



1. Introduction
labelisect We begin with a loose definition of the fractals we consider. We are given t affine, invertible contractions  $\psi_i\colon \textbf{R}^d\rightarrow \textbf{R}^d$; the fractal G is the unique compact set of Rd such that
$\psi_i\colon \textbf{R}^d\rightarrow \textbf{R}^d$; the fractal G is the unique compact set of Rd such that
 \begin{equation*} G=\bigcup_{i=1}^t\psi_i(G). \end{equation*}
\begin{equation*} G=\bigcup_{i=1}^t\psi_i(G). \end{equation*}As shown in [Reference Kusuoka11], it is possible to define on G a natural measure and bilinear form; these objects are connected [Reference Johansson, Öberg and Pollicott6, Reference Morris13, Reference Piraino16] to Gibbs measures for systems of d × d matrices. We briefly outline the approach of [Reference Bessi2] and [Reference Bessi3], which derives Kusuoka’s measure and bilinear form from a matrix-valued Gibbs measure.
First of all, under the hypotheses of § 2, the maps ψi are the branches of the inverse of an expansive map  $F\colon G\rightarrow G$, and the construction of Gibbs measures for expansive maps is a staple of dynamical systems theory [Reference Mañé12, Reference Parry and Pollicott15, Reference Viana23]. Let
$F\colon G\rightarrow G$, and the construction of Gibbs measures for expansive maps is a staple of dynamical systems theory [Reference Mañé12, Reference Parry and Pollicott15, Reference Viana23]. Let  $q\in\{0,1,\dots,d \}$ and let
$q\in\{0,1,\dots,d \}$ and let  $\Lambda^q(\textbf{R}^d)$ be the space of q-forms on Rd; since
$\Lambda^q(\textbf{R}^d)$ be the space of q-forms on Rd; since  $\Lambda^q(\textbf{R}^d)$ inherits an inner product from Rd, we can define M q, the space of self-adjoint operators (or symmetric matrices) on
$\Lambda^q(\textbf{R}^d)$ inherits an inner product from Rd, we can define M q, the space of self-adjoint operators (or symmetric matrices) on  $\Lambda^q(\textbf{R}^d)$. Let
$\Lambda^q(\textbf{R}^d)$. Let
 \begin{equation*}(D\psi_i)_\ast\colon \Lambda^q(\textbf{R}^d)\rightarrow \Lambda^q(\textbf{R}^d)\end{equation*}
\begin{equation*}(D\psi_i)_\ast\colon \Lambda^q(\textbf{R}^d)\rightarrow \Lambda^q(\textbf{R}^d)\end{equation*}be the pull-back operator induced by the maps  $D\psi_i$, i.e.,
$D\psi_i$, i.e.,
 \begin{align}
[(D\psi_i)_\ast\omega](v_1,\dots,v_q)=\omega(D\psi_i\cdot v_1,\dots,D\psi_i\cdot v_k).
\end{align}
\begin{align}
[(D\psi_i)_\ast\omega](v_1,\dots,v_q)=\omega(D\psi_i\cdot v_1,\dots,D\psi_i\cdot v_k).
\end{align} The linear map  $(D\psi_i)_\ast$ induces a push-forward operator
$(D\psi_i)_\ast$ induces a push-forward operator
 \begin{equation*}\Psi_i\colon M^q\rightarrow M^q \end{equation*}
\begin{equation*}\Psi_i\colon M^q\rightarrow M^q \end{equation*}by
 \begin{align}
(\Psi_i(A)\cdot v,w)=(A\cdot(D\psi_i)_\ast v,(D\psi_i)_\ast w)\quad \text{or}\quad \Psi_i(A)={{}^{t}}(D\psi_i)_\ast\cdot A\cdot(D\psi_i)_\ast.
\end{align}
\begin{align}
(\Psi_i(A)\cdot v,w)=(A\cdot(D\psi_i)_\ast v,(D\psi_i)_\ast w)\quad \text{or}\quad \Psi_i(A)={{}^{t}}(D\psi_i)_\ast\cdot A\cdot(D\psi_i)_\ast.
\end{align} In the formula above, we have denoted by  $(\cdot,\cdot)$ the inner product of
$(\cdot,\cdot)$ the inner product of  $\Lambda^q(\textbf{R}^d)$ and by
$\Lambda^q(\textbf{R}^d)$ and by  ${{}^{t}} B$ the transpose of the matrix B.
${{}^{t}} B$ the transpose of the matrix B.
For  $\alpha\in(0,1]$, we define
$\alpha\in(0,1]$, we define  $C^{0,\alpha}(G,\textbf{R})$ in the standard way, i.e.,
$C^{0,\alpha}(G,\textbf{R})$ in the standard way, i.e.,  $V\in C^{0,\alpha}(G,\textbf{R})$ if there is C > 0 such that
$V\in C^{0,\alpha}(G,\textbf{R})$ if there is C > 0 such that
 \begin{equation*}|V(x)-V(y)|\le C||x-y||^\alpha \quad \text{for all}\ x,y\in G. \end{equation*}
\begin{equation*}|V(x)-V(y)|\le C||x-y||^\alpha \quad \text{for all}\ x,y\in G. \end{equation*} For  $V\in C^{0,\alpha}(G,\textbf{R})$, we define a Ruelle operator
$V\in C^{0,\alpha}(G,\textbf{R})$, we define a Ruelle operator  ${\cal L}_{G,V}$ in the following way:
${\cal L}_{G,V}$ in the following way:
 \begin{equation*}{\cal L}_{G,V}\colon C(G,M^q)\rightarrow C(G,M^q)\end{equation*}
\begin{equation*}{\cal L}_{G,V}\colon C(G,M^q)\rightarrow C(G,M^q)\end{equation*} \begin{align}
({\cal L}_{G,V}A)(x)=\sum_{i=1}^t\Psi_i(A\circ{\psi_i(x)})\cdot {\rm e}^{V\circ\psi_i(x)}.
\end{align}
\begin{align}
({\cal L}_{G,V}A)(x)=\sum_{i=1}^t\Psi_i(A\circ{\psi_i(x)})\cdot {\rm e}^{V\circ\psi_i(x)}.
\end{align} As we recall in Proposition 2.2 below, there is a unique  $\beta_{G,V} \gt 0$ and a function
$\beta_{G,V} \gt 0$ and a function  $Q_{G,V}\in C(G,M^q)$ such that
$Q_{G,V}\in C(G,M^q)$ such that  $Q_{G,V}(x)$ is positive-definite for all
$Q_{G,V}(x)$ is positive-definite for all  $x\in G$ and
$x\in G$ and
 \begin{align}
{\cal L}_{G,V}Q_{G,V}=\beta_{G,V}Q_{G,V}.
\end{align}
\begin{align}
{\cal L}_{G,V}Q_{G,V}=\beta_{G,V}Q_{G,V}.
\end{align} Moreover, the eigenvalue  $\beta_{G,V}$ is simple, i.e.,
$\beta_{G,V}$ is simple, i.e.,  $Q_{G,V}$ is unique up to multiplication by a scalar.
$Q_{G,V}$ is unique up to multiplication by a scalar.
By Riesz’s representation theorem, the dual space of  $C(G,M^q)$ is the space of M q-valued Borel measures on G, which we denote by
$C(G,M^q)$ is the space of M q-valued Borel measures on G, which we denote by  ${\cal M}(G,M^q)$. Since
${\cal M}(G,M^q)$. Since  ${\cal L}_{G,V}$ is a bounded operator by (3), its adjoint
${\cal L}_{G,V}$ is a bounded operator by (3), its adjoint
 \begin{equation*}{\cal L}_{G,V}^\ast\colon {\cal M}(G,M^d)\rightarrow {\cal M}(G,M^d) \end{equation*}
\begin{equation*}{\cal L}_{G,V}^\ast\colon {\cal M}(G,M^d)\rightarrow {\cal M}(G,M^d) \end{equation*}is again bounded. Again by Proposition 2.2 below, there is  $\mu_{G,V}\in{\cal M}(G,M^d)$, unique up to multiplication by a scalar, such that for the same eigenvalue
$\mu_{G,V}\in{\cal M}(G,M^d)$, unique up to multiplication by a scalar, such that for the same eigenvalue  $\beta_{G,V}$ of (4), we have
$\beta_{G,V}$ of (4), we have
 \begin{align}
{\cal L}_{G,V}^\ast\mu_{G,V}=\beta_{G,V}\mu_{G,V}.
\end{align}
\begin{align}
{\cal L}_{G,V}^\ast\mu_{G,V}=\beta_{G,V}\mu_{G,V}.
\end{align} The measure  $\mu_{G,V}$ is semi-positive definite in the following sense: for all Borel sets
$\mu_{G,V}$ is semi-positive definite in the following sense: for all Borel sets  $B\subset G$,
$B\subset G$,  $\mu_{G,V}(B)$ is a semi-positive definite matrix.
$\mu_{G,V}(B)$ is a semi-positive definite matrix.
Kusuoka’s measure  $\kappa_{G,V}$ is the scalar measure on G defined by
$\kappa_{G,V}$ is the scalar measure on G defined by
 \begin{equation*}\kappa_{G,V}\colon=(Q_{G,V},\mu_{G,V})_{\rm HS} . \end{equation*}
\begin{equation*}\kappa_{G,V}\colon=(Q_{G,V},\mu_{G,V})_{\rm HS} . \end{equation*} On the right hand side of the above formula, there is the Hilbert–Schmidt product of the density  $Q_{G,V}$ with the measure
$Q_{G,V}$ with the measure  $\mu_{G,V}$; the details are given in § 2. An important fact is that
$\mu_{G,V}$; the details are given in § 2. An important fact is that  $\kappa_{G,V}$ is ergodic for the expansive map F.
$\kappa_{G,V}$ is ergodic for the expansive map F.
In dynamical systems, the positive eigenvector  $\mu_{G,V}$ of
$\mu_{G,V}$ of  ${\cal L}_{G,V}^\ast$ is usually called a Gibbs measure [Reference Parry and Pollicott15, Reference Viana23] and that is how, in the following, we shall call our matrix-valued
${\cal L}_{G,V}^\ast$ is usually called a Gibbs measure [Reference Parry and Pollicott15, Reference Viana23] and that is how, in the following, we shall call our matrix-valued  $\mu_{G,V}$; the logarithm of the eigenvalue
$\mu_{G,V}$; the logarithm of the eigenvalue  $P(V)\colon=\log\beta_{G,V}$ is called the pressure. This immediately raises the question whether our pressure, like its scalar counterpart, is the maximal value of a natural functional. The paper in [Reference Feng and Käenmäki5] gives a positive answer to this question, but [Reference Feng and Käenmäki5] considers scalar Gibbs measures on a system of matrices, while in Theorem 1, we are interested in defining a pressure for matrix-valued measures.
$P(V)\colon=\log\beta_{G,V}$ is called the pressure. This immediately raises the question whether our pressure, like its scalar counterpart, is the maximal value of a natural functional. The paper in [Reference Feng and Käenmäki5] gives a positive answer to this question, but [Reference Feng and Käenmäki5] considers scalar Gibbs measures on a system of matrices, while in Theorem 1, we are interested in defining a pressure for matrix-valued measures.
When  $M\in M^q$ is semi-positive definite, we write
$M\in M^q$ is semi-positive definite, we write  $M\ge 0$; we define
$M\ge 0$; we define  ${\cal K}_V$ as the set of the couples
${\cal K}_V$ as the set of the couples  $\{m,M \}$, where m is a non-atomic, F-invariant probability measure on G and
$\{m,M \}$, where m is a non-atomic, F-invariant probability measure on G and  $M\colon G\rightarrow M^d$ is a Borel function such that
$M\colon G\rightarrow M^d$ is a Borel function such that
 \begin{align}
M(x)\ge 0\quad \text{and}\quad (Q_{G,V}(x),M(x))_{\rm HS}=1\quad \text{for}\ m\text{-a.e.}\ x\in G.
\end{align}
\begin{align}
M(x)\ge 0\quad \text{and}\quad (Q_{G,V}(x),M(x))_{\rm HS}=1\quad \text{for}\ m\text{-a.e.}\ x\in G.
\end{align} We denote by h(m) the entropy of m with respect to F; the reader can find a definition in [Reference Walters24]. In § 2, we shall see that  $\mu_{G,V}$ is absolutely continuous with respect to
$\mu_{G,V}$ is absolutely continuous with respect to  $\kappa_{G,V}$, and thus
$\kappa_{G,V}$, and thus  $\mu_{G,V}=M_{G,V}\cdot\kappa_V$, where
$\mu_{G,V}=M_{G,V}\cdot\kappa_V$, where  $M_{G,V}\colon G\rightarrow M^q$ is a Borel function that satisfies (6), i.e.,
$M_{G,V}\colon G\rightarrow M^q$ is a Borel function that satisfies (6), i.e.,  $\{\kappa_{G,V},M_{G,V} \}\in{\cal K}_V$.
$\{\kappa_{G,V},M_{G,V} \}\in{\cal K}_V$.
Theorem 1. Let the fractal G satisfy hypotheses (F1)–(F4) and  $(ND_q)$ of § 2. Let
$(ND_q)$ of § 2. Let  $V\in C^{0,\alpha}(G,\textbf{R})$ and let
$V\in C^{0,\alpha}(G,\textbf{R})$ and let  $\kappa_{G,V}=(Q_{G,V},\mu_{G,V})_{\rm HS}$ be Kusuoka’s measure for the potential V. Let
$\kappa_{G,V}=(Q_{G,V},\mu_{G,V})_{\rm HS}$ be Kusuoka’s measure for the potential V. Let  $\beta_{G,V}$ be the eigenvalue of
$\beta_{G,V}$ be the eigenvalue of  ${\cal L}_{G,V}$ as illustrated in (4) and let us set
${\cal L}_{G,V}$ as illustrated in (4) and let us set  $P(V)=\log\beta_{G,V}$. Then,
$P(V)=\log\beta_{G,V}$. Then,
 \begin{equation*}P(V)=h(\kappa_{G,V})+\int_G V(x)\, {\rm d} \kappa_{G,V}(x)\end{equation*}
\begin{equation*}P(V)=h(\kappa_{G,V})+\int_G V(x)\, {\rm d} \kappa_{G,V}(x)\end{equation*} \begin{equation*}+\sum_{i=1}^t\int_G\log(Q_{G,V}(x),{{}^{t}}\Psi_i\circ M_{G,V}\circ F(x))_{\rm HS}
{\rm d} \kappa_{G,V}(x) \end{equation*}
\begin{equation*}+\sum_{i=1}^t\int_G\log(Q_{G,V}(x),{{}^{t}}\Psi_i\circ M_{G,V}\circ F(x))_{\rm HS}
{\rm d} \kappa_{G,V}(x) \end{equation*} \begin{equation*}
=\sup_{\{m,M \}\in{\cal K}_V}\left\{
h(m)+\int_G V(x)\, {\rm d} m(x)\right.\end{equation*}
\begin{equation*}
=\sup_{\{m,M \}\in{\cal K}_V}\left\{
h(m)+\int_G V(x)\, {\rm d} m(x)\right.\end{equation*} \begin{align}
\left.+\sum_{i=1}^t\int_{G}\log(Q_{G,V} (x),{{}^{t}}\Psi_i\circ M\circ F (x))_{HS}
{\rm d} m(x)
\right\}.
\end{align}
\begin{align}
\left.+\sum_{i=1}^t\int_{G}\log(Q_{G,V} (x),{{}^{t}}\Psi_i\circ M\circ F (x))_{HS}
{\rm d} m(x)
\right\}.
\end{align} Some remarks. First, in the classical case of [Reference Parry and Pollicott14] and [Reference Walters24], the topological entropy (i.e., the pressure of the function  $V\equiv 0$) is always positive, while in our case, it can be positive, negative or zero. Indeed, the contribution of the last term in (7) is non-positive, since the maps ψi are contractions. It is well known (see for instance [Reference Kajino7]) that for a famous example, the harmonic Sierpinski gasket with q = 1, the pressure of the zero function is negative, since
$V\equiv 0$) is always positive, while in our case, it can be positive, negative or zero. Indeed, the contribution of the last term in (7) is non-positive, since the maps ψi are contractions. It is well known (see for instance [Reference Kajino7]) that for a famous example, the harmonic Sierpinski gasket with q = 1, the pressure of the zero function is negative, since  $\beta_{G,0}=\frac{3}{5}$.
$\beta_{G,0}=\frac{3}{5}$.
The second remark is that the raison d’être of hypotheses (F1)–(F4) is to translate Theorem 1 to a theorem on the shift on t symbols, where we shall prove it. We have stated it on the fractal to underline the existence of a Riemannian structure on G, which is natural with respect to the dynamics.
The last remark is that the measure  $\kappa_{G,V}$ coincides with that found in [Reference Feng and Käenmäki5] and [Reference Morris13]; this is shown in the appendix of [Reference Morris13] and we give another proof after Lemma 2.3. We also remark that the papers [Reference Feng and Käenmäki5], [Reference Morris13] and [Reference Piraino16] are more general than ours: they consider the pressure of a real power s of the Lyapounov exponent, while we fix s = 2.
$\kappa_{G,V}$ coincides with that found in [Reference Feng and Käenmäki5] and [Reference Morris13]; this is shown in the appendix of [Reference Morris13] and we give another proof after Lemma 2.3. We also remark that the papers [Reference Feng and Käenmäki5], [Reference Morris13] and [Reference Piraino16] are more general than ours: they consider the pressure of a real power s of the Lyapounov exponent, while we fix s = 2.
Another property of the scalar Gibbs measures is that they satisfy a central limit theorem; we recall its statement from [Reference Viana23] and [Reference Parry and Pollicott15].
Let m be an F-invariant probability measure on G and let ϕ be any function in  $C^{0,\alpha}(G,\textbf{R})$, which satisfies
$C^{0,\alpha}(G,\textbf{R})$, which satisfies
 \begin{align}
\int_G\phi(x)\, {\rm d} m(x)=0.
\end{align}
\begin{align}
\int_G\phi(x)\, {\rm d} m(x)=0.
\end{align}We define
 \begin{equation*}\sigma^2=\int_G\phi^2(x)\, {\rm d} m(x)+
2\sum_{j\ge 1}\int_G\phi(x)\cdot\phi\circ F^j(x)\, {\rm d} m(x) . \end{equation*}
\begin{equation*}\sigma^2=\int_G\phi^2(x)\, {\rm d} m(x)+
2\sum_{j\ge 1}\int_G\phi(x)\cdot\phi\circ F^j(x)\, {\rm d} m(x) . \end{equation*}We say that m satisfies a central limit theorem if, for all functions ϕ as above, the three points below hold.
(1)
 $\sigma\in[0,+\infty)$.
$\sigma\in[0,+\infty)$.(2) If σ = 0, then
$\phi= u\circ F-u$ for some $u\in L^2(G,m)$.(3) If σ > 0, then for all intervals
$A\subset\textbf{R}$, we have that
\begin{equation*}m\left\{
x\in G\colon \frac{1}{\sqrt n}\sum_{j=0}^{n-1}\phi\circ F^j(x)\in A
\right\} \rightarrow\frac{1}{\sigma\sqrt{2\pi}}\int_A{\rm e}^{-\frac{z^2}{2\sigma^2}}\, {\rm d}z. \end{equation*}





It turns out [Reference Viana23] that m satisfies a central limit theorem if it has an exponential decay of correlations, which means the following: there are  $C,\delta \gt 0$ such that, for all
$C,\delta \gt 0$ such that, for all  $\phi,\psi\in C^{0,\alpha}(G,\textbf{R})$, we have
$\phi,\psi\in C^{0,\alpha}(G,\textbf{R})$, we have
 \begin{equation*}\left\vert
\int_G\phi(x)\psi\circ F^n(x)\, {\rm d} m(x)-
\int_G\phi(x)\, {\rm d} m(x)\int_G\psi(x) \,{\rm d} m(x)
\right\vert \le C {\rm e}^{-n\delta} . \end{equation*}
\begin{equation*}\left\vert
\int_G\phi(x)\psi\circ F^n(x)\, {\rm d} m(x)-
\int_G\phi(x)\, {\rm d} m(x)\int_G\psi(x) \,{\rm d} m(x)
\right\vert \le C {\rm e}^{-n\delta} . \end{equation*} Moreover, the constant C only depends on  $||\psi||_{L^1}$ and
$||\psi||_{L^1}$ and  $||\phi||_{C^{0,\alpha}}+||\phi||_{L^1}$, while δ does not depend on anything.
$||\phi||_{C^{0,\alpha}}+||\phi||_{L^1}$, while δ does not depend on anything.
Since Kusuoka’s measure  $\kappa_{G,V}$ satisfies the formula above by point (6) of Proposition 2.2, we have that
$\kappa_{G,V}$ satisfies the formula above by point (6) of Proposition 2.2, we have that  $\kappa_{G,V}$ satisfies a central limit theorem.
$\kappa_{G,V}$ satisfies a central limit theorem.
Next, we want to count periodic orbits, a task that does not look very interesting because our hypotheses on the fractal G and the expansive map F imply almost immediately that there is a bijection between the periodic orbits of F and those of a Bernoulli shift on t elements. What we are going to do is to count periodic orbits, but weighted by their Lyapounov exponents. In order to be more precise, we need some notation.
Let
 \begin{equation*}x_0=x,\quad x_1=F(x_0),\quad\dots,\quad x_{i+1}=F(x_i),\quad\dots \end{equation*}
\begin{equation*}x_0=x,\quad x_1=F(x_0),\quad\dots,\quad x_{i+1}=F(x_i),\quad\dots \end{equation*}be a periodic orbit with minimal period n; in other words,  $x_i=x_{i+n}$ for all
$x_i=x_{i+n}$ for all  $i\ge 0$ and n is the smallest integer with this property. We group in a set τ all the points of the orbit
$i\ge 0$ and n is the smallest integer with this property. We group in a set τ all the points of the orbit
 \begin{align}
\tau=\{x_0,x_1,\dots,x_{n-1} \}
\end{align}
\begin{align}
\tau=\{x_0,x_1,\dots,x_{n-1} \}
\end{align}and we define
 \begin{align}
\lambda(\tau)=n=\sharp\tau,\quad
\Psi_{x_0\cdots x_{n-1}}& =\Psi_{x_{n-1}}\circ\cdots\circ\Psi_{x_0},\quad {{}^{t}}\Psi_{x,n}={{}^{t}}\Psi_{x_0\cdots x_{n-1}} \\ & \qquad \quad ={{}^{t}}\Psi_{x_0}\circ\cdots\circ{{}^{t}}\Psi_{x_{n-1}}.
\end{align}
\begin{align}
\lambda(\tau)=n=\sharp\tau,\quad
\Psi_{x_0\cdots x_{n-1}}& =\Psi_{x_{n-1}}\circ\cdots\circ\Psi_{x_0},\quad {{}^{t}}\Psi_{x,n}={{}^{t}}\Psi_{x_0\cdots x_{n-1}} \\ & \qquad \quad ={{}^{t}}\Psi_{x_0}\circ\cdots\circ{{}^{t}}\Psi_{x_{n-1}}.
\end{align} Note the reverse order in the definition of  $\Psi_{x_0\cdots x_{n-1}}$.
$\Psi_{x_0\cdots x_{n-1}}$.
Let  $\hat V\in C^{0,\alpha}(G,\textbf{R})$ be positive and let us set
$\hat V\in C^{0,\alpha}(G,\textbf{R})$ be positive and let us set  $\hat V(\tau)=V(x_0)+\cdots +V(x_{n-1})$; for
$\hat V(\tau)=V(x_0)+\cdots +V(x_{n-1})$; for  $r\ge 1$, we define for
$r\ge 1$, we define for  $c\in\textbf{R}$ such that
$c\in\textbf{R}$ such that  $P(-c\hat V)=0$,
$P(-c\hat V)=0$,
 \begin{align}
\pi(r)=\sum_{\tau\colon {\rm e}^{|c|\hat V(\tau)}\le r} {\rm tr}[{{}^{t}}\Psi_{x_0}\circ\cdots\circ{{}^{t}}\Psi_{x_{n-1}}],
\end{align}
\begin{align}
\pi(r)=\sum_{\tau\colon {\rm e}^{|c|\hat V(\tau)}\le r} {\rm tr}[{{}^{t}}\Psi_{x_0}\circ\cdots\circ{{}^{t}}\Psi_{x_{n-1}}],
\end{align}where τ and  $x_0\cdots x_{n-1}$ are related as in (9); by the cyclical invariance of the trace of a product,
$x_0\cdots x_{n-1}$ are related as in (9); by the cyclical invariance of the trace of a product,  ${\rm tr}[{{}^{t}}\Psi_{x_0}\circ\cdots\circ{{}^{t}}\Psi_{x_{n-1}}]$ does not depend on where we place x 0 along the periodic orbit. As we shall see in § 4, the summands on the right side of (11) are all positive.
${\rm tr}[{{}^{t}}\Psi_{x_0}\circ\cdots\circ{{}^{t}}\Psi_{x_{n-1}}]$ does not depend on where we place x 0 along the periodic orbit. As we shall see in § 4, the summands on the right side of (11) are all positive.
We saw in Theorem 1 that the topological entropy (i.e., P(V) with  $V\equiv 0$) can be positive, negative or zero; we have to exclude the case in which it is zero. Moreover, we have to make the usual distinction [Reference Parry and Pollicott14, Reference Parry and Pollicott15] between the weakly mixing and non-weakly mixing case because they have different asymptotics. For simplicity, in point (1) of Theorem 2, we shall consider only one case of a non-weakly mixing suspension, i.e., the one with
$V\equiv 0$) can be positive, negative or zero; we have to exclude the case in which it is zero. Moreover, we have to make the usual distinction [Reference Parry and Pollicott14, Reference Parry and Pollicott15] between the weakly mixing and non-weakly mixing case because they have different asymptotics. For simplicity, in point (1) of Theorem 2, we shall consider only one case of a non-weakly mixing suspension, i.e., the one with  $\hat V\equiv 1$. In the scalar case, a delicate study of the dynamics (chapters 4–6 of [Reference Parry and Pollicott15]) shows that the topological weak mixing property for the suspension by the function
$\hat V\equiv 1$. In the scalar case, a delicate study of the dynamics (chapters 4–6 of [Reference Parry and Pollicott15]) shows that the topological weak mixing property for the suspension by the function  $\hat V$ is equivalent to the fact that the zeta function can be extended to a non-zero analytic function on
$\hat V$ is equivalent to the fact that the zeta function can be extended to a non-zero analytic function on  ${\rm Re}(s)=1$, save for a simple pole at 1. In point (2) of Theorem 2, we shall simply suppose that this extension is possible since we do not know how to adapt [Reference Parry and Pollicott15] to our situation.
${\rm Re}(s)=1$, save for a simple pole at 1. In point (2) of Theorem 2, we shall simply suppose that this extension is possible since we do not know how to adapt [Reference Parry and Pollicott15] to our situation.
Theorem 2. Let  $\hat V\in C^{0,\alpha}(G,\textbf{R})$ be a potential such that
$\hat V\in C^{0,\alpha}(G,\textbf{R})$ be a potential such that  $\hat V(x) \gt 0$ for all
$\hat V(x) \gt 0$ for all  $x\in G$, and let c be the unique real such that the pressure of
$x\in G$, and let c be the unique real such that the pressure of  $-c\hat V$ is zero. Let π be defined as in (11) and let us suppose that
$-c\hat V$ is zero. Let π be defined as in (11) and let us suppose that  $c\not=0$.
$c\not=0$.
(1) Let
$\hat V\equiv 1$ and let us set for simplicity $\beta=\beta_{G,0}$. Then, if we take $c=\log\beta$ in (11), we have
(12)if β > 1; if β < 1,\begin{align}
\limsup_{r\rightarrow+\infty}\frac{\pi(r)\log r}{r}\le\frac{\beta}{\beta-1}\log\beta
\end{align}$\pi(r)$ is bounded.(2) Let now
$\hat V\in C^{0,\alpha}(G,\textbf{R})$ be strictly positive and let us suppose that the zeta function of § 5 below can be extended to a continuous, non-zero function on $\{{\rm Re}(s)\ge 1 \}\setminus \{1 \}$, with a simple pole in s = 1 in the case c > 0. Then,
(13)\begin{align}
\limsup_{r\rightarrow+\infty}\frac{\pi(r)\log r}{r}\le
\left\{
\begin{aligned}
1 & \ \text{if}\ c \gt 0\\
0 &\ \text{if}\ c \lt 0 .
\end{aligned}
\right.
\end{align}Naturally, in the second case, the inequality is an equality.








Note that in the case c > 0, we are only giving an estimate from above on the asymptotics, while [Reference Parry and Pollicott15] gives much more, an equality.
As a last remark, we make no pretence at novelty: already in [Reference Ruelle22], D. Ruelle considered transfer operators and zeta functions acting on matrices. Moreover, the paper [Reference Kigami and Lapidus10] applies similar techniques to a different problem, the Weyl statistics for the eigenvalues of the Laplacian on fractals.
This paper is organized as follows. In § 2, we set the notation and define our family of fractals; it is the standard definition of an iterated function system. We end this section recalling the construction of Kusuoka’s measure  $\kappa_{\hat V}$ from [Reference Bessi2] and [Reference Bessi3]. In § 3, we prove Theorem 1, in § 4, we recall an argument of [Reference Parry and Pollicott15] for the proof of Theorem 2 in the non-weakly mixing case; we shall apply this argument to the simple case
$\kappa_{\hat V}$ from [Reference Bessi2] and [Reference Bessi3]. In § 3, we prove Theorem 1, in § 4, we recall an argument of [Reference Parry and Pollicott15] for the proof of Theorem 2 in the non-weakly mixing case; we shall apply this argument to the simple case  $\hat V\equiv 0$ (or
$\hat V\equiv 0$ (or  $\hat V\equiv 1$, since all constants induce the same Kusuoka’s measure). In § 5, we prove Theorem 2 in the ‘weakly mixing’ case; we follow closely the arguments of [Reference Parry and Pollicott15].
$\hat V\equiv 1$, since all constants induce the same Kusuoka’s measure). In § 5, we prove Theorem 2 in the ‘weakly mixing’ case; we follow closely the arguments of [Reference Parry and Pollicott15].
2. Preliminaries and notation
The Perron–Frobenius theorem
We recall without proof a few facts from [Reference Viana23]; we refer the reader to [Reference Birkhoff4] for the original treatment.
Let E be a real vector space; a cone on E is a subset  $C\subset E\setminus \{0 \}$ such that, if
$C\subset E\setminus \{0 \}$ such that, if  $v\in C$, then
$v\in C$, then  $tv\in C$ for all t > 0. We define the closure
$tv\in C$ for all t > 0. We define the closure  $\bar C$ of C as the set of all
$\bar C$ of C as the set of all  $v\in E$ such that there is
$v\in E$ such that there is  $w\in C$ and
$w\in C$ and  $t_n\searrow 0$ such that
$t_n\searrow 0$ such that  $v+t_nw\in C$ for all
$v+t_nw\in C$ for all  $n\ge 1$.
$n\ge 1$.
In the following, we shall always deal with convex cones C such that
 \begin{align}
\bar C\cap(-\bar C)=\{0 \} .
\end{align}
\begin{align}
\bar C\cap(-\bar C)=\{0 \} .
\end{align} Given  $v_1,v_2\in C$, we define
$v_1,v_2\in C$, we define
 \begin{equation*}\alpha(v_1,v_2)=\sup\{
t \gt 0\colon v_2-tv_1\in C
\} , \end{equation*}
\begin{equation*}\alpha(v_1,v_2)=\sup\{
t \gt 0\colon v_2-tv_1\in C
\} , \end{equation*} \begin{equation*}\frac{1}{\beta(v_1,v_2)}=\sup\{
t \gt 0\colon v_1-tv_2\in C
\} \end{equation*}
\begin{equation*}\frac{1}{\beta(v_1,v_2)}=\sup\{
t \gt 0\colon v_1-tv_2\in C
\} \end{equation*} \begin{equation*}\theta(v_1,v_2)=
\log\frac{\beta(v_1,v_2)}{\alpha(v_1,v_2)} . \end{equation*}
\begin{equation*}\theta(v_1,v_2)=
\log\frac{\beta(v_1,v_2)}{\alpha(v_1,v_2)} . \end{equation*} We define an equivalence relation on C saying that  $v\simeq w$ if v = tw for some t > 0. It turns out that θ is a metric on
$v\simeq w$ if v = tw for some t > 0. It turns out that θ is a metric on  $\frac{C}{\simeq}$ though it can assume the value
$\frac{C}{\simeq}$ though it can assume the value  $+\infty$. As shown in [Reference Viana23], it separates points thanks to (2.1).
