


1 Introduction
By way of a lead-in to the present study, the examples collected in (1) illustrate a range of maximizers and the dialogue dynamics in a forgery case tried at the Old Bailey Courthouse in London in 1775:
(1)
(a) Q. Are you perfectly sure that he said, he himself had seen Mr. Adair when he was going to ride, or that his sister, or any body else had?
Drummond. I am perfectly sure, he said, that he himself saw Mr. Adair, that he was in his boots, and he luckily catched him just before he was going to take a ride.
(b) Q. You have said in the gross, that she took it wholly upon herself?
Drummond. She did,
(c) Q. Did she do that in the presence of the prisoner?
Drummond. Yes, she said he was totally innocent, and she was the person that forged the bond, and begg'd us for God's sake to have mercy upon an innocent man, to consider his wife and children.
(d) She wrote upon a bit of paper, William Adair, or part of the name, so extremely like the signature to the bond, that it satisfied me, and I burnt the paper.
(e) Perreau (prisoner): […] if my subsequent proceedings, and the alacrity I shewed in going with Mr. Drummond to Mr. Adair, together with my conduct before this gentleman, is, as I apprehend it is, absolutely irreconcilable with a conciousness of guilt, the circumstances above mentioned will serve to shew with what a degree of credulity the artifices of Mrs. Rudd had furnished me.
(t17750531-1)Footnote 2
Perfectly, wholly, totally, extremely, absolutely and other forms like them contribute to a more assertive and emphatic expression and thus potentially also to the speaker sounding more urgent, certain and convincing (cf. also Pahta Reference Pahta, Dossena and Taavitsainen2006a: 209; Reference Pahta, Gotti and Salager-Meyer2006b). Such impressions help in constructing a speaker persona and stance that can be strategically used in the courtroom. The above examples illustrate different speaker roles and contexts where maximizers can serve important functions: questioners, usually lawyers or judges, use them in their prompts (1a, b) and witnesses in their answers (1a, c, d), partly primed by the question wording (1a), both highlighting important aspects of the dialogue dynamics in discourse. They occur in short question–answer sequences, as in (1a–c), in longer witness statements (1d), as well as in long deliveries of defense, as in (1e) by the accused person. Apart from presenting ample occasion for the use of maximizers, the courtroom context also assembles speakers from all walks of life, thus providing a kind of sociolinguistic mirror of the southeastern English population in the late modern period. The sociolinguistic perspective is all the more important as intensifiers have been identified as a linguistic area characterized by constant and extensive change (e.g. Bolinger Reference Bolinger1972: 18; Peters Reference Peters and Kastovsky1994: 271; Ito & Tagliamonte Reference Ito and Tagliamonte2003: 257). The present investigation seeks to illuminate the history of a group of eleven amplifiers with an original extremity meaning (labelled maximizers here) in the late modern period, more precisely their sociolinguistic and sociopragmatic behavior in the courtroom data provided by the Old Bailey Corpus (1.0, extended version), covering the period 1720–1913 (Huber et al. Reference Huber, Nissel, Maiwald and Widlitzki2012). This group is singled out here because of the items’ stronger reinforcing potential (in contrast to, e.g., very, so), which should be relevant for expressing higher speaker commitment in court. Also, this group has not so far been in the focus of an investigation, either historically (versus Peters’ (Reference Peters1993) study on boosters, for example) or in modern sociolinguistics, which tends to pay more attention to high-frequency items, and usually boosters (e.g. Tagliamonte Reference Tagliamonte2008).
2 Maximizers: a linguistic and socio-historical survey
Our investigation proceeds from a form- or item-based approach, taking the lists provided by Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985: 590) for maximizers and by Huddleston & Pullum (Reference Huddleston and Pullum2002: 721) for the maximal group of intensifiers as the starting point. These two lists show large-scale overlap, but with some items only given by Quirk et al. (bold) and one only by Huddleston & Pullum (underlined): absolutely, altogether, completely, entirely, extremely, fully, perfectly, quite, thoroughly, totally, utterly, wholly, in all respects, most. What unites these items is that their lexical meaning involves features of extremity, totality, or finiteness. It is this original meaning and its potential persistence (in grammaticalization terms, cf. Hopper Reference Hopper, Traugott and Heine1991) that explains their common use and classification as maximizers, i.e. as targeting the upper extreme or top end of the degree scale (as defined by both Quirk et al. and Huddleston & Pullum), and which is illustrated in the entirely innocent of our title (i.e. ‘innocent to the full extent, not a trace of guilt’). An instance like a completely swollen face (t18380129-618) shows that these items need not always strictly indicate the top of the scale, but only a high area on it (and thus may admittedly be rather booster-like), as there is no clear natural limit to swelling.Footnote 3 However, comparing this phrase in booster uses such as ‘a very/greatly/badly/awfully swollen face’ to ‘a completely/totally/extremely swollen face’ shows the latter to still have a somewhat stronger effect. This ties in with the research of Loftus & Palmer (Reference Loftus and Palmer1974), which has shown word choice (in their case, e.g., smash vs hit) to have a relevant effect on speaker perception and memory.
