



1. Introduction and summary
For a given set of  $n$ events, let
$n$ events, let 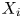 $X_i$ be the indicator variable of event
$X_i$ be the indicator variable of event 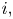 $i,$ and let
$i,$ and let  $W = \sum _{i=1}^{n} X_i$ denote the number of these events that occur. We are interested in using simulation to estimate
$W = \sum _{i=1}^{n} X_i$ denote the number of these events that occur. We are interested in using simulation to estimate 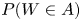 $P(W \in A)$ for a specified set
$P(W \in A)$ for a specified set  $A$. We show how to utilize an identity used by Chen and Stein in their work on bounding the error of a Poisson approximation to
$A$. We show how to utilize an identity used by Chen and Stein in their work on bounding the error of a Poisson approximation to  $P(W \in A)$ (see [Reference Barbour, Holst and Janson1] or [Reference Ross5]) to yield a new approach for obtaining an unbiased simulation estimator of
$P(W \in A)$ (see [Reference Barbour, Holst and Janson1] or [Reference Ross5]) to yield a new approach for obtaining an unbiased simulation estimator of  $P(W \in A).$
$P(W \in A).$
In Section 2, we review the relevant Chen-Stein theory for Poisson approximations and illustrate our starting point in utilizing the identity to obtain a simulation estimator. To highlight the promise of the proposed approach, Section 3 considers the case where the Bernoulli random variables  $X_1, \ldots, X_n$ are independent. In Section 4, we present a simulation estimator in the general case of dependent
$X_1, \ldots, X_n$ are independent. In Section 4, we present a simulation estimator in the general case of dependent  $X_1, \ldots, X_n$. We prove that the variance of the new simulation estimator of
$X_1, \ldots, X_n$. We prove that the variance of the new simulation estimator of  $P(W > 0)$ is at most
$P(W > 0)$ is at most 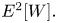 $E^{2}[W].$ In Section 5, we consider the problem of estimating
$E^{2}[W].$ In Section 5, we consider the problem of estimating  $P(N > m)$ where
$P(N > m)$ where  $N$ is the time of the first occurrence in the sequence
$N$ is the time of the first occurrence in the sequence  $Y_1, Y_2, \ldots$ of a certain pattern. In Section 5.1, we develop a simulation estimator when
$Y_1, Y_2, \ldots$ of a certain pattern. In Section 5.1, we develop a simulation estimator when  $Y_1, Y_2, \ldots$ are independent and identically distributed, and in Section 5.2, when they represent the sequence of states of a stationary Markov chain. Numerical examples compare the variance of the proposed estimators with those of the raw simulation estimator
$Y_1, Y_2, \ldots$ are independent and identically distributed, and in Section 5.2, when they represent the sequence of states of a stationary Markov chain. Numerical examples compare the variance of the proposed estimators with those of the raw simulation estimator  $I\{N > m\}$ and of the conditional Bernoulli sampling estimator. Numerical examples related to the generalized coupon collecting problem, partial sums of independent normal random variables, and system reliability are presented in Section 6.
$I\{N > m\}$ and of the conditional Bernoulli sampling estimator. Numerical examples related to the generalized coupon collecting problem, partial sums of independent normal random variables, and system reliability are presented in Section 6.
To obtain the simulation estimator we are proposing, one has to be able to simulate the Bernoulli random variables  $X_1, \ldots, X_n$ conditional on
$X_1, \ldots, X_n$ conditional on  $X_i = 1,$ which may be difficult in certain models. When this is so, we show in Section 7 how we can unconditionally simulate
$X_i = 1,$ which may be difficult in certain models. When this is so, we show in Section 7 how we can unconditionally simulate  $X_1, \ldots, X_n$ and still make use of our proposed estimator, as long as none of the values
$X_1, \ldots, X_n$ and still make use of our proposed estimator, as long as none of the values  $E[X_i]$ are very small. (This is analogous to using a post-stratification simulation estimator, see [Reference Ross6].) In Section 7, we consider the problem of estimating
$E[X_i]$ are very small. (This is analogous to using a post-stratification simulation estimator, see [Reference Ross6].) In Section 7, we consider the problem of estimating  $P(\sum _{i=1}^{n} a_i X_i \geq k)$ where
$P(\sum _{i=1}^{n} a_i X_i \geq k)$ where  $a_1, \ldots, a_n$ are positive constants, and present a nonnegative unbiased simulation estimator that is always less than or equal to the Markov inequality bound on this probability.
$a_1, \ldots, a_n$ are positive constants, and present a nonnegative unbiased simulation estimator that is always less than or equal to the Markov inequality bound on this probability.
2. Some relevant Chen-Stein theory
Suppose that  $X_i,\ i = 1, \ldots, n$, are Bernoulli random variables with means
$X_i,\ i = 1, \ldots, n$, are Bernoulli random variables with means  $\lambda _i = E[X_i],\ i = 1, \ldots, n$; set
$\lambda _i = E[X_i],\ i = 1, \ldots, n$; set  $W = \sum _{i=1}^{n} X_i$ and let
$W = \sum _{i=1}^{n} X_i$ and let 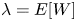 $\lambda = E[W]$. Also, let
$\lambda = E[W]$. Also, let  $P_{\lambda }(A) = \sum _{i \in A} e^{- \lambda } \lambda ^{i}/i!$ be the probability that a Poisson random variable with mean
$P_{\lambda }(A) = \sum _{i \in A} e^{- \lambda } \lambda ^{i}/i!$ be the probability that a Poisson random variable with mean  $\lambda$ lies in
$\lambda$ lies in  $A$.
$A$.
For any set of nonnegative integers  $A$, let
$A$, let  $f_A$ be recursively defined as follows:
$f_A$ be recursively defined as follows:
 \begin{align} f_A(0) & = 0 \end{align}
\begin{align} f_A(0) & = 0 \end{align}
 \begin{align} \lambda f_A(j+1) & = j f_A(j) + I\{j \in A\} - P_{\lambda}(A),\quad j \geq 0. \end{align}
\begin{align} \lambda f_A(j+1) & = j f_A(j) + I\{j \in A\} - P_{\lambda}(A),\quad j \geq 0. \end{align}
The following lemma is key to the Chen-Stein approach.
Lemma 1. For all  $A,\ |f_A(j) - f_A(i) | \leq ({(1 - e^{-\lambda })}/{\lambda }) |j-i|$.
$A,\ |f_A(j) - f_A(i) | \leq ({(1 - e^{-\lambda })}/{\lambda }) |j-i|$.
It follows from (2) that
 $$\lambda f_A(W+1) - W f_A(W) = I\{W \in A\} - P_{\lambda}(A).$$
$$\lambda f_A(W+1) - W f_A(W) = I\{W \in A\} - P_{\lambda}(A).$$
Taking expectations yields that
 \begin{equation} \lambda E[ f_A(W+1) ]- E[W f_A(W)] = P(W \in A) - P_{\lambda}(A). \end{equation}
\begin{equation} \lambda E[ f_A(W+1) ]- E[W f_A(W)] = P(W \in A) - P_{\lambda}(A). \end{equation}
Now,
 \begin{align} E[W f_A(W)] & = \sum_{i=1}^{n} E[X_i f_A( W)] \nonumber\\ & = \sum_{i=1}^{n} E[ f_A(W)\,|\,X_i = 1] \lambda_i \nonumber\\ & = \sum_{i=1}^{n} E[f_A(1+V_i)]\lambda_i \end{align}
\begin{align} E[W f_A(W)] & = \sum_{i=1}^{n} E[X_i f_A( W)] \nonumber\\ & = \sum_{i=1}^{n} E[ f_A(W)\,|\,X_i = 1] \lambda_i \nonumber\\ & = \sum_{i=1}^{n} E[f_A(1+V_i)]\lambda_i \end{align}
where  $V_1, \ldots, V_n$ are any random variables such that
$V_1, \ldots, V_n$ are any random variables such that  $V_i =_{st} \sum _{j \neq i} X_j \,|\,X_i = 1$. It follows from (3) and (4) that
$V_i =_{st} \sum _{j \neq i} X_j \,|\,X_i = 1$. It follows from (3) and (4) that
 $$\sum_i \lambda_i \left( E[ f_A(W+1) ]- E[f_A(1+V_i) ] \right) = P(W \in A) - P_{\lambda}(A) .$$
$$\sum_i \lambda_i \left( E[ f_A(W+1) ]- E[f_A(1+V_i) ] \right) = P(W \in A) - P_{\lambda}(A) .$$
Hence,
 \begin{equation} P(W \in A) - P_{\lambda}(A) = \sum_i \lambda_i E \left[ f_A(W+1) - f_A(1+V_i) \right] \end{equation}
\begin{equation} P(W \in A) - P_{\lambda}(A) = \sum_i \lambda_i E \left[ f_A(W+1) - f_A(1+V_i) \right] \end{equation}
which, from Lemma 1, yields that
 \begin{equation} |P(W \in A) - P_{\lambda}(A)| \leq \frac{1 - e^{-\lambda}}{\lambda} \sum_i \lambda_i E[ |W- V_i|] \end{equation}
\begin{equation} |P(W \in A) - P_{\lambda}(A)| \leq \frac{1 - e^{-\lambda}}{\lambda} \sum_i \lambda_i E[ |W- V_i|] \end{equation}
which is the Chen-Stein bound. (It is important to note that the preceding bound holds for any random vector  $V_1, \ldots, V_n$ for which the distribution of
$V_1, \ldots, V_n$ for which the distribution of 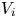 $V_i$ is the conditional distribution of
$V_i$ is the conditional distribution of  $\sum _{j \neq i} X_j$ given that
$\sum _{j \neq i} X_j$ given that  $X_i = 1$.) For more about Poisson approximation bounds, see [Reference Barbour, Holst and Janson1] or [Reference Ross5].
$X_i = 1$.) For more about Poisson approximation bounds, see [Reference Barbour, Holst and Janson1] or [Reference Ross5].
We propose to use the identity (5), which we rewrite as
 \begin{equation} P(W \in A) = P_{\lambda}(A) + \sum_i \lambda_i E \left[ f_A(W+1) - f_A(1+V_i) \right], \end{equation}
\begin{equation} P(W \in A) = P_{\lambda}(A) + \sum_i \lambda_i E \left[ f_A(W+1) - f_A(1+V_i) \right], \end{equation}
as the starting point of our simulation approach for estimating 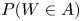 $P(W \in A)$. In all cases, we will make modifications so as to increase the efficiency of the simulation estimators. We first consider the case where the
$P(W \in A)$. In all cases, we will make modifications so as to increase the efficiency of the simulation estimators. We first consider the case where the  $X_i$ are independent.
$X_i$ are independent.
3. The independent case
Suppose  $X_1, \ldots, X_n$ are independent. Because
$X_1, \ldots, X_n$ are independent. Because  $\sum _{j \neq i} X_j$ is independent of
$\sum _{j \neq i} X_j$ is independent of  $X_i,$ it follows that
$X_i,$ it follows that  $\sum _{j \neq i} X_j=_{st} \sum _{j \neq i} X_j \,|\,X_i = 1,$ which allows us to let
$\sum _{j \neq i} X_j=_{st} \sum _{j \neq i} X_j \,|\,X_i = 1,$ which allows us to let  $V_i = \sum _{j \neq i} X_j = W - X_i$. Hence,
$V_i = \sum _{j \neq i} X_j = W - X_i$. Hence,
 \begin{align*} E[f_A(W+1) - f_A(V_i + 1)] & = E[f_A(W+1) - f_A(V_i + 1)\,|\,X_i = 1 ] \lambda_i \\ & = E[ f_A(W-X_i + 2) - f_A(W-X_i + 1) ] \lambda_i. \end{align*}
\begin{align*} E[f_A(W+1) - f_A(V_i + 1)] & = E[f_A(W+1) - f_A(V_i + 1)\,|\,X_i = 1 ] \lambda_i \\ & = E[ f_A(W-X_i + 2) - f_A(W-X_i + 1) ] \lambda_i. \end{align*}
Thus, from (7), we see that
 \begin{equation} P(W \in A) = P_{\lambda}(A) + \sum_i \lambda_i^{2} E[ f_A(W-X_i + 2) - f_A(W-X_i + 1)] .\end{equation}
\begin{equation} P(W \in A) = P_{\lambda}(A) + \sum_i \lambda_i^{2} E[ f_A(W-X_i + 2) - f_A(W-X_i + 1)] .\end{equation}
We propose to simulate  $X_1, \ldots, X_n$ and to estimate
$X_1, \ldots, X_n$ and to estimate  $P(W \in A)$ by the unbiased estimator
$P(W \in A)$ by the unbiased estimator
 \begin{equation} {\mathcal{E}} = P_{\lambda}(A) + \sum_i \lambda_i^{2} (f_A(W-X_i + 2) - f_A(W-X_i + 1)) .\end{equation}
\begin{equation} {\mathcal{E}} = P_{\lambda}(A) + \sum_i \lambda_i^{2} (f_A(W-X_i + 2) - f_A(W-X_i + 1)) .\end{equation}
