


1 Introduction
The task of determining an author’s native language (L1) based on their writing in a non-native or second language (L2) is known as Native Language Identification (NLI). NLI works by identifying language use patterns that are common to certain groups of speakers that share the same L1. The general framework of an NLI system is depicted in Figure 1. This process is underpinned by the presupposition that an author’s linguistic background will dispose them towards particular language production patterns in their subsequently learnt languages, as influenced by their mother tongue. This relates to the issue of Cross-linguistic Influence (CLI), and will be discussed in Section 2.1.
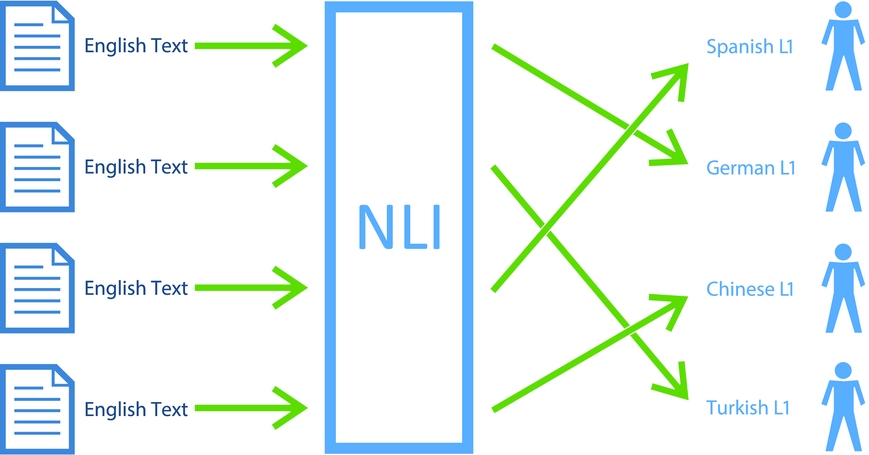
Fig. 1. An example of an NLI system that attempts to classify the native languages (L1) of the authors of non-native (L2) English texts.
Most studies conducted to date approach NLI as a multiclass supervised classification task. In this experimental design, the L1 metadata are used as class labels and the individual writings are used as training and testing data. Using lexical and syntactic features of increasing sophistication, researchers have obtained good results under this paradigm. Recently, it has also been shown that these machine learning methods outperform human experts for this task (Malmasi et al. Reference Malmasi, Tetreault and Dras2015b).
NLI technology has practical applications in various fields. One potential application of NLI is in the field of forensic linguistics (Gibbons Reference Gibbons2003; Coulthard and Johnson Reference Coulthard and Johnson2007), a juncture where the legal system and linguistic stylistics intersect (McMenamin Reference McMenamin2002; Gibbons and Prakasam Reference Gibbons and Prakasam2004). In this context, NLI can be used as a tool for Authorship Profiling (Grant Reference Grant2007) in order to provide evidence about the linguistic background of an author.
There are a number of situations where a text, such as an anonymous letter, is the central piece of evidence in an investigation. The ability to extract additional information from an anonymous text can enable the authorities and intelligence agencies to learn more about threats and those responsible for them. Clues about the L1 of a writer can help investigators in determining the source of anonymous text and the importance of this analysis is often bolstered by the fact that in such scenarios, the only data available to users and investigators is the text itself. NLI can be applied in such contexts to glean information about the discriminant L1 cues in an anonymous text. One recently studied example is the analysis of extremist related activity on the web (Abbasi and Chen Reference Abbasi and Chen2005).
Accordingly, we can see that from a forensic point of view, NLI can be a useful tool for intelligence and law enforcement agencies. In fact, recent NLI research such as that related to the work presented by Perkins (Reference Perkins2014) has already attracted interest and funding from intelligence agencies (Perkins Reference Perkins2014, 17).
While NLI has such applications in security, most research has a strong linguistic motivation relating to language teaching and learning. Rising numbers of language learners have led to an increasing need for language learning resources, which has in turn fuelled much of the language acquisition research of the past decade.
In connection to the field of Second Language Acquisition (SLA) research, NLI can be used to identify the most challenging aspects of a language for learners from specific backgrounds. In this context, by identifying L1-specific language usage and error patterns, NLI can be used to better understand SLA and develop teaching methods, instructions and learner feedback that is specific to their mother tongue. This tailored evaluation can be derived from language-specific models, whereby learners are provided with customized and specific feedback, determined by their L1. For example, algorithms based on these models could provide students with much more specific and focused feedback when used in automated writing evaluation systems (Rozovskaya and Roth Reference Rozovskaya and Roth2011). The application of these tools and scientific methods like NLI could potentially assist researchers in creating effective teaching practices and is an area of active research.
In conjunction with SLA, researchers are interested in the nature and degree to which an L1 affects the acquisition and production of other consequently learnt language (Ortega Reference Ortega2009, 31). NLI-based analyses could be used to help researchers in linguistics and cognitive science to better understand the process of L2 acquisition and language transfer effects. Such analyses are often done manually in SLA, and are difficult to perform for large corpora. Smaller studies can yield poor results due to the sample size, leading to extreme variability (Ellis Reference Ellis2008). Recently, researchers have noted that Natural Language Processing (NLP) has the tools to use large amounts of data to automate this analysis using complex feature types, thereby motivating studies in NLI.
1.1 Moving beyond English NLI
While it has attracted significant attention from researchers, almost all of the NLI research to date has focused exclusively on English L2 data. In fact, most work in SLA and NLP for that matter has dealt with English. This is largely due to the fact that since World War II, the world has witnessed the ascendancy of English as its lingua franca. While English is the L1 of over 400 million people in the US, UK and the Commonwealth, there are also over a billion people who speak English as their second or foreign language (Guo and Beckett Reference Guo and Beckett2007). This has created a global environment where learning multiple languages is not exceptional and this has fuelled the growing research into L2 acquisition.
However, while English is one of the most widely spoken languages in the world, there are still a sizeable number of jobs and activities in parts of the world where the acquisition of a language other than English is a necessity.
One such example is Finland, where due to the predicted labour shortage, the government has adopted policies encouraging economic and work-related migration (Ministry of Labour 2006), with an emphasis on the role of the education system. Aiding new immigrants to learn the Finnish language has been a key pillar of this policy, particularly as learning the language of the host nation has been found to be an important factor for social integration and assimilation (Nieminen Reference Nieminen2009). This, in turn, has motivated research in studying the acquisition of Finnish to identify the most challenging aspects of the process.Footnote 1
Another such example is that of Chinese. Interest in learning Chinese is rapidly growing, leading to increased research in teaching Chinese as a foreign language and the development of related resources such as learner corpora (Chen, Wang and Cai Reference Chen, Wang and Cai2010). This booming growth in Chinese language learning (Zhao and Huang Reference Zhao and Huang2010; Rose and Carson Reference Rose and Carson2014), related to the dramatic globalization of the past few decades and a shift in the global language order (Tsung and Cruickshank Reference Tsung and Cruickshank2011), has brought with it learners from diverse backgrounds. Consequently, a key challenge here is the development of appropriate resources – language learning tools, assessments and pedagogical materials – driven by language technology, applied linguistics and SLA research (Tsung and Cruickshank Reference Tsung and Cruickshank2011).
Yet another case is the teaching of Arabic as a foreign language which has experienced unparalleled growth in the past two decades. For a long time, the teaching of Arabic was not considered a priority, but this view has now changed. Arabic is now perceived as a critical and strategically useful language (Ryding Reference Ryding, Wahba, Taha and England2013), with enrolments rising rapidly and already at an all-time high (Wahba, Taha and England Reference Wahba, Taha and England2013).
These trends of focusing on other languages is also reflected in the NLP community, evidenced by the continuously increasing research focus on tools and resources for languages like Arabic (Habash Reference Habash2010) and Chinese (Wong et al. Reference Wong, Li, Xu and Zhang2009).
Given the increasing research focusing on other L2s, we believe that there is a need to apply NLI to other languages, not only to gauge their applicability but also to aid in teaching research for other emerging languages. This need is partially driven by the increasing number of learners of other languages, as described above.
An important question that arises here is how linguistic and typological differences with English may affect NLI performance. The six languages investigated here vary significantly with respect not only to English, but also amongst themselves, in various linguistic subsystems; these differences are detailed in Section 3. In this regard, the current study aims to assess whether these differences significantly impact NLI performance for different L2s.
1.2 Goals and objectives
There are several aims of the present research relating to various aspects of NLI. The overarching goal here is to experiment with the extension of NLI to languages other than English. One objective is to investigate the efficacy of the type of features that have been common to almost all NLI approaches to date for several languages which are significantly different from English. Answering this question requires the identification of the relevant non-English learner corpora. This data is then used in our first two experiments to assess whether NLI techniques and features work across a diverse set of languages. Having identified the required corpora, our next objective here is to use cross-lingual evidence to investigate core issues in NLI.
While NLI research has investigated the characteristics that distinguish L1 groups, this has not been wholly extended to automatically discriminating native and non-native texts. This extension, using appropriate native control data, is another aim of the work presented here.
Another issue that arises in this type of multilingual research is the use of multiple part-of-speech tagsets developed for different languages. Differences in the granularity of the tags mean that they are often not directly comparable. This is investigated by one of our experiments where we compare the performance of different tagsets and also convert the tags for each language to a more general and common tagset in order to make the results more directly comparable across the languages.
A large range of feature types have been proposed for NLI and researchers have used varying combinations of these features. However, no attempts have been made to measure the degree of dependence, overlap and complementarity between different features. Accordingly, another aim of the present inquiry is to apply and evaluate a suitable method for measuring and quantifying this interfeature diversity and to assess how the results compare across languages.
The final objective of the paper relates to estimating the upper limits of NLI accuracy. Evidence from current research indicates that some texts, particularly those of more proficient authors, can be challenging to classify. Other work in NLI has shown that ensembles of classifiers work well and in our final experiment we use an oracle classifier to derive an upper limit for classification accuracy with our feature set. This is something that has not been previously investigated and can be a helpful baseline to guide and interpret future research. The objective of these last two experiments is not solely focused on the machine learning aspects, but also relates to seeing if the same patterns are reflected across languages, which is of importance to multilingual research in this area.
1.3 Paper outline
The rest of this paper is organized as follows. We begin by reviewing previous research in Section 2. The data and corpora we use are presented in Section 3. Our methodology is outlined in Section 4 and the feature types used therein are described in Section 5. The descriptions and results from our experiments are detailed in Sections 6– 11 and followed by a general discussion in Section 12 that summarizes the conclusions of our experiments and outlines some directions for future research.
2 Related work
2.1 Cross-linguistic influence
CLI, also referred to as language transfer, is one of the major topics in the field of SLA. It has been said that being a speaker of some specific L1 can have direct and indirect consequences on an individual’s usage of some later-learned language (Jarvis and Crossley Reference Jarvis and Crossley2012), and this is the effect that is studied under the heading of CLI. With this in mind, SLA research aims to find distributional differences in language use between L1s, often referred to as overuse, the extensive use of some linguistic structures, and underuse, the underutilization of particular structures, also known as avoidance (Gass and Selinker Reference Gass and Selinker2008).
We now briefly turn our attention to a discussion of how these transfer effects manifest themselves in the language production of a learner. These manifestations include positive transfer, overuse and avoidance, as described below.
2.1.1 Positive transfer
This type of transfer is generally facilitated by similarities between the native tongue and L2s. The transfer effect can also differ for the various subsystems of a language. The degree of similarity between two languages may vary in their vocabulary, orthography, phonology or syntax. For example, high similarities in one aspect such as vocabulary may facilitate high levels of transfer in language pairs such as Spanish–Portuguese or German–Dutch, but not as much in other facets (Ellis Reference Ellis2008). Such effects can also be observed in orthographic systems where Chinese and Japanese native speakers (NSs) may find it easier to learn each other’s languages in comparison with those that speak a language which utilizes a phonetic alphabet.
2.1.2 Underuse (avoidance)
The underutilization of particular linguistic structures is known as avoidance. While the existence of this phenomenon has been established, the source of this underproduction is a debated topic (Gass and Selinker Reference Gass and Selinker2008). One possible explanation is that avoidance is chiefly caused by the dissimilarities between two languages. Evidence for this hypothesis was provided from a seminal experiment by Schachter (Reference Schachter1974) which demonstrated that English learners of Japanese and Chinese backgrounds made significantly fewer relative clause errors than their Farsi and Arabic speaking counterparts. This was not because Japanese and Chinese had syntactic structures more similar to English (in fact, the opposite is true), but rather because they were mostly avoiding the use of such structures. Another reason for avoidance may be the inherent complexity of the structures themselves (Gass and Selinker Reference Gass and Selinker2008).
2.1.3 Overuse
The above-mentioned avoidance or underuse of specific linguistic structures may result in the overuse of other structures. In learners, this may manifest itself as the reluctance to produce more complex constructions, instead opting to use combinations of simple sentences to express their ideas. Ellis (Reference Ellis2008) also discusses how overuse can occur due to intralingual processes such as overgeneralization. This usually occurs when regular rules are applied to irregular forms of verbs or nouns, such as saying runned or shoeses.
These are the types of patterns that SLA researchers attempt to uncover using learner corpora (Granger Reference Granger2009). While there are some attempts in SLA to use computational approaches on small-scale data, e.g. Chen (Reference Chen2013) and Lozanó and Mendikoetxea (Reference Lozanó and Mendikoetxea2010), these still use fairly elementary computational tools, including mostly manual approaches to annotation.
