a)$
is learned by using a Bellman equation. An actor is updated by using a chain rule to an expected return from a start distribution
 $J$
according to parameters of the actor:
$J$
according to parameters of the actor:
 \begin{equation} \begin{split} \nabla _{\theta _{\mu }}J\approx \mathbb{E}_{s_{t}\sim \rho ^{\beta }}[\nabla _{\theta ^{\mu }}Q(s,a\mid \theta ^{Q}))\mid _{ s=s_{t}, a=\mu (s_{t}\mid \theta ^{\mu })}] \\ =\mathbb{E}_{s_{t}\sim \rho ^{\beta }}[\nabla _{a}Q(s,a\mid \theta ^{Q})\mid _{s=s_{t},a=\mu (s_{t})}\nabla _{\theta _{\mu }}\mu (s\mid \theta ^{\mu })\mid s=s_{t}].\\ \end{split} \end{equation}
\begin{equation} \begin{split} \nabla _{\theta _{\mu }}J\approx \mathbb{E}_{s_{t}\sim \rho ^{\beta }}[\nabla _{\theta ^{\mu }}Q(s,a\mid \theta ^{Q}))\mid _{ s=s_{t}, a=\mu (s_{t}\mid \theta ^{\mu })}] \\ =\mathbb{E}_{s_{t}\sim \rho ^{\beta }}[\nabla _{a}Q(s,a\mid \theta ^{Q})\mid _{s=s_{t},a=\mu (s_{t})}\nabla _{\theta _{\mu }}\mu (s\mid \theta ^{\mu })\mid s=s_{t}].\\ \end{split} \end{equation}
To accelerate the convergence of DDPG, weights of the network are updated by a back propagation algorithm based on an experience replay technology. Transitions are sampled from environments according to the exploration policy and a tuple
 $(s_t, a_t, r_t, s_{t+1})$
is stored in a replay buffer
$(s_t, a_t, r_t, s_{t+1})$
is stored in a replay buffer
 $\mathfrak{R}$
. The oldest samples are discarded when
$\mathfrak{R}$
. The oldest samples are discarded when
 $\mathfrak{R}$
is full. The actor and critic networks are updated by sampling a minibatch uniformly from
$\mathfrak{R}$
is full. The actor and critic networks are updated by sampling a minibatch uniformly from
 $\mathfrak{R}$
at each timestep. Since DDPG is an off-line policy algorithm,
$\mathfrak{R}$
at each timestep. Since DDPG is an off-line policy algorithm,
 $\mathfrak{R}$
should be large enough to improve its benefit.
$\mathfrak{R}$
should be large enough to improve its benefit.
3.2. Reward function
A proper reward function is key to a successful reinforcement learning algorithm. This work proposes the following reward function to plan a safe path toward the target for the CDM, i.e.,
 \begin{equation} R= \left \{ \begin{array}{lr} 500, \qquad \qquad case \, 1\\ c_{1}R_{1}+c_{2}R_{2}, \quad case \, 2\\ -50, \qquad \qquad case \, 3\\ \end{array} \right . \end{equation}
\begin{equation} R= \left \{ \begin{array}{lr} 500, \qquad \qquad case \, 1\\ c_{1}R_{1}+c_{2}R_{2}, \quad case \, 2\\ -50, \qquad \qquad case \, 3\\ \end{array} \right . \end{equation}
where
 $case 1$
is the robot arrives at the target,
$case 1$
is the robot arrives at the target,
 $case 2$
is the robot moves toward the target,
$case 2$
is the robot moves toward the target,
 $case 3$
is the robot collides with obstacles,
$case 3$
is the robot collides with obstacles,
 $R_{1}$
is the distance reward between the end effector and the target,
$R_{1}$
is the distance reward between the end effector and the target,
 $R_{2}$
is a distance reward between the end effector and the obstacle and
$R_{2}$
is a distance reward between the end effector and the obstacle and
 $c_{1}$
and
$c_{1}$
and
 $c_{2}$
are weights that decide priority during training. The distance reward
$c_{2}$
are weights that decide priority during training. The distance reward
 $R_{1}$
is computed by using a Huber-Loss function:
$R_{1}$
is computed by using a Huber-Loss function:
 \begin{equation} R_{1}= \left \{ \begin{array}{lr} \frac{1}{2}d^{2}, \quad |d|\lt \delta \\ \delta (|d|-\frac{1}{2}\delta ), \quad otherwise\\ \end{array}, \right . \end{equation}
\begin{equation} R_{1}= \left \{ \begin{array}{lr} \frac{1}{2}d^{2}, \quad |d|\lt \delta \\ \delta (|d|-\frac{1}{2}\delta ), \quad otherwise\\ \end{array}, \right . \end{equation}
where
 $d$
is the Euclidean distance between CDM’s end effector and the target and
$d$
