



1. Introduction
A growing body of research is interested in the relation between processing complexity and grammatical explicitness (Ferreira & Dell, Reference Ferreira and Dell2000; Haspelmath, Reference Haspelmath2008; Hawkins, Reference Hawkins2002, Reference Hawkins2004; Jaeger, Reference Jaeger2006, Reference Jaeger2010; Rohdenburg, Reference Rohdenburg2016). This interest stems from two branches of linguistic inquiry: corpus-based alternation studies and psycholinguistics. On the one hand, corpus linguists turn to processing complexity as a possible explanation for the distributions they find in bodies of natural language use, and for the constraints they posit in probabilistic grammars (Bresnan, Cueni, Nikitina, & Baayen, Reference Bresnan, Cueni, Nikitina, Baayen, Bouma, Krämer and Zwarts2007; Gries, Reference Gries, Dehé, Jackendoff, McIntyre and Urban2002, Reference Gries2003; Grondelaers, Reference Grondelaers2000; Grondelaers & Speelman, Reference Grondelaers and Speelman2007; Shank, Plevoets, & Bogaert, Reference Shank, Plevoets, Bogaert, Yoon and Gries2016). On the other hand, psycholinguists are ex officio concerned with language processing and employ grammatical alternations as useful case studies to test processing hypotheses (Arnold, Wasow, Asudeh, & Alrenga, Reference Arnold, Wasow, Asudeh and Alrenga2004; Ferreira & Hudson, Reference Ferreira and Hudson2011; Ferreira & Schotter, Reference Ferreira and Schotter2013). These two research traditions are increasingly converging, with corpus linguists asking questions on language processing (Grondelaers, Speelman, Drieghe, Brysbaert, & Geeraerts, Reference Grondelaers, Speelman, Drieghe, Brysbaert and Geeraerts2009; Jaeger, Reference Jaeger, Bender and Arnold2011), and psycholinguists turning to corpus research as a methodology that is complementary to experimental work (Gennari & Macdonald, Reference Gennari and Macdonald2009; Roland, Elman, & Ferreira, Reference Roland, Elman and Ferreira2006). The present investigation is of the first type, that is, a corpus-based alternation study primarily interested in the mechanisms causing the correlation between complexity and explicitness. This correlation is most famously expressed in Rohdenburg’s Complexity Principle:
In case of more or less explicit grammatical options, the more explicit one(s) will tend to be favored in cognitively more complex environments. (Rohdenburg, Reference Rohdenburg1996, p. 151)
We then aim to answer two questions:
(i) What drives the correlation between complexity and explicitness as we find it in corpora?
(ii) Does the correlation hold in all linguistic contexts, and if not, in which ones?
Concerning the first question, the different explanations for the cause of the Complexity Principle can be divided into three viewpoints. The first viewpoint asserts that the Complexity Principle is chiefly caused by cognitive processing during language production (e.g., Ferreira & Dell, Reference Ferreira and Dell2000; MacDonald, Reference MacDonald2013). Explicit coding would present a convenient way to buy time for the language producer when processing demands are high, such as in complex linguistic environments. The second viewpoint states that the Complexity Principle is primarily the result of restrictions on the physical language channel (e.g., Fenk & Fenk-Oczlon, Reference Fenk, Fenk-Oczlon, Köhler and Rieger1993; Fenk-Oczlon, Reference Fenk-Oczlon, Bybee and Hopper2001; Jaeger, Reference Jaeger2010). These restrictions introduce noise into the language channel that may disrupt the flow of information, and as a result, additional coding is required to smooth out the peaks in information density that typically arise in complex environments. Finally, the third viewpoint proposes that the correlation emerges primarily due to cognitive comprehension processing (e.g., Bolinger, Reference Bolinger, Brettschneider and Lehmann1980; Clark & Murphy, Reference Clark and Murphy1982; Garnsey, Pearlmutter, Myers, & Lotocky, Reference Garnsey, Pearlmutter, Myers and Lotocky1997; Hawkins, Reference Hawkins2004). That is, explicit coding is first and foremost aimed at optimizing the addressee’s comfort. More complex environments would then be coded using the more explicit grammatical option, because the explicit coding of the syntactic structure simplifies parsing. Our case study will allow us to differentiate between on the one hand the production and channel perspective and on the other the comprehension perspective, but not between the production and channel perspective.
Concerning the second question, we will specifically look at different word orders. We will argue that the various explanations for the correlation make different predictions about how the correlation behaves in particular word order contexts in our case study. In this way, answering the second research question can lead to an answer to the first question.
Most research on the topic has looked into the English that-alternation, as in (1), as a case study (a.o. Bolinger, Reference Bolinger1972; Ferreira & Dell, Reference Ferreira and Dell2000; Ferreira & Hudson, Reference Ferreira and Hudson2011; Ferreira & Schotter, Reference Ferreira and Schotter2013; Jaeger, Reference Jaeger2005, Reference Jaeger2010, Reference Jaeger, Bender and Arnold2011; Jaeger & Wasow, Reference Jaeger and Wasow2005; Roland et al., Reference Roland, Elman and Ferreira2006; for an overview, see Shank et al., Reference Shank, Plevoets, Bogaert, Yoon and Gries2016, pp. 202–213). We will turn to a similar alternation in Dutch that has thus far not been looked at, namely the alternation between a direct object and prepositional object of the verb zoeken ‘to search’, as in (2). Just as the English conjunction that may be used to introduce a complement clause, the Dutch preposition naar ‘to’ may optionally introduce the theme of this verb (Haeseryn, Romijn, Geerts, de Rooij, & van den Toorn, Reference Haeseryn, Romijn, Geerts, de Rooij and van den Toorn1997, p. 1168).Footnote 1 We thus consider the form with naar to be the explicit variant. Still, this alternation does differ from the English that-alternation in a number of important aspects, which will enable us to differentiate between the viewpoints.
(1) I would guess (that) Al Gore will not endorse anyone. (COCA, cited in Shank et al., Reference Shank, Plevoets, Bogaert, Yoon and Gries2016, p. 208)
(2) Men zoekt (naar) een alternatief. (WR-P-P-G-0000001757.p.1.s.5)
One searches (to) an alternative
‘They are searching for an alternative.’
The following section discusses the contrasting viewpoints introduced above in further detail. The third section presents the employed case study, the corpus, our operationalization of complexity, and the composition of the dataset. The fourth section works out the predictions made by each viewpoint regarding our case study, and composes a mixed regression model to test these predictions. The final section summarizes the conclusions, discusses the relevance of the findings for several strands of research, and ends with a number of suggestions for further study.
