



1 Introduction
Studying the rise of populism represents a particularly important case of contemporary political analysis (Hunger and Paxton Reference Hunger and Paxton2022; Mudde and Kaltwasser Reference Mudde and Kaltwasser2018). Populist parties and actors have been identified as one of the main challenges in liberal societies, posing a dangerous threat to democratic values (e.g., Urbinati Reference Urbinati1998) and driving ideological polarization (Roberts Reference Roberts2022). Others, however, describe populism as a corrective to representative democracy, giving a voice to those who feel unheard and excluded (e.g., Laclau Reference Laclau2005). The common core of populists across the globe is their emphasis on an antagonistic relationship between the virtuous people and the corrupt elite (Bonikowski and Gidron Reference Bonikowski and Gidron2016; Mudde Reference Mudde2004). Understanding populist rhetoric and claims that support this antagonism is thereby key to explaining their electoral success (de Vreese et al. Reference de Vreese, Esser, Aalberg, Reinemann and Stanyer2018). By focusing on populist language, researchers can develop more granular measurements regarding its dynamics and contexts in comparison to, for instance, classic survey items (Klamm, Rehbein, and Ponzetto Reference Klamm, Rehbein and Ponzetto2023).
Yet, most efforts to detect populism in texts do not unleash the potential of state-of-the-art NLP models. Even recent (quantitative) approaches apply dictionaries to identify populist statements (Gründl Reference Gründl2022). Since dictionaries are simple frequency counts based on manually curated lists of phrases, they can neither consider the context in which a word is used nor identify more abstract meanings (e.g., idioms). Those (and other) shortcomings have been mostly overcome by transformer-based models (Vaswani et al. Reference Vaswani2017). Transformers can capture words’ contextual information and long-distance dependencies so that their increased prediction accuracy set new standards for NLP model architectures. In particular, BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) provides a pre-trained language representation that can be fine-tuned with relatively small samples and outperforms traditional ML approaches (Wankmüller Reference Wankmüller2022). Those promises notwithstanding, only few studies have made use of transformer-based models to detect populism—one focusing on the U.S. (Bonikowski, Luo, and Stuhler Reference Bonikowski, Luo and Stuhler2022), the other dedicated to extracting entities (Klamm, Rehbein, and Ponzetto Reference Klamm, Rehbein and Ponzetto2023).
This paper aims to extend this rather short list. We emphasize two main contributions:Footnote
1
first, we introduce a unique dataset annotated by five specialized coders based on German plenary debates from 2013 to 2021 (8,795 sentences). We focus on two concepts that make up “populism as content” (de Vreese et al. Reference de Vreese, Esser, Aalberg, Reinemann and Stanyer2018): anti-elitism and people-centrism. To investigate how the “thin-centered ideology” (Mudde Reference Mudde2004; Mudde and Kaltwasser Reference Mudde and Kaltwasser2018) of populism is “thickened,” we further annotate how it is attached to left-wing (i.e., socialism) or right-wing (i.e., nativism) host ideologies (Hunger and Paxton Reference Hunger and Paxton2022). Second, this paper presents PopBERT, a readily applicable classifier to detect populism and its host ideology for the German language based on the
 $GBERT_{Large}$
model (Chan, Schweter, and Möller Reference Chan, Schweter and Möller2020). However, as a complex phenomenon that eludes clear-cut “right” or “wrong” distinctions, populism presents a challenging task for NLP models that are most often trained on objective, binary ground-truth data (Plank Reference Plank2022). We will therefore discuss several validity checks to explain how PopBERT performs substantively to underline its capability to detect German populist language in a fine-grained, context-sensitive manner.
$GBERT_{Large}$
model (Chan, Schweter, and Möller Reference Chan, Schweter and Möller2020). However, as a complex phenomenon that eludes clear-cut “right” or “wrong” distinctions, populism presents a challenging task for NLP models that are most often trained on objective, binary ground-truth data (Plank Reference Plank2022). We will therefore discuss several validity checks to explain how PopBERT performs substantively to underline its capability to detect German populist language in a fine-grained, context-sensitive manner.
2 Detecting Populism in Texts
Manual content analysis has a long tradition in the social sciences, such as for the measurement of populism (for an overview, see Aslanidis Reference Aslanidis2018). In their pioneering work, Jagers and Walgrave (Reference Jagers and Walgrave2007) used manual coding to measure populism in six Belgian parties’ political television broadcasts. They define populism as a communicative appeal to the people, including references to the sovereignty of the people and the popular will, which might be complemented by anti-elitism and exclusionism of certain groups. In contrast, Ernst, Engesser, and Esser (Reference Ernst, Engesser and Esser2017b) use an ideational definition of populism introduced by Mudde (Reference Mudde2004), in which anti-elitism plays a constitutive part to identify populist key messages in Facebook and Twitter posts. Most recently, Schürmann and Gründl (Reference Schürmann and Gründl2022) manually examined 3,500 Facebook posts and demonstrated that outsider parties more frequently combine populist and crisis-related content compared to established parties. As every element of the corpus is individually evaluated against the codebook, manual coding may be seen as gold standard regarding the validity of text analysis. However, manual content analysis faces severe constraints concerning the feasible amount of data and metrics’ reliability. This forces researchers, for instance, to select samples (Schürmann and Gründl Reference Schürmann and Gründl2022) or make qualitative choices on which statements should be coded (Ernst, Engesser, and Esser Reference Ernst, Engesser and Esser2017b). Others use holistic grading to scale complete texts for a comparative analysis of populist leaders (Hawkins and Kaltwasser Reference Hawkins and Kaltwasser2018). While shifting the level of coding, holistic grading does not solve the problem of reliability and feasibility for large corpora.
