


In this paper, we investigate whether and how the way people choose between “alternate ways of saying ‘the same’ thing” (Labov, Reference Labov1972:188) depends on the situational context, that is, register. In the literature, register is seen as “a cover term for any language variety defined by its situational characteristics, including the speaker's purpose, the relationship between speaker and hearer, and the production circumstances” (Biber, Reference Biber, Lüdeling and Kytö2009:823). Against this backdrop, this paper investigates whether language-internal probabilistic constraints on variation (i.e., conditioning factors) have different effects across four different registers of British English at the intersection between mode and formality: spoken informal (conversation), spoken formal (parliamentary debates), written informal (blogs) and written formal (quality newspaper prose).
As a case study, we will explore the alternation between expressions of future temporal reference (henceforth FTR) in English:Footnote 1
(1) In practice, however, experts think the most likely alien life forms we will come across are going to be some kind of alien microbes. (The Independent, 02/07/2018)
From the extensive variationist literature on this variable (see following section for a review), we know that variation between will and be going to is conditioned by a number of language-internal constraints such as animacy of the subject. What still remains to be investigated is whether these constraints have different effects across different registers. In the methodology adopted in the present study, register differences are identified when (a) in corpus-based regression models, register enters into significant interactions with language-internal constraints, and (b) in a rating-task experiment, participants’ naturalness ratings converge with the predictions of the corpus-based model.
Why should we care about register differences? We know that register variation, much like variation in general, is ubiquitous in human language (Ferguson, Reference Ferguson1983:154), and knowing how to use language in particular situations is a key component of language users’ linguistic knowledge, or “pragmatic competence” (Kecskés, Reference Kecskés2014:71). Previously, research on register differences has focused on the text frequencies of particular linguistic features in specific registers (e.g., How often or rarely do we find particular linguistic features, such as passive constructions, in particular registers?). The flagship method in this line of research is the Multi-Dimensional (MD) approach developed by Douglas Biber (Reference Biber1988), which measures co-occurrence patterns of linguistic features.
Alternatively, variationists (in the spirit of Labov, Reference Labov1972) may approach register variation by asking the following question: “When speakers can choose between different ways of saying the same thing, what is the extent to which they draw on the same or different choice-making processes in different registers?” The majority opinion in the variationist (socio)linguistics community is that “internal constraints … are normally independent of social and stylistic factors” (Labov, Reference Labov2010:265; see also Guy, Reference Guy2005:562; Rickford, Reference Rickford2014:596). Style in the Labovian sense refers to the tendency for speakers to adapt their speech in response to particular social and contextual configurations (i.e., style is intraspeaker variation). An important parameter of style is how much attention the speaker pays to their speech (Labov, Reference Labov1972:208). For example, a speaker may shift from a casual speaking style to a more careful speaking style as a function of the context of the utterance. Style in this conventional sense mainly covers spoken language and phonological variation. Registers in the Biberian sense, on the other hand, are defined in terms of a functional relationship between linguistic features and the situational context. This means that linguistic choices reflect the needs of the speaker/writer in different situations of language use to accomplish a particular function, such as referring to the speaker or addressee by means of first- and second-person pronouns in highly interactive registers like conversations (Biber, Reference Biber1988:105).
Under the not implausible assumption that register is, at its core, a social factor, and that register distinctions should be (cognitively and otherwise) fairly analogous to stylistic factors (see also Finegan & Biber, Reference Finegan, Biber, Eckert and Rickford2001:239), one would then hypothesize that internal constraints should be stable across registers. In the English FTR alternation, for example, we would expect that animacy of the subject has the same effect in spoken informal as in written formal registers. However, the few studies that have examined register differences from a variationist perspective do not necessarily agree about whether variable grammars are stable or not across registers. On the one hand, Tagliamonte (Reference Tagliamonte2016) reports that internal constrains conditioning the FTR alternation are fairly invariant in a corpus of e-mails, web instant messaging, and text messages. Travis and Lindstrom (Reference Travis and Lindstrom2016) arrive at a similar conclusion, investigating subject expression (third-person subject versus ∅) in dialogic conversations and monologic narratives. On the other hand, Grafmiller (Reference Grafmiller2014), for the genitive alternation in English (the speech of the president versus the president's speech) across six spoken and written registers, uncovers substantial interactions between external, stylistic constraints and the probabilistic weights of language-internal constraints.
The theoretical relevance of the topic is considerable and boils down to the question of how many variable/probabilistic grammars it takes to use language across registers. If the results of the present study indicate that linguistic choice-making differs as a function of register, what would come into play is Guy's Grammatical Difference Hypothesis (Guy, Reference Guy2015), according to which employing different constraints differently in different situations means having different grammars (see also Kroch, Reference Kroch1989:239 for such a multiple grammars view). This finding would in turn support the conclusion that language users have a range of different register-specific grammars, similar to diglossia. Against this backdrop, we would like to approach the issue of whether internal constraints are independent of style/register with an open mind. Our research question, then, is the following: How register-specific is knowledge about grammatical variation? In other words: How variable are variable grammars across registers?
