




The empirical covariance matrix for continuous data is consistent and asymptotically normal, enabling the use of a single asymptotic framework for inference in structural equation models (Browne, Reference Browne1984; Satorra, Reference Satorra1989). But with ordinal data, the situation is more complex.
When the data is a random sample of vector variables with ordinal coordinates, it is usually inappropriate to estimate structural equation models directly on the covariance matrix of the observations (Bollen, Reference Bollen1989, Chapter 9). Instead, the correlation matrix of a latent continuous random vector Z is used as input for the models, such as ordinal factor analysis (Christoffersson, Reference Christoffersson1975; Muthén, Reference Muthén1978), ordinal principal component analysis (Kolenikov & Angeles, Reference Kolenikov and Angeles2009), ordinal structural equation models (Jöreskog, Reference Muthén1984; Muthén, Reference Jöreskog1994), and, more recently, ordinal methods in network psychometrics (Epskamp, Reference Epskamp2017; Isvoranu & Epskamp, Reference Isvoranu and Epskamp2021; Johal & Rhemtulla, Reference Johal and Rhemtulla2021).
The polychoric correlation (Olsson, Reference Olsson1979) is the correlation of a latent bivariate normal variable based on ordinal data. While the polychoric correlation is an important dependency measure for ordinal variables under the bivariate normality assumption, its prime application lies in empirical psychometrics. In particular, it is employed in the two-stage estimation method for ordinal factor analysis and ordinal structural equation models. To employ the two-stage method, first estimate the latent correlation matrix using polychoric correlations, then fit a covariance model to this correlation matrix (Jöreskog, Reference Jöreskog2005). The method is implemented in current software packages such as EQS (Bentler, Reference Bentler2006), Mplus (Muthén & Muthén, Reference Muthén and Muthén2012), LISREL (Jöreskog & Sörbom, Reference Jöreskog and Sörbom2015), and lavaan (Rosseel, Reference Rosseel2012), and is frequently employed by researchers.
The polychoric correlation is guaranteed to equal the true latent correlation only if the continuous latent vector is bivariate normal, and is not, in general, robust against non-normality (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2019b, Reference Foldnes and Grønneberga). Moreover, the inconsistent estimates of the latent correlation are transferred to ordinal structural equation models (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2021). Multivariate normality has some testable implications (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2019b; Jöreskog, Reference Maydeu-Olivares2006; Maydeu-Olivares, Reference Foldnes and Grønneberg2019b), and empirical datasets are frequently incompatible with it (Foldnes & Grønneberg, Reference Grønneberg and Foldnes2022). It is therefore important to consider what can be said about the latent correlations that can generate an observed ordinal variable under weaker conditions than bivariate normality.
This paper continues Grønneberg, Moss, and Foldnes (Reference Grønneberg, Moss and Foldnes2020) in calculating the possible values of a latent correlation when knowing only the marginal distributions of the latent variable, but not its copula. This type of calculation is called partial identification analysis (Manski, Reference Tamer2010; Tamer, Reference Manski2003). While Grønneberg et al. (Reference Grønneberg, Moss and Foldnes2020) studied binary data, we study ordinal data with an arbitrary number of categories. As in Grønneberg et al. (Reference Grønneberg, Moss and Foldnes2020), our analysis is at the population level. Inference for partial identification sets can be done using the methods of Tamer (Reference Tamer2010, Section 4.4). Our partial identification analyses are done for a single latent correlation only, even though the multivariate setting is of greater psychometric interest. Simultaneous partial identification sets for the covariance matrix will be difficult to calculate, as even the set of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$3\times 3$$\end{document}
 correlation matrices without any restrictions is hard to describe (Li & Tam, Reference Li and Tam1994).
correlation matrices without any restrictions is hard to describe (Li & Tam, Reference Li and Tam1994).
Let Z be a bivariate continuous latent variable with correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
 , which we call the latent correlation. We are dealing with ordinal variables
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X,Y)$$\end{document}
, which we call the latent correlation. We are dealing with ordinal variables
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X,Y)$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I, J$$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I, J$$\end{document}
 categories generated via the equations
categories generated via the equations
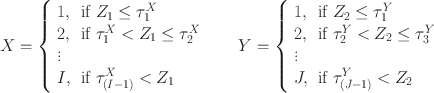
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau ^X\in \mathbb {R}^{I-1}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau ^Y\in \mathbb {R}^{J-1}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau ^Y\in \mathbb {R}^{J-1}$$\end{document}
 are strictly increasing vectors of deterministic thresholds. Our goal is to identify the possible values of the latent correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
are strictly increasing vectors of deterministic thresholds. Our goal is to identify the possible values of the latent correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
 from the distribution of the latent variable, plus potentially some more information.
from the distribution of the latent variable, plus potentially some more information.
