



1. Introduction
1.1. Metaphor and perception
Metaphor is one of the prominent figurative devices in our cognitive system. Research on metaphor and theory of metaphor have advanced our understanding of the conceptual systems underpinning human language and advanced findings in the fields of lexical semantics, cognitive linguistics and computational linguistics. Lakoff and Johnson (Reference Lakoff and Johnson1980) describe metaphor as a cognitive mechanism (a property of language) reflected by our conceptual system for structuring our understanding of the world. Using metaphors, we can relate our known experiences to a multitude of other subjects and contexts that are more complex, implicit or less known. In general, metaphor is widely used in a language for effective communication, which usually involves a domain transfer (Ahrens and Jiang Reference Ahrens and Jiang2020), concreteness contrast (Maudslay et al. Reference Maudslay, Pimentel, Cotterell and Teufel2020), or semantic surprise (Zhang and Barnden Reference Zhang and Barnden2013). The common theoretical premise is that this degree of complexity is driven by the concept of embodiment (Gibbs et al. Reference Gibbs, Lima and Francozo2004), which involves a mapping from a more embodied and concrete domain to a less embodied one. That is, metaphors use our shared bodily experience to describe more abstract concepts. For instance, the metaphorical expression ‘apple of my eye’ uses the concrete and embodied apple to describe more abstract concept of ‘something to be cherished’. Other than having a solid body, embodiment is also often described by the perception of our body, and the degree of bodily involvement of the particular perception. For instance, tactile sense requires actual contact with the body and is considered the most concrete sensory domain. Based on this interpretation, metaphorical expressions are highly reliant on bodily experiences, especially perception.
1.2. Metaphor detection
Metaphor detection can refer generally to the identification of metaphorical expressions, or more specifically to the identification of the source domain, target domain, and mapping principles of each metaphorical expression. Past studies on metaphor detection can be broadly classified as theory-oriented or processing-oriented. For the identification of metaphor, the best-known framework is the metaphor identification procedure (MIP) by the Pragglejaz Group (Pragglejaz Group 2007), which focuses on how to differentiate the metaphorical usages of a linguistic expression from other usages, including literal, ironic, metonymic, etc. Earlier theoretical works typically assume that metaphorical expressions are already identified with consensus. This accounts for why a set of criteria for identifying metaphor, that is the MIP (Steen Reference Steen2010), was proposed only recently despite the long history of metaphor analysis in the literature. Several NLP studies on the identification of metaphorical expressions predates the MIP [e.g., Martin (Reference Martin1990); Fass (Reference Fass1991)]. Fass (Reference Fass1991), for instance, focused on differentiating metaphoric expressions from metonymic expressions, a topic that remains challenging both theoretically and computationally. On the other hand, since the emergence of the Conceptual Metaphor Theory (CMT, Lakoff and Johnson Reference Lakoff and Johnson1980), there has been continuous attention in theoretical studies on the identification of mappings between target and source domains [e.g., Gentner (Reference Gentner1988); Gibbs (Reference Gibbs1996); Kovecses (Reference Kovecses2000)]. Computational work on the identification of mapping and interpretation soon followed [e.g., Ahrens et al. (Reference Ahrens, Chung and Huang2003); Veale (Reference Veale2003); Mason (Reference Mason2004)].
More recently, the processing of metaphoric expression has become one of the most important challenges in the processing of non-literal, figurative language (Veale, Shutova, and Klebanov Reference Veale, Shutova and Klebanov2016). Metaphor detection can be formalized in several ways, for example sequence-to-sequence labeling (Gao et al. Reference Gao, Choi, Choi and Zettlemoyer2018; Chen et al. Reference Chen, Hai, Wang, Li, Wang and Luan2021; Raval et al. Reference Raval, Sedghamiz, Santus, Alhanai, Ghassemi and Chersoni2021), IOB (inside-outside-beginning) tagging or sequence chunking (Bizzoni and Ghanimifard Reference Bizzoni and Ghanimifard2018; Tanasescu et al. Reference Tanasescu, Kesarwani and Inkpen2018; Rohanian et al. Reference Rohanian, Rei, Taslimipoor and Ha2020), as a paraphrasing task (Shutova Reference Shutova2010), and token-level binary classification (Leong, Klebanov, and Shutova Reference Leong, Klebanov and Shutova2018; Leong et al. Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020; Su et al. Reference Su, Fukumoto, Huang, Li, Wang and Chen2020), and so on. For replicability and evaluation, the current study adopts the model of two shared tasks on metaphor detection focusing on token-level binary classification. Take Example 1 for illustration. Given a sentence
 $S = w_1, \ldots, w_n$
with n words and a target word
$S = w_1, \ldots, w_n$
with n words and a target word
 $w_t \in S$
, the classification task predicts the metaphoricity (i.e., metaphorical or literal) of the target word
$w_t \in S$
, the classification task predicts the metaphoricity (i.e., metaphorical or literal) of the target word
 $w_t$
. We aim at developing a metaphor detection model for a binary classification task.
$w_t$
. We aim at developing a metaphor detection model for a binary classification task.
Example 1.
 \begin{align*}\begin{array}{l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l} \textrm{The} & \textrm{Ahlbergs} & \textrm{have} & \textrm{been} & \textrm{accused} & \textrm{of} & \textrm{not} & \textrm{facing} & \textrm{up} & \textrm{to} & \textrm{the} & \textrm{harsh}\\w_1 & w_2 & w_3 & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots\\\textrm{realities} & \textrm{of} & \textrm{life} &, & \textrm{of} & \textrm{being} & \textrm{too} & \textrm{cozy} & \textrm{and} & \textbf{sweet} &, \\\ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & w_t & w_n\end{array}\end{align*}
\begin{align*}\begin{array}{l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l@{\quad}l} \textrm{The} & \textrm{Ahlbergs} & \textrm{have} & \textrm{been} & \textrm{accused} & \textrm{of} & \textrm{not} & \textrm{facing} & \textrm{up} & \textrm{to} & \textrm{the} & \textrm{harsh}\\w_1 & w_2 & w_3 & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots\\\textrm{realities} & \textrm{of} & \textrm{life} &, & \textrm{of} & \textrm{being} & \textrm{too} & \textrm{cozy} & \textrm{and} & \textbf{sweet} &, \\\ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & \ldots & w_t & w_n\end{array}\end{align*}
The model returns a binary output, that is 1 if the target word
 $w_t$
(‘sweet’ in Example 1 in S) is metaphorical or 0 otherwise. Here the target word ‘sweet’ is marked as a metaphorical use following the metaphor identification procedure (MIP) (Steen Reference Steen2010). The word ‘sweet’ in its context demonstrates a meaning of pleasant experience which is part of the property of sweetness yet not denoting the gustatory meaning, where a modality shift is observed. Evaluation of the performance of the model is then calculated by the widely adopted metrics of Precision, Recall and F1-score based on the predictions of the model by reference to the gold labels in the entire dataset.
$w_t$
(‘sweet’ in Example 1 in S) is metaphorical or 0 otherwise. Here the target word ‘sweet’ is marked as a metaphorical use following the metaphor identification procedure (MIP) (Steen Reference Steen2010). The word ‘sweet’ in its context demonstrates a meaning of pleasant experience which is part of the property of sweetness yet not denoting the gustatory meaning, where a modality shift is observed. Evaluation of the performance of the model is then calculated by the widely adopted metrics of Precision, Recall and F1-score based on the predictions of the model by reference to the gold labels in the entire dataset.
1.3. The linguistic motivation
Metaphor is an important device for the linguistic representation of embodied cognition [e.g., Gibbs (Reference Gibbs2006); Lakoff (Reference Lakoff2012)]. Since the sensory inputs are the main sources of information of the embodied world, sensory information plays an essential role in the conceptualizing and mapping of metaphor. That is, the sense modalities (touch, hearing, smell, taste, vision, and interoception) as perceptual domains in our cognitive system can either serve as the source domain of metaphors (Yu Reference Yu2003; Zhao Reference Zhao2018) or provide crucial information about the source domains. In addition to the perceptual manifestations, the action effectors (mouth/throat, hand/arm, foot/leg, head, and torso), serve as another fundamental way to reflect human experience and their cognition in language. The actions denoted in word concepts can affect people’s way of using metaphors, a notion noted as an embodied metaphor (Gibbs et al. Reference Gibbs, Lima and Francozo2004; Casasanto and Gijssels Reference Casasanto and Gijssels2015), as exemplified in “
 $\text{head}_{{high-embodied}}$
of [Pembridge Investments]
$\text{head}_{{high-embodied}}$
of [Pembridge Investments]
 ${}_{{low-embodied}}$
”. The word ‘head’ serves as the effector or the location of effectors of all the sensory modalities and is highly embodied, while its modified phrase ‘Pembridge Investments’ demonstrates no obvious sense modality or action effector. The sense modalities and their action effectors provide information about the physical world; their lexical realizations are the sources of linguistic devices utilized in figurative language. These assumptions motivate the current work to explore their interactions and hence contribute to metaphor detection.Footnote
a
${}_{{low-embodied}}$
”. The word ‘head’ serves as the effector or the location of effectors of all the sensory modalities and is highly embodied, while its modified phrase ‘Pembridge Investments’ demonstrates no obvious sense modality or action effector. The sense modalities and their action effectors provide information about the physical world; their lexical realizations are the sources of linguistic devices utilized in figurative language. These assumptions motivate the current work to explore their interactions and hence contribute to metaphor detection.Footnote
a
1.4. Research design and objectives
We propose to incorporate the perceptual-actional information associated with words, as provided by the sensorimotor norms (Lynott et al. Reference Lynott, Connell, Brysbaert, Brand and Carney2019) (cf. detailed introduction in Section 3), for metaphor detection. Such information, as discussed above, links each lexical concept to the physical world, and in turn plays a central role in the interpretation and modeling of metaphor. As the sensorimotor norms represent knowledge of embodied cognition, the theoretical premise of the current study is that the incorporation of direct information about the embodied physical world facilitates metaphor detection.
To utilize the ubiquitous dual-mapping anchored from the perceptual and actional experiences, we propose a series of sensorimotor-enriched machine learning models for metaphor detection based on two publicly available benchmark datasets–the VUA corpus (Steen Reference Steen2010) and the TOEFL corpus (Klebanov, Leong, and Flor Reference Klebanov, Leong and Flor2018) (cf. Section 3). A series of machine learning models are adopted to attest to the generic power of the sensorimotor-enhanced models for metaphor detection, including statistical Machine Learning models, word embeddings, and Deep Learning models. We use the sensorimotor norms for constructing a conceptual representation of the target word and its surrounding words, combining advanced NLP technologies in representing the semantic and conceptual information of words.
