



1. Introduction
While computability theory studies the boundary between what can and cannot be computed effectively without putting any specific constraint on the underlying algorithm, complexity theory refines the analysis by classifying the computable functions based on the amount of resources algorithms computing those functions require when executed by paradigmatic machines like Turing machines. Resources of interest can be computation time, space, or communication, while bounds are not expressed as fixed, absolute constants but rather parametrically – and asymptotically – on the size of the input. This way algorithms are allowed to consume larger and larger amounts of resources when the size of the input increases, and what matters is not the absolute value, but the rate of growth.
A complexity class can thus be defined as the collection of all those functions which can be computed by an algorithm working within resource bounds of a certain kind. As an example, we can form the class
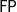 $\mathsf{FP}$
of those functions which can be computed in polynomial time, that is, within an amount of computation time bounded by a polynomial on the size of the input. As another example, we can form the class
$\mathsf{FP}$
of those functions which can be computed in polynomial time, that is, within an amount of computation time bounded by a polynomial on the size of the input. As another example, we can form the class
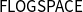 $\mathsf{FLOGSPACE}$
of those functions which can be computed in logarithmic space. Complexity theory has developed grandly since its inception (see Cobham Reference Cobham1965; Hartmanis and Stearns Reference Hartmanis and Stearns1965), and nowadays, many complexity classes are studied, even if much remains to be discovered about their being distinct or not. Traditionally, complexity classes are studied by carefully analyzing the combinatorial behavior of machines rather than looking at the structural and morphological aspects of the underlying algorithm. (For an introduction to computational complexity theory, we recommend the textbooks by Goldreich Reference Goldreich2008 and Arora and Barak Reference Arora and Barak2009).
$\mathsf{FLOGSPACE}$
of those functions which can be computed in logarithmic space. Complexity theory has developed grandly since its inception (see Cobham Reference Cobham1965; Hartmanis and Stearns Reference Hartmanis and Stearns1965), and nowadays, many complexity classes are studied, even if much remains to be discovered about their being distinct or not. Traditionally, complexity classes are studied by carefully analyzing the combinatorial behavior of machines rather than looking at the structural and morphological aspects of the underlying algorithm. (For an introduction to computational complexity theory, we recommend the textbooks by Goldreich Reference Goldreich2008 and Arora and Barak Reference Arora and Barak2009).
Starting from the early nineties, researchers in mathematical logic and theoretical computer science have introduced implicit characterizations of (some of) the various complexity classes. By implicit, we here mean that classes are not given by explicitly constraining the amount of resources a machine is allowed to use, but rather by imposing linguistic constraints on the way algorithms can be formulated, that is, on their structure. This idea has developed into an area called implicit computational complexity (ICC in the following), which at the time of writing is very active, with annual thematic workshops specifically devoted to it.
Many areas within logic and computer science have been affected: from recursion theory, within which the first attempts at characterizing the feasible functions have been given, to the field of type theory, in which restrictions on algorithms are given as formal systems of types, to proof theory, in which the structure of proofs and the dynamics of cut-elimination is leveraged when defining appropriate restrictions.
The purpose of this survey is to give the reader the possibility of understanding what implicit computational complexity is, the typical flavor of the results obtained in it, and how these results are proved. We will focus our attention on characterizations of complexity classes in terms of proof theory and higher-order programming languages, an area of ICC which Martin Hofmann has contributed to shaping and in which he had a fundamental role since the very beginning.
2. A Bird’s Eye View on Complexity and Higher-Order Programs
Most programming languages are designed to be expressive: not only many alternative constructs are usually available, but the class of computational tasks programs can solve is kept as large as possible. In fact, one of the first theorems any programming language designer proves about a new idiom is its being Turing powerful, namely that any computable function can be encoded into it. Any such programming language, for obvious reasons, is simply too powerful to guarantee bounds on the amount of resources programs need, that is, to guarantee complexity bounds. But are all constructs any given programming language offers equally harmful, in this respect? In other words, could we remove or refine them, this way obtaining a reasonably expressive programming language in which programs consume by construction a bounded amount of computational resources? This can be seen as the challenge from which one starts when defining ICC systems.
One could for example consider Kleene’s algebra of general recursive functions as a rudimentary programming language in which programs are built from some basic building blocks, the initial functions, by way of composition, primitive recursion, and minimization. As is well-known, dropping minimization makes this formalism strictly less expressive: the functions one represents (the so-called primitive recursive functions) are, at least, all total. Primitive recursive functions are however well beyond any reasonable complexity class: they are after all the class of functions which can be computed in time and space bounded by primitive recursive functions, the latter being strictly larger than Kalmar’s elementary functions. Essentially, this is due to the possibility of having nested recursive definitions. As an example, one can first define addition from the initial functions
 \begin{align*} \mathit{add}(0,x)&=x;\\[3pt] \mathit{add}(n+1,x)&=\mathit{add}(n,x)+1; \end{align*}
\begin{align*} \mathit{add}(0,x)&=x;\\[3pt] \mathit{add}(n+1,x)&=\mathit{add}(n,x)+1; \end{align*}
and then define exponentiation
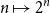 $n\mapsto 2^n$
from addition as follows:
$n\mapsto 2^n$
from addition as follows:
 \begin{align*} \mathit{exp}(0)&=1;\\[3pt] \mathit{exp}(n+1)&=\mathit{add}(\mathit{exp}(n),\mathit{exp}(n)). \end{align*}
\begin{align*} \mathit{exp}(0)&=1;\\[3pt] \mathit{exp}(n+1)&=\mathit{add}(\mathit{exp}(n),\mathit{exp}(n)). \end{align*}
Composing
 $\mathit{exp}$
with itself allows us to form towers of exponentials of arbitrary size, thus saturating the Kalmar elementary functions. A recursion on
$\mathit{exp}$
with itself allows us to form towers of exponentials of arbitrary size, thus saturating the Kalmar elementary functions. A recursion on
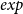 $\mathit{exp}$
leads us even beyond the aforementioned class, already too broad complexity-wise. Rather than removing primitive recursion from the algebra up-front (which would have too strong an impact on the expressive power of the underlying function algebra), we could somehow refine the algebra by distinguishing arguments that matter for complexity from arguments that do not: the arguments of any function f are dubbed either normal, when their value can have a relatively big impact on f’s complexity, or safe when their value can only influence f’s behavior very mildly, combinatorially speaking. If
$\mathit{exp}$
leads us even beyond the aforementioned class, already too broad complexity-wise. Rather than removing primitive recursion from the algebra up-front (which would have too strong an impact on the expressive power of the underlying function algebra), we could somehow refine the algebra by distinguishing arguments that matter for complexity from arguments that do not: the arguments of any function f are dubbed either normal, when their value can have a relatively big impact on f’s complexity, or safe when their value can only influence f’s behavior very mildly, combinatorially speaking. If
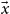 $\vec{x}$
are the normal parameters and
$\vec{x}$
are the normal parameters and
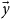 $\vec{y}$
are the safe ones, we indicate the value of f on
$\vec{y}$
are the safe ones, we indicate the value of f on
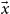 $\vec{x}$
and
$\vec{x}$
and
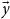 $\vec{y}$
as
$\vec{y}$
as
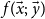 $\mathit{f}(\vec{x};\ \vec{y})$
, where the semicolon serves to separate the normal from the safe. This way, the usual scheme of primitive recursion can be restricted as follows:
$\mathit{f}(\vec{x};\ \vec{y})$
, where the semicolon serves to separate the normal from the safe. This way, the usual scheme of primitive recursion can be restricted as follows:
 \begin{align*} \mathit{f}(0,\vec{x};\ \vec{y})&=h(\vec{x};\ \vec{y});\\[3pt] \mathit{f}(n+1,\vec{x};\ \vec{y})&=g(n,\vec{x};\ \vec{y},f(n,\vec{x};\ \vec{y})).\end{align*}
\begin{align*} \mathit{f}(0,\vec{x};\ \vec{y})&=h(\vec{x};\ \vec{y});\\[3pt] \mathit{f}(n+1,\vec{x};\ \vec{y})&=g(n,\vec{x};\ \vec{y},f(n,\vec{x};\ \vec{y})).\end{align*}
Please notice that the way we define f from g and h is morphologically identical to what happens in the usual primitive recursive scheme. That it is a restriction is a consequence of the distinction between normal and safe arguments: indeed, the recursive call
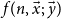 $f(n,\vec{x};\ \vec{y})$
is required to be forwarded to one of g’s safe argument, while f’s first parameter must be normal. This makes
$f(n,\vec{x};\ \vec{y})$
is required to be forwarded to one of g’s safe argument, while f’s first parameter must be normal. This makes
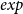 $\mathit{exp}$
not expressible anymore and gives rise to new function algebra called safe recursion and due to Bellantoni and Cook (Reference Bellantoni and Cook1992) (
$\mathit{exp}$
not expressible anymore and gives rise to new function algebra called safe recursion and due to Bellantoni and Cook (Reference Bellantoni and Cook1992) (
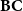 $\mathbf{BC}$
in the following). Is one getting close to any reasonably small complexity class, this way? Surprisingly, the answer is positive:
$\mathbf{BC}$
in the following). Is one getting close to any reasonably small complexity class, this way? Surprisingly, the answer is positive:
Theorem (Bellantoni and Cook Reference Bellantoni and Cook1992) The class
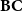 $\mathbf{BC}$
equals the class
$\mathbf{BC}$
equals the class
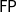 $\mathsf{FP}$
of polynomial time computable functions. This breakthrough result, discovered independently by Leivant (Reference Leivant1993) in a slightly different setting, can be seen as the starting point of ICC and has given rise to a variety of characterizations of different complexity classes along the same lines, from polynomial space (Leivant and Marion Reference Leivant and Marion1994; Oitavem Reference Oitavem2008) to nondeterministic polynomial time (Oitavem Reference Oitavem2011), from circuit classes (Leivant Reference Leivant1998) to logarithmic space (Neergaard Reference Neergaard2004).
