



Psychological scales and educational tests are developed to measure a particular construct by selecting items from several identified domains (Gibbons et al. Reference Gibbons, Bock, Hedeker, Weiss, Segawa, Bhaumik, Kupfer, Frank, Grochocinski and Stover2007). For example, a questionnaire or instrument, used in psychometrics to assess abstract concepts, such as the well-being has a large number of items or questions that are sampled from several subdomains such as depression, anxiety and stress. This special classification of items in educational assessments is termed ‘testlets’ (Wainer and Kiely Reference Wainer and Kiely1987). It is essential to investigate the factorial structure, as implementing unstructured factor models on testlet-based items could result in biased estimates and a poor fit (Wang and Wilson Reference Wang and Wilson2005; DeMars Reference DeMars2006; Zenisky et al. Reference Zenisky, Hambleton and Sireci2002; Sireci et al. Reference Sireci, Thissen and Wainer1991; Lee and Frisbie Reference Lee and Frisbie1999; Wainer and Thissen Reference Wainer and Thissen1996).
To account for the homogeneous dependence in several subdomains of some larger domain, Gibbons and Hedeker (Reference Gibbons and Hedeker1992) and Gibbons et al. (Reference Gibbons, Bock, Hedeker, Weiss, Segawa, Bhaumik, Kupfer, Frank, Grochocinski and Stover2007) proposed bi-factor models for binary and ordinal items, respectively. They consist of a common factor, that is linked to all items, and non-overlapping group-specific factors. The common factor explains the dependence between all the items, while the group-specific factors explain the dependence amongst items within each domain or group. The items are assumed to be independent given the group-specific and common factors.
An alternative way of modelling items that are split into several domains is via the second-order model (e.g., de la Torre and Song Reference de la Torre and Song2009; Rijmen Reference Rijmen2010), where items are indirectly mapped to an overall (second-order) factor via non-overlapping group-specific (first-order) factors. Second-order models are suitable when the first-order factors are associated with each other, and there is a second-order factor that accounts for the relations among the first-order factors. The second-order model can be described as an independent clusters factor model (McDonald Reference McDonald1999) with a single second-order factor.
The bi-factor and the second-order models are not generally equivalent (Yung et al. Reference Yung, Thissen and McLeod1999; Gustafsson and Balke Reference Gustafsson and Balke1993; Mulaik and Quartetti Reference Mulaik and Quartetti1997; Rijmen Reference Rijmen2010), unless proportionality constraints are imposed by using the Schmid–Leiman transformation method (Schmid and Leiman Reference Schmid and Leiman1957). More importantly, both models are restricted to the MVN assumption for the latent variables, which might not be valid. Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015) emphasized that if the ordinal variables in item response can be thought of as discretization of latent random variables that are maxima/minima or mixtures of means, then the use of factor models based on the MVN assumption for the latent variables could provide poor fit. In the context of item response data, latent maxima, minima and means can arise depending on how a respondent considers specific items. An item might make the respondent think about M past events which, say, have values
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$W_1,\ldots ,W_M$$\end{document}
 . In answering the item, the subject might take the average, maximum or minimum of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$W_1,\ldots ,W_M$$\end{document}
. In answering the item, the subject might take the average, maximum or minimum of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$W_1,\ldots ,W_M$$\end{document}
 and then convert to the ordinal scale depending on the magnitude. The case of a latent maxima/minima can occur if the response is based on a best or worst case.
and then convert to the ordinal scale depending on the magnitude. The case of a latent maxima/minima can occur if the response is based on a best or worst case.
Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015) have studied factor copula models for item response where for the first factor there are bivariate copulas that couple each item to the first latent variable, and for the second factor there are copulas that link each item to the second latent variable conditioned on the first factor (leading to conditional dependence parameters), etc. They have shown that there is an improvement on the factor models based on the MVN assumption for the latent variables both conceptually and in fit to data. This improvement relies on the aforementioned reasons, i.e., items can have more probability in joint upper or lower tail than would be expected with a discretized MVN or items can be considered as discretized maxima/minima or mixtures of discretized means rather than discretized means. When all the bivariate copulas are bivariate normal (BVN), then the resulting model is the same as the discretized MVN model with a p-factor correlation matrix (Maydeu-Olivares Reference Maydeu-Olivares2006), also known as the p-dimensional normal ogive model (Jöreskog and Moustaki Reference Jöreskog and Moustaki2001). For example, the 1-factor copula model with BVN copulas is the same as the variant of Samejima’s (Reference Samejima1969) graded response IRT model, known as normal ogive model (McDonald Reference McDonald, van der Linden and Hambleton1997) with an 1-factor correlation matrix. We refer to Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015, Section 2.3) for further details and explanations on the normal ogive models as special cases of factor copula models.
In this paper, we propose copula extensions for bi-factor and second-order models. The construction of the bi-factor copula model exploits the use of bivariate copulas that link the items to the common and group-specific factors. Note that if there is only one group of items, then the bi-factor model reduces to the two-factor copula model in Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015). Similarly with the bi-factor copula model, we also use bivariate copulas to construct the second-order copula model. In this case, there are bivariate copulas that link the items to the group-specific factors, and also bivariate copulas that link the group-specific to the second-order factor. To account for the dependence between the items and group-specific factors, each group of variables in fact is modelled using the one-factor copula model proposed by Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015). In addition, if there is only one group of items, then the second-order copula model reduces to the one-factor copula model. Hence, the proposed models contain the one- and two-factor copula models in Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015) as special cases, while allowing flexible dependence structure for both within- and between-group dependence. As a result, the models are suitable for modelling a high-dimensional item response classified into non-overlapping groups.
The proposed copula constructions are truncated vine copula models (Brechmann et al. Reference Brechmann, Czado and Aas2012) that involve both observed and latent variables. Joe et al. (Reference Joe, Li and Nikoloulopoulos2010) have shown that by choosing bivariate linking copulas appropriately, truncated vine copula models can have a wide range of asymmetric dependence as well as tail dependence (dependence among extreme values) and different lower/upper tail dependence parameters for each bivariate margin. Hence, the bi-factor and second-order copula models will be useful when the items have more probability in joint upper or lower tail than would be expected with a discretized MVN. If the bivariate linking copulas are BVN, then the Gaussian bi-factor and second-order models are special cases of our constructions which are the discrete counterparts of the structured factor copula models Krupskii and Joe (Reference Krupskii and Joe2015) where dependence and tail properties are obtained.
The remainder of the paper proceeds as follows: Section 1 introduces the bi-factor and second-order copula models for item response and discusses their relationship with the existing models. Estimation techniques and computational details are provided in Sect. 2. Section 3 proposes simple diagnostics based on semi-correlations and a heuristic method to select suitable bivariate copulas and build plausible bi-factor and second-order copula models. Section 4 summarizes the assessment of goodness of fit of these models using the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic of Maydeu-Olivares and Joe (Reference Maydeu-Olivares and Joe2006), which is based on a quadratic form of the deviations of sample and model-based proportions over all bivariate margins. Section 5 contains an extensive simulation study to gauge the small-sample efficiency of the proposed estimation, investigate the misspecification of the bivariate copulas, and examine the reliability of the model selection and goodness-of-fit techniques. Section 6 presents an application of our methodology to the Toronto Alexithymia Scale. In this example, it turns out that our models, with linking copulas selected according to the items being discretized latent minima or mixtures of discretized means, provide better fit than the Gaussian bi-factor and second-order models. We conclude with some discussion in Sect. 7.
statistic of Maydeu-Olivares and Joe (Reference Maydeu-Olivares and Joe2006), which is based on a quadratic form of the deviations of sample and model-based proportions over all bivariate margins. Section 5 contains an extensive simulation study to gauge the small-sample efficiency of the proposed estimation, investigate the misspecification of the bivariate copulas, and examine the reliability of the model selection and goodness-of-fit techniques. Section 6 presents an application of our methodology to the Toronto Alexithymia Scale. In this example, it turns out that our models, with linking copulas selected according to the items being discretized latent minima or mixtures of discretized means, provide better fit than the Gaussian bi-factor and second-order models. We conclude with some discussion in Sect. 7.
1. Bi-factor and Second-Order Copula Models
Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\underbrace{Y_{11}, \ldots ,Y_{d_11}}_1,\ldots , \underbrace{Y_{1g},\ldots , Y_{d_gg}}_g, \ldots , \underbrace{Y_{1G}, \ldots , Y_{d_GG}}_G$$\end{document}
 denote the item response variables classified into the G non-overlapping groups. There are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_g$$\end{document}
denote the item response variables classified into the G non-overlapping groups. There are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_g$$\end{document}
 items in group g;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
items in group g;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 and collectively there are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=\sum _{g=1}^{G} d_g$$\end{document}
and collectively there are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=\sum _{g=1}^{G} d_g$$\end{document}
 items, which are all measured on an ordinal scale;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}\in \{0,\ldots ,K-1\}$$\end{document}
items, which are all measured on an ordinal scale;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}\in \{0,\ldots ,K-1\}$$\end{document}
 . Let the cutpoints in the uniform U(0, 1) scale for the jg’th item be
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,k}$$\end{document}
. Let the cutpoints in the uniform U(0, 1) scale for the jg’th item be
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,k}$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$k=1,\ldots ,K-1$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$k=1,\ldots ,K-1$$\end{document}
 , with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,0}=0$$\end{document}
, with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,0}=0$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,K}=1$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,K}=1$$\end{document}
 . These correspond to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,k}=\Phi (\alpha _{jg,k})$$\end{document}
. These correspond to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$a_{jg,k}=\Phi (\alpha _{jg,k})$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,k}$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,k}$$\end{document}
 are cutpoints in the normal N(0, 1) scale.
are cutpoints in the normal N(0, 1) scale.
The bi-factor and second-order factor copula models are presented in Sects. 1.1 and 1.2, respectively. Section 1.3 discusses their relationship with the existing Gaussian bi-factor and second-order models, and Sect. 1.4 provides the bivariate linking copulas we consider along with their properties.
1.1. Bi-factor Copula Model
Consider a common factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 and G group-specific factors
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_1,\ldots ,V_G$$\end{document}
and G group-specific factors
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_1,\ldots ,V_G$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0,V_1,\ldots ,V_G$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0,V_1,\ldots ,V_G$$\end{document}
 are independent and standard uniformly distributed. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
are independent and standard uniformly distributed. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 be the jth observed variable in group g, with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$y_{jg}$$\end{document}
be the jth observed variable in group g, with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$y_{jg}$$\end{document}
 being the realization. The bi-factor model assumes that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{1g},\ldots , Y_{d_gg}$$\end{document}
being the realization. The bi-factor model assumes that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{1g},\ldots , Y_{d_gg}$$\end{document}
 are conditionally independent given
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
are conditionally independent given
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
 , and that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
, and that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 in group g does not depend on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_{g'}$$\end{document}
in group g does not depend on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_{g'}$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g\ne g'$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g\ne g'$$\end{document}
 . Figure 1 depicts a graphical representation of the model.
. Figure 1 depicts a graphical representation of the model.

Figure 1. Graphical representation of the bi-factor copula model with G group-specific factors and a common factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 .
.
The joint probability mass function (pmf) is given by:
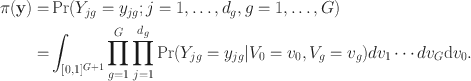
According to Sklar’s theorem (Reference Sklar1959), there exists a bivariate copula
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
 such that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\Pr (Y_{jg} \le y_{jg}, V_0 \le v_0)= C_{Y_{jg},V_0}\bigl (F_{{Y_{jg}}}(y_{jg}), v_0\bigr )$$\end{document}
such that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\Pr (Y_{jg} \le y_{jg}, V_0 \le v_0)= C_{Y_{jg},V_0}\bigl (F_{{Y_{jg}}}(y_{jg}), v_0\bigr )$$\end{document}
 , for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$v_0 \in [0,1]$$\end{document}
, for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$v_0 \in [0,1]$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
 is the copula that links the item
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
is the copula that links the item
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 with the common factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
with the common factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{Y_{jg}}$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{Y_{jg}}$$\end{document}
 is the cumulative distribution function (cdf) of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
is the cumulative distribution function (cdf) of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 ; note that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{Y_{jg}}$$\end{document}
; note that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{Y_{jg}}$$\end{document}
 is a step function with jumps at
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$0,\ldots ,K-1$$\end{document}
is a step function with jumps at
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$0,\ldots ,K-1$$\end{document}
 , i.e.,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{Y_{jg}}(y_{jg})=a_{jg,y_{jg}+1}$$\end{document}
, i.e.,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{Y_{jg}}(y_{jg})=a_{jg,y_{jg}+1}$$\end{document}
 . Then, it follows that,
. Then, it follows that,
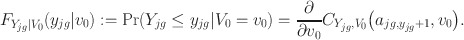
For shorthand notation, we let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg}|V_0}\bigl (a_{jg,y_{jg}+1}|v_0\bigr ) = \frac{\partial }{\partial v_0} C_{Y_{jg},V_0}\bigl ( a_{jg,y_{jg}+1}, v_0\bigr )$$\end{document}
 .
