



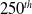
1. Introduction
Robots are reprogrammable machines used to perform repetitive or dangerous tasks instead of humans. They can be categorized into platform-dependent and mobile robots. According to World Robotics 2021 data, approximately 3 million industrial robots are in operation worldwide, with 384 thousand installed in 2020. Energy efficiency is crucial in industrial applications as it can lead to significant cost savings and environmental benefits. Many industries consume vast amounts of energy to run their processes, and energy efficiency can help reduce this energy consumption. Improving energy efficiency in industrial processes involves identifying areas where energy can be conserved and implementing measures to reduce energy waste. This can include using more energy-efficient equipment, optimizing processes to reduce energy consumption, and implementing energy management systems. Not only does energy efficiency lead to cost savings, but it also helps reduce greenhouse gas emissions and contributes to a cleaner environment. Moreover, energy efficiency can enhance the competitiveness of industries by improving productivity, reducing operational costs, and enhancing the reliability of energy supply.
Industrial robots have become increasingly popular in manufacturing and other industrial applications due to their ability to perform repetitive and complex tasks with precision and speed. However, these robots consume a significant amount of energy, which can lead to high operating costs and environmental impacts. Therefore, energy-saving measures are critical to improve the sustainability of industrial robot applications. There are various ways to reduce energy consumption in industrial robots, such as using more efficient motors, reducing idle time, and optimizing the robot’s movements. By implementing these measures, companies can save a considerable amount of energy and reduce their operating costs. Moreover, reducing energy consumption in industrial robots can help minimize their carbon footprint, contribute to a more sustainable manufacturing process, and align with environmental regulations. Therefore, energy-saving measures in industrial robots are essential for both economic and environmental reasons, and companies should prioritize them in their operations. In 2021, the number of robot installations reached a historic high of 517,385 units, marking a growth rate of 31% compared with 2020. This surge exceeded the previous record level of 423,321 units achieved in 2018 by 22%. Additionally, the operational stock of industrial robots was estimated to be 3,477,127 units in 2021. As a result, it is imperative for companies to prioritize the efficiency of their robots and invest in developing this feature to gain a competitive edge. All of these statistical contents have been taken from the International Federation of Robotics [1].
Numerous tasks have been proposed for robots in the literature. For a robot to perform a given task accurately, it must follow a predefined path or trajectory. Trajectory tracking involves following a path that changes over time and is used for tasks like welding and sealing. In contrast, path following involves adhering to a fixed path and is used in mobile robot navigation and industrial robot handling.
Several studies have explored model-based approaches for path following in robotics. For instance, Lin et al. [Reference Lin, Zhao and Ding2] presented a data-driven method for online path correction in industrial robots, addressing joint position errors that impact path accuracy. Raikwar et al. [Reference Raikwar, Fehrmann and Herlitzius3] proposed a stable navigational algorithm for orchard robots designed to operate effectively in Global Navigation Satellite Systems (GNSS)-denied environments. Khaled et al. [Reference Khaled, Akhrif and Bonev4] introduced an active disturbance rejection control scheme to improve the path accuracy of Mecademic’s Meca500 six-axis industrial robot. Model-based approaches are particularly suited for scenarios where accurate models of the robot and environment are available, offering predictability and stability but requiring complex modeling. Conversely, artificial intelligence (AI)-based approaches are advantageous in environments where creating precise models is challenging or where adaptability is essential, providing flexibility and learning capabilities but often requiring substantial data and computational resources.
There has been an extensive research on visual-based path following in robotics. Genk et al. [Reference Geng, Zhang, Tian and Zhou5] developed a novel algorithm for welding industrial robots that performs path extraction on complex surfaces by iteratively processing images from a 3D camera. However, due to differences in robots, processes, and cameras, the current work, when compared solely on methods, operates faster as it is noniterative. Other studies have developed structures for visual path tracking that are trained with data provided by operators using methods akin to end-to-end learning [Reference Chen and Birchfield6, Reference Okamoto, Itti and Tsiotras7]. This study eliminates the need for operator data. Instead, after updating the neural network weights with supervised learning, reinforcement learning is employed to enhance the robustness of the responses. Moreover, most reinforcement learning algorithms are typically applied in simulation environments to avoid potential damage to the robot or surroundings during the trial-and-error training phase [Reference Duan, Suen and Zou8, Reference Baltes, Christmann and Saeedvand9]. Consequently, networks trained in simulations often do not perform as expected in real-world environments. The hybrid learning method proposed in this study, incorporating reinforcement learning, demonstrates smooth operation in real-world settings.
A four-phase hybrid approach to solve the multiobjective trajectory planning problem for industrial robots has been presented in [Reference Chettibi10], combining robustness and flexibility. Zhang et al. [Reference Zhang and Shi11] presented a trajectory planning method for manipulators that includes time and jerk optimization with obstacle avoidance. Yang et al. [Reference Yang, Dong and Dai12] proposed a collision avoidance trajectory planning method for dual-robot systems. Katiyar et al. [Reference Katiyar and Dutta13] proposed an approach for a 14-DOF Rover Manipulator System’s end-effector path tracking. Tang et al. [Reference Tang, Zhou and Xu14] presented a path obstacle avoidance algorithm for a 6-DOF robotic arm.