$\mathsf{FP}$
of polynomial time computable functions. This breakthrough result, discovered independently by Leivant (Reference Leivant1993) in a slightly different setting, can be seen as the starting point of ICC and has given rise to a variety of characterizations of different complexity classes along the same lines, from polynomial space (Leivant and Marion Reference Leivant and Marion1994; Oitavem Reference Oitavem2008) to nondeterministic polynomial time (Oitavem Reference Oitavem2011), from circuit classes (Leivant Reference Leivant1998) to logarithmic space (Neergaard Reference Neergaard2004).
The lesson by Bellantoni and Cook is that refining a closure operator rather than removing it up-front can be a very effective strategy to tune the expressive power of the underlying algebra and turn it into a characterization of a complexity class. This can also form the basis for the definition of type systems so as to go towards programming languages and calculi capable of handling higher-order functions, and we will give an overview of the results one can obtain this way in Section 3 below. Are function algebras the only kind of computational model amenable to such a refinement? Is it possible that other programming languages and logical formalisms can be treated similarly? We will give an answer to this question in the rest of this section.
Suppose, for example, that one wants to follow the same kind of path Bellantoni and Cook followed, but from a very different starting point, namely looking at the
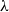 $\lambda$
-calculus rather than at recursive functions. The pure, untyped
$\lambda$
-calculus rather than at recursive functions. The pure, untyped
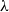 $\lambda$
-calculus is a minimal programming language whose terms are those generated by the following grammar:
$\lambda$
-calculus is a minimal programming language whose terms are those generated by the following grammar:
 \begin{equation*}M::=x\;|\;\lambda {x}.{M}\mid MM\end{equation*}
\begin{equation*}M::=x\;|\;\lambda {x}.{M}\mid MM\end{equation*}
and whose dynamics is captured by rewriting, and in particular by so-called
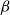 $\beta$
-reduction:
$\beta$
-reduction:
 $$(\lambda x.M)N{ \to _\beta }M\{ x/N\} $$
$$(\lambda x.M)N{ \to _\beta }M\{ x/N\} $$
The obtained language is well-known to be Turing-powerful: there are various ways of representing the natural numbers and functions between them which make this very simple formal system capable of capturing all computable functions. In doing so, the
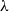 $\lambda$
-calculus shows its capability of simulating many different operators (e.g., conditionals, recursion, and iteration) within a very simple framework in which the basic computation step, namely
$\lambda$
-calculus shows its capability of simulating many different operators (e.g., conditionals, recursion, and iteration) within a very simple framework in which the basic computation step, namely
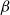 $\beta$
, is so simple and apparently innocuous. What is it that makes
$\beta$
, is so simple and apparently innocuous. What is it that makes
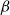 $\beta$
so powerful, computationally speaking? The answer lies in the possibility for a
$\beta$
so powerful, computationally speaking? The answer lies in the possibility for a
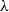 $\lambda$
-abstraction
$\lambda$
-abstraction
 $\lambda {x}.{M}$
to not only forward the argument N to M when applied to the former, but also to duplicate it. Take, for example, the paradigmatic divergent term
$\lambda {x}.{M}$
to not only forward the argument N to M when applied to the former, but also to duplicate it. Take, for example, the paradigmatic divergent term
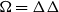 $\Omega=\Delta\Delta$
, where
$\Omega=\Delta\Delta$
, where
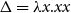 $\Delta=\lambda {x}.{xx}$
. The fact that
$\Delta=\lambda {x}.{xx}$
. The fact that
 $\Omega$
rewrites to itself (thus giving rise to divergence, and ultimately rendering the pure
$\Omega$
rewrites to itself (thus giving rise to divergence, and ultimately rendering the pure
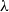 $\lambda$
-calculus inadequate for ICC) fundamentally relies on the fact that two occurrences of the abstracted variable occur in the body of
$\lambda$
-calculus inadequate for ICC) fundamentally relies on the fact that two occurrences of the abstracted variable occur in the body of
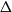 $\Delta$
. Similarly, Turing’s fixed-point combinator
$\Delta$
. Similarly, Turing’s fixed-point combinator
 \begin{equation*}\Theta=(\lambda {x}.{\lambda {y}.{y(xxy)}})((\lambda {x}.{\lambda {y}.{y(xxy)}})\end{equation*}
\begin{equation*}\Theta=(\lambda {x}.{\lambda {y}.{y(xxy)}})((\lambda {x}.{\lambda {y}.{y(xxy)}})\end{equation*}
can be used to simulate recursion, since for every M it holds that
 $\Theta M$
rewrites in two
$\Theta M$
rewrites in two
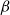 $\beta$
-steps to
$\beta$
-steps to
 $M(\Theta M)$
. And, again, all this crucially relies on the possibility of duplicating, since both the argument and part of the combinator itself are duplicated along the reduction process.
$M(\Theta M)$
. And, again, all this crucially relies on the possibility of duplicating, since both the argument and part of the combinator itself are duplicated along the reduction process.
When looking for a subrecursive variation on the pure
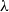 $\lambda$
-calculus, many roads have been followed, the most explored one being the use of type systems, namely of formal systems which single out certain
$\lambda$
-calculus, many roads have been followed, the most explored one being the use of type systems, namely of formal systems which single out certain
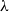 $\lambda$
-terms as typable, guaranteeing at the same time that all typable programs satisfy certain properties, typical examples being safety and reachability properties. In particular, many of the introduced type systems guarantee that
$\lambda$
-terms as typable, guaranteeing at the same time that all typable programs satisfy certain properties, typical examples being safety and reachability properties. In particular, many of the introduced type systems guarantee that
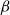 $\beta$
-reduction is strongly normalizing on all typable
$\beta$
-reduction is strongly normalizing on all typable
 $\lambda$
-terms, namely that divergence is simply impossible. Sometimes, one can also go beyond that and introduce systems of types which guarantee various forms of bounded termination. We will give a survey on all this in Section 3 below.
$\lambda$
-terms, namely that divergence is simply impossible. Sometimes, one can also go beyond that and introduce systems of types which guarantee various forms of bounded termination. We will give a survey on all this in Section 3 below.
But there is another, more fundamental, way of keeping the complexity of
 $\beta$
-reduction under control, namely acting directly on duplication, as suggested by Girard (Reference Girard1987) in his work on linear logic. There, the main intuition is precisely the one of decomposing intuitionistic implication (thus
$\beta$
-reduction under control, namely acting directly on duplication, as suggested by Girard (Reference Girard1987) in his work on linear logic. There, the main intuition is precisely the one of decomposing intuitionistic implication (thus
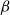 $\beta$
-reduction) into a linear implication and an exponential modality. Without delving into the proof-theoretical details of all this, we can already grasp the essence by considering a refinement
$\beta$
-reduction) into a linear implication and an exponential modality. Without delving into the proof-theoretical details of all this, we can already grasp the essence by considering a refinement
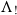 $\Lambda_!$
of the pure
$\Lambda_!$
of the pure
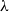 $\lambda$
-calculus:
$\lambda$
-calculus:
 \begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\;|\;\lambda\!!{x}.{M}\mid MM\;|\;!{M}\end{equation*}
\begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\;|\;\lambda\!!{x}.{M}\mid MM\;|\;!{M}\end{equation*}
Besides the usual operators, we find new ones, namely the so-called boxes, that is, terms of the form
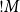 $!{M}$
, and two kinds of abstractions, namely nonlinear ones, of the form
$!{M}$
, and two kinds of abstractions, namely nonlinear ones, of the form
 $\lambda\!!{x}.{M}$
, and linear ones, of the form
$\lambda\!!{x}.{M}$
, and linear ones, of the form
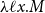 $\lambda \ell{x}.{M}$
. The latter is dubbed well-formed only if x occurs free in M at most once and outside the scope of any box. The
$\lambda \ell{x}.{M}$
. The latter is dubbed well-formed only if x occurs free in M at most once and outside the scope of any box. The
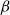 $\beta$
-reduction rule has to be refined itself into a linear rule and a nonlinear rule:
$\beta$
-reduction rule has to be refined itself into a linear rule and a nonlinear rule:
 \begin{equation*}(\lambda \ell{x}.{M})N\rightarrow_{\ell\beta} M\{{x}/{N}\}\qquad\qquad(\lambda\!!{x}.{M})!{N}\rightarrow_{!\beta} M\{{x}/{N}\}\end{equation*}
\begin{equation*}(\lambda \ell{x}.{M})N\rightarrow_{\ell\beta} M\{{x}/{N}\}\qquad\qquad(\lambda\!!{x}.{M})!{N}\rightarrow_{!\beta} M\{{x}/{N}\}\end{equation*}
This refinement by itself does not allow us to tame the expressive power of the underlying computational model: the pure
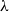 $\lambda$
-calculus can be retrieved in all its strength and wildness thanks to nonlinear abstractions, that is, the following embedding allows to simulate
$\lambda$
-calculus can be retrieved in all its strength and wildness thanks to nonlinear abstractions, that is, the following embedding allows to simulate
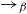 $\rightarrow_\beta$
by way of
$\rightarrow_\beta$
by way of
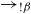 $\rightarrow_{!\beta}$
:
$\rightarrow_{!\beta}$
:
 \begin{equation*}({x})_{!}=x\qquad({\lambda {x}.{M}})_{!}=\lambda\!!{x}.{({M})_{!}}\qquad({MN})_{!}=({M})_{!}{!{({N})_{!}}}\end{equation*}
\begin{equation*}({x})_{!}=x\qquad({\lambda {x}.{M}})_{!}=\lambda\!!{x}.{({M})_{!}}\qquad({MN})_{!}=({M})_{!}{!{({N})_{!}}}\end{equation*}
Indeed:
 \begin{equation*}({(\lambda {x}.{M})N})_{!}=(\lambda\!!{x}.{({M})_{!}})!({N})_{!}\rightarrow_{!\beta}({M})_{!}\{{x}/{({N})_{!}}\}=({M\{{x}/{N}\}})_{!}\end{equation*}
\begin{equation*}({(\lambda {x}.{M})N})_{!}=(\lambda\!!{x}.{({M})_{!}})!({N})_{!}\rightarrow_{!\beta}({M})_{!}\{{x}/{({N})_{!}}\}=({M\{{x}/{N}\}})_{!}\end{equation*}
(where the last step is nothing more than a straightforward substitution lemma).