To address this question, we utilize a methodology that combines corpus analysis with experimentation. The corpus component of our analysis is an exercise in “corpus-based variationist linguistics” (Szmrecsanyi, Reference Szmrecsanyi2017), because we draw on publicly available corpora and use multivariate analysis methods that are faithful to the Principle of Accountability (Labov, Reference Labov1969:737f., fn. 20; Labov, Reference Labov1972:72). To ascertain the cognitive/psychological plausibility of the corpus findings, we conduct a rating task experiment in which participants are asked to indicate how natural two continuations are given the situational context. The experimental design is inspired by Bresnan (Reference Bresnan, Featherston and Sternefeld2007) that in turn builds on Bresnan, Cueni, Nikitina, and Baayen (Reference Bresnan, Cueni, Nikitina, Baayen, Boume, Kraemer and Zwarts2007). Bresnan et al. (Reference Bresnan, Featherston and Sternefeld2007) investigated the dative alternation (He gave the child a present versus He gave a present to the child) with corpus data and used regression analysis to identify ten linguistic constraints predicting variant choice. Based on this corpus study, Bresnan (Reference Bresnan, Featherston and Sternefeld2007) designed an experiment in which participants were presented with authentic corpus extracts with varying probabilities for the prepositional dative. Participants saw both dative variants, the originally uttered variant and a constructed alternative. They were then asked to distribute one hundred points over the two variants as a function of the perceived naturalness of the variants. Afterwards, Bresnan (Reference Bresnan, Featherston and Sternefeld2007) correlated the experimental ratings with the probabilities predicted by the corpus-based regression model. Results showed that the participants’ ratings corresponded well with the corpus-based probabilities. Meanwhile, a number of studies have applied a similar methodology, likewise indicating a convergence between corpus-based findings and rating data (see review in Klavan & Divjak, Reference Klavan and Divjak2016).
Key results of our investigation include the following: there is considerable variability across registers, as evidenced by five interactions between register and language-internal constraints. That is, effect size and effect direction of internal effects differ as a function of register. Moreover, participants’ ratings converge on the probability, suggesting that their grammatical knowledge includes knowledge about probabilistic register differences.
FTR in English: the essentials
FTR in English is a well-known variable in variationist sociolinguistics. Historically, de-andative be going to (originally with spatial meaning) as a future marker is the incoming variant. As a future marker, be going to is first attested in the fifteenth century (Danchev & Kytö, Reference Danchev, Kytö and Kastovsky1994:61) and has seen a rise in frequency of occurrence since the late seventeenth century, when its grammaticalization as future marker was complete (Mair, Reference Mair2006:96f.). Be going to originally had an intentional meaning rooted in the present state of affairs (Beheydt, Reference Beheydt, Delbecque, van der Auwera and Geeraerts2005:253; Leech, Hundt, Mair, & Smith, Reference Leech, Hundt, Mair and Smith2009:107f.) but is now considered to have a fairly neutral future meaning (Brisard, Reference Brisard, Verspoor, Lee and Sweetser1997). Meanwhile, will, derived from Old English willan, has lost its originally volitional meaning over the centuries (Aijmer, Reference Aijmer and Fisiak1985). Will initially exhibited a preference for human subjects before its use was extended to nonhuman subjects. The original meaning of both future markers might be retained in contemporary usage to some extent (Bybee, Perkins, & Pagliuca, Reference Bybee, Perkins and Pagliuca1994:5-6, 17), reflected by the effects of grammatical subject, verb type, and proximity of future time reference on variant choice (see section “Corpus study”).
Corpus linguists have demonstrated that registers differ with regard to variant rates (Berglund, Reference Berglund1997; Biber, Johansson, Leech, Conrad, & Finegan, Reference Biber, Johansson, Leech, Conrad and Finegan1999:488f.; Mair, Reference Mair, Hickey and Puppel1997; Tagliamonte, Reference Tagliamonte2016). For example, be going to is more common in spoken language than in written language, in imaginative compared to informative written texts, and also occurs frequently in reported speech (Berglund, Reference Berglund1997; see also Biber et al., Reference Biber, Johansson, Leech, Conrad and Finegan1999:489, 495f.). Accordingly, be going to is often said to be the more informal variant that nonetheless spread to more formal registers due to the colloquialization of the norms of written English (Mair, Reference Mair, Hickey and Puppel1997, Reference Mair2006:95; Nesselhauf, Reference Nesselhauf2010).
Regarding the language-internal conditioning of FTR choice, the variationist literature suggests that be going to is favored in interrogative sentences, in subordinate clauses and particularly in conditional if-clauses, while will is the preferred variant in the apodosis of conditional clauses (Denis & Tagliamonte, Reference Denis and Tagliamonte2018; Fehringer & Corrigan, Reference Fehringer and Corrigan2015; Tagliamonte, Durham, & Smith, Reference Tagliamonte, Durham and Smith2014; Torres Cacoullos & Walker, Reference Torres Cacoullos and Walker2009). These effects are consistent across varieties of English. Other constraints, such as sentence polarity, proximity of future time reference, constraints pertaining to the grammatical subject and lexical verb type have yielded mixed results.
Corpus study: methods
Data
All of our corpus materials cover British English (and all stimuli and participants in the experiment likewise use British English). Following Koch & Oesterreicher (Reference Koch, Oesterreicher, Lange, Weber and Wolf2012), we distinguish four broad registers at the intersection between mode of communication and formality: spoken informal, spoken formal, written informal, and written formal. For the spoken informal register, we analyze the Spoken BNC2014, which features about 11.5 million words from spontaneous conversations (n = 1251) among family members and friends (n = 672), self-recorded between 2012 and 2016 (Love, Dembry, Hardie, Brezina, & McEnery, Reference Love, Dembry, Hardie, Brezina and McEnery2017). For the spoken formal register, we draw on a sixty-million-word corpus of parliamentary proceedings from debates in the House of Commons that took place between December 2007 and March 2014, provided by the Political Mashup Project (Marx & Schuth, Reference Marx, Schuth, Calzolari, Choukri, Maegaard, Mariani, Odijk, Piperidis, Rosner and Tapias2010).Footnote 2 The British English blogs component of the Corpus of Global Web-based English (GloWbE), consisting of about 148 million words (Davies, Reference Davies2013; Davies & Fuchs, Reference Davies and Fuchs2015), constitutes the written informal register. As written formal register, we chose newspaper articles published between 2016 and 2019 in the British edition of the quality newspaper The Independent, amounting to about 113.5 million words (Bušta, Herman, Jakubíček, Krek, & Novak, Reference Bušta, Herman, Jakubíček, Krek and Novak2017).
