



Central Tibetan (ISO 639-3, bod) is a Tibetic language that belongs to the Bodish branch of the Tibeto-Burman subgroup within the Sino-Tibetan language family (Thurgood & Lapolla, Reference Thurgood and Lapolla2016). The Tibetic languages refer to a variety of languages that derive from Old Tibetan, including Central Tibetan (Ü-Tsang Tibetan), Khams Tibetan and Amdo Tibetan (Tournadre, Reference Tournadre2014; Tournadre & Suzuki, Reference Tournadre and Suzuki2022; Zhang, Reference Zhang1996). The modern Tibetic languages have many cognates and regular phonological correspondences with Classical Literary Tibetan (Goldstein et al., Reference Goldstein, Rimpoche and Phuntshog1991; Tournadre, Reference Tournadre2014), a common written language developed in the Tibetan cultural sphere, including regions of China, Pakistan, India, Nepal and Bhutan. Most Tibetic languages can be written with the Tibetan script, which preserves the old phonology and orthography of Classical Literary Tibetan.
The Central Tibetan language includes subgroups such as Ü, Tsang, Nagari, etc. (Qu & Jing, Reference Qu and Jing2017; Tournadre & Dorje, Reference Tournadre and Dorje2003; Tournadre & Suzuki, Reference Tournadre and Suzuki2022; Zhang, Reference Zhang1996). The Ü and Tsang dialects are spoken in Lhasa and Shigatse regions respectively. The Ü variety spoken in Lhasa, the capital of the Tibet Autonomous Region (see Figure 1), is generally known as standard spoken Tibetan. It is a regional common language in Central Tibet and is even regarded as the lingua franca of the greater Tibetan areas, including the Amdo and Khams regions, and of overseas Tibetan diasporic communities.
The current illustration describes the sound system of Lhasa Tibetan. It provides a comprehensive synthesis of previous accounts (Dawson, Reference Dawson1980b; DeLancey, 2003; Gong, Reference Gong2020; T. Hu, Reference Hu1980, Reference Hu and Ma2003; Tournadre & Dorje, Reference Tournadre and Dorje2003; Zhou, Reference Zhou1983). Moreover, this paper extends previous work by presenting instrumental phonetic data, which provides further insight on some critical issues about Lhasa Tibetan, e.g., the organization of its vowel, vowel harmony and word-tone systems. Some of these issues remain to be further investigated in future studies. The phonetic data comes from a male speaker (TN) and a female speaker (DY) in their twenties. The two speakers were born in Lhasa and speak Lhasa Tibetan as a native language. They are also fluent in Mandarin Chinese and have a good knowledge of English. Their speech described in this illustration is representative of standard Central Tibetan and broadly conforms to pronunciation standards adopted in standard Central Tibetan textbooks (Chang & Shefts, Reference Chang and Shefts1964; Goldstein & Nornang, Reference Goldstein and Nornang1970; Tournadre & Dorje, Reference Tournadre and Dorje2003; Zhou, Reference Zhou1983)

Figure 1. Map of the Tibet Autonomous Region. The location of Lhasa is indicated by the red triangle.
Consonants

Onset consonant
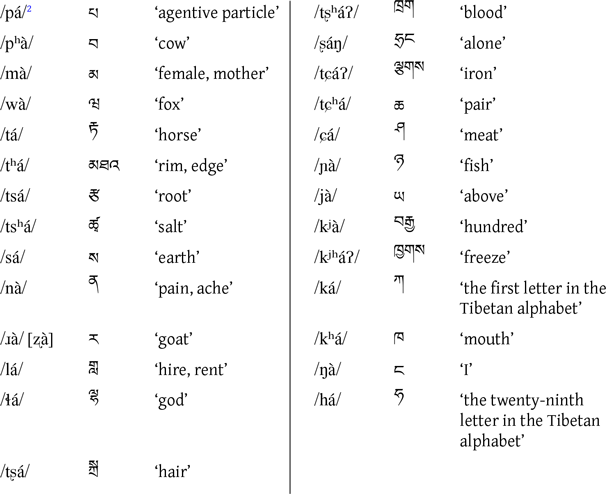
Coda consonant

Plosives, affricates and fricatives
The plosives in Lhasa Tibetan contrast in four places of articulation – bilabial, alveolar, palatalized velar and velar. The distinction between palatalized velar and velar can be discerned from the formant transition (see Figure 2). For example, a notable difference between /k/ and /kʲ/ followed by /a/ lies in the second formant frequency transition. Compared with /ka/, the second formant frequency transition of /kʲa/ exhibits a large and steep fall.