We will show that knowing only the marginals of Z is insufficient for pinpointing the latent correlation to high precision, even when the number of categories is as high as ten. High precision can only be achieved by making assumptions about the copula of the latent variable as well. We calculate the set of possible values of the latent variable when the copula of the latent variable is known to be symmetric and its marginals are known. While this reduces the range of the possible values of the latent variable, the reduction is small. We also study partial identification of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
 when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
 is directly observed, i.e., the polyserial correlation (Olsson, Drasgow, & Dorans, Reference Olsson, Drasgow and Dorans1982) without assuming bivariate normality. Methods for calculating the resulting bounds on the latent correlations are implemented in the R package polyiden available in the online supplementary material and on GithubFootnote 1.
is directly observed, i.e., the polyserial correlation (Olsson, Drasgow, & Dorans, Reference Olsson, Drasgow and Dorans1982) without assuming bivariate normality. Methods for calculating the resulting bounds on the latent correlations are implemented in the R package polyiden available in the online supplementary material and on GithubFootnote 1.
The core results of this paper generalize the results in Grønneberg et al. (Reference Grønneberg, Moss and Foldnes2020) from two categories to an arbitrary number of categories. Our emphasis is on aspects that appear when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
 or
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
or
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
 is higher than 2, such as asymptotic results when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
is higher than 2, such as asymptotic results when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
 or
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
or
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
 increase separately. We show that when the marginal distributions of the latent variable are known, the latent correlation is asymptotically identified when both
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
increase separately. We show that when the marginal distributions of the latent variable are known, the latent correlation is asymptotically identified when both
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
 increase. Moreover, when only
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
increase. Moreover, when only
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J$$\end{document}
 increases, the identification region of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
increases, the identification region of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
 approaches the identification region found when one variable is directly observed.
approaches the identification region found when one variable is directly observed.
We consider the case where the copula of the latent variables is completely unknown (or known to be symmetric) except for the restrictions given from the distribution of the observations. As argued above, additional assumptions on the copula are needed to better pinpoint the latent correlation. One possibility is to consider a parametric class of copulas, and identify the set of possible Pearson correlations compatible with this class. Another possibility is to consider stronger but still nonparametric assumptions, such ellipticity. Such additional assumptions would lead to shorter partial identification sets than those we find, but their calculation is outside the scope of the paper.
There are several alternative ways of formulating psychometric models for ordinal data that are not dependent on latent correlations, the most prominent being variants of item response theory (see, e.g., Bartholomew, Steele, Galbraith, & Moustaki, Reference Bartholomew, Steele, Galbraith and Moustaki2008). While a large class of commonly used item response theory models are mathematically equivalent to ordinal covariance models (Foldnes & Grønneberg, Reference Takane and De Leeuw1987; Takane & De Leeuw, Reference Foldnes and Grønneberg2019a), the models are usually estimated directly in terms of the model parameters using maximum likelihood or Bayesian methods (Van der Linden, Reference Van der Linden2017, Section III). These models are usually conceptualized in fully parametric terms, so our analysis is less relevant for such models.
In cases where the dimensionality of the item response theory model is unknown, i.e., the model is not fully specified in terms of continuously varying parameters, a factor analysis based on polychoric correlations is sometimes recommended, see, e.g., Mair (Reference Mair2018, Section 4.1.2), Brown and Croudace (Reference Brown and Croudace2014, p. 316), Revicki, Chen, and Tucker (Reference Revicki, Chen and Tucker2014, p. 344), Zumbo (Reference Zumbo, Rao and Sinharay2006, Section 3.1). From this perspective, our work also has relevance for item response theory models.
Recently, structural equation models based on copulas have been suggested (Krupskii & Joe, Reference Krupskii and Joe2013, Reference Krupskii and Joe2015), and Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015) deals specifically with copula motivated models for ordinal data. Since we focus specifically on correlations, our analysis is not relevant for such models.
We focus exclusively on the Pearson correlation of the latent continuous vector Z, and do not consider the more general problem of quantifying and analyzing dependence between discrete variables. Several papers have been written in this more general direction. For instance, Liu, Li, Yu, and Moustaki (Reference Liu, Li, Yu and Moustaki2021) introduces partial association measures between ordinal variables, Nešlehová (Reference Nešlehová2007) discuss rank correlation measures for non-continuous variables, and Wei and Kim (Reference Wei and Kim2017) introduces a measure for asymmetric association for two-way contingency tables. Constraints on concordance measures in bivariate discrete data are derived in Denuit and Lambert (Reference Denuit and Lambert2005). Finally, we mention the multilinear extension copula discussed in Genest, Nešlehová, and Rémillard (Reference Genest, Nešlehová and Rémillard2014); Genest, Nešlehová, and Rémillard (Reference Genest, Nešlehová and Rémillard2017) which provides an abstract inference framework for a large class of copula based empirical methods for count data.
