


1 Common ground: SOTA-chasing considered harmful
Given its unpopularity, why are so many papers chasing state-of-the-art (SOTA) numbers? The point of this paper is not to argue against SOTA-chasing but to identify some of the root causes behind SOTA-chasing and to offer some constructive suggestions for the future.
This paper will define SOTA-chasing to refer to papers that report SOTA numbers, but contribute little of lasting value to the literature. The point is the pointlessness.
Rogers posted an excellent blog on SOTA-chasing.Footnote a Her blog addresses two questions that will also be discussed in this paper:
-
1. How did we get here?
-
2. And what can we do about it?
There are plenty of additional criticisms of SOTA-chasing in the literature (Bender et al. Reference Bender, Gebru, McMillan-Major and Shmitchell2021; Raji et al. Reference Raji, Bender, Paullada, Denton and Hanna2021). We have added our own criticism of SOTA-chasing:
There has been a trend for publications to report better and better numbers, but less and less insight. The literature is turning into a giant leaderboard, where publication depends on numbers and little else (such as insight and explanation). It is considered a feature that machine learning has become so powerful (and so opaque) that it is no longer necessary (or even relevant) to talk about how it works. (Church Reference Church2017)
The next two sections will discuss costs of SOTA-chasing and root causes.
2 SOTA-chasing: Costs
The next three subsections will discuss three types of costs:
1. Leaderboards emphasize competition, distracting attention from more important opportunities to advance the field,
-
2. SOTA-chasing is sucking the oxygen out of the room, discouraging interdisciplinary collaboration with colleagues in linguistics, lexicography, psychology, etc., and
-
3. Claims of superhuman performance (on tasks that appear to be more realistic than they are) create unrealistic expectations that could lead to yet another AI winter.Footnote b
2.1 Incentives and coopetition: Leaderboards considered harmful
It is a cliche that whatever you measure, you get. Leaderboards emphasize winners and losers. If you do a Google search for “meme: mine is bigger than yours,” you will find a bunch of rude, childish, and even dangerous images of nuclear brinkmanship. International relations and science should be better than school boys playing king-of-the-hill. Hopefully, there is more to the literature than boys being boys.
TRECFootnote c (Text REtrieval Conference) emphasizes coopetition.Footnote d (Voorhees Reference Voorhees2021) as opposed competition. In her keynote at SIGIR-2020,Footnote e as well as her invited talk at the ACL-2021 Workshop on Benchmarking,Footnote f Voorhees observed that:
• competing may give you a bigger piece of the pie …
• … while cooperation makes the whole pie bigger Footnote g
TREC participants are asked to sign a form that forbids explicit advertising of TREC results. This prohibition was mentioned a number of times in the videos of the 25th anniversary of TREC.Footnote h While participants appreciate the principle, the temptation to boast is difficult to resist.
Voorhees is making an important point. Consider the overview paper to the TREC Deep Learning track.Footnote i (Craswell et al. Reference Craswell, Mitra, Yilmaz, Campos and Voorhees2020), for example, where methods are split into three types: nnlm (neural net language models such as BERT), nn (other types of neural nets), and trad (traditional methods). Their Figure 1 shows performance is best for nnlm and worst for trad. That is, nnlm  $>$ nn
$>$ nn  $>$ trad. In this way, coopetition produces important insights that advance the field in meaningful ways, in contrast with leaderboards that emphasize competition and schoolyard nonsense such as “mine is bigger than yours.”
$>$ trad. In this way, coopetition produces important insights that advance the field in meaningful ways, in contrast with leaderboards that emphasize competition and schoolyard nonsense such as “mine is bigger than yours.”
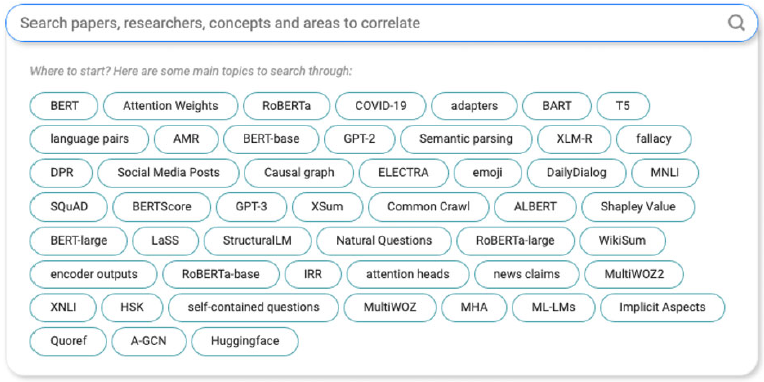
Figure 1. Default search concepts for ACL-2021, according to semantic paths (see footnote Footnote al).
As a second example of coopetition and competition, consider MRQA (Machine Reading for Question Answering) (Fisch et al. Reference Fisch, Talmor, Jia, Seo, Choi and Chen2019). The call for papersFootnote j highlights a number of admirable objectives such as domain transfer, interpretability, robustness, and error analysis, but unfortunately, the shared taskFootnote k leads with a leaderboard and congratulates the winners, with no mention of the more admirable objectives.
With a slightly different design, the shared task could have provided some interesting insights into domain transfer. Table 1 of (Fisch et al. Reference Fisch, Talmor, Jia, Seo, Choi and Chen2019) lists 18 QA benchmarks, split up into three groups of six benchmarks. The three groups are used for train, validation, and test, respectively. Suppose instead of using this train/validation/test split, we used a number of different splits. Could we learn that transfer is more successful for some splits than others?