Figure 2. The first, second and third formant frequency trajectories for syllables /kà/ and /kʲà/. The syllable /kà/ is taken from the disyllabic word ‘favorite’ (TN: [kà ɕǿʔ] and DY: [kà ɕø̀ː]). The syllable /kʲà/ is taken from the disyllabic word ‘China’ ([kʲà náʔ]). One example token for each speaker and each consonant category is selected for the illustration.
The plosives also contrast in aspiration – voiceless aspirated and voiceless unaspiratedFootnote 3. The voice onset time (VOT) of the two categories is presented in Figure 3. The aspirated plosives have longer VOT than the unaspirated ones.
Deaspiration can occur for the aspirated plosives and affricates in the second syllable of a disyllabic word (Dawson, Reference Dawson1980b), e.g., DY: [kʲà kɔ́ʔ] < [kʲà] + [kʰɔ́ʔ] ‘Chinese hotpot.’ Both aspirated and unaspirated stops can undergo intervocalic voicingFootnote 4, e.g., DY: [kʲà ɡɛ́ʔ] < [kʲà] + [kɛ́ʔ] ‘the Chinese language.’ In some cases, intervocalic plosive can become an approximant, e.g., TN: [kʲà ɰɔ́ʔ] < [kʲà] + [kʰɔ́ʔ] ‘Chinese hotpot.’
The fricatives in Lhasa Tibetan have four places of articulation – alveolar, alveolo-palatal, retroflex and glottal. The smoothed long-term average spectra (LTAS) of the fricatives are shown in Figure 4. For DY, the alveolo-palatal fricatives have more energy than the alveolar fricatives in the lower-frequency region (e.g., 0–5000 Hz), whereas the opposite is true in the higher-frequency region. However, for TN, the difference is much smaller. The speaker DY also exhibits a canonical distinction in spectral peak, that is, the alveolar fricative exhibits a higher-frequency spectral peak than the alveolo-palatal one, but TN exhibits no difference in spectral peak. The articulatory mechanisms underlying this speaker-specific acoustic difference remain to be determined in future studies.

Figure 3. The VOT (mean + sd) of the initial voiceless aspirated and unaspirated plosives for speakers DY and TN. For each speaker and each aspiration category, eight plosive tokens (two repetitions for each place of articulation) are used in the acoustic analysis.

Figure 4. The smoothed long-term average spectra (LTAS) of the alveolar, alveolo-palatal, retroflex and glottal fricatives for speakers DY and TN. The fricative portion segmented from the speech signal is used for the analysis. For each speaker, the fricative spectra are averaged across two repetitions of the tokens /sá/, /ɕá/, /ʂáŋ/ and /há/.
Realization of /ɹ/
The approximant /ɹ/ has four realizations [ɹ], [ʐ], [ɾ] and [r]. Example waveforms and spectrograms are shown in Figure 5. The /ɹ/ in DY’s production of [ɹìŋ ɕǿʔ] ‘longest’ can be transcribed as an approximant [ɹ] without notable frication. The [ʐ] realization of /ɹ/ occurs in TN’s production of /ɹà/ [ʐà] ‘goat.’ A flap [ɾ] is present in DY’s production of /kʲà ɹíʔ/ [kʲà ɾíʔ] ‘the Chinese people.’ The /ɹ/ can also be realized as a trill [r], e.g., in initial position, TN: /ɹè mø~̀𐋐/ [rè mø~̀𐋐] ‘envision,’ or in final position, TN: /kʰàɹ/ [kʰàr] ‘dancing.’