How should one proceed, then? A simple idea consists in dropping nonlinearity altogether, thus getting rid of boxes and nonlinear abstractions in the underlying calculus:
 \begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\mid MM\end{equation*}
\begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\mid MM\end{equation*}
This way, one obtains a calculus, called the affine
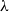 $\lambda$
-calculus and indicated as
$\lambda$
-calculus and indicated as
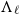 $\Lambda_\ell$
, in which divergence is simply absent, for very good reasons: along any
$\Lambda_\ell$
, in which divergence is simply absent, for very good reasons: along any
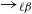 $\rightarrow_{\ell\beta}$
step, the size (i.e., the total number of symbols) in the underlying term strictly decreases. How about the expressive power of the obtained calculus? Apparently, this is quite limited: even though some of the number schemes in the literature (e.g., so-called Scott numerals) can indeed be seen as terms in
$\rightarrow_{\ell\beta}$
step, the size (i.e., the total number of symbols) in the underlying term strictly decreases. How about the expressive power of the obtained calculus? Apparently, this is quite limited: even though some of the number schemes in the literature (e.g., so-called Scott numerals) can indeed be seen as terms in
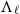 $\Lambda_\ell$
, the class of functions which are representable in the calculus is very small, well below any complexity class. Things change, however, if one consider
$\Lambda_\ell$
, the class of functions which are representable in the calculus is very small, well below any complexity class. Things change, however, if one consider
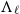 $\Lambda_\ell$
as a computational model for boolean functions. If this is the case, a nice, and tight correspondence between terms and boolean circuits starts to show up, leading to the following result:
$\Lambda_\ell$
as a computational model for boolean functions. If this is the case, a nice, and tight correspondence between terms and boolean circuits starts to show up, leading to the following result:
Theorem (Mairson and Terui Reference Mairson and Terui2003) Given a term M in
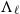 $\Lambda_\ell$
, testing whether it reduces via
$\Lambda_\ell$
, testing whether it reduces via
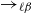 $\rightarrow_{\ell\beta}$
to a specific normal form is a
$\rightarrow_{\ell\beta}$
to a specific normal form is a
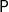 $\mathsf{P}$
-complete problem. This does not mean, however, that every polynomial time problem can somehow be represented as a term in
$\mathsf{P}$
-complete problem. This does not mean, however, that every polynomial time problem can somehow be represented as a term in
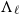 $\Lambda_\ell$
. Instead, instances of any problem in
$\Lambda_\ell$
. Instead, instances of any problem in
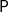 $\mathsf{P}$
can very cheaply be turned into terms in such a way that solving the problem boils down to reducing the term. More results along these lines will be discussed in Section 4.
$\mathsf{P}$
can very cheaply be turned into terms in such a way that solving the problem boils down to reducing the term. More results along these lines will be discussed in Section 4.
If one is rather interested in uniform encodings, that is, in encodings of problems (and not problem instances) into terms, the natural way to proceed consists in allowing nonlinear abstractions to occur in the calculus, at the same time constraining, in various ways, the way x can occur in M whenever forming the term
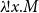 $\lambda\!!{x}.{M}$
. Indeed, some such constraints have been analyzed in the literature, giving rise to characterizations of different complexity classes. We will review some of them in Section 4, but it is instructive to see how this turns out to be possible by way of a simple example, namely the so-called soft
$\lambda\!!{x}.{M}$
. Indeed, some such constraints have been analyzed in the literature, giving rise to characterizations of different complexity classes. We will review some of them in Section 4, but it is instructive to see how this turns out to be possible by way of a simple example, namely the so-called soft
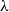 $\lambda$
-calculus
$\lambda$
-calculus
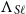 $\Lambda_{S\ell}$
, due to Baillot and Mogbil (Reference Baillot and Mogbil2004), and inspired by soft linear logic (Lafont Reference Lafont2004).
$\Lambda_{S\ell}$
, due to Baillot and Mogbil (Reference Baillot and Mogbil2004), and inspired by soft linear logic (Lafont Reference Lafont2004).
Suppose, as an example, that whenever one forms
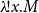 $\lambda\!!{x}.{M}$
, the variable x is allowed to occur free in M:
$\lambda\!!{x}.{M}$
, the variable x is allowed to occur free in M:
-
(1). either at most once and in the scope of a single occurrence of the
 $!$
operator;
$!$
operator; -
(2). or possibly more than once, but outside the scope of any
$!$
operator.

In other words, terms like
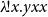 $\lambda\!!{x}.{yxx}$
or
$\lambda\!!{x}.{yxx}$
or
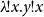 $\lambda\!!{x}.{y!{x}}$
would be considered legal, while
$\lambda\!!{x}.{y!{x}}$
would be considered legal, while
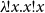 $\lambda\!!{x}.{x!x}$
would not be. To realize why this is a sensible restriction, observe how, whenever firing a nonlinear
$\lambda\!!{x}.{x!x}$
would not be. To realize why this is a sensible restriction, observe how, whenever firing a nonlinear
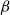 $\beta$
-step, a term in the form
$\beta$
-step, a term in the form
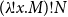 $(\lambda\!!{x}.{M})!{N}$
becomes
$(\lambda\!!{x}.{M})!{N}$
becomes
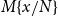 $M\{{x}/{N}\}$
, and either multiple copies of N are produced along the substitution process, all of them lying outside of any
$M\{{x}/{N}\}$
, and either multiple copies of N are produced along the substitution process, all of them lying outside of any
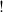 $!$
operator, or N is not copied at all, staying at the same nesting depth it was before the rewriting step. Summing up, while reducing any term of
$!$
operator, or N is not copied at all, staying at the same nesting depth it was before the rewriting step. Summing up, while reducing any term of
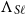 $\Lambda_{S\ell}$
, the actual size of the term can definitely increase, but it does so in a very controlled and predictable way. Observe how allowing multiple occurrences of x at different depths when forming nonlinear abstractions would allow to type divergent terms, like
$\Lambda_{S\ell}$
, the actual size of the term can definitely increase, but it does so in a very controlled and predictable way. Observe how allowing multiple occurrences of x at different depths when forming nonlinear abstractions would allow to type divergent terms, like
 \begin{equation*}({\Omega})_{!}=(\lambda\!!{x}.{x!x})!{(\lambda\!!{x}.{x!x})}.\end{equation*}
\begin{equation*}({\Omega})_{!}=(\lambda\!!{x}.{x!x})!{(\lambda\!!{x}.{x!x})}.\end{equation*}
As one can easily check,
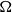 $\Omega$
is not a term of
$\Omega$
is not a term of
 $\Lambda_{S\ell}$
.
$\Lambda_{S\ell}$
.
Summing up, we described two ways of refining and restricting universal computational models so as to make them capable of capturing relatively small complexity classes. Both of them rely on finding the right parameters to act on, namely recursion depth (in recursion theory), and duplication (in the
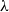 $\lambda$
-calculus). Are there other ways of achieving the same goal? The answer is affirmative, and we will say a few words about that in Section 5 below. The next two sections, however, are meant to be surveys on works about type systems and linear logic fragments, respectively.
$\lambda$
-calculus). Are there other ways of achieving the same goal? The answer is affirmative, and we will say a few words about that in Section 5 below. The next two sections, however, are meant to be surveys on works about type systems and linear logic fragments, respectively.
3. Type Systems
Type systems are among the most successful lightweight formal methods and are particularly fit for languages with higher-order functions, namely the ones we are interested in here. Most type systems automatically ensure safety properties: well-typed programs cannot go wrong, even if the converse does not hold. Besides safety, some type systems also guarantee reachability: well-typed programs cannot diverge, that is, they are guaranteed to reach a final state or normal form. Again, the converse is not guaranteed to hold, except for peculiar forms of type systems (e.g., intersection types, by Coppo and Dezani-Ciancaglini Reference Coppo and Dezani-Ciancaglini1980). A refinement of reachability, namely termination in a bounded number of steps, could give further guarantees as for the feasibility of the underlying algorithm, rather than mere totality.
Traditionally, one very natural way of defining type systems guaranteeing termination properties consists in deriving them from proof systems through the so-called Curry-Howard correspondence (see the textbooks by Girard et al. Reference Girard, Taylor and Lafont1989 and SØ rensen and Urzyczyn 2006 for an introduction). This way, termination is a byproduct of the cut-elimination or normalization properties for the underlying logical system, precisely because
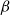 $\beta$
-reduction mimics them. This is the case in the so-called simply-typed
$\beta$
-reduction mimics them. This is the case in the so-called simply-typed
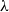 $\lambda$
-calculus, which corresponds to intuitionistic propositional logic, or in the polymorphic
$\lambda$
-calculus, which corresponds to intuitionistic propositional logic, or in the polymorphic
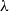 $\lambda$
-calculus, itself a sibling of second-order intuitionistic logic. In the aforementioned systems, however, the obtained class of terms is not fit for a characterization of complexity classes in the spirit of ICC. For example, the class of polymorphically typable
$\lambda$
-calculus, itself a sibling of second-order intuitionistic logic. In the aforementioned systems, however, the obtained class of terms is not fit for a characterization of complexity classes in the spirit of ICC. For example, the class of polymorphically typable
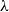 $\lambda$
-terms is so huge that it represents all functions on the natural numbers which are provably total in second-order arithmetic. As another example, simply-typed
$\lambda$
-terms is so huge that it represents all functions on the natural numbers which are provably total in second-order arithmetic. As another example, simply-typed
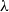 $\lambda$
-terms require hyper-exponential time to be reduced to their normal forms (see Fortune et al. Reference Fortune, Leivant and O’Donnell1983), but the functions which can be encoded as simply-typed terms do not include some, like the identity, which are part of all reasonable complexity classes, see the work by Zaionc (Reference Zaionc1990, Reference Zaionc1991).
$\lambda$
-terms require hyper-exponential time to be reduced to their normal forms (see Fortune et al. Reference Fortune, Leivant and O’Donnell1983), but the functions which can be encoded as simply-typed terms do not include some, like the identity, which are part of all reasonable complexity classes, see the work by Zaionc (Reference Zaionc1990, Reference Zaionc1991).