The sensorimotor feature of the word “reduced” in the VUA corpus is presented in a JSON line in Example 2, where x stores the values of the sensorimotor predictors, with a feature dictionary of 64 attribute values. As the sensorimotor norms for each word constitute 64 dimensions of features, the customized sensorimotor representation for each word in the datasets hence contains a 64-dimension vector of perception-action ratings [cf. the original data in Lynott et al. (Reference Lynott, Connell, Brysbaert, Brand and Carney2019)]. Such information is used for concatenation with word embeddings for knowledge enhancement. In addition to providing a cognitively and linguistically motivated model of word representations (cf. Sections 3.1 and 4.2), we will also test the extent of how such information may enhance performance for automatic metaphor detection (cf. Section 5).
Example 2.

2. Related work
Figurative, or non-literal, language has been one of the most challenging and theoretically interesting topics in NLP for the past two decades. Computational approaches to the study of metaphor can be traced back to as early as J. Martin’s 1988 thesis (Martin Reference Martin1990), and Fass (Reference Fass1991). The 2003 ACL Workshop on the Lexicon and Figurative Language marked the start of the recent surge of NLP studies of metaphor detection with two papers dedicated to this topic: Ahrens et al. (Reference Ahrens, Chung and Huang2003), and Veale (Reference Veale2003). Later, Veale et al. (Reference Veale, Shutova and Klebanov2016) presented a comprehensive survey of NLP studies up to the time of publication.
In general, NLP studies of metaphor detection can be categorized into three approaches, based on the primary sources of information utilized in the detection process. Note that since NLP studies often incorporate information from multiple sources, these approaches are not mutually exclusive. The papers reviewed below are classified by the core elements of their research designs, especially in terms of their innovation and contribution.
First, the linguistic information-based approach was introduced the earliest, including Wilks et al. (Reference Wilks, Dalton, Allen and Galescu2013) and the above mentioned (Martin Reference Martin1990; Fass Reference Fass1991; Ahrens et al. Reference Ahrens, Chung and Huang2003; Veale Reference Veale2003). This approach typically relies on lexical or contextual linguistic information to identify a metaphorical usage. Ahrens et al. (Reference Ahrens, Chung and Huang2003) stand out in adopting an ontology-based mapping theory of metaphor, hence integrated the meta-linguistic ontological information. This approach is later elaborated with additional grammatical features: such as semantic classes (Klebanov et al. Reference Klebanov, Leong, Heilman and Flor2015), and constructions and frames (Hong Reference Hong2016). More recent studies adopting this approach tend to also involve statistic models for the actual processing but continue to incorporate significant linguistically encoded information such as bigrams (Bizzoni and Ghanimifard Reference Bizzoni and Ghanimifard2018), and emotion (Dankers et al. Reference Dankers, Rei, Lewis and Shutova2019). Lastly, we also consider studies that leverage a linguistic task that presupposes shared linguistic information as an innovative extension of this approach. Shutova (Reference Shutova2010)’s work leveraging paraphrasing is a good example.
The second is the machine learning based approach that, unlike the linguistic approach, does not rely on explicitly represented information. That is, various learning algorithms, especially the recently dominant Deep Learning methods, are applied to ‘learn’ to identify metaphors from a large training data sets. This approach typically requires pre-trained data sets, likely derived from earlier studies, but requires no external knowledge. Standard technologies adopted include statistical machine learning, deep neural networks, transformer-based pre-trained models, etc. Typical statistical models include Naive Bayes, Support Vector Machine and Decision Trees. Deep neural networks use many layers of nodes to derive high-level functions from input information, such as CNN, RNN and LSTM. A transformer model (such as BERT) is also a neural network that can learn context and, thus, meaning by tracking relationships in sequential data (i.e., words in a sentence) by applying an evolving set of mathematical techniques, called attention or self-attention. Transformers are among the newest, and one of the most powerful classes, of models invented to date. More details are given below, with the caveat that machine learning is used in almost all current NLP studies.
Lastly, a cognition-language incorporation approach has emerged recently. Broadly motivated by the theory of embodied cognition, the approach typically integrates behavioral or neuro-cognitive data, such as visual information (Shutova, Kiela, and Maillard Reference Shutova, Kiela and Maillard2016). More specifically, this approach often leverages lexically linked perceptual or behavioural information such as sensorimotor knowledge (Barsalou Reference Barsalou1999; Wilson Reference Wilson2002). The sensorimotor norms data was originally collected based on behavioral experiments thus typically smaller in scale; they can be replicated and scaled up using automatic norms prediction models [e.g., Chersoni et al. (Reference Chersoni, Xiang and Huang2020)]. The scaling up, and cross-lingual bootstrapping makes this dataset suitable as part of the training data for deep learning approaches. The motivation to incorporate sensorimotor norms, similar to Shutova et al. (Reference Shutova, Kiela and Maillard2016)’s extraction of visual information from text, is to model the contribution of perceptual input to interpretation. More specifically, note that current theories of metaphor generally agree that metaphors involve mapping from more embodied concepts to less embodied concepts. Hence the perceptual input of embodied information would contribute to the identification of the embodied possible sources. Recently, Kennington (Reference Kennington2021) enriched language models with the Lancaster norms and image vectors. These current approaches tend to incorporate some aspects of the earlier two approaches. A detailed review on these works is summarized below.
2.1. Linguistic information based approach
First NLP studies on metaphor detection adopted linguistic theories guidelines for identifying and categorizing metaphors [e.g., Ahrens et al. (Reference Ahrens, Chung and Huang2003); Mao, Lin, and Guerin (Reference Mao, Lin and Guerin2019); Shutova (Reference Shutova2010); Veale (Reference Veale2003)]. Earlier works [e.g., Martin (Reference Martin1990); Fass (Reference Fass1991); Ahrens et al. (Reference Ahrens, Chung and Huang2003); Veale (Reference Veale2003)] applied linguistic information directly as rule-based heuristics. Per recent trends in NLP, later studies leverage linguistic information for the preparation of training data. Such studies can be considered as the pivots between the linguistic information-based approach and the machine learning based approach. Two sets of linguistically informed guidelines are mostly commonly adopted for labeling metaphorical expressions. The first one is the Metaphor Identification Procedure (MIP), proposed by the Pragglejaz Group (2007), based on the principle that a metaphor can be recognized based on semantic gaps, that is when the contextual meaning of a word is different from its literal meaning. Another guideline is the Selectional Preference Violation (SPV) principle proposed by Wilks (Reference Wilks1975), which identifies a metaphoric expression as a target word with a meaning that violates the selectional restrictions of its neighboring words (Wilks et al. Reference Wilks, Dalton, Allen and Galescu2013). For example, in “Don’t twist my words”, the word ‘twist’ denotes an abstract meaning of misunderstanding someone given the context of “my words”, which is different from the basic lexical sense of bending and distorting a physical body. In addition, ‘word’ is a non-physical object, but the basic sense of ‘to twist’ requires a physical object, hence there is a violation of selectional restriction. These above are how MIP and SPV identify metaphorical expressions respectively. In principle, the two well-known procedures identify metaphors by judging the semantic gap/or violation of the target word with its context. A natural extension is the combination of both sets of principles: MIP and SPV (Zhang and Liu Reference Zhang and Liu2022).
Although both MIP and SPV acknowledge the mismatched meanings between the verb ‘to twist’ and the noun ‘words’, they are unable to pinpoint the metaphoric expression. For MIP, the meaning of ‘words’ in this context refers to something the subject expressed (by speaking or writing) that is different from its basic meaning of lexical/linguistic units in a dictionary. For SPV, it is clear that the collocation of the two expressions violates selectional restrictions. But there is no objective way to determine the directionality of violation. As such, both methods require substantial human intervention, which is more vulnerable to inter-rater disagreement. Thus, NLP studies rarely rely on linguistic theory based methods only.Footnote b
2.2. Machine learning based approach
Recent studies of metaphor detection, just like other NLP tasks, converged on the machine learning methods. These models are neural networks trained on the training data set to learn to identify metaphorical usages. Some popular deep learning models used for metaphor detection include Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTM) networks, and Transformer-based models like BERT (Devereux, Shutova, and Huang Reference Devereux, Shutova and Huang2018) and RoBERTa (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019).
A representative work by Wu et al. (Reference Wu, Wu, Chen, Wu, Yuan and Huang2018) adopted both Bi-LSTM and CNN for metaphor detection. Feature-wise, Wu et al. (Reference Wu, Wu, Chen, Wu, Yuan and Huang2018) employed Word2Vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013) as basic features and test different linguistic features such as part-of-speech (POS) and word clustering information. More relevant works include Gao et al. (Reference Gao, Choi, Choi and Zettlemoyer2018) who employed Bi-LSTM as an encoder using GloVe (Pennington, Socher, and Manning Reference Pennington, Socher and Manning2014) and ELMo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018) as text input representation; Brooks and Youssef (Reference Brooks and Youssef2020) built up an ensemble model of RNNs together with attention-based Bi-LSTMs for metaphor detection. Chen et al. (Reference Chen, Leong, Flor and Klebanov2020) adopted BERT to obtain sentence embeddings, and then applied a linear layer with softmax to each token for metaphoricity predictions. DeepMet (Su et al. Reference Su, Fukumoto, Huang, Li, Wang and Chen2020) utilized RoBERTa with various linguistic features. IlliniMet (Gong et al. Reference Gong, Gupta, Jain and Bhat2020) combined RoBERTa to obtain word embeddings in concatenation with linguistic features (e.g., WordNet, VerbNet, POS, topicality, concreteness), and then fed them into a fully-connected feedforward network to make predictions. MelBert (Choi et al. Reference Choi, Lee, Choi, Park, Lee, Lee and Lee2021) proposed metaphor-aware late interaction over BERT, combining pre-trained contextualized models with metaphor identification theories. With strong representation power and generalization capability, such methods show leading performances in almost all fields of work in NLP.
In sum, supervised (or semi-supervised) machine learning has been proven useful for metaphor detection. Typically, metaphorical words or expressions are manually annotated by human experts, which are then used as knowledge-incorporated external resources for many metaphor detection tasks (Leong et al. Reference Leong, Klebanov and Shutova2018, Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020). In addition to the annotated training set, recent deep learning studies using BERT or other large neural language models require substantial computational resources for pre-training and fine-tuning. In several recent studies, people aim to adopt alternative techniques to compress BERT-based models for more reasonable production environments using methods such as weight pruning, matrix factorization, and knowledge distillation (Zafrir et al. Reference Zafrir, Boudoukh, Izsak and Wasserblat2019; Rogers, Kovaleva, and Rumshisky Reference Rogers, Kovaleva and Rumshisky2020; Zafrir et al. Reference Zafrir, Larey, Boudoukh, Shen and Wasserblat2021).