$+\infty$. As shown in [Reference Viana23], it separates points thanks to (2.1).
We recall the statement of the Perron–Frobenius theorem.
Theorem 2.1. Let  $C\subset E$ be a convex cone satisfying (2.1) and let
$C\subset E$ be a convex cone satisfying (2.1) and let  $L\colon E\rightarrow E$ be a linear map such that
$L\colon E\rightarrow E$ be a linear map such that  $L(C)\subset C$. Let us suppose that
$L(C)\subset C$. Let us suppose that
 \begin{equation*}D\colon=\sup\{
\theta(L(v_1),L(v_2))\colon v_1,v_2\in C
\} \lt +\infty . \end{equation*}
\begin{equation*}D\colon=\sup\{
\theta(L(v_1),L(v_2))\colon v_1,v_2\in C
\} \lt +\infty . \end{equation*}Then, the following three points hold.
(1) For all
$v_1,v_2\in C$, we have that
\begin{equation*}\theta(L(v_1),L(v_2))\le(1-{\rm e}^{-D})\theta(v_1,v_2) . \end{equation*}(2) If
$(\frac{C}{\simeq},\theta)$ is complete, then L has a unique fixed point $v\in\frac{C}{\simeq}$. Since L is linear, this means that there is $v\in C$, unique up to multiplication by a positive constant, and a unique λ > 0 such that
\begin{equation*}Lv=\lambda v . \end{equation*}(3) Let
$(\frac{C}{\simeq},\theta)$ be complete and let v be the fixed point of point (2). Then, if $v_0\in C$, we have that
\begin{equation*}\theta(L^n v_0,v)\le
\frac{(1-{\rm e}^{-D})^n}{{\rm e}^{-D}}\theta(v_0,v). \end{equation*}









Fractal sets
The fractals we consider are a particular case of what in [Reference Kigami9] (see definitions 1.3.4 and 1.3.13) are called ‘post-critically finite self-similar structures’.
(F1) We are given t affine bijections
$\psi_i\colon \textbf{R}^d\rightarrow \textbf{R}^d$, $i\in\{1,\dots,t \}$, satisfying
(2.2)\begin{align}
\eta\colon=\sup_{i\in\{1,\dots,t \}}Lip(\psi_i) \lt 1.
\end{align}By Theorem 1.1.7 of [Reference Kigami9], there is a unique non-empty compact set
$G\subset\textbf{R}^d$ such that
(2.3)\begin{align}
G=\bigcup_{i\in\{1,\dots,t \}}\psi_i(G).
\end{align}In the following, we shall always rescale the norm of Rd in such a way that
(2.4)\begin{align}
{\rm diam}(G)\le 1.
\end{align}If (F1) holds, then the dynamics of F on G can be coded. Indeed, we define Σ as the space of sequences
\begin{equation*}\Sigma=
\{
( x_i )_{i\ge 0}\colon x_i\in(1,\dots,n)
\} \end{equation*}with the product topology. One metric that induces this topology is the following: for
$\gamma\in(0,1)$, we set
(2.5)\begin{align}
d_\gamma(( x_i )_{i\ge 0},( y_i )_{i\ge 0})=
\inf\{
\gamma^{k+1}\colon x_i=y_i\quad \text{for}\ i\in\{0,\dots,k \}
\}
\end{align}with the convention that the inf on the empty set is 1.
We define the shift σ as
\begin{equation*}\sigma\colon \Sigma\rightarrow \Sigma,\qquad
\sigma\colon ( x_0,x_1,x_2,\dots )\rightarrow ( x_1,x_2,x_3,\dots ) . \end{equation*}If
$x=(x_0x_1\cdots)\in\Sigma$, we set $ix=(ix_0x_1\cdots)$.For
$x=(x_0x_1\cdots)\in\Sigma$, we define the cylinder of Σ
\begin{equation*}[x_0\cdots x_l]=\{
( y_i )_{i\ge 0}\in\Sigma\colon y_i=x_i\ \text{for}\ i\in(0,\dots,l)
\} . \end{equation*}For
$x=(x_0x_1\cdots)\in\Sigma$ and $l\in\textbf{N}$, we set
\begin{equation*}\psi_{x_0\cdots x_l}=\psi_{x_0}\circ\cdots\circ\psi_{x_l} \end{equation*}and
(2.6)\begin{align}
[x_0\cdots x_l]_G=\psi_{x_0}\circ\psi_{x_{1}}\circ\cdots\circ\psi_{x_l}(G) .
\end{align}Formula (2.6) immediately implies that, for all
$i\in(1,\dots,t)$,
(2.7)\begin{align}
\psi_i([x_1\cdots x_l]_G)=[i x_1\cdots x_l]_G .
\end{align}Since the maps ψi are continuous and G is compact, the sets
$[x_0\cdots x_l]_G\subset G$ are compact. By (2.3), we have that $\psi_i(G)\subset G$ for $i\in(1,\dots,t)$; together with (2.6); this implies that, for all $( x_i )_{i\ge 0}\in\Sigma$ and $l\ge 1$,
(2.8)\begin{align}
[x_0\cdots x_{l-1} x_l]_G\subset [x_0\cdots x_{l-1}]_G .
\end{align}From (2.2), (2.4) and (2.6), we get that, for all
$l\ge 0$,
(2.9)\begin{align}
{\rm diam} ([x_0\cdots x_l]_G)\le\eta^{l+1} .
\end{align}By (2.8) and (2.9) and the finite intersection property, we get that, if
$( x_i )_{i\ge 0}\subset\Sigma$, then
(2.10)\begin{equation}\bigcap_{l\ge 1}[x_0\cdots x_{l}]_G\end{equation}is a single point, which we call
$\Phi(( x_i )_{i\ge 0})$; Formula (2.9) implies in a standard way that the map $\Phi\colon \Sigma\rightarrow G$ is continuous. It is not hard to prove, using (2.3), that Φ is surjective. In our choice of the metric dγ on Σ, we shall always take $\gamma\in(\eta,1)$; we endow G with the Euclidean distance on Rd. With this choice of the metrics, (2.5) and (2.9) easily imply that Φ is 1-Lipschitz. By (2.7) and the definition of Φ, we see that
(2.11)\begin{align}
\psi_i\circ\Phi(x)=\Phi(ix).
\end{align}(F2) We ask that, if
$i\not=j$, then $\psi_i(G)\cap\psi_j(G)$ is a finite set. We set
\begin{equation*}{\cal F}\colon=\bigcup_{i\not =j}\psi_i(G)\cap\psi_j(G) . \end{equation*}(F3) We ask that, if
$i=(i_0i_1\cdots)\in\Sigma$ and $l\ge 1$, then $\psi_{i_0\cdots i_{l-1}}^{-1}({\cal F})\cap{\cal F}=\emptyset$.We briefly prove that (F1)–(F3) imply that the coding Φ is finite-to-one and that the set
$N\subset\Sigma$, where Φ is not injective and is countable. More precisely, we assert that the points of G in
(2.12)\begin{align}
H\colon={\cal F}\cup\bigcup_{l\ge 0}\bigcup_{x\in\Sigma}
\psi_{x_0\cdots x_l}({\cal F})
\end{align}have at most t preimages and that those outside H have only one preimage.
We begin by showing this latter fact. If
$y\in G\setminus{\cal F}$, then $y=\Phi(( x_j )_{j\ge 0})$ can belong by (F2) to at most one $\psi_i(G)$, and thus there is only one choice for x 0. Using the fact that $\psi_{x_0}$ is a diffeomorphism, we see that there is at most one choice for x 1 if moreover $y\not\in\psi_{x_0}({\cal F})$; iterating, we see that the points in H c have one preimage.If
$y\in{\cal F}$, then y can belong to at most t sets $\psi_i(G)$, and thus there are at most t choices for x 0. As for the choice for x 1, once we have fixed x 0, then we have that $y\in\psi_{x_0}\circ\psi_{x_1}(G)$, i.e., that $\psi_{x_0}^{-1}(y)\in\psi_{x_1}(G)$. Since $y\in{\cal F}$, (F3) implies that $\psi_{x_0}^{-1}(y)\not\in{\cal F}$ and thus we have at most one choice for x 1. Iterating, we see that there is at most one choice for $x_2,x_3$, etc. If $y\not\in{\cal F}$ but $y\in\psi_{x_0}({\cal F})$, then we have one choice for x 0 but t choices for x 1; arguing as above, we see that there is at most one choice for x 2, x 3, etc. Iterating, we get the assertion.(F4) We ask that there are disjoint open sets
${\cal O}_1,\dots,{\cal O}_n\subset\textbf{R}^d$ such that
\begin{equation*}G\cap{\cal O}_i=\psi_i(G)\setminus{\cal F}\quad \text{for}\ i\in(1,\dots,n) . \end{equation*}We define a map
$F\colon \bigcup_{i=1}^n{\cal O}_i\rightarrow \textbf{R}^d$ by
\begin{equation*}F(x)=\psi_i^{-1}(x)\quad \text{if}\ x\in{\cal O}_i . \end{equation*}This implies the second equality below; the first one holds by the formula above if we ask that
$\psi({\cal O}_i)\subset{\cal O}_i$.
(2.13)\begin{align}
F\circ\psi_i(x)=x\qquad\forall x\in{\cal O}_i\quad \text{and}\quad \psi_i\circ F(x)=x\qquad\forall x\in{\cal O}_i .
\end{align}We call ai the unique fixed point of ψi; note that, by (2.3),
$a_{i}\in G$. If $x\in{\cal F}$, we define $F(x)=a_{i}$ for some arbitrary ai. This defines F as a Borel map on all of G, which satisfies (2.13).

































































From (2.6) and the definition of Φ, we see that  $\Phi([x_0\cdots x_l])=[x_0\cdots x_l]_G$. We saw earlier that Φ is finite-to-one and that there are at most countably many points with more that one preimage; an immediate consequence is that the set
$\Phi([x_0\cdots x_l])=[x_0\cdots x_l]_G$. We saw earlier that Φ is finite-to-one and that there are at most countably many points with more that one preimage; an immediate consequence is that the set
 \begin{equation*}\Phi^{-1} ([x_0\cdots x_l]_G)\setminus [x_0\cdots x_l] \end{equation*}
\begin{equation*}\Phi^{-1} ([x_0\cdots x_l]_G)\setminus [x_0\cdots x_l] \end{equation*} is at most countable. Let us suppose that  $\Phi(x_0x_1\cdots)\in{\cal O}_i$; the discussion after (F3) implies that there is only one choice for x 0 and it is
$\Phi(x_0x_1\cdots)\in{\cal O}_i$; the discussion after (F3) implies that there is only one choice for x 0 and it is  $x_0=i$; by the first formula of (2.13), this implies the second equality below; the first and last ones are the definition of Φ.
$x_0=i$; by the first formula of (2.13), this implies the second equality below; the first and last ones are the definition of Φ.
 \begin{equation*}F\circ\Phi(x_0x_1\cdots)=F\left(
\bigcap_{l\ge 0}\psi_{x_0x_1\cdots x_l}(G)
\right) =
\bigcap_{l\ge 0}\psi_{x_1x_2\cdots x_l}(G)=\Phi\circ\sigma(x_0x_1\cdots) . \end{equation*}
\begin{equation*}F\circ\Phi(x_0x_1\cdots)=F\left(
\bigcap_{l\ge 0}\psi_{x_0x_1\cdots x_l}(G)
\right) =
\bigcap_{l\ge 0}\psi_{x_1x_2\cdots x_l}(G)=\Phi\circ\sigma(x_0x_1\cdots) . \end{equation*}This yields the first equality below, while the second one is (2.11).
 \begin{align}
\left\{
\begin{matrix}
\Phi\circ\sigma(x)=F\circ\Phi(x)\ \text{save possibly when } \Phi(x)\in {\cal F}\text{,}\\
\Phi(ix) =\psi_i(\Phi(x)) \qquad\forall x\in\Sigma,
\quad\forall i\in (1,\dots,n) .
\end{matrix}
\right.
\end{align}
\begin{align}
\left\{
\begin{matrix}
\Phi\circ\sigma(x)=F\circ\Phi(x)\ \text{save possibly when } \Phi(x)\in {\cal F}\text{,}\\
\Phi(ix) =\psi_i(\Phi(x)) \qquad\forall x\in\Sigma,
\quad\forall i\in (1,\dots,n) .
\end{matrix}
\right.
\end{align}In other words, up to a change of coordinates, shifting the coding one place to the left is the same as applying F.
A particular case we have in mind is the harmonic Sierpinski gasket on R2 (see for instance [Reference Kajino7]). We set
 \begin{equation*}T_1=\left(
\begin{matrix}
\frac{3}{5},&0\cr
0,&\frac{1}{5}
\end{matrix}
\right) , \quad
T_2=\left(
\begin{matrix}
\frac{3}{10},&\frac{\sqrt 3}{10}\cr
\frac{\sqrt 3}{10},&\frac{1}{2}
\end{matrix}
\right) ,\quad
T_3=\left(
\begin{matrix}
\frac{3}{10},&-\frac{\sqrt 3}{10}\cr
-\frac{\sqrt 3}{10},&\frac{1}{2}
\end{matrix}
\right) , \end{equation*}
\begin{equation*}T_1=\left(
\begin{matrix}
\frac{3}{5},&0\cr
0,&\frac{1}{5}
\end{matrix}
\right) , \quad
T_2=\left(
\begin{matrix}
\frac{3}{10},&\frac{\sqrt 3}{10}\cr
\frac{\sqrt 3}{10},&\frac{1}{2}
\end{matrix}
\right) ,\quad
T_3=\left(
\begin{matrix}
\frac{3}{10},&-\frac{\sqrt 3}{10}\cr
-\frac{\sqrt 3}{10},&\frac{1}{2}
\end{matrix}
\right) , \end{equation*} \begin{equation*}A=\left(
\begin{matrix}
0\cr
0
\end{matrix}
\right),\qquad
B=\left(
\begin{matrix}
1\cr
\frac{1}{\sqrt 3}
\end{matrix}
\right) ,\qquad
C=\left(
\begin{matrix}
1\cr
-\frac{1}{\sqrt 3}
\end{matrix}
\right) \end{equation*}
\begin{equation*}A=\left(
\begin{matrix}
0\cr
0
\end{matrix}
\right),\qquad
B=\left(
\begin{matrix}
1\cr
\frac{1}{\sqrt 3}
\end{matrix}
\right) ,\qquad
C=\left(
\begin{matrix}
1\cr
-\frac{1}{\sqrt 3}
\end{matrix}
\right) \end{equation*}and
 \begin{equation*}\psi_1(x)=T_1(x),\quad \psi_2(x)=
B +T_2\left(
x-B
\right),\quad
\psi_3(x)=
C +T_3\left(
x-C
\right) . \end{equation*}
\begin{equation*}\psi_1(x)=T_1(x),\quad \psi_2(x)=
B +T_2\left(
x-B
\right),\quad
\psi_3(x)=
C +T_3\left(
x-C
\right) . \end{equation*} Referring to Figure 1, ψ 1 brings the triangle  $G_0\colon\!=ABC$ into Abc; ψ 2 brings G 0 into Bac and ψ 3 brings G 0 into Cba. We set
$G_0\colon\!=ABC$ into Abc; ψ 2 brings G 0 into Bac and ψ 3 brings G 0 into Cba. We set  ${\cal F}=\{a,b,c \}$ and take
${\cal F}=\{a,b,c \}$ and take  ${\cal O}_1$,
${\cal O}_1$,  ${\cal O}_2$,
${\cal O}_2$,  ${\cal O}_3$ as three disjoint open sets which contain, respectively, the triangle Abc minus
${\cal O}_3$ as three disjoint open sets which contain, respectively, the triangle Abc minus  $b,c$, Bca minus
$b,c$, Bca minus  $c,a$ and Cba minus
$c,a$ and Cba minus  $a,b$; in this way, hypotheses (F1)–(F4) hold. It is easy to check that also hypothesis (ND)1 is satisfied.
$a,b$; in this way, hypotheses (F1)–(F4) hold. It is easy to check that also hypothesis (ND)1 is satisfied.

Figure 1. The first two prefractals of the harmonic Gasket.
We define the map F as
 \begin{equation*}F(x)=\psi_i^{-1}(x)\quad \text{if}\ x\in{\cal O}_i \end{equation*}
\begin{equation*}F(x)=\psi_i^{-1}(x)\quad \text{if}\ x\in{\cal O}_i \end{equation*} and we extend it arbitrarily on  ${\cal F}=\{a,b,c \}$, say
${\cal F}=\{a,b,c \}$, say  $F(a)=A$,
$F(a)=A$,  $F(b)=B$ and
$F(b)=B$ and  $F(c)=C$.
$F(c)=C$.
For  $q\in(1,\dots,d)$, we consider
$q\in(1,\dots,d)$, we consider  ${\Lambda^q}(\textbf{R}^d)$, the space of q-forms on Rd; if
${\Lambda^q}(\textbf{R}^d)$, the space of q-forms on Rd; if  $(\cdot,\cdot)$ is an inner product on Rd, it induces an inner product on the monomials of
$(\cdot,\cdot)$ is an inner product on Rd, it induces an inner product on the monomials of  $\Lambda^q(\textbf{R}^d)$ by
$\Lambda^q(\textbf{R}^d)$ by
 \begin{equation*}((v_1\wedge\cdots\wedge v_q),(w_1\wedge\cdots\wedge w_q))= (v_1\wedge\cdots\wedge v_q) (i(w_1),\cdots, i(w_q)), \end{equation*}
\begin{equation*}((v_1\wedge\cdots\wedge v_q),(w_1\wedge\cdots\wedge w_q))= (v_1\wedge\cdots\wedge v_q) (i(w_1),\cdots, i(w_q)), \end{equation*} where  $i\colon \Lambda^1(\textbf{R}^d)\rightarrow \textbf{R}^d$ is the Riesz map, i.e., the natural identification of a Hilbert space with its dual. This product extends by linearity to all
$i\colon \Lambda^1(\textbf{R}^d)\rightarrow \textbf{R}^d$ is the Riesz map, i.e., the natural identification of a Hilbert space with its dual. This product extends by linearity to all  $\Lambda^q(\textbf{R}^d)$, which thus becomes a Hilbert space.
$\Lambda^q(\textbf{R}^d)$, which thus becomes a Hilbert space.
As a consequence, if A is a matrix bringing  $\Lambda^q(\textbf{R}^d)$ into itself, we can define its adjoint
$\Lambda^q(\textbf{R}^d)$ into itself, we can define its adjoint  ${{}^{t}} A$. We shall denote by M q the space of all self-adjoint operators (a.k.a. symmetric matrices) on
${{}^{t}} A$. We shall denote by M q the space of all self-adjoint operators (a.k.a. symmetric matrices) on  ${\Lambda^q}(\textbf{R}^d)$. Again since
${\Lambda^q}(\textbf{R}^d)$. Again since  ${\Lambda^q}(\textbf{R}^d)$ is a Hilbert space, we can define the trace
${\Lambda^q}(\textbf{R}^d)$ is a Hilbert space, we can define the trace  ${\rm tr}(A)$ of
${\rm tr}(A)$ of  $A\in M^q$ and thus the Hilbert–Schmidt product
$A\in M^q$ and thus the Hilbert–Schmidt product
 \begin{equation*}(\cdot,\cdot)_{\rm HS}\colon M^q\times M^q\rightarrow \textbf{R}\end{equation*}
\begin{equation*}(\cdot,\cdot)_{\rm HS}\colon M^q\times M^q\rightarrow \textbf{R}\end{equation*} \begin{equation*}(A,B)_{\rm HS}\colon={\rm tr}(A{{}^{t}} B)={\rm tr}(AB), \end{equation*}
\begin{equation*}(A,B)_{\rm HS}\colon={\rm tr}(A{{}^{t}} B)={\rm tr}(AB), \end{equation*}where the second equality comes from the fact that B is symmetric.
Thus, M q is a Hilbert space whose norm is
 \begin{equation*}||A||_{\rm HS}=\sqrt{(A,A)_{\rm HS}}.\end{equation*}
\begin{equation*}||A||_{\rm HS}=\sqrt{(A,A)_{\rm HS}}.\end{equation*} Since  $\Lambda^k(\textbf{R}^d)$ is a Hilbert space, we shall see its elements b as column vectors, on which the elements
$\Lambda^k(\textbf{R}^d)$ is a Hilbert space, we shall see its elements b as column vectors, on which the elements  $M\in M^q$ act to the left: Mb.
$M\in M^q$ act to the left: Mb.
Matrix-valued measures
Let  $(E,\hat d)$ be a compact metric space; in the following,
$(E,\hat d)$ be a compact metric space; in the following,  $(E,\hat d)$ will be either one of the spaces
$(E,\hat d)$ will be either one of the spaces  $(\Sigma,d_\gamma)$ or
$(\Sigma,d_\gamma)$ or  $(G,||\cdot||)$ defined above. We denote by
$(G,||\cdot||)$ defined above. We denote by  $C(E,M^q)$ the space of continuous functions from E to M q and by
$C(E,M^q)$ the space of continuous functions from E to M q and by  ${\cal M}(E,M^q)$ the space of the Borel measures on E valued in M q. If
${\cal M}(E,M^q)$ the space of the Borel measures on E valued in M q. If  $\mu\in{\cal M}(E,M^q)$, we denote by
$\mu\in{\cal M}(E,M^q)$, we denote by  $||\mu||$ its total variation measure; it is standard [Reference Rudin20] that
$||\mu||$ its total variation measure; it is standard [Reference Rudin20] that  $||\mu||(E) \lt +\infty$ and that
$||\mu||(E) \lt +\infty$ and that
 \begin{equation*}\mu=M\cdot||\mu||\end{equation*}
\begin{equation*}\mu=M\cdot||\mu||\end{equation*} where  $M\colon E\rightarrow M^q$ is Borel and
$M\colon E\rightarrow M^q$ is Borel and
 \begin{align}
||M(x)||_{\rm HS}=1\quad \text{for}\ ||\mu||\text{-a.e.}\ x\in E.
\end{align}
\begin{align}
||M(x)||_{\rm HS}=1\quad \text{for}\ ||\mu||\text{-a.e.}\ x\in E.
\end{align} Let now  $\mu\in{\cal M}(E,M^q)$ and let
$\mu\in{\cal M}(E,M^q)$ and let  $f\colon E\rightarrow M^q$ be a Borel function such that
$f\colon E\rightarrow M^q$ be a Borel function such that  $||f||_{\rm HS}\in L^1(E,||\mu||)$. We define
$||f||_{\rm HS}\in L^1(E,||\mu||)$. We define
 \begin{align}
\int_E(f, {\rm d} \mu)_{\rm HS}\colon=
\int_E(f(x),M(x))_{\rm HS} {\rm d} ||\mu||(x) .
\end{align}
\begin{align}
\int_E(f, {\rm d} \mu)_{\rm HS}\colon=
\int_E(f(x),M(x))_{\rm HS} {\rm d} ||\mu||(x) .
\end{align} Note that the integral on the right converges: indeed, the function  $x\rightarrow(f(x),M(x))$ is in
$x\rightarrow(f(x),M(x))$ is in  $L^1(G,||\mu||)$ by our hypotheses on f, (2.15) and Cauchy–Schwarz. A particular case we shall use often is when
$L^1(G,||\mu||)$ by our hypotheses on f, (2.15) and Cauchy–Schwarz. A particular case we shall use often is when  $f\in C(E,M^q)$.
$f\in C(E,M^q)$.
If  $\mu\in{\cal M}(E,M^q)$ and
$\mu\in{\cal M}(E,M^q)$ and  $a,b\colon E\rightarrow {\Lambda^q}(\textbf{R}^d)$ are Borel functions such that
$a,b\colon E\rightarrow {\Lambda^q}(\textbf{R}^d)$ are Borel functions such that  $||a||\cdot||b||\in L^1(E,||\mu||)$, we can define
$||a||\cdot||b||\in L^1(E,||\mu||)$, we can define
 \begin{equation*}\int_E(a, {\rm d} \mu\cdot b)\colon=
\int_E(
a(x),M(x)b(x)
)\, {\rm d} ||\mu||(x) . \end{equation*}
\begin{equation*}\int_E(a, {\rm d} \mu\cdot b)\colon=
\int_E(
a(x),M(x)b(x)
)\, {\rm d} ||\mu||(x) . \end{equation*} Note again that the function  $x\rightarrow(a(x),M(x)b(x))$ belongs to
$x\rightarrow(a(x),M(x)b(x))$ belongs to  $L^1(G,||\mu||)$ by our hypotheses on a, b, (2.15) and Cauchy–Schwarz. We have written
$L^1(G,||\mu||)$ by our hypotheses on a, b, (2.15) and Cauchy–Schwarz. We have written  $M(x)b(x)$ because, as we said above, we consider the elements of
$M(x)b(x)$ because, as we said above, we consider the elements of  $\Lambda^q(\textbf{R}^d)$ as column vectors. Since
$\Lambda^q(\textbf{R}^d)$ as column vectors. Since
 \begin{equation*}(a\otimes b,M)_{\rm HS}=(a,Mb), \end{equation*}
\begin{equation*}(a\otimes b,M)_{\rm HS}=(a,Mb), \end{equation*}we have that
 \begin{align}
\int_E(a, {\rm d} \mu\cdot b)=
\int_E(a\otimes b, {\rm d} \mu)_{\rm HS} .
\end{align}
\begin{align}
\int_E(a, {\rm d} \mu\cdot b)=
\int_E(a\otimes b, {\rm d} \mu)_{\rm HS} .
\end{align} By Riesz’s representation theorem, the duality coupling  ${\langle \cdot ,\cdot\rangle}$ between
${\langle \cdot ,\cdot\rangle}$ between  $C(E,M^q)$ and
$C(E,M^q)$ and  ${\cal M}(E,M^q)$ is given by
${\cal M}(E,M^q)$ is given by
 \begin{equation*}{\langle f ,\mu\rangle}\colon=
\int_E(f, {\rm d} \mu)_{\rm HS}, \end{equation*}
\begin{equation*}{\langle f ,\mu\rangle}\colon=
\int_E(f, {\rm d} \mu)_{\rm HS}, \end{equation*}where the integral on the right is defined by (2.16).
Let  $\mu\in{\cal M}(E,M^q)$; we say that
$\mu\in{\cal M}(E,M^q)$; we say that  $\mu\in{\cal M}_+(E,M^q)$ if
$\mu\in{\cal M}_+(E,M^q)$ if  $\mu(A)$ is a semi-positive-definite matrix for all Borel sets
$\mu(A)$ is a semi-positive-definite matrix for all Borel sets  $A\subset E$. By Lusin’s theorem (see [Reference Bessi2] for more details), this is equivalent to saying that
$A\subset E$. By Lusin’s theorem (see [Reference Bessi2] for more details), this is equivalent to saying that
 \begin{align}
{\langle f ,\mu\rangle}\ge 0
\end{align}
\begin{align}
{\langle f ,\mu\rangle}\ge 0
\end{align} for all  $f\in C(E,M^q)$ such that
$f\in C(E,M^q)$ such that  $f(x)\ge 0$ (i.e., it is semi-positive definite) for all
$f(x)\ge 0$ (i.e., it is semi-positive definite) for all  $x\in E$. An equivalent characterization is that, in the polar decomposition (2.15),
$x\in E$. An equivalent characterization is that, in the polar decomposition (2.15),  $M(x)\ge 0$ for
$M(x)\ge 0$ for  $||\mu||$-a.e.
$||\mu||$-a.e.  $x\in E$.
$x\in E$.
As a consequence of the characterization (2.18),  ${\cal M}_+(E,M^q)$ is a convex set closed for the weak
${\cal M}_+(E,M^q)$ is a convex set closed for the weak $\ast$ topology of
$\ast$ topology of  ${\cal M}(E,M^q)$.
${\cal M}(E,M^q)$.
If  $\mu\in{\cal M}(E,M^q)$ and
$\mu\in{\cal M}(E,M^q)$ and  $A\colon E\rightarrow M^q$ belongs to
$A\colon E\rightarrow M^q$ belongs to  $L^1(E,||\mu||)$, we define the scalar measure
$L^1(E,||\mu||)$, we define the scalar measure  $(A,\mu)_{\rm HS}$ by
$(A,\mu)_{\rm HS}$ by
 \begin{equation*}\int_E f(x)\, {\rm d} (A,\mu)_{\rm HS}(x)=
\int_E(f(x)A(x), {\rm d} \mu(x))_{\rm HS}\end{equation*}
\begin{equation*}\int_E f(x)\, {\rm d} (A,\mu)_{\rm HS}(x)=
\int_E(f(x)A(x), {\rm d} \mu(x))_{\rm HS}\end{equation*} for all  $f\in C(E,\textbf{R})$. Recalling the definition (2.16) of the integral on the right, we have that
$f\in C(E,\textbf{R})$. Recalling the definition (2.16) of the integral on the right, we have that
 \begin{equation*}(A,\mu)_{\rm HS}=(A,M)_{\rm HS}\cdot||\mu||, \end{equation*}
\begin{equation*}(A,\mu)_{\rm HS}=(A,M)_{\rm HS}\cdot||\mu||, \end{equation*} where  $\mu=M\cdot||\mu||$ is the polar decomposition of µ as in (2.15).
$\mu=M\cdot||\mu||$ is the polar decomposition of µ as in (2.15).
We recall (a proof is, for instance, in [Reference Bessi2]) that, if  $A,B,C\in M^q$, if
$A,B,C\in M^q$, if  $A\ge B$ and
$A\ge B$ and  $C\ge 0$, then
$C\ge 0$, then
 \begin{align}
(A,C)_{\rm HS}\ge(B,C)_{\rm HS} .
\end{align}
\begin{align}
(A,C)_{\rm HS}\ge(B,C)_{\rm HS} .
\end{align} As a consequence, we have that, if  $f,g\in C(E,M^q)$ satisfy
$f,g\in C(E,M^q)$ satisfy  $f(x)\ge g(x)$ for all
$f(x)\ge g(x)$ for all  $x\in E$ and if
$x\in E$ and if  $\mu\in{\cal M}_+(E,M^q)$, then
$\mu\in{\cal M}_+(E,M^q)$, then
 \begin{align}
\int_E(f(x), {\rm d} \mu(x))_{\rm HS}\ge \int_E(g(x), {\rm d} \mu(x))_{\rm HS}.
\end{align}
\begin{align}
\int_E(f(x), {\rm d} \mu(x))_{\rm HS}\ge \int_E(g(x), {\rm d} \mu(x))_{\rm HS}.
\end{align} Let  $Q\in C(E,M^q)$ be such that
$Q\in C(E,M^q)$ be such that  $Q(x) \gt 0$ for all
$Q(x) \gt 0$ for all  $x\in E$; by compactness, we can find ϵ > 0 such that
$x\in E$; by compactness, we can find ϵ > 0 such that
 \begin{align}
\epsilon Id\le Q(x)\le\frac{1}{\epsilon}Id\qquad\forall x\in E .
\end{align}
\begin{align}
\epsilon Id\le Q(x)\le\frac{1}{\epsilon}Id\qquad\forall x\in E .
\end{align} It is shown in [Reference Bessi2] that there is  $C_1=C_1(\epsilon) \gt 0$ such that, if Q satisfies (2.21) and
$C_1=C_1(\epsilon) \gt 0$ such that, if Q satisfies (2.21) and  $\mu\in{\cal M}_+(E,M^q)$, then
$\mu\in{\cal M}_+(E,M^q)$, then
 \begin{align}
\frac{1}{C_1(\epsilon)}||\mu||\le
(Q,\mu)_{\rm HS}\le
C_1(\epsilon)||\mu||.
\end{align}
\begin{align}
\frac{1}{C_1(\epsilon)}||\mu||\le
(Q,\mu)_{\rm HS}\le
C_1(\epsilon)||\mu||.