If one is really interested in giving implicit characterizations of complexity classes by way of type systems, one is thus forced to follow different routes, some of which we will describe in the rest of this section.
3.1 Higher-order primitive recursion
One way to enrich the simply-typed
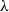 $\lambda$
-calculus so as to turn it into a language with a very high expressive power is to endow it with constants for the natural numbers, and operators for primitive recursion at all finite types. As is well-known, the obtained system, the so-called GÖdel’s System
$\lambda$
-calculus so as to turn it into a language with a very high expressive power is to endow it with constants for the natural numbers, and operators for primitive recursion at all finite types. As is well-known, the obtained system, the so-called GÖdel’s System
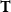 $\mathbf{T}$
, is capable of representing all functions on the natural numbers which are provably total in first-order Peano’s Arithmetic. As such, then,
$\mathbf{T}$
, is capable of representing all functions on the natural numbers which are provably total in first-order Peano’s Arithmetic. As such, then,
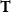 $\mathbf{T}$
cannot be close to the characterization of any complexity classes.
$\mathbf{T}$
cannot be close to the characterization of any complexity classes.
System
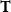 $\mathbf{T}$
, however, can be seen as nothing more than a generalization of Kleene’s primitive recursion to higher-order types. It is thus very natural to wonder whether one could turn safe recursion into a sub-recursive type system guaranteeing polynomial time computability. A naive idea is that the underlying function space can be refined into two:
$\mathbf{T}$
, however, can be seen as nothing more than a generalization of Kleene’s primitive recursion to higher-order types. It is thus very natural to wonder whether one could turn safe recursion into a sub-recursive type system guaranteeing polynomial time computability. A naive idea is that the underlying function space can be refined into two:
-
• The space
$\square A\rightarrow B$
of functions depending on a safe argument of type A and returning an element of type B. -
• The space
$\blacksquare A\rightarrow B$
of functions depending on a normal argument of type A and returning an element of a type B.
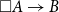
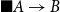
This allows us to define a type system very much in the style of safe recursion. This, however, does not lead us to a characterization of the polynomial computable functions. Consider the following higher-order function
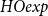 $\mathit{HOexp}$
, whose type is
$\mathit{HOexp}$
, whose type is
 $\blacksquare\mathit{NAT}\rightarrow\square\mathit{NAT}\rightarrow\mathit{NAT}$
$\blacksquare\mathit{NAT}\rightarrow\square\mathit{NAT}\rightarrow\mathit{NAT}$
 \begin{align*} \mathit{HOexp}(0)&=\lambda x.\mathit{succ}(x);\\[3pt] \mathit{HOexp}(n+1)&=\lambda x.\mathit{HOexp}(n)(\mathit{HOexp}(n)(x)).\end{align*}
\begin{align*} \mathit{HOexp}(0)&=\lambda x.\mathit{succ}(x);\\[3pt] \mathit{HOexp}(n+1)&=\lambda x.\mathit{HOexp}(n)(\mathit{HOexp}(n)(x)).\end{align*}
The behavior of this function is intrinsically exponential,
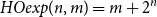 $\mathit{HOexp}(n,m)=m+2^n$
. Actually, the obtained system, call it
$\mathit{HOexp}(n,m)=m+2^n$
. Actually, the obtained system, call it
 $\mathbf{HOSR}$
, can be proved to precisely characterize Kalmar’s elementary time:
$\mathbf{HOSR}$
, can be proved to precisely characterize Kalmar’s elementary time:
Theorem (Leivant Reference Leivant1999b)
 $\mathbf{HOSR}$
precisely captures the class
$\mathbf{HOSR}$
precisely captures the class
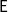 $\mathsf{E}$
of Kalmar’s elementary functions. If one wants to trim the complexity of the calculus down to complexity classes capturing notions of feasibility, the key idea consists in imposing linearity restrictions. The exponential behavior
$\mathsf{E}$
of Kalmar’s elementary functions. If one wants to trim the complexity of the calculus down to complexity classes capturing notions of feasibility, the key idea consists in imposing linearity restrictions. The exponential behavior
 $\mathit{HOexp}$
exhibits is essentially due to the fact that two recursive calls take place in the inductive case. If one imposes linearity constraints on higher-order variables, one indeed obtains a calculus, called
$\mathit{HOexp}$
exhibits is essentially due to the fact that two recursive calls take place in the inductive case. If one imposes linearity constraints on higher-order variables, one indeed obtains a calculus, called
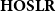 $\mathbf{HOSLR}$
which has the desired property:
$\mathbf{HOSLR}$
which has the desired property:
Theorem (Hofmann Reference Hofmann1997b)
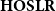 $\mathbf{HOSLR}$
precisely captures
$\mathbf{HOSLR}$
precisely captures
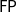 $\mathsf{FP}$
. Hofmann’s result has been proved by way of a realizability interpretation, which has been later turned into a more general and flexible tool by Dal Lago and Hofmann (Reference Dal Lago and Hofmann2011). An earlier and very influential work by Hofmann (Reference Hofmann2000b) proved – by way of linear combinatory algebras – that an extension of
$\mathsf{FP}$
. Hofmann’s result has been proved by way of a realizability interpretation, which has been later turned into a more general and flexible tool by Dal Lago and Hofmann (Reference Dal Lago and Hofmann2011). An earlier and very influential work by Hofmann (Reference Hofmann2000b) proved – by way of linear combinatory algebras – that an extension of
 $\mathbf{HOSLR}$
to a larger class of datatypes remain sound. A system essentially equivalent to
$\mathbf{HOSLR}$
to a larger class of datatypes remain sound. A system essentially equivalent to
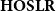 $\mathbf{HOSLR}$
has been analyzed from a more syntactical viewpoint, obtaining results analogous to Theorem 3.1 but having a more operational flavor, by Bellantoni et al. (Reference Bellantoni, Niggl and Schwichtenberg2000). Probabilistic variations on
$\mathbf{HOSLR}$
has been analyzed from a more syntactical viewpoint, obtaining results analogous to Theorem 3.1 but having a more operational flavor, by Bellantoni et al. (Reference Bellantoni, Niggl and Schwichtenberg2000). Probabilistic variations on
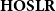 $\mathbf{HOSLR}$
have been considered and proved to be useful tools in the study of cryptographic constructions, by Mitchell et al. (Reference Mitchell, Mitchell and Scedrov1998), Zhang (Reference Zhang2009), and Cappai and Dal Lago (Reference Cappai and Dal Lago2015). Contrary to what happens in the realm of first-order function algebras (see, e.g., the work by Avanzini and Dal Lago Reference Avanzini and Dal Lago2018), higher-order safe recursion is very fragile as a characterization of the polytime computable functions: switching from word algebras to tree algebras makes the class of representable functions go up to
$\mathbf{HOSLR}$
have been considered and proved to be useful tools in the study of cryptographic constructions, by Mitchell et al. (Reference Mitchell, Mitchell and Scedrov1998), Zhang (Reference Zhang2009), and Cappai and Dal Lago (Reference Cappai and Dal Lago2015). Contrary to what happens in the realm of first-order function algebras (see, e.g., the work by Avanzini and Dal Lago Reference Avanzini and Dal Lago2018), higher-order safe recursion is very fragile as a characterization of the polytime computable functions: switching from word algebras to tree algebras makes the class of representable functions go up to
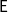 $\mathsf{E}$
, as proved by Dal Lago (Reference Dal Lago2009b).
$\mathsf{E}$
, as proved by Dal Lago (Reference Dal Lago2009b).
3.2 Non-size increasing computation
Systems like
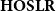 $\mathbf{HOSLR}$
are implicit, thus providing simple characterizations of the complexity class
$\mathbf{HOSLR}$
are implicit, thus providing simple characterizations of the complexity class
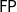 $\mathsf{FP}$
. As such, they can be seen as compositional verification methodologies for the complexity analysis of programs. This is true, of course, if the fact that all typable programs represent polynomial time functions is proved operationally, that is, by showing that those programs can be reduced themselves within some polynomial time bounds. This observation has led many researchers to work on the use of systems based on predicative recursion, and ICC in general, as static analysis techniques.
$\mathsf{FP}$
. As such, they can be seen as compositional verification methodologies for the complexity analysis of programs. This is true, of course, if the fact that all typable programs represent polynomial time functions is proved operationally, that is, by showing that those programs can be reduced themselves within some polynomial time bounds. This observation has led many researchers to work on the use of systems based on predicative recursion, and ICC in general, as static analysis techniques.
Quite soon, however, strong limitations to these ideas emerged, as observed by Hofmann (Reference Hofmann1999):
Although these systems allow one to express all polynomial time functions, they reject many natural formulations of obviously polynomial time algorithms. The reason is that under the predicativity regime, a recursively defined function is not allowed to serve as step function of a subsequent recursive definition. However, in most functional programs involving inductive data structures such iterated recursion does occur.
In other words, even if extensionally complete, these systems tend to be intentionally very weak, ruling out many useful and popular algorithmic schemes which, although giving rise to polynomial time functions, requires forms of nested recursion. Examples include the so-called InsertionSort algorithm, which was observed not to be expressible in, say,
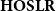 $\mathbf{HOSLR}$
(see again Hofmann Reference Hofmann1999).
$\mathbf{HOSLR}$
(see again Hofmann Reference Hofmann1999).
A way out consists in taking another property of programs as the one on which potentially problematic programs (i.e., programs with too high a complexity) are ruled out. Rather than saying that nested recursions are simply not allowed, it is possible to define a type system in such a way that all typable programs are by construction non-size-increasing. This way, since recurring or iterating over a non-size-increasing (polytime) function is always safe, iteration and recursion can be made more liberal, and nesting is indeed allowed. This idea, introduced by Hofmann (Reference Hofmann1999), has been explored in various directions by Hofmann (Reference Hofmann2000c, 2002, 2003) and ultimately gave rise to the fruitful line of work on amortized resource analysis (see, as an example, the work by Jost et al. Reference Jost, Hammond, Loidl and Hofmann2010 or the many recent contributions on the subject).
