


1 Introduction
The analysis of the distribution of laryngeal features in Tyrolean, a non-standard variety of German, provides evidence for a typologically interesting pattern: while laryngeal contrasts in stops are maintained in intersonorant contexts and neutralised word-finally, as in most German varieties, in Tyrolean they are also neutralised in word-initial position. Initial neutralisation shows a certain degree of inter- and intraspeaker variability and correlates with place of articulation: labials are neutralised more often than velars, and velars more often than alveolars.
Initial neutralisation of laryngeal contrasts is a typologically rare pattern. Word- and syllable-initial positions are in fact usually considered to be positions which favour the preservation of contrasts (Beckman Reference Beckman1998, Lombardi Reference Lombardi1999; but see Smith Reference Smith2002 on neutralisation in prominent positions). The only other case of initial laryngeal neutralisation we are aware of is in Bakairi, which bans voiced obstruents from word-initial position (Wetzels & Mascaró Reference Wetzels and Mascaró2001).
Laryngeal contrast in Tyrolean is thus restricted to intersonorant contexts, where the acoustic correlates show that it is implemented via the feature [voice] (supported by a lowered F0 on the following vowel and increased closure duration), not by [spread glottis], as has been claimed for other varieties of German (see discussion in §2). A phonetic event similar to aspiration is found only in word-final contexts, where it can be interpreted as a correlate of the task of word-list reading.
(1) gives an overview of laryngeal contrasts as realised by speakers who exhibit initial neutralisation for all places of articulation.
-
(1)


In what follows, we first discuss laryngeal contrasts in Tyrolean in the context of German dialects, reviewing previous acoustic studies with similar scope, as well as the dialectological literature in general (§2).
In §3, the distribution of laryngeal contrasts in Tyrolean is established in a detailed acoustic study of fortis and lenis stops in word-initial, word-medial intersonorant and word-final positions, as well as in obstruent clusters. Voice onset time (VOT), voicing and closure duration measures of the relevant consonants are provided, as well as the F0 and H1–H2* values of the following vowel. Mixed-effects linear models are applied to the acoustic data both to determine which of the parameters are significantly related to the lenis–fortis contrast and to control for the role of individual variability.
2 Laryngeal contrasts: Tyrolean in the context of German dialects
Tyrolean is a non-standard variety of German spoken in the Bundesland Tyrol, Austria and in South Tyrol, Italy. According to traditional dialectological classification, the Tyrolean dialects belong to the group of Southern Bavarian dialects (Wiesinger Reference Wiesinger, Besch, Knoop, Putschke and Wiegand1983). Our study is based on the Tyrolean variety spoken in the city of Merano/Meran, Italy. The Tyrolean dialects spoken in Italy show a clear pattern of diglossia: they are spoken in informal, semi-formal and sometimes even formal contexts. The dialects are roofed by a regional variety of Standard German, which is used in written contexts and orally only in very formal situations (Lanthaler Reference Lanthaler and Stickel1997, Reference Lanthaler, Egger and Lanthaler2001). In our study, we concentrate on the non-standard variety used by speakers, and disregard their standard variety.
The Tyrolean spoken in South Tyrol is set in a particular language contact situation, with respect to varieties of both Germanic and Romance. While language contact with the Middle Bavarian varieties of Austria (Mittelbairisch) has always been strong, given the intense cultural and economic relationships, contact with the Alemannic varieties of Switzerland is historically much less important, as testified by the isoglosses dividing the Alemannic and Bavarian regions (Wiesinger Reference Wiesinger, Besch, Knoop, Putschke and Wiegand1983). With respect to Romance varieties, language contact up to the end of World War I was limited to the non-standard Romance varieties of Trentino (at the southern border of South Tyrol) and the Ladin varieties of the Dolomite valleys. After the annexation of South Tyrol to Italy in 1919, a northern version of Standard Italian, taught at school as a second language, became part of the linguistic repertoire of Tyrolean speakers, and is used in communication with Italian native speakers.
Given the genealogical relationship of Tyrolean to other German varieties, previous studies on laryngeal contrasts in standard and non-standard varieties of German are summarised here, in order to be able to compare our findings with theirs. Most studies of laryngeal contrasts in German are based on ‘Modern Standard German’, which, as will become clear from the descriptions, is usually identified as the standard variety of German spoken in the northern and middle regions of Germany. We will first summarise the literature on this variety, and then turn to analyses concerned with more regional standard and non-standard varieties of German.
In Modern Standard German, as in most varieties of German, two series of stops are found, distinguished by a single laryngeal feature. Traditionally, dialectologists call these two series fortis (corresponding to orthographic <p t k>) and lenis (corresponding to <b d g>). Following Beckman et al. (Reference Beckman, Jessen and Ringen2013), we will use the terms fortis and lenis throughout this paper, without implying that they have any phonetic or phonological content. The terminology is useful for referring to distinct natural classes of stops whose exact specification has yet to be determined.
The traditional phonological literature on German identifies [voice] as the relevant laryngeal specification of obstruents in Modern Standard German, and claims that obstruents contrast for this feature in syllable-initial position, while undergoing a process of neutralisation (final devoicing) in syllable codas, which removes the marked feature [voice] (Wiese Reference Wiese1996, Lombardi Reference Lombardi1999).
This proposal is challenged by Jessen & Ringen (Reference Jessen and Ringen2002) and Beckman et al. (Reference Beckman, Jessen and Ringen2006, Reference Beckman, Jessen and Ringen2009, Reference Beckman, Jessen and Ringen2013), who claim that the main laryngeal feature distinguishing stops in Modern Standard German is not [voice], but [spread glottis], phonetically realised by positive VOT in the long-lag range, and audible as aspiration.Footnote 1 In the [spread glottis] account, it is assumed that stops in German contrast for [spread glottis] in word-initial and intersonorant position, while undergoing fortition in word-final position, adding the feature [spread glottis].
In utterance-initial position, Beckman et al. (Reference Beckman, Jessen and Ringen2013: 261) state that lenis stops in Modern Standard German are ‘not usually produced with voicing during closure (negative VOT)’.Footnote 2 By contrast, ‘true voice languages’, such as French, Russian, Spanish and Hungarian, are reported to show regular prevoicing word-initially.Footnote 3 In intersonorant position, vocal fold vibration is interpreted in the [spread glottis] account as ‘passive voicing’, lacking an active voicing gesture such as vocal fold slacking or tongue-root advancement (Jessen & Ringen Reference Jessen and Ringen2002: 190, Beckman et al. Reference Beckman, Jessen and Ringen2013: 269). In word-final position, defenders of the [spread glottis] account propose that a process of fortition takes place, in the form of addition of [spread glottis] to lenis stops (see also Iverson & Salmons Reference Iverson, Salmons, van Oostendorp, Ewen, Hume and Rice2011, and Kohler Reference Kohler1977: 160 and Ramers Reference Ramers1998: 25 for final aspiration in German). However, the analysis of aspiration in word-final position is complicated by the difficulty of determining its phonetic correlates in this context (see Harris Reference Harris, Nasukawa and Backley2009: 18, and §3.3.3). In word-medial clusters, after a voiceless consonant, Jessen & Ringen (Reference Jessen and Ringen2002) assume that lenis stops are realised as voiceless in Modern Standard German and in Austrian German, since passive voicing is possible only in intersonorant contexts. They discuss the examples Jagden ‘hunts’ and Mägde ‘maids’, which are realised in their experiment without voicing, as Ja[kt]en and Mä[kt]e. Notice, however, that there is no independent evidence for the lenis status of the second consonant in the cluster, apart from orthographic convention, since there are no paradigmatically related words where the putative lenis /d/ would appear in a different environment (e.g. in intersonorant position, where passive voicing would identify it as lenis). More generally, there are no monomorphemic words in German containing clusters where the second consonant could be clearly identified as lenis. For this reason, in the present study we use compounds; fortis–lenis clusters are created by the sequence of last segment of the first part of the compound and the first segment of the second part (see §3.3.4).
The analyses presented so far describe laryngeal contrasts in Modern Standard German, as spoken in Germany. However, German is a polycentric language, with official status in various countries, where slightly different varieties of German are recognised as standard (e.g. Austrian German, Swiss German; see Schmidt & Herrgen Reference Schmidt and Herrgen2011 for discussion), each roofing the respective non-standard varieties. Jessen & Ringen (Reference Jessen and Ringen2002: 190) and Moosmüller & Ringen (Reference Moosmüller and Ringen2004) claim that the distribution of laryngeal features in the non-standard or regional varieties of German is similar to that of Modern Standard German. However, there is evidence that this is not entirely true. In particular, southern varieties of German (whether standard or non-standard) seem to differ conspicuously from middle and northern varieties, in terms of both the relevant laryngeal feature ([voice], rather than [spread glottis]) and its distribution in various phonological contexts.
For example, the maps in Kleiner (Reference Kleiner2011–17) show clearly that the German-speaking area is delimited by a southern belt where speakers avoid aspiration in their regional Standard German pronunciation. Stops, such as t in Gelatine ‘gelatine’ or p in pensionierte ‘retired’, are mostly pronounced without aspiration. As is observed in the comment to the maps, the belt characterised by lack of aspiration corresponds almost exactly to the Southern Bavarian dialect area, including the Northern Italian region of South Tyrol. Reduced aspiration is also encountered in the Swiss regions where Alemannic varieties are spoken.
The acoustic analysis of Austrian German in Moosmüller & Ringen (Reference Moosmüller and Ringen2004) casts further doubts on an interpretation that considers [spread glottis] to be the relevant contrastive feature in all German varieties. It also shows that laryngeal contrasts are neutralised not only in word-final, but also in word-initial position. Moosmüller & Ringen investigate the pronunciation of speakers of the standard variety of Austrian German, i.e. speakers who probably have a Middle Bavarian dialect background. They analyse fortis and lenis obstruents in word-initial contexts following a voiceless segment (e.g. köstliches Bier ‘delicious beer’), in intervocalic contexts and in medial clusters. Word-final contexts were not tested. The authors find aspiration as a consistent cue only for word-initial fortis velar /k/.Footnote 4 In all other contexts, aspiration is not a relevant cue for stop contrasts. Furthermore, lenis consonants are not voiced initially, and are voiced, partially voiced or voiceless intervocalically. The only clear phonetic correlate of the contrast between fortis and lenis stops in Austrian German is closure duration, and even this cue is statistically significant only in intervocalic position. The authors conclude that the observed pattern points to a system with initial neutralisation (except for velars) and a length contrast in intervocalic position. They assume that the [spread glottis] feature has two phonetic correlates: greater closure duration and aspiration. Austrian German, on this assumption, is heading towards neutralisation of the [spread glottis] contrast, which is manifested only intervocalically (as closure duration) and initially (on velars). Note, however, that Moosmüller & Ringen (Reference Moosmüller and Ringen2004: 56) did not test items of the Mieter–Mieder type, where fortis and lenis stops follow a long vowel. Testing these would allow preceding vowel length to be controlled for. The extent to which vowel length influences the length of a following consonant in Austrian German therefore remains an open issue.