Figure 5. Waveforms and spectrograms for different realizations of /ɹ/: (1) initial approximant [ɹ-], (2) initial fricative [ʐ-], (3) intervocalic flap [-ɾ-], (4) initial trill [r-], (5) final trill [-r], and (6) long vowel [-Vː].
Consonant deletion and compensatory vowel lengthening
The coda /ɹ/ is frequently dropped in colloquial speechFootnote 5, resulting in compensatory lengthening of the vowel [𐁖ː], e.g., TN: /kʰàɹ/ [kʰàː] ‘dancing’ (see Figure 5). In colloquial speech, /l/ is not pronounced and the vowel is lengthened, e.g., (/kʰɛ́l/), /kʰɛ́ː/ ‘spin (yarn)’. The coda /ŋ/ can be reduced in colloquial speech, leading to vowel lengthening and nasalization as illustrated by the example /kʰáŋ/, /kʰa~́ː/ ‘house.’ The reduction or deletion of a glottal stop [ʔ] can also cause compensatory lengthening of the preceding vowel, e.g., TN: [tʂɔ̀ː ɰʲí] < [tʂɔ̀ʔ] + [kʲʰí] ‘nomad’s dog.’
Fossilized consonants

In Lhasa Tibetan, some consonant segments are silent when a morpheme is produced in isolation but emerge when combined with another morpheme in a phonological word. This phenomenon is called fossilized consonants (DeLancey, 2003). These fossilized consonants are modern reflexes of consonants in a complex onset of Classical Literary Tibetan. A more general term used in the literature for describing this phenomenon is ‘ghost segments,’ which are either not realized phonetically or occur only in some specific contexts. A well-known example of ghost consonants is French liaison, where the liaison consonants are silent in isolation but can emerge between two words (Côté, Reference Côté2011).
For the first example shown in the table, the morpheme ![]() ‘ten’ is pronounced as [tɕú] in isolation. The prefix letter
‘ten’ is pronounced as [tɕú] in isolation. The prefix letter ![]() , which reflects Old Tibetan prefix consonant b (Wylie, Reference Wylie1959), is silent. However, when this morpheme occurs finally in a disyllabic word like ‘forty,’ a resyllabified [p] is added to the preceding syllable [ɕì] ‘four’ as a coda. Then, the disyllabic word ‘forty’ is pronounced as [ɕìp tɕú]. The productivity of fossilized consonants varies for different consonants. The fossilized nasal seems to be more productive than other fossilized consonants (DeLancey, 2003).
, which reflects Old Tibetan prefix consonant b (Wylie, Reference Wylie1959), is silent. However, when this morpheme occurs finally in a disyllabic word like ‘forty,’ a resyllabified [p] is added to the preceding syllable [ɕì] ‘four’ as a coda. Then, the disyllabic word ‘forty’ is pronounced as [ɕìp tɕú]. The productivity of fossilized consonants varies for different consonants. The fossilized nasal seems to be more productive than other fossilized consonants (DeLancey, 2003).
Vowels
Monophthongs
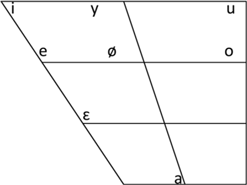


Figure 6. The acoustic vowel space of the eight short vowels (DY: left; TN: right). Each cross denotes the mean F1 and F2. The tokens for the formant frequency analysis are taken from the short vowel example list. The formant frequency values shown are averaged across all the data points of the vowel portion and across two repetitions of each token. The formant frequency is measured using the formant tracking algorithm implemented in PRAAT.
Despite some discrepancies in previous accounts of the Lhasa Tibetan vowel system, it is generally agreed that Lhasa Tibetan distinguishes eight short vowels – /i, e, ɛ, y, ø, u, o, aFootnote 6/ (Dawson, 1980a; DeLancey, 2003; Gong, Reference Gong2020; T. Hu, Reference Hu and Ma2003; Zhou, Reference Zhou1983). Figure 6 shows the acoustic vowel space of the eight short vowels.
The vowels in Lhasa Tibetan can also differ in nasalization and length. Example waveforms and spectrograms for short, long and nasalized vowels produced by TN are shown in Figure 7. The long vowels of Lhasa Tibetan reflect Old Tibetan coronal sonorant codas. The nasalized vowels of Lhasa Tibetan reflect Old Tibetan alveolar nasal coda and sometimes velar nasal coda. The conditioning environments for vowel lengthening and nasalization are not completely lost in Lhasa Tibetan. For example, the coda /l/ is generally not pronounced and the coda /ɹ/ is frequently dropped in colloquial speech, but these codas can be retained in more formal speech. The velar nasal coda /ŋ/ can be reduced, causing vowel lengthening and nasalization, but it is not completely lost.