The structure of the paper is as follows. We start by studying partial identification sets for latent correlations based on ordinal variables in Sect. 1. Then, in Sect. 2, we study the same problem, but allow
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
 to be directly observed. In Sect. 3 we illustrate the results with a detailed example, and Sect. 4 concludes the paper. All proofs and technical details are in the online appendix, including a short introduction to copulas. Scripts in R (R Core Team, 2020) for numerical computations are available in the online supplementary material.
to be directly observed. In Sect. 3 we illustrate the results with a detailed example, and Sect. 4 concludes the paper. All proofs and technical details are in the online appendix, including a short introduction to copulas. Scripts in R (R Core Team, 2020) for numerical computations are available in the online supplementary material.
1. Latent Correlations on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I\times J$$\end{document}
 Tables
Tables

We work with the distribution function of the ordinal variable
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X, Y)$$\end{document}
 , which can be described by the cumulative probability matrix
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}$$\end{document}
, which can be described by the cumulative probability matrix
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}$$\end{document}
 with elements
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}_{ij} = P(X\le i,Y\le j)$$\end{document}
with elements
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}_{ij} = P(X\le i,Y\le j)$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$i = 1,\ldots ,I,\;j= 1,\ldots ,J$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$i = 1,\ldots ,I,\;j= 1,\ldots ,J$$\end{document}
 . The model for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X, Y)$$\end{document}
. The model for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X, Y)$$\end{document}
 follows the discretization model defined in eq. (1) for some continuous Z with marginal distribution functions
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
follows the discretization model defined in eq. (1) for some continuous Z with marginal distribution functions
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
 .
.
Observe that
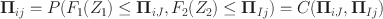
where C is the copula of Z (see, e.g., Nelsen, Reference Nelsen2007). It follows that the copula C restricted to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$A = \{{\varvec{\Pi }}_{iJ},i=1,\cdots , I\}\times \{{\varvec{\Pi }}_{Ij} \mid j = 1,\cdots , J\}$$\end{document}
 encodes all available information about Z. Since A is a product set with both factors containing 0 and 1, the restriction of C to A is a subcopula of C (Carley, Reference Carley2002).
encodes all available information about Z. Since A is a product set with both factors containing 0 and 1, the restriction of C to A is a subcopula of C (Carley, Reference Carley2002).
Now we are ready to state our first result.
Proposition 1
For any cumulative probability matrix
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}$$\end{document}
 , the latent correlation can be any number in
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(-1,1)$$\end{document}
, the latent correlation can be any number in
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(-1,1)$$\end{document}
 when the marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1}$$\end{document}
when the marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{2}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{2}$$\end{document}
 are unrestricted.
are unrestricted.
Proof
See the online appendix, Section 8.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}

Proposition 1 implies that we have to know something about the marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
 to get non-trivial partial identification sets for the latent correlation. Now we consider the case when both marginals are known. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
to get non-trivial partial identification sets for the latent correlation. Now we consider the case when both marginals are known. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
 be a set of bivariate distribution functions, and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (F)$$\end{document}
be a set of bivariate distribution functions, and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (F)$$\end{document}
 be the Pearson correlation for a bivariate distribution F. Define the partial identification set for the latent correlation as
be the Pearson correlation for a bivariate distribution F. Define the partial identification set for the latent correlation as
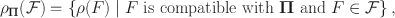
where F is compatible with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}$$\end{document}
 if equation (2) holds for its copula.
if equation (2) holds for its copula.
Now define the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I\times J$$\end{document}
 matrices
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha ,\beta ,\gamma ,\delta $$\end{document}
matrices
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha ,\beta ,\gamma ,\delta $$\end{document}
 with elements
with elements
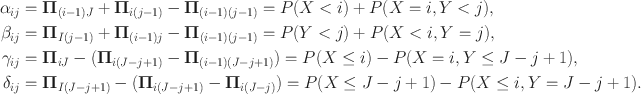
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}_{0j} = {\varvec{\Pi }}_{i0}=0$$\end{document}
 . Then define the vectors
. Then define the vectors
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a\frown b$$\end{document}
 is the concatenation of the vectors a, b and
is the concatenation of the vectors a, b and
is the vectorization of A, obtained from stacking the columns of A on top of each other. The matrices in (4) are the same as the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha ,\beta ,\gamma ,\delta $$\end{document}
 matrices of Genest and Nešlehová (Reference Genest and Nešlehová2007, p. 481) and Carley (Reference Carley2002), only the order of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma $$\end{document}
matrices of Genest and Nešlehová (Reference Genest and Nešlehová2007, p. 481) and Carley (Reference Carley2002), only the order of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma $$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta $$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta $$\end{document}
 has been changed. We have made this minor modification as it is needed to make
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u^U$$\end{document}
has been changed. We have made this minor modification as it is needed to make
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u^U$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u^L$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u^L$$\end{document}
 increasing, which simplifies the statement of the next result.
increasing, which simplifies the statement of the next result.