Note that it follows from Lemma 1 that
 $$\left|\sum_i \lambda_i^{2} (f_A(W-X_i + 2) - f_A(W-X_i + 1))\right| \leq \frac{1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2}$$
$$\left|\sum_i \lambda_i^{2} (f_A(W-X_i + 2) - f_A(W-X_i + 1))\right| \leq \frac{1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2}$$
and so
 $$P_{\lambda}(A) - \frac{1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2} \leq {\mathcal{E}} \leq P_{\lambda}(A) + \frac{1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2}.$$
$$P_{\lambda}(A) - \frac{1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2} \leq {\mathcal{E}} \leq P_{\lambda}(A) + \frac{1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2}.$$
Because  $P(a \leq X \leq b) = 1$ implies that
$P(a \leq X \leq b) = 1$ implies that  $\mbox {Var}(X) \leq (b-a)^{2}/4,$ it follows from the preceding that
$\mbox {Var}(X) \leq (b-a)^{2}/4,$ it follows from the preceding that
 \begin{equation} \mbox{Var}( {\mathcal{E}} ) \leq \left(\frac{ 1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2}\right)^{2} .\end{equation}
\begin{equation} \mbox{Var}( {\mathcal{E}} ) \leq \left(\frac{ 1 - e^{-\lambda}} {\lambda} \sum_i \lambda_i^{2}\right)^{2} .\end{equation}
For instance, if  $n=100,\ \lambda _i = i/c$, then when
$n=100,\ \lambda _i = i/c$, then when  $c=1,000$ we have
$c=1,000$ we have  $\mbox {Var}( {\mathcal {E}} ) \leq 0.00443$. Even in cases where the Poisson approximation is not particularly good, the approach works well. For instance, when
$\mbox {Var}( {\mathcal {E}} ) \leq 0.00443$. Even in cases where the Poisson approximation is not particularly good, the approach works well. For instance, when  $c=200$ (and so
$c=200$ (and so  $\lambda _i$ becomes as large as
$\lambda _i$ becomes as large as  $0.5$), we have
$0.5$), we have  $\mbox {Var}( {\mathcal {E}} ) \leq 0.1122$. That is, even in the latter case, the variance of the estimator of any probability concerning
$\mbox {Var}( {\mathcal {E}} ) \leq 0.1122$. That is, even in the latter case, the variance of the estimator of any probability concerning  $W$ (even one having probability close to
$W$ (even one having probability close to  $1/2$) cannot exceed
$1/2$) cannot exceed  $0.1122$. However, in any particular case, the actual variances may be quite a bit smaller than the preceding bounds. We illustrate by an example.
$0.1122$. However, in any particular case, the actual variances may be quite a bit smaller than the preceding bounds. We illustrate by an example.
Example 1. Let  $X_1, \ldots, X_{20}$ be independent Bernoullis with means
$X_1, \ldots, X_{20}$ be independent Bernoullis with means  $E[X_i] = \lambda _i = {i}/{50},\ i = 1, \ldots, 20$. In this case,
$E[X_i] = \lambda _i = {i}/{50},\ i = 1, \ldots, 20$. In this case,  $E[W ] = \sum _{i=1}^{20} ({i}/{50}) = 4.2$. Suppose we want to estimate (a)
$E[W ] = \sum _{i=1}^{20} ({i}/{50}) = 4.2$. Suppose we want to estimate (a)  $P(W \geq 5)$ and (b)
$P(W \geq 5)$ and (b)  $P(W \geq 11)$. Using that
$P(W \geq 11)$. Using that  $P(Z \geq 5) = 0.410173,\ P(Z \geq 11) =0.004069$, where
$P(Z \geq 5) = 0.410173,\ P(Z \geq 11) =0.004069$, where  $Z$ is Poisson with mean
$Z$ is Poisson with mean  $4.2$, a simulation consisting of
$4.2$, a simulation consisting of  $10,000$ runs yielded that for
$10,000$ runs yielded that for  $A = \{W \geq 5\}$
$A = \{W \geq 5\}$
 $$E[{\mathcal{E}}_A ] \approx 0.414851,\quad \mbox{Var}( {\mathcal{E}}_A) \approx 0.003741,$$
$$E[{\mathcal{E}}_A ] \approx 0.414851,\quad \mbox{Var}( {\mathcal{E}}_A) \approx 0.003741,$$
whereas, for  $B = \{W \geq 11 \}$
$B = \{W \geq 11 \}$
 $$E[{\mathcal{E}}_B ] \approx 0.000517,\quad \mbox{Var}( {\mathcal{E}}_B ) \approx 0.000044,$$
$$E[{\mathcal{E}}_B ] \approx 0.000517,\quad \mbox{Var}( {\mathcal{E}}_B ) \approx 0.000044,$$
where  ${\mathcal {E}}_C$ refers to (9) when
${\mathcal {E}}_C$ refers to (9) when  $A = C$. Consequently, the variance of the estimators is much below
$A = C$. Consequently, the variance of the estimators is much below  $0.072487$, the upper bound given by (10). The variances are also much below those of the indicator estimators which have
$0.072487$, the upper bound given by (10). The variances are also much below those of the indicator estimators which have  $\mbox {Var}( I\{ W \in A\}) \approx 0.242750$ and
$\mbox {Var}( I\{ W \in A\}) \approx 0.242750$ and  $\mbox {Var}( I\{ W \in B\}) \approx 0.000517$.
$\mbox {Var}( I\{ W \in B\}) \approx 0.000517$.
Remark. We have considered the case of independent  $X_i$ not because a simulation is needed to determine the distribution of their sum but to indicate the promise of our approach. (To compute the mass function of
$X_i$ not because a simulation is needed to determine the distribution of their sum but to indicate the promise of our approach. (To compute the mass function of  $W$ when
$W$ when  $X_1, \ldots, X_n$ are independent, let
$X_1, \ldots, X_n$ are independent, let  $P(i, j) = P(X_1 + \cdots + X_i = j)$. Starting with
$P(i, j) = P(X_1 + \cdots + X_i = j)$. Starting with  $P(1, 0) = 1 - \lambda _1,\ P(1, 1) = \lambda _1,$ and using that
$P(1, 0) = 1 - \lambda _1,\ P(1, 1) = \lambda _1,$ and using that  $P(i, j) = 0\ \mbox {if}\ i < j,$ we can recursively compute these values by using that
$P(i, j) = 0\ \mbox {if}\ i < j,$ we can recursively compute these values by using that  $P(i, j) = P(i-1, j-1) \lambda _i + P(i-1,j) (1 - \lambda _i)$.) The exact values in Example 1 are
$P(i, j) = P(i-1, j-1) \lambda _i + P(i-1,j) (1 - \lambda _i)$.) The exact values in Example 1 are  $P(W \geq 5) = 0.4143221438$ and
$P(W \geq 5) = 0.4143221438$ and  $P(W \geq 11) = 0.0004586525$.
$P(W \geq 11) = 0.0004586525$.
4. The general case
In this section, we no longer suppose that  $X_1, \ldots, X_n$ are independent, but allow them to have an arbitrary joint mass function. The proposed simulation approach for estimating
$X_1, \ldots, X_n$ are independent, but allow them to have an arbitrary joint mass function. The proposed simulation approach for estimating  $P(W \in A)$ starts by noting that if we let
$P(W \in A)$ starts by noting that if we let  $I$ be independent of all the other random variables and be such that
$I$ be independent of all the other random variables and be such that
 $$P(I = i) = \lambda_i/\lambda,\quad i = 1, \ldots, n$$
$$P(I = i) = \lambda_i/\lambda,\quad i = 1, \ldots, n$$
then we obtain from (7) that
 $$P(W \in A) = P_{\lambda}(A) + \lambda E [ f_A(W+1) - f_A(1+V_I)].$$
$$P(W \in A) = P_{\lambda}(A) + \lambda E [ f_A(W+1) - f_A(1+V_I)].$$
This yields the unbiased estimator
 \begin{equation} {\mathcal{E}} = P_{\lambda}(A) + \lambda (f_A(W+1) - f_A(1+V_I)). \end{equation}
\begin{equation} {\mathcal{E}} = P_{\lambda}(A) + \lambda (f_A(W+1) - f_A(1+V_I)). \end{equation}
That is, the simulation procedure is to generate  $I$, and if
$I$, and if  $I=i$ to then generate
$I=i$ to then generate  $W$ and
$W$ and  $V_i$ to obtain the value of the preceding estimator. To utilize this approach, we must be able to generate
$V_i$ to obtain the value of the preceding estimator. To utilize this approach, we must be able to generate  $V_i$ for each
$V_i$ for each  $i$. In addition, we want to couple the generated values of
$i$. In addition, we want to couple the generated values of  $W$ and
$W$ and  $V_I$ to be close to each other, so as to result in a small variance of the estimator.
$V_I$ to be close to each other, so as to result in a small variance of the estimator.
One important case where we can analytically show that  $\mbox {Var}({\mathcal {E}})$ is very small in comparison to
$\mbox {Var}({\mathcal {E}})$ is very small in comparison to  $P(W \in A)$, at least when the latter probability is itself small, is when
$P(W \in A)$, at least when the latter probability is itself small, is when  $A = \{0\}$. The following examples illustrate the ubiquity of this important case, which occurs when we are interested in the probability of a union of events.
$A = \{0\}$. The following examples illustrate the ubiquity of this important case, which occurs when we are interested in the probability of a union of events.
1. Consider independent trials that each result in any of the outcomes
 $1, \ldots, n$ with probabilities $p_1,\ldots, p_n,\ \sum _{i=1}^{n} p_i = 1,$ and suppose that there are specified numbers $r_1, \ldots,r_n$.
$1, \ldots, n$ with probabilities $p_1,\ldots, p_n,\ \sum _{i=1}^{n} p_i = 1,$ and suppose that there are specified numbers $r_1, \ldots,r_n$.The generalized birthday problem is interested in
$M$, the number of trials until there have been $r_i$ type $i$ outcomes for some $i=1, \ldots, n$. (The classical problem has $n=365,\ p_i = 1/n,\ r_i = 2, i = 1, \ldots, n$.) With $N_i$ being the number of type $i$ outcomes in the first $k$ trials, $i=1, \ldots, n,$ and $X_i = I\{N_i \geq r_i\}$, we have that $P(M > k) = P(\sum _{i=1}^{n} X_i =0)$.The generalized coupon collecting problem concerns
$N,$ the number of trials until there have been at least $r_i$ type $i$ outcomes for every $i=1, \ldots, n$. (The classical coupon collecting problem has all $r_i =1$.) With $N_i$ defined as the number of type $i$ outcomes in the first $k$ trials, $i=1, \ldots, n,$ and $X_i = I\{N_i < r_i\},$ we have that $P(N \leq k) = P(\sum _{i=1}^{n} X_i = 0)$.2. In reliability systems with components
$1, \ldots, m,$ we often suppose that there are specified subsets of components $C_1, \ldots, C_n$, none of which is a subset of another, such that the system fails if and only if all components in at least one of these subsets are failed. Thus, with $X_i$ being the indicator of the event that all components in $C_i$ are failed, $P(\mbox {system works}) = P( \sum _{i=1}^{n} X_i = 0)$. The subsets $C_1, \ldots, C_n$ are called the minimal cut sets of the system.3. With
$Y_1, Y_2, \ldots$ being the successive states of a stationary Markov chain, a quantity of interest is $N,$ the first time that the pattern $y_1, y_2, \ldots, y_r$ appears. With $X_i$ defined as the indicator of the event that $Y_i = y_1, Y_{i+1} = y_2, \ldots, Y_{i+r-1} = y_r,$ then $P(N > n+r-1) = P( \sum _{i=1}^{n}X_i = 0)$.4. In DNA matching problems (see [Reference Lippert, Huang and Waterman2]), we are often interested in the largest common subsequence in the sequences
$Z_1, \ldots, Z_{r+k-1}$ and $Y_1, \ldots, Y_{s+k-1}$. In particular, we often want to determine the probability that there would be a common subsequence of length $k$ if the $r+s+2k-2$ data values were independent and identically distributed with a specified mass function $\alpha _t,\ t \geq 1.$ If we let $X_{i,j},\ i,j \geq 1,$ equal the indicator of the event that $Z_{i+m} = Y_{j+m},\ m = 0, \ldots, k-1$ the probability there are such subsequences is $P(\sum _{i \leq r,\ j \leq s} X_{i,j}> 0)$.5. If
$Y_1, \ldots, Y_n$ is multivariate normal, then $P(\max _i Y_i \leq x) = P( \sum _{i=1}^{n} I\{Y_i > x\}= 0)$.