But how can all this be made concrete? Actually, the ingredients are relatively simple:
-
• On the one hand, the underlying system of types must enforce an affine regime where every free variable occurs at most once, even when it is of ground type. In other words, there is just one way of typing functions, namely by linear types in the form
$A\multimap B$
. -
• On the other hand, every function inducing a strict increase on the input length must “pay the price” by taking an additional input of type
$\diamond$
, itself providing the “missing size.” As an example, the successor function has type
$\diamond\multimap\mathit{NAT}\multimap\mathit{NAT}$
. It is of course important to guarantee that no closed term of type
$\diamond$
can be built.
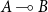
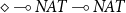
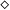
This way, a type system called
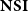 $\mathbf{NSI}$
is defined and proved to characterize the polynomial time computable problems:
$\mathbf{NSI}$
is defined and proved to characterize the polynomial time computable problems:
Theorem (Hofmann Reference Hofmann1999) The type system
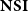 $\mathbf{NSI}$
characterizes the class
$\mathbf{NSI}$
characterizes the class
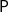 $\mathsf{P}$
. Variations of
$\mathsf{P}$
. Variations of
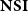 $\mathbf{NSI}$
in which the language of terms is made to vary lead to characterizations of larger complexity classes, like
$\mathbf{NSI}$
in which the language of terms is made to vary lead to characterizations of larger complexity classes, like
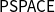 $\mathsf{PSPACE}$
and
$\mathsf{PSPACE}$
and
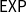 $\mathsf{EXP}$
, as shown in the work by Hofmann (Reference Hofmann2002, Reference Hofmann2003), witnessing the flexibility and interest of the approach.
$\mathsf{EXP}$
, as shown in the work by Hofmann (Reference Hofmann2002, Reference Hofmann2003), witnessing the flexibility and interest of the approach.
4. Linear Logic
As explained in Section 2, one natural way of taming the expressive power of systems like the
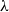 $\lambda$
-calculus is to control copying by decomposing functions in the sense of functional programming into copiers and forwarders, similarly to what we did by going from
$\lambda$
-calculus is to control copying by decomposing functions in the sense of functional programming into copiers and forwarders, similarly to what we did by going from
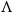 $\Lambda$
to
$\Lambda$
to
 $\Lambda_!$
. This enables the definition of restrictions to
$\Lambda_!$
. This enables the definition of restrictions to
 $\Lambda_!$
obtained by tuning the way nonlinear abstractions can manipulate duplicable terms, that is, to which extent boxes can be copied, opened, and thrown inside other boxes.
$\Lambda_!$
obtained by tuning the way nonlinear abstractions can manipulate duplicable terms, that is, to which extent boxes can be copied, opened, and thrown inside other boxes.
There is a natural way of interpreting all this in terms of logic and types, which is precisely how this line of research comes into being. We are referring here to Linear Logic as introduced by Girard (Reference Girard1987). Among many other things, Linear Logic can be seen as a way of decomposing the type of functions
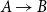 $A\rightarrow B$
as traditionally found in type systems into
$A\rightarrow B$
as traditionally found in type systems into
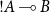 $!A\multimap B$
where the
$!A\multimap B$
where the
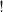 $!$
operator, called the bang, is the type of duplicable versions of objects of type A, while
$!$
operator, called the bang, is the type of duplicable versions of objects of type A, while
 $\multimap$
is a binary type constructor allowing to build spaces of linear functions, which in this context can be taken as functions using their argument at most once. This way, restricting the copying process can be done by acting on the axioms the bang operator is required to satisfy, which in full linear logic are the following ones:
$\multimap$
is a binary type constructor allowing to build spaces of linear functions, which in this context can be taken as functions using their argument at most once. This way, restricting the copying process can be done by acting on the axioms the bang operator is required to satisfy, which in full linear logic are the following ones:
 \begin{align*} !A&\multimap!A\otimes !A\\[2pt] !A&\multimap 1\\[2pt] !A&\multimap A\\[2pt] !A&\multimap!!A\end{align*}
\begin{align*} !A&\multimap!A\otimes !A\\[2pt] !A&\multimap 1\\[2pt] !A&\multimap A\\[2pt] !A&\multimap!!A\end{align*}
The first two axioms (contraction and weakening, respectively) state that an object of type
 $!A$
can be duplicated and discarded, while the following two (dereliction and digging, respectively) allow for such a duplicable object to be turned into one of type A or
$!A$
can be duplicated and discarded, while the following two (dereliction and digging, respectively) allow for such a duplicable object to be turned into one of type A or
 $!!A$
(respectively) by either forgetting its nature as a duplicable object or by turning it into a duplicable duplicable object. These axioms can be seen as saying that
$!!A$
(respectively) by either forgetting its nature as a duplicable object or by turning it into a duplicable duplicable object. These axioms can be seen as saying that
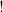 $!$
is categorically a comonad, but can also be seen as the types of appropriate combinators written in
$!$
is categorically a comonad, but can also be seen as the types of appropriate combinators written in
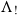 $\Lambda_!$
:
$\Lambda_!$
:
 \begin{align*} \mathit{CONTRACTION}&\triangleq\lambda\!!{x}.{\langle x,x\rangle}:!A\multimap!A\otimes !A\\[2pt] \mathit{WEAKENING}&\triangleq\lambda\!!{x}.{*}:A\multimap 1\\[2pt] \mathit{DERELICTION}&\triangleq\lambda\!!{x}.{x}:!A\multimap A\\[2pt] \mathit{DIGGING}&\triangleq\lambda\!!{x}.{!{!{x}}}:!A\multimap!!A\end{align*}
\begin{align*} \mathit{CONTRACTION}&\triangleq\lambda\!!{x}.{\langle x,x\rangle}:!A\multimap!A\otimes !A\\[2pt] \mathit{WEAKENING}&\triangleq\lambda\!!{x}.{*}:A\multimap 1\\[2pt] \mathit{DERELICTION}&\triangleq\lambda\!!{x}.{x}:!A\multimap A\\[2pt] \mathit{DIGGING}&\triangleq\lambda\!!{x}.{!{!{x}}}:!A\multimap!!A\end{align*}
By dropping some of the above principles, one could get meaningful fragments of linear logic, with the hope of capturing complexity classes this way. This has materialized in many different forms, which we are going to examine in the rest of this section, somehow by reverse chronological order (this way facilitating the nonexpert reader).
4.1. Soft linear logic
One drastic way of taming the expressive power of linear logic is the one we have already considered in Section 2, namely going to systems like
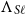 $\Lambda_{S\ell}$
in which boxes are opened whenever copied. This, correspond to collapsing the four comonadic axioms into just one:
$\Lambda_{S\ell}$
in which boxes are opened whenever copied. This, correspond to collapsing the four comonadic axioms into just one:
 \begin{equation*}\mathit{MULTIPLEXOR}^n\triangleq\lambda\!!{x}.{\langle \underbrace{x,\ldots,x}_{n \textrm{times}}\rangle}:!A\multimap \underbrace{A\otimes\cdots\otimes A}_{n \textrm{times}}\end{equation*}
\begin{equation*}\mathit{MULTIPLEXOR}^n\triangleq\lambda\!!{x}.{\langle \underbrace{x,\ldots,x}_{n \textrm{times}}\rangle}:!A\multimap \underbrace{A\otimes\cdots\otimes A}_{n \textrm{times}}\end{equation*}
Logically speaking, this amounts to switching to soft linear logic (
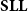 $\mathbf{SLL}$
, introduced by Lafont Reference Lafont2004), which can indeed be proved to be a characterization of the polynomial time computable problems:
$\mathbf{SLL}$
, introduced by Lafont Reference Lafont2004), which can indeed be proved to be a characterization of the polynomial time computable problems:
Theorem (Lafont Reference Lafont2004) The logic
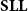 $\mathbf{SLL}$
characterizes the class
$\mathbf{SLL}$
characterizes the class
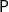 $\mathsf{P}$
of polynomial time computable problems. Soft linear logic has proved to be amenable to many adaptations and variations. First of all, changing the way strings are represented leads to a characterization of polytime computable functions, as proved by Gaboardi and Ronchi Della Rocca (Reference Gaboardi and Ronchi Della Rocca2007). Then, other complexity classes can be proved to be captured, of course by a careful variation of the underlying language of terms, an example being
$\mathsf{P}$
of polynomial time computable problems. Soft linear logic has proved to be amenable to many adaptations and variations. First of all, changing the way strings are represented leads to a characterization of polytime computable functions, as proved by Gaboardi and Ronchi Della Rocca (Reference Gaboardi and Ronchi Della Rocca2007). Then, other complexity classes can be proved to be captured, of course by a careful variation of the underlying language of terms, an example being
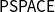 $\mathsf{PSPACE}$
(see Gaboardi et al. Reference Gaboardi, Marion and Ronchi Della Rocca2012). The work by Redmond (Reference Redmond2007); Redmond (Reference Redmond2015); Redmond (Reference Redmond2016) is remarkable in its way of exploring the possible ramifications of the ideas behind soft linear logic from a categorical and rewriting perspective. The calculus
$\mathsf{PSPACE}$
(see Gaboardi et al. Reference Gaboardi, Marion and Ronchi Della Rocca2012). The work by Redmond (Reference Redmond2007); Redmond (Reference Redmond2015); Redmond (Reference Redmond2016) is remarkable in its way of exploring the possible ramifications of the ideas behind soft linear logic from a categorical and rewriting perspective. The calculus
 $\Lambda_{S\ell}$
has been introduced and studied by Baillot and Mogbil (Reference Baillot and Mogbil2004). The robustness of the paradigm is witnessed by works generalizing it to higher-order processes (by Dal Lago et al. Reference Dal Lago, Martini and Sangiorgi2016), session types (by Dal Lago and Di Giamberardino Reference Dal Lago and Di Giamberardino2016), and quantum computation (by Dal Lago et al. Reference Dal Lago, Masini and Zorzi2010).
$\Lambda_{S\ell}$
has been introduced and studied by Baillot and Mogbil (Reference Baillot and Mogbil2004). The robustness of the paradigm is witnessed by works generalizing it to higher-order processes (by Dal Lago et al. Reference Dal Lago, Martini and Sangiorgi2016), session types (by Dal Lago and Di Giamberardino Reference Dal Lago and Di Giamberardino2016), and quantum computation (by Dal Lago et al. Reference Dal Lago, Masini and Zorzi2010).
