


Recent studies of a number of different varieties of English have reported parallel developments within the short front vowels (Boberg, Reference Boberg2005; Cox & Palethorpe, Reference Cox and Palethorpe2008; Roeder & Jarmasz, Reference Roeder and Jarmasz2010; Torgersen, Kerswill, & Fox, Reference Torgersen, Kerswill, Fox and Hinskens2006). One particular element involves the lowering of the front open-mid vowel, also known as short-E, and referred to by Wells (Reference Wells1982:128) as the dress vowel: “those words whose citation form in Received RP has the stressed vowel /e/ and in GenAm /ε/.” Hence, the change is often referred to as dress-lowering. The result of this lowering is that /ε/ is realized more like /æ/ so that words such as dress [drεs], neck [nεk], get [gεt] sound more like drass [dræs], nack [næk], and gat [gæt]. The change is illustrated further by Boberg (Reference Boberg2005:150), who observed that “among young Canadian women in particular, the pronunciation of /ε/ is sometimes low enough to produce potential confusion with /æ/, at least when taken out of context, as when left and bet sound somewhat like laughed and bat.”
An intriguing aspect of dress-lowering is that it is reported in a number of unrelated and geographically separate varieties. It is found in American varieties, including Californian (Hinton, Moonwomon, Bremnar, Luthin, Van Clay, Lerner, & Cocoran, Reference Hinton, Moonwomon, Bremner, Luthin, Van Clay, Lerner and Corcoran1987) and Philadelphian English (Labov, Reference Labov, Labov and Sankoff1980); across a wide range of Canadian varieties (Clarke, Elms, & Youssef, Reference Clarke, Elms and Youssef1995; Roeder & Jarmasz, Reference Roeder and Jarmasz2010), such as in Toronto (De Decker & Mackenzie, Reference De Decker and Mackenzie2000), Montreal (Boberg, Reference Boberg2005), Newfoundland (Hofmann, Reference Hofmann2014), and Halifax and Vancouver (Boberg, Reference Boberg2010; Sadlier-Brown & Tamminga, Reference Sadlier-Brown, Tamminga and Jones2008); British varieties including London (Tollfree, Reference Tollfree, Foulkes and Docherty1999; Torgersen et al., Reference Torgersen, Kerswill, Fox and Hinskens2006); Irish English in Dublin (Hickey, Reference Hickey2013, Reference Hickey2017); and also in Australian English (Cox & Palethorpe, Reference Cox and Palethorpe2008) as illustrated in Figure 1.
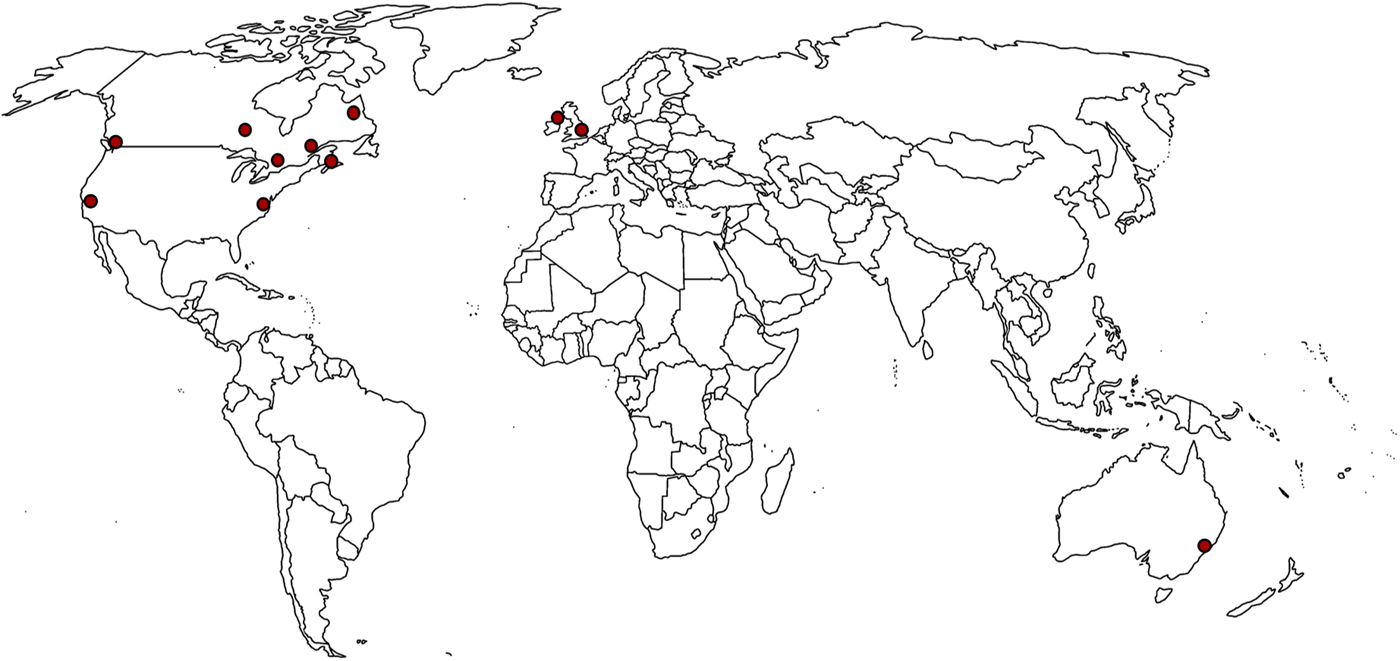
Figure 1. World map indicating varieties demonstrating dress-lowering.
Although these varieties are geographically remote, they share a number of commonalities with regards to their social profiles as pertains to dress-lowering. Clarke et al. (Reference Clarke, Elms and Youssef1995:220) labeled the change “a middle-class phenomenon,” with the majority of studies finding that the change is propelled by young, middle-class females. For example, Hinton et al. (Reference Hinton, Moonwomon, Bremner, Luthin, Van Clay, Lerner and Corcoran1987:123) noted that the change is most evident in “young middle-class Anglo urban Californians.” Clarke et al. (Reference Clarke, Elms and Youssef1995:224) also suggested that despite living “thousands of miles away,” the influence of this Anglo urban Californian accent is the social trigger for DRESS-lowering for Canadian speakers. Even further afield, Hickey (Reference Hickey2013, Reference Hickey2017) proposed that the desire to emulate this Californian accent propels the ongoing change in Dublin English. He suggested that young females “who vie with each other for status as ‘trendy’ or ‘cool’” internalize then produce the model through exposure to American television (Hickey, Reference Hickey2013:11).
Given the recurrent description for dress-lowering as a young, female, middle-class, and urban change, it may be somewhat surprising that dress-lowering is also observed in a dialect from northeast Scotland (1a–d) that is working-class, rural, and typically very slow to adopt innovation (e.g., Smith, Reference Smith2001a, Reference Smith2001b, Reference Smith, Kay, Horobin and Smith2004, Reference Smith, Kirk and Ó Baoill2005).
- (1)
a. There's folk camp out just to get [gæt] in. (Ben, young male)
b. Aye you'll have to text [tækst] me and tell me fitt it is. (Kelly, young female)
c. She likes it but it's twelve [twælv] hour shifts. (Emily, young female)
d. Yous can do the rest [ræst], it's your problem. (George, young male)
So rapid is this change in this community that it may lead to misunderstandings between the older and younger generations, as exemplified in the exchange between the second author of this paper and a younger member of the community in (2):
(2)
Author: What's your name?
Young female: Erin [ærən]
Author: Aaron? [arən]
Young female: ‘Erin’ [εrən]
This begs an important question: why does Buckie, a working-class, rural community, exhibit dress-lowering, an innovative form associated with young, urban, middle-class speakers? We suggest that although this changes looks the same across a number of varieties, the drivers may, in fact, be different. In other words, the same “product” may arise from different “processes.” In order to address this possibility, we provide an apparent time analysis of this change across three generations of speakers. We first situate the current study by providing a summary of previous research on dress-lowering.
dress-lowering: background
Previous accounts of varieties across the English-speaking world demonstrate that both social and linguistic pressures contribute to dress-lowering. The change is said to be conditioned, or even driven, by a number of internal factors, and affects the whole lexicon (e.g., Hockett, Reference Hockett1958; Labov, Reference Labov1994). The majority of studies report that it progresses in a phonetically gradual manner, where the vowel category moves incrementally through the vowel space so that over time the vowel appears shifted.Footnote 1 Although the end result is the same across a number of unrelated varieties—the dress vowel is lowered (and/or retracted)—different mechanisms have been proposed to account for this change.
In some varieties, the shift is described as being part of a larger, ongoing chain shift within the short vowel system (Clarke et al., Reference Clarke, Elms and Youssef1995:212; Cox, Reference Cox1996:12–14; Cox & Palethorpe, Reference Cox and Palethorpe2008:342; Labov, Ash, & Boberg, Reference Labov, Ash and Boberg2006:220). Here, often the initial trigger is attributed to the merging of the cot/caught vowels, with the subsequent backing of the trap vowel leaving a gap that the dress vowel then gravitates toward. In other words, because of the merger, there is a vacant space for /æ/ to move into, and, in turn the short front vowels follow via a drag chain. Alternative accounts suggest that while there are ongoing changes occurring simultaneously within the vowel system, the driving mechanism is not a chain shift, but instead a parallel analogous process (e.g., Boberg, Reference Boberg2005, Reference Boberg2010; Lawrance, Reference Lawrance2002). In line with the chain shift interpretation, the analogy account identifies the backward shifting of the trap vowel as the trigger in the system. In this scenario, instead of dress lowering to fill the void, it backs in-step with the retraction of the trap vowel and then subsequently lowers.Footnote 2
While the accounts differ with regard to the exact propagation of the change (chain or analogy), the common element is the presence of a backed trap vowel, which may or may not have been induced through a recently merged cot/caught vowel (Boberg, Reference Boberg2005; Clarke et al., Reference Clarke, Elms and Youssef1995; D'Arcy, Reference D'Arcy2005; Esling & Warkentyne, Reference Esling, Warkentyne and Clarke1993; Hollett, Reference Hollett2006). Indeed, Boberg (Reference Boberg2005:150) suggested that, given this constellation of vowels (where trap is backed), dress-lowering is “an automatic response to its phonological input condition,” suggesting a change that is primarily motivated by internal linguistic pressures.
In addition to systemic pressures, more local constraints may also be implicated. A common finding among studies that report on phonetic effects is that following and preceding /l/s and /r/s favor the change. For instance, Hickey (Reference Hickey2013) found that both preceding (e.g., left, let, rest, red), and following (e.g., sell, tell, terrify, berry) liquids promote lowering. Hinton et al. (Reference Hinton, Moonwomon, Bremner, Luthin, Van Clay, Lerner and Corcoran1987:121), on the other hand, found that it was only following liquids that conditioned the change, where “before /l/ and /r/ the front vowels are lowered and backed.” De Decker and MacKenzie (Reference De Decker and Mackenzie2000:6) also reported that it is the following environment that conditions dress-lowering. While the effects of liquids may be more widespread, a number of dialect-specific effects are also reported. For instance, in Dublin, Hickey (Reference Hickey and Hickey2016:29) observed that presibilant environments (e.g., fresh, desk) exhibit the greatest degree of lowering while prenasal environments (e.g., friend) inhibit short front vowel lowering.Footnote 3
In tandem with these systemic and local constraints, a number of social constraints are also attested for dress-lowering, where it is associated with young, middle-class, urban, females (Clarke et al., Reference Clarke, Elms and Youssef1995:220; Hickey, Reference Hickey2013:11; Hinton et al., Reference Hinton, Moonwomon, Bremner, Luthin, Van Clay, Lerner and Corcoran1987:123; Hofmann, Reference Hofmann2014:339). For example, Hofmann's (Reference Hofmann2014:303) apparent-time study found that dress is more backed and lowered in the younger speakers in St. John's, Newfoundland. Boberg (Reference Boberg2005, Reference Boberg2010), too, found a significant age effect for dress-retraction in his survey of Canada more generally. In their study of the Canadian Shift, Clarke et al. (Reference Clarke, Elms and Youssef1995:216–217) found women in the lead, a finding echoed by Roeder and Jarmasz (Reference Roeder and Jarmasz2010: 396) in their study in Toronto. In terms of geography, Boberg (Reference Boberg2008:138) reported that the shift in Canada is resisted by “areas that are somewhat isolated from the main centers of English Canadian urban culture in Toronto and Vancouver.”