Moosmüller & Ringen's data are in accordance with acoustic studies on Middle Bavarian, the non-standard variety usually used by speakers who have Austrian German as their standard variety. Bannert (Reference Bannert1976), in a detailed acoustic study of initial and medial stops in Middle Bavarian, reaches the conclusion that the laryngeal contrasts in initial stops in these varieties are completely neutralised, while intervocalic stops vary in length according to the vowel that precedes them: long vowels are followed by short stops and short vowels are followed by long stops. Such a system can be interpreted as having only one series of voiceless unaspirated stops, with consonantal length being dependent on the length of the preceding vowel.
In the traditional dialectological literature, initial neutralisation of the fortis–lenis contrast has been described for Tyrolean, although not investigated acoustically (Kranzmayer Reference Kranzmayer1956: 76f). Schatz (Reference Schatz1897: 21) observes for the Tyrolean dialect of Imst that labials are neutralised to fortis /p/ in word-initial positions in general, while alveolars and velars are neutralised to fortis in postpausal contexts. The neutralisation of word-initial fortis /p/ and lenis /b/ is also acknowledged in Schatz's (Reference Schatz1955–56) Tyrolean dictionary, which has no entry for the letter <b>. Hopfgartner (Reference Hopfgartner1970: 181f) describes labials in the Tyrolean dialect of Ahrntal as neutralised in word-initial position in general, alveolars as neutralised in postpausal contexts and variably in word-initial position, and velars as not neutralised. In a recent dialect survey, Scheutz (Reference Scheutz and Scheutz2016: 51f) describes labials as consistently neutralised, and alveolars and velars as variably neutralised in initial contexts, for all Tyrolean varieties spoken in South Tyrol.
One step further south, beyond the borders of the contiguous German-speaking area, data from the Germanic language islands of Mòcheno and Cimbro in Northern Italy suggest a dialect continuum across the Bavarian dialects, which sees a step-by-step progression of neutralisation of the laryngeal contrast, involving increasingly larger phonological contexts (Alber Reference Alber2014, Alber et al. Reference Alber, Rabanus, Tomaselli, Pezze, Beni and Miotti2014). Auditory judgements indicate that stops contrast for [voice] in initial and intersonorant position in these varieties, while they undergo final devoicing in final position. This would mean that neutralisation of laryngeal contrasts targets only final positions in these most southern of Bavarian varieties, but also involves initial positions in the Tyrolean varieties, while the Middle Bavarian dialects display complete neutralisation of laryngeal contrasts.
The distribution of the fortis–lenis contrast seems to play out differently in the Alemannic varieties, which, as Bavarian, are part of the larger Upper German dialect area, but have undergone many sound changes distinct from the Bavarian area. Krähenmann (Reference Krähenmann2001) shows that laryngeal contrasts in the Alemannic dialect of Thurgovian have been neutralised in favour of a distinction in consonant length. Differences in the closure duration of fortis and lenis stops are significant in intersonorant contexts (within and across words), as well as in absolute word-final position. In initial position there is no measurable phonetic cue for a fortis–lenis distinction, but the geminate–singleton contrast reappears as soon as a word is preceded by a word ending in a sonorant.
The literature summarised here suggests that there are important differences across the German-speaking area with respect to both the implementation and the distribution of laryngeal features. While it has been claimed that Modern Standard German as spoken in Germany distinguishes two series of stops by means of the feature [spread glottis], there is evidence from both dialectological and acoustic studies that aspiration plays only a subordinate role in southern varieties of German. Furthermore, inside the spectrum of Bavarian dialects and standard varieties based on them (Austrian German), it can be observed that laryngeal contrasts tend to be neutralised not only in word-final position, as in other German varieties, but also in initial and intersonorant positions. The Tyrolean varieties occupy a particularly interesting position on this spectrum, since they preserve a contrast for [voice] in intersonorant position, but neutralise it word-initially, thus forming the missing link between German varieties with neutralisation in final position only (the Germanic language islands of Northern Italy) and varieties with complete neutralisation of laryngeal contrasts (the Middle Bavarian dialects). The resulting system is of general typological interest, since Tyrolean neutralises contrasts in word-initial position, a position which is usually assumed to be particularly favourable to the preservation of contrast.
3 An acoustic study of laryngeal contrasts in Tyrolean
3.1 Experimental setting
For the creation of our acoustic corpus, ten speakers were selected (six female, four male, aged from 22 to 41) from the city and surroundings of Merano/Meran. We will refer to the native variety of these speakers as Tyrolean, without further specifying any subgroup inside the Tyrolean dialect area. All speakers had a solid dialect background, in the sense that they had been born and lived most of their lives in Merano/Meran, and spoke Tyrolean on an everyday basis in all contexts, except the most formal. All of the speakers had compulsory schooling in German, where they were exposed to (a regional variety of) Standard German, and learned Italian as a second language at school, from approximately the age of seven.
The speakers were asked to read a word-list, pronouncing every item twice. The recording session was made in a soundproof booth at the Alpine Laboratory of Phonetics and Phonology at the Free University of Bozen-Bolzano. A Sennheiser ME66 microphone was placed in front of the speakers, at an approximate distance of 25 cm. The audio signal was recorded directly to a computer at a sampling frequency of 44.1 kHz. Data were subsequently downsampled to 16 kHz and digitised at 16-bit rate. Acquisition and editing of audio files were made with GoldWave software (version 5.69); acoustic analysis and measurements were carried out with Praat (Boersma & Weenink Reference Boersma and Weenink2013) and VoiceSauce (Shue et al. Reference Shue, Vicenik, Yu, Lee and Zee2011).
Since Tyrolean is not generally written, an orthography for the dialect was developed on the basis of the phoneme inventories proposed in Bauer (Reference Bauer2011) and Alber (Reference Alber, Bidese and Cognola2013, Reference Alber2014), following the orthographic principles developed by Rowley (Reference Rowley2003) for a neighbouring variety, Mòcheno. Speakers read a short text to familiarise themselves with this orthography before they were exposed to the test items. None of the speakers had problems reading the text or recognising the test items (see Krähenmann Reference Krähenmann2001 for a similar experimental design).
For the selection of items, four contexts were chosen: (a) word-initial (prevocalic) position, (b) word-medial (intersonorant) position, (c) word-final (postvocalic) position and (d) post-obstruent position in word-medial consonant clusters.Footnote 5
Word-initial contexts coincide with utterance-initial postpausal contexts, and the influence of preceding segments can thus be successfully excluded. For the consonant cluster context in (d), the target stop was the initial consonant of the second element of a compound, which followed a final fortis obstruent in the first element. Compounds were chosen because there are no other lexical items in Tyrolean containing word-medial consonant clusters involving sequences for lenis and fortis consonants at all places of articulation.Footnote 6 (2) contains an example for each context (a full list of items is given in the online appendix).Footnote 7
-
(2)

Three stimuli were presented for each category: fortis and lenis stops, context and place of articulation.Footnote 8 In addition to fortis /p t k/ and lenis /b d g/, three items per context were presented containing the affricate /kx/, which the dialectological literature claims to be a phoneme distinct from /k/ (see e.g. Rowley Reference Rowley1986 for Mòcheno). Items containing /kx/ were indeed identified by spectral moments analysis (Forrest et al. Reference Forrest, Weismer, Milenkovic and Dougall1988) as containing an affricate, and could be successfully distinguished from non-affricated /k/. They do not appear in the acoustic analysis. The attribution of segments to the phoneme categories lenis and fortis was decided on historical grounds: if a word contained a lenis historically (and hence in its Modern Standard German cognate), it was presented orthographically as <b d g>; if it contained a historical fortis, it was presented as orthographic <p t k>. Thus the initial segment of Modern Standard German Baum ‘tree’ was considered to be a lenis, and hence presented as <Baam>, even if, due to initial neutralisation (see §3.3.1), it was pronounced by most speakers with [p]. The experimental conditions were thus explicitly designed to test the hypothesis of a phonemic contrast based on the historical contrast between lenis and fortis.
For word-medial intersonorant contexts, items containing a long stem vowel were chosen whenever possible (this was the case in 100% of items containing alveolar /t d/). This allowed us to control for the variable of preceding vowel length, which might have influenced the length of a following obstruent, leading to lengthening of the obstruent after a short vowel (see Alber Reference Alber2014 for a discussion of consonant gemination in Tyrolean and neighbouring varieties).
A total of 83 items was presented to the participants (see the appendix for full list); since each was produced twice, 1660 tokens were registered and annotated, of which 65 had to be discarded. Waveforms and spectrograms of the recorded stops were annotated and analysed in Praat, according to the following parameters.
(a) Voice onset time (VOT): in word-initial and word-medial intersonorant contexts, VOT was measured as the time-span from the burst (identified by a sudden increase in the amplitude of the waveform) to the beginning of the following vowel. The onset of the vowel was measured at the beginning of the first well-formed cycle in the waveform at a zero crossing (Cho & Ladefoged Reference Cho and Ladefoged1999: 215). Voice onset is not available in final contexts; for stops in word-final position, the time lapse from the burst to the end of the voiceless noise accompanying the release of the stop was measured (cf. Harris Reference Harris, Nasukawa and Backley2009).
(b) Percentage of voicing during closure: during closure, glottal activity identified by periodicity in the waveform and the presence of a high-intensity signal at low frequencies (voice bar) were measured. In order to determine the end of glottal vibration, the last complete cycle of vibration at a zero crossing was measured. As an additional cue, sudden decrease of intensity was taken into account. The percentage of voicing was derived from the absolute value of voicing duration in relation to the absolute closure duration.