2. Production, channel, or comprehension?
1.1. production
The most direct way in which complexity can affect explicitness is through cognitive production processing. Making sentence structure explicit by including the optional complementizer that or the preposition naar evidently requires some effort from the producer, but this effort would buy time for the producer to formulate a complex complement clause or noun phrase, thereby relieving pressure on production facilities (Ferreira & Dell, Reference Ferreira and Dell2000, pp. 298–300). The primary cause of the correlation between complexity and explicitness would then be the cognitive effort of the producer. It is still possible that the comprehender also benefits from the use of explicit coding in complex contexts, but only in a derived or secondary way. Two production accounts that allow for this are the PDC-model (Production–Distribution–Comprehension) proposed in Gennari and Macdonald (Reference Gennari and Macdonald2009), MacDonald (Reference MacDonald2013), and MacDonald and Thornton (Reference MacDonald and Thornton2009), and the ‘collateral signals’ account (cf. Clark, Reference Clark, Horn and Ward2004, pp. 373–381, as well as Brennan & Williams, Reference Brennan and Williams1995; Clark & Fox Tree, Reference Clark and Fox Tree2002; Collard, Corley, MacGregor, & David, Reference Collard, Corley, MacGregor and David2008; Corley & Hartsuiker, Reference Corley, Hartsuiker, Alterman and Kirsh2003; Fox Tree & Clark, Reference Fox Tree and Clark1997; Smith & Clark, Reference Smith and Clark1993, and references cited therein).
According to the PDC-model, pressures in production processing determine the distributions that we find in language use. In turn, these distributions shape an individual’s grammar, and finally, this probabilistic grammar is employed in comprehension. This means that the comprehender will expect the form of new sentences to confirm to this grammar, and thus to the form of previously heard sentences, whose realization was optimized for production. When a newly heard sentence then contradicts the comprehender’s expectations by not being optimized for production, but rather for comprehension, this would – seemingly paradoxically – cause comprehension difficulties.
According to the collateral signals account, the use of optional markers informs the comprehender about the state of production. For example, production difficulties may be a cue to the comprehender that the following words are difficult to integrate in the existing context. The comprehender can then prepare for this by cancelling his or her expectations about upcoming material (Grondelaers et al., Reference Grondelaers, Speelman, Drieghe, Brysbaert and Geeraerts2009, pp. 159–160).
1.2. channel
The channel perspective is rooted in Shannon Information Theory (Cover & Thomas, Reference Cover and Thomas1991; Shannon, Reference Shannon1948). It searches the root cause of the Complexity Principle not in any kind of cognitive processing by either producer or comprehender, but rather in the physical language channel between producer and comprehender (Fenk & Fenk-Oczlon, Reference Fenk, Fenk-Oczlon, Köhler and Rieger1993; Fenk-Oczlon, Reference Fenk-Oczlon, Bybee and Hopper2001; Jaeger, Reference Jaeger2010; Levy & Jaeger, Reference Levy, Jaeger, Schölkopf, Platt and Hoffman2007). As such, it is different from both the production and comprehension perspective.
This perspective states that human language use constitutes a form of information exchange, and that the language channel is a type of information channel. Like any kind of information channel, the language channel is prone to noise. This noise introduces the risk of information loss. The more information is packed into a signal, e.g., into a string of words, the more information will be lost if the signal is damaged by noise. In other words, the more dense the information flowing through a channel, the higher the risk of noise causing substantial information loss. Meanwhile, the less dense the information flowing through the channel, the less efficiently the channel is being used. As a result of these competing pressures, any information channel has an associated optimal level of information density that balances risk of information loss with efficiency of use. The users of a channel will attempt to approximate this level at all times, resulting in a more or less constant density of the information flow through the channel. This has been called the principle of Uniform Information Density (Jaeger, Reference Jaeger2010).
The channel of natural language has been noted to be particularly prone to noise (Levinson, Reference Levinson2000, p. 28). For example, in the case of spoken language, background noises may cause some words to become unrecognizable to the comprehender. If the producer then chooses to express his message in as few words as possible, such noises may already cause too much information to be lost and may thus render the original message irretrievable. In the case of written language, sources of noise include typos, imperfect eyesight, bad printing quality, and illegible handwriting. In the case of sign language, they may include sore muscles and visual clutter.
Optional markers that make syntactic structure explicit, such as English that or Dutch naar, may then present a way to tune the information density of an utterance. Such markers will be low in inherent information content, as they can apparently be added or removed without drastically altering the message expressed by the sentence. Additionally, they explicitly flag what follows as respectively a complement clause or a theme argument, hence rendering it more predictable. According to Information Theory, information equates with the negative logarithm of predictability. As such, these markers effectively reduce the information density of the following complement clause or theme argument. As a result, since complex elements tend to be high in information density and simple elements tend to be low, these markers would more often appear with complex elements. This then constitutes the correlation described by the Complexity Principle (Jaeger, Reference Jaeger2010, pp. 26–28).
In this text, we present the channel-driven account separately from both the comprehension and production perspective for two reasons. First and foremost, it is fundamentally different from both the comprehension and production perspective in stating that the root cause of the Complexity Principle is not to be sought in any kind of cognitive processing, but rather in the physical limitations on the language channel. Second, if one would have to include it under either the production or comprehension perspective, it is not clear which one would be more appropriate. On the one hand, the channel-driven account pivots on successful communication. The question is whether the information contained in the message reaches the comprehender, and one could therefore include it under the comprehension perspective (cf. Jaeger, Reference Jaeger2013). On the other hand, the noise in the language channel and therefore the cause of maximal information density stems for a large part, though not completely, from properties of the producer, namely the limitations of our physical articulators (Levinson, Reference Levinson2000, p. 28). Moreover, Ferreira and Schotter (2013, p. 1569) have argued for a strong affinity between the channel- and production-driven accounts, viewing them as merely “different levels of description of the same sort of phenomenon”. According to this viewpoint, the production-driven account would be seen as the cognitive implementation of the principle of Uniform Information Density, which makes sure that language producers in practice always approximate the optimal level of information density.
1.3. comprehension
Finally, explicitly encoding the syntactic structure of a sentence evidently simplifies parsing and thus comprehension. In the case of that, the optional marker signals to the comprehender that the producer is entering a complement clause. In the case of naar, the optional word is a fixed preposition with the verb zoeken ‘to search’ and it could be argued, according to the comprehension perspective, that it therefore expedites the linkage between the verb and its complement by flagging the following noun phrase as its complement with an explicit formal marker.
Still, the choice whether or not to use such optional elements of course rests with the producer, not the comprehender. There are then two ways in which comprehension processing can still affect this choice. The first is speaker’s altruism or strong audience-design (Hawkins, Reference Hawkins2002, Reference Hawkins2004; Kirby, Reference Kirby1999, p. 60). This states that, if the producer is going to utter a complex phrase, s/he will choose the structure that is easiest to parse for the comprehender, even if this requires more effort from his/her part. Of course, the producer then needs to have some way of knowing which structure is easiest to parse, i.e., s/he needs to have access to some metric of parsing effort.