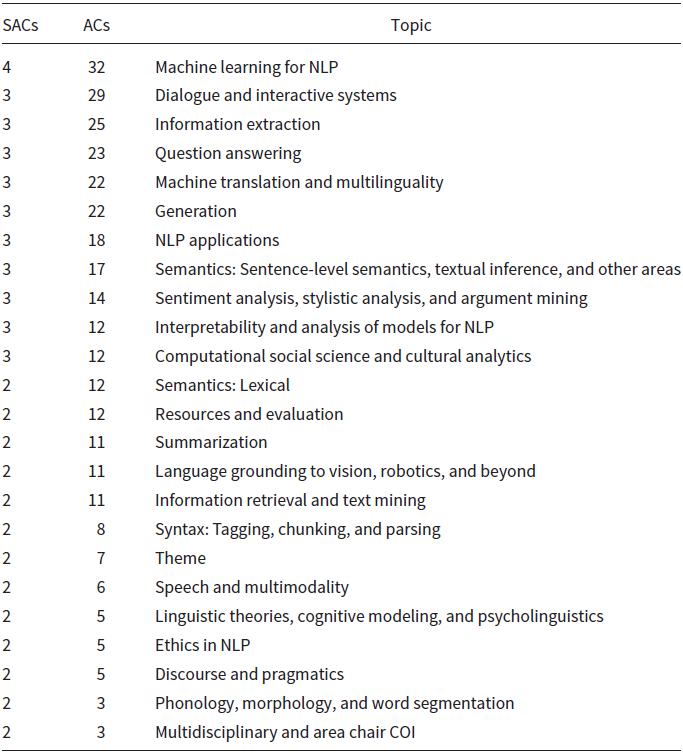
Table 1. ACL-2021 topics, sorted by the number of senior area chairs (SACs) and area chairs (ACs), based on footnote Footnote ai
MRQA identifies some interesting similarities and differences among the 18 benchmarks:
• source of documents: Wikipedia/Web snippets/misc
– Wikipedia (7 benchmarks): DROP, HotpotQA, QAMR, RelationExtraction, SQuAD, TREC, Natural Questions
– Web snippets (3 benchmarks): TriviaQA, SearchQA, ComplexWebQ
– misc (8 benchmarks): MCTest, RACE, DuoRC, NewsQA, BioASQ, QAST, BioProcess, TextbookQA
• source of questions: Crowdsourced/Domain Experts/misc
– Crowdsourced (9 benchmarks): ComplexWebQ, DROP, DuoRC, HotpotQA, MCTest, NewsQA, QAMR, SQuAD, TREC
– Domain Experts (5 benchmarks): BioASQ, BioProcess, QAST, RACE, TextbookQA
– misc (4 benchmarks): SearchQA, Questions Natural, RelationExtraction, TriviaQA
• source of answers: based on documents/not based on documents
– based on documents (9 benchmarks): SQuAD HotpotQA, DROP, RACE, TextbookQA, BioProcess, MCTest, QAMR, QAST
– not based on documents (9 benchmarks): NewsQA TriviaQA, SearchQA, Natural Questions, BioASQ, DuoRC, RelationExtraction, ComplexWebQ, TREC
It would be very interesting to know if these patterns are important for transfer or not. There is pretty clear evidence, for example, that constructed (crowdsourced) questions are easier than questions from query logs. TREC QA,Footnote l for example, started with “constructed” questions in 1999, but quickly moved to “real” questions from query logs for subsequent TREC QA tracks (2000–2007) because constructed questions are too easy for systems and unrealistic (Voorhees Reference Voorhees2001). Based on these observations, transfer might also be more effective between benchmarks that are similar to one another in terms of the source of questions, documents, and/or answers. In this way, coopetition could produce important insights that advance the field in more meaningful ways than leaderboards and competition.
It also helps to advance the field when benchmarks are realistic. Most of the benchmarks in MRQA are based on benchmarks from academia, except for Natural Questions. To construct more realistic benchmarks, it is advisable to work with industry and make sure the benchmark is representative of a real problem that they care about. A number of companies have been involved in a number of benchmark efforts:
• Microsoft Bing: TREC Web trackFootnote m (1999–2014), TREC Deep Learning trackFootnote n (Craswell et al. Reference Craswell, Mitra, Yilmaz, Campos and Voorhees2020)
• Baidu: DuReaderFootnote o (He et al. Reference He, Liu, Liu, Lyu, Zhao, Xiao, Liu, Wang, Wu, She, Liu, Wu and Wang2018)
• Google: Natural QuestionsFootnote p (Kwiatkowski et al. Reference Kwiatkowski, Palomaki, Redfield, Collins, Parikh, Alberti, Epstein, Polosukhin, Devlin, Lee, Toutanova, Jones, Kelcey, Chang, Dai, Uszkoreit, Le and Petrov2019)
There are also connections between the TREC QA trackFootnote q (1999–2007) and IBM Watson Jeopardy! In this case, IBM started in 2006 with a system designed for the TREC QA track and discovered that that system did not work well enough for Jeopardy questions,Footnote r as discussed at a celebration for the 25th anniversary of TREC.Footnote s After 5 years of hard work, the IBM system beat the two best human Jeopardy players in 2011, but their 2011 system was probably very different from their 2006 system because, among other things, the TREC QA tasks are not very representative of the Jeopardy task. The Jeopardy task is a problem that matters to IBM marketing, though problems such as web search are probably more real than Jeopardy.Footnote t
Unfortunately, while we all know that IBM won, much less is remembered about how that was accomplished (Ferrucci et al. Reference Ferrucci, Brown, Chu-Carroll, Fan, Gondek, Kalyanpur, Lally, Murdock, Nyberg, Prager, Schlaefer and Welty2010; Ferrucci Reference Ferrucci2012), and how that achievement could have advanced the field toward more admirable goals. We should follow Voorhees’s advice and replace competition with coopetition. The point is not who wins, but insights that advance the field.
2.2 Sucking the oxygen out of the room
What is not happening as a result of too much SOTA-chasing? It is becoming harder and harder to publish computational linguistics in a conference on computational linguistics. Students preparing for their first ACL paper may find textbooks on machine learning: (Bishop Reference Bishop2016; Goodfellow et al. Reference Goodfellow, Bengio and Courville2016) to be more helpful than textbooks on computational linguistics: (Manning and Schutze Reference Manning and Schutze1999; Jurafsky Reference Jurafsky2000; Eisenstein Reference Eisenstein2019) and handbooks (Dale et al. Reference Dale, Moisl and Somers2000; Mitkov Reference Mitkov2003; Clark et al. Reference Clark, Fox and Lappin2013).
ACL conferences used to be more inclusive. We used to see more people at our meetings from more fields such as linguistics, philosophy, lexicography, psychology, etc. ACL venues used to reach out to HLT (human language technology), a combination of computational linguistics, speech and information retrieval/web search. Lots of people used to publish in more combinations of fields/venues: computational linguistics (ACL, EMNLP, NAACL, EACL, Coling), Machine Learning (NeurIPS), Speech (ICASSP,Footnote u InterspeechFootnote v), Information Retrieval (SIGIR,Footnote w TREC), Web Search (WWW,Footnote x WSDMFootnote y), Datamining (KDDFootnote z), Language Resources (LRECFootnote aa), etc.
Why do we no longer see these people at ACL? It became clear to us that many of them no longer feel welcome when we attended an ACL-2014 workshop in honor of Chuck Fillmore.Footnote ab The workshop was bitter sweet. They were grateful that Chuck won a Lifetime Achievement Award,Footnote ac but they were also mourning his passing, and there were concerns about the relevancy of their work to where ACL was going. Fillmore’s “Case for Case” (Fillmore Reference Fillmore, Bach and Harms1968) has more than 11k citations in Google Scholar, but ACL is no longer interested in this approach, or in linguistic resources such as FrameNet (and much of what is discussed at LREC).
Reviewers, these days, sometimes suggest that resources such as FrameNet and WordNet are no longer relevant now that BERT works as well as it does. Such remarks discourage diversity. People who have invested in resources may find such remarks offensive (and unethical).