One such example is the study of Diéz-Bedmar and Papp (Reference Diéz-Bedmar and Papp2008), comparing Chinese and Spanish learners of English with respect to the English article system (a, an, the). Drawing on 175 texts, they take a particular theoretical analysis (the so-called Bickerton semantic wheel), use the simple Wordsmith tools designed to extract data for lexicographers to identify errors in a semi-automatic way, and evaluate using hypothesis testing (chi-square and z-tests, in their case). In contrast, using fully automatic techniques would mean that – in addition to being able to process more data – any change in assumptions or in theoretical approach could be made easily, without need for manual reannotation of the data.
Among the efflorescence of work in Computational Linguistics, researchers have turned their attention to investigating these phenomena through predictive computational models. The majority of these models are based on the aforementioned theories relating to learner interlanguage. NLI is one such area where work has focused on automatic learner L1 classification using machine learning with large-scale data and sophisticated linguistic features (Tetreault et al. Reference Tetreault, Blanchard, Cahill and Chodorow2012). Other work has linked this directly to issues of interest in SLA: linking errors and L1 (Kochmar Reference Kochmar2011), methods for proposing potential SLA hypotheses (Swanson and Charniak Reference Swanson and Charniak2013; Malmasi and Dras Reference Malmasi and Dras2014b), and so on. This is also the approach pursued in this work, where a large learner corpora of different languages will be used in conjunction with automatic linguistic annotation and machine learning methods.
2.2 Relation to language teaching and learning
The large demand for result-oriented language teaching and learning resources is an important motivating factor in SLA research (Ortega Reference Ortega2009; Richards and Rodgers Reference Richards and Rodgers2014). Today, we live in a world where there are more bilingual individuals than monolinguals, but multilingualism does not automatically imply having attained full mastery of multiple languages. As the world continues on the path to becoming a highly globalized and interconnected community, the learning of foreign languages is becoming increasingly common and is driven by a demand for language skills (Tinsley Reference Tinsley2013). All of this provides intrinsic motivation for many of the learners to continue improving their language skills beyond that of basic communication or working proficiency towards near-native levels. In itself, this is not easy task, but a good starting point is to reduce those idiosyncratic language use patterns caused by the influence of the L1. The first step towards this is to identify such usage patterns and transfer effects through studies such as this one.
The motivations for identifying L1-related language production patterns are manifold. Such techniques can help SLA researchers identify important L1-specific learning and teaching issues. In turn, the identification of such issues can enable researchers to develop pedagogical material that takes into consideration a learner’s L1 and addresses them. This equates to teaching material that is tailored for students of an L1 group. Some research into the inclusion of L1 knowledge in teaching material has already been conducted.
Horst, White and Bell (Reference Horst, White and Bell2010) investigated how L1 knowledge can be incorporated into language instruction in order to facilitate learning. They approached this by designing a series of cross-linguistic awareness activities which were tested with francophone learners of English at a school in Montreal, Quebec, Canada. The cross-linguistic awareness material was developed by identifying commonalities between French and English. Next, a set of 11 cross-linguistic awareness teaching packages were developed and piloted in an intensive year-long English as a Second Language (ESL) program. Although they did not conduct empirical evaluation with a control group, observations and interviews indicate that this is a promising approach that can address a wide range of linguistic phenomena.
Laufer and Girsai (Reference Laufer and Girsai2008) investigated the effects of explicit contrastive analysis on vocabulary acquisition. Three groups of L2 English learners of the same L1 were used to form separate instructional conditions: meaning focused instruction, non-contrastive form-focused instruction and contrastive analysis and translation. The contrastive analysis and translation performed translation tasks and was also provided a contrastive analysis of the target items and their L1 translation options. One week later, all groups were tested for retention of the target items and the contrastive analysis and translation group significantly outperformed the others. These results are interpreted as evidence for L1 influence on L2 vocabulary acquisition.
Such findings from SLA research, although not the principal source of knowledge for teachers, are considered helpful to them and have great pedagogical relevance. Although a more comprehensive exposition of the pedagogical aspects of SLA is beyond the scope of our work, we refer the interested reader to Lightbown (Reference Lightbown2000) for an overview of SLA research in the classroom and how it can influence teaching.
2.3 Native language identification
NLI is a fairly recent but rapidly growing area of research. While some early research was conducted in the early 2000s, most work has only appeared in the last few years. This surge of interest, coupled with the inaugural shared task in 2013 (Tetreault et al. Reference Tetreault, Blanchard and Cahill2013), has resulted in NLI becoming a well-established NLP task. We point out just the previous research on the task relevant to the present article.
The earliest work on detecting L2 is that of Tomokiyo and Jones (Reference Tomokiyo and Jones2001) whose main aim was to detect non-native speech using part-of-speech and lexical n-grams, and to also determine the L1 of the non-native speakers (NNSs). They were able to achieve 100 per cent accuracy in their study, which included six Chinese and thirty-one Japanese speakers.
Koppel et al. (Reference Koppel, Schler and Zigdon2005a, Reference Koppel, Schler and Zigdon2005b) established the text classification paradigm now widely used in the area. Texts ranging from 500 to 850 words from five L1s were selected from the first version of the International Corpus of Learner English (ICLE) (Granger et al. Reference Granger, Dagneaux, Meunier and Paquot2009). They used a set of syntactic, lexical and stylistic features that included function words, character n-grams and part-of-speech (POS) bigrams, together with spelling mistakes. Using an Support Vector Machine (SVM) classifier, the achieved a classification accuracy of 80 per cent with ten-fold cross-validation – a strong result given the 20 per cent chance baseline.
Wong and Dras (Reference Wong and Dras2011) proposed exploiting parse structures for NLI. They explored the usefulness of syntactic features in a broader sense by characterizing syntactic errors with cross sections of parse trees obtained from statistical parsing. More specifically, they utilized two types of parse tree substructure to use as classification features – horizontal slices of the trees and the feature schemas used in discriminative parse reranking (Charniak and Johnson Reference Charniak and Johnson2005). Only using non-lexicalized rules and rules with function words, they found that this improves the results significantly by capturing more syntactic structure. These kinds of syntactic features performed significantly better than lexical features alone, giving the best performance on the ICLE (v.2) dataset at the time. Other syntactic information, in such forms as Tree Substitution Grammars (Swanson and Charniak Reference Swanson and Charniak2012) or dependency relations (Tetreault et al. Reference Tetreault, Blanchard, Cahill and Chodorow2012), have subsequently also been used.
This set of core function word and POS-based features were used by most follow-up studies, including Tsur and Rappoport (Reference Tsur and Rappoport2007), Estival et al. (Reference Estival, Gaustad, Pham, Radford and Hutchinson2007), Kochmar (Reference Kochmar2011), Brooke and Hirst (Reference Brooke and Hirst2011, Reference Brooke and Hirst2012a) and Wong, Dras and Johnson (Reference Wong, Dras and Johnson2012).
Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) proposed the use of classifier ensembles for NLI. In their study, they used an ensemble of logistic regression learners each trained on a wide range of features that included POS n-grams, function words, spelling errors and writing quality markers, amongst others. This was in contrast with previous work that had combined all features in a single space. The set of features used here was also the largest of any NLI study to date. With this system, the authors reported state of the art accuracies of 90.1 per cent and 80.9 per cent on the ICLE and Toefl11 corpora (introduced in this work and now standard – see Section 3.7.2), respectively.
We note that this approach, and previous work, made no attempt to measure the diversity between feature types to determine if any feature pairs are capturing the same information. This is an important factor to consider, particularly when building ensembles with many feature types.
Increased interest in NLI brought unprecedented levels of research focus and momentum, resulting in the first NLI shared task being held in 2013.Footnote 2 The shared task aimed to facilitate the comparison of results by providing a large NLI-specific dataset and evaluation procedure, to enable direct comparison of results achieved through different methods. Overall, the event was considered a success, drawing twenty-nine entrants and experts from not only Computational Linguistics, but also SLA. The best teams achieved accuracies of around 80 per cent on this 11-class classification task where the great majority of entries used standard features such as POS n-grams. A detailed summary of the results can be found in Tetreault et al. (Reference Tetreault, Blanchard and Cahill2013).
We can identify a number of relevant trends from this survey of NLI literature. First, we observe that function words and POS n-grams constitute a core set of standard features for this task: these will be our fundamental features as well. Second, facilitated by the large body of learner English data that has accumulated over the last few decades, NLI researchers have focused almost exclusively on English. With this in mind, one of the central contributions of this work is the extension of NLI to additional, non-English L2s such as Italian and German. Third, there are a number of issues worth closer analysis, including the above-mentioned issue of feature diversity.
2.3.1 From NLI to language transfer hypotheses
NLI methods have also been extended to investigating language transfer and cross-linguistic effects, as described in this section. The learner corpora are used to extract potential language transfer effects between the languages in each corpus using data-driven methodology such as the one proposed by Swanson and Charniak (Reference Swanson and Charniak2014). Malmasi and Dras (Reference Malmasi and Dras2014b) also propose such a method using SVM weights and apply it to generate potential language transfer hypotheses from the writings of English learners in the Toefl11 corpus.
For Spanish L1 authors, they extract both underuse and overuse lists of syntactic dependencies. The top three overuse rules show the word that is very often used as the subject of verbs. This is almost certainly a consequence of the prominent syntactic role played by the Spanish word que which, depending on the context, is equivalent to the English words whom, who, which, and most commonly, that. Another rule shows they often use this as a determiner for plural nouns. A survey of the corpus reveals many such errors in texts of Spanish learners, e.g. ‘this actions’ or ‘this emissions’. Yet another rule shows that the adjectival modifier of a plural noun is being incorrectly pluralized to match the noun in number as would be required in Spanish, for example, ‘differents subjects’. Some examples of these dependencies are shown in Figure 2. Turning to the underused features in Spanish L1 texts, they show that four related features rank highly, demonstrating that these is not commonly used as a determiner for plural nouns and which is rarely used as a subject.
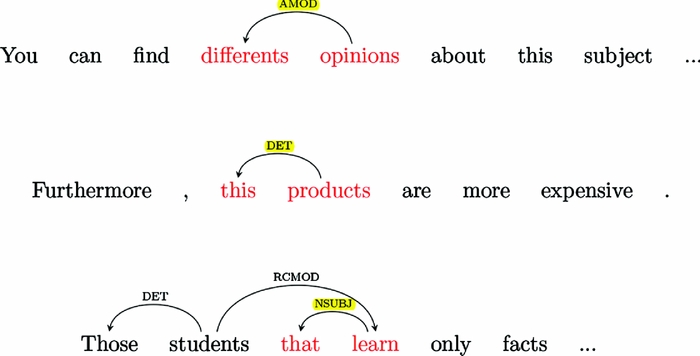
Fig. 2. Three of the most common overuse patterns found in the writing of L1 Spanish learners. They show erroneous pluralization of adjectives, determiner misuse and overuse of the word that.
3 Learner corpora and languages
In this section, we outline the data used in this study. This includes the six L2 languages: in addition to outlining the corpora and their characteristics, we also describe how these languages differ linguistically and typologically to English, the most commonly investigated language in NLI.
Learner corpora – datasets comprised of the writings of learners of a particular language – are a key component of language acquisition research and their utilization has been considered ‘a revolution in applied linguistics’ (Granger Reference Granger1994).
They are designed to assist researchers studying various aspects of learner interlanguage and are often used to investigate learner language production in an exploratory manner in order to generate hypotheses. Recently, learner corpora have also been utilized in various NLP tasks including error detection and correction (Gamon et al. Reference Gamon, Chodorow, Leacock, Tetreault, Ballier, Díaz-Negrillo and Thompson2013), language transfer hypothesis formulation (Swanson and Charniak Reference Swanson and Charniak2014) and NLI (Tetreault et al. Reference Tetreault, Blanchard and Cahill2013). In fact, they are a core component of NLI research.
While such corpus-based studies have become an accepted standard in SLA research and relevant NLP tasks, there remains a paucity of large-scale L2 corpora. For L2 English, the two main datasets are the ICLE (Granger Reference Granger2003) and Toefl11 (Blanchard et al. Reference Blanchard, Tetreault, Higgins, Cahill and Chodorow2013) corpora, with the latter being the largest publicly available corpus of non-native English writing.Footnote 3
A major concern for researchers is the paucity of quality learner corpora that target languages other than English (Nesselhauf Reference Nesselhauf and Sinclair2004). The aforementioned data scarcity is far more acute for L2 other than English and this fact has not gone unnoticed by the research community (Abuhakema et al. Reference Abuhakema, Faraj, Feldman and Fitzpatrick2008; Lozano and Mendikoetxea Reference Lozano, Mendikoetxea, Ballier, Díaz-Negrillo and Thompson2013). Such corpora are few in number and this scarcity potentially stems from the costly resources required for the collection and compilation of sufficient texts for developing a large-scale learner corpus.
Additionally, there are a number of characteristics and design requirements that must be met for a corpus to be useful for NLI research. An ideal NLI corpus should
-
• have multiple and diverse L1 groups represented,
-
• be balanced by topic so as to avoid topic bias,Footnote 4
-
• be balanced in proficiency across the groups,
-
• contain similar numbers of texts per L1, i.e. be balanced by class,
-
• be sufficiently large in size to reliably identify intergroup differences.
One key contribution of this work is the identification and evaluation of corpora that meet as many of these requirements as possible. The remainder of this section outlines the languages and corresponding datasets which we have identified as being potentially useful for this research and provides a summary of their key characteristics. A summary of the basic properties of the data for each language is shown in Table 1. Additionally, a listing of the L1 groups and text counts for each corpus can be found in Table 2, which also shows the average text length for documents in each class in tokens, except for Chinese, which is measured in characters.
Table 1. A summary of the basic properties of the L2 data used in our study. The text length is the average number of tokens across the texts along with the standard deviation in parentheses