While most of these robots are conventional, some researchers have aimed to modernize them. For example, Oh et al. [Reference Oh, Kim, Na and Youn15] achieved fault detection in industrial robots using a recursive convolutional neural network (CNN). Chen et al. [Reference Chen, Cao, Wu and Zhang16] performed fault prediction for heavy-duty robots with a CNN structure. Bingol et al. [Reference Bingol and Aydogmus17] used CNNs for classifying motor torque information to ensure safe human–robot interaction and employed speech for communication between humans and industrial robots [Reference Bingol and Aydogmus18]. AI has been used to model industrial robot energy consumption [Reference Yan and Zhang19], and deep learning structures have been applied to solve inverse kinematics in parallel industrial robots [Reference Toquica, Oliveira, Souza, Motta and Borges20]. Rath et al. [Reference Rath and Subudhi21] utilized a model predictive controller for path following in an autonomous submarine vehicle, and Zheng et al. [Reference Zheng, Tao, Sun, Sun, Chen, Sun and Xie22] developed a soft actor–critic-based controller for unmanned surface vehicles. Mondal et al. [Reference Mondal, Ray, Reddy and Nandy23] implemented a fuzzy logic controller for wheeled mobile robots, and other studies focused on optimal path following using least-squares methods [Reference Handler, Harker and Rath24], deep reinforcement learning [Reference Maldonado-Ramirez, Rios-Cabrera and Lopez-Juarez25], and 3D path-following control algorithms [Reference Wen and Pagilla26]. Learning involves using experiences gained from new situations. It can be categorized into supervised, unsupervised, and reinforcement learning. Supervised learning uses datasets of input–output pairs, unsupervised learning focuses on the relationships between input data, and reinforcement learning establishes relationships between state and reward pairs [Reference Bingol27]. For example, trajectory planning for industrial robots has been performed using a region-based CNN trained through supervised learning [Reference Yang, Li, Yu, Li and Gao28], and supervised learning has enabled humanoid robots to determine hand location [Reference Almeida, Vicente and Bernardino29]. Position estimation for the KUKA KR240 R2900 robot [Reference Bilal, Unel, Tunc and Gonul30] and motion planning optimization for assembly robots [Reference Ying, Pourhejazy, Cheng and Cai31] have also used supervised learning. The current paper employs a CNN structure for visual path following, trained with both supervised and reinforcement learning algorithms. Reinforcement learning includes value and policy learning. The double deep Q-network (DQN) algorithm, a value learning method, has been used to guide mobile robots along paths [Reference Zhang, Gai, Zhang, Tang, Liao and Ding32] and navigate to targets [Reference Wang, Elfwing and Uchibe33]. The DQN structure has also been applied to detect odor/gas sources [Reference Chen, Fu and Huang34] and track weld seams [Reference Zou, Chen, Chen and Li35]. Policy learning methods, such as the proximal policy optimization (PPO) algorithm, have been used for path planning in multirobot systems [Reference Wen, Wen, Di, Zhang and Wang36], industrial robots [Reference Bingol37], and real-time motion planning [Reference Kamali, Bonev and Desrosiers38]. The current study uses the PPO algorithm for reinforcement learning. Hybrid learning methods are also explored in the literature. For instance, fuzzy logic algorithms have been combined with genetic algorithms for controlling multiple mobile robot systems [Reference Liu and Kubota39], and genetic fuzzy logic controllers have been used for mobile robot systems [Reference Desouky and Schwartz40]. Fault detection in industrial robots has been addressed by combining artificial neural networks with support vector machines [Reference Long, Mou, Zhang, Zhang and Li41]. Hybrid learning often involves optimizing one method’s parameters using another or connecting different structures in sequence.
As a distinct approach from previous literature, this study aims to combine the advantages of supervised and reinforcement learning algorithms while addressing their disadvantages. This study addresses the challenge of developing an efficient and accurate visual path-following algorithm for industrial robots. Traditional supervised learning methods, while somewhat effective, have limitations in accuracy and processing speed when applied to real-world scenarios. To overcome these limitations, a novel hybrid learning approach is proposed, combining supervised learning with reinforcement learning. The hybrid learning method significantly reduces the average error in the robot’s path-following capabilities, achieving an average error of 30.9 mm compared with 39.3 mm with supervised learning alone. It also reduces the processing time required for path-following tasks, averaging 31.7 s compared with 35.0 s with supervised learning. Additionally, the hybrid learning method decreases the total power consumption of the robot’s motors, enhancing energy efficiency. By addressing these multifaceted issues, the study demonstrates that the proposed hybrid learning approach offers a more effective and efficient solution for visual path following in industrial robots compared with traditional supervised learning methods. This approach not only improves the accuracy and speed of the robot’s performance but also enhances energy efficiency, which is crucial for industrial applications.
Contribution of this work: A novel hybrid learning approach is introduced, combining supervised and reinforcement learning for visual path following in industrial robots. This method significantly improves accuracy, processing speed, and energy efficiency compared with traditional approaches, as demonstrated on the KUKA Agilus KR6 R900 six-axis robot. These contributions provide a more effective solution for industrial automation, particularly in energy-sensitive applications.
2. Method
2.1. Theoretical framework
A hybrid approach can improve performance compared with pure supervised or reinforcement learning techniques by combining the strengths of both methods. Supervised learning provides accurate and efficient learning from labeled data, allowing the model to generalize well on seen examples, while reinforcement learning excels in decision-making and learning from interactions with the environment, helping the model adapt to new situations. By combining these strengths, hybrid approaches make better use of available data, such as using supervised learning to pretrain a model, reducing the exploration space, and speeding up convergence in reinforcement learning. This combination also improves generalization across different environments and scenarios. Moreover, incorporating supervised learning can guide the model in environments with sparse or delayed rewards, making the learning process more efficient. The initial foundation provided by supervised learning reduces the need for extensive exploration in reinforcement learning, balancing exploration and exploitation more effectively. Knowledge from supervised learning can be transferred to reinforcement learning in different domains, enhancing the model’s performance across various tasks. By combining the strengths of both supervised and reinforcement learning, hybrid approaches achieve improved performance, robustness, and efficiency.
2.2. System design
Until recently, industrial robots were only used as machines that could perform certain preprogrammed tasks. However, for more effective use of robots, they must be able to make decisions like humans. AI-supported algorithms can enable standard robots to become smarter machines, allowing them to learn by themselves, much like humans. With this ability, a robot can respond optimally in situations it has not encountered before. The goal of this study was to create an AI-based algorithm for an industrial robot, eliminating the need for reprogramming and calibration for different tasks.