Even people in Machine Learning have reservations about SOTA-chasing. Rahimi gave a Test of Time Award talk at NIPS-2017 titled “Machine Learning has become Alchemy.”Footnote ad NIPS (now called NeurIPS) used to be more receptive to theory and what Rahimi referred to as the rigor police. Apparently, SOTA-chasing is squeezing out many important topics including theory and computational linguistics.
There is a different kind of rigor in other fields such as Lexicography, Library Science, and Information Retrieval, where proper attribution is taken very seriously. People in these fields care deeply about sampling (balance), what came from where, and what is representative of what. They will feel unwelcome when SOTA-chasing moves too quickly with less rigor. Consider the reference to TREC in HuggingFaceFootnote ae as well as Table 1 of MRQA (Fisch et al. Reference Fisch, Talmor, Jia, Seo, Choi and Chen2019), as discussed in Section 2.1. There have been 30 text retrieval conferences (TREC)Footnote af thus far. For each of those 30 conferences, there are many tracks and many datasets with many contributions from many people. We asked someone familiar with TREC for help disambiguating the references to TREC in HuggingFace and MRQA. The response was uncharacteristically sharp:
A reference to simply the “TREC collection” is underspecified to the point of being worthless, as you suspected
It is important, especially in certain fields, to give credit where credit is due. Citing work with proper attributions will make our field more inclusive and more attractive to people in other fields with different priorities and diverse views of rigor. Proper citations will also facilitate replication.
2.2.1 What counts as computational linguistics (CL)?
As empiricists, we like to start with data. Here are seven ways to characterize CL. The first three have been discussed above, and the last four will be discussed below.
1. Interdisciplinary collaboration: Formal Linguistics, Philosophy,Footnote ag Psychology, Machine Learning, Statistics, Computer Science, Electrical Engineering, Phonology, Phonetics
2. Textbooks:Footnote ah (Manning and Schutze Reference Manning and Schutze1999; Jurafsky Reference Jurafsky2000; Eisenstein Reference Eisenstein2019) and handbooks: (Dale et al. Reference Dale, Moisl and Somers2000; Mitkov Reference Mitkov2003; Clark et al. Reference Clark, Fox and Lappin2013)
3. Conference Venues: ACL, NeurIPS, AAAI, ICASSP, INTERSPEECH, TREC, LREC, WWW, WSDM, KDD
4. Organization of ACL Program Committees (Table 1)
5. Concepts suggested by search engine (Figure 1)
6. Studies of ACL Anthology (Anderson et al. Reference Anderson, Jurafsky and McFarland2012; Vogel and Jurafsky Reference Vogel and Jurafsky2012)
7. Studies of Papers with Code (PWC) (Koch et al. Reference Koch, Denton, Hanna and Foster2021)
2.2.2 Organization of ACL program committees
Until recently, areas played an important role in setting the agenda. Table 1 shows the organization of the ACL-2021 Program Committee by area.Footnote ai Some areas have more SACs (senior area chairs) and ACs (area chairs) than others because some areas receive more submissions than others.
The call for papersFootnote aj encourages authors to submit their paper to one of these areas. Before the new ARR process (see Section 3.2 on reviewing processes), authors could expect their paper to be handled by experts in the area. Handling includes both reviewing as well as assignments of papers to reviewers. Assignments used to be made by domain experts that know who’s who and what’s what. When assignments were made by domain experts, reviewers were more qualified and more sympathetic to the area than they are these days. As will be discussed in Section 3.2, the new ARR process no longer uses areas and domain experts to assign papers to reviewers, and consequently, assignments are probably more random.
Sessions were also typically organized by area. This way, the audience knew what to expect in a session on a particular topic.
These changes to the reviewing process have huge consequences on the field. There will be less diversity. Areas that are not well covered by action editors (AEs) will suffer. The rich will get richer. Areas near the top of Table 1 will benefit, and areas near the bottom of Table 1 will suffer, though there will be a few exceptions for a few micro-topics that happen to be favored by the (iffy) software for routing papers to reviewers.
2.2.3 Concepts suggested by search engine
As mentioned above, conference sessions used to be organized by areas. But that is changing as areas become deemphasized. The Program for ACL-2021,Footnote ak for example, leads with a pointer to a search engine.Footnote al This search engine offers a set of default concepts to search on, as shown in Figure 1. These concepts in Figure 1 are very different from areas in Table 1. The concepts emphasize datasets (COVID-19, Common Crawl, MNLI, SQuAD) and models (BERT, RoBERTa, BART).
The areas in Table 1 are closer to textbooks/handbooks on computational linguistics: (Manning and Schutze Reference Manning and Schutze1999; Dale et al. Reference Dale, Moisl and Somers2000; Jurafsky Reference Jurafsky2000; Mitkov Reference Mitkov2003; Clark et al. Reference Clark, Fox and Lappin2013; Eisenstein Reference Eisenstein2019), and the concepts in Figure 1 are closer to textbooks on machine learning: (Bishop Reference Bishop2016; Goodfellow et al. Reference Goodfellow, Bengio and Courville2016). Replacing the areas in Table 1 with the concepts in Figure 1 will have a dramatic impact on the field of computational linguistics. There will be less diversity and less room for papers that do not mention popular datasets and popular models.
2.2.4 Studies of ACL anthology
The ACL Anthology provides a very different perspective from Figure 1. At ACL-2012, there was a Special Workshop on Rediscovering 50 Years of DiscoveriesFootnote am (Banchs Reference Banchs2012). A number of papers at that workshop provide tables of topics such as Table 1 in (Anderson et al. Reference Anderson, Jurafsky and McFarland2012) and Figures 7 and 8Footnote an in (Vogel and Jurafsky Reference Vogel and Jurafsky2012). These topics look similar to topics covered in textbooks such as (Jurafsky Reference Jurafsky2000). Perhaps that should not be a surprise since Jurafsky is an author of all of those references. We are concerned, though, about the relatively small overlap between these topics and what we see in more recent ACL conferences. Recent ACL meetings appear to be moving toward Figure 1 and away from Table 1.
2.2.5 Studies of papers with code (PWC)
Analyses of PWC may be more useful than ACL Anthology for appreciating the move toward SOTA-chasing. Figure 3 of (Koch et al. Reference Koch, Denton, Hanna and Foster2021) reports usage of datasets in PWC. One might expect usage to be heavily skewed, following a Zipf-like law. They find that usage is becoming more and more concentrated over time in a small number of places. From this perspective, it is not surprising that 50% of the usage can be attributed to a short list of institutions:
• Non-profit: Stanford, Princeton, Max Planck, CUHK, TTIC, NYU, Georgia Tech, Berkeley
• Corporate: Microsoft, Google, AT&T, Facebook
These results are perhaps not that surprising, but we found it remarkable what is missing from this list: for example, National Library of Medicine (PubMed),Footnote ao Linguistic Data Consortium.Footnote ap PWC probably has better coverage of machine learning than other fields such as speech, medicine, law, information retrieval, web search, etc. Venues such as TREC, LREC, KaggleFootnote aq and many others are not well covered in PWC. PWC probably has more coverage of universities than industry and government (NIST, DARPA). PWC is probably missing much of what is happening in Asia, considering how much participation in ACL meetings is coming from Asia.