Figure 7. Example waveforms and spectrograms for short, long and nasalized vowels produced by TN – (1) short [i] in /ɹì/ [ʐì] ‘hill’; (2) long [iː] in /ɹìː/ [ʐìː] ‘fall’; (3) nasalized [ı~ː] in /ɹı~̀ː/ [ʐı~̀ː] ‘price.’
Diphthongs

Diphthongs are relatively rare in Lhasa Tibetan native words. The sequence /iu/ and /au/, originating from syllable fusion, can be treated as diphthongs. The diphthong system of other Central Tibetan dialects, like Ngari Tibetan, is more fully developed than that of Lhasa Tibetan (Qu & Tan, Reference Qu and Tan1983; Qu & Jing, Reference Qu and Jing2017). The diphthong resulting from syllable fusion exhibits different acoustic patterns from two consecutive vowels in an unfused syllable. For example, the diphthong [àu] in [tàu] originates from syllable fusion – [tàu] < /tà wó/ ‘spouse.’ In this example, the unfused form exhibits two intensity bursts, but the fused form exhibits only one (see Figure 8 for an example from DY). Moreover, the unfused form has a clearer formant structure for individual syllables and a longer duration than the fused form.

Figure 8. Examples of syllable fusion (data from DY). The waveforms and spectrograms illustrate the fused form [tàu] (left) and unfused form [tà wó] (right) of the word ‘spouse.’
The diphthong is comparable in duration to the long vowel and the nasalized vowel. All these vowels are longer in duration than the short vowel. Figure 9 displays the acoustic duration of each vowel category – short vowel, long vowel, nasalized vowel and diphthong.