is the Euclidean distance between CDM’s end effector and the target and
 $\delta$
is a parameter that determines the smoothness. The second reward
$\delta$
is a parameter that determines the smoothness. The second reward
 $R_{2}$
relates to the distance between the robot and the nearest obstacle. It is computed as:
$R_{2}$
relates to the distance between the robot and the nearest obstacle. It is computed as:
 \begin{equation} R_{2}=\left(\frac{d_{o}}{ \skew{10}\check{d}+ d_{o}}\right)^{p}, \end{equation}
\begin{equation} R_{2}=\left(\frac{d_{o}}{ \skew{10}\check{d}+ d_{o}}\right)^{p}, \end{equation}
where
 $d_{o}$
is set as a constant to ensure
$d_{o}$
is set as a constant to ensure
 $R_{2}\in (0, 1)$
,
$R_{2}\in (0, 1)$
,
 $\skew{10}\check{d}$
is the minimum distance between the end effector and the obstacle and
$\skew{10}\check{d}$
is the minimum distance between the end effector and the obstacle and
 $p$
is an exponential decay of the negative reward. Parameters of DDPG used in this work are listed in Table III.
$p$
is an exponential decay of the negative reward. Parameters of DDPG used in this work are listed in Table III.
Table III. Parameters of deep deterministic policy gradient.

3.3. Path following of CDMs
To control CDM to move along a planned path, a tip-following method as shown in Fig. 3 is adopted. Joints and links of CDM should be matched with the planned path. The planned path is discretized into some waypoints. As shown in Fig. 3
(a),
 $k_{i}$
is a key point located at the center of mass of universal joint
$k_{i}$
is a key point located at the center of mass of universal joint
 $i$
, the pedestal is fixed with
$i$
, the pedestal is fixed with
 $k_{1}$
and
$k_{1}$
and
 $M_{i}$
is the
$M_{i}$
is the
 $i$
-
$i$
-
 $th$
mark point located on the path. In this work, a set of points denoted as
$th$
mark point located on the path. In this work, a set of points denoted as
 $\boldsymbol{M}$
are generated by discretizing the path. The length of a curve between adjacent points is set as a constant
$\boldsymbol{M}$
are generated by discretizing the path. The length of a curve between adjacent points is set as a constant
 $s_{d}$
.
$s_{d}$
.
When
 $k_{1}$
is located at a discrete point of the path, the point is defined as
$k_{1}$
is located at a discrete point of the path, the point is defined as
 $p_{k_{1}}$
. Other key points
$p_{k_{1}}$
. Other key points
 $p_{k_{i}}$
need satisfy the constraint:
$p_{k_{i}}$
need satisfy the constraint:
 \begin{equation} \min |\overrightarrow{p_{k_{i}}p_{k_{i-1}}}|-d_{l}, k_{i}\in (k_{i-1}, n\times p), \end{equation}
\begin{equation} \min |\overrightarrow{p_{k_{i}}p_{k_{i-1}}}|-d_{l}, k_{i}\in (k_{i-1}, n\times p), \end{equation}
where
 $n\times p$
is the number of all discretization points.
$n\times p$
is the number of all discretization points.
To find
 $p_{k_{i}}$
, this work adopts an iteratively sequential searching method proposed in refs. [Reference Wang, Tang, Gu and Zhu19, Reference Tang, Zhu, Zhu and Gu20]. As shown in Fig. 3
(a),
$p_{k_{i}}$
, this work adopts an iteratively sequential searching method proposed in refs. [Reference Wang, Tang, Gu and Zhu19, Reference Tang, Zhu, Zhu and Gu20]. As shown in Fig. 3
(a),
 $p_{^{t}k_{i}}$
is the nearest mark point to the key point
$p_{^{t}k_{i}}$
is the nearest mark point to the key point
 $k_{i}$
at time
$k_{i}$
at time
 $t$
. In the next time step, key points move forward along the direction of discrete points:
$t$
. In the next time step, key points move forward along the direction of discrete points:
 \begin{equation} ^{t+1}k_{i}-^{t+1}k_{i-1} \approx ^{t}k_{i}-^{t}k_{i-1} = \Delta k, \end{equation}
\begin{equation} ^{t+1}k_{i}-^{t+1}k_{i-1} \approx ^{t}k_{i}-^{t}k_{i-1} = \Delta k, \end{equation}
where
 $\Delta k= d_{l}/s_{d}$
. Index
$\Delta k= d_{l}/s_{d}$
. Index
 $^{t+1}k_{i}$
can be predicted.