Figure 1. Block diagram of system.
Simulation and experimental studies were carried out using the system presented in Figure 1. The artificial neural networks designed for the system were trained using an industrial robot (ABB IRB4600-40) in the Webots robot simulator program environment. Simulation parameters were chosen as default, with gravity of 9.81 m/s
 $^2$
, basic time step of 32 ms, 3D display frame per second of 60, physics disable linear velocity threshold of 0.01 m/s, physics disable angular velocity threshold of 0.01 rad/s, drag force scale of 30, and drag torque scale of 5. As a next step, the networks trained in the simulation environment were experimentally tested on a real industrial robot (KUKA Agilus KR6 R900 sixx). In addition, the networks developed with a real image taken from the real system were tested in the simulation environment. The generated path was used for the real robot trajectory. A view of the created simulation environment is shown in Figure 2. The mass of the ABB robot shown in Figure 2 is about 435 kg, the payload of the robot is 40 kg, the reach distance is 2550 mm, and the repeatability of the robot is about 0.06 mm. A camera and a pen were mounted on the tool center point (TCP) of the manipulator. The resolution of the camera was adjusted as
$^2$
, basic time step of 32 ms, 3D display frame per second of 60, physics disable linear velocity threshold of 0.01 m/s, physics disable angular velocity threshold of 0.01 rad/s, drag force scale of 30, and drag torque scale of 5. As a next step, the networks trained in the simulation environment were experimentally tested on a real industrial robot (KUKA Agilus KR6 R900 sixx). In addition, the networks developed with a real image taken from the real system were tested in the simulation environment. The generated path was used for the real robot trajectory. A view of the created simulation environment is shown in Figure 2. The mass of the ABB robot shown in Figure 2 is about 435 kg, the payload of the robot is 40 kg, the reach distance is 2550 mm, and the repeatability of the robot is about 0.06 mm. A camera and a pen were mounted on the tool center point (TCP) of the manipulator. The resolution of the camera was adjusted as
 $64\times 64$
with RGB video format. The pen on the TCP was used to simulate a dummy sealing operation on the determined trajectory on the workbench as labeled
$64\times 64$
with RGB video format. The pen on the TCP was used to simulate a dummy sealing operation on the determined trajectory on the workbench as labeled
 $ path$
on the figure.
$ path$
on the figure.

Figure 2. Simulation environment for training procedure.
2.3. Supervised learning
Supervised learning is a technique that establishes a relationship between the input and output of a system. The dataset comprises an input–output dataset (
 $D(x_i,y_i)$
). The learning process involves the following steps: generating the dataset, standardizing the data, determining the network architecture, and training and testing the network.
$D(x_i,y_i)$
). The learning process involves the following steps: generating the dataset, standardizing the data, determining the network architecture, and training and testing the network.
In this study, the dataset was collected from a training path created as shown in Figure 3 for the robot’s TCP traveling on the path. The path was created by combining a total of 16 different paths consisting of linear and sinusoidal functions, considering the possible paths that a real robot may experience. For the training, the background color was taken as gray
 $ [Color Code :\; \#8C99AA]$
, and the line color was adjusted dark red
$ [Color Code :\; \#8C99AA]$
, and the line color was adjusted dark red
 $ [Color Code:\; \#782829]$
, in accordance with the color tones from a real photo taken via a camera from the experimental environment. The distance between two consecutive points on the training path was constrained between 1 and 2 cm, and the path consists of a total of 362 waypoints. An image was taken with the camera mounted on the robot at each path step, and the position difference between the two steps (
$ [Color Code:\; \#782829]$
, in accordance with the color tones from a real photo taken via a camera from the experimental environment. The distance between two consecutive points on the training path was constrained between 1 and 2 cm, and the path consists of a total of 362 waypoints. An image was taken with the camera mounted on the robot at each path step, and the position difference between the two steps (
 $\Delta _x$
and
$\Delta _x$
and
 $\Delta _y$
) was recorded by moving the robot on the training path. The input data of the dataset consisted of recorded images taken from the camera on the TCP, and the output of the dataset was formed by the position differences that occurred during the TCP motion.
$\Delta _y$
) was recorded by moving the robot on the training path. The input data of the dataset consisted of recorded images taken from the camera on the TCP, and the output of the dataset was formed by the position differences that occurred during the TCP motion.
The output data were standardized with the equation given in Eq. (1) to make the learning process more stable:
 \begin{equation} \begin{split} D_{\mathcal{S}}(y_i) = \frac{D(y_i)-\overline{D(y_i)}}{\sigma \left (D(y_i)\right )} \end{split} \end{equation}
\begin{equation} \begin{split} D_{\mathcal{S}}(y_i) = \frac{D(y_i)-\overline{D(y_i)}}{\sigma \left (D(y_i)\right )} \end{split} \end{equation}
where
 $\sigma$
is the standard deviation and the output of dataset is symbolized as
$\sigma$
is the standard deviation and the output of dataset is symbolized as
 $D(y_i)$
in Eq. (1).
$D(y_i)$
in Eq. (1).
 $ \overline{D(y_i)}$
is the mean value of the data. The standard output data
$ \overline{D(y_i)}$
is the mean value of the data. The standard output data
 $D_{\mathcal{S}}(y_i)$
must be between -1 and 1 to be applied in the hyperbolic tangent (
$D_{\mathcal{S}}(y_i)$
must be between -1 and 1 to be applied in the hyperbolic tangent (
 $tan_h$
) activation function.
$tan_h$
) activation function.
 $tan_h$
function enables the explore process to work more stable in the reinforcement learning process.
$tan_h$
function enables the explore process to work more stable in the reinforcement learning process.