2.3. Cognition-language incorporation approach
Metaphors, as described in the introductory section, are a cognitive mechanism to express new and novel experiences or knowledge using old and familiar experiences. As a linguistic device, its most prominent feature is the lack of any overt linguistic marking. This is why the linguistic knowledge based and machine learning based approaches, at least in the early data preparation stage, require human expertise to manually annotate the training data. Given the cost of human intervention in annotation for both linguistic and machine learning based approaches, there are some recent attempts to incorporate cognitive knowledge in metaphor identification. One of the first cognition-language incorporation resources applied was the shared conceptual knowledge of ontology, and SUMO ontology in particular (Ahrens et al. Reference Ahrens, Chung and Huang2003; Huang et al. Reference Huang, Prévot, Su and Hong2007; Dunn Reference Dunn2014). The rationale is that since ontologies are shared conceptual knowledge, they are a potentially powerful tool to represent the differences between and map from source domain to the target domain. Following the same rationale, and based on the common belief that wordnets are linguistic ontologies, WordNet, FrameNet, and VerbNet were also adopted (Zhang and Barnden Reference Zhang and Barnden2013; Jang et al. Reference Jang, Moon, Jo and Rosé2015; Klebanov, Leong, and Gutierrez Reference Klebanov, Leong and Gutierrez2016).
Another characteristic of metaphor that different theories generally agree upon is the embodied cognition hypothesis: that a metaphor is the use of a more embodied (i.e., concrete) concept to describe a less embodied (i.e., abstract) concept [e.g., Gibbs et al. (Reference Gibbs, Lima and Francozo2004); Lakoff (Reference Lakoff2012)]. Since embodied concepts are attested by sensory inputs (Barsalou Reference Barsalou1999), NLP studies explored the incorporation of sensory input-related resources, such as sensory lexicon, synaesthesia, and vision-based information (Shutova et al. Reference Shutova, Kiela and Maillard2016; Tekiroğlu, Özbal, and Strapparava Reference Tekiroğlu, Özbal and Strapparava2015), property norms (Zayed, McCrae, and Buitelaar Reference Zayed, McCrae and Buitelaar2018), information about concreteness, imageability (Maudslay et al. Reference Maudslay, Pimentel, Cotterell and Teufel2020), or emotion (Rai et al. Reference Rai, Chakraverty, Tayal, Sharma and Garg2019), etc.
An emergent trend that is highly interdisciplinary is to leverage neuro-cognitive research outcomes in NLP. Although no metaphor processing study has adopted this new paradigm yet, this new trend may well be the next direction to go. The crucial breakthrough is the direct adaptation of behavioral or brain activity data, instead of the lexical information from the sensory domain as reported earlier. The main goal is to synergize neurocognitive and computational approaches for significant breakthroughs. Two recently founded/revamped workshop series spear-headed this new development: Linguistic and Neuro-Cognitive Resources (Devereux et al. Reference Devereux, Shutova and Huang2018), and cognitive ordering and computational linguistics (Chen et al. Reference Chen, Hai, Wang, Li, Wang and Luan2021). The eye-tracking dataset is the earliest adopted data set to NLP, such as Long et al. (Reference Long, Xiang, Lu, Huang and Li2019) and Barrett and Hollenstein (Reference Barrett and Hollenstein2020), Baroni and Lenci (Reference Baroni and Lenci2010). There was even a shared task on using NLP to predict eye-tracking results (Hollenstein et al. Reference Hollenstein, Chersoni, Jacobs, Oseki, Prévot and Santus2021). In addition, there are several attempts in CL to incorporate brain measurement data, such as fMRI and EEG, for modeling word embedding results (Chen et al. Reference Chen, Hai, Wang, Li, Wang and Luan2021). Continuing in this direction, our current study proposes to utilize sensory domain behavioral data for automatic metaphor detection.
2.4. Innovation of our work
To date, metaphor detection remains a challenging task because the semantic and ontological differences between metaphorical and non-metaphorical expressions are often subtle and contextually dependent. Existing methods show different strengths for detecting metaphors, yet each has its respective disadvantages. Knowledge- or theory-based methods (Hong Reference Hong2016; Mao et al. Reference Mao, Lin and Guerin2019) tend to show generalization problems that are not widely applicable in real settings. State-of-the-art ML-based NLP models (Devereux et al. Reference Devereux, Shutova and Huang2018; Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019; Brooks and Youssef Reference Brooks and Youssef2020) are less interpretive to understand the intrinsic properties of metaphors. The innovation of our work is to model word meaning representations for metaphor detection via both word embeddings and perception-action knowledge. We take the foundational perception-action knowledge from embodied cognition and combine it with word embeddings and deep neural networks, with the expectation of a robust model metaphor processing that will both improve NLP performance and inform our understanding of embodied cognition.
Among previous studies, Tekiroğlu et al. (Reference Tekiroğlu, Özbal and Strapparava2015) is the most similar to our work in that they incorporated both the sensorial features and linguistic synesthesia of the five sense modalities. Different from us, this work did not incorporate either sensory modality exclusivity or sensorimotor norm and relied mainly on information based on the Sensicon extracted from WordNet. They also focus on the adjective-noun pairs extracted from a dependency-parsed corpus (DPC). Note that at the time of their study sensory modality exclusivity was already available, although the sensorimotor norms had not been published yet. Thus our current study is distinguished from Tekiroğlu et al. (Reference Tekiroğlu, Özbal and Strapparava2015), especially in terms of incorporating the lexicon-based behavioral norms from empirical studies. In addition, following results from recent studies, we added interoceptive as the sixth sense modality. The incorporation of the two behavioral norms is crucial as it allows empirical data of embodied cognition to play a role in the detection of metaphors. We use the complete sensorimotor ratings for each word to form a word vector space, which is used to complement word embeddings. In addition, our study probes further into the correlation of the various modalities and actions for predicting metaphors, as well as conducts cross-sectional experiments to look into a wider range of factors, for example text genre, POS, and language proficiency.
These research objectives on metaphor, as preliminarily attested by the several prototype experiments in metaphor detection competitions (Leong et al. Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020; Wan et al. Reference Wan, Ahrens, Chersoni, Jiang, Su, Xiang and Huang2020a, Reference Wan, Xing, Su, Liu and Huang2020b; Wan and Xing Reference Wan and Xing2020), will fill a much-needed gap in linguistic and computational research on metaphor identification. Note that the current work is motivated by yet distinct from these preliminary studies. For instance, Wan et al. (Reference Wan, Ahrens, Chersoni, Jiang, Su, Xiang and Huang2020a) adopted simple statistical models (e.g., Logistic Regression) and some basic linguistic features apart from the conceptual and embodiment features. In addition, no deep neural network models were attested for further comparisons. As for the paper in Wan and Xing (Reference Wan and Xing2020); Wan et al. (Reference Wan, Xing, Su, Liu and Huang2020b), though they employed neural network models, the experiments were run on only one dataset-VUA, and there are no subcategory experiments to look into the variation across genre, POS and language proficiency. In addition, the current work probes further into the issue of metaphors with more in-depth linguistic introspection and case-error analysis.
3. Data
3.1. The sensorimotor norms
As observed in the VUA corpus, the prevalence of concept mapping in terms of modality senses or bodily involvement between the target word and its immediate context implies a high probability of metaphorical usage. We propose to leverage perception-action information for modeling such concept mapping to facilitate metaphor detection, as well as to probe into the mapping mechanism of finer categories.
The Lancaster Sensorimotor norms collected by Lynott et al. (Reference Lynott, Connell, Brysbaert, Brand and Carney2019) are adopted for enriching word representations in this study. The data includes a most comprehensive measure of the sensorimotor strength (0–5 scale indicating different degrees of sense modalities and action effectors) for around 40K English words across six perceptual modalities: touch, hearing, smell, taste, vision, and interoception, as well as five action effectors: mouth/throat, hand/arm, foot/leg, head (excluding mouth/throat), and torso. These norms represent the largest ever set of semantic norms for English, incorporating almost 40,000 words; they provide far greater lexical coverage than has been possible with previous norms, encompassing the majority of words known to an average adult speaker of English [i.e., approximating a full-size adult conceptual system; Brysbaert et al. (Reference Brysbaert, Warriner and Kuperman2014)]. In the two datasets of the current work, 95% of the lexical words are covered in the sensorimotor lexicon. The data has been published in a top-tier journal in psycho-linguistics (Research Behavior Methods) which has gone through a rigorous review on the quality and reliability of the annotation (The mean alpha across all dimensions was
 $\geq$
.8 and each individual dimension had alpha
$\geq$
.8 and each individual dimension had alpha
 $\geq$
.7 (i.e., very good agreement overall).)
$\geq$
.7 (i.e., very good agreement overall).)
Among the six modality senses, the visual sense allows us to see the external world; the hearing sense permits us to hear the sounds; the gustatory sense considers tastes; the olfactory sense accounts for odors; the tactile sense perceives temperature, pain, and textures of objects; the interoceptive sense detects the internally stimulated feelings of hunger, exhaustion, disgust, etc. We use our body parts to undertake and experience these perceptions, as foregrounded in Figure 1. For example, we need to move our head or torso when we view the surroundings; we will open our mouth and articulate with our throat when we talk; we use our hands (and arms) to reach and grasp for objects, and we also resort to our feet (and legs) to walk or to kick. The scale of these dimensions is judged in terms of how the participants experience these concepts through each of the perceptions and actions they perceive, on a scale from 0 = no feelings at all, to 5 = very strong feelings. In addition, the dominant effectors and exclusivityFootnote c were likewise assigned to each word, expanding the paradigm of those in the modality exclusivity studies (Lynott and Connell Reference Lynott and Connell2009) with the addition of action effectors.
The augmentation and consolidation of perception and motion in this large-scale norming study compared to other relevant studies of other minority languages demonstrate a more fine-grained picture depicting how the specific sensorimotor information is encoded in the language. To demonstrate the structure of the sensorimotor norms, we provide five sample words and their six sensory scores and five action effectors, as provided by the sensorimotor norms, in Table 1 for illustration.
Table 1. The perceptual-actual ratings of five sample words in the sensorimotor norms
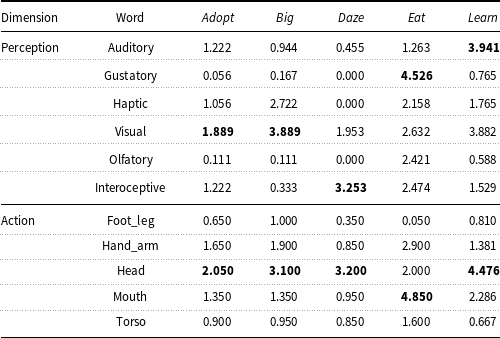
The dominant modality and action effector are highlighted in bold.