$^{t+1}k_{i}$
can be predicted.

Figure 3. The tip-following method of cable-driven manipulators. (a) Iteration of links. (b) The interpolation algorithm.
Algorithm 2: The Key Point Searching Algorithm.
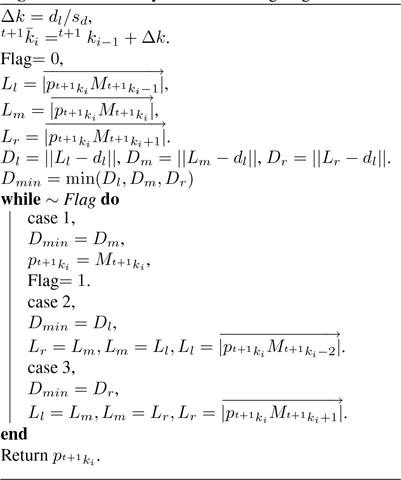

Figure 4. Simulations of path planning by using the proposed deep deterministic policy gradient algorithm. (a) The planned path. (b) The reward converges to a stable state.
With these predictions, the points
 $p_{^{t+1}k_{i}}$
corresponding to
$p_{^{t+1}k_{i}}$
corresponding to
 $^{t+1}k_{i}$
need to be verified whether satisfy (14) by using Algorithm 2. Although
$^{t+1}k_{i}$
need to be verified whether satisfy (14) by using Algorithm 2. Although
 $p_{^{t}k_{i}}$
is the nearest mark point to the key point
$p_{^{t}k_{i}}$
is the nearest mark point to the key point
 $k_{i}$
, the distance between
$k_{i}$
, the distance between
 $p_{^{t}k_{i}}$
and
$p_{^{t}k_{i}}$
and
 $p_{^{t+1}k_{i-1}}$
is unequal to the link’s length. A point certifies Equation (14) needs to be found around
$p_{^{t+1}k_{i-1}}$
is unequal to the link’s length. A point certifies Equation (14) needs to be found around
 $k_{i}$
. As shown in Fig. 3
(b),
$k_{i}$
. As shown in Fig. 3
(b),
 $M_{t+1_{k_{i}}}$
is the predicted
$M_{t+1_{k_{i}}}$
is the predicted
 $p_{^{t+1}k_{i}}$
,
$p_{^{t+1}k_{i}}$
,
 $M_{t+1_{k_{i-1}}}$
and
$M_{t+1_{k_{i-1}}}$
and
 $M_{t+1_{k_{i+1}}}$
are its adjacent mark points. The expected
$M_{t+1_{k_{i+1}}}$
are its adjacent mark points. The expected
 $p_{^{t+1}k_{i}}$
locates the blue arc. The center and the radius of the arc are
$p_{^{t+1}k_{i}}$
locates the blue arc. The center and the radius of the arc are
 $p_{^{t+1}k_{i-1}}$
and
$p_{^{t+1}k_{i-1}}$
and
 $d_{l}$
, respectively. The expected
$d_{l}$
, respectively. The expected
 $p_{^{t+1}k_{i}}$
can be computed by using the geometric relationships. Positions of all joints can be computed based on the planned path after this iteration.
$p_{^{t+1}k_{i}}$
can be computed by using the geometric relationships. Positions of all joints can be computed based on the planned path after this iteration.
4. Evaluation
To test the proposed DDPG-based path-planning method, we have conducted a group of simulations and experiments. In these experiments, the end effector of the CDM is required to move from a start point
 $(130,0,0)$
to a target position
$(130,0,0)$
to a target position
 $(235,0,0)$
while avoiding six cylinders with a radius of 5 cm and a height of 20 cm. Their coordinates are (160,-4,0), (160,0,0), (160,4,0), (185,-2,0), (185,2,0) and (210,0,0), respectively. The initial pitch and yaw angles of all joints of the CDM are 0 degrees. Through multiple experiments, parameters of DDPG are compared and selected as shown in Table III.
$(235,0,0)$
while avoiding six cylinders with a radius of 5 cm and a height of 20 cm. Their coordinates are (160,-4,0), (160,0,0), (160,4,0), (185,-2,0), (185,2,0) and (210,0,0), respectively. The initial pitch and yaw angles of all joints of the CDM are 0 degrees. Through multiple experiments, parameters of DDPG are compared and selected as shown in Table III.