 $D_{\mathcal{S}}(y_i)$
is normalized
$D_{\mathcal{S}}(y_i)$
is normalized
 $D_{\mathcal{N}}(y_i)$
using Eq. (2). In addition, the brightness values of the input data
$D_{\mathcal{N}}(y_i)$
using Eq. (2). In addition, the brightness values of the input data
 $D(x_i)$
are randomly adjusted up to 10% during the training process to obtain a robust trained network working with the real image:
$D(x_i)$
are randomly adjusted up to 10% during the training process to obtain a robust trained network working with the real image:
 \begin{equation} \begin{split} D_{\mathcal{N}}(y_i)= \frac{2\left (D_{\mathcal{S}}(y_i)-min\left (D_{\mathcal{S}}(y_i)\right )\right ) }{max\left (D_{\mathcal{S}}(y_i)\right )-min\left (D_{\mathcal{S}}(y_i)\right )}-1 \end{split} \end{equation}
\begin{equation} \begin{split} D_{\mathcal{N}}(y_i)= \frac{2\left (D_{\mathcal{S}}(y_i)-min\left (D_{\mathcal{S}}(y_i)\right )\right ) }{max\left (D_{\mathcal{S}}(y_i)\right )-min\left (D_{\mathcal{S}}(y_i)\right )}-1 \end{split} \end{equation}
In this study, Table I presents the CNN architecture that is used as a supervised learning structure because regression will be applied to the input images.
Table I. CNN architecture.


Figure 3. Training trajectory path.
The
 $Convolution\,Layer$
is a customized neural network structure shown in Table I. This network produces output by convolutional processing of the input data. The shape column in the table presents the number of the filter (
$Convolution\,Layer$
is a customized neural network structure shown in Table I. This network produces output by convolutional processing of the input data. The shape column in the table presents the number of the filter (
 $FS$
) and kernel size (
$FS$
) and kernel size (
 $KS$
). The last column shows the activation functions used in the related line. The pooling layer produces output based on the neighborhood relationship of the data input. The hyperparameters of this layer are kernel size and neighborhood function. In the study, maximum (
$KS$
). The last column shows the activation functions used in the related line. The pooling layer produces output based on the neighborhood relationship of the data input. The hyperparameters of this layer are kernel size and neighborhood function. In the study, maximum (
 $max$
) was used as the pooling function. The dense layer was fully connected to the previous layer and produces the output after the necessary mathematical calculations. The neuron size was shown as
$max$
) was used as the pooling function. The dense layer was fully connected to the previous layer and produces the output after the necessary mathematical calculations. The neuron size was shown as
 $NS$
. In this study, rectified linear units (
$NS$
. In this study, rectified linear units (
 $ReLU$
) and
$ReLU$
) and
 $tan_h$
were used as activation functions.
$tan_h$
were used as activation functions.
The training process was started after the creating the dataset (
 $D(x_i,y_i)$
) and the CNN architecture given in Table I. The dataset was divided into 90% for training and 10% testing. Adam optimization method and mean absolute error loss function were used in the training process. The number of training epoch was taken as 500. The learning rate decay function for supervised learning is as follows: If the epoch is less than 100, the learning rate is set to 1e-4. If the epoch is between 100 and 200, the learning rate is reduced to 1e-5. If the epoch is between 200 and 400, the learning rate is further reduced to 1e-6. For epochs greater than or equal to 400, the learning rate is fixed at 5e-7. This decay function progressively reduces the learning rate as the training progresses, allowing for fine-tuning of the model parameters in the later stages of training. In this study, distance was measured in meters, and the learning rates were intentionally set lower than those in other studies in the literature. The training was carried out in two stages, the first 250 epochs were performed and recorded, and the last 250 epochs were performed using this record.
$D(x_i,y_i)$
) and the CNN architecture given in Table I. The dataset was divided into 90% for training and 10% testing. Adam optimization method and mean absolute error loss function were used in the training process. The number of training epoch was taken as 500. The learning rate decay function for supervised learning is as follows: If the epoch is less than 100, the learning rate is set to 1e-4. If the epoch is between 100 and 200, the learning rate is reduced to 1e-5. If the epoch is between 200 and 400, the learning rate is further reduced to 1e-6. For epochs greater than or equal to 400, the learning rate is fixed at 5e-7. This decay function progressively reduces the learning rate as the training progresses, allowing for fine-tuning of the model parameters in the later stages of training. In this study, distance was measured in meters, and the learning rates were intentionally set lower than those in other studies in the literature. The training was carried out in two stages, the first 250 epochs were performed and recorded, and the last 250 epochs were performed using this record.
2.4. Reinforcement learning
Reinforcement learning is the process of enabling predetermined structures to produce optimal outputs based on instantaneous state information. There are two types of reinforcement learning: value learning and policy learning. Value learning is applied to systems with a fixed output space, while policy learning is applied to systems with a fixed output space width. In this study, the system output is the position difference (
 $\Delta _x$
and
$\Delta _x$
and
 $\Delta _y$
) of the robot’s TCP, and these position differences are not constant. Therefore, the policy learning method was chosen for this application.
$\Delta _y$
) of the robot’s TCP, and these position differences are not constant. Therefore, the policy learning method was chosen for this application.
The action of the designated agent is called policy. Politics (
 $\pi$
) is the establishment of a probabilistic distribution relationship between the state space (
$\pi$
) is the establishment of a probabilistic distribution relationship between the state space (
 $\mathcal{S}$
) and the action space (
$\mathcal{S}$
) and the action space (
 $\mathcal{A}$
). It can be shown as
$\mathcal{A}$
). It can be shown as
 $\pi :\; \mathcal{S} \rightarrow \mathcal{P}(\mathcal{A})$
. This probabilistic relationship is instantaneous (
$\pi :\; \mathcal{S} \rightarrow \mathcal{P}(\mathcal{A})$
. This probabilistic relationship is instantaneous (
 $s_t=(x_1,a_1,\ldots, a_{t-1},x_t)$
), instantaneous output (
$s_t=(x_1,a_1,\ldots, a_{t-1},x_t)$
), instantaneous output (
 $a_t$
), instantaneous reward (
$a_t$
), instantaneous reward (
 $r_t=(s_t,a_t)$
), and the next state (
$r_t=(s_t,a_t)$
), and the next state (
 $s_{t+1}$
).