Our search terms are based on the above list, as it covers a wide range of central terms in Present-day English (PDE), whose development in LModE, the period directly leading up to the present, is of special interest. Three items from this list will be excluded, however. In order to focus on the word class adverb, which is the most typical realization of intensifiers, we ignore the phrasal form in all respects. Furthermore, we omit quite and most, because both have prominent alternative uses in the degree area, as compromiser and as superlative marker, respectively.Footnote 4 Our search list thus comprises the following eleven items, where applicable both in their -ly and their zero-marked forms, as the latter were still in use in our period (cf. Nevalainen Reference Nevalainen, Rissanen, Kytö and Heikkonen1997, Reference Nevalainen2008; Nevalainen & Rissanen Reference Nevalainen, Rissanen, Tyrkkö, Timofeeva and Salenius2013):
absolutely, altogether, completely, entirely, extremely, fully, perfectly, thoroughly, totally, utterly, wholly
These maximizers can intensify adjectives, adverb(ial)s, verbs, participles, prepositional phrases and particles, but the focus in empirical work so far has been mostly on their modification of adjectives (e.g. Ito & Tagliamonte Reference Ito and Tagliamonte2003; Pahta Reference Pahta, Dossena and Taavitsainen2006a, b; Tagliamonte Reference Tagliamonte2008). Because of our item-based approach, we will be able to consider these items in all of their linguistic contexts. Of course, the target of modification needs to allow a degree reading for intensification to occur. See section 3.1 for our screening methodology.
Typical present-day maximizers like absolutely, completely, entirely, extremely, fully, perfectly and totally are comparatively infrequent with 1 to 5 per 100,000 words and sometimes (extremely, entirely) restricted to academic writing (Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan1999: 565). In Biber's (Reference Biber1988) research, amplifiers are a feature characterizing involved language production, which tends to be found in informal contexts. The (in)formality issue that is apparent here is of interest with regard to the more formal courtroom context of this study, which, however, assembles many speakers (witnesses) not overly familiar with this formal situation. It could also be of relevance, given the socially mixed nature of our historical ‘informants’, that eight of our forms are not only foreign in origin but also show this more clearly than, e.g., very, by their polysyllabicity (3–4 syllables), thus increasing their formality.
There have been only a few diachronic studies involving maximizers. Méndez-Naya (Reference Méndez-Naya2008) shows how the low-frequency degree adverb downright ‘out-and-out, absolutely’, with both booster and maximizer uses, develops from the seventeenth century onwards as a result of intertwined lexicalization and grammaticalization. Out-related intensifiers are shown by Méndez-Naya (Reference Méndez-Naya2014) to be mostly shortlived, with only utterly and outright surviving into the (late) modern period. Another maximizing form, intensifying all, is traced as far back as Old English by Buchstaller & Traugott (Reference Buchstaller and Traugott2006).Footnote 5 Apart from focusing only on one or a few forms each, two of these studies are also more qualitative than quantitative in nature. From a broader perspective, the historical competition between zero vs -ly forms (in intensifying and other uses) was the focus of Nevalainen (Reference Nevalainen, Rissanen, Kytö and Heikkonen1997, Reference Nevalainen2008), outlining a path from coexisting forms to sole surviving -ly forms, with some exceptions, such as the surviving zero forms very, pretty, etc. The zero forms were still fairly frequent in Nevalainen's seventeenth-century data and can be expected to also appear in our Old Bailey maximizer data.