Note that this account of speaker’s altruism is not a case of true altruism, as the producer may also indirectly benefit from forming easily comprehensible sentences. For one, comprehenders may be more inclined to listen to and act on the messages formulated by such producers. Moreover, communication is fundamentally a collaborative task, meaning that producers have to make at least some effort in order to be comprehensible (Zipf, Reference Zipf1949).Footnote 2 It then only seems a minor step to say that they also make the effort to use optional markers in order to be easily comprehensible.
The second way in which comprehension processing may affect choices in production is hearer selection (Kirby, Reference Kirby1999, pp. 31–62, see Ferreira & Schotter, Reference Ferreira and Schotter2013,p. 1568, for a similar proposal). This differs from speaker’s altruism in that comprehension steers production in a more indirect way. It proposes that only constructions which lead to successful comprehension become entrenched in grammar, or that those which lead to more effortless comprehension become more strongly entrenched than those which require more effort. Once entrenched in grammar, these constructions can in turn affect the production of the language user in question. In other words, tendencies that obstruct comprehension processing are selected against in language evolution. While this account dispenses with the assumption that some metric of parsing effort is directly taken into account during production, it does require that entrenchment be dependent on successful or easy comprehension. This proposal can be seen as the reversal of the PDC-model from the production perspective. Figure 1 presents a comparison of the two.

Fig. 1. Hearer selection versus the PDC-model.
Note: Distribution here refers to natural language usage as we find it in corpora, and grammar stands for the cognitive organization of one’s experience with language (Bybee, Reference Bybee2006, p. 711).
So far, empirical findings from experiments and corpora appear to favor the channel and production perspectives over the comprehension perspective. Ferreira and Dell (Reference Ferreira and Dell2000) find no evidence that language users employ explicitness to simplify comprehension in controlled experiments, while they do find evidence that lexical availability during production plays a role. Likewise, Elsness (Reference Elsness1984) and Roland et al. (Reference Roland, Elman and Ferreira2006) find no indications that, in corpora, language users use the optional complementizer that to facilitate comprehension processing. Further indications from experiments and corpora in favor of the channel perspective are presented in Fenk-Oczlon (Reference Fenk-Oczlon, Bybee and Hopper2001), Jaeger (Reference Jaeger2010), and Levy and Jaeger (Reference Levy, Jaeger, Schölkopf, Platt and Hoffman2007); and in favor of the production perspective in Ferreira and Hudson (Reference Ferreira and Hudson2011), Ferreira and Schotter (Reference Ferreira and Schotter2013), Gennari and Macdonald (Reference Gennari and Macdonald2009), Kraljic and Brennan (Reference Kraljic and Brennan2005), MacDonald (Reference MacDonald2013), and MacDonald and Thornton (Reference MacDonald and Thornton2009). For other studies investigating the differences between cognitive processing in language production and comprehension, see Bock, Irwin, and Davidson (Reference Bock, Irwin, Davidson, Henderson and Ferreira2004), Tanner and Bulkes (Reference Tanner and Bulkes2015), Tanner, Nicol, and Brehm (Reference Tanner, Nicol and Brehm2014), and references cited therein.
3. Data
3.1. case study and corpus
The employed case study concerns the alternation between a direct and prepositional object of the Dutch verb zoeken ‘to search’. The theme of this verb may be overtly marked by the preposition naar, and thus be realized as a prepositional object, as in (3), or this preposition may be dropped, and the theme realized as a simple direct object, as in (4). The reference grammar Algemene Nederlandse Spraakkunst explicitly states that the two variants of the alternation are synonymous (Haeseryn et al., Reference Haeseryn, Romijn, Geerts, de Rooij and van den Toorn1997, p. 1168).
(3) Kee schildert en zoekt naar sponsors. (WR-P-P-G-0000011665.p.3.s.5)
Kee paints and searches to sponsors
‘Kee paints and looks for sponsors.’
(4) Vzw De Scute zoekt daarom nog sponsors.
non-profit organization De Scute searches therefore still sponsors
(WR-P-P-G-0000350208.p.4.s.2)
‘That’s why non-profit organization De Scute is still looking for new sponsors.’
As the source of the data, we employ the SoNaR corpus of written Dutch (Oostdijk, Reynaert, Hoste, & Schuurman, Reference Oostdijk, Reynaert, Hoste, Schuurman, Spyns and Odijk2013b), more specifically, the version that is syntactically annotated by the Alpino-parser (van Noord, Reference van Noord2006, see Bouma & Kloosterman, Reference Bouma and Kloosterman2002, Reference Bouma and Kloosterman2007, on how to best access XML-treebanks).Footnote 3 We have two main reasons for choosing a corpus of written language. First and foremost, the Complexity Principle has been observed not only in spoken language, but also in written language (a.o. Bouma, Reference Bouma, Wieling, Kroon, van Noord and Bouma2017; Rohdenburg, Reference Rohdenburg1996, Reference Rohdenburg2016; Shank et al., Reference Shank, Plevoets, Bogaert, Yoon and Gries2016). In this paper, we are primarily looking to explain why the Complexity Principle holds in written language. Still, we currently see no compelling reasons to assume that there are fundamentally different explanations for the Principle in spoken versus written language. In fact, there is ample research showing that findings based on written language are generally in accordance with findings from spoken language with regard to the relation between explicitness and complexity (Grondelaers, Reference Grondelaers2000; Grondelaers, Speelman, & Geeraerts, Reference Grondelaers, Speelman and Geeraerts2003; Jaeger, Levy, Wasow, & Orr, Reference Jaeger, Levy, Wasow and Orr2005; Jaeger & Wasow, Reference Jaeger and Wasow2005). Still, even if future research would reveal fundamental differences, it is not the case that written language processing is a priori less interesting than spoken language processing; this would simply limit the relevance of our research to the former.
Second, because we analyze observational data from corpora of natural language rather than experimental data from lab settings, we will need to deal with a number of confounds.Footnote 4 This means we will need sufficient datapoints to be able to control for these. The only way to acquire a sufficiently large dataset is to turn to a corpus of written text. In this choice for written data, we follow earlier studies on complexity, including Bloem, Versloot, and Weerman (Reference Bloem, Versloot and Weerman2017), Gennari and Macdonald (Reference Gennari and Macdonald2009), Gries (Reference Gries, Dehé, Jackendoff, McIntyre and Urban2002), Grondelaers et al. (Reference Grondelaers, Speelman, Drieghe, Brysbaert and Geeraerts2009), Jaeger (Reference Jaeger, Bender and Arnold2011), MacDonald and Thornton (Reference MacDonald and Thornton2009), Rohdenburg, (2016), Roland et al. (Reference Roland, Elman and Ferreira2006), and Willems and De Sutter (Reference Willems and De Sutter2015).