(c) F0 coefficients: VoiceSauce software (Shue et al. Reference Shue, Vicenik, Yu, Lee and Zee2011), implemented in Matlab, was used to calculate F0 and the harmonic and formant spectra amplitudes. In order to avoid discontinuities and random variation in pitch-tracking, F0 was measured using the Straight algorithm provided by the software (Kawahara et al. Reference Kawahara, de Cheveigné and Patterson1998). The algorithm computes instantaneous frequency-based F0 using the following default parameters: pre-emphasis 0.96, window length 25 ms and frame shift 1 ms. The vocalic interval was divided into five subsegments, and the mean value of F0 was calculated for the first subsegment, corresponding to the vowel onset. F0 measurements were then transformed and normalised according to the procedure illustrated in Shultz et al. (Reference Shultz, Francis and Llanos2012) in order to facilitate interspeaker comparison (especially across gender).Footnote 9 Values above zero represent higher-than-average onset frequencies, while negative values represent lower-than-average frequencies.
(d) H1–H2*: F0 measurements were used to calculate the harmonic spectra magnitudes. Harmonics were computed pitch-synchronously over a three pitch period window, instead of computing spectra over a fixed time window. The harmonic difference measure H1–H2 was corrected (H1–H2*) to reduce the effect of vowel formants (Hanson Reference Hanson1997), in order to allow interspeaker comparison.Footnote 10 Neither F0 nor H1–H2* values were extracted in word-final contexts, where the consonant was not followed by a vowel.
(e) Absolute closure duration: closure duration was measured for all except word-initial contexts. In word-medial intersonorant and word-final contexts, the beginning of the closure phase was identified at the offset of the preceding vowel or sonorant as the last clearly detectable period of vocal fold vibration in the waveform at a zero crossing. The end of the closure was identified as the point in time where the release burst started. In consonant-cluster contexts, closure duration was measured as the time interval between the release burst of C1 and the release burst of C2. When a clear release for C1 was not detectable, the token was discarded. Sixteen tokens, distributed uniformly across the items, were left out of the analysis for this reason.
3.2 Acoustic parameters, thresholds and statistical analysis
In order to determine whether an acoustic cue is relevant in contrasting fortis and lenis stops, we refer, whenever possible, to the threshold levels indicated in the literature for acoustic parameters participating in lexical contrasts. In addition, a statistical analysis was performed to establish which of the acoustic parameters significantly distinguish between fortis and lenis stops. Only if threshold levels lie above those indicated in the literature and statistical significance is reached do we acknowledge that the relevant parameter participates in the implementation of contrast.
With respect to VOT, the main indicator for a contrast in terms of [spread glottis], we follow Cho & Ladefoged (Reference Cho and Ladefoged1999) in assuming that a positive VOT value above 90 ms characterises highly aspirated stops, a value above 50 ms slightly aspirated stops and one below 30 ms unaspirated stops. Threshold levels of this type are used also in comparable analyses, such as that of Moosmüller & Ringen (Reference Moosmüller and Ringen2004) on laryngeal contrasts in Austrian German.
It is more difficult to establish a threshold above which a stop can considered to be voiced, since clear indications are seldom given in the literature and, to our knowledge, no perception experiments are available with respect to German indicating the amount of vocal fold vibration required for a stop to be perceived as voiced.
With respect to Dutch, van Alphen & Smits (Reference Alphen and Smits2004) observe that from the perception point of view any amount of prevoicing unmistakably signals that a stop is voiced. Voicing is not even a prerequisite for a stop to be perceived as voiced, since other cues can lead to the percept of voicing (e.g. a lowering of F0 in the following vowel; see below). Moosmüller & Ringen (Reference Moosmüller and Ringen2004: 60), in their acoustic study of Austrian German, categorise stops as voiced if the percentage of voicing during the closure period is 50% or higher. Beckman et al. (Reference Beckman, Jessen and Ringen2013: 271), on the other hand, consider a stop to be fully voiced only when its voicing ratio is 90% or higher.
Most of the stops in our dataset are realised with variable amounts of voicing. During the closure phase the periodic signal typically dissipates before the stop burst (a pattern described as ‘bleed’ by Davidson Reference Davidson2016). We therefore follow Moosmüller & Ringen (Reference Moosmüller and Ringen2004) and Beckman et al. (Reference Beckman, Jessen and Ringen2013) in assuming that the relevant measure in intersonorant and final positions is the percentage of voicing of a stop (rather than the absolute time-span of vocal fold vibration), and that a stop has to be considered voiced if the vocal folds vibrate during most of its closure period. For these contexts we thus treat voicing either as a continuous percentage whose values range from 0% to 100% (final context) or as a categorical variable (see the discussion of ceiling effects below), assuming in both cases that 90% is the threshold for a stop to be considered to be voiced (similar to Beckman et al. Reference Beckman, Jessen and Ringen2013).
In utterance-initial position, however, where there is no preceding context, it is not possible to determine the beginning of the stop closure acoustically. For this reason, the absolute values of voicing during closure are taken into account in this position. Lisker & Abramson (Reference Lisker and Abramson1964) observe that voiced stops have a minimal value of −35 ms in four languages with a two-way contrast between voiced and voiceless unaspirated stops. We take this minimal value to be the threshold value which allows speakers to classify a stop as voiced.
It has been shown that F0 may play a role in implementing the contrast between fortis and lenis stops, along one of the following lines: (i) a lowered F0 in the onset of a following vowel may occur as an automatic correlate of voiced stops, and a high F0 value as a correlate of stiff vocal folds (Kohler Reference Kohler1985, Honda et al. Reference Honda, Hirai and Kusakawa1993, Hoole et al. Reference Hoole, Honda, Murano, Fuchs, Pape, Yehia, Demolin and Laboissière2006); (ii) inverse correlation of VOT and F0 suggests that F0 is used as a strategy to enhance phonological contrasts (Kingston & Diehl Reference Kingston and Diehl1994). Our study does not provide evidence for one hypothesis or the other (see Kirby & Ladd Reference Kirby and Ladd2015 for discussion), but a statistically significant difference in F0 between fortis and lenis stops is taken as evidence that F0 is involved in the implementation of some laryngeal contrast, while the absence of a difference is taken as evidence that the contrast is neutralised in a particular context. No relevant threshold levels are found in the literature for this parameter.
The difference in amplitude of the first and second harmonics of a vowel has been observed to be an indicator of breathiness, and may thus indicate a [spread glottis] feature in the preceding consonant (Chapin Ringo Reference Chapin Ringo1988, Stevens & Hanson Reference Stevens, Hanson, Fujimura and Hirano1995, Ní Chasaide & Gobl Reference Ní Chasaide, Gobl, Hardcastle and Laver1997; see Jessen Reference Jessen1998: 110 for discussion of the role of H1–H2* in Modern Standard German). We therefore take an increased H1–H2* difference in the following vowel as a potential indicator for aspiration in fortis consonants. More generally, if the H1–H2* value differs significantly between fortis and lenis stops, this could be interpreted as an indicator of the presence of a laryngeal contrast, assuming that H1–H2* values can provide additional cues for a contrast which otherwise is assumed to involve [voice] (see Kong et al. Reference Kong, Beckman and Edwards2012 for a similar interpretation of laryngeal contrast in Japanese). As for F0, no threshold levels are available for this parameter.
Closure duration was measured word-medially, word-finally and in obstruent clusters. With Payne (Reference Payne2005: 157), we assume that a closure-duration difference below 25 ms is not noticeable. Whenever values lie above this threshold, the ratio between closure duration in fortis and lenis stops is considered to be the significant acoustic value. A difference in consonantal length between fortis and lenis stops, expressed by a high closure-duration ratio, can appear as the correlate of a contrast in terms of [voice]. As observed by Lisker (Reference Lisker1957) and Fuchs (Reference Fuchs2005), there is a clear relationship between obstruent voicing and closure duration: the longer the duration of the closure, the more likely the disappearance of voicing, given the effort to maintain vocal fold vibration over time. Ohala (Reference Ohala and MacNeilage1983: 195) notes that this might be the reason why voiced stops tend to be shorter than voiceless stops in the languages of the world. Alternatively, a difference in closure duration between fortis and lenis stops could indicate that Tyrolean has developed a length contrast, as in the Alemannic varieties (Krähenmann Reference Krähenmann2001).
The values reported in the literature for the closure-duration ratio of voiced and voiceless stops, as well as those for singleton–geminate contrasts, vary considerably cross-linguistically. Ratios of closure duration correlated to a contrast in terms of [voice] are usually lower than those reported for length contrasts, but reach them in some cases. From the data in Cohn et al. (Reference Cohn, Ham, Podesva, Ohala, Hasegawa, Ohala, Granville and Bailey1999) for voiced vs. voiceless stops in word-medial contexts, a ratio of 1.25 can be calculated for Madurese, 1.50 for Buginese and 1.52 for Toba Batak. For Italian, Payne (Reference Payne2005) finds a ratio of 1.56 for voiced vs. voiceless singleton stops in a context comparable to the one investigated in our study, and for Dutch, Kuijpers (Reference Kuijpers1996: 369) reports a mean closure duration in intervocalic contexts of 39 ms for voiced and of 69 ms for voiceless stops, equivalent to a ratio of 1.76.
As for singleton–geminate contrasts, in a literature overview Hamzah et al. (Reference Hamzah, Fletcher and Hajek2016) report ratios ranging from a minimum of 1.45 in Cypriot Greek, through 1.70 in Russian and 2.35 in Japanese, to a maximum of 2.93 in Turkish, for stops in word-medial intersonorant position. For Standard Italian as spoken in Tuscany, Payne (Reference Payne2005) measures a singleton–geminate ratio of 2.31. For Alemannic singleton and geminate stops, in Krähenmann (Reference Krähenmann2001) we find a ratio of 2.71 word-medially after long vowels and 3.03 after short vowels (2001: 127).