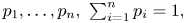





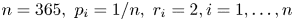


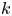
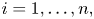










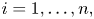


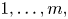






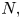














The unbiased estimator of  $P(W=0)$ given by (11) is
$P(W=0)$ given by (11) is
 \begin{equation} {\mathcal{E}} = e^{-\lambda} + \lambda (f_0(W+1) - f_0(1+V_I)) \end{equation}
\begin{equation} {\mathcal{E}} = e^{-\lambda} + \lambda (f_0(W+1) - f_0(1+V_I)) \end{equation}
where  $f_0 = f_{\{0\}}.$ To bound the variance of
$f_0 = f_{\{0\}}.$ To bound the variance of  ${\mathcal {E}}$, we use, as shown in [Reference Ross7], that
${\mathcal {E}}$, we use, as shown in [Reference Ross7], that
 \begin{equation} f_0(j) = \int_0^{1} e^{-\lambda t} t^{j-1}\,dt,\quad j \geq 1 \end{equation}
\begin{equation} f_0(j) = \int_0^{1} e^{-\lambda t} t^{j-1}\,dt,\quad j \geq 1 \end{equation}
from which it follows that  $f_0(j)$ is, for
$f_0(j)$ is, for  $j > 0,$ a decreasing, convex, positive function. Because this implies that for
$j > 0,$ a decreasing, convex, positive function. Because this implies that for  $i>0,\ j>0$
$i>0,\ j>0$
 $$|f_0(i) - f_0(j)| \leq f_0(\min(i,j)) \leq f_0(1) = \frac{1 - e^{- \lambda}}{\lambda},$$
$$|f_0(i) - f_0(j)| \leq f_0(\min(i,j)) \leq f_0(1) = \frac{1 - e^{- \lambda}}{\lambda},$$
we obtain from (12) that
 \begin{equation} |{\mathcal{E}} - e^{-\lambda}| \leq 1 - e^{-\lambda}. \end{equation}
\begin{equation} |{\mathcal{E}} - e^{-\lambda}| \leq 1 - e^{-\lambda}. \end{equation}
Consequently,
 $$\mbox{Var}( {\mathcal{E}} ) \leq (1 - e^{-\lambda})^{2} \leq \lambda^{2} .$$
$$\mbox{Var}( {\mathcal{E}} ) \leq (1 - e^{-\lambda})^{2} \leq \lambda^{2} .$$
Because typically  $P(W > 0) \approx \lambda$ when
$P(W > 0) \approx \lambda$ when  $P(W>0)$ is small, it appears in this case that
$P(W>0)$ is small, it appears in this case that  $\mbox {Var}( {\mathcal {E}} )$ is an order of magnitude lower than
$\mbox {Var}( {\mathcal {E}} )$ is an order of magnitude lower than  $P(W>0) (1 - P(W>0)) \approx \lambda (1-\lambda ) \approx \lambda,$ which is the variance of the raw simulation estimator
$P(W>0) (1 - P(W>0)) \approx \lambda (1-\lambda ) \approx \lambda,$ which is the variance of the raw simulation estimator  $I\{W>0\}$.
$I\{W>0\}$.
The bound given by (14) can be strengthened when  $W$ and
$W$ and  $V_I$ can be generated so that
$V_I$ can be generated so that  $W \geq V_I$, which is possible when
$W \geq V_I$, which is possible when  $W$ is stochastically larger than
$W$ is stochastically larger than  $V_i$ for all
$V_i$ for all 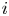 $i$, as is the case in the generalized birthday and coupon collecting problems. With such a coupling, it follows from (12) and the fact that
$i$, as is the case in the generalized birthday and coupon collecting problems. With such a coupling, it follows from (12) and the fact that  $f_0$ is decreasing that
$f_0$ is decreasing that  ${\mathcal {E}} \leq e^{- \lambda },$ and so
${\mathcal {E}} \leq e^{- \lambda },$ and so
 $$2\,e^{- \lambda} - 1 \leq {\mathcal{E}} \leq e^{- \lambda}$$
$$2\,e^{- \lambda} - 1 \leq {\mathcal{E}} \leq e^{- \lambda}$$
showing, in this case, that
 $$\mbox{Var}( {\mathcal{E}} ) \leq \frac{(1 - e^{-\lambda})^{2}}{4} \leq \frac{\lambda^{2}}{4}.$$
$$\mbox{Var}( {\mathcal{E}} ) \leq \frac{(1 - e^{-\lambda})^{2}}{4} \leq \frac{\lambda^{2}}{4}.$$
Remarks.
1. Another unbiased estimator of
$P(W=0)$ is the conditional Bernoulli sampling estimator ${\mathcal {E}}_{\rm CBSE} = 1 - {\lambda }/{(1 + V_I)}$ (see [Reference Ross6] Sect. 10.1). However, in our simulation experiments, it turns out that CBSE is typically not competitive with ${\mathcal {E}},$ and that the variance of the best linear combination of these two estimators is only marginally less than $\mbox {Var} ( {\mathcal {E}} )$.2. When computing
$f_A(j)$ by using the recursive equations given by Eqs. (1) and (2), one must be very careful that the computation of $P_{\lambda }(A)$ is very precise. For otherwise, round off errors build up quickly. This can be avoided for the function $f_0(j)$ by using Eq. (13) and standard numerical approximation techniques. (For instance, as it is easily shown that $g_j(t) \equiv e^{- \lambda t} t^{j-1}$ is, for $j \geq 2,$ an increasing function of $t$ for $t \in [0, 1]$, it follows in this case that for any $m$, ${\sum _{i=1}^{m} g_j((i-1)/m)}/{m} \leq f_0(j) \leq {\sum _{i=1}^{m} g_j(i/m)}/{m}.$)3. Although the values
$f_A(j)$ must be computed with great precision, their computation does not add much time to the total simulation. This is because not only does the estimator from each simulation run require only $2$ values of $f_A(j),$ but once these values are computed they can be used for other runs needing them. Consequently, when compared with using the Monte-Carlo estimator $I\{ W \in A\},$ the additional computation time needed for our estimator primarily depends on the additional simulation beyond generating $W$ that is needed to generate $V_I$.4. As will be seen in the Examples to follow, the coupling of
$W$ and $V_I$ often results in only a minimal additional simulation effort, beyond that of generating $W$, needed to generate our estimator.
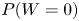