$s_{t+1}$
).
 $x_t$
is a time-dependent observation of a stochastic environment (
$x_t$
is a time-dependent observation of a stochastic environment (
 $E$
). Accordingly, discounted future reward (
$E$
). Accordingly, discounted future reward (
 $R_t$
) can be defined as given in Eq. (3). Moreover, the detailed information about this equations are given in [Reference Schulman, Wolski, Dhariwal, Radford and Klimov42, Reference Lillicrap, Hunt, Pritzel, Heess, Erez, Tassa, Silver and Wierstra43]:
$R_t$
) can be defined as given in Eq. (3). Moreover, the detailed information about this equations are given in [Reference Schulman, Wolski, Dhariwal, Radford and Klimov42, Reference Lillicrap, Hunt, Pritzel, Heess, Erez, Tassa, Silver and Wierstra43]:
 \begin{equation} \begin{split} R_t=\sum _{i=t}^{T}\gamma ^{i-t}r(s_i,a_i), \gamma \in [0,1] \end{split} \end{equation}
\begin{equation} \begin{split} R_t=\sum _{i=t}^{T}\gamma ^{i-t}r(s_i,a_i), \gamma \in [0,1] \end{split} \end{equation}
where
 $\gamma$
denotes reduction coefficient. The purpose of policy learning is to learn to maximize the initial distribution (
$\gamma$
denotes reduction coefficient. The purpose of policy learning is to learn to maximize the initial distribution (
 $J$
), which can be determined in Eq. (4):
$J$
), which can be determined in Eq. (4):
 \begin{equation} \begin{split} J= \mathbb{E}_{r_i,s_i\sim E,a_i\sim \pi }[R_1] \end{split} \end{equation}
\begin{equation} \begin{split} J= \mathbb{E}_{r_i,s_i\sim E,a_i\sim \pi }[R_1] \end{split} \end{equation}
The value
 $R_1$
represents a reward that is calculated using the initial distribution. The action-value function for output
$R_1$
represents a reward that is calculated using the initial distribution. The action-value function for output
 $a_t$
in state
$a_t$
in state
 $s_t$
, as determined by the specified policy, is given by Eq. (5):
$s_t$
, as determined by the specified policy, is given by Eq. (5):
 \begin{equation} \begin{split} Q^\pi (s_t,a_t)= \mathbb{E}_{r_i\geq t,s_i\gt t\sim E,a_i\sim \pi }[R_t|s_t,a_t] \end{split} \end{equation}
\begin{equation} \begin{split} Q^\pi (s_t,a_t)= \mathbb{E}_{r_i\geq t,s_i\gt t\sim E,a_i\sim \pi }[R_t|s_t,a_t] \end{split} \end{equation}
Given that reinforcement learning is a dynamic process, Bellman’s equation can be used, as given in Eq (6):
 \begin{equation} \begin{split} Q^\pi (s_t,a_t)= \mathbb{E}_{r_t,s_{t+1}\sim E}[r(s_t,a_t)+\gamma \mathbb{E}_{a_{t+1}\sim \pi }[Q^\pi (s_{t+1},a_{t+1})] \end{split} \end{equation}
\begin{equation} \begin{split} Q^\pi (s_t,a_t)= \mathbb{E}_{r_t,s_{t+1}\sim E}[r(s_t,a_t)+\gamma \mathbb{E}_{a_{t+1}\sim \pi }[Q^\pi (s_{t+1},a_{t+1})] \end{split} \end{equation}
The target policy function can be defined as
 $\mu:\;\mathcal{S}\leftarrow \mathcal{A}$
. In this study, the action-critic method was chosen, and these constructs were trained using the PPO algorithm presented in Table II. Probability ratio is given in Eq. (7):
$\mu:\;\mathcal{S}\leftarrow \mathcal{A}$
. In this study, the action-critic method was chosen, and these constructs were trained using the PPO algorithm presented in Table II. Probability ratio is given in Eq. (7):
Table II. PPO algorithm.

 \begin{equation} \begin{split} \mathcal{R}_{t}(\theta ) = \frac{\pi _{\theta }(a_t\ s_t)}{\pi _{\theta _{old}}(a_t\ s_t)} \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{R}_{t}(\theta ) = \frac{\pi _{\theta }(a_t\ s_t)}{\pi _{\theta _{old}}(a_t\ s_t)} \end{split} \end{equation}
The loss function used in the PPO algorithm is presented in Eq. (8). The detailed information about PPO algorithm has been presented in [Reference Schulman, Wolski, Dhariwal, Radford and Klimov42, Reference Schulman, Levine, Abbeel, Jordan and Moritz44]:
 \begin{equation} \begin{split} \mathcal{L}(\theta ) = \hat{\mathbb{E}}_t\left [min\left (\mathcal{R}_{t}(\theta )\hat{A}_{T},clip\left (\mathcal{R}_{t}(\theta ),1 \pm \epsilon \right )\hat{A}_{T}\right )\right ] \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}(\theta ) = \hat{\mathbb{E}}_t\left [min\left (\mathcal{R}_{t}(\theta )\hat{A}_{T},clip\left (\mathcal{R}_{t}(\theta ),1 \pm \epsilon \right )\hat{A}_{T}\right )\right ] \end{split} \end{equation}
In Equation 8,
 $\theta$
,
$\theta$
,
 $\hat{A}_{T}$
,
$\hat{A}_{T}$
,
 $clip$
, and
$clip$
, and
 $\epsilon$
represent the network weights, advantage estimation, clipping function, and clipping coefficient, respectively. The CNN structures used for the actor and critic in this study are presented in Tables I and III, respectively.
$\epsilon$
represent the network weights, advantage estimation, clipping function, and clipping coefficient, respectively. The CNN structures used for the actor and critic in this study are presented in Tables I and III, respectively.
