



No CrossRef data available.
Article contents
Variational inference as iterative projection in a Bayesian Hilbert space with application to robotic state estimation
Published online by Cambridge University Press: 24 October 2022
Abstract
Variational Bayesian inference is an important machine learning tool that finds application from statistics to robotics. The goal is to find an approximate probability density function (PDF) from a chosen family that is in some sense “closest” to the full Bayesian posterior. Closeness is typically defined through the selection of an appropriate loss functional such as the Kullback-Leibler (KL) divergence. In this paper, we explore a new formulation of variational inference by exploiting the fact that (most) PDFs are members of a Bayesian Hilbert space under careful definitions of vector addition, scalar multiplication, and an inner product. We show that, under the right conditions, variational inference based on KL divergence can amount to iterative projection, in the Euclidean sense, of the Bayesian posterior onto a subspace corresponding to the selected approximation family. We work through the details of this general framework for the specific case of the Gaussian approximation family and show the equivalence to another Gaussian variational inference approach. We furthermore discuss the implications for systems that exhibit sparsity, which is handled naturally in Bayesian space, and give an example of a high-dimensional robotic state estimation problem that can be handled as a result. We provide some preliminary examples of how the approach could be applied to non-Gaussian inference and discuss the limitations of the approach in detail to encourage follow-on work along these lines.
Keywords
- Type
- Research Article
- Information
- Copyright
- © The Author(s), 2022. Published by Cambridge University Press
References
Adamčík, M., “The information geometry of Bregman divergences and some applications in multi-expert reasoning,” Entropy 16(12), 6338–6381 (2014).CrossRefGoogle Scholar
Aitchison, J., “The statistical analysis of compositional data (with discussion),” J. R. Stat. Soc. Ser. B 44, 139–177 (1982).Google Scholar
Amari, S.-I., “The EM algorithm and information geometry in neural network learning,” Neural Comput. 7(1), 13–18 (1995).CrossRefGoogle Scholar
Amari, S.-I., “Natural gradient works efficiently in learning,” Neural Comput. 10(2), 251–276 (1998).CrossRefGoogle Scholar
Amari, S.-I.. Information Geometry and Its Applications (Springer, Japan, 2016).CrossRefGoogle Scholar
Amari, S.-I., Kurata, K. and Nagaoka, H., “Information geometry of Boltzmann machines,” IEEE T rans. Neural Netw. 3(2), 260–271 (1992).CrossRefGoogle ScholarPubMed
Ambrogioni, L., Güçlü, U., Güçlütürk, Y., Hinne, M., Maris, E. and van Gerven, M. A. J., “Wasserstein Variational Inference,” In: 32nd Conference on Neural Information Processing Systems (NIPS 2018), Montréal, Canada (2018).Google Scholar
Barber, D.. Bayesian Reasoning and Machine Learning (Cambridge University Press, Cambridge, UK, 2012).CrossRefGoogle Scholar
Barfoot, T. D., Stochastic Decentralized Systems, Ph.D. Thesis (University of Toronto, 2002).Google Scholar
Barfoot, T. D.. State Estimation for Robotics (Cambridge University Press, Cambridge, UK, 2017).CrossRefGoogle Scholar
Barfoot, T. D.. Multivariate Gaussian Variational Inference by Natural Gradient Descent,” Technical report (Autonomous Space Robotics Lab, University of Toronto, (2020), arXiv:2001.10025 [stat.ML].Google Scholar
Barfoot, T. D. and D’Eleuterio, G. M. T., “An Algebra for the Control of Stochastic Systems: Exercises in Linear Algebra,” In: Proceedings of the 5th International Conference on Dynamics and Control of Structures in Space (DCSS), Cambridge, England (2002).Google Scholar
Barfoot, T. D. and D’Eleuterio, G. M. T., “Stochastic Algebra for Continuous Variables, Technical report,” University of Toronto Institute for Aerospace Studies (2003).Google Scholar
Barfoot, T. D., Forbes, J. R. and Yoon, D. J., “Exactly sparse Gaussian variational inference with application to derivative-free batch nonlinear state estimation,” Int. J. Robot. Res. (IJRR) 39(13), 1473–1502 (2020), 1911, (arXiv:1911.08333 [cs.RO]).CrossRefGoogle Scholar
Barfoot, T. D., Tong, C. H. and Sarkka, S., “Batch Continuous-Time Trajectory Estimation as Exactly Sparse Gaussian Process Regression,” In: Proceedings of Robotics: Science and Systems (RSS), Berkeley, USA (2014).Google Scholar
Bayes, T., “Essay towards solving a problem in the doctrine of chances,” Philos. Trans. R. Soc. Lond. 53, 370–418 (1763).Google Scholar
Blei, D. M., Kucukelbir, A. and McAuliffe, J. D., “Variational inference: A review for statisticians,” J. Am. Stat. Assoc. 112(518), 859–877 (2017).CrossRefGoogle Scholar