We created a dataset that contains a total of 2,600 tokens of the FTR alternation. From each corpus, a random sample of 650 FTR tokens was included, half of which are tokens of will and the other half of be going to. We opted for such a balanced sample because we are not interested in variant rates but in the probabilistic conditioning of variant choice in each register; balancing the dataset in this way does therefore not pose a threat to the statistical analysis. As to data extraction, we used simple string matching of full and contracted FTR variants, which initially resulted in an enormous database (e.g., more than 490,000 concordance lines in total for the spoken formal register alone). To keep manual coding efforts manageable, we subsequently checked a random subset of one thousand concordance lines per corpus for the variable context and included the first 650 truly variable tokens in these subsets in the dataset. With that being said, to obtain a rough estimation of the rates of occurrence of FTR variants in each register, we counted the number of FTR tokens in a small sample of one hundred hits from each corpus. Table 1 reports the rates of occurrence of FTR variants in each of the one hundred hits sample per register subject to study in this paper.
Table 1. Number of verified FTR hits and variant rates in the four corpora, according to a random sample of N = 100 hits per register

Circumscribing the variable context
Our definition of the variation context largely overlaps with that of Denis and Tagliamonte (Reference Denis and Tagliamonte2018). In short, all instances of lexical go and nominal will were excluded. Likewise, tokens of past tense be going to were weeded out, as well as tag-question contexts. For reasons of space, the full definition is provided in the supplementary materials (available at https://osf.io/n943g).
Constraints
Language-internal constraints
As mentioned above, the set of constraints we consider includes the usual suspects in the literature on FTR variation and largely overlaps with Denis and Tagliamonte (Reference Denis and Tagliamonte2018). In what follows, we briefly list the constraints under study and refer the reader to the full coding scheme, including distributional statistics, in the supplementary materials (https://osf.io/n943g).
• Sentence type: Declarative sentences (2a) versus interrogative sentences (2b)
(2) a. Drumkit will not be available. (GloWbE-GB, blogs)
b. Are you going to see him at the weekend? (Spoken BNC2014, SVBH, S0084)
• Clause type: Main clauses (3a) versus subordinate clauses (3b); tokens were coded as “subclause” if they occurred in a clause introduced by a subordinating conjunction and as “main clause” if the clause was introduced by a coordinating conjunction or no conjunction (Quirk, Greenbaum, Leech, & Svartvik, Reference Quirk, Greenbaum, Leech and Svartvik1985:44, 998f.).
(3) a. Setting up home in a new country is going to be challenging. (GloWbE-GB, blogs)
b. The trial continues on Monday when Husband will resume giving evidence.
(The Independent, 16/06/2018)
Apodosis (4a) versus protasis (4b) in conditional clauses
(4) a. The Conservatives will lose the general election if they lose “just six seats” Theresa May has said. (The Independent, 20/05/2017)
b. And I remain suspicious as to what is likely to be cut instead, if they are going to be protecting this particular benefit. (House of Commons, 08/12/2009, John Mason)
• Polarity: Affirmative (5a) versus negative (5b) sentence polarity; tokens were coded as “negative” whenever a negative particle (not or n't) or a negative form (no, nobody, no one, never) occurred in the same clause.
(5) a. In terms of a vote in Parliament, we are obviously gonna vote today. (House of Commons, 24/06/2009, David Miliband)
b. In arguebly [sic] the best news i've heard all year we will never see GTA turned into a movie, Why? (GloWbE-GB, blogs)
• Grammatical person of the subject: First-person (6a) versus second-person (6b) versus third-person subjects (6c)
(6) a. first person: and then I'll be thirty (Spoken BNC2014, SC67, S0627)
b. second person: You are not going to enjoy your life if you don't enjoy yourself. (GloWbE-GB, blogs)
c. third person: Could he tell me when that community hospital is going to open in Wellingborough? (House of Commons, 11/12/2008, Peter Bone)
• Animacy of the subject: Animate (7a) versus inanimate (7b); tokens were coded as “animate” when the subject was a human or an animal, while all other tokens (including collective nouns) were coded as “inanimate” (see Zaenen et al., Reference Zaenen, Carletta, Garretson, Bresnan, Koontz-Garboden, Nikitina, O'Connor, Wasow, Webber and Byron2004).
(7) a. Cool, we're gonna cook soon, aren't we? (Spoken BNC2014, S38V, S0192)
b. More details of how cash will be awarded under the fund are understood to be on the way in the coming weeks. (The Independent, 24/10/2016)
• Proximity of future temporal reference: Proximate (8a) versus distal (8b) versus no reference contexts (8c); following Denis and Tagliamonte (Reference Denis and Tagliamonte2018), tokens were coded as “proximate” if the future event occurred the same day, as “distal” if it had a specified time in the future beyond the same day, or as “no reference” if there was no specific point in time.
(8) a. I know the honourable Lady wants to intervene, and I will take an intervention in a moment (House of Commons, 07/09/2011, Nadine Dorries)
b. I'm going to see the hygienist on Tuesday (Spoken BNC2014, SZQX, S0439)
c. We are pretty much guaranteed that everything we own will break at some point in the future. (GloWbE-GB, blogs)
• Presence of temporal adverbial: Present (9a) versus absent (9b) in the same clause; temporal adverbs (indicating event time, frequency, duration, or time relationship), bare time adverbs, and nonfinite temporal adverbials (e.g., prepositional phrases) were considered temporal adverb(ial)s.