Regarding sociolinguistic aspects, as there are no studies limited to maximizers only, we comment on a number of studies on intensifiers in general. It has been observed that amplifiers are used more frequently by middle-class and by educated speakers (e.g. Macaulay Reference Macaulay2002; Ito & Tagliamonte Reference Ito and Tagliamonte2003; Nevalainen Reference Nevalainen2008). In his study of amplifiers in an early version of the Old Bailey Corpus, Bernaisch (Reference Bernaisch2014) found that higher social classes used amplifiers more often than lower social classes. As for gender, intensifiers have often been associated with female usage (for early views antedating modern sociolinguistic methodology, see, e.g., Stoffel Reference Stoffel1901: 101; Jespersen Reference Jespersen1922: 249–50). Generalizable overarching results on gender-specific usage of established forms remain modest (Ito & Tagliamonte Reference Ito and Tagliamonte2003; Nevalainen Reference Nevalainen2008; Tagliamonte Reference Tagliamonte2008),Footnote 6 although Fuchs (Reference Fuchs2017) and Hessner & Gawlitzek (Reference Hessner and Gawlitzek2017), in their studies on data from the British National Corpus (BNC; 1994 and 2014 versions), point to gender being an influential factor, with women leading in the use of intensifiers, including amplifiers, in PDE (for the BNC (1994), see Hoffmann et al. Reference Hoffmann, Evert, Smith, Lee and Berglund2008, and for the Spoken BNC2014, see Love et al. Reference Love, Dembry, Hardie, Brezina and McEnery2017). This was also the result that Bernaisch (Reference Bernaisch2014) reached in his study of the Old Bailey Corpus: women used amplifiers more than men, despite some fluctuation in the degree to which they did so across the period studied. In PDE, the spread of new forms often tends to be promoted by female speakers (Tagliamonte Reference Tagliamonte2008: 288). Some differences according to age or with respect to user groups and individual types have been found (e.g. Tagliamonte Reference Tagliamonte2008). We will not be able to follow up the aspect of age with our kind of data (see section 3 below), but we will document distributions of types across speaker groups.
The present study aims at investigating the following aspects: (i) the frequency development of our whole group of maximizers and of individual items over the period 1720 to 1913; (ii) the sociolinguistics of maximizers, i.e. what role gender and social class play in the development; and (iii) the sociopragmatics of maximizers, namely in how far their use is determined by the speakers’ functional roles in the courtroom (as witnesses, defendants, judges, etc.). While the results will be most informative for the courtroom register, we believe that our results also point to the general state of intensification in LModE, given the rich representation of the various social echelons of society.
3 Data and methodology
3.1 Corpus and data screening
As mentioned above, our data come from the extended version of the Old Bailey Corpus (version 1.0), which is a 19-million-word corpus drawn from trial transcripts from London's central criminal court. The transcripts in the corpus document spoken English from 1720 through 1913 (Huber et al. Reference Huber, Nissel, Maiwald and Widlitzki2012, Reference Huber, Nissel and Puga2016).Footnote 7 They were taken down in shorthand by scribes in the courtroom and are arguably as near as we can get to the spoken language of the time (see Huber Reference Huber, Meurman-Solin and Nurmi2007 for more background). We divided the corpus into five subperiods of approximately forty years each, so as to be able to trace developments over time. The corpus is encoded for speakers’ gender, their social class (according to the historical social class scheme known as HISCLASS),Footnote 8 and their role in the courtroom (whether they were defendants, judges, lawyers, victims or witnesses).
Table 1 presents a summary of the corpus composition according to our subdivisions and socio-functional characteristics. Male voices clearly dominate, as they account for 83 percent of the words by speakers annotated for gender. Similarly, speakers from the higher classes are overrepresented in terms of word count (69%). As for speaker roles, witnesses are the main informants (68%), followed by victims (18%) and defendants (6%), whereas the professionals, lawyers (5%) and judges (3%), contributed least.Footnote 9 Note that the totals for gender, social classes and speaker roles do not add up to the corpus total, due to insufficient speaker information in a considerable number of cases. Social class information is known for 62 percent of the words in the corpus, and the figures for speaker role and gender are 87 percent and 96 percent, respectively (these figures pertain to the extended version of the OBC; for the later 2.0 version, see Huber et al. Reference Huber, Nissel and Puga2016: 7).
Table 1. Word counts of the Old Bailey Corpus, extended versionFootnote 10
We carried out the searches with the help of the OBC's concordancer, which exports keyword-in-context search results together with the meta-data into Excel. For identifying the relevant instances in the raw data, we applied a set of screening criteria. We screened all hits to remove false positives, such as suffixless forms that were adjectival (e.g. the entire family), regular lexical meanings/manner uses (e.g. perfectly ‘in a perfect manner’) and emphatic/(truth) emphasizer uses (e.g. absolutely ‘yes’). Items which allow various readings, such as intensifying or emphasizing ones, are taken as maximizer uses if accompanying gradable targets (e.g. absolutely silly with drink) or in the particular combination coercing a degree reading, e.g. agree absolutely (as opposed to absolutely died with no possible coercing).