\end{align} Let  $Q\in C(E,M^q)$ satisfy (2.21); we say that
$Q\in C(E,M^q)$ satisfy (2.21); we say that  $\mu\in{\cal P}_Q$ if
$\mu\in{\cal P}_Q$ if  $\mu\in{\cal M}_+(E,M^q)$ and
$\mu\in{\cal M}_+(E,M^q)$ and
 \begin{align}
{\langle Q ,\mu\rangle}=1 .
\end{align}
\begin{align}
{\langle Q ,\mu\rangle}=1 .
\end{align} We saw after Formula (2.18) that  ${\cal M}_+(E,M^q)$ is convex and closed for the weak
${\cal M}_+(E,M^q)$ is convex and closed for the weak $\ast$ topology; Formula (2.23) implies that
$\ast$ topology; Formula (2.23) implies that  ${\cal P}_Q$ is also closed and convex; (2.22) and (2.23) imply that it is compact.
${\cal P}_Q$ is also closed and convex; (2.22) and (2.23) imply that it is compact.
Cones in function spaces
We say that  $f\in C_+(E,M^q)$ if
$f\in C_+(E,M^q)$ if  $f\in C(E,M^q)$ and f(x) is positive-definite for all
$f\in C(E,M^q)$ and f(x) is positive-definite for all  $x\in E$. It is easy to see that
$x\in E$. It is easy to see that  $C_+(E,M^q)$ is a convex cone in
$C_+(E,M^q)$ is a convex cone in  $C(E,M^q)$ satisfying (2.1). We let
$C(E,M^q)$ satisfying (2.1). We let  $\theta^+$ denote the hyperbolic distance on
$\theta^+$ denote the hyperbolic distance on  $\frac{C_+(E,M^q)}{\simeq}$.
$\frac{C_+(E,M^q)}{\simeq}$.
Let a > 0 and  $\alpha\in(0,1]$; we say that
$\alpha\in(0,1]$; we say that  $A\in Log C^{a,\alpha}_+(E)$ if
$A\in Log C^{a,\alpha}_+(E)$ if  $A\in C_+(E,M^q)$ and for all
$A\in C_+(E,M^q)$ and for all  $x,y\in E$, we have
$x,y\in E$, we have
 \begin{equation*}A(y)\,{\rm e}^{-a\hat d(x,y)^\alpha}\le A(x)\le A(y)\,{\rm e}^{a\hat d(x,y)^\alpha}, \end{equation*}
\begin{equation*}A(y)\,{\rm e}^{-a\hat d(x,y)^\alpha}\le A(x)\le A(y)\,{\rm e}^{a\hat d(x,y)^\alpha}, \end{equation*}where the inequality is the standard one between symmetric matrices.
It is easy to check that  $LogC^{a,\alpha}_+(E)$ is a convex cone satisfying (2.1). We let θ a denote the hyperbolic distance on
$LogC^{a,\alpha}_+(E)$ is a convex cone satisfying (2.1). We let θ a denote the hyperbolic distance on  $\frac{LogC^{a,\alpha}_+(E)}{\simeq}$.
$\frac{LogC^{a,\alpha}_+(E)}{\simeq}$.
Next, we introduce the subcone of the elements  $A\in LogC^{a,\alpha}_+(E)$ whose eigenvalues are bounded away from zero. In other words, we define
$A\in LogC^{a,\alpha}_+(E)$ whose eigenvalues are bounded away from zero. In other words, we define
 \begin{equation*}||A||_{\infty}=\sup_{x\in E}||A(x)||_{\rm HS},\end{equation*}
\begin{equation*}||A||_{\infty}=\sup_{x\in E}||A(x)||_{\rm HS},\end{equation*}and for ϵ > 0, we set
 \begin{equation*}LogC^{a,\alpha}_\epsilon(E)=\{
A\in LogC_+^{a,\alpha}(E)\colon A(x)\ge\epsilon||A||_\infty Id\qquad\forall x\in E
\}. \end{equation*}
\begin{equation*}LogC^{a,\alpha}_\epsilon(E)=\{
A\in LogC_+^{a,\alpha}(E)\colon A(x)\ge\epsilon||A||_\infty Id\qquad\forall x\in E
\}. \end{equation*}The Ruelle operator
Recall that the maps ψi of § (2.2) are affine and injective; in particular,  $D\psi_i$ is a constant, non-degenerate matrix. We define the pull-back
$D\psi_i$ is a constant, non-degenerate matrix. We define the pull-back  $(D\psi_i)_\ast\colon \Lambda^q(\textbf{R}^d)\rightarrow \Lambda^q(\textbf{R}^d)$ as in (1) and the push-forward
$(D\psi_i)_\ast\colon \Lambda^q(\textbf{R}^d)\rightarrow \Lambda^q(\textbf{R}^d)$ as in (1) and the push-forward  $\Psi_i\colon M^q\rightarrow M^q$ as in (2). Let
$\Psi_i\colon M^q\rightarrow M^q$ as in (2). Let  $\alpha\in(0,1]$ and let
$\alpha\in(0,1]$ and let  $V\in C^{0,\alpha}(G,\textbf{R})$.
$V\in C^{0,\alpha}(G,\textbf{R})$.
The Ruelle operator  ${\cal L}_{G,V}$ on
${\cal L}_{G,V}$ on  $C(G,M^q)$ is the one defined by (3).
$C(G,M^q)$ is the one defined by (3).
We also define a Ruelle operator  ${\cal L}_{\Sigma,V}$ on
${\cal L}_{\Sigma,V}$ on  $C(\Sigma,M^q)$: defining (ix) as in § 2, we set
$C(\Sigma,M^q)$: defining (ix) as in § 2, we set
 \begin{equation*}{\cal L}_{\Sigma,V}\colon C(\Sigma,M^q)\rightarrow C(\Sigma,M^q),\end{equation*}
\begin{equation*}{\cal L}_{\Sigma,V}\colon C(\Sigma,M^q)\rightarrow C(\Sigma,M^q),\end{equation*} \begin{align}
({\cal L}_{\Sigma,V} A)(x)=\sum_{i=1}^t {\rm e}^{V\circ\Phi(ix)}\Psi_i(A(ix)) .
\end{align}
\begin{align}
({\cal L}_{\Sigma,V} A)(x)=\sum_{i=1}^t {\rm e}^{V\circ\Phi(ix)}\Psi_i(A(ix)) .
\end{align} Note that  $V\circ\Phi$ is α-Hölder: indeed, V is α-Hölder and we saw in § 2 that Φ is 1-Lipschitz.
$V\circ\Phi$ is α-Hölder: indeed, V is α-Hölder and we saw in § 2 that Φ is 1-Lipschitz.
In order to apply the Perron–Frobenius theorem, we need a non-degeneracy hypothesis.
(ND)${}_q$

We suppose that there is γ > 0 such that, if  $c,e\in{\Lambda^q}(\textbf{R}^d)$, we can find
$c,e\in{\Lambda^q}(\textbf{R}^d)$, we can find  $i\in(1,\dots,t)$ such that
$i\in(1,\dots,t)$ such that
 \begin{equation*}|((D\psi_{i})_\ast c, e)|\ge\gamma ||c||\cdot||e|| . \end{equation*}
\begin{equation*}|((D\psi_{i})_\ast c, e)|\ge\gamma ||c||\cdot||e|| . \end{equation*} In other words, we are asking that, for all  $c\in\Lambda^q(\textbf{R}^d)\setminus\{0 \}$,
$c\in\Lambda^q(\textbf{R}^d)\setminus\{0 \}$,  $(D\psi_{i})_\ast c$ is a base of
$(D\psi_{i})_\ast c$ is a base of  $\Lambda^q(\textbf{R}^d)$; clearly, this implies that
$\Lambda^q(\textbf{R}^d)$; clearly, this implies that  $t \ge \left( {\matrix{\matrix{d \hfill \cr q \hfill \cr} \cr } } \right)$.
$t \ge \left( {\matrix{\matrix{d \hfill \cr q \hfill \cr} \cr } } \right)$.
We state the standard theorem on the existence of Gibbs measures, whose proof [Reference Parry and Pollicott15, Reference Viana23] adapts easily to our situation; the details are in [Reference Bessi2] and [Reference Bessi3].
Proposition 2.2. Let  $(E,\hat d,S)$ be either one of
$(E,\hat d,S)$ be either one of  $(\Sigma,d_\gamma,\sigma)$ or
$(\Sigma,d_\gamma,\sigma)$ or  $(G,||\cdot||,F)$; let
$(G,||\cdot||,F)$; let  $V\in C^{0,\alpha}(\Sigma,\textbf{R})$ such that
$V\in C^{0,\alpha}(\Sigma,\textbf{R})$ such that  $V=\tilde V\circ\Phi$ for some
$V=\tilde V\circ\Phi$ for some  $\tilde V\in C^{0,\alpha}(G,\textbf{R})$. Let the Ruelle operators
$\tilde V\in C^{0,\alpha}(G,\textbf{R})$. Let the Ruelle operators  ${\cal L}_{\Sigma,V}$ and
${\cal L}_{\Sigma,V}$ and  ${\cal L}_{G,V}$ be defined as in (2.24) and (3), respectively. Then, the following holds.
${\cal L}_{G,V}$ be defined as in (2.24) and (3), respectively. Then, the following holds.
(1) There are
$a,\epsilon \gt 0$, $Q_{E,V}\in LogC^{a-1,\alpha}_{\epsilon}(E)$ and $\beta_{E,V} \gt 0$ such that
\begin{equation*}{\cal L}_{E,V} Q_{E,V}=\beta_{E,V} Q_{E,V}. \end{equation*}If
$Q^{\prime} \in C(E,M^q)$ is such that
\begin{equation*}{\cal L}_{E,V} Q^{\prime}=\beta_{E,V} Q^{\prime}, \end{equation*}then
$Q^{\prime}=\eta Q_{E,V}$ for some $\eta\in\textbf{R}$.(2) Since
$Q_{E,V}\in LogC^{a-1,\alpha}_{\epsilon(a)}(E)$, $Q_{E,V}$ satisfies (2.21), and we can define ${\cal P}_{Q_{E,V}}$ as in (2.23). Then, there is a unique $\mu_{E,V}\in{\cal P}_{Q_{E,V}}$ such that
\begin{equation*}{\cal L}_{E,V}^\ast\mu_{E,V}=\beta_{E,V}\mu_{E,V}. \end{equation*}(3) Let
$A\in C(E,M^q)$; then,
\begin{equation*}\frac{1}{\beta^k_{E,V}}{\cal L}_{E,V}^k A\rightarrow Q_{E,V}{\langle A ,\mu_{E,V}\rangle} \end{equation*}uniformly as
$k\rightarrow+\infty$. If $A\in LogC^{a,\alpha}_+(E)$, then the convergence above is exponentially fast. A consequence of this is the last assertion of point (1), i.e., that the eigenvalue $\beta_{E,V}$ of point (1) is simple.(4)
$\mu_{E,V}(E)$ is a positive-definite matrix.(5) The Gibbs property holds; in other words, there is
$D_1 \gt 0$ such that
\begin{equation*}\frac{{\rm e}^{V^l(x)}}{D_1\beta^l_{E,V}}{{}^{t}}\Psi_{x_0\ldots x_{l-1}}\cdot\mu_{E,V}(E)\le
\mu_{E,V}([x_0\ldots x_{l-1}]_{\alpha})\le
D_1\cdot\frac{{\rm e}^{V^l(x)}}{\beta^l_{E,V}}{{}^{t}}\Psi_{x_0\ldots x_{l-1}}\cdot\mu_{E,V}(E) . \end{equation*}In the formula above,
$[x_0\ldots x_{l-1}]_\alpha=[x_0\ldots x_{l-1}]$ if we are on Σ and $[x_0\ldots x_{l-1}]_\alpha=[x_0\ldots x_{l-1}]_G$ if we are on G. We have also set
\begin{equation*}V^l(x)=V(x)+V\circ\sigma(x)+\ldots+V\circ\sigma^{l-1}(x) \end{equation*}if we are on Σ and
\begin{equation*}V^l(x)=\tilde V(x)+\tilde V\circ F(x)+\ldots+\tilde V\circ F^{l-1}(x) \end{equation*}if we are on G. Lastly,
${{}^{t}}\Psi_{x_0\ldots x_{l-1}}$ is defined as in (10).(6) Let us define
$\kappa_{E,V}=(Q_{E,V},\mu_{E,V})_{\rm HS}$; then $\kappa_{E,V}$ is an atomless probability measure ergodic for S. Actually, the mixing property holds, which we state in the following way: if $g\in C(E,\textbf{R})$ and $A\in C(E,M^q)$, then
\begin{equation*}\int_E(g\circ S^n\cdot A, {\rm d} \mu_{E,V})_{\rm HS}\rightarrow
\int_E(gQ_{E,V}, {\rm d} \mu_{E,V})_{\rm HS}\cdot
\int_E(A, {\rm d} \mu_{E,V})_{\rm HS}. \end{equation*}The convergence is exponentially fast if
$A\in LogC^{a,\alpha}_+(E)$ and $g\in C^{0,\alpha}(E,\textbf{R})$.

































Definition. We shall say that  $\mu_{E,V}$ is the Gibbs measure on E and that
$\mu_{E,V}$ is the Gibbs measure on E and that  $\kappa_{E,V}=(Q_{E,V},\mu_{E,V})_{\rm HS}$ is Kusuoka’s measure on E. Since
$\kappa_{E,V}=(Q_{E,V},\mu_{E,V})_{\rm HS}$ is Kusuoka’s measure on E. Since  $\mu_{E,V}\in{\cal P}_{Q_{{E,V}}}$,
$\mu_{E,V}\in{\cal P}_{Q_{{E,V}}}$,  $\kappa_{E,V}$ is a probability measure.
$\kappa_{E,V}$ is a probability measure.
We recall Lemma 4.6 of [Reference Bessi3], which shows that there is a natural relationship between Gibbs measures on Σ and G; the notation is that of Proposition 2.2.
Lemma 2.3. We have that  $\beta_{G,V}=\beta_{\Sigma,V}$; we shall call βV their common value. Up to multiplying one of them by a positive constant, we have that
$\beta_{G,V}=\beta_{\Sigma,V}$; we shall call βV their common value. Up to multiplying one of them by a positive constant, we have that  $Q_{\Sigma,V}=Q_{G,V}\circ\Phi$; the conjugation
$Q_{\Sigma,V}=Q_{G,V}\circ\Phi$; the conjugation  $\Phi\colon \Sigma\rightarrow G$ is that of (2.11). For this choice of
$\Phi\colon \Sigma\rightarrow G$ is that of (2.11). For this choice of  $Q_{\Sigma,V}$ and
$Q_{\Sigma,V}$ and  $Q_{G,V}$, let
$Q_{G,V}$, let  $\mu_{\Sigma,V}$ and
$\mu_{\Sigma,V}$ and  $\mu_{G,V}$ be as in point (2) of Proposition 2.2; then
$\mu_{G,V}$ be as in point (2) of Proposition 2.2; then  $\mu_{G,V}=\Phi_\sharp\mu_{\Sigma,V}$ and
$\mu_{G,V}=\Phi_\sharp\mu_{\Sigma,V}$ and  $\kappa_{G,V}=\Phi_\sharp\kappa_{\Sigma,V}$, where
$\kappa_{G,V}=\Phi_\sharp\kappa_{\Sigma,V}$, where  $\Phi_\sharp$ denotes the push-forward by Φ.
$\Phi_\sharp$ denotes the push-forward by Φ.
Definition. Let βV be the eigenvalue of the lemma above; we shall say that  $P(V)\colon=\log\beta_V$ is the pressure of the potential V.
$P(V)\colon=\log\beta_V$ is the pressure of the potential V.
Just a word on the relationship with [Reference Feng and Käenmäki5] and [Reference Morris13]. It is standard [Reference Bessi2] that, if  $V\equiv 0$, then the eigenfunction Q is constant and
$V\equiv 0$, then the eigenfunction Q is constant and  $D_1=1$ in point (5) of Proposition 2.2. On constant matrices, our operator
$D_1=1$ in point (5) of Proposition 2.2. On constant matrices, our operator  ${\cal L}_{\Sigma,V}$ and the operator LA of Proposition 15 of [Reference Morris13] coincide; in particular, they have the same spectral radius and the same maximal eigenvector, Q. Looking at the eigenvalues, this means that our
${\cal L}_{\Sigma,V}$ and the operator LA of Proposition 15 of [Reference Morris13] coincide; in particular, they have the same spectral radius and the same maximal eigenvector, Q. Looking at the eigenvalues, this means that our  $\beta_{\Sigma,V}$ coincides with their
$\beta_{\Sigma,V}$ coincides with their  ${\rm e}^{P(A,2)}$. Moreover, when
${\rm e}^{P(A,2)}$. Moreover, when  $V\equiv 0$,
$V\equiv 0$,  $\kappa_{\Sigma,V}$ coincides with the measure m on the shift defined in [Reference Feng and Käenmäki5] and [Reference Morris13]; we briefly prove why this is true.
$\kappa_{\Sigma,V}$ coincides with the measure m on the shift defined in [Reference Feng and Käenmäki5] and [Reference Morris13]; we briefly prove why this is true.
A theorem of [Reference Feng and Käenmäki5], recalled as Theorem 2 in [Reference Morris13], says that the probability measure m of [Reference Morris13] satisfies the following: there are C > 0 and  $P(A,2)\in\textbf{R}$ such that, for all
$P(A,2)\in\textbf{R}$ such that, for all  $x_1,\dots,x_n\in\{1,\dots,t \}$, we have
$x_1,\dots,x_n\in\{1,\dots,t \}$, we have
 \begin{equation*}\frac{1}{C}m([x_1\cdots x_n])\le
\frac{||A_{x_n}\cdot\cdots\cdot A_{x_1}||_{\rm HS}^2}{{\rm e}^{nP(A,2)}}\le
Cm([x_1\cdots x_n]) . \end{equation*}
\begin{equation*}\frac{1}{C}m([x_1\cdots x_n])\le
\frac{||A_{x_n}\cdot\cdots\cdot A_{x_1}||_{\rm HS}^2}{{\rm e}^{nP(A,2)}}\le
Cm([x_1\cdots x_n]) . \end{equation*} We have already seen that  $P(A,2)=\beta_V$. Together with the Gibbs property of Proposition 2.2, the formula above implies that m is absolutely continuous with respect to
$P(A,2)=\beta_V$. Together with the Gibbs property of Proposition 2.2, the formula above implies that m is absolutely continuous with respect to  $\kappa_{\Sigma,V}$. Since m is invariant and
$\kappa_{\Sigma,V}$. Since m is invariant and  $\kappa_{G,V}$ is ergodic, they must coincide.
$\kappa_{G,V}$ is ergodic, they must coincide.
Before stating the last lemma of this section, we need to define the Lyapounov exponents of the fractal. We consider the map
 \begin{equation*}H\colon G\rightarrow M^d\end{equation*}
\begin{equation*}H\colon G\rightarrow M^d\end{equation*} \begin{equation*}H\colon x\rightarrow (D\psi_i)_\ast\quad \text{if}\ x\in{\cal O}_i, \end{equation*}
\begin{equation*}H\colon x\rightarrow (D\psi_i)_\ast\quad \text{if}\ x\in{\cal O}_i, \end{equation*} which is defined  $\kappa_{G,V}$-a.e. on G. For the expanding map F defined in (F4), we set
$\kappa_{G,V}$-a.e. on G. For the expanding map F defined in (F4), we set
 \begin{equation*}H^l(x)=H(x)\cdot H(F(x))\cdot\cdots\cdot H(F^{l-1}(x)). \end{equation*}
\begin{equation*}H^l(x)=H(x)\cdot H(F(x))\cdot\cdots\cdot H(F^{l-1}(x)). \end{equation*} Since Kusuoka’s measure  $\kappa_{G,V}$ is ergodic for the map F, we can apply the results of [Reference Ruelle21] (see [Reference Kelliher8] for a more elementary presentation) and get that for
$\kappa_{G,V}$ is ergodic for the map F, we can apply the results of [Reference Ruelle21] (see [Reference Kelliher8] for a more elementary presentation) and get that for  $\kappa_{G,V}$-a.e.
$\kappa_{G,V}$-a.e.  $x\in G$, there is
$x\in G$, there is  $\Lambda_x\in M^d$ such that
$\Lambda_x\in M^d$ such that
 \begin{align}
\lim_{l\rightarrow+\infty}
\left[H^l(x)\cdot\mu_{G,V}(G)\cdot{{}^{t}} H^l(x)\right]^\frac{1}{2l}=\Lambda_x.
\end{align}
\begin{align}
\lim_{l\rightarrow+\infty}
\left[H^l(x)\cdot\mu_{G,V}(G)\cdot{{}^{t}} H^l(x)\right]^\frac{1}{2l}=\Lambda_x.
\end{align} The fact that  $\kappa_{G,V}$ is ergodic for F implies by [Reference Ruelle21] that neither the eigenvalues of
$\kappa_{G,V}$ is ergodic for F implies by [Reference Ruelle21] that neither the eigenvalues of  $\Lambda_x$ nor their multiplicities depend on x.
$\Lambda_x$ nor their multiplicities depend on x.
Though we would not need it in the following, we recall Lemma 6.2 of [Reference Bessi3].
Lemma 2.4. Let the maps ψi, the Gibbs measure  $\mu_{G,V}$ and Kusuoka’s measure
$\mu_{G,V}$ and Kusuoka’s measure  $\kappa_{G,V}$ be as in Theorem 2.1. Let us suppose that the maximal eigenvalue of
$\kappa_{G,V}$ be as in Theorem 2.1. Let us suppose that the maximal eigenvalue of  $\Lambda_x$ is simple and let us call
$\Lambda_x$ is simple and let us call  $\hat E_x$ its eigenspace; let
$\hat E_x$ its eigenspace; let  $P_{\hat E_x}$ be the orthogonal projection on
$P_{\hat E_x}$ be the orthogonal projection on  $\hat E_x$. Then, we have that
$\hat E_x$. Then, we have that
 \begin{equation*}\mu_{G,V}=P_{\hat E_x}||\mu_{G,V}|| . \end{equation*}
\begin{equation*}\mu_{G,V}=P_{\hat E_x}||\mu_{G,V}|| . \end{equation*} Moreover, we have that, for  $\kappa_{G,V}$-a.e.
$\kappa_{G,V}$-a.e.  $x\in G$,
$x\in G$,
 \begin{align}
P_{\hat E_x}=\lim_{l\rightarrow+\infty}
\frac{H^l(x)\cdot\mu_{G,V}(G)\cdot{{}^{t}} H^l(x)}{|| H^l(x)\cdot\mu_{G,V}(G)\cdot{{}^{t}} H^l(x) ||_{\rm HS}} .
\end{align}
\begin{align}
P_{\hat E_x}=\lim_{l\rightarrow+\infty}
\frac{H^l(x)\cdot\mu_{G,V}(G)\cdot{{}^{t}} H^l(x)}{|| H^l(x)\cdot\mu_{G,V}(G)\cdot{{}^{t}} H^l(x) ||_{\rm HS}} .
\end{align}3. Pressure
We define the map  $\gamma_i\colon \Sigma\rightarrow \Sigma$ by
$\gamma_i\colon \Sigma\rightarrow \Sigma$ by  $\gamma_i(x)=ix$. As in the last section, (E, S) is either one of
$\gamma_i(x)=ix$. As in the last section, (E, S) is either one of  $(\Sigma,\sigma)$ or (G, F); in both cases, we denote by αi a branch of the inverse of S, i.e.,
$(\Sigma,\sigma)$ or (G, F); in both cases, we denote by αi a branch of the inverse of S, i.e.,  $\alpha_i=\gamma_i$ if
$\alpha_i=\gamma_i$ if  $E=\Sigma$ and
$E=\Sigma$ and  $\alpha_i=\psi_i$ if E = G. If m is a probability measure on E invariant for the map S, we denote by h(m) its entropy.
$\alpha_i=\psi_i$ if E = G. If m is a probability measure on E invariant for the map S, we denote by h(m) its entropy.
Given a potential  $V\in C^{0,\alpha}$(E,R), let
$V\in C^{0,\alpha}$(E,R), let  $Q_{E,V}$ be as in Proposition 2.2; we define
$Q_{E,V}$ be as in Proposition 2.2; we define  ${\cal K}_V(E)$ as the set of the couples
${\cal K}_V(E)$ as the set of the couples  $\{m,M \}$, where m is a non-atomic, S-invariant probability measure on E and
$\{m,M \}$, where m is a non-atomic, S-invariant probability measure on E and  $M\colon E\rightarrow M^q$ is a Borel function such that
$M\colon E\rightarrow M^q$ is a Borel function such that
 \begin{equation*}M(x)\ \text{is semi-positive definite and}\ (Q_{E,V}(x),M(x))_{\rm HS}=1 \ \text{for}\ m\text{-a.e.}\ x\in E. \end{equation*}
\begin{equation*}M(x)\ \text{is semi-positive definite and}\ (Q_{E,V}(x),M(x))_{\rm HS}=1 \ \text{for}\ m\text{-a.e.}\ x\in E. \end{equation*} As a consequence of the equality above, defining  ${\cal P}_{Q_{E,V}}$ as in (2.23), we have
${\cal P}_{Q_{E,V}}$ as in (2.23), we have
 \begin{align}
m=(Q_{E,V},Mm)_{\rm HS}\ \text{and thus}\ Mm\in {\cal P}_{Q_{E,V}}.
\end{align}
\begin{align}
m=(Q_{E,V},Mm)_{\rm HS}\ \text{and thus}\ Mm\in {\cal P}_{Q_{E,V}}.
\end{align} Let now  $\kappa_{E,V}$ and
$\kappa_{E,V}$ and  $\mu_{E,V}$ be as in Proposition 2.2; recalling that
$\mu_{E,V}$ be as in Proposition 2.2; recalling that  $||\mu_{E,V}||$ and
$||\mu_{E,V}||$ and  $\kappa_{E,V}$ are mutually absolutely continuous by (2.22), we can write
$\kappa_{E,V}$ are mutually absolutely continuous by (2.22), we can write
 \begin{equation*}\mu_{E,V}=\tilde M_{E,V}\cdot||\mu_{E,V}||=
M_{E,V}\cdot\kappa_{E,V}, \end{equation*}
\begin{equation*}\mu_{E,V}=\tilde M_{E,V}\cdot||\mu_{E,V}||=
M_{E,V}\cdot\kappa_{E,V}, \end{equation*} with  $M_{E,V}=\tilde M_{E,V}\cdot\frac{{\rm d} ||\mu_{E,V}||}{{\rm d} \kappa_{E,V}}$, where the derivative is in the Radon-Nikodym sense. This yields the first equality below, while the second one comes from the definition of
$M_{E,V}=\tilde M_{E,V}\cdot\frac{{\rm d} ||\mu_{E,V}||}{{\rm d} \kappa_{E,V}}$, where the derivative is in the Radon-Nikodym sense. This yields the first equality below, while the second one comes from the definition of  $\kappa_{E,V}$ in point (6) of Proposition 2.2.
$\kappa_{E,V}$ in point (6) of Proposition 2.2.
 \begin{equation*}(Q_{E,V},M_{E,V})_{\rm HS}\cdot\kappa_{E,V}=
(Q_{E,V},\tilde M_{E,V})_{\rm HS}\cdot||\mu_{E,V}||=\kappa_{E,V}. \end{equation*}
\begin{equation*}(Q_{E,V},M_{E,V})_{\rm HS}\cdot\kappa_{E,V}=
(Q_{E,V},\tilde M_{E,V})_{\rm HS}\cdot||\mu_{E,V}||=\kappa_{E,V}. \end{equation*}As a consequence, we get that
 \begin{equation*}(Q_{E,V}(x),M_{E,V}(x))_{\rm HS}= 1\quad \text{for}\ \kappa_{E,V}\ \text{-a.e.}\ x\in G,\end{equation*}
\begin{equation*}(Q_{E,V}(x),M_{E,V}(x))_{\rm HS}= 1\quad \text{for}\ \kappa_{E,V}\ \text{-a.e.}\ x\in G,\end{equation*} i.e., that  $(\kappa_{E,V},M_{E,V})\in{\cal K}_V(E)$.
$(\kappa_{E,V},M_{E,V})\in{\cal K}_V(E)$.
We denote by  ${\cal B}$ the Borel σ-algebra of E and by
${\cal B}$ the Borel σ-algebra of E and by  $m[\alpha_i(E)|S^{-1}(x)]$ the conditional expectation of
$m[\alpha_i(E)|S^{-1}(x)]$ the conditional expectation of  $1_{\alpha_i(E)}$ with respect to the sigma-algebra
$1_{\alpha_i(E)}$ with respect to the sigma-algebra  $S^{-1}({\cal B})$; paradoxically, this notation means that
$S^{-1}({\cal B})$; paradoxically, this notation means that  $m[\alpha_i(E)|S^{-1}(x)]$ is a Borel function of S(x).
$m[\alpha_i(E)|S^{-1}(x)]$ is a Borel function of S(x).
We denote by h(m) the entropy of an S-invariant measure on E. For  $\{m,M \}\in{\cal K}_V(E)$, we set
$\{m,M \}\in{\cal K}_V(E)$, we set
 \begin{equation*}I_E(m,M)\colon=
h(m)+\int_EV(x)\, {\rm d} m(x)\end{equation*}
\begin{equation*}I_E(m,M)\colon=
h(m)+\int_EV(x)\, {\rm d} m(x)\end{equation*} \begin{align}
+\sum_{i=1}^t
\int_E\log(Q_{E,V}(x),{{}^{t}}\Psi_i\circ M\circ S(x))_{\rm HS}\, {\rm d} m(x).
\end{align}
\begin{align}
+\sum_{i=1}^t
\int_E\log(Q_{E,V}(x),{{}^{t}}\Psi_i\circ M\circ S(x))_{\rm HS}\, {\rm d} m(x).
\end{align}By the last two formulas, (7) becomes
 \begin{equation*}I_G(\kappa_{G,V},M_{G,V})=\sup_{\{m,M \}\in{\cal K}_V(G)}I_G(m,M). \end{equation*}
\begin{equation*}I_G(\kappa_{G,V},M_{G,V})=\sup_{\{m,M \}\in{\cal K}_V(G)}I_G(m,M). \end{equation*} The definition of IE in (3.2) implies immediately that IE is conjugation-invariant; in particular, if  $\Phi\colon \Sigma\rightarrow G$ is the coding of § 2 and
$\Phi\colon \Sigma\rightarrow G$ is the coding of § 2 and  $(m,M)\in{\cal K}_V(\Sigma)$, then
$(m,M)\in{\cal K}_V(\Sigma)$, then
 \begin{equation*}I_\Sigma(m,M)=I_G(\Phi_\sharp m,M\circ\Phi^{-1}) , \end{equation*}
\begin{equation*}I_\Sigma(m,M)=I_G(\Phi_\sharp m,M\circ\Phi^{-1}) , \end{equation*} where  $\Phi_\sharp m$ denotes the push-forward; note that Φ−1 is defined m-a.e.: indeed,
$\Phi_\sharp m$ denotes the push-forward; note that Φ−1 is defined m-a.e.: indeed,  $(m,M)\in{\cal K}_V(G)$ implies that m is non-atomic and we have shown in § 2 that the set
$(m,M)\in{\cal K}_V(G)$ implies that m is non-atomic and we have shown in § 2 that the set  $\{y\in G\;\colon\;\sharp\Phi^{-1}(y) \gt 1 \}$ is countable.
$\{y\in G\;\colon\;\sharp\Phi^{-1}(y) \gt 1 \}$ is countable.
By the two formulas above and Lemma 2.3, (7) is equivalent to
 \begin{align}
I_\Sigma(\kappa_{\Sigma,V},M_{\Sigma,V})=
\sup_{\{m,M \}\in{\cal K}_V(\Sigma)}I_\Sigma(m,M)
\end{align}
\begin{align}
I_\Sigma(\kappa_{\Sigma,V},M_{\Sigma,V})=
\sup_{\{m,M \}\in{\cal K}_V(\Sigma)}I_\Sigma(m,M)
\end{align}and this is what we shall prove.