Considering that a language such as Dutch, for which no lexical length contrast is assumed, displays a closure-duration ratio for voiced and voiceless stops similar to the closure-duration ratio that Russian displays for the singleton–geminate contrast, we conclude that no reliable threshold level can be identified above which closure duration implements a length contrast. In the absence of clear threshold levels to distinguish between closure duration as a correlate of [voice] and closure duration as implementation of lexical length, in §3.3 we will discuss the two possibilities in combination with the other acoustic cues present in the various contexts.
Whenever threshold levels are available, we consider the acoustic parameters discussed here as relevant in implementing a contrast only if the difference in values for lenis and fortis stops results in statistical significance and if values reach the established threshold levels. The thresholds described define the nature of the acoustic events and, more importantly, help to delimit the boundaries of phonological categories. Continuous changes in acoustic parameters may be treated by speaker-hearers as similar or different, according to both general processes of speech perception (e.g. the granularity of our perceptual space) and language-specific phonological categories. As a result, for instance, significant VOT differences between two sets of stops below the threshold of 30 ms should not necessarily be regarded as evidence of a contrast based on VOT. Similarly, difference in closure duration below 25 ms might be statistically significant, but perceptually too shallow to implement a contrast.
The statistical analysis in this study is based on a set of (generalised) mixed-effects linear models, to test whether lenis and fortis stops are significantly different on the basis of one or more acoustic parameters (Baayen et al. Reference Baayen, Davidson and Bates2008). For each context, the models are composed of one dependent variable corresponding to one of the acoustic parameters and one or more predictors, divided into fixed and random factors. The main predictor is the lenis–fortis contrast, but place of articulation is also controlled for, because of the well-known effects on VOT. Thus the models may have one of VOT, prevoicing, F0, H1–H2* and closure duration as the dependent variable, while the lenis–fortis distinction and place of articulation are considered as fixed explanatory factors. Since a high degree of individual and word variation is observed in the dataset, by-subject and by-item random intercepts were factored into the models. All the models were fitted in R (R Core Team 2016), using the lme4 (Bates et al. Reference Bates, Mächler, Bolker and Walker2015) and lmerTest packages (Kuznetsova et al. Reference Kuznetsova, Brockhoff and Christensen2014). The latter package allows us to assign a p-value to the coefficients in the mixed-effects linear model, using Satterthwaite approximations to degrees of freedom.
3.3 Results
In the next sections, the results of the acoustic and the statistical analysis will be discussed in detail for each context. An overview of values for the probability of distribution of VOT, percentage of voicing during closure, F0, H1–H2* and closure duration for each context (except word-final) is presented in Fig. 1.
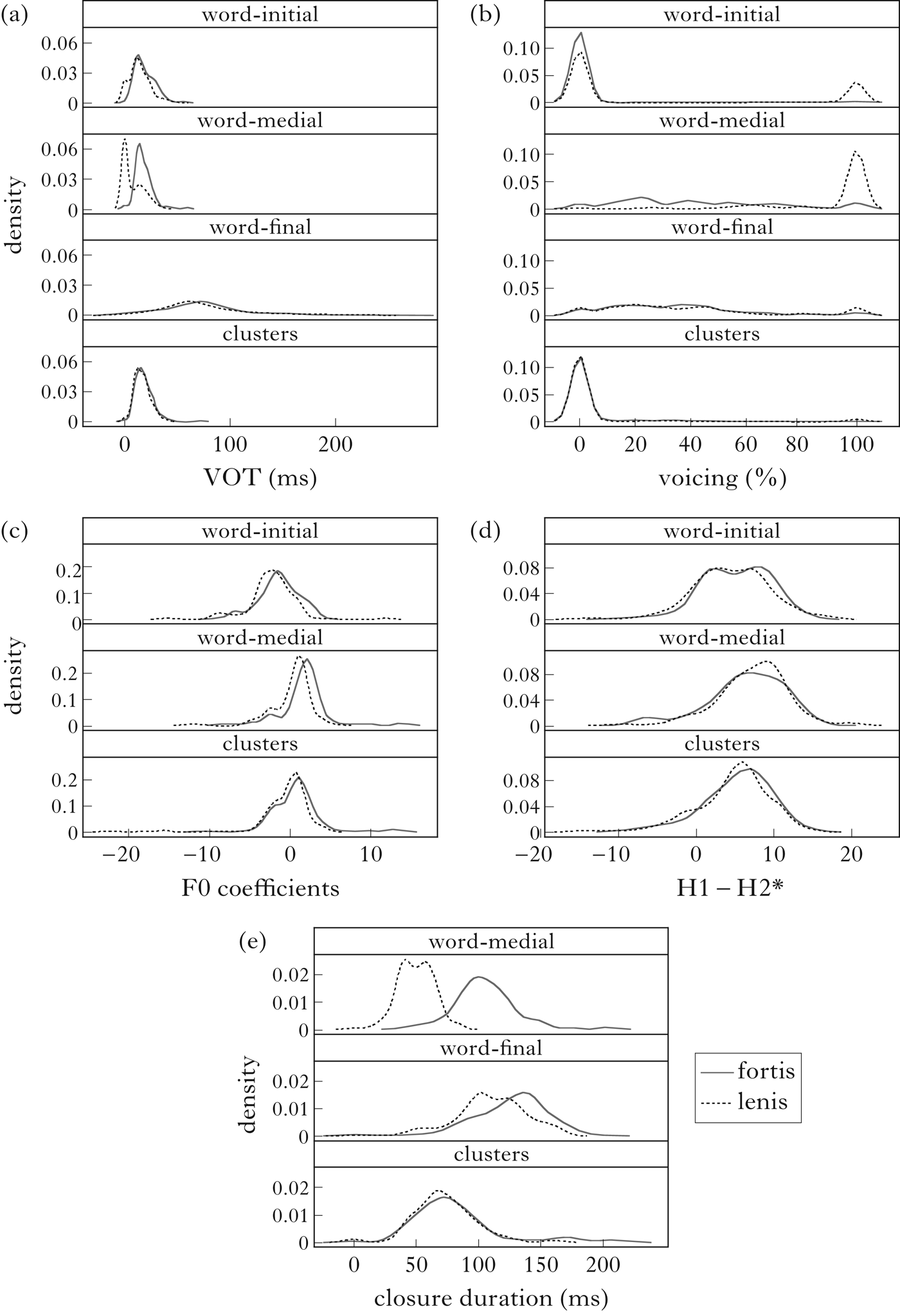
Figure 1 Distributions of (a) VOT, (b) voicing, (c) F0 coefficients, (d) H1–H2* and (e) closure duration by context and fortis vs. lenis.
As Fig. 1a shows, VOT values appear to be under 90 ms (highly aspirated stops) in all except word-final contexts. Most of the tokens are actually concentrated below 20–25 ms, i.e. below the threshold of 30 ms set for aspiration. This indicates that the fortis stops contained in our dataset should be classified as non-aspirated (Lisker & Abramson Reference Lisker and Abramson1964).
With respect to voicing (Fig. 1b), values point to a clear contrast in intersonorant position only. In word-initial context, a peak for voiceless lenis and fortis consonants and a smaller peak for voiced lenis consonants can be observed, suggesting that lenis consonants are often, but not always, devoiced in this context. In word-medial intersonorant context, we find a peak for lenis consonants at high voice percentages, indicating a [voice] contrast. The second element of a word-medial obstruent cluster exhibits a high proportion of voiceless items for both lenis and fortis consonants, suggesting neutralisation. The same is true for word-final contexts. In this case, however, neutralisation is achieved by different means: the values of the two groups of stops show a similar flat uniform distribution.
Figs 1c and d show that lenis and fortis consonants have similar F0 and H1–H2* values. Statistical analysis shows that the difference between the H1–H2* values for lenis and fortis is not significant in any context. The lenis–fortis distinction, on the other hand, has a significant effect on the F0 coefficients in word-medial intersonorant contexts and in obstruent clusters. We will conclude that F0 and H1–H2* play different roles in implementing contrast in Tyrolean: while H1–H2* is clearly not related to the contrast investigated, F0 seems to behave as a redundant cue for voicing that enhances the contrast word-medially.
Differences in closure duration (Fig. 1e) are significant in both word-medial intersonorant and word-final positions. In word-final position, as well as in consonant clusters, the durational difference between fortis and lenis stops does not reach levels which can be considered to be noticeable (<25 ms). The role of closure duration in word-medial contexts will be discussed in detail in §3.3.2, where it will be concluded that, although the values are compatible both with an interpretation of closure duration supporting a contrast in terms of [voice] and with an interpretation of closure duration implementing a length contrast, the former interpretation is more plausible.
Tyrolean thus appears to be a dialect where the lenis–fortis contrast, if implemented at all, is implemented by the feature [voice], supported by F0 and closure duration. Neither VOT nor H1–H2* plays any role in contrasting lenis and fortis stops.
Table I anticipates the results of our study, indicating where threshold levels are reached, whether the statistical analysis produces significant results for the acoustic parameters and which interpretation in terms of contrastive features or neutralisation will be given for each context. As can be gleaned from the table and will be discussed in detail in §3.3.2–§3.3.4, the contrast between fortis and lenis stops is supported fully by threshold levels and statistical results only in word-medial intersonorant contexts, by the acoustic parameters of prevoicing, F0 and closure duration. Weaker support for the contrast, in terms of statistical results only, comes from VOT, but threshold levels are not reached in this case. We interpret these results as indicating the presence of a feature [voice] implementing a laryngeal contrast in word-medial stops.
Table I Summary of results for threshold levels and statistical analysis for each of the five contexts. n/m=not measurable; n/a=not applicable; *=statistically significant, but with extremely low probability of voiced stops (see discussion in §3.3.1).
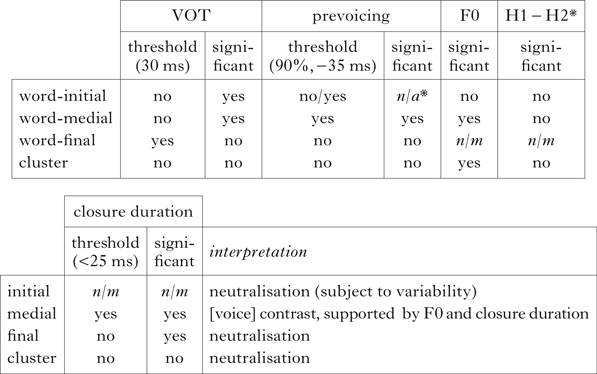
In word-final contexts and obstruent clusters, laryngeal contrasts appear to be neutralised, no clear acoustic parameters emerge (see §3.3.3 for discussion of high VOT values and closure duration in word-final position, and of F0 in CC clusters).