(9) a. The Bank's more comprehensive data on UK household borrowing will come out later this month. (The Independent, 24/11/2017)
b. Man, I think it's gonna be awesome (Spoken BNC2014, SBM6, S0330)
• Lexical verb type: Dynamic/nonmotion (10a) versus motion (10b) versus stative verbs (10c)
(10) a. dynamic: I'm going to try and post more outfit posts from now on. (GloWbE-GB, blogs)
b. motion: I'll just go round the rooms and spray all of them before we go to bed (BNC2014, S4HW, 1180:S0688)
c. stative: When are people in Northern Ireland gonna see it's working? (House of Commons, 09/02/2011, Shaun Woodward)
Register
Register was coded to distinguish between the four broad categories “spoken informal,” “spoken formal,” “written informal,” and “written formal,” according to the corpora described in the section on our corpus data above.
Random effects
In the regression analysis, we included random effects for speaker or author identity to account for possible idiosyncrasies. Previous studies also found collocations of FTR variants with certain lexical verbs in particular constraint settings (Berglund, Reference Berglund2000:45-51; Torres Cacoullos & Walker, Reference Torres Cacoullos and Walker2009:338-340). To account for skewings of lexical verbs toward particular constraint configurations, a random effect for lexical verb was added so that the model assumes a different intercept for each lexical verb, meaning that it accounts for the fact that a verb might tend to occur more often with be going to while another might tend to be more associated with will in a specific constraint configuration.
Analysis
We fitted a mixed-effects logistic regression model in R (version 4.0.3, R Core Team, 2020) using the lme4-package (Bates, Mächler, Bolker, & Walker, Reference Bates, Mächler, Bolker and Walker2015) to calculate the odds for be going to, given the constraints described above and their interactions with register. We used treatment coding and set the reference level of register to “spoken informal.” All reference levels of the language-internal constraints were set to the most common levels for the will-variant. In addition to the fixed effects, random effects for speaker/writer as well as lexical verb were added to allow for intercept adjustments.
Starting from the maximal model, we reduced the model by following a backward elimination procedure, that is, by dropping non-significant coefficients one by one and comparing models using the Akaike Information Criterion (see Gries, Reference Gries2015). The resulting model has a C-index of 0.74, indicating acceptable discrimination between the two FTR variants (see Hosmer & Lemeshow, Reference Hosmer and Lemeshow2000:162). This C-index is comparable to the one reported in Tagliamonte et al. (Reference Tagliamonte, Durham and Smith2014). Our model correctly predicts the outcome in 67.2% of the observations (baseline 50%). With a condition index of κ = 15.33, we conclude that our model has medium collinearity, which–as Baayen (Reference Baayen2008:182) argues–is not harmful.
Experiment: methods
Design and procedure
The experiment focuses on contrasts between two registers, specifically, the spoken informal and written formal registers, because differences between the effects of these registers were the largest in the corpus study (see section “Corpus results”). We did not include all four registers in order to reduce the length of the experiment. Our experiment had a within-subject design, meaning that each participant was presented with items from both registers and all items from each register. Participants read authentic corpus excerpts that included either a choice between will and be going to, a lexical choice, or a choice between the relativizers which and that, which have been shown to be associated with written formal and spoken informal language use (Biber et al., Reference Biber, Johansson, Leech, Conrad and Finegan1999:610). Participants were instructed to rate the variants as a function of their naturalness, given the context. They were able to indicate their preferences by means of a slider bar, allowing for gradient ratings. In addition, we included eight simple comprehension questions to ensure that the participants read and understood the content of the excerpts. The experimental data was collected through a web-based survey, using Qualtrics Research Services. At the beginning of the experiment, participants gave their informed written consent to participate in the experiment, followed by a sociodemographic questionnaire. Participants were provided with detailed instructions and an example of the task before completing the rating task. Afterwards, participants were asked about their intuitions about potential meaning differences between the two FTR markers as well as their intuitions regarding the purpose of the study. Participants received an appropriate expense allowance, complying with minimum wage standards.
Materials
The material consisted of thirty-two authentic corpus excerpts, half of which came from the spoken informal corpus, and the other half from the written formal corpus. Per register, there were six excerpts with a choice between will and be going to covering the whole probability range (i.e., six bins) and ten excerpts serving as filler items to distract participants from the target items. Six out of these ten fillers involved a choice between the relativizers which and that, and the remaining four filler items involved a lexical choice between nouns with equivalent meaning (view versus perspective, idea versus notion, chance versus opportunity, and problem versus issue).Footnote 3 These fillers were carefully chosen in order to assess whether participants take the register context into account for their ratings. If they do, we expect that formal variants presented in the formal register receive higher ratings compared to formal variants presented in the informal register.