Notation. Since from now on we shall work on Σ, we simplify our notation:
 \begin{align*}{\cal L}_V\colon={\cal L}_{\Sigma,V},\quad
\kappa_V\colon=\kappa_{\Sigma,V},
\mu_V\colon=\mu_{\Sigma,V},
\beta_V\colon=\beta_{\Sigma,V},
P_V\colon=\log\beta_{\Sigma,V},
\quad Q_V\colon=Q_{\Sigma, V}. \end{align*}
\begin{align*}{\cal L}_V\colon={\cal L}_{\Sigma,V},\quad
\kappa_V\colon=\kappa_{\Sigma,V},
\mu_V\colon=\mu_{\Sigma,V},
\beta_V\colon=\beta_{\Sigma,V},
P_V\colon=\log\beta_{\Sigma,V},
\quad Q_V\colon=Q_{\Sigma, V}. \end{align*} We begin writing  $I_\Sigma$ in a slightly different way. Since
$I_\Sigma$ in a slightly different way. Since  $m[\gamma_i(E)|\sigma^{-1}(x)]$ is the conditional expectation of
$m[\gamma_i(E)|\sigma^{-1}(x)]$ is the conditional expectation of  $1_{\gamma_i(\Sigma)}$ with respect to
$1_{\gamma_i(\Sigma)}$ with respect to  $\sigma^{-1}({\cal B})$, we get the first equality below; the second one follows since
$\sigma^{-1}({\cal B})$, we get the first equality below; the second one follows since  $\gamma_i\circ\sigma$ is the identity on
$\gamma_i\circ\sigma$ is the identity on  $\gamma_i(\Sigma)$; the last equality follows since the sets
$\gamma_i(\Sigma)$; the last equality follows since the sets  $\gamma_i(\Sigma)$ are a partition of Σ.
$\gamma_i(\Sigma)$ are a partition of Σ.
 \begin{equation*}\sum_{i=1}^t\int_\Sigma m[\gamma_i(\Sigma)|\sigma^{-1}(x)]\cdot\log(Q_{V}\circ\gamma_i\circ\sigma(x),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}
\, {\rm d} m(x)\end{equation*}
\begin{equation*}\sum_{i=1}^t\int_\Sigma m[\gamma_i(\Sigma)|\sigma^{-1}(x)]\cdot\log(Q_{V}\circ\gamma_i\circ\sigma(x),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}
\, {\rm d} m(x)\end{equation*} \begin{equation*}=\sum_{i=1}^t\int_{\gamma_i(\Sigma)}\log(Q_{V}\circ\gamma_i\circ\sigma(x),{{}^{t}}\Psi_i\circ M\circ\sigma(x))_{\rm HS}\, {\rm d} m(x) \end{equation*}
\begin{equation*}=\sum_{i=1}^t\int_{\gamma_i(\Sigma)}\log(Q_{V}\circ\gamma_i\circ\sigma(x),{{}^{t}}\Psi_i\circ M\circ\sigma(x))_{\rm HS}\, {\rm d} m(x) \end{equation*} \begin{equation*}=\sum_{i=1}^t
\int_{\gamma_i(\Sigma)}\log(Q_{V}(x),{{}^{t}}\Psi_i\circ M\circ\sigma(x))_{\rm HS}\, {\rm d} m(x)\end{equation*}
\begin{equation*}=\sum_{i=1}^t
\int_{\gamma_i(\Sigma)}\log(Q_{V}(x),{{}^{t}}\Psi_i\circ M\circ\sigma(x))_{\rm HS}\, {\rm d} m(x)\end{equation*} \begin{equation*}=\int_\Sigma\log(Q_{V}(x),{{}^{t}}\Psi_i\circ M\circ\sigma(x))_{\rm HS}\, {\rm d} m(x). \end{equation*}
\begin{equation*}=\int_\Sigma\log(Q_{V}(x),{{}^{t}}\Psi_i\circ M\circ\sigma(x))_{\rm HS}\, {\rm d} m(x). \end{equation*}We can thus rewrite (3.2) as
 \begin{equation*}I_\Sigma(m,M)\colon=
h(m)+\int_\Sigma V(x)\, {\rm d} m(x)\end{equation*}
\begin{equation*}I_\Sigma(m,M)\colon=
h(m)+\int_\Sigma V(x)\, {\rm d} m(x)\end{equation*} \begin{align}
+\sum_{i=1}^t\int_\Sigma m[\gamma_i(\Sigma)|\sigma^{-1}(x)]\cdot\log(Q_{V}\circ\gamma_i\circ\sigma(x),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}\,
{\rm d} m(x).
\end{align}
\begin{align}
+\sum_{i=1}^t\int_\Sigma m[\gamma_i(\Sigma)|\sigma^{-1}(x)]\cdot\log(Q_{V}\circ\gamma_i\circ\sigma(x),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}\,
{\rm d} m(x).
\end{align} Let m be a σ-invariant probability measure on Σ; in Formula (3.5), we express  $m[i|\sigma^{-1}(x)]$ using disintegration; in (3.6), we express it as a limit. We recall that a statement of the disintegration theorem is in Theorem 5.3.1 of [Reference Ambrosio, Gigli and Savaré1]; the full theory is in [Reference Schwarz19], while [Reference Rokhlin17] and [18] follow a different approach.
$m[i|\sigma^{-1}(x)]$ using disintegration; in (3.6), we express it as a limit. We recall that a statement of the disintegration theorem is in Theorem 5.3.1 of [Reference Ambrosio, Gigli and Savaré1]; the full theory is in [Reference Schwarz19], while [Reference Rokhlin17] and [18] follow a different approach.
We disintegrate m with respect to the map  $\sigma\colon \Sigma\rightarrow \Sigma$, which is measurable from
$\sigma\colon \Sigma\rightarrow \Sigma$, which is measurable from  ${\cal B}$ to
${\cal B}$ to  ${\cal B}$ and preserves m. The disintegration theorem implies the first equality below, the second one follows from the fact that m is σ-invariant.
${\cal B}$ and preserves m. The disintegration theorem implies the first equality below, the second one follows from the fact that m is σ-invariant.
 \begin{equation*}m=\tilde\eta_{x}\otimes(\sigma_\sharp m)=\tilde\eta_{x}\otimes m . \end{equation*}
\begin{equation*}m=\tilde\eta_{x}\otimes(\sigma_\sharp m)=\tilde\eta_{x}\otimes m . \end{equation*} This means the following: first,  $\tilde\eta_{x}$ is a probability measure on Σ, which concentrates on
$\tilde\eta_{x}$ is a probability measure on Σ, which concentrates on  $\sigma^{-1}(x)$. Second, if
$\sigma^{-1}(x)$. Second, if  $B\in{\cal B}$, then the map
$B\in{\cal B}$, then the map  $\colon x\rightarrow \tilde\eta_{x}(B)$ is
$\colon x\rightarrow \tilde\eta_{x}(B)$ is  ${\cal B}$-measurable. Lastly, if
${\cal B}$-measurable. Lastly, if  $f\colon \Sigma\rightarrow \textbf{R}$ is a bounded
$f\colon \Sigma\rightarrow \textbf{R}$ is a bounded  ${\cal B}$-measurable function, then
${\cal B}$-measurable function, then
 \begin{equation*}\int_{\Sigma}f(x)\, {\rm d} m(x)=
\int_\Sigma {\rm d} \sigma_\sharp( m)(x)\int_\Sigma f(z)\, {\rm d} \tilde\eta_{x}(z) . \end{equation*}
\begin{equation*}\int_{\Sigma}f(x)\, {\rm d} m(x)=
\int_\Sigma {\rm d} \sigma_\sharp( m)(x)\int_\Sigma f(z)\, {\rm d} \tilde\eta_{x}(z) . \end{equation*} We set  $\eta_x=\tilde\eta_{\sigma(x)}$; by the remarks above, ηx concentrates on
$\eta_x=\tilde\eta_{\sigma(x)}$; by the remarks above, ηx concentrates on  $\sigma^{-1}(\sigma(x))$, i.e., on the fibre containing x, and, if
$\sigma^{-1}(\sigma(x))$, i.e., on the fibre containing x, and, if  $B\in{\cal B}$, the map
$B\in{\cal B}$, the map  $\colon x\rightarrow \eta_x(B)$ is
$\colon x\rightarrow \eta_x(B)$ is  $\sigma^{-1}({\cal B})$-measurable.
$\sigma^{-1}({\cal B})$-measurable.
Let  $g\colon \Sigma\rightarrow \textbf{R}$ be a bounded Borel function; the first equality below comes from the disintegration above; the second one follows from the fact that
$g\colon \Sigma\rightarrow \textbf{R}$ be a bounded Borel function; the first equality below comes from the disintegration above; the second one follows from the fact that  $\sigma_\sharp m=m$ and the definition of ηx. The third equality follows from the fact that
$\sigma_\sharp m=m$ and the definition of ηx. The third equality follows from the fact that  $g\circ\sigma$ is constantly equal to
$g\circ\sigma$ is constantly equal to  $g\circ\sigma(x)$ on the fibre
$g\circ\sigma(x)$ on the fibre  $\sigma^{-1}(\sigma(x))$ on which
$\sigma^{-1}(\sigma(x))$ on which  $\eta_x=\tilde\eta_{\sigma(x)}$ concentrates.
$\eta_x=\tilde\eta_{\sigma(x)}$ concentrates.
 \begin{equation*}\int_\Sigma 1_{[i]}(x) g\circ\sigma(x)\, {\rm d} m(x)=
\int_\Sigma {\rm d} m(x)\int_\Sigma 1_{[i]}(z)g\circ\sigma(z)\, {\rm d} \tilde\eta_x(z)\end{equation*}
\begin{equation*}\int_\Sigma 1_{[i]}(x) g\circ\sigma(x)\, {\rm d} m(x)=
\int_\Sigma {\rm d} m(x)\int_\Sigma 1_{[i]}(z)g\circ\sigma(z)\, {\rm d} \tilde\eta_x(z)\end{equation*} \begin{equation*}=\int_\Sigma {\rm d} m(x)\int_\Sigma 1_{[i]}(z)g\circ\sigma(z)\, {\rm d} \eta_x(z)=
\int_\Sigma g\circ\sigma(x)\, {\rm d} m(x)\int_\Sigma 1_{[i]}(z)\, {\rm d} \eta_x(z). \end{equation*}
\begin{equation*}=\int_\Sigma {\rm d} m(x)\int_\Sigma 1_{[i]}(z)g\circ\sigma(z)\, {\rm d} \eta_x(z)=
\int_\Sigma g\circ\sigma(x)\, {\rm d} m(x)\int_\Sigma 1_{[i]}(z)\, {\rm d} \eta_x(z). \end{equation*} Since  $g\circ\sigma$ is an arbitrary, bounded
$g\circ\sigma$ is an arbitrary, bounded  $\sigma^{-1}({\cal B})$-measurable function and we saw above that
$\sigma^{-1}({\cal B})$-measurable function and we saw above that  $\eta_x([i])$ is
$\eta_x([i])$ is  $\sigma^{-1}({\cal B})$-measurable, the formula above is the definition of conditional expectation. In other words, we have the first equality below, while the second one is trivial.
$\sigma^{-1}({\cal B})$-measurable, the formula above is the definition of conditional expectation. In other words, we have the first equality below, while the second one is trivial.
 \begin{align}
m[i|\sigma^{-1}(x)]=\eta_{x}([i])=\int_\Sigma 1_{[i]}(z)\, {\rm d} \eta_{x}(z) .
\end{align}
\begin{align}
m[i|\sigma^{-1}(x)]=\eta_{x}([i])=\int_\Sigma 1_{[i]}(z)\, {\rm d} \eta_{x}(z) .
\end{align}Rokhlin’s theorem [Reference Rokhlin17, 18] is an analogue of Lebesgue’s differentiation theorem for sequences of finer and finer partitions; the ones we consider are
 \begin{equation*}\{
\sigma^{-1}[x_0\ldots x_l]\colon \{x_i \}_{i\ge 0}\in\Sigma\qquad l\ge 0
\}.
\end{equation*}
\begin{equation*}\{
\sigma^{-1}[x_0\ldots x_l]\colon \{x_i \}_{i\ge 0}\in\Sigma\qquad l\ge 0
\}.
\end{equation*} These partitions generate  $\sigma^{-1}({\cal B})$; by Rokhlin’s theorem, for m-a.e.
$\sigma^{-1}({\cal B})$; by Rokhlin’s theorem, for m-a.e.  $x\in\Sigma$,
$x\in\Sigma$,  $\eta_x([i])$ is the limit of the quotient of the measure of
$\eta_x([i])$ is the limit of the quotient of the measure of  $[i]$ intersected with the element of the partition containing
$[i]$ intersected with the element of the partition containing  $\sigma^{-1}(\sigma(x))$ (i.e., the fibre containing x) and the measure of this element. This yields the first equality below, while the second one follows by the definition of σ and the third one from the fact that m is σ-invariant.
$\sigma^{-1}(\sigma(x))$ (i.e., the fibre containing x) and the measure of this element. This yields the first equality below, while the second one follows by the definition of σ and the third one from the fact that m is σ-invariant.
 \begin{equation*}\eta_{x}([i])=
\lim_{l\rightarrow+\infty}
\frac{
m([i]\cap\sigma^{-1}(\sigma[x_0\cdots x_l]))
}{
m(\sigma^{-1}(\sigma[x_0\cdots x_l]))
}\end{equation*}
\begin{equation*}\eta_{x}([i])=
\lim_{l\rightarrow+\infty}
\frac{
m([i]\cap\sigma^{-1}(\sigma[x_0\cdots x_l]))
}{
m(\sigma^{-1}(\sigma[x_0\cdots x_l]))
}\end{equation*} \begin{equation*}=\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m(\sigma^{-1}([x_1\cdots x_l]))
} =
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
}. \end{equation*}
\begin{equation*}=\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m(\sigma^{-1}([x_1\cdots x_l]))
} =
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
}. \end{equation*} We already know it, but from the formula above, it follows again that  $\eta_x([i])$ is
$\eta_x([i])$ is  $\sigma^{-1}({\cal B})$-measurable. Expressing
$\sigma^{-1}({\cal B})$-measurable. Expressing  $\eta_x([i])$ as a limit as in the formula above and using (3.5), we get that, for m-a.e.
$\eta_x([i])$ as a limit as in the formula above and using (3.5), we get that, for m-a.e.  $x\in\Sigma$,
$x\in\Sigma$,
 \begin{align}
m[i|\sigma^{-1}(x)]=
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
}.
\end{align}
\begin{align}
m[i|\sigma^{-1}(x)]=
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
}.
\end{align}We recall a lemma of [Reference Parry and Pollicott15].
Lemma 3.1. Let m be an invariant probability measure on Σ; then, for m-a.e.  $x\in\Sigma$, we have
$x\in\Sigma$, we have
 \begin{align}
\sum_{i=1}^t m[i|\sigma^{-1}(x)]=1.
\end{align}
\begin{align}
\sum_{i=1}^t m[i|\sigma^{-1}(x)]=1.
\end{align}Proof. The first equality below is (3.6), and it holds for m-a.e.  $x\in\Sigma$; the second one follows since the cylinders
$x\in\Sigma$; the second one follows since the cylinders  $[ix_1\cdots x_l]$ are disjoint as i varies in
$[ix_1\cdots x_l]$ are disjoint as i varies in  $(1,\dots,t)$; the third one follows by the definition of the map σ and the last one from the fact that m is σ-invariant.
$(1,\dots,t)$; the third one follows by the definition of the map σ and the last one from the fact that m is σ-invariant.
 \begin{equation*}\sum_{i=1}^t m[i|\sigma^{-1}(x)]=
\lim_{l\rightarrow+\infty}\sum_{i=1}^t\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
} \end{equation*}
\begin{equation*}\sum_{i=1}^t m[i|\sigma^{-1}(x)]=
\lim_{l\rightarrow+\infty}\sum_{i=1}^t\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
} \end{equation*} \begin{equation*}=\lim_{l\rightarrow+\infty}
\frac{
m\left(
\bigcup_{i=1}^t[ix_1\cdots x_l]
\right)
}{
m([x_1\cdots x_l])
}
=
\lim_{l\rightarrow+\infty}
\frac{
m(
\sigma^{-1}([x_1\cdots x_l])}{
m([x_1\cdots x_l])
}
=1 . \end{equation*}
\begin{equation*}=\lim_{l\rightarrow+\infty}
\frac{
m\left(
\bigcup_{i=1}^t[ix_1\cdots x_l]
\right)
}{
m([x_1\cdots x_l])
}
=
\lim_{l\rightarrow+\infty}
\frac{
m(
\sigma^{-1}([x_1\cdots x_l])}{
m([x_1\cdots x_l])
}
=1 . \end{equation*}We also recall from [Reference Parry and Pollicott15] a consequence of the Kolmogorov–Sinai formula ([Reference Walters24]): if m is an invariant probability measure on Σ, then
 \begin{align}
h(m)=
-\sum_{i=1}^t\int_\Sigma
m[i|\sigma^{-1}(x)]\cdot\log m[i|\sigma^{-1}(x)]\, {\rm d} m(x).
\end{align}
\begin{align}
h(m)=
-\sum_{i=1}^t\int_\Sigma
m[i|\sigma^{-1}(x)]\cdot\log m[i|\sigma^{-1}(x)]\, {\rm d} m(x).
\end{align}The next lemma is another well-known fact.
Lemma 3.2. Let m be an invariant probability measure on Σ; let  $\gamma_i\colon (x_0x_1\ldots)\rightarrow (ix_0x_1\cdots)$ and let us suppose that
$\gamma_i\colon (x_0x_1\ldots)\rightarrow (ix_0x_1\cdots)$ and let us suppose that
 \begin{align}
(\gamma_i)_\sharp m=am
\end{align}
\begin{align}
(\gamma_i)_\sharp m=am
\end{align} for a probability density a which is positive on  $[i]$. Then,
$[i]$. Then,
 \begin{align}
m[i|\sigma^{-1}(x)]=\frac{1}{a\circ\gamma_i\circ\sigma(x)} .
\end{align}
\begin{align}
m[i|\sigma^{-1}(x)]=\frac{1}{a\circ\gamma_i\circ\sigma(x)} .
\end{align}Proof. The first equality below is (3.6), and it holds for m-a.e.  $x=(x_0x_1\cdots)\in\Sigma$; the second one follows from the definition of γi and of the push-forward; the third one follows from (3.9) and the fourth one from Rokhlin’s theorem applied to the partition of
$x=(x_0x_1\cdots)\in\Sigma$; the second one follows from the definition of γi and of the push-forward; the third one follows from (3.9) and the fourth one from Rokhlin’s theorem applied to the partition of  $[i]$ given by the sets
$[i]$ given by the sets  $[ix_1\cdots x_l]$ as
$[ix_1\cdots x_l]$ as  $l\ge 1$ and
$l\ge 1$ and  $(ix_0x_1\cdots)\in\Sigma$; it holds for m-a.e.
$(ix_0x_1\cdots)\in\Sigma$; it holds for m-a.e.  $x\in \Sigma$. The last equality follows from the definition of γi and σ.
$x\in \Sigma$. The last equality follows from the definition of γi and σ.
 \begin{equation*}m[i|\sigma^{-1}(x)]=
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
} =
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
[(\gamma_i)_\sharp m]([ix_1\cdots x_l])
} \end{equation*}
\begin{equation*}m[i|\sigma^{-1}(x)]=
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
m([x_1\cdots x_l])
} =
\lim_{l\rightarrow+\infty}\frac{
m([ix_1\cdots x_l])
}{
[(\gamma_i)_\sharp m]([ix_1\cdots x_l])
} \end{equation*} \begin{equation*}=\lim_{l\rightarrow+\infty}
\frac{m([ix_1\cdots x_l])}{\int_{[ix_1\cdots x_l]}a(z)\, {\rm d} m(z)}
=
\frac{1}{a(ix_1x_2\cdots)}=
\frac{1}{a\circ\gamma_i\circ\sigma(x)} . \end{equation*}
\begin{equation*}=\lim_{l\rightarrow+\infty}
\frac{m([ix_1\cdots x_l])}{\int_{[ix_1\cdots x_l]}a(z)\, {\rm d} m(z)}
=
\frac{1}{a(ix_1x_2\cdots)}=
\frac{1}{a\circ\gamma_i\circ\sigma(x)} . \end{equation*}Lemma 3.3. Let  $V\in C^{0,\alpha}(\Sigma,\textbf{R})$, let µV and QV be as in the notation after Formula (3.3); let
$V\in C^{0,\alpha}(\Sigma,\textbf{R})$, let µV and QV be as in the notation after Formula (3.3); let  $\gamma_i\colon \Sigma\rightarrow \Sigma$ be as in Lemma 3.2. Then, the following formulas hold.
$\gamma_i\colon \Sigma\rightarrow \Sigma$ be as in Lemma 3.2. Then, the following formulas hold.
 \begin{align}
(\gamma_i)_\sharp\mu_V=\beta_V\,{\rm e}^{-V(x)}\cdot({{}^{t}}\Psi_i)^{-1}\cdot\mu_V|_{[i]} .
\end{align}
\begin{align}
(\gamma_i)_\sharp\mu_V=\beta_V\,{\rm e}^{-V(x)}\cdot({{}^{t}}\Psi_i)^{-1}\cdot\mu_V|_{[i]} .
\end{align} \begin{align}
(\gamma_i)_\sharp\kappa_V=\beta_V \,{\rm e}^{-V(x)}(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot\mu_V|_{[i]})_{\rm HS}
\end{align}
\begin{align}
(\gamma_i)_\sharp\kappa_V=\beta_V \,{\rm e}^{-V(x)}(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot\mu_V|_{[i]})_{\rm HS}
\end{align} or equivalently, setting  $\mu_V=M_V\cdot\kappa_V$,
$\mu_V=M_V\cdot\kappa_V$,
 \begin{align}
(\gamma_i)_\sharp\kappa_V=1_{[i]}(x)\cdot \beta_V \,{\rm e}^{-V(x)}(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(x))_{\rm HS}
\cdot\kappa_V.
\end{align}
\begin{align}
(\gamma_i)_\sharp\kappa_V=1_{[i]}(x)\cdot \beta_V \,{\rm e}^{-V(x)}(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(x))_{\rm HS}
\cdot\kappa_V.
\end{align}Lastly,
 \begin{align}
\kappa_V[i|\sigma^{-1}(x)]=
\frac{
{\rm e}^{V(i\sigma(x))}
}{
\beta_V(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
} .
\end{align}
\begin{align}
\kappa_V[i|\sigma^{-1}(x)]=
\frac{
{\rm e}^{V(i\sigma(x))}
}{
\beta_V(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
} .
\end{align}Proof. We begin with (3.11). We recall that the Gibbs property follows iterating Lemma 4.1 of [Reference Bessi3], which says the following: let  $\eta\in(0,1)$ be as in (2.2); then, there is
$\eta\in(0,1)$ be as in (2.2); then, there is  $D_1 \gt 0$ such that, for all
$D_1 \gt 0$ such that, for all  $x=(x_0x_1\cdots)\in\Sigma$ and
$x=(x_0x_1\cdots)\in\Sigma$ and  $l\in\textbf{N}$,
$l\in\textbf{N}$,
 \begin{equation*}\frac{1}{\beta_V}{\rm e}^{-D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot\mu_V([x_1\cdots x_{l-1}])\le
\mu_V([x_0x_1\cdots x_{l-1}])\end{equation*}
\begin{equation*}\frac{1}{\beta_V}{\rm e}^{-D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot\mu_V([x_1\cdots x_{l-1}])\le
\mu_V([x_0x_1\cdots x_{l-1}])\end{equation*} \begin{align}
\le\frac{1}{\beta_V}{\rm e}^{D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot\mu_V([x_1\cdots x_{l-1}]),
\end{align}
\begin{align}
\le\frac{1}{\beta_V}{\rm e}^{D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot\mu_V([x_1\cdots x_{l-1}]),
\end{align}where the inequalities are the standard ones between symmetric matrices.
The first equality below is the definition of the push-forward, the second one follows by the definition of γi.
 \begin{equation*}[(\gamma_i)_\sharp\mu_V]([x_0x_1\cdots x_{l-1}])=\mu_V(\gamma_i^{-1}([x_0x_1\cdots x_{l-1}]))
=\left\{
\begin{aligned}
\mu_V([x_1\cdots x_{l-1}]) &\quad \text{if } x_0=i\cr
0 &\quad \text{otherwise.}
\end{aligned}
\right.\end{equation*}
\begin{equation*}[(\gamma_i)_\sharp\mu_V]([x_0x_1\cdots x_{l-1}])=\mu_V(\gamma_i^{-1}([x_0x_1\cdots x_{l-1}]))
=\left\{
\begin{aligned}
\mu_V([x_1\cdots x_{l-1}]) &\quad \text{if } x_0=i\cr
0 &\quad \text{otherwise.}
\end{aligned}
\right.\end{equation*} Since both  $(\gamma_i)_\sharp\mu_V$ and
$(\gamma_i)_\sharp\mu_V$ and  $\mu_V|_{[i]}$ concentrate on
$\mu_V|_{[i]}$ concentrate on  $[i]$, it suffices to show that the two measures of (3.11) coincide on the Borel sets of
$[i]$, it suffices to show that the two measures of (3.11) coincide on the Borel sets of  $[i]$. Thus, in the formula above, we suppose that
$[i]$. Thus, in the formula above, we suppose that  $x_0=i$ and we rewrite (3.15) in this case.
$x_0=i$ and we rewrite (3.15) in this case.
 \begin{equation*}\frac{1}{\beta_V}\,{\rm e}^{-D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot
[(\gamma_i)_\sharp\mu_V]([x_0x_1\cdots x_{l-1}])\le
\mu_V([x_0x_1\cdots x_{l-1}])\end{equation*}
\begin{equation*}\frac{1}{\beta_V}\,{\rm e}^{-D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot
[(\gamma_i)_\sharp\mu_V]([x_0x_1\cdots x_{l-1}])\le
\mu_V([x_0x_1\cdots x_{l-1}])\end{equation*} \begin{equation*}\le\frac{1}{\beta_V}\,{\rm e}^{D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot
[(\gamma_i)_\sharp\mu_V]([x_0x_1\cdots x_{l-1}]) . \end{equation*}
\begin{equation*}\le\frac{1}{\beta_V}\,{\rm e}^{D_1\eta^{\alpha l}}\cdot {\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot
[(\gamma_i)_\sharp\mu_V]([x_0x_1\cdots x_{l-1}]) . \end{equation*} This is true for all  $x\in[x_0x_1\cdots x_{l-1}]$; by the last formula and monotonicity of the integral, we get that
$x\in[x_0x_1\cdots x_{l-1}]$; by the last formula and monotonicity of the integral, we get that
 \begin{equation*}\frac{1}{\beta_V}\,{\rm e}^{-D_1\eta^{\alpha l}}
\int_{[x_0x_1\ldots x_{l-1}]}{\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot {\rm d} [(\gamma_i)_\sharp\mu_V](x)\le
\mu_V([x_0\cdots x_{l-1}])\end{equation*}
\begin{equation*}\frac{1}{\beta_V}\,{\rm e}^{-D_1\eta^{\alpha l}}
\int_{[x_0x_1\ldots x_{l-1}]}{\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot {\rm d} [(\gamma_i)_\sharp\mu_V](x)\le
\mu_V([x_0\cdots x_{l-1}])\end{equation*} \begin{equation*}\le\frac{1}{\beta_V}\,{\rm e}^{D_1\eta^{\alpha l}}
\int_{[x_0x_1\cdots x_{l-1}]}{\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot {\rm d} [(\gamma_i)_\sharp\mu_V](x). \end{equation*}
\begin{equation*}\le\frac{1}{\beta_V}\,{\rm e}^{D_1\eta^{\alpha l}}
\int_{[x_0x_1\cdots x_{l-1}]}{\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot {\rm d} [(\gamma_i)_\sharp\mu_V](x). \end{equation*} Fix  $k\ge 1$; since
$k\ge 1$; since  $[x_0\cdots x_k]$ is the disjoint union of the cylinders
$[x_0\cdots x_k]$ is the disjoint union of the cylinders  $[x_0\cdots x_k x_{k+1}\cdots x_l]$, the last formula and the fact that
$[x_0\cdots x_k x_{k+1}\cdots x_l]$, the last formula and the fact that  ${\rm e}^{D_1\eta^{\alpha l}}\rightarrow 1$ as
${\rm e}^{D_1\eta^{\alpha l}}\rightarrow 1$ as  $l\rightarrow+\infty$ imply easily that if
$l\rightarrow+\infty$ imply easily that if  $x_0=i$ and
$x_0=i$ and  $k\ge 1$, then
$k\ge 1$, then
 \begin{equation*}\mu_V([x_0\cdots x_{k-1}])=
\frac{1}{\beta_V}\int_{[x_0x_1\cdots x_{k-1}]}
{\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot {\rm d} [(\gamma_i)_\sharp\mu_V](x) . \end{equation*}
\begin{equation*}\mu_V([x_0\cdots x_{k-1}])=
\frac{1}{\beta_V}\int_{[x_0x_1\cdots x_{k-1}]}
{\rm e}^{V(x)}\cdot{{}^{t}}\Psi_i\cdot {\rm d} [(\gamma_i)_\sharp\mu_V](x) . \end{equation*} Since the cylinders  $[x_0\cdots x_{k-1}]$ generate the Borel sets of
$[x_0\cdots x_{k-1}]$ generate the Borel sets of  $[x_0]=[i]$, the last formula implies that
$[x_0]=[i]$, the last formula implies that
 \begin{equation*}\mu_V|_{[i]}=\frac{1}{\beta_V}\,{\rm e}^V\cdot{{}^{t}}\Psi_i\cdot[(\gamma_i)_\sharp\mu_V]\end{equation*}
\begin{equation*}\mu_V|_{[i]}=\frac{1}{\beta_V}\,{\rm e}^V\cdot{{}^{t}}\Psi_i\cdot[(\gamma_i)_\sharp\mu_V]\end{equation*}from which (3.11) follows.
Now to (3.12). Let  $f\colon \Sigma\rightarrow \textbf{R}$ be a bounded Borel function. The first equality below is the definition of the push-forward, the second one of κV; the third one comes because, by definition,
$f\colon \Sigma\rightarrow \textbf{R}$ be a bounded Borel function. The first equality below is the definition of the push-forward, the second one of κV; the third one comes because, by definition,  $\sigma\circ\gamma_i$ is the identity on Σ. The fourth one follows from the definition of the push-forward and the last one from (3.11).
$\sigma\circ\gamma_i$ is the identity on Σ. The fourth one follows from the definition of the push-forward and the last one from (3.11).
 \begin{equation*}\int_{[i]} f(x)\, {\rm d} [(\gamma_i)_\sharp\kappa_V](x)=
\int_{\Sigma} f\circ\gamma_i(z)\, {\rm d} \kappa_V(z)\end{equation*}
\begin{equation*}\int_{[i]} f(x)\, {\rm d} [(\gamma_i)_\sharp\kappa_V](x)=
\int_{\Sigma} f\circ\gamma_i(z)\, {\rm d} \kappa_V(z)\end{equation*} \begin{equation*}=\int_\Sigma f\circ\gamma_i(z)(Q_V(z), {\rm d} \mu_V(z))_{\rm HS}=
\int_\Sigma f\circ\gamma_i(z)(Q_V\circ\sigma\circ\gamma_i(z), {\rm d} \mu_V(z))_{\rm HS}\end{equation*}
\begin{equation*}=\int_\Sigma f\circ\gamma_i(z)(Q_V(z), {\rm d} \mu_V(z))_{\rm HS}=
\int_\Sigma f\circ\gamma_i(z)(Q_V\circ\sigma\circ\gamma_i(z), {\rm d} \mu_V(z))_{\rm HS}\end{equation*} \begin{equation*}=\int_{[i]}f(x)\cdot
(Q_V\circ\sigma(x), {\rm d} [(\gamma_i)_\sharp\mu_V](x))_{\rm HS}=
\int_{[i]}f(x)\cdot\beta_V \,{\rm e}^{-V(x)}\cdot
(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot {\rm d} \mu_V(x))_{\rm HS}. \end{equation*}
\begin{equation*}=\int_{[i]}f(x)\cdot
(Q_V\circ\sigma(x), {\rm d} [(\gamma_i)_\sharp\mu_V](x))_{\rm HS}=
\int_{[i]}f(x)\cdot\beta_V \,{\rm e}^{-V(x)}\cdot
(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot {\rm d} \mu_V(x))_{\rm HS}. \end{equation*} This shows (3.12); as for Formula (3.13), it follows from (3.12) and the fact that  $\mu_V=M_V\cdot\kappa_V$.