Figure 9. The vowel duration of the four vowel categories – short, long, nasalized and diphthong (DY: left; TN: right). The dot and error bar show mean ± standard deviation based on tokens taken from the vowel example list. (Number of tokens: TN – short: 16, long: 16, nasalized: 16, diphthong: 4; DY – short: 16, long: 15, nasalized: 10, diphthong: 4).
Vowel variants
In addition to these vowels, some researchers postulate additional vowels /ɪ, ʊ, ɔ, ə/ (Dawson, 1980a, Reference Dawson1980b; Gong, Reference Gong2020). These vowels typically occur as allophonic variants in certain conditioning environments, e.g., before specific codas, as a result of syllable fusion in colloquial speech, and in vowel harmony, but they have been argued to be more contrastive when the original conditioning environments are lost. Due to the emerging contrastive role of these vowels, some proposals have incorporated these additional vowels into the vowel system of Lhasa Tibetan, and analyze the system as having one set of constricted or RTR (retracted tongue root) vowels /ɪ, ɛ, ʊ, ɔ, ə, a/ and another set of unconstricted or ATR (advanced tongue root) vowels /i, e, u, o, y, ø/ (Dawson, 1980a, Reference Dawson1980b; Gong, Reference Gong2020).
However, this analysis is not fully supported by the current data. Gong (Reference Gong2020) argues that the vowels [ɪ, ʊ] occur before the coda /-ɹ/, e.g., /tìɹ/ [tÌɾ] ‘here (formal)’ and /súɹ/ [sʊ́ɹ] ‘who (formal)’, or in long vowels when the coda /-ɹ/ is dropped, e.g., /tìː/ [tÌː] ‘here (colloquial)’ and /súː/ [sʊ́ː] ‘who (colloquial).’ The examples in the latter case are cited as evidence for the phonemic status of [ɪ] and [ʊ]. However, in our data, we only found allophonic variants [ɪ, ʊ] before /-ɹ/, as in the formal forms of ‘here’ and ‘who.’ The colloquial forms of them are pronounced as [tɛ̀ː] and [sɔ́ː] instead of [tÌː] and [sʊ́ː]. There is no evidence that the two speakers in the current study represent [ɪ] and [ʊ] as phonemes. Moreover, Gong (Reference Gong2020) provides additional examples of the vowel [ʊ] resulting from syllable fusion and argues for its phonemic status, e.g., [kʰʊ́ː] (colloquial) < /kʰú wáː/ (formal) ‘liquid, soup’ and [tɕʊ̀ː] (colloquial) < /tɕì wàː/ (formal) ‘flea.’ However, for our speakers, the colloquial fused form of ‘liquid, soup’ is [kʰɔ́ː]. For the colloquial form of ‘flea,’ the two speakers differ in their pronunciations – DY: [tɕìp] and TN: [tɕɔ̀:]. These data suggest some variability of the colloquial pronunciations in the Lhasa Tibetan speech community.
For the vowel [ɔ], previous description and our data suggest that it occurs before the coda -ʔ (Gong, Reference Gong2020), e.g., /lòʔ/ [lɔ̀ʔ] ‘come back.’ This vowel also occurs in long vowels with dropped /-ɹ/, e.g., /kòː/ [kɔ̀ː] ‘elapse (colloquial)’ and, in syllable fusion, e.g., [tʰɔ́ː] (colloquial) < /tʰó wáː/ (formal) ‘hammer’ (also in the colloquial forms of ‘liquid, soup’ and TN’s ‘flea’ as discussed above). For the vowel [ə], previous description and our data suggest that it occurs before the coda /-p/, e.g., /tʰáp/ [tʰə́p] ‘canteen’ or in syllable fusion, e.g., [kə̀m] (colloquial) (DY) < /kʰàŋ pʰú/ (formal) ‘pea pod’ (DY, TN) (Gong, Reference Gong2020; Qu & Jing, Reference Qu and Jing2017). Moreover, the reduced variant of /a/ in the final position of a disyllabic word can also be transcribed as [ə] (Dawson, Reference Dawson1980b), e.g., ‘flag’ /tʰàɹ tɕʰá/ [tʰàɾ tɕə́] (DY, see Figure 11 for an illustration of its reduced F1).
The vowels [ɔ] and [ə] originating from syllable fusion seem to be more contrastive than the other proposed additional vowels, but the contrast occurs primarily in colloquial speech. It is still likely that the conditioning environments are not fully lost in formal speech. One solution is to treat the emerging vowel contrast as part of a ‘colloquial’ sound system as opposed to a canonical ‘formal’ system (Zhou, Reference Zhou1984). A further issue is whether some of these additional vowels can be analyzed as diphthongs. For example, Zhou (Reference Zhou1984) treats the [ɪ] and [ʊ] conditioned by /-ɹ/ as diphthongs [ie] and [uo]. Taken together, while the proposal of additional vowels offers insight into the complexity of the Lhasa Tibetan vowel system, there are theoretical and empirical issues that need to be addressed in future studies. Supporting instrumental data are required to fully reveal the categorical or gradient properties of these vowel variants in various contexts.
Vowel harmony: Regressive harmony
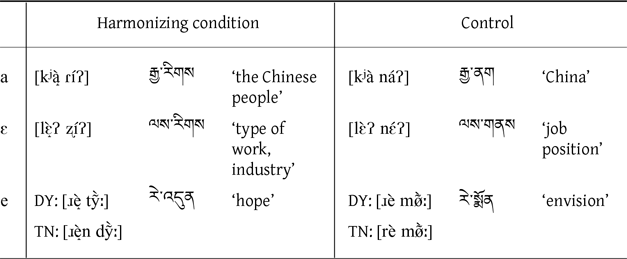

The vowel harmony in Lhasa Tibetan is described as a type of vowel height raising harmony (Chang & Shefts, Reference Chang and Shefts1964; Dawson, Reference Dawson1980b; DeLancey, 2003; Miller, Reference Miller1966; Sprigg, Reference Sprigg1961; Ulving, Reference Ulving2008). The high vowels [i, y, u, ə] in a phonological word, raise the non-high vowels [a, ɛ, e, ø, o] of adjacent syllables. The harmonized or raised non-high vowels [a̝, ɛ̝, e̝, ø̝, o̝] become more similar to vowels [ə, e, i, y, u]. There is both regressive and progressive vowel harmony in Lhasa Tibetan.
In regressive harmony, the high vowel of the second syllable raises the non-high vowel of the first syllable. The table above displays the speech materials used for examining regressive harmony. The materials consist of two groups of disyllabic words, which represent the ‘non-high + high’ harmonizing condition and ‘non-high + non-high’ control condition respectively. In the harmonizing condition, the first non-high vowel is supposed to be raised by the second high vowel due to regressive harmony. Figure 10 illustrates the mean F1 for the harmonized non-high vowel in the harmonizing condition and the original non-high vowel in the control condition. The harmonized non-high vowel generally has lower mean F1 than the original non-high vowel for both speakers, suggesting that the regressive raising harmony is an active phonological process for both speakers.