Expert-curated dictionaries represent such an approach by providing static, discrete definitions for individual words. Among the first to implement dictionary-based approaches to measure populism are Rooduijn and Pauwels (Reference Rooduijn and Pauwels2011). Following the definition of Mudde (Reference Mudde2004), they conceptualize populism as a thin ideology with the central concepts of people-centrism and anti-elitism. The authors argue that their dictionary approach addresses weaknesses of previous studies, such as the low reliability of holistic grading (Hawkins Reference Hawkins2009) or the lack of addressing validity as in Jagers and Walgrave (Reference Jagers and Walgrave2007). Bonikowski and Gidron (Reference Bonikowski and Gidron2016) seek to detect populist claims in U.S. presidential elections campaign speeches. Similarly, Gründl (Reference Gründl2022) develops a dictionary for measuring populism in social media postings of German-speaking politicians and parties which yields a better fit to expert ratings than previous approaches. Although dictionary-based measurements handle large amounts of processed text with perfect reliability, they have constraints regarding the significant manual work needed to design rule-based heuristics accounting for even basic linguistic patterns like negations, and, much more so, context-sensitive meanings or paraphrasing idioms. Furthermore, dictionaries attempting to capture populism vary widely in the number and conjugations of terms used, with no clear criterion for what an extensive dictionary might be (Pauwels Reference Pauwels, Heinisch, Holtz-Bacha and Mazzoleni2017).
These (and other) shortcomings have been tackled by next-generation language representations, in particular, by transformer models. The landmark model was developed by Vaswani et al. (Reference Vaswani2017). The key innovation of the transformer architecture is the ability to represent words together with their contexts, that is, different occurrences of the same word are represented by different vectors. Transformers achieve this by employing self-attention, a mechanism that enables the model to attend to different parts of the input and to determine their relative importance. Since the attention mechanism used in transformer models can consider the whole input sequence, it can capture long-range dependencies and effectively model complex linguistic phenomena like polysemy (e.g., multiple meanings of “good”) or idioms (e.g., “on cloud nine”).
However, we only identified two related studies using transformer models, and two other papers that use supervised machine learning. Bonikowski, Luo, and Stuhler (Reference Bonikowski, Luo and Stuhler2022) characterize populism as anti-elitism when communicated in a moralizing way. They detect anti-elitism in speeches of presidential election campaigns in the U.S. at the level of paragraphs by fine-tuning six independent binary transformer-based RoBERTa models. Dai and Kustov (Reference Dai and Kustov2022) also apply an ideational framework and aim to identify anti-elitism as well as people-centrism. While they use the same data source as Bonikowski, Luo, and Stuhler (Reference Bonikowski, Luo and Stuhler2022), they rely on Doc2Vec embeddings instead of transformers. The same approach is used by Di Cocco and Monechi (Reference Di Cocco and Monechi2022). Instead of annotating text or paragraphs, they characterize the samples for each speaker as being populist or not by assigning labels based on their party family. As Jankowski and Huber (Reference Jankowski and Huber2023) lay out in their detailed critique on Di Cocco and Monechi (Reference Di Cocco and Monechi2022), however, deriving a measure by learning a classifier based on the differences in the communicative styles of groups is insufficient. The classification then just resembles the measurement of the group-discerning features plus some error due to misclassification. Only recently, Klamm, Rehbein, and Ponzetto (Reference Klamm, Rehbein and Ponzetto2023) introduced an annotated dataset of German parliamentary speeches from 2017 to 2021. They label references to the people and the elite, building on Mudde’s ideational framework outlined by Wirth et al. (Reference Wirth2016). While their data and theoretical background are close to our approach, they do not classify anti-elitism or people-centrism in text snippets but focus on detecting entities (e.g., organizations or persons) that refer to the people or the elite (or their antidotes).
Summarizing the state of the art in detecting populism in texts, we find, first, that most scholars apply an ideational approach with an emphasis on anti-elitism (Mudde Reference Mudde2004). Second, prior studies use varying lengths of coding units. As the type of text snippets varies (sometimes even within studies through different lengths of paragraphs), this reduces comparability (Aslanidis Reference Aslanidis2018). Third, only a few attempts to detect populist language exist that exploit the possibilities of state-of-the-art NLP models. Since the utilization of transformer-based classifications rests on concise annotations, we elaborate on the theoretical understanding of populism in the next section.