Table 2. A breakdown of the six languages and the L1 classes used in our study. Texts is the number of documents in each L1 class and Length represents the average text length in tokens, except for Chinese, which is measured in characters

3.1 Italian
Italian, a Romance language similar to French and Spanish, is a modern descendant of Latin. It uses the same alphabet as English, although certain letters such as j and x are only used in foreign words. As a result of being related to Latin, there are various cognates between English and Italian, including a range of false friends.
Morphologically, it is a little more complicated in some ways than English. Nouns are inflected for gender (male or female) and number. However, Italian differs from other Romance languages in this regard in that the plural marker is realized as a vowel change in the gender marker and not through the addition of an -s morpheme. Certain nouns, such as weekdays, are not capitalized. Verbs are inflected for tense and person. In addition to the five inflected tenses, others are formed via auxiliaries. An important aspect of the verbal system is the presence of the subjunctive mood across the verb tenses. At the sentence level, SVO is the normal order, although post-verbal subjects are also allowed depending on the semantic context of the subject and verb. Pronouns are frequently dropped in Italian and this could lead to a different, possibly slightly more compact, function word distribution.
Adjectives can be positioned both pre- and post-nominally in nominal groups, with the position marking a functional aspect of its use as either descriptive (pre-nominal) or restrictive (post-nominal). This could result in a wider, more sparse distribution of POS n-grams. Possessives also behave in the same manner as adjectives in most contexts. A more detailed exposition of these linguistic properties, amongst others, can be found in Vincent (Reference Vincent and Comrie2009).
For our Italian data, we utilize the VALICO Corpus (Corino Reference Corino2008). VALICO (Varietà di Apprendimento della Lingua Italiana Corpus Online, i.e. the Online Corpus of Learner Varieties of Italian) includes approximately 1 million tokens of learner Italian writing from a wide range of L1s along with the associated metadata.
Although over twenty L1 groups are represented in the data, many do not have sufficient data for our purposes. We have selected the top fourteen native languages by the number of available texts as the rest of the classes contain too few texts; these are shown in Table 2. In terms of the number of L1 classes, this is the highest number used in our experiments. On the other hand, there is significant imbalance in the number of texts per class.
3.2 German
The German language, spoken by some 100 million NSs, is an official language of Germany, Austria, Switzerland, Luxembourg and Liechtenstein.
English and German are similar in many aspects and both belong to the Indo-European language family, as part of the West Germanic group within the Germanic branch (Hawkins Reference Hawkins and Comrie2009).
In spite of this typological closeness, there are a number of differences that may cause problems for NLI with our standard features. German has a much richer case and morphology system compared to English and this may lead to different usage patterns of function words. Furthermore, German also has a more variable word ordering system with more long-distance dependencies, potentially leading to a wider set of POS n-grams. It is not clear how well this feature can capture potential L1-influenced ordering patterns.
The largest publicly available selection of German learner texts can be found in the FALKO (fehlerannotierten Lernerkorpus) corpusFootnote 5 by Siemen et al. (Reference Siemen, Lüdeling and Müller2006) and this is the source of the German data used in this work.
It has several subcorpora, including the essay subcorpus (argumentative essays written by learners) and summary subcorpus (text summaries written by learners). It also contains baseline corpora with texts written by German NSs. For the purposes of our experiments, we combine the essay and summary texts, but do not use the longitudinal subcorpus texts. A listing of the L1 groups and text counts of the corpus subset we use can be found in Table 2.
3.3 Spanish
As the Romance language with the greatest number of speakers, Spanish is the official language of some twenty countries.
Much like German, many aspects of Spanish grammar are similar to English, so our feature set may not have any issues in capturing L1-based interlanguage differences. Although Spanish syntax is mostly SVO, it also has a somewhat richer morphology and a subjunctive mood (Green Reference Green and Comrie2009), though we do not expect these differences to pose a challenge. Pronouns are also frequently dropped and this information is captured by POS tags rather than function words. There is also a complete agreement system for number and gender within noun phrases, resulting in a wider distribution of POS n-grams. Spanish also makes pervasive use of auxiliaries, with more than fifty verbs that have auxiliary functions (Green Reference Green and Comrie2009, 214). This is a difference that affects distributions of both function words and POS tags.
Our Spanish learner texts were sourced from the Anglia Ruskin University (ARU) Spanish learner corpus. This is a multiple-L1 corpusFootnote 6 comprised of Spanish texts that were produced by students either as course work or as part of exams. The texts are entered exactly as written by students and have not been corrected. The learners include undergraduates at Anglia Ruskin learning Spanish and some ERASMUS (European Region Action Scheme for the Mobility of University Students) students from France, Germany and Italy. These students have varied nationalities and backgrounds (56 per cent do not have English as L1).
Each text includes metadata with the following information: the task set, the conditions (exam/course work), the text type (narrative, description, etc.), proficiency level (beginner, intermediate or advanced), course book (where known), student identity number, L1 and gender.
A total of twenty L1s are represented in the version of the data that we received in July 2013, but many of these have too few texts to be effectively used in our experiments. Since not all the represented L1s have sufficient amounts of data, we only make use of the top six L1 categories (English, Italian, French, Japanese, Greek and German), as shown in Table 2.
3.4 Chinese
Chinese, an independent branch of the Sino-Tibetan family, is spoken by over a billion people. Unlike the other languages used in this study, Chinese orthography does not use an alphabet, but rather a logosyllabic system where each character may be an individual word or a constituent syllable.
Chinese is also an isolating language: there is little grammatical inflectional morphology. In contrast, other languages use inflection and auxiliaries to encode information about who did what to whom and when. In Chinese, some of this information is conveyed via word order – much like in English – and an understanding of the context. Gender, number and tense may be indicated through lexical choices, or omitted entirely. More details about these unique characteristics of Chinese can be found in Li and Thompson (Reference Li, Thompson and Comrie2009).
Levy and Manning (Reference Levy and Manning2003) point out three ways in which these difference may manifest themselves:
First, Chinese makes less use of function words and morphology than English: determinerless nouns are more widespread, plural marking is restricted and rare, and verbs appear in a unique form with few supporting function words. Second, whereas English is largely left-headed and right-branching, Chinese is more mixed: most categories are right-headed, but verbal and prepositional complements follow their heads. Significantly, this means that attachment ambiguity among a verb’s complements, a major source of parsing ambiguity in English, is rare in Chinese. The third major difference is subject pro-drop — the null realization of uncontrolled pronominal subjects — which is widespread in Chinese, but rare in English. This creates ambiguities between parses of subject-less structures as IP or as VP, and between interpretations of preverbal NPs as NP adjuncts or as subjects.
(Levy and Manning (2003: 439–440))Given these differences, an interesting question is whether previously used features can capture the differences in the interlanguage of Chinese learners. For example, POS-based features have relied heavily on the ordering of tag sequences which are often differentiated by morphological inflections – Can these features differentiate L1s in the absence of the same amount of information? The same question can be asked of function words, how does their reduced frequency affect NLI accuracy?
Growing interest has led to the recent development of the Jinan Chinese Learner Corpus (JCLC) (Wang, Malmasi and Huang Reference Wang, Malmasi and Huang2015), the first large-scale corpus of L2 Chinese consisting of university student essays. Learners from fifty-nine countries are represented and proficiency levels are sampled representatively across beginner, intermediate and advanced levels. However, texts by learners from other Asian countries are disproportionately represented, with this likely being due to geographical proximity and links to China.
For this work, we extracted 3.75 million tokens of text from the JCLC in the form of individual sentences.Footnote 7 Following the methodology of Brooke and Hirst (Reference Brooke and Hirst2011), we combine the sentences from the same L1 to generate texts of 600 tokens on average, creating a set of documents suitable for NLI.Footnote 8
Although there are over fifty L1s available in the corpus, we choose the top eleven languages, shown in Table 2, to use in our experiments. This is due to two considerations. First, while many L1s are represented in the corpus, most have relatively few texts. Choosing the top eleven classes allows us to have a large number of classes and also ensure that there is sufficient data per-class. Secondly, this is the same number of classes used in the NLI 2013 shared task, enabling us to draw cross-language comparisons with the shared task results.
3.5 Arabic
Arabic, part of the Semitic family of languages, is the official language of over twenty countries. It is comprised of many regional dialects with the Modern Standard Arabic variety having the role of a common dialect across the Arabic-speaking population.
A wide range of differences from English, some of which are highlighted below, make this an interesting test case for current NLI methods. More specifically, a rich morphology and grammar could pose challenges for syntactic features in NLI.
Arabic orthography is very different from English with right-to-left text that uses connective letters. Moreover, this is further complicated due to the presence of word elongation, common ligatures, zero-width diacritics and allographic variants. The morphology of Arabic is also quite rich with many morphemes that can appear as prefixes, suffixes or even circumfixes. These mark grammatical information including case, number, gender and definiteness amongst others. This leads to a sophisticated morphotactic system. Nouns are inflected for gender, number, case and determination, which is marked using the al- prefix. Verbal morphology consists of affixes for marking mood, person and aspect. For further information, we refer the reader to the thorough overview in Kaye (Reference Kaye and Comrie2009).
Other researchers have noted that this morphological complexity means that Arabic has a high vocabulary growth rate, leading to issues in tasks such as language modelling (Vergyri et al. Reference Vergyri, Kirchhoff, Duh and Stolcke2004; Diab Reference Diab2009). This issue could also be problematic for our POS n-gram features. Arabic function words have previously been used for authorship attribution (Abbasi and Chen Reference Abbasi and Chen2005) and our experiments will evaluate their utility for NLI.
The need for L1-specific SLA research and teaching material is particularly salient for a complex language such as Arabic which has several learning stages (Mansouri Reference Mansouri2005), such as phrasal and interphrasal agreement morphology, which are hierarchical and generally acquired in a specific order (Nielsen Reference Nielsen1997).
No Arabic learner corpora were available for a long time, but recently, the first version of the Arabic Learner CorpusFootnote 9 (ALC) was released by Alfaifi and Atwell (Reference Alfaifi and Atwell2013). The corpus includes texts by Arabic learners studying in Saudi Arabia, mostly timed essays written in class. In total, sixty-six different L1 backgrounds are represented. While texts by native Arabic speakers studying to improve their writing are also included, we do not utilize these. Both plain text and XML versions of the learner writings are provided with the corpus. Additionally, an online version of the corpus with more advanced search and browsing functionality has recently been made available.Footnote 10
We use the more recent second version of the ALC (Alfaifi, Atwell and Hedaya Reference Alfaifi, Atwell and Hedaya2014) as the data for our experiments. While there are sixty-six different L1s in the corpus, the majority of these have fewer than ten texts and cannot reliably be used for NLI. Instead, we use a subset of the corpus consisting of the top seven L1s by number of texts and as a result of this, this Arabic dataset is the smallest corpus used in an NLI experiment to date. The languages and document counts in each class are shown in Table 2.
3.6 Finnish