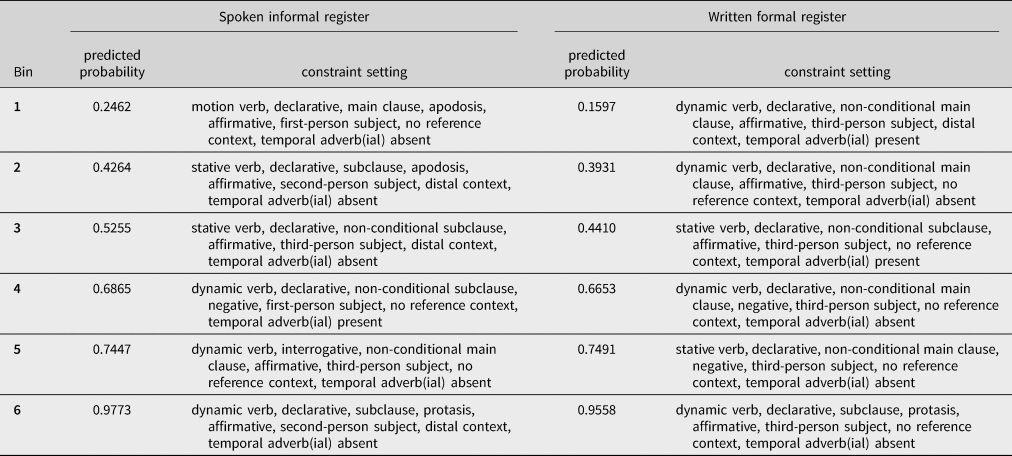
The experiment was designed to examine the combined effect of all predictors on the choice of the FTR variant in two registers. To this end, the probability of be going to reflecting this combined effect was calculated based on a model of the two registers included in the experiment, using the same procedure as for the corpus-based model. After backward elimination, this model included the same fixed effects as the full model. Random effects did not improve model fit and were therefore excluded. Items were randomly selected from six probability bins from the whole range, with matched probabilities per bin across the two registers. To avoid a possible priming bias (in both filler and target items), we ensured that there were no instances of will or be going to other than the target variants that the participants were asked to rate. Table 2 gives an overview of the constraint settings and the corpus-based predicted probabilities for each item.
Table 2. Overview of FTR items and their constraint settings per register and probability bin
We created two lists to counterbalance the presentation order of the variants. That is, if a particular variant was presented on the left side in Item 1 in List 1, this variant was presented on the right side in List 2. There were two versions of each list with varied order for items and register blocks. While Version A began with all items from the written formal register, Version B began with the spoken informal register. In each version of the experiment, no more than two target items or two filler items of the same type followed one another. Each participant saw only one list and version of the experiment. At the beginning of each block, we presented pictures to reinforce the register context. Participants saw a family chatting at a breakfast table or a group of friends having drinks before the spoken informal block. They saw a title page from The Independent before the written formal block. In addition, the layout of the items was aimed to mimic a real-life layout of newspaper articles or a written representation of dialogues (see Supplementary materials available at https://osf.io/n943g).
Participants
In total, 140 British English native speakers (seventy female, seventy male; mean age 52.8 years, age range: 18-82 years) were sampled through Qualtrics Research Services. Participants came from all over Great Britain, including Scotland, Wales, and Northern Ireland. Thus, our sample includes participants from different age groups, regions, and educational backgrounds (and so is considerably more representative and responsible sociolinguistically than the typical undergraduate student sample common in psycholinguistics).
To ensure data quality, five participants who answered less than six out of eight comprehension questions correctly were excluded from the analysis. In addition, seven participants who took less than thirteen minutes to complete the survey were excluded because we believe that it is not possible to work diligently on this task in that amount of time. Another fourteen participants spent more than thirty-three minutes on the survey, which is above 1.5 times the interquartile range. We decided to exclude these participants as well, following best practices for web-based experiments (Speed, Wnuk, & Majid, Reference Speed, Wnuk, Majid, de Groot and Haagoort2017). Data collected from the remaining 114 participants (fifty-nine female, fifty-five male; mean age: 53.3 years, age range: 18-82 years) were entered into the analysis. Their average time spent on the survey was 19.44 minutes (SD = 4.63).
Analysis
Mixed-effects linear regression models were fitted to the rating data, using the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in R (R Core Team, 2020). We fitted separate models for the ratings on the target items and for the ratings on the filler items. For the analysis, we transformed the raw scale of the ratings (ranging from -100 to 100) to a scale from 0 to 100, reflecting the participants’ preference for the be going to-variant of the FTR alternation and the formal variants in the filler items. The rescaled ratings were then z-transformed. In both models, we included crossed random effects for participant and for item to account for possible idiosyncrasies. For the model on the target items, we also included predicted probability in the slope of the random effect for participant. Predicted corpus probability as well as register-specific verb frequency served as fixed effects. Continuous predictors were z-transformed. In the filler model, we included register and filler type in the slope of the random effect for participant. Register and filler type also served as fixed effects, with an interaction between the two. These maximal models were then simplified by means of a stepwise backward elimination of nonsignificant random slopes, interactions and predictors.
ResultsFootnote 4
Corpus results
Table 3 shows the model output of the mixed-effects regression model after backward elimination. The model made intercept adjustments for speaker/writer (σ2 = 0.09, SD = 0.30; N = 274) and lexical verb (σ2 = 0.14, SD = 0.37; N = 55).Footnote 5 The model's largest adjustments in favor of will are for the verbs show, provide, continue, give, and find; the verbs take, happen, get, do, and cost have the largest adjustments in favor of be going to.