The following result extends Proposition 5 in Genest and Nešlehová (Reference Genest and Nešlehová2007), who built their result on the work of Carley (Reference Carley2002) on maximal extensions of subcopulas, to the case of non-uniform marginals.
Theorem 1
Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
 be the set of distributions with continuous and strictly increasing marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
be the set of distributions with continuous and strictly increasing marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
 with finite variance. Then
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _{\varvec{\Pi }}(\mathcal {F}) = [\rho _L, \rho _U]$$\end{document}
with finite variance. Then
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _{\varvec{\Pi }}(\mathcal {F}) = [\rho _L, \rho _U]$$\end{document}
 where
where
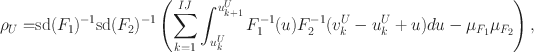
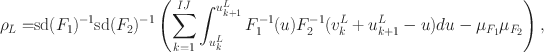
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1}^{-1}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{2}^{-1}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{2}^{-1}$$\end{document}
 are the generalized inverses of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1},F_{2}$$\end{document}
are the generalized inverses of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1},F_{2}$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mu _{F_{1}},\mu _{F_{2}}$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mu _{F_{1}},\mu _{F_{2}}$$\end{document}
 are the means of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1}$$\end{document}
are the means of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{1}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{2}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{2}$$\end{document}
 , and where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$ {\text {sd}} (F_1), {\text {sd}} (F_2)$$\end{document}
, and where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$ {\text {sd}} (F_1), {\text {sd}} (F_2)$$\end{document}
 are the standard deviations of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
are the standard deviations of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
 .
.
Proof
See the online appendix, Section 11.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}

Example 1
Let us compute the partial identification limits in Theorem 1 for a sequence of cumulative probability matrices. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
 have a bivariate normal copula with correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho = 0.7$$\end{document}
have a bivariate normal copula with correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho = 0.7$$\end{document}
 . We study what an analyst who does not know the copula structure of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
. We study what an analyst who does not know the copula structure of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
 can say about
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
can say about
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
 .
.
To generate thresholds that plausibly fit real world settings and can be applied for any number of categories, we fit a statistical model to the marginal probability distribution of the bfi dataset from the psych package, a dataset described in more detail in Sect. 3. We estimated the parameters of a Beta distribution that best correspond to the ordinal marginals of the questions A2 and A5 using a least squares procedure; see the code for details. While the bfi dataset has six categories, we can emulate the marginal probabilities for any number of categories by choosing cutoffs
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}_{iJ})_{i=1}^I$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}_{Ij})_{j=1}^J$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}_{Ij})_{j=1}^J$$\end{document}
 as follows. The cutoffs for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
as follows. The cutoffs for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
 with k categories are equal to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Q_1(i/k)$$\end{document}
with k categories are equal to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Q_1(i/k)$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$i = 1,\ldots ,(k-1)$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$i = 1,\ldots ,(k-1)$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Q_1$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Q_1$$\end{document}