Bregman, L. M., “The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming,” USSR Comput. Math. Math. Phys. 7(3), 200–217 (1967).CrossRefGoogle Scholar
Csiszár, I., “
 $I$
-Divergence geometry of probability distributions and minimization problems,” Ann. Probab. 3(1), 146–158 (1975).CrossRefGoogle Scholar
$I$
-Divergence geometry of probability distributions and minimization problems,” Ann. Probab. 3(1), 146–158 (1975).CrossRefGoogle Scholar
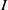 $I$
-Divergence geometry of probability distributions and minimization problems,” Ann. Probab. 3(1), 146–158 (1975).CrossRefGoogle Scholar
$I$
-Divergence geometry of probability distributions and minimization problems,” Ann. Probab. 3(1), 146–158 (1975).CrossRefGoogle ScholarCsiszár, I. and Tusnády, G., “Information Geometry and Alternating Minimization Procedures,” In: Statistics and Decisions, Supplement Issue No. 1, R. Oldenberg, (1984).Google Scholar
Egozcue, J., Pawlowsky-Glahn, V., Tolosana-Delgado, R., Ortego, M. I. and van den Boogaart, K. G., “Bayes spaces: use of improper distributions and exponential families,” RACSAM: Rev. Real Acad. Ciencias Exactas, Físicas Naturales. Ser. A. Mat. 107(2), 475–486 (2013).CrossRefGoogle Scholar
Egozcue, J. J., Diaz-Barrero, J. L. and Pawlowsky-Glahn, V., “Hilbert space of probability density functions based on Aitchison geometry,” Acta Math. Sin. 22(4), 1175–1182 (2006).CrossRefGoogle Scholar
Fisher, R. A., “On the mathematical foundations of theoretical statistics,” Philos. Trans. R. Soc. Lond. Ser. A, Containing Papers of a Mathematical or Physical Character 222(594-604), 309–368 (1922).Google Scholar
Hinton, G. E. and van Camp, D., “Keeping Neural Networks Simple by Minimizing the Description Length of the Weights,” In: Sixth ACM Conference on Computational Learning Theory, Santa Cruz, California (1993).Google Scholar
Jazwinski, A. H.. Stochastic Processes and Filtering Theory (Academic, New York, 1970).Google Scholar
Jordan, M. I., Ghahramani, Z., Jaakkola, T. and Saul, L. K., “An introduction to variational methods for graphical models,” Mach. Learn. 37(2), 183–233 (1999).CrossRefGoogle Scholar
Kullback, S. and Leibler, R. A., “On information and sufficiency,” Ann. Math. Stat. 22(1), 79–86 (1951).CrossRefGoogle Scholar
Laplace, P.-S., , Philosophical Essay on Probabilities, Springer, (1995). translated by Andrew I. Dale from Fifth French Edition, 1825.Google Scholar
Li, Y. and Turner, R. E., “Rényi Divergence Variational Inference,” In: 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain (2016).Google Scholar
Magnus, J. R. and Neudecker, H., “The elimination matrix: some lemmas and applications,” SIAM J. Algebraic Discret. Methods 1(4), 422–449 (1980).CrossRefGoogle Scholar
Magnus, J. R. and Neudecker, H.. Matrix Differential Calculus with Applications in Statistics and Econometrics (John Wiley & Sons, Hoboken, NJ and Chichester, West Sussex, 2019).CrossRefGoogle Scholar
Manton, J. H. and Amblard, P.-O., “A Primer on Reproducing Kernel Hilbert Spaces, Technical report,” The University of Melbourne and CNRS (2015), arXiv:1408.0952v2 [math.HO].CrossRefGoogle Scholar
McGrayne, S. B.. The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy (Yale University Press, New Haven, Connecticut, 2011).Google Scholar
Monge, G., “Mémoire sur la théorie des déblais et des remblais,” In: Histoire de l’Académie Royale des Sciences de Paris, (1781).Google Scholar
Painsky, A. and Wornell, G. G., Bregman divergence bounds and universality properties of the logarithmic loss, Department of Industrial Engineering, Tel Aviv University (2020). Technical report, arXiv: 1810.07014v2 [cs.IT].Google Scholar
Pawlowsky-Glahn, V. and Egozcue, J. J., “Geometric approach to statistical analysis on the simplex,” Stoch. Environ. Res. Risk Assess. 15(5), 384–398 (2001).CrossRefGoogle Scholar
Rényi, A., “On Measure of Entropy and Information,” In: Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, vol. 1, (1961) pp. 547–561.Google Scholar
Shannon, C. E., “A mathematical theory of communication,” Bell Syst. Tech. J. 27(3), 379–423,623–656 (1948).CrossRefGoogle Scholar
Stein, C. M., “Estimation of the mean of a multivariate normal distribution,” Ann. Stat. 9(6), 1135–1151 (1981).CrossRefGoogle Scholar
Takahashi, K., Fagan, J. and Chen, M.-S., “A Sparse Bus Impedance Matrix and its Application to Short Circuit Study,” In: Proceedings of the PICA Conference (1973).Google Scholar
van den Boogaart, K. G., Egozcue, J. J. and Pawlowsky-Glahn, V., “Bayes linear spaces,” Stat. Oper. Res. Trans. 34(2), 201–222 (2010).Google Scholar
van den Boogaart, K. G., Egozcue, J. J. and Pawlowsky-Glahn, V., “Bayes Hilbert spaces,” Aust. N. Z. Stat. 56(2), 171–194 (2014).CrossRefGoogle Scholar
Wainwright, M. J. and Jordan, M. I., “Graphical models, exponential families, and variational inference,” Mach. Learn. 1(1-2), 1–305 (2008).Google Scholar