3.2 Statistical methodology
For our sociolinguistic line of inquiry, we are taking advantage of OBC's coding of speakers’ gender, class and speaker role in the courtroom. As emerges from table 1, the word counts of the speaker groups are distributed unevenly across these focal parameters. Another complicating feature of our data is that, in the pool of speakers, the parameters are correlated; there are, for instance, systematic links between (i) speaker role and social class (judges and lawyers are by definition in the higher classes) and (ii) speaker role and gender (there are no female judges or lawyers). As a result, isolated comparisons, say, between male and female speakers, are biased by the share of variation that is in fact attributable to speaker role and social class. To deal with this complexity in our investigation, we opt for a multiple regression model that simultaneously incorporates all predictors of interest (in our case time, gender, social class and speaker role), as strongly advocated by Jenset & McGillivray (Reference Jenset and McGillivray2017). This allows us to more reliably assess the unique contribution of each predictor, holding the other ones constant. As our interest in the present investigation is to understand variation in the usage rate of maximizers, we employ a negative binomial regression model (Hilbe Reference Hilbe2011). This technique, which can be considered a more flexible version of the Poisson model, has been successfully applied to the study of word frequency distributions in the statistical literature (e.g. Mosteller & Wallace Reference Mosteller and Wallace1964). In our case, the model incorporates the speakers for whom all three socio-functional parameters (gender, class and speaker role) are known, which is approximately half of the 110,251 speakers in the corpus. However, in connection with this, we must note that the annotation scheme of the OBC does not allow us to link utterances by the same speaker across trial days. This is to say that our analysis treats the utterances by, say, the same judge on different trial days (or in different trials) as utterances from different individuals. As our regression model therefore slightly overestimates the number of speakers in the OBC data, we must consider the statistical uncertainties associated with our estimates as lower bounds of the true uncertainties in our substantive conclusions.
We apply Bayesian inference using Stan (Carpenter et al. Reference Carpenter, Gelman, Hoffman, Lee, Goodrich, Betancourt, Brubaker, Guo, Li and Riddell2017) via the brms package (Bürkner Reference Bürkner2017) in R (R Core Team 2018). The structure of the model is as follows: the response variable is the number of maximizers by a speaker on a trial day. To account for differences in total number of words by different speakers, an offset is included in the model with the log of the word count. The predictors are Gender (female, male), Class (higher, lower), Role (defendant, judge, lawyer, victim, witness) and Year (continuous), the first category for each being the reference category (i.e. female, higher, defendant). Pairwise interactions were tested but found to be insignificant and were thus removed from the final model.
As regards the technical specifications of the model estimation, the number of Markov chains are three with a burn-in period of 1,000 (and a total of 3,000) iterations. All Rhat values are equal to one, indicating convergence to equilibrium distributions. The intercept is given a N(-8, 2) prior, and the beta coefficients are given N(0, 2) priors. Further details about the analysis are deferred to section 5 and the supplementary materials.Footnote 11
Finally, in terms of socio-historical linguistics and historical pragmatics methodology, our results reflect what past spoken interaction in a courtroom was like, and we relate our findings to what research has shown for PDE intensifier usage. However, as much of the latter research has been carried out in contexts other than the courtroom, we need to factor in differences not only in diachrony but also in the speech situations. We also pay attention to findings presented in previous research on historical material.
4 Distribution of maximizers types in the OBC
After all exclusions (section 3.1), our searches yielded a total of 4,291 relevant hits (which equals 22.5 instances per 100,000 words), distributed across n = 11 lexical types (including -ly/zero). After an outline of the distribution of maximizer types in the OBC in the present section, we will discuss the findings relating to our sociopragmatic research questions in section 5. Figure 1 shows the occurrence rates for the n = 11 attested maximizers in our data; raw counts and relative frequencies (percentage among all maximizers) are given in the right margin. The most common maximizers in the OBC are, in descending order, perfectly, entirely, extremely, fully and completely. The top three maximizers are also the most common ones in the multi-genre Corpus of Nineteenth-Century English (CONCE; see Kytö & Rudanko, Reference Kytö and Rudankoin preparation), which proves them to be typical LModE maximizers. Perfectly dominates the OBC field with n = 1,872 instances (44% of all maximizer tokens), at an average of 10 per 100,000 words occurring more than twice as often as any other maximizer. A rough and ready comparison with the spoken BNC (1990s) shows modern perfectly (3 per 100,000 words) to be in the middle rank of maximizers only, with fully, entirely, extremely, totally, completely, absolutely (in rising order) being used more frequently.Footnote 12 The changing fate of perfectly (having declined) and, e.g., totally (having risen) thus bear out Peters’ (Reference Peters and Kastovsky1994: 271) statement that intensifiers are ‘subject to fashion’. The rise and fall of forms is equally seen in Tagliamonte & Roberts’ (Reference Tagliamonte and Roberts2005: 293) observations on long-standing so becoming suddenly much more popular in PDE.

Figure 1. The distribution of maximizers in the OBC extended version: occurrence rates (per 100,000 words) for the n = 11 types. Raw token frequencies and the share of the occurrences of a type among all maximizers (%) are listed in the right margin. Asterisks mark items occurring as both suffixed and zero forms.Footnote 13
The zero forms included in figure 1 are rare overall, but are quite resilient with one type, namely full, which even survives into the present.