Table 3. Mixed-effects logistic regression model with treatment contrast coding. Predictions are for be going to. Significant p-values are printed in bold.Footnote 6 The values of n and %(bgt) are reported for the full dataset (main effects) or for each cell (interactions). Main effects of predictors involved in interactions with register represent the effects found in the spoken informal register. Therefore, nonsignificant main effects are included in the modelFootnote 7
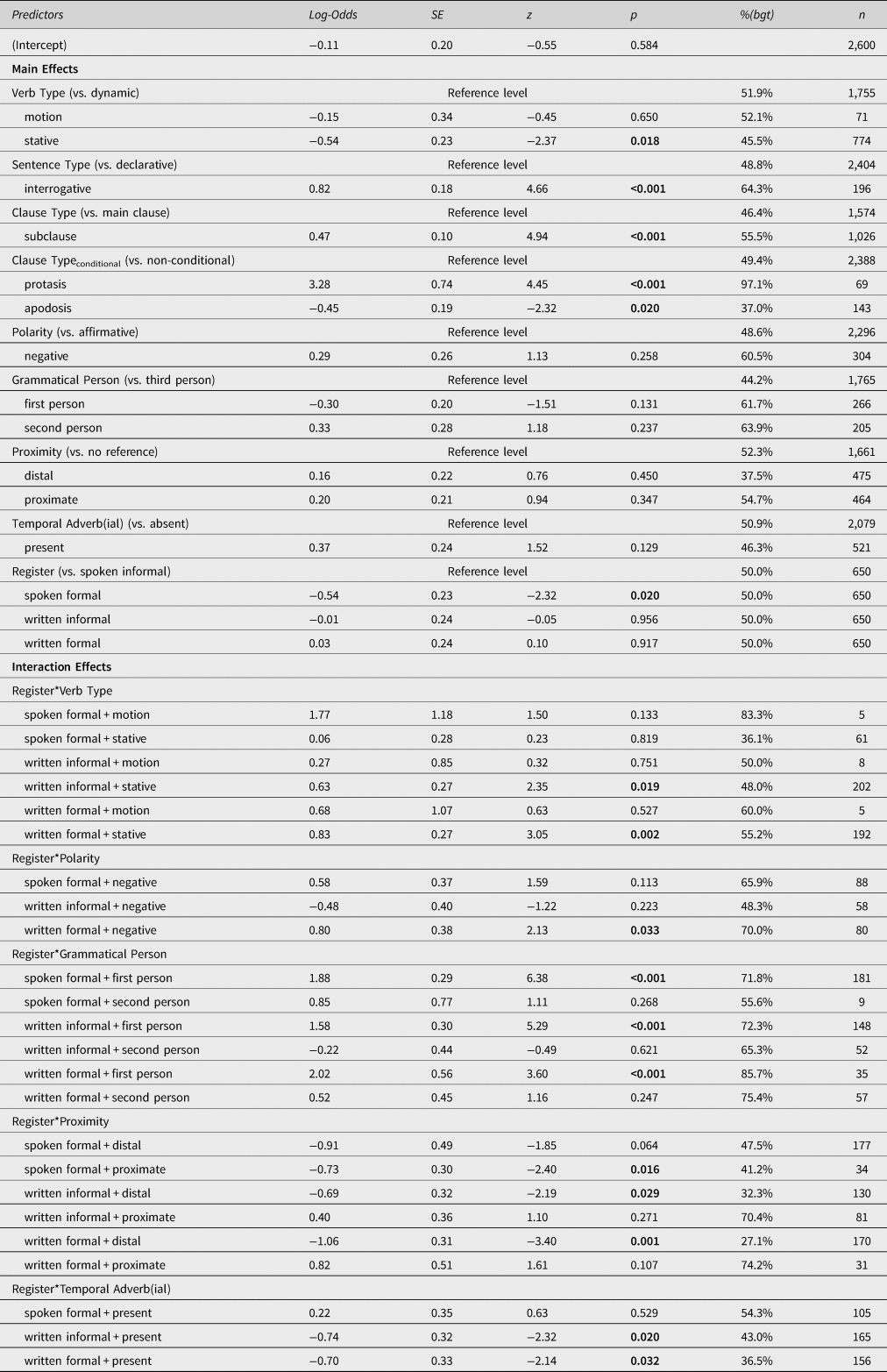
A positive coefficient (log-odds value) indicates that the respective predictor level favors the predicted outcome (i.e., be going to in this model); a negative coefficient indicates that the respective predictor level disfavors the predicted outcome. Main effects are in line with previous findings in that interrogative sentences, subordinate clauses, and protasis clauses prefer be going to, and apodosis clauses prefer will. Animacy of the grammatical subject did not emerge as significant. In addition to these main effects, register modulates the effects of five internal constraints: While stative lexical verbs increase the odds for be going to in the written informal and written formal registers, they increase the odds in favor of will in the spoken informal register. Negative polarity favors be going to in the written formal register, but there is no such effect in the other registers. First-person subjects increase the odds for be going to across all registers other than spoken informal conversations.Footnote 8 Distal future time contexts show a preference for will in both written registers, and proximate future contexts prefer will in the spoken formal register. When a temporal adverbial is present, the odds for be going to decrease significantly in the written registers but not in the two spoken registers included here.
These results clearly demonstrate that there is considerable variation in the variable grammar across registers, with register modulating both the effect size and the effect direction of probabilistic constraints in the FTR alternation. The model also shows that differences between the variants are leveled in the spoken informal register, as evidenced by the absence of significant main effects for polarity, grammatical person, proximity of future time reference and presence of temporal adverbial (see Table 3). Furthermore, the effects in the written registers differ substantially from those found in the spoken informal register.
Experimental results
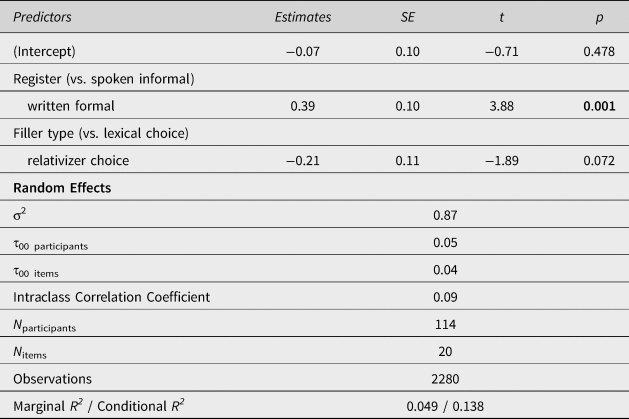
Overall, participants answered 91.12% of the comprehension questions correctly. Figure 1 shows the effects plots for the ratings of the filler items. Participants gave significantly higher ratings to formal variants in items of the written formal register compared to formal variants in spoken informal items. There was also a marginally significant effect of filler type (i.e., relativizer versus lexical fillers), indicating that formal lexical variants generally received higher ratings than the relativizer which (see Table 6 in the appendix). These patterns in the filler data therefore confirm that participants took the register context into account when completing the survey. Taken together, accuracy results and filler data suggest that participants worked diligently on the task and that the intended register manipulation was successful.