The final language included in the present work is Finnish, a member of the Baltic-Finnic language group and spoken predominantly in the Republic of Finland and Estonia.
Finnish is an agglutinative language and this poses a particular challenge. In terms of morphological complexity, it is among the world’s most extreme: its number of cases, for example, places it in the highest category in the comparative World Atlas of Language Structures (Iggesen Reference Iggesen2013). Comrie (Reference Comrie1989) proposed two scales for characterizing morphology, the index of synthesis (based on the number of categories expressed per morpheme) and the index of fusion (based on the number of categories expressed per morpheme). While an isolating language like Vietnamese would have an index of synthesis score close to 1, the lowest possible score, Finnish scores particularly high on this metric (Pirkola Reference Pirkola2001). Because of this morphological richness, and because it is typically associated with freeness of word order, Finnish potentially poses a problem for the quite strongly lexical features currently used in NLI. For more details, we refer the interested reader to Branch (Reference Branch and Comrie2009) where a detailed discussion of these characteristics is presented.
The Finnish texts used here were sourced from the Corpus of Advanced Learner Finnish (LAS2) which consists of L2 Finnish writings (Ivaska Reference Ivaska2014). The texts are being collected as part of an ongoing project at the University of TurkuFootnote 11 since 2007 with the goal of collection suitable data than allows for quantitative and qualitative analysis of Finnish interlanguage.
The current version of the corpus contains approximately 630k tokens of text in 640 texts collected from writers of fifteen different L1 backgrounds. The included L1 backgrounds are: Czech, English, Erzya, Estonian, German, Hungarian, Icelandic, Japanese, Komi, Lithuanian, Polish, Russian, Slovak, Swedish and Udmurt. The corpus texts are available in an XML format and have been annotated in terms of parts of speech, word lemmas, morphological forms and syntactic functions.
While there are fifteen different L1s represented in the corpus, the majority of these have fewer than ten texts and cannot reliably be used for NLI. Instead, we use a subset of the corpus consisting of the top seven L1s by number of texts. The languages and document counts in each class are shown in Table 2.
3.7 Other corpora
In this section, we describe a number of other corpora that we use in this work, namely for Experiment 3.
3.7.1 The CEDEL2 corpus
One of the first large-scale English L1–Spanish L2 corpora, the CEDEL2 corpus (Lozano Reference Lozano and Bretones Callejas2009; Lozano and Mendikoetxea Reference Lozano, Mendikoetxea, Ballier, Díaz-Negrillo and Thompson2013) was developed as a part of a research project (at the Universidad Autónoma de Madrid and Universidad de Granada in Spain) that aims to investigate how English-speaking learners acquire Spanish. It contains Spanish texts written by English L1 speakers as well as Spanish NS controls for comparative purposes. The non-native writings are further classified into three groups according to their proficiency level (Beginner, Intermediate and Advanced). This data differs from the above-described corpora as it does not contain multiple L1 groups.
3.7.2 The Toefl11 corpus
Initially released as part of the 2013 NLI Shared task, the Toefl11 corpus (Blanchard et al. Reference Blanchard, Tetreault, Higgins, Cahill and Chodorow2013) is the first dataset designed specifically for the task of NLI and developed with the aim of addressing the deficiencies of other previously used corpora. By providing a common set of L1s and evaluation standards, the authors set out to facilitate the direct comparison of approaches and methodologies.
It consists of 12, 100 learner texts from speakers of eleven different languages, making it the largest publicly available corpus of non-native English writing. The texts are independent task essays written in response to eight different prompts,Footnote 12 and were collected in the process of administering the Test of English as a Foreign Language (TOEFL®) between 2006 and 2007. The eleven L1s are Arabic, Chinese, French, German, Hindi, Italian, Japanese, Korean, Spanish, Telugu and Turkish. This dataset was designed specifically for NLI and the authors balanced the texts by topic and L1. Furthermore, the proficiency level of the author of each text (low, medium or high) is also provided as metadata.
Furthermore, as all of the texts were collected through the Education Testing Service’s electronic test delivery system, this ensures that all of the data files are encoded and stored in a consistent manner. The corpus was released through the Linguistic Data Consortium in 2013.
3.7.3 The LOCNESS corpus
The Louvain Corpus of Native English Essays (LOCNESS)Footnote 13 – part of the Louvain family of corpora – is comprised of essays written by native English speakers. The corpus contains c. 324k tokens of text produced by British and American students. This corpus can serve as native control data for L2 English texts, given the lack of NS data in the Toefl11 corpus.
3.8 Data preparation challenges
The use of such varied corpora can pose several technical and design challenges which must be addressed. Based on our experience, we list here some of issues that we encountered during these experiments, and how they were addressed.
3.8.1 File formats
Corpora can exist in several file formats, the most common of which are XML, HTML, word processor documents (Microsoft Word or RTF) and plain text. As a first step, it was necessary to convert all the files to a common machine-readable format before the data could be processed. We chose to convert all of the documents into a standard text format for maximum compatibility.
3.8.2 File encoding
The choice of text encoding is particularly important when working with languages that use characters beyond the ASCII range. To maximize compatibility with languages and software tools, we encoded our text files as Unicode using the UTF-8 encoding without a Byte Order Mark. We also note that some languages may be represented by various character encoding standards,Footnote 14 so we found that developing programs and tools that work with a unified character encoding such as Unicode was the best way to maximize their compatibility so that they work with as many languages as possible.
3.8.3 Unicode normalization
This is the process of converting Unicode strings so that all canonical-equivalent stringsFootnote 15 have the exact same binary representation.Footnote 16 It may also be necessary to remove certain characters that are not part of the target language. Without the application of such safeguards, experimental results may be compromised by the occurrence of characters and symbols that only appear in texts from specific corpora or speakers of certain L1s. This effect has previously been noted by Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) where idiosyncrasies such as the presence of characters which only appear in texts written by speakers of certain languages can compromise the usability of the corpus. This is because such characters can become strongly associated with a class and artificially inflate classification results, thus making it hard to assess the true performance of the features.
3.8.4 Segmentation and tokenization
Corpora are made available with differing levels of linguistic processing. Some are pre-tokenized, some may be sentence or paragraph segmented while others are simply the raw files as produced by the original authors. It is crucial to consistently maintain all files in the same format to avoid feature extraction errors. For example, if extracting character n-grams from a set of tokenized and untokenized texts, the extracted features will differ and this may influence the classification process. Accordingly, we made sure all the files had comparable formats and structures. We stored the documents with one sentence per line and each sentence was tokenized.
3.8.5 Annotations and idiosyncrasies
Some corpora may be annotated with additional information such as errors, corrections of errors or discourse/topical information. Where present, we removed all such information so that only the original text, as produced by the author, remained. Another minor issue has to do with the class labels that various corpora use to represent the different languages. For example, the FALKO Corpus uses the ISO 639 three-letter language codes while other corpora simply use the language names or even numbers. It was necessary to create a unified set of language codes or identifiers and assign them to the texts accordingly.
4 Experimental methodology
We also follow the supervised classification approach described in Section 2. We devise and run experiments using several models that capture different types of linguistic information. For each model, features are extracted from the texts and a classifier is trained to predict the L1 labels using the features.
4.1 Classification
We use a linear Support Vector Machine to perform multiclass classification in our experiments. In particular, we use the LIBLINEARFootnote 17 SVM package (Fan et al. Reference Fan, Chang, Hsieh, Wang and Lin2008) which has been shown to be efficient for text classification problems with large numbers of features and documents such as the present work. It has also been demonstrated to be the most effective classifier for NLI in the 2013 NLI Shared Task (Tetreault et al. Reference Tetreault, Blanchard and Cahill2013). More specifically, we make use of the L2-regularized L2-loss support vector classification (dual) solver.
4.2 Evaluation
Consistent with most NLI studies and the 2013 shared task, we report our results as classification accuracy under k-fold cross-validation, with k = 10. In recent years, this has become an emergent de facto standard for reporting NLI results.
For creating our folds, we employ stratified cross-validation which aims to ensure that the proportion of classes within each partition is equal (Kohavi Reference Kohavi1995).
For comparison purposes, we define a majority baseline, calculated by using the largest class in the dataset as the classification output for all input documents. For example, in the case of the L2 Chinese data listed in Table 2, the largest L1 class is Filipino with 415 documents in a dataset with 3,216 documents in total. The majority baseline is thus calculated as 415/3216 = 12.9 per cent.
No other baselines are available here as this is the first NLI work on these corpora.
4.3 NLP tools
In this section, we briefly list and describe the tools used to process our data.
4.3.1 Chinese and German
For processing these two languages, the Stanford CoreNLPFootnote 18 suite of NLP tools (Manning et al. Reference Manning, Surdeanu, Bauer, Finkel, Bethard and McClosky2014) and the provided models were used to tokenize POS tag and parse the unsegmented corpus texts.
4.3.2 Arabic
The tokenization and word segmentation of Arabic is an important preprocessing step for addressing the orthographic issues discussed in Section 3.5. For this task, we utilize the Stanford Word Segmenter (Monroe et al. Reference Monroe, Green and Manning2014).Footnote 19 The Arabic texts were POS tagged and parsed using the Stanford Arabic Parser.Footnote 20
4.3.3 Spanish and Italian
All of the processing on these language was performed using FreeLing (Carreras et al. Reference Carreras, Chao, Padró and Padró2004; Padró and Stanilovsky Reference Padró and Stanilovsky2012), an open-source suite of language analysers with a focus on multilingual NLP.
4.3.4 Finnish
We did not use any NLP tools for Finnish as the corpus we use is already annotated.
5 Features
5.1 Part-of-speech tags
Parts of speech are linguistic categories (or word classes) assigned to words that signify their syntactic role. Basic categories include verbs, nouns and adjectives but these can be expanded to include additional morphosyntactic information. The assignment of such categories to words in a text adds a level of linguistic abstraction.
In our work, the POS tags for each text are predicted with a POS tagger and n-grams of order 1–3 are extracted from the tags. These n-grams capture (very local) syntactic patterns of language use and are used as classification features. Previous research and results from our own experiments show that sequences of size 4 or greater achieve lower accuracy, possibly due to data sparsity, so we do not present them in our work.
The different languages and NLP tools used to process them each utilize distinct POS tagsets. For example, our Chinese data is tagged using the Penn Chinese Treebank tagset (Xia Reference Xia2000). For Italian and Spanish, the EAGLES TagsetFootnote 21 is used while for German the Stuttgart/Tübinger Tagset (STTS) is used (Schiller et al. Reference Schiller, Teufel and Thielen1995).
A summary of these tagsets can be found in Table 3. Looking at these values, it becomes evident that some languages have a much more detailed tag set than for other languages. It has been standard in monolingual research to just use the best available tagger and tagset that were explicitly developed for some particular language. However, this approach can be problematic in multilingual research where the tagsets, and consequently the classification results obtained by employing them, are not comparable. One possibility is to convert the tags for each language to a more general and common tagset; this would make the results more directly comparable across the languages. This issue will be further explored in Experiment IV, which is presented in Section 9.
Table 3. A listing of the tagsets used for the languages in our experiments, including the size of the tagset