In sum, dress-lowering results from a correspondence between both internal and external factors. A backed trap vowel is identified as the necessary “pivot” (Clarke et al., Reference Clarke, Elms and Youssef1995:212) that triggers the change. Following the initial trigger, several phonetic environments, such as laterals or sibilants, further accelerate the change. In addition to the advantageous phonological conditions, favorable social associations may also play a role in the propagation of this change. Its link to certain groups, such as dynamic, affluent Californians, may make it particularly attractive to socially aspirant young females such as Hickey's (Reference Hickey and Hickey2016:30–31) young female broadcasters on Irish television and radio.
How does the rural, working-class community of Buckie fit into this picture? In what follows, we investigate how this change manifests acoustically over time across both social and linguistic constraints.
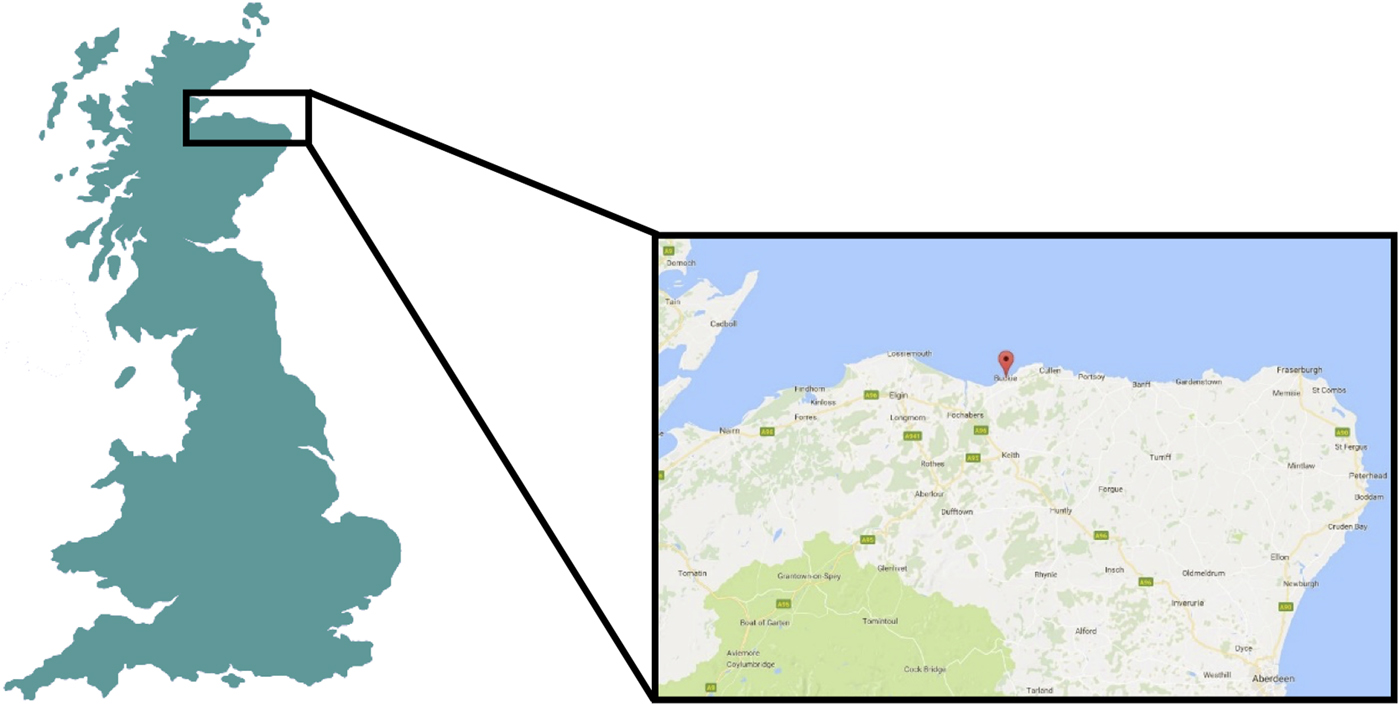
Figure 2. The research site Buckie, Scotland (© 2017, Google Maps).
DATA
The community and participant sample
Buckie is a small fishing town situated on the northeast coast of Scotland; 60 miles from Aberdeen (see Figure 2). Due to economic independence as a result of the fishing industry, until recently the community was isolated geographically, socially, and culturally from more mainstream norms. Thus, Buckie is a classic “relic” area, where linguistic forms from the history of English, which have long disappeared in other more mainstream varieties, are still in use (e.g., Smith, Reference Smith2001a, Reference Smith2001b, Reference Smith, Kay, Horobin and Smith2004, Reference Smith, Kirk and Ó Baoill2005). The following extract between a female participant from the older cohort and the interviewer, also native to Buckie, illustrates some of these forms. These include traditional lexical forms such as ken for ‘know’ and wifies for ‘women’, unshifted vowels such as ab[u:]t for ab[ʌʉ]t, archaic prefixes such atween for ‘between’ and abody for ‘everybody’, and a host of other forms as underlined in (3).
(3)
Rose: In that day, your father wouldna've gien to a pub, would he have ?
Poppy: No, on Hogmanay the wifies got a wee sherry in a wee sherry glass, and the mannies got a whisky. That was your Hogmanay.
Rose: That was it.
Poppy: There was nothin’ in atween.
Rose: No.
Poppy: A sherry or a whisky, that was fit, that was it, and you used to hae [u:]t a wee spread. Maybe a bit o’ shortbread or a sponge that your mother had made. You used to sit and take the bells in. Ken this, fan I think ab[u:]t it, abody was happy.
The younger speakers, too, exhibit an array of relic forms, as in (4):
(4) Well, we're gan back to drink there afore we go [u:]t so it's nae as if we're gan to be [u:]t fae early on so we'll, ken, have a giggle and a couple of drinks afore we go [u:]t so it'll probably be abo[u:]t nine, ten o'clock afore we're actually [ʌʉ]t. (Cheryl, young female).
Buckie is not immune to change, however. Glottal replacement is widespread (Smith & Holmes-Elliott, Reference Smith and Holmes-Elliott2017) although other supra-local features such as th-fronting and l-vocalization (e.g., Kerswill, Reference Kerswill, Britain and Cheshire2003) remain absent in the dialect.
The sample consists of 24 speakers, stratified by age and gender as shown in Table 1, and was recorded as part of a larger project One Speaker, Two Dialects: Bidialectalism across the Generations in a Scottish Community (Smith, Reference Smith2013–2016). Participant selection is based on the following criteria: (a) both parents born and raised in the community, (b) where applicable, spouse from the community, (c) no more than one year spent away from the community, (d) no education beyond secondary school level. For the data used here, the speakers were recorded with a community ‘insider’ using classic sociolinguistic interview techniques (Labov, Reference Labov, Baugh and Sherzer1984). Each interview was fully transcribed using Transcriber (Boudahmane, Manta, Antoine, Galliano, & Barras, Reference Boudahmane, Manta, Antoine, Galliano and Barras2008), creating a speech-to-orthography time-aligned corpus of approximately 1 million words.
Table 1. Sample stratified by age and gender

Dataset, acoustic measures
Due to the phonetically gradual nature of dress-lowering, we employed an acoustic analysis of the data (see also Boberg, Reference Boberg2005; Cox & Palethorpe, Reference Cox and Palethorpe2008; Torgersen et al., Reference Torgersen, Kerswill, Fox and Hinskens2006). Following transcription, the recordings were automatically aligned and vowel measures extracted using FAVE-align (Rosenfelder, Fruehwald, Evanini, & Yuan, Reference Rosenfelder, Fruehwald, Evanini and Jiahong2011). The forced-alignment was hand-checked and any misaligned elements were manually corrected.
We restricted our analysis to stressed vowels as they are less susceptible to articulatory undershoot (see, e.g., de Jong, Reference de Jong1995:499; Shockey, Reference Shockey2003:20). The data were normalized using the modified Watt and Fabricius (Reference Watt and Fabricius2002) method in order to control for the effects of anatomical differences on acoustic measures.Footnote 4 Overall, 952 tokens were analyzed with each of the 24 speakers contributing between 30 and 50 tokens.Footnote 5
We analyzed dress-lowering using a number of acoustic measures. To enable us to first investigate the overall trajectory of the change, we used a measure that combines both F1 and F2 (SPACE-value). To enable us to assess whether the backing or lowering of the dress vowel target is the more vigorous element of the change (cf. Boberg, Reference Boberg2005, Reference Boberg2010; Hofmann, Reference Hofmann2014), we also examined F1 and F2 separately.
Coding
We coded for age in order to test our initial observation that dress-lowering appeared to be a change in progress. We sampled speakers from three discrete generations or life stages (old: 69–80; middle: 45–62; and young: 16–22). Hence, we used a categorical coding of age as opposed to a continuous measure. We also coded for gender in order to test whether Buckie behaved similarly to the majority of dialects studied to date, where women are found to lead this change. The data were also coded for a number of linguistic factors. We undertook a comprehensive coding system that included all possible following and preceding phonetic environments and their combination. This totaled over 30 different contextual configurations. While the more elaborated categories represent the phonetic detail at a qualitative level, low cell counts are unwieldy for statistical analysis. We thus collapsed these smaller categories into larger groups based on patterns of use in the data. Two binary categories emerged from this analysisFootnote 6:
1. DRESS: all nonlateral following environments—ten, set, stress, very, deck, etc.
2. TWELVE: following lateral environments—bell, yell, melt, etc.
Statistical analysis
Statistical analysis was carried out in R (R Core Team, 2013) using linear mixed-effects models using the lme4 package (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015). Each phonetic correlate was modeled using fully saturated models containing all fixed factors and their interactions. Speaker and word were entered as random factors. Models were then stepped using the (step) function of the lmerTest R package (Kuznetsova, Brockhoff, & Christensen, Reference Kuznetsova, Brockhoff and Christensen2016), which eliminates nonsignificant factors until the best fit of the data is reached. Our interpretation of the data is based on the best-fit models and within factor-level contrasts derived using differences of least squares means.Footnote 7
RESULTS: DRESS
dress-lowering and the vowel system
dress-lowering has been described as part of a larger, ongoing chain shift. To examine whether this is the case in these data, we first inspected how this change patterned in relation to the entire Buckie vowel space. Normalized (Lobanov, Reference Lobanov1971) F1 and F2 measures of six vowel categories: fleece, dress, cat, force, ghoul, and goose were used in order to map the most peripheral points of the Buckie vowel system.Footnote 8 The results of this mapping are shown in Figure 3.Footnote 9
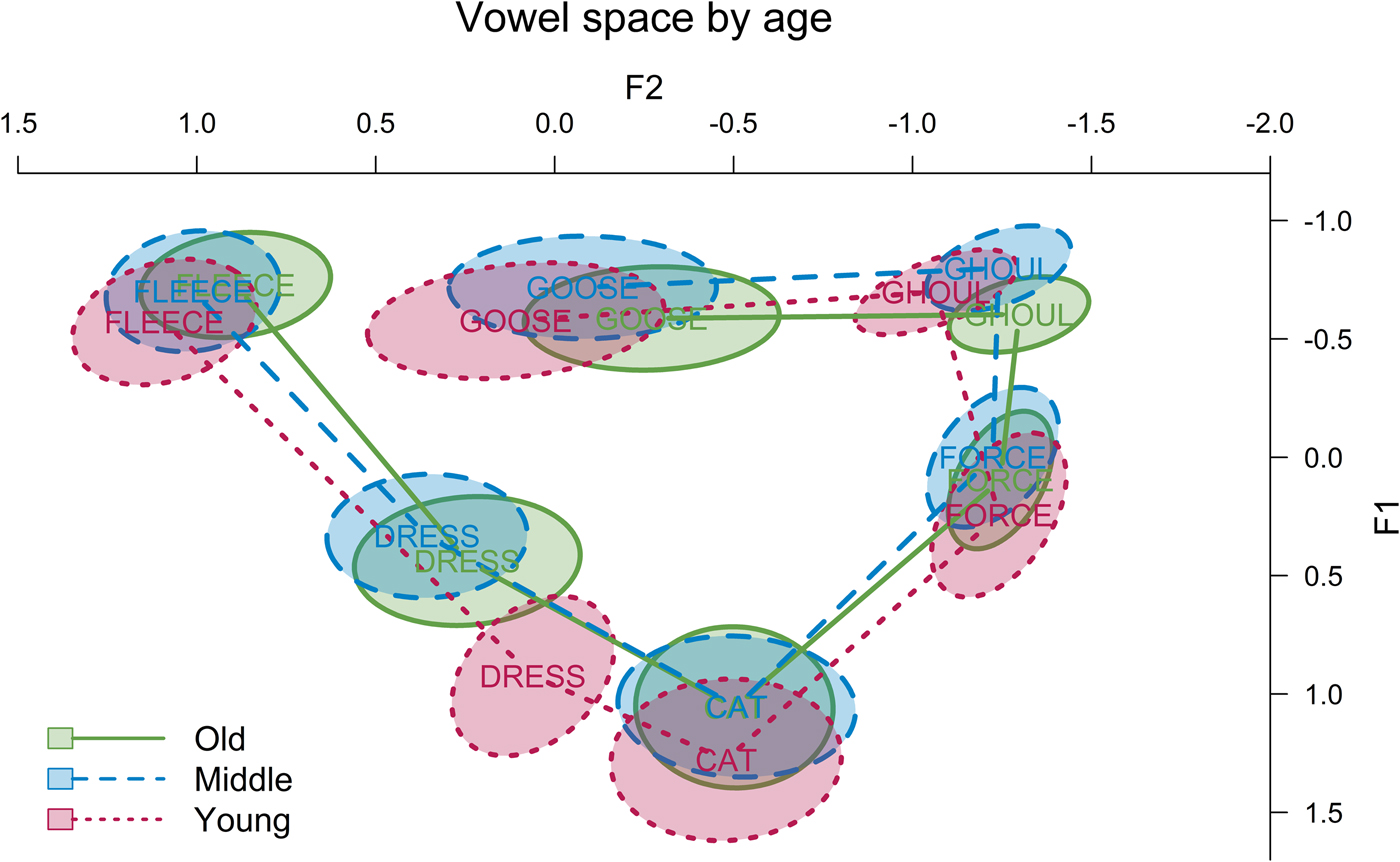
Figure 3. Buckie vowel space by age (based on 12,040 tokens of Lobanov-normalized F1 and F2).