3 Conceptualizing Populism
Populism, even in its narrow use as a scientific concept, covers different understandings of the phenomenon (for an overview of the literature on populism, see Hunger and Paxton Reference Hunger and Paxton2022; Rovira Kaltwasser et al. Reference Rovira Kaltwasser, Taggart, Espejo and Ostiguy2017). Nevertheless, the literature increasingly converges on the ideational definition (Bonikowski, Luo, and Stuhler Reference Bonikowski, Luo and Stuhler2022; Hawkins et al. Reference Hawkins, Carlin, Littvay and Kaltwasser2019; Klamm, Rehbein, and Ponzetto Reference Klamm, Rehbein and Ponzetto2023; Mudde Reference Mudde2004). In this conceptualization, populism concerns an antagonistic relationship between the corrupt elite and the virtuous people. Indeed, even scholars working within alternative theories of populism such as the discourse-theoretical (Laclau Reference Laclau2005) and sociocultural definitions (Moffitt Reference Moffitt2016; Ostiguy Reference Ostiguy, Kaltwasser, Taggart, Espejo and Ostiguy2017) refer to these key components of populism. The ideational approach thus rests on two central concepts: anti-elitism and people-centrism. While populism is viewed as a “thin-centered ideology” (Mudde Reference Mudde2004; Mudde and Kaltwasser Reference Mudde and Kaltwasser2018)—a set of ideas with limited programmatic scope compared to “thick ideologies” like nativism or socialism (to which populism may be attached)—it is often used in discourses to frame content (de Vreese et al. Reference de Vreese, Esser, Aalberg, Reinemann and Stanyer2018). Following this characterization, populism is a set of ideas that can be discursively expressed (Hawkins and Kaltwasser Reference Hawkins and Kaltwasser2017).
Populists claim to express the “will of the people” (Hawkins et al. Reference Hawkins, Carlin, Littvay and Kaltwasser2019), in which the people are characterized as homogenous or monolithic (Albertazzi and McDonnell Reference Albertazzi and McDonnell2008; Jagers and Walgrave Reference Jagers and Walgrave2007; March Reference March2012). However, who belongs to these people is only an “imagined heartland” (Mudde Reference Mudde2004; Taggart Reference Taggart2000). Conceptions of the people may be, for instance, cultural (as a nation or ethnos) or economic (as a class-based understanding of deprived citizens; Kriesi Reference Kriesi2014; Canovan Reference Canovan, Mény and Surel2002). To which groups politicians appeal (Thau Reference Thau2019) and to which they make claims (Saward Reference Saward2006) is therefore a question of who they view as part of their represented constituency. Similarly to the differing interpretations of the people, the elite depends on the context and host ideology. Different groups may be targeted, such as political, economic, cultural, intellectual, or legal elites (Albertazzi and McDonnell Reference Albertazzi and McDonnell2008; Jagers and Walgrave Reference Jagers and Walgrave2007).
If the attached host ideology of populists is nativism, scholars speak of right-wing populism (Mudde Reference Mudde2007). Nativism is defined as “an ideology, which holds that states should be inhabited exclusively by members of the native group (‘the nation’) and that non-native elements (persons and ideas) are fundamentally threatening to the homogenous nation-state” (Mudde Reference Mudde2007, 18). Essentially, nativism is an exclusionary worldview that primarily defines the people by who and what does not belong to it: immigrants, asylum seekers or (indigenous) ethnic minorities, “sexual deviants,” feminists, welfare recipients, or international organizations (Mudde and Kaltwasser Reference Mudde and Kaltwasser2013; Rooduijn, de Lange, and van der Brug Reference Rooduijn, de Lange and van der Brug2014). Thus, nativism can be understood as the ideological core of radical right ideology so that we speak of right-wing populism when it is attached to populist language (Habersack and Werner Reference Habersack and Werner2023; Mudde Reference Mudde2007; Rooduijn and Akkerman Reference Rooduijn and Akkerman2017).
In contrast to right-wing populism, which defines who is part of the people in exclusionary terms, left-wing populism is inclusionary rather than exclusionary (Mudde and Kaltwasser Reference Mudde and Kaltwasser2013). They claim to represent socio-economically marginalized groups such as immigrants, LGBTQI or unemployed people (March Reference March2017; Rooduijn and Akkerman Reference Rooduijn and Akkerman2017). Hence, left-wing populism focuses on class as its defining feature. It frames the people mainly as “the deprived” in socio-economic terms and elites as part of profiteers of the capitalist (neoliberal, market-oriented) system (March Reference March2012).
Regardless of left-wing or right-wing ideologies, the relationship between people and elites is described as oppositional and antagonistic, representing a moral dichotomy (Dai and Kustov Reference Dai and Kustov2022; Hawkins Reference Hawkins2009; Hawkins et al. Reference Hawkins, Carlin, Littvay and Kaltwasser2019; Mudde Reference Mudde2004). This Manichean struggle defines virtuous people who oppose a corrupt elite (Rovira Kaltwasser et al. Reference Rovira Kaltwasser, Taggart, Espejo and Ostiguy2017; Hawkins Reference Hawkins2009). Populism is thus based on a moral divide: the people are understood as good and pure, and the elite as bad and evil. While the people are the only legitimate source of power (Aslanidis Reference Aslanidis2018), the elite deprives the people of rights, values, wealth, or even their identity (Albertazzi and McDonnell Reference Albertazzi and McDonnell2008; Aslanidis Reference Aslanidis2018). Hence, anti-elitism or people-centrism has to be combined with moralistic language to be considered as populist language. This also enables us to distinguish between a rational critique of elites and populist language. Like other recent studies, we therefore consider a moralizing frame as a necessary condition for any populist statement and take it as a modeling challenge to measure it (Bonikowski, Luo, and Stuhler Reference Bonikowski, Luo and Stuhler2022; Dai and Kustov Reference Dai and Kustov2022; Klamm, Rehbein, and Ponzetto Reference Klamm, Rehbein and Ponzetto2023; Mudde Reference Mudde, Kaltwasser, Taggart, Espejo and Ostiguy2017). Thus, we view all three defining characteristics as necessary conditions of populist language.
