


1. INTRODUCTION
Exploring the distance between languages has its roots in the areas of dialectology and general linguistics, particularly in language typology (e.g. Herlin & Kotilainen Reference Herlin, Kotilainen, Fischer, Norde and Perridon2004, Kolehmainen, Miestamo & Nordlund Reference Kolehmainen, Miestamo and Nordlund2013). It can be used as a tool for establishing relationships between languages as they are now, and in enquiry into historic developments. The object of such studies is the language system, so objective measures for the actual distance are sought. In the area of second or foreign language acquisition the distance between languages is also of interest, but for different reasons: it is often seen as an explanatory factor in language learning. The linguistic distance between the first language (L1) and the language to be learnt (L2) may be established by using the same measures as in language typology (Schepens, van der Silk & van Hout Reference Schepens, van Hout, Borin and Saxena2013). However, the distance or similarity which learners perceive, the psycho-typological distance, differs from the objective distance both quantitatively and qualitatively (Ringbom Reference Ringbom2007, Jarvis & Pavlenko Reference Jarvis and Pavlenko2008). Language learners do not seek to grasp the whole linguistic system but want to make sense of what they see or hear. For them the distance between languages is an obstacle and similarity is an aid.
Measuring the degree of similarity between two whole languages is extremely difficult and subject to many sources of error even in the era of automatic parsing programs and large language corpora (Heeringa et al. Reference Heeringa, Kleiweg, Gooskens and Nerbonne2006). Even very small and limited language areas such as noun inflection, the focus of this article, are hard to compare. Reliable methods for quantifying the distance between languages are scarce (Schepens et al. Reference Schepens, van Hout, Borin and Saxena2013), although some advances have been made (see e.g. lexicostatistical studies by Gray & Atkinson (Reference Gray and Atkinson2003) and Holman et al. (Reference Holman, Wichmann, Brown, Velupillai, Müller and Bakker2008).
The research presented in this article is part of the Receptive Multilingualism (REMU) network (https://www.uef.fi/web/remu2015), which conducts research on two closely related languages, Estonian and Finnish, with the aim of creating a holistic model of the effects of perceived and actual similarity on mutual intelligibility. The current authors concentrate on defining and measuring similarity while other network members work on mutual intelligibility (see e.g. Kaivapalu & Muikku-Werner Reference Kaivapalu and Muikku-Werner2010; Muikku-Werner & Heinonen Reference Muikku-Werner and Heinonen2012; Paajanen & Muikku-Werner Reference Paajanen and Muikku-Werner2012; Muikku-Werner Reference Muikku-Werner2013, Reference Muikku-Werner2014a, b; Kaivapalu Reference Kaivapalu2015) and receptive multilingualism in practice (Härmävaara Reference Härmävaara2013, Reference Härmävaara2014). In this article we view the distance between morphological forms of Estonian and Finnish through the eyes of (potential) learners, people who have no previous knowledge of the target language (TL). These findings are compared with what can be found using objective measurements.
Alphabetic writing systems make us see written languages as strings of letters which form words and sentences. When we try to decipher words of a language new to us we attempt to read them letter by letter to see if the resulting words might resemble something we recognize from other languages, carrying a meaning that might fit the context. The ability to read even affects the phonological skills which help us remember and repeat words we hear, making it harder for non-literate learners to notice linguistic forms and learn new words (see e.g. Reis & Castro-Caldas Reference Reis and Castro-Caldas1997, Dellatolas et al. Reference Dellatolas, Braga, Souza, Filho, Queiroz and Deloche2003). The image of words as strings of letters has a strong influence on how literate language users perceive language.
Against this background, it is not surprising that the surface distance between two languages is often measured by comparing strings of letters, using what is called the Levenshtein algorithm. It is based on the number of different, missing or additional letters (or sounds, if spoken languages are compared), usually in relation to the total length of the words. There are several versions of the Levenshtein Distance (LD) measure (see e.g. Beijering, Gooskens & Heeringa Reference Beijering, Gooskens and Heeringa2008, Wichmann et al. Reference Wichmann, Holman, Bakker and Brown2010); the one used in this article (see Section 4) is the one also used in Heeringa et al. (Reference Heeringa, Golubović, Gooskens, Schüppert, Swarte and Voigt2013, Reference Heeringa, Swarte, Schüppert and Gooskens2014) as it is the most suitable one for comparing morphology. The results are compared with perceptions of similarity by language users (see Kaivapalu & Martin Reference Kaivapalu, Martin, Paulasto, Meriläinen, Riionheimo and Maria2014, also Section 4 below). As the perceptions of similarity differ from the Levenshtein Distance, we focus on what factors might cause this discrepancy. We discuss alternative ways of describing the perceived similarity, looking at the phonological and morphological closeness of the languages and on some background factors such as the social, geographical, historical and paradigmatic variety of participants’ L1s. The languages discussed here are Finnish and Estonian, two closely related languages with fairly transparent alphabetic orthography. The linguistic level chosen for comparison is noun morphology. Both languages inflect nouns extensively and the two inflectional systems share many features, described in more detail in Section 3 (for examples see also e.g. Remes Reference Remes2009). Both are basically agglutinative languages but a major difference is the more central role of fusion in Estonian. A large proportion of the lexicon is also of common origin, even if some historical sound changes often obscure immediate perceptions of similarity.