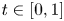











5. Pattern problem examples
In this section, we consider some examples where we are interested in whether a certain pattern occurs at some point within the sequence of random variables  $Y_1, \ldots, Y_s$ (see [Reference Lladser, Betterton and Knight3,Reference Regnier and Szpankowski4] for applications).
$Y_1, \ldots, Y_s$ (see [Reference Lladser, Betterton and Knight3,Reference Regnier and Szpankowski4] for applications).
5.1. A pattern problem with independent data
Suppose  $Y_i,\ i \geq 1$ are independent and identically distributed with mass function
$Y_i,\ i \geq 1$ are independent and identically distributed with mass function  $P(Y_i = j) = p_j,\ \sum _{j=1}^{k} p_j = 1$. Let
$P(Y_i = j) = p_j,\ \sum _{j=1}^{k} p_j = 1$. Let  $N$ be the first time that there is a run of
$N$ be the first time that there is a run of  $r$ consecutive equal values. That is,
$r$ consecutive equal values. That is,  $N = \min \{m: Y_m= Y_{m-1} = \cdots = Y_{m-r+1}\}$, and suppose we are interested in estimating
$N = \min \{m: Y_m= Y_{m-1} = \cdots = Y_{m-r+1}\}$, and suppose we are interested in estimating  $p \equiv P(N > n+r-1)$. To utilize our approach, we generate
$p \equiv P(N > n+r-1)$. To utilize our approach, we generate  $Y_1, \ldots, Y_{n+r-1}$ to determine
$Y_1, \ldots, Y_{n+r-1}$ to determine  $W = \sum _{i=1}^{n} X_i,$ where
$W = \sum _{i=1}^{n} X_i,$ where  $X_i$ is the indicator of the event that
$X_i$ is the indicator of the event that  $Y_i=\cdots = Y_{i+r-1}$. We now generate
$Y_i=\cdots = Y_{i+r-1}$. We now generate  $I$ which, because
$I$ which, because 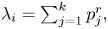 $\lambda _i = \sum _{j=1}^{k} p_j^{r},$ is equally likely to be any of the values
$\lambda _i = \sum _{j=1}^{k} p_j^{r},$ is equally likely to be any of the values  $1, \ldots, n$. Suppose
$1, \ldots, n$. Suppose  $I=i$, we then generate
$I=i$, we then generate  $J$ such that
$J$ such that 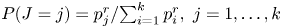 $P(J = j) = {p_j^{r}}/{\sum _{i=1}^{k} p_i^{r}},\ j = 1, \ldots, k$ and, if
$P(J = j) = {p_j^{r}}/{\sum _{i=1}^{k} p_i^{r}},\ j = 1, \ldots, k$ and, if  $J = j,$ reset the values of
$J = j,$ reset the values of  $Y_i, \ldots, Y_{i+r-1}$ to now all equal
$Y_i, \ldots, Y_{i+r-1}$ to now all equal 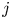 $j$. Letting
$j$. Letting  $V$ be the number of times there is a run of
$V$ be the number of times there is a run of  $r$ equal values when using the reset values, then
$r$ equal values when using the reset values, then  $V =_{st} 1 + \sum _{j \neq i} X_j\,|\,X_i = 1$. Consequently, with
$V =_{st} 1 + \sum _{j \neq i} X_j\,|\,X_i = 1$. Consequently, with 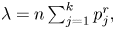 $\lambda = n \sum _{j=1}^{k} p_j^{r},$ the estimator of
$\lambda = n \sum _{j=1}^{k} p_j^{r},$ the estimator of  $P(N > n+r-1) = P(W = 0)$ is
$P(N > n+r-1) = P(W = 0)$ is
 \begin{equation} {\mathcal{E}} = e^{-\lambda} + \lambda (f_0(W+1) - f_0(V)). \end{equation}
\begin{equation} {\mathcal{E}} = e^{-\lambda} + \lambda (f_0(W+1) - f_0(V)). \end{equation}
This estimator can be improved by taking its conditional expectation given all variables except  $J.$ That is, consider
$J.$ That is, consider
 $${\mathcal{E}}^{*} \equiv E[ {\mathcal{E}} \,|\, I,Y_1, \ldots, Y_{n+r-1}].$$
$${\mathcal{E}}^{*} \equiv E[ {\mathcal{E}} \,|\, I,Y_1, \ldots, Y_{n+r-1}].$$
Now, letting  $V^{*}_j$ be the number of times there is a run of
$V^{*}_j$ be the number of times there is a run of  $r$ consecutive equal values when
$r$ consecutive equal values when 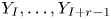 $Y_I, \ldots, Y_{I+r-1}$ are reset to all equal
$Y_I, \ldots, Y_{I+r-1}$ are reset to all equal  $j$ then, with
$j$ then, with 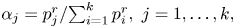 $\alpha _j = {p_j^{r}}/{\sum _{i=1}^{k} p_i^{r}},\ j = 1, \ldots, k,$ we have
$\alpha _j = {p_j^{r}}/{\sum _{i=1}^{k} p_i^{r}},\ j = 1, \ldots, k,$ we have
 \begin{equation} {\mathcal{E}}^{*} = e^{-\lambda} + \lambda \sum_{j=1}^{k} \alpha_j (f_0(W+1) - f_0(V^{*}_j) ). \end{equation}
\begin{equation} {\mathcal{E}}^{*} = e^{-\lambda} + \lambda \sum_{j=1}^{k} \alpha_j (f_0(W+1) - f_0(V^{*}_j) ). \end{equation}
Example 2. Suppose that  $n=1,000$ and
$n=1,000$ and  $P(Y_i = i) = 1/5,\ i = 1, \ldots, 5$. The following table, based on the results from
$P(Y_i = i) = 1/5,\ i = 1, \ldots, 5$. The following table, based on the results from  $10,000$ simulation runs, gives for various values of
$10,000$ simulation runs, gives for various values of  $r,$ the values (as determined by the simulation) of
$r,$ the values (as determined by the simulation) of  $p = P(W=0)$,
$p = P(W=0)$,  $p(1-p)$ (equal to the variance of the indicator estimator),
$p(1-p)$ (equal to the variance of the indicator estimator),  $\mbox {Var} ({\mathcal {E}}_{\rm CBSE} ),\ \mbox {Var} ({\mathcal {E}}),$ and
$\mbox {Var} ({\mathcal {E}}_{\rm CBSE} ),\ \mbox {Var} ({\mathcal {E}}),$ and  $\mbox {Var} ({\mathcal {E}}^{*}),$ where
$\mbox {Var} ({\mathcal {E}}^{*}),$ where  ${\mathcal {E}}^{*}$ is as given in (16). The simulation also gave the value of
${\mathcal {E}}^{*}$ is as given in (16). The simulation also gave the value of  $\mbox {Cov} ({\mathcal {E}}, {\mathcal {E}}_{\rm CBSE}),$ which enabled us to determine
$\mbox {Cov} ({\mathcal {E}}, {\mathcal {E}}_{\rm CBSE}),$ which enabled us to determine  $V_b,$ the variance of the best linear combination of these two unbiased estimators (equal to the variance obtained when using
$V_b,$ the variance of the best linear combination of these two unbiased estimators (equal to the variance obtained when using 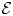 ${\mathcal {E}}$ along with
${\mathcal {E}}$ along with  ${\mathcal {E}} - {\mathcal {E}}_{\rm CBSE}$ as a control variable). That is, it gave the value of
${\mathcal {E}} - {\mathcal {E}}_{\rm CBSE}$ as a control variable). That is, it gave the value of
 $$V_b = \min_{\alpha} \mbox{Var}(\alpha {\mathcal{E}} + (1 - \alpha) {\mathcal{E}}_{\rm CBSE} ) = \mbox{Var}( {\mathcal{E}})\left(1 -\mbox{Corr}^{2} ( {\mathcal{E}},{\mathcal{E}} - {\mathcal{E}}_{\rm CBSE} ) \right) .$$
$$V_b = \min_{\alpha} \mbox{Var}(\alpha {\mathcal{E}} + (1 - \alpha) {\mathcal{E}}_{\rm CBSE} ) = \mbox{Var}( {\mathcal{E}})\left(1 -\mbox{Corr}^{2} ( {\mathcal{E}},{\mathcal{E}} - {\mathcal{E}}_{\rm CBSE} ) \right) .$$
As indicated in the table, 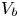 $V_b$ is only marginally less than
$V_b$ is only marginally less than  $\mbox {Var}({\mathcal {E}}),$ and much larger than
$\mbox {Var}({\mathcal {E}}),$ and much larger than 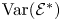 $\mbox {Var}({\mathcal {E}}^{*} )$.
$\mbox {Var}({\mathcal {E}}^{*} )$.
 $$\left(\begin{array}{ccccccc} r & p & p(1-p) & \mbox{Var} ( {\mathcal{E}}_{\rm CBSE} ) & \mbox{Var}({\mathcal{E}}) & V_b & \mbox{Var}({\mathcal{E}}^{*} ) \\ 5 & 0.276018 & 0.199832 & 0.194959 & 0.028545 & 0.026579 & 0.006636 \\ 6 & 0.773515 & 0.175190 & 0.009301 & 0.005185 & 0.005072 & 0.000444\\ 7 & 0.950120 & 0.047392 & 3.1819 \times 10^{{-}4} & 2.7736 \times 10^{{-}4} & 2.7643 \times 10^{{-}4} & 8.7166 \times 10^{{-}6} \\ 8 & 0.989804 & 0.010092 & 1.2331 \times 10^{{-}5} & 1.1964\times 10^{{-}5} & 1.1958 \times 10^{{-}5} & 2.3745 \times 10^{{-}7} \end{array}\right) .$$
$$\left(\begin{array}{ccccccc} r & p & p(1-p) & \mbox{Var} ( {\mathcal{E}}_{\rm CBSE} ) & \mbox{Var}({\mathcal{E}}) & V_b & \mbox{Var}({\mathcal{E}}^{*} ) \\ 5 & 0.276018 & 0.199832 & 0.194959 & 0.028545 & 0.026579 & 0.006636 \\ 6 & 0.773515 & 0.175190 & 0.009301 & 0.005185 & 0.005072 & 0.000444\\ 7 & 0.950120 & 0.047392 & 3.1819 \times 10^{{-}4} & 2.7736 \times 10^{{-}4} & 2.7643 \times 10^{{-}4} & 8.7166 \times 10^{{-}6} \\ 8 & 0.989804 & 0.010092 & 1.2331 \times 10^{{-}5} & 1.1964\times 10^{{-}5} & 1.1958 \times 10^{{-}5} & 2.3745 \times 10^{{-}7} \end{array}\right) .$$
Remark. Because of our coupling of  $V$ and
$V$ and  $W$, the simulation effort needed to obtain our estimator is basically the same as needed to obtain
$W$, the simulation effort needed to obtain our estimator is basically the same as needed to obtain  $W$.
$W$.
5.2. A pattern problem with Markov chain generated data
Consider a stationary Markov chain  $Y_m,\ m \geq 1,$ with transition probabilities
$Y_m,\ m \geq 1,$ with transition probabilities  $P_{u,v}$ and stationary probabilities
$P_{u,v}$ and stationary probabilities  $\pi _u$. Let
$\pi _u$. Let  $Q_{u,v} = {\pi _v P_{v,u}}/{\pi _u}$ be the transition probabilities of the reverse chain. We are interested in the probability that the pattern
$Q_{u,v} = {\pi _v P_{v,u}}/{\pi _u}$ be the transition probabilities of the reverse chain. We are interested in the probability that the pattern  $y_1, \ldots, y_r$ does not appear within the first
$y_1, \ldots, y_r$ does not appear within the first  $n+r-1$ data values. To use our method, let
$n+r-1$ data values. To use our method, let 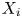 $X_i$ be the indicator of the event that
$X_i$ be the indicator of the event that  $Y_{i} = y_{1}, \ldots, Y_{i+r-1} = y_r$ and note that
$Y_{i} = y_{1}, \ldots, Y_{i+r-1} = y_r$ and note that 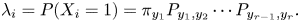 $\lambda _i = P(X_i = 1) = \pi _{y_1} P_{y_1, y_2} \cdots P_{y_{r-1}, y_r}.$ With
$\lambda _i = P(X_i = 1) = \pi _{y_1} P_{y_1, y_2} \cdots P_{y_{r-1}, y_r}.$ With  $W=\sum _{i=1}^{n} X_i,$ we are interested in
$W=\sum _{i=1}^{n} X_i,$ we are interested in  $P(W = 0)$.
$P(W = 0)$.
To estimate  $P(W=0)$, first generate
$P(W=0)$, first generate  $I,$ equally likely to be any of
$I,$ equally likely to be any of  $1,\ldots, n$. Suppose
$1,\ldots, n$. Suppose 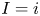 $I=i$.
$I=i$.
1. Set
$Y_{i} = y_{1}, \ldots, Y_{i+r-1} = y_r$.2. For
$j \geq i+r,$ if $Y_{j-1} = u$, then let $Y_j = v$ with probability $P_{u,v}$. (In other words, starting at time $i+r-1,$ generate the remaining states in sequence by using the transition probability $P_{u,v}.$)3. For
$j < i,$ if $Y_{j+1} = u$, then let $Y_j = v$ with probability $Q_{u,v}$. (So going backwards from time $i$ we generate the states using the transition probabilities of the reversed chain).












