


No CrossRef data available.
Published online by Cambridge University Press: 04 January 2016
The design of an efficient sampling scheme for the study of population and space in the nineteenth century is a challenging problem for historians. To examine the relationship of social life to the general form of the city, the sample must cover the whole territory. Working on that scale however, a researcher ordinarily sacrifices detail to achieve coverage. But to examine the constraints and the routine which are part of everyday experience, the sample must provide that very detail- intensive observations of small areal sub-populations. When the researcher has that detail, he/she ordinarily sacrifices the attempt to achieve uniform coverage of the city as a whole. The two goals have seemed mutually exclusive in any single sampling design. Thus the historical study of the American city has often followed two distinct lines of approach: either gross patterns in urban land use have been investigated to understand aspects of the city’s change, its dynamics of growth, and the development of suburbanization, for example; or intensive studies of the experience of neighborhoods or single ethnic or social groups have been conducted.
The authors wish to thank Karol P. Krotki for his assistance in computing the standard errors of estimate, Charles Tilly and David Bien for their comments on the manuscript. The design of the sample and the data collection have been made possible by grants from the Michigan Society of Fellows and of the Population Development Fund of the Ford Foundation. A copy of the report on the analysis of the 1880 data set “Detroit en 1880, essai d’histoire urbaine” is available as a special working paper of the Center for Research on Social Organization of The University of Michigan, 330 Packard Street, Ann Arbor, Michigan 48104.
1 In addition to Cochran, W.G., Sampling Techniques (New York, 1963)Google Scholar the historian may wish to consult Shofield, R.S., “Sampling in Historical Research” in Wrigley, E.A., Nineteenth Century Society (Cambridge, 1972), 146–90CrossRefGoogle Scholar.
2 Warner, Sam Bass, The Private City, Philadelphia in Three Periods of Its Growth (Philadelphia, 1968)Google Scholar; Jackson, K.T., “Urban Deconcentration in the Nineteenth Century: A Statistical Inquiry,” in Schnore, L.F., ed., The New Urban History (Princeton, 1975), 110–42.Google Scholar
3 Rischin, M., The Promised City: New York’s Jews, 1870-1914 (Cambridge, 1962).Google Scholar
4 Woods, R. and Kennedy, A., The Zone of Emergence, Observations on the Lower, Middle and Upper Working Class Communities of Boston, 1905-1914 (Cambridge, 1962)Google Scholar original manuscript, 1904-1914.
5 Problems of record linkage have usually been studied in terms of nominal linkages in various sources rather than of people and areas. See Wrigley, E.A., ed., Identifying People in the Past (London, 1973).Google Scholar
6 Robinson, E. and Pidgeon, R.H., Atlas of the City of Detroit and Suburbs Embracing Portions of Hamtramck, Springwells and Greenfield Townships (New York, 1885).Google Scholar
7 For selected references on the use of the manuscript census by historians, see Sharpless, J.B. and Shortridge, R.M., “Biased Underenumeration in Census Manuscripts: Methodological Implications,” Journal of Urban History, 1, 4 (August 1975) 409–439.CrossRefGoogle Scholar
8 McKenzie, R.D., The Neighborhood: a Study of Local Life in the City of Columbus, Ohio (Chicago, 1923)Google Scholar; Keller, S., The Urban Neighborhood: A Sociological Perspective (New York, 1968).Google Scholar
9 If the blocks are selected without replacement and if any of the four corners can then be independently chosen for each block, there is a possibility of overlapping fronts between clusters if two selected primary blocks happen to be contiguous. 
10 The Census Bureau’s enumeration districts boundaries are useful to narrow down the search in the documents.
11 Statistics of the Population of the United States at the 10th Census–June 1, 1880 (Washington, D.C., 1883), 420.
12 ![]() involves the sum of products of random variables. Formulae for variances of such products may be found in Goodman, L.A., “On the Exact Variance of Products,” Journal of the American Statistical Association, 55 (1960), 708–713.CrossRefGoogle Scholar
involves the sum of products of random variables. Formulae for variances of such products may be found in Goodman, L.A., “On the Exact Variance of Products,” Journal of the American Statistical Association, 55 (1960), 708–713.CrossRefGoogle Scholar
13 Variances shown in Table 3 are computed with the following formula: 
14 For the five plates without census data (5, 14, 17-19), we estimated the mean number of people per front. A scatter plot of the number of people per front against the percentage of P and O blocks per plate for the fifteen plates with census data led us to classify them into three groups:
1) few people per front (<21) and small proportion of P and O blocks (<65%): plates 20 and 10
2) many people per front (>60) and large proportion of P and O blocks (>70%): plates 2, 6, 7, 8, 9, 11, 12, 13, 15, 16
3) middle group: fewer than forty-two people per front and over 70 percent of P and O blocks in the plate: plates 1, 3 and 4.
On the basis of the proportion of P and O blocks, plates 5, 17, 18 and 19 were assigned to group 1 and plate 14 to group 3. At this stage, these plates lacking census data were assigned the mean number of people per front for their assigned group.


17 Including a research trip to the University of Pittsburgh library, where the original manuscripts are deposited, to read the few unreadable pages of the microfilm of the National Archives.
18 Our prediction was most inaccurate for ![]() the mean number of people per front in Category 3. We had corrected some of this expected underestimation by generally overestimating
the mean number of people per front in Category 3. We had corrected some of this expected underestimation by generally overestimating ![]() the mean number of enumerable fronts per cluster:
the mean number of enumerable fronts per cluster:
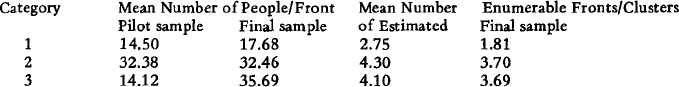
19 The 1880 City Directory of Detroit, 966 pages. (Detroit, 1880).
20 These are the most commonly used. The routines for match merging the data-sets and computing summary statistics at various levels of analysis are available in the Michigan Interactive Data Analysis System. See D.J. Fox and K.E. Guire, Documentation for MIDAS, revised edition August 1974, Statistical Research Laboratory of The University of Michigan, Ann Arbor, Michigan 48104.
21 The stratum of a cluster of six fronts is identified by its primary block.
22 In the original sample design there were eighty strata—twenty plates, each with four types of blocks. However, only four different sampling fractions were used, and thus there are only four different values of wh. These correspond effectively to P and O blocks for each of the three groups of plates shown in Table 6 and to the ND and V blocks over all plates. The actual weights used were taken as being proportional to Ni/ni where the constant of proportionality was chosen so that the weighted sum of the sample number of persons in each of these four categories reproduced the total sample size of 12,185 persons. Details are shown on following page.

23 The formula for the estimated variance of r is given by 
where

and

Also,

and 

Finally the standard error of r is given by
![]()
see Kish, Leslie, Survey Sampling (New York, 1965)Google Scholar, chap. 6: “unequal clusters.”
24 Statistics of the Population of the United States at the 10th Census, op. cit.: 536-41, 420, 876.
25 See Zunz, Oliver, “Detroit en 1880: espace et ségrégation,” Annales E.S.C., 32, 1 (Janvier-Fevrier 1977), 106–136Google Scholar and “The Organization of the American City in the Late Nineteenth Century: Ethnic Structure and Spatial Arrangement in Detroit,” The Journal of Urban History, 3, 4 (August 1977), 443-466.