


No CrossRef data available.
Article contents
The sectional curvature of the infinite dimensional manifold of Hölder equilibrium probabilities
Published online by Cambridge University Press: 18 December 2024
Abstract
Here we consider the discrete time dynamics described by a transformation 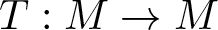 $T:M \to M$, where T is either the action of shift
$T:M \to M$, where T is either the action of shift 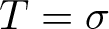 $T=\sigma$ on the symbolic space
$T=\sigma$ on the symbolic space 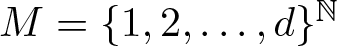 $M=\{1,2, \ldots,d\}^{\mathbb{N}}$, or, T describes the action of a d to 1 expanding transformation
$M=\{1,2, \ldots,d\}^{\mathbb{N}}$, or, T describes the action of a d to 1 expanding transformation 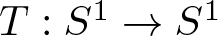 $T:S^1 \to S^1$ of class
$T:S^1 \to S^1$ of class 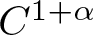 $C^{1+\alpha}$ (for example
$C^{1+\alpha}$ (for example 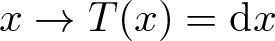 $x \to T(x) =\mathrm{d} x $ (mod 1)), where
$x \to T(x) =\mathrm{d} x $ (mod 1)), where 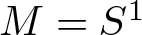 $M=S^1$ is the unit circle. It is known that the infinite-dimensional manifold
$M=S^1$ is the unit circle. It is known that the infinite-dimensional manifold  $\mathcal{N}$ of Hölder equilibrium probabilities is an analytical manifold and carries a natural Riemannian metric. Given a certain normalized Hölder potential A denote by
$\mathcal{N}$ of Hölder equilibrium probabilities is an analytical manifold and carries a natural Riemannian metric. Given a certain normalized Hölder potential A denote by 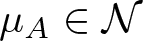 $\mu_A \in \mathcal{N}$ the associated equilibrium probability. The set of tangent vectors X (functions
$\mu_A \in \mathcal{N}$ the associated equilibrium probability. The set of tangent vectors X (functions 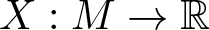 $X: M \to \mathbb{R}$) to the manifold
$X: M \to \mathbb{R}$) to the manifold  $\mathcal{N}$ at the point µA (a subspace of the Hilbert space
$\mathcal{N}$ at the point µA (a subspace of the Hilbert space 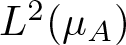 $L^2(\mu_A)$) coincides with the kernel of the Ruelle operator for the normalized potential A. The Riemannian norm
$L^2(\mu_A)$) coincides with the kernel of the Ruelle operator for the normalized potential A. The Riemannian norm 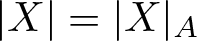 $|X|=|X|_A$ of the vector X, which is tangent to
$|X|=|X|_A$ of the vector X, which is tangent to  $\mathcal{N}$ at the point µA, is described via the asymptotic variance, that is, satisfies
$\mathcal{N}$ at the point µA, is described via the asymptotic variance, that is, satisfies
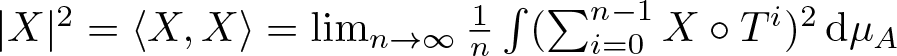 $ |X|^2 = \langle X, X \rangle = \lim_{n \to \infty}\frac{1}{n} \int (\sum_{i=0}^{n-1} X\circ T^i )^2 \,\mathrm{d} \mu_A$.
$ |X|^2 = \langle X, X \rangle = \lim_{n \to \infty}\frac{1}{n} \int (\sum_{i=0}^{n-1} X\circ T^i )^2 \,\mathrm{d} \mu_A$.
Consider an orthonormal basis Xi, 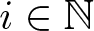 $i \in \mathbb{N}$, for the tangent space at µA. For any two orthonormal vectors X and Y on the basis, the curvature
$i \in \mathbb{N}$, for the tangent space at µA. For any two orthonormal vectors X and Y on the basis, the curvature 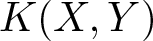 $K(X,Y)$ is
$K(X,Y)$ is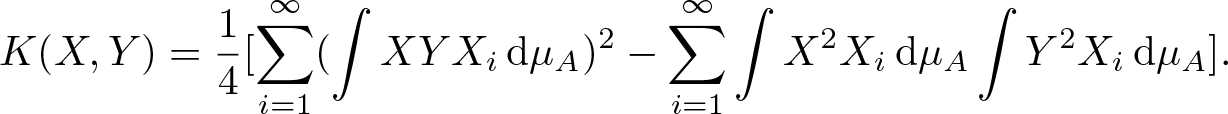 \begin{equation*}K(X,Y) = \frac{1}{4}[ \sum_{i=1}^\infty (\int X Y X_i \,\mathrm{d} \mu_A)^2 - \sum_{i=1}^\infty \int X^2 X_i \,\mathrm{d} \mu_A \int Y^2 X_i \,\mathrm{d} \mu_A ].\end{equation*}
\begin{equation*}K(X,Y) = \frac{1}{4}[ \sum_{i=1}^\infty (\int X Y X_i \,\mathrm{d} \mu_A)^2 - \sum_{i=1}^\infty \int X^2 X_i \,\mathrm{d} \mu_A \int Y^2 X_i \,\mathrm{d} \mu_A ].\end{equation*}
When the equilibrium probabilities µA is the set of invariant Markov probabilities on 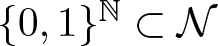 $\{0,1\}^{\mathbb{N}}\subset \mathcal{N}$, introducing an orthonormal basis
$\{0,1\}^{\mathbb{N}}\subset \mathcal{N}$, introducing an orthonormal basis 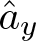 $\hat{a}_y$, indexed by finite words y, we show explicit expressions for
$\hat{a}_y$, indexed by finite words y, we show explicit expressions for 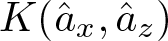 $K(\hat{a}_x,\hat{a}_z)$, which is a finite sum. These values can be positive or negative depending on A and the words x and z. Words
$K(\hat{a}_x,\hat{a}_z)$, which is a finite sum. These values can be positive or negative depending on A and the words x and z. Words  $x,z$ with large length can eventually produce large negative curvature
$x,z$ with large length can eventually produce large negative curvature 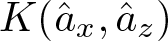 $K(\hat{a}_x,\hat{a}_z)$. If
$K(\hat{a}_x,\hat{a}_z)$. If 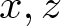 $x, z$ do not begin with the same letter, then
$x, z$ do not begin with the same letter, then 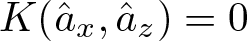 $K(\hat{a}_x,\hat{a}_z)=0$.