 is the quantile function of a Beta distributed variable with parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _1 = 2.7, \beta _2 = 1.1$$\end{document}
is the quantile function of a Beta distributed variable with parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _1 = 2.7, \beta _2 = 1.1$$\end{document}
 . The cutoffs for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
. The cutoffs for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
 are generated in the same way, but with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _2 = 2.3, \beta _2 = 1.2$$\end{document}
are generated in the same way, but with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _2 = 2.3, \beta _2 = 1.2$$\end{document}
 .
.
In Fig. 1, we see the partial identification region as a function of I, J when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I = J$$\end{document}
 . The latent marginals are either standard normal, standard Laplace distributed, or uniform on [0, 1]. The dotted line is the latent correlation (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho = 0.7$$\end{document}
. The latent marginals are either standard normal, standard Laplace distributed, or uniform on [0, 1]. The dotted line is the latent correlation (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho = 0.7$$\end{document}
 ) when the marginals are normal. The true latent correlations are 0.682 when the marginals are uniform and 0.686 when the marginals are Laplace distributed.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}
) when the marginals are normal. The true latent correlations are 0.682 when the marginals are uniform and 0.686 when the marginals are Laplace distributed.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}

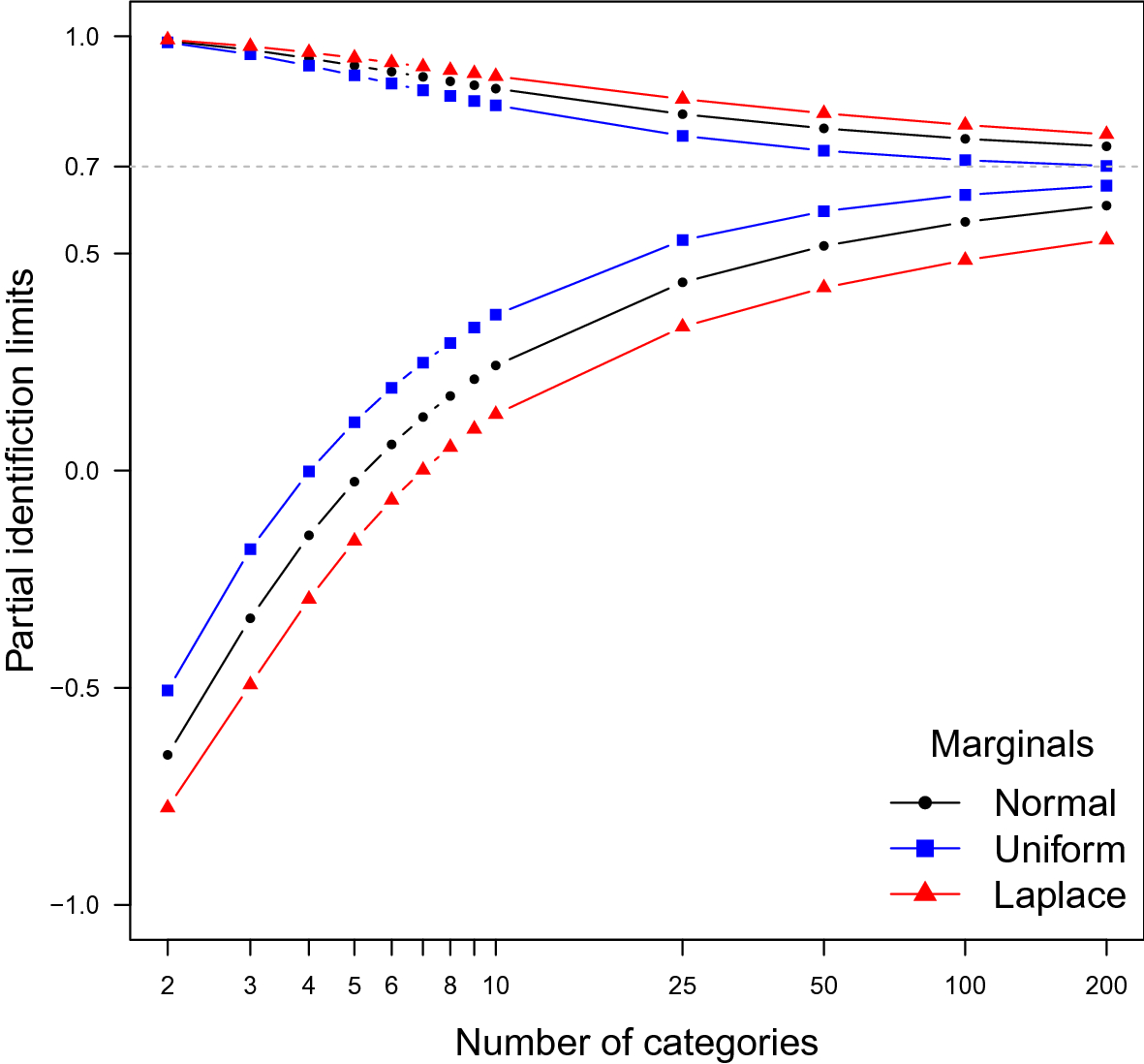
Figure 1. Upper and lower limits for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _{\varvec{\Pi }}(\mathcal {F})$$\end{document}
 when the marginals are fixed. The dashed line is the polychoric correlation, corresponding to normal marginals and the normal copula.
when the marginals are fixed. The dashed line is the polychoric correlation, corresponding to normal marginals and the normal copula.
Figure 1 suggests two conclusions. First, when the latent copula is completely unknown the identification sets are too wide to be informative even for a large number of categories, such as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I= J= 10$$\end{document}
 . Second, the partial correlation sets converge to the true latent correlations as the number of categories go to infinity. This is indeed the case when the marginals are known, as shown by the following corollary.
. Second, the partial correlation sets converge to the true latent correlations as the number of categories go to infinity. This is indeed the case when the marginals are known, as shown by the following corollary.
Consider a sequence
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)_{n=1}^\infty $$\end{document}
 of cumulative probability matrices where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^n$$\end{document}
of cumulative probability matrices where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^n$$\end{document}
 has
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I_n, J_n$$\end{document}
has
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I_n, J_n$$\end{document}
 categories. We say that the sequence
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)$$\end{document}
categories. We say that the sequence
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)$$\end{document}
 has its
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
has its
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
 -mesh uniformly decreasing to 0 if
-mesh uniformly decreasing to 0 if
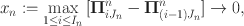
and, likewise, its
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
 -mesh is uniformly decreasing to 0 if
-mesh is uniformly decreasing to 0 if
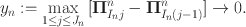
For a copula C and marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
 , let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (C;F_1,F_2)$$\end{document}
, let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (C;F_1,F_2)$$\end{document}
 be the Pearson correlation of the combined distribution
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(x_1,x_2) \mapsto C(F_1(x_1), F_2(x_2))$$\end{document}
be the Pearson correlation of the combined distribution
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(x_1,x_2) \mapsto C(F_1(x_1), F_2(x_2))$$\end{document}
 .