Let  $V = 1+V_I$ be the number of times the pattern
$V = 1+V_I$ be the number of times the pattern 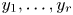 $y_1, \ldots, y_r$ appears in
$y_1, \ldots, y_r$ appears in  $Y_1, \ldots, Y_{n+r-1}$.
$Y_1, \ldots, Y_{n+r-1}$.
To generate  $W$, we will define a new Markov chain with transition probabilities
$W$, we will define a new Markov chain with transition probabilities  $P_{u,v}$ and let
$P_{u,v}$ and let  $W$ be the number of times the pattern appears. However, we will do it in a way so that it is related to the
$W$ be the number of times the pattern appears. However, we will do it in a way so that it is related to the  $Y$-chain above. It is defined as follows. To begin, recall that the generated value of
$Y$-chain above. It is defined as follows. To begin, recall that the generated value of  $I$ was
$I$ was  $I=i$. We define the new chain—let its states be
$I=i$. We define the new chain—let its states be  $W_1, \ldots, W_{n+r-1}$—as follows:
$W_1, \ldots, W_{n+r-1}$—as follows:
1. Simulate
$W_i$ by using that $P(W_i = k) = \pi _k.$2. For
$j < i,$if
$W_{j+1} = Y_{j+1}$, set $W_k = Y_k$ for all $k=1, \ldots, j$.2. if
$W_{j+1} \neq Y_{j+1}$, then if $W_{j+1} = u$, then let $W_j = v$ with probability $Q_{u,v}.$3. For
$j>i$. Starting with the simulated value of $W_i,$ generate the states $W_{i+1}$ up to $W_{i+r-1}$ by using the transition probabilities $P_{u,v}$. For the states at times $j \geq i+r$ do the following:if
$W_{j-1} = Y_{j-1}$, set $W_k = Y_k$ for all $k \geq j$.3. if
$W_{j-1} \neq Y_{j-1}$, then if $W_{j-1} = u,$ let $W_j = v$ with probability $P_{u,v}$.

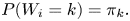
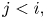






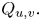













Let  $W$ be the number of times the pattern appears in
$W$ be the number of times the pattern appears in  $W_1, \ldots, W_{n+r-1}$.
$W_1, \ldots, W_{n+r-1}$.
So in generating the chain for determining  $W$ we start by generating the value of
$W$ we start by generating the value of 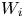 $W_i$ and using its value we then use the transition probabilities until we have generated the values of
$W_i$ and using its value we then use the transition probabilities until we have generated the values of 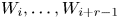 $W_i, \ldots, W_{i+r-1}$. For times larger than
$W_i, \ldots, W_{i+r-1}$. For times larger than  $i+r-1$, we will continue generating according to the transition probabilities
$i+r-1$, we will continue generating according to the transition probabilities  $P_{u,v},$ except that if at some time we are in the same state as the Y-chain was at that time then we just let the W chain's value equal the Y-chain's value from then on. We do the same thing going backwards in time, except that we use the reverse transition probabilities. (If it is easier to generate from the original chain than from the reversed chain, we can reverse the procedure by first generating the states of the forward chain to determine
$P_{u,v},$ except that if at some time we are in the same state as the Y-chain was at that time then we just let the W chain's value equal the Y-chain's value from then on. We do the same thing going backwards in time, except that we use the reverse transition probabilities. (If it is easier to generate from the original chain than from the reversed chain, we can reverse the procedure by first generating the states of the forward chain to determine  $W$ and then generate the chain that determines the value of
$W$ and then generate the chain that determines the value of  $V$, coupling its values with those of the first chain when appropriate.)
$V$, coupling its values with those of the first chain when appropriate.)
The estimator of  $P(W = 0)$ is
$P(W = 0)$ is
 $${\mathcal{E}} = e^{- \lambda} + \lambda(f_0(W+1) - f_0(V) ).$$
$${\mathcal{E}} = e^{- \lambda} + \lambda(f_0(W+1) - f_0(V) ).$$
Example 3. The following example will consider  $4$ Markov chains, all with states
$4$ Markov chains, all with states  $0, 1$. The transitions probabilities for these chains are
$0, 1$. The transitions probabilities for these chains are
Case 1:
$P_{00} = 0.3,\ P_{10} = 0.2$Case 2:
$P_{00} = 0.3,\ P_{10} = 0.8$Case 3:
$P_{00} = 0.5,\ P_{10} = 0.6$Case 4:
$P_{00} = 0.5,\ P_{10} = 0.8$
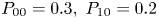

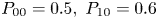

For each chain, we use the preceding approach to estimate 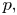 $p,$ the probability that the pattern
$p,$ the probability that the pattern  $0000011111$ does not occur in the first 5,009 data values. The following table, based on
$0000011111$ does not occur in the first 5,009 data values. The following table, based on  $10,000$ simulation runs, gives (as determined by the simulation) the variances of
$10,000$ simulation runs, gives (as determined by the simulation) the variances of  ${\mathcal {E}}$ and of
${\mathcal {E}}$ and of 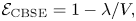 ${\mathcal {E}}_{\rm CBSE} = 1 - {\lambda }/{V},$ as well as
${\mathcal {E}}_{\rm CBSE} = 1 - {\lambda }/{V},$ as well as  $V_b,$ the variance of the best convex linear combination of these estimators.
$V_b,$ the variance of the best convex linear combination of these estimators.
 $$\left(\begin{array}{cccccc} \mbox{Case } & p & p(1-p) & \mbox{Var}({\mathcal{E}}_{\rm CBSE} ) & \mbox{Var}({\mathcal{E}} ) & V_b \\ 1 & 0.074597 & 0.069033 & 0.309118 & 0.000458 & 0.000456 \\ 2 & 0.976097 & 0.023332 & 3.61369 \times 10^{{-}6} & 1.43963 \times 10^{{-}8} & 1.43420 \times 10^{{-}8} \\ 3 & 0.111967 & 0.099430 & 0.268122 & 0.0004628 & 0.0004627 \\ 4 & 0.857370 & 0.122287 & 7.95539 \times 10^{{-}4} & 2.2507 \times 10^{{-}6} & 2.2445 \times 10^{{-}6} \end{array}\right).$$
$$\left(\begin{array}{cccccc} \mbox{Case } & p & p(1-p) & \mbox{Var}({\mathcal{E}}_{\rm CBSE} ) & \mbox{Var}({\mathcal{E}} ) & V_b \\ 1 & 0.074597 & 0.069033 & 0.309118 & 0.000458 & 0.000456 \\ 2 & 0.976097 & 0.023332 & 3.61369 \times 10^{{-}6} & 1.43963 \times 10^{{-}8} & 1.43420 \times 10^{{-}8} \\ 3 & 0.111967 & 0.099430 & 0.268122 & 0.0004628 & 0.0004627 \\ 4 & 0.857370 & 0.122287 & 7.95539 \times 10^{{-}4} & 2.2507 \times 10^{{-}6} & 2.2445 \times 10^{{-}6} \end{array}\right).$$
Remarks.
1. Because
$0 \leq 1 - {\mathcal {E}}_{\rm CBSE} = {\lambda }/{V} \leq \lambda,$ it follows that $\mbox {Var}({\mathcal {E}}_{\rm CBSE} ) \leq \lambda ^{2}/4,$ and so always has a small variance when $\lambda$ is small. However, its variance can be large when $\lambda > 1,$ and that is the reason why it is large in Cases $1$ and $3$, which have respective values $\lambda = 2.58048$ and $\lambda = 2.18182$. The estimator ${\mathcal {E}}$ has a small variance in all cases.2. Because the pattern
$0000011111$ has “no overlap” (in the sense that no part of an occurring pattern can be utilized in the next occurrence of the pattern), the Poisson approximation $P(W = 0) \approx e^{-\lambda }$ would be expected to be quite accurate, and indeed it yields the following estimates of $p$ in the four cases: 0.075738, 0.976098, 0.112836, and 0.857404. On the other hand, if the pattern were $1111111111$, then it would not be expected to be so accurate. Indeed, when the transition probabilities are as given in Case 3, the Poisson estimator of the probability that this pattern does not occur within the first 5,009 data values is $0.55172,$ whereas simulation shows that $p = 0.69673,\ p(1-p) = 0.21130,\ \mbox {Var}({\mathcal {E}}) = 0.021106$. Thus, once again ${\mathcal {E}}$ has a very small variance.