$K(\hat{a}_x,\hat{a}_z)=0$.
Keywords
MSC classification
- Type
- Research Article
- Information
- Copyright
- © The Author(s), 2024. Published by Cambridge University Press on Behalf of The Edinburgh Mathematical Society.
Footnotes
Partially supported by CNPq
References
Baladi, V., Positive Transfer Operators and Decay of Correlations (World Sci., River Edge, NJ, 2000).CrossRefGoogle Scholar
Biliotti, L. and Mercuri, F., Riemannian Hilbert manifolds. Hermitian-Grassmannian Submanifolds, 261–271, Springer Proc. Math. Stat. 203 (Springer, Singapore, 2017).Google Scholar
Bomfim, T., Castro, A. and Varandas, P., Differentiability of thermodynamical quantities in non-uniformly expanding dynamics, Adv. Math. 292 (9) (2016), 478–528.CrossRefGoogle Scholar
Bridgeman, M., Canary, R. and Sambarino, A., An introduction to pressure metrics on higher Teichmüller spaces, Ergodic Theory and Dynam. Systems, 38 (6) (2018), 2001–2035.CrossRefGoogle Scholar
Chae, S. B., Holomorphy and Calculus in Normed Spaces (CRC Press Boca Raton, New York, 1985).Google Scholar
Cioletti, L., Hataishi, L., Lopes, A. O. and Stadlbauer, M., Spectral triples on thermodynamic formalism and dixmier trace representations of Gibbs measures: theory and examples. arXiv 2022.Google Scholar
da Silva, E. A., da Silva, R. R. and Souza, R. R., The analyticity of a generalized Ruelle’s operator, Bull. Brazil. Math. Soc. (N.S.) 45 (1) (2014), 53–72.CrossRefGoogle Scholar
Giulietti, P., Kloeckner, B., Lopes, A. O. and Marcon, D., The calculus of thermodynamical formalism, Journ. of the European Math. Society 20(10) (2018), 2357–2412.CrossRefGoogle Scholar
Ji, C., Estimating functionals of one-dimensional Gibbs states, Probab. Th. Rel. Fields 82 (1989), 155–175.CrossRefGoogle Scholar
Kessebohmer, M. and Samuel, T., Spectral metric spaces for Gibbs measures, Journal of Functional Analysis 265 (2013), 1801–1828.CrossRefGoogle Scholar
Lopes, A. O. and Mengue, J., On information gain, Kullback-Leibler divergence, entropy production and the involution kernel, Discr. and Cont. Dyn. Systems - Series A 42, (7) (2022), 3593–3627.CrossRefGoogle Scholar
Lopes, A. O. and Ruggiero, R. O., Nonequilibrium in thermodynamic formalism: the second law, gases and information geometry, Qual. Theo. of Dyn. Syst. 21(21) (2022), 1–44.Google Scholar
Lopes, A. O. and Ruggiero, R. O., Geodesics and dynamical information projections on the manifold of Hölder equilibrium probabilities, arXiv, (2022).Google Scholar
Ma, L. and Pollicott, M., Rigidity of pressures of Hölder potentials and the fitting of analytic functions via them, Arxiv Syst. 44(12) (2024), 3530–3564.Google Scholar
McMullen, C. T., Thermodynamics, dimension and the Weil–Petersson metric, Invent. Math. 173 (2008), 365–425.CrossRefGoogle Scholar
Parry, W. and Pollicott, M., Zeta functions and the periodic orbit structure of hyperbolic dynamics, Astérisque (1990), 187–188.Google Scholar
Petkov, V. and Stoyanov, L., Spectral estimates for Ruelle transfer operators with two parameters and applications, Discr. Cont. Dyn. Sys. A 36 (2016), 6413–6451.Google Scholar
Petkov, V. and Stoyanov, L., Spectral estimates for Ruelle operators with two parameters and sharp large deviations, Disc. and Cont. Dyn. Syst., 39(11), (2019), 6391–6417.CrossRefGoogle Scholar
Pollicott, M. and Sharp, R., A Weil–Petersson type metric on spaces of metric graphs, Geom. Dedicata 172 (1) (2014), 229–244.CrossRefGoogle Scholar
Whittlesey, E. F., Analytic functions in Banach spaces, Proc. Amer. Math. Soc. 16 (5) (1965), 1077–1083.CrossRefGoogle Scholar