The distribution of the vowel space in Figure 3 shows that while there are slight fluctuations in several of the vowels across the three generations, none come close to the degree of shifting demonstrated by dress, where there is barely any overlap between the old/middle and the younger speakers. Our initial observation that dress is changing is supported by this figure.
Note, too, that in line with Boberg's (Reference Boberg2010) description, the vowel retracts as well as lowers. This has important implications for how we carry out the analysis of dress. In acoustic terms, it is necessary to take account of both the first and second formants as these are most commonly associated with the height (F1) and back (F2) dimensions of the vowel space (e.g., Johnson, Reference Johnson2011:144). Our first analysis investigates the overall shift using a metric that combines F1 and F2 in order to capture the movement of the shift down and back: the SPACE-value. Following this, we consider F1 and F2 separately in order to test whether the shift is more apparent along a particular dimension. By doing so, we will be able to assess the mechanism of the change in this variety: is it shift (Clarke et al., Reference Clarke, Elms and Youssef1995), analogous retraction (Boberg, Reference Boberg2005, Reference Boberg2010), or something else entirely?
SPACE-value: F2 − F1
Initially, we want to capture the change as it both backs and lowers along the front vowel limit (as in Figure 3). In other words, as we need to track the overall movement of the change, we require a single metric that combines the first two formants. One way to represent this shift is to use the SPACE-value measure, which represents the relative distance between F1 and F2 through subtracting the first formant value from the second (F2 − F1) (Ramsammy & Turton, Reference Ramsammy and Turton2012). As the vowel becomes lower and more backed, the difference between F2 and F1, that is the SPACE-value, decreases, as shown in Figure 4. Therefore, higher, more front vowels are associated with larger SPACE-values, and lower, backer vowels with smaller measures.
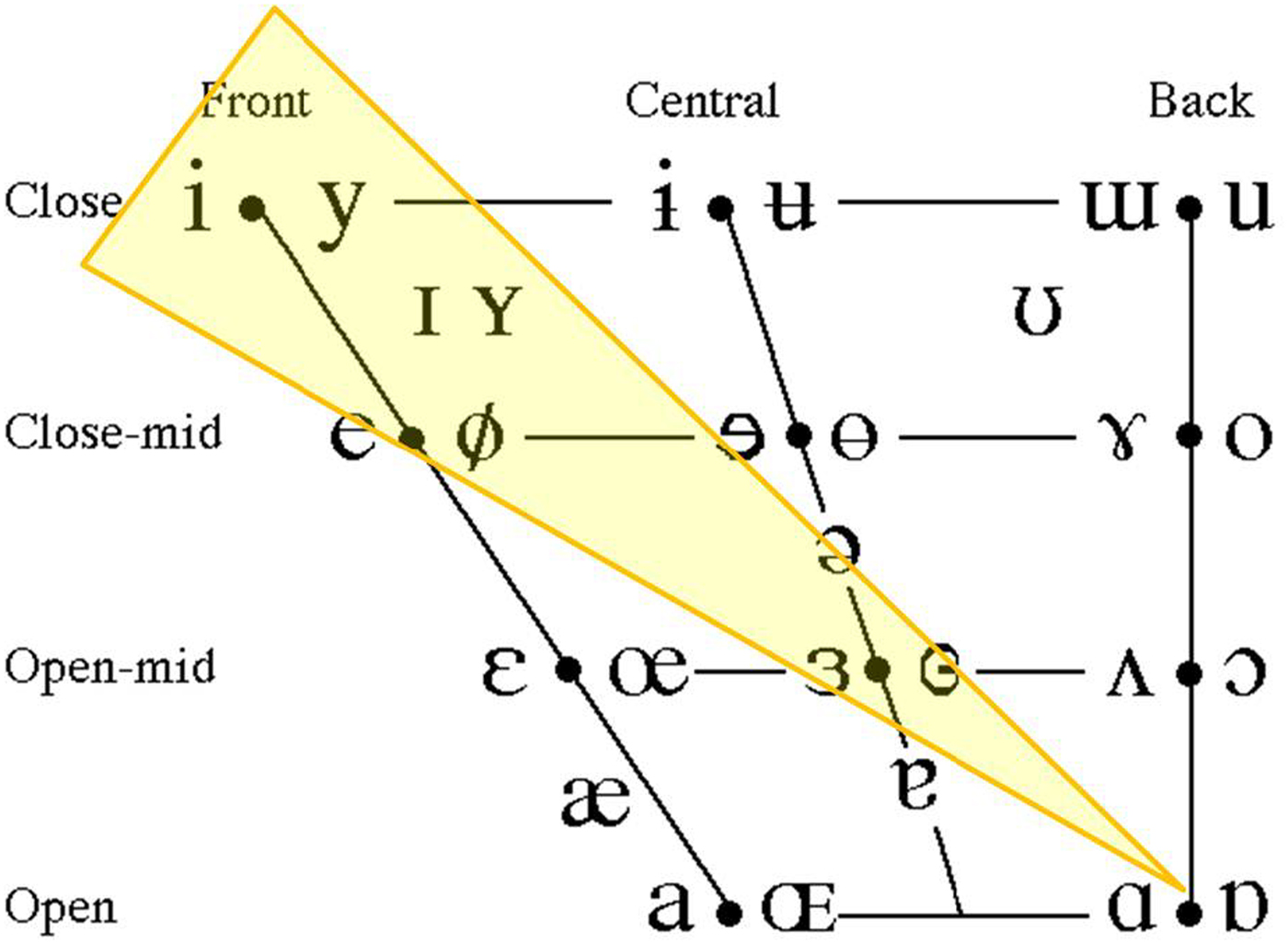
Figure 4. Diagram of SPACE-value (from Ramsammy & Turton, Reference Ramsammy and Turton2012).
SPACE-value measures were calculated for the normalized vowel measures for individual vowel tokens. For each measure, we first present the results of the overall multivariate analysis followed by a discussion of the individual factors.
SPACE-value results
Table 2 presents the best fit of the stepped lmer model for the SPACE-value measure and shows the factors and their within-factor level contrasts selected as significant by the model. Age and following phonetic environment were selected as highly significant. However, the fixed interaction between these factors was not significant, suggesting that the phonetic conditioning patterned in the same way for each of the generations. Gender was not significant as a fixed factor nor as a fixed interaction with age.Footnote 10 The results indicate that the backing and lowering of dress is a change in progress, where lower estimates (smaller SPACE-values), are significantly associated with younger speakers. Phonetic environment is significant for the combined dependent measure where following laterals (the TWELVE category) are also associated with more advanced estimates of the change. We now consider these findings in more detail by examining the within-factor level contrasts. Figure 5 shows how the SPACE-value patterns across age.
Table 2. Linear mixed-effects model for normalized SPACE-value

Number of observations: 952; groups: word (251, SD = .11), speaker (24, SD = .09).
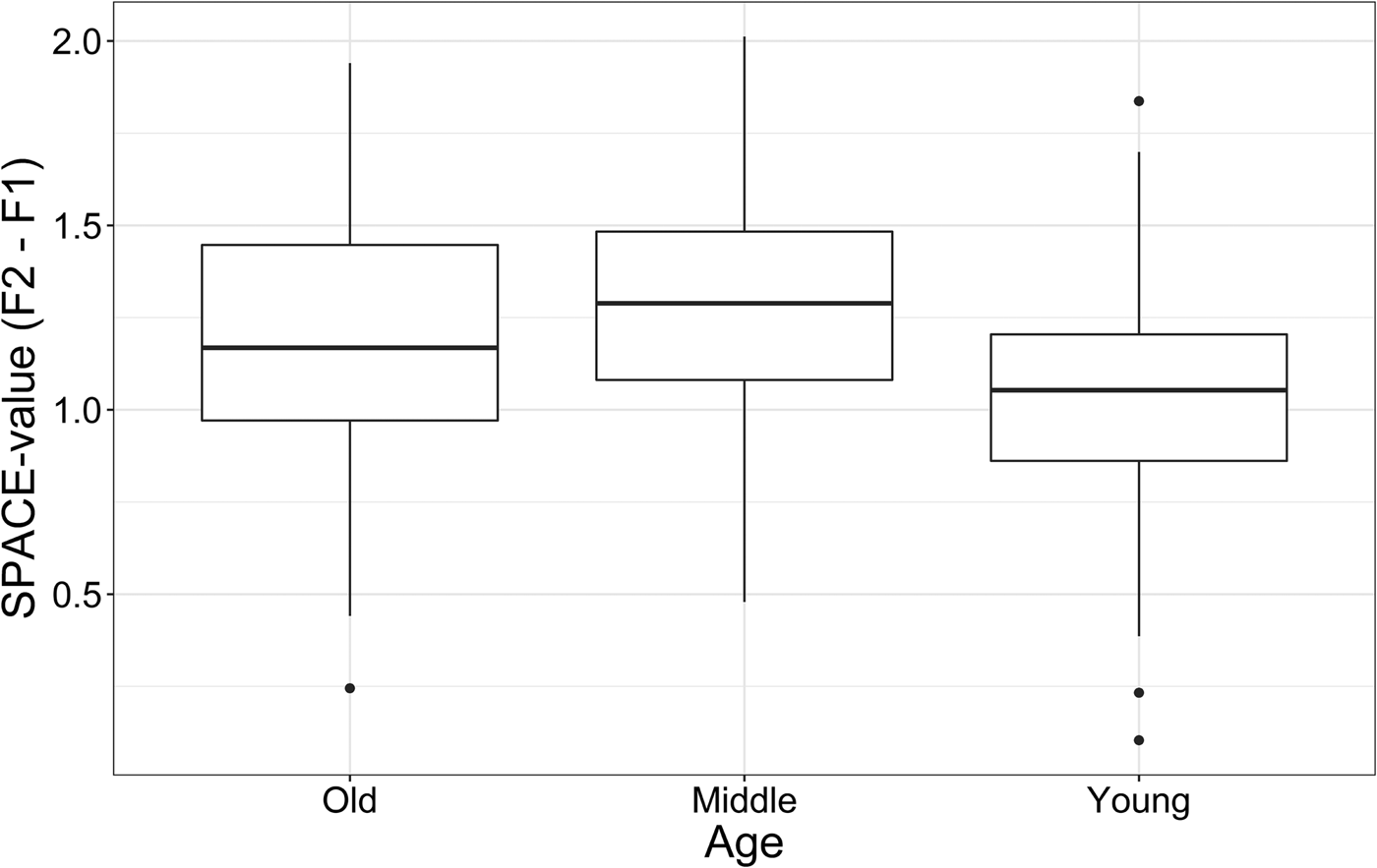
Figure 5. dress vowel normalized SPACE-value (F2-F1) by age.