4 Data and Methods
4.1 Model Architecture
If key components of the populist worldview (i.e., moralizing anti-elitism/people-centrism) are expressed publicly, it is possible to determine the relative strength of populist language rather than categorizing actors as populist or non-populist a priori (Aslanidis Reference Aslanidis2016; Hawkins et al. Reference Hawkins, Carlin, Littvay and Kaltwasser2019). Thus, instead of understanding an actor as populist or non-populist, we classify their communications (Rooduijn, de Lange, and van der Brug Reference Rooduijn, de Lange and van der Brug2014; de Vreese et al. Reference de Vreese, Esser, Aalberg, Reinemann and Stanyer2018). For that purpose, we rely on fine-tuning a BERT model. BERT (Bidirectional Encoder Representations from Transformers) is the most well-known transformer-based pre-trained model for English (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). While the seminal paper by Vaswani et al. (Reference Vaswani2017) used a left-to-right architecture in which every token only attended to previous ones, Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019) incorporated context from both directions. The procedure involves masking a random subset of words in a given input and training the model to predict the missing words based on their context. While the essence of BERT is relatively simple—predict each of the masked words by its context—pre-training the model on large-scale corpora provides enough contextualized information to capture a deep understanding of language.
In particular, we rely on
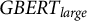 $GBERT_{large}$
(Chan, Schweter, and Möller Reference Chan, Schweter and Möller2020). We utilize the pooled output of the trained model and a following linear layer with a tanh activation function. Building upon this, we employ a fully connected layer with a sigmoid activation function and choose binary cross-entropy loss as our loss function. Hence, we follow common settings for this model and task.Footnote
2
$GBERT_{large}$
(Chan, Schweter, and Möller Reference Chan, Schweter and Möller2020). We utilize the pooled output of the trained model and a following linear layer with a tanh activation function. Building upon this, we employ a fully connected layer with a sigmoid activation function and choose binary cross-entropy loss as our loss function. Hence, we follow common settings for this model and task.Footnote
2
4.2 Corpus
We fine-tune
 $GBERT_{Large}$
with parliamentary debates of the German Bundestag. Fine-tuning improves downstream performance and reduces the need for heavy engineering of task-specific architectures (Wankmüller Reference Wankmüller2022). Moreover, it usually requires fewer training instances than a standard supervised model that would learn the task “from scratch,” especially in the case of imbalanced data (Miller, Linder, and Mebane Reference Miller, Linder and Mebane2020).
$GBERT_{Large}$
with parliamentary debates of the German Bundestag. Fine-tuning improves downstream performance and reduces the need for heavy engineering of task-specific architectures (Wankmüller Reference Wankmüller2022). Moreover, it usually requires fewer training instances than a standard supervised model that would learn the task “from scratch,” especially in the case of imbalanced data (Miller, Linder, and Mebane Reference Miller, Linder and Mebane2020).
We collect the parliamentary debates from Open Discourse, which provides a relational database with full-text data of Bundestag speeches (Richter et al. Reference Richter2020). The study of legislative debates has long been neglected in research (Proksch and Slapin Reference Proksch and Slapin2012). In the last two decades, however, scholars have begun to discover parliamentary speeches as a means to study contemporary political debates (Bächtiger Reference Bächtiger, Martin, Saalfeld and Strøm2014). In particular, parliamentary speeches are instruments by which politicians are granted visibility from a larger public audience (Tresch Reference Tresch2009). From an analytical perspective to study populism, parliamentary speeches offer “a rich source to learn about representation and party politics […] Unlike party manifestos, whose analysis hinges on a static analysis of party documents released before each election, legislative debates allow for a dynamic and more comprehensive understanding of party positions” (Fernandes, Debus, and Bäck Reference Fernandes, Debus and Bäck2021, 1034).
To ensure comparability of language comprehension within the dataset, we focus on a period covering the 18th and 19th legislative terms (October 2013 to October 2021). We chose this time frame because the AfD (Alternative for Germany) entered the parliament in 2017. Thus, our corpus spans their appearance and a prior period. This period of the Bundestag corpus allows researchers to study if and how political language is affected by populist challengers.
A speech is defined as all verbal acts delivered by an actor during a single plenary session. We only use speeches assigned to a political faction, leaving us with a corpus of 32,348 speeches.Footnote 3 However, the duration of contributions in the German Bundestag varies significantly, because speeches are delivered orally and transcribed by parliamentary staff so that segmentations (e.g., paragraphs) are often neither reliable nor comparable (Aslanidis Reference Aslanidis2018). Therefore, our investigation rests on the fine-grained level of grammatical sentences providing researchers with the flexibility to aggregate scores on the desired level.Footnote 4 In total, the final corpus comprises 1,258,876 sentences.