Figure 10. Illustration of regressive raising harmony (left: DY; right: TN). The F1 values shown are averaged across all the data points of the whole vowel portion and across two repetitions of each token. The red line represents the harmonized non-high vowel in the harmonizing condition while the blue line represents the original non-high vowel in the control condition.
Vowel harmony: progressive harmony

In progressive harmony, the high vowel of the first syllable raises the non-high vowel of the second syllable. The table above shows the test materials for examining progressive harmony. The materials consist of two groups of disyllabic words, which represent the ‘high + non-high’ harmonizing condition and ‘non-high + non-high’ control condition respectively. In the harmonizing condition, the second non-high vowel is supposed to be raised by the first high vowel due to progressive harmony. Figure 11 illustrates the mean F1 for the harmonized non-high vowel in the harmonizing condition and the original non-high vowel in the control condition. For TN, the harmonized non-high vowel generally has lower mean F1 than the original non-high vowel, although the vowel /a/ seems to be less affected by progressive harmony than the other vowels. For DY, progressive harmony seems to be inconsistent because only the vowels /ɛ, ø, o/ exhibit lower F1 in the harmonizing condition than the control condition. However, one limitation of the current study is that the sample size is small. In future investigations, more data need to be collected from more speakers to reveal a fuller picture of vowel patterns in Lhasa Tibetan.
The current transcription of harmonized vowels [a̝, ɛ̝, e̝, ø̝, o̝] does not assume a categorical shift from non-high vowels [a, ɛ, e, ø, o] to vowels [ə, e, i, y, u]. Indeed, TN’s F1 data suggests that the raised vowel [ɛ̝] does not seem to have the same height as the vowel [e] (see Figures 10 and 11). In a more complex system with additional vowels as proposed by Gong (Reference Gong2020), the non-high vowels [a, ɛ, e, ø, o, ɔ] are typically analyzed as raised categorically to vowels [ə, ɪ, i, y, u, ʊ]. The vowels [ə, ɪ, ʊ] are treated as raised variants of [a, ɛ, ɔ]. However, this analysis might not hold if vowel categories like [ɪ, ʊ] do not exist for some Lhasa Tibetan speakers as discussed in the vowel variants section or if vowel harmony is gradient in Lhasa Tibetan. It is unclear how native speakers produce and perceive a raised vowel in harmony. For example, it is unknown whether native speakers represent the raised [ɔ̝] as a variant similar to [o], [ʊ] or [u]. The categorical or gradient nature of vowel harmony in Lhasa Tibetan remains to be investigated using a more rigorous experimental design.

Figure 11. Illustration of progressive raising harmony (left: DY; right: TN). The F1 values shown are averaged across all the data points of the whole vowel portion and across two repetitions of each token. The red line represents the harmonized non-high vowel in the harmonizing condition while the blue line represents the original non-high vowel in the control condition. Note that the progressive raising harmony is less consistent for DY. Moreover, DY’s /a/ in the word-final position exhibits some reduction, resulting in an [ə]-like vowel, which has lower F1 than the canonical [a].
Syllabic structure
A typical syllable of Lhasa Tibetan has the structure (C)V(ː)(C)(C). All the syllables must have a vowel nucleus, which can be either a short V or a long Vː, while onset and coda consonants are optional. The rhymes can be classified into short rhymes and long rhymes. A short rhyme contains a short vowel V or a short vowel with an obstruent coda (VC[+obs]) like /-p/ or /-ʔ/. A long rhyme contains a long vowel (Vː), a short vowel with a sonorant coda (VC[+son]), or a nasalized vowel (V~ː). The rhyme length of VC[+son]ʔ like VNʔ is controversial. F. Hu & Xiong (Reference Hu and Xiong2010) found that VNʔ has longer duration than Vʔ, suggesting a long rhyme for VNʔ. However, in the current dataset, only TN’s production supports the durational difference between Vʔ and VNʔ (see the monosyllabic tones section for a more detailed discussion).
Tones
Tibetan tones originate from laryngeal features of the onset and coda consonants in Old Tibetan (Huang, Reference Huang1995; Sun, Reference Sun1997, Reference Sun2003). Compared with Khams and Amdo Tibetan dialects, Lhasa Tibetan represents a relatively advanced stage of Tibetan tonogenesis, where lexical tones are relatively stable and distinctive.
Monosyllabic tones