.
The observed variables also load on the group-specific factors; hence to account for this dependence, we let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0 }$$\end{document}
 be a bivariate copula that links the item
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
be a bivariate copula that links the item
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 with the group-specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
with the group-specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
 given the common factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
given the common factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 . Hence,
. Hence,
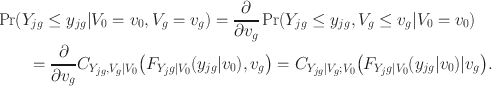
To this end, the pmf of the bi-factor copula model takes the form
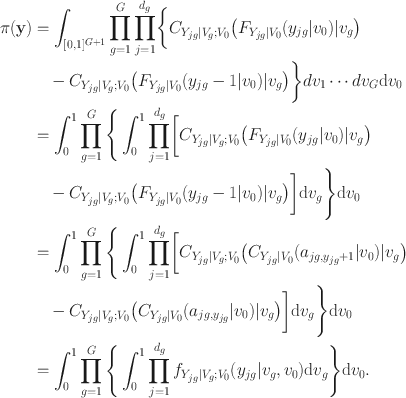
It is shown that the pmf is represented as an one-dimensional integral of a function which is in turn a product of G one-dimensional integrals. Thus, we avoid
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(G+1)$$\end{document}
 -dimensional numerical integration.
-dimensional numerical integration.
In addition to the computational advancements the proposed model offers, it can provide, with appropriately chosen linking copulas, more probability in joint upper or lower tail than would be expected with a discretized MVN. The bi-factor copula can be explained as a 2-truncated vine. d-dimensional vine copulas can cover flexible dependence structures through the specification of d bivariate marginal copulas at level 1 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d(d-1)/2$$\end{document}
 bivariate conditional copulas at higher levels (Nikoloulopoulos et al. Reference Nikoloulopoulos, Joe and Li2012). For the d-dimensional bi-factor copula, the pairs at level 1 are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},V_0$$\end{document}
bivariate conditional copulas at higher levels (Nikoloulopoulos et al. Reference Nikoloulopoulos, Joe and Li2012). For the d-dimensional bi-factor copula, the pairs at level 1 are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},V_0$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 , the pairs at level 2 are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},V_g|V_0$$\end{document}
, the pairs at level 2 are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},V_g|V_0$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 , and for higher levels the (conditional) copula pairs are set to independence. That is the bi-factor copula has d bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
, and for higher levels the (conditional) copula pairs are set to independence. That is the bi-factor copula has d bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
 that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},\,g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},\,g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 in the 1st level of the vine, d bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}$$\end{document}
in the 1st level of the vine, d bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}$$\end{document}
 that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},\,g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},\,g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g,\,g=1,\ldots ,G$$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g,\,g=1,\ldots ,G$$\end{document}
 given
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
given
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 in the 2nd level of the vine, and independence copulas in all the remaining levels of the vine (truncated after the 2nd level). From results in Joe et al. (Reference Joe, Li and Nikoloulopoulos2010) and Krupskii and Joe (Reference Krupskii and Joe2015), upper or lower tail dependent copulas in levels 1 and 2 will lead to items that have more probability in joint upper or lower tail than would be expected with a discretized MVN.
in the 2nd level of the vine, and independence copulas in all the remaining levels of the vine (truncated after the 2nd level). From results in Joe et al. (Reference Joe, Li and Nikoloulopoulos2010) and Krupskii and Joe (Reference Krupskii and Joe2015), upper or lower tail dependent copulas in levels 1 and 2 will lead to items that have more probability in joint upper or lower tail than would be expected with a discretized MVN.
For the parametric version of the bi-factor copula model, we let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}$$\end{document}
 be parametric copulas with dependence parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg}$$\end{document}
be parametric copulas with dependence parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta _{jg}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta _{jg}$$\end{document}
 , respectively.
, respectively.
1.2. Second-Order Copula Model
Assume that for a fixed
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G$$\end{document}
 , the items
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{1g},\ldots , Y_{d_gg}$$\end{document}
, the items
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{1g},\ldots , Y_{d_gg}$$\end{document}
 are conditionally independent given the first-order factors
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g \sim U(0,1),\,g=1,\ldots ,G$$\end{document}
are conditionally independent given the first-order factors
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g \sim U(0,1),\,g=1,\ldots ,G$$\end{document}
 and that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{V}=(V_1,\ldots ,V_G)$$\end{document}
and that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{V}=(V_1,\ldots ,V_G)$$\end{document}
 are conditionally independent given the second-order factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0 \sim U(0,1)$$\end{document}
are conditionally independent given the second-order factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0 \sim U(0,1)$$\end{document}
 . That is the joint distribution of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{V}$$\end{document}
. That is the joint distribution of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{V}$$\end{document}
 has an one-factor structure. We also assume that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
has an one-factor structure. We also assume that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 in group g does not depend on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_{g'}$$\end{document}
in group g does not depend on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_{g'}$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g\ne g'$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g\ne g'$$\end{document}
 . Figure 2 depicts the graphical representation of the model.
. Figure 2 depicts the graphical representation of the model.
The joint pmf takes the form
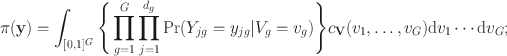
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c_\textbf{V}$$\end{document}
 is the one-factor copula density (Krupskii and Joe Reference Krupskii and Joe2013) of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{V}$$\end{document}
is the one-factor copula density (Krupskii and Joe Reference Krupskii and Joe2013) of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{V}$$\end{document}
 , viz.
, viz.
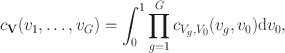
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c_{V_g,V_0}$$\end{document}
 is the bivariate copula density of the copula
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{V_g,V_0}$$\end{document}
is the bivariate copula density of the copula
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{V_g,V_0}$$\end{document}
 linking
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
linking
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 .
.
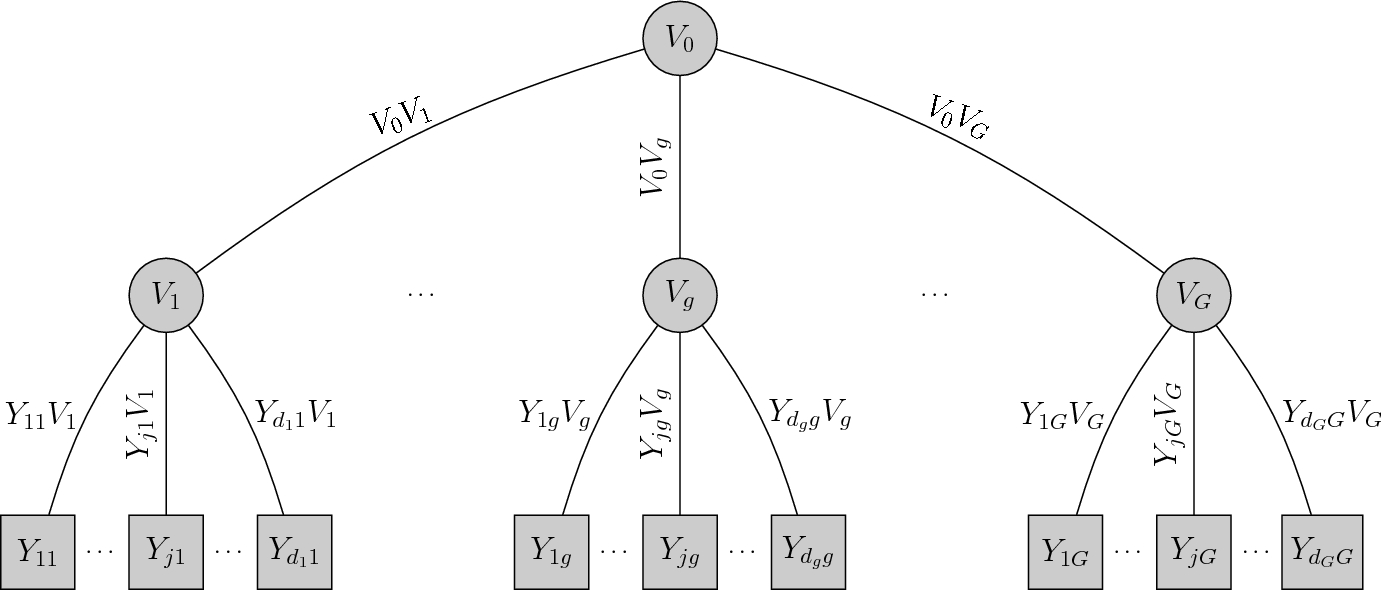
Figure 2. Graphical representation of the second-order copula model with G first-order factors and one second-order factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 .
.
Letting
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g}$$\end{document}
 be a bivariate copula that joins the item
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
be a bivariate copula that joins the item
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 and the group-specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
and the group-specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
 such that
such that
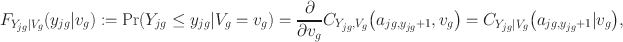
the pmf of the second-order copula model becomes
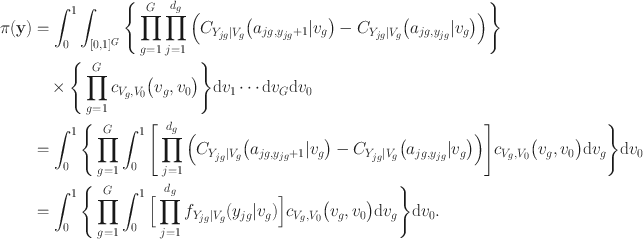
Similarly with the bi-factor copula model, the pmf is represented as an one-dimensional integral of a function, which is in turn a product of G one-dimensional integrals.
In addition to the computational advancements, the second-order model offers, it can provide, with appropriately chosen linking copulas, more probability in joint upper or lower tail than would be expected with a discretized MVN. The second-order copula can be explained as an 1-truncated vine. For the d-dimensional second-order copula, the pairs at level 1 are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},V_g$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0,V_g$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0,V_g$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G$$\end{document}
 , and for higher levels the (conditional) copula pairs are set to independence. That is the second copula has d bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g}$$\end{document}
, and for higher levels the (conditional) copula pairs are set to independence. That is the second copula has d bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g}$$\end{document}
 that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},\,g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg},\,g=1,\ldots ,G,\,j=1,\ldots ,d_g$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g,\,g=1,\ldots ,G$$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g,\,g=1,\ldots ,G$$\end{document}
 and G bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{V_g,V_0}$$\end{document}
and G bivariate copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{V_g,V_0}$$\end{document}
 that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_{g},\,g=1,\ldots ,G$$\end{document}
that link
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_{g},\,g=1,\ldots ,G$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 in the 1st level of the vine, and independence copulas in all the remaining levels of the vine (truncated after the 1st level). Joe et al. (Reference Joe, Li and Nikoloulopoulos2010) have shown that in order for a vine copula to have tail dependence for all bivariate margins, it is only necessary for the bivariate copulas in level 1 to have tail dependence and it is not necessary for the conditional bivariate copulas in levels
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$2,\ldots ,d$$\end{document}
in the 1st level of the vine, and independence copulas in all the remaining levels of the vine (truncated after the 1st level). Joe et al. (Reference Joe, Li and Nikoloulopoulos2010) have shown that in order for a vine copula to have tail dependence for all bivariate margins, it is only necessary for the bivariate copulas in level 1 to have tail dependence and it is not necessary for the conditional bivariate copulas in levels
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$2,\ldots ,d$$\end{document}
 to have tail dependence. Hence, upper or lower tail dependent copulas in level 1 will lead to will lead to items that have more probability in joint upper or lower tail than would be expected with a discretized MVN.
to have tail dependence. Hence, upper or lower tail dependent copulas in level 1 will lead to will lead to items that have more probability in joint upper or lower tail than would be expected with a discretized MVN.