Speakers of Finnish and Estonian are aware of the fact that the two languages resemble each other, i.e. they expect to be able to understand at least something when they encounter L2 speech or writing. Thus when they read a word, they are likely to assume that the same word might exist in their L1. They look for similarity. But what is the conscious perception of similarity based on? The overall aim of this article is to explore this issue: are consciously processed similarity perceptions based simply on similarities between strings of letters (or sounds in speech, but in this study only written material is included) or on the perceived similarity of linguistic units, such as words, stems, or formatives. The question is obviously related to to an issue of broad concern in language in general, that is, the relationship between surface forms and meaningful units.
The LD assumes symmetry between the languages being compared. In our earlier research (Kaivapalu & Martin Reference Kaivapalu, Martin, Paulasto, Meriläinen, Riionheimo and Maria2014:305−308) we have shown that the perceived similarity is not symmetrical: Finns see more similarity in the same set of words than Estonians do. This is also true of the larger set of data of this study. Asymmetry has been found in other language pairs, too (see e.g. Moberg et al. Reference Moberg, Gooskens, Nerbonne, Vaillette, Dirix, Schuurman, Vandeghinste and Van Eynde2006). In this article we search for potential causes of the asymmetry.
One way to approach the differences between actual and perceived distance or similarity between languages is calculating the rank correlation of the results achieved by methods designed to measure the two types of differences (e.g. Jarvis Reference Jarvis2016, Letica Krevelji Reference Letica Krevelji2016). However, the correlations found in this way are not always qualitatively equal. One reason is the asymmetry mentioned above. Deletions and insertions may also not have an equal role in perceptions. Probing the qualitative differences is the main contribution of this article.
The LD can be calculated for word stems and formatives separately. As the formatives of Estonian are harder to perceive as independent units, due to more extensive fusion, we will also explore these differences to explain the asymmetry. The detailed analysis of the effect of the stem and formative relations will also contribute to the comparison of the two measures themselves. The research questions are:
-
1. While the LD can claim objectivity and measure ‘actual’ distance or similarity between two sets of linguistic items, to what extent does it explain the perception of the speakers of the two languages?
-
2. Are insertions and deletions really of equal value, as assumed in the calculations of the LD? How do insertions and deletions relate to the perceived asymmetry between the speakers of Estonian and Finnish? Although an experimental exploration of insertions and deletions is not possible within this article, we will suggest how this could be done.
2. BACKGROUND
The construct and taxonomy of similarity as well as some tentative results of our similarity perception measure (Index of Perceived Similarity, IPS) were discussed in Kaivapalu & Martin (Reference Kaivapalu, Martin, Paulasto, Meriläinen, Riionheimo and Maria2014). As suggested in the introduction above, similarity can be objective or actual on the one hand and perceived, on the other (Ringbom Reference Ringbom2007:7–8, 24–26; Jarvis & Pavlenko Reference Jarvis and Pavlenko2008:176–182). Learners’ reliance on perceived similarity can also be divided into item and system (procedural) (Ringbom Reference Ringbom2007:54–58), or process similarity (Martin Reference Martin, Kaivapalu and Pruuli2006, Kaivapalu & Martin Reference Kaivapalu and Martin2007), depending on the domain of the study. item similarity refers to the similarity of individual forms, such as sound, letter, morpheme, word or phrase, whereas system similarity is defined as a set of principles for organizing forms paradigmatically and syntagmatically (Ringbom & Jarvis Reference Ringbom, Jarvis, Long and Doughty2009:108–109). Our test is intended to measure item similarity, but the comments of some participants indicate that they do compare the items to other items in the test, thus introducing some aspects of system similarity, e.g. the paradigmatic nature of the inflectional system (see also Kaivapalu Reference Kaivapalu2005:267–272), in their perceptions.
The degree of similarity also varies (Kaivapalu & Martin Reference Kaivapalu, Martin, Paulasto, Meriläinen, Riionheimo and Maria2014:291). Items to be compared can be identical or bear a closer or more remote resemblance to each other. The distance between two items can be calculated using, for instance, LD, and the items can thus be ranked at a certain distance from each other, providing that the properties included in the calculations are valid. Averages of perceived similarity scores given by a sufficient number of participants can also be ranked and the two lists compared, as is done below. Such scores, however, are more dependent on the properties of the task as a whole, the background of the participants, the scoring system etc. The potential for error in each of the methods of measuring similarity is discussed in Section 6 of this article.