Word-initial contexts, as will be shown, also involve neutralisation. In this context neutralisation is subject to interspeaker and intraspeaker variability, and is dependent on place of articulation. For those speakers who display a contrast in this context, the contrast is again realised via [voice].
3.3.1 Word-initial contexts
The realisation of laryngeal contrasts in word-initial contexts differs from speaker to speaker. While none of the speakers produces significant amounts of aspiration in fortis consonants, they differ in their production of lenis consonants: these are produced with prevoicing by some speakers, and as voiceless by others. As a consequence, laryngeal contrasts are neutralised by many speakers in this context, though not by all. We first discuss the values for fortis consonants for all speakers, and then the more complex situation with lenis consonants.
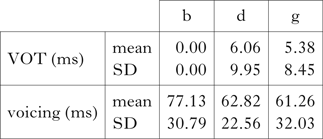
Fortis consonants in word-initial position exhibit positive VOT values ranging from 13 ms for labials to 24 ms in velars (see Table II). For comparison, Ringen & Kulikov (Reference Ringen and Kulikov2012) report a mean VOT value of 23 ms for word-initial fortis stops in Russian, a ‘true voice language’. It can be concluded that the fortis consonants /p t k/ are pronounced as voiceless stops without aspiration in this context, given that none of them reaches the threshold level of 30 ms.
Table II Mean acoustic values of fortis and lenis stops in word-initial context.

For lenis consonants, Table II shows that the mean values of prevoicing would appear to be below our established threshold. However, in this specific context the percentage of prevoicing does not behave as a continuous variable. As Fig. 1b shows, prevoicing in word-initial context is not continuously distributed; rather, the data points in our sample can have a value of either 0% or 100%. Thus prevoicing is more appropriately treated as a binary variable that is realised as either a voiceless or a fully voiced stop.
A closer look at the data reveals that word-initial lenis consonants exhibit a high degree of interspeaker variability, as illustrated in Fig. 2. While all but one speaker realised word-initial labials as voiceless, behaviour between speakers varied for alveolars and velars. With respect to alveolars, four of the ten speakers produced more than half of the six lenis items with some prevoicing, four produced fewer than half or none of the items as voiced and two produced exactly half of the items with prevoicing. Velar lenis were produced with prevoicing more than half of the times by two speakers, exactly half by one speaker and less than half of the time or never by the remaining speakers.
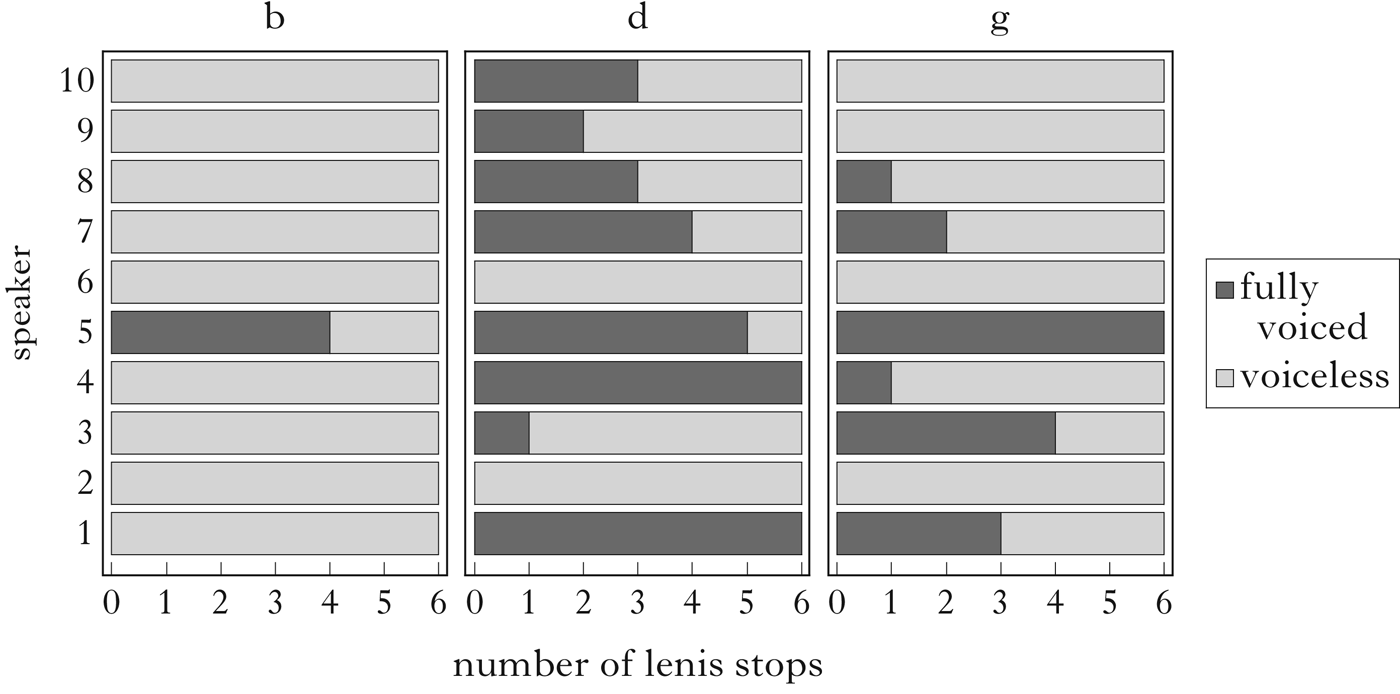
Figure 2 Number of lenis stops in word-initial contexts produced with prevoicing by each speaker.
We interpret these data as symptoms of an ongoing process of word-initial neutralisation, which correlates with place of articulation (labials are neutralised more often than velars, which in turn are neutralised more often than alveolars), but also depends on the individual speaker.Footnote 11 For the purpose of our acoustic analysis, we therefore split the sample into two groups, taking the alveolar context as the most significant environment for detecting contrast: group A consists of the four speakers (1, 4, 5, 7) who implemented a laryngeal contrast for alveolars, and group B consists of the four speakers who seemed to neutralise contrasts in this context (2, 3, 6, 9). Speakers 8 and 10, who implemented contrasts in alveolars half of the time, are not considered in what follows.
Group A speakers did not produce all lenis stops with prevoicing. However, the values of the stops produced with voicing (38 out of 72) are clearly above the threshold of −35 ms, as shown in Table III.
Table III Mean acoustic values of prevoiced lenis stops in word-initial context for group A speakers (contrast).
Group B speakers produced only 7 out of 72 items with prevoicing. This means that they were much more sensitive to the process of initial neutralisation than group A speakers. However, the few items that were produced with prevoicing again had a voicing duration above the threshold of −35 ms, except for two items, as shown in Table IV.
Table IV Acoustic values of seven productions of prevoiced lenis stops in word-initial context for group B speakers (neutralisation).

We conclude that both group A and group B speakers exhibit – to different degrees – a process of initial neutralisation of laryngeal contrasts. However, when a contrast is realised, it is realised through prevoicing of the lenis stop, with values above the threshold of −35 ms.
Note that our hypothesis of variable initial neutralisation is a conservative one. Generally, the mean values for prevoicing in true voice languages seems to be higher than −35 ms. Calculating the mean value of the negative VOTs reported by Lisker & Abramson (Reference Lisker and Abramson1964) for utterance-initial position in the true voice languages Hungarian, Spanish and Tamil gives a value of −89.44 ms. If our threshold level was raised to similar values, the conclusion would be that contrast is neutralised completely in word-initial position, for all speakers of Tyrolean and all places of articulation. Choosing the lowest possible threshold level (−35 ms) allows us to detect the variability of the process, but it is nevertheless clear that initial neutralisation is pervasive.
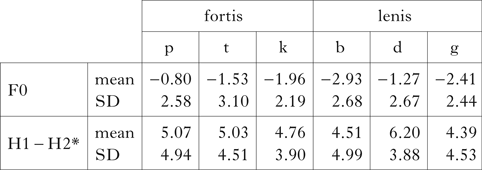
As already observed in Figs 1c and d, the mean values of F0 and H1–H2* do not show any clear pattern with respect to a distinction in the behaviour of the two sets of stops, as shown in Table V.Footnote 12
Table V Mean acoustic values of onset F0 and H1–H2*.
In order to test our descriptive hypothesis with the statistical analysis, the acoustic parameters were modelled using linear mixed-effects models (§3.2). Four models were obtained, corresponding to the following measures: VOT, prevoicing, F0 coefficient and H1–H2*.
(a) VOT. The model in Table VI includes Lenis/fortis and Place of articulation (POA) as main fixed effects, and Subject and Item as random intercepts. The table gives the estimated value for each fixed-effect coefficient, along with its standard error, Restricted Maximum Likelihood (REML) t-test value and the corresponding significance value (using Satterthwaite approximations to degrees of freedom).
Table VI Mixed-effects linear model for word-initial contexts, with VOT as dependent variable.
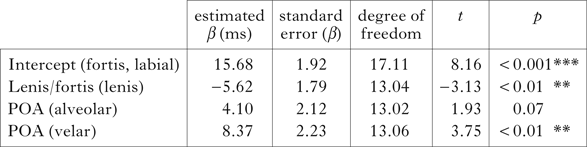
Both predictors seem to have significant effects on VOT. First, the effect of place of articulation on VOT follows the general expectation: velars > alveolars > labials. Second, the model predicts that VOT in lenis stops is 5.6 ms shorter than in fortis stops.
However, the values predicted by the model lie below the threshold of 30 ms. Acoustically, both lenis and fortis should therefore be considered as non-aspirated sounds, which implies that stops in initial position are not characterised by aspiration. In fact, even though the absolute temporal distance between lenis and fortis is statistically significant (~5 ms), it is a temporal difference that is hardly perceivable, and consequently not sufficient to express a phonemic contrast (by comparison, in Cantonese the average temporal distance between voiceless non-aspirated and aspirated stops is 64 ms; Lisker & Abramson Reference Lisker and Abramson1964).