For the parametric version of the second-order copula model, we let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{V_g,V_0}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{V_g,V_0}$$\end{document}
 be parametric copulas with dependence parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg}$$\end{document}
be parametric copulas with dependence parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta _{g}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta _{g}$$\end{document}
 , respectively.
, respectively.
1.3. Special Cases
In this subsection, we show what happens when all bivariate copulas are BVN. Let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
 be the underlying continuous variable of the ordinal variable
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
be the underlying continuous variable of the ordinal variable
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 , i.e.,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg} = y_{jg}$$\end{document}
, i.e.,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg} = y_{jg}$$\end{document}
 if
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,y_{jg}} \le Z_{jg} \le \alpha _{jg,y_{jg}+1}$$\end{document}
if
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,y_{jg}} \le Z_{jg} \le \alpha _{jg,y_{jg}+1}$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,K} = \infty $$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,K} = \infty $$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,0} = -\infty $$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha _{jg,0} = -\infty $$\end{document}
 .
.
For the bi-factor model, if
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}(\cdot ;\theta _{jg})$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}(\cdot ;\delta _{jg})$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}(\cdot ;\delta _{jg})$$\end{document}
 are BVN copulas,
are BVN copulas,
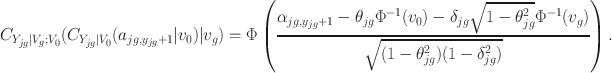
Hence, the pmf for the bi-factor copula model in (1) becomes:
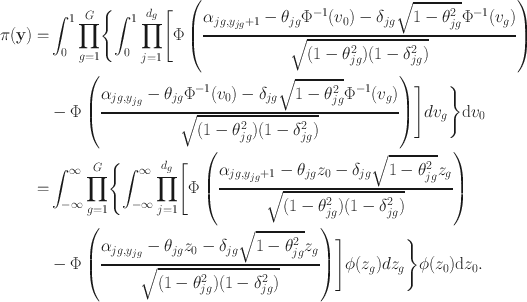
This model is the same as the Gaussian bi-factor model (Gibbons and Hedeker Reference Gibbons and Hedeker1992; Gibbons et al. Reference Gibbons, Bock, Hedeker, Weiss, Segawa, Bhaumik, Kupfer, Frank, Grochocinski and Stover2007) with stochastic representation

where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{jg}=\delta _{jg}\sqrt{1 - \theta _{jg}^2}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{0},Z_{g},\epsilon _{jg}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{0},Z_{g},\epsilon _{jg}$$\end{document}
 are iid N(0, 1) random variables. The parameter
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg}$$\end{document}
are iid N(0, 1) random variables. The parameter
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg}$$\end{document}
 of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_0}$$\end{document}
 is the correlation of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
is the correlation of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0$$\end{document}
 , and the parameter
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta _{jg}$$\end{document}
, and the parameter
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\delta _{jg}$$\end{document}
 of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}$$\end{document}
of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{Y_{jg},V_g|V_0}$$\end{document}
 is the partial correlation between
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
is the partial correlation between
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{g}=\Phi ^{-1}(V_g)$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{g}=\Phi ^{-1}(V_g)$$\end{document}
 given
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0=\Phi ^{-1}(V_0)$$\end{document}
given
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0=\Phi ^{-1}(V_0)$$\end{document}
 .
.
It implies that the underlying random variables
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
 ’s have a multivariate Gaussian distribution where the off-diagonal entries of the correlation matrix have the form
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{j_1g}\theta _{j_2g} + \gamma _{j_1g}\gamma _{j_2g}$$\end{document}
’s have a multivariate Gaussian distribution where the off-diagonal entries of the correlation matrix have the form
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{j_1g}\theta _{j_2g} + \gamma _{j_1g}\gamma _{j_2g}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{j_1g_1}\theta _{j_2g_2}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{j_1g_1}\theta _{j_2g_2}$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$ j_1 \ne j_2$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$ j_1 \ne j_2$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g_1 \ne g_2$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g_1 \ne g_2$$\end{document}
 , respectively. For the Gaussian bi-factor model to be identifiable, the number of dependence parameters has to be
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$2d - N_{1}-N_{2}$$\end{document}
, respectively. For the Gaussian bi-factor model to be identifiable, the number of dependence parameters has to be
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$2d - N_{1}-N_{2}$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N_{1}$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N_{1}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N_{2}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N_{2}$$\end{document}
 is the number of groups that consist of 1 and 2 items, respectively. For a group g of size 1 with variable j,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_g$$\end{document}
is the number of groups that consist of 1 and 2 items, respectively. For a group g of size 1 with variable j,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_g$$\end{document}
 is absorbed with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\epsilon _{jg}$$\end{document}
is absorbed with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\epsilon _{jg}$$\end{document}
 because
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{jg}$$\end{document}
because
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{jg}$$\end{document}
 would not be identifiable. For a group g of size 2 with variable indices
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$j_1,j_2$$\end{document}
would not be identifiable. For a group g of size 2 with variable indices
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$j_1,j_2$$\end{document}
 , the parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{j_1g}$$\end{document}
, the parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{j_1g}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{j_2g}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{j_2g}$$\end{document}
 appear only in one correlation; hence, one of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{j_1g},\gamma _{j_2g}$$\end{document}
appear only in one correlation; hence, one of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{j_1g},\gamma _{j_2g}$$\end{document}
 can be taken as 1 without loss of generality. For the bi-factor copula with non-Gaussian linking copulas, near non-identifiability can occur when there are groups of size 2; in this case, one of the linking copulas to the group latent variable can be fixed at comonotonicity.
can be taken as 1 without loss of generality. For the bi-factor copula with non-Gaussian linking copulas, near non-identifiability can occur when there are groups of size 2; in this case, one of the linking copulas to the group latent variable can be fixed at comonotonicity.
For the Gaussian second-order model, let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0,Z_1',\ldots ,Z_G'$$\end{document}
 be the dependent latent N(0, 1) variables, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0$$\end{document}
be the dependent latent N(0, 1) variables, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0$$\end{document}
 is the second-order factor and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_g'=\beta _{g}Z_0+\sqrt{1-\beta _{g}^2}Z_g$$\end{document}
is the second-order factor and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_g'=\beta _{g}Z_0+\sqrt{1-\beta _{g}^2}Z_g$$\end{document}
 is the first-order factor for group g. That is, there is an one second-order factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0$$\end{document}
is the first-order factor for group g. That is, there is an one second-order factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_0$$\end{document}
 , and the first-order factors
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_1',\ldots ,Z_G'$$\end{document}
, and the first-order factors
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_1',\ldots ,Z_G'$$\end{document}
 are linear combinations of the second-order factor, plus a unique variable
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_g$$\end{document}
are linear combinations of the second-order factor, plus a unique variable
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_g$$\end{document}
 for each first-order factor. The stochastic representation is (Krupskii and Joe Reference Krupskii and Joe2015):
for each first-order factor. The stochastic representation is (Krupskii and Joe Reference Krupskii and Joe2015):
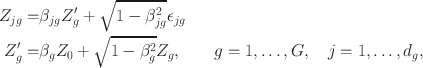
or
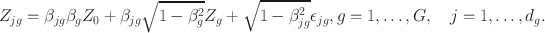
Hence, this is a special case of (3) where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta _{jg} = \beta _{jg} \beta _{g}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{jg} = \beta _{jg} \sqrt{1-\beta _{g}^2}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\gamma _{jg} = \beta _{jg} \sqrt{1-\beta _{g}^2}$$\end{document}
 .
.
1.4. Other Choices of Parametric Bivariate Copulas
In line with Nikoloulopoulos and Joe (Reference Nikoloulopoulos and Joe2015), we use bivariate parametric copulas that can be used when considering latent maxima, minima or mixtures of means. For different dependent items based on latent maxima or minima, multivariate extreme value and copula theory (e.g., Joe Reference Joe1997) can be used to select suitable copulas that link observed to latent variables. Copulas that arise from extreme value theory have more probability in one joint tail (upper or lower) than expected with a discretized MVN distribution or a MVN copula with discrete margins. If item responses are based on discretizations of latent variables that are means, then it is possible that there can be more probability in both the joint upper and joint lower tail, compared with discretized MVN models. This happens if the respondents consist of a ‘mixture’ population (e.g., different locations or genders). From the theory of elliptical distributions and copulas (e.g., McNeil et al. Reference McNeil, Frey and Embrechts2005), it is known that the multivariate Student-t distribution as a scale mixture of MVN has more dependence in the tails. Extreme value and elliptical copulas can model item response data that have reflection asymmetric and symmetric dependence, respectively.
A bivariate copula C is reflection symmetric if its density satisfies
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(u_1,u_2)=c(1-u_1,1-u_2)$$\end{document}
 for all
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$0\le u_1,u_2\le 1$$\end{document}
for all
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$0\le u_1,u_2\le 1$$\end{document}
 . Otherwise, it is reflection asymmetric often with more probability in the joint upper tail or joint lower tail. Upper tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(1-u,1-u)=O(u^{-1})$$\end{document}
. Otherwise, it is reflection asymmetric often with more probability in the joint upper tail or joint lower tail. Upper tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(1-u,1-u)=O(u^{-1})$$\end{document}
 as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0$$\end{document}
as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0$$\end{document}
 and lower tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(u,u)=O(u^{-1})$$\end{document}
and lower tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(u,u)=O(u^{-1})$$\end{document}
 as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0$$\end{document}
as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0$$\end{document}
 . If
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(U_1,U_2)\sim C$$\end{document}
. If
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(U_1,U_2)\sim C$$\end{document}
 for a bivariate copula C, then
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(1-U_1,1-U_2)\sim \widehat{C}$$\end{document}
for a bivariate copula C, then
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(1-U_1,1-U_2)\sim \widehat{C}$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{C}(u_1,u_2)=u_1+u_2-1+C(1-u_1,1-u_2)$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{C}(u_1,u_2)=u_1+u_2-1+C(1-u_1,1-u_2)$$\end{document}
 is the survival or reflected copula of C; this “reflection” of each uniform U(0, 1) random variable about 1/2 changes the direction of tail asymmetry.
is the survival or reflected copula of C; this “reflection” of each uniform U(0, 1) random variable about 1/2 changes the direction of tail asymmetry.
After briefly providing definitions of tail dependence and reflection symmetry/asymmetry, we provide below the bivariate copula choices we consider:
-
• The extreme value Gumbel copula with cdf
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} C(u_1,u_2;\theta )=\exp \Bigl [-\Bigl \{(-\log u_1)^{\theta } +(-\log u_2)^{\theta }\Bigr \}^{1/\theta }\Bigr ], \theta \ge 1. \end{aligned}$$\end{document}A model with bivariate Gumbel copulas has latent (ordinal) variables that can be considered as (discretized) maxima, and there is more probability in the joint upper tail as the Gumbel copula has reflection asymmetry and upper tail dependence.
-
• The survival Gumbel (s.Gumbel) copula with cdf
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} C(u_1,u_2;\theta )= & {} u_1+u_2-1 \\ {}{} & {} + \exp \Bigl [-\Bigl \{\bigl (-\log (1-u_1)\bigr )^{\theta } +\bigl (-\log (1-u_2)\bigr )^{\theta }\Bigr \}^{1/\theta }\Bigr ], \theta \ge 1. \end{aligned}$$\end{document}A model with bivariate s.Gumbel copulas has latent (ordinal) variables that can be considered as (discretized) minima, and there is more probability in the joint lower tail as the s.Gumbel copula has reflection asymmetry and lower tail dependence.