Similarity or distance across many language pairs has been studied before. The Levenshtein algorithm has been used in the large European Micrela project (van Heuven, Gooskens & Van Bezooijen Reference van Heuven, Gooskens, van Bezooijen, Navracsics and Batyi2015), which studies the mutual intelligibility and distance of several Germanic, Romance, and Slavic languages (Heeringa et al. Reference Heeringa, Golubović, Gooskens, Schüppert, Swarte and Voigt2013), and particularly by Heeringa et al. (Reference Heeringa, Swarte, Schüppert and Gooskens2014) to compare Germanic languages. Another measure of the distance or similarity between languages is the conditional entropy, which measures the amount of regularity in the sound or grapheme correspondences between the two languages (Frinsel et al. Reference Frinsel, Kingma, Swarte and Gooskens2015). Most studies compare whole words or longer units but the effects of stems and affixes have also been studied before (Heeringa et al. Reference Heeringa, Swarte, Schüppert and Gooskens2014).
The results of such measures of the surface distance are often compared to overall similarity perceptions of languages or dialects, either without determining what exactly is supposed to be similar (e.g. Letica Krevelji Reference Letica Krevelji2016) or concentrating on phonological or semantic or functional similarity (e.g. Tang & van Heuven 2015, Jarvis Reference Jarvis2016). Morphological similarity has been focused on before mainly for Germanic languages (Heeringa et al. Reference Heeringa, Wieling, van denBerg, Nerbonne, Lenz, Gooskens and Reker2009, Reference Heeringa, Swarte, Schüppert and Gooskens2014; Heeringa & Hinksens Reference Heeringa and Hinksens2011). The advantage of the similarity test used here (see Section 4 below) is that it does not ask about similarity in general but makes the participants compare given forms, in the knowledge they have been given that they have the same function and represent the same grammatical form. The disadvantage is, of course, that it covers only one area of language, noun inflection. Also, the connection to mutual intelligibility may be weaker than in tests which search for overall similarity.
Explanations for the difference between objective and perceived similarity and for the asymmetry of perceptions have been sought in exposure to dialects (Delsing & Lundin Åkesson Reference Delsing and Åkesson2005, Gooskens Reference Gooskens2006, Berthele Reference Berthele2008, Gooskens & Heeringa Reference Gooskens and Heeringa2014), with the idea that extensive variation in the L1 would help in seeing similarity in a closely related L2. This is one of the explanations explored also in this article. Another causal relationship can be found by charting the time the participants spend exposed to the L2 by reading or watching TV, etc. (e.g. Delsing & Lundin Åkesson Reference Delsing and Åkesson2005). It is hard to find Finnish participants who have never heard Estonian spoken on TV or seen a few words written on packages etc. The same is true of Estonian people: Finnish is occasionally present in their lives, albeit not very noticeably. The older generation of Northern Estonians was exposed to Finnish TV during the Soviet era but this is not the case with the participants of this study, who are nearly all young adults. We excluded potential participants who had studied the TL or lived in the TL country.
Yet another sometimes quoted explanation for the results is language attitude (Gooskens Reference Gooskens2006). With regard to the languages in our study, it has been found that the attitudes of young people in Finland and Estonia to each other and each other's language are generally either fairly neutral or positive (Junttila Reference Junttila, Kaivapalu and Pruuli2006:151–152).
3. FINNISH AND ESTONIAN NOUN MORPHOLOGY
Estonian (Est.) and Finnish (Fin.) are basically agglutinative languages, which indicate grammatical roles as well as semantic information by inflectional suffixes. Noun stems are followed by markers for number (0 for singular, t/d or i/j for plural) and case endings, e.g. Fin. talo-i-ssa ‘house-pl-ine’, Est. talu-de-s ‘farm-pl-ine’.Footnote 1 The number of cases varies somewhat, depending on the way they are defined, but the most commonly quoted number for both languages is 14. For Finnish, the accusative forms that only exist for some pronouns are not counted (EKG I:§48; Viitso Reference Viitso2003a:32–34; ISK:§81; Karlsson Reference Karlsson2015:3). The case inventory is the same for both languages apart from the instructive (only in Finnish) and the terminative (only in Estonian). The case ending may be followed by a possessive suffix in Finnish and/or by another clitic (in both languages), e.g. Fin. talo-i-ssa-mme-kin ‘house-pl-ine-poss.1pl-cli’, Est. talu-de-s-ki ‘farm-pl-ine-cli’. In this study noun forms in the singular or plural and in a variety of cases are explored. The combination of the plural marker and a case ending is here called an inflectional formative.