Table III. Critic CNN structure.

In this study, the image
 $s_t$
was obtained from the camera mounted on the manipulator’s TCP, and the position difference in the
$s_t$
was obtained from the camera mounted on the manipulator’s TCP, and the position difference in the
 $x$
and
$x$
and
 $y$
axes was determined as
$y$
axes was determined as
 $a_t$
. The reward function
$a_t$
. The reward function
 $r_t$
was determined according to Eq. 9. In this study, an acceptable following distance of 0.02 m was determined, and the reward function
$r_t$
was determined according to Eq. 9. In this study, an acceptable following distance of 0.02 m was determined, and the reward function
 $r_t$
was based on this threshold. If a similar study were to be conducted in the future, these values could be updated based on the requirements of that study:
$r_t$
was based on this threshold. If a similar study were to be conducted in the future, these values could be updated based on the requirements of that study:
 \begin{equation} \begin{split} r_t = \begin{cases} 10 &:\; \text{if } \Delta _t\lt 0.01\\ 5 &:\; \text{if } \Delta _t\lt 0.02\\ -1 &:\; \text{if } \Delta _t\lt 0.05\\ -2 &:\; \text{if } \Delta _t\lt 0.1\\ -5 &:\; \text{otherwise} \\ \end{cases} \end{split} \end{equation}
\begin{equation} \begin{split} r_t = \begin{cases} 10 &:\; \text{if } \Delta _t\lt 0.01\\ 5 &:\; \text{if } \Delta _t\lt 0.02\\ -1 &:\; \text{if } \Delta _t\lt 0.05\\ -2 &:\; \text{if } \Delta _t\lt 0.1\\ -5 &:\; \text{otherwise} \\ \end{cases} \end{split} \end{equation}
 $\Delta _t$
represents the state of TCP relative to the path that is presented in Eq. (10):
$\Delta _t$
represents the state of TCP relative to the path that is presented in Eq. (10):
 \begin{equation} \begin{split} \Delta _t=\sqrt{(x_{TCP_t}-x_{Path_t})^2+(y_{TCP_t}-y_{Path_t})^2} \end{split} \end{equation}
\begin{equation} \begin{split} \Delta _t=\sqrt{(x_{TCP_t}-x_{Path_t})^2+(y_{TCP_t}-y_{Path_t})^2} \end{split} \end{equation}
In this study, the Adam optimization method was used with the following parameters:
 $\gamma$
= 0.99,
$\gamma$
= 0.99,
 $\epsilon$
= 0.2, buffer size = 1024, and batch size = 64. The learning rate decay function for reinforcement learning is as follows: For epochs less than 150, the learning rate of the actor network is set to 1e-6, and the learning rate of the critic network is set to 2e-6. For epochs greater than or equal to 150, the learning rate of the actor network is reduced to 5e-7, and the learning rate of the critic network is reduced to 1e-6. This decay function adjusts the learning rates of both the actor and critic networks to optimize the training process for reinforcement learning. In addition, the training process was continued for 250 epochs.
$\epsilon$
= 0.2, buffer size = 1024, and batch size = 64. The learning rate decay function for reinforcement learning is as follows: For epochs less than 150, the learning rate of the actor network is set to 1e-6, and the learning rate of the critic network is set to 2e-6. For epochs greater than or equal to 150, the learning rate of the actor network is reduced to 5e-7, and the learning rate of the critic network is reduced to 1e-6. This decay function adjusts the learning rates of both the actor and critic networks to optimize the training process for reinforcement learning. In addition, the training process was continued for 250 epochs.
2.5. Hybrid learning
In this study, the hybrid learning approach was developed by first training with supervised learning and then applying reinforcement learning algorithms.

Figure 4. Hybrid learning block diagram.
A CNN model is trained using supervised learning and a dataset, as shown in Figure 4. The trained CNN is then further trained using reinforcement learning in a simulation environment. The motivation behind this proposed method was to combine the learning speed and accuracy of supervised learning with the robustness of reinforcement learning. Supervised learning provides two main advantages: optimizing weights in the neural network and predicting accurate results. The results were then made more robust by reinforcement learning, a learning method based on the principles of exploration and exploitation. This approach results in a learning method that was more robust than supervised learning and faster than reinforcement learning. However, this proposed method also had the disadvantage of requiring the design of an environment in which reinforcement learning can work, in contrast to supervised learning.
3. Experimental study and discussion
In the experimental setup, hyperparameters were configured as follows: loss clipping was set to 0.2, consistent with the original PPO paper [Reference Schulman, Wolski, Dhariwal, Radford and Klimov42]. The discount factor was set to 0.99, adhering to the recommendations outlined in the same foundational study. The buffer size was configured at 1024, with a batch size of 64 to facilitate efficient training. To introduce variability and enhance model robustness, noise was generated using a random normal distribution with a mean (loc) of 0 and a standard deviation (scale) of 0.02. Additionally, the dataset was partitioned with 90% of the images used for training and 10% for testing. The images were reshaped to a resolution of 64x64 pixels, and a batch size of 32 was employed during the training process. These hyperparameter choices and preprocessing steps align with established practices in reinforcement learning and image processing literature, ensuring both stability and performance in the training and evaluation phases.
An industrial robot consists of three parts: the manipulator, the cabinet, and the SmartPad. The manipulator is the moving part of the robot that performs the desired operations using motors and gears. The electronics and software of the robot, such as the motor driver circuits and operating system, are located inside the cabinet. The SmartPad provides communication between the robot and the operator (human, user). The KUKA Agilus KR6 R900 sixx robot and the experimental environment used in this study are presented in Figure 5. The robot has a weight of 52 kg and can carry a payload of up to 6 kg. It has a maximum reach of 901.5 mm. The photograph shown in Figure 5 was taken by the robot’s camera in the experimental environment to test the developed method with real input.

Figure 5. Experimental setup and real photo of test path.