-
• The elliptical bivariate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
copula with cdf
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} C(u_1,u_2;\theta )=\mathcal {T}_2\Bigl (\mathcal {T}^{-1}(u_1;\nu ),\mathcal {T}^{-1}(u_2;\nu );\theta ,\nu \Bigr ),-1\le \theta \le 1, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {T}(;\nu )$$\end{document}
is the univariate Student t cdf with (non-integer)
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\nu $$\end{document}
degrees of freedom, and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {T}_2$$\end{document}
is the cdf of a bivariate Student-t distribution with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\nu $$\end{document}
degrees of freedom and correlation parameter
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta $$\end{document}
. A model with bivariate
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
copulas has latent (ordinal) variables that can be considered as mixtures of (discretized) means, since the bivariate Student-t distribution arises as a scale mixture of bivariate normals. A small value of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\nu $$\end{document}
, such as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$1 \le \nu \le 5$$\end{document}
, leads to a model with more probabilities in the joint upper and joint lower tails compared with the BVN copula as the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
copula has reflection symmetric upper and lower tail dependence.













The BVN and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 are comprehensive copulas, i.e., they interpolate between countermonotonicity (perfect negative dependence) to comonotonicity (perfect positive dependence), but the Gumbel copulas interpolates between independence and perfect positive dependence. Nevertheless, negative dependence or interpolation between perfect negative dependence and independence can be obtained from the Gumbel copulas by considering reflection of one of the uniform random variables on (0, 1). If
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(U_1,U_2)\sim C$$\end{document}
are comprehensive copulas, i.e., they interpolate between countermonotonicity (perfect negative dependence) to comonotonicity (perfect positive dependence), but the Gumbel copulas interpolates between independence and perfect positive dependence. Nevertheless, negative dependence or interpolation between perfect negative dependence and independence can be obtained from the Gumbel copulas by considering reflection of one of the uniform random variables on (0, 1). If
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(U_1,U_2)\sim C$$\end{document}
 for a bivariate copula C with positive dependence, then
for a bivariate copula C with positive dependence, then
-
• \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(1-U_1,U_2)\sim \widehat{C}^{(1)}$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{C}^{(1)}(u_1,u_2)=u_2-C(1-u_1,u_2)$$\end{document}
is the 1-reflected copula of C with negative lower-upper tail dependence; -
• \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(U_1,1-U_2)\sim \widehat{C}^{(2)}$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\widehat{C}^{(2)}(u_1,u_2)=u_1-C(u_1,1-u_2)$$\end{document}
is the 2-reflected copula of C with negative upper-lower dependence.




Negative upper-lower tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(1-u,u)=O(u^{-1})$$\end{document}
 as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0^+$$\end{document}
as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0^+$$\end{document}
 and negative lower-upper tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(u,1-u)=O(u^{-1})$$\end{document}
and negative lower-upper tail dependence means that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$c(u,1-u)=O(u^{-1})$$\end{document}
 as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0^+$$\end{document}
as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$u\rightarrow 0^+$$\end{document}
 (Joe Reference Joe, Kurowicka and Joe2011). The proposed models can provide, with linking copulas that allow for negative (tail) dependence, negative (tail) dependence between the observed variables as the dependence between the observed and latent variables is inherited to the dependence amongst the observed variables.
(Joe Reference Joe, Kurowicka and Joe2011). The proposed models can provide, with linking copulas that allow for negative (tail) dependence, negative (tail) dependence between the observed variables as the dependence between the observed and latent variables is inherited to the dependence amongst the observed variables.
In Fig. 3, to depict the concepts of refection symmetric or asymmetric tail dependence, we show contour plots of the corresponding copula densities with standard normal margins and dependence parameters corresponding to Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 value of 0.6 in absolute value. To make the models comparable, we convert the BVN/
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
value of 0.6 in absolute value. To make the models comparable, we convert the BVN/
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 and (reflected) Gumbel copula parameters to Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
and (reflected) Gumbel copula parameters to Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 ’s via
’s via
and
respectively. Sharper corners (relative to ellipse) in Fig. 3 indicate tail dependence.

Figure 3. Contour plots of bivariate copulas with standard normal margins and dependence parameters corresponding to Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 value of 0.6 in absolute value.
value of 0.6 in absolute value.
The Kendall’s tau parameters, which are strictly increasing functions of the copula parameters, account for the dependence dominated by the middle of the data, and they are expected to be similar among different families of bivariate copulas. However, the tail dependence varies and it is a property to consider when choosing among different families of bivariate copulas (Nikoloulopoulos and Karlis Reference Nikoloulopoulos and Karlis2008).
2. Estimation and Computational Details
For the set of all parameters, let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }=(\textbf{a},\varvec{\theta }_g,\varvec{\delta }_{g})$$\end{document}
 for the bi-factor copula model and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }=(\textbf{a},\varvec{\theta }_g,\varvec{\delta })$$\end{document}
for the bi-factor copula model and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }=(\textbf{a},\varvec{\theta }_g,\varvec{\delta })$$\end{document}
 for the second-order copula model, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{a}=(a_{jg,k}: j=1,\ldots ,d_g, g=1,\ldots ,G, k=1,\ldots ,K-1)$$\end{document}
for the second-order copula model, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{a}=(a_{jg,k}: j=1,\ldots ,d_g, g=1,\ldots ,G, k=1,\ldots ,K-1)$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }_g=(\theta _{1g}, \ldots , \theta _{jg}, \ldots ,\theta _{d_gg}: g=1,\ldots ,G)$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }_g=(\theta _{1g}, \ldots , \theta _{jg}, \ldots ,\theta _{d_gg}: g=1,\ldots ,G)$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }_{g}=(\delta _{1g}, \ldots , \delta _{jg}, \ldots ,\delta _{d_gg}: g=1,\ldots ,G)$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }_{g}=(\delta _{1g}, \ldots , \delta _{jg}, \ldots ,\delta _{d_gg}: g=1,\ldots ,G)$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }=(\delta _{1}, \ldots ,\delta _{G})$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }=(\delta _{1}, \ldots ,\delta _{G})$$\end{document}
 . The dimension of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{a}$$\end{document}
. The dimension of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{a}$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }_g$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }_g$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }_{g}$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }_{g}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\delta }$$\end{document}
 are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d(K-1)$$\end{document}
are
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d(K-1)$$\end{document}
 , d, d and G, respectively. Hence, the dimension q of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }$$\end{document}
, d, d and G, respectively. Hence, the dimension q of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }$$\end{document}
 is
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d(K+1)$$\end{document}
is
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d(K+1)$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$dK +G$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$dK +G$$\end{document}
 for the bi-factor and second-order copula model, respectively.
for the bi-factor and second-order copula model, respectively.
With sample size n and data
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{y}_1,\ldots ,\textbf{y}_n$$\end{document}
 , the joint log-likelihood of the bi-factor and second-order copula is
, the joint log-likelihood of the bi-factor and second-order copula is
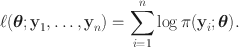
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi (\textbf{y}_i;\varvec{\theta })$$\end{document}
 as in (1) and (2), respectively. Maximum likelihood (ML) estimation, i.e., maximization of (7), is numerically possible but time-consuming for large d because the large number of univariate cutpoints and dependence parameters. Hence, we approach estimation using the two-step Inference Function of Margins (IFM) method (Joe and Xu Reference Joe and Xu1996; Joe Reference Joe1997). Joe (Reference Joe2005) has established its asymptotic efficiency and has shown that can efficiently, in the sense of computing time and asymptotic variance, estimate the univariate and dependence parameters.
as in (1) and (2), respectively. Maximum likelihood (ML) estimation, i.e., maximization of (7), is numerically possible but time-consuming for large d because the large number of univariate cutpoints and dependence parameters. Hence, we approach estimation using the two-step Inference Function of Margins (IFM) method (Joe and Xu Reference Joe and Xu1996; Joe Reference Joe1997). Joe (Reference Joe2005) has established its asymptotic efficiency and has shown that can efficiently, in the sense of computing time and asymptotic variance, estimate the univariate and dependence parameters.
In the first step of the IFM, the univariate parameters, i.e., the cutpoints, are estimated using the univariate sample proportions. The univariate cutpoints for the jth item in group g are estimated as
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\hat{a}_{jg,k} = \sum _{y=0}^{k} p_{jg,y}$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$p_{jg,y}\,,y=0,\ldots ,K-1$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$p_{jg,y}\,,y=0,\ldots ,K-1$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,G$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$j=1,\ldots ,d_g$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$j=1,\ldots ,d_g$$\end{document}
 are the univariate sample proportions. In the second step of the IFM method, the joint log-likelihood in (7) is maximized over the copula parameters with the cutpoints fixed as estimated at the first step. That is for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$i=1,\ldots ,n$$\end{document}
are the univariate sample proportions. In the second step of the IFM method, the joint log-likelihood in (7) is maximized over the copula parameters with the cutpoints fixed as estimated at the first step. That is for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$i=1,\ldots ,n$$\end{document}
 we start from a d-variate sample
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$y_{i11}, \ldots ,y_{id_11},\ldots , y_{i1G}, \ldots , y_{id_GG}$$\end{document}
we start from a d-variate sample
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$y_{i11}, \ldots ,y_{id_11},\ldots , y_{i1G}, \ldots , y_{id_GG}$$\end{document}
 from which d estimators
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{11}(y_{i11}), \ldots ,F_{d_11}(y_{id_11}), \ldots , F_{1G}(y_{i1G}), \ldots ,$$\end{document}
from which d estimators
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{11}(y_{i11}), \ldots ,F_{d_11}(y_{id_11}), \ldots , F_{1G}(y_{i1G}), \ldots ,$$\end{document}
 \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{d_GG}(y_{id_GG})$$\end{document}
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$F_{d_GG}(y_{id_GG})$$\end{document}
 are obtained. We use these estimators, i.e., the cutpoints, to transform the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$y_{i11}, \ldots ,y_{id_11},\ldots , y_{i1G},$$\end{document}
are obtained. We use these estimators, i.e., the cutpoints, to transform the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$y_{i11}, \ldots ,y_{id_11},\ldots , y_{i1G},$$\end{document}
 \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\ldots , y_{id_GG}$$\end{document}
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\ldots , y_{id_GG}$$\end{document}
 sample to a uniform sample
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\alpha }}_{11,y_{i11}+1},\ldots ,{\hat{\alpha }}_{d_11,y_{id_11}+1},\ldots {\hat{\alpha }}_{1G,y_{i1G}+1}, \ldots , {\hat{\alpha }}_{d_GG,y_{id_GG}+1}$$\end{document}
sample to a uniform sample
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\alpha }}_{11,y_{i11}+1},\ldots ,{\hat{\alpha }}_{d_11,y_{id_11}+1},\ldots {\hat{\alpha }}_{1G,y_{i1G}+1}, \ldots , {\hat{\alpha }}_{d_GG,y_{id_GG}+1}$$\end{document}
 on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$[0, 1]^d$$\end{document}
on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$[0, 1]^d$$\end{document}
 and then fit the factor copula model at the second step. Hence, the IFM approach can be regarded as a two-step approach on the original data or simply as the standard one-step ML method on the transformed (copula) data. Note also in passing that compared to the ML, the IFM method is not as punishing for misspecification of the dependence structure (Joe and Xu Reference Joe and Xu1996; Xu Reference Xu1996).
and then fit the factor copula model at the second step. Hence, the IFM approach can be regarded as a two-step approach on the original data or simply as the standard one-step ML method on the transformed (copula) data. Note also in passing that compared to the ML, the IFM method is not as punishing for misspecification of the dependence structure (Joe and Xu Reference Joe and Xu1996; Xu Reference Xu1996).