In the agglutinative process the stem and the suffixes interact (Karlsson Reference Karlsson1983:277–304). The stem may undergo consonant gradation (EKG I:144–170; ISK:§41; Viitso Reference Viitso2003b:196–198; Karlsson Reference Karlsson2015:30–40), e.g. Fin. mu rr e ‘dialect.nom.sg’: mu rt e-i-ssa ‘dialect-pl-ine’ or Est. mu rr e ‘dialect.nom.sg’: mu rd e-i-s ‘dialect-pl-ine’ or other less regular changes of consonants or vowels, e.g. Fin. saun a ‘sauna.nom.sg’: saun o -i-ssa ‘sauna-pl-ine’, where the stem-final -a- is replaced by -o- before the plural -i- (Karlsson Reference Karlsson2015:40–44) or Est. puna ne ‘red.nom.sg’: puna se ‘red.gen.sg’ where -ne in the nominative singular is replaced by -se in the genitive singular and all other cases except the nominative singular (EKG I:175–176). Some of these changes are shared by both Finnish and Estonian, some are language specific.
A major difference between the noun morphology of the two languages is the Estonian so-called stem plural (EKG I:208–214; Viitso Reference Viitso2003a:37), an inflected form with no formative, e.g. lub a ‘permission.nom.sg’: lub e ‘permission.par.pl.’. In such cases, mostly in the partitive plural and more rarely in other plural case forms, the stem vowel is replaced by another vowel. Another difference between the Estonian and Finnish case systems is the Estonian genitive singular, which has no case ending, e.g. tuba ‘room.nom.sg’: toa ‘room.gen.sg’. The case function of genitive is represented only by a special stem allomorph (Viitso Reference Viitso2003a:33). Such forms do not exist in Finnish and can be predicted to be confusing for Finns. They are at one extreme of a continuum between fully agglutinative and fully fusional inflectional forms. The test words represent various stages on this continuum (Figure 1).

Figure 1 Agglutination and fusion in Finnish and Estonian noun inflection.
Figure 1 does not describe historical relationships but current surface forms. While many stems and most of the inflectional material in Estonian and Finnish are of the same historical origin, sound changes have rendered many items different. The same material may also exist in both languages but be distributed in a different way. A good example is provided by the plural markers -i/j- and -t (-te-/-de-), which are used in both languages but the i-plural is much more common in Finnish and the t-plural in Estonian (Remes Reference Remes2009:94–95).
4. DATA AND METHOD
The two ways of measuring similarity between linguistic forms discussed in this study are the Levenshtein Distance (LD) (Heeringa et al. Reference Heeringa, Golubović, Gooskens, Schüppert, Swarte and Voigt2013, Reference Heeringa, Swarte, Schüppert and Gooskens2014) for objective similarity and the Index of Perceived Similarity (IPS) developed by the authors (Kaivapalu & Martin Reference Kaivapalu, Martin, Paulasto, Meriläinen, Riionheimo and Maria2014). The data are the quantitative LD and IPS results from a list of test items targeting the variation in actual similarity between Estonian and Finnish inflectional morphology. The test contains 48 pairs of Estonian and Finnish words, chosen on the basis of a historical-comparative and typological analysis of the two languages (Remes Reference Remes1995, Reference Remes2009). The test word pairs share the same stem (i.e. the same stem with the same meaning exists in both languages but may have a somewhat different surface form) and represent the same inflectional form (case and number), again with variance in the surface form. The list of test pairs is divided into four similarity categories (mixed in the actual test): (i) similar stem, similar inflectional formative; (ii) similar stem, different formative; (iii) different stem, similar formative; and (iv) different stem, different formative. The hypothesis is that the first category would show the highest degree of similarity, the last category the lowest. When the list is presented to the participants, the first member in each pair is given to the Estonians in Estonian and to the Finns in Finnish, with the familiar language thus offered as the basis for comparison.
Four test groups, students in different universities in Estonia and Finland, were set up: two groups of L1 speakers, one of Finnish (n = 115) and one of Estonian (n = 109), and two groups of L2 speakers of these languages, their L1s Swedish (L2 Finnish, n = 105) and Russian (L2 Estonian, n = 80) respectively. None of the participants had studied the target language (Estonian for Finns, Finnish for Estonians) or lived in the target language country, although most of them were very likely to know that Finnish and Estonian are closely related and some had visited the country of the target language briefly as tourists. Due to limited space, this article deals only with the perceptions of L1 speakers, focusing on the symmetry of perceived similarity; for the perceptions of L2 speakers, see Kaivapalu & Martin Reference Kaivapalu and Martin2016.
In the IPS test the participants were asked to rate the 48 pairs of inflected words as similar, somewhat similar, or different. They were also given the opportunity to comment on their choice in writing. The test answers were collected on a computerized form. The IPS score of each test item was then calculated by giving two points for each ‘similar’ answer, one for ‘somewhat similar’ and none for ‘different’ and by adding up all of the points. The results are shown in Table 1 below.