.
Corollary 1
Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
 be the set of distributions with continuous and strictly increasing marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
be the set of distributions with continuous and strictly increasing marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)$$\end{document}
 be a sequence of cumulative probability matrices compatible with C whose
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
be a sequence of cumulative probability matrices compatible with C whose
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
 -mesh and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
-mesh and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
 -mesh uniformly decrease to 0. Then the latent correlation identification set converges to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (C;F_1,F_2)$$\end{document}
-mesh uniformly decrease to 0. Then the latent correlation identification set converges to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (C;F_1,F_2)$$\end{document}
 , i.e.,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\lim _{n\rightarrow \infty } \rho _{{\varvec{\Pi }}^n}(\mathcal {F}) = \rho (C;F_1,F_2)$$\end{document}
, i.e.,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\lim _{n\rightarrow \infty } \rho _{{\varvec{\Pi }}^n}(\mathcal {F}) = \rho (C;F_1,F_2)$$\end{document}
 .
.
Proof
See the online appendix, Section 12.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}

Figure 1 illustrates Corollary 1. The sequence of ordinal distributions has uniformly decreasing X-mesh and Y-mesh, and the partial identification sets for normal marginals clearly converge to the true correlation as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n\rightarrow \infty $$\end{document}
 .
.
In Theorem 1, the latent marginals are fixed, and the latent copula is unknown. The numerical illustration in Fig. 1 shows that, even with a large number of categories such as ten, the partial identification intervals for latent correlations are rather wide. If our goal is to make the intervals shorter, we will have to add some restrictions to the copula. In Section 10 in the online appendix, we conduct a partial identification analysis based on the assumption that the latent copula is symmetric (Nelsen, Reference Nelsen2007, p. 32). Unfortunately, symmetry does not shorten the identification intervals by much. More work is needed to find tractable restrictions on the copula that make the identification intervals shorter.
2. Latent Correlations with One Ordinal Variable
Until now, we have studied the case where we could observe neither
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_1$$\end{document}
 nor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
nor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
 . Now we take a look at the case when we are able to observe one of them. That is, we still observe the ordinal
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
. Now we take a look at the case when we are able to observe one of them. That is, we still observe the ordinal
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
 from the discretization model of equation (1) but now we also observe the continuous
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
from the discretization model of equation (1) but now we also observe the continuous
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
 . We are still interested in the correlation between the latent
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_1$$\end{document}
. We are still interested in the correlation between the latent
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_1$$\end{document}
 and the now observed
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
and the now observed
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_2$$\end{document}
 . Mirroring the fully ordinal case, the latent correlation is identified when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(Z_1, Z_2)$$\end{document}
. Mirroring the fully ordinal case, the latent correlation is identified when
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(Z_1, Z_2)$$\end{document}
 is bivariate normal, and can be estimated by the polyserial correlation (Olsson et al., Reference Olsson, Drasgow and Dorans1982). As before, the latent variable has known marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
is bivariate normal, and can be estimated by the polyserial correlation (Olsson et al., Reference Olsson, Drasgow and Dorans1982). As before, the latent variable has known marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
 but unknown copula C. Again, the latent correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
but unknown copula C. Again, the latent correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho $$\end{document}
 is not identified, and we find the partial identification set.
is not identified, and we find the partial identification set.
Assume that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document}
 is continuous and strictly increasing, which implies that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V = F_2(Z_2)$$\end{document}
is continuous and strictly increasing, which implies that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V = F_2(Z_2)$$\end{document}
 is uniformly distributed. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star $$\end{document}
is uniformly distributed. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star $$\end{document}
 be the cumulative distribution of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X, V)$$\end{document}
be the cumulative distribution of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(X, V)$$\end{document}
 , that is,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star _{iv} = P(X\le i, V \le v)$$\end{document}
, that is,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star _{iv} = P(X\le i, V \le v)$$\end{document}
 . If C is the copula of Z, we get the relationship
. If C is the copula of Z, we get the relationship
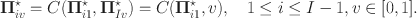
Whenever C is a copula that satisfies the equation above, we say that C
is compatible with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star $$\end{document}
 . From the results of Tankov (Reference Tankov2011), we can derive the maximal and minimal copula bounds for every C satisfying Eq. (9). Using these bounds, we can derive the following result, which generalizes Proposition 3 in Grønneberg et al. (Reference Grønneberg, Moss and Foldnes2020). We use the notation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$x^+ = \max (x,0)$$\end{document}
. From the results of Tankov (Reference Tankov2011), we can derive the maximal and minimal copula bounds for every C satisfying Eq. (9). Using these bounds, we can derive the following result, which generalizes Proposition 3 in Grønneberg et al. (Reference Grønneberg, Moss and Foldnes2020). We use the notation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$x^+ = \max (x,0)$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$x^- = \min (x,0)$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$x^- = \min (x,0)$$\end{document}
 .