$\mu_V=M_V\cdot\kappa_V$.
We recall a well-known fact: if
 \begin{align}
p_i,q_i\ge 0,\quad
\sum_{i=1}^t p_i=\lambda \gt 0,\quad
\sum_{i=1}^t q_i=1,
\end{align}
\begin{align}
p_i,q_i\ge 0,\quad
\sum_{i=1}^t p_i=\lambda \gt 0,\quad
\sum_{i=1}^t q_i=1,
\end{align}then
 \begin{align}
-\sum_{i=1}^t q_i\,\log q_i+\sum_{i=1}^t q_i\,\log p_i\le\log\lambda
\end{align}
\begin{align}
-\sum_{i=1}^t q_i\,\log q_i+\sum_{i=1}^t q_i\,\log p_i\le\log\lambda
\end{align} with equality if and only if  $q_i=\frac{p_i}{\lambda}$ for all
$q_i=\frac{p_i}{\lambda}$ for all  $i\in(1,\dots,t)$.
$i\in(1,\dots,t)$.
Usually (see for instance [Reference Parry and Pollicott15] or [Reference Walters24]), this formula is stated for λ = 1; applying this particular case to  $\left\{\frac{p_i}{\lambda} \right\}_i$, we get the general one.
$\left\{\frac{p_i}{\lambda} \right\}_i$, we get the general one.
For completeness’ sake, we prove below another well-known formula from page 36 of [Reference Parry and Pollicott15]: if  $g\colon \Sigma\rightarrow \textbf{R}$ is a continuous function and m is an invariant probability measure, then the second equality below comes from the definition of conditional expectation; the last one comes from the fact that the sets
$g\colon \Sigma\rightarrow \textbf{R}$ is a continuous function and m is an invariant probability measure, then the second equality below comes from the definition of conditional expectation; the last one comes from the fact that the sets  $[i]$ form a partition of Σ.
$[i]$ form a partition of Σ.
 \begin{equation*}\sum_{i=1}^t\int_\Sigma g(ix_1\cdots)m[i|\sigma^{-1}(x)]\, {\rm d} m(x)=
\sum_{i=1}^t\int_\Sigma g\circ\gamma_i\circ\sigma(x) m[i|\sigma^{-1}(x)]\, {\rm d} m(x)\end{equation*}
\begin{equation*}\sum_{i=1}^t\int_\Sigma g(ix_1\cdots)m[i|\sigma^{-1}(x)]\, {\rm d} m(x)=
\sum_{i=1}^t\int_\Sigma g\circ\gamma_i\circ\sigma(x) m[i|\sigma^{-1}(x)]\, {\rm d} m(x)\end{equation*} \begin{align}
=\sum_{i=1}^t\int_\Sigma g\circ\gamma_i\circ\sigma(x) 1_{[i]}(x)\, {\rm d} m(x)=
\sum_{i=1}^t\int_{[i]}g(ix_1\cdots)\, {\rm d} m(x)=
\int_\Sigma g(x)\, {\rm d} m(x).
\end{align}
\begin{align}
=\sum_{i=1}^t\int_\Sigma g\circ\gamma_i\circ\sigma(x) 1_{[i]}(x)\, {\rm d} m(x)=
\sum_{i=1}^t\int_{[i]}g(ix_1\cdots)\, {\rm d} m(x)=
\int_\Sigma g(x)\, {\rm d} m(x).
\end{align}Proof of Theorem 1
As we saw at the beginning of this section, it suffices to show Formula (3.3), and this is what we shall do.
For  $\{m,M \}\in{\cal K}_V(\Sigma)$ and
$\{m,M \}\in{\cal K}_V(\Sigma)$ and  $x\in\Sigma$, we define the following two functions of x.
$x\in\Sigma$, we define the following two functions of x.
 \begin{align}
q_i(x)=m[i|\sigma^{-1}(x)],\qquad
p_i(x)={\rm e}^{V(i\sigma(x))}(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}.
\end{align}
\begin{align}
q_i(x)=m[i|\sigma^{-1}(x)],\qquad
p_i(x)={\rm e}^{V(i\sigma(x))}(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}.
\end{align} By (3.7),  $\{q_i \}_i$ satisfies (3.16) for m-a.e.
$\{q_i \}_i$ satisfies (3.16) for m-a.e.  $x\in\Sigma$; we show that, setting
$x\in\Sigma$; we show that, setting  $\lambda=\beta_V$,
$\lambda=\beta_V$,  $\{p_i \}_i$ too satisfies (3.16) m-a.e.. The first equality below comes from the definition of pi in the formula above, and for the second one, we transpose; the third one follows by the definition of
$\{p_i \}_i$ too satisfies (3.16) m-a.e.. The first equality below comes from the definition of pi in the formula above, and for the second one, we transpose; the third one follows by the definition of  ${\cal L}_V={\cal L}_{\Sigma,V}$ in (2.24); the fourth one comes from the fact that
${\cal L}_V={\cal L}_{\Sigma,V}$ in (2.24); the fourth one comes from the fact that  ${\cal L}_{V}Q_V=\beta_V Q_V$ and the last equality follows from the fact that
${\cal L}_{V}Q_V=\beta_V Q_V$ and the last equality follows from the fact that  $(m,M)\in{\cal K}_V(\Sigma)$.
$(m,M)\in{\cal K}_V(\Sigma)$.
 \begin{equation*}\sum_{i=1}^t p_i=\sum_{i=1}^t{\rm e}^{V(i\sigma(x))}\cdot
(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS} \end{equation*}
\begin{equation*}\sum_{i=1}^t p_i=\sum_{i=1}^t{\rm e}^{V(i\sigma(x))}\cdot
(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS} \end{equation*} \begin{equation*}=\sum_{i=1}^t {\rm e}^{V(i\sigma(x))}(\Psi_i\cdot Q_V(i\sigma(x)),M\circ\sigma(x))_{\rm HS} \end{equation*}
\begin{equation*}=\sum_{i=1}^t {\rm e}^{V(i\sigma(x))}(\Psi_i\cdot Q_V(i\sigma(x)),M\circ\sigma(x))_{\rm HS} \end{equation*} \begin{equation*}=(({\cal L}_{V}Q_V)(\sigma(x)),M\circ\sigma(x))_{\rm HS}=
\beta_V\cdot (Q_V\circ\sigma(x),M\circ\sigma(x))_{\rm HS}=
\beta_V. \end{equation*}
\begin{equation*}=(({\cal L}_{V}Q_V)(\sigma(x)),M\circ\sigma(x))_{\rm HS}=
\beta_V\cdot (Q_V\circ\sigma(x),M\circ\sigma(x))_{\rm HS}=
\beta_V. \end{equation*} Since (3.16) is satisfied, Formula (3.17) holds, implying that for m-a.e.  $x\in G$, we have
$x\in G$, we have
 \begin{equation*}-\sum_{i=1}^tq_i(x)\,\log q_i(x)+
\sum_{i=1}^t q_i(x)[V(i\sigma(x))+\log(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}]\le
\log\beta_V. \end{equation*}
\begin{equation*}-\sum_{i=1}^tq_i(x)\,\log q_i(x)+
\sum_{i=1}^t q_i(x)[V(i\sigma(x))+\log(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}]\le
\log\beta_V. \end{equation*}Integrating against m, we get that
 \begin{equation*}-\sum_{i=1}^t\int_\Sigma q_i(x)\,\log q_i(x)\, {\rm d} m(x)\end{equation*}
\begin{equation*}-\sum_{i=1}^t\int_\Sigma q_i(x)\,\log q_i(x)\, {\rm d} m(x)\end{equation*} \begin{equation*}+\sum_{i=1}^t\int_\Sigma
q_i(x)[V(i\sigma(x))+\log( Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}] {\rm d} m(x)\le
\log\beta_V. \end{equation*}
\begin{equation*}+\sum_{i=1}^t\int_\Sigma
q_i(x)[V(i\sigma(x))+\log( Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M\circ\sigma(x))_{\rm HS}] {\rm d} m(x)\le
\log\beta_V. \end{equation*}By the first one of (3.19) and (3.8), we get that
 \begin{equation*}-\sum_{i=1}^t\int_\Sigma q_i(x)\,\log q_i(x)\, {\rm d} m(x)=h(m). \end{equation*}
\begin{equation*}-\sum_{i=1}^t\int_\Sigma q_i(x)\,\log q_i(x)\, {\rm d} m(x)=h(m). \end{equation*}The first one of (3.19) and (3.18) imply that
 \begin{equation*}\sum_{i=1}^t\int_\Sigma
q_i(x) V(i\sigma(x))\, {\rm d} m(x)=
\int_\Sigma V(x)\, {\rm d} m(x). \end{equation*}
\begin{equation*}\sum_{i=1}^t\int_\Sigma
q_i(x) V(i\sigma(x))\, {\rm d} m(x)=
\int_\Sigma V(x)\, {\rm d} m(x). \end{equation*} The last three formulas imply that, if  $(m,M)\in{\cal K}_V(\Sigma)$ and
$(m,M)\in{\cal K}_V(\Sigma)$ and  $I_\Sigma$ is defined as in (3.4), then
$I_\Sigma$ is defined as in (3.4), then
 \begin{equation*}I_\Sigma(m,M)\le\log\beta_V. \end{equation*}
\begin{equation*}I_\Sigma(m,M)\le\log\beta_V. \end{equation*} To end the proof of (3.3), it suffices to show that, in the formula above, equality is attained when  $\{m,M\}=\{\kappa_V,M_V \}$. The only inequality in the derivation of the formula above is that of (3.17), which becomes an equality if
$\{m,M\}=\{\kappa_V,M_V \}$. The only inequality in the derivation of the formula above is that of (3.17), which becomes an equality if
 \begin{align}
q_i(x)=\frac{p_i(x)}{\beta_V}\quad \text{for}\ i\in(1,\dots,t)\ \text{and}\ \kappa_V\text{-a.e.}\ x\in\Sigma.
\end{align}
\begin{align}
q_i(x)=\frac{p_i(x)}{\beta_V}\quad \text{for}\ i\in(1,\dots,t)\ \text{and}\ \kappa_V\text{-a.e.}\ x\in\Sigma.
\end{align} This is what we are going to prove. The first equality below is the definition of qi in (3.19) for  $m=\kappa_V$, and the second one is (3.14).
$m=\kappa_V$, and the second one is (3.14).
 \begin{align}
q_i(x)=\kappa_V[i|\sigma^{-1}(x)]=
\frac{
{\rm e}^{V(i\sigma(x))}
}{
\beta_V(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
}.
\end{align}
\begin{align}
q_i(x)=\kappa_V[i|\sigma^{-1}(x)]=
\frac{
{\rm e}^{V(i\sigma(x))}
}{
\beta_V(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
}.
\end{align} We assert that (3.20) would follow if there were some positive Borel function  $\lambda\colon \Sigma\rightarrow \textbf{R}$ such that
$\lambda\colon \Sigma\rightarrow \textbf{R}$ such that
 \begin{align}
{{}^{t}}\Psi_i\cdot M_V\circ\sigma(x)=\lambda(x) M_V(i\sigma(x))
\end{align}
\begin{align}
{{}^{t}}\Psi_i\cdot M_V\circ\sigma(x)=\lambda(x) M_V(i\sigma(x))
\end{align} for m-a.e.  $x\in\Sigma$.
$x\in\Sigma$.
Indeed, this formula implies the two outermost equalities below; the two innermost ones come from the fact that  $\{\kappa_V,M_V \} \in{\cal K}_V(\Sigma)$.
$\{\kappa_V,M_V \} \in{\cal K}_V(\Sigma)$.
 \begin{equation*}\frac{
1
}{
(Q_V\circ\sigma(x),{{}^{t}}\Psi_i^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
} =
\frac{
\lambda(x)
}{
(Q_V\circ\sigma(x),M_V\circ\sigma(x))_{\rm HS}
} =\lambda(x)\end{equation*}
\begin{equation*}\frac{
1
}{
(Q_V\circ\sigma(x),{{}^{t}}\Psi_i^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
} =
\frac{
\lambda(x)
}{
(Q_V\circ\sigma(x),M_V\circ\sigma(x))_{\rm HS}
} =\lambda(x)\end{equation*} \begin{equation*}=\lambda(x)(Q_V(i\sigma(x)),M_V(i\sigma(x)))_{\rm HS}=
(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M_V\circ\sigma(x))_{\rm HS}. \end{equation*}
\begin{equation*}=\lambda(x)(Q_V(i\sigma(x)),M_V(i\sigma(x)))_{\rm HS}=
(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M_V\circ\sigma(x))_{\rm HS}. \end{equation*}The first equality below is (3.21); the second one is the formula above; the last one is (3.19).
 \begin{equation*}q_i(x)=
\frac{
{\rm e}^{V(i\sigma(x))}
}{
\beta_V(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
}\end{equation*}
\begin{equation*}q_i(x)=
\frac{
{\rm e}^{V(i\sigma(x))}
}{
\beta_V(Q_V\circ\sigma(x),({{}^{t}}\Psi_i)^{-1}\cdot M_V(i\sigma(x)))_{\rm HS}
}\end{equation*} \begin{equation*}=\frac{1}{\beta_V}\,{\rm e}^{V(i\sigma(x))}\cdot
(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M_V\circ\sigma(x))_{\rm HS}=
\frac{p_i(x)}{\beta_V}, \end{equation*}
\begin{equation*}=\frac{1}{\beta_V}\,{\rm e}^{V(i\sigma(x))}\cdot
(Q_V(i\sigma(x)),{{}^{t}}\Psi_i\cdot M_V\circ\sigma(x))_{\rm HS}=
\frac{p_i(x)}{\beta_V}, \end{equation*}proving (3.20).
In order to show (3.22), it suffices to recall that, for κV-a.e.  $x\in\Sigma$,
$x\in\Sigma$,
 \begin{equation*}M_V(x)\cdot\frac{{\rm d} \kappa_V}{{\rm d} ||\mu||}(x)
=\lim_{l\rightarrow+\infty}
\frac{
{{}^{t}}\Psi_{x_0\cdots x_{l-1}}\cdot\mu_V(E)
}{
||{{}^{t}}\Psi_{x_0\cdots x_{l-1}}\cdot\mu_V(E)||_{\rm HS}
} . \end{equation*}
\begin{equation*}M_V(x)\cdot\frac{{\rm d} \kappa_V}{{\rm d} ||\mu||}(x)
=\lim_{l\rightarrow+\infty}
\frac{
{{}^{t}}\Psi_{x_0\cdots x_{l-1}}\cdot\mu_V(E)
}{
||{{}^{t}}\Psi_{x_0\cdots x_{l-1}}\cdot\mu_V(E)||_{\rm HS}
} . \end{equation*}The proof of this equality follows from point (5) of Proposition 2.2 and Rokhlin’s theorem; the details are in [Reference Bessi3]. By (10), the last formula easily implies (3.22).
4. The non-weakly mixing case
In this section, we give an estimate from above on the asymptotics of the periodic orbits of the shift when the potential  $\hat V$ is constant. This is the so-called non-weakly mixing case of [Reference Parry and Pollicott15] and [Reference Parry and Pollicott14], in the sense that the shift is weakly mixing, but its suspension by
$\hat V$ is constant. This is the so-called non-weakly mixing case of [Reference Parry and Pollicott15] and [Reference Parry and Pollicott14], in the sense that the shift is weakly mixing, but its suspension by  $\hat V\equiv 1$ is not; we refer the reader to [Reference Parry and Pollicott15] for a precise definition of these objects.
$\hat V\equiv 1$ is not; we refer the reader to [Reference Parry and Pollicott15] for a precise definition of these objects.
The first order of business is to show that counting periodic orbits on Σ is the same as counting periodic orbits on G. We do this in Lemma 4.1 below, but we need a hypothesis stronger that (F3).
(F3+) We ask that, if  $i_0,\dots, i_{l-1},j_0,\dots,j_{k-1}\in(1,\dots,p)$, then
$i_0,\dots, i_{l-1},j_0,\dots,j_{k-1}\in(1,\dots,p)$, then
 \begin{equation*}\psi^{-1}_{i_0\cdots i_{l-1}}\circ\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}({\cal F})\cap{\cal F}=\emptyset\end{equation*}
\begin{equation*}\psi^{-1}_{i_0\cdots i_{l-1}}\circ\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}({\cal F})\cap{\cal F}=\emptyset\end{equation*} unless k = 0, when  $\psi_{j_0\cdots j_{k-1}}=id$ by definition and thus the composition of the three maps on the left is the identity. Note that, since
$\psi_{j_0\cdots j_{k-1}}=id$ by definition and thus the composition of the three maps on the left is the identity. Note that, since  $\psi_{j_0\cdots j_{k-1}}$ is a diffeomorphism, (F3+) implies (F3) taking l = 0.
$\psi_{j_0\cdots j_{k-1}}$ is a diffeomorphism, (F3+) implies (F3) taking l = 0.
We briefly show that (F3+) holds for the harmonic Sierpinski gasket. Since  $\psi_{i_0\cdots i_{l-1}}$ is a diffeomorphism, we can rewrite (F3+) as
$\psi_{i_0\cdots i_{l-1}}$ is a diffeomorphism, we can rewrite (F3+) as
 \begin{align}
\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}({\cal F})\cap
\psi_{i_0\cdots i_{l-1}}({\cal F})=\emptyset.
\end{align}
\begin{align}
\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}({\cal F})\cap
\psi_{i_0\cdots i_{l-1}}({\cal F})=\emptyset.
\end{align} We use the notation of Figure 1 and distinguish two cases: in the first one, the cell  $\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}(G)$ is not contained in the cell
$\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}(G)$ is not contained in the cell  $\psi_{i_0\cdots i_{l-1}}(G)$; then the two cells can intersect only at points of the type
$\psi_{i_0\cdots i_{l-1}}(G)$; then the two cells can intersect only at points of the type  $\psi_{i_0\cdots i_{l-1}}(R)$ with
$\psi_{i_0\cdots i_{l-1}}(R)$ with  $R\in\{A,B,C \}$; these points are not in
$R\in\{A,B,C \}$; these points are not in  $\psi_{i_0\cdots i_{l-1}}({\cal F})$ since
$\psi_{i_0\cdots i_{l-1}}({\cal F})$ since  $\psi_{i_0\cdots i_{l-1}}$ is a diffeomorphism and
$\psi_{i_0\cdots i_{l-1}}$ is a diffeomorphism and  $\{A,B,C \}$ and
$\{A,B,C \}$ and  ${\cal F}$ are disjoint.
${\cal F}$ are disjoint.
The second case is when  $\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}(G)\subset\psi_{i_0\cdots i_{l-1}}(G)$; if
$\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}(G)\subset\psi_{i_0\cdots i_{l-1}}(G)$; if  $k\ge l$, this implies that
$k\ge l$, this implies that 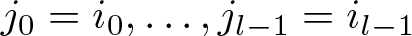 $j_0=i_0,\dots,j_{l-1}=i_{l-1}$. Applying
$j_0=i_0,\dots,j_{l-1}=i_{l-1}$. Applying  $\psi_{i_0\cdots i_{l-1}}^{-1}$, (4.1) becomes
$\psi_{i_0\cdots i_{l-1}}^{-1}$, (4.1) becomes
 \begin{equation*}\psi_{j_l\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}({\cal F})\cap{\cal F}=\emptyset, \end{equation*}
\begin{equation*}\psi_{j_l\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}({\cal F})\cap{\cal F}=\emptyset, \end{equation*} which is true since (F3) holds on the harmonic gasket. If k < l, we note the following: if  $\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}(G)\subset\psi_{i_0\cdots i_{l-1}}(G)$, then the first l indices of
$\psi_{j_0\cdots j_{k-1}}\circ\psi_{i_0\cdots i_{l-1}}(G)\subset\psi_{i_0\cdots i_{l-1}}(G)$, then the first l indices of  $j_0\cdots j_{k-1}i_0\cdots i_{l-1}$ must be
$j_0\cdots j_{k-1}i_0\cdots i_{l-1}$ must be  $i_0\cdots i_{l-1}$. In other words, we have that
$i_0\cdots i_{l-1}$. In other words, we have that  $j_0=i_0,\dots, j_{k-1}=i_{k-1}$ and also
$j_0=i_0,\dots, j_{k-1}=i_{k-1}$ and also  $i_0=i_k,\dots, i_{l-k-1}=i_{l-1}$. Now we apply
$i_0=i_k,\dots, i_{l-k-1}=i_{l-1}$. Now we apply  $\psi_{i_0\cdots i_{l-1}}^{-1}$ and (4.1) becomes
$\psi_{i_0\cdots i_{l-1}}^{-1}$ and (4.1) becomes
 \begin{equation*}\psi_{i_{l-k}\cdots i_{l-1}}({\cal F})\cap{\cal F}=\emptyset,\end{equation*}
\begin{equation*}\psi_{i_{l-k}\cdots i_{l-1}}({\cal F})\cap{\cal F}=\emptyset,\end{equation*}which is implied by (F3).
Lemma 4.1. Let (F1)–(F2)–(F3+)–(F4) hold. Then, the map  $\Phi\colon \Sigma\rightarrow G$ of § 2 is a bijection between the periodic points of
$\Phi\colon \Sigma\rightarrow G$ of § 2 is a bijection between the periodic points of  $(\Sigma,\sigma)$ and those of (G, F).
$(\Sigma,\sigma)$ and those of (G, F).
Proof. We consider the set H of (2.12); since after this formula, we saw that the conjugation is injective on  $\Phi^{-1}(H^c)$, and it suffices to show the following:
$\Phi^{-1}(H^c)$, and it suffices to show the following:
(1) every periodic orbit of F has a periodic coding, which is trivial, and
(2) the points of H do not have a periodic coding (and thus, in particular, are not periodic.)
For point (2), we begin to show that the points with a periodic coding are not in  ${\cal F}$. Indeed, if
${\cal F}$. Indeed, if  $x=(x_0x_1\dots)$ satisfies
$x=(x_0x_1\dots)$ satisfies  $x_i=x_{i+n}$ for all i, then by the second formula of (2.14), we get that
$x_i=x_{i+n}$ for all i, then by the second formula of (2.14), we get that  $\psi_{x_0\cdots x_{n-1}}\circ\Phi(x)=\Phi(x)$; now (F3) implies that
$\psi_{x_0\cdots x_{n-1}}\circ\Phi(x)=\Phi(x)$; now (F3) implies that  $\Phi(x)\not\in {\cal F}$.
$\Phi(x)\not\in {\cal F}$.
But points with a periodic coding are not even in  $\psi_{w_0\cdots w_l}({\cal F})$. Indeed, let
$\psi_{w_0\cdots w_l}({\cal F})$. Indeed, let  $x=(x_0x_1\cdots)$ be n-periodic and let us suppose that
$x=(x_0x_1\cdots)$ be n-periodic and let us suppose that  $\Phi(x)=\psi_{w_0\cdots w_l}(z)$ for some
$\Phi(x)=\psi_{w_0\cdots w_l}(z)$ for some  $z\in{\cal F}$; then, again by (2.14),
$z\in{\cal F}$; then, again by (2.14),
 \begin{equation*}\psi_{x_0\cdots x_{n-1}}\circ\psi_{w_0\cdots w_l}(z)=\psi_{w_0\cdots w_l}(z). \end{equation*}
\begin{equation*}\psi_{x_0\cdots x_{n-1}}\circ\psi_{w_0\cdots w_l}(z)=\psi_{w_0\cdots w_l}(z). \end{equation*} Applying to both sides, the inverse of  $\psi_{w_0\cdots w_l}$ (which is a diffeomorphism) (F3+) shows that
$\psi_{w_0\cdots w_l}$ (which is a diffeomorphism) (F3+) shows that  $z\not\in{\cal F}$, as we wanted.
$z\not\in{\cal F}$, as we wanted.
Thus, from now on we shall count periodic orbits on Σ; since we work on Σ, we stick to the notation after (3.3), but often writing β instead of βV.
Definition. We say that two periodic orbits  $x,x^{\prime}\in\Sigma$ are equivalent if there is
$x,x^{\prime}\in\Sigma$ are equivalent if there is  $k\in\textbf{N}$ such that
$k\in\textbf{N}$ such that  $x_i^{\prime}=x_{i+k}$ for all
$x_i^{\prime}=x_{i+k}$ for all  $i\ge 0$. We call
$i\ge 0$. We call  $\tau=\{x \}$, the equivalence class of x; if x has minimal period n, then τ has n elements. Said differently, we are going to count the periodic orbits τ, not the periodic points
$\tau=\{x \}$, the equivalence class of x; if x has minimal period n, then τ has n elements. Said differently, we are going to count the periodic orbits τ, not the periodic points  $( x_i )\in\Sigma$.
$( x_i )\in\Sigma$.
Let now  $\Psi_i\colon M^q\rightarrow M^q$ be as in (2); let
$\Psi_i\colon M^q\rightarrow M^q$ be as in (2); let  $x=(x_0x_1\cdots)\in\Sigma$ and let
$x=(x_0x_1\cdots)\in\Sigma$ and let  $l\in\textbf{N}$; we define
$l\in\textbf{N}$; we define  ${{}^{t}}\Psi_{x,l}$ as in (10). The definition of the Hilbert–Schmidt product and (2) easily imply that
${{}^{t}}\Psi_{x,l}$ as in (10). The definition of the Hilbert–Schmidt product and (2) easily imply that
 \begin{equation*}{{}^{t}}\Psi_i(A)=(D\psi_i)_\ast\cdot A\cdot{{}^{t}}(D\psi_i)_\ast. \end{equation*}
\begin{equation*}{{}^{t}}\Psi_i(A)=(D\psi_i)_\ast\cdot A\cdot{{}^{t}}(D\psi_i)_\ast. \end{equation*}Iterating this formula and recalling (10), we get that
 \begin{align}
{{}^{t}}\Psi_{x,l}(A)=(D\psi_{x_0\cdots x_{l-1}})_\ast\cdot A\cdot
{{}^{t}}(D\psi_{x_0\dots x_{l-1}})_\ast.
\end{align}
\begin{align}
{{}^{t}}\Psi_{x,l}(A)=(D\psi_{x_0\cdots x_{l-1}})_\ast\cdot A\cdot
{{}^{t}}(D\psi_{x_0\dots x_{l-1}})_\ast.
\end{align}Lemma 4.2. Let the operators  ${{}^{t}}\Psi_{x,l}\colon M^q\rightarrow M^q$ be defined as in (10) or, which is equivalent, (4.2); recall that
${{}^{t}}\Psi_{x,l}\colon M^q\rightarrow M^q$ be defined as in (10) or, which is equivalent, (4.2); recall that  $m={\rm dim}M^q$. Let
$m={\rm dim}M^q$. Let  $x\in\Sigma$ be n-periodic, with n not necessarily minimal. Then, the linear operator
$x\in\Sigma$ be n-periodic, with n not necessarily minimal. Then, the linear operator  ${{}^{t}}\Psi_{x,l}\colon M^q\rightarrow M^q$ satisfies the five points below.
${{}^{t}}\Psi_{x,l}\colon M^q\rightarrow M^q$ satisfies the five points below.
(1) For all
$l\ge 0$, we can order the eigenvalues $\alpha_{x,1},\dots,\alpha_{x,m}$ of ${{}^{t}}\Psi_{x,l}$ in such a way that
(4.3)\begin{align}
1 \gt \alpha_{x,1}\ge |\alpha_{x,2}| \ge\cdots\ge |\alpha_{x,m}| \gt 0.
\end{align}Note that the largest eigenvalue is real.
(2) In the same hypotheses,
$\alpha_{x,i}=\alpha_{\sigma^j(x),i}$ for all $j\ge 0$ and all $i\in(1,\dots,m)$. Since $\alpha_{x,i}$ does not depend on the particular point of the orbit on which we calculate it, if n is the minimal period and $\tau=\{x \}$, then we can set $\alpha_{\tau,i}\colon=\alpha_{x,i}$.(3) Let
$x\in\Sigma$ be n-periodic with n minimal and let $k\in\textbf{N}$. Then, the eigenvalues of ${{}^{t}}\Psi_{x,kn}$ are
\begin{equation*}\alpha_{x,1}^k,\alpha_{x,2}^k,\dots,\alpha_{x,m}^k\quad \text{with}\ |\alpha_{x,i}^k|\in(0,1)\quad\forall i. \end{equation*}By point (2), they are all shift-invariant.
(4) Let x be a periodic orbit of period n and let
$k,j\in\textbf{N}$; then,
\begin{equation*}{\rm tr}{{}^{t}}\Psi_{x,kn}={\rm tr}{{}^{t}}\Psi_{\sigma^j(x),kn} . \end{equation*}In other words, the trace of
${{}^{t}}\Psi_{x,kn}$ is the same for all x on the same orbit.(5) For an n-periodic
$x\in\Sigma$ and $k\in\textbf{N}$, we have that
\begin{equation*}0\le{\rm tr}{{}^{t}}\Psi_{x,kn}.\end{equation*}




















Proof. We begin with Formula (4.3) of point (1): since by (4.2),  ${{}^{t}}\Psi_{x,l}$ is the composition of bijective operators, and it is bijective too; thus, all its eigenvalues are non-zero and we get the inequality on the right of (4.3). We shall show at the end that
${{}^{t}}\Psi_{x,l}$ is the composition of bijective operators, and it is bijective too; thus, all its eigenvalues are non-zero and we get the inequality on the right of (4.3). We shall show at the end that  $\alpha_{x,1}$, the eigenvalue with largest modulus, is positive and smaller than 1.
$\alpha_{x,1}$, the eigenvalue with largest modulus, is positive and smaller than 1.
Point (2) follows because the eigenvalues of a product of invertible matrices do not change under cyclical permutations of the factors, which implies that the eigenvalues of  ${{}^{t}}\Psi_{x,n}={{}^{t}}\Psi_{x_0}\circ\dots\circ{{}^{t}}\Psi_{x_{n-1}}$ coincide with those of
${{}^{t}}\Psi_{x,n}={{}^{t}}\Psi_{x_0}\circ\dots\circ{{}^{t}}\Psi_{x_{n-1}}$ coincide with those of  ${{}^{t}}\Psi_{\sigma(x),n}={{}^{t}}\Psi_{x_1}\circ\dots\circ{{}^{t}}\Psi_{x_{n-1}}\circ{{}^{t}}\Psi_{x_{0}}$.
${{}^{t}}\Psi_{\sigma(x),n}={{}^{t}}\Psi_{x_1}\circ\dots\circ{{}^{t}}\Psi_{x_{n-1}}\circ{{}^{t}}\Psi_{x_{0}}$.
Point (3) follows from two facts: the first one is that, by (10) or (4.2),  ${{}^{t}}\Psi_{x,kn}=({{}^{t}}\Psi_{x,n})^k$; the second one is that the eigenvalues of A k are the kth powers of the eigenvalues of A. Point (2) implies the last assertion about shift-invariance.
${{}^{t}}\Psi_{x,kn}=({{}^{t}}\Psi_{x,n})^k$; the second one is that the eigenvalues of A k are the kth powers of the eigenvalues of A. Point (2) implies the last assertion about shift-invariance.
Point (4) is an immediate consequence of point (3).
Next, to point (5). If  $A\in M^q$ is semi-positive definite, then
$A\in M^q$ is semi-positive definite, then  ${{}^{t}}\Psi_{x,l}(A)$ is semi-positive definite by (4.2). By (2.19), this implies that
${{}^{t}}\Psi_{x,l}(A)$ is semi-positive definite by (4.2). By (2.19), this implies that
 \begin{equation*}({{}^{t}}\Psi_{x,l}(A),A)_{\rm HS}\ge 0. \end{equation*}
\begin{equation*}({{}^{t}}\Psi_{x,l}(A),A)_{\rm HS}\ge 0. \end{equation*} If the matrix  ${{}^{t}}\Psi_{x,l}$ on M q were self-adjoint, this would end the proof, but this is not the case. However, the last formula implies that
${{}^{t}}\Psi_{x,l}$ on M q were self-adjoint, this would end the proof, but this is not the case. However, the last formula implies that  ${\rm tr}{{}^{t}}\Psi_{x,kn}\ge 0$ follows if we find an orthonormal base of M q all whose elements are semi-positive-definite. A standard one is this: if
${\rm tr}{{}^{t}}\Psi_{x,kn}\ge 0$ follows if we find an orthonormal base of M q all whose elements are semi-positive-definite. A standard one is this: if  $\{e_i \}$ is an orthonormal base of
$\{e_i \}$ is an orthonormal base of  $\Lambda^q(\textbf{R}^d)$, just take
$\Lambda^q(\textbf{R}^d)$, just take  $\frac{1}{2}(e_i\otimes e_j+e_j\otimes e_i)$.