For the bi-factor copula model, numerical evaluation of the joint pmf can be achieved with the following steps:
-
(a) Calculate Gauss–Legendre quadrature (Stroud and Secrest Reference Stroud and Secrest1966) points \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{\mathcal {v}_q: q=1,\ldots ,n_q\}$$\end{document}
and weights
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{w_q: q=1,\ldots ,n_q\}$$\end{document}
in terms of standard uniform. -
(b) Numerically evaluate the joint pmf
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} \int _0^1 \prod _{g=1}^{G} \Bigg \{ \int _0^1 \prod _{j=1}^{d_g} f_{Y_{jg}|V_{jg};V_0}(y_{jg}|v_g,v_0) \textrm{d}{v_g} \Bigg \} \textrm{d}{v_0} \end{aligned}$$\end{document}in a double sum
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} \sum _{q_1=1}^{n_q} w_{q_1} \prod _{g=1}^{G} \Bigg \{ \sum _{q_2=1}^{n_q} w_{q_2} \prod _{j=1}^{d_g} f_{Y_{jg}|V_{jg};V_0}(y_{jg}|\mathcal {v}_{q_2},\mathcal {v}_{q_1}) \Bigg \}. \end{aligned}$$\end{document}




For the second-order copula model, numerical evaluation of the joint pmf can be achieved with the following steps:
-
1. Calculate Gauss–Legendre quadrature points \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{\mathcal {v}_q : q=1,\ldots , n_q \}$$\end{document}
and weights
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{w_q : q=1,\ldots , n_q \}$$\end{document}
in terms of standard uniform. -
2. Numerically evaluate the joint pmf
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} \int _0^1 \Bigg \{ \prod _{g=1}^{G} \int _0^1 \Big [ \prod _{j=1}^{d_g} f_{Y_{jg}|V_g}(y_{jg}|v_g;\theta _{jg}) \Big ] c_{V_g,V_0}\bigl (v_g,v_0;\delta _{g}\bigr ) \textrm{d}{v_g} \Bigg \} \textrm{d}{v_0} \end{aligned}$$\end{document}in a double sum
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\begin{aligned} \sum _{q_1=1}^{n_q} w_{q_1} \Bigg \{ \prod _{g=1}^{G} \sum _{q_2=1}^{n_q} w_{q_2} \Big [ \prod _{j=1}^{d_g} f_{Y_{jg}|V_g}(y_{jg}|\mathcal {v}_{q_2|q_1};\theta _{jg}) \Big ] \Bigg \}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\mathcal {v}_{q_2|q_1} = C^{-1}_{Y_{jg}|V_g;V_0}( {v}_{q_2} | {v}_{q_1};\delta _{g})$$\end{document}
. Note that the independent quadrature points
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{\mathcal {v}_{q_1}: q_1 = 1,\ldots ,n_q\}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\{\mathcal {v}_{q_2}: q_2 = 1,\ldots ,n_q\}$$\end{document}
have been converted to dependent quadrature points that have an one-factor copula distribution
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{X}(\cdot ;\varvec{\delta })$$\end{document}
.








The estimated copula parameters can be obtained by using a quasi-Newton (Nash Reference Nash1990) method applied to the logarithm of the joint likelihood. With Gauss–Legendre quadrature, the same nodes and weights are used for different functions; this helps in yielding smooth numerical derivatives for numerical optimization via quasi-Newton. Our comparisons show that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n_q=25$$\end{document}
 quadrature points are adequate with good precision.
quadrature points are adequate with good precision.
3. Bivariate Copula Selection
In the following subsections, we describe simple diagnostics based on semi-correlations and a heuristic method that automatically selects the bivariate parametric copula families that build either the bi-factor or the second-order copula model.
Choices of copulas with upper or lower tail dependence are better if the items have more probability in joint lower or upper tail than would be expected with the BVN copula. This can be shown with summaries of polychoric correlations in the upper and lower joint tail (Kadhem and Nikoloulopoulos Reference Kadhem and Nikoloulopoulos2021). In the context of items that can be split into G non-overlapping groups, such that there is homogeneous dependence within each group, it is sufficient to (a) summarize the average of the polychoric semi-correlations for all pairs within each of the G groups and for all pairs of items, and (b) not mix bivariate copulas for a single factor; hence, for both the bi-factor and second-order copula models we allow
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$G+1$$\end{document}
 different copula families, one for each group specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
different copula families, one for each group specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
 and one for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
and one for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
 .
.
We distinguish the simple descriptives, i.e., the semi-correlations, from the heuristic algorithm and model fitting. On the one hand, the descriptive statistics can suggest more probability to the lower or upper tail for many pairs of items, but bi-factor and second-order copula models with asymmetrical dependence can be used to check whether the two tails are significantly different.
3.1. Simple Diagnostics Based on Semi-correlations
Consider again the underlying N(0, 1) latent variables
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
 ’s of the ordinal variables
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
’s of the ordinal variables
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 ’s. The correlations of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
’s. The correlations of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Z_{jg}$$\end{document}
 ’s in the upper and lower tail, hereafter semi-correlations, are defined as (Joe Reference Joe2014, p. 71):
’s in the upper and lower tail, hereafter semi-correlations, are defined as (Joe Reference Joe2014, p. 71):
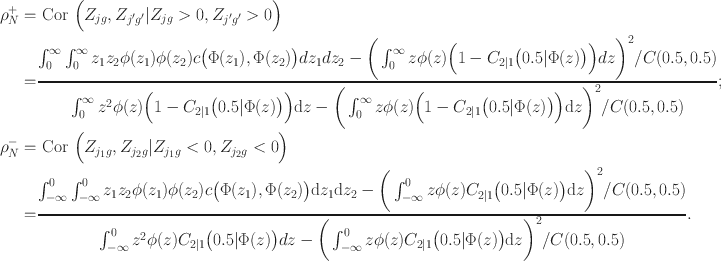
From the above expressions, it is clear that the semi-correlations depend only on the copula C of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\Bigl (\Phi (Z_{jg}),$$\end{document}
 \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\Phi (Z_{j'g'})\Bigr )$$\end{document}
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\Phi (Z_{j'g'})\Bigr )$$\end{document}
 ;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{2|1}$$\end{document}
;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$C_{2|1}$$\end{document}
 is the conditional copula cdf. For the BVN and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
is the conditional copula cdf. For the BVN and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{-}=\rho _N^{+}$$\end{document}
copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{-}=\rho _N^{+}$$\end{document}
 , while for the Gumbel and s.Gumbel copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{-}<\rho _N^{+}$$\end{document}
, while for the Gumbel and s.Gumbel copulas
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{-}<\rho _N^{+}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{-}>\rho _N^{+}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{-}>\rho _N^{+}$$\end{document}
 , respectively. The sample versions of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{+},\rho _N^{-}$$\end{document}
, respectively. The sample versions of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\rho _N^{+},\rho _N^{-}$$\end{document}
 for item response data are the polychoric correlations in the joint lower and upper quadrants of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
for item response data are the polychoric correlations in the joint lower and upper quadrants of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{j'g'}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{j'g'}$$\end{document}
 (Kadhem and Nikoloulopoulos Reference Kadhem and Nikoloulopoulos2021).
(Kadhem and Nikoloulopoulos Reference Kadhem and Nikoloulopoulos2021).
3.2. Selection Algorithm
We propose a heuristic method that selects appropriate bivariate copulas for each factor of the bi-factor and second-order copula models. It starts with an initial assumption, that all bivariate linking copulas are BVN copulas, i.e. the starting model is either the Gaussian bi-factor or second-order model, and then, sequentially other copulas with lower or upper tail dependence are assigned to the factors where necessary to account for more probability in one or both joint tails. The selection algorithm involves the following steps:
-
1. Fit the bi-factor or second-order copula model with BVN copulas.
-
2. Fit all the possible bi-factor or second-order copula models, iterating over all the copula candidates that link all items \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$Y_{jg}$$\end{document}
’s in group g or each group-specific factor
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
, respectively, to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
. -
3. Select the copula family that corresponds to the lowest Akaike information criterion (AIC), that is, \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\text {AIC}= -2 \times \ell +2 \times \#\text {copula parameters}$$\end{document}
. -
4. Fix the selected copula family that links the observed (bi-factor model) or latent (second-order model) variables to \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_0$$\end{document}
. -
5. For \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\dots ,G$$\end{document}
:
-
(a) Fit all the possible models, iterating over all the copula candidates that link all the items in group g to the group-specific factor \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
. -
(b) Select the copula family that corresponds to the lowest AIC.
-
(c) Fix the selected linking copula family for all the items in group g with \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$V_g$$\end{document}
.
-








For vine copula models (bi-factor and second-order copula models are vine copula models that involve both observed and latent variables), Dissmann et al. (Reference Dissmann, Brechmann, Czado and Kurowicka2013) also found that bivariate copula selection based on AIC seems to be better than even using bivariate goodness-of-fit tests. The goodness-of-fit procedures involve a global distance measure between the model-based and empirical distribution; hence, they might not be sensitive to tail behaviours and are not diagnostics in the sense of suggesting improved parametric models in the case of small p-values (Joe Reference Joe2014, p. 254). A smaller AIC indicates a model that better approximates both the dependence structure of the data and the strength of dependence in the tails.
4. Goodness of Fit
We will use the limited information
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic proposed by Maydeu-Olivares and Joe (Reference Maydeu-Olivares and Joe2006) to evaluate the overall fit of the proposed bi-factor and second-order copula models. The
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
statistic proposed by Maydeu-Olivares and Joe (Reference Maydeu-Olivares and Joe2006) to evaluate the overall fit of the proposed bi-factor and second-order copula models. The
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic is based on a quadratic form of the deviations of sample and model-based proportions over all bivariate margins. For the bi-factor and second-order copula models with parameter vector
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }$$\end{document}
statistic is based on a quadratic form of the deviations of sample and model-based proportions over all bivariate margins. For the bi-factor and second-order copula models with parameter vector
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\theta }$$\end{document}
 of dimension q, let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\pi }_2(\varvec{\theta })=\bigl (\dot{\varvec{\pi }}_1(\varvec{\theta })^\top ,\dot{\varvec{\pi }}_2(\varvec{\theta })^\top \bigr )^\top $$\end{document}
of dimension q, let
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\pi }_2(\varvec{\theta })=\bigl (\dot{\varvec{\pi }}_1(\varvec{\theta })^\top ,\dot{\varvec{\pi }}_2(\varvec{\theta })^\top \bigr )^\top $$\end{document}
 be the column vector of the univariate and bivariate model-based marginal probabilities that do not include category 0 with sample counterpart
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{p}_2=(\dot{\textbf{p}}_1^\top ,\dot{\textbf{p}}_2^\top )^\top $$\end{document}
be the column vector of the univariate and bivariate model-based marginal probabilities that do not include category 0 with sample counterpart
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{p}_2=(\dot{\textbf{p}}_1^\top ,\dot{\textbf{p}}_2^\top )^\top $$\end{document}
 . The total number of the univariate and bivariate residuals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\bigl (\textbf{p}_2-\varvec{\pi }_2({\hat{\varvec{\theta }}})\bigr )^\top $$\end{document}
. The total number of the univariate and bivariate residuals
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\bigl (\textbf{p}_2-\varvec{\pi }_2({\hat{\varvec{\theta }}})\bigr )^\top $$\end{document}
 is
is
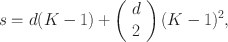
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d (K-1)$$\end{document}
 is the dimension of the univariate residuals and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\left( {\begin{array}{c}d\\ 2\end{array}}\right) (K - 1)^2$$\end{document}
is the dimension of the univariate residuals and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\left( {\begin{array}{c}d\\ 2\end{array}}\right) (K - 1)^2$$\end{document}
 is the dimension of the bivariate residuals excluding category 0.
is the dimension of the bivariate residuals excluding category 0.