4.3 Annotation Process
The performance of a classification task rests, to large parts, on the quality of the annotations that underlie the fine-tuning of BERT. However, the literature does not provide universally valid recommendations, particularly when it comes to fuzzy and ambiguous concepts like populism (Klamm, Rehbein, and Ponzetto Reference Klamm, Rehbein and Ponzetto2023; Uma et al. Reference Uma, Fornaciari, Hovy, Paun, Plank and Poesio2021). To detect populist language, we therefore rely on specialized annotators instead of crowd workers.Footnote 5
We created a detailed codebook (see Appendix 2 of the Supplementary Material) based on Wirth et al. (Reference Wirth2016) and Ernst, Engesser, and Esser (Reference Ernst, Engesser and Esser2017b). We stick as closely as possible to the theoretical arguments outlined in Section 3 and aim to identify anti-elitism and people-centrism. As a necessary condition, annotators were instructed to label these dimensions only when the sentence contained moralistic language. Since both dimensions may appear separately, annotators assess both labels independently and can assign multiple annotations per sentence. Therefore, as outlined below, we follow a multilabel approach (Erlich et al. Reference Erlich, Dantas, Bagozzi, Berliner and Palmer-Rubin2022).Footnote 6
Furthermore, annotators also coded left-wing or right-wing host ideology, yet only if it co-occurred with one of the two core dimensions.Footnote 7 For instance, if the people are described as excluding non-native groups, the text should be marked as right-wing. When the people are viewed from a class-based perspective instead (e.g., “the workers”), the sentence should be labeled as left-wing.
We started the annotation process with a stratified random sample of 2,858 sentences. A first stratum ensured sufficient representation of all parties by sampling uniformly from the speeches of all parties. Since populist rhetoric is a rare event in parliamentary speeches, we used the dictionary from Gründl (Reference Gründl2022) as a second stratum. It allowed us to draw an equal number of positive and negative scoring sentences for each party.
We ran seven additional rounds of annotations, each consisting of between 500 and 1,000 sentences. We utilized active learning to derive samples that maximize performance. Active learning is a common method in ML to reduce the labeling effort by selecting cases from which the supervised models profit most (Miller, Linder, and Mebane Reference Miller, Linder and Mebane2020). In our case, we focused on ambiguous cases (i.e., edge cases) and cases from underrepresented categories.
In total, this iterative process yielded 8,795 annotated sentences. The number of sentences by dimension can be found in column N of Table 1. Therein, we also provide the percentage agreement among coders for sentences (proportion of sentences where all coders agree on a label), Fleiss’
 $\kappa $
(a chance-adjusted multi-annotator metric, so it is not dependent on the number of positive cases; Fleiss Reference Fleiss1971), and the averaged pairwise F1 score over all coders. While the percentage agreement naturally increases as the dimension becomes less prevalent in the dataset,
$\kappa $
(a chance-adjusted multi-annotator metric, so it is not dependent on the number of positive cases; Fleiss Reference Fleiss1971), and the averaged pairwise F1 score over all coders. While the percentage agreement naturally increases as the dimension becomes less prevalent in the dataset,
 $\kappa $
achieves only moderate values. However, the agreement of our coders is comparable to other studies that also annotate rather subjective concepts like morality (e.g., Kobbe et al. Reference Kobbe, Rehbein, Hulpus and Stuckenschmidt2020) or emotions (e.g., Wood et al. Reference Wood, McCrae, Andryushechkin and Buitelaar2018).
$\kappa $
achieves only moderate values. However, the agreement of our coders is comparable to other studies that also annotate rather subjective concepts like morality (e.g., Kobbe et al. Reference Kobbe, Rehbein, Hulpus and Stuckenschmidt2020) or emotions (e.g., Wood et al. Reference Wood, McCrae, Andryushechkin and Buitelaar2018).
Table 1 Number of annotated sentences in the dataset. In total, 8,795 sentences were annotated by five coders each. Column N indicates how many of these sentences were labeled by at least one coder with the respective dimension. The remaining three columns provide information about the inter-annotator agreement among the five coders for each dimension.

The next crucial step was the aggregation of annotations, that is, deciding how to deal with annotator disagreement. The most common approach in NLP is majority voting—selecting the most frequently occurring label among all annotations for each sentence as ground truth. However, such an approach has significant limitations (Davani, Díaz, and Prabhakaran Reference Davani, Díaz and Prabhakaran2022; Uma et al. Reference Uma, Fornaciari, Hovy, Paun, Plank and Poesio2021). First, insisting on a singular truth can neglect the subtle characteristics of the analyzed concept. Second, annotators’ personal experiences, socio-demographic background, and beliefs can affect their judgments, especially for subjective tasks such as identifying hate speech or political stances. As a result, majority voting might marginalize less common viewpoints (Cabitza, Campagner, and Basile Reference Cabitza, Campagner and Basile2023).Footnote 8
Our inter-annotator agreement results indicated that identifying populism is such a subjective task. Moreover, discussions with annotators showed that, in particular, the condition of moralistic language was disputed. We therefore decided that each labeled instance might reflect an aspect of populism. Hence, if at least one coder identifies a dimension of populism in a sentence, we assume that there is something worth learning for the model, and we take this sentence as a positive instance.Footnote 9
The classification represents a multilabel task in which each sentence may encompass multiple dimensions simultaneously. Take the following sentence as an example: “The consequences of your [the government] inaction are paid by society, paid by taxpayers, paid by farmers.”Footnote 10 In this sentence, the elite is criticized with a moralizing undertone. At the same time, the speaker aligns themselves with the people, represented by “taxpayers” and “farmers,” which provides compelling evidence to label it as people-centric. Using a multilabel model has another advantage, we augment our data on the populist dimensions by learning the host ideology separately. In a multiclass model, we would need to create all combinations of our dimensions: left-wing, neutral, and right-wing anti-elite (the same for people-centrism). The classification in the neutral anti-elite category would no longer be influenced by the samples that fall into either of the other two categories. Using a multilabel approach, we resolve this division and learn the categories independently.