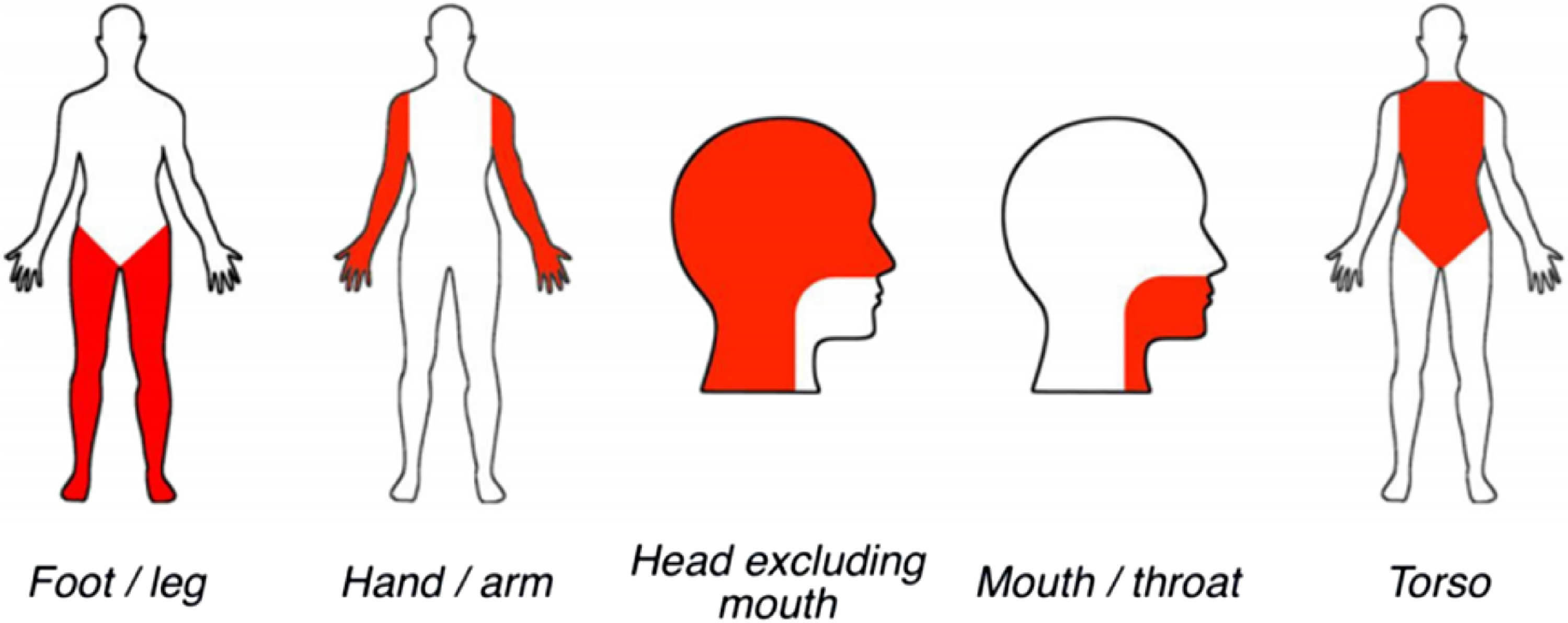
Figure 1. Avatar images describing the area of each effector during action strength norming. Figure downloaded from Lynott et al. (Reference Lynott, Connell, Brysbaert, Brand and Carney2019).
Table 1 and Example 2 demonstrate how words are represented and rated in terms of the perception-action dimension scale with examples of five words. The vector for each word (in each column) is composed of 64 dimensions of perception and action values, as well as some derived statistics, such as standard deviation, modality/action exclusivity, dominant modality/action effector, etc. In Table 1, we only display the mean of the six perception modalities and the five action effector scores here to provide a brief overview. The perception and action effector with the highest scores (highlighted in bold) respectively mark the dominant sense modality and action effector for each word, such as ‘Visual’ and ‘Head’ for the word ‘Big’; ‘Gustatory’ and ‘Mouth’ for the word ‘Eat’. The fact that the perception and action as the two embodied bases of human cognition can be captured by these two attributes in the model suggests that it could serve as very useful resource for linguistic processing (Chersoni et al. Reference Chersoni, Xiang and Huang2020).
3.2. The metaphor detection datasets
For the metaphor detection experiments, we adopt two benchmark datasets–the VUA and TOEFL corpora that are commonly used by NLP system competitions on Figurative Language Processing. The series of shared tasks on metaphor detection have also adopted the two datasets for open competition (Leong et al. Reference Leong, Klebanov and Shutova2018, Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020). The two datasets are regarded as the most representative and large-scale data of metaphors in general with human validation of the metaphor labeling based on the MIPVU protocol. Although there are two other widely adopted datasets in the metaphor detection literature–MOH-X (Mohammad, Shutova, and Turney Peter Reference Mohammad, Shutova and Turney Peter2016) and TroFi (Birke and Sarkar Reference Birke and Sarkar2006), they are designed for verbal metaphors instead of all lexical categories and are much smaller in size.Footnote d There are a total of four tracks for evaluation: VUA AllPOS, VUA Verbs, TOEFL AllPOS, and TOEFL Verbs. The AllPOS track is concerned with the detection of all content words, that is nouns, verbs, adverbs and adjectives while the Verbs track is concerned only with verbs. Function words are not considered for evaluation.
The metaphorical labels in the two datasets are prelabelled by Tekiroğlu et al. (Reference Tekiroğlu, Özbal and Strapparava2015) and Klebanov et al. (Reference Klebanov, Leong and Flor2018) for all lexical words (ALLPOS) that have been widely used by many previous works on metaphor detection (Leong et al. Reference Leong, Klebanov and Shutova2018, Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020). The current work, and many other reported systems, have evaluated on model performance by either (1) focusing on verbs only; and/or (2) on all POS labels. Many existing studies look at verbal metaphors in particular because verbs denote more metaphoric meaning, as also testified by our result in Figure 5. Our methodology is not just driven by verb-based metaphors, as our experimental results (as shown in Section 5.4.1) have also attested the possible POS effects on metaphor detection, which demonstrate a consistent improvement of adding sensorimotor information to the model for either verbs or other lexical categories, despite slight variances within each category.
All the results of the testing systems are publicly available online.Footnote e Details of the two datasets are provided below.
3.2.1. The VUA dataset
The first dataset is the VU Amsterdam Metaphor Corpus (VUA) (Steen Reference Steen2010). This corpus is a benchmark dataset released for the shared tasks of metaphor detection (Leong et al. Reference Leong, Klebanov and Shutova2018, Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020), which is publicly available for standard reference. It is a subcorpus of the British National Corpus with manually annotated labels indicating the metaphoricity of each token in the corpus. It consists of 115 text fragments sampled across four genres: Academic, News, Conversation, and Fiction. The text genre composition is provided in Table 2.
Table 2. Text genre composition of the VUA corpus
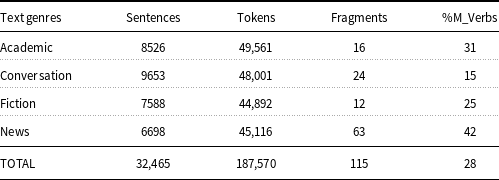
“%M_Verbs” denotes the proportion of metaphorical verbs in each text genre.
The data has been annotated using the MIPVU procedure (Steen Reference Steen2010) with a strong inter-annotator agreement (
 $k\gt 0.8$
). Examples of the sentences in the corpus are demonstrated in Figure 2. Each token in the corpus is encoded with a unique id composed of the text fragment id, sentence id and the token sequence number in each sentence. Thus, the word ‘corporate’ in the first sentence of Figure 2 has the id of ‘ale-fragment01-1-2’. Each metaphorical expression is marked by the label of ‘M_’ for distinction. Based on these gold labels, we can conduct supervised machine learning experiments.
$k\gt 0.8$
). Examples of the sentences in the corpus are demonstrated in Figure 2. Each token in the corpus is encoded with a unique id composed of the text fragment id, sentence id and the token sequence number in each sentence. Thus, the word ‘corporate’ in the first sentence of Figure 2 has the id of ‘ale-fragment01-1-2’. Each metaphorical expression is marked by the label of ‘M_’ for distinction. Based on these gold labels, we can conduct supervised machine learning experiments.

Figure 2. Sample of the annotated data in the VUA corpus.
3.2.2. The TOEFL dataset
The second dataset labeled for metaphor was sampled from the publicly available ETS Corpus of Non-Native Written English, which was first introduced by Klebanov et al. (Reference Klebanov, Leong and Flor2018). The annotated data comprises essay responses to eight persuasive/argumentative prompts, for three native languages of the writers (Japanese, Italian, Arabic), and for two proficiency levels–medium and high. The argumentative metaphors are annotated with average inter-annotator agreement
 $k = 0.56-0.62$
by Klebanov et al. (Reference Klebanov, Leong and Flor2018). We use the data partition of 180 essays as training data and 60 essays as testing data. Table 3 shows some descriptive characteristics of the two datasets: the number of texts (#text), sentences (#sentence), tokens (#token), and metaphorical proportion (%M) in the data.Footnote
f
$k = 0.56-0.62$
by Klebanov et al. (Reference Klebanov, Leong and Flor2018). We use the data partition of 180 essays as training data and 60 essays as testing data. Table 3 shows some descriptive characteristics of the two datasets: the number of texts (#text), sentences (#sentence), tokens (#token), and metaphorical proportion (%M) in the data.Footnote
f
Table 3. Data partition for both VUA and TOEFL datasets
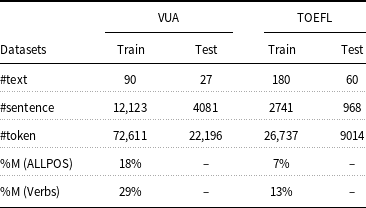
The statistics show that verbs contain a much higher portion of metaphors than the other lexical categories as suggested by the %M. This may be due to the fact that verbs are shown to be more mutable [i.e., more likely to change meaning, see Gentner and France (Reference Gentner and France1988); Ahrens (Reference Ahrens1999)]. We will revisit this issue in the discussion of results from the perspective of POS in Section 5.
4. Methodology
This work proposes an innovative method for metaphor detection based on the idea that the basic modality senses ( touch, hearing, smell, taste, vision and interoception) and action effectors (mouth/throat, hand/arm, foot/leg, head, torso) of words as indicated by the sensorimotor norms (Lynott et al. Reference Lynott, Connell, Brysbaert, Brand and Carney2019) provide crucial information for metaphoricity inference. We utilize both feature engineering and deep neural networks for implementation,Footnote g as detailed in the following subsections.
4.1. Baseline methods
We adopt the following three strong baselines for peer comparisons to our proposed models.
-
B1 (Baseline 1): The first baseline is a feature based statistical Machine Learning model proposed by Klebanov et al. (Reference Klebanov, Leong, Heilman and Flor2014) which has been widely adopted as a common strong baseline for many metaphor detection shared tasks. Despite a simple method, it demonstrates surprisingly better performance than many advanced deep learning models. The features include lemmatized unigrams, generalized WordNet semantic classes, and differences in concreteness ratings between verbs/adjectives and nouns (UL + WordNet + CCDB). This baseline is similar to our first model as we also utilize both knowledge features and statistical ML models (e.g., logistic regression). Therefore, it can serve as an effective baseline for our model comparisons.