Figure 5 provides further support for the findings in Figure 3 and the model in Table 2. Within-factor comparisons revealed that the difference between the older and middle cohorts was not significant (p = .2). In contrast, the young speakers were shown to be significantly lower and/or backer than the middle (p < .0001) and also the older (p < .0001) cohort of speakers.
As outlined under Coding, following phonetic environment was collapsed into a two-way split: following laterals, and all other environments (the DRESS category). Figure 6 shows how this factor patterns across the age groups. Following laterals (the TWELVE set) promote lower and backer realizations across all age groups (p < .001). Furthermore, the figure indicates that the strength of the effect of following laterals is greatest for the young speakers.
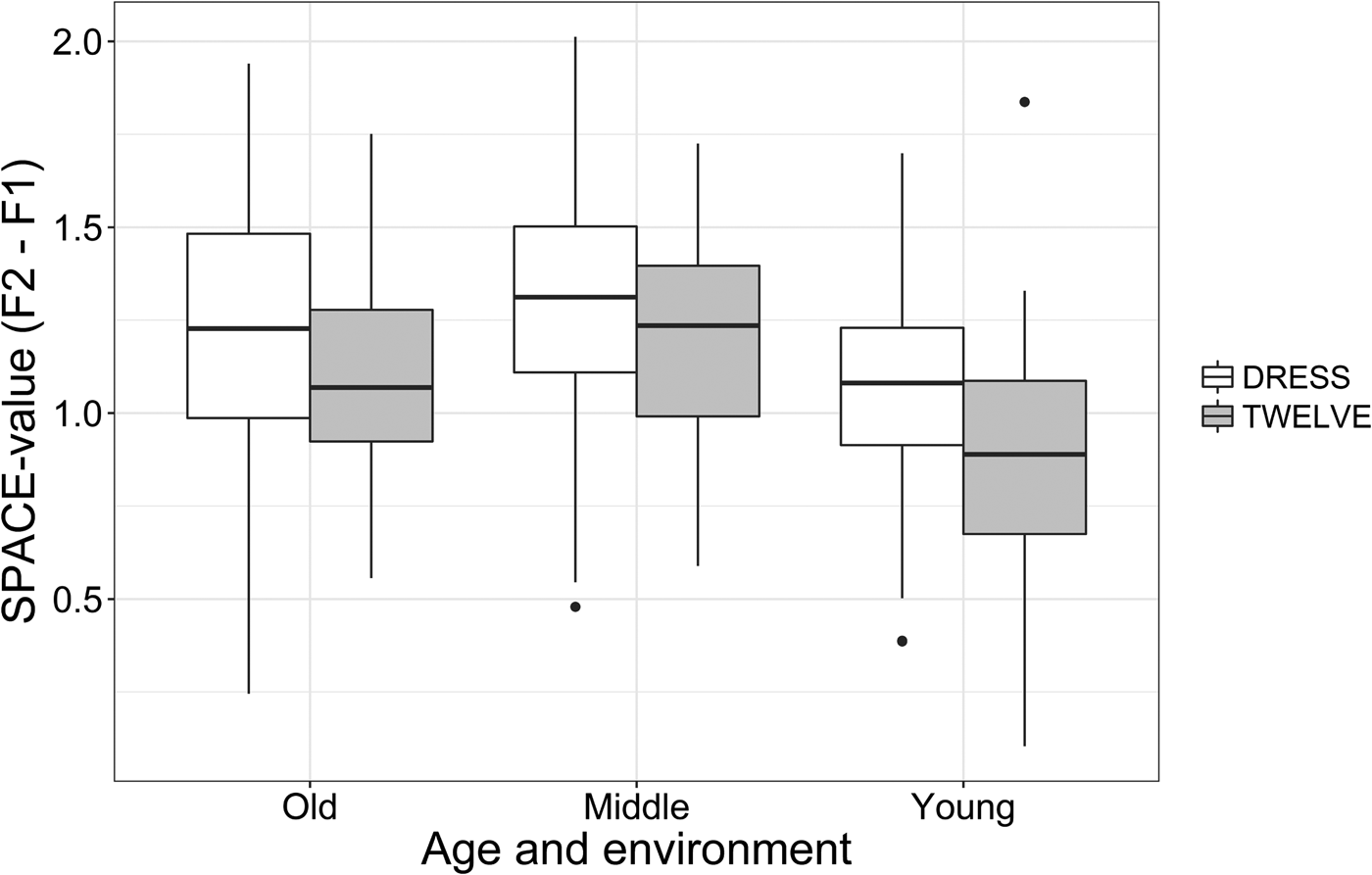
Figure 6. dress vowel normalized SPACE-value (F2-F1) by age and following environment.
We now examine the profile of this change across the formants individually. If the change is a shift, we would expect to see uniform patterning across the two formants as it lowers and retracts along the front track (e.g., Clarke et al., Reference Clarke, Elms and Youssef1995). If the elements occur separately, we might expect to see contrasting patterns across the individual formants. We first present our analysis of F1.
Table 3. Linear mixed-effects model for normalized F1 measure of dress vowel

Number of observations: 952; groups: word (251, SD = .05), speaker (24, SD = .08).
F1 results
Table 3 presents the best fit of the stepped lmer model for normalized F1. Table 3 shows the factors and their within-factor level contrasts selected as significant by the model for normalized F1. In line with the SPACE-value measure, gender did not significantly constrain the variation. Age was selected as significant, and the interaction between age and following phonetic environment was also significant, where younger speakers exhibit significantly higher F1 measures of dress environment tokens than older speakers. Within-factor comparisons of least squares means are used in order to compare the conditioning of following environment across the age groups. First, we consider the apparent time view of the change as shown in Figure 7 which echoes the pattern revealed in the mapping of the vowel space and the SPACE-value. F1 increases significantly in apparent time: higher F1 values (and lower vowel tokens) are associated with younger speakers. There is a significant difference between the young and middle age cohorts (p < .001), but no significant difference between the older and middle speakers (p = .9). Thus, as with Figure 5, the change centers on the younger cohort only.
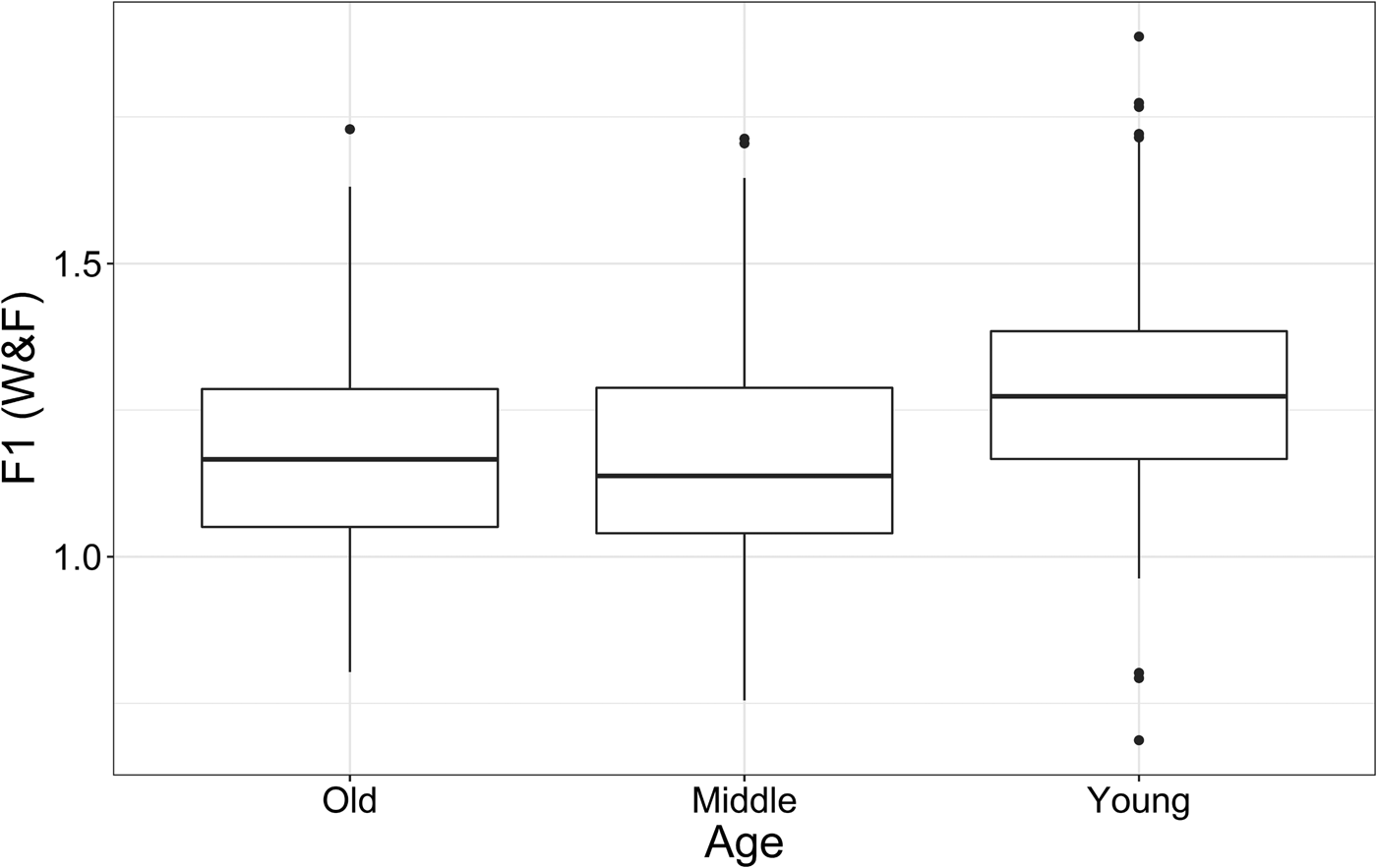
Figure 7. dress vowel normalized F1 by age.
Figure 8 shows the patterning of F1 across age and the two following phonetic environments: following /l/ (TWELVE) and the remaining contexts (DRESS). The effect of following environment is not consistent across the age groups. In short, laterals promote significantly lower dress tokens, that is higher F1 measures, only within the young cohort (p < .001) and not for the older (p = .95) or middle (p = .65) speakers. This finding contrasts to the SPACE-value measure where following laterals conditioned the change consistently across the generations. This suggests that the consistency shown across the SPACE-value measure was the result of F2, the measure of backing. Our analysis of F2 will reveal whether this is the case.
