

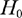 as providing the same evidence for a particular alternative
as providing the same evidence for a particular alternative 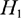 , irrespective of
, irrespective of Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Spanos, Aris
2013.
Revisiting the Likelihoodist Evidential Account [Comment on “A Likelihood Paradigm for Clinical Trials”].
Journal of Statistical Theory and Practice,
Vol. 7,
Issue. 2,
p.
187.
Robert, Christian P.
2014.
On the Jeffreys-Lindley Paradox.
Philosophy of Science,
Vol. 81,
Issue. 2,
p.
216.
Spanos, Aris
2014.
Recurring controversies aboutPvalues and confidence intervals revisited.
Ecology,
Vol. 95,
Issue. 3,
p.
645.
Madden, L. V.
Shah, D. A.
and
Esker, P. D.
2015.
Does the P Value Have a Future in Plant Pathology?.
Phytopathology®,
Vol. 105,
Issue. 11,
p.
1400.
Autzen, Bengt
2016.
Significance testing, p-values and the principle of total evidence.
European Journal for Philosophy of Science,
Vol. 6,
Issue. 2,
p.
281.
Robert, Christian P.
2016.
The expected demise of the Bayes factor.
Journal of Mathematical Psychology,
Vol. 72,
Issue. ,
p.
33.
Nasir, Muhammad Ali
and
Soliman, Alaa M.
2017.
Macroeconomic Policy Coordination & Implications for Financial Markets in a Bayesian VAR Framework.
SSRN Electronic Journal,
Villa, Cristiano
and
Walker, Stephen
2017.
On the mathematics of the Jeffreys–Lindley paradox.
Communications in Statistics - Theory and Methods,
Vol. 46,
Issue. 24,
p.
12290.
Ohlson, James A.
2017.
Researcherss Data Analysis Choices: An Excess of False Positives?.
SSRN Electronic Journal ,
Cousins, Robert D.
2017.
The Jeffreys–Lindley paradox and discovery criteria in high energy physics.
Synthese,
Vol. 194,
Issue. 2,
p.
395.
Mayo, Deborah G.
2018.
Statistical Inference as Severe Testing.
Ohlson, James A.
2018.
Researchers’ Data Analysis Choices: An Excess of False Positives?.
SSRN Electronic Journal ,
Greenland, Sander
2019.
Valid
P
-Values Behave Exactly as They Should: Some Misleading Criticisms of
P
-Values and Their Resolution With
S
-Values
.
The American Statistician,
Vol. 73,
Issue. sup1,
p.
106.
Makowski, Dominique
Ben-Shachar, Mattan S.
Chen, S. H. Annabel
and
Lüdecke, Daniel
2019.
Indices of Effect Existence and Significance in the Bayesian Framework.
Frontiers in Psychology,
Vol. 10,
Issue. ,
Johannesson, Eric
2020.
Classical versus Bayesian Statistics.
Philosophy of Science,
Vol. 87,
Issue. 2,
p.
302.
Lovric, Miodrag M.
2020.
On the Authentic Notion, Relevance, and Solution of the Jeffreys-Lindley Paradox in the Zettabyte Era.
Journal of Modern Applied Statistical Methods,
Vol. 18,
Issue. 1,
p.
2.
Johannesson, Erik
Ohlson, James A.
and
Zhai, Weihuan
2020.
The Explanatory Power of Explanatory Variables.
SSRN Electronic Journal,
Spanos, Aris
2021.
Bernoulli’s golden theorem in retrospect: error probabilities and trustworthy evidence.
Synthese,
Vol. 199,
Issue. 5-6,
p.
13949.
Massimi, Michela
2021.
Cosmic Bayes. Datasets and priors in the hunt for dark energy.
European Journal for Philosophy of Science,
Vol. 11,
Issue. 1,
Rochefort-Maranda, Guillaume
2021.
Inflated effect sizes and underpowered tests: how the severity measure of evidence is affected by the winner’s curse.
Philosophical Studies,
Vol. 178,
Issue. 1,
p.
133.