5 Results
To meet the requirements of the complex task of detecting populist language in text, we present, on the one hand, common performance indicators for ML models, that is, precision, recall, and summarizing F1 scores for each dimension. On the other hand, we employ a battery of validity checks to (i) examine the intuition behind typical sentences for each dimension, (ii) aggregate sentences on the level of parties and speakers to compare our results to expert surveys and other classification models, and (iii) measure external validity by out-of-sample predictions.
5.1 Model Performance
We used a train-test split of 80% to 20%. A five-fold grid search cross-validation on the train set indicated a batch size of eight, a learning rate of 9e-6 (combined with a cosine annealing learning rate scheduler), a weight decay of 0.01, and three epochs as the best hyperparameter setup.
The performance of PopBERT is shown in Table 2.Footnote 11 Of the two main dimensions, the model’s ability to detect anti-elitism is clearly higher than for people-centrism. This is in accordance with results reported by Klamm, Rehbein, and Ponzetto (Reference Klamm, Rehbein and Ponzetto2023). There may be two reasons: first, we found around twice as many instances of anti-elitism in the Bundestag corpus than people-centrism; second, the definition of people-centrism relies more on individual perspectives (e.g., which groups qualify as instances of “the people”). However, even the lower F1 scores for people-centrism are in the same range as reported by Bonikowski, Luo, and Stuhler (Reference Bonikowski, Luo and Stuhler2022)—albeit for different dimensions, but in a similar setup. While we do not have any comparable studies for detecting left-wing or right-wing populist ideology in text, the F1 scores of 0.73 and 0.67, respectively, represent no outliers from our main dimensions.
Table 2 Performance of the model on the 20% test set.

A tendency across almost all dimensions in Table 2 is that recall is higher than precision. While false negatives (responsible for low recall) would be eliminated from a subsequent evaluation of the results and cannot be examined or adjusted, aggregating multiple predictions (e.g., one prediction per sentence of a speech) or setting higher thresholds should reduce the number of false positives (responsible for low precision). Since our classifier will mostly be applied to aggregated levels (e.g., speakers), we argue that higher values on recall—which will not be improved by aggregations—are more important than precision—which can be mitigated by aggregating.
5.2 Revealing Populist Language in the Bundestag
Out of all 1,258,876 classified sentences from the 18th and 19th Bundestag, we find 7.4% to contain anti-elitism, 2.1% people-centrism, 1.2% a left-wing host ideology, and 0.5% a right-wing host ideology. The first attempt to validate the classifications is to examine the intuition behind typical sentences for each dimension. For that purpose, we selected sentences representing different dimensions and combinations thereof to provide qualitative insights into how the model works (Table 3). While we have no ground truth in a strict sense, the predictions make intuitive sense (more examples based on a stratified random sample can be found in Appendix 3 of the Supplementary Material).
Table 3 Selected examples. Three sentences have been manually selected that correspond to only one of the two core dimensions (anti-elitism or people-centrism) as well as three sentences containing both dimensions simultaneously. For each of these, one sentence is predicted to be neutral, one is attached to a left-wing, and one to a right-wing host ideology.

Note: Bold values lie above the thresholds stated in footnote 11.
Consider the examples of anti-elitism (sentences 1–3 in Table 3). As described by theory, each of them addresses parts of the perceived elite in a moralizing way (i.e., opposition parties, speculators, and “your policies”). Sentence 2 is also attached to the left-wing ideology since the criticized group is part of the financial elite, which is one of the main antagonists of the political left. In contrast, sentence 3 criticizes the government’s execution of the asylum policy, a typical link made by right-wing ideologists. Accordingly, the sentences illustrating people-centrism address either “the(se) people” directly (sentences 4 and 5), or representative parts like “the German taxpayer” in sentence 6. The last group of examples shows instances that contain both dimensions, that is, addresses a perceived elite in a pejorative way and makes a claim for the people (or some explicit part of those, e.g., “tenants,” “taxpayers on earth,” or “German female retirees”). The model marks sentences revolving around social class as left-wing and statements that seek to blame immigrants as right-wing.
Table 3 also indicates a comparison to the approach of Gründl (Reference Gründl2022). Although he did not intend to identify populist language in parliamentary speeches but in social media posts, his dictionary is the only other classifier of German populist speech. However, many of the classified sentences by PopBERT would not have been considered populist by a dictionary approach. If we, for example, look at sentence 9, our classifier assigns anti-elitism, people-centrism, and right-wing populism, while the dictionary does not consider it as populist language. Sentence 6 exemplifies an instance of people-centrism. Here, the idiom referring to the people represented by the German taxpayer is not detected by the dictionary approach.
Many important questions of political analysis are, however, not answered on the level of sentences but address aggregations of texts. Figure 1 presents the average values of populist rhetoric for each dimension by party.Footnote 12 Each dimension confirms the expected results: the AfD demonstrates by far the highest values in the right-wing and anti-elitist dimensions, while politicians from DIE LINKE use more left-wing populist sentences than the other parties. Interestingly though, the AfD also exhibits a considerable share of left-wing utterances. In general, the distribution of people-centrism across all parties is more balanced than anti-elitism, with the AfD, LINKE, and SPD most often using people-centric sentences.