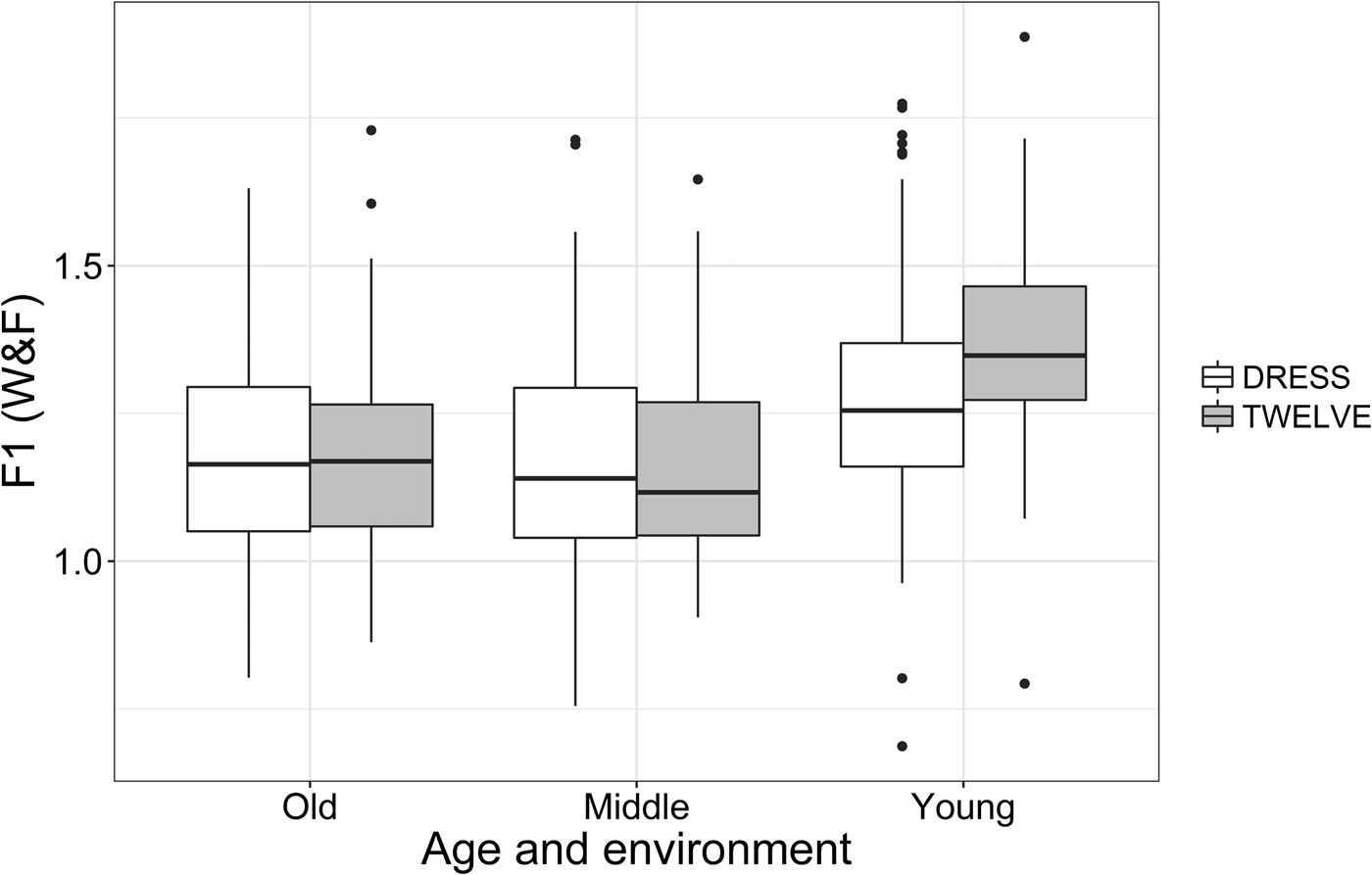
Figure 8. dress vowel normalized F1 by age and following phonetic environment.
F2 results
Table 4 presents the best fit of the stepped lmer model for normalized F2, and shows again, gender is not a significant predictor. Age is significant where younger speakers have lower F2 estimates (backer average vowel tokens, than the middle-aged and older speakers. Following phonetic environment is also highly significant and does not significantly interact with age (p = .8). In contrast to F1, the model for F2 closely matches the findings from the combined SPACE-value analysis. This suggests that the overall shift is better characterized by changes in F2 than in F1. In other words, the shift backward contributes more to the overall profile of the change than the movement downward. We turn now to examine how this change patterns across the factors we coded for.
Table 4. Linear mixed-effects model for normalized F2 measure of dress vowel

Number of observations: 952; groups: word (251, SD = .08), speaker (24, SD = .08).
Figure 9 shows how F2 patterns across the age groups. Similar to Figure 5, the figure shows are different from the middle and older generations: while the within-factor analysis revealed that there was no significant difference between the older and middle cohorts (p = .2), for the young speakers F2 was significantly lower than for the middle (p = .002) and the older speakers (p = .039). In line with F1 and the combined SPACE-value measure, the younger speakers mark the first significant development in the change.
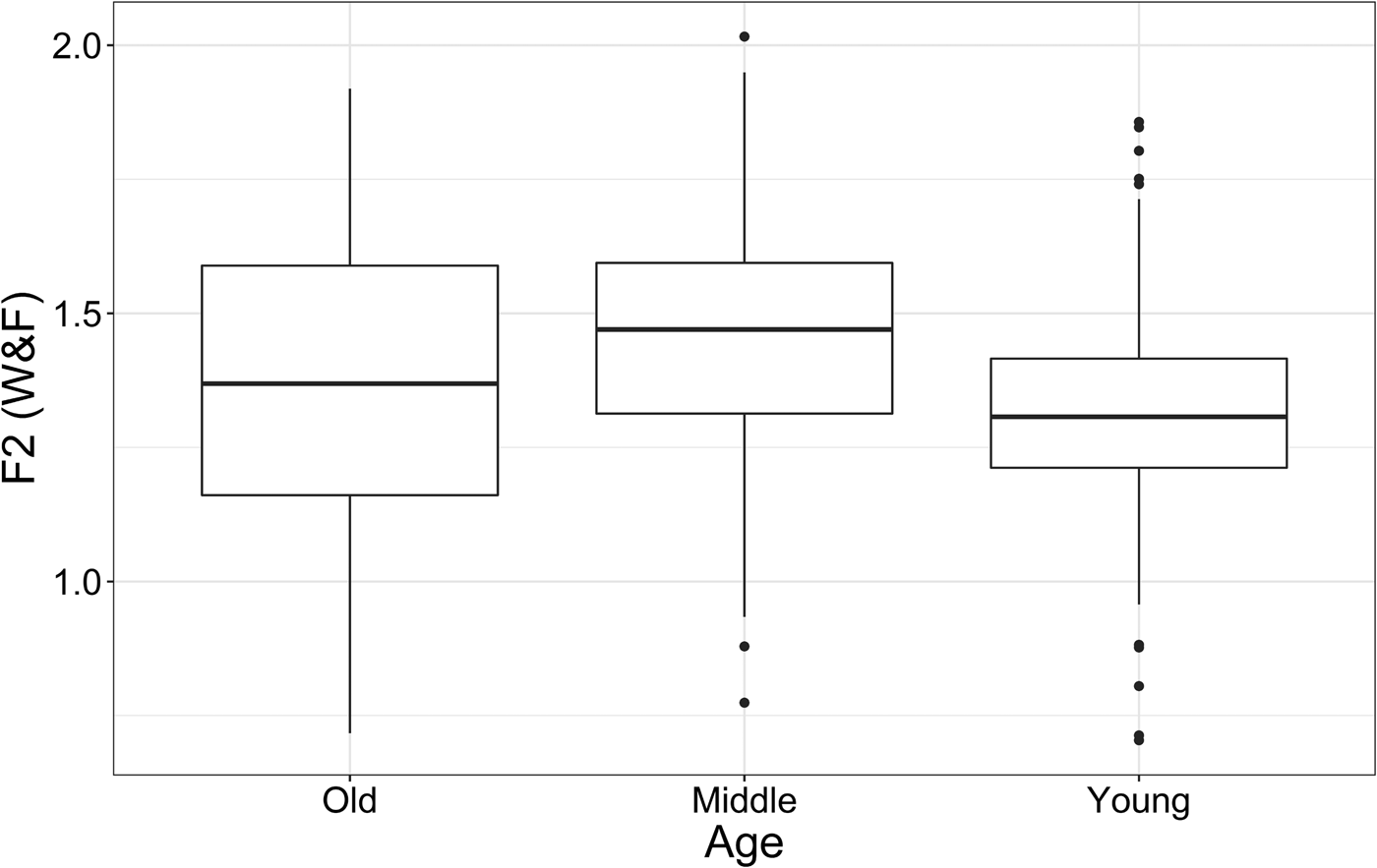
Figure 9. dress vowel normalized F2 by age.
The analysis of the SPACE-value (Figure 5) showed that following environment conditioned the variation across all age groups. In contrast, the analysis of F1 (Figure 7) showed that following environment was only significant for the youngest cohort. Figure 10 shows how this factor patterns across age for F2. Following phonetic environment has a consistent effect across the age groups. As indicated by the model in Table 4, following laterals significantly promote the change across all age groups. The F2 results match those from the combined measure. This leads us to conclude that it is the differences in F2 that account for the patterns observed in the SPACE-value.
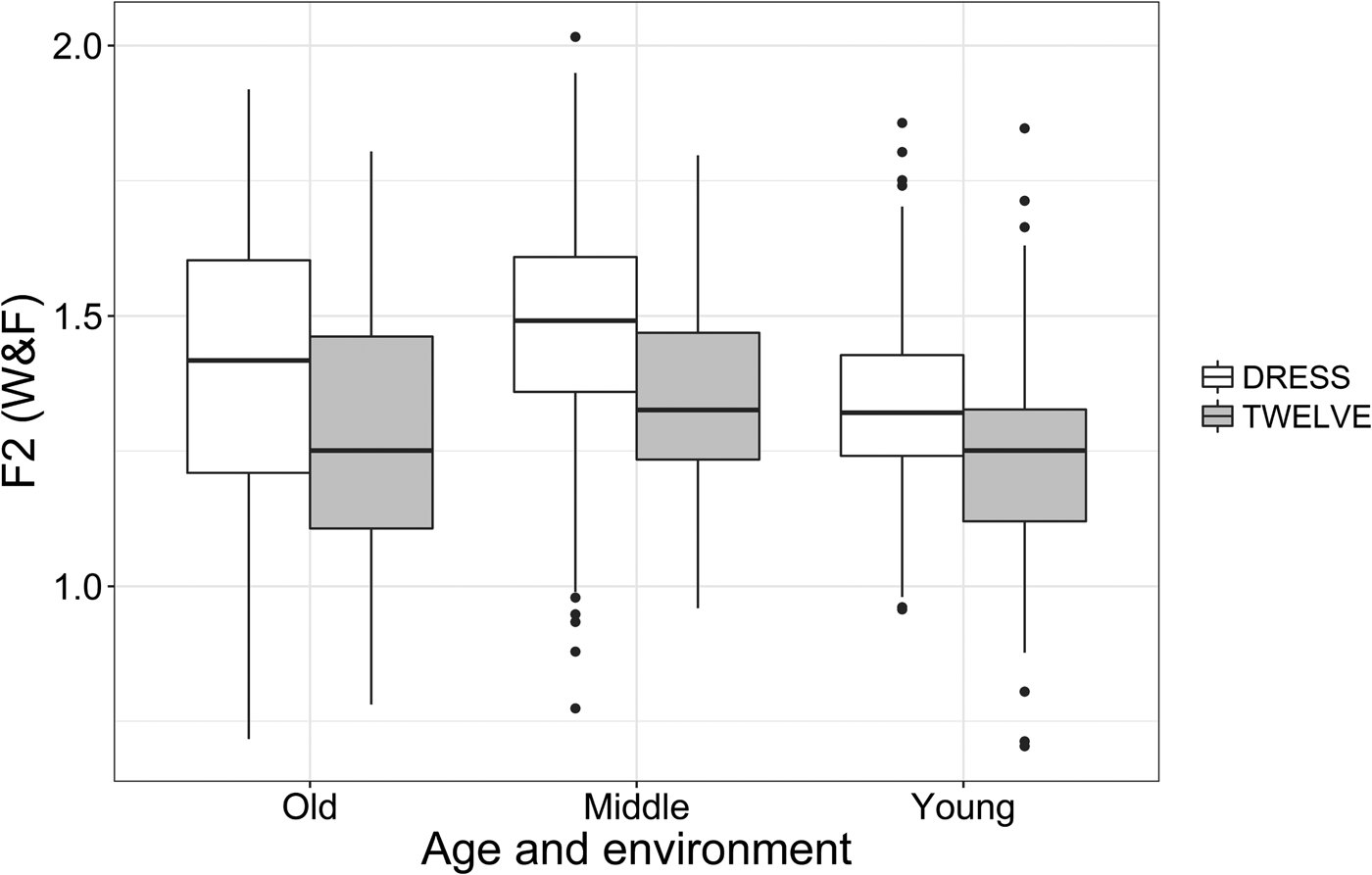
Figure 10. dress vowel normalized F2 by age and following phonetic environment.