4.2. Elementary linear logic
Rather than forcing boxes to be opened whenever copied, one could simply rule out dereliction and digging, this way enabling a form of stratification, obtaining a system in which contraction and weakening are the only two valid axioms. The obtained system, called elementary linear logic (
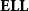 $\mathbf{ELL}$
in the following), is due to Girard (Reference Girard1998), but has been studied in a slightly different form by Danos and Joinet (Reference Danos and Joinet2003). It characterizes the Kalmar elementary functions, hence the name:
$\mathbf{ELL}$
in the following), is due to Girard (Reference Girard1998), but has been studied in a slightly different form by Danos and Joinet (Reference Danos and Joinet2003). It characterizes the Kalmar elementary functions, hence the name:
Theorem (Danos and Joinet Reference Danos and Joinet2003; Girard Reference Girard1998) The logic
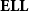 $\mathbf{ELL}$
characterizes the Kalmar elementary functions. Elementary linear logic has also been studied from other viewpoints, namely as a type system for the pure
$\mathbf{ELL}$
characterizes the Kalmar elementary functions. Elementary linear logic has also been studied from other viewpoints, namely as a type system for the pure
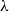 $\lambda$
-calculus enabling efficient optimal reduction algorithms, by Asperti et al. (Reference Asperti, Coppola and Martini2004), Coppola and Martini (Reference Coppola and Martini2006) and later by Baillot et al. (Reference Baillot, Coppola and Dal Lago2011). Even if the expressive power of the system can be seen as admittedly too large, Baillot (Reference Baillot2015) showed how it can be tamed by considering programs having specific types, this way obtaining characterizations of
$\lambda$
-calculus enabling efficient optimal reduction algorithms, by Asperti et al. (Reference Asperti, Coppola and Martini2004), Coppola and Martini (Reference Coppola and Martini2006) and later by Baillot et al. (Reference Baillot, Coppola and Dal Lago2011). Even if the expressive power of the system can be seen as admittedly too large, Baillot (Reference Baillot2015) showed how it can be tamed by considering programs having specific types, this way obtaining characterizations of
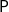 $\mathsf{P}$
and
$\mathsf{P}$
and
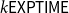 ${{k}}\mathsf{EXPTIME}$
(for every
${{k}}\mathsf{EXPTIME}$
(for every
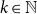 $k\in\mathbb{N}$
).
$k\in\mathbb{N}$
).
4.3. Light linear logic
The idea of seeing boxes as rigid entities as embodied by
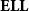 $\mathbf{ELL}$
can also be turned into a system characterizing the polynomial time computable functions, thus trimming the expressive power of the underlying logic down to the realm of feasibility. This, however, requires a significant change in the structure of formulas and rules. More specifically, not one but two kinds of boxes are necessary, namely the usual one, supporting weakening and contraction, and a new one, indicated as
$\mathbf{ELL}$
can also be turned into a system characterizing the polynomial time computable functions, thus trimming the expressive power of the underlying logic down to the realm of feasibility. This, however, requires a significant change in the structure of formulas and rules. More specifically, not one but two kinds of boxes are necessary, namely the usual one, supporting weakening and contraction, and a new one, indicated as
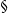 $\S$
. The syntax of
$\S$
. The syntax of
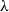 $\lambda$
-terms has to be appropriately tailored:
$\lambda$
-terms has to be appropriately tailored:
 \begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\;|\;\lambda\!!{x}.{M}\;|\;\lambda\S {x}.{M}\;|\;MM\;|\;!{M}\;|\;\S {M}.\end{equation*}
\begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\;|\;\lambda\!!{x}.{M}\;|\;\lambda\S {x}.{M}\;|\;MM\;|\;!{M}\;|\;\S {M}.\end{equation*}
Besides the two
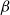 $\beta$
-rules we already know, there is a third one, namely the following:
$\beta$
-rules we already know, there is a third one, namely the following:
 $$(\lambda \S x.M)\S N{ \to _\beta }M\{ x/N\} .$$
$$(\lambda \S x.M)\S N{ \to _\beta }M\{ x/N\} .$$
Whenever forming a nonlinear abstraction
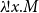 $\lambda\!!{x}.{M}$
, the variable x can appear more than once in M, and this occurrence needs to be in the scope of exactly one
$\lambda\!!{x}.{M}$
, the variable x can appear more than once in M, and this occurrence needs to be in the scope of exactly one
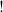 $!$
or
$!$
or
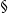 $\S$
operator. On the other hand, for
$\S$
operator. On the other hand, for
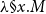 $\lambda\S {x}.{M}$
to be well-formed it must be that x occurs at most once in M and in the scope of exactly one
$\lambda\S {x}.{M}$
to be well-formed it must be that x occurs at most once in M and in the scope of exactly one
 $\S$
operator. Finally, an additional constraint has to be enforced, namely that whenever forming
$\S$
operator. Finally, an additional constraint has to be enforced, namely that whenever forming
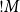 $!{M}$
, the subterm M has to have at most one free variable. From an axiomatic viewpoint, this corresponds to switching to the following schemes
$!{M}$
, the subterm M has to have at most one free variable. From an axiomatic viewpoint, this corresponds to switching to the following schemes
 \begin{align*} !A&\multimap!A\otimes !A;\\ !A&\multimap 1;\\ !A&\multimap \S A.\end{align*}
\begin{align*} !A&\multimap!A\otimes !A;\\ !A&\multimap 1;\\ !A&\multimap \S A.\end{align*}
The constraint about boxes having at most one free variable corresponds to the failure of the following axiom
 \begin{equation*}!A\multimap !B\multimap !(A\otimes B)\end{equation*}
\begin{equation*}!A\multimap !B\multimap !(A\otimes B)\end{equation*}
which instead holds in
 $\mathbf{SLL}$
and
$\mathbf{SLL}$
and
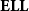 $\mathbf{ELL}$
. The obtained logical system characterizes the polynomial time computable functions:
$\mathbf{ELL}$
. The obtained logical system characterizes the polynomial time computable functions:
Theorem (Asperti and Roversi Reference Asperti and Roversi2002; Girard Reference Girard1998) The logic
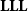 $\mathbf{LLL}$
characterizes the class
$\mathbf{LLL}$
characterizes the class
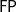 $\mathsf{FP}$
. Light linear logic has been the first truly implicit characterization of the polytime computable functions as a fragment of linear logic, and as such a breakthrough contribution to the field. The original formulation by Girard (Reference Girard1998) was actually different and more complex than the one we have sketched, essentially due to the presence of so-called additive connectives, which were initially thought to be necessary to encode polytime machines. A much simpler system, called light affine logic (
$\mathsf{FP}$
. Light linear logic has been the first truly implicit characterization of the polytime computable functions as a fragment of linear logic, and as such a breakthrough contribution to the field. The original formulation by Girard (Reference Girard1998) was actually different and more complex than the one we have sketched, essentially due to the presence of so-called additive connectives, which were initially thought to be necessary to encode polytime machines. A much simpler system, called light affine logic (
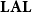 $\mathbf{LAL}$
in the following, and due to Asperti Reference Asperti1998; Asperti and Roversi Reference Asperti and Roversi2002), has been proved complete for polytime functions by Roversi (Reference Roversi1999) relying on the presence of free weakening, namely the axiom
$\mathbf{LAL}$
in the following, and due to Asperti Reference Asperti1998; Asperti and Roversi Reference Asperti and Roversi2002), has been proved complete for polytime functions by Roversi (Reference Roversi1999) relying on the presence of free weakening, namely the axiom
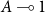 $A\multimap 1$
. In other words, any object can be discarded, even if not lying inside a box.
$A\multimap 1$
. In other words, any object can be discarded, even if not lying inside a box.
Light linear logic and light affine logic have been analyzed from many different perspectives. Stemming from the already mentioned work on type systems for
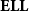 $\mathbf{ELL}$
, various type systems have been introduced being inspired by
$\mathbf{ELL}$
, various type systems have been introduced being inspired by
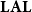 $\mathbf{LAL}$
but whose underlying language is the pure untyped
$\mathbf{LAL}$
but whose underlying language is the pure untyped
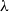 $\lambda$
-calculus. This includes works by Baillot (Reference Baillot2002), Atassi et al. (Reference Atassi, Baillot and Terui2007), Coppola et al. (Reference Coppola, Dal Lago and Rocca2008), and Baillot and Terui (Reference Baillot and Terui2009). The difficulties here come from the fact that the information about duplicability of subterms is lost if considering the ordinary
$\lambda$
-calculus. This includes works by Baillot (Reference Baillot2002), Atassi et al. (Reference Atassi, Baillot and Terui2007), Coppola et al. (Reference Coppola, Dal Lago and Rocca2008), and Baillot and Terui (Reference Baillot and Terui2009). The difficulties here come from the fact that the information about duplicability of subterms is lost if considering the ordinary
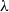 $\lambda$
-calculus as the underlying language of programs. This renders type inference, but even subject reduction, problematic. The ways out vary from switching to a dual version of the underlying logic to considering call-by-value rather than call-by-name reduction. Interestingly, Murawski and Ong (Reference Murawski and Ong2004) proved that light affine logic and safe recursion are, although equivalent from an extensional perspective, incomparable as for their intensional expressive power.
$\lambda$
-calculus as the underlying language of programs. This renders type inference, but even subject reduction, problematic. The ways out vary from switching to a dual version of the underlying logic to considering call-by-value rather than call-by-name reduction. Interestingly, Murawski and Ong (Reference Murawski and Ong2004) proved that light affine logic and safe recursion are, although equivalent from an extensional perspective, incomparable as for their intensional expressive power.
Light linear logic and soft linear logic are both extensionally complete for the polynomial time computable functions, but are very poor as for the class of algorithms they can capture. Their type languages, indeed, are very simple and only reflect some qualitative information about the iterative structure of the underlying term. As a consequence, many algorithmic patterns (including, again, certain forms of nested recursion) are simply ruled out. In other words, the situation is quite similar to the one we described in Section 3.2, when talking about
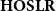 $\mathbf{HOSLR}$
. How could one catch more algorithms staying within the realm of linear logic? How could one get the kind of quantitative refinement needed for a more powerful methodology?