Figure 1 Populist dimensions in speeches of the Bundestag, by party. Each dimension represents the average of model predictions across all sentences for each party. The values are normalized to their maximum value to highlight the proportions between the parties. Subplots with unstandardized values can be found in Appendix 4 of the Supplementary Material.
We can also compare PopBERT’s predictions on the party level with the Chapel Hill Expert Survey (CHES; Jolly et al. Reference Jolly2022) and the Populism and Political Parties Expert Survey (POPPA; Meijers and Zaslove Reference Meijers and Zaslove2021). Both surveys are conducted by field experts and cover two dimensions that roughly correspond to the definitions of anti-elitism and people-centrism used throughout this paper. Due to the differing temporal coverage, we juxtapose the CHES data from 2019 and the POPPA data from 2018 with the values we have calculated for the 19th term. We find strong correlations (Pearson’s r,
 $N=6$
) for both anti-elitism (
$N=6$
) for both anti-elitism (
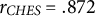 $r_{CHES}=.872$
,
$r_{CHES}=.872$
,
 $r_{POPPA}=.830$
) and people-centrism (
$r_{POPPA}=.830$
) and people-centrism (
 $r_{CHES}=.785$
,
$r_{CHES}=.785$
,
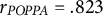 $r_{POPPA}=.823$
), indicating that our results align well with the ratings of experts as expressed in the surveys.
$r_{POPPA}=.823$
), indicating that our results align well with the ratings of experts as expressed in the surveys.
Yet, some scholars argue that it is a combination of both dimensions, anti-elitism and people-centrism, that constitutes populist statements (Dai and Kustov Reference Dai and Kustov2022). To meet this definition, we compare several aggregation strategies. First, we propose a simple multiplicative index. For that purpose, we take the average for each dimension over all statements of a party (or any other level) during a certain period and then multiply both averages. This ensures that higher values in both dimensions also result in a higher index value, while the absence of at least one dimension yields an index value of 0. Furthermore, it penalizes textual units where the dimensions are distributed unevenly compared to units with a more equal distribution over both dimensions.
Panel (a) of Figure 2 displays the results of the multiplicative populism index per party and speech in the 18th and 19th Bundestag. Again, we observe the highest manifestation of populism in speeches of the AfD, followed by DIE LINKE, while the governing parties are found at the lower end of the spectrum.Footnote 13

Figure 2 Populism by party in the 18th and 19th Bundestag using different aggregation methods. The panels depict (a) a multiplicative index of populism, (b) the Goertz Index, (c) the Bollen Index, and (d) the Sartori Index.
Yet, how researchers aggregate multidimensional concepts has wide-ranging implications (Wuttke, Schimpf, and Schoen Reference Wuttke, Schimpf and Schoen2020). We therefore compare three additional operationalizations as brought forward by Wuttke, Schimpf, and Schoen (Reference Wuttke, Schimpf and Schoen2020) comprising (i) the Bollen Index, which is defined as the mean of both dimensions; (ii) the Goertz Index, which is the minimum of both dimensions; and (iii) the Sartori Index, defined as 1 if both dimensions are above a certain threshold and 0 otherwise (panel (b)–(d) of Figure 2).Footnote 14 The alternative measures show similar results like the multiplicative index (Figure 2). However, the difference between the AfD and other parties is particularly pronounced using the multiplicative index.
As an additional validation, we aggregate sentences by members of the parliament in order to create a ranking of politicians using the most populist rhetoric.Footnote 15 Table 4 presents politicians with the highest propensity for populist statements and indicates two notable trends: first, the entry of the AfD into the Bundestag brought about a significant shift. In the 18th term, politicians of DIE LINKE dominated the list. Since entering in 2017, however, AfD members clearly took the lead in using populist language. Second, top-ranking individuals in both terms are prominent public figures known for their provocative statements. These figures include, for instance, Sarah Wagenknecht (DIE LINKE), who has authored several controversial books, has a substantial followership on social media platforms, and, only recently, funded her own party. In the 19th term, Alice Weidel was among the politicians using populist rhetoric most frequently. She is also a controversial political figure with a significant social media presence.
Table 4 Ranking of members in the German Bundestag using populist language, 18th and 19th electoral term. The ranking rests on a multiplicative index for anti-elitism and people-centrism. Alternative aggregation strategies are presented in Appendix 7 of the Supplementary Material.

One of the main challenges for developing a language model to detect populism in texts—as it is for many complex phenomena (Plank Reference Plank2022)—is the lack of a binary answer of whether a label or prediction is correct. As a final step, we therefore searched the literature for “true” populist statements, that is, experts claim that a statement is populist. We identified four studies that provide 17 prototypical examples of populist statements from Facebook posts (Ernst et al. Reference Ernst, Engesser, Büchel, Blassnig and Esser2017a; Schürmann and Gründl Reference Schürmann and Gründl2022) and presidential campaign speeches (Bonikowski, Luo, and Stuhler Reference Bonikowski, Luo and Stuhler2022; Dai and Kustov Reference Dai and Kustov2022) (see Appendix 5 of the Supplementary Material for details). We use these text snippets for an out-of-sample prediction. For 16 out of 17 sample sentences (94.1%), the classifier predicts at least one of the core dimensions correctly. The single exception is a sentence that represents a populist dimension—“restoring sovereignty” (Ernst, Engesser, and Esser Reference Ernst, Engesser and Esser2017b)—that is not part of the theoretical concept underlying PopBERT (cf. Section 3). Even though each example’s wording, style, and length differ considerably, the results strongly support the notion that PopBERT is able to detect different dimensions of populism in out-of-sample texts.