Summary and discussion of dress results
We can now summarize our findings across the three measures. Across each of our analyses, there was significant change in apparent time. The analysis of the SPACE-value revealed an overall shift in the dress vowel, and the separate analyses of F1 and F2 both showed significant differences demonstrating dress was lowering and retracting in apparent time. For all three analyses, only the young group showed a significant difference across apparent time, indicating that this group represents the first significant increment of the change.
The uniformity of the aggregate findings across age, where all three measures behave identically, means we cannot use this evidence to infer whether the change is predominantly a lowering or a retraction. However, examination of the internal constraints may shed light on this issue. Following laterals (the TWELVE set) significantly promoted the change across all three analyses. Closer inspection revealed that the details of this conditioning were not uniform across all three measures. For the SPACE-value and F2, following laterals promoted more extreme measures for every age cohort. For F1, this effect was only significant for the younger speakers. This lack of uniformity has implications for our understanding of the shift. The statistical matching of the SPACE-value and F2 models suggests that the changes in F2 are the primary component of this shift. This would indicate that the change in Buckie more closely matches Boberg's (Reference Boberg2010) description of the shift in Canada, where he suggests that the mechanism is an analogous retraction followed by lowering, as opposed to a classic drag chain shift where both elements progress in tandem (cf. Clarke et al., Reference Clarke, Elms and Youssef1995). This interpretation is bolstered by the observation that phonetic conditioning emerges earlier in F2 than in F1.
In sum, our analyses indicate that internal, systemic, rather than social pressures, are driving this change. Specifically, coda /l/ promotes a lower and more backed articulation of the vowel. However, while this account may describe the mechanism, it does not explain why this change has happened: if /l/ provides a trigger, it is not clear why these effects only take hold in the systems of the youngest speakers. In other words, if the necessary “input conditions” existed in the form of the lateral environment, why has it only triggered the change now? One possibility is that older and younger speakers exhibit different articulations of /l/. Thus, changes in the dress vowel may be related to other changes in progress and more specifically /l/. In the next section, we look in more detail at /l/-quality in the data in order to investigate this possibility.
ANALYSIS OF /l/
Light and dark /l/, quality and distribution
Traditionally, English /l/ has been described in terms of two distincrt allophones: light (or clear) [l] and dark [ɫ] (Giles & Moll, Reference Giles and Moll1975; Jones, Reference Jones1909; Sweet, Reference Sweet1908).Footnote 11 Dark and light allophones have been shown to exist in complementary distribution where light [l]s appear in syllable onsets and dark [ɫ]s in syllable codas. For instance, the contrasting /l/ quality in pairs of words such as leak and keel: [lik] versus [kiɫ], or lip and pill: [lɪp] versus [pɪɫ], in some English varieties.Footnote 12 However, while this distribution is shown for the majority of English dialects (Boersma & Hayes, Reference Boersma and Hayes2001; Chomsky & Halle, Reference Chomsky and Halle1968; Giles & Moll, Reference Giles and Moll1975; Hayes, Reference Hayes, Dekkers, van der Leeuw and van de Weijer2000; Tollfee, Reference Tollfree, Foulkes and Docherty1999), there is evidence to suggest that the distribution is not universal. Carter (Reference Carter, Local, Ogden and Temple2003:240) showed that some Irish English varieties exhibited light [l]s in all positions and, conversely, particular Scottish varieties showed dark [ɫ]s in both onsets and codas. Similarly, Turton (Reference Turton2014, Reference Turton2017) argued that both types of varieties of English exist: those that exhibit two distinct allophones and those that do not. Dialects can therefore demonstrate /l/ variation along two dimensions: (a) overall quality, that is darkness/lightness, and (b) positional distribution of allophonic variants. Our initial auditory impression suggests that Buckie, along with other Scottish varieties, exhibits dark [ɫ]s in both onsets and codas. However, it may be that /l/ quality is changing in Buckie, or it could be that there is a change in the allophonic distribution of /l/ variants. In other words, there may be increasing or decreasing allophony over time. If such changes are occurring, they may, in turn, be implicated in the changes evidenced in dress. It is to this question that we now turn.
Measuring /l/-quality
In articulatory terms, /l/ darkness generally correlates with the degree or timing of coronal/dorsal constriction. In light [l]s, the coronal constriction precedes the dorsal one, and in dark [ɫ]s, the dorsal gesture comes first (Sproat & Fujimura, Reference Sproat and Fujimura1993; Turton, Reference Turton2017). As a resonant phoneme, lateral consonants exhibit formant structures (Espy-Wilson, Reference Espy-Wilson1992) and darkness, or velar constriction, can be analyzed through examining the relationship between the first and second formants. Specifically, lighter [l]s have higher F2 and lower F1, whereas darker [ɫ]s have lower F2 and higher F1 (Carter, Reference Carter, Local, Ogden and Temple2003; Dalston, Reference Dalston1975; Espy-Wilson, Reference Espy-Wilson1992; Huffman, Reference Huffman1997; Oxley, Buckingham, Roussel, & Daniloff, Reference Oxley, Buckingham, Roussel and Daniloff2006; Recasens, Reference Recasens2004; Sproat & Fujimura, Reference Sproat and Fujimura1993; Van Hofwegen, Reference Van Hofwegen2011). Figures 11 and 12 present spectrograms that illustrate the relationship between F1 and F2 for clear [l] and dark [ɫ] taken from Southern British English, an accent that exhibits the onset/coda, clear/dark distribution (Bladon & Al Bamerni, Reference Bladon and Al-Bamerni1976; Bladon & Nolan, Reference Bladon and Nolan1977).
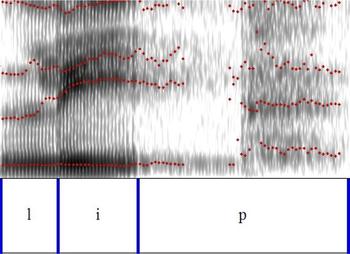
Figure 11. Spectrogram of clear initial [l] token from ‘leap'.

Figure 12. Spectrogram of dark coda [ɫ] token from ‘peel'.
Figure 11 reveals a prototypical clear [l]: F1 is relatively low (351 Hz) while F2 is high (1668 Hz). Figure 12 shows the opposite pattern: F1 is higher (480 Hz) and F2 is lower (1044 Hz). Therefore, one method used to analyze the light-dark cline acoustically is to calculate the difference between F1 and F2 where larger differences are predicted for lighter [l]s (e.g., Oxley, Roussel, & Buckingham, Reference Oxley, Roussel and Buckingham2007; Sproat & Fujimura, Reference Sproat and Fujimura1993; Van Hofwegen, Reference Van Hofwegen2011).Footnote 13
Following Carter and Local (Reference Carter and Local2007:185), we restricted our treatment of onset contexts to stressed word-initial tokens and coda contexts to monosyllabic word-final examples and limited our analysis to tokens occurring within a high-mid front vowel context, as in (5a, b).Footnote 14
- (5)
a. Onset: see little, my letter, be leaving, sea level
b. Coda: sell it, tell everyone, well into, will enter
We extracted F1 and F2 measures from 20 onset and 20 coda token contexts from each speaker. In order to minimize the effects of coarticulation, formant measures came from the midpoint of the steady state of the lateral (e.g., Huffman, Reference Huffman1997; Sproat & Fujimura, Reference Sproat and Fujimura1993; Van Hofwegen, Reference Van Hofwegen2011). A total of 1090 tokens were included in our final analysis of /l/. Reported statistics come from best-fit stepped lmer models.
/l/-quality in Buckie
Our analysis showed an average first and second formant difference (referred to henceforth as “F2-F1”) of 585 Hz in onset, and 531 Hz in coda positions. For comparison, Sproat and Fujimura's (Reference Sproat and Fujimura1993:299) description of canonical light and dark [ɫ] report an average difference of 1077.19 Hz for light [l] compared to 656.9 Hz for dark [ɫ]. Thus in contrast to the syllabic allophony common to the majority of English dialects (cf. Carter, Reference Carter, Local, Ogden and Temple2003), Buckie exhibits a very dark [ɫ] in both onsets and codas. However, these aggregate figures include all age groups and may mask ongoing change, which could shed any light on why coda /l/ promotes dress-lowering in younger but not middle or older speakers. In order to investigate this possibility, we conduct an apparent time analysis of /l/ to investigate how /l/ quality patterns across the generations.
Apparent time: /l/ allophony
Table 5 presents the best-fit of the lmer model for F2-F1 difference and indicates that there is a significant interaction between age and position where the difference between F1 and F2 is increasing over time for onset positions. Figure 13 illustrates this effect and shows how this measure patterns across the age cohorts in both onset (white) and coda (gray) contexts. As described in Measuring l-quality, we would expect to see larger F2-F1 differences for lighter [l]s.
Table 5. Linear mixed-effects regression model for F2-F1 difference

Number of observations: 1090; groups: word (191, SD = 74.36), speaker (24, SD = 107.06).
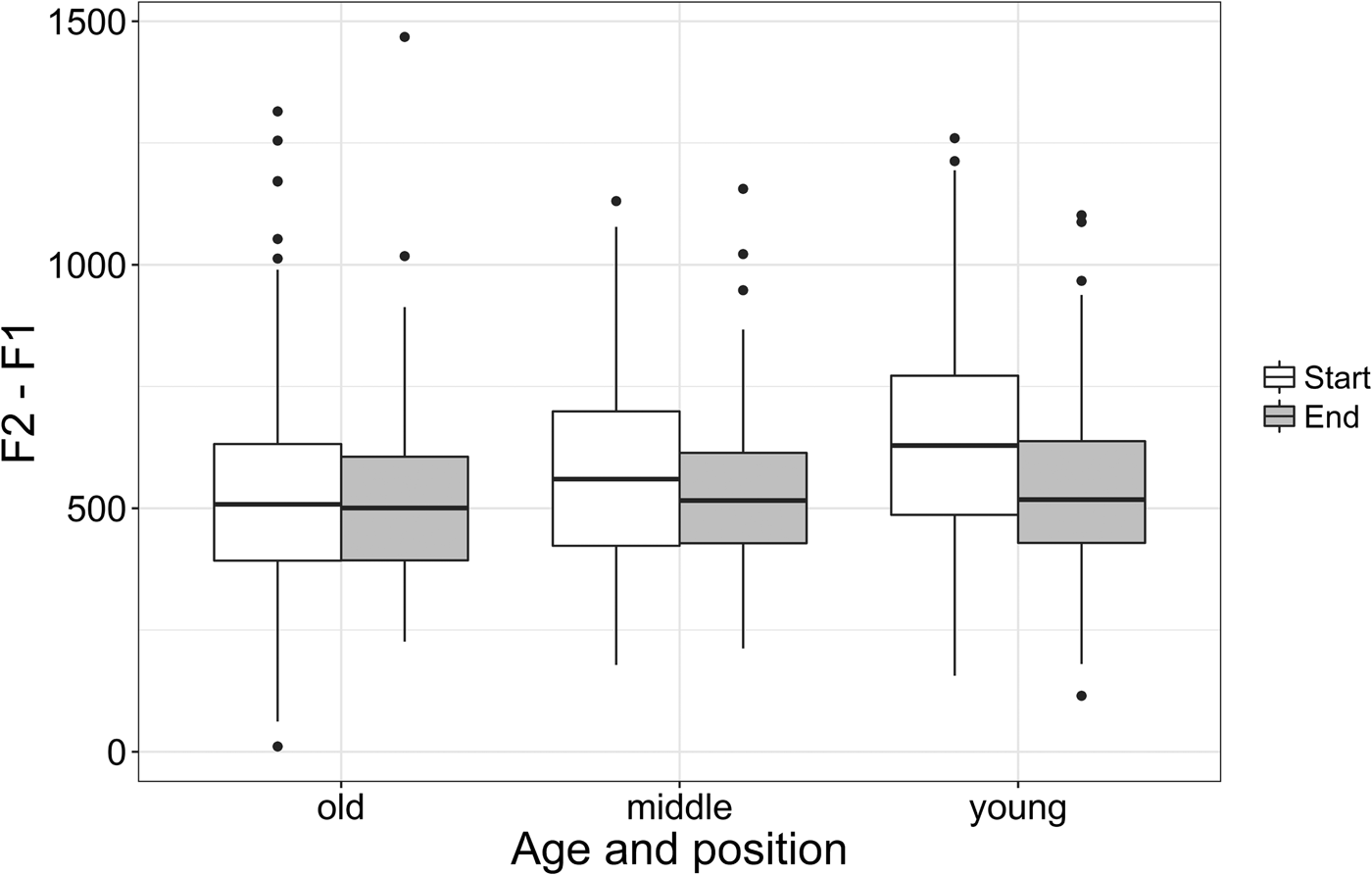
Figure 13. F1 and F2 difference for onset and coda /l/ by age.