There is general consensus that Lhasa Tibetan has two lexical tones based on overall pitch height – the high tone H á and the low tone L à (DeLancey, 2003; T. Hu, Reference Hu1980, Reference Hu and Ma2003; Lim, Reference Lim2018; Sedláčcek, Reference Sedláček1959; Sprigg, Reference Sprigg1955, Reference Sprigg1981, Reference Sprigg1993; Sun, Reference Sun1997; Zhou, Reference Zhou1983). While a two-tone analysis sufficiently captures the tonal contrast in Lhasa Tibetan, the pitch realization varies significantly according to rhyme types. Researchers have proposed various analyses for capturing these pitch patterns by incorporating either a falling versus non-falling pitch contour distinction or a short versus long tone length distinction into their tonal description (T. Hu, Reference Hu1980, Reference Hu and Ma2003; Sun, Reference Sun1997; Zhou, Reference Zhou1983). For example, a four-tone description with a falling/non-falling distinction further subdivides H and L into high-level, high-falling, low rising and low rising-falling tones. The falling pitch contour is carried by checked syllables with a final bilabial plosive /-p/ or a final glottal plosive /-ʔ/. Another type of four-tone description incorporates tone length difference – short high tone, long high tone, short low tone and long low tone. Long tones are carried by syllables with long rhymes (Vː, VC[+son] and V~ː), whereas short tones are carried by syllables with short rhymes (V and VC[+obs]).
Pitch contour and tonal length can be combined with pitch height in different ways, yielding different six-tone and eight-tone descriptions (Dawson, Reference Dawson1980b; F. Hu & Xiong, Reference Hu and Xiong2010; T. Hu, Reference Hu1980). One such six-tone description includes short high level tone, long high level tone, short low rising tone, long low rising tone, high falling tone, and low rising-falling tone (Dawson, Reference Dawson1980b; T. Hu, Reference Hu1980). F. Hu & Xiong (Reference Hu and Xiong2010) further propose an eight-tone description which subdivides the high falling and low rising-falling tones based on tone length – long high falling, short high falling, long low rising-falling and short low rising-falling tones. Their proposal is based on the finding that the falling and rising-falling contours realized on the VC[+son]ʔ rhyme like VNʔ have longer duration than those realized on the Vʔ rhyme.
In this illustration, a two-tone analysis is adopted, but to illustrate the various pitch realizations, the materials for monosyllabic tones cover as many rhyme types in Lhasa Tibetan as possible. The F0 trajectories of the monosyllabic tones are displayed in Figure 12. The pitch height patterns of both speakers are consistent with a two-tone analysis. For the detailed pitch realizations, the speaker TN exhibits eight patterns based on rhyme types, although the difference in tonal length between VNʔ and Vʔ rhymes is smaller than that reported in F. Hu & Xiong (Reference Hu and Xiong2010). However, the speaker DY does not show a tone length difference for the falling tone and the rising-falling tone, which is more consistent with the six-tone description (Dawson, Reference Dawson1980b; T. Hu, Reference Hu1980).

Figure 12. The F0 tracks of Lhasa Tibetan monosyllabic tones (left: DY; right: TN) based on one repetition of the tokens in the example list of monosyllabic tones. The F0 tracks begin from the vocalic portion of the rhyme (time point 0). Note that for DY, the long high falling and long low rising-falling tones are not distinguishable from the short high falling and short low rising-falling tones, whereas the production of TN exhibits some distinction in tone length.
Polysyllabic tones