5.2 Function words
In contrast to content words, function words do not have any meaning themselves, but rather can be seen as indicating the grammatical relations between other words. In a sense, they are the syntactic glue that hold much of the content words together and their role in assigning syntax to sentences is linguistically well defined. They generally belong to a language’s set of closed-class words and embody relations more than propositional content. Examples include articles, determiners, conjunctions and auxiliary verbs.
Function words are considered to be highly context- and topic-independent but other open-class words can also exhibit such properties. In practical applications, such as Information Retrieval, such words are often removed as they are not informative and stoplists for different languages have been developed for this purpose. These lists contain ‘stop words’ and formulaic discourse expressions such as above-mentioned or on the other hand.
Function words’ topic independence has led them to be widely used in studies of authorship attribution (Mosteller and Wallace Reference Mosteller and Wallace1964) as well as NLIFootnote 22 and they have been established to be informative for these tasks. Much like Information Retrieval, the function word lists used in these tasks are also often augmented with stoplists and this is also the approach that we take.
Such lists generally contain anywhere from fifty to several hundred words, depending on the granularity of the list and also the language in question. Table 4 lists the number of such words that we use for each language.
Table 4. Function word counts for the various languages in our study

The English word list was obtained from the Onix Text Retrieval Toolkit.Footnote 23 For Chinese, we compiled a list of 449 function words using Chinese language teaching resources. The complete list can be accessed online.Footnote 24 The lists for the rest of the languages have been sourced from the multilingual Information Retrieval resources made available by Prof. Jacques Savoy and can also be accessed online.Footnote 25
As seen in Table 4, there is some variation between the list sizes across the languages. This is generally due to lexical differences and the degree of morphological complexity as the lists contain all possible inflections of the words. For example, the Finnish list contains the words heihin, heille, heiltä, heissä, heistä and heitä, all of which are declensions of the third person plural pronoun he. Other languages may have fewer such inflected words, leading to different list sizes.
5.3 Phrase structure rules
Also known as Context-free Grammar Production Rules, these are the rules used to generate constituent parts of sentences, such as noun phrases. The rules are extracted by first generating constituent parses for all sentences. The production rules, excluding lexicalizations, are then extracted. Figure 3 illustrates this with an example tree and its rules.

Fig. 3. A constituent parse tree for an example sentence along with the context-free grammar production rules which can be extracted from it.
These context-free phrase structure rules capture the overall structure of grammatical constructions and global syntactic patterns. They can also encode highly idiosyncratic constructions that are particular to some L1 group. They have been found to be useful for NLI (Wong and Dras Reference Wong and Dras2011) and we utilize them as classification features in some of our experiments. It should also be noted that the extraction of this feature is predicated upon the availability of an accurate parser for the target language. Unfortunately, this is not the case for all of our languages.
5.4 Unused lexical features
A number of other lexical features that directly use the tokens in a text, including character and word n-grams, have also been investigated for NLI. However, the use of these lexical features cannot be justified in all circumstances due to issues with topic bias (Brooke and Hirst Reference Brooke and Hirst2012a), as we describe here. Topic bias can occur as a result of the themes or topics of the texts to be classified not being evenly distributed across the classes. For example, if in our training data all the texts written by English L1 speakers are on topic A, while all the French L1 authors write about topic B, then we have implicitly trained our classifier on the topics as well. In this case, the classifier learns to distinguish our target variable through another confounding variable. This concept is illustrated in Figure 4.

Fig. 4. An example of a dataset that is not balanced by topic: class 1 contains mostly documents from topic A while class 2 is dominated by texts from topic B. Here, a learning algorithm may distinguish the classes through other confounding variables related to topic.
Other researchers like Brooke and Hirst (Reference Brooke and Hirst2012b), however, argue that lexical features cannot be simply ignored. Given the relatively small size of our data and the inability to reach definitive conclusions regarding this, we do not attempt to explore this issue in the present work.
6 Experiment I – evaluating features
Our first experiment is aimed at evaluating whether the types of NLI systems and features sets employed for L2 English writings can also work for other languages. We perform NLI on the datasets of the languages described above, running experiments within each corpus, over all of the L1 classes described in Section 3.
There have been conflicting results about the optimal feature representation to use for NLI. Some have reported that binary representations perform better (Brooke and Hirst Reference Brooke and Hirst2012b; Wu et al. Reference Wu, Lai, Liu and Ng2013) while others argue that frequency-based representations yield better results (Jarvis et al. Reference Jarvis, Bestgen and Pepper2013; Lahiri and Mihalcea Reference Lahiri and Mihalcea2013). This is an issue that we explore here by comparing both representations across all of our data. This can help inform current research by determining if there are any patterns that hold cross-linguistically.
Consequently, each experiment is run with two feature representations: binary (encoding presence or absence of a feature) and normalized frequencies, where feature values are normalized to text length using the l 2-norm. We also combine the features into a single vector to create combined classifiers to assess if a union of the features can yield higher accuracy.
6.1 Results and discussion
The results for all of our languages are included in Table 5. The majority baseline is calculated by using the largest class as the default classification label chosen for all texts. For each language, we report results using two feature representations: binary (bin) and normalized frequencies (freq).
Table 5. NLI classification accuracy (per cent) for Chinese (eleven classes), Arabic (seven classes), Italian (fourteen classes), Finnish (nine classes), German (eight classes) and Spanish (six classes). Results are reported using both binary and frequency-based feature representations. The production rules features were only tested on some languages

6.2 General observations
A key finding from this experiment is that NLI models can be successfully applied to non-English data. This is an important step for furthering NLI research as the field is still relatively young and many fundamental questions have yet to be answered.
We also assess the overlap of the information captured by our models by combining them all into one vector to create a single classifier. From Table 5, we see that for each feature representation, the combined feature results are higher than the single best feature. This demonstrates that for at least some of the features, the information they capture is orthogonal and complementary, and combining them can improve results.
We also note the difference in the efficacy of the feature representations and see a clear preference for frequency-based feature values – they outperform the binary representations in all cases. Others have found that binary features are the most effective for English NLI (Brooke and Hirst Reference Brooke and Hirst2012b), but our results indicate the frequency representation is more useful in this task. The combination of both feature representations has also been reported to be effective in previous research (Malmasi et al. Reference Malmasi, Wong and Dras2013).Footnote 26
Below, we note language-specific details and analyses.
6.3 Chinese
The results show that POS tags are very useful features here. The trigram frequencies give the best accuracy of 55.60 per cent, suggesting that there exist group-specific patterns of Chinese word order and category choice which provide a highly discriminative cue about the L1. This is interesting given that fixed word order is important in Chinese, as discussed in Section 3.4. Function word frequency features provide an accuracy of 51.91 per cent, significantly higher than the baseline. As for English L2 texts, this suggests the presence of L1-specific grammatical and lexical choice patterns that can help distinguish the L1, potentially due to cross-linguistic transfer. We also use phrase structure rules as classification feature, achieving an accuracy of 49.80 per cent. Again, as for English L2 data, the syntactic substructures would seem to contain characteristic and idiosyncratic constructions specific to L1 groups and that these syntactic cues strongly signal the writer’s L1.
The Chinese data is the largest corpus used in this work and also has the same number of classes as the Toefl11 corpus used in the 2013 NLI shared task. This enables us to compare the results across the datasets to see how these features perform across languages. However, there are also a number of caveats to bear in mind: the corpora differ in size and the Chinese data is not balanced by class as Toefl11 is. We perform the same experiments on Toefl11 using the English CoreNLP models, Penn Treebank POS tagset and our set of 400 English function words. Figure 5 shows the results side by side.
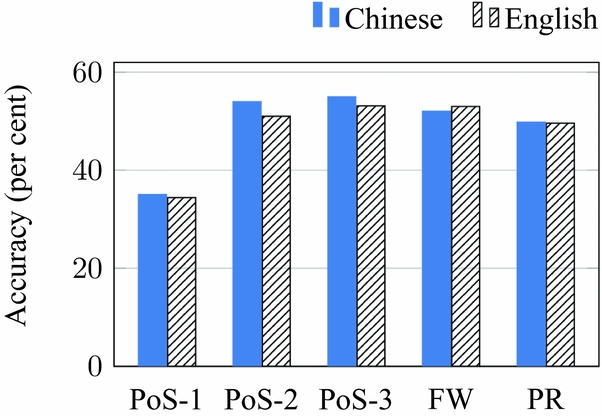
Fig. 5. Comparing feature performance on the CLC and Toefl11 corpora. POS-1/2/3: POS uni/bi/trigrams, FW: Function words, PR: Production rules.
Perhaps surprisingly, we see that the results closely mirror each other across corpora in terms of relative strengths of feature types. This may be connected to the strongly configurational nature of both English and Chinese.
6.4 Arabic
The frequency distributions of the production rules yield 31.7 per cent accuracy and function words achieve 29.2 per cent. While all the models provide results above the baseline, POS tag n-grams are the most useful features. Combining all of the models into a single feature space provides the highest accuracy of 41 per cent.
The Arabic results deviate from the other language in several ways. First, the improvement over the baseline is much lower than for other languages. Second, although POS bigrams provide the highest accuracy for a single feature type with 37.6 per cent, this is very similar to the POS unigrams and trigrams. Production rules were also worse than POS n-grams. Third, although the combined model is higher than the single-feature models, this is a much smaller boost compared to other languages. All of these issues could potentially be due to data size.
The Arabic data is our smallest corpus, which to the best of our knowledge, is the smallest dataset used for NLI in terms of document count and length. In this regard, we are surprised by relatively high classification accuracy of our system, given the restricted amount of training data available. While it is hard to make comparisons with most other experiments due to differing number of classes, one comparable study is that of Wong and Dras (Reference Wong and Dras2009) which used some similar features on a 7-class English dataset. Despite their use of a much larger dataset,Footnote 27 our individual models are only around 10 per cent lower in accuracy.
In their study of NLI corpora, Brooke and Hirst (Reference Brooke and Hirst2011) showed that increasing the amount of training data makes a very significant difference in NLI accuracy for both syntactic and lexical features. This was verified by Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) who showed that there is a very steep rise in accuracy as the corpus size is increased towards 11,000 texts.Footnote 28 Based on this, we expect that given similarly sized training data, an Arabic NLI system can achieve similar accuracies.
6.5 Italian
We make use of all fourteen classes available in the VALICO corpus. This is the largest number of classes in this work and one of the highest to be used in an NLI experiment.Footnote 29 Function words scored 50.1 per cent accuracy and POS trigrams yielded 56.89 per cent. Combining all of the features together improves this to 69.09 per cent, four times higher than the baseline.
6.6 Finnish
Here, we observe that the distribution of function words yields 54.6 per cent accuracy. This is perhaps unexpected in that Finnish, as a morphologically rich language, has a reduced role for function words relative to other languages. We believe their usefulness here is due to the use of an IR stoplist which contains more than just linguistically defined closed-class words.
The best single-feature accuracy of 54.8 per cent comes from POS trigrams. This may also be unexpected, given that Finnish has much freer word order than the other languages in this study. But the gap over function words is only 0.2 per cent, compared to the strongly configurational Chinese and Italian, where the gap is 4–6 per cent.
The combined model provides the highest accuracy of 58.86 per cent, around 4 per cent better than the best single feature type. An interesting difference is that POS unigrams achieve a much lower accuracy of 36.3 per cent.
6.7 German
Here, function words are the best single feature for this language. This deviates from the results for the other languages where POS n-grams are usually the best syntactic feature. Again, this may reflect the nature of the language: German, like Finnish, is not (strongly) configurational.
6.8 Spanish
The pattern here is most similar to Chinese and Italian.
6.9 Learning curves
We can also examine the learning curves of these features across various languages to see if the learning rates differ cross-linguistically.
These curves are generated by incrementally increasing the size of the training set, from 10 per cent through to 90 per cent. We produce one curve for each feature-language pair, using two of the best performing features: Function words and POS trigrams. As a dataset needs to be sufficiently large for training on 10 per cent of it to give a meaningful result, we analyse the curves only for the English Toefl11 data and our two biggest non-English datasets: Chinese and Italian. The curves are presented in Figure 6.