$\mathbf{HOSLR}$
. How could one catch more algorithms staying within the realm of linear logic? How could one get the kind of quantitative refinement needed for a more powerful methodology?
An earlier system, introduced by Girard et al. (Reference Girard, Scedrov and Scott1992), is Bounded Linear Logic,
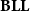 $\mathbf{BLL}$
. As we will see soon,
$\mathbf{BLL}$
. As we will see soon,
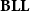 $\mathbf{BLL}$
formulas contain some genuinely quantitative information about the input-output behavior of programs and as such can be seen as being fundamentally different from light or soft linear logic. After its inception, however,
$\mathbf{BLL}$
formulas contain some genuinely quantitative information about the input-output behavior of programs and as such can be seen as being fundamentally different from light or soft linear logic. After its inception, however,
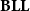 $\mathbf{BLL}$
has remained in oblivion for at least ten years, as observed by Hofmann (Reference Hofmann2000a):
$\mathbf{BLL}$
has remained in oblivion for at least ten years, as observed by Hofmann (Reference Hofmann2000a):
[Bounded Linear Logic] allows for the definition of all polynomial time computable functions […], where enforcement of these bounds is intrinsically guaranteed by the type system and does neither rely on external reasoning nor an ad hoc solution […]. Unfortunately, BLL has received very little attention since its publication; a further elaboration might prove worthwhile
Indeed, when seen as a type system for the
 $\lambda$
-calculus,
$\lambda$
-calculus,
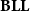 $\mathbf{BLL}$
guarantees that typable terms both satisfy some quantitative constraints about the relation between the input and output size and can be computed in a polynomial amount of time. The former is explicit in formulas, while the latter is somehow hidden, but emerges in a natural way. Indeed, the two play well together when proving that polynomial time computability is compositional.
$\mathbf{BLL}$
guarantees that typable terms both satisfy some quantitative constraints about the relation between the input and output size and can be computed in a polynomial amount of time. The former is explicit in formulas, while the latter is somehow hidden, but emerges in a natural way. Indeed, the two play well together when proving that polynomial time computability is compositional.
But how is
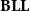 $\mathbf{BLL}$
actually defined? Rather than relying on the comonad
$\mathbf{BLL}$
actually defined? Rather than relying on the comonad
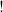 $!$
, it is based on a graded version of it parameterized on the natural numbers, for which the four familiar axioms from linear logic become the following ones:
$!$
, it is based on a graded version of it parameterized on the natural numbers, for which the four familiar axioms from linear logic become the following ones:
 \begin{align*} !_{n+m}A & \multimap !_{n}A\otimes !_{m}A;\\[3pt] !_{n}A & \multimap 1;\\[3pt] !_{1+n}A & \multimap A;\\[3pt] !_{nm}A & \multimap !_{n}!_{m}A;\end{align*}
\begin{align*} !_{n+m}A & \multimap !_{n}A\otimes !_{m}A;\\[3pt] !_{n}A & \multimap 1;\\[3pt] !_{1+n}A & \multimap A;\\[3pt] !_{nm}A & \multimap !_{n}!_{m}A;\end{align*}
where n and m are natural numbers. In other words, duplicable objects are handled without dropping any of the four axioms, but taking them in quantitative form. To reach completeness, a slightly more general formulation needs to be considered, namely one in which n and m are multivariate polynomials (i.e., the so-called resource polynomials, inspired by Girard’s earlier work on finite dilators) rather than plain natural numbers. This way, for example, contraction turns out to have the following form:
 \begin{equation*}!_{x<p+q}A\multimap !_{x<p}A\otimes !_{y<q}A[x\leftarrow y+q].\end{equation*}
\begin{equation*}!_{x<p+q}A\multimap !_{x<p}A\otimes !_{y<q}A[x\leftarrow y+q].\end{equation*}
Intuitively, the formula
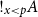 $!_{x<p}A$
can thus be read as follows:
$!_{x<p}A$
can thus be read as follows:
 \begin{equation*}A[x\leftarrow 0]\otimes A[x\leftarrow 1]\otimes \ldots\otimes A[x\leftarrow p-1].\end{equation*}
\begin{equation*}A[x\leftarrow 0]\otimes A[x\leftarrow 1]\otimes \ldots\otimes A[x\leftarrow p-1].\end{equation*}
This allows for an alternative and somehow richer representation of data. As an example, the usual second-order impredicative encoding of natural number
 \begin{equation*}\mathit{NAT}\triangleq\forall \alpha.(\alpha\rightarrow\alpha)\rightarrow\alpha\rightarrow\alpha,\end{equation*}
\begin{equation*}\mathit{NAT}\triangleq\forall \alpha.(\alpha\rightarrow\alpha)\rightarrow\alpha\rightarrow\alpha,\end{equation*}
becomes the following one
 \begin{equation*}\mathit{NAT}_p\triangleq\forall \alpha.!_{x<p}(\alpha(x)\multimap\alpha(x+1))\multimap\alpha(0)\multimap\alpha(p),\end{equation*}
\begin{equation*}\mathit{NAT}_p\triangleq\forall \alpha.!_{x<p}(\alpha(x)\multimap\alpha(x+1))\multimap\alpha(0)\multimap\alpha(p),\end{equation*}
which is parameterized by a polynomial p and as such can be assigned only to (Church representation) of natural numbers of bounded value. This, by the way, allows for a very liberal form of fold combinator. This is indeed one of the main ingredients towards the following:
Theorem (Girard et al. Reference Girard, Scedrov and Scott1992) The logic
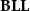 $\mathbf{BLL}$
characterizes
$\mathbf{BLL}$
characterizes
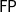 $\mathsf{FP}$
. Subsequently to the inception of
$\mathsf{FP}$
. Subsequently to the inception of
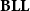 $\mathbf{BLL}$
, Pitt (Reference Pitt1994) introduced a term calculus in which the computational and programming aspects of it were very thoroughly analyzed. But after that, not so much happened for some years, except for the alternative, realizability-based proof of polytime soundness, due to Hofmann and Scott (Reference Hofmann and Scott2004). After a ten year hiatus in which research was rather directed towards simpler characterizations of complexity classes like light or soft linear logic, the interest around
$\mathbf{BLL}$
, Pitt (Reference Pitt1994) introduced a term calculus in which the computational and programming aspects of it were very thoroughly analyzed. But after that, not so much happened for some years, except for the alternative, realizability-based proof of polytime soundness, due to Hofmann and Scott (Reference Hofmann and Scott2004). After a ten year hiatus in which research was rather directed towards simpler characterizations of complexity classes like light or soft linear logic, the interest around
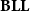 $\mathbf{BLL}$
has been rising again for ten years now, due to the higher intensional expressive power this system offers. In particular,
$\mathbf{BLL}$
has been rising again for ten years now, due to the higher intensional expressive power this system offers. In particular,
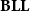 $\mathbf{BLL}$
has been shown by Dal Lago and Hofmann (Reference Dal Lago and Hofmann2010a) to subsume many heterogeneous ICC systems, while a system of linear dependent types derived from
$\mathbf{BLL}$
has been shown by Dal Lago and Hofmann (Reference Dal Lago and Hofmann2010a) to subsume many heterogeneous ICC systems, while a system of linear dependent types derived from
 $\mathbf{BLL}$
has been proved by Dal Lago and Gaboardi (Reference Dal Lago and Gaboardi2011) and Dal Lago and Petit (Reference Dal Lago and Petit2013); Dal Lago and Petit (Reference Dal Lago and Petit2014) to be relatively complete as a way to analyze the complexity of evaluation of programs.
$\mathbf{BLL}$
has been proved by Dal Lago and Gaboardi (Reference Dal Lago and Gaboardi2011) and Dal Lago and Petit (Reference Dal Lago and Petit2013); Dal Lago and Petit (Reference Dal Lago and Petit2014) to be relatively complete as a way to analyze the complexity of evaluation of programs.
4.5. Some further lines of work
Apart from the subsystems of linear logic we have mentioned so far, others have been the subject of some investigation by the ICC community.
What happens, as an example, if duplication and erasure are simply forbidden? As already mentioned in Section 2, one ends up in a purely affine
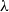 $\lambda$
-calculus in which only the linear abstraction is available:
$\lambda$
-calculus in which only the linear abstraction is available:
 \begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\mid MM\end{equation*}
\begin{equation*}M::=x\;|\;\lambda \ell{x}.{M}\mid MM\end{equation*}
From a purely proof-theoretical perspective, this system is known as Multiplicative Linear Logic,
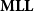 $\mathbf{MLL}$
. As we mentioned above, the size of the underlying term (or proof) strictly decreases along any (linear)
$\mathbf{MLL}$
. As we mentioned above, the size of the underlying term (or proof) strictly decreases along any (linear)
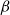 $\beta$
-reduction sequence, and thus, reduction cannot take time significantly higher than the size of the starting term, thus of the input. This of course prevents complexity classes like
$\beta$
-reduction sequence, and thus, reduction cannot take time significantly higher than the size of the starting term, thus of the input. This of course prevents complexity classes like
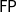 $\mathsf{FP}$
to be captured by the logic the usual way, that is, by stipulating that any function
$\mathsf{FP}$
to be captured by the logic the usual way, that is, by stipulating that any function
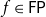 $f\in\mathsf{FP}$
has to be represented uniformly as a single term
$f\in\mathsf{FP}$
has to be represented uniformly as a single term
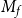 $M_f$
. On the other hand, a deep connection between
$M_f$
. On the other hand, a deep connection between
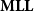 $\mathbf{MLL}$
proofs and boolean circuits have been discovered by Mairson (Reference Mairson2004), and Mairson and Terui (Reference Mairson and Terui2003), and later strengthened by Terui (Reference Terui2004b), whose work highlights a deep connection between the depth in boolean circuits and the logical depth of cut-formulas in proofs.