Figure 13 reveals that in line with our auditory impression, /l/ is becoming lighter over time as shown through the increased F2-F1 measures in both contexts, but particularly in onsets. We can also see the development of an onset/coda allophony: the difference between the white and gray boxes becomes larger as the age cohorts get younger. This observation is confirmed by the statistical analysis where comparison of least squares means revealed that syllabic position only conditioned the variation significantly for the young cohort (p < .001). Figure 14 recasts this trend through charting the difference in Hertz between the first two formants (F2-F1) between onset and coda positions across the age cohorts (referred to as allophony score). The difference between F1 and F2 distance for onset and coda contexts is increasing over time, and this steadily increasing difference indicates the ongoing development of a positionally conditioned allophony in the Buckie dialect.
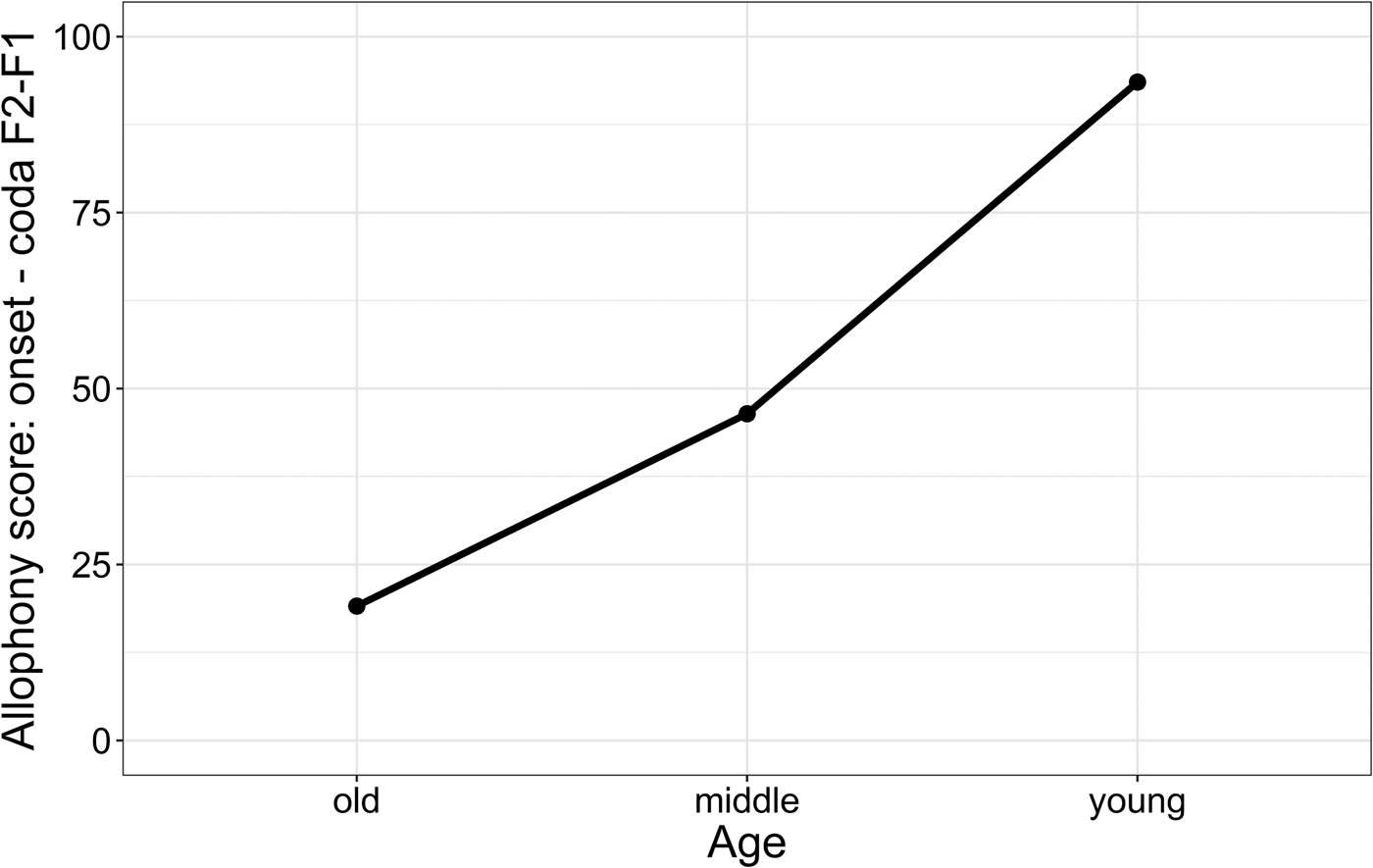
Figure 14. Allophony score (onset – coda, F2-F1 measurements) by age.
/l/ results: F1 and F2
Our examination of the relationship between the first and second formants revealed that Buckie is developing the /l/ allophony in line with the general English pattern. Our original impetus for examining /l/ quality was to investigate why following laterals promote a shift in the dress vowel. On the surface, there is an articulatory and an acoustic link between the changes in the dress vowel and coda /l/ darkening: they both involve retraction and lowering, and they both share the same acoustic correlates, namely a rise in F1 and a lowering in F2. However, as Figure 14 illustrates, the most prominent element of this development occurs in the lightening of onset /l/s, not in the darkening of coda /l/s. It is therefore not clear why coda /l/s would create a favorable environment for dress-lowering. One way of tackling this question is to examine the individual formants, as this approach may be particularly useful in Buckie due to its prototypically dark [ɫ]. Explicitly, while changes in /l/ quality are typically associated with F2 (Carter & Local, Reference Carter and Local2007; Stuart-Smith, Macdonald, José, & Sóskuthy, Reference Stuart-Smith, Macdonald, José and Sóskuthy2015), Oxley et al. (Reference Oxley, Roussel and Buckingham2007:528) suggested that if /l/ is already very dark, as is the case in Buckie, there may be a compensatory raising of F1 in the coda position, as “there might be an interplay between F2 and F1 in the form of F1 raising to effect darker codas when F2 was already low.” In order to inspect the potential interplay between the formants in our data, we examined F1 and F2 separately. Figures 15 and 16 show F1 (above) and F2 (below) across age and position.

Figure 15. F1 onset and coda /l/ by age.
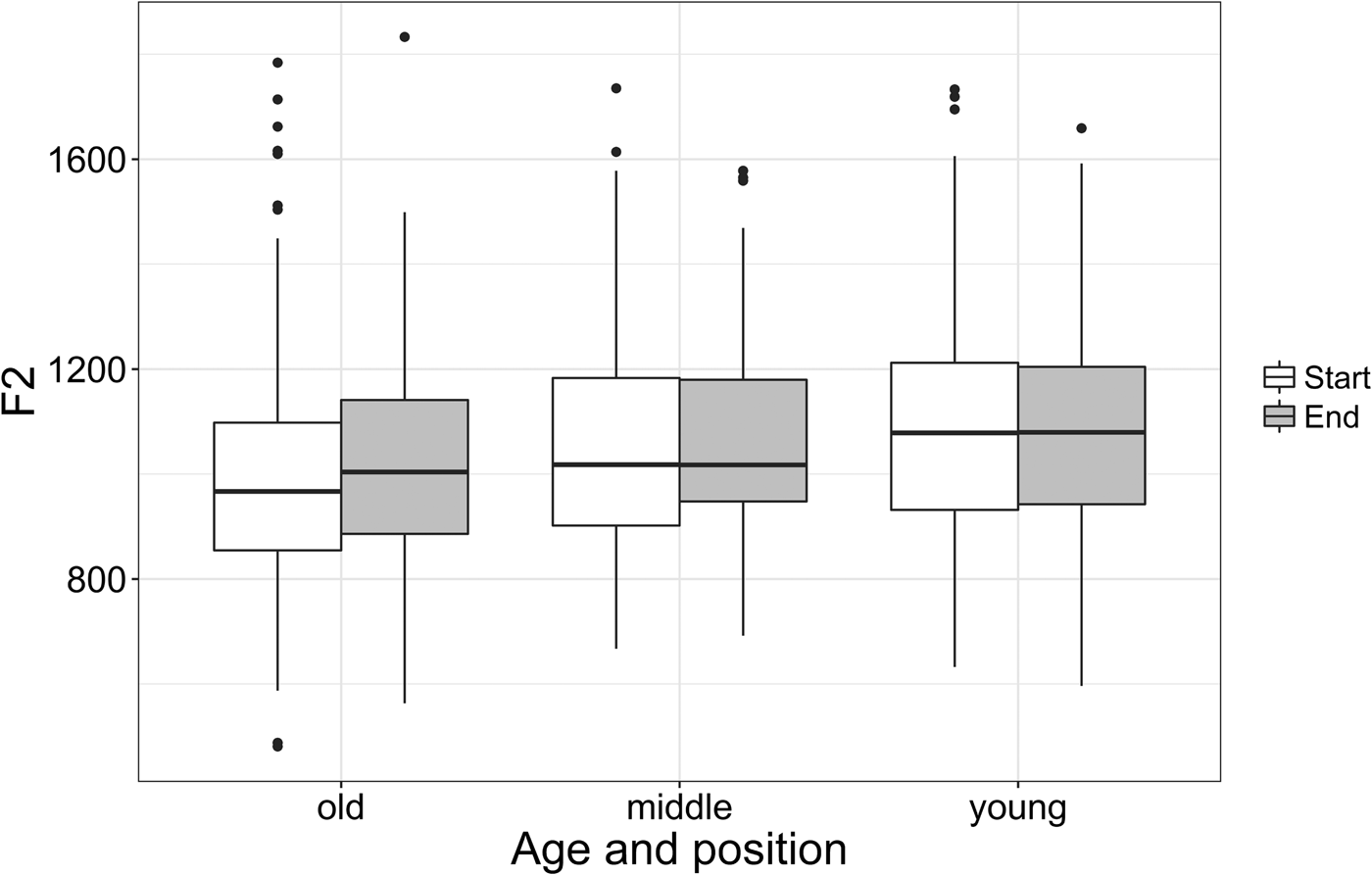
Figure 16. F2 onset and coda /l/ by age.
Figures 15 and 16 show that while F2 remains relatively stable across time, F1 shows a divergent pattern where it is lowered in onsets and slightly raised in codas. Our statistical analysis supports these observations: F2 showed no significant differences across time, but our F1 model revealed a significant interaction term for position and age, as shown in Table 6.
Table 6. Linear mixed-effects regression model for F1

Number of observations: 1090; groups: word (191, SD = 27.81), speaker (24, SD = 45.43).
Further within contrast comparison revealed that F1 was significantly different in onsets and codas for the middle (p < .001) and young speakers (p < .001). In other words, what we find is that the difference between F1 is diverging over time where it is raising in onsets and lowering in codas. This result echoes those of Oxley et al. (Reference Oxley, Roussel and Buckingham2007:539) where “syllable position in dark-l in back vowel contexts seems to be evident mainly in F1 behavior,” with increased F1 values for dark [ɫ] found in coda positions.
Summary of /l/
Three main findings emerge from our analysis of /l/:
1. Buckie is developing /l/ allophony over time where onsets are becoming lighter and codas are becoming darker.
2. The F2-F1 difference between onsets and codas is only significant for young speakers.
3. The analyses of the individual formants revealed that the change is driven primarily by changes in F1.
DISCUSSION
Following our examination of dress-lowering across a number of social and linguistic constraints, we are now in a position to synthesize these results in light of our larger research aims. First, what motivates dress-lowering in Buckie, and, how can this inform on this change more widely? And more crucially, what are the implications for broader theories of language change?