The test path consisted of a total of 145 steps from five different subfunctions. The path is 920 mm long on the
 $x$
-axis and 760 mm wide on the
$x$
-axis and 760 mm wide on the
 $y$
-axis. In addition, the photograph shown in Figure 5 was used as input for the developed system without any preprocessing that would alter the pixel values.
$y$
-axis. In addition, the photograph shown in Figure 5 was used as input for the developed system without any preprocessing that would alter the pixel values.
In this study, a hybrid learning method combining supervised learning and reinforcement learning was trained for the same action CNN structure. First, the supervised learning method was trained using the training dataset for 500 epochs. As shown in Figure 6(a), Stage 1 progressed rapidly with supervised Learning training, while in Stage 2, progress stalled after convergence at the
 $250^{th}$
epoch. Stages 2 and 3 continued training together for up to 250 epochs. To obtain a valid comparison for this study, both trainings were terminated at the
$250^{th}$
epoch. Stages 2 and 3 continued training together for up to 250 epochs. To obtain a valid comparison for this study, both trainings were terminated at the
 $500^{th}$
epoch.
$500^{th}$
epoch.

Figure 6. (a) Training performance of supervised learning, (b) training performance of reinforcement learning.
The actor network was saved after the completion of the
 $250^{th}$
epoch during supervised learning. This saved actor network was then used for reinforcement learning for the next 250 epochs. The reward and average reward graphs created during reinforcement learning are shown in Figure 6(b). If the episode count is above 100, the average reward is calculated based on the last 100 rewards. Otherwise, the average reward is calculated up to the current episode count. The networks trained in the simulation environment were tested using the photograph taken from the experimental environment. In the simulation environment, the robot was tested 10 times by moving it in positive and negative directions along the
$250^{th}$
epoch during supervised learning. This saved actor network was then used for reinforcement learning for the next 250 epochs. The reward and average reward graphs created during reinforcement learning are shown in Figure 6(b). If the episode count is above 100, the average reward is calculated based on the last 100 rewards. Otherwise, the average reward is calculated up to the current episode count. The networks trained in the simulation environment were tested using the photograph taken from the experimental environment. In the simulation environment, the robot was tested 10 times by moving it in positive and negative directions along the
 $x$
-axis. The average errors and elapsed times of the tests are shown in Figure 7. The purpose of this study is visual path tracking. For robotic systems, a path is a set of defined position information that is independent of time. In this work, the error symbolizes the difference between the robot’s position and the expected path position. Descriptive analysis of the two methods used in the test environment is presented in Table IV. It can be observed that a statistically significant difference was found between the learning types in terms of error and duration (p < 0.05).
$x$
-axis. The average errors and elapsed times of the tests are shown in Figure 7. The purpose of this study is visual path tracking. For robotic systems, a path is a set of defined position information that is independent of time. In this work, the error symbolizes the difference between the robot’s position and the expected path position. Descriptive analysis of the two methods used in the test environment is presented in Table IV. It can be observed that a statistically significant difference was found between the learning types in terms of error and duration (p < 0.05).
Table IV. Descriptive analysis of test environment results.

SD: standard deviation, IQR: interquartile range, *
 $p\lt 0.05$
$p\lt 0.05$

Figure 7. Performance metrics of supervised and hybrid learning for 10 tests: (a) position error, (b) elapsed time comparison.
One of the paths was chosen randomly and used for the experimental study with the KUKA Agilus KR6 R900 sixx robot. The real robot’s TCP movements of the process are shown in Figure 8(a). P1 denotes the start point of the movements, and P2 is the last point of the trajectory path. The robot first moved from 0 mm to 935 mm in the positive
 $x$
-axis direction and then moved in the opposite direction. In addition, the errors of the predictions are shown in Figure 8(b). The mean values of the supervised learning and hybrid learning were obtained as 37.36 mm and 34.18 mm, respectively.
$x$
-axis direction and then moved in the opposite direction. In addition, the errors of the predictions are shown in Figure 8(b). The mean values of the supervised learning and hybrid learning were obtained as 37.36 mm and 34.18 mm, respectively.

Figure 8. (a) Trajectory with TCP movement along positive x-axis, (b) errors of positive travel, (c) trajectory with TCP movement along the negative x-axis, (d) errors of negative travel.
The robot was moved using the linear movement (LIN) command with a speed of 2
 $m/s$
between points on the path. Hybrid learning completed the process approximately 716 ms earlier than the supervised learning method. The motor power of the robot’s axes was measured using the robot trend feature of the KUKA, as shown in Figure 9. The red markers indicate the end of the hybrid learning process, while the blue markers signify the end of the supervised learning process. The power consumption of the motors was found to be almost the same for both methods. However, the hybrid learning method completed the process in a shorter time than the supervised learning method, resulting in reduced total power consumption.
$m/s$
between points on the path. Hybrid learning completed the process approximately 716 ms earlier than the supervised learning method. The motor power of the robot’s axes was measured using the robot trend feature of the KUKA, as shown in Figure 9. The red markers indicate the end of the hybrid learning process, while the blue markers signify the end of the supervised learning process. The power consumption of the motors was found to be almost the same for both methods. However, the hybrid learning method completed the process in a shorter time than the supervised learning method, resulting in reduced total power consumption.

Figure 9. Power consumption of robot axis motors during movement.
Figure 10 shows two videos that were recorded during the experimental study. Photos of the experimental process were created by cropping the recorded videos at a rate of 0.5 fps. The first row of photos depicts the process using the supervised learning algorithm, while the second row shows the process based on hybrid learning. Photos numbered 1 and 11 mark the start point of the processes, and the middle of the trajectory path is marked as 6/7. As shown, the method based on hybrid learning completed the process faster than the other method.

Figure 10. Cropped video files with 0.5 fps for two proposed methods.