The PWC view of CL, as well as Figure 1, is probably more representative of where CL is going than other views discussed above such as Table 1, textbooks/handbooks, ACL Anthology. That said, we hope CL does not go down this rabbit hole. It is not a promising direction. We are particularly concerned that the PWC view and SOTA-chasing will reduce diversity and squeeze out many alternative perspectives.
2.3 Unrealistic expectations: Superhuman performance, seriously???
We now turn to the third of the three costs of SOTA-chasing mentioned at the beginning of Section 2. Claims of superhuman performance (on tasks that appear to be more realistic than they are) create unrealistic expectations that could lead to an AI winter.
It is not hard to construct CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart)Footnote ar as well as the reverse, which we call reverse CAPTCHAs. For standard CAPTCHAs, you can bet on people to succeed and machines to fail, whereas for reverse CAPTCHAs, you can bet on machines to succeed and people to fail.
Technology is often amazing, though sometimes exhausting, embarrassing, unethical, and/or dangerous. It is easy to find examples in the news and in social media of amusing/scary “computer errors.” Alexa recently told a 10-year-old girl to do something dangerous with a penny and electricity.Footnote as,Footnote at Gmail autocorrect recently sent an embarrassing email where an interest in speaking with a business associate somehow came out as an interest in sleeping with the business associate.
Computers are being used for all sorts of use cases, raising some serious ethical questions (O’Neil Reference O’Neil2016). In one case, a judge ruled that Google translate is not good enough to count as consent for a police search.Footnote au Society will need to address many more ethical questions like this.
If machines were actually better than people at transcribing speech and machine translation, then why are there so many “computer errors” in captions for services such as YouTube and Zoom? There is always more work to do. There are a few tasks, like playing chess, where computers are much better than people. But there are many tasks that are important for commercial applications, like captions, where there are opportunities for improvement.
There have been claims at WMT (Workshop on Machine Translation) (Barrault et al. Reference Barrault, Bojar, Costa-jussÀ, Federmann, Fishel, Graham, Haddow, Huck, Koehn, Malmasi, Monz, MÜller, Pal, Post and Zampieri2019) and elsewhere suggesting machines have achieved more than they have (parity/superhuman performance). The community tends to remember this simple take-away message, despite reassessments (Toral Reference Toral2020), and cautionary caveats such as this:
This result has to be regarded with a great caution and considering the technical details of the… evaluation method as well as… Importantly, the language pairs where the parity was reached last year were not confirmed by the evaluation this year and a similar situation can repeat. (Barrault et al. Reference Barrault, Bojar, Costa-jussÀ, Federmann, Fishel, Graham, Haddow, Huck, Koehn, Malmasi, Monz, MÜller, Pal, Post and Zampieri2019)
Replication is a major problem for many fields, as will be discussed in Section 4 on the replication crisis. One of the root causes behind the replication crisis is over-confidence in the scientific method.
Evaluations can also be misleading because of over-confidence in the methodology and metrics such as BLEU. The community is more likely to remember the superhuman result than cautionary caveats/reassessments such as your mileage may vary (YMMV).Footnote av
Consider technology for translating meetings, for example. This technology is amazingly good, but far from human parity. The first author has considerable experience with this technology because he works for a Chinese company and does not speak Chinese. When he has access to a human interpreter, he is much more engaged in the meeting (and not nearly as exhausted).
When this technology was first introduced, everyone was impressed with how well it worked. The live stream was displayed on stage so everyone in the room could read whatever was said over the house speakers in real time in both English and Chinese. The chair of one high-profile session made a point to call out the technology.Footnote aw
Now that the technology has been around for a few years, the technology is no longer displayed on stage (perhaps because of a few inevitable embarrassing mistakes). The latest version runs on phones, so only those of us who need the technology can see (and hear) everything (warts and all) in both English and Chinese. The technology is even better than it used to be, especially with respect to latency, but even so, it is far from human parity.
Others who do not use the technology as much as we do may be misled by evaluations that report superhuman BLEU scores and latency. While the machine may be better than people in those terms, BLEU and latency are not the terms that matter. Professional interpreters translate what needs to be said when it needs to be said, and human interpreters do not make “computer errors.”
We can correct some computer errors. For example, when the machine says “ecology” in a Baidu meeting, the speaker is probably talking about “eco-systems.” Other computer errors are more challenging. One time, we guessed the machine made an error when it used a politically sensitive word. We asked for clarification after the meeting. In this case, it turned out that the translation was actually correct, but the context was “lost in translation.” When we have access to a human interpreter, there are more opportunities to ask for clarifications and less need to do so.
Given realities such as these, when evaluations produce numbers that are too good to be true (using inappropriate metrics such as BLEU and average latency), why do we take these numbers so seriously? We have so much confidence in our evaluation methodology that we believe the results (and gloss over caveats/reassessments), even when we know the results cannot be right:
The first principle is that you must not fool yourself and you are the easiest person to foolFootnote ax —Feynman
A number of evaluations are reporting that machines are better than people on a number of tasksFootnote ay,Footnote az,Footnote ba,Footnote bb,Footnote bc,Footnote bd (Nangia and Bowman Reference Nangia and Bowman2019; Nguyen et al. Reference Nguyen, Stueker and Waibel2021). We all know these superhuman numbers are too good to be true and unlikely to transfer beyond academic benchmarks to tasks that matter for commercial practice. No one will remember the caveats/reassessments, but they will remember the unrealistic expectations, and that will not be good for the long-term health of the field.
Viewed in this way, the successes of deep nets on so many benchmarks could be interpreted as a criticism of these benchmarks. Benchmarks tend to focus too much on tasks that are ideal for technologies we already have. But benchmarks should place greater emphasis on opportunities for improvement. Benchmarks should be different from PR hype. The point of benchmarks is not to make our technology look good (or better than it is), but to help set the agenda for future work. Evaluations provide credible measurements of progress, as well as realistic expectations for the future.
We are not objecting to evaluation, and measuring real progress. But we are objecting to “gains” that are more noise/hope/hype than progress. The difference between the top two places on a leaderboard may not be significant or replicable or interesting.