The estimated values of by-subject and by-word intercept variances are σ2 = 6.3 and σ2 = 9.7, and are both highly significant (p < 0.001). Thus both subjects and words differ in their mean values of VOT.
(b) Prevoicing. For the word-initial context, prevoicing is expressed by the speakers as a categorical distinction (see the distribution in Fig. 1b) between voiceless and voiced. Prevoicing is analysed as a categorical binomial variable, and the stops are classified either as fully voiced (100% voicing during closure) or as voiceless (0%).
The analysis of prevoicing in word-initial context is a mixed-effects logistic regression (we used the glmer function from the lme4 package) – a technique used to analyse categorical binary variables – with Lenis/fortis and POA as main fixed effects and Subject and Item as random intercepts. The reference value for the dependent variable is ‘fully voiced’. The effects of the predictors should therefore be interpreted as affecting the probability of producing a fully voiced stop. The (generalised) linear mixed model is fit by maximum likelihood, using Laplace approximation.
Fortis and lenis appear to be significantly different with respect to voicing. However, fortis is almost categorically voiceless and, consequently, the few occurrences of voiced lenis clearly exert a positive effect, leading to overall statistical significance. Fortis stops have a larger (negative) effect (β = −9.77) on voicing: when a fortis stop is produced, the expected probability of it being voiced is extremely low.Footnote 13 This means that the production of a voiced fortis stop is a very unlikely, almost impossible, event. Similarly, although lenis stops are strongly positively related to voicing (β = 5.46), the predicted probability of producing a voiced lenis remains very low (0.12; see Fig. 3a).
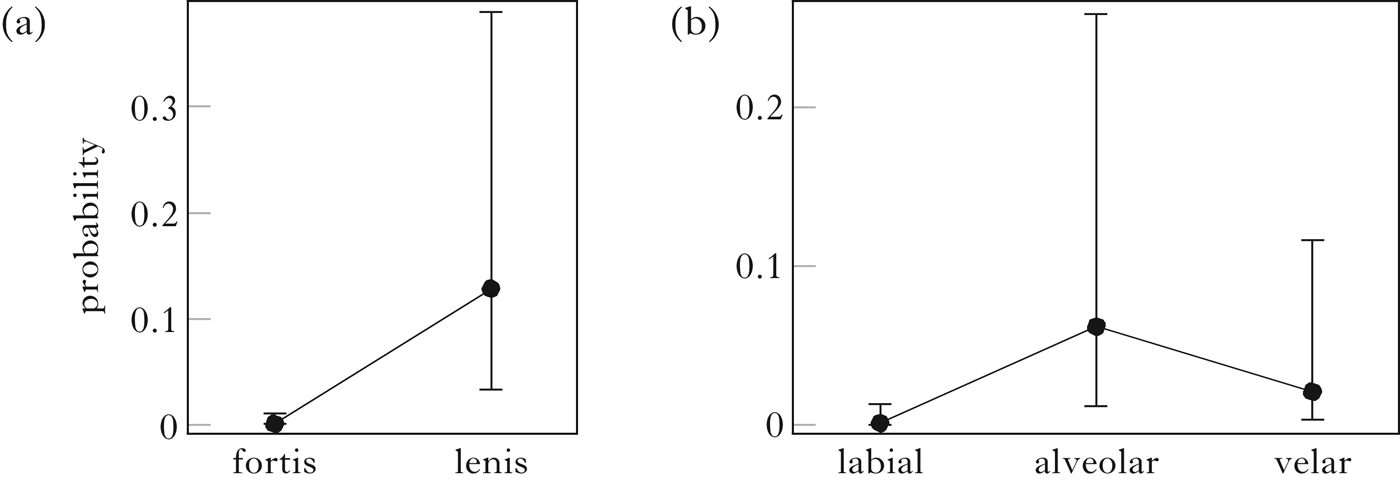
Figure 3 Predicted probability of producing a voiced stop in word-initial contexts.
Place of articulation has a significant effect on voicing, and confirms the results of the descriptive analysis. Fig. 3b gives the predicted probabilities, computed from the coefficients in Table VII. The voicing contrast is completely neutralised for labials, almost completely for velars, and weakly preserved for alveolars. If there had been a voice contrast in the plosive set, we might have expected that the probability of producing voiced stops would have been around 0.5. On the contrary, statistical analysis confirms that labials and velars stops are neutralised, and that alveolars weakly preserve a voice contrast: i.e. one alveolar out of 20 is voiced.
Table VII Mixed-effects logistic regression for word-initial contexts, with voicing as dependent variable.
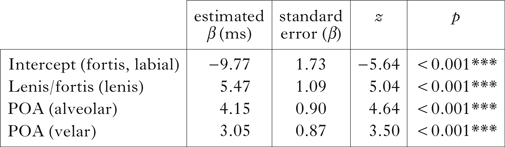
Moreover, if the interaction Lenis/fortis × POA is included in a new model,Footnote 14 an additional significant positive effect of alveolar lenis stops on voicing (β = 4.39, p < 0.0001) can be observed. The effect increases the predicted probability of producing an alveolar lenis stop as voiced to 0.5.
Finally, random factor analysis confirms a high degree of by-subject, but not by-word, variability.
(c) F0 coefficients. The analysis indicates that, overall, neither Lenis/fortis (χ2(1) = 2.1035, p = 0.15) nor POA (χ2(2) = 2.8958, p = 0.24) is significant.Footnote 15 Subject (χ2(1) = 239, p < 0.001) and Word (χ2(1) = 117, p <0.001) variation is significant.
(d) H1–H2*. The analysis of the spectral tilt measure H1–H2* reveals no significant effect of the two fixed factors: Lenis/fortis (χ2(1) = 0.7512, p = 0.39) and POA (χ2(2) = 0.3864, p = 0.82). Subject (χ2(1) = 10.97, p < 0.001) and Word (χ2(1) = 6.82, p < 0.01) variation is significant.
We can conclude from the threshold levels and the statistical results that the system of Tyrolean is characterised by word-initial neutralisation, but that when a contrast is implemented, it is realised by means of the feature [voice], not [spread glottis]. No other acoustic means, such as F0 perturbation or spectral harmonic difference, are used to implement a phonemic contrast here. Initial neutralisation is sensitive to place of articulation: contrast is neutralised more often in labials than in velars, and more often in velars than in alveolars. Furthermore, it is subject to interspeaker and intraspeaker variability.
Interspeaker and intraspeaker variability could either be ascribed to an ongoing sound change, or be interpreted as the result of language contact. Since specific dialect background, age and educational background were controlled for, and gender does not seem to play any role in the distinguishing groups A and B, these sociolinguistic variables can be excluded. Influence of the orthography used for the presentation of the test items, which could have affected some speakers but not others, can also be excluded. This is shown by the high number of cases in which speakers were able to abstract away from the orthographic representation: in 126 out of 180 cases they pronounced an initial lenis as voiceless, even though it was presented as <b d g>.Footnote 16 Moreover, reducing variability to pronunciation guided by orthography would not explain the observed correlation between initial neutralisation and place of articulation observed in the dialectological literature (Schatz Reference Schatz1897, Hopfgartner Reference Hopfgartner1970, Scheutz Reference Scheutz and Scheutz2016; see discussion in §2).
In the light of the Bavarian dialect continuum of neutralisation of laryngeal contrasts, which first affected final position (as in the Germanic language islands of Northern Italy), then initial position (Tyrolean) and finally intersonorant position (Middle Bavarian), we can argue that speakers who preserve contrast in word-initial position are behaving more conservatively, while those who neutralise are part of a more innovative group, applying a process of initial neutralisation not yet implemented by all speakers.
It is possible, however, that the different behaviour of the speakers reflects different degrees of exposure to the languages with which Tyrolean has contact, i.e. Italian on the one hand and the Middle Bavarian dialects of Austria on the other. While preservation of contrast could be favoured by the influence of Standard Italian and its regional non-standard varieties, which consistently preserve laryngeal contrasts word-initially, neutralisation in the same context might be the result of the influence of the Middle Bavarian dialects spoken in Austria, which neutralise laryngeal contrasts in all contexts (see §2). Whether the hypothesis of the influence of language contact is correct can be proved only once the sample of data is extended to varieties where the influence of neighbouring languages can be controlled for (e.g. the Tyrolean dialects of Austria, where the influence of Italian can be excluded, or to the Northern Italian Germanic language islands, where the influence of Middle Bavarian is presumably reduced).
Whether the pattern is contact-induced or not, the variability of word-initial neutralisation does point to Tyrolean as a dialect of transition between systems in the south, which preserve word-initial contrast, and systems in the north, which neutralise laryngeal contrasts completely.
3.3.2 Word-medial intersonorant contexts
Similarly to word-initial contexts, fortis consonants in word-medial intersonorant contexts have positive VOT values below the threshold of 30 ms, ranging from 14 ms for labials to 21 ms for velars, as shown in Table VIII. Lenis consonants exhibit a high voicing ratio for all places of articulation, close to or above the threshold of 90%. No threshold levels can be indicated for F0 or H1–H2*, but their statistical significance is discussed below.
Table VIII Mean acoustic values of stops in word-medial intersonorant contexts.
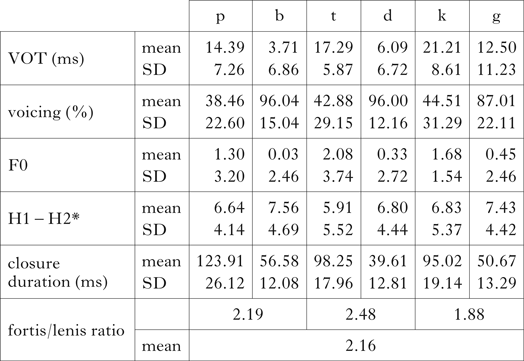
The absolute values of closure duration all lie above the threshold of noticeable durational difference (25 ms). There are no clear threshold levels indicated in the literature to determine when closure-duration ratios should be interpreted as the correlate of a contrast in terms of [voice], rather than the implementation of a singleton–geminate contrast. The mean closure-duration ratio between fortis and lenis consonants in Tyrolean is rather high (2.16), but lies below the values for the singleton–geminate contrast in Italian (2.35; Payne Reference Payne2005) and Alemannic (2.71 after short vowels, 3.03 after long vowels; Krähenmann Reference Krähenmann2001). Dutch, where a contrast of [voice] rather than length is assumed, displays a ratio of 1.76 between voiced and voiceless stops (Kuijpers Reference Kuijpers1996), showing that high closure-duration ratios could also be a correlate of a contrast in terms of [voice].