-
B2 (Baseline 2): The second baseline is the approach proposed by Brooks and Youssef (Reference Brooks and Youssef2020) which uses bidirectional attention mechanisms for metaphor detection. In this model, each word is represented by an 11-gram which contains the target word in the center together with five neighboring words as the context; each word in the 11-gram is represented by a 1324 dimensional word embedding (concatenation of ELMo and GloVe embeddings). Brooks and Youssef (Reference Brooks and Youssef2020) experimented with ensembles of models that implement different architectures (in terms of attention) trained on POS information. This baseline is similar to our second model which also utilizes attention based Bi-LSTM, but the difference is that we adopt Sensorimotor vector instead of ELMo. Therefore, it can serve as another effective comparison to our deep learning method.
-
B3 (Baseline 3): The third baseline is a minimal adaptation of our second model (cf. SGNN in Section 4.2.2) that replaces the sensorimotor vector of each word with an equal dimension of random vectors. This baseline is used to rule out the possibility that the effect of incorporating sensorimotor knowledge into the deep neural networks is caused by increased vector space. Hence we model a baseline architecture similar to SGNN except that randomly generated vectors are concatenated as the additional vector space to word embeddings.
4.2. Sensorimotor-enriched modeling
4.2.1. SFeature (Statistical models with sensorimotor feature)
Our first model is based on feature engineering with statistical machine learning. For comparison purposes, we modeled three other categories of features in addition to perceptual norms (i.e., sensorimotor features). These include word-ngram, lemma-ngram and POS-ngram, word embeddings, and cosine similarity between the target and its neighboring words, as well as B1 as mentioned in the above section. We use three statistical models and ensemble learning strategies during training so as to test the cross-model consistency of the various features, as detailed below:
-
Sensorimotor Feature: We model the perceptual-actional knowledge to a word by mapping the target word to the sensorimotor norms data and acquiring the sensorimotor vector space for each word in the corpus. The acquired vector space for all the words in the corpus forms a sensorimotor feature matrix, which contains dictionaries of four key-value pairs, including the target word, its id, the feature attribute in terms of sensorimotor ratings (x), as well as the metaphoricity label of each word in the corpus (y). Such feature structure is formatted in JSON lines to work with Unix-style text processing tools and shell pipelines, as demonstrated in Example 2. Unmatched words (those not covered in the sensorimotor norms data) are assigned the average sensorimotor values for each feature dimension.
-
Collocations: Three sets of collocational features are constructed to represent the lexical, syntactic, and grammatical information of the target nodes and their neighbors: Trigram, FL (Fivegram Lemma), FPOS (Fivegram POS tags). In the preliminary experiments, we tested on different window sizes ranging from 2 to 10 for the POS ngrams. The results show that trigrams and fivegrams produced superior performances and we focus on the two features for the collocation baseline. The two corpora are lemmatized using the NLTK WordNetLemmatizer and POS tagged using the NLTK averaged perception tagger (Loper and Bird Reference Loper and Bird2002) before constructing such features.
-
Word Embeddings: We also utilize word embeddings to capture the semantic information of words based on the distributional hypothesis on word meaning [e.g., Lenci (Reference Lenci2008)]. Three models are used: GoogleNews.300d, Internal-W2V.300d (pre-trained using the VUA and TOEFL corpora), and the GloVe vectors. GoogleNews in this work is pre-trained using the continuous bag-of-words architecture for computing vector representations of words (Church Reference Church2017). GloVe is an unsupervised learning algorithm for obtaining vector representations for words. We use the 300d vectors pre-trained on Wikipedia 2014+Gigaword 5 (Pennington et al. Reference Pennington, Socher and Manning2014).
-
Cosine Similarity: We also investigate the cosine similarity (CS) measures for computing word sense distances between each word and their neighboring lexical words in a given sentence. This approach can be traced back to earlier vector space neighborhood models of lexical meaning [e.g., Ploux and Victorri (Reference Ploux and Victorri1998)], as well as cosine similarity measurements of semantic relations and semantic distance [e.g., Turney and Littman (Reference Turney and Littman2005); Baroni and Lenci (Reference Baroni and Lenci2010)]. It has been applied to detect other non-literal meanings (Xu et al. Reference Xu, Santus, Laszlo and Huang2015), as well as the differentiation of different semantic relations in the TOEFL dataset (Santus et al. Reference Santus, Chiu, Lu, Lenci and Huang2016). Recently, it has also been applied to metaphor detection (Rai et al. Reference Rai, Chakraverty, Tayal and Kukreti2018). The neighboring lexical words are syntactically close content words that occur in the same clause of the target word. The CS was computed based on the averaged cosine distance between the word embedding vectors. Three different sets of CS features are constructed in this work by using the above three different word embedding models: CS-Google, CS-GloVe, CS-Internal (word vectors trained on the VUA and TOEFL corpora).
These features provide meaning representations of the target words and their neighbors in terms of their senses modalities, action effectors, exclusivity etc., as illustrated by the various predictors of each word in Example 2 [cf. more information on the data structure in Lynott et al. (Reference Lynott, Connell, Brysbaert, Brand and Carney2019)]. Wan et al. (Reference Wan, Ahrens, Chersoni, Jiang, Su, Xiang and Huang2020a), reporting our pilot study, showed that these features are highly indicative of metaphorical uses and are hence hypothesized as more distinctive features than the strong baselines.
With the above features, three traditional classifiers are used for predicting the metaphoricity of the tokens, including Logistic Regression (LR), Linear Support Vector Classification (LSVC) and a Random Forest Classifier (RFC). The Machine Learning experiments are run through utilities provided in the SciKit-Learn Laboratory (SKLL) (Pedregosa et al. Reference Pedregosa, Varoquaux, Gramfort, Michel, Thirion, Grisel, Blondel, Müller, Nothman, Louppe, Prettenhofer, Weiss, Dubourg, Vanderplas, Passos, Cournapeau, Brucher, Perrot and Duchesnay2011). For parameter tuning, we use grid search to find optimal parameters for the learners, as in Table 4.
Table 4. Parameter setting for the three statistical classifiers

4.2.2. SGNN (Sensorimotor with Glove Neural Network)
SGNN is the second model we propose based on the sensorimotor information and neural networks. In the SGNN model, words are processed with the integration of sensorimotor vectors and word embeddings, as depicted in Figure 3. Since we aim to compare a sensorimotor features driven system with a pre-trained method (e.g., word embedding with BERT), we do not combine these two models. BERT may show overwhelming performance given the large pretrained models and training data used, as well as the vast amounts of hyper-parameters that rely on high-capacity GPU. For most of the fine-tuning experiment in the BERT-based models, more than 16 GB of GPU memory for BERT-Large is needed. However, one major purpose of our study is to introspect metaphors in-depth (in a cost-effective way) from the perspective of the perceptual and actional features to interpret the language mechanism in modeling metaphors. We make use of these features and look into their sub-dimension effects on metaphor detection through sub-experiments and look at the variances through the model performances instead of just pursuing model enhancement.
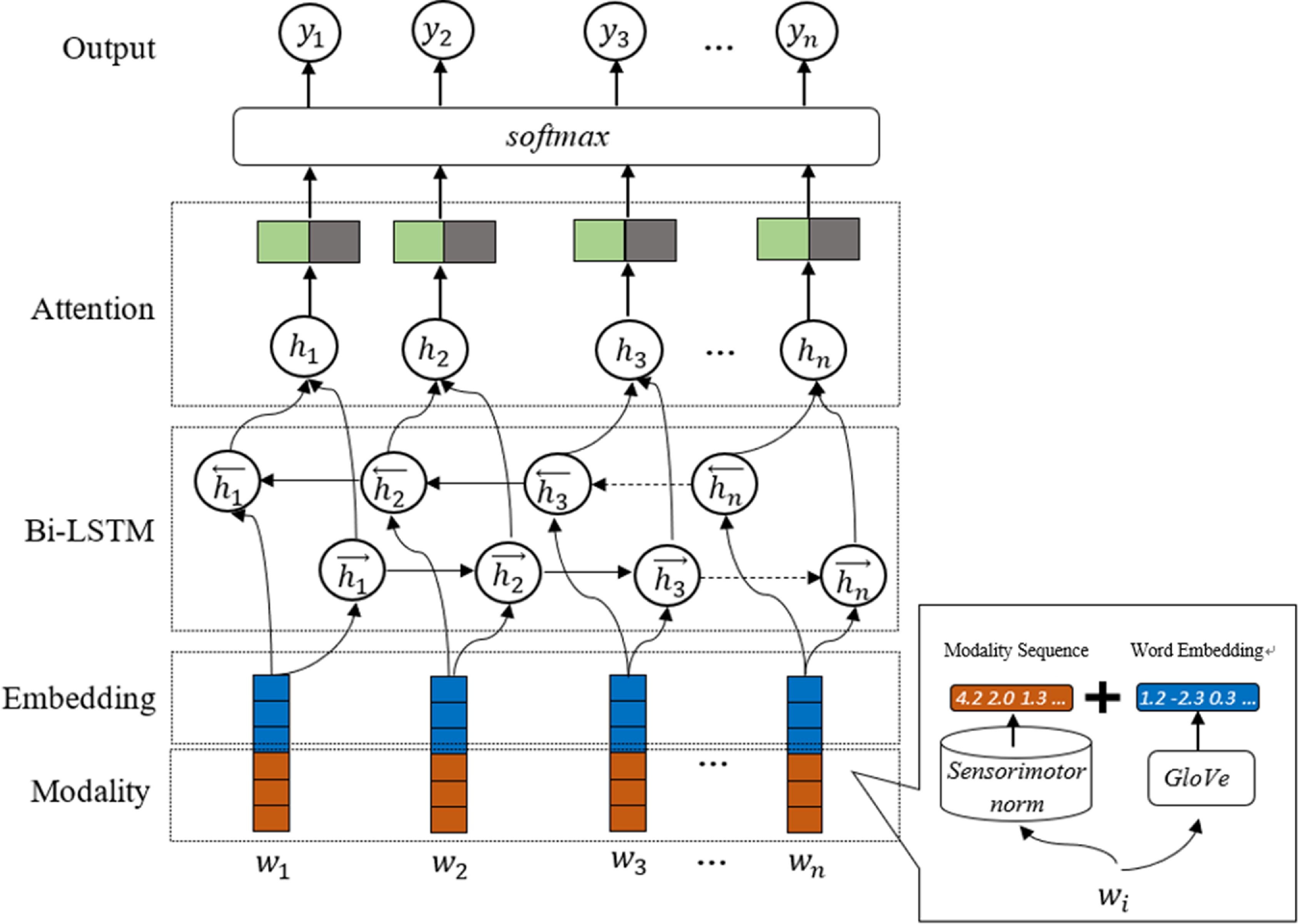
Figure 3. The architecture of the SGNN model.