There are several studies in the literature that are similar to the present study. In [Reference Maldonado-Ramirez, Rios-Cabrera and Lopez-Juarez25], an industrial KUKA KR16HW robot was visually guided to follow a specified path using a CNN structure, similar to our work. However, the CNN structure in that study was trained using only reinforcement learning algorithms, and the training process took approximately
 $10^6$
steps. One advantage of that study was that it included a real production process. In contrast, our proposed hybrid learning method reduced the training process to just 500 steps. Another study with a similar approach to hybrid learning added a support vector machine to the output of an artificial neural network for fault detection in an industrial robot [Reference Long, Mou, Zhang, Zhang and Li41]. Several studies have combined these approaches to create hybrid systems [Reference Liu and Kubota39, Reference Desouky and Schwartz40]. Although these studies did not specify any differences from the present work, the same structure was trained using different learning methods, and their performance was compared with the present work.
$10^6$
steps. One advantage of that study was that it included a real production process. In contrast, our proposed hybrid learning method reduced the training process to just 500 steps. Another study with a similar approach to hybrid learning added a support vector machine to the output of an artificial neural network for fault detection in an industrial robot [Reference Long, Mou, Zhang, Zhang and Li41]. Several studies have combined these approaches to create hybrid systems [Reference Liu and Kubota39, Reference Desouky and Schwartz40]. Although these studies did not specify any differences from the present work, the same structure was trained using different learning methods, and their performance was compared with the present work.
The study has some constraints, which can be divided into algorithmic, hardware, and software limitations. The proposed method can only work on labeled data because it combines supervised and reinforcement learning methods. This is an algorithmic limitation of the study. In the performed application, the hardware limitation is that data collected from the real environment had to be processed by an external computer before the robot could follow the created path. This prevented the robot from performing the process online. The software constraint is that the developed software works only on the specified plane. The
 $z$
-axis was not taken into account in the presented study, but a depth camera could be added to measure the distance between the TCP and the table surface if needed. Other software constraints include ground texture, path color, and path thickness. However, these constraints can be overcome by training a CNN architecture using the proposed method with training routes that have different ground textures, path colors, and path thicknesses.
$z$
-axis was not taken into account in the presented study, but a depth camera could be added to measure the distance between the TCP and the table surface if needed. Other software constraints include ground texture, path color, and path thickness. However, these constraints can be overcome by training a CNN architecture using the proposed method with training routes that have different ground textures, path colors, and path thicknesses.
Path following is a method that can be used in industrial robots for manufacturing process such as sealing and grinding. In the current study, the aim was to develop an effective path following method for industrial robots. As the first step of the study, a system similar to the experimental environment was modeled using the Webots simulation environment. A dataset consisting of image and position differences was collected from the simulation environment. The actor networks were trained using this dataset with both supervised and hybrid learning methods. The trained networks were tested with a real image taken from the experimental environment. The results of the tests show that the actor network trained with supervised learning followed the path with an average error of 39.30 mm, while the network trained with hybrid learning had an average error of 30.75 mm. The actor networks trained with supervised and hybrid learning had average elapsed times of 35.02 and 31.69 s, respectively, and there was a statistically significant difference in both the errors and elapsed times between the two methods (p < 0.05). As the last step of the study, the method was tested by selecting one of the generated paths at random and tested with the KUKA Agilus KR6 R900 sixx robot.
The motor powers of the robot’s axes were measured during the test process. The results showed that two learning methods offered nearly the same performance for the time axis. However, the hybrid-based method consumed less power than the supervised method because it completed the path faster. In this way, the robot controlled with the neural network trained with the hybrid learning method consumed less energy for the same task than the robot controlled with the neural network trained with the supervised learning method. This difference is small because there is a certain speed constraint in a specified short-term process. This energy difference is expected to increase in tasks with longer task duration and faster movement. As a result, the proposed hybrid learning model exhibited fewer errors and faster path following than the supervised learning method. Additionally, the proposed hybrid learning method required less elapsed time to train than traditional reinforcement learning methods. In future studies, various real industrial applications will be implemented using networks trained with the proposed learning method.
4. Conclusion
This study presents a novel hybrid learning approach that synergizes the advantages of both supervised and reinforcement learning to enhance the performance of visual path-following algorithms for industrial robots. The proposed hybrid method effectively combines the precision of supervised learning with the adaptability of reinforcement learning, addressing the limitations inherent in each technique when used in isolation. The hybrid approach demonstrated significant improvements over traditional supervised learning methods. Utilizing supervised learning for initial model training, the approach reduced the exploration space required for reinforcement learning, resulting in a notable decrease in path-following error from 39.3 mm to 30.9 mm and a reduction in processing time from 35.0 s to 31.7 s. Additionally, the hybrid method decreased the total power consumption of the robot’s motors, enhancing energy efficiency, which is crucial for industrial applications where energy costs are a concern.
The increasing global prevalence of industrial robots underscores the importance of adopting energy-efficient solutions. With over 3 million robots in operation and half a million new additions annually, optimizing energy usage in robotic systems is imperative. This study illustrates that AI-assisted algorithms can achieve substantial gains in efficiency, even on a small scale. Future research should focus on extending these findings to real-world industrial processes with extended duty cycles to further validate the energy efficiency and overall effectiveness of the hybrid approach. In conclusion, the integration of supervised and reinforcement learning methods offers a promising avenue for enhancing the accuracy, speed, and energy efficiency of robotic systems. The hybrid approach not only improves performance in visual path-following tasks but also addresses critical challenges related to energy consumption, paving the way for more sustainable and efficient industrial automation solutions.
Author contributions
MCB conceived of the presented idea, developed the theory and performed the computations, discussed the results, and contributed to the final article. OA developed the theory and performed the computations, discussed the results, and contributed to the final article.
Financial support
The authors would like to thank the FIRAT University Scientific Research Projects Unit (FUBAP) for their financial support for the current study (Project No:TEKF.21.31).
Competing interests
The authors declare no conflicts of interest exist.
Ethical standard
Not applicable.