3 Root causes for SOTA-chasing
Sections 3.1 and 3.2 will discuss two possible root causes for SOTA-chasing:
1. Lack of leadership and long-term strategic planning: historically, the agenda was determined top-down by a relatively small number of influential leaders in academia, industry, and government, but these days, the agenda is evolving more bottom-up via social media and websites such as papers with code (PWC)Footnote be and HuggingFace’s lists of frequently downloaded models and datasets.Footnote bf As a result of these changes, the emphasis has become more short-term and more transactional.
2. Poor reviewing as a result of poor assignments of papers to reviewers by a combination of iffy programs and ineffective processes for correcting the mistakes of these programs.
3.1 SOTA-chasing: A consequence of a lack of leadership
SOTA-chasing may have evolved out of the evaluation tradition, which has a long history. (Raji et al. Reference Raji, Bender, Paullada, Denton and Hanna2021) start by summarizing some of this history in (Lewis and Crews Reference Lewis and Crews1985; Liberman Reference Liberman2010; Church Reference Church2018a). Historically, there was a point to the emphasis on evaluation; evaluation used to be more than pointless SOTA-chasing.
Many first-hand accounts of this history were presented at the ACL-2021 Workshop on Benchmarking: Past, Present, and Future (BPPF) (Church et al. Reference Church, Liberman and Kordoni2021a). Videos and slides are posted on github.Footnote bg
Much of this history involves influential leaders such as John Mashey, Fred Jelinek, and Charles Wayne, as will be discussed in Section 3.1.1. Before Mashey, Jelinek and Wayne, the agenda was largely set by many other influential leaders: Pierce, Skinner, Shannon, Licklider, Minsky, Chomsky, and others (Church Reference Church2011). These days, one might try to argue that the agenda is coming top-down from Turing Award Winners such as Hinton, Bengio, LeCun, Pearl, and others. Bengio, for example, is working on some long-standing hard problems in Artificial Intelligence such as causalityFootnote bh (Bengio et al. Reference Bengio, Deleu, Rahaman, Ke, Lachapelle, Bilaniuk, Goyal and Pal2019; SchÖlkopf et al. Reference SchÖlkopf, Locatello, Bauer, Ke, Kalchbrenner, Goyal and Bengio2021) and compositionality.Footnote bi Despite such top-down efforts, though, we view SOTA-chasing as evidence that the agenda is, in fact, emerging more bottom-up from community-driven sources such as papers with code (PWC) and HuggingFace.
This paper will suggest that SOTA-chasing is a consequence of a lack of top-down leadership. Students need help finding projects to work on. Success is measured transactionally. What does it take to get a paper accepted in the next conference? Publish or perish. Unless we offer a more promising alternative, students are likely to turn to PWC to find a project that is likely to “succeed” in the next round of conference reviews. Long-term success is more of a concern for more established researchers with more experience and more responsibility for the long-term health of the field.
Established researchers, such as authors of textbooks, used to play more of a role in setting the agenda. The connection between textbooks (Manning and Schutze Reference Manning and Schutze1999; Jurafsky Reference Jurafsky2000; Eisenstein Reference Eisenstein2019) and ACL meetings used to be stronger than it is today, as discussed in Section 2.2.
These days, the agenda is determined more bottom-up by mouse clicks. Everyone has an equal vote. The author of a textbook has no more vote than a student just starting out. Consequently, short-term concerns tend to dominate long-term concerns since the voting block of students starting out is much larger than the relatively small number of established researchers. The agenda is no longer determined by authors of textbooks and influencers such as John Mashey, Fred Jelinek and Charles Wayne.
3.1.1 Mashey, Jelinek and Wayne
John Mashey was one of the founders of SPEC,Footnote bj,Footnote bk an important benchmark for measuring CPU performance since 1988. SPEC has probably had more influence over commercial practice than all of the benchmarks in PWC combined.
Fred Jelinek was a manager in charge of much of IBM’s work in Speech (Jelinek Reference Jelinek1976; Jelinek Reference Jelinek1997) and Machine Translation (Brown et al. Reference Brown, Cocke, Della Pietra, Della Pietra, Jelinek, Lafferty, Mercer and Roossin1990; Brown et al. Reference Brown, Della Pietra, Della Pietra and Mercer1993) in the 1970s and 1980s, before moving to Johns Hopkins University and creating CLSP (Center for Language and Speech Processing).Footnote bl Bob Mercer worked closely with Fred Jelinek when they were both at IBM. Both Jelinek and Mercer received ACL Lifetime Achievement Awards in 2009 and 2014, respectively (see footnote Footnote ac). Mercer was an early advocate of end-to-end methods (Church and Mercer Reference Church and Mercer1993). Jelinek preferred the older term: self-organizing systems (Farley and Clark Reference Farley and Clark1954; Von Foerster Reference Von Foerster1960; Jelinek Reference Jelinek1990).
Charles Wayne played an important role in US government funding agencies including DARPAFootnote bm and NSA.Footnote bn In the US government, projects are typically designed to run for 5 years or so but somehow our field enjoyed nearly continuous funding for three decades starting in the mid-1980s (Church Reference Church2018a; Liberman and Wayne Reference Liberman and Wayne2020).
LibermanFootnote bo,Footnote bp attributes the funding success to Wayne’s emphasis on evaluation. Before Wayne, there had been an “AI Winter,” largely as a result of Pierce’s criticism of speech recognition in “Whither Speech Recognition?” (Pierce Reference Pierce1969) and Pierce’s criticism of Machine Translation in the ALPAC reportFootnote bq (Pierce and Carroll Reference Pierce and Carroll1966):
It is clear that glamour and any deceit in the field of speech recognition blind the takers of funds as much as they blind the givers of funds. Thus, we may pity workers whom we cannot respect. (Pierce Reference Pierce1969), p. 1049
Wayne’s emphasis on evaluation was more glamour-and-deceit-proof than previous approaches to Artificial Intelligence. This approach enabled funding to start after a long “AI Winter” and to continue for many decades because funders could measure progress over time. Crucially, though, unlike many of the benchmarks that we work on today, the benchmarks under Wayne’s leadership were very much driven by top-down strategic planning, with clear long-term goals.
Wayne encouraged interdisciplinary collaboration. He created a series of HLT (Human Language Technology) conferences by reaching out to natural language processing (NLP), information retrieval (IR), and speech. Wayne also played an important role in the creation of TREC (Text REtrieval Conference).Footnote br TREC is closely associated with NIST (National Institute of Standards and Technology), part of the U.S. Department of Commerce.
3.1.2 Strategic planning in government
There is a long tradition of top-down strategic planning in government agencies such as NIST and DARPA. NIST’s mission is:Footnote bs
To promote U.S. innovation and industrial competitiveness by advancing measurement science, standards, and technology in ways that enhance economic security and improve our quality of life.
Their core competences are measurement science, rigorous traceability, and development and use of standards.