Figure 2 shows the distribution of the n = 7 most frequent maximizers over time, which together constitute more than 90 percent of our data. Figure 2a displays the proportional use, indicating the share (percentage) of each maximizer within a given subperiod. We observe the most striking behavior for perfectly, which rises from 16 to 39 percent over the eighteenth century and then clearly takes over the system of maximizers towards the mid nineteenth century, when it accounts for about half the tokens in our data. By contrast, entirely shows a moderate decline from just above 20 to c. 15 percent, and a clear decline is notable for extremely (c. 35 to c. 5%). U-shaped trends are discernible for fully (c. 10 to 5 to 10%) and absolutely (c. 10 to 0 to c. 10%), while altogether and completely meander between 0 and 10 percent. Figure 2b shows the occurrence rate of each item within each subperiod (per 100,000 words). These rates are distorted by a pronounced peak in maximizer use in the second subperiod, from 1760 to 1799 (see section 5.1 for discussion).
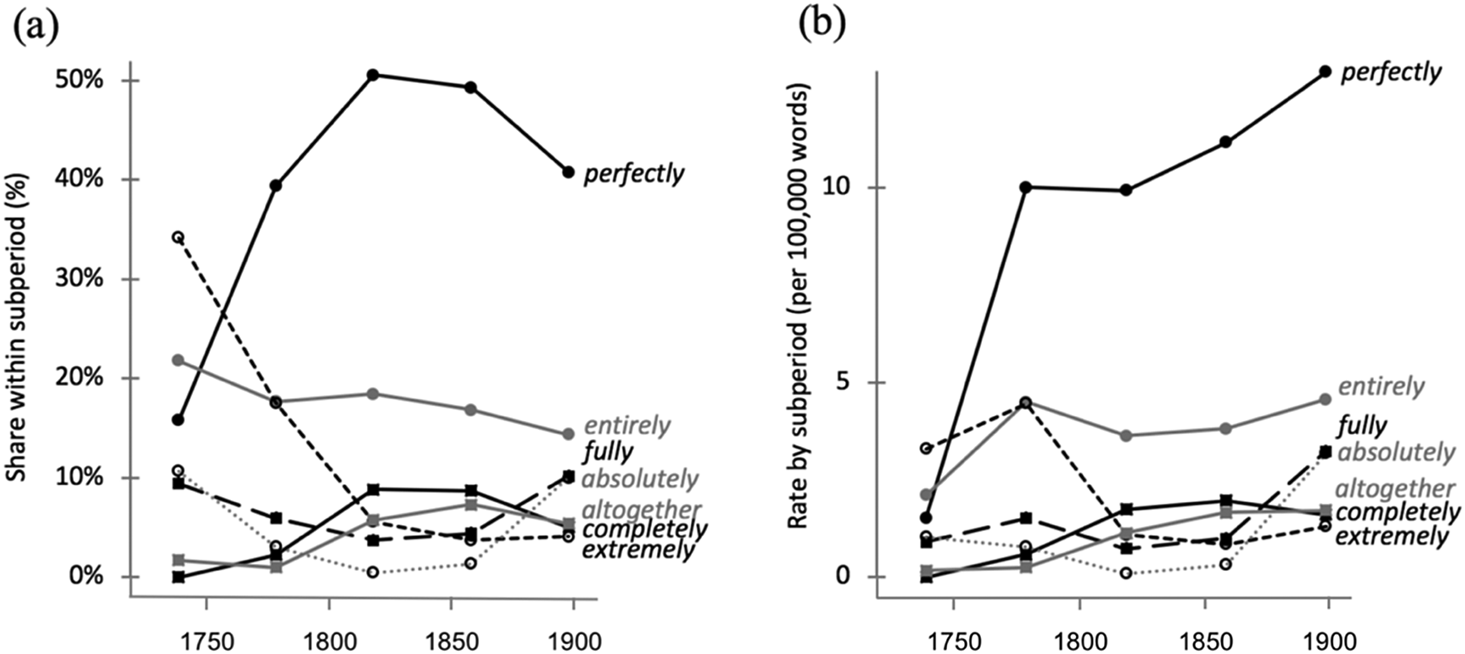
Figure 2. Distribution of the n = 7 most frequent maximizers across time periods: (a) the proportional use, showing the share (%) of each maximizer within a given subperiod; (b) the occurrence rate (per 100,000 words) of each item within a given subperiod. Time points reflect the following intervals: 1720–59, 1760–99, 1800–39, 1840–79, 1880–1913.