Fig. 6. The learning curves (classification accuracy score versus training set size) for two feature types, Function words and POS trigrams, across three languages: English (Toefl11, row 1), Chinese (CLC, row 2) and Italian (VALICO, row 3).
The curves demonstrate similar rates of learning across languages. We also note that while the relationship between function word and POS trigram features is not perfectly constant across number of training examples, there are still discernible trends. The English and Chinese data are most suitable for direct comparison as they have the same number of classes. Here, we see that Function words provide similar accuracy scores across both languages with 2000 training documents. They also plateau at a similar score. Similar patterns can be observed for POS trigrams.
7 Experiment II – comparing languages
The focus of our second experiment is to compare the performance of our feature set across a range of languages. Here, we are interested in a more direct cross-linguistic comparison on datasets with equal numbers of classes. We approach this by using subsets of our corpora so that they all have the same number of number of classes.
We run this experiment using our two biggest corpora, Chinese and Italian. Additionally, we also compare our results to a subset of the Toefl11 L2 English corpus. Table 6 shows the six languages that were selected from each of the three corpora. The number of documents within each class are kept even. These languages were chosen in order to maximize the number of classes and the number of documents within each class.
Table 6. The six L1 classes used for each language in Experiment II

Given that the results of Experiment I favoured the use of frequency-based feature values, we also use them here. We anticipate that the results will be higher than the previous experiment, given that there are fewer classes.
7.1 Results
The results for all three languages are shown in Table 7. Each language has a majority class baseline of 16.67 per cent as the class sizes are balanced. The results follow a similar pattern as the previous experiments with POS trigrams being the best single feature and a combination of everything achieving the best results.
Table 7. Comparing classification results across languages

Chinese yields 68.14 per cent accuracy, while Italian and English data obtain 67.61 per cent and 70.05 per cent, respectively. All of these are more than four times higher than the baseline.
7.2 Discussion
These results, shown graphically in Figure 7, demonstrate very similar performances across three different L2 corpora, much like the results in Experiment 1 for comparing English and Chinese performances. The results are particularly interesting as the features are performing almost identically across entirely different L1–L2 pairs. Again, as in Section 6.1, this may be related to the degree of configurationality in these languages.
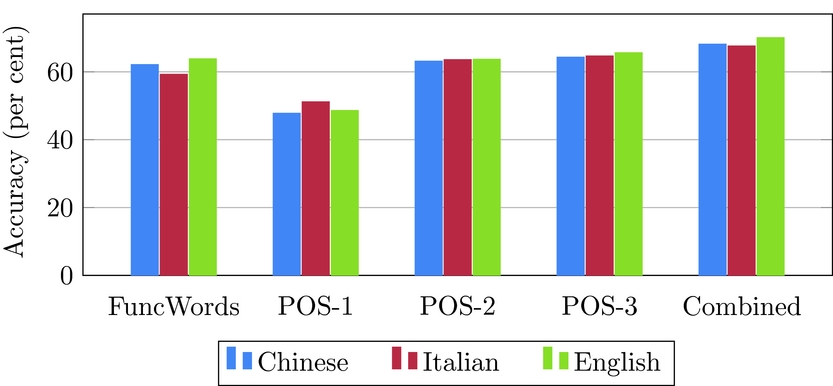
Fig. 7. Performance of our syntactic features (Function words and part-of-speech 1–3 grams) across the three languages.
Here, we also see that combining the features provides the best results in all cases. We also note that the English data is much larger than the others. It contains a total of 6,600 texts (evenly distributed with 1,100 per language) and this is a probably reason for the slightly higher performance.
8 Experiment III – identifying non-native writing
Our third experiment involves using the previously described features to classify texts as either having been written by a NS or NNS author. This should be a feasible task, given the results of the previous experiments. The objective here to see to what degree our features can distinguish the writings of NNSs and how this performance varies across the three different languages for which we have NS data: Finnish, Spanish and English.
We approach this in a similar manner to the previous experiments, with the exception that this is a binary classification task for distinguishing two classes: NS author and NNS author. Texts for the NNS class will come from learner corpora of three different languages while data from NS controls is used for the NS class, as we describe here.
For Finnish, we utilize a set of 100 control texts included in the LAS2 corpus that are written by native Finnish speakers. These represent the NS class. This is contrasted against the NNS class which includes 100 texts in total, sampled as evenly as possibleFootnote 30 from each languageFootnote 31 listed in Table 2.
For Spanish, we use the CEDEL2 corpus, described in Section 3.7.1. Here, we use 700 NS texts along with another set of 700 NNS texts randomly drawn from the essays of L1 English speakers. All texts are sourced from the same corpus and have a similar topic distribution.
Finally, we also apply these methods to L2 English data using the Toefl11 and LOCNESS corpora, described in Section 3.7. This is required as the Toefl11 corpus does not contain any native control texts. The NS class is composed of 400 NS essays taken from the LOCNESS corpus and the NNS data comes from the Toefl11 corpus. We sample this data evenly from the eleven L1 non-native classes, selecting thirty-six or thirty-seven texts from each to create a total of 400 texts.
The number of documents in both classes for each language are equal, hence all results are compared against a random baseline of 50 per cent. This experiment only uses frequency-based feature value representations and results are reported as classification accuracy under 10-fold cross-validation.
8.1 Results and discussion
Table 8 shows the results for all three languages, demonstrating that all features greatly surpass the 50 per cent baseline for all languages. The use of function words is the best single feature for two of the three languages, but combining all the features provides the best accuracy of approximately 95 per cent in all cases.
Table 8. Accuracy for classifying texts as native or non-native

Our Finnish data is relatively small with 100 documents in each class, thus we see that our commonly used features are largely sufficient for this task, even on a small dataset. The combined model achieves an accuracy of 94.92 per cent.
For Spanish, all features with the exception of POS unigrams achieve accuracies of over 90 per cent. When combined, the model yields the best accuracy of per cent.
The Spanish and Finnish results are very similar, despite Spanish having a much larger dataset. To investigate this further, we examined the learning curve for the best Spanish feature – POS trigrams – as shown in Figure 8.
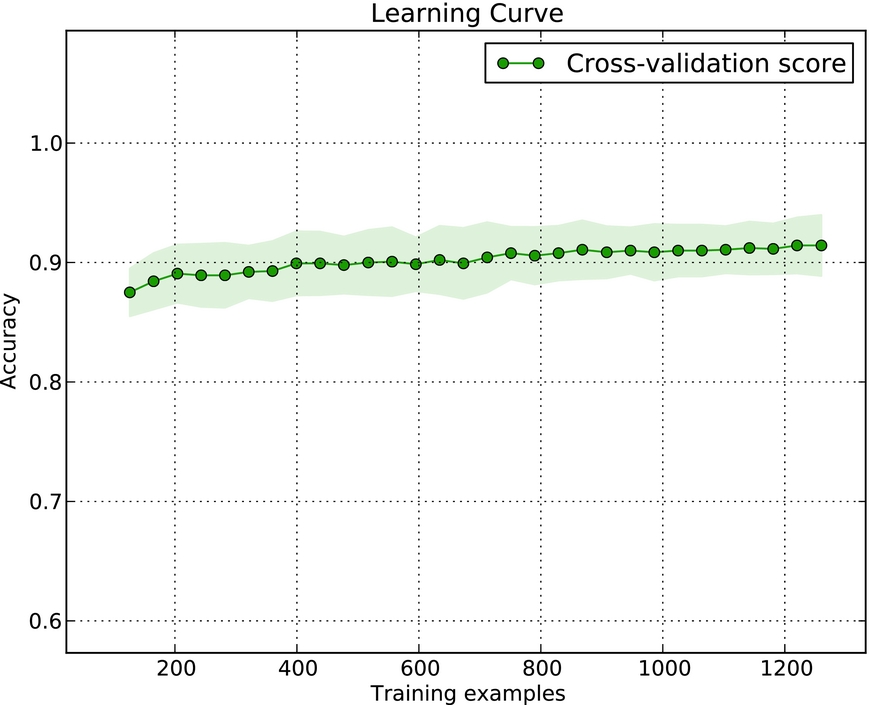
Fig. 8. A learning curve for the Spanish NS author versus non-native speaker author classifier trained on POS trigrams. The standard deviation range is also highlighted.
We note that although the accuracy increases as amount of data increases, the curve is much flatter than those for NLI in Section 6. However, this is offset by the fact that the curve’s starting point is much higher, achieving over 85 per cent accuracy by using only 10 per cent of the data for training.
The English results are very similar to those from the other languages and the combined model scores a cross-validation accuracy of 96.45 per cent. The texts in the English experiment here – unlike the Finnish and Spanish data – are sourced from different corpora, but while they are all student essays, they may differ significantly in topic, genre and style. This was a limitation that we were unable to overcome with the currently available data. In the future work, further topic-controlled experiments can also be performed for English using a dataset that contains sufficient amounts of native and non-native data for the same topic.
One direction for future experiments is the investigation of the relationship between L2 proficiency and the detection accuracy of NNS writing. Previous results by Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) show that NLI accuracy decreases as writing proficiency improves and becomes more native-like, but would this pattern hold here as well? Another potential path for future work is to extend this experiment to the sub-document level to evaluate the applicability of this approach at the paragraph, or even sentence level.
An analysis of what is being learnt by the models here can be useful for understanding the syntactic and stylistic factors that seem to make native writing so easily distinguishable. An exposition of features whose presence, or absence, characterizes non-native writing could also be of use in language teaching and pedagogical research.
It should also be noted that it is possible to approach this problem as a verification task (Koppel and Schler Reference Koppel and Schler2004) instead of a binary classification one. In this scenario, the methodology is one of novelty or outlier detection where the goal is to decide if a new observation belongs to the training distribution or not. This can be achieved using one-class classifiers such as a one-class SVM (Schölkopf et al. Reference Schölkopf, Platt, Shawe-Taylor, Smola and Williamson2001). One option is select native writing as the inlier training class as it is easier to characterize native writing and more importantly, training data is more readily available. It is also harder to define non-native writing as there can be many varieties, as we have shown in our experiments thus far. This is something we aim to investigate in future work by comparing the two approaches.
9 Experiment IV – the effects of POS tagset size on NLI accuracy
POS tagging is a core component of many NLP systems and this is no different in the case of NLI, as evidenced by experimental results thus far. Over the last few decades, a variety of tagsets have been developed for various languages and treebanks. Each of these tagsets is often unique and tailored to the features of a specific language. Within the same language, the existing tagsets can differ in their level of granularity.
Tagsets differ in size according to their level of syntactic categorization which provides different levels of syntactically meaningful information. They can be very fine-grained in their distinction between syntactic categories by including more morphosyntactic information such as gender, number, person, case, tense, verb transitivity and so on. Alternatively, a more coarse-grained tagset may only use broader syntactic categories such as verb or noun. This can be observed by looking at some of the tagsets developed for English, e.g.