In the early 1960s, Licklider created IPTO (Information Processing Techniques Office) under DARPA with the mission to:Footnote bt
create a new generation of computational and information systems that possess capabilities far beyond those of current systems. These cognitive systems—systems that know what they’re doing:
1. will be able to reason, using substantial amounts of appropriately represented knowledge;
2. will learn from their experiences and improve their performance over time;
3. will be capable of explaining themselves and taking naturally expressed direction from humans;
4. will be aware of themselves and able to reflect on their own behavior;
5. will be able to respond robustly to surprises, in a very general way.
Our field has made considerable progress on some of these goals, though much work remains to be done.
While it is tempting to blame many of the leaders mentioned in this history for the current SOTA-chasing craze, that would be unfair. SOTA-chasing, as defined above, involves pointless numbers with little long-term strategic value, whereas the leaders in this history made important long-term contributions to the field largely because they placed such a high value on long-term strategic planning.
3.2 SOTA-chasing: A consequence of poor reviewing processes
In addition to a lack of leadership, another root cause of SOTA-chasing is poor reviewing processes. Rogers’s blog attributes SOTA-chasing to lazy/poor reviewing, information overload (drowning in papers), and glorification of benchmarks, though there is more discussion of poor reviewing in her blog than glorification of benchmarks. Her blog leads with the following tweet:Footnote bu
Another @emnlp2019 reviewer’s 3-line review concludes: “The main weakness of the paper is the results do not beat the state of the art models.” This is a tired take and a lazy, backwards way to think about research.
It is a shame that EMNLP reviewing is as bad as it is. EMNLP’s poor reviewing is particularly ironic given that we created EMNLP largely as a reaction to ACL’s poor reviewing, as discussed in Section 1.2 of (Church Reference Church2020). EMNLP reviewing is used to be quicker than ACL by construction.Footnote bv These days, EMNLP reviewing is no quicker (and no better) since all ACL* conferences use the same (broken) processes. Putting all our eggs in one basket is not a solution, especially if the basket is known to be defective.
There have been many criticisms of reviewing recently. Rogers’s blog offers a number of constructive suggestions to reviewers. While we agree that reviewing is bad, and even worse than it used to be, blaming the reviewers is unlikely to lead to improvements. Reviewers do what reviewers do. Creating more tutorials,Footnote bw rules and process are unlikely to help.
It is widely agreed that ACL reviewing is an opportunity for improvement. The ACL has recently rolled out a new rolling review process (ARR)Footnote bx based on open review. Perhaps ARR will improve matters, though we have serious doubts.
Best practices tend to start by identifying root cause(s). Introducing change for change sake is unlikely to lead to improvements. Roll out new processes gradually; do not make too many changes at the same time.
One thing is certain: as shown in Table 2, ACL-2022 is no faster than ACL-2021. It is claimed that ARR is faster:
The original goal of ARR was to have all reviews and meta-reviews completed within 35 days. The process requires that each paper has 3 reviews, and once those are complete, a meta-review. This is a pretty tight turnaround. By comparison, in ACL 2021, … the time from submission to notification amounted to 92 days, nearly 3 times what ARR is aiming for.Footnote by
Table 2. ACL-2022 (after ARR) is no faster than ACL-2021 (before ARR)

but ACL-2022 used ARR and ACL-2021 did not. If ARR really was 3x faster, why doesn’t that speed up show up in the schedules in Table 2?
Speed is important, but quality is even more important. Why is reviewing so bad? Reviewers are tired and underpaid, as Rogers points out in her blog. But that is also true of researchers. Most of us do what we do because we care deeply about what we do. Researchers are also tired and underpaid. That is not the root cause for bad reviewing.
A more likely root cause is the assignment of papers to reviewers. ARR has a number of serious design flaws that make it very likely that reviewers will be less qualified/sympathetic than they used to be. It used to be rare for students to be invited to review. Reviewers were typically authors of cited papers, increasing the odds that reviewers would be familiar with relevant background material, and positively inclined toward the general approach. Reviewers used to have more expertise in the topic than the target audience for the paper. Unfortunately, that is no longer the case.
It appears that ARR automates the assignment of papers too much. In Section 2.7.1 of (Church Reference Church2020), we discussed a number of common methods for assigning papers to reviewers:
1. Delegate to authors (keywords)
2. Delegate to reviewers (bidding)
3. Delegate to middle management (manual assignments)
4. Delegate to software using automated routing (Yarowsky and Florian Reference Yarowsky and Florian1999)
5. Semi-automatic routing (automatic routing with manual post-editing).
ARR uses automatic routing with too little post-editing. Action editors are asked to over-ride initial assignments,Footnote bz but this process is unworkable because of fluctuations in the workload. There were just barely enough AEs for the October-2021 round of ARR, but not nearly enough for November 2021 because of a submission deadline for ACL-2022.
To make matters worse, ARR eliminated areas, a huge mistake in our opinion, because action editors cannot be expected to know who’s who and what’s what in all areas.
We prefer a recursive structure where papers are assigned to subcommittees going down the tree, until the number of papers is small enough that a subcommittee can handle the load. With this structure, the subcommittee chair can be expected to know who’s who and what’s what in their subarea. Chairs should be encouraged to send papers back up the tree if they receive papers that go beyond their expertise.
There are some obvious weaknesses with automatic routing and the ARR process. We described our experience with (Yarowsky and Florian Reference Yarowsky and Florian1999) in (Church Reference Church2020). Automatic routing loves conflicts of interest. If there is a way to send a paper to reviewers with conflicts of interest, automatic routing programs will do just that.
Since ACL-2022 makes it possible to see the names of the other reviewers, we can check for conflicts of interest. ACL-2022 assigned one paper to two reviewers that work closely together. When we complained to the meta-reviewer, after apologizing for taking a long time to reply (because the system was sending too many unimportant emails), the meta-reviewer made it clear that there are too many such conflicts to fix.
Perhaps ARR chose to use automatic routing to cope with the scale. This is not a good reason though. The routing process is extremely important. If a paper is sent to an unqualified/unsympathetic reviewer, then the reviewer is likely to essentially “abstain” and kill the paper with an average/low score.
Automating the routing process is disrespectful to authors and reviewers and the community. Reviewers do not like to review papers outside their area. Authors work hard on their submissions. We owe them more than “abstentions.” The community deserves to know that published papers have been credibly reviewed by qualified reviewers with considerably more expertise in the area than the target audience. It is a violation of ethics to route papers the way we do without a reasonable number of qualified experts involved in the routing process.
Why does ARR believe that it is necessary to automate the process? Scale was mentioned above. ACL does receive quite a few submissions. There were about 3000 submissions in November 2021, about an order of magnitude more than we had for EMNLP in 1999. For EMNLP-1999, the first author assigned each paper to a subcommittee in two days, at a rate of 2 minutes per paper. Those subcommittees would then assign papers to reviewers.