What does this choice for written data mean for the three perspectives introduced in the previous section? In general, the choice is favorable for the comprehension perspective. First, it benefits the comprehension perspective in that we expect writers to bear in mind the ease with which their readers read their texts, at least to a greater extent or more explicitly than speakers would take into consideration the comprehension processing required from their hearers. As such, written language would be more prone to tendencies that reduce effort in comprehension processing.
Second, the choice for written data is disadvantageous to the production and channel perspectives. Regarding the production perspective, its reasoning primarily relates the spoken language. As such, we need the extra assumption that the (probabilistic) grammar of language users is first and foremost shaped by their experiences in spoken language, since this forms the majority of the linguistic input, and that this same grammar is then employed when processing written language. The correlation between complexity and explicitness in written language would then be a second-order effect, i.e., an effect that is retained even when its original cause is not directly present, because it has become entrenched in probabilistic grammar. Such second-order effects have also been demonstrated in morphology (Pijpops & Van de Velde, Reference Pijpops and Van de Velde2016, Reference Pijpops and Van de Velde2018). Regarding the channel perspective, the information channel of written language is probably less prone to noise than the channel of spoken language. Therefore, it would arguably be associated with a higher optimal level of information density.Footnote 5 As such, the channel would generate less pressure to use optional markers in complex environments in the case of written language than in the case of spoken language. Still, the channel of written language would still have some optimal level of information density. As such, the reasoning behind this perspective still holds. To sum up, the choice of written data results in a conservative research design regarding the production and channel perspectives.
3.2. operationalization of complexity
There are at least two principal ways of contrasting the three perspectives using corpus data. The first is to formulate three separate operationalizations of complexity, each tailored to each perspective. For instance, one operationalization would be more suited for production complexity, while another operationalization would better measure information density, etc. (see Menn & Duffield, Reference Menn, Duffield, Newmeyer and Preston2014, for a discussion on several operationalizations of complexity). Next, we could investigate which is the best correlate of explicitness, viz. in our case, the best correlate of the probability of the prepositional variant. However, these various operationalizations of complexity are likely to strongly correlate with one another, making it hard to disentangle them. We therefore opt for the second way, which is to employ a single operationalization of complexity that works for all perspectives. We can then compare the contexts in which it is correlated with explicitness.
As an operationalization of complexity, we use the variable theme complexity, counted as the natural logarithm of the number of words of the theme argument. While this may not constitute the most advanced operationalization of complexity, it is robust, reliable, largely independent of the employed parsing formalism, and it works for each perspective, as we will now argue.Footnote 6
For the production and comprehension perspective, the choice for theme complexity is quite straightforward. Regarding the production perspective, the optional preposition naar always appears right in front of the theme argument, at exactly the moment when the producer needs to plan the theme. When the theme is long and the producer is hence under high processing pressure, this would be the most opportune moment to buy extra processing time. Regarding the comprehension perspective, having to parse a long noun phrase puts a large strain on cognitive comprehension facilities. As such, it would be most useful to have a formal marker right in front of this noun phrase that explicitly marks it as the theme argument.
The operationalization of theme complexity for the channel perspective requires some more clarification. It is based on the presumption that longer themes tend to be more specific than short themes. In turn, more specific themes are harder to predict, which means they contain more information. For instance, the theme in (5) is a lot more specific and hence contains more information than the theme in (6). As argued above, themes that contain more information have a greater need for a preceding preposition naar ‘to’ to reduce their information density.
(5) De provincie zocht naar een educatieve oplossing om toch
The county searched to an educational solution to still
enige greep te krijgen op minderjarige overtreders van het
some handle to get on underage transgressors of the
verkeersreglement.
traffic regulations (WR-P-P-G-0000619732.p.4.s.2)
‘The country administration is searching for an educational solution to get some handle on underage transgressors of traffic regulations.’
(6) De provincie Gelderland zoekt een oplossing.
The county Gelderland searches a solution (WR-P-P-G-0000037003.p.1.s.4)
‘The country of Gelderland is searching for a solution.’
3.3. dataset
All 79,410 instances of zoeken that appeared with a theme argument were extracted from the corpus and annotated with information based on the Alpino-parses. Not all of these data could be used, however.
First, the dataset still contained a number of instances of fixed collocations, viz. zijn heil zoeken bij ‘flee to, turn to’ as in (7) (959 instances), ergens niets/niks te zoeken hebben ‘have no reason to be somewhere’ as in (8)–(9) (728 instances) and zijn toevlucht zoeken ‘seek refuge’ as in (10) (957 instances). The meaning of these fixed collocations is non-compositional and they never appear in the variant with naar. As such, these 2,644 instances were excluded from the dataset.
(7) Velen zochten hun heil bij familie in Zuid-Servië en
many searched their salvation with family in South-Serbia and Kosovo.
Kosovo
(WR-P-P-G-0000023743.p.4.s.4)
‘Many fled to family in southern Serbia and Kosovo.’
(8) Zij hebben hier niets te zoeken.
They have here nothing to search (WR-P-P-G-0000012841.p.2.s.6)
‘They have no reason to be here.’
(9) Zo lang dit geen VN-operatie is, hebben wij daar niks te
So long this no UN_operation is have we there nothing to
zoeken.
search
(WR-P-P-G-0000017711.p.4.s.1)
‘As long as this is no UN operation, we have no reason to be there.’
(10) Deze winkelier heeft inmiddels zijn toevlucht gezocht in
this shopkeeper has meanwhile his refuge searched in
het buitenland.
the outside_country
(WR-P-P-G-0000041098.p.3.s.3)
‘Meanwhile, this shopkeeper has sought refuge abroad.’