The descriptive analysis leads to the conclusion that fortis consonants have to be considered voiceless, and unaspirated and lenis consonants voiced. Fortis stops are longer than lenis stops, with the closure-duration ratio reaching a value intermediate between that of some Germanic languages for which a length contrast is assumed (Alemannic) and others for which a contrast in terms of [voice] is assumed (Dutch). The statistical analysis confirms the significant effects of voicing percentage and F0, as parameters indicating a voice contrast. Significant values emerge also for VOT and closure duration.
The models below are developed using mixed-effects linear regression. The dependent variables tested are: VOT, proportion of voicing, F0, H1–H2* and closure duration.
(a) VOT. The analysis indicates that both Lenis/fortis and Place of articulation have a significant effect on positive VOT. By-subject variation is also significant (σ2 = 7.4, p < 0.001). Results for the fixed effects are given in Table IX.
Table IX Mixed-effects linear model for word-medial intersonorant contexts, with VOT as dependent variable.
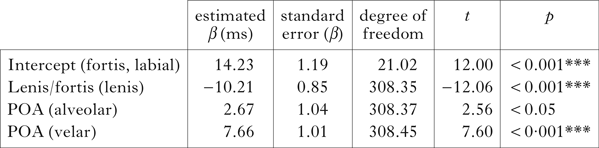
This analysis confirms the results for the initial context. Lenis/fortis has a similar overall effect on VOT (cf. Table VI). The polarity of the effects is analogous (e.g. the negative effect of lenis on VOT) as well as the estimated value of the intercept (14.23, approximately similar to 15.68 for the initial context). The most relevant difference between the models is the increased magnitude of the negative effect of lenis on VOT (−10.21, as opposed to −5.62), possibly indicating a higher number of voiced stops in this context.
As discussed above, VOT for this set of stops falls well below the aspiration threshold of 30 ms, indicating that even these sounds do not have a long VOT. The result is therefore interpreted as absence of a feature [spread glottis], notwithstanding the statistical significance of VOT.
(b) Prevoicing. In this context, voicing can be implemented either as full voicing or as partial voicing. In the latter case, the periodic signal dies out before the stop release (as in the ‘bleed’ voicing type reported in Davidson Reference Davidson2016). Given the distribution of prevoicing in Fig. 1b, it seems more appropriate to treat it as a binary category rather than a continuous variable, which also avoids a ceiling effect in the scale adopted here – i.e. a high number of cases scoring 100% voicing – which might distort the results of the analysis. Thus the values for prevoicing are partly voiced (0–90%) and fully voiced (>90%).
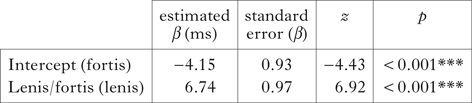
The results clearly support our descriptive hypothesis. There is a significant effect of Lenis/fortis on the probability of producing a fully voiced stop (χ2(1) = 35.98, p < 0.001). As shown in Table X, lenis stops are produced as fully voiced (β = 6.744), while fortis stops are partly voiced, thus displaying varying proportions of voicing. The model containing POA is not significant (χ2(2) = 2.18, p = 0.33). If we compute the predicted values from the coefficients, we would expect 93% of lenis stops to be fully voiced, but only 1% of fortis stops.
Table X Mixed-effects logistic regression for word-medial intersonorant contexts, with prevoicing as dependent variable.
(c) F0 coefficients. The variation in F0 coefficients is predictable from the lenis–fortis opposition. The model shows a significant main effect of Lenis/fortis, whereas POA does not play any significant role. The direction of the effect follows the general expectations: F0 coefficients are higher for fortis stops (β = 1.68, p < 0.001) than for lenis stops (β = −1.4, p < 0.001). As in the previous models, there is also a pervasive significant effect of the random factor Subject (σ2 = 0.9, p < 0.001). We interpret these results as showing that a lowered F0 supports the main contrastive feature [voice].
(d) H1–H2*. The analysis of the spectral tilt H1–H2* indicates that there are no significant effects for either fixed factor (log-likelihood test: Lenis/fortis χ2(1) = 2.73, p = 0.09; POA χ2(2) = 2.3394, p = 0.31).
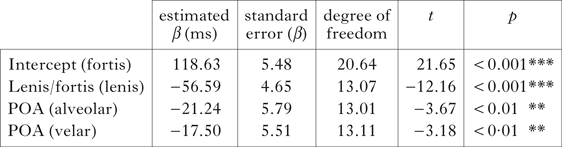
(e) Closure duration. The model includes Closure duration as the dependent variable, and Lenis/fortis and POA as main predictors. Subject and Item were added to the model as random factors. The analysis shows a significant effect of the lenis–fortis distinction on closure duration. Lenis stops exhibit shorter duration (β = −56.59 ms) than fortis stops (β = 118.62 ms), as shown in Table XI. There is also a significant effect of POA, which follows a pattern in which labials are the longest, followed by velars and then alveolars. This finding seems to mirror the voicing contrast in initial position, where alveolars are more likely to be voiced and to preserve a contrast.
Table XI Mixed-effects linear model for word-medial intersonorant contexts, with closure duration as dependent variable.
A second model was carried out to exclude the potential influence of the length of the preceding vowel on closure duration. The set of alveolar stops was specifically designed to control for this factor, since all vowels preceding alveolars are phonologically long in our sample.
In the model, Closure duration is the dependent variable, and Lenis/fortis is the main fixed factor. As in all the other models, Subject and Word are random factors. For this reduced dataset analysis, Lenis/fortis is again a significant predictor of closure-duration variability. The overall pattern is similar to the model in Table XI. Fortis and lenis are distinguished by closure duration: fortis have longer closure duration (β = 98.149 ms, p < 0.001), whereas lenis stops have significantly shorter duration (β = −58.479 ms, p < 0.001). The results of this statistical analysis suggest that closure duration is independent of vowel length.
In summary, both the acoustic and the statistical analyses indicate a contrast between lenis and fortis stops in word-medial context. As in other contexts, the VOT levels are below threshold, excluding a contrast in terms of [spread glottis], while those of prevoicing are clearly above threshold, indicating that [voice] is the relevant laryngeal feature. The statistical significance of both the prevoicing and the F0 parameters also support a [voice] contrast. Closure duration could be interpreted as the correlate of a contrast in [voice], but also as a contrast in terms of consonant length (see the discussion in §3.2). Note, however, that the hypothesis that [voice] is the main feature is in line with the significant results obtained for the F0 parameter, which can be interpreted as support for a distinction in terms of [voice] but not of length. Furthermore, in word-initial contexts speakers realise a contrast via [voice], if they realise one at all, a fact which could not be explained if a singleton–geminate contrast was assumed, as this would predict complete neutralisation in initial contexts.
Note that also the contact situation of Tyrolean does not favour the interpretation of the development of a singleton–geminate contrast. The most important contact variety of Tyrolean is Middle Bavarian, in which consonant length is dependent on vowel length, but which does not have a consonantal length contrast. The Alemannic varieties, which do have a length contrast, are part of a different dialect group, and contact with this variety has not been important for the Tyrolean spoken in South Tyrol. For the Romance varieties, there has historically been some language contact with the non-standard varieties of Northern Italy, which, as opposed to Standard Italian (but like all other western Romance languages), do not display any length contrast in their consonantal system (Benincà et al. Reference Benincà, Parry, Pescarini, Ledgeway and Maiden2016: 187). Since 1919, Standard Italian has become part of the repertory of Tyrolean speakers, but in its regional variety it is spoken by speakers without a length contrast in their non-standard substrate; their pronunciation of geminates may be orthography-driven (Bertinetto & Loporcaro Reference Bertinetto and Loporcaro2005: 134).
We conclude that the contrast in the Tyrolean obstruent system is based on a laryngeal contrast, rather than on a distinction in length, and that it can be identified as a contrast in terms of [voice].Footnote 17
3.3.3 Word-final contexts
As can be seen in Table XII, word-final contexts are the only environments in which stops in Tyrolean show audible aspiration-like events, realised as frication noise lasting well beyond the 30 ms VOT established as a threshold in §3.2, and reaching 86 ms for the velar fortis consonant /k/ (see also Krähenmann Reference Krähenmann2001: 128 for high VOT values in final position in Alemannic varieties). Note furthermore that the realisation of aspiration in this context is characterised by a high degree of variability (compare the standard deviation in this dataset with that in word-initial and word-medial intersonorant contexts). Stops are realised with aspiration of this type both in the fortis and the lenis series. Voicing, on the other hand, is below 90% for all stops (indeed, it is below the 50% established as a threshold for voicing by Moosmüller & Ringen Reference Moosmüller and Ringen2004: 60). The mean closure-duration ratio of fortis and lenis stops is 1.15, a value below those commonly observed in consonant systems based either on a [voice] contrast or on a singleton–geminate contrast. Moreover, the durational difference between fortis and lenis stops averages 16.2 ms, a value below those assumed in the literature to be still noticeable by hearers (Payne Reference Payne2005: 167).
Table XII Mean acoustic values of stops in word-final contexts.
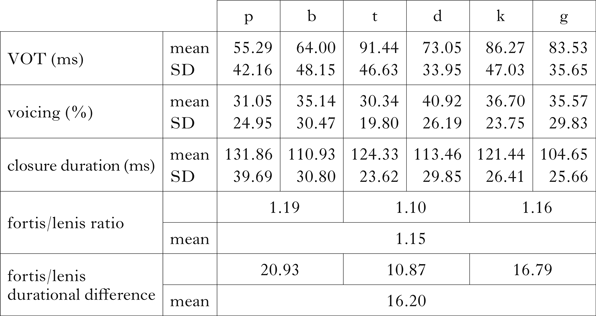
The acoustic data thus show that laryngeal contrasts appear to be neutralised word-finally in Tyrolean, as in most dialects of German. Neutralisation in this context is in part confirmed by the statistical analysis, which reveals that both VOT (here duration of frication noise) and the percentage of voicing are not significantly related to fortis/lenis. The log-likelihood comparisons against the null model indicate that the main predictor is not significant in either case (VOT model χ2(1) = 0.575, p = 0.44; Voicing model χ2(1) = 2.3629, p = 0.12). We only found an expected effect of place of articulation on VOT (χ2(2) = 14.537, p < 0.001), but not on voicing (χ2(2) = 0.6128, p = 0.73).