The present work also makes use of a slew of different tagsets for the different languages, which were outlined in Section 5. Since the n-grams extracted from these POS tags can help capture characteristic word ordering and error patterns, it could be argued that a larger tagset can generate more discriminative sequences and thus yield better classification performance. However, it can also result in much larger and more sparse feature vectors.
Accordingly, the aim of this experiment is to assess the effect of POS tagset size on classification accuracy, hypothesizing that a larger target will provide better results. We also aim to compare the effectiveness of POS tags cross-linguistically. This could also enable us to better understand the results from Section 6 and what impact the different granularity of tagsets might have had.
Some previous research has examined this issue on L2 English data, but no complete comparison is available. Gyawali, Ramirez and Solorio (Reference Gyawali, Ramirez and Solorio2013) report that the use of a smaller tagset reduced English NLI accuracy. To further investigate this issue, we conduct a more thorough, cross-linguistic comparative evaluation of tagset performance.
9.1 A universal part of speech tagset
While a number of different tagsets have been proposed, certain tasks such as cross-lingual POS tagging (Täckström et al. Reference Täckström, Das, Petrov, McDonald and Nivre2013), multilingual parsing (McDonald et al. Reference McDonald2013) or drawing comparisons across tagsets require the use of a common tagset across languages. To facilitate such cross-lingual research, Petrov et al. (Reference Petrov, Das, McDonald, Chair, Choukri, Declerck, Doan, Maegaard, Mariani, Moreno, Odijk and Piperidis2012) propose a Universal POS tagset (UPOS) consisting of twelve coarse POS categories that are considered to be universal across languages.Footnote 32
We utilize this UPOS in this experiment and convert the tags in the three largest datasets available: English, Chinese and Italian. By mapping from each language-specific tagset to the universal one, we obtain POS data in a common format across all languages. This enables us to compare the relative performance of the original and reduced tagset data. It also permits us to compare the utility of POS tags as a classification feature across languages. For English, we experiment with three tagsets: CLAWS, Penn Treebank and UPOS.
9.2 Results and discussion
The results for English are shown in Figure 9 and demonstrate that the largest tagset – CLAWS – provides the best classification accuracy. Classification accuracy continues to drop as the tagset gets smaller.
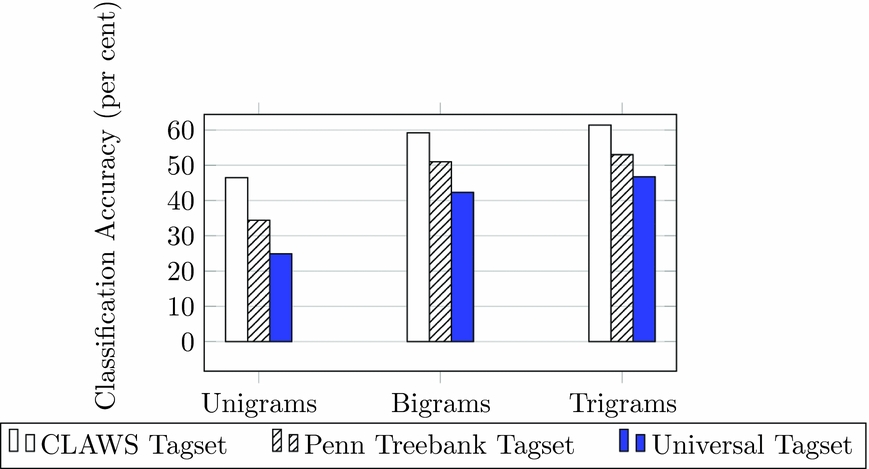
Fig. 9. NLI classification accuracy for L2 English data from the Toefl11 corpus, using POS n-grams extracted with the CLAWS, Penn Treebank and Universal POS tagsets.
Figures 10 and 11 show the results for Chinese and Italian, respectively. Here, we see a similar pattern, but the performance drop is much steeper for Italian. This is likely because the Italian data uses a much more fine-grained tagset than Chinese.Footnote 33
Fig. 10. NLI classification accuracy for the L2 Chinese data, using POS n-grams extracted with the Penn Chinese Treebank and Universal POS tagsets.
Fig. 11. NLI classification accuracy for the L2 Italian data using POS n-grams extracted with the EAGLES and the Universal POS tagsets.
A notable finding here, related to our first hypothesis, is that larger tagsets always yield higher classification results. Evidence from all three languages supported this.
However, these results also show that even with only twelve POS tags, the UPOS set retains around 80 per cent of the classification accuracy of the full tagsets. This finding signals that the great majority of the syntactic patterns that are characteristic of L1 groups are related to the ordering of the most basic word categories. This can be further investigated by comparing learner data with the same L1 but multiple L2sFootnote 34 to find common transfer patterns related to that L1.
Another interesting observation is that the UPOS results are quite similar and closely mirror each other across the three languages. Prima facie, this supports previous findings suggesting that a systematic pattern of cross-linguistic transfer may exist, where the degree of transfer is independent of the L1 and L2 (Malmasi and Dras Reference Malmasi and Dras2014a). While these results are certainly not conclusive, this is a question that merits further investigation, pending the availability of additional learner corpora in the future.
Finally, as evidenced by our results, we can also conclude that the use of a universal tagset can be helpful in comparing the performance of syntactic features such as POS tags in cross-lingual studies where the languages use distinct tagsets.
10 Experiment V – bounding classification accuracy
Another interesting question about NLI research concerns the maximum potential accuracy that can be obtained for a dataset. More specifically, given a dataset, a selection of features and classifiers, what is an upper bound on the performance that could possibly be achieved by an NLI system that always picks the best candidate?
This question, not previously addressed in the context of NLI to date, is the focus of the next experiment. Such a measure is an interesting and useful upper-limit baseline for researchers to consider when evaluating their work, since obtaining 100 per cent classification accuracy may not be a reasonable or even feasible goal. However, the derivation of such a value is not a straightforward process. In this section, we present an experiment that investigates this issue with the aim of deriving such an upper limit for NLI accuracy.
A possible approach to this question, and one that we employ here, is the use of an ‘Oracle’ classifier. This method has previously been used to analyse the limits of majority vote classifier combination (Kuncheva et al. Reference Kuncheva, Bezdek and Duin2001; Wozniak and Zmyslony Reference Wozniak and Zmyslony2010). An oracle is a type of multiple classifier fusion method that can be used to combine the results of an ensemble of classifiers which are all used to classify a dataset.
The oracle will assign the correct class label for an instance if at least one of the constituent classifiers in the system produces the correct label for that data point. Some example oracle results for an ensemble of three classifiers are shown in Table 9. The probability of correct classification of a data point by the oracle is
 $$\begin{equation*}
P_{\text{Oracle}} = 1 - P(\text{All Classifiers Incorrect})
\end{equation*}$$
$$\begin{equation*}
P_{\text{Oracle}} = 1 - P(\text{All Classifiers Incorrect})
\end{equation*}$$
Table 9. Example oracle results for an ensemble of three classifiers

Oracles are usually used in comparative experiments and to gauge the performance and diversity of the classifiers chosen for an ensemble (Kuncheva Reference Kuncheva2002; Kuncheva et al. Reference Kuncheva, Whitaker, Shipp and Duin2003). They can help us quantify the potential upper limit of an ensemble’s performance on the given data and how this performance varies with different ensemble configurations and combinations.
One scenario is the use of an oracle to evaluate the utility of a set of feature types. Here, each classifier in the ensemble is trained on a single feature type. Another scenario involves the combination of different learning algorithms,Footnote 35 trained on similar features, to form an ensemble in order to evaluate the potential benefits and limits of combining different classification approaches.
In this experiment, we use our feature set on our biggest datasets: Chinese, Italian and English. Following the above-described oracle methodology, we train a single linear SVM classifier for each feature type to create our NLI classifier ensemble, noting that Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) found ensembles of classifiers over feature types to produce higher results. We do not experiment with combining different machine learning algorithms here; instead, we focus on gauging the potential of the feature set.
The oracle classifier fusion method is then run on each ensemble so that the correct label is assigned to each document if any of the classifiers in the ensemble classify it correctly. These labels are then used to calculate the potential accuracy of the ensemble on the dataset. We perform this procedure for each language.
10.1 Results
The oracle results for the three languages are shown in Table 10 and contrasted against the majority class baseline and our combined features classifier. These results establish that NLI systems have the potential to achieve high classification accuracy. Analysing the relative increase over the baseline shows better performance on larger datasets.
Table 10. Oracle classifier accuracy for the three languages in experiment V