Second, prepositional objects in Dutch enjoy greater liberties in positioning than direct objects. Dutch word order functions a lot like German word order, and is also characterized by a bipolar structure (i.e., the so-called Klammernstruktur; see König & Gast, Reference König and Gast2009, Ch. 10; Zifonun, Hoffmann, & Strecker, Reference Zifonun, Hoffmann and Strecker1997, p. 1498; Zwart, Reference Zwart2011, p. 26). This can be seen in Table 1. Bare noun phrases such as subjects or direct objects are grammatically limited to the prefield before the first verbal pole (1a) or the midfield between the poles (1b). They cannot grammatically be placed in the postfield, i.e., the position behind the second verbal pole (1c), the only exception being when they are realized as a subordinate clause. By contrast, prepositional phrases such as the prepositional object have access to the prefield, midfield, and postfield (2a–c). This means that when the prepositional object is placed in postfield position, the preposition naar cannot be dropped without overhauling the sentence structure. As such, these 6,454 instances were also removed from the dataset.
table 1. Various placement options for the theme when realized as direct or prepositional object in Dutch. Only when realized as a prepositional object can the theme be placed in postfield position

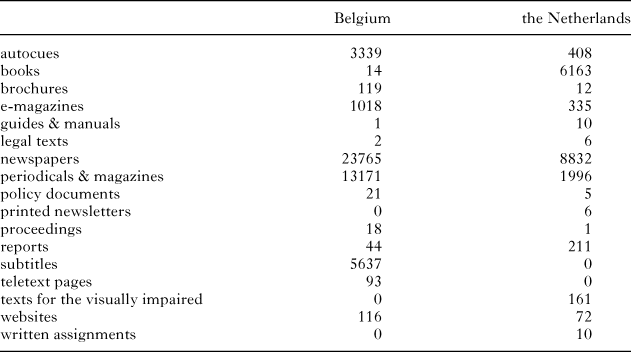
Finally, we will want to control for the country of origin, which can be either the Netherlands or Belgium. However, the country of origin was not known for 4,726 instances, which were therefore removed from the dataset. This left us with 65,586 observations. Table 2 shows how they are distributed among countries and corpus components.
table 2. Number of instances in our dataset from each country and each corpus component
From the final dataset, 1,000 instances were randomly selected and subjected to manual checking. Of these, we identified 18 cases in which we disagreed with the Alpino-parses on the exact demarcation of the theme, which was judged to be an acceptable level of noise. Earlier research has also shown that automatically generated datasets do not compromise the reliability of the results, while offering important advantages in reproducibility and scalability (cf. Bloem, Reference Bloem, Baski, Kupietz, Lüngen, Witt, Barbaresi, Biber and Clematide2016; Bloem, Versloot, & Weerman, Reference Bloem, Versloot and Weerman2014; Bouma, Reference Bouma, Wieling, Kroon, van Noord and Bouma2017; Theijssen, Boves, Halteren, & Oostdijk, Reference Theijssen, Boves, Halteren and Oostdijk2010).
4. Hypotheses and analysis
In order to differentiate between the three perspectives, we will distinguish between those instances where the verb zoeken precedes the theme, as in (11), and those where the theme precedes the verb, as in (12). Instances where the initial part of the theme precedes the verb and the remainder follows it, as in (13), are counted amongst those where the theme precedes the verb, since the preposition naar, if it is present, would also precede the verb, as does the syntactic head of the theme.Footnote 7 We will now argue that the production and channel perspectives predict a negative correlation between the complexity of the theme and the propensity for the explicit prepositional variant in cases such as (12), and positive correlation in cases such as (11). Meanwhile, the comprehension perspective will be argued to predict a positive correlation in both cases, and an even stronger positive correlation in cases such as (12) than in cases such as (11).
(11) We zoeken naar de oorzaak, maar hebben nog geen idee.
we search to the cause but have still no idea
(WR-P-P-G-0000039610.p.2.s.5)
‘We are looking for the cause, but we have no idea so far.’
(12) We zijn dus wel gedwongen nu al naar een
We are thus PART forced now already to a
goede vervanger te zoeken.
good substitute to search
(WS-U-T-B-0000000070.p.13.s.3)
‘We are thus forced to already look for a good substitute.’
(13) … als je naar een oplossing zoekt die perfect aansluit bij je
if you to a solution search that perfectly fits to your
bancaire behoeften.
banking needs
(WR-P-P-G-0000229626.p.13.s.1)
‘… if you are looking for a solution that fits your banking needs perfectly.’
4.1. production hypothesis
The production perspective proposed that naar presents a way to buy time for the producer to formulate a complex theme. When the theme precedes the verb, however, this purchase comes at a serious cost. Only a handful of Dutch verbs combine with a prepositional object with naar. Using naar would therefore force the producer to already decide on which verb s/he is going to use. The planning scope of producers is limited, and the longer and more complex the upcoming theme argument, the less cognitive resources are available to simultaneously consider the choice of verb (see Gleitman, January, Nappa, & Trueswell, Reference Gleitman, January, Nappa and Trueswell2007; Konopka, Reference Konopka2012, and references cited therein). Meanwhile, if the producer chooses to realize the theme as a bare noun phrase, s/he can postpose the choice of verb until after the theme in completed. Moreover, if the producer has already decided on the future verb while building the upcoming complex theme, s/he will be forced to retain this verb in working memory until s/he has completed the formulation of the theme. Leaving this choice until later would allow him/her to free up this working memory.
An example with a complex preverbal theme is given in (14). When the producer includes naar in (14), his or her choice of verb will be limited to zocht ‘searched’ and perhaps streefde ‘strove’. In other words, s/he would have to consider the choice of verb, exactly when facing the arduous task of planning the complex theme. Meanwhile, if the producer does not include naar, the choice of verb can be left for the future. In (14), reasonable options to finish the sentence would include zocht ‘searched’, but also wilde volgen ‘wanted to follow’, probeerde te vinden ‘tried to find’, nastreefde ‘pursue’, etc.
(14) De Wereldraad van Kerken heeft dat niet gedaan, omdat hij
The World Council of Churches has that not done, because he
van begin af aan (naar) een derde weg tussen het
of start off on (to) a third way between the
communistische oostblok en het vrije, kapitalistische westen zocht.
communist Eastern bloc and the free, capitalist West searched.
(WR-P-P-G-0000103341.p.3.s.3)
‘The World Council of Churches has not done that, because, from the very beginning, it was searching for a third way between the communist Eastern bloc and the free, capitalist West.’
To sum up, when the theme precedes the verb, more complex themes are likely to elicit the use of the variant without naar. Conversely, in instances where the theme is not complex, the producer is hardly under any processing pressure, and s/he might very well contemplate the choice of verb early on and choose to include naar. We therefore make the following prediction.
Production Hypothesis: There should be a negative correlation between theme complexity and the likelihood of naar when the theme precedes the verbs, and a positive correlation when the verb precedes the theme.
4.2. channel hypothesis
Taking the channel perspective, a parallel reasoning can be made. In cases where the theme precedes the verb, the presence of the preposition naar limits the number of verbs that may follow. Hence naar makes the following verb zoeken more predictable and therefore reduces its information content. Of course, since naar does not actually change the meaning of the sentence, this information does not just disappear; it is rather transferred over from the verb to the preposition. To sum up, the preposition signals a lot of information about the verb that is to follow.