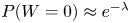




Example 4. Consider the Markov chain with states  $1, 2, 3$ and transition probability matrix
$1, 2, 3$ and transition probability matrix
 $$\left(\begin{array}{ccc} 0.5 & 0.4 & 0.1 \\ 0.6 & 0.2 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{array}\right)$$
$$\left(\begin{array}{ccc} 0.5 & 0.4 & 0.1 \\ 0.6 & 0.2 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{array}\right)$$
and suppose we are interested in estimating  $p$, the probability, starting in steady state, that the pattern
$p$, the probability, starting in steady state, that the pattern  $1, 2, 3, 1, 3, 2, 2, 1, 2, 3$ does not occur within
$1, 2, 3, 1, 3, 2, 2, 1, 2, 3$ does not occur within  $5,009$ data values. In this case, a simulation based on 10,000 runs, yielded the estimates
$5,009$ data values. In this case, a simulation based on 10,000 runs, yielded the estimates
 $$p=0.9893264,\quad \mbox{Var}({\mathcal{E}}_{\rm CBSE} ) = 3.18819 \times 10^{{-}7},\quad \mbox{Var}({\mathcal{E}} ) = 1.97215 \times 10^{{-}31}.$$
$$p=0.9893264,\quad \mbox{Var}({\mathcal{E}}_{\rm CBSE} ) = 3.18819 \times 10^{{-}7},\quad \mbox{Var}({\mathcal{E}} ) = 1.97215 \times 10^{{-}31}.$$
Remark. Because we need to generate two Markov chains to obtain our estimator, the simulation effort could be twice what is needed to generate 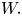 $W.$ However, because of the coupling of these two chains, if the number of states of the Markov chain is not too large, then the number of additional simulations needed beyond generating one chain is minimal. In any case, in the preceding examples, the variance of our estimator is much smaller than
$W.$ However, because of the coupling of these two chains, if the number of states of the Markov chain is not too large, then the number of additional simulations needed beyond generating one chain is minimal. In any case, in the preceding examples, the variance of our estimator is much smaller than  $\mbox {Var}(I\{W = 0\}) =p(1-p)$.
$\mbox {Var}(I\{W = 0\}) =p(1-p)$.
5.3. Additional examples
Example 5 (A Generalized Coupon Collecting Problem).
Suppose that 1,000 balls are independently distributed into  $10$ urns with each ball going into urn
$10$ urns with each ball going into urn  $i$ with probability
$i$ with probability 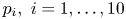 $p_i,\ i=1, \ldots, 10$. Let
$p_i,\ i=1, \ldots, 10$. Let  $N_i$ denote the number of balls that go into urn
$N_i$ denote the number of balls that go into urn  $i$ and set
$i$ and set  $X_i = I\{N_i < r_i\}$. With
$X_i = I\{N_i < r_i\}$. With  $W = \sum _{i=1}^{10} X_i$, we are interested in estimating
$W = \sum _{i=1}^{10} X_i$, we are interested in estimating  $P(W=0)$.
$P(W=0)$.
To determine the value of our estimator  ${\mathcal {E}} = e^{-\lambda } + \lambda (f_0(W+1) - f_0(V)),$ first generate the multinomial vector
${\mathcal {E}} = e^{-\lambda } + \lambda (f_0(W+1) - f_0(V)),$ first generate the multinomial vector  $(N_1, \ldots, N_{10})$ and use it to determine
$(N_1, \ldots, N_{10})$ and use it to determine  $W$. We will also use these
$W$. We will also use these  $N_i$ to determine
$N_i$ to determine  $V (= V_I + 1)$. Let
$V (= V_I + 1)$. Let  $\lambda _i = E[X_i] =P(\mbox {Bin}(1,000, p_i) < r_i)$, where
$\lambda _i = E[X_i] =P(\mbox {Bin}(1,000, p_i) < r_i)$, where  $\mbox {Bin}(n,p)$ is binomial with parameters
$\mbox {Bin}(n,p)$ is binomial with parameters  $(n,p)$; let
$(n,p)$; let  $\lambda = \sum _{i=1}^{10} \lambda _i,$ and do the following:
$\lambda = \sum _{i=1}^{10} \lambda _i,$ and do the following:
1. Generate
$I$ where $P(I = i) = \lambda _i/\lambda$. Suppose $I =j$.2. If
$N_j < r_j$ let $V = W$.3. If
$N_j \geq r_j$ generate $Y,$ a binomial $(1,000, p_j)$ random variable conditioned to be less than $r_j$. Suppose $Y=k.$ Then, remove $N_j - k$ balls from box $j$, putting each of these balls into one of the urns $i, i \neq j$ with prob $p_i/(1-p_j)$. Let $N^{*}_1, \ldots, N^{*}_{10}$ be the new number of balls in each urn after the preceding is done. Let $V = \sum _{k=1}^{10} I\{ N^{*}_k < r_k\}$.
















A simulation of  $10,000$ runs, when
$10,000$ runs, when  $p_i = {(10 + i)}/{155},\ r_i = 60+4i,\ i=1, \ldots, 10,$ yielded the result
$p_i = {(10 + i)}/{155},\ r_i = 60+4i,\ i=1, \ldots, 10,$ yielded the result
 $$P(W = 0)= 0.572859,\quad \mbox{Var}({\mathcal{E} }) = 0.006246.$$
$$P(W = 0)= 0.572859,\quad \mbox{Var}({\mathcal{E} }) = 0.006246.$$
Because  $\lambda = 0.493024,$ the Poisson approximation of
$\lambda = 0.493024,$ the Poisson approximation of  $P(W = 0)$ is
$P(W = 0)$ is  $e^{-\lambda } = 0.610779$.
$e^{-\lambda } = 0.610779$.
Remark. Because of our coupling of  $V$ and
$V$ and  $W,$ the simulation needed beyond obtaining
$W,$ the simulation needed beyond obtaining  $W$ is minimal. Either no additional simulation, except for
$W$ is minimal. Either no additional simulation, except for  $I,$ is needed or, no matter how many urns, one would need to then simulate a binomial conditioned to be smaller than some value (easily done by the discrete inverse transform algorithm) and then generate a small number of additional random variables that are used to modify the number of balls in urns
$I,$ is needed or, no matter how many urns, one would need to then simulate a binomial conditioned to be smaller than some value (easily done by the discrete inverse transform algorithm) and then generate a small number of additional random variables that are used to modify the number of balls in urns  $j,\ j \neq I$.
$j,\ j \neq I$.
Example 6. (A Partial Sums Example).
Suppose  $Z_1, \ldots, Z_{20}$ are independent and identically distributed standard normals. Let
$Z_1, \ldots, Z_{20}$ are independent and identically distributed standard normals. Let
 $$S_i = \sum_{j=1}^{i} Z_j,\quad X_i = I\{|S_i | > c \sqrt{i}\},\quad W = \sum_{i=1}^{20} X_i.$$
$$S_i = \sum_{j=1}^{i} Z_j,\quad X_i = I\{|S_i | > c \sqrt{i}\},\quad W = \sum_{i=1}^{20} X_i.$$
Suppose we want to estimate  $P(W = 0)$ and
$P(W = 0)$ and  $P(W=2)$. To obtain our simulation estimators, we use that the joint distribution of
$P(W=2)$. To obtain our simulation estimators, we use that the joint distribution of  $Z_k$ and
$Z_k$ and  $S_k$ is bivariate normal with correlation
$S_k$ is bivariate normal with correlation  $1/\sqrt {k}$. From this, it follows that the conditional distribution of
$1/\sqrt {k}$. From this, it follows that the conditional distribution of  $Z_k$ given that
$Z_k$ given that  $S_k= y$ is normal with mean
$S_k= y$ is normal with mean  $y/k$ and variance
$y/k$ and variance  ${(k-1)}/{k}$. Using the preceding and that
${(k-1)}/{k}$. Using the preceding and that  $\lambda _i = 2 P(Z_1 > c),$ the simulation estimator is obtained as follows:
$\lambda _i = 2 P(Z_1 > c),$ the simulation estimator is obtained as follows:
• Generate
$I$ such that $P(I = i) = 1/20,\ i = 1, \ldots, 20$.• If
$I=i,$ generate a normal with mean $0$ and variance $i$ that is conditioned to be greater than $c \sqrt {i}.$ (This is efficiently done either by using the reject procedure with an exponential distribution—see [Reference Ross6] pp. 218–219—or, with $\Phi$ being the standard normal distribution function and $U$ being uniform on $(0, 1),$ by letting $U^{*} = \Phi (c) + (1-\Phi (c)) U$ and using $\sqrt {i} \Phi ^{-1}(U^{*}).)$ Let the value of this generated random variable be $s_i$.• Generate
$Z_i$ conditional on $S_i = s_i$. Let $z_i$ be the generated value.• Generate
$Z_{i-1}$ conditional on $S_{i-1}= s_i - z_i$. Let $z_{i-1}$ be the generated value.• Generate
$Z_{i-2}$ conditional on $S_{i-2}= s_i - z_i - z_{i-1}$. Let $z_{i-2}$ be the generated value.• Continue the preceding until you have generated
$Z_1.$• Generate independent standard normals
$Z_{i+1}, \ldots, Z_{20}$ and let their values be $z_{i+1}, \ldots, z_{20}$.• With
$s_j = \sum _{k=1}^{j} z_k,\ j=1, \ldots, 20,$ let $V = \mbox {number}\ j: |s_j| > c \sqrt {j}$.• Generate independent standard normals
$Z_{1}, \ldots, Z_{i}.$ Using these along with the previously generated $Z_{i+1}, \ldots, Z_{20}$ determine the value of $W$.• Using the preceding generated values of
$V = 1+V_I$ and $W$ along with $\lambda = 40 P(Z > c),$ obtain the values of the estimators.