5 The sociolinguistics of maximizers in the OBC
5.1 Overview
As stated above, the OBC offers a sociolinguistic panopticon, which we will now explore in more detail. Recall that our primary concern is to understand how the occurrence rate of maximizers varies across time and as a function of the social characteristics of the speaker. In the ensuing subsections, we will discuss the results for each of these predictors, time, speaker role, social class, gender.Footnote 14 Figure 3 presents the unique contribution of each predictor, holding the other variables constant; the sequence of predictors in figure 3 is ordered from higher to lower significance. The quantities in the display are model-based estimated rates (per 100,000 words) for each condition, with the other predictors set to their average values. The error bars/bands reflect 50 percent and 95 percent credible intervals, which denote the statistical uncertainty in the estimates.

Figure 3. Diachronic and social patterns in the usage rate of maximizers.Footnote 15 Each pane shows for a given predictor model-based rate estimates (per 100,000 words), statistically controlling for the other predictors in the model. The latter are held at average values.Footnote 16 The error bars/bands denote 50 percent and 95 percent credible intervals. The gray estimates in the first pane illustrate the curious non-linearity across the subperiods.
5.2 Time
Looking at the left-most pane in figure 3, we can see that there is a general diachronic increase in maximizer use. On average, from the early eighteenth to the end of the nineteenth century the model-based rate triples from just above 10 to above 30 per 100,000 words. We decided to model time as a simple continuous predictor, which yields the upward trend in figure 3. It should be noted, however, that our diachronic breakdown into five subperiods (intervals) of approximately forty years each yields a different pattern. For comparison, estimates for the individual subperiods are added in gray. They are not part of the model but are offered here to make transparent the non-linearity that is suggested by our data. At present, we can offer no explanation for the curious peak during the second subperiod (1760 to 1799), an idiosyncrasy that is also noticeable in the results obtained by Bernaisch (Reference Bernaisch2014). This deviation from a linear increase will need to be investigated further, for instance, by considering possible connections to specific scribal or publishing practices in this subperiod.Footnote 17 In other words, we are skeptical as to the linguistic significance of the peak and assume that the increase over time is best captured by a simple linear trend, pending further evidence.
The individual maximizer types naturally contribute in various ways to the clear linear increase across time in figure 3, perfectly seemingly more than the other types, as might be inferred from the dominance of this maximizer in figure 2. To test whether the effect of Year, in our case the sharp linear increase across the Time pane of figure 3, is mostly due to any individual type, the types can be added as random slopes to the analysis or a separate analysis can be run that excludes the type(s) in question. As the former procedure brought along convergence issues, we proceeded to carry out a separate analysis of our full data exclusive of perfectly. The analysis produced essentially the same stable linear increase across time, again a tripling of the estimated rate across the total period studied, thus ruling out any skewing effect of this maximizer in figure 3.
5.3 Speaker role
The second pane in figure 3 shows that the rate of maximizers varies systematically with speaker role. We can see here a proportionally greater use by judges, lawyers and defendants. Judges and lawyers are professionals with key roles in the courtroom, either presiding over the case, or driving the prosecution or attending to their clients’ needs. At the same time, much is at stake for defendants, who stand at trial accused of crimes or other misdemeanors and strive to be acquitted. Thus, on average, the model-based usage rate for defendants (25 per 100,000 words) exceeds that of witnesses (13 per 100,000 words) by a factor of about 1.9. Judges and lawyers cover the middle ground. Focusing on the courtroom uses, one finds typical contexts for judges and lawyers to be first of all questions, as in (2)–(7); we have no access to the percentage that questions make up in the speech volume across the speaker groups, but we comment on the examples to illustrate the potential that questions provide for the frequent use of maximizers.
(2) Had you completely finished loading? (t18620303-304, lawyer)
(3) Was daylight entirely gone? (t17870110-38, judge)
(4) Does that membrane cover the passage completely? (t17771015-1, judge)
(5) Were these sashes glazed? – Yes. – Fully glazed so as to keep out the weather? – Yes; the man is here that bought the glass. (t17790519-3, lawyer)
(6) Do you mean to swear you were perfectly sober? (t18021027-26, judge)
(7) How came you to be so extremely correct to take notes on one side, and not the other? (t17551022-31, lawyer)
Examples (2)–(7) mark a desire for precision in establishing the circumstances of a crime and the evidence, which is especially clear in (5), where the lawyer first asks an unintensified question and follows it up by an intensified and more precise one. Examples (6)–(7) have on top of that a more insistent, even challenging nature. Example (6) tries to nail down the addressee to a definite statement, after drinking had already been the topic earlier. Example (7) may be taken to imply a criticism of the addressee, as to possible intentional misconduct. While the question context is very prominent for lawyers, another such maximizer-inducing context for judges and lawyers is provided by intensified declaratives as in (8). These occur in interchanges between courtroom participants, such as between lawyers (8), between judge and jury (9), or between judge and lawyer (10), with the maximizer strengthening the force of the speech act as well as the commitment of the speaker.