This means that, in instances where the preposition precedes the verb, the preposition already carries a lot of information. Combining such an informationally heavy preposition with a complex, informationally heavy theme would lead to a peak in information density, which should be avoided. Instead, combining the heavy preposition with a simple, informationally light theme would smooth out the information density.
Of course, this reasoning only holds for instances where the theme precedes the verb. When the verb precedes the theme, the preposition evidently cannot signal any information about the verb, because the verb is already known at that point. As such, the now informationally light preposition can nicely combine with complex, informationally heavy themes. This leads to the following prediction, which is identical to the prediction made by the production hypothesis.
Channel Hypothesis: There should be a negative correlation between theme complexity and the likelihood of naar when the theme precedes the verbs, and a positive correlation when the verb precedes the theme.
In objection to the reasoning above, it could be claimed that, when the theme precedes the verb, the addition of naar doesn’t actually make the verb that much more predictable. Perhaps the theme by itself already narrows down the list of possible verbs to a large degree, and naar doesn’t do much to narrow it down even further. We can then ask, for all instances in our dataset where the theme precedes the verb, how much more predictable naar would actually make the verb, if it were included. We estimate this in the following way. First, we look at the lemmas of the syntactic heads of the themes. We will refer to these lemmas as ‘theme lemmas’. For each theme lemma in the subset of our dataset where the theme precedes the verb, we count the number of times it appears as the syntactic head of a noun phrase with zoeken, in the SoNaR corpus.Footnote 8 Next, we count the number of times it appears as the syntactic head of a noun phrase with any verb. Finally, we divide the former by the latter. This yields for each theme lemma the probability that it combines with the verb zoeken. The average of these probabilities over the subset of our dataset where the theme precedes the verb is 0.0279.Footnote 9 This means that, given the theme lemma, there’s on average a 2.79% chance that the upcoming verb is zoeken.
We now do the same calculations for the variant with naar. We count for each theme lemma in the same subset the number of times it appears as the syntactic head of a prepositional phrase introduced by naar with zoeken, in the SoNaR corpus. Next, we count the number of times it appears as the syntactic head of a prepositional phrase introduced by naar with any verb. Finally, we divide the former by the latter. The average of these probabilities over the same subset is 0.2364. This means that, given the theme lemma and the preposition naar, there’s on average a 23.64% chance that the verb will be zoeken. Including naar thus makes us on average 8.5 times more confident in our guess that the following verb is zoeken, which we regard as a considerable increase.
The next paragraph outlines this reasoning more formally. Although the following procedure may seem to take a different outlook on the issue, the calculations are fundamentally the same. The procedure is based on Jaeger (2010, p. 28), who estimates the Shannon information of a complement clause in a similar way, i.e., by taking the negative logarithm of the probability that a complement cause would follow, given the matrix verb lemma. These calculations are necessarily only approximate measurements (Jaeger, Reference Jaeger2010, p. 28).
We assume that the sentences in (15) are all synonymous, i.e., that they all contain the same information in total. Now we want to estimate the difference in Shannon information of naar when the theme precedes the verb (15a) versus when the verb precedes the theme (15b), as expressed in (i). Under the current reasoning, we expect this difference to be positive, because that would mean that naar is informationally heavier when it precedes the verb than when it follows the verb. The difference corresponds to the degree to which naar in (15a) makes the verb more predictable.Footnote 10 That is, it corresponds to the difference in information of zoeken in (15a) versus in (15c), as expressed in (ii). We now assume that it is primarily the theme lemma that makes zoeken in (15c) more predictable and we therefore estimate the information of zoeken in (15c) as its information given the theme lemma. Correspondingly, we estimate the information of zoeken in (15a) as its information given the theme lemma and naar. We now have (iii). Shannon information can be calculated as the negative logarithm of the probability, which gives us (iv).Footnote 11 For each instance of a preverbal theme in our dataset, we then calculate the probabilities in (iv) as described above, which gives us the estimated 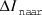 ${\rm{\Delta }}{I_{{\rm{naar}}}}$. Finally, we take the average of these, as in (v). This means that naar is on average estimated to be 3.70 bits heavier when the theme precedes the verb than when the verb precedes the theme.
${\rm{\Delta }}{I_{{\rm{naar}}}}$. Finally, we take the average of these, as in (v). This means that naar is on average estimated to be 3.70 bits heavier when the theme precedes the verb than when the verb precedes the theme.
- (15)
(a) Ik heb gisteren naar een schaar gezocht.
I have yesterday to a scissors searched
(b) Ik heb gisteren gezocht naar een schaar.
I have yesterday searched to a scissors
(c) Ik heb gisteren een schaar gezocht.
I have yesterday a scissors searched
‘I have searched for a pair of scissors yesterday.’
(i)
 $\,\Delta {I_{{\rm{naar}}}} = I\left( {{\rm{naar}}|preverbal\,theme} \right) - I{\rm{(naar}}\,{\rm{|}}\,postverbal\,theme)\,$
$\,\Delta {I_{{\rm{naar}}}} = I\left( {{\rm{naar}}|preverbal\,theme} \right) - I{\rm{(naar}}\,{\rm{|}}\,postverbal\,theme)\,$(ii)
$\, = I\left( {{\rm{zoeken}}|preverbal\,theme\& direct\,obj.} \right) - I\left( {{\rm{zoeken}}|preverbal\,theme\& prep.\,obj.} \right)$(iii)
$\approx I{\rm{(zoeken}}|preverbal\,theme\,lemma) - I\left( {{\rm{zoeken}}|preverbal\,theme\,lemma\& {\rm{naar}}} \right)$(iv)
$\, = - {\log _2}p\left( {{\rm{zoeken}}|preverbal\,th.\,lemma} \right) + {\log _2}p{\rm{(zoeken}}|preverbal\,th.\,lemma\& {\rm{naar}})$(v)
$\,Average\,\Delta {I_{{\rm{naar}}}} \approx 3.70\,bits$
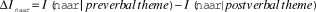
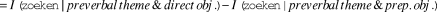
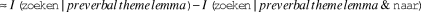
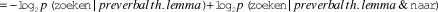

This would mean that the information content of the preposition naar is dependent upon its position relative to the verb. If the verb precedes naar, the preposition evidently cannot contain any information about the verb, since the verb is already known when naar is heard or read. Since naar is thus informationally light, it can nicely combine with a complex, informationally heavy theme. Meanwhile, if naar precedes the verb, it is burdened with a large chunk of the information content otherwise contributed by the verb, thus rendering it informationally heavy. In that case, it would be preferable not to combine it with a complex, informationally heavy theme.