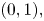








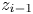














Note that because, given  $I = i,$ the distribution of the estimator will be the same whether
$I = i,$ the distribution of the estimator will be the same whether  $S_i > c \sqrt {i}$ or
$S_i > c \sqrt {i}$ or  $S_i < - c \sqrt {i} ,$ we have arbitrarily assumed the former.
$S_i < - c \sqrt {i} ,$ we have arbitrarily assumed the former.
The following table, based on  $10,000$ simulation runs, gives the simulation estimates of the variances of
$10,000$ simulation runs, gives the simulation estimates of the variances of  ${\mathcal {E}}_0$ and
${\mathcal {E}}_0$ and  ${\mathcal {E}}_2,$ the proposed estimators for
${\mathcal {E}}_2,$ the proposed estimators for  $P(W = 0)$ and for
$P(W = 0)$ and for 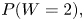 $P(W=2),$ for
$P(W=2),$ for  $c=2$ and
$c=2$ and 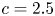 $c=2.5$.
$c=2.5$.
 $$\left(\begin{array}{ccccc} \mbox{Case} & P(W=0) & \mbox{Var}({\mathcal{E}}_0 ) & P(W=2) & \mbox{Var}({\mathcal{E}}_2 ) \\ c=2 & 0.76980 & 3.842 \times 10^{{-}3} & 0.03788 & 4.644 \times 10^{{-}4} \\ c=2.5 & 0.92279 & 3.519 \times 10^{{-}5} & 0.01347 & 3.177 \times 10^{{-}6} \end{array}\right).$$
$$\left(\begin{array}{ccccc} \mbox{Case} & P(W=0) & \mbox{Var}({\mathcal{E}}_0 ) & P(W=2) & \mbox{Var}({\mathcal{E}}_2 ) \\ c=2 & 0.76980 & 3.842 \times 10^{{-}3} & 0.03788 & 4.644 \times 10^{{-}4} \\ c=2.5 & 0.92279 & 3.519 \times 10^{{-}5} & 0.01347 & 3.177 \times 10^{{-}6} \end{array}\right).$$
Remark. If  $I=i$, both
$I=i$, both  $V$ and
$V$ and  $W$ use the values
$W$ use the values  $Z_{i+1}, \ldots, Z_{20}$. Consequently, for a given
$Z_{i+1}, \ldots, Z_{20}$. Consequently, for a given  $c,$ the simulation effort to obtain our estimators is about
$c,$ the simulation effort to obtain our estimators is about  $1.5$ times that needed to generate
$1.5$ times that needed to generate  $Z_1, \ldots, Z_{20}$.
$Z_1, \ldots, Z_{20}$.
Example 7 (A Reliability Application).
Consider a system of five independent components, and suppose that the system is failed if and only if all of the components of any of the component sets  $C_1 = \{1,2\},\ C_2 = \{ 4, 5\},\ C_3 = \{1, 3, 5\},\ C_4 = \{2, 3, 4\}\,$ are all failed. Suppose further that component
$C_1 = \{1,2\},\ C_2 = \{ 4, 5\},\ C_3 = \{1, 3, 5\},\ C_4 = \{2, 3, 4\}\,$ are all failed. Suppose further that component  $i$ is failed with probability
$i$ is failed with probability  $q_i$ where
$q_i$ where  $q_1 = c/10,\ q_2 = c/12,\ q_3 = c/15,\ q_4 = c/20,\ q_5 = c/30$. We want to use simulation to estimate the probability that the system is not failed for various values of
$q_1 = c/10,\ q_2 = c/12,\ q_3 = c/15,\ q_4 = c/20,\ q_5 = c/30$. We want to use simulation to estimate the probability that the system is not failed for various values of  $c$. Thus, with
$c$. Thus, with  $X_i$ being the indicator variable that all components in
$X_i$ being the indicator variable that all components in  $C_i$ are failed, and
$C_i$ are failed, and  $W = \sum _{i=1}^{4} X_i$ we are interested in
$W = \sum _{i=1}^{4} X_i$ we are interested in  $P(W = 0).$ For various values of
$P(W = 0).$ For various values of 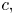 $c,$ the following table gives, as determined by the simulation,
$c,$ the following table gives, as determined by the simulation,  $P(W=0)$ as well as
$P(W=0)$ as well as  $\mbox {Var}({\mathcal {E}}_{\rm CBSE} )$ and
$\mbox {Var}({\mathcal {E}}_{\rm CBSE} )$ and  $\mbox {Var}({\mathcal {E}})$ where, with
$\mbox {Var}({\mathcal {E}})$ where, with  $\lambda = E[W],$
$\lambda = E[W],$
 $${\mathcal{E}} = e^{-\lambda} + \lambda( f_0(W+1) - f_0(V)),\quad {\mathcal{E}}_{\rm CBSE} = 1 - \frac{\lambda}{V} .$$
$${\mathcal{E}} = e^{-\lambda} + \lambda( f_0(W+1) - f_0(V)),\quad {\mathcal{E}}_{\rm CBSE} = 1 - \frac{\lambda}{V} .$$
The table also gives  $V_b$, the variance of the best unbiased linear combination of these two estimators. The table is based on the results of
$V_b$, the variance of the best unbiased linear combination of these two estimators. The table is based on the results of  $50,000$ simulation runs.
$50,000$ simulation runs.
 $$\left(\begin{array}{ccccc} \mbox{c } & p & \mbox{Var}({\mathcal{E}}_{\rm CBSE} ) & \mbox{Var}({\mathcal{E}} ) & V_b \\ 1 & 0.989579 & 4.2032 \times 10^{{-}7} & 4.8889 \times 10^{{-}7} & 3.7883 \times 10^{{-}7} \\ 2 & 0.95721 & 2.6329 \times 10^{{-}5} & 3.0573 \times 10^{{-}5} & 2.3200 \times 10^{{-}5} \\ 3 & 0.90248 & 0.000293 & 0.000315 & 0.000243 \\ 5 & 0.73230 & 0.005685 & 0.005228 & 0.00422 \end{array}\right) .$$
$$\left(\begin{array}{ccccc} \mbox{c } & p & \mbox{Var}({\mathcal{E}}_{\rm CBSE} ) & \mbox{Var}({\mathcal{E}} ) & V_b \\ 1 & 0.989579 & 4.2032 \times 10^{{-}7} & 4.8889 \times 10^{{-}7} & 3.7883 \times 10^{{-}7} \\ 2 & 0.95721 & 2.6329 \times 10^{{-}5} & 3.0573 \times 10^{{-}5} & 2.3200 \times 10^{{-}5} \\ 3 & 0.90248 & 0.000293 & 0.000315 & 0.000243 \\ 5 & 0.73230 & 0.005685 & 0.005228 & 0.00422 \end{array}\right) .$$
Thus, interestingly, it appears that except for when  $c=5,$ the conditional Bernoulli sampling estimator appears to have a smaller variance than does the one based on the Chen-Stein identity.
$c=5,$ the conditional Bernoulli sampling estimator appears to have a smaller variance than does the one based on the Chen-Stein identity.
Remark. Because  $W$ is obtained by simulating the state—either failed or not—of each component, and
$W$ is obtained by simulating the state—either failed or not—of each component, and  $V$ is then obtained by simulating
$V$ is then obtained by simulating  $I$ and using the earlier simulated states for all components not in
$I$ and using the earlier simulated states for all components not in  $C_I$, there is basically no additional simulation effort needed to obtain our estimator.
$C_I$, there is basically no additional simulation effort needed to obtain our estimator.
6. A post-simulation approach
There are many models where it is very difficult to simulate the system conditional on  $X_i = 1$. (For instance, suppose a customer has just arrived at a stationary
$X_i = 1$. (For instance, suppose a customer has just arrived at a stationary  $M/M/1$ queueing system and we are interested in the distribution of number of the next
$M/M/1$ queueing system and we are interested in the distribution of number of the next  $n$ customers that have to spend longer than
$n$ customers that have to spend longer than  $x$ in the system.) If none of
$x$ in the system.) If none of  $\lambda _1, \ldots, \lambda _n$ is very small, one possibility is to unconditionally simulate the system to obtain
$\lambda _1, \ldots, \lambda _n$ is very small, one possibility is to unconditionally simulate the system to obtain  $X_1, \ldots, X_n,$ and then use the resulting data to yield realizations of the quantities
$X_1, \ldots, X_n,$ and then use the resulting data to yield realizations of the quantities  $V_i$ for those
$V_i$ for those  $i$ for which
$i$ for which  $X_i = 1$. In this way, a single simulation run would yield the values of
$X_i = 1$. In this way, a single simulation run would yield the values of  $W = \sum _{i=1}^{n} X_i$ and of
$W = \sum _{i=1}^{n} X_i$ and of  $W$ of the random variables
$W$ of the random variables  $V_1, \ldots, V_n$. We could then use the identity
$V_1, \ldots, V_n$. We could then use the identity
 $$P(W \in A) = P_{\lambda}(A) + \lambda E[f_A(W+1)] - \sum_{i=1}^{n} \lambda_i E[f_A(V_i + 1)]$$
$$P(W \in A) = P_{\lambda}(A) + \lambda E[f_A(W+1)] - \sum_{i=1}^{n} \lambda_i E[f_A(V_i + 1)]$$
to obtain a simulation estimator of  $P(W \in A)$. Namely, if we have
$P(W \in A)$. Namely, if we have  $r$ simulation runs, with
$r$ simulation runs, with  $X_1^{t}, \ldots, X_n^{t}$ being the simulated vector in run
$X_1^{t}, \ldots, X_n^{t}$ being the simulated vector in run  $t,$ then we can estimate
$t,$ then we can estimate  $E[f_A(W + 1)]$ by
$E[f_A(W + 1)]$ by  $({1}/{r})\sum _{t=1}^{r} f_A(1+ \sum _{i=1}^{n} X_i^{t}),$ and
$({1}/{r})\sum _{t=1}^{r} f_A(1+ \sum _{i=1}^{n} X_i^{t}),$ and  $E[f_A(V_i + 1)]$ by
$E[f_A(V_i + 1)]$ by  ${\sum _{t=1}^{r} I\{X^{t}_i = 1\} f_A(1 + \sum _{j \neq i} X^{t}_j )}/{\sum _{t=1}^{r} I\{X^{t}_i = 1\}}$.
${\sum _{t=1}^{r} I\{X^{t}_i = 1\} f_A(1 + \sum _{j \neq i} X^{t}_j )}/{\sum _{t=1}^{r} I\{X^{t}_i = 1\}}$.
Example 8. Each of  $200$ balls independently goes into box
$200$ balls independently goes into box  $i$ with probability
$i$ with probability  $p_i = {(10+i)}/{155},\ i = 1, \ldots, 10$. With
$p_i = {(10+i)}/{155},\ i = 1, \ldots, 10$. With  $N_i$ denoting the number of balls that go into box
$N_i$ denoting the number of balls that go into box  $i$, let
$i$, let  $X_i = I\{N_i < 12+i\},\ i=1,\ldots, 10,\ W = \sum _{i=1}^{10} X_i,$ and let
$X_i = I\{N_i < 12+i\},\ i=1,\ldots, 10,\ W = \sum _{i=1}^{10} X_i,$ and let  $p = P(W \leq 3)$. We want to determine
$p = P(W \leq 3)$. We want to determine  $p$ by simulation.
$p$ by simulation.
Using our technique, we let  $r=100$ and repeated this procedure
$r=100$ and repeated this procedure  $300$ times. With
$300$ times. With  ${\mathcal {E}}$ being the estimator of
${\mathcal {E}}$ being the estimator of  $p,$ based on
$p,$ based on  $r=100$ simulation runs, the simulation gave that
$r=100$ simulation runs, the simulation gave that
 $$E[{\mathcal{E}} ] = 0.852839,\quad \mbox{Var}({\mathcal{E}}) = 0.000663.$$
$$E[{\mathcal{E}} ] = 0.852839,\quad \mbox{Var}({\mathcal{E}}) = 0.000663.$$
The preceding variance can be compared to  $p(1-p)/100 = 0.001255,$ the variance of the raw simulation estimator based on
$p(1-p)/100 = 0.001255,$ the variance of the raw simulation estimator based on  $100$ runs. (If we would have done the simulation as in Example 5, then the resulting variance based on a single simulation run is
$100$ runs. (If we would have done the simulation as in Example 5, then the resulting variance based on a single simulation run is  $0.036489$, giving that the variance of the average of
$0.036489$, giving that the variance of the average of  $100$ runs is 0.000365.)
$100$ runs is 0.000365.)
7. Estimating probabilities of positive linear combinations
As before let  $X_1, \ldots, X_n$ be Bernoulli random variables, and let
$X_1, \ldots, X_n$ be Bernoulli random variables, and let  $\lambda _i = E[X_i],\ i=1, \ldots, n$. With
$\lambda _i = E[X_i],\ i=1, \ldots, n$. With  $S= \sum _{i=1}^{n} a_iX_i,$ where
$S= \sum _{i=1}^{n} a_iX_i,$ where  $a_1, \ldots, a_n$ are arbitrary positive constants, suppose we are interested in estimating
$a_1, \ldots, a_n$ are arbitrary positive constants, suppose we are interested in estimating  $p =P(S \geq k)$. We now develop a simulation procedure that yields a nonnegative unbiased estimator that is always less than or equal to the Markov inequality bound
$p =P(S \geq k)$. We now develop a simulation procedure that yields a nonnegative unbiased estimator that is always less than or equal to the Markov inequality bound  $E[S]/k$.
$E[S]/k$.
To obtain our estimator, note that for any random variable  $R$
$R$
 \begin{equation} E[SR] = \sum_{i=1}^{n} a_i E[X_i R] = \sum_{i=1}^{n} a_i E[R\,|\,X_i = 1] \lambda_i. \end{equation}
\begin{equation} E[SR] = \sum_{i=1}^{n} a_i E[X_i R] = \sum_{i=1}^{n} a_i E[R\,|\,X_i = 1] \lambda_i. \end{equation}
Now, let  $I$ be independent of
$I$ be independent of 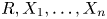 $R, X_1, \ldots, X_n$ and be such that
$R, X_1, \ldots, X_n$ and be such that
 $$P(I = i) = a_i/a,\quad i=1,\ldots, n \quad \mbox{where}\ a = \sum_{i=1}^{n} a_i.$$
$$P(I = i) = a_i/a,\quad i=1,\ldots, n \quad \mbox{where}\ a = \sum_{i=1}^{n} a_i.$$
Noting that
 $$P(I=i\,|\,X_I = 1) = \frac{ a_i \lambda_i }{ \sum_{i=1}^{n} a_i \lambda_i } = \frac{ a_i \lambda_i }{ E[S] }$$
$$P(I=i\,|\,X_I = 1) = \frac{ a_i \lambda_i }{ \sum_{i=1}^{n} a_i \lambda_i } = \frac{ a_i \lambda_i }{ E[S] }$$
yields that
 $$E[R\,|\,X_I = 1] = \sum_{i=1}^{n} E[R\,|\,X_I = 1,\ I=i] a_i\lambda_i/E[S] = \sum_{i=1}^{n} E[R\,|\,X_i=1] a_i\lambda_i/E[S].$$
$$E[R\,|\,X_I = 1] = \sum_{i=1}^{n} E[R\,|\,X_I = 1,\ I=i] a_i\lambda_i/E[S] = \sum_{i=1}^{n} E[R\,|\,X_i=1] a_i\lambda_i/E[S].$$
Hence, from (17), we obtain the following result.
Lemma 2. For any random variable  $R$
$R$
 $$E[SR] = E[S] E[R\,|\,X_I = 1].$$
$$E[SR] = E[S] E[R\,|\,X_I = 1].$$
This yields
Proposition 1.
 $$P( S \geq k) = E[S] E\left[\frac{ I\{S \geq k\} }{S} \,|\, X_I = 1\right].$$
$$P( S \geq k) = E[S] E\left[\frac{ I\{S \geq k\} }{S} \,|\, X_I = 1\right].$$
Proof. Letting  $R = 0$ if
$R = 0$ if  $S=0$ and
$S=0$ and  $R = I\{S \geq k\}/S$ if
$R = I\{S \geq k\}/S$ if  $S > 0,$ and applying Lemma 2 yields the result. □
$S > 0,$ and applying Lemma 2 yields the result. □
It follows from Proposition 1 that we can estimate  $P(S \geq k)$ by first simulating
$P(S \geq k)$ by first simulating  $I$ conditional on
$I$ conditional on  $X_I = 1$. If
$X_I = 1$. If 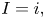 $I=i,$ then simulate
$I=i,$ then simulate  $X_j,\ j \neq i,$ conditional on
$X_j,\ j \neq i,$ conditional on  $X_i = 1$, let
$X_i = 1$, let  $S^{*} = a_i + \sum _{j \neq i} a_jX_j$ and return the estimate
$S^{*} = a_i + \sum _{j \neq i} a_jX_j$ and return the estimate  $E[S] I\{S^{*} \geq k\} / S^{*}$. Because
$E[S] I\{S^{*} \geq k\} / S^{*}$. Because  $0 \leq I\{S^{*} \geq k\} / S^{*} \leq 1/k,$ this estimator is always nonnegative and at most the Markov inequality bound of
$0 \leq I\{S^{*} \geq k\} / S^{*} \leq 1/k,$ this estimator is always nonnegative and at most the Markov inequality bound of  $P(S \geq k)$; thus, it should have a small variance when this bound is small.
$P(S \geq k)$; thus, it should have a small variance when this bound is small.
7.1. When the $X_i$ are independent