With a sample size n, the limited-information
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic is given by
statistic is given by
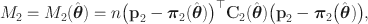
with
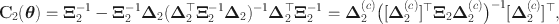
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Delta }_2=\partial \varvec{\pi }_2(\varvec{\theta })/\partial \varvec{\theta }^\top $$\end{document}
 is an
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s\times q$$\end{document}
is an
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s\times q$$\end{document}
 matrix of full column rank q with the first-order derivatives of the univariate and bivariate marginal probabilities with respect to the estimated model parameters (in the Supplementary Tables 1–5 of the electronic supplementary material, we provide details on the calculation of these derivatives),
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Delta }_2^{(c)}$$\end{document}
matrix of full column rank q with the first-order derivatives of the univariate and bivariate marginal probabilities with respect to the estimated model parameters (in the Supplementary Tables 1–5 of the electronic supplementary material, we provide details on the calculation of these derivatives),
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Delta }_2^{(c)}$$\end{document}
 is an
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s\times (s-q)$$\end{document}
is an
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s\times (s-q)$$\end{document}
 orthogonal complement to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Delta }_2$$\end{document}
orthogonal complement to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Delta }_2$$\end{document}
 of full column rank
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s-q$$\end{document}
of full column rank
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s-q$$\end{document}
 , such that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$[\varvec{\Delta }_2^{(c)}]^\top \varvec{\Delta }_2=\textbf{0}$$\end{document}
, such that
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$[\varvec{\Delta }_2^{(c)}]^\top \varvec{\Delta }_2=\textbf{0}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_2$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_2$$\end{document}
 is the asymptotic
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s \times s$$\end{document}
is the asymptotic
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s \times s$$\end{document}
 covariance matrix of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\sqrt{n}\bigl (\textbf{p}_2-\varvec{\pi }_2({\hat{\varvec{\theta }}})\bigr )^\top $$\end{document}
covariance matrix of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\sqrt{n}\bigl (\textbf{p}_2-\varvec{\pi }_2({\hat{\varvec{\theta }}})\bigr )^\top $$\end{document}
 .
.
The asymptotic covariance matrix
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_2$$\end{document}
 can be partitioned according to the partitioning of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{p}_2$$\end{document}
can be partitioned according to the partitioning of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{p}_2$$\end{document}
 into
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{11}=\sqrt{n}\text{ Acov }(\dot{\textbf{p}}_1)$$\end{document}
into
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{11}=\sqrt{n}\text{ Acov }(\dot{\textbf{p}}_1)$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{21}=\sqrt{n}\text{ Acov }(\dot{\textbf{p}}_2,\dot{\textbf{p}}_1)$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{21}=\sqrt{n}\text{ Acov }(\dot{\textbf{p}}_2,\dot{\textbf{p}}_1)$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{22}=\sqrt{n}\text{ Acov }(\dot{\textbf{p}}_2)$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{22}=\sqrt{n}\text{ Acov }(\dot{\textbf{p}}_2)$$\end{document}
 , where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\text{ Acov }(\cdot )$$\end{document}
, where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\text{ Acov }(\cdot )$$\end{document}
 denotes asymptotic covariance matrix. The elements of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{11}$$\end{document}
denotes asymptotic covariance matrix. The elements of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{11}$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{21}$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{21}$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{22}$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\varvec{\Xi }_{22}$$\end{document}
 involve up to the 4-dimensional probabilities as shown below:
involve up to the 4-dimensional probabilities as shown below:
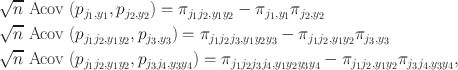
where
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$ \pi _{j,y} = \Pr (Y_j = y)$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi _{j_1j_2,y_1y_2}= \Pr (Y_{j_1} = y_1,Y_{j_2} = y_2)$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi _{j_1j_2,y_1y_2}= \Pr (Y_{j_1} = y_1,Y_{j_2} = y_2)$$\end{document}
 ,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi _{j_1j_2j_3,y_1y_2y_3}=\Pr (Y_{j_1} = y_1,Y_{j_2} = y_2,Y_{j_3} = y_3)$$\end{document}
,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi _{j_1j_2j_3,y_1y_2y_3}=\Pr (Y_{j_1} = y_1,Y_{j_2} = y_2,Y_{j_3} = y_3)$$\end{document}
 , and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi _{j_1j_2j_3j_4,y_1y_2y_3y_4}=\Pr (Y_{j_1} = y_1,Y_{j_2} = y_2,Y_{j_3} = y_3,Y_{j_4} = y_4)$$\end{document}
, and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\pi _{j_1j_2j_3j_4,y_1y_2y_3y_4}=\Pr (Y_{j_1} = y_1,Y_{j_2} = y_2,Y_{j_3} = y_3,Y_{j_4} = y_4)$$\end{document}
 .
.
The limited information statistic
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 under the null hypothesis has an asymptotic distribution that is
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\chi ^2$$\end{document}
under the null hypothesis has an asymptotic distribution that is
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\chi ^2$$\end{document}
 with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s-q$$\end{document}
with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$s-q$$\end{document}
 degrees of freedom as the IFM estimate
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\varvec{\theta }}}$$\end{document}
degrees of freedom as the IFM estimate
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\varvec{\theta }}}$$\end{document}
 is
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\sqrt{n}$$\end{document}
is
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\sqrt{n}$$\end{document}
 -consistent.
-consistent.
5. Simulations
An extensive simulation study is conducted to (a) gauge the small-sample efficiency of the IFM estimation method and investigate the misspecification of the bivariate pair-copulas, (b) examine the reliability of using the heuristic algorithm to select the true (simulated) bivariate linking copulas, and (c) study the small-sample performance of the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic.
statistic.
We randomly generate 1000 datasets with samples of size
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n=500$$\end{document}
 or 1000 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=16$$\end{document}
or 1000 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=16$$\end{document}
 items, with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=3$$\end{document}
items, with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=3$$\end{document}
 or
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=5$$\end{document}
or
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=5$$\end{document}
 equally weighted categories, that are equally separated into
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$G=4$$\end{document}
equally weighted categories, that are equally separated into
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$G=4$$\end{document}
 non-overlapping groups from the bi-factor and second-order copula model. In each simulated model, we use different linking copulas to cover different types of dependence. To make the models comparable, we convert the BVN/
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
non-overlapping groups from the bi-factor and second-order copula model. In each simulated model, we use different linking copulas to cover different types of dependence. To make the models comparable, we convert the BVN/
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 and Gumbel/s.Gumbel copula parameters to Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
and Gumbel/s.Gumbel copula parameters to Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 ’s via the relations in (5) and (6), respectively. For the bi-factor copula models, we set
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\theta }_g)=(0.45,0.55,0.65,0.75)$$\end{document}
’s via the relations in (5) and (6), respectively. For the bi-factor copula models, we set
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\theta }_g)=(0.45,0.55,0.65,0.75)$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\delta }_g)=(0.30,0.35,$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\delta }_g)=(0.30,0.35,$$\end{document}
 0.40, 0.50) for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,4$$\end{document}
0.40, 0.50) for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,4$$\end{document}
 . For the second-order copula models, we set
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\theta }_g)=(0.4,0.5,0.6,0.7)$$\end{document}
. For the second-order copula models, we set
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\theta }_g)=(0.4,0.5,0.6,0.7)$$\end{document}
 for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,4$$\end{document}
for
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$g=1,\ldots ,4$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\delta })=(0.30,0.35,0.40,0.45)$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\delta })=(0.30,0.35,0.40,0.45)$$\end{document}
 .
.
The Kendall’s tau parameters
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\theta }_g)$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\delta }_g)$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau (\varvec{\delta }_g)$$\end{document}
 as described above are common for each group; hence, Table 1 (Table 2) contains the group estimated average biases, root mean square errors (RMSE), and standard deviations (SD), scaled by n, for the IFM (ML) estimates under different pair-copulas from the bi-factor and second-order copula models. In the true (simulated) models, the linking copulas are Gumbel copulas. Given the large number of cutpoints as the number of categories K increases, for ML estimation we restrict ourselves to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=3$$\end{document}
as described above are common for each group; hence, Table 1 (Table 2) contains the group estimated average biases, root mean square errors (RMSE), and standard deviations (SD), scaled by n, for the IFM (ML) estimates under different pair-copulas from the bi-factor and second-order copula models. In the true (simulated) models, the linking copulas are Gumbel copulas. Given the large number of cutpoints as the number of categories K increases, for ML estimation we restrict ourselves to
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=3$$\end{document}
 categories.
categories.
Table 1. Small sample of size
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n = 500$$\end{document}
 simulations (10
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^3$$\end{document}
simulations (10
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^3$$\end{document}
 replications) from the bi-factor and second-order copula models with Gumbel copulas and group estimated average biases, root mean square errors (RMSE), and standard deviations (SD), scaled by n, for the IFM estimates under different pair-copulas from the bi-factor and second-order copula models.
replications) from the bi-factor and second-order copula models with Gumbel copulas and group estimated average biases, root mean square errors (RMSE), and standard deviations (SD), scaled by n, for the IFM estimates under different pair-copulas from the bi-factor and second-order copula models.
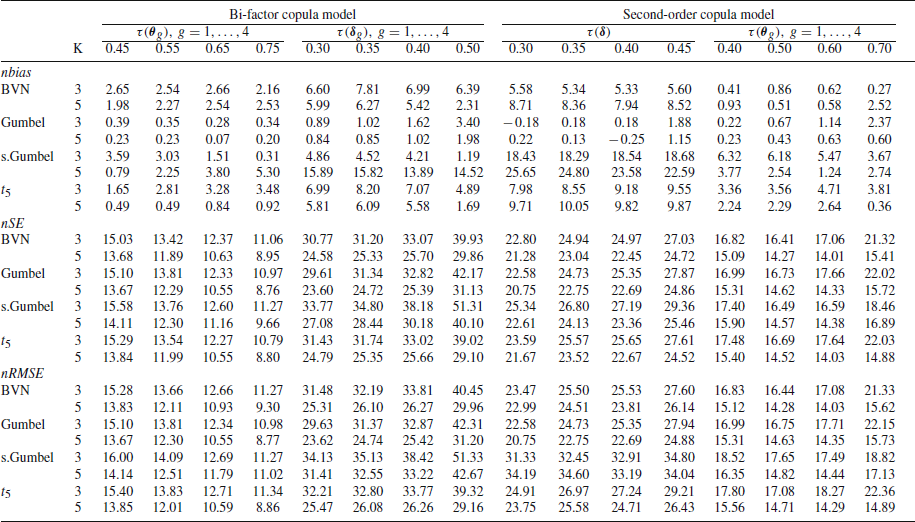
Table 2. Small sample of size
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n = 500$$\end{document}
 simulations (10
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^3$$\end{document}
simulations (10
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^3$$\end{document}
 replications) from the bi-factor and second-order copula models with Gumbel copulas and group estimated average biases, root mean square errors (RMSE), and standard deviations (SD), scaled by n, for the ML estimates under different pair-copulas from the bi-factor and second-order copula models.
replications) from the bi-factor and second-order copula models with Gumbel copulas and group estimated average biases, root mean square errors (RMSE), and standard deviations (SD), scaled by n, for the ML estimates under different pair-copulas from the bi-factor and second-order copula models.
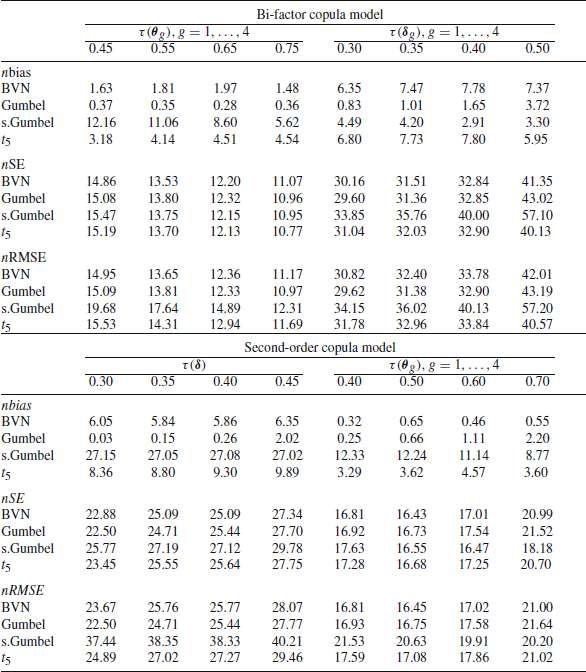
Conclusions from the values in the tables are the following:
-
• IFM with the true bi-factor or second-order model is highly efficient according to the simulated biases, SDs and RMSEs.
-
• The IFM estimates of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
’s are not robust under bivariate copula misspecification and their biases increase when the assumed bivariate copula has tail dependence of opposite direction from the true bivariate copula. For example, in Table 1 the scaled biases for the IFM estimates increase substantially when the linking copulas are the s.Gumbel copulas. -
• IFM is not as punishing for bivariate copula misspecification as ML estimation. For example, the scaled biases for the ML estimates are even larger when the bivariate linking copulas are misspecified to the s.Gumbel copulas.