4.3. comprehension hypothesis
Finally, the comprehension perspective stated that for the comprehender naar functions as a signpost that simplifies the parsing of a complex theme. Such a signpost would be especially useful if a complex theme precedes the main verb, since in that case it already gives considerable information about the verb that is to follow, as argued above. Because the main verb for a large part determines the structure of the entire sentence, knowledge of this verb would further simplify parsing to a great extent (Müller, Reference Müller2006; Müller & Wechsler, Reference Müller and Wechsler2014). As such, we formulate the following hypothesis.
Comprehension Hypothesis: There should be a strong positive correlation between theme complexity and the likelihood of naar when the theme precedes the verbs, and a weaker positive correlation when the verb precedes the theme.
To sum up, our three perspectives make different predictions about how the correlation between complexity and explicitness behaves in different linguistic contexts. In particular, we have argued that the relevant distinction will be one between a context where the theme precedes the verb and one where the verb precedes the theme. We will now check this, which will yield an answer to the second research question. If we find any of the hypotheses above to be confirmed, this will also answer our first research question.
4.4 analysis
To test the hypotheses made in the previous subsections, we compose a mixed logistic regression model that has as the dependent variable the presence or absence of naar and theme complexity as a fixed effect.Footnote 12 Theme complexity is a numeric variable, so it can be directly implemented as a parameter in the model.
We also add the variable verb–theme order as a fixed effect, as well as an interaction between theme complexity and verb–theme order. This variable distinguishes between the contexts where the theme precedes the verb, and those where the verb precedes the theme. For a categorical variable such as verb–theme order, we need an additional coding step to implement it into the regression formula. For this, we use user-defined sum-to-zero contrasts, also called user-defined sum coding. This type of coding has a number of advantages over more traditional treatment contrasts or dummy coding. Most notably, the odds ratios can be interpreted as deviations to the group mean instead of to a reference level that sometimes needs to be chosen arbitrarily. For a more in-depth discussion of user-defined contrasts in linguistics, see Heller (2018, pp. 85–88). Verb–theme order has only two levels, viz. theme–verb and verb–theme, so can be implemented into the regression formula with just one parameter. For the instances of theme–verb, this parameter is set to 1. For those of verb–theme, it is set to –1.
The variable Verb–theme order has some correlates that we want to control for. These are the variables clause type and verb finiteness, which are both added as fixed effects. Clause type distinguishes between main clauses and subordinate clauses. It is implemented as a single parameter that was set to 1 if the occurrence appears in a main clause, and –1 if it appears in a subordinate clause. Verb finiteness distinguishes between instances where the main verb zoeken ‘search’ is a finite form, an infinitive, or a participle. Because this variable has three levels, it is implemented with two parameters. The first parameter distinguishes between the finite and non-finite forms. It is set to 1 for finite forms, and –0.5 for infinitives and participles. The second parameter then distinguishes between the infinitives and the participles. It was set to 0 for finite forms, to 1 for infinitives, and –1 for participles.
Previous research on a similar alternation in Dutch, the er-alternation, has revealed that, although the processing motivation for er is highly comparable in Belgian and Netherlandic Dutch, there are considerable differences between the Belgian and Netherlandic models (Grondelaers, van den Bosch, Speelman, & van Hout, Reference Grondelaers, van den Bosch, Speelman and van Hout2015; Grondelaers, Speelman, & Geeraerts, Reference Grondelaers, Speelman, Geeraerts, Kristiansen and Dirven2008; van den Bosch, Grondelaers, & Speelman, forthcoming). We therefore also include the variable Country as a fixed effect in the model. This variable is implemented as a single parameter, set to 1 for Belgian occurrences, and –1 for occurrences from the Netherlands.
As mentioned above, the variants with and without naar of the verb zoeken ‘search’ are considered synonymous (Haeseryn et al., Reference Haeseryn, Romijn, Geerts, de Rooij and van den Toorn1997, p. 1168). Still, subtle semantic differences have been proposed for similar alternations in English (Goldberg, Reference Goldberg1995, pp. 118–119, 1999, pp. 198–200; Perek, Reference Perek2015) and we want to err on the right side of caution.Footnote 13 Based on theoretical accounts such as Goldberg (Reference Goldberg1995), Hopper and Thompson (Reference Hopper and Thompson1980), and Langacker (Reference Langacker1991), it could be suggested that the prepositional variant implies a form of directionality, or movement to a place, while the transitive variant implies an undergoer being affected. These notions relate to the theme argument. For example, when the theme is a place, as in (16), the act of searching typically implies an attempt to move to that place, and we could therefore theorize a preference for the prepositional variant. Meanwhile, in (17), the act of searching implies an attempt to formulate the formulas, i.e., to bring the formulas into being. In other words, the formulas are deeply affected by the act of searching. As such, we could theorize a preference for the transitive variant.
(16) We zochten naar een aanlegplaats en zagen er geen, dus
We searched to a landing_place and saw there no so
we bleven op een afstand liggen.
we stayed on a distance lay
(WR-P-P-B-0000000170.p.2076.s.3)
‘We were searching for a landing place, but didn’t see any, so we kept our distance.’
(17) Vicsek zoekt wiskundige formules die hun vormen beschrijven.
Vicsek searches mathematical formulas that their form describe
(WR-P-E-G-0000004047.p.139.s.1)
‘Vicsek searches for mathematical formulas that describe their shapes.’
We will attempt to control for such a semantic differentiation by looking at the theme lemmas. For instance, in (16), the theme lemma is aanlegplaats ‘landing place’, and in (17), it is formule ‘formula’.Footnote 14 In particular, we take over a technique first proposed by Levshina and Heylen (Reference Levshina, Heylen, Boogaart, Colleman and Rutten2014) and elaborated upon by Speelman, Heylen, and Grondelaers (forthc.), which involves adding a variable called semantic cluster. For each full nominal theme lemma, we calculated a distributional vector based on the SoNaR corpus, and then clustered these vectors into 50 semantic groups.Footnote 15 The variable semantic cluster then distinguished between these clusters. In this way, the theme lemma aanlegplaats ‘landing place’ is grouped in a semantic cluster with other places, such as opvanglocatie ‘shelter location’, weideland ‘pasture’, and slaapplek ‘sleeping place’, while the theme lemma formule ‘formula’ ends up in a cluster with lemmas like methode ‘method’, tactiek ‘tactic’, and techniek ‘technique’. The pronominal theme lemmas were not clustered, but rather directly added as individual levels of this variable.
Semantic Cluster was then introduced into the regression model as a random effect with random intercepts. The variable was added as a random effect rather than a fixed effect because: (i) it only functions as a control variable, and we are currently not directly interested in its effects; (ii) it has 96 distinct levels; and (iii) the levels of the variable are in principle not exhaustive, i.e., the verb zoeken ‘search’ could be used with a theme lemma that does not fit into any of the clusters in our present dataset (Speelman, Heylen, & Geeraerts, Reference Speelman, Heylen, Geeraerts, Speelman, Heylen and Geeraerts2018a, p. 3).