This process is embarrassingly parallel. Thus, with about ten people doing what the first author did for EMNLP-1999, we could route the 3000 papers to subcommittees in two days. The process also scales recursively. If a subcommittee receives too many papers, we can split the subcommittee recursively into subcommittees, as needed. The entire routing process should require no more than a week.
In principle, the law of large numbers should make it easier to find good matches between papers and reviewers. Scale is not an excuse for disrespecting authors and reviewers.
To make matters even worse, ARR uses the wrong population to sample reviewers. Now that all authors are required to review, including studentsFootnote ca and authors from other areas, it is very likely that reviewers will be unqualified and unmotivated. The process should sample reviewers from the population of published/cited papers, not submitted papers.
Chairs are always looking for more reviewers. Selecting reviewers from cited papers should help since the set of cited papers is much larger than the set of submitted papers.Footnote cb
There had been some talk when ARR was first proposed about minimum requirements for reviewers in terms of h-index and/or publications, but since ARR makes it easy to see the names of other reviewers, it is easy to verify that many/most of reviewers are not as qualified as they were a few decades ago.
SOTA-chasing is a natural consequence of these new (but not improved) processes. Since authors cannot assume that reviewers are qualified or sympathetic to the area, authors need to come up with a simple argument that will work with unmotivated reviewers. Empirically, authors have discovered that SOTA-chasing is effective with random reviewers.
We cannot blame authors for doing what they are doing. Nor can we blame reviewers for doing what they are doing. We have seen the problem, and it is us.
3.2.1 Recommendations
What can we do about bad reviewing?
1. Governance: Leadership and organizational structure
2. Dashboards: Goals, Milestones, Metrics
3. Incentives: Align incentives across organization
ARR looks like it was designed by academics that have never worked in a large organization. Leadership and organizational structure are important now that conferences have become as large as they are. We need to run the review process more like a large company or military organization, with clear roles and responsibilities.
The current ARR process has too much turnover. Chairs of conferences are only involved in the process for a few months. It takes more experience than that to run a large organization.
Executives in large companies have often worked for few decades in a number of different positions within the organization for about 18 months per rotation. After “punching their ticket” in this way, they have a broad understanding of the organization from many perspectives, as well as a valuable personal network so they can call in favors as necessary. The top of the reviewing organization should be an executive with this kind of experience and personal connections.
The rest of the organization needs to scale appropriately so people are not running around like headless chickens because they have too much work to do. As mentioned above, scale is not an excuse for doing a bad job. Large organizations are all about logistics and process. The organization is not running smoothly if people are working too hard. Accomplishments count more than activities.
It should be clear who is responsible for what. If systems are sending out too many emails that no one is reading, it should be clear who is responsible for fixing that. And no one should have responsibility without authority or vice versa.
In addition to governance, we also need goals, milestones, and metrics. It is important that these are aligned. Many organizations end up optimizing the wrong metric (Goldratt and Cox Reference Goldratt and Cox2016). Factories in the failed Soviet Union, for example, produced too many widgets that no one wanted. It is important to match supply and demand.
So too, a reviewing process should not be optimizing throughput, but the quality of the results. Metrics such as citations can be used to measure progress toward these goals. Milestones are often defined in terms of metrics and dates. For example, a sales organization might set a milestone for sales at the end of every month. Similarly, a reviewing organization could set milestones to make sure the reviewing process is on schedule.
Less is more. If the dashboard is too complicated, no one will look at it. The dashboard should be actionable. It should lead with an executive summary, a single page that an executive can understand. Other people should be able drill down to see more detailed views that are more relevant to their roles and responsibilities.
Visibility is essential. If people cannot see the dashboard, they will not use it.
Avoid micro-managing. If everyone understands their roles and responsibilities, as well as their metrics and milestones, then they will figure out how to get the job done. There are too many long documents on the ACL wiki that no one is reading. Do not create documents that are not read. Better to emphasize metrics. If you create a document, measure usage, and reward people that create resources that are found to be useful by the metrics.
With appropriate incentives, governance, and dashboards, everyone in the organization will figure out what needs to be done. This type of structure scales more effectively than centralized planning where everyone waits for instructions from above.
4 Replication crisis
The media has coined the term, replication crisis,Footnote cc,Footnote cd following some influential papers such as “Why Most Published Research Findings Are False” (Ioannidis Reference Ioannidis2005). The replication crisis is yet another example, like evaluation, of over-confidence in accepted practices and the scientific method, even when such practices lead to absurd consequences. Several surveys suggest that most/much of the literature is wrong:
Amgen researchers declared that they had been unable to reproduce the findings in 47 of 53 “landmark” cancer papers (Begley and Ellis Reference Begley and Ellis2012; Baker Reference Baker2016b)
More than 70% of researchers have tried and failed to reproduce another scientist’s experimentsFootnote ce (Baker Reference Baker2016a).
Even the famous “marshmellow” experiment may be wrong:
A new replication study of the well-known “marshmallow test”—a famous psychological experiment designed to measure children’s self-control—suggests that being able to delay gratification at a young age may not be as predictive of later life outcomes as was previously thoughtFootnote cf,Footnote cg (Watts et al. Reference Watts, Duncan and Quan2018)
Ironically, there are suggestions these criticisms of replicability are themselves difficult to replicate. Some suggest that “only” 14% of the literature is wrong (Jager and Leek Reference Jager and Leek2014a; Ioannidis Reference Ioannidis2014; Jager and Leek Reference Jager and Leek2014b), though even 14% is considerably more than chance based on p-values. Standard assumptions based on p-values may not hold because of an unethical (but not uncommon) practice known as “p-hacking” (Bruns and Ioannidis Reference Bruns and Ioannidis2016).
Following the cliche, to err is human; to really foul things up requires a computer, machine learning could easily make the replication crisis even worse. Suppose p-hacking is a reverse CAPTCHA, an optimization that machines can do better than people can. To make matters even worse, given how hard it is to figure out what deep nets are doing, we might not even know if our nets are “doing real science” or adding automation to the replication crisis.
What are the root causes for the replication crisis? Much of the discussion points to incentive structures, and especially: publish or perish. Surprising results are more likely to be accepted, especially in top venues with low acceptance rates. As a result, the literature is full of experiments reporting “significant results” on surprising hypotheses. By construction, such results are unexpected, publishable, and probably wrong. This process encourages lots of junior researchers to try lots of long-short experiments, and publish the few that reach “significance.” Normally, in a casino, the house almost always wins by construction, but in this case, the literature is designed to fail. A few lucky researchers will win the lottery and land a good job, but the literature will end up full of false positives.
The incentive structures in our field may also be suboptimal. If we encourage too much SOTA-chasing, then the literature will be full of papers that will not stand up to the test of time, by construction.