In the SGNN model, we map the words to the sensorimotor norms and obtain the modality representations (64 dimensions for each word). At the same time, we obtain the word vectors (300 dimension for each word) using GloVe and then concatenate them as inputs to neural networks. The red boxes represent the vector of sensorimotor information for each input word; the blue boxes are the word embeddings. For those words not mapped in the sensorimotor norms, we assigned three kinds of values, including all zeros, random values following normal distribution, as well as average scores of the sensory words in the corpus. In the end, we chose to use the average score for each dimension of the out-of-dictionary words to optimize our results.
The Bi-LSTM layer produces a hidden status for each word (
 $w_i$
) in a given sentence. We use this status to calculate an attention weight which is multiplied by the output of the Bi-LSTM layer. The green box corresponds to the attention weight for each word, and the grey box represents the hidden vector. Let H
$w_i$
) in a given sentence. We use this status to calculate an attention weight which is multiplied by the output of the Bi-LSTM layer. The green box corresponds to the attention weight for each word, and the grey box represents the hidden vector. Let H
 $\in$
R
$\in$
R
 $^{d\times N}$
be a matrix consisting of hidden vectors
$^{d\times N}$
be a matrix consisting of hidden vectors
 $[\vec{h_1},\vec{h_2}\ldots .\vec{h_N}]$
that is produced by LSTM, where d is the size of hidden layers and N is the length of the given sentence. The attention mechanism will generate an attention weight
$[\vec{h_1},\vec{h_2}\ldots .\vec{h_N}]$
that is produced by LSTM, where d is the size of hidden layers and N is the length of the given sentence. The attention mechanism will generate an attention weight
 $\alpha$
. The final sentence representation is given by:
$\alpha$
. The final sentence representation is given by:
 \begin{equation*} \textbf {h} = \textbf {H} \times \boldsymbol {\alpha }^T \end{equation*}
\begin{equation*} \textbf {h} = \textbf {H} \times \boldsymbol {\alpha }^T \end{equation*}
We also add a Linear layer. The final probability distribution is:
 \begin{equation*} y = \text{softmax}(\textbf {W}_s\textbf {h} + b_s) \end{equation*}
\begin{equation*} y = \text{softmax}(\textbf {W}_s\textbf {h} + b_s) \end{equation*}
Let y be the target distribution for the sentence,
 $b_s$
be the bias offset, and
$b_s$
be the bias offset, and
 $\hat{y}$
be the predicted metaphoricity distribution. We train the model to minimize the cross-entropy error between
$\hat{y}$
be the predicted metaphoricity distribution. We train the model to minimize the cross-entropy error between
 $y$
and
$y$
and
 $\hat{y}$
for all sentences.
$\hat{y}$
for all sentences.
 \begin{equation*} \text{loss} = - \sum _i \sum _jy_i^j\log\hat {y}_i^j + \lambda \mid \mid \theta \mid \mid ^2 \end{equation*}
\begin{equation*} \text{loss} = - \sum _i \sum _jy_i^j\log\hat {y}_i^j + \lambda \mid \mid \theta \mid \mid ^2 \end{equation*}
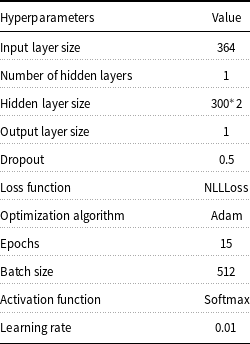
Then, we get a probability distribution of 0–1 label to train the model and get the predictions. Our evaluation adopts the commonly used metrics precision (P), recall (R), and F1-measure (F1). In addition, we use the default hyperparameters of attention-based Bi-LSTM and estimate them by using a grid search within a reasonable range. Each value of the hyperparameters is shown in Table 5.
Table 5. The hyperparameter setting of the SGNN model
5. Results and discussions
5.1. Evaluation of SFeature
This evaluation section focuses on the salience of the various features for metaphor detection as well as their fitness to the three statistical classifiers by focusing on the VUA Verbs track. The evaluation results on the individual features in terms of the F1-score are summarized in Table 6.
Table 6. Feature evaluation on the VUA Verbs track
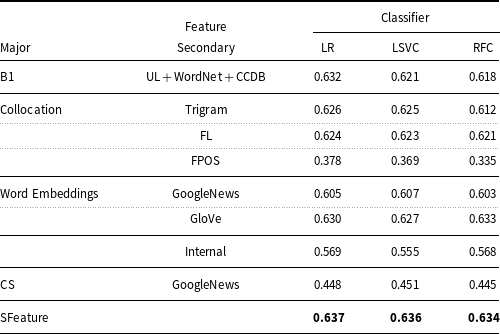
The best performance for each classifier is highlighted in bold.
Results in Table 6 show that the best individual feature is the sensorimotor vectors with the LR classifier, followed by B1, W2V.GloVe, Trigram and FL. These results verify the potential contribution of sensorimotor features to metaphor detection. The sensorimotor consistently led to better results for metaphor detection as compared to the other features. The performances of the three classifiers are quite close for each feature set, with LR performing slightly better.
In addition to the evaluation of individual features, we use the best feature set and classifier (LR) in the above evaluation for testing on all four tracks. The results of our method on the test sets of the four tracks in terms of F1-score are summarized in Table 7.Footnote h
Table 7. Comparison of SFeature to B1 on all the four tracks
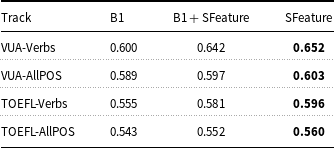
The best performance is highlighted in bold.
In Table 7, ‘B1+SFeature’ stands for ‘Sensorimotor feature fused with baseline 1’ and the best results for the four tracks are highlighted in bold. The sensorimotor feature shows consistent improvement (1–5%F1) over baseline 1 and is also more effective when used alone. The evaluation results demonstrate the effectiveness of using the sensorimotor feature for metaphor detection. In addition, the results show that the models perform much better for predicting verbs than other lexical categories for both datasets. As highlighted in Table 7, the SFeature model shows 5.2% F1 and 4.1 F1% improvement for verbs over B1 in the two datasets respectively, while the improvements for the averaged performance of the four POS categories in the two datasets are much smaller: 1.4% F1 and 1.7% F1 respectively. Overall, using SFeature shows enhancement for metaphor detection on all lexical categories.
5.2. Evaluation of SGNN
Recall that, in addition to traditional classifiers, we also concatenated sensorimotor information with word embeddings and applied the model to deep neural networks to further explore the performance of sensorimotor-enriched modeling. The evaluation results in this section are summarized in Table 8 in terms of P(recision), R(ecall), and F1(-score).
Table 8. Results of sensorimotor-enriched models with neural networks on the Verbs track
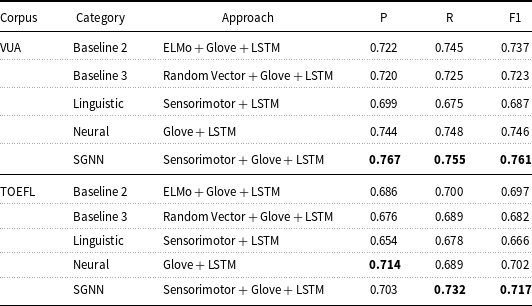
The best performance in terms of P, R, F1 is highlighted in bold.
For a meaningful comparison to other work, we focus on the Verbs track first and randomly select a development set (4,380 tokens) from the training set (17,240 tokens) in proportion to the Train/Test ratio of the task in Leong et al. (Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020). The current focus on the Verbs track is because most of the reported work for the same task and on the same datasets conduct their experiments on the Verbs track so that we could compare the results directly. The reported results on the ALLPOS track are incomplete and hence incomparable. We report the peer results in Table 9 to observe the model performance across external groups (between models), and then look further into the POS variances within groups (between lexical categories) in Section 5.4.1.
Table 9. Comparison of our result to state-of-the-art works on the Verbs track of the VUA corpus

The best performance is highlighted in bold.
As introduced in Section 4.1, B2 and B3 are implemented for direct comparisons to SGNN. We also implement several other approaches with a minimal difference to SGNN for a more comprehensive comparison that could potentially differentiate the contribution of the linguistic features and neural networks. Table 8 clearly shows that the sensorimotor enhanced models perform better: a 2.4% F1 improvement of SGNN over B1, a 3.8% F1 improvement over B2, a 7% F1 improvement over a pure linguistic model, a 1.5% F1 improvement over the pure neural network model. The improvements are salient and consistent in almost all cases, exception for the precision of the neural model for the TOEFL Corpus, although both the recall and F-score improved. Note that replacing the sensorimotor vectors with randomly generated vectors (B3) does not help improve the performance compared to the one without enhancement. It is shown that adding random vectors lowers the performances across the board. Both facts support our assumption that adding sensorimotor information into the model enhances performance, and that the enhancement is not due to a random effect or the increased vector space.
To further demonstrate the effectiveness of our second proposed model, we compare our results to recent related works on the same dataset focusing on the Verbs track, as displayed in Table 9. All the results are publicly available, as reported in Leong et al. (Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020).
In Table 9, our method is highlighted in italics. Despite using simple neural networks, our method obtains very promising results: it outperforms all the other related works to various degrees (0.5–11% F1 gain), reaching state-of-the-art performance. Overall, our results are consistently superior to the three strong baselines and other linguistically-based or pure deep learning approaches. The above evaluations demonstrate the effectiveness of our model for metaphor detection, supporting our hypothesis that metaphor often anchors the perception-action schema via their source domains.
5.3. Case analysis
To shed light on the contribution of sensorimotor embedding to the detection of metaphors, we conduct case analysis of the improvement. That is, the examples that are correctly predicted by SGNN, but not by the B2 counterpart. Typical samples are provided in Table 10.Footnote i
Table 10. Examples of erroneous predictions by B2 but not by SGNN

The word (of the source domain) is highlighted in bold, and the word (of the target domain) is underlined.
The source and target domains of the target word and its immediate context are based on the pre-labeled data of the metaporical expressions. We also map the source domain and target domain words to the sensorimotor norms data to get their dominant perception and action information. The dominant perception and action of the words as provided in the norms indicate the most salient perceptual and actional effectors of the word in a person’s conceptual system. For instance, the word ‘big’ possesses a Visual-Head dominant sensorimotor, while its real meaning in the first example is to modify ‘responsibilities’ which possesses an Interoception-Head dominant sensorimotor. The modality shift from Visual to Interoceptive indexes a metaphor with a high probability and hence the sensorimotor-enriched model can correctly predict such cases. Other examples in Table 10 show similar patterns of having a sensorimotor dominance shift either from one modality to another or from one action to another, or both. Note that the sensorimotor information serves as a complementary representation to word embeddings and the effectiveness will not be maximized if used alone. There are also metaphors without sensorimotor mismatches between the target word and its context, as in the following examples.