4.1. Simulations
In our simulations, Simulink, CoppeliaSim and Pycharm are used. Communication among different platforms is implemented through a remote API. Two groups of simulation are conducted in Simulink and CoppeliaSim, respectively. In Simulink and CoppeliaSim, a virtual robot is built according to the size of our prototype and a multi-obstacle environment is conducted.
The passable path is planned by DDPG algorithm and CDM is controlled by the tip-following method to move toward the target. As shown in Fig. 4 (a), DDPG algorithm can plan a passable path (black curve) in a multi-obstacle environment. The reward can converge to a stable state as shown in Fig. 4 (b). Angles and positions of links are computed by using the tip-following method. As shown in Fig. 5 (a) and (b), the CDM can move along the planned path (black curve) without collision in Simulink and CoppeliaSim. Joint angles are measured and saved to analyze the motion controlled by the proposed methods. As shown in Fig. 5 (c), all the angles are always less than 40 degrees while moving from the start point to the target point. They are smooth enough and satisfy to mechanical constraints of the joints.
4.2. Physical experiments
Prototype experiences are used to test our path planning and following methods of CDMs. As shown in Fig. 6
(a), the robotic manipulator is connected by 8 sections. The platform is powered by a stepper motor (57TB6600). Each section can rotate between
 $[{-}45^{\circ }, +45^{\circ }]$
. Motors communicate with a PC via an analyzer (Kvaser Leaf Light v2). Geometric parameters of our CDM are summarized in Table IV.
$[{-}45^{\circ }, +45^{\circ }]$
. Motors communicate with a PC via an analyzer (Kvaser Leaf Light v2). Geometric parameters of our CDM are summarized in Table IV.
Table IV. Geometric parameters of cable-driven manipulator.


Figure 5. Simulations of path planning and following of a cable-driven manipulator by using the proposed methods. (a) Simulations in Simulink. (b) Simulations in CoppeliaSim. (c) Joint angles.
To control CDM move toward the target along a desired path, a closed-loop control framework is designed. Links and obstacles are wrapped by tapes to fix markers. To measure states of CDM accurately, each link attached with 3 markers is defined as a rigid body. Positions of all markers can be measured by a 3-D OptiTrack motion capture system. States of CDM can be computed by using these data and its kinematics model. Passable paths are planned by using DDPG. Positions of all links are computed by the tip-following method. Joint angles and cable lengths are computed according to multi-level relationships among motors, joints and the end effector of the robot. As shown in Fig. 6 (b), our CDM controlled by the proposed methods can plan a possible path and move toward a target position smoothly without collision in a multi-obstacle environment.

Figure 6. The cable-driven manipulator (CDM) prototype and experiments. (a) The structure of CDM. (b) Experiments of path planning and following of CDM by using the proposed methods.
5. Conclusion and future work
In this work, a specialized DDPG-based path-planning algorithm is designed for CDMs. A reward function under constraint of CDMs’ features and multi obstacles is designed to train the DDPG path-planning network. To control the robot moving along the planned path without collisions, a tip-following method is used. Various simulations and experiments are conducted in CoppeliaSim and Simulink to validate the effectiveness of the proposed algorithms. In order to demonstrate the practicality of the motion control methods, they are verified on a 17-DOF CDM prototype through simulations and experiments. The results validate the effectiveness of our path planning and following methods.
The CDM designed in this work can only move in environments with prior static obstacles automatically. However, in most real tasks, there are many dynamic obstacles. In future work, we will improve its mechanisms using methods proposed in refs. [Reference Aimedee, Gogu, Dai, Bouzgarrou and Bouton31, Reference Salerno, Zhang, Menciassi and Dai32] and optimize its control by combining environmental perception and understanding algorithms proposed in refs. [Reference Cao, Li, Zhang, Zhou and Abusorrah33, Reference Mu, Zhang, Ma, Zhou and Cao34].
Author contributions
Dong Zhang, Renjie Ju and Zhengcai Cao conceived and designed the study and wrote the article.
Financial support
This work is supported by National Natural Science Foundation of China (52105005), the Beijing Natural Science Foundation (L223019), Open Foundation of State Key Laboratory of High-end Compressor and System Technology (SKL-YSJ202311) and Fundamental Research Funds for the Central Universities (ZY2415).
Competing interests
The authors declare no competing interests exist.
Ethical approval
The authors declare none.