To control for the influence of register, the corpus component was also added as an additional random effect with random intercepts. It would also have been possible to consider register a fixed effect. In that case, one would typically use coarse-grained levels that are exhaustive, such as formal register vs. informal register. However, we prefer to directly use the more fine-grained distinction between individual corpus components, which means that the levels are not repeatable when a follow-up study would use a different corpus. As such, we opt for random effects. For a discussion of the merits of both approaches, see Speelman et al. (2018a, p. 3).
This model was then fitted to the data. Multicollinearity was not found to be a problem, with the condition number (κ = 6.28) below the conventional threshold of 15 (Wolk, Bresnan, Rosenbach, & Szmrecsanyi, Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013, p. 401). The model has a C-index of 0.734 (Somer’s Dxy = 4.67), indicating acceptable discrimination (Hosmer & Lemeshow, Reference Hosmer and Lemeshow2000, p. 162). The model specifications can be found in Table 3.Footnote 16 The presence of naar is the success level of the response variable, so the intercept represents the odds of naar, with all parameters of the model set to 0. That is, it represents the odds of naar for themes that are 1 word long (theme complexity = log(1) = 0), averaged over all categorical variables. The Odds Ratio of 1.20 for clause type indicates that the odds of naar increase with factor 1.20 in main clauses, compared to the mean of both clause types, for themes of 1 word, averaged over both countries, etc.
table 3. Mixed effects logistic regression model predicting the presence of preposition naar

Figure 2 shows the effect plot of the interaction between theme complexity and verb–theme order, which visualizes the estimated probability of naar as a function of theme complexity for the observations where the theme precedes the verb, and for those where the verb precedes the theme. We find a negative correlation when the theme precedes the verb and a positive correlation when the verb precedes the theme. This confirms the Production and Channel Hypotheses.

Fig. 2. Effect plot of the interaction between theme complexity and verb–theme order. When the theme precedes the verb, the likelihood of naar decreases as the theme becomes more complex. Meanwhile, when the verb precedes the theme, the opposite effect arises. This confirms both the producer- and channel-driven explanations of the Complexity Principle.
5. Discussion and conclusions
We can now formulate an answer to the research questions, which are repeated below.
(i) What drives the correlation between complexity and explicitness as we find it in corpora?
(ii) Does the correlation hold in all contexts, and if not, in which ones?
As for the first question, our results indicate that, with regard to the alternation under scrutiny, the correlation between complexity and explicitness is primarily motivated by either production processing or channel constraints. This dovetails with the majority of the literature on the influence of production vs. comprehension processing, including Ferreira and Dell, (2000), Kraljic and Brennan (Reference Kraljic and Brennan2005), Roland et al. (Reference Roland, Elman and Ferreira2006), Ferreira and Hudson (Reference Ferreira and Hudson2011), Ferreira and Schotter (Reference Ferreira and Schotter2013), Gennari and Macdonald (Reference Gennari and Macdonald2009), Jaeger (Reference Jaeger2010), Levy and Jaeger (Reference Levy, Jaeger, Schölkopf, Platt and Hoffman2007), MacDonald (Reference MacDonald2013), and MacDonald and Thornton (Reference MacDonald and Thornton2009).
Still, it should be noted that our results do not entail that the use of explicit coding is completely unbeneficial to the comprehender. Regarding the production perspective, we included both the PDC-model and the collateral signals account, both of which hold that the comprehender does benefit, albeit in an indirect way. There is, in fact, strong evidence that the comprehender interprets both disfluencies and grammatical markers such as the English subordinator that and Dutch existential er as signals of upcoming production difficulties or unpredictable material (Grondelaers et al., Reference Grondelaers, Speelman, Drieghe, Brysbaert and Geeraerts2009; Jaeger, Reference Jaeger2005, see also Clark & Fox Tree, Reference Clark and Fox Tree2002; Collard et al., Reference Collard, Corley, MacGregor and David2008; Corley & Hartsuiker, Reference Corley, Hartsuiker, Alterman and Kirsh2003). Perhaps it is more relevant for the comprehender to receive notifications on the current state of production than to procure sentences that are (marginally) easier to parse. Additional research would need to confirm whether the comprehender does indeed interpret the Dutch preposition naar as such a signal, but our current results certainly do not exclude it; they rather indicate that it is possible. Regarding the channel perspective, it may very well be in the interest of the comprehender to burden his or her own cognitive processing if a more important goal is safeguarded. For example, it is in the interest of both the comprehender and the producer to make sure that as little information as possible is lost in the noisy language channel by making sure the information density does not exceed its optimal level too much or too often. If that leads to tendencies that require more cognitive effort during parsing, this may very well be a price worth paying.
Meanwhile, for the tradition of corpus-based alternation research that is not primarily concerned with language processing, the answer to the second research question is perhaps more interesting. Here, our findings indicate that the Complexity Principle should not be interpreted as a blind law, but rather as a general tendency that holds in most, but not all contexts. This is also argued by Rohdenburg (Reference Rohdenburg2016) and Willems and De Sutter (Reference Willems and De Sutter2015), who propose further refinements to the Complexity Principle. In order to determine in which context we can expect the Principle to hold, we need to consider its underlying mechanism, as well as the specifics of the case study. For example, we have shown that the order of theme and verb is a relevant distinction in our case study, with the effect of the Complexity Principle reversing when the theme precedes the verb. Such context-determined restrictions to the Principle present a possible caveat for alternation studies, which do not always take the underlying mechanisms of the Complexity Principle into account.
There are many possibilities for further research. One possibility is to design a clever operationalization to differentiate between on the one hand the production-driven account proposed in Ferreira and Dell (Reference Ferreira and Dell2000) and MacDonald (Reference MacDonald2013), and on the other hand, the channel-driven model underlying the principle of Uniform Information Distribution (Fenk-Oczlon, Reference Fenk-Oczlon, Bybee and Hopper2001; Jaeger, Reference Jaeger2010). It is certainly possible that both influence the choice for explicit grammatical coding, but the question would then be how we can predict which mechanism is at play under which conditions, or which takes precedence when their predictions collide. Going further, we would want to differentiate between the accounts subsumed under the production perspective, viz. PDC-model and the collateral signal account.
Another possibility for further research is to repeat the same investigation on other case studies and other languages. We hope our current focus on Dutch may inspire researchers on this topic to take under scrutiny case studies outside the English language. Finally, a large-scale alternation study on the direct vs. prepositional object alternation in Dutch is still necessary. Such a study would map out all alternating verbs and aim to shed light on all other major factors governing the alternation, including those of semantic and lectal nature, and how they possibly interact.