To examine the reliability of using the heuristic algorithm to select the true (simulated) bivariate linking copulas, samples of size 500 were generated from various bi-factor and second-order copula models. Table 3 presents the number of times that the true (simulated) bivariate linking copulas were chosen over 1000 simulation runs. It is revealed that the model selection algorithm performs extremely well for various bi-factor and second-order copulas models with different choices of linking copulas as the number of categories K increases. For a small K dependence in the tails cannot be easily quantified. Hence, for example, when the true copula is the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_5$$\end{document}
 which has the same upper and lower tail dependence, the algorithm selected either
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_5$$\end{document}
which has the same upper and lower tail dependence, the algorithm selected either
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_5$$\end{document}
 or BVN which has zero lower and upper tail dependence, because both copulas provide reflection symmetric dependence.
or BVN which has zero lower and upper tail dependence, because both copulas provide reflection symmetric dependence.
Table 3. Small sample of size
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n = 500$$\end{document}
 simulations (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$10^3$$\end{document}
simulations (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$10^3$$\end{document}
 replications) from the bi-factor and second-order copula models with various linking copulas and frequencies of the true bivariate copula identified using the model selection algorithm.
replications) from the bi-factor and second-order copula models with various linking copulas and frequencies of the true bivariate copula identified using the model selection algorithm.

To check whether the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\chi ^2_{s-q}$$\end{document}
 is a good approximation for the distribution of the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
is a good approximation for the distribution of the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic under the null hypothesis, samples of sizes 500 and 1000 were generated from various bi-factor second-order copula models. Table 4 contains four common nominal levels of the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
statistic under the null hypothesis, samples of sizes 500 and 1000 were generated from various bi-factor second-order copula models. Table 4 contains four common nominal levels of the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic under the bi-factor and second-order copula models with different bivariate copulas. As can be seen in the table, the observed levels of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
statistic under the bi-factor and second-order copula models with different bivariate copulas. As can be seen in the table, the observed levels of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 are close to the nominal
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
are close to the nominal
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha $$\end{document}
 levels and remain accurate even for extremely sparse tables (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=16$$\end{document}
levels and remain accurate even for extremely sparse tables (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=16$$\end{document}
 and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=5$$\end{document}
and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=5$$\end{document}
 ).
).
Table 4. Small sample of size
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n =\{500,1000\}$$\end{document}
 simulations (10
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^3$$\end{document}
simulations (10
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^3$$\end{document}
 replications) from bi-factor and second-order copula models and the empirical rejection levels at
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha = \{0.20, 0.10, 0.05, 0.01\}$$\end{document}
replications) from bi-factor and second-order copula models and the empirical rejection levels at
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\alpha = \{0.20, 0.10, 0.05, 0.01\}$$\end{document}
 , degrees of freedom (df), mean and variance.
, degrees of freedom (df), mean and variance.
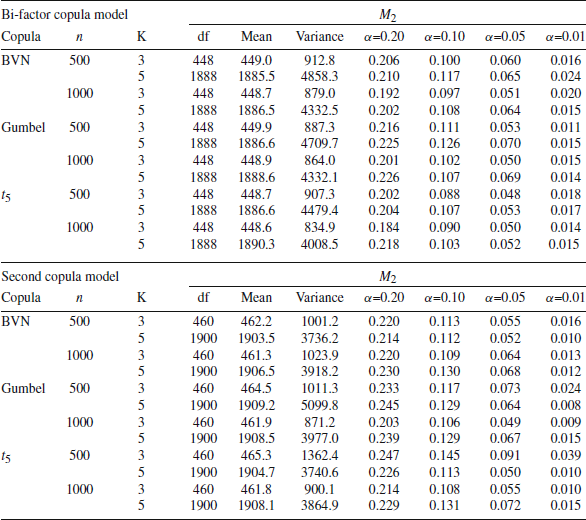
6. Application
The Toronto Alexithymia Scale (TAS) is the most utilized measure of alexithymia in empirical research (e.g., Bagby et al. Reference Bagby, Parker and Taylor1994; Taylor et al. Reference Taylor, Bagby and Parker2003; Parker et al. Reference Parker, Taylor and Bagby2003; Gignac et al. Reference Gignac, Palmer and Stough2007; Reise et al. Reference Reise, Bonifay and Haviland2013; Tuliao et al. Reference Tuliao, Klanecky, Landoy and McChargue2020; Carnovale et al. Reference Carnovale, Taylor, Parker, Sanches and Bagby2021) and is composed of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d=20$$\end{document}
 items. The aforementioned works suggest that the items measure 3 facets of alexithymia, namely Difficulty Identifying Feelings (DIF;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_1=7$$\end{document}
items. The aforementioned works suggest that the items measure 3 facets of alexithymia, namely Difficulty Identifying Feelings (DIF;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_1=7$$\end{document}
 items), Difficulty Describing Feelings (DDF;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_2=5$$\end{document}
items), Difficulty Describing Feelings (DDF;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_2=5$$\end{document}
 items), Externally Oriented Thinking (EOT;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_3=8$$\end{document}
items), Externally Oriented Thinking (EOT;
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$d_3=8$$\end{document}
 items), where each facet represents different non-overlapping items. Therefore, a 3-factor model was initially called, but given the hypothesized association among the three facets of the alexithymia construct, oblique (correlated) factor or bi-factor models have been used (e.g., Bagby et al. Reference Bagby, Parker and Taylor1994; Parker et al. Reference Parker, Taylor and Bagby2003; Gignac et al. Reference Gignac, Palmer and Stough2007). Tuliao et al. (Reference Tuliao, Klanecky, Landoy and McChargue2020) has demonstrated that a bi-factor model outperforms any other competing factor model for the TAS scale. To this end, recent studies adopted the bi-factor structure for the TAS scale (e.g., Carnovale et al. Reference Carnovale, Taylor, Parker, Sanches and Bagby2021) and further supported a general alexithymia factor and group-specific factors (DIF, DDf and EOT) that account for homogeneous dependence amongst the non-overlapping items. Note also in passing that estimating a 3-factor or an oblique 3-factor model is computationally demanding as it requires 3-dimensional integration. This is not case for the bi-factor or second-order (an oblique 3-factor model where the group-specific factors are linked to another latent variable via a 1-factor model) models. In spite of the fact they involve
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$G+1=4$$\end{document}
items), where each facet represents different non-overlapping items. Therefore, a 3-factor model was initially called, but given the hypothesized association among the three facets of the alexithymia construct, oblique (correlated) factor or bi-factor models have been used (e.g., Bagby et al. Reference Bagby, Parker and Taylor1994; Parker et al. Reference Parker, Taylor and Bagby2003; Gignac et al. Reference Gignac, Palmer and Stough2007). Tuliao et al. (Reference Tuliao, Klanecky, Landoy and McChargue2020) has demonstrated that a bi-factor model outperforms any other competing factor model for the TAS scale. To this end, recent studies adopted the bi-factor structure for the TAS scale (e.g., Carnovale et al. Reference Carnovale, Taylor, Parker, Sanches and Bagby2021) and further supported a general alexithymia factor and group-specific factors (DIF, DDf and EOT) that account for homogeneous dependence amongst the non-overlapping items. Note also in passing that estimating a 3-factor or an oblique 3-factor model is computationally demanding as it requires 3-dimensional integration. This is not case for the bi-factor or second-order (an oblique 3-factor model where the group-specific factors are linked to another latent variable via a 1-factor model) models. In spite of the fact they involve
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$G+1=4$$\end{document}
 latent variables, only require one-dimensional integrals of a function which in turn is a product of 3 one-dimensional integrals.
latent variables, only require one-dimensional integrals of a function which in turn is a product of 3 one-dimensional integrals.
We use a dataset of 1925 university students from the French-speaking region of Belgium (Briganti and Linkowski Reference Briganti and Linkowski2020). Students were 17 to 25 years old, and 58% of them were female and 42% were male. They were asked to respond to each item using one of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$K=5$$\end{document}
 categories: “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$1=$$\end{document}
categories: “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$1=$$\end{document}
 completely disagree”, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$2=$$\end{document}
completely disagree”, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$2=$$\end{document}
 disagree”, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$3=$$\end{document}
disagree”, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$3=$$\end{document}
 neutral, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$4=$$\end{document}
neutral, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$4=$$\end{document}
 agree”, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$5=$$\end{document}
agree”, “
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$5=$$\end{document}
 completely agree”. The dataset and full description of the items can be found in the R package BGGM (Williams and Mulder Reference Williams and Mulder2020).
completely agree”. The dataset and full description of the items can be found in the R package BGGM (Williams and Mulder Reference Williams and Mulder2020).
For these items, a respondent might be thinking about the average “sensation” of many past relevant events, leading to latent means. That is, based on the item descriptions, this seems more natural than a discretized maxima or minima. Since the sample is a mixture (male and female students), we can expect a priori that a bi-factor or second-order copula model with
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 copulas might be plausible, as in this case the items can be considered as mixtures of discretized means.
copulas might be plausible, as in this case the items can be considered as mixtures of discretized means.
In Table 5, we summarize the averages of polychoric semi-correlations for all pairs within each facet of alexithymia and for all pairs of items along with the theoretical semi-correlations in (8) under different choices of copulas. For a BVN/
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 copula, the copula parameter is the sample polychoric correlation, while for a Gumbel/s.Gumbel copula the polychoric correlation was converted to Kendall’s tau with the relation in (5) and then from Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
copula, the copula parameter is the sample polychoric correlation, while for a Gumbel/s.Gumbel copula the polychoric correlation was converted to Kendall’s tau with the relation in (5) and then from Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 to Gumbel/s.Gumbel copula parameter via the functional inverse in (6). The summary of findings from the diagnostics in the table show that the items appear to be a mixed selection between discretized means and minima. For the indicators of the DIF factor (items in group 1) there is more correlation in the joint lower tail, i.e., the items are based on discretizations of latent variables that are minima and have more probability in the joint lower tail, suggesting the use of s.Gumbel linking copulas when modelling the responses to these items. All the other items have stronger correlation in both the joint upper and joint lower tail than with the BVN, i.e., the items are based on discretizations of latent variables that are means and have more probability in both the joint lower and upper tail, suggesting the use of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
to Gumbel/s.Gumbel copula parameter via the functional inverse in (6). The summary of findings from the diagnostics in the table show that the items appear to be a mixed selection between discretized means and minima. For the indicators of the DIF factor (items in group 1) there is more correlation in the joint lower tail, i.e., the items are based on discretizations of latent variables that are minima and have more probability in the joint lower tail, suggesting the use of s.Gumbel linking copulas when modelling the responses to these items. All the other items have stronger correlation in both the joint upper and joint lower tail than with the BVN, i.e., the items are based on discretizations of latent variables that are means and have more probability in both the joint lower and upper tail, suggesting the use of
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 bivariate linking copulas as the respondents consist of a “mixture” population (different genders), Hence, a bi-factor or second-order copula model with the aforementioned linking copulas might provide a better fit than the (Gaussian) models with BVN copulas.
bivariate linking copulas as the respondents consist of a “mixture” population (different genders), Hence, a bi-factor or second-order copula model with the aforementioned linking copulas might provide a better fit than the (Gaussian) models with BVN copulas.
Table 5. Average observed polychoric correlations and semi-correlations for all pairs within each group and for all pairs of items for the Toronto Alexithymia Scale (TAS), along with the corresponding theoretical semi-correlations for BVN,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_5$$\end{document}
 , Frank, Gumbel , and survival Gumbel (s.Gumbel) copulas.
, Frank, Gumbel , and survival Gumbel (s.Gumbel) copulas.