(8) I entirely concur with my learned friend. (t17900417-1, lawyer)
(9) I must tell the Jury to put the letter intirely out of the question. (t18000219-72, judge)
(10) You may make any observations you think proper, in arrest of judgment, but I think the justice of the country would be totally defeated if such an objection was to be admitted. (t17981205-25, judge)
(11) You have both been convicted upon evidence which appears to me, as it has done to a very cautious and attentive Jury, perfectly satisfactory, each of you of felony, but unquestionably your degree of guilt is extremely different (t17860719-64, judge)
(12) I apprehended they must prove a knowledge in these persons as connected with the conspiracy stated upon the record, or else your Lordship sees the extent to which it will go; for, unless some knowledge is proved in the defendants upon this record, they might as well extend it to what passed at York, or any other part of the kingdom; and I am sure your Lordship would tell me directly, unless these defendants could be proved to have a perfect knowledge of what these men were about, it is utterly impossible to give that evidence which is contended for on the part of the prosecution (t17980704-61, lawyer)
Examples (11)–(12) are part of longer monologues. At the beginning of his final statement in (11) the judge first stresses the validity of the conviction as such (booster very, maximizer perfectly), but then goes on to clearly differentiate between the two defendants, in the further course spelling out the nature of extremely different and the correspondingly differing punishments. In the lawyer's argument (12), which follows an objection he had raised but which was ultimately rejected, the maximizer also works within the argumentative process, here trying to predicate a (hypothetical) specific and strong conviction of the judge. Thus, precision, argumentation and confrontation may be taken to be the major contexts of intensification with legal professionals.
It is less easy to generalize across lay speakers’ use, partly because they contribute a much greater share of data and partly because the three groups have diverging interests and needs.Footnote 18 A full-scale collocational analysis (which will be conducted at a later stage in the project) may show which parts of the crime and its context are especially prone to intensification. A more cursory investigation already yields one prominent observation: intensified statements referring to states of awareness, knowing, truth and certainty are fairly common with witnesses, visible in collocations like those in (13)–(19).
(13) I am acquainted with the hand-writing of Mr. Wilmot extremely well (t17551204-20)
(14) I saw his face very plain, and therefore am absolutely positive to M'Donald (t17750426-21)
(15) I fully recognise the prisoner (t18820626-679)
(16) He was apprehended so shortly after, that I perfectly recollect the time. (t17970712-56)
(17) I am perfectly certain he is the man. (t18720708-535)
(18) I did not hear the deceased state that I had done so, but I heard the statement read out and he assented to it in my presence, it is entirely a falsehood (t18741123-31)
(19) it is an infamous accusation and utterly devoid of truth. (t18901215-91)
In (13)–(19), the speakers use the maximizers to emphasize the reliability of their knowledge and thus of their statements in court. Emphatic denials, as in (18)–(19), highlight both the involvement and the commitment of the speakers.
5.4 Gender
We find in figure 3 that male speakers show higher model-based usage rates of maximizers than female speakers (c. 22 vs 15 per 100,000 words, a factor of 1.43). This is in contrast to previous research, which has found either no generalizable gender difference or a higher use by female speakers regarding amplifiers on the whole (see section 2). Interpolating from results obtained for PDE usage, there is some indication that our courtroom context might be responsible for this result. Yaguchi et al. (Reference Yaguchi, Iyeiri and Baba2010) have found that women use fewer intensifiers than men in more formal in contrast to less formal settings (such as White House Press briefings/Faculty Meetings versus exploratory committee meetings). Similarly in our period, the formal and content-driven nature of the courtroom may have inhibited women. Men's higher frequency is also reached by the usage of a greater variety of types in some subperiods. While the only maximizer used exclusively by women in any subperiod is totally (1 occ. in the first subperiod), the items used exclusively by men in any subperiod are wholly (first, third and fifth subperiod), altogether (second), thoroughly (third), absolutely (fourth) and utterly (in the fifth subperiod).
Regarding types, Nevalainen (Reference Nevalainen2008) and Tagliamonte (Reference Tagliamonte2008) have also pointed to possible gender-related (dis)preferences. To follow this lead, table 2 lists, for male and female speakers, the top six maximizers in each time subperiod.