$\frac{1}{2}(e_i\otimes e_j+e_j\otimes e_i)$.
We show that the maximal eigenvalue in (4.3) is a positive real. Let us consider the cone  $C\subset M^q$ of positive-definite matrices; in the last paragraph, we saw that
$C\subset M^q$ of positive-definite matrices; in the last paragraph, we saw that  ${{}^{t}}\Psi_{x,l}(C)\subset C$. We would like to apply Theorem 2.1 to this situation, but we do not know whether the constant D in its statement is finite. It is easy to see that if ϵ > 0, then
${{}^{t}}\Psi_{x,l}(C)\subset C$. We would like to apply Theorem 2.1 to this situation, but we do not know whether the constant D in its statement is finite. It is easy to see that if ϵ > 0, then  $D \lt +\infty$ for the operator
$D \lt +\infty$ for the operator  ${{}^{t}}\Psi_{x,l}+\epsilon Id$; if we apply Theorem 2.1 and let
${{}^{t}}\Psi_{x,l}+\epsilon Id$; if we apply Theorem 2.1 and let  $\epsilon\searrow 0$, we get that the eigenvalue
$\epsilon\searrow 0$, we get that the eigenvalue  $\alpha_{x,1}$ of maximal modulus of
$\alpha_{x,1}$ of maximal modulus of  ${{}^{t}}\Psi_{x,l}$ is non-negative real, as we wanted.
${{}^{t}}\Psi_{x,l}$ is non-negative real, as we wanted.
Lastly, we end the proof of (4.3) showing that all eigenvalues have modulus smaller than 1. We shall use a version of the sup norm on  $\Lambda^q(\textbf{R}^d)$: if
$\Lambda^q(\textbf{R}^d)$: if  $\omega\in\Lambda^q(\textbf{R}^d)$, we set
$\omega\in\Lambda^q(\textbf{R}^d)$, we set
 \begin{equation*}||\omega||_{\sup}=
\sup\{
\omega(v_1,\ldots,v_q)\;\colon\; ||v_1||\cdot\dots\cdot||v_q||\le 1
\}. \end{equation*}
\begin{equation*}||\omega||_{\sup}=
\sup\{
\omega(v_1,\ldots,v_q)\;\colon\; ||v_1||\cdot\dots\cdot||v_q||\le 1
\}. \end{equation*} Since  $D\psi_i$ is a contraction, (1) implies immediately that
$D\psi_i$ is a contraction, (1) implies immediately that  $(D\psi_i)_\ast$ contracts the sup norm:
$(D\psi_i)_\ast$ contracts the sup norm:
 \begin{equation*}||(D\psi_i)_\ast\omega||_{\sup} \lt ||\omega||_{\sup}. \end{equation*}
\begin{equation*}||(D\psi_i)_\ast\omega||_{\sup} \lt ||\omega||_{\sup}. \end{equation*} Since the spectrum of  ${{}^{t}}\Psi_i$ coincides with that of
${{}^{t}}\Psi_i$ coincides with that of  $\Psi_i$, it suffices to show that the modulus of the eigenvalues of
$\Psi_i$, it suffices to show that the modulus of the eigenvalues of  $\Psi_i$ is smaller than 1, and this is what we shall do. Let
$\Psi_i$ is smaller than 1, and this is what we shall do. Let  $A\in M^q$ be such that
$A\in M^q$ be such that  $\Psi_iA=\lambda A$;
$\Psi_iA=\lambda A$;  $|\lambda| \lt 1$ follows if we show that, for some norm
$|\lambda| \lt 1$ follows if we show that, for some norm  $|| \cdot ||_{1}$ over M q, we have
$|| \cdot ||_{1}$ over M q, we have
 \begin{equation*}||\Psi_iA||_{1} \lt ||A||_1 . \end{equation*}
\begin{equation*}||\Psi_iA||_{1} \lt ||A||_1 . \end{equation*} The function  $||\cdot||_1$ defined below is a norm on the space M q of symmetric matrices.
$||\cdot||_1$ defined below is a norm on the space M q of symmetric matrices.
 \begin{equation*}||A||_1=\sup_{||\omega||_{\sup}\le 1}|(A\omega,\omega)|. \end{equation*}
\begin{equation*}||A||_1=\sup_{||\omega||_{\sup}\le 1}|(A\omega,\omega)|. \end{equation*} The first equality below comes from the definition of the norm in the formula above and the definition of  $\Psi_i$ in (2); the second one is the definition of the adjoint; the inequality comes from the fact that
$\Psi_i$ in (2); the second one is the definition of the adjoint; the inequality comes from the fact that  $(D\psi_i)_\ast$ contracts the norm: the set of the forms
$(D\psi_i)_\ast$ contracts the norm: the set of the forms  $(D\psi_i)_\ast \omega$ with
$(D\psi_i)_\ast \omega$ with  $||\omega||_{\sup}\le 1$ is contained in a sphere of radius strictly smaller than 1. The last equality is again the definition of the norm.
$||\omega||_{\sup}\le 1$ is contained in a sphere of radius strictly smaller than 1. The last equality is again the definition of the norm.
 \begin{equation*}||\Psi_i(A)||_1=
\sup_{||\omega||_{\sup}\le 1}|({{}^{t}}(D\psi_i)_\ast A(D\psi_i)_\ast \omega,\omega)|\end{equation*}
\begin{equation*}||\Psi_i(A)||_1=
\sup_{||\omega||_{\sup}\le 1}|({{}^{t}}(D\psi_i)_\ast A(D\psi_i)_\ast \omega,\omega)|\end{equation*} \begin{equation*}=\sup_{||\omega||_{\sup}\le 1}|( A(D\psi_i)_\ast \omega,(D\psi_i)_\ast \omega)| \lt \sup_{||\omega||_{\sup}\le 1}|(A\omega,\omega)|=||A||_1. \end{equation*}
\begin{equation*}=\sup_{||\omega||_{\sup}\le 1}|( A(D\psi_i)_\ast \omega,(D\psi_i)_\ast \omega)| \lt \sup_{||\omega||_{\sup}\le 1}|(A\omega,\omega)|=||A||_1. \end{equation*}From now on the argument is that of [Reference Parry and Pollicott15], with some minor notational changes.
We begin to assume that the potential V depends only on the first two coordinates, i.e., that
 \begin{align}
V(x)=V(x_0,x_1) .
\end{align}
\begin{align}
V(x)=V(x_0,x_1) .
\end{align}We are going to see that in this case, the maximal eigenvalue of the Ruelle operator coincides with that of a finite-dimensional matrix; another consequence will be that the zeta function of Formula (4.11) below is meromorphic.
We consider  $(M^q)^t$, the space of column vectors
$(M^q)^t$, the space of column vectors
 \begin{align}
M=\left(
\begin{matrix}
M_1\cr
\vdots\cr
M_t
\end{matrix}
\right),
\end{align}
\begin{align}
M=\left(
\begin{matrix}
M_1\cr
\vdots\cr
M_t
\end{matrix}
\right),
\end{align} where the entries are matrices  $M_i\in M^q$; we denote by
$M_i\in M^q$; we denote by  $\hat d$ the dimension of
$\hat d$ the dimension of  $(M^q)^t$; clearly,
$(M^q)^t$; clearly,  $\hat d=m\cdot t$ for m as in Lemma 4.2. For
$\hat d=m\cdot t$ for m as in Lemma 4.2. For  $j\in (1,\dots,t)$, we define
$j\in (1,\dots,t)$, we define
 \begin{equation*}L_V^j\colon (M^q)^t\rightarrow M^q,\qquad
L^j_VM=\sum_{i=1}^t \Psi_i(M_i)
\,{\rm e}^{V(i,j)}. \end{equation*}
\begin{equation*}L_V^j\colon (M^q)^t\rightarrow M^q,\qquad
L^j_VM=\sum_{i=1}^t \Psi_i(M_i)
\,{\rm e}^{V(i,j)}. \end{equation*}With the notation of (4.5) and of the last formula, we define an operator
 \begin{equation*}L_V\colon (M^q)^t\rightarrow (M^q)^t, \qquad
L_VM=\left(
\begin{matrix}
L^1_VM\cr
\vdots\cr
L^t_VM
\end{matrix}
\right). \end{equation*}
\begin{equation*}L_V\colon (M^q)^t\rightarrow (M^q)^t, \qquad
L_VM=\left(
\begin{matrix}
L^1_VM\cr
\vdots\cr
L^t_VM
\end{matrix}
\right). \end{equation*}It is easy to decompose the matrix LV into t × t blocks from M q into itself; the jith block of LV is given by
 \begin{align}
L_V^{ij}={\rm e}^{V(i,j)} \Psi_i.
\end{align}
\begin{align}
L_V^{ij}={\rm e}^{V(i,j)} \Psi_i.
\end{align}We define the positive cone
 \begin{equation*}(M^q)^t_+\subset (M^q)^t \end{equation*}
\begin{equation*}(M^q)^t_+\subset (M^q)^t \end{equation*} as the set of the arrays (4.5) such that Mi is positive-definite for all  $i\in(1,\dots,t)$.
$i\in(1,\dots,t)$.
On the cone  $(M^q)_+^t$, we define the hyperbolic distance θ as in § 2. The nondegeracy hypothesis
$(M^q)_+^t$, we define the hyperbolic distance θ as in § 2. The nondegeracy hypothesis  $(ND)_q$ of § 2 implies easily that
$(ND)_q$ of § 2 implies easily that
 \begin{equation*}{\rm diam}_\theta[L_V((M^q)^t_+)] \lt +\infty. \end{equation*}
\begin{equation*}{\rm diam}_\theta[L_V((M^q)^t_+)] \lt +\infty. \end{equation*} We skip the standard proof of the formula above and of the fact that  $((M^q)^t_+,\theta)$ is complete; by (4.9) below, they are a consequence of the corresponding facts on
$((M^q)^t_+,\theta)$ is complete; by (4.9) below, they are a consequence of the corresponding facts on  $LogC^{\alpha,a}_+(\Sigma)$, which are proven in [Reference Bessi2] and [Reference Bessi3].
$LogC^{\alpha,a}_+(\Sigma)$, which are proven in [Reference Bessi2] and [Reference Bessi3].
By Theorem 2.1, these two facts imply that LV has a couple eigenvalue-eigenvector
 \begin{align}
(\beta^{\prime},Q^{\prime})\in(0,+\infty)\times(M^q)^t_+ .
\end{align}
\begin{align}
(\beta^{\prime},Q^{\prime})\in(0,+\infty)\times(M^q)^t_+ .
\end{align} An element  $M\in (M^q)^t$ defines a function
$M\in (M^q)^t$ defines a function  $M\in C(\Sigma,\textbf{R})$, which depends only on the first coordinate of
$M\in C(\Sigma,\textbf{R})$, which depends only on the first coordinate of  $x=(x_0x_1\dots)$; we continue to denote it by M:
$x=(x_0x_1\dots)$; we continue to denote it by M:
 \begin{align}
M(x)\colon=M_{x_0}.
\end{align}
\begin{align}
M(x)\colon=M_{x_0}.
\end{align} Let V be as in (4.4) and let M depend only on the first coordinate as in (4.8); by (2.24) and (4.6), we easily see that, for all  $x=(x_0x_1\cdots)\in\Sigma$,
$x=(x_0x_1\cdots)\in\Sigma$,
 \begin{align}
({\cal L}_VM)(x)=(L_VM)_{x_0} .
\end{align}
\begin{align}
({\cal L}_VM)(x)=(L_VM)_{x_0} .
\end{align} As a consequence,  $(\beta^{\prime},Q^{\prime})$ of (4.7) is a couple eigenvalue-eigenvector for
$(\beta^{\prime},Q^{\prime})$ of (4.7) is a couple eigenvalue-eigenvector for  ${\cal L}_V$ too; by the uniqueness of Proposition 2.2, we get that, if we multiply Q ʹ by a suitable positive constant,
${\cal L}_V$ too; by the uniqueness of Proposition 2.2, we get that, if we multiply Q ʹ by a suitable positive constant,
 \begin{equation*}(\beta_V,Q_V)=(\beta^{\prime},Q^{\prime}) . \end{equation*}
\begin{equation*}(\beta_V,Q_V)=(\beta^{\prime},Q^{\prime}) . \end{equation*} In particular,  $Q_V(x)=Q_{x_0}^{\prime}$, i.e. QV depends only on the first coordinate.
$Q_V(x)=Q_{x_0}^{\prime}$, i.e. QV depends only on the first coordinate.
Recall that we have set  $\hat d={\rm dim}(M^q)^t$; an immediate consequence of the Perron–Frobenius theorem is that all other eigenvalues of LV have modulus strictly smaller that
$\hat d={\rm dim}(M^q)^t$; an immediate consequence of the Perron–Frobenius theorem is that all other eigenvalues of LV have modulus strictly smaller that  $\beta={\rm e}^{P(V)}$. Let us call them names:
$\beta={\rm e}^{P(V)}$. Let us call them names:
 \begin{align}
\lambda_{2,V},\lambda_{3,V},\ldots,\lambda_{\hat d,V}\quad \text{with }|\lambda_{j,V}| \lt \beta={\rm e}^{P(V)}\ \text{for}\ j\ge 2.
\end{align}
\begin{align}
\lambda_{2,V},\lambda_{3,V},\ldots,\lambda_{\hat d,V}\quad \text{with }|\lambda_{j,V}| \lt \beta={\rm e}^{P(V)}\ \text{for}\ j\ge 2.
\end{align}Definition. We define Fixn as the set of  $(x_0x_1\cdots)\in\Sigma$ such that
$(x_0x_1\cdots)\in\Sigma$ such that  $x_i=x_{i+n}$ for all
$x_i=x_{i+n}$ for all  $i\ge 0$; note that n is any period, not necessarily the minimal one.
$i\ge 0$; note that n is any period, not necessarily the minimal one.
We define the zeta function  $\zeta(z,V)$ as
$\zeta(z,V)$ as
 \begin{align}
\zeta(z,V)=
\exp\sum_{n\ge 1}\frac{z^n}{n}\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n},
\end{align}
\begin{align}
\zeta(z,V)=
\exp\sum_{n\ge 1}\frac{z^n}{n}\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n},
\end{align} where  ${{}^{t}}\Psi_{x,n}$ is defined as in (4.2) and V n as in point 5 of Proposition 2.2.
${{}^{t}}\Psi_{x,n}$ is defined as in (4.2) and V n as in point 5 of Proposition 2.2.
We recall Proposition 5.1 of [Reference Parry and Pollicott15].
Proposition 4.3. Let  $V\in C^{0,\alpha}(\Sigma,\textbf{R})$ and let
$V\in C^{0,\alpha}(\Sigma,\textbf{R})$ and let  $\beta={\rm e}^{P(V)}$ be as in Proposition 2.2; then, the radius of convergence of the power series in (4.11) is
$\beta={\rm e}^{P(V)}$ be as in Proposition 2.2; then, the radius of convergence of the power series in (4.11) is
 \begin{align}
R={\rm e}^{-P(V)}=\frac{1}{\beta}.
\end{align}
\begin{align}
R={\rm e}^{-P(V)}=\frac{1}{\beta}.
\end{align}Proof. We begin to note that the innermost sum in (4.11) is non-negative: indeed, all the summands are non-negative by point (5) of Lemma 4.2. Thus, we can take logarithms, and (4.12) is implied by the first equality below, while the second one is the definition of P(V).
 \begin{align}
\lim_{n\rightarrow+\infty}
\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}=\log\beta=P(V).
\end{align}
\begin{align}
\lim_{n\rightarrow+\infty}
\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}=\log\beta=P(V).
\end{align} We show this. Since  $V\in C^{0,\alpha}(\Sigma,\textbf{R})$, for any given ϵ > 0, we can find a function
$V\in C^{0,\alpha}(\Sigma,\textbf{R})$, for any given ϵ > 0, we can find a function  $W\colon \Sigma\rightarrow \textbf{R}$ depending only on finitely many coordinates such that
$W\colon \Sigma\rightarrow \textbf{R}$ depending only on finitely many coordinates such that
 \begin{align}
||W-V||_{\sup} \lt \epsilon .
\end{align}
\begin{align}
||W-V||_{\sup} \lt \epsilon .
\end{align} Up to enlarging our symbol space, we can suppose that W depends only on the first two coordinates, i.e., that it satisfies (4.4). Thus, we can define an operator LW as in (4.6); this formula implies easily that the ith block on the diagonal of  $L^n_W$ is given by
$L^n_W$ is given by
 \begin{equation*}\sum_{\{x\in Fix_n,\ x_0=i \}}{\rm e}^{W^n(x)}\Psi_{x,n}, \end{equation*}
\begin{equation*}\sum_{\{x\in Fix_n,\ x_0=i \}}{\rm e}^{W^n(x)}\Psi_{x,n}, \end{equation*} where  $x=(x_0x_1\cdots)$,
$x=(x_0x_1\cdots)$,  $\Psi_{x,n}=\Psi_{x_{n-1}}\circ\cdots\circ\Psi_{x_0}$ and W n is defined as in Proposition 2.2. Since
$\Psi_{x,n}=\Psi_{x_{n-1}}\circ\cdots\circ\Psi_{x_0}$ and W n is defined as in Proposition 2.2. Since  ${\rm tr}({{}^{t}} B)={\rm tr}(B)$, the first equality below follows; the second one comes from the formula above and the linearity of the trace; the last one follows from (4.10) for LW.
${\rm tr}({{}^{t}} B)={\rm tr}(B)$, the first equality below follows; the second one comes from the formula above and the linearity of the trace; the last one follows from (4.10) for LW.
 \begin{align}
\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}=
\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}\Psi_{x,n}=
{\rm tr}(L^n_W)={\rm e}^{nP(W)}+\lambda^n_{2,W}+\dots+\lambda^n_{\hat d,W} .
\end{align}
\begin{align}
\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}=
\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}\Psi_{x,n}=
{\rm tr}(L^n_W)={\rm e}^{nP(W)}+\lambda^n_{2,W}+\dots+\lambda^n_{\hat d,W} .
\end{align}Since we saw above that the left hand side is positive, we can take logarithms in the last formula; we get the equality below, while the limit follows from the inequality of (4.10) applied to W.
 \begin{equation*}\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}=
\frac{1}{n}\,\log[{\rm e}^{nP(W)}+\lambda^n_{2,W}+\dots+\lambda^n_{\hat d,W}]\rightarrow P(W). \end{equation*}
\begin{equation*}\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}=
\frac{1}{n}\,\log[{\rm e}^{nP(W)}+\lambda^n_{2,W}+\dots+\lambda^n_{\hat d,W}]\rightarrow P(W). \end{equation*} This is (4.13) for the potential W; it implies that (4.13) for the potential V if we show that, as  $W\rightarrow V$ in
$W\rightarrow V$ in  $C(\Sigma,\textbf{R})$, we have that
$C(\Sigma,\textbf{R})$, we have that
 \begin{align}
P(W)\rightarrow P(V)
\end{align}
\begin{align}
P(W)\rightarrow P(V)
\end{align}and
 \begin{align}
\sup_{n\ge 1}
\left\vert
\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}-
\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}
\right\vert\rightarrow 0.
\end{align}
\begin{align}
\sup_{n\ge 1}
\left\vert
\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}-
\frac{1}{n}\,\log\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}
\right\vert\rightarrow 0.
\end{align} Formula (4.16) follows immediately from the theorem of contractions depending on a parameter applied to the operator  ${\cal L}_V$ on the cone
${\cal L}_V$ on the cone  $LogC^{\alpha,a}_+(\Sigma)$ with the hyperbolic metric.
$LogC^{\alpha,a}_+(\Sigma)$ with the hyperbolic metric.
For (4.17), we begin to note that, by (4.14),
 \begin{equation*}{\rm e}^{-n\epsilon}\cdot {\rm e}^{W^n(x)}\le
{\rm e}^{V^n(x)}\le
{\rm e}^{n\epsilon}\cdot {\rm e}^{W^n(x)}. \end{equation*}
\begin{equation*}{\rm e}^{-n\epsilon}\cdot {\rm e}^{W^n(x)}\le
{\rm e}^{V^n(x)}\le
{\rm e}^{n\epsilon}\cdot {\rm e}^{W^n(x)}. \end{equation*} Since  ${\rm tr}{{}^{t}}\Psi_{x,n}\ge 0$ by Lemma 4.2, the formula above implies that
${\rm tr}{{}^{t}}\Psi_{x,n}\ge 0$ by Lemma 4.2, the formula above implies that
 \begin{equation*}{\rm e}^{-n\epsilon}\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}\le
\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}\le
{\rm e}^{n\epsilon}\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n} . \end{equation*}
\begin{equation*}{\rm e}^{-n\epsilon}\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}\le
\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n}\le
{\rm e}^{n\epsilon}\sum_{x\in Fix_n}{\rm e}^{W^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n} . \end{equation*}Taking logarithms, (4.17) follows and we are done.
Now we suppose that (4.4) holds. The first equality below is the definition (4.11); the second and third ones come from formula (4.15) applied to the potential V. The next two equalities come from the properties of the logarithm, the last one comes from the definition of  $\lambda_{i,V}$ in (4.10); the matrix Id is the identity on
$\lambda_{i,V}$ in (4.10); the matrix Id is the identity on  $(M^q)^t$.
$(M^q)^t$.
 \begin{align}
\zeta(z,V)=&
\exp\sum_{n\ge 1}\frac{z^n}{n}\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n} \\
=\exp\sum_{n\ge 1}\frac{z^n}{n}{\rm tr}(L^n_V)=&
\exp\sum_{n\ge 1}\frac{z^n}{n}\left[
{\rm e}^{nP(V)}+\lambda^n_{2,V}+\dots+\lambda^n_{\hat d,V}
\right] \\ &
=\exp[
-\log(1-z\,{\rm e}^{P(V)})-\log(1-\lambda_{2,V}z)-\dots-\log(1-\lambda_{\hat d,V}z)
] \\ &
=\frac{
1
}{
(1-z\,{\rm e}^{P(V)})(1-\lambda_{2,V}z)\cdot\dots\cdot(1-\lambda_{\hat d,V}z)
} \\ &
=\frac{1}{
{\rm det}(Id-zL_V)
}.
\end{align}
\begin{align}
\zeta(z,V)=&
\exp\sum_{n\ge 1}\frac{z^n}{n}\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr}{{}^{t}}\Psi_{x,n} \\
=\exp\sum_{n\ge 1}\frac{z^n}{n}{\rm tr}(L^n_V)=&
\exp\sum_{n\ge 1}\frac{z^n}{n}\left[
{\rm e}^{nP(V)}+\lambda^n_{2,V}+\dots+\lambda^n_{\hat d,V}
\right] \\ &
=\exp[
-\log(1-z\,{\rm e}^{P(V)})-\log(1-\lambda_{2,V}z)-\dots-\log(1-\lambda_{\hat d,V}z)
] \\ &
=\frac{
1
}{
(1-z\,{\rm e}^{P(V)})(1-\lambda_{2,V}z)\cdot\dots\cdot(1-\lambda_{\hat d,V}z)
} \\ &
=\frac{1}{
{\rm det}(Id-zL_V)
}.
\end{align} Thus, if (4.4) holds (or if V depends on finitely many coordinates, which we have seen to be equivalent), the function  $\zeta(z,V)$ is meromorphic.
$\zeta(z,V)$ is meromorphic.
Definition. Let  $x\in\Sigma$ be periodic of minimal period n, and let
$x\in\Sigma$ be periodic of minimal period n, and let  $\tau=\{x \}$ be its equivalence class; with the notation of Lemma 4.2, we define
$\tau=\{x \}$ be its equivalence class; with the notation of Lemma 4.2, we define
 \begin{align}
\lambda(\tau)\colon=\sharp\tau=n,
V(\tau)\colon=V^n(x),
\alpha_{\tau,i}\colon=\alpha_{x,i},
{\rm tr}{{}^{t}}\Psi_\tau\colon={\rm tr}{{}^{t}}\Psi_{x,n}=\alpha_{\tau,1}+\dots+\alpha_{\tau,m} .
\end{align}
\begin{align}
\lambda(\tau)\colon=\sharp\tau=n,
V(\tau)\colon=V^n(x),
\alpha_{\tau,i}\colon=\alpha_{x,i},
{\rm tr}{{}^{t}}\Psi_\tau\colon={\rm tr}{{}^{t}}\Psi_{x,n}=\alpha_{\tau,1}+\dots+\alpha_{\tau,m} .
\end{align} Periodicity implies immediately that  $V(\tau)$ does not depend on the representative
$V(\tau)$ does not depend on the representative  $x\in\tau$ we choose. As for
$x\in\tau$ we choose. As for  $\alpha_{\tau,i}$ and
$\alpha_{\tau,i}$ and  ${\rm tr}{{}^{t}}\Psi_\tau$, they too do not depend on the representative
${\rm tr}{{}^{t}}\Psi_\tau$, they too do not depend on the representative  $x\in\tau$ by points (2) and (4) of Lemma 4.2.
$x\in\tau$ by points (2) and (4) of Lemma 4.2.
As a further bit of notation, we call  $\tau^{\prime}$ a k-multiple of a prime orbit τ. More precisely,
$\tau^{\prime}$ a k-multiple of a prime orbit τ. More precisely,  $\tau^{\prime}=(\tau,k)$, where
$\tau^{\prime}=(\tau,k)$, where  $\tau=\{x \}$ is a periodic orbit of minimal period n and
$\tau=\{x \}$ is a periodic orbit of minimal period n and  $k\in\textbf{N}$; we set
$k\in\textbf{N}$; we set
 \begin{align}
\left\{
\begin{aligned}
\Lambda(\tau^{\prime})&\colon=\lambda(\tau)=n\cr
\lambda(\tau^{\prime})&\colon=kn\cr
{\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}&\colon={\rm tr}{{}^{t}}\Psi_{x,kn}=\alpha^k_{\tau,1}+\dots+\alpha^k_{\tau,m}\cr
V(\tau^{\prime})&\colon=V^{kn}(x)=kV(\tau).
\end{aligned}
\right.
\end{align}
\begin{align}
\left\{
\begin{aligned}
\Lambda(\tau^{\prime})&\colon=\lambda(\tau)=n\cr
\lambda(\tau^{\prime})&\colon=kn\cr
{\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}&\colon={\rm tr}{{}^{t}}\Psi_{x,kn}=\alpha^k_{\tau,1}+\dots+\alpha^k_{\tau,m}\cr
V(\tau^{\prime})&\colon=V^{kn}(x)=kV(\tau).
\end{aligned}
\right.
\end{align} In the third formula above, the second equality is point (3) of Lemma 4.2; the notation for the eigenvalues is that of (4.19). In the last formula above, the second equality is an immediate consequence of periodicity. We stress again that none of the expressions above depends on the particular  $x\in\tau$ we choose.
$x\in\tau$ we choose.
Now we can give an alternate expression for the zeta function  $\zeta(z,V)$; this time, we do not require (4.4). The first equality below is the definition of
$\zeta(z,V)$; this time, we do not require (4.4). The first equality below is the definition of  $\zeta(z,V)$ in (4.11); for the second one, we group together in the innermost sum all the multiples of a periodic orbit. In the third one, the outer sum is over the prime orbits τ; we recall that τ has n elements and use (4.20). The last two equalities follow from the properties of the logarithm.
$\zeta(z,V)$ in (4.11); for the second one, we group together in the innermost sum all the multiples of a periodic orbit. In the third one, the outer sum is over the prime orbits τ; we recall that τ has n elements and use (4.20). The last two equalities follow from the properties of the logarithm.
 \begin{equation*}\zeta(z,V)=
\exp\sum_{n\ge 1}\frac{z^n}{n}\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr} {{}^{t}}\Psi_{x,n}\end{equation*}
\begin{equation*}\zeta(z,V)=
\exp\sum_{n\ge 1}\frac{z^n}{n}\sum_{x\in Fix_n}{\rm e}^{V^n(x)}{\rm tr} {{}^{t}}\Psi_{x,n}\end{equation*} \begin{equation*}=\exp\sum_{n\ge 1}\frac{1}{n}\sum_{\{\sigma^n(x)=x,\ n\ {\rm least} \}}
\sum_{k\ge 1}{\rm e}^{kV^n(x)}{\rm tr}({{}^{t}}\Psi_{x,kn})\cdot\frac{z^{nk}}{k}\end{equation*}
\begin{equation*}=\exp\sum_{n\ge 1}\frac{1}{n}\sum_{\{\sigma^n(x)=x,\ n\ {\rm least} \}}
\sum_{k\ge 1}{\rm e}^{kV^n(x)}{\rm tr}({{}^{t}}\Psi_{x,kn})\cdot\frac{z^{nk}}{k}\end{equation*} \begin{equation*}=\exp\sum_\tau\sum_{k\ge 1}{\rm e}^{kV(\tau)}[\alpha^k_{\tau,1}+\dots+\alpha^k_{\tau,m}]
\frac{z^{\lambda(\tau)k}}{k}\end{equation*}
\begin{equation*}=\exp\sum_\tau\sum_{k\ge 1}{\rm e}^{kV(\tau)}[\alpha^k_{\tau,1}+\dots+\alpha^k_{\tau,m}]
\frac{z^{\lambda(\tau)k}}{k}\end{equation*} \begin{equation*}=\exp \left\{
-\sum_\tau\sum_{j=1}^{m}\log[1-\alpha_{\tau,j}\,{\rm e}^{V(\tau)}\cdot z^{\lambda(\tau)}]
\right\} \end{equation*}
\begin{equation*}=\exp \left\{
-\sum_\tau\sum_{j=1}^{m}\log[1-\alpha_{\tau,j}\,{\rm e}^{V(\tau)}\cdot z^{\lambda(\tau)}]
\right\} \end{equation*} \begin{equation*}=\prod_\tau\prod_{j=1}^{m}
\frac{
1
}{
1-\alpha_{\tau,j}\,{\rm e}^{V(\tau)}\cdot z^{\lambda(\tau)}
} . \end{equation*}
\begin{equation*}=\prod_\tau\prod_{j=1}^{m}
\frac{
1
}{
1-\alpha_{\tau,j}\,{\rm e}^{V(\tau)}\cdot z^{\lambda(\tau)}
} . \end{equation*}We single out two equalities from the formula above.
 \begin{equation*}\zeta(z,V)=\prod_\tau\prod_{j=1}^{m}
\frac{
1
}{
1-\alpha_{\tau,j}\,{\rm e}^{V(\tau)}\cdot z^{\lambda(\tau)}
} \end{equation*}
\begin{equation*}\zeta(z,V)=\prod_\tau\prod_{j=1}^{m}
\frac{
1
}{
1-\alpha_{\tau,j}\,{\rm e}^{V(\tau)}\cdot z^{\lambda(\tau)}
} \end{equation*} \begin{align}
=\exp\sum_\tau\sum_{j=1}^{m}\sum_{k\ge 1}
\frac{\alpha^k_{\tau,j}\cdot {\rm e}^{kV(\tau)}\cdot z^{k\lambda(\tau)}}{k} .
\end{align}
\begin{align}
=\exp\sum_\tau\sum_{j=1}^{m}\sum_{k\ge 1}
\frac{\alpha^k_{\tau,j}\cdot {\rm e}^{kV(\tau)}\cdot z^{k\lambda(\tau)}}{k} .
\end{align} By Proposition 4.3, we know that the series above converges if  $|z| \lt \frac{1}{\beta}$; by the way, this justifies the formal manipulations above.
$|z| \lt \frac{1}{\beta}$; by the way, this justifies the formal manipulations above.