6 Discussion
This paper introduced PopBERT, a transformer-based language model to identify populist language. The model was trained on speeches from the German parliament spanning 2013 to 2021. Using a widely accepted theoretical framework, we annotated two key dimensions of populism: anti-elitism and people-centrism. Additionally, we labeled instances in which left-wing or right-wing host ideologies are attached to the “thin ideology” of populism (Mudde Reference Mudde2004). The resulting multilabel classifier demonstrated high precision and, in particular, recall. We further assessed the model’s concept validity through out-of-sample performance and its correspondence to intuitive and expert judgments at different aggregation levels.
Various potential applications of PopBERT can be envisioned. For instance, researchers may identify rhetorical patterns, contextual factors, or temporal dynamics underlying populist language and so examine how populists frame their messages and which social, economic, or cultural issues they emphasize. Information on personal characteristics of politicians might also contribute to current calls in the CL community for a closer inspection of the interplay between socio-demographic attributes and language usage (Hovy and Yang Reference Hovy and Yang2021). Studies merging personal characteristics with political content—such as the correlation between politicians’ gender and their prevalent issues (Bäck and Debus Reference Bäck and Debus2019)—already exemplify promising avenues for future research. Ultimately, PopBERT’s ability to identify populist statements, investigate their content, and link them to personal attributes may shed light on the relationship between the success of populists and their language usage.
The detailed codebook and annotator-level labels might also contribute to methodological advances in detecting complex political concepts in language. Researchers could also apply the model cross-domain and use it, for example, to identify populist language in German newspapers or social media posts. It would be straightforward to enrich the dataset with only a small amount of domain-specific data and train a customized model according to specific needs.
While the ambiguity of the populism concept yielded only moderate agreement rates similar to studies modeling phenomena like emotions or morality (Kobbe et al. Reference Kobbe, Rehbein, Hulpus and Stuckenschmidt2020; Wood et al. Reference Wood, McCrae, Andryushechkin and Buitelaar2018), future comparisons of different methodologies across the same concept should help develop important—and, to a large extent, still missing—guidelines for large-scale language models. In the wake of an emerging perspectivism methodology in CL (Plank Reference Plank2022), we would therefore like to encourage researchers to analyze systematic variations in the coding behavior exhibited by our annotators. Our five coders’ (dis-)agreement could shed further light on which models work best for social constructs such as populism. More elaborate model architectures or a more complex definition of the target labels, such as soft labels (Uma et al. Reference Uma, Fornaciari, Hovy, Paun, Plank and Poesio2020), seem to be promising future research opportunities. Finally, annotations and models might be easily updated with additional labels for existing dimensions or combined with complementary classifiers (Klamm, Rehbein, and Ponzetto Reference Klamm, Rehbein and Ponzetto2023).
An important limitation of PopBERT, however, is that it is trained on plenary debates in the Bundestag, that is, it is limited to (rather formal) German language. Still, there exist several other cases in which it may be applied, for example, the Swiss and Austrian parliaments. The German federal system also rests on 16 state-level parliaments which may allow researchers to compare and contrast subnational with national levels. Nevertheless, the application to other languages represents one of the crucial steps for future research. To facilitate the development of non-German populist classifiers, we provide a multilingual model that may be used as a fundament for detecting populist rhetoric in a variety of languages.
While we intentionally chose sentence-level annotations to create a flexible model with broad applicability, we are aware that longer text segments would have likely reduced disagreement among coders. Selecting text ranges is always a compromise between model applicability and interpretability. We decided to favor applicability using the sentence level because other researchers can then aggregate the predictions to contexts of their choosing such as paragraphs, speeches, politicians, or parties. A final limitation is that our sampling strategy using active learning has yielded a time-specific sample. Therefore, we cannot evaluate how the model performs in other periods. Despite these limitations, PopBERT and its accompanying dataset may provide valuable tools for studying populism in German texts, opening further ways of interdisciplinary research, and contributing to a deeper understanding of the causes and effects of populist language.
Acknowledgements
We are grateful to the anonymous reviewers, Sophia Hunger, Lukas Wertz, Marius Kaffai, and the participants of the SICSS Munich for their insightful comments.
Funding Statement
This research was supported by grants from the Deutsche Forschungsgemeinschaft (DFG, ref. UP 31/1) and the Ministry of Science, Research, and the Arts Baden-Württemberg (Az. 33-7533-9-19/54/5).
Competing Interests
The authors declare no competing interests.
Data Availability Statement
Replication data are available in a Harvard Dataverse repository at https://doi.org/10.7910/DVN/HZMSUR. This repository also holds the manually labeled data and models that are compared in the Supplementary Material. The model installation and usage instructions for the main model are available at https://huggingface.co/luerhard/PopBERT. The code is available at https://github.com/luerhard/PopBERT.
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2024.12.









 Open access
Open access