Figure 1. Participants’ ratings in favor of the formal variants in filler items. Formal variants received higher ratings in the written register (left panel) and higher ratings in items with a lexical choice compared to relativizer items (right panel).
As for the target items, consisting of a choice between will and be going to, the final model includes a main effect for predicted corpus probability (see Table 4). That is, participants gave higher ratings for the be going to variant as the corpus-based probability of be going to increases (see Figure 2). Verb frequency did not contribute to explaining the variance. Repeated measures correlation analysis (Bakdash & Marusich, Reference Bakdash and Marusich2017) confirms that there is a positive correlation with medium strength between the corpus-based probability and the participants’ ratings (r rm = 0.35, p < .001). In sum, the experimental findings suggest that language users have knowledge about register-specific probabilistic patterns of variant choice.

Figure 2. Participants’ ratings plotted against the corpus-based probability for be going to. Regression line with positive slope suggests that participants’ ratings match with the corpus model's predictions.
Table 4. Mixed-effects linear regression model of the items including a choice between will and be going to. σ2 is the mean random effect variance of the model; τ00 is the between-subject or between-item variance
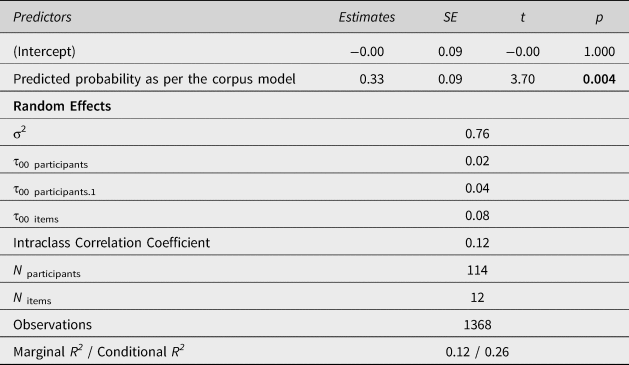
Table 5 shows the corpus-based predicted probability and mean ratings as well as median per item in both registers. As can be seen, the mean and median ratings increase in a linear fashion for the spoken informal register, while they do not increase linearly in items of the written formal register. This may indicate that participants’ probabilistic knowledge is more entrenched in this register, which would be in line with a usage-based account of linguistic knowledge and overall rates of occurrence in the two registers (see Table 1). Note that for the regression model, ratings were z-transformed in order to account for participants’ individual preferences of using the rating scale (Schütze & Sprouse, Reference Schütze, Sprouse, Podesva and Sharma2013:43), and random effects for participant and item were included. This may explain why we do not obtain a main effect for, or interaction with, register in the regression analysis although descriptive statistics suggest otherwise.
Table 5. Corpus-based predicted probability, mean rating, standard deviation, and median for the be going to variant per register and item

General discussion and conclusion
This study has investigated whether the probabilistic conditioning of variation between overt markers of future temporal reference (FTR) in English, will and be going to, differs across four registers of British English at the intersection between mode and formality. The answer, in a nutshell, is: Yes, it does—register differences are not “quantitatively simple” (Guy, Reference Guy2005:562, about stylistic variation).
On the empirical plane, we carried out a corpus study based on a variationist dataset covering n = 2,600 tokens that we richly annotated for nine well-known language-internal constraints on FTR variation. The logistic regression model that was fitted on this dataset probes the register-specificity of the conditioning of FTR by testing the significance of interaction effects between register and the language-internal constraints under investigation. On the basis of the corpus-based regression model, we then conducted a supplementary rating task experiment (n = 114 participants) to assess native speakers’ intuitions about the two variants in context.
Corpus analysis shows that there are indeed a great deal of differences across registers. Specifically, we found that the effects of five (out of nine) internal constraints vary as a function of register. For instance, be going to is favored in contexts of negation in newspaper articles, but not in spontaneous conversations. Distal future contexts favor will in all registers included in this study except for spoken informal conversations. Similarly, first-person subjects favor be going to in all registers other than spoken informal. In addition, will is preferred when a temporal adverbial is present only in the written registers, and stative verbs favor be going to in writing, but will in conversations. Taken together, it seems that the effects found in spoken informal conversations are generally different from those found in writing.
The supplementary rating task experiment provides converging evidence that the probabilistic conditioning of variation differs as a function of register: Participant ratings of the naturalness of FTRs in two registers (spoken informal conversations and written formal newspaper articles) were in line with the variant selection probabilities calculated via the corpus model.
In summary, corpus evidence and experimental evidence agree that the conditioning of FTR variation is sensitive to, and is a function of, the situational context, that is, register. We would like to briefly note here that this finding corresponds to related work on the dative alternation in English (Engel, Grafmiller, Rosseel, & Szmrecsanyi, Reference Szmrecsanyi and Engel2022; Engel, Grafmiller, Rosseel, Szmrecsanyi, & Van de Velde, Reference Engel, Grafmiller, Rosseel, Szmrecsanyi, Van de Velde, Seoane and Biber2021). Using a similar methodology as in the present study—combining the variationist method with corpus and experimental data—these other studies likewise report significant interference between register and the probabilistic conditioning of the dative alternation. This leads to the conclusion that the patterns reported in the present paper are unlikely to be variable- or alternation-specific.