However, closure duration was found to be significantly related to the lenis–fortis distinction, but not to place of articulation.Footnote 18 Log-likelihood test shows that Lenis/fortis has an overall significant effect on closure duration (χ2(1) = 7.916, p < 0.01) and the estimated coefficients indicate that the duration of fortis stops (β = 125.19 ms, p < 0.001) is greater than lenis stops (β = −16.35 ms, p < 0.01). The difference in this context is less marked than the duration contrast in word-medial intersonorant context (~16 ms), although statistically significant.
Since closure-duration ratios do not reach the values observed in the literature for either laryngeal or length contrasts, and the durational difference is below levels which can assumed to be noticeable, the hypothesis that contrast is implemented in terms of length alone was discarded. Rather, it might be the case that the significance of the parameter of closure duration is the result of the structure of our stimuli, which in this context could not be perfectly balanced according to preceding vowel length. The combinations short vowel + fortis and long vowel + lenis are prevalent, favouring a long realisation of fortis stops and a short realisation of lenis stops. There is only one minimal pair with long vowel + lenis vs. fortis – the items grood ‘straight’ and Root ‘advice’ – that allows for a controlled comparison. A mixed-effects model of this case reveals no significant effect of Lenis/fortis on closure duration (log-likelihood test χ2(1) = 2.7472, p = 0.10).
In sum, the analysis of the main acoustic parameters (VOT, prevoicing, F0, H1–H2* and closure duration), indicates neutralisation of contrast in final position, a result in line with the process of final devoicing observed in most German dialects.
However, the high VOT values of both fortis and lenis stops in this (and only this) position call for some explanation. The fact that aspirated stops are produced in the very context in which neutralisation occurs is obviously not the result of [spread glottis] playing a contrastive role in the consonant system of Tyrolean. Nor does it seem likely that the frication noise observed on word-final stops is the result of fortition, given that word-final positions are weak. Furthermore, as Harris (Reference Harris, Nasukawa and Backley2009) points out, in absolute final position there is no following vowel with respect to which VOT can be calculated, and what is heard as ‘aspiration’ in this context has to be some property other than VOT, namely a ‘voiceless noise burst accompanying the release of the plosive’ (Harris Reference Harris, Nasukawa and Backley2009: 18).
We suggest that the voiceless noise burst encountered in this context should be interpreted as a phonetic effect linked to final positions of a specific kind. Local et al. (Reference Local, Kelly and Wells1986) and Docherty et al. (Reference Docherty, Foulkes, Milroy, Milroy and Walshaw1997) observe that stops in Tyneside English are fully released and aspirated in word-final position by speakers reading a word-list, even though word-final contexts are targets of glottalisation in conversational speech. The authors relate word-final release and aspiration in word-list readings to word-final release found in conversational speech in very specific contexts, which can be interpreted as turn-final or prepausal. Thus final release and aspiration would have a discourse-marking function signalling turn-finality (or the beginning of a pause) and this would be the reason for aspiration also appearing in items read in a word-list (see Local Reference Local2003 and Simpson Reference Simpson, Celata and Calamai2014 for the same interpretation). The situation in Tyneside English is parallel to that in Tyrolean, although analysis of the word-final context in conversational speech would be required to confirm the validity of the interpretation of aspiration as a discourse marker in Tyrolean.
Note that the interpretation of word-final aspiration as a phonetic event with a pragmatic function also opens a new line of investigation for word-final aspiration in Modern Standard German, which thus need not necessarily be interpreted as the addition of a feature [spread glottis] (see also Jessen & Ringen Reference Jessen and Ringen2002: 213 for similar considerations).
3.3.4 Obstruent clusters
For the investigation of obstruent clusters, compounds were elicited in which the last segment of the first element of the compound was the first obstruent of a cluster, C1, and the first segment of the second element of the compound was the second obstruent, C2 (e.g. Haustor ‘gate’, where C1 is /s/ and C2 /t/). The target of our analysis was C2, for which the same phonetic variables were measured as for word-medial intersonorant contexts. C1 was a fortis obstruent in all items. The selection of compounds as test items is not ideal, since it is not clear whether the juncture between the two elements of the compound constitutes a word-medial context and, as a consequence, we cannot exclude the possibility that postlexical processes play a role. Our choice was driven by the fact that there are few word-internal clusters containing both fortis and lenis stops in Tyrolean.
The acoustic values in Table XIII show that both fortis and lenis stops are realised as voiceless and unaspirated: in this context, none of VOT, voicing percentage or absolute duration of voicing reaches the threshold level. Closure-duration ratios are even lower than in word-final contexts. Thus the acoustic analysis suggests that the fortis–lenis contrast is completely neutralised in obstruent clusters.
Table XIII Mean acoustic values of C2 in obstruent clusters.
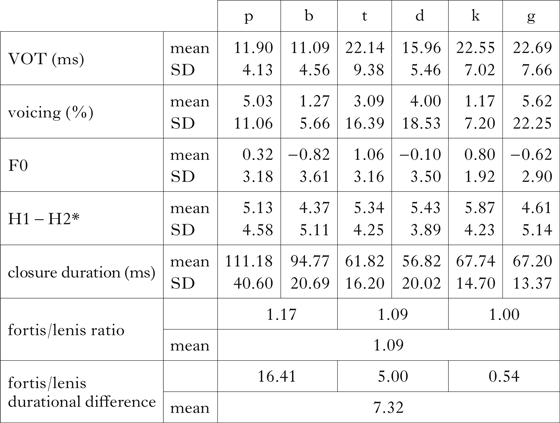
Note that neutralisation does not occur only for the group B speakers, for whom it is expected in word-initial contexts. Neutralisation to voiceless occurs also in the pronunciation of group A speakers, for whom some degree of contrast was observed in word-initial contexts.
As for the previous contexts, the statistical analysis is a mixed-effects linear regression. The results support the view of neutralisation to voiceless. The main fixed effect Lenis/fortis is not significantly related to any of the acoustic measures investigated. The variability of VOT (χ2(1) = 0.5016, p = 0.47), Proportion of voicing (χ2(1) = 0.0578, p = 0.81), Closure duration (χ2(1) = 0.6566, p = 0.41) and H1–H2* (χ2(1) = 0.955, p = 0.32) is not predictable from the lenis–fortis distinction.
The only exception to this general trend is F0, which displays a significant difference between fortis (intercept: β = 0.71) and lenis (β = −1.21) stops. In the absence of relations to any of the other acoustic parameters, it is not clear how the significant effect of Lenis/fortis on F0 coefficients should be interpreted. Further perception experiments would be needed to determine whether a difference in F0 alone allows the speaker to discriminate between fortis and lenis stops in this context. For the time being we conclude that in the absence of the main cue of contrast, prevoicing, the fortis–lenis contrast has to be considered to be neutralised.
The interpretation of the neutralisation of laryngeal contrasts at the compound juncture could be an indication of a (lexical) process of progressive assimilation, where C2 assimilates to C1. This would mean that [voice] should be considered not as a privative feature, but rather as a binary feature [±voice], and assimilation as spreading of the value [−voice] from C1 to C2 (see Wetzels & Mascaró Reference Wetzels and Mascaró2001, who analyse cases of progressive devoicing in Dutch in these terms). Alternatively, the phenomenon could be considered as conditioned by the morphological structure of the items (see Lombardi Reference Lombardi1996 for analyses in terms of output–output faithfulness for morphologically conditioned progressive assimilation). Finally, devoicing in this context could be interpreted as a postlexical process. Kuzla et al. (Reference Kuzla, Ernestus, Mitterer, Fougeron, Kühnert, D'Imperio and Vallée2010), analysing the German lenis fricatives /v z/ following fortis /t/, state that progressive voice assimilation is gradient, and moderated by prosodic structure: the lower the boundary in the prosodic hierarchy, the stronger the effect of devoicing. Since a word boundary is lower in the prosodic hierarchy than a phrase boundary, lenis fricatives are devoiced more in the former context than in the latter. If devoicing in Tyrolean compounds is a postlexical process, an underlying specification for [voice] in terms of a privative feature could be maintained.
In the absence of further data concerning obstruent clusters in Tyrolean and patterns of assimilation which might occur in them, we refrain from drawing conclusions. What is clear, however, is that laryngeal contrasts (except for F0) are also neutralised in this context.
4 Conclusion
For the analysis of laryngeal contrasts in Tyrolean, ten speakers performed a word-reading task. Test items covered fortis and lenis stops for all places of articulation, in absolute word-initial position, word-medial (intersonorant) position, absolute word-final position and (post-obstruent) consonant clusters. Acoustic measurements for VOT, prevoicing, F0, H1–H2* and closure duration, and their statistical analysis, revealed that contrast is implemented only word-medially, by the acoustic cue of prevoicing supported by distinctive values for F0 and closure duration.
The typologically interesting result of our investigation is that in this dialect, laryngeal contrasts tend to be neutralised not only word-finally, as in most German dialects, but also word-initially, where languages usually preserve, rather than neutralise, contrasts.
Word-initial neutralisation exhibits a certain degree of interspeaker and intraspeaker variability, and is sensitive to place of articulation, with labials being neutralised more often than velars, and velars more often than alveolars. Variability of initial neutralisation could be interpreted as the effect of an ongoing process of sound change bringing the Tyrolean pattern closer to the pattern of Middle Bavarian, where laryngeal contrasts are neutralised completely. Alternatively, variability might be due to the influence of the contact languages of Tyrolean, i.e. Italian and Middle Bavarian, where the former might inhibit and the latter favour initial neutralisation.
The acoustic analysis shows furthermore that [spread glottis] does not play any role in implementing a contrast in this southernmost of German varieties. An aspiration-like phonetic event is observed only word-finally, where contrasts are neutralised, and can be interpreted as a pragmatic cue typically observed in word-list readings.

