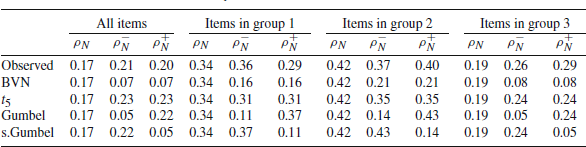
Then, we fit the bi-factor and second-order models with the bivariate copulas selected by the heuristic algorithm in Sect. 3.2. For a baseline comparison, we also fit their special cases; these are the one- and two-factor copula models where we have also selected the bivariate copulas using the heuristic algorithm proposed by Kadhem and Nikoloulopoulos (Reference Kadhem and Nikoloulopoulos2021). To show the improvement of the copula models over their Gaussian analogues, we have also fitted all the classes of copula models with BVN copulas. The fitted models are compared via the AIC, since the number of parameters is not the same between the models. In addition, we use Vuong’s test (Vuong Reference Vuong1989) to show if (a) the best fitted model according to the AICs provides better fit than the other fitted models and (b) a model with the selected copulas provides better fit than the one with BVN copulas. The Vuong’s test is the sample version of the difference in Kullback–Leibler divergence between two models and can be used to differentiate two parametric models which could be non-nested. For the Vuong’s test we provide the 95% confidence interval of the test statistic (Joe Reference Joe2014, p. 258). If the interval does not contain 0, then the best fitted model according to the AICs is better if the interval is completely above 0. To assess the overall goodness-of-fit of the bi-factor and second-order copula models, we use the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistic, along with the Root Mean Square Error of Approximation based on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
statistic, along with the Root Mean Square Error of Approximation based on
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 (Maydeu-Olivares and Joe Reference Maydeu-Olivares and Joe2014), viz.
(Maydeu-Olivares and Joe Reference Maydeu-Olivares and Joe2014), viz.
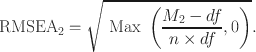
Table 6. AICs, Vuong’s 95% CIs, and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistics for the 1-factor, 2-factor, bi-factor and second-order copula models with BVN copulas and selected copulas, along with the maximum deviations of observed and expected counts for all pairs within each group and for all pairs of items for the Toronto Alexithymia Scale.
statistics for the 1-factor, 2-factor, bi-factor and second-order copula models with BVN copulas and selected copulas, along with the maximum deviations of observed and expected counts for all pairs within each group and for all pairs of items for the Toronto Alexithymia Scale.
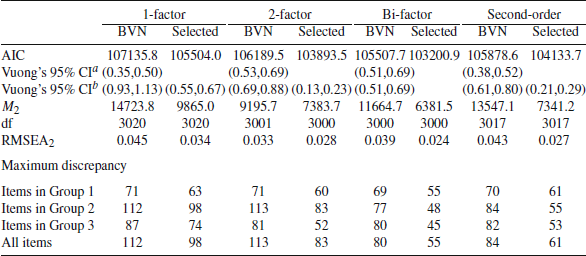
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^\textrm{a}\hbox {Selected}$$\end{document}
 factor copula model versus its Gaussian special case.
factor copula model versus its Gaussian special case.
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$^\textrm{b}\hbox {Selected}$$\end{document}
 Bi-factor copula model versus any other fitted model.
Bi-factor copula model versus any other fitted model.
Table 6 gives the AICs, the 95% CIs of Vuong’s tests and the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistics for all the fitted models. The best fitted model, based on AIC values, is the bi-factor copula model obtained from the selection algorithm. The best-fitted bi-factor copula model results when we use s.Gumbel for the DIF factor,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_3$$\end{document}
statistics for all the fitted models. The best fitted model, based on AIC values, is the bi-factor copula model obtained from the selection algorithm. The best-fitted bi-factor copula model results when we use s.Gumbel for the DIF factor,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_3$$\end{document}
 for both the DDF and EOT factors and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_2$$\end{document}
for both the DDF and EOT factors and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_2$$\end{document}
 for the common factor (alexithymia). This is in line with the preliminary analyses based on the interpretations of items as mixtures of means and the diagnostics in Table 5. The proposed model selection algorithm has selected the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
for the common factor (alexithymia). This is in line with the preliminary analyses based on the interpretations of items as mixtures of means and the diagnostics in Table 5. The proposed model selection algorithm has selected the
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_\nu $$\end{document}
 copula that has the same lower and upper tail dependence for the common and all the group specific factors except the group specific factor in group 1 for which the survival Gumbel copula has been selected. For the items in group 1, the largest difference
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\rho }}_N^--{\hat{\rho }}_N^+=0.07$$\end{document}
copula that has the same lower and upper tail dependence for the common and all the group specific factors except the group specific factor in group 1 for which the survival Gumbel copula has been selected. For the items in group 1, the largest difference
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\rho }}_N^--{\hat{\rho }}_N^+=0.07$$\end{document}
 is found showing more dependence in the lower tail and the fact that for this group the survival Gumbel copula is selected it shows that this difference is statistically significant. No other difference is statistically significant. It is revealed that the DIF items and DIF factor are discretized and latent minima, respectively, as the participants seem to reflect that they “disagree” or “completely disagree” having difficulty identifying feelings. From the Vuong’s 95% Cls and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
is found showing more dependence in the lower tail and the fact that for this group the survival Gumbel copula is selected it shows that this difference is statistically significant. No other difference is statistically significant. It is revealed that the DIF items and DIF factor are discretized and latent minima, respectively, as the participants seem to reflect that they “disagree” or “completely disagree” having difficulty identifying feelings. From the Vuong’s 95% Cls and
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistics, it is shown that factor copula models provide a big improvement over their Gaussian analogues and that the selected bi-factor copula model outperforms all the fitted models.
statistics, it is shown that factor copula models provide a big improvement over their Gaussian analogues and that the selected bi-factor copula model outperforms all the fitted models.
The highly statistical significant
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$M_2$$\end{document}
 statistics are not surprising since one should expect discrepancies between the postulated parametric model and the population probabilities, when the sample size or dimension is sufficiently large (Maydeu-Olivares and Joe Reference Maydeu-Olivares and Joe2014) as in our case; none should expect a model with 3000 df to fit exactly. To further show that the fit has been improved we have calculated the maximum deviations of observed and model-based counts for each bivariate margin, that is,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$D_{j_1j_2}=n\max _{y_1,y_2}|p_{j_1,j_2,y_1,y_2}-\pi _{j_1,j_2,y_1,y_2}({\hat{\varvec{\theta }}})|$$\end{document}
statistics are not surprising since one should expect discrepancies between the postulated parametric model and the population probabilities, when the sample size or dimension is sufficiently large (Maydeu-Olivares and Joe Reference Maydeu-Olivares and Joe2014) as in our case; none should expect a model with 3000 df to fit exactly. To further show that the fit has been improved we have calculated the maximum deviations of observed and model-based counts for each bivariate margin, that is,
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$D_{j_1j_2}=n\max _{y_1,y_2}|p_{j_1,j_2,y_1,y_2}-\pi _{j_1,j_2,y_1,y_2}({\hat{\varvec{\theta }}})|$$\end{document}
 . In Table 6, we summarize the averages of these deviations for all pairs within each group and for all pairs of items. Overall, the maximum discrepancies have been sufficiently reduced in the selected bi-factor model.
. In Table 6, we summarize the averages of these deviations for all pairs within each group and for all pairs of items. Overall, the maximum discrepancies have been sufficiently reduced in the selected bi-factor model.
Table 7 gives the copula parameter estimates in Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 scale and their standard errors (SE) for the selected bi-factor copula model and the Gaussian bi-factor model as the benchmark model. The SEs of the estimated parameters are obtained by the inversion of the Hessian matrix at the second step of the IFM method. These SEs are adequate to assess the flatness of the log-likelihood. Proper SEs that account for the estimation of cutpoints can be obtained by jackknifing the two-stage estimation procedure. The loading parameters (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\tau }}$$\end{document}
scale and their standard errors (SE) for the selected bi-factor copula model and the Gaussian bi-factor model as the benchmark model. The SEs of the estimated parameters are obtained by the inversion of the Hessian matrix at the second step of the IFM method. These SEs are adequate to assess the flatness of the log-likelihood. Proper SEs that account for the estimation of cutpoints can be obtained by jackknifing the two-stage estimation procedure. The loading parameters (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\hat{\tau }}$$\end{document}
 ’s converted to BVN copula parameters via the functional inverse in (5) and then to loadings using the relations in Section 2.3) show that the common alexithymia factor is mostly loaded on DIF and DDF items, suggesting that items in the domains DIF and DDF are good indicators for alexithymia. The items in the EOT although they loaded on the EOT latent factor, they had poor loadings in the common alexithymia factor.
’s converted to BVN copula parameters via the functional inverse in (5) and then to loadings using the relations in Section 2.3) show that the common alexithymia factor is mostly loaded on DIF and DDF items, suggesting that items in the domains DIF and DDF are good indicators for alexithymia. The items in the EOT although they loaded on the EOT latent factor, they had poor loadings in the common alexithymia factor.
Table 7. Estimated copula parameters and their standard errors (SE) in Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 scale for the bi-factor copula models with BVN copulas and selected copulas for the Toronto Alexithymia Scale.
scale for the bi-factor copula models with BVN copulas and selected copulas for the Toronto Alexithymia Scale.

7. Discussion
For items from several domains, we have proposed bi-factor and second-order copula models where we replace BVN distributions, between observed and latent variables, with bivariate copulas. Our copula constructions include the Gaussian bi-factor and second-order models as special cases and can provide a substantial improvement over the Gaussian models based on AIC, Vuong’s and goodness-of-fit statistics. Hence, superior statistical inference for the loadings can be achieved. We have demonstrated that the Kendall’s
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\tau $$\end{document}
 ’s or loading parameters are not robust under bivariate linking copula misspecification and their biases increase when the assumed bivariate copula has tail dependence of opposite direction from the true bivariate copula.
’s or loading parameters are not robust under bivariate linking copula misspecification and their biases increase when the assumed bivariate copula has tail dependence of opposite direction from the true bivariate copula.
The improvement relies on the fact that when we use appropriate bivariate copulas other than BVN copulas in the construction, there is an interpretation of latent variables that can be maxima/minima or mixture of means instead of means. The bi-factor and second-order copula models, if other than BVN copulas are called, have a latent structure that is not additive as in (3) and (4), respectively. The bi-factor copula (dependence) parameters are interpretable as dependence of an observed variable with the common factor, or conditional dependence of an observed variable with the group-specific latent variable given the common factor, i.e., the bi-factor copula model permits conditional dependence within identified subsets of items.
Both the bi-factor and second-order copula models lead to substantial simplification of the joint likelihood. The joint pmfs in (1) and (2) reduce to one-dimensional integrals of a function which in turn is a product of G one-dimensional integrals. Hence, the evaluation of the joint likelihood requires only low-dimensional integration, as in the one- and two-factor copula models, regardless of the dimension
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$G+1$$\end{document}
 of the factors. This is an advantage over the p-factor (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$p>2$$\end{document}
of the factors. This is an advantage over the p-factor (
\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$p>2$$\end{document}
 ) copula models where the joint pmf requires p-dimensional integration and becomes intractable as the number of factors increases. Hence, the proposed structured multidimensional factor models provide parsimonious factor solutions without any computational deficiencies as in the p-factor copula models when p increases.
) copula models where the joint pmf requires p-dimensional integration and becomes intractable as the number of factors increases. Hence, the proposed structured multidimensional factor models provide parsimonious factor solutions without any computational deficiencies as in the p-factor copula models when p increases.
We have proposed a numerically stable likelihood estimation technique based on Gauss–Legendre quadrature. The use of independent Gauss–Legendre quadrature points for this kind of models has been proposed in Krupskii and Joe (Reference Krupskii and Joe2015). For the bi-factor copula models for item response the integrants are bounded and thus independent Gauss–Legendre points are fine. For the second-order copula models for item response the integrants can be unbounded as copula densities can be unbounded, hence we have proposed the novel use of dependent Gauss–Legendre quadrature points that have an 1-factor copula distribution.
Building on the models proposed in this paper, there are several extensions that can be implemented. The adoption of the structure of the Gaussian tri-factor and third-order models (e.g., Rijmen et al. Reference Rijmen, Jeon, von Davier and Rabe-Hesketh2014), to account for any additional layer of dependence, is feasible using the notion of truncated vine copulas that involve both observed and latent variables.
Acknowledgements
We would like to thank the associate editor and referees for their careful reading and insightful comments that led to an improved presentation. The simulations presented in this paper were carried out on the High Performance Computing Cluster supported by the Research and Specialist Computing Support service at the University of East Anglia.





























 Open access
Open access