Example 2-6.
-
Ex.2: Another reason is the advancement in Science. Both Visual-Head
-
Ex.3: This is the general scheme of a normal Italian family’s dynamic. Both Visual-Hand/Arm
-
Ex.4: fought for equal rights, he believed that all men are created equal. Both Visual-Head
-
Ex.5: Lastly, the family structure has been changing. Both Visual- Hand/Arm
-
Ex.6: A lot of things become forbidden just for physical reasons. Both Visual-Head
Metaphors involve various kinds of domain transfer which can anchor a wide range of basic cognition states such as modality and embodiment experiences. However, its detection is still challenging due to the subtle differences between the metaphorical expressions and their context, and the perception and interpretation of metaphors can vary from person to person. Some may be regarded as dead metaphors that are only used as part of an idiom chunk or other formulaic expressions. Such expressions should be recorded as constructions. Nevertheless, with the incorporation of sensorimotor vector space, word embedding, and linguistic theories, this work has shown promising results of the concerted efforts for metaphor detection, contributing to the interpretation and enhancement of the peer models.
5.4. Cross-sectional comparison
In this section, we explore the issue of whether the performance of the sensorimotor enhanced model is dependent on certain textual properties or not. We examine the performance of the model vis-à-vis parts-of-speech (POS) categories, text genres, and language proficiency levels, as detailed below.
5.4.1. Part of speech
Metaphorical expressions have been suggested to show variance among words of different lexical categories (Shinohara Reference Shinohara1999; Ahrens and Huang Reference Ahrens and Huang2002; Zhao Reference Zhao2018; Dong, Fang, and Qiu Reference Dong, Fang and Qiu2020). In particular, verbs are argued to be more likely to employ metaphors (Leong et al. Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020), perhaps because of the mutability of verbs (Gentner and France Reference Gentner and France1988; Ahrens Reference Ahrens1999) and that the relational meanings of verbs often rely on metaphoricity (Gentner and Asmuth Reference Gentner and Asmuth2019; Song et al. Reference Song, Zhou, Fu, Liu and Liu2021). We provide the distribution of literal words (f_L) and metaphorical words (f_M) across the four POS categories in the two datasets in Figure 4.
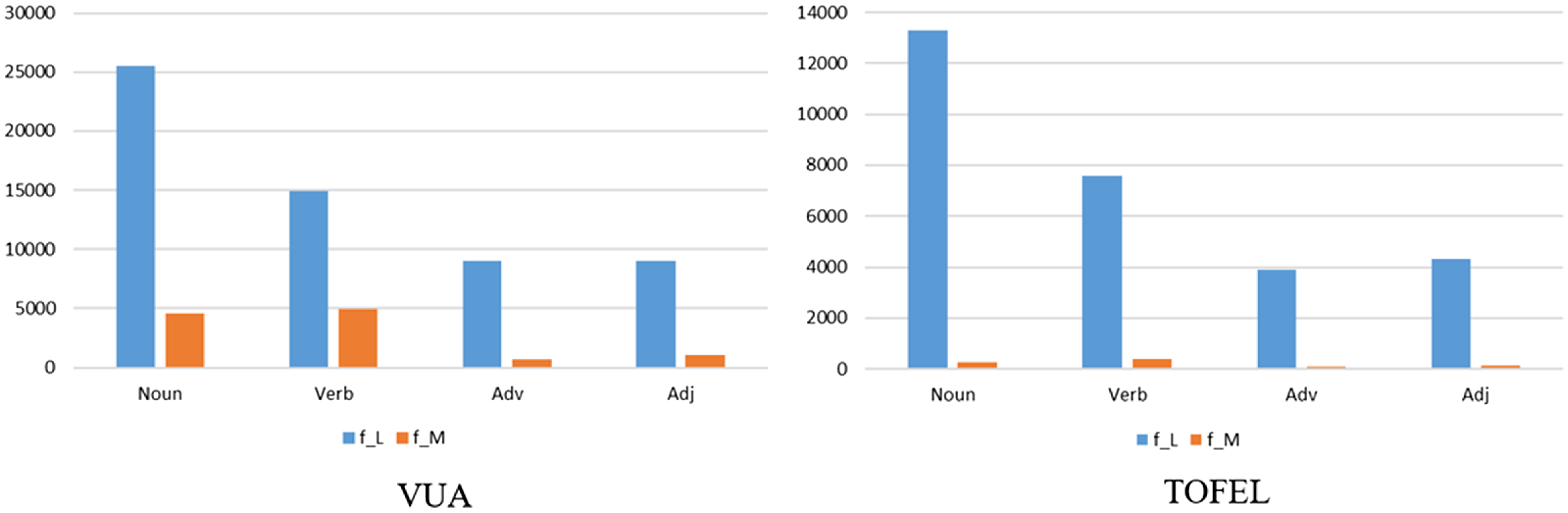
Figure 4. Distribution of metaphorical words across the four POS categories in the two datasets. (f_M: frequency of metaphorical words, f_L: frequency of literal words.)
According to Figure 4, the four POS categories show different metaphorical distributions in both datasets. Though the occurrences of metaphors in the four POS categories vary to a great extent, the distribution patterns of the metaphorical words and literal words for both datasets are uniform. That is, in terms of literal meaning, the frequency of the four POS categories is the same for both datasets: Noun, Verb, Adverb, and Adjective; in terms of metaphoric meaning, the frequency of the four POS categories are different but the pattern is similar for both datasets: Verb, Noun, Adjective, and Adverb. Among the four, verbs show the highest metaphorical uses, followed by nouns. We aim to investigate how the sensorimotor incorporated model performs in the four different lexical categories (results presented in Table 11), and to what degrees the performances vary.
Table 11. Results of model performances across POS categories in the two datasets

The top and second performance gains are highlighted in bold and italics respectively.
Table 11 shows that, based on the VUA dataset, sensorimotor methods outperform the baselines consistently across all the POS categories. In particular, the performance gains by sensorimotor methods are the greatest for the Nouns and Adjectives despite the fact verbs are the most frequent among all the metaphorical expressions. This result is consistent with that of the TOEFL dataset, except that Adverbs show no performance gain by the sensorimotor enhanced models. We suspect the reasons why the sensorimotor model works particularly well for nouns and adjectives are: (1) that a general machine learning method tends to perform better on the more frequently attested cases, that is verbs; hence leaves little room for improvement, and (2) that most synesthetic metaphors, mapping between two sensory domains such as ‘sweet voices’, occur with nouns and adjectives, such as in the example of “sweet voice”. Although adjective-noun expressions are not the highest structure among all the metaphorical expressions, they benefit the most from the sensorimotor-enhanced model according to the result in Table 11. In other words, the sensorimotor norms supplement information for the less frequently attested POS in training data. The sensorimotor knowledge for adjective-nouns provides informative information for identifying metaphors in the model, as demonstrated by the many synesthetic metaphors. Since other models tend to perform well on verbal metaphors, the enhancement of our model on verbs is relatively minor. However, the overall performance of the four POS categories is consistently improved by the sensorimotor model for both datasets, confirming the effectiveness of leveraging sensorimotor information for metaphor detection.
5.4.2. Text genre
Lexical choices are well attested to vary across different texts. The VUA corpus consists of 115 fragments sampled across four genres from the British National Corpus: Academic, News, Conversation, and Fiction. Two previous shared tasks on metaphor detection have adopted this corpus for competition (Leong et al. Reference Leong, Klebanov and Shutova2018, Reference Leong, Klebanov, Hamill, Stemle, Ubale and Chen2020). The published results demonstrated a pattern that are highly consistent across the participant systems: metaphor detection of texts of Academic and News genres is substantially easier than Fiction and Conversation. This can be accounted for by the fact that Literary and Conversation genres are more creative and more likely to use novel metaphors. While metaphoric uses in Academic and News genres typically are dominated by conventional metaphors, conventional metaphors are also well-attested in training data and hence easier to detect. Given the nature of different usages of metaphors among different genres, they offer another good test to better understand the contribution of the sensorimotor norms to metaphor detection. Thus we conducted further experiments by dividing the dataset into the four subsets according to their text genres and trained the model with the entire training data, but tested on the same sample size from the four text genres respectively. Results are shown in Table 12.
Table 12. Results of our methods in comparison to the two baselines across the four text genres

The top and second performance gains are highlighted in bold and italics respectively.
As expected, all the metaphor detection models in Table 12 perform the best in the Academic texts. In addition, the sensorimotor enhanced model gained greater improvement in the other three text genres. In particular, SFeature outperforms the B1 model the most for the News genre with a 2.8% F1 gain, followed by the Fiction genre (a 1.8% F1 gain). In addition, SGNN outperforms the B2 model the most for the Conversation genre with a 5.7% F1 gain, followed by the Fiction genre with a 4.9% F1 gain. This result indicates that genre differences did not contribute to the gains achieved by our model and that the gains by the sensorimotor enhanced models are likely due to its ability to detect novel usages of metaphors.
5.4.3. Language proficiency
Metaphorical expressions have been regarded as an important linguistic index of the language proficiency of writers (Klebanov et al. Reference Klebanov, Leong and Flor2018). That is one of the main reasons that the TOEFL corpus is structured according to two language proficiency levels (Medium and High). We experiment on the two subcategories of data in the TOEFL corpus to further explore the possible interaction of the sensorimotor enriched model with language proficiency level for metaphor detection. Results are provided in Table 13.
Table 13. Results of our methods in comparison to the two baselines for the two language proficiency levels

Best performance gain is highlighted in bold.
Interestingly, the results in Table 13 suggest no apparent relation between the language proficiency level, with the sensorimotor-enhanced modele as the feature-based method showing a higher performance gain for high proficiency writing, and the neural network method showing a higher performance gain for medium proficiency writing. Note that there is also a low proficiency subset in the original dataset of TOEFL. This portion of data was excluded from the metaphor labelling by the dataset developer due to too many grammar errors. This fact suggests that grammatical proficiency itself may compound the task of metaphor detection, and the different frequency of metaphoric uses may not be the salient factor. Given potential compounding factors as well as the relatively small size of annotated data of learners’ corpus, the issue of correlation between proficiency and metaphor detection cannot currently be resolved.
5.5. Interplay of the 11 sensorimotor dimensions with metaphor prediction
The above models have incorporated all the sensorimotor features; thus, it is not possible to know which dimension plays a more salient role in predicting metaphors. To find the best predictors, we use binary logistic regression for modeling the relations between the 11 sensorimotor dimensions with the metaphoricity of words. We aim to see which dimension is more salient for predicting the metaphoricity in words. We use the TOEFL corpus for running the model. There are 26,736 lexical words in the TOEFL corpus; each word is mapped to the sensorimotor lexicon and a successful mapping returns an 11-dimension vector to the word in terms of the 11 sensorimotor ratings; y is the metaphoricity of the target word. Figure 5 demonstrates the data frame of the x (sensorimotor features) and y (metaphoricity gold label). Due to space limitations, only 20 instances are presented.