Our findings have implications for at least two branches of linguistics concerned with variation. First, register analysts working in text-linguistic paradigms (Biber, Reference Biber1988) may want to take note that, according to our results, register differences are not all about frequencies and co-occurrence patterns of linguistic features. Rather, register also shapes the arguably deeper probabilistic conditioning of linguistic variation. This recognition opens up new avenues for research into register differences. Register emerges as an even more fundamental determinant of linguistic variation than has been traditionally assumed (see Szmrecsanyi, Reference Szmrecsanyi2019:93f.).
Second, of course, our results have implications for empirical practice and theory formation in variationist linguistics. More often than not, previous empirical variationist work has failed to obtain significant register effects, or “breakdown[s] of grammar from one register to the next” (Tagliamonte, Reference Tagliamonte2016:27f.). But then again, it is arguable whether the analysis methods of previous work in this line of research have been sophisticated enough to diagnose significant register differences. We propose that the methodology that we have used in the present paper—fitting one encompassing regression model across registers and testing interaction effects between register and the language-internal constraints under investigation—is the silver bullet to check the register-specificity of variable grammars. Needless to say, supplementary experimental evidence, for example via rating task experiments such as the one reported on here that are customary in Probabilistic Grammar research (Bresnan & Ford, Reference Bresnan and Ford2010) are an ideal way to check the robustness of findings deriving from naturalistic/observational data, whether it be corpora or sociolinguistic interviews.
On the theoretical plane, our point of departure was the theorem that “internal constraints … are normally independent of social and stylistic factors” (Labov, Reference Labov2010:265). We reasoned that register differences can be plausibly assumed to be akin to stylistic variation in this regard. As our results have demonstrated, this assumption is incorrect. Unlike stylistic variation, register differences are not quantitatively simple. Specifically, register differences do not only concern differences in the selection frequency of variants but also affect the conditioning of variation. This leads, then, to a discussion of whether we are justified in claiming that different registers are associated with different variable grammars (or probabilistic grammars, in the terminology of, for example, Szmrecsanyi, Grafmiller, Bresnan, Rosenbach, Tagliamonte, & Todd, Reference Szmrecsanyi, Grafmiller, Bresnan, Rosenbach, Tagliamonte and Todd2017:1). Inspired by previous work in comparative variation analysis (Guy, Reference Guy2015; Tagliamonte, Reference Tagliamonte, Chambers and Schilling-Estes2013), we apply three criteria for positing distinct variable grammars, in descending order of conservativeness:
1. The set of constraints is different.
2. The constraints are the same, but they have different effect directions.
3. The set of constraints is the same and the effect directions are identical, but the effect sizes demonstrate a statistically significant difference.
Criterion 1 we do not explicitly address in the present study (but supplementary analysis suggests that the number of constraints can differ across registers; see Szmrecsanyi & Engel, Reference Szmrecsanyi and Engel2022). What we did demonstrate in this paper is that register modulates both the effect size and the effect direction of constraints in FTR variation. On this basis, we feel justified in arguing that different registers can be associated with different variable grammars.
That variable grammars are variable across registers has two implications. First, we may wonder about the primacy of the vernacular as a “representative” style or register, if, as our results suggest, it is not always possible to generalize from one register to the next (see also D'Arcy & Tagliamonte, Reference D'Arcy and Tagliamonte2015). Second, as we mentioned in the Introduction section, Guy's Grammatical Difference Hypothesis (Guy, Reference Guy2015) suggests that employing different constraints differently in different situations means that language users, to the extent that they master different registers, have at their disposal a range of different register-specific grammars.
Limitations of this study and directions for future research include the following. Due to our comparatively coarse operationalization of register, we might have failed to observe finer-grained distinctions within individual registers. Recent text-linguistic studies have shown that some registers, such as online blogs or conversations, are intrinsically hybrid (Biber & Egbert, Reference Biber and Egbert2018; Biber, Egbert, Keller, & Wizner, Reference Biber, Egbert, Keller and Wizner2021). Future research into probabilistic conditioning should thus investigate this issue. Another limitation is that we restricted attention to pairwise comparisons between informal conversations (“the vernacular”) and each of the other registers. More work is needed to understand how informal writing differs from formal writing, formal speech from formal writing, and so on. In addition, more research examining other variables beyond FTR variation is advised to obtain a fuller picture of the kind of constraints that are particularly variable across registers (see Tamminga, MacKenzie, & Embick, Reference Tamminga, MacKenzie and Embick2016). In this way, the field will be better equipped to assess the cognitive underpinnings of register variation. And finally, of course, the analysis needs to be extended to other languages. Are register differences in, say, English more or less pronounced than register differences in, say, French or Chinese? This kind of analysis will open up exciting avenues for new research agendas at the intersection of variationist sociolinguistics, register analysis and cross-linguistic typology.
Acknowledgments
We are grateful for constructive feedback by two anonymous reviewers. Thanks go to Elsy Andries for help in creating the dataset, and to Michael Lang, Tanguy Dubois, and Matt Hunt Gardner for helpful feedback on earlier versions of the manuscript. The usual disclaimers apply. Funding by Research Foundation–Flanders (FWO), grant # G0D4618N, is gratefully acknowledged.
Competing interests
The authors declare no competing interests.
Data availability statement
Data and code are available at: https://doi.org/10.17605/osf.io/n943g
Appendix
Table 6. Mixed-effects linear regression model of the items including a choice between lexical variants or between the relativizers which and that. σ2 is the mean random effect variance of the model; τ00 is the between-subject or between-item variance









 Open access
Open access