Proof of point (1) of Theorem 2
The first equality below comes from (4.18) and requires (4.4); for the second one, we use (4.10).
 \begin{equation*}\zeta(z,V)=
\frac{
1
}{
{\rm det}(Id-zL_V)
} \end{equation*}
\begin{equation*}\zeta(z,V)=
\frac{
1
}{
{\rm det}(Id-zL_V)
} \end{equation*} \begin{equation*}=\frac{1}{1-\beta z}\cdot
\prod_{j=2}^{\hat d}\frac{1}{1-\lambda_{j,V}z}. \end{equation*}
\begin{equation*}=\frac{1}{1-\beta z}\cdot
\prod_{j=2}^{\hat d}\frac{1}{1-\lambda_{j,V}z}. \end{equation*}In other words,
 \begin{align}
\zeta(z,V)\cdot (1-\beta z)=\tilde\alpha(z)
\end{align}
\begin{align}
\zeta(z,V)\cdot (1-\beta z)=\tilde\alpha(z)
\end{align} and, by the inequality of (4.10), there is ϵ > 0 such that  $\tilde\alpha$ is non-zero and analytic in
$\tilde\alpha$ is non-zero and analytic in
 \begin{align}
B_\epsilon\colon=\left\{
z\in\textbf{C}\colon |z| \lt \frac{{\rm e}^\epsilon}{\beta}
\right\} .
\end{align}
\begin{align}
B_\epsilon\colon=\left\{
z\in\textbf{C}\colon |z| \lt \frac{{\rm e}^\epsilon}{\beta}
\right\} .
\end{align} The first equality below follows taking derivatives in the last expression of (4.21); recall that  $\lambda(\tau)$ is defined in (4.19). Differentiating the product in (4.22) and recalling that
$\lambda(\tau)$ is defined in (4.19). Differentiating the product in (4.22) and recalling that  $\tilde\alpha\not=0$ in Bϵ, we see that the second equality below holds for a function α analytic in the ball Bϵ of (4.23).
$\tilde\alpha\not=0$ in Bϵ, we see that the second equality below holds for a function α analytic in the ball Bϵ of (4.23).
 \begin{equation*}\sum_\tau\sum_{j=1}^{m}\sum_{k\ge 1}\lambda(\tau)\cdot\alpha^k_{\tau,j}\cdot {\rm e}^{kV(\tau)}\cdot
z^{k\cdot\lambda(\tau)-1}=\frac{
\zeta^{\prime}(z,V)
}{
\zeta(z,V)
} \end{equation*}
\begin{equation*}\sum_\tau\sum_{j=1}^{m}\sum_{k\ge 1}\lambda(\tau)\cdot\alpha^k_{\tau,j}\cdot {\rm e}^{kV(\tau)}\cdot
z^{k\cdot\lambda(\tau)-1}=\frac{
\zeta^{\prime}(z,V)
}{
\zeta(z,V)
} \end{equation*} \begin{align}
=\frac{\beta}{1-\beta z}+\alpha(z).
\end{align}
\begin{align}
=\frac{\beta}{1-\beta z}+\alpha(z).
\end{align} From now on we shall suppose that  $V\equiv 0$. We rewrite (4.24) under this assumption; for the term on the left, we sum on the periodic orbits
$V\equiv 0$. We rewrite (4.24) under this assumption; for the term on the left, we sum on the periodic orbits  $\tau^{\prime}=(\tau,k)$ and use (4.20); for the term on the right, we use the geometric series.
$\tau^{\prime}=(\tau,k)$ and use (4.20); for the term on the right, we use the geometric series.
 \begin{equation*}\frac{1}{z}\sum_{\tau^{\prime}}\Lambda(\tau^{\prime})
{\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}
\cdot z^{\lambda(\tau^{\prime})}=
\frac{
\zeta^{\prime}(z,V)
}{
\zeta(z,V)
} \end{equation*}
\begin{equation*}\frac{1}{z}\sum_{\tau^{\prime}}\Lambda(\tau^{\prime})
{\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}
\cdot z^{\lambda(\tau^{\prime})}=
\frac{
\zeta^{\prime}(z,V)
}{
\zeta(z,V)
} \end{equation*} \begin{equation*}=\frac{1}{z}\sum_{n\ge 1}(\beta z)^n+\alpha(z). \end{equation*}
\begin{equation*}=\frac{1}{z}\sum_{n\ge 1}(\beta z)^n+\alpha(z). \end{equation*}Subtracting the sum on the right, we get that
 \begin{equation*}\sum_{n\ge 1}z^{n-1}\left[
\sum_{\lambda(\tau^{\prime})=n}\Lambda(\tau^{\prime}){\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}
-\beta^n
\right] =\alpha(z) . \end{equation*}
\begin{equation*}\sum_{n\ge 1}z^{n-1}\left[
\sum_{\lambda(\tau^{\prime})=n}\Lambda(\tau^{\prime}){\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}
-\beta^n
\right] =\alpha(z) . \end{equation*} Since α is analytic in the disc Bϵ of (4.23), we get that the radius of convergence of the series on the left is  $\frac{{\rm e}^\epsilon}{\beta} \gt \frac{1}{\beta}$. Since the general term of a converging series tends to zero, we deduce that, for any smaller ϵ > 0,
$\frac{{\rm e}^\epsilon}{\beta} \gt \frac{1}{\beta}$. Since the general term of a converging series tends to zero, we deduce that, for any smaller ϵ > 0,
 \begin{align}
\frac{{\rm e}^{n\epsilon}}{\beta^n}\left[
\sum_{\lambda(\tau^{\prime})=n}\Lambda(\tau^{\prime}){\rm tr}
{{}^{t}}\Psi_{\tau^{\prime}}-\beta^n
\right] \rightarrow 0\quad \text{as}\ n\rightarrow+\infty.
\end{align}
\begin{align}
\frac{{\rm e}^{n\epsilon}}{\beta^n}\left[
\sum_{\lambda(\tau^{\prime})=n}\Lambda(\tau^{\prime}){\rm tr}
{{}^{t}}\Psi_{\tau^{\prime}}-\beta^n
\right] \rightarrow 0\quad \text{as}\ n\rightarrow+\infty.
\end{align} In particular, the sequence above is bounded by some  $D_1 \gt 0$.
$D_1 \gt 0$.
We consider the case β > 1; we define  $\eta(r)$ in the first equality below, where the sum is over the periodic orbits
$\eta(r)$ in the first equality below, where the sum is over the periodic orbits  $\tau^{\prime}=(\tau,k)$, not just the prime ones; λ and Λ are defined in (4.20). The second equality comes (for r integer) by adding and subtracting.
$\tau^{\prime}=(\tau,k)$, not just the prime ones; λ and Λ are defined in (4.20). The second equality comes (for r integer) by adding and subtracting.
 \begin{equation*}\eta(r)\colon=\sum_{\lambda(\tau^{\prime})\le r}
\Lambda(\tau^{\prime}){\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}\end{equation*}
\begin{equation*}\eta(r)\colon=\sum_{\lambda(\tau^{\prime})\le r}
\Lambda(\tau^{\prime}){\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}\end{equation*} \begin{align}
=\sum_{n\in[1,r]}\left[
\sum_{\lambda(\tau^{\prime})=n}\left(
\Lambda(\tau^{\prime}){\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}
\right)
-\beta^n
\right] +
\beta\frac{\beta^r-1}{\beta-1}.
\end{align}
\begin{align}
=\sum_{n\in[1,r]}\left[
\sum_{\lambda(\tau^{\prime})=n}\left(
\Lambda(\tau^{\prime}){\rm tr}{{}^{t}}\Psi_{\tau^{\prime}}
\right)
-\beta^n
\right] +
\beta\frac{\beta^r-1}{\beta-1}.
\end{align} By (4.26) and the remark after (4.25), there is  $D_1 \gt 0$, independent of r, such that the first inequality below holds; the second one holds for some
$D_1 \gt 0$, independent of r, such that the first inequality below holds; the second one holds for some  $D_2=D_2(\beta) \gt 0$ independent of r by the properties of the geometric series; note that
$D_2=D_2(\beta) \gt 0$ independent of r by the properties of the geometric series; note that  $\frac{\beta}{e^\epsilon} \gt 1$ if ϵ is small enough, since we are supposing that β > 1.
$\frac{\beta}{e^\epsilon} \gt 1$ if ϵ is small enough, since we are supposing that β > 1.
 \begin{align}
\left\vert
\eta(r)-\frac{\beta^{r+1}-\beta}{\beta-1}
\right\vert \le
D_1\sum_{n\in[1,r]}\left(\frac{\beta}{e^{\epsilon }}\right)^n\le
D_2\frac{\beta^r}{e^{\epsilon r}} .
\end{align}
\begin{align}
\left\vert
\eta(r)-\frac{\beta^{r+1}-\beta}{\beta-1}
\right\vert \le
D_1\sum_{n\in[1,r]}\left(\frac{\beta}{e^{\epsilon }}\right)^n\le
D_2\frac{\beta^r}{e^{\epsilon r}} .
\end{align} For  ${\rm tr}{{}^{t}}\Psi_\tau$ defined as in (4.19) and
${\rm tr}{{}^{t}}\Psi_\tau$ defined as in (4.19) and  $r\ge 1$, we set
$r\ge 1$, we set
 \begin{align}
\pi^{\prime}(r)=\sum_{\lambda(\tau)\le r }
{\rm tr}({{}^{t}}\Psi_\tau),
\end{align}
\begin{align}
\pi^{\prime}(r)=\sum_{\lambda(\tau)\le r }
{\rm tr}({{}^{t}}\Psi_\tau),
\end{align}where τ varies among the prime orbits.
For γ > 1, we set  $r=\gamma y$; (4.28) implies the equality below; the inequality follows since
$r=\gamma y$; (4.28) implies the equality below; the inequality follows since  $\frac{\lambda(\tau)}{y} \gt 1$ on the set of the first sum, while
$\frac{\lambda(\tau)}{y} \gt 1$ on the set of the first sum, while  $\frac{\lambda(\tau)}{y}\ge 0$ for all τ; recall that
$\frac{\lambda(\tau)}{y}\ge 0$ for all τ; recall that  ${\rm tr}{{}^{t}}\Psi_\tau^k\ge 0$ by Lemma 4.2. The second equality comes from the definition of η in (4.26) and the notation (4.20).
${\rm tr}{{}^{t}}\Psi_\tau^k\ge 0$ by Lemma 4.2. The second equality comes from the definition of η in (4.26) and the notation (4.20).
 \begin{equation*}\pi^{\prime}(r)=\pi^{\prime}(y)+
\sum_{\{\tau\colon y \lt \lambda(\tau)\le r \}}{\rm tr}({{}^{t}}\Psi_{\tau})\end{equation*}
\begin{equation*}\pi^{\prime}(r)=\pi^{\prime}(y)+
\sum_{\{\tau\colon y \lt \lambda(\tau)\le r \}}{\rm tr}({{}^{t}}\Psi_{\tau})\end{equation*} \begin{equation*}\le\pi^{\prime}(y)+\sum_{\{(k,\tau)\colon k\cdot\lambda(\tau)\le r \}}\frac{\lambda(\tau)}{y}
{\rm tr}({{}^{t}}\Psi_{\tau})^k=
\pi^{\prime}(y)+\frac{1}{y}\eta(r) . \end{equation*}
\begin{equation*}\le\pi^{\prime}(y)+\sum_{\{(k,\tau)\colon k\cdot\lambda(\tau)\le r \}}\frac{\lambda(\tau)}{y}
{\rm tr}({{}^{t}}\Psi_{\tau})^k=
\pi^{\prime}(y)+\frac{1}{y}\eta(r) . \end{equation*} If we multiply this inequality by  $\frac{r}{\beta^r}$ and recall that
$\frac{r}{\beta^r}$ and recall that  $r=\gamma y$, we get
$r=\gamma y$, we get
 \begin{align}
\frac{r\cdot\pi^{\prime}(r)}{\beta^r} \le
\frac{(\gamma y)\cdot\pi^{\prime}(y)}{\beta^{\gamma y}}+
\frac{\gamma\cdot\eta(r)}{\beta^r}.
\end{align}
\begin{align}
\frac{r\cdot\pi^{\prime}(r)}{\beta^r} \le
\frac{(\gamma y)\cdot\pi^{\prime}(y)}{\beta^{\gamma y}}+
\frac{\gamma\cdot\eta(r)}{\beta^r}.
\end{align} In Lemma 4.4, we are going to show that, if  $\gamma^{\prime} \gt 1$, then
$\gamma^{\prime} \gt 1$, then
 \begin{align}
\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime} y}}\rightarrow 0\quad \text{as}\ y\rightarrow+\infty.
\end{align}
\begin{align}
\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime} y}}\rightarrow 0\quad \text{as}\ y\rightarrow+\infty.
\end{align}We show that the last two formulas imply
 \begin{align}
\limsup_{r\rightarrow+\infty}
\frac{r\cdot\pi^{\prime}(r)}{\beta^r}\le
\gamma\cdot\frac{\beta}{\beta-1}.
\end{align}
\begin{align}
\limsup_{r\rightarrow+\infty}
\frac{r\cdot\pi^{\prime}(r)}{\beta^r}\le
\gamma\cdot\frac{\beta}{\beta-1}.
\end{align} For the proof, we fix  $\gamma^{\prime}\in(1,\gamma)$; (4.29) implies the first inequality below, while (4.30) and the fact that
$\gamma^{\prime}\in(1,\gamma)$; (4.29) implies the first inequality below, while (4.30) and the fact that  $\beta^{\gamma-\gamma^{\prime}} \gt 1$ imply the second one; the last one comes from (4.27).
$\beta^{\gamma-\gamma^{\prime}} \gt 1$ imply the second one; the last one comes from (4.27).
 \begin{equation*}\limsup_{r\rightarrow+\infty}\frac{r\cdot\pi^{\prime}(r)}{\beta^r}\le
\gamma\limsup_{y\rightarrow+\infty}\frac{y}{\beta^{(\gamma-\gamma^{\prime})y}}\cdot
\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime} y}} +
\gamma\limsup_{r\rightarrow+\infty}\frac{\eta(r)}{\beta^r}\end{equation*}
\begin{equation*}\limsup_{r\rightarrow+\infty}\frac{r\cdot\pi^{\prime}(r)}{\beta^r}\le
\gamma\limsup_{y\rightarrow+\infty}\frac{y}{\beta^{(\gamma-\gamma^{\prime})y}}\cdot
\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime} y}} +
\gamma\limsup_{r\rightarrow+\infty}\frac{\eta(r)}{\beta^r}\end{equation*} \begin{equation*}\le\gamma\limsup_{r\rightarrow+\infty}\frac{\eta(r)}{\beta^r}\le
\gamma\cdot\frac{\beta}{\beta-1} . \end{equation*}
\begin{equation*}\le\gamma\limsup_{r\rightarrow+\infty}\frac{\eta(r)}{\beta^r}\le
\gamma\cdot\frac{\beta}{\beta-1} . \end{equation*}This shows (4.31).
Since γ > 1 is arbitrary, (4.31) implies that
 \begin{equation*}\limsup_{r\rightarrow+\infty}\frac{\pi^{\prime}(r)r}{\beta^r}\le\frac{\beta}{\beta-1} . \end{equation*}
\begin{equation*}\limsup_{r\rightarrow+\infty}\frac{\pi^{\prime}(r)r}{\beta^r}\le\frac{\beta}{\beta-1} . \end{equation*} Consider now the function π of (11) with  $\hat V\equiv 1$; in this case, it is immediate that the constant c of Theorem 2 is
$\hat V\equiv 1$; in this case, it is immediate that the constant c of Theorem 2 is  $\log\beta \gt 0$, where β is the eigenvalue for the zero potential. By the definition of
$\log\beta \gt 0$, where β is the eigenvalue for the zero potential. By the definition of  $\pi^{\prime}$ in (4.28), we get that
$\pi^{\prime}$ in (4.28), we get that
 \begin{equation*}\pi(r)=\sum_{{\rm e}^{c\lambda(\tau)}\le r}{\rm tr}\Psi_\tau=
\pi^{\prime}\left(
\frac{\log r}{c}
\right) . \end{equation*}
\begin{equation*}\pi(r)=\sum_{{\rm e}^{c\lambda(\tau)}\le r}{\rm tr}\Psi_\tau=
\pi^{\prime}\left(
\frac{\log r}{c}
\right) . \end{equation*} Since  $c=\log\beta$, the last two formulas imply (12).
$c=\log\beta$, the last two formulas imply (12).
The case β < 1 is simpler: (4.26) and (4.28) imply the first inequality below, the second one comes from (4.25) and the last one from the fact that β < 1.
 \begin{equation*}\pi^{\prime}(r)\le\eta(r)\end{equation*}
\begin{equation*}\pi^{\prime}(r)\le\eta(r)\end{equation*} \begin{equation*}\le\sum_{n\in[1,r]}\left[
\beta^n+D_1\frac{\beta^n}{{\rm e}^{n\epsilon}}
\right] \le D_2. \end{equation*}
\begin{equation*}\le\sum_{n\in[1,r]}\left[
\beta^n+D_1\frac{\beta^n}{{\rm e}^{n\epsilon}}
\right] \le D_2. \end{equation*}Now (12) follows.
Now there is only one only missing ingredient, the proof of (4.30); we begin with some preliminaries.
We note that, by point (5) of Lemma 4.2,
 \begin{equation*}\sum_{i=1}^m\alpha_{\tau,i}^k\ge 0. \end{equation*}
\begin{equation*}\sum_{i=1}^m\alpha_{\tau,i}^k\ge 0. \end{equation*} If we assume that x > 0, this implies the first inequality below; the second inequality comes from the fact that  $x\ge\log(1+x)$ and the formula above again. The two equalities that bookend the formula come from the properties of the logarithm.
$x\ge\log(1+x)$ and the formula above again. The two equalities that bookend the formula come from the properties of the logarithm.
 \begin{equation*}\prod_{i=1}^m\frac{1}{1-\alpha_{\tau,i}\cdot x}=
\exp\left[
\sum_{k\ge 1}\frac{1}{k}x^k\left(
\sum_{i=1}^m\alpha_{\tau,i}^k
\right)
\right] \end{equation*}
\begin{equation*}\prod_{i=1}^m\frac{1}{1-\alpha_{\tau,i}\cdot x}=
\exp\left[
\sum_{k\ge 1}\frac{1}{k}x^k\left(
\sum_{i=1}^m\alpha_{\tau,i}^k
\right)
\right] \end{equation*} \begin{equation*}\ge\exp\left[
\left(
\sum_{i=1}^m\alpha_{\tau,i}
\right)x
\right] \end{equation*}
\begin{equation*}\ge\exp\left[
\left(
\sum_{i=1}^m\alpha_{\tau,i}
\right)x
\right] \end{equation*} \begin{align}
\ge\exp\left[
\left(
\sum_{i=1}^m\alpha_{\tau,i}
\right)\log(1+x)
\right] =
\left( 1+x \right)^{\sum_{i=1}^m\alpha_{\tau,i}}.
\end{align}
\begin{align}
\ge\exp\left[
\left(
\sum_{i=1}^m\alpha_{\tau,i}
\right)\log(1+x)
\right] =
\left( 1+x \right)^{\sum_{i=1}^m\alpha_{\tau,i}}.
\end{align}Lemma 4.4. Formula (4.30) holds for all  $\gamma^{\prime} \gt 1$.
$\gamma^{\prime} \gt 1$.
Proof. Since  $\gamma^{\prime} \gt 1$ and we are supposing β > 1,
$\gamma^{\prime} \gt 1$ and we are supposing β > 1,
 \begin{equation*}\frac{1}{\beta^{\gamma^{\prime}}} \lt \frac{1}{\beta} . \end{equation*}
\begin{equation*}\frac{1}{\beta^{\gamma^{\prime}}} \lt \frac{1}{\beta} . \end{equation*} Together with Proposition 4.3, this implies that  $\frac{1}{\beta^{\gamma^{\prime}}}$ belongs to the disk where
$\frac{1}{\beta^{\gamma^{\prime}}}$ belongs to the disk where  $\zeta(z,0)$ converges. Now we take y > 1; since
$\zeta(z,0)$ converges. Now we take y > 1; since  $\frac{1}{\beta^{\gamma^{\prime}}} \gt 0$ and
$\frac{1}{\beta^{\gamma^{\prime}}} \gt 0$ and  ${\rm tr}(\Psi_\tau) \gt 0$ by Lemma 4.2, (4.21) implies the first inequality below, while the first equality comes from the properties of the logarithm; recall that
${\rm tr}(\Psi_\tau) \gt 0$ by Lemma 4.2, (4.21) implies the first inequality below, while the first equality comes from the properties of the logarithm; recall that  $V\equiv 0$. For the second inequality, we apply (4.32) to the innermost product. For the third inequality, we note that
$V\equiv 0$. For the second inequality, we apply (4.32) to the innermost product. For the third inequality, we note that  $1+\frac{1}{\beta^{\gamma^{\prime}\cdot y}}$ is smaller than all the factors in the product. The second equality comes from the definition of
$1+\frac{1}{\beta^{\gamma^{\prime}\cdot y}}$ is smaller than all the factors in the product. The second equality comes from the definition of  $\pi^{\prime}$ in (4.28). The second last inequality follows from the binomial theorem, while the last one is obvious.
$\pi^{\prime}$ in (4.28). The second last inequality follows from the binomial theorem, while the last one is obvious.
 \begin{equation*}\zeta\left(\frac{1}{\beta^{\gamma^{\prime}}},0\right)\ge
\exp\sum_{\lambda(\tau)\le y}\sum_{j=1}^m\sum_{k\ge 1}
\frac{\alpha^k_{\tau,j}\,{\rm e}^{kV(\tau)}\frac{1}{\beta^{\gamma^{\prime} k\lambda(\tau)}}}{k}\end{equation*}
\begin{equation*}\zeta\left(\frac{1}{\beta^{\gamma^{\prime}}},0\right)\ge
\exp\sum_{\lambda(\tau)\le y}\sum_{j=1}^m\sum_{k\ge 1}
\frac{\alpha^k_{\tau,j}\,{\rm e}^{kV(\tau)}\frac{1}{\beta^{\gamma^{\prime} k\lambda(\tau)}}}{k}\end{equation*} \begin{equation*}=\prod_{\lambda(\tau)\le y}\prod_{i=1}^m
\frac{1}{1-\frac{\alpha_{\tau,i}}{\beta^{\gamma^{\prime}\cdot\lambda(\tau)}}} \end{equation*}
\begin{equation*}=\prod_{\lambda(\tau)\le y}\prod_{i=1}^m
\frac{1}{1-\frac{\alpha_{\tau,i}}{\beta^{\gamma^{\prime}\cdot\lambda(\tau)}}} \end{equation*} \begin{equation*}\ge\prod_{\lambda(\tau)\le y}\left(
1+\frac{1}{\beta^{\gamma^{\prime}\cdot\lambda(\tau)}}
\right)^{\sum_{i=1}^m\alpha_{\tau,i}} \ge
\prod_{\lambda(\tau)\le y }
\left(
1+\frac{1}{\beta^{\gamma^{\prime}\cdot y}}
\right)^{\sum_{i=1}^m\alpha_{\tau,i}}\end{equation*}
\begin{equation*}\ge\prod_{\lambda(\tau)\le y}\left(
1+\frac{1}{\beta^{\gamma^{\prime}\cdot\lambda(\tau)}}
\right)^{\sum_{i=1}^m\alpha_{\tau,i}} \ge
\prod_{\lambda(\tau)\le y }
\left(
1+\frac{1}{\beta^{\gamma^{\prime}\cdot y}}
\right)^{\sum_{i=1}^m\alpha_{\tau,i}}\end{equation*} \begin{equation*}=\left(
1+\frac{1}{\beta^{\gamma^{\prime}\cdot y}}
\right)^{\pi^{\prime}(y) }\ge
1+\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime}\cdot y}}\ge
\frac{\pi^{\prime}(y) }{\beta^{\gamma^{\prime}\cdot y}} . \end{equation*}
\begin{equation*}=\left(
1+\frac{1}{\beta^{\gamma^{\prime}\cdot y}}
\right)^{\pi^{\prime}(y) }\ge
1+\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime}\cdot y}}\ge
\frac{\pi^{\prime}(y) }{\beta^{\gamma^{\prime}\cdot y}} . \end{equation*} Thus,  $\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime}\cdot y}}$ is bounded for all
$\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime}\cdot y}}$ is bounded for all  $\gamma^{\prime},y \gt 1$, which implies that
$\gamma^{\prime},y \gt 1$, which implies that
 \begin{equation*}\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime}\cdot y}}\rightarrow 0\quad \text{for}\ y\rightarrow+\infty \end{equation*}
\begin{equation*}\frac{\pi^{\prime}(y)}{\beta^{\gamma^{\prime}\cdot y}}\rightarrow 0\quad \text{for}\ y\rightarrow+\infty \end{equation*} for all  $\gamma^{\prime} \gt 1$.
$\gamma^{\prime} \gt 1$.
5. The weakly mixing case
In this section, we shall work with a potential  $\hat V$ such that
$\hat V$ such that  $\hat V \gt 0$. We begin with the following lemma.
$\hat V \gt 0$. We begin with the following lemma.
Lemma 5.1. Let  $c\in\textbf{R}$, let
$c\in\textbf{R}$, let  $\hat V\in C^{0,\alpha}(\Sigma,\textbf{R})$ be positive and let
$\hat V\in C^{0,\alpha}(\Sigma,\textbf{R})$ be positive and let  $P(-c\hat V)=\log\beta_{-c\hat V}$ be as in the notation after Formula (3.3). Then, there is a unique
$P(-c\hat V)=\log\beta_{-c\hat V}$ be as in the notation after Formula (3.3). Then, there is a unique  $c\in\textbf{R}$ such that
$c\in\textbf{R}$ such that
 \begin{align}
P(-c\hat V)=0.
\end{align}
\begin{align}
P(-c\hat V)=0.
\end{align} Moreover, c > 0 if  $P(0) \gt 0$ and c < 0 if
$P(0) \gt 0$ and c < 0 if  $P(0) \lt 0$.
$P(0) \lt 0$.
Proof. The thesis follows from the intermediate value theorem and the three facts below.
(1) The function  $\colon c\rightarrow P(-c\hat V)$ is continuous. To show this, we recall that
$\colon c\rightarrow P(-c\hat V)$ is continuous. To show this, we recall that  $P(-c\hat V)=\log\beta_{-c\hat V}$, where
$P(-c\hat V)=\log\beta_{-c\hat V}$, where  $\beta_{-c\hat V}$ is the maximal eigenvalue of the Ruelle operator
$\beta_{-c\hat V}$ is the maximal eigenvalue of the Ruelle operator  ${\cal L}_{-c\hat V}$; thus, it suffices to show that
${\cal L}_{-c\hat V}$; thus, it suffices to show that  $\colon c\rightarrow \beta_{-c\hat V}$ is continuous. Recall that Proposition 2.2 follows from the Perron–Frobenius Theorem 2.1, which says that the eigenvector
$\colon c\rightarrow \beta_{-c\hat V}$ is continuous. Recall that Proposition 2.2 follows from the Perron–Frobenius Theorem 2.1, which says that the eigenvector  $Q_{-c\hat V}$ is the fixed point of a contraction; now the theorem of contractions depending on a parameter implies that
$Q_{-c\hat V}$ is the fixed point of a contraction; now the theorem of contractions depending on a parameter implies that  $Q_{-c\hat V}$ (or, better, its ray) and
$Q_{-c\hat V}$ (or, better, its ray) and  $\beta_{-c\hat V}$ depend continuously on c.
$\beta_{-c\hat V}$ depend continuously on c.
(2) The second fact is that the map  $\colon c\rightarrow P(-c\hat V)$ is strictly monotone decreasing. To show this, we set
$\colon c\rightarrow P(-c\hat V)$ is strictly monotone decreasing. To show this, we set  $\epsilon\colon=\min\hat V$ and note that ϵ > 0 since
$\epsilon\colon=\min\hat V$ and note that ϵ > 0 since  $\hat V$ is continuous and positive and Σ is compact. Let
$\hat V$ is continuous and positive and Σ is compact. Let  $c^{\prime} \gt c$ and let Q be a positive eigenvector of
$c^{\prime} \gt c$ and let Q be a positive eigenvector of  ${\cal L}_{-c\hat V}$; then we have the equality below, while the inequality (between matrices, of course) comes from (2.24).
${\cal L}_{-c\hat V}$; then we have the equality below, while the inequality (between matrices, of course) comes from (2.24).
 \begin{equation*}{\cal L}_{-c^{\prime}\hat V}Q\le
{\rm e}^{-\epsilon(c^{\prime}-c)}{\cal L}_{-c\hat V}Q=
\beta_{-c\hat V}\cdot {\rm e}^{-\epsilon(c^{\prime}-c)}\cdot Q . \end{equation*}
\begin{equation*}{\cal L}_{-c^{\prime}\hat V}Q\le
{\rm e}^{-\epsilon(c^{\prime}-c)}{\cal L}_{-c\hat V}Q=
\beta_{-c\hat V}\cdot {\rm e}^{-\epsilon(c^{\prime}-c)}\cdot Q . \end{equation*} Iterating, we get the second inequality below, while the first one comes from the fact that  ${\cal L}_{-c^{\prime}\hat V}$ preserves positive-definiteness.
${\cal L}_{-c^{\prime}\hat V}$ preserves positive-definiteness.
 \begin{equation*}0\le
\left(
\frac{{\cal L}_{-c^{\prime}\hat V}}{\beta_{-c\hat V}}
\right)^n Q \le
{\rm e}^{-\epsilon n(c^{\prime}-c)}Q\rightarrow 0 . \end{equation*}
\begin{equation*}0\le
\left(
\frac{{\cal L}_{-c^{\prime}\hat V}}{\beta_{-c\hat V}}
\right)^n Q \le
{\rm e}^{-\epsilon n(c^{\prime}-c)}Q\rightarrow 0 . \end{equation*}By point (3) of Proposition 2.2, this implies that
 \begin{equation*}0 \lt \beta_{-c^{\prime}\hat V} \lt \beta_{-c\hat V} , \end{equation*}
\begin{equation*}0 \lt \beta_{-c^{\prime}\hat V} \lt \beta_{-c\hat V} , \end{equation*}as we wanted.
(3) The last fact is that  $P(-c\hat V)\rightarrow\pm\infty$ as
$P(-c\hat V)\rightarrow\pm\infty$ as  $c\rightarrow\mp\infty$; since
$c\rightarrow\mp\infty$; since  $P(-c\hat V)=\log\beta_{-c\hat V}$, this is equivalent to
$P(-c\hat V)=\log\beta_{-c\hat V}$, this is equivalent to  $\beta_{-c\hat V}\searrow 0$ as
$\beta_{-c\hat V}\searrow 0$ as  $c\nearrow+\infty$ and
$c\nearrow+\infty$ and  $\beta_{-c\hat V}\nearrow+\infty$ if
$\beta_{-c\hat V}\nearrow+\infty$ if  $c\searrow-\infty$. This follows easily from the formula in point (2) above.
$c\searrow-\infty$. This follows easily from the formula in point (2) above.
Definition. Having fixed c so that (5.1) holds, we set  $V=|c|\hat V\ge 0$; in some of the formulas below, we shall have to flip signs according to the sign of c.
$V=|c|\hat V\ge 0$; in some of the formulas below, we shall have to flip signs according to the sign of c.
We shall count periodic orbits according to a ‘length’ induced by  $\hat V$; by Lemma 5.3, it is equivalent whether we use the length induced by V or by
$\hat V$; by Lemma 5.3, it is equivalent whether we use the length induced by V or by  $\hat V$, and we shall use the former.
$\hat V$, and we shall use the former.
Let  $g\colon \Sigma\rightarrow \textbf{R}$ be a function; let g n be as in point (5) of Proposition 2.2 and let Fixn be as in the definition after (4.10); we set
$g\colon \Sigma\rightarrow \textbf{R}$ be a function; let g n be as in point (5) of Proposition 2.2 and let Fixn be as in the definition after (4.10); we set
 \begin{equation*}Z(g)=\sum_{n\ge 1}\frac{1}{n}\sum_{x\in{Fix}_n}
{\rm e}^{g^n(x)}\cdot{\rm tr}({{}^{t}}\Psi_{x,n}) \end{equation*}
\begin{equation*}Z(g)=\sum_{n\ge 1}\frac{1}{n}\sum_{x\in{Fix}_n}
{\rm e}^{g^n(x)}\cdot{\rm tr}({{}^{t}}\Psi_{x,n}) \end{equation*}and
 \begin{equation*}\zeta_{-V}(s)=\exp Z(-sV)\end{equation*}
\begin{equation*}\zeta_{-V}(s)=\exp Z(-sV)\end{equation*} \begin{align}
=\exp\sum_{n\ge 1}\frac{1}{n}\sum_{x\in{Fix}_n}
{\rm e}^{-V^n(x)\cdot s}\cdot{\rm tr}({{}^{t}}\Psi_{x,n}) .