$\mathbf{MLL}$
proofs and boolean circuits have been discovered by Mairson (Reference Mairson2004), and Mairson and Terui (Reference Mairson and Terui2003), and later strengthened by Terui (Reference Terui2004b), whose work highlights a deep connection between the depth in boolean circuits and the logical depth of cut-formulas in proofs.
A related line of work is about linear approximations and parsimony, and is due to Mazza and co-authors. The original idea by Mazza (Reference Mazza2014) stems from the so-called Approximation Theorem (well-known since the original work by Girard Reference Girard1987) and sees arbitrary computations being approximated by affine ones, namely by (families of) terms in the linear
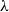 $\lambda$
-calculus. This allows to capture non-uniform complexity classes like
$\lambda$
-calculus. This allows to capture non-uniform complexity classes like
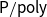 $\mathsf{P/poly}$
and
$\mathsf{P/poly}$
and
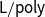 $\mathsf{L/poly}$
, as proved by Mazza and Terui (Reference Mazza and Terui2015), but also of uniform classes like
$\mathsf{L/poly}$
, as proved by Mazza and Terui (Reference Mazza and Terui2015), but also of uniform classes like
 $\mathsf{LOGSPACE}$
, (see Mazza Reference Mazza2015).
$\mathsf{LOGSPACE}$
, (see Mazza Reference Mazza2015).
A somewhat different line of work which is certainly worth being mentioned is the one by Baillot and Mazza (Reference Baillot and Mazza2010) on linear logic by levels, in which the stratification constraint intrinsic to
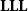 $\mathbf{LLL}$
and
$\mathbf{LLL}$
and
 $\mathbf{ELL}$
is replaced by a more flexible mechanism which allows to capture more algorithmic schemes, while still allowing for complexity bounds. Remarkably, linear logic by level is permissive enough to capture all (propositional, multiplicative, and exponential) linear logic proofs, as shown by Gaboardi et al. (Reference Gaboardi, Roversi and Vercelli2009), thus going beyond systems like
$\mathbf{ELL}$
is replaced by a more flexible mechanism which allows to capture more algorithmic schemes, while still allowing for complexity bounds. Remarkably, linear logic by level is permissive enough to capture all (propositional, multiplicative, and exponential) linear logic proofs, as shown by Gaboardi et al. (Reference Gaboardi, Roversi and Vercelli2009), thus going beyond systems like
 $\mathbf{ELL}$
.
$\mathbf{ELL}$
.
One last series of results which is worth being mentioned is concerned with linear logic and infinitary and coinductive data. The paper by Gaboardi and PÉchoux (Reference Gaboardi and PÉchoux2015) on algebras and coalgebras in the light affine
 $\lambda$
-calculus shows that the kind of distributive laws which are necessary to model coalgebras are compatible with the polytime bounds which are the essence of
$\lambda$
-calculus shows that the kind of distributive laws which are necessary to model coalgebras are compatible with the polytime bounds which are the essence of
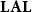 $\mathbf{LAL}$
. Infinitary data structures can however be captured differently, namely by going towards something similar to the so-called infinitary
$\mathbf{LAL}$
. Infinitary data structures can however be captured differently, namely by going towards something similar to the so-called infinitary
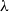 $\lambda$
-calculus, see Dal Lago (Reference Dal Lago2016). Interestingly, the decomposition linear logic provides offers precisely the kind of tools one needs to guarantee properties like confluence and productivity. Remarkably, all this amounts to defining yet another fragment of linear logic, namely the one, called
$\lambda$
-calculus, see Dal Lago (Reference Dal Lago2016). Interestingly, the decomposition linear logic provides offers precisely the kind of tools one needs to guarantee properties like confluence and productivity. Remarkably, all this amounts to defining yet another fragment of linear logic, namely the one, called
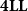 $\mathbf{4LL}$
in which only dereliction is forbidden.
$\mathbf{4LL}$
in which only dereliction is forbidden.
5. Other Approaches and Results
Up to now, we have focused our attention on characterizations of complexity classes by way of type systems and fragments of linear logic. This, however, does not mean that no other approaches exist, even within the realm of higher-order programming languages or proof theory. This section is meant to somehow complete the picture by giving pointers to alternative approaches, all within logic and programming language theory.
First of all, one has certainly to mention arithmetic, which can of indeed be seen as a way to represent (recursive) functions, but also to prove them total. The provably total functions of Peano Arithmetic form a huge class (mutatis mutandis, the same captured by GÖdel’s
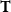 $\mathbf{T}$
), but refinements of them capturing complexity classes, also known as systems of bounded arithmetic, have been known since the pioneering work by Parikh (Reference Parikh1971) and have later been studied in depth especially by Buss (Reference Buss1986). Despite their being able to capture the various levels of the polynomial hierarchy, systems of bounded arithmetic cannot be said to be truly implicit, given that explicit polynomial bounds are present in their syntax, in particular at the level of quantifiers. This is also apparent in
$\mathbf{T}$
), but refinements of them capturing complexity classes, also known as systems of bounded arithmetic, have been known since the pioneering work by Parikh (Reference Parikh1971) and have later been studied in depth especially by Buss (Reference Buss1986). Despite their being able to capture the various levels of the polynomial hierarchy, systems of bounded arithmetic cannot be said to be truly implicit, given that explicit polynomial bounds are present in their syntax, in particular at the level of quantifiers. This is also apparent in
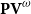 $\mathbf{PV}^\omega$
, a typed
$\mathbf{PV}^\omega$
, a typed
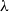 $\lambda$
-calculus whose terms are meant to be realizers of bounded arithmetic formulas, and which has been used by Cook and Urquhart (Reference Cook and Urquhart1993) to prove bounded arithmetic systems to be sound characterizations of complexity classes. Along the same lines, but somehow reverse-engineering some of the type systems for higher-order recursion we described in Section 3, one can define systems of feasible arithmetic, as shown by Bellantoni and Hofmann (Reference Bellantoni and Hofmann2002), and Aehlig et al. (Reference Aehlig, Berger, Hofmann and Schwichtenberg2004). Similarly, light affine logic has been the starting point for defining a system of feasible set theory by Terui (Reference Terui2004a), later adapted to soft linear logic by McKinley (Reference McKinley2008).
$\lambda$
-calculus whose terms are meant to be realizers of bounded arithmetic formulas, and which has been used by Cook and Urquhart (Reference Cook and Urquhart1993) to prove bounded arithmetic systems to be sound characterizations of complexity classes. Along the same lines, but somehow reverse-engineering some of the type systems for higher-order recursion we described in Section 3, one can define systems of feasible arithmetic, as shown by Bellantoni and Hofmann (Reference Bellantoni and Hofmann2002), and Aehlig et al. (Reference Aehlig, Berger, Hofmann and Schwichtenberg2004). Similarly, light affine logic has been the starting point for defining a system of feasible set theory by Terui (Reference Terui2004a), later adapted to soft linear logic by McKinley (Reference McKinley2008).
Providing higher-order programming languages with satisfactory forms of denotational semantics has been an active research topic for many decades, starting from the late sixties (see the textbook by Amadio and Curien (Reference Amadio and Curien1998) for a modern introduction to the subject). Given the elusive nature of complexity classes, about which very few separation results are currently known, it is natural to look for an appropriate mathematical framework in which languages characterizing mainstream classes can be interpreted. This observation has triggered many investigations about the denotational semantics of ICC systems, and in particular of those we have introduced in this paper. Coherent and relational semantics, the preferred ways of giving meaning to linear logic proofs, have been adapted to logical systems such as
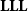 $\mathbf{LLL}$
by Baillot (Reference Baillot2004), and
$\mathbf{LLL}$
by Baillot (Reference Baillot2004), and
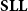 $\mathbf{SLL}$
and
$\mathbf{SLL}$
and
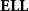 $\mathbf{ELL}$
by Laurent and Tortora de Falco (Reference Laurent and Tortora de Falco2006). An abstract approach to stratification has been proposed by Boudes et al. (Reference Boudes, Mazza and Tortora de Falco2015). Another semantic framework which provides useful insights on the interplay of duplication and complexity is certainly the Geometry of Interaction, due to Girard (Reference Girard1988), which can be seen both as a denotational semantics and as an implementation mechanism. In the former sense, it provides a fine-grain tool for the analysis of the complexity of reduction, this way allowing for alternative, more compact proofs of soundness, as shown by Dal Lago (Reference Dal Lago2009a). In the latter sense, it has been proved to induce space-efficient implementations, thus enabling the characterization of sub-linear complexity classes, as shown by SchÖpp (Reference SchÖpp2007), Dal Lago and SchÖpp (Reference Dal Lago and SchÖpp2010, Reference Dal Lago and SchÖpp2016).
$\mathbf{ELL}$
by Laurent and Tortora de Falco (Reference Laurent and Tortora de Falco2006). An abstract approach to stratification has been proposed by Boudes et al. (Reference Boudes, Mazza and Tortora de Falco2015). Another semantic framework which provides useful insights on the interplay of duplication and complexity is certainly the Geometry of Interaction, due to Girard (Reference Girard1988), which can be seen both as a denotational semantics and as an implementation mechanism. In the former sense, it provides a fine-grain tool for the analysis of the complexity of reduction, this way allowing for alternative, more compact proofs of soundness, as shown by Dal Lago (Reference Dal Lago2009a). In the latter sense, it has been proved to induce space-efficient implementations, thus enabling the characterization of sub-linear complexity classes, as shown by SchÖpp (Reference SchÖpp2007), Dal Lago and SchÖpp (Reference Dal Lago and SchÖpp2010, Reference Dal Lago and SchÖpp2016).
6. Conclusion
This paper is meant to be an introduction to implicit computational complexity and, in particular, to how complexity can be tamed in higher-order programs. Even if the scope of the survey is relatively restricted, there are certain areas which we have deliberately left out, the most prominent example being the one on characterizations of higher-type complexity classes: there seem to be intriguing relations between some of the characterizations we presented here and higher-type complexity classes, which are however not completely understood yet.
The present survey is by no means meant to be comprehensive, and it was written to be a memory of Martin Hofmann’s contributions to ICC, and an ideal follow-up to his survey (Hofmann Reference Hofmann2000a), twenty years after its appearance.

 Open access
Open access