Table 2. Top six maximizers per subperiod in rank order by gender, with frequencies per 100,000 words (raw frequencies in parentheses)

In terms of the ranking order of the top six maximizer types displayed in table 2, women and men use the same top six maximizers in the first, third and fourth subperiods and the same top four maximizers in the second subperiod, but they use them to varying degrees. Table 2 further shows that from the second subperiod onwards women and men agree in their top maximizer, perfectly, and from the third subperiod onwards in their top two, perfectly and entirely. Men lead the development with respect to both of these items, as the normalized figures for perfectly (female/male usage per 100,000 words across the subperiods: 1.7/1.6, 5.1/11.0, 8.4/10.3, 9.3/11.6, 10.7/13.4) and for entirely (the corresponding figures: 1.2/2.4, 3.9/4.6, 2.1/4.0, 1.9/4.2, 2.9/4.8) show. This result concurs with that presented in Bernaisch (Reference Bernaisch2014), who also found that men adopted perfectly earlier than women and used perfectly more often than women.
5.5 Social class
The last pane in figure 3 (section 5.1) shows the estimated average rates for higher and lower social classes. The data suggest that speakers of higher ranks resort to maximization more frequently (at a model-based usage rate of about 22 per 100,000 words) compared to lower-class speakers (16 per 10,000 words). The rates differ by a factor of 1.4. This social-class finding is in line with previous research (see Bernaisch Reference Bernaisch2014 on amplifiers overall): according to Macaulay (Reference Macaulay2002) and Ito & Tagliamonte (Reference Ito and Tagliamonte2003), middle-class and educated speakers use more intensifiers than the lower classes in PDE.
Higher-class usage is partly represented by the speech of lawyers and judges already illustrated in examples (2)–(12) above. Among higher-class lay speakers one finds the interesting cases of professional or ‘expert’ witnesses, such as a police officer in (20a) or a medical doctor in (20b). Their assertiveness, expressed among other things by intensifiers, will arise both from their knowledgeableness and their greater ease with the formal courtroom situation. Non-expert witnesses, like the one innocently involved in a fraud case in (21), use maximizers to upgrade their own assessments of the crime situation, here specifically the fact that they could not possibly have known at the time and prevented the crime. It would be of interest to compare the intensifying behavior of expert versus non-expert lay speakers in the courtroom in a further study.
(20)
(a) Her face was absolutely battered beyond recognition, and she could hardly talk. (t19090518-25, witness, m, higher)
(b) the scars of the wounds were remaining on her neck, they were not completely healed, a process of healing was taking place called scabbing (t18750201-190, witness, m, higher)
(21) he gave so minute a description of every person on board and of every circumstance, (…) I gave him a certificate, being fully persuaded he was Peter Berry, and the East India Company give a sum of money to seamen, who have been captured in the East Indies (t17911026-51, witness, m, higher)
(22) I am extremely sorry for what I have done — it was through distress. (t18210912-47, defendant, m, higher)
Higher-class defendants as in (22) are apparently rare. Here we see a defendant speech context commonly intensified, namely their final statement in court, emphasizing either their innocence or their regret.
5.6 Summary
To summarize, our analysis of diachronic and sociolinguistic trends in the usage rate of maximizers suggests the following rank-order in terms of predictor importance: (i) time emerges as the primary factor, with the usage rate in 1913 exceeding that in 1720 by a factor of 3.1; (ii) speaker role also shows a notable association with maximizer frequency, with defendants and witnesses differing by a factor of 1.9. The rate ratios for (iii) male vs female speakers (1.43) and (iv) higher vs lower classes (1.4) are somewhat lower.
6 Concluding discussion
The courtroom speakers in the Old Bailey made use of the whole range of maximizers given as typical forms in modern grammars (apart from the exclusions explained above). The frequencies in particular of the prominent types indicate them to be representative of core and mainstream usage in the eighteenth and nineteenth centuries. Perfectly, and to a lesser extent entirely, stand out as the most period-typical items. On the whole, the use of maximizers shows a rising trend. As the public, formal and fact-oriented context may indeed have inhibited any greater use, we assume that the increase in casual and/or involved speech may have been even more pronounced, but this would need to be tested with a more diverse database.
Our courtroom speakers on the whole evince a similar behavior. The various groups all show rising frequencies, and they converge increasingly in their formal preferences. Nevertheless, some differences do remain. Male speakers use more maximizers, which stands in contrast to research usually finding a female lead in the use of intensifiers overall. We suggest that this could be due to the influence of the formal and potentially sobering effect of the courtroom, but it could also be due to a greater proportion of the male speakers belonging to the well-educated group and to middle/higher status ranks, both of which have been shown to intensify more. Of course, such men might also have been less intimidated in court and thus less linguistically inhibited, while female and lower-class speakers (with considerable overlap between those two groups) might have reacted to the context by performing more linguistic accommodation. The already-noted social facts could explain the higher intensification incidence of judges and lawyers, but an equally important role could be played by their sense of ease in the environment and their strategic exploitation of intensifiers. Defendants also display a higher usage than witnesses or victims, however, which points to the fact that those with a higher and permanent involvement in the proceedings intensify more.






 Open access
Open access