.
Theorem 2
Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
 be continuous and strictly increasing with finite variance, and let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
be continuous and strictly increasing with finite variance, and let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
 be the set of distributions with marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1$$\end{document}
be the set of distributions with marginals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_2$$\end{document}
 . Then the set of latent correlations that is compatible with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C,F_1,F_2$$\end{document}
. Then the set of latent correlations that is compatible with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C,F_1,F_2$$\end{document}
 is
is
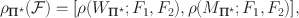
where

Proof
See the online appendix, Section 13.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}

Remark 1
To calculate the correlation
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho (C,F_1,F_2)$$\end{document}
 , one may use the Höffding (Reference Höffding1940) formula,
, one may use the Höffding (Reference Höffding1940) formula,

where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$ {\text {sd}} (F_1), {\text {sd}} (F_2)$$\end{document}
 are the standard deviations of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
are the standard deviations of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1,F_2$$\end{document}
 .
.
Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)_{n=1}^\infty $$\end{document}
 be a sequence of cumulative probability matrices where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I_n = I\ge 2$$\end{document}
be a sequence of cumulative probability matrices where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I_n = I\ge 2$$\end{document}
 is fixed and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J_n \rightarrow \infty $$\end{document}
is fixed and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J_n \rightarrow \infty $$\end{document}
 . Then we ought to regain the polyserial identification set of Theorem 2 under reasonable assumptions. This is formalized and confirmed by the following corollary.
. Then we ought to regain the polyserial identification set of Theorem 2 under reasonable assumptions. This is formalized and confirmed by the following corollary.
Corollary 2
Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)_{n=1}^\infty $$\end{document}
 be a sequence of cumulative probability matrices compatible with C. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
be a sequence of cumulative probability matrices compatible with C. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
 be fixed for all n and let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J_n$$\end{document}
be fixed for all n and let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$J_n$$\end{document}
 diverge to infinity, and let the Y-mesh of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)_{n=1}^\infty $$\end{document}
diverge to infinity, and let the Y-mesh of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$({\varvec{\Pi }}^n)_{n=1}^\infty $$\end{document}
 decrease uniformly toward 0. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star $$\end{document}
decrease uniformly toward 0. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{\Pi }}^\star $$\end{document}
 have
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
have
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$I$$\end{document}
 categories and be compatible with C. If
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
categories and be compatible with C. If
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {F}$$\end{document}
 is the set of distributions with continuous and strictly increasing marginal distributions
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
is the set of distributions with continuous and strictly increasing marginal distributions
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_1, F_2$$\end{document}
 , then
, then

Proof
See the online appendix, Section 14.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\square $$\end{document}


Theorem 2 and Corollary 2 are illustrated in Fig. 2. We use the same setup as Example 1 on p. 1. The marginals of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
 are normal and known to be so, the true copula is bivariate normal, but this is not known, and the true latent correlation is 0.35. The number of categories for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
are normal and known to be so, the true copula is bivariate normal, but this is not known, and the true latent correlation is 0.35. The number of categories for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$X$$\end{document}
 is 4. The number of categories for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
is 4. The number of categories for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y$$\end{document}
 increase indefinitely, and the Y-mesh uniformly decreases toward 0. We used the polyserialiden function in the R package polyiden to calculate the polyserial bounds.
increase indefinitely, and the Y-mesh uniformly decreases toward 0. We used the polyserialiden function in the R package polyiden to calculate the polyserial bounds.
3. An Empirical Example Using Data from the International Personality Item Pool
The R package psychTools (Revelle, Reference Revelle2019) contains the dataset bfi, which is a small subset of the data presented and analyzed in Revelle, Wilt, and Rosenthal (Reference Revelle, Wilt and Rosenthal2010) based on items from the International Personality Item Pool (Goldberg, Reference Goldberg, Mervielde, Deary, De Fruyt and Ostendorf1999). The bfi dataset contains 2800 responses to 25 items, and are organized by the five factors of personality: Agreeableness (A1–A5), Conscientiousness (C1–C5), Extraversion (E1–E5), Neuroticism (N1–N5), and Openness to experience (O1–O5). Each response is graded on a 6-point scale from “Very Inaccurate” to “Very Accurate.” A sample question is A2: “Inquire about others’ well-being.” We have flipped the ratings on reverse-coded items, and omitted all rows with missing values, resulting in 2236 remaining observations.
The polychoric correlations are visualized in Fig. 3. This dataset has been used for illustrations in several contexts, for instance in the second empirical example of McNeish (Reference McNeish2018), who analyzed the data using a five factor model estimated via polychoric correlations as well as Pearson correlations.
Figure 3. Polychoric correlation estimates for 25 items from the International Personality Item Pool (Goldberg, Reference Goldberg, Mervielde, Deary, De Fruyt and Ostendorf1999).