The Levenshtein Distance refers to the ‘cost’ of moving from one item to the other in the comparison. In this study, the LD is – as usual – implemented as a symmetrical measure, i.e. the distance is considered to be the same regardless of the direction of comparison. The cost is determined by aligning the two items, matching a vowel with a vowel and a consonant with a consonant and then calculating the cost of changing one string for the other (Heeringa et al. Reference Heeringa, Golubović, Gooskens, Schüppert, Swarte and Voigt2013). An example from our data, ‘rain-pl-ine’, is seen in Figure 2.
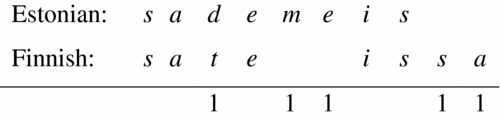
Figure 2 An example of calculating Levenshtein Distance.
Every difference, insertion, and deletion within the two strings is weighed as 1. The result (here 5) is then divided by the total length of the string (here 10). In the example (Figure 2) the LD is thus 0.5 or 50%. LD refers to surface distance, calculating only what can be seen, without making any functional assumptions: a different letter means a difference. LDs were calculated for the morphological form as a whole, for the stem, and for the inflectional formative of every test word pair (Heeringa et al. Reference Heeringa, Swarte, Schüppert and Gooskens2014). LD and IPS values were correlated using IBM SPSS version22. In cases of significant correlation between LD and IPS, multiple linear regression analyses (Field Reference Field2009) were applied.
5. RESULTS
In this section, the test results are discussed by comparing the LDs of the test items with the IPS scores of the participant groups in the test as a whole and in the four morphological categories described above. The LDs and IPS scores of individual test items can be found in appendix Table A1. Table 1 presents the total number of word pairs (balanced for the number of participants) rated by the Finns and Estonians as similar, somewhat similar or different, and the IPS for the Finns and Estonians (on calculating IPS, see Section 4 above).
Table 1. Total numbers of answers by the Finns and Estonians and the Index of Perceived Similarity.
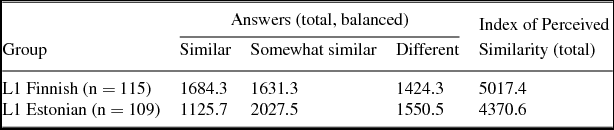
While the LD is always symmetrical across languages, the IPS need not be. The results show that the Finns see more similarity between Finnish and Estonian inflectional morphology than the Estonians do: the results reveal a statistically significant difference (p < .001) between the IPS of the Finns and Estonians. The Finns have also answered similar and somewhat similar more often than different, while the Estonians have perceived most test word pairs as somewhat similar and have chosen different more often than similar. So, the perceptions of the two groups are not symmetrical.
To explain the asymmetry of the similarity perceptions of the two participant groups, the LDs of every individual test item were calculated for the morphological form as a whole, for the stem and for the inflectional formative (see Appendix) and then the LD and the IPS values were correlated. A significant correlation (r = –.751, p < .01) between the LD and IPS of morphological form as a whole was found for Finns (Figure 3). The negative value of r indicates the inverse relationship between the LD and the IPS: as the LD indicates distance rather than similarity, the lower the LD and the higher the IPS are, the more similar are the word pairs. For the Estonians, no correlation (r = .079, p > .05) was found between the LD and the IPS, as can be seen in Figure 3. Also, the correlations between the LDs of the stems and the morphological formatives and the IPSs of the Finns are statistically significant (r = –.638, p = .000 and –.468, p = .001 respectively) while the correlations between the LD and the IPS scores of the Estonians are not (r = –.120, p = .417 and –.240, p = .100 respectively). This will be explored further in order to find explanations for the asymmetry and variation in the results by comparing the correlations broken down by morphological category and also by examining the comments made by the participants.

Figure 3 Correlations between the Levenshtein Distance (LD) of the morphological forms as a whole and the IPS of the Finns (Pearson), r = –.751, p = .000.

Figure 4 Correlations between the Levenshtein Distance (LD) of the morphological forms as a whole and the Index of Perceived Similarity (IPS) of the Estonians (Pearson), r = .079, p = .595.
To find out the LD's predictability for the IPS in cases of significant correlation (the results of the Finns), regression analyses were applied (Table 2). According to the multiple linear regression analysis, the best predictor for the similarity perceptions of the Finnish group is the LD of the morphological form (the combinaton of stem and formative) as a whole; this explains 56% of the similarity perceptions. The LD of the stem predicts 40% and the LD of the formative only 21% of the similarity perceptions. The impact of other factors on perceiving similarity is addressed in Section 6 below.
Table 2. The predictability of the Levenshtein value for the similarity perceived by the Finns.