The results indicate that at least one of our feature types was able to correctly classify some 85 per cent of the texts in each dataset. However, even under this best scenario, we should note that not a single classifier is able to correctly predict the label for the remaining per cent of the data. This suggests that a certain portion of L2 texts are not distinguishable by any of our current features. This value is similar across the three languages, indicating that this may be a more general trend.
10.2 Discussion
This experiment presented a new type of analysis for predicting the ‘potential’ upper limit of NLI accuracy on a dataset. This upper limit can vary depending on which components – feature types and algorithms – are used to build the NLI system. Alongside other baseline measures, the Oracle performance can be helpful in interpreting the relative performance of an NLI system.Footnote 36
A useful application of this method is to isolate the subset of wholly misclassified texts for further investigation and error analysis. This segregated data can then be independently studied to better understand the aspects that make it hard to classify them correctly. This can also be used to guide feature engineering practices in order to develop features that can distinguish these challenging data points.
The method can also be applied in a cross-corpus setting, as described in Section 11.2. Here, the oracle could be useful in measuring the potential cross-corpus accuracy, particularly in settings where the source and target corpora differ significantly in domain, genre or style. The oracle method can help assess how effective the training data are for each target corpus.
As the Oracle accuracy is similar across the three languages, this may indicate a more general trend related to writing proficiency and the maximum classification potential. Previously, the work of Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) demonstrated that classification gets increasingly harder as writer proficiency increases. This higher proficiency makes it more challenging to discern the native-like writings of authors of distinct L1 backgrounds. It may also point to a deficiency in the feature set: a portion of the data are indistinguishable using the current features.
We must also bear in mind that these Oracle figures would be produced by an absolutely optimal system that would always make the correct decision using this pool of classifiers. While these Oracle results could be interpreted as potentially attainable, this may not be feasible and practical limits could be substantially lower. In practice, this type of Oracle measure can be used to guide the process of choosing the pool of classifiers that form an ensemble.
11 Measuring and analysing feature diversity
Results from our previous experiments show that while some feature types yield similar accuracies independently, such as those in Table 5, combining them can improve performance. This indicates that the information they capture is diverse, but how diverse are they and how can we measure the level of independence between the feature types?
This is a question that was recently investigated by Malmasi and Cahill (Reference Malmasi and Cahill2015) who used Yule’s Q coefficient of association as one approach to measuring the degree of diversity between features. They applied this method to English data from the Toefl11 corpus and in this section we expand this evaluation to include other languages. We begin by comparing the approach to an ablative analysis and describing the Q coefficient.
An ablation study is a common approach in machine learning that aims to measure the contribution of each feature in a multicomponent system. This ablative analysis is usually carried out by measuring the performance of the entire system with all components (i.e. features) and then progressively removing the components one at a time to see how the performance degrades.Footnote 37 While useful for estimating the potential contribution of a component, this type of analysis does not directly inform us about the pairwise relation between any two given components. In their study of classifying discourse cohesion relations, Wellner et al. (Reference Wellner, Pustejovsky, Havasi, Rumshisky and Sauri2006) performed an ablation analysis of their feature classes and note:
From the ablation results [. . .] it is clear that the utility of most of the individual features classes is lessened when all the other feature classes are taken into account. This indicates that multiple feature classes are responsible for providing evidence [about] given discourse relations. Removing a single feature class degrades performance, but only slightly, as the others can compensate.
This highlights the need to quantify the overlap between any two given components in a system. Our approach to estimating the amount of diversity between two feature types is based on measuring the level of agreement between the two for predicting labels on the same set of documents. Here, we aim to examine feature differences by holding the classifier parameters and data constant.
Previous research has suggested that Yule’s Q coefficient statistic (Yule Reference Yule1912; Warrens Reference Warrens2008) is a useful measure of pairwise dependence between two classifiers (Kuncheva et al. Reference Kuncheva, Whitaker, Shipp and Duin2003). This notion of dependence relates to complementarity and orthogonality, and is an important factor in combining classifiers (Lam Reference Lam2000).
Yule’s Q statistic is a correlation coefficient for binary measurements and can be applied to classifier outputs for each data point where the output values represent correct (1) and incorrect (0) predictions made by that learner. Each classifier Ci produces a result vector yi = [y i, 1, . . ., y i, N ] for a set of N documents where y i, j = 1 if Ci correctly classifies the jth document, otherwise it is 0. Given these output vectors from two classifiers Ci and Ck , a 2 × 2 contingency table can be derived:
 $$\begin{equation*}
\begin{array}{lll}& C_{k}\ \ {\rm Correct} & C_{k}\ \ {\rm Wrong} \\
C_{i} {\rm Correct} & N^{11} & N^{10} \\
C_{i} {\rm Wrong} & N^{01} & N^{00} \\
\end{array}
\end{equation*}$$
$$\begin{equation*}
\begin{array}{lll}& C_{k}\ \ {\rm Correct} & C_{k}\ \ {\rm Wrong} \\
C_{i} {\rm Correct} & N^{11} & N^{10} \\
C_{i} {\rm Wrong} & N^{01} & N^{00} \\
\end{array}
\end{equation*}$$
Here, N 11 is the frequency of items that both classifiers predicted correctly, N 00 where they were both wrong, and so on. The Q coefficient for the two classifiers can then be calculated as follows:
 $$
Q_{i,k} = \frac{N^{11}N^{00} - N^{01}N^{10}}{N^{11}N^{00} + N^{01}N^{10}}
$$
$$
Q_{i,k} = \frac{N^{11}N^{00} - N^{01}N^{10}}{N^{11}N^{00} + N^{01}N^{10}}
$$
This distribution-free association measureFootnote 38 is based on taking the products of the diagonal cell frequencies and calculating the ratio of their difference and sum.Footnote 39 Q ranges between − 1 and + 1, where − 1 signifies negative association, 0 indicates no association (independence) and + 1 means perfect positive correlation (dependence).
In this experiment, our classifiers are always of the same type, a linear SVM classifier, but they are trained with different features on the very same dataset. This allows us to measure the dependency between feature types themselves.
11.1 Results
We calculate the Q coefficient for our largest dataset, Chinese, using all five features listed in Table 5. For comparison purposes, we also calculate Q for the same features on the Arabic and Toefl11 English data. The matrices of the Q coefficients for all features and languages are shown graphically in Figure 12. We did not find a negative correlation between any of our features.
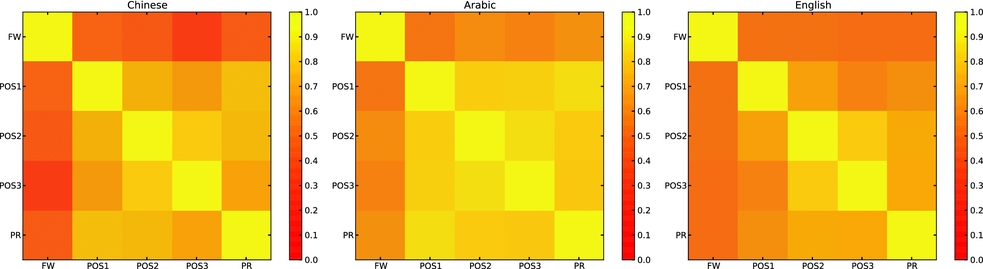
Fig. 12. The Q coefficient matrices of five features for Chinese (l), Arabic (m) and English (r). The matrices are displayed as heat maps. POS 1/2/3: POS uni/bi/trigrams, FW: Function words, PR: Production rules.
The values for Chinese show a weak correlation of 0.3 between Function words and all other features. Production rules also have a moderate correlation with POS trigrams. Additionally, although their outputs are weakly to moderately correlated, these three features yield similar accuracy when used independently. Such features, with high individual accuracy yet low output correlation are ideal sources of diversity when combining classifiers.
Looking at the other languages, we also observe very similar patterns across the data, as can be seen by comparing the plots in Figure 12. This seems to suggest that these correlation patterns may hold cross-lingually.
To test the validity of these results, we re-run the Chinese experiment from Section 6, this time combining the top three features with the lowest average Q coefficient, weighted by their classification error.Footnote 40 These features are Function words, Production rules and POS trigrams and combining them yields an accuracy of 70.7 per cent, compared to 70.6 per cent for using all five features. This, then, suggests that the most diverse features contribute the most to the combined classifier and that removing redundant information can increase accuracy. Having several highly dependent feature types may make it harder for a learner to overcome their errors.
11.2 Discussion
Such analyses can help us better understand the linguistic properties of the features and guide interpretation of the results. This analysis can be used to examine the orthogonality or complementarity between features, particularly those of the same type. One such example would be a comparison between two syntactic features, context-free grammar production rules and grammatical dependencies, both of which are based on parsing and known to be useful for NLI. The measure is most useful when comparing features with similar individual performance to identify those with the highest diversity. As shown by our results, this can be utilized for finding combinations of diverse and high performing features.
This information can also be useful in creating classifier ensembles. One goal in creating such committee-based classifiers is the identification of the most diverse independent learners and this research can be applied to that end. By selecting fewer but less redundant features, it should be possible to build simpler models with equal, if not better, performance.
Another promising application is in a cross-corpus setting where a model is trained on one corpus and tested on a different one. This approach has been applied in NLI using several L2 English corpora (Tetreault et al. Reference Tetreault, Blanchard, Cahill and Chodorow2012; Ionescu, Popescu and Cahill Reference Ionescu, Popescu and Cahill2014; Malmasi and Dras Reference Malmasi and Dras2015b). In one such study, Brooke and Hirst (Reference Brooke and Hirst2012b) investigated the utility of a standard feature set across several corpora and compared their cross-corpus performance, similar to our within-corpus study in Experiment I. In this context, the feature diversity measures can be applied in a cross-corpus setting to see if the same patterns found here are also present. This can help us better understand interfeature correlations when they are applied across differing genres, domains and registers and how this may differ from the same correlations within a single corpus.
An important direction for future research is the expansion of the current analysis to more languages and features, as the required resources become available. This could help identify specific feature correlations that are present across languages.
The analysis could also be expanded within a single corpus. The largest number of NLI features have been explored for English and they include, inter alia, Tree Substitution Grammar fragments, Brown clusters, Adaptor Grammars, Dependencies, spelling errors and n-gram language models. A logical extension of this line of inquiry is the application of this method to study the levels of interdependence and redundancy between these myriad features. Such an analysis has not been attempted to date and could yield insightful findings for NLI and SLA research.
12 General discussion and conclusion
The present study has examined a number of different issues from a cross-lingual perspective, making a number of novel contributions to NLI research. Using up to six language to inform our research, our experiments use evidence from multiple languages to support their results and to identify general patterns that hold across multiple languages. The most prominent finding here is that NLI techniques can be successfully applied to a range of languages that differ from English, which has been the focus of almost all previous research.
To the best of our knowledge this is the first sizeable study of NLI with a primary focus on multiple non-English L2 corpora. This includes the identification of relevant data and tools for conducting cross-lingual NLI research. We believe this is an important step for furthering NLI research as the field is still relatively young and many fundamental questions remain unanswered. These results are useful for gaining deeper insights about the technique and exploring its potential application in a range of contexts, including education, SLA and forensic linguistics.
Our first two experiments evaluated our features and data, showing that the selected commonly used features perform well and at approximately similar rates across languages, taking into account corpus size; they also suggest that the effectiveness of particular feature types is related to the typological character of the L2 to some extent. The third experiment compared non-native and native control data, showing that they can be discerned with 95 per cent accuracy. We also looked at some issues that have not previously been addressed for NLI. Experiment V also presented a new type of NLI error analysis aimed at calculating the upper limits of classification accuracy in this task, something not done to date. Our feature diversity analysis in Section 11 presented an approach for estimating the diversity and dependence of linguistic features.
We also note the difference in the efficacy of the feature representations and see a clear preference for frequency-based feature values. Others have found that binary features are the most effective for English NLI (Brooke and Hirst Reference Brooke and Hirst2012b), but our results indicate frequency information is more informative in this task.
Additionally, the corpora we have identified here can be used in other NLP tasks, including error detection and correction. This, of course, depends largely on the kinds of annotations the corpora have. If not already present, the corpora would need to be annotated for grammatical errors and their corrections.
There are also a number of methodological shortcomings that merit discussion. In its current state, research in non-English NLI is affected by many of the same issues that were prevalent in English NLI research prior to the release of the Toefl11 corpus. This includes the lack of a common evaluation framework and a paucity of large-scale datasets that are controlled for topic, the number of texts across the various L1 classes and also text length.
This study is affected by many such issues, e.g. a lack of even amounts of training data, as none of the non-English corpora used here were designed specifically for NLI. However, it should be noted that many of the early studies in English NLI were performed under similar circumstances. These issues were noted at the time, but did not deter researchers as corpora with similar issues were used for many years. Non-English NLI is also at a similar state where the extant corpora are not optimal for the task, but no other alternatives exist for conducting this research.
In addition to this data paucity, the lack of NLP tools for all languages is another limiting factor that hinders further research. Many aspects of NLI studies require the use of accurate parsers and taggers to extract relevant information from learner texts. The set of features used in this work was limited by the availability of linguistic tools for our chosen languages.
Finally, we would also like to point to the failure to distinguish between the L2 and any other acquired languages as a more general criticism of the NLI literature to date. The current body of NLI literature fails to distinguish whether the learner language is in fact the writer’s L2, or whether it is possibly a third language (L3). None of the corpora used here contain this metadata.
It has been noted in the SLA literature that when acquiring an L3, there may be instances of both L1- and L2-based transfer effects on L3 production (Ringbom Reference Ringbom2001). Studies of such L2 transfer effects during L3 acquisition have been a recent focus in CLI research (Murphy Reference Murphy2005).
One potential reason for this shortcoming in NLI is that none of the commonly used corpora distinguish between the L2 and L3; they only include the author’s L1 and the language being learned. This language is generally assumed to be an L2, but may not be case. At its core, this issue relates to corpus linguistics and the methodology used to create learner corpora. The thorough study of these effects is contingent upon the availability of more detailed language profiles of authors in learner corpora. The manifestation of these interlanguage transfer effects (the influence of one L2 on another) is dependent on the status, recency and proficiency of the learner’s acquired languages (Cenoz and Jessner Reference Cenoz, Hufeisen and Jessner2001). Accordingly, these variables need to be accounted for by the corpus creation methodology.
It should also be noted that based on currently available evidence, identifying the specific source of CLI in speakers of an L3 or additional languages (L4, L5, etc.) is not an easy task. Recent studies point to the methodological problems in studying productions of multilinguals (Dewaele Reference Dewaele1998; Williams and Hammarberg Reference Williams and Hammarberg1998; De Angelis Reference De Angelis2005).
From an NLP standpoint, if the author’s acquired languages or their number is known, it may be possible to attempt to trace different transfer effects to their source using advanced segmentation techniques. We believe that this is an interesting task in itself and a potentially promising area of future research.
Although specific directions for future research were discussed within each experiment, there are also a number of broader avenues for future work. The extension of these experiments to additional languages is the most straightforward direction for future research. The goal here would be to verify if the trends and patterns found in this work can be replicated in other languages. This can be expanded to a more comprehensive framework for comparative studies using equivalent syntactic features but with distinct L1–L2 pairs to help us better understand CLI and its manifestations. Such a framework could also help us better understand the differences between different L1–L2 language pairs.
The potential expansion of the experimental scope to include more linguistically sophisticated features also merits further investigation, but this is limited by the availability of language-specific NLP tools and resources. Such features include dependency parses, language models, stylometric measures and misspellings. The cross-lingual comparison of these features may identify additional trends.
A common theme across the first three experiments was that the combination of features provided the best results. This can be further extended by the application of classifier ensemble methods. This could be done by aggregating the output of various classifiers to classify each document, similar to the work of Tetreault et al. (Reference Tetreault, Blanchard, Cahill and Chodorow2012) for English NLI. Such ensemble classifiers have also proven to be useful for related tasks such as dialect identification (Malmasi and Dras Reference Malmasi and Dras2015a; Malmasi et al. Reference Malmasi, Refaee and Dras2015a). The methods described in our feature diversity analysis from Section 11 can help guide the selection of diverse features to reduce redundancy in the classifier committee.
Acknowledgements
We would like to thank the anonymous reviewers for their extensive and constructive comments. We would also like to thank Ilmari Ivaska and Kirsti Siitonen making the Finnish learner data available. We also thank Anne Ife for providing the Spanish learner corpus.






