\end{align}
\begin{align}
=\exp\sum_{n\ge 1}\frac{1}{n}\sum_{x\in{Fix}_n}
{\rm e}^{-V^n(x)\cdot s}\cdot{\rm tr}({{}^{t}}\Psi_{x,n}) .
\end{align} We must understand for which values of s the series above converges; since by (4.11),  $\zeta_{-V}(s)=\zeta(1,-sV)$, the radius of convergence of
$\zeta_{-V}(s)=\zeta(1,-sV)$, the radius of convergence of  $\zeta(\cdot,-sV)$ must be larger than 1. By Proposition 4.3, this holds if
$\zeta(\cdot,-sV)$ must be larger than 1. By Proposition 4.3, this holds if  $\beta_{-sV} \lt 1$; now recall that c satisfies (5.1); since
$\beta_{-sV} \lt 1$; now recall that c satisfies (5.1); since  $V=|c|\hat V$, we get that
$V=|c|\hat V$, we get that  $\beta_{-V}=1$ if c > 0 and
$\beta_{-V}=1$ if c > 0 and  $\beta_V=1$ if c < 0. Let us suppose that c > 0; since the last lemma implies that the function
$\beta_V=1$ if c < 0. Let us suppose that c > 0; since the last lemma implies that the function  $\colon s\rightarrow \beta_{-sV}$ is monotone decreasing, we get that
$\colon s\rightarrow \beta_{-sV}$ is monotone decreasing, we get that  $\zeta_{-V}(s)$ converges if s > 1. If c < 0, we see that
$\zeta_{-V}(s)$ converges if s > 1. If c < 0, we see that  $\beta_{-sV}=\beta_{sc\hat V}$; recall that
$\beta_{-sV}=\beta_{sc\hat V}$; recall that  $\beta_{-c\hat V}=\beta_V=1$ and that
$\beta_{-c\hat V}=\beta_V=1$ and that  $\colon s\rightarrow \beta_{-sV}$ is monotone decreasing; all these facts imply that
$\colon s\rightarrow \beta_{-sV}$ is monotone decreasing; all these facts imply that  $\zeta_V(s)$ converges if
$\zeta_V(s)$ converges if  $s \gt -1$.
$s \gt -1$.
Actually,  $\zeta_{-V}(s)$ converges for
$\zeta_{-V}(s)$ converges for  ${\rm Re}(s) \gt 1$ in one case and in
${\rm Re}(s) \gt 1$ in one case and in  ${\rm Re}(s) \gt -1$ in the other one; we skip the easy proof of this fact, which is based on the last paragraph and the fact that
${\rm Re}(s) \gt -1$ in the other one; we skip the easy proof of this fact, which is based on the last paragraph and the fact that  ${\rm tr}({{}^{t}}\Psi_{x,n})\ge 0$.
${\rm tr}({{}^{t}}\Psi_{x,n})\ge 0$.
Throughout this section, we are going to use the notation of (4.19) and (4.20); now we proceed to find an analogue of (4.21). We could use the fact that  $\zeta_{-V}(s)=\zeta(1,-sV)$, but we repeat the proof of § 4.
$\zeta_{-V}(s)=\zeta(1,-sV)$, but we repeat the proof of § 4.
The first equality below is the definition (5.2). For the second one, we recall from Lemma 4.2 that, if x is a periodic orbit of minimal period n, then the eigenvalues of  ${{}^{t}}\Psi_{x,kn}$ are
${{}^{t}}\Psi_{x,kn}$ are  $\alpha_{x,i}^k=\alpha_{\tau,i}^k$ and
$\alpha_{x,i}^k=\alpha_{\tau,i}^k$ and  $V^{nk}(x)=kV^n(x)=kV^n(\tau)$. The third equality comes from (4.19) and the fact that τ, the equivalence class of x, has n elements. The last two equalities follow from the properties of the logarithm.
$V^{nk}(x)=kV^n(x)=kV^n(\tau)$. The third equality comes from (4.19) and the fact that τ, the equivalence class of x, has n elements. The last two equalities follow from the properties of the logarithm.
 \begin{equation*}\zeta_{-V}(s)=\exp\sum_{n\ge 1}\frac{1}{n}
\sum_{x\in Fix_n}{\rm e}^{-V^n(x)\cdot s}{\rm tr}({{}^{t}}\Psi_{x,n})\end{equation*}
\begin{equation*}\zeta_{-V}(s)=\exp\sum_{n\ge 1}\frac{1}{n}
\sum_{x\in Fix_n}{\rm e}^{-V^n(x)\cdot s}{\rm tr}({{}^{t}}\Psi_{x,n})\end{equation*} \begin{equation*}=\exp\sum_{n\ge 1}\frac{1}{n}\sum_{\{\sigma^n(x)=x,\ n\ least \}}\sum_{k\ge 1}
\sum_{i=1}^{m}
\frac{{\rm e}^{-kV^n(x)\cdot s}}{k}\cdot\alpha_{x,i}^k\end{equation*}
\begin{equation*}=\exp\sum_{n\ge 1}\frac{1}{n}\sum_{\{\sigma^n(x)=x,\ n\ least \}}\sum_{k\ge 1}
\sum_{i=1}^{m}
\frac{{\rm e}^{-kV^n(x)\cdot s}}{k}\cdot\alpha_{x,i}^k\end{equation*} \begin{equation*}=\exp\sum_\tau\sum_{k\ge 1}\sum_{i=1}^{m}\frac{
{\rm e}^{-kV(\tau)\cdot s}\alpha_{\tau,i}^k
}{
k
} =
\exp\left\{
-\sum_\tau\sum_{i=1}^{m}\log\left[
1-{\rm e}^{-V(\tau)\cdot s}\cdot\alpha_{\tau,i}
\right]
\right\} \end{equation*}
\begin{equation*}=\exp\sum_\tau\sum_{k\ge 1}\sum_{i=1}^{m}\frac{
{\rm e}^{-kV(\tau)\cdot s}\alpha_{\tau,i}^k
}{
k
} =
\exp\left\{
-\sum_\tau\sum_{i=1}^{m}\log\left[
1-{\rm e}^{-V(\tau)\cdot s}\cdot\alpha_{\tau,i}
\right]
\right\} \end{equation*} \begin{align}
=\prod_\tau\prod_{i=1}^{m}\frac{
1
}{
1-{\rm e}^{-V(\tau)\cdot s}\cdot\alpha_{\tau,i}
} .
\end{align}
\begin{align}
=\prod_\tau\prod_{i=1}^{m}\frac{
1
}{
1-{\rm e}^{-V(\tau)\cdot s}\cdot\alpha_{\tau,i}
} .
\end{align}Standing hypothesis
Our standing hypothesis from now on is that, when c > 0, the function  $\zeta_{-V}(s)$ can be extended to a continuous function on
$\zeta_{-V}(s)$ can be extended to a continuous function on  $\{{\rm Re}(s)\ge 1 \}\setminus \{1 \}$, with a simple pole at s = 1. When c < 0, we do not make any hypothesis: it will suffice the fact, which we saw above, that ζ −V extends to a holomorphic function in
$\{{\rm Re}(s)\ge 1 \}\setminus \{1 \}$, with a simple pole at s = 1. When c < 0, we do not make any hypothesis: it will suffice the fact, which we saw above, that ζ −V extends to a holomorphic function in  ${\rm Re}(s) \gt -1$. In other words, we are supposing that
${\rm Re}(s) \gt -1$. In other words, we are supposing that
 \begin{align}
\zeta_{-V}(s)=\left\{
\begin{aligned}
\frac{\tilde\alpha_+(s)}{(s-1)}&\quad \text{if}\ c \gt 0\cr
\tilde\alpha_-(s)&\quad \text{if}\ c \lt 0,
\end{aligned}
\right.
\end{align}
\begin{align}
\zeta_{-V}(s)=\left\{
\begin{aligned}
\frac{\tilde\alpha_+(s)}{(s-1)}&\quad \text{if}\ c \gt 0\cr
\tilde\alpha_-(s)&\quad \text{if}\ c \lt 0,
\end{aligned}
\right.
\end{align} with  $\tilde\alpha_+$ analytic and non-zero in
$\tilde\alpha_+$ analytic and non-zero in  ${\rm Re}(s)\ge 1$ if c > 0, and
${\rm Re}(s)\ge 1$ if c > 0, and  $\tilde\alpha_-$ analytic and non-zero in
$\tilde\alpha_-$ analytic and non-zero in  ${\rm Re}(s) \gt -1$ if c < 0.
${\rm Re}(s) \gt -1$ if c < 0.
Remark. In the scalar case of [Reference Parry and Pollicott14], the fact that the zeta function has no zeroes on the line  ${\rm Re}(s)=1$ has a connection with the dynamics, being equivalent to the fact that the suspension flow by
${\rm Re}(s)=1$ has a connection with the dynamics, being equivalent to the fact that the suspension flow by  $\hat V$ is topologically mixing. One of the ways to express the topologically mixing property is the following. We define the operator
$\hat V$ is topologically mixing. One of the ways to express the topologically mixing property is the following. We define the operator
 \begin{equation*}V\colon C(\Sigma,\textbf{C})\rightarrow C(\Sigma,\textbf{C}), \end{equation*}
\begin{equation*}V\colon C(\Sigma,\textbf{C})\rightarrow C(\Sigma,\textbf{C}), \end{equation*} \begin{equation*}(Vw)(x)={\rm e}^{-ia\hat V(x)}w\circ\sigma(x) . \end{equation*}
\begin{equation*}(Vw)(x)={\rm e}^{-ia\hat V(x)}w\circ\sigma(x) . \end{equation*}We say that the suspension flow (which we leave undefined) is weakly topologically mixing if Vw = w implies that a = 0 and that w is constant. As we said, we shall not study the connection between this property and the behaviour of the zeta function on the critical line.
Next, we set
 \begin{align}
N(\tau)={\rm e}^{V(\tau)}={\rm e}^{|c|\hat V(\tau)}.
\end{align}
\begin{align}
N(\tau)={\rm e}^{V(\tau)}={\rm e}^{|c|\hat V(\tau)}.
\end{align}With this notation, we can rewrite one equality of (5.3) as
 \begin{equation*}\zeta_{-V}(s)=\exp\sum_{k\ge 1}\sum_\tau\sum_{i=1}^{m}
\frac{N(\tau)^{-sk}}{k}\alpha_{\tau,i}^k . \end{equation*}
\begin{equation*}\zeta_{-V}(s)=\exp\sum_{k\ge 1}\sum_\tau\sum_{i=1}^{m}
\frac{N(\tau)^{-sk}}{k}\alpha_{\tau,i}^k . \end{equation*} As we saw after (5.2), this holds in  $Re(s) \gt 1$ if c > 0, and in
$Re(s) \gt 1$ if c > 0, and in  $Re(s) \gt -1$ if c < 0.
$Re(s) \gt -1$ if c < 0.
Now we take derivatives in two different expressions for  $\log\zeta_{-V}(s)$; for the equality on the left, we differentiate the formula above, for that on the right we differentiate (5.4) and recall that
$\log\zeta_{-V}(s)$; for the equality on the left, we differentiate the formula above, for that on the right we differentiate (5.4) and recall that  $\tilde\alpha_\pm\not=0$; the function
$\tilde\alpha_\pm\not=0$; the function  $\alpha_+$ is analytic in an open half-plane containing
$\alpha_+$ is analytic in an open half-plane containing  $Re(s)\ge 1$ and
$Re(s)\ge 1$ and  $\alpha_-$ is analytic in the open half-plane
$\alpha_-$ is analytic in the open half-plane  $Re(s) \gt -1$.
$Re(s) \gt -1$.
 \begin{equation*}-\sum_{k\ge 1}\sum_\tau\sum_{i=1}^{m}
[\log N(\tau)]\cdot N(\tau)^{-sk}\cdot\alpha_{\tau,i}^k\end{equation*}
\begin{equation*}-\sum_{k\ge 1}\sum_\tau\sum_{i=1}^{m}
[\log N(\tau)]\cdot N(\tau)^{-sk}\cdot\alpha_{\tau,i}^k\end{equation*} \begin{align}
=\frac{
\zeta_{-V}^{\prime}(s)
}{\zeta_{-V}(s) }=
\left\{
\begin{aligned}
-\frac{1}{s-1}+\alpha_+(s)&\quad \text{if}\ c \gt 0\cr
\alpha_-(s)& \quad \text{if}\ c \lt 0 .
\end{aligned}
\right.
\end{align}
\begin{align}
=\frac{
\zeta_{-V}^{\prime}(s)
}{\zeta_{-V}(s) }=
\left\{
\begin{aligned}
-\frac{1}{s-1}+\alpha_+(s)&\quad \text{if}\ c \gt 0\cr
\alpha_-(s)& \quad \text{if}\ c \lt 0 .
\end{aligned}
\right.
\end{align} We denote by  $\lfloor a\rfloor$ the integer part of
$\lfloor a\rfloor$ the integer part of  $a\ge 0$; recall that we saw at the beginning of this section that
$a\ge 0$; recall that we saw at the beginning of this section that  $V=|c|\hat V \gt 0$; by (5.5), this implies that
$V=|c|\hat V \gt 0$; by (5.5), this implies that  $\log N(\tau)$ is always positive. As a consequence, for
$\log N(\tau)$ is always positive. As a consequence, for  $r\ge 1$, we can define
$r\ge 1$, we can define  $n(r,\tau)\ge 0$ by
$n(r,\tau)\ge 0$ by
 \begin{equation*}n(r,\tau)\colon=
\left\lfloor
\frac{
\log r
}{
\log N(\tau)
}
\right\rfloor . \end{equation*}
\begin{equation*}n(r,\tau)\colon=
\left\lfloor
\frac{
\log r
}{
\log N(\tau)
}
\right\rfloor . \end{equation*} We define the function  $S\colon (1,+\infty)\rightarrow \textbf{R}$ in the first equality below; the second one comes from the definition of
$S\colon (1,+\infty)\rightarrow \textbf{R}$ in the first equality below; the second one comes from the definition of  $n(r,\tau)$ above and the fact that
$n(r,\tau)$ above and the fact that  $N(\tau)\ge 1$.
$N(\tau)\ge 1$.
 \begin{equation*}S(r)\colon=\sum_{\{(\tau,n)\colon N(\tau)^n\le r\}}\sum_{i=1}^{m}
( \log N(\tau) )\cdot\alpha_{\tau,i}^n\end{equation*}
\begin{equation*}S(r)\colon=\sum_{\{(\tau,n)\colon N(\tau)^n\le r\}}\sum_{i=1}^{m}
( \log N(\tau) )\cdot\alpha_{\tau,i}^n\end{equation*} \begin{align}
=\sum_{\{\tau\colon N(\tau)\le r \}}( \log N(\tau) )\cdot
\sum_{n=1}^{n(r,\tau)}
\left( \sum_{i=1}^{m} \alpha_{\tau,i}^n \right) .
\end{align}
\begin{align}
=\sum_{\{\tau\colon N(\tau)\le r \}}( \log N(\tau) )\cdot
\sum_{n=1}^{n(r,\tau)}
\left( \sum_{i=1}^{m} \alpha_{\tau,i}^n \right) .
\end{align} Note that S is monotone increasing and thus its derivative  $ {\rm d} S$ is a positive measure; from the first sum above, we gather that each orbit
$ {\rm d} S$ is a positive measure; from the first sum above, we gather that each orbit  $\tau^{\prime}=(\tau,k)$ contributes to
$\tau^{\prime}=(\tau,k)$ contributes to  $ {\rm d} S$ the measure
$ {\rm d} S$ the measure
 \begin{equation*}\sum_{i=1}^{m}
\left(\log N(\tau)\right)
\alpha_{\tau,i}^k
\cdot\delta_{N(\tau)^k}, \end{equation*}
\begin{equation*}\sum_{i=1}^{m}
\left(\log N(\tau)\right)
\alpha_{\tau,i}^k
\cdot\delta_{N(\tau)^k}, \end{equation*} where δx denotes the Dirac delta centred at x. Let now c > 0; the second equality below is the right hand side of (5.6); the first equality follows from the formula above, the left hand side of (5.6) and the fact that  $N(\tau)\ge 1$ by (5.5). The integral is Stieltjes and
$N(\tau)\ge 1$ by (5.5). The integral is Stieltjes and  $Re(s) \gt 1$.
$Re(s) \gt 1$.
 \begin{align}
-\int_1^{+\infty}r^{-s}\, {\rm d} S(r)=
\frac{
\zeta^{\prime}_{-V}(s)
}{
\zeta_{-V}(s)
}=\frac{-1}{s-1}+\alpha_+(s).
\end{align}
\begin{align}
-\int_1^{+\infty}r^{-s}\, {\rm d} S(r)=
\frac{
\zeta^{\prime}_{-V}(s)
}{
\zeta_{-V}(s)
}=\frac{-1}{s-1}+\alpha_+(s).
\end{align} When c < 0, we do the same thing, but using the second expression on the right of (5.6); the equalities hold for  $s \gt -1$.
$s \gt -1$.
 \begin{align}
-\int_{1}^{+\infty}r^{-s}\, {\rm d} S(r)=
\frac{
\zeta^{\prime}_{-V}(s)
}{
\zeta_{-V}(s)
}=\alpha_-(s).
\end{align}
\begin{align}
-\int_{1}^{+\infty}r^{-s}\, {\rm d} S(r)=
\frac{
\zeta^{\prime}_{-V}(s)
}{
\zeta_{-V}(s)
}=\alpha_-(s).
\end{align}We recall the Wiener–Ikehara Tauberian theorem. A proof is in Appendix I of [Reference Parry and Pollicott15]; for the whole theory, we refer the reader to [Reference Wiener25].
Theorem 5.2. Assume that the formula below holds, where  $A\in\textbf{R}$, the integral on the left is Stieltjes, α is analytic in
$A\in\textbf{R}$, the integral on the left is Stieltjes, α is analytic in  ${\rm Re}(s) \gt 1$ and has a continuous extension to
${\rm Re}(s) \gt 1$ and has a continuous extension to  ${\rm Re}(s)\ge 1$; the function S is monotone increasing.
${\rm Re}(s)\ge 1$; the function S is monotone increasing.
 \begin{equation*}\int_1^{+\infty}r^{-s}\, {\rm d} S(x)=\frac{A}{s-1}+\alpha(s). \end{equation*}
\begin{equation*}\int_1^{+\infty}r^{-s}\, {\rm d} S(x)=\frac{A}{s-1}+\alpha(s). \end{equation*}Then,
 \begin{align}
\lim_{s\rightarrow+\infty}\frac{S(s)}{s}=A.
\end{align}
\begin{align}
\lim_{s\rightarrow+\infty}\frac{S(s)}{s}=A.
\end{align} For  $N(\tau)$ defined as in (5.5), we set, as in (11),
$N(\tau)$ defined as in (5.5), we set, as in (11),
 \begin{align}
\pi(r)=\sum_{N(\tau)\le r }\sum_{i=1}^{m}\alpha_{\tau,i}.
\end{align}
\begin{align}
\pi(r)=\sum_{N(\tau)\le r }\sum_{i=1}^{m}\alpha_{\tau,i}.
\end{align}Lemma 5.3. Let the potentials  $V,\hat V \gt 0$ be as at the beginning of this section; let π be defined as in (5.10) and let
$V,\hat V \gt 0$ be as at the beginning of this section; let π be defined as in (5.10) and let
 \begin{align}
\hat\pi(r)=
\sum_{{\rm e}^{\hat V(\tau)}\le r }{\rm tr}{{}^{t}}\Psi_\tau.
\end{align}
\begin{align}
\hat\pi(r)=
\sum_{{\rm e}^{\hat V(\tau)}\le r }{\rm tr}{{}^{t}}\Psi_\tau.
\end{align}Then,
 \begin{align}
\hat\pi(r)=
\pi(r^{|c|}).
\end{align}
\begin{align}
\hat\pi(r)=
\pi(r^{|c|}).
\end{align}In particular, if
 \begin{align}
\lim_{r\rightarrow+\infty}\frac{\pi(r)\,\log r}{r}\le A ,
\end{align}
\begin{align}
\lim_{r\rightarrow+\infty}\frac{\pi(r)\,\log r}{r}\le A ,
\end{align}then
 \begin{align}
\lim_{r\rightarrow+\infty}\frac{\hat\pi(r)\,\log r}{r^{|c|}}\le\frac{A}{|c|} .
\end{align}
\begin{align}
\lim_{r\rightarrow+\infty}\frac{\hat\pi(r)\,\log r}{r^{|c|}}\le\frac{A}{|c|} .
\end{align}Lastly, if we had ≥ in (5.13), then we would have ≥ also in (5.14).
Proof. We define  $N(\tau)$ as in (5.5); the first equality below comes from the fact that
$N(\tau)$ as in (5.5); the first equality below comes from the fact that  $V=|c|\hat V$ and the second one is (5.5).
$V=|c|\hat V$ and the second one is (5.5).
 \begin{equation*}{\rm e}^{\hat V(\tau)}={\rm e}^{\frac{1}{|c|}V(\tau)}=N(\tau)^\frac{1}{|c|} . \end{equation*}
\begin{equation*}{\rm e}^{\hat V(\tau)}={\rm e}^{\frac{1}{|c|}V(\tau)}=N(\tau)^\frac{1}{|c|} . \end{equation*} The first equality below is the definition of  $\hat\pi$ in (5.11); since
$\hat\pi$ in (5.11); since  $|c| \gt 0$, the second one comes from the formula above and the third one is the definition of π in (5.10).
$|c| \gt 0$, the second one comes from the formula above and the third one is the definition of π in (5.10).
 \begin{equation*}\hat\pi(r)=
\sum_{{\rm e}^{\hat V(\tau) }\le r }\sum_{i=1}^m\alpha_{\tau,i}=
\sum_{{\rm e}^{V(\tau) }\le r^{|c|} }\sum_{i=1}^m\alpha_{\tau,i}=
\pi(r^{|c|}) . \end{equation*}
\begin{equation*}\hat\pi(r)=
\sum_{{\rm e}^{\hat V(\tau) }\le r }\sum_{i=1}^m\alpha_{\tau,i}=
\sum_{{\rm e}^{V(\tau) }\le r^{|c|} }\sum_{i=1}^m\alpha_{\tau,i}=
\pi(r^{|c|}) . \end{equation*}This shows (5.12); now a simple calculation shows that (5.13) implies (5.14).
Proof of point (2) of Theorem 2
By Lemma 5.3, formula (13) of Theorem 2 follows if we show (5.13) with A = 1 when c > 0 and with A = 0 when c < 0; this is what we shall do.
We distinguish two cases: when c > 0, (5.8)+ implies that S satisfies the hypotheses of Theorem 5.2 for A = 1 and thus (5.9) holds, always for A = 1; a consequence is the asymptotic sign in the formula below, which holds for  $r\rightarrow+\infty$. The equality comes from (5.7).
$r\rightarrow+\infty$. The equality comes from (5.7).
 \begin{align}
r\simeq S(r)=
\sum_{N(\tau)\le r} (\log N(\tau)) \sum_{n=1}^{n(t,\tau)}
\left( \sum_{i=1}^{m}\alpha_{\tau,i}^n \right).
\end{align}
\begin{align}
r\simeq S(r)=
\sum_{N(\tau)\le r} (\log N(\tau)) \sum_{n=1}^{n(t,\tau)}
\left( \sum_{i=1}^{m}\alpha_{\tau,i}^n \right).
\end{align} Now we consider γ > 1 and, for  $r\ge 1$, we define
$r\ge 1$, we define  $y=y(r)$ by the formula below.
$y=y(r)$ by the formula below.
 \begin{align}
1\le y=r^\frac{1}{\gamma} \lt r.
\end{align}
\begin{align}
1\le y=r^\frac{1}{\gamma} \lt r.
\end{align} The first equality below comes from the definition of  $\pi(r)$ in (5.10); for the first inequality, we use point (5) of Lemma 4.2 and the fact that
$\pi(r)$ in (5.10); for the first inequality, we use point (5) of Lemma 4.2 and the fact that  $\frac{\log N(\tau)}{\log y}\ge 1$ if
$\frac{\log N(\tau)}{\log y}\ge 1$ if  $N(\tau)\ge y$ and
$N(\tau)\ge y$ and  $\frac{\log N(\tau)}{\log y}\ge 0$ in all cases; this follows from (5.5) and the fact that V > 0. The second equality comes from (5.7); the equality at the end comes by (5.16).
$\frac{\log N(\tau)}{\log y}\ge 0$ in all cases; this follows from (5.5) and the fact that V > 0. The second equality comes from (5.7); the equality at the end comes by (5.16).
 \begin{equation*}\pi(r)=\pi(y)+
\sum_{y \lt N(\tau)\le r }{\rm tr}({{}^{t}}\Psi_{\tau})\end{equation*}
\begin{equation*}\pi(r)=\pi(y)+
\sum_{y \lt N(\tau)\le r }{\rm tr}({{}^{t}}\Psi_{\tau})\end{equation*} \begin{equation*}\le\pi(y)+\sum_{\{(\tau,k)\colon N(\tau)^k\le r \}}\frac{\log N(\tau)}{\log y}
{\rm tr}({{}^{t}}\Psi_{\tau}^k)\end{equation*}
\begin{equation*}\le\pi(y)+\sum_{\{(\tau,k)\colon N(\tau)^k\le r \}}\frac{\log N(\tau)}{\log y}
{\rm tr}({{}^{t}}\Psi_{\tau}^k)\end{equation*} \begin{equation*}=\pi(y)+\frac{1}{\log y}S(r)=\pi(y)+\frac{\gamma}{\log r}S(r). \end{equation*}
\begin{equation*}=\pi(y)+\frac{1}{\log y}S(r)=\pi(y)+\frac{\gamma}{\log r}S(r). \end{equation*} If we multiply the last formula by  $\frac{\log r}{r}$ and recall (5.16), we get
$\frac{\log r}{r}$ and recall (5.16), we get
 \begin{align}
(\log r)\cdot\frac{\pi(r)}{r}\le
\frac{\pi(y)}{y^\gamma}\cdot\gamma\cdot\log y+\gamma\cdot\frac{S(r)}{r} .
\end{align}
\begin{align}
(\log r)\cdot\frac{\pi(r)}{r}\le
\frac{\pi(y)}{y^\gamma}\cdot\gamma\cdot\log y+\gamma\cdot\frac{S(r)}{r} .
\end{align} In Lemma 4.2, we are going to see that, if  $\gamma^{\prime} \gt 1$, then
$\gamma^{\prime} \gt 1$, then
 \begin{align}
\limsup_{y\rightarrow+\infty}\frac{\pi(y)}{y^{\gamma^{\prime}}} \lt +\infty.
\end{align}
\begin{align}
\limsup_{y\rightarrow+\infty}\frac{\pi(y)}{y^{\gamma^{\prime}}} \lt +\infty.
\end{align} Let now  $\gamma^{\prime}\in(1,\gamma)$; Formula (5.17) implies the inequality below, (5.18) and (5.15) imply the equality.
$\gamma^{\prime}\in(1,\gamma)$; Formula (5.17) implies the inequality below, (5.18) and (5.15) imply the equality.
 \begin{equation*}\limsup_{r\rightarrow+\infty}\frac{\pi(r)\,\log r}{r}\end{equation*}
\begin{equation*}\limsup_{r\rightarrow+\infty}\frac{\pi(r)\,\log r}{r}\end{equation*} \begin{equation*}\le\gamma\cdot\limsup_{y\rightarrow+\infty}
\frac{\pi(y)}{y^{\gamma^{\prime}}}\cdot\frac{\log y}{y^{\gamma-\gamma^{\prime}}}+
\gamma\cdot\limsup_{r\rightarrow+\infty}\frac{S(r)}{r}=\gamma. \end{equation*}
\begin{equation*}\le\gamma\cdot\limsup_{y\rightarrow+\infty}
\frac{\pi(y)}{y^{\gamma^{\prime}}}\cdot\frac{\log y}{y^{\gamma-\gamma^{\prime}}}+
\gamma\cdot\limsup_{r\rightarrow+\infty}\frac{S(r)}{r}=\gamma. \end{equation*}Recalling that γ > 1 is arbitrary, we get the inequality of (5.13) with A = 1, i.e., Formula (13) of Theorem 2.
The case c < 0 is similar. Formula (5.8)+ implies that S satisfies the hypotheses of Theorem 5.2 for A = 0; in turn, this implies that
 \begin{equation*}\frac{S(r)}{r}\rightarrow 0\ \text{as}\ r\rightarrow+\infty . \end{equation*}
\begin{equation*}\frac{S(r)}{r}\rightarrow 0\ \text{as}\ r\rightarrow+\infty . \end{equation*}Now the same argument as above implies that
 \begin{equation*}\frac{\pi(r)\log(r)}{r}\rightarrow 0\quad \text{as}\ r\rightarrow+\infty . \end{equation*}
\begin{equation*}\frac{\pi(r)\log(r)}{r}\rightarrow 0\quad \text{as}\ r\rightarrow+\infty . \end{equation*}Now (5.18) is the only missing ingredient of the proof of Theorem 2.
Lemma 5.4. If  $\gamma^{\prime} \gt 1$, Formula (5.18) holds.
$\gamma^{\prime} \gt 1$, Formula (5.18) holds.
Proof. We show the case c > 0, since the other one is analogous. We take γ > 1 and y > 1; recall that we saw after (5.2) that  $\zeta_{-V}(s)$ is analytic in
$\zeta_{-V}(s)$ is analytic in  $Re(s) \gt 1$; as a consequence, (5.3) holds for
$Re(s) \gt 1$; as a consequence, (5.3) holds for  $s=\gamma$; by point (5) of Lemma 4.2, this yields the first inequality below. As for the equality, it comes from the properties of the logarithm as in (5.3). For the second inequality, we use (4.32). For the third inequality, we note that
$s=\gamma$; by point (5) of Lemma 4.2, this yields the first inequality below. As for the equality, it comes from the properties of the logarithm as in (5.3). For the second inequality, we use (4.32). For the third inequality, we note that  $(1+y^{-\gamma})$ is the smallest argument; the last inequality follows by the binomial theorem.
$(1+y^{-\gamma})$ is the smallest argument; the last inequality follows by the binomial theorem.
 \begin{equation*}\zeta_{-V}(\gamma)\ge
\exp\sum_{N(\tau)\le y}\sum_{k\ge 1}\sum_{i=1}^m
\frac{{\rm e}^{-k V(\tau)\cdot\gamma}\alpha^k_{\tau,i}}{k}\end{equation*}
\begin{equation*}\zeta_{-V}(\gamma)\ge
\exp\sum_{N(\tau)\le y}\sum_{k\ge 1}\sum_{i=1}^m
\frac{{\rm e}^{-k V(\tau)\cdot\gamma}\alpha^k_{\tau,i}}{k}\end{equation*} \begin{equation*}=\prod_{N(\tau)\le y}\prod_{i=1}^m\frac{1}{1-{\rm e}^{-V(\tau)\cdot \gamma}\alpha_{\tau,i}}\ge
\prod_{N(\tau)\le y}\prod_{i=1}^m[
1+N(\tau)^{-\gamma}
]^{\alpha_{i,\tau}} \end{equation*}
\begin{equation*}=\prod_{N(\tau)\le y}\prod_{i=1}^m\frac{1}{1-{\rm e}^{-V(\tau)\cdot \gamma}\alpha_{\tau,i}}\ge
\prod_{N(\tau)\le y}\prod_{i=1}^m[
1+N(\tau)^{-\gamma}
]^{\alpha_{i,\tau}} \end{equation*} \begin{equation*}\ge(1+y^{-\gamma})^{\pi(y)}\ge\frac{\pi(y)}{y^\gamma}.\end{equation*}
\begin{equation*}\ge(1+y^{-\gamma})^{\pi(y)}\ge\frac{\pi(y)}{y^\gamma}.\end{equation*} Thus, for y sufficiently large,  $\frac{\pi(y)}{y^\gamma}$ is smaller than
$\frac{\pi(y)}{y^\gamma}$ is smaller than  $\zeta_{-V}(\gamma)$.
$\zeta_{-V}(\gamma)$.
Funding Statement
This work was partially supported by the PRIN2009 grant ‘Critical Point Theory and Perturbative Methods for Nonlinear Differential Equations’.
Competing interests
The author declares none.


 Open access
Open access