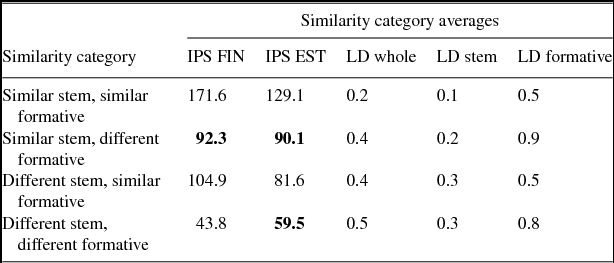
To investigate the relations between the LD and the IPS in more detail and also for the Estonian group, these relationships were analyzed by similarity categories: the word form pairs with (i) similar stem and similar formative, (ii) similar stem but different formative, (iii) different stem but similar formative, and (iv) different stem and formative, in Finnish and Estonian (Table 3). According to a paired samples t-test, a statistically significant difference between the IPS of the Finns and Estonians was found for three similarity categories: word form pairs with similar stem and similar formative (t = 12.812, p = .000), different stem but similar formative (t = 2.880, p = .016), and different stem and formative (t = –2.679, p = .021). For the second similarity category, word form pairs with a similar stem but a different formative, no statistically significant difference was found (t = .145, p = .887). The results show that the Estonians perceive almost as much or more similarity than the Finns do in word form pairs with a higher LD, which indicates a bigger difference in word forms. Especially word forms with a higher LD of the morphological formative have been perceived more similar by the Estonians than by the Finns. These results indicate that the Estonians tend to see more similarity than the Finns do in the more different forms.
Table 3. The average Index of Perceived Similarity (IPS) and Levenshtein Distance (LD) of the Finns (FIN) and Estonians (EST) by similarity categories. Bold indicates the categories where the Estonians see more similarities than the Finns or where the difference between similarity perceptions of the two participant groups is not significant.
Looking at the individual word form pairs where the Estonians perceived more similarity than the Finns (Table 4), the results indicate two main tendencies. The first one concerns the typologically different partitive plural forms in Estonian and Finnish: the stem plural in Estonian and the agglutinative i-plural in Finnish. The second tendency concerns the word pairs where there is a great difference either in the stem or in the plural and case formative in the two languages. The results indicate that the Estonians are better able to see through the surface differences that are due to the discrepancies in the inflectional systems of the two languages. Further proof for this interpretation is provided by the Estonians’ comments in Section 6.
Table 4. Word form pairs with higher Index of Perceived Similarity (IPS) in the results of the Estonians (EST) and Levenshtein Distances (LDs). Bold in the example words emphasizes differences between Estonian and Finnish inflectional forms.

The second research question addresses the relationship of differences, insertions, and deletions to similarity perceptions. In many test word pairs there is something added from the point of view of the Estonians and something deleted from the point of view of the Finns (see Table 5), either at the end of the word (e.g. raamatu-st ‘book-ela’ – raamatu-st a ‘bible-ela’, sinis-te ‘blue-pl’ – sinis-te-n ‘blue-pl-gen’) or in the middle and at the end of the word (e.g. vangla-s ‘prison-ine’ – vankila-ssa ‘prison-ine’). In most of these word pairs the Finns see systematically more similarity than the Estonians.
Table 5. Additions and deletions in test pairs: Index of Perceived Similarity (IPS) of Finns (FIN) and Estonians (EST). Bold in the example words emphasizes differences between Estonian and Finnish inflectional forms.

There are some word pairs where the differences between the Finns and the Estonians are very small (Table 5), as Est. nobeda-i-le ‘speedy-pl-all’ and Fin. nope-i-lle ‘speedy-pl-all’ or Est. lään-de ‘west-ill’ and Fin. länte-en ‘west-ill’. In the word pairs nobeda-i-le – nope-i-lle ‘speedy-pl-all’ and sademe-i-s ‘rain-pl-ine’ – sate-i-ssa ‘rain-pl-ine’, where from Finns’ point of view there is an additional syllable, the Estonians perceived more similarity. Also in the word pairs järve ‘lake.ill’ – järve-en ‘lake-ill’ and pesa ‘nest.par’ – pesä-ä ‘nest-par’ the IPS scores of Estonians are higher. The results provide tentative evidence that deletions and additions are, contrary to what is assumed in the calculations of the LD, not of equal value for similarity perceptions: according to the IPS scores, deletions seem to be more transparent in terms of perceiving similarity than additions. Further evidence for this is provided in the next section. In the word pairs in Table 5, several factors discussed above overlap: the stems are similar but there are considerable differences in the formatives, or the formatives are missing, which is particularly confusing for the Finns.
6. DISCUSSION
In this section, the results presented above are discussed in the light of the comments written by the participants when completing the test. All the comments were collected and classified, and the following categories were found: social, geographical, historical (examples(1a–e) below) and morphological variation, as in (2a, b); awareness of the morphological structure of words (stems and formatives), as in (3a–i); strings of letters, phonology (pronunciation), as in (3e, h); and paradigmatic awareness, as in (4a–c). The comments have been translated into English, with the original language in brackets. For the glosses of the words cited in the comments, please see Table A1 in the appendix.