Logistic regression is a method for fitting a regression curve,
 $y = f(x)$
, when y is a categorical variable. The typical use of this model is predicting y given a set of predictors x. The categorical variable y, in general, can assume different values. In the simplest case scenario y is binary meaning that it can assume either the value 1 or 0. We run the binomial model using R and the results are provided in Table 14.
$y = f(x)$
, when y is a categorical variable. The typical use of this model is predicting y given a set of predictors x. The categorical variable y, in general, can assume different values. In the simplest case scenario y is binary meaning that it can assume either the value 1 or 0. We run the binomial model using R and the results are provided in Table 14.
Table 14. The binary logistic regression results for predicting metaphoricity of words

Signif. codes: 0 ‘* * *’ 0.001 ‘* *’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1.
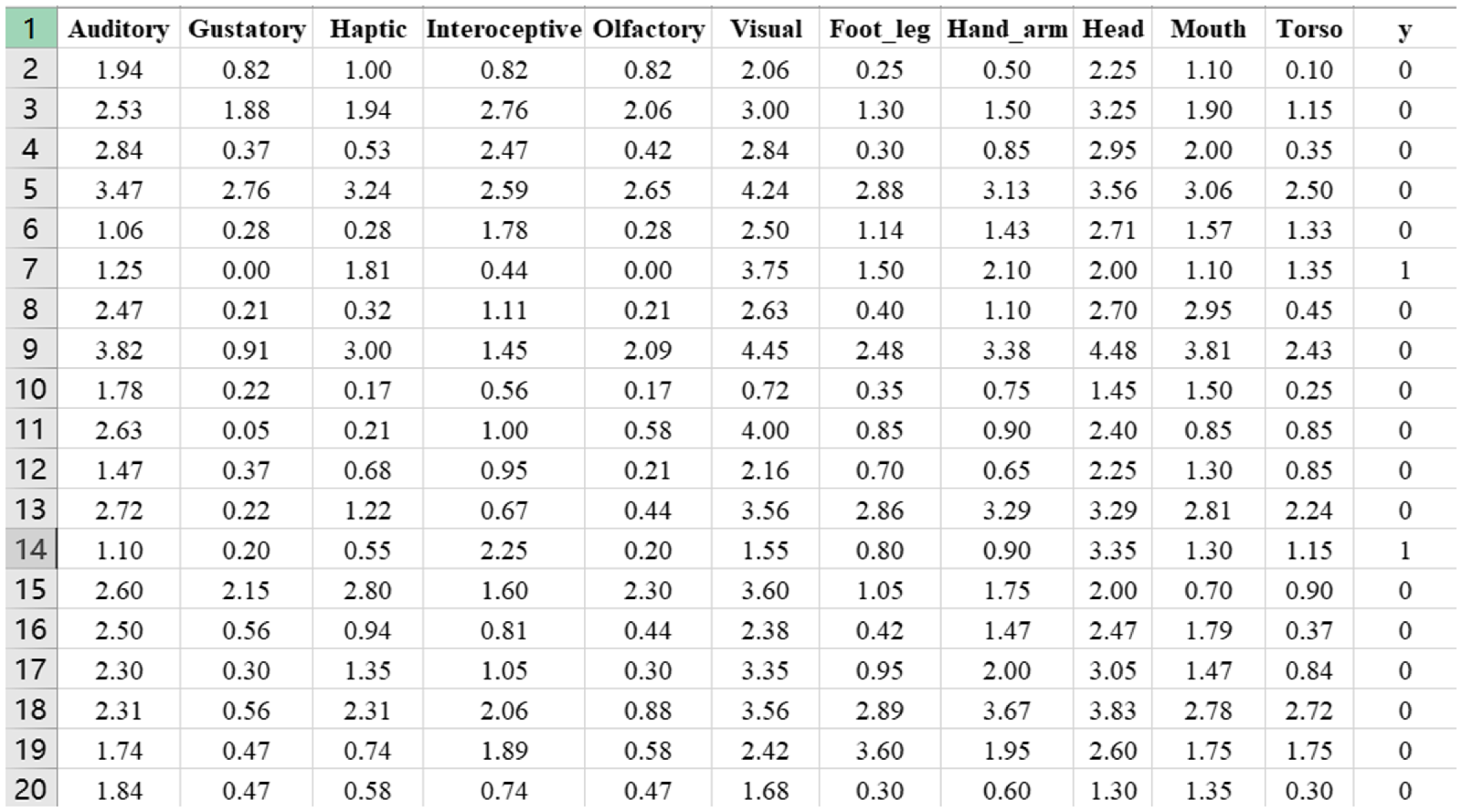
Figure 5. Data frame of the sensorimotor and metaphor data.
The logistic regression result in Table 14 suggests that the interoceptive modality and the hand/arm action effector are the most reliable predictors for metaphors and both show a positive coefficient for predicting a metaphorical expression. In contrast, the olfactory, mouth/throat, and head effectors are negatively related to metaphors, also with significance. This aligns with the observation that metaphors are often expressed via various hand movement activities, as in the expression ‘to break through’. Note also that the most significant positive predictor belongs to the action effector category (i.e., hand/arm) and the sensory modality (i.e., interoceptive). Action effectors are also body parts associated with embodied activities and often serve as the source domain of a conceptual metaphor. In contrast, the interoceptive modality, which is associated with mental states, typically occurs as target domains as they are highly abstract. Thus, we postulate that it is the strength of association to either a source domain or a target domain that provides the best predictions.
6. Conclusion
Following the emergent but challenging trend to synergize neuro-cognitive information in NLP, this paper proposes a novel method for metaphor detection combining sensorimotor norms (Lynott et al. Reference Lynott, Connell, Brysbaert, Brand and Carney2019) with word embeddings (Pennington et al. Reference Pennington, Socher and Manning2014). The basic perceptual senses (touch, hearing, smell, taste, vision and interoception) and action effectors ( mouth/throat, hand/arm, foot/leg, head and torso), identified as such by the sensorimotor norms, provide crucial information for metaphoricity inference and interpretation that is supplementary to word embeddings. That is, the occurrence of a mismatch in perception and (or) action of a target word with its context tends to be metaphorical. We experience and learn from the physical world through our five senses and actions. The sensory, as well as the embodiment lexicon as a collection of sensorimotor words, can hence be considered as basic units of conceptualization of our knowledge of the physical world. These conceptualization units can be utilized as a useful resource for linguistic modeling (Chersoni et al. Reference Chersoni, Xiang and Huang2020; Zhong, Ahrens, and Huang Reference Zhong, Ahrens and Huang2023). On such a basis, we have looked at how such information facilitates metaphor detection. We use statistical machine learning, Bi-LSTM, and other DL architectures for a comprehensive attestation of our proposed method. Results show that the proposed model with access to sensorimotor scores outperforms the counterpart models by at least 0.5% F1, proving that perceptual-conceptual indices are crucial for identifying metaphors. The proposed model achieves results that (1) are significantly higher than one without such information, and (2) show leading performances as compared to most related works on record. The results of the study are in line with results from our pilot study (Wan et al. Reference Wan, Ahrens, Chersoni, Jiang, Su, Xiang and Huang2020a, Reference Wan, Xing, Su, Liu and Huang2020b), and strengthen the conclusion that sensory modalities and motor effectors are crucial to metaphors (relevant to both our understanding of metaphors and to NLP).
In addition, sub-experiments are conducted on different lexical categories (nouns, verbs, adjectives and adverbs) with different genres of data (conversation, news, fiction and academic writing) among people of different language proficiency (high and medium) to probe into the grammatical, stylistic and other influence on the model. In particular, the performance gains by sensorimotor methods are the greatest for nouns and adjectives although verbs take the largest proportion of all the metaphorical expressions. This is possibly because the majority of words in the sensorimotor lexicon are nouns or adjectives. It is also observed that most of the synesthetic metaphors occur among nouns and adjectives, such as in the example of “sweet voice”. In addition, although all the models perform the best in the Academic texts for the task of metaphor detection, our proposed methods show greater improvement in the other three genres of texts, including Conversation, News, and Fiction, indicating the high generalization ability of a sensorimotor enriched neural network, which captures the knowledge of semantic, cognitive, and conceptional information in one shot.
There are several interesting directions for future work: First, we will extend our research methods to other types of figurative language. Second, we will run our model on other datasets such as MOH-X (Mohammad et al. Reference Mohammad, Shutova and Turney Peter2016) and TroFi (Birke and Sarkar Reference Birke and Sarkar2006) to further attest to the efficiency of our model in terms of model robustness and generalization abilities. Third, through the case analysis, we found that multiple word metaphors affected the performance of the metaphor detection model. We will further consider multi-word metaphor detection using our current approach. We will also try alternative methods in introducing sensorimotor information using other paradigms rather than concatenating embedding with the hope of further enriching the content. In addition to perceptual and actional dimensions, we are also interested to explore other dimensions such as the emotional and imageability predictors for metaphors and probe into their possible relations.
In addition to modeling static conceptual features, some studies (Yee and Thompson-Schill Reference Yee and Thompson-Schill2016; Trott and Bergen Reference Trott and Bergen2022) have also addressed the effects of modeling contextualized features across time scales or on communication efficiency. However, these two studies were not specifically designed for metaphor detection. Still, the idea of contextualized sensorimotor representations can be a very interesting way to probe further into linguistically-enriched methods for metaphor detection in future work.
Note that the existing sensorimotor norms laid the ground work for other enriched neuro-cognitive information that is lexically anchored (Banks and Connell Reference Banks and Connell2023; Reilly, Flurie, and Peelle Reference Reilly, Flurie and Peelle2020; Zhong and Ahrens Reference Zhong and Ahrens2023). In addition, sensorimotor norms are now available for Chinese (Zhong et al. Reference Zhong, Wan, Ahrens and Huang2022), Italian (Repetto et al. Reference Repetto, Rodella, Conca, Santi and Catricalà2022), and Russian (Miklashevsky Reference Miklashevsky2020), among others. Lastly, Chersoni et al. (Reference Chersoni, Xiang and Huang2020), Chersoni et al. (Reference Chersoni, Santus, Huang and Lenci2021a), and Chersoni et al. (Reference Chersoni, Hollenstein, Jacobs, Oseki, Prévot and Santus2021b) illustrated that it is possible to bootstrap sensorimotor norms of a different language based on existing norms. These ongoing developments suggest that our proposed approach has the potential of both bridging to richer neuro-cognitive resources and expanding to multi- and cross-lingual language processing.




















 Open access
Open access