Polychoric correlations and models that use them for input in their estimation, hinges on the exact normality of each bivariate pair of the latent continuous variable
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
 . As shown theoretically in this paper, and through simulation in Foldnes and Grønneberg (Reference Foldnes and Grønneberg2019b, Reference Foldnes and Grønneberg2021), polychoric correlations are not robust against latent non-normality. The assumption of joint normality has testable implications, and we applied the parametric bootstrap test of Foldnes and Grønneberg (Reference Foldnes and Grønneberg2019b) using the R package discnorm (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2020), which has been shown to behave well in the simulation studies of Foldnes and Grønneberg (Reference Foldnes and Grønneberg2019b, Reference Foldnes and Grønneberg2021). We test both multivariate normality of the 25 dimensional random vector, as well as bivariate normality of each pair of variables. The resulting p values for the joint test of multivariate normality was zero within numerical precision. Out of 300 pairs, 184 pairs had a p value of latent normality also equal to zero within numerical precision, 287 pairs had a p value less than
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$5 \%$$\end{document}
. As shown theoretically in this paper, and through simulation in Foldnes and Grønneberg (Reference Foldnes and Grønneberg2019b, Reference Foldnes and Grønneberg2021), polychoric correlations are not robust against latent non-normality. The assumption of joint normality has testable implications, and we applied the parametric bootstrap test of Foldnes and Grønneberg (Reference Foldnes and Grønneberg2019b) using the R package discnorm (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2020), which has been shown to behave well in the simulation studies of Foldnes and Grønneberg (Reference Foldnes and Grønneberg2019b, Reference Foldnes and Grønneberg2021). We test both multivariate normality of the 25 dimensional random vector, as well as bivariate normality of each pair of variables. The resulting p values for the joint test of multivariate normality was zero within numerical precision. Out of 300 pairs, 184 pairs had a p value of latent normality also equal to zero within numerical precision, 287 pairs had a p value less than
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$5 \%$$\end{document}
 , and the mean of the p values equaled
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$0.99 \%$$\end{document}
, and the mean of the p values equaled
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$0.99 \%$$\end{document}
 . Latent normality is therefore not a tenable assumption, with the possible exception of bivariate latent normality between some pairs of variables.
. Latent normality is therefore not a tenable assumption, with the possible exception of bivariate latent normality between some pairs of variables.
We therefore calculate the lower and upper latent correlation bounds from Theorem 1, when assuming marginal but not bivariate normality. The results are visualized in Fig. 4. The bounds are large for all variables; the sign of the correlations are unknown in most cases, even in the same factor, though we see indications of white regions in the lower bounds (indicating lower bounds near zero) for the agreeableness items, the conscientiousness items, extroversion items, and neuroticism items, but not for the openness items. For neuroticism (N1–N5), most of the correlations are positive. There are some other pairs with lower bounds near zero, such as the bright region between A5 and E3–E4, where the lower bounds are near zero and the upper bounds are close to one, which under the assumption of latent marginal normality shows that the latent correlations between these items are estimated to be positive.
Figure 4. Upper (blue) and lower (red) correlation bounds for the items in the International Personality Item Pool (Goldberg, Reference Goldberg, Mervielde, Deary, De Fruyt and Ostendorf1999).
4. Conclusion
We have calculated partial identification sets for latent correlations based on the distribution of ordinal data under the assumption that the marginal distributions of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
 are known. The most common number of categories is 5 and 7 (Flora & Curran, Reference Rhemtulla, Brosseau-Liard and Savalei2012; Rhemtulla, Brosseau-Liard, & Savalei, Reference Flora and Curran2004), and for these numbers the partial identification sets are rather wide. Merely knowing the latent marginal distributions is usually insufficient, and knowing that the latent copula is symmetric does not help. More knowledge is required in order to get informative partial identification sets.
are known. The most common number of categories is 5 and 7 (Flora & Curran, Reference Rhemtulla, Brosseau-Liard and Savalei2012; Rhemtulla, Brosseau-Liard, & Savalei, Reference Flora and Curran2004), and for these numbers the partial identification sets are rather wide. Merely knowing the latent marginal distributions is usually insufficient, and knowing that the latent copula is symmetric does not help. More knowledge is required in order to get informative partial identification sets.
Since the partial identification sets are wide, a psychometrician wishing to estimate latent correlations must know more about the latent distribution class than just its marginals and possibly knowing that the copula is symmetric. For instance, the copula class could be known to belong to a certain class of distributions, or the psychometrician may know that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z$$\end{document}
 follows a model class, such as a factor model. Such knowledge would reduce the partial identification sets of the model parameters.
follows a model class, such as a factor model. Such knowledge would reduce the partial identification sets of the model parameters.
Funding
Open Access funding provided by BI Norwegian Business School.








 Open access
Open access