The first research question deals with the relationship between the ‘actual’ distance or similarity between two sets of linguistic items, here operationalized by the use of the LD, and perceived similarity, here the IPS scores. The results confirm what has been shown in previous research, that unlike the LD, the IPS is not symmetrical: Finns see more similarity than do Estonians. One reason may be the wider variation in Finnish. The five million speakers of Finnish are spread over an area many times larger than Estonia and speak many more dialects in their everyday life than Estonians do. The difference between the standard and spoken language is bigger in Finnish than in Estonian, and many features of spoken Finnish are similar to the Estonians’ standard language. Finns are thus exposed to several morphological forms for one function, which may enable them to see more similarity between a given Finnish form and the corresponding Estonian form. Exposure to dialects has also been suggested elsewhere as a factor for mutual intelligibility (e.g. Delsing & Lundin Åkesson Reference Delsing and Åkesson2005, Gooskens Reference Gooskens2006, Gooskens & Heeringa Reference Gooskens and Heeringa2014). It is also given as a reason for the choice ‘similar’ in the comments in our test (here translated from Finnish or Estonian, with the original language indicated in parentheses), as in (1a–c):
-
(1)

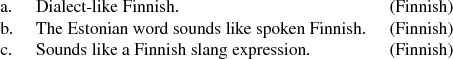
Although there is less regional variation in Estonian – because of the smaller number of speakers in a much smaller area and possibly also because of a heavier emphasis on standard language in the educational system – references to dialects can also be found in comments made by the Estonian group, as in (1d–e), which is a continuation of the list in (1) above:
-
(1)
Both groups thus search for sources of similarity in language-internal variation, but the Finns do so much more frequently than the Estonians. Dialects are most frequently mentioned, but slang and spoken language are also quite commonly mentioned. References to old forms also occur, indicating knowledge of historical variance. Occasionally also unrelated words or words from another language are discussed, but usually in connection with perceived difference rather than similarity.
In addition to dialects and other variants, internal variation in the standard language is mentioned as in (2a–b).
-
(2)

Alternative forms seem to be a good route for perceiving similarity. Another interesting finding is that the correlation between the LD and the IPS is significant for the Finnish group but there seems to be no such correlation for the Estonian group. This can be interpreted as suggesting that the Finns pay more attention to strings of letters, the same aspect of similarity that the LD measures, while the Estonians more often compare morphological forms rather than surface similarity. Estonians are also more likely to give explanations which display linguistic knowledge, exemplified in (3a–g):
-
(3)

Comments employing linguistic knowledge are rare and less explicit among the Finns:
-
(3)

The differences in the comments reflect the Estonians’ better ability to analyze the forms beyond the surface strings. It is hard to say whether or not this is due to the less agglutinative nature of Estonian, which requires speakers to interpret function even when there is no surface formative, while in Finnish each morphological function is expressed by an affix (even if the combinations of affixes sometimes fuse into formatives which are not easy to dissect). It is also possible that the explicit teaching of morphology in Estonian schools causes this; certainly it helps the participants to express themselves in linguistic terms.
Finnish agglutinative forms include parts that are familiar to Estonians, even if they may not be used in the context of a particular test word. This may help the Estonians to see the most different word pairs as more similar than Finns do. Estonians are also used to the variation in stem vowels common in Finnish plurals. Other stem vowel changes often seem to throw the Finns off course.
Another problematic issue for the Finns are the stem plurals, which completely lack a formative. This is not surprising, as it deviates from the one morpheme – one meaning principle typical of Finnish. Also t-plurals are easier for the Estonians to see as similar to Finnish i-plurals. Both exist in both languages but they differ in their distribution (see Section 3). The greater frequency of the t-plural in Estonian and many alternative forms apparently make it easier for the Estonians to see the underlying functional similarity.
In spite of all the advantages for seeing similarity enjoyed by the Estonians and listed above, the Finns clearly see much more similarity than the Estonians do. This links to the second research question, which asks whether deletions and insertions are of equal value in perception. Finnish word forms often contain material which is not present in the corresponding Estonian form, most commonly at the end of the word, within the inflectional formative, but also sometimes within the stem (Table 4). For this reason, Finns looking at Estonian words see something lacking, while Estonians see something unnecessary in the Finnish words. The IPS results of this group of test words show that the fact that something is missing from the viewpoint of L1 is a smaller obstacle to perceiving similarity than the situation where there is something extra. This is also reflected in the comments, which often refer to spoken Finnish or the dialect of the Turku region, both well-known for dropping the final vowel. Dropping the -n indicating the genitive form is also very common in spoken Finnish. Accepting missing sounds or letters seems easy for the Finnish participants.
The Estonians, however, seem to find it harder to see similarity when the Finnish word contains material which is not present in the Estonian word. It is possible that additional material provokes the participants unconsciously to search for a function for the extra material while missing material does not trigger a similar response. This is a very tentative suggestion, which needs to be further investigated.