Lhasa Tibetan has been analyzed as possessing a template-based word-tone system, where polysyllabic tone patterns follow specific tonal templates (Sprigg, Reference Sprigg1955, Reference Sprigg1981, Reference Sprigg1993; Sun, Reference Sun1997). According to the template-tone analysis, disyllabic tonal templates include HH (55˥ 51˥, 55˥ 54˦, 55˥ 55˥), LH (11˩ 51˥, 11˩ 54˦) and LL (11˩ 114) (T. Hu, Reference Hu1980; Qu, Reference Qu1981; Sedláčcek, Reference Sedláček1959; Sprigg, Reference Sprigg1955, Reference Sprigg1981, Reference Sprigg1993; Sun, Reference Sun1997).
In Lhasa Tibetan disyllabic words, there is non-final pitch contour reduction, that is, generally only level pitches (11˩ and 55˥) are allowed in non-final syllables. For instance, non-final L (13˧, 131 and 114) becomes level 11˩, and non-final H (54˦, 51˥ and 55˥) becomes level 55˥. Moreover, the H versus L tones are generally only contrastive on the first syllable. For the second syllable with a short rhyme, it carries a default H (51˥, 54˦). However, for the second syllable with a long rhyme like Vː, VC[+son] and V~ː, it acquires its pitch height from the first syllable, regardless of its original monosyllabic tone specification. For example, the second syllable with a long rhyme bears an L tone (114) when preceded by an L tone (13˧, 131 and 114), e.g., [ɲɛː˩ ɰa~ː] < [ɲɛː] + [kʰa~ː˥] ‘bedroom,’ whereas it bears an H tone (55˥) when preceded by an H tone (54˦, 51˥ and 55˥), e.g., [mɛ~ː˥ ɡa~ː˥] (DY)/[mɛ~ː˥ ɰa~ː˥] (TN) < [mɛ~ː˥] + [kʰa~ː˥] ‘hospital.’ The pitch tracks of disyllabic tones are shown in Figure 13.

Figure 13. The F0 tracks of Lhasa Tibetan disyllabic tones (top: DY; bottom: TN). For each tonal template, there are six tokens taken from the example list of disyllabic tones. The F0 trajectories are aligned by the end of the first syllable (indicated by a dashed line corresponding to time point 0).
For trisyllabic tones, tonal templates like LHH and HHH have been proposed (Lim, Reference Lim2018; Qu, Reference Qu1981; Qu & Tan, Reference Qu and Tan1983; Sun, Reference Sun1997). Based on this proposal, the L versus H contrast is only licensed word-initially while the second syllable and the third syllable bear H tones only. Moreover, the pitch contour difference is allowed on the third syllable only. Quadrisyllabic tonal templates can be analyzed as the combination of two disyllabic tonal patterns, e.g., HHHH, LHHH, HHLH and LHLH (Lim, Reference Lim2018; Qu & Tan, Reference Qu and Tan1983). However, it should be noted that trisyllabic and quadrisyllabic tonal patterns cannot always be predicted based on these templates. Due to morphological or semantic factors, the grouping of syllables into phonological words in trisyllabic and quadrisyllabic words can vary considerably, complicating the template-based analysis of trisyllabic and quadrisyllabic tones (see Lim, Reference Lim2018 and Qu, Reference Qu1981 for more details).
Neutral tones

Certain grammatical words in Lhasa Tibetan can be analyzed as carrying neutral tones (or toneless). The neutral tone acquires its pitch from its adjacent syllable. For example, the tone specification of the negator /ma/ ‘not’ is altered depending on the monosyllabic tone of the following syllable.
Transcription of the recorded passage

Transcription
A broad phonemic transcription is adopted in this section. Vowel harmony and plosive deaspiration are not transcribed. Phonological tones are indicated by diacritics. Many functional words are transcribed as having a phonological low tone, which is generally realized as a low level pitch. Minor and major breaks are indicated by | and ‖ respectively. Abbreviations used for the gloss: DEF = definite; INDEF = indefinite; ERG = ergative; OBL = oblique; ASS = associative; GEN = genitive; INS = instrumental; ABL = ablative; FAC = factual; PST = past; PERF = perfect; FUT = future; NMLZ = nominalizer.


Acknowledgments
I am grateful to my two consultants Tenzin Norbu and Dekyi Yungdron for participating in this study and to Yangchen Lhamo for her help with the translation of the recorded passage ‘The North Wind and the Sun.’ I also thank the audio manager André Radtke, the editors Marija Tabain and Marc Garellek, and two anonymous reviewers for their constructive comments. Thanks are due as well to Ngawang Lopsang Choepel, Tsering Sangmo, Tupten Galtso, Galsang Gyatso, Ogyen Bamo, Zongba Yangji, Tsewang Nogdrup, Thupten Rinchen, Champa Dolker, Dekyi Yangdron and Tsering Chugye for sharing their knowledge of Central Tibetan, and to Zhendong Liu for checking interlinear gloss in the passage section.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0025100324000033
















 Open access
Open access