What can be done about the replication crisis? Many suggestions have been discussed in the references above and elsewhere:
1. More robust experimental design
2. Better statistics
3. Better mentorship
4. More process/requirements/paperwork (checklists)
5. Pre-registration of experiments
Surveys report large majorities in support of many of these proposals.
There is general agreement that the literature is not self-correcting (Ioannidis Reference Ioannidis2012), and the replication crisis is unlikely to fix itself without intervention. There is also agreement on the need to take action soon:
given that these ideas are being widely discussed, even in mainstream media, tackling the initiative now may be crucial. “If we don’t act on this, then the moment will pass, and people will get tired of being told that they need to do something” (Baker Reference Baker2016a)
Much of this literature focuses on the dangers of misusing p-values, but misuse of p-values is just one of many ways for the literature to fool the public (and itself). As mentioned above, the community tends to remember superhuman performance on a benchmark, but not the cautionary caveats/reassessments.
There has been quite a bit of discussion of replication in our field, as well.Footnote ch Thanks to websites such as github and HuggingFace, replication in our field is easier than it used to be.
Even so, perhaps due to the use of crowdsourcing on these sites, as well as the lack of peer review, it can be difficult to figure out what came from where and what is representative of what. Consider, for example, two HuggingFace datasets: (1) ptb_text_only Footnote ci and (2) trec (see footnote Footnote ae). As mentioned in Section 2.2, there have been 30 TREC conferences so far, and each conference runs many tracks. We need to find a way to encourage better citations that give credit where credit is due. Different people are responsible for the data for different tracks.
As discussed in Section 11 of (Church et al. Reference Church, Yuan, Guo, Wu, Yang and Chen2021b), the documentation suggests that ptb_text_only is from (Marcus et al. Reference Marcus, Santorini and Marcinkiewicz1993). That said, credit should go to the people that collected the corpus since the parse trees, the main contribution of (Marcus et al. Reference Marcus, Santorini and Marcinkiewicz1993), are no longer in the “text-only” version: ptb_text_only. In addition, most of the content words have been replaced with  $<unk>$, making it much easier (and less useful) to predict the next “word,” though these predictions have subsequently become the standard PTB task in PWC.Footnote cj Since this task has little to do with P (the data was not collected at Penn) and little to do with TB (there are no treebanks) and little to do with words, perhaps we should refer to this task as “
$<unk>$, making it much easier (and less useful) to predict the next “word,” though these predictions have subsequently become the standard PTB task in PWC.Footnote cj Since this task has little to do with P (the data was not collected at Penn) and little to do with TB (there are no treebanks) and little to do with words, perhaps we should refer to this task as “ $<unk>$ prediction in the non-P non-TB corpus.”
$<unk>$ prediction in the non-P non-TB corpus.”  $<unk>$ prediction, is, of course, a silly task. No one should care very much about how well computers can predict
$<unk>$ prediction, is, of course, a silly task. No one should care very much about how well computers can predict  $<unk>$, or whether they can do that better than people.
$<unk>$, or whether they can do that better than people.  $<$unk
$<$unk $>$ prediction might appear to be related to (Shannon Reference Shannon1951), but predicting entropy of English is a real problem with important applications, and
$>$ prediction might appear to be related to (Shannon Reference Shannon1951), but predicting entropy of English is a real problem with important applications, and  $<$unk
$<$unk $>$ prediction is not.
$>$ prediction is not.
Similar comments may apply to many other popular benchmarks such as SQuAD, where superhuman performance is claimed (see footnote bd) on a task with constructed questions. As discussed in Section 2.1, TREC QA started with constructed questions, but quickly moved to real questions from query logs for subsequent TREC QA tracks (2000–2007) because constructed queries are too easy for systems, and unrealistic (Voorhees Reference Voorhees2001).
To summarize, many fields including our own are undergoing a replication crisis. It is helpful to shed light on the crisis, though we wish we had more constructive suggestions to offer. Many fields are taking steps to address these concerns. Github and HuggingFace have been helpful in our field though we need to be more careful documenting what came from where, and how these datasets/benchmarks fit into a larger strategic roadmap for advancing the field.
That said, we fear that process improvements, such as many of the suggestions above (that are supported by large majorities), are unlikely to be effective, and may even distract the community from addressing root causes. The system would be more self-correcting if incentives were aligned. Researchers need to believe that the best way to advance their career is to do what is in the best long-term interest of the field. As long as researchers are thinking short-term and transactional, then their incentives will not be aligned with the long-term interests of the field.
5 Conclusions/Recommendations
Many papers are SOTA-chasing, and more will do so in the future. SOTA-chasing comes with many costs. We discussed three costs:
1. Too much competition (and not enough coopetition)
2. Sucking the oxygen out of the room (discouraging diversity)
3. Claims of superhuman performance set unrealistic expectations
The first two are opportunity costs. SOTA-chasing distracts attention away from more promising opportunities. The last cost is a risk. Everyone will remember the claims, and no one will remember cautionary caveats/reassessments. We may not have claimed to have solved all the worlds’ problems, but that is what they will remember, and they will be disappointed when we fail to deliver.
After discussing those three costs, we discussed two root causes: (1) lack of leadership and (2) iffy reviewing processes. Historically, the agenda was determined top-down by influencers in academia, industry, and government, but these days, the agenda is determined more bottom-up by social media (e.g., papers with code, HuggingFace).
SOTA-chasing can also be viewed as a vote of no confidence in the reviewing process. The reviewing process is so bad that authors have discovered that SOTA-chasing is more likely to get past unqualified/unsympathetic reviewers than alternatives that require reviewers with more domain expertise. It is tempting to blame the reviewers for their lack of expertise, but we believe the problem is more with the matching process than the reviewers. It should be possible to find qualified reviewers, but not with the current processes for assigning papers to reviewers.
After discussing root causes, we then discussed the replication crisis. The replication crisis is yet another example, like evaluation, of over-confidence in accepted practices and the scientific method, even when such practices lead to absurd consequences.
What do we do about SOTA-chasing? It is tempting to skip steps and discuss diagnosis and therapy, but the first step is to get past denial. If we can agree on priorities such as
1. need for leadership, and
2. need for better processes for matching papers and reviewers
then we can come up with a list of next steps to make progress on those priorities.
These days, it is hard for the ACL exec to set the agenda because the exec is too large, and too many positions rotate too quickly. When Don Walker was in charge, the ACL exec was more like the executive branch of government, and less like a committee/legislative branch of government. Before Don Walker passed away, the exec was smaller, and he controlled most of the votes from 1976 to 1993.Footnote ck It is difficult for a large organization such as the ACL to run effectively without more leadership. Committees are effective for some tasks such as reaching consensus, but it is hard for large committees to lead.




 Open access
Open access