The research questions did not address the issue of item vs. system similarity, since in the test the word pairs were presented one by one and we assumed that they would also be compared only within each pair. Some comments, however, reveal that at least some participants compared word pairs to other word pairs in the list or to other morphological forms of the same word, as in (4a–c):
-
(4)

Especially the last comment reveals the participant's awareness of the paradigmatic character of the inflectional system of her/his L1, Finnish (Paunonen Reference Paunonen, Hakulinen and Leino1983:59). This search for some systematicity is also a natural way to approach an unknown language (see also about applying paradigmatic analogy in the production process, Kaivapalu Reference Kaivapalu2005:267–272). Regardless of whether a language is seen as a set of rules a learner has to acquire or as a multitude of constructions from which regularities emerge, learners are aware of the fact that language items bear some relation to each other.
7. CONCLUSIONS
A simple answer to the question posed by the title of this article, ’Perceived similarity between written Estonian and Finnish: Strings of letters or morphological units?’, is that it depends on the L1 of the participant and on the task. The Finns see more similarity than do the Estonians, and more than half of that similarity is explained by similarity in the strings of letters. No correlation was found between strings of letters and the similarity perceptions of the Estonians. Other sources for perceiving similarity were explored by analyzing the participants’ comments and by comparing the morphology of the two closely related languages.
Comments that explain some of the findings mostly refer to variation in the L1, the language the participant knows well. Another large group of comments are those that display linguistic knowledge, with or without linguistic terminology: stems, endings, rules, sound changes etc. are mentioned as an explanation for similarity or difference. The prevalence of comments varies by group. The L1 Finnish group takes advantage of the variety in Finnish: regional dialects, spoken colloquial forms, slang, and old or literary forms provide them with more potential for comparison than the Estonian group employs. The Estonians, on the other hand, often refer to morphological knowledge and use more linguistic terminology, probably due to the inclusion of morphological analysis in the school curriculum. The comparison of forms letter by letter is infrequent in the L1 groups, but the fact that it occurs at all reinforces the statistical results: surface forms matter.
The task itself obviously directs participants’ attention and influences the results. The task in this study was carefully designed to contain a balance of the different types of relationships between Estonian and Finnish morphological forms. This proved essential, as the similarity perceptions of the Finns and the Estonians differed by the type of difference present in the word pair. The Finns found pairs with (from their point of view) missing letters similar, while Estonians were more able to see through the surface string in word pairs where fusion and agglutination were being compared. We also tried to exclude semantic and functional considerations by emphasizing that both parts of the word pair to be compared had the same meaning and represented the same grammatical form (case and number). A factor we were not able to keep constant was the frequency of the words in each language, but apparently all the words were familiar to the participants, as this did not give rise to any comments.
The ability to perceive similarity between linguistic items depends on linguistic awareness and a conscious processing of language. Most comparisons are item-based, as was expected, but paradigm-level considerations, comparing words within paradigms, employing knowledge of forms outside the test, were also present, as were comparisons within the list of word pairs. Word forms do not exist in a vacuum but invoke other forms and other words. Item similarity overlaps with system similarity.
The test was not systematically designed to explore the issue of the (un)equal value of deletions and insertions. It is actually surprising that users of the LD or other measures of linguistic distance have shown so little interest in this question. In this study, where it is only relevant to some parts of the test, the issue still explains a substantial part of the differences between the groups. Estonians who encounter insertions find it harder to see similarity than Finns who encounter deletions. This finding invites new research. We need a test that concentrates on deletions and insertions in a way that excludes the alternative explanation in this test, the influence of spoken Finnish and dialects (e.g. the possibility of dropping the final -n in spoken Finnish). The hypothesis that additional material in one of the words to be compared prompts participants unconsciously to search for a function for the extra material needs to be tested, although it is not easy to find a way of doing this. It would probably require multiple methods. We also need to explore the roles of conscious and unconscious processing, not only for this issue but for perceiving similarity in general. A reaction time test is already in progress.
If the final goal of the study of similarity across languages is to explore mutual intelligibility or help people learn each other's languages, as it is in the REMU project, it really is the perceptions of language users that matter rather than objective distance. In this article only a small area of language is targeted but the results raise interesting questions and can provide advice and ideas for testing perceived similarity in other areas of related languages.
ACKNOWLEDGEMENTS
Marianna Penttilä and Kärt Kaivapalu helped to sort out the comments in all four languages. Marianna Penttilä, Ingrid Krall and Anastassia Kallikorm helped in collecting the data. Ats Kaivapalu and Scott Jarvis performed the regression analysis. Many thanks to all of them. We are also very grateful to the three anonymus reviewers for their valuable comments.
APPENDIX
Table A1. The Levenhstein Distances (LDs) and Index of Perceived Similarity (IPS) scores of individual test items. Continued on next page.