In this case, use that
 \begin{align*} P(S \geq k) & = \sum_{i=1}^{n} E\left[\left.\frac{ I\{S \geq k\} }{S} \right| X_i= 1\right] a_i \lambda_i \\ & = E\left[\sum_{i=1}^{n} a_i \lambda_i \frac{I\{a_i + S - a_iX_i \geq k\}}{a_i + S - a_iX_i}\right]. \end{align*}
\begin{align*} P(S \geq k) & = \sum_{i=1}^{n} E\left[\left.\frac{ I\{S \geq k\} }{S} \right| X_i= 1\right] a_i \lambda_i \\ & = E\left[\sum_{i=1}^{n} a_i \lambda_i \frac{I\{a_i + S - a_iX_i \geq k\}}{a_i + S - a_iX_i}\right]. \end{align*}
So the simulation approach, in this case, is to generate  $X_1, \ldots, X_n,$ let
$X_1, \ldots, X_n,$ let  $S = \sum _i a_i X_i,$ and use the estimator
$S = \sum _i a_i X_i,$ and use the estimator  $\sum _{i=1}^{n} a_i \lambda _i ({I\{a_i + S - a_iX_i \geq k\}}/{(a_i + S - a_iX_i)})$.
$\sum _{i=1}^{n} a_i \lambda _i ({I\{a_i + S - a_iX_i \geq k\}}/{(a_i + S - a_iX_i)})$.
Example 9. Suppose the  $X_i$ are independent with
$X_i$ are independent with  $\lambda _i = {(i+20)}/{240},\ i = 1, \ldots, 100$ and
$\lambda _i = {(i+20)}/{240},\ i = 1, \ldots, 100$ and  $a_i = 20 - i/10,\ i = 1, \ldots, 100$. The mean and variance of the estimator of
$a_i = 20 - i/10,\ i = 1, \ldots, 100$. The mean and variance of the estimator of  $P(S > 410)$ are, respectively, 0.451232 and 0.173305. The mean and variance of the estimator of
$P(S > 410)$ are, respectively, 0.451232 and 0.173305. The mean and variance of the estimator of  $P(S > 440)$ are, respectively, 0.286072 and 0.140649. (The variances in these two cases can be compared with the variances of the raw simulation estimators
$P(S > 440)$ are, respectively, 0.286072 and 0.140649. (The variances in these two cases can be compared with the variances of the raw simulation estimators  $I\{S > 410\}$ and
$I\{S > 410\}$ and  $I\{ S > 410\},$ which are, respectively, 0.247622 and 0.204235.)
$I\{ S > 410\},$ which are, respectively, 0.247622 and 0.204235.)
7.2. The general case
In the general case, we generate  $I$ such that
$I$ such that  $P(I = i ) = a_i \lambda _i /E[S],\ i = 1, \ldots, n$. If
$P(I = i ) = a_i \lambda _i /E[S],\ i = 1, \ldots, n$. If  $I=i,$ we generate
$I=i,$ we generate  $X_1, \ldots, X_n$ conditional on
$X_1, \ldots, X_n$ conditional on 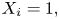 $X_i = 1,$ set
$X_i = 1,$ set  $S^{*} = a_i + \sum _{j \neq i} a_j X_j$ and use the estimator
$S^{*} = a_i + \sum _{j \neq i} a_j X_j$ and use the estimator 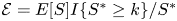 ${\mathcal {E}} = E[S] I\{S^{*} \geq k\} / S^{*}$.
${\mathcal {E}} = E[S] I\{S^{*} \geq k\} / S^{*}$.
Example 10. In the multinomial example considered in Example 8, suppose that  $a_i = 20-i,\ i = 1,\ldots,10$ and that we want the mean and variance of the estimators of
$a_i = 20-i,\ i = 1,\ldots,10$ and that we want the mean and variance of the estimators of  $p=P(S > k)$ for
$p=P(S > k)$ for  $k=40, 45, 50, 55$. Using the approach of this section, the results are given by the following table.
$k=40, 45, 50, 55$. Using the approach of this section, the results are given by the following table.
 $$\left(\begin{array}{cccc} k & p= P(S > k) & p(1-p) & \mbox{Var}({\mathcal{E}}) \\ 40 & 0.460100 & 0.248408 & 0.135402 \\ 45 & 0.340522 & 0.224567 & 0.125781 \\ 50 & 0.200719 & 0.160431 & 0.089031 \\ 55 & 0.129894 & 0.113022 & 0.060730 \end{array}\right) .$$
$$\left(\begin{array}{cccc} k & p= P(S > k) & p(1-p) & \mbox{Var}({\mathcal{E}}) \\ 40 & 0.460100 & 0.248408 & 0.135402 \\ 45 & 0.340522 & 0.224567 & 0.125781 \\ 50 & 0.200719 & 0.160431 & 0.089031 \\ 55 & 0.129894 & 0.113022 & 0.060730 \end{array}\right) .$$
Thus, in all cases, the variance of the proposed estimator of  $P(S > k)$ is quite a bit less than
$P(S > k)$ is quite a bit less than  $\mbox {Var}( I\{S > k\})$.
$\mbox {Var}( I\{S > k\})$.
Acknowledgments
We would like to thank Rundong Ding for carrying out the simulation computations.
Competing interest
The authors declare no conflict of interest.


 Open access
Open access