We began our investigation by asking what was driving an apparently urban, middle-class, shift within a rural, relic, working-class dialect. Our first results showed that the younger speakers evidenced significant lowering of dress compared to the middle-aged and older speakers. Moreover, the patterning of constraints suggested that this change is driven by internal, systemic pressures in Buckie: gender did not significantly constrain the variation but phonetic environment did. Specifically, following /l/s (the TWELVE set) showed a greater degree of retraction across all ages but retraction and lowering for the younger cohort only. Figure 17 shows this effect within the context of the whole vowel space, which means it is possible to trace the emergence of this shift in greater detail. For the older speakers, the TWELVE set is slightly but visibly backed, and for the middle speakers, the TWELVE set is slightly backed and lowered (although only the retraction of TWELVE, not the lowering, is statistically significant). However, for the younger speakers, these tendencies are amplified, with the categories showing striking differences: they are almost separate from the general dress group and overlap with the cat measures.
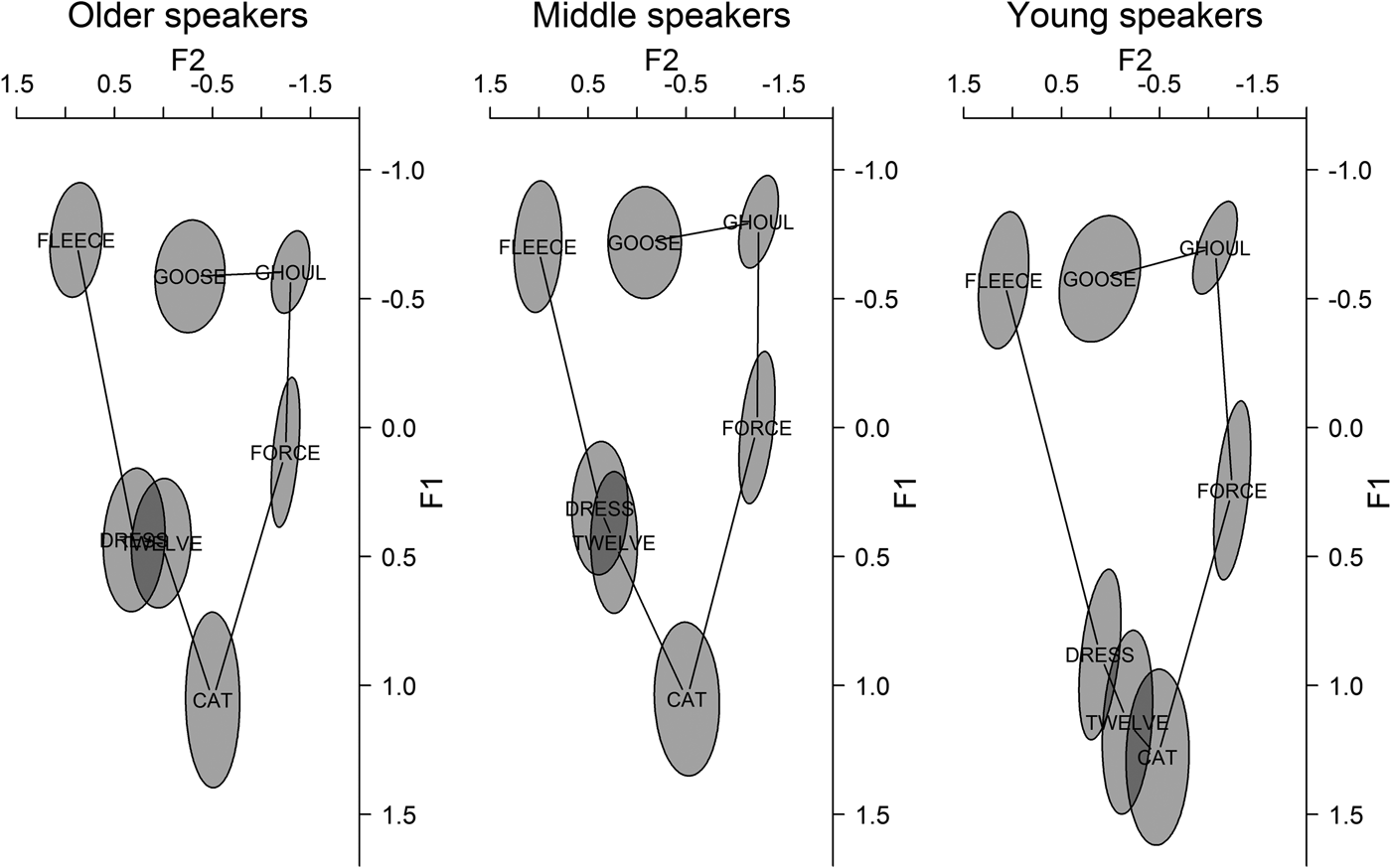
Figure 17. Buckie vowel space by age (DRESS and TWELVE categories separated).
While this may be a reasonable account of how the process operates, it does not explain why the lateral environment exhibits this different effect across the generations. In order to investigate this further, we examined the changing profile of /l/ across time. Could changes in dress be linked to changes in /l/ quality? Our analyses suggest that they can. As mentioned, both changes share articulatory (velar constriction) and acoustic (raised F1 and lowered F2) properties. Moreover, it was arguably the examination of the relative contribution of the individual formants in the developing /l/ allophony that gave the clearest explanatory link between these changes and thus why we see the difference between generations. Our results showed the development of /l/ allophony in Buckie where /l/ is light in onsets and dark in codas. Although /l/ quality is most commonly associated with F2 (e.g., Carter & Local, Reference Carter and Local2007; Stuart-Smith et al., Reference Stuart-Smith, Macdonald, José and Sóskuthy2015), the striking finding for the development in Buckie was that it was brought about through changes in F1 (cf. similar findings reported by Oxley et al., Reference Oxley, Roussel and Buckingham2007). In short, there is a symbiotic relationship between the two changes in acoustic terms. Figure 18 demonstrates this symbiosis between dress-lowering (F1) and /l/ allophony for each speaker, where it reveals a visible trend between increased allophony and dress-lowering.Footnote 15 As the /l/ allophony increases, so too does dress-lowering. This finding goes some way to explaining why only the younger speakers show both retraction and lowering: if a lower F1 is more typical of younger speakers’ coda laterals, then this feature would be likely to spread to the preceding vowel through a process of coarticulation. In this way, greater /l/ allophony can be linked to lower vowel targets. This, in turn, speaks to the underlying mechanism of dress-lowering in Buckie. In our summary of the dress findings, based on the earlier emergence of the conditioning effects in F2, we suggested that the shift was better described as an analogous retraction (cf. Boberg Reference Boberg2005, Reference Boberg2010) rather than a drag chain shift (cf. Clarke et al., Reference Clarke, Elms and Youssef1995). Through our subsequent integration of the two changes, it would now appear that the mechanism is phonological shift induced by systematic coarticulatory variation.
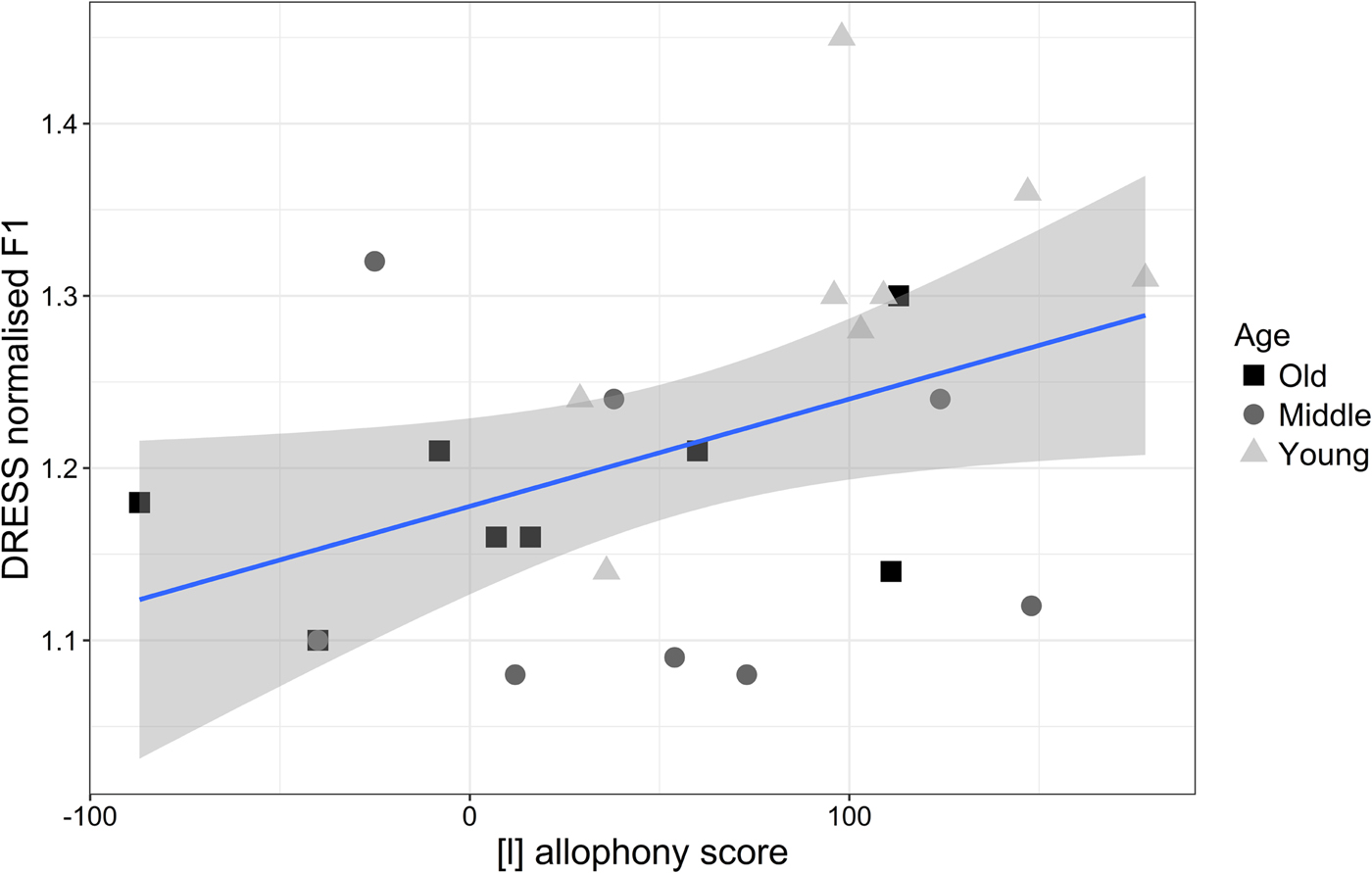
Figure 18. Average dress normalized F1 and allophony (onset F1-F2)−(coda F1-F2).
This account fits well within prevailing models of sound change where coarticulatory-induced variation can provide the trigger for wider phonological change. In this type of sound change, phonetic tendencies, promoted by particular environments, become generalized through a process of perceptual compensation and are applied more broadly across a category, which in turn results in wholesale phonological shift (Beddor, Reference Beddor2009; Blevins, Reference Blevins2004; Harrington, Kleber, & Reubold, Reference Harrington, Kleber and Reubold2008; Ohala, Reference Ohala, Masek, Hendrick and Miller1981). Specifically, in Buckie, following laterals promote backer and lower dress realizations and this tendency affects all /ε/ environments in the younger speakers. This is shown by their significantly different TWELVE and DRESS targets compared to those of the middle and older generations. Indeed, /l/ is frequently shown to strongly condition variation in ongoing sound change where following /l/ promotes a backer and/or lower articulation of the vowel. The outcome is that the coarticulatory conditioning erodes over time and the result is a shift that affects the entire category. This coarticulatory account of phonological shift is well attested. For example, Beddor (Reference Beddor2009) argued that the phonological nasalization of vowels in American English results from a process of coarticulation. Harrington et al. (Reference Harrington, Kleber and Reubold2008:2830–2384) also provided a similar account in their study of goose-fronting in Standard Southern British English, where they observed that the shifted targets are accompanied by weaker phonetic conditioning. They argued that this provides evidence for the coarticualtory trigger of sound change as “listeners give up on compensating perceptually for coarticulation.” The result is a shifted vowel in perception and production. This type of process, where coarticulation and perception interact, may account for the change in the dress vowel, where the young speaker-listeners in Buckie do not factor out the coarticulatory effects of following laterals, and as a result, the entire category shifts.
We began by posing a question: why do we find an urban, middle-class innovation appearing in a rural working-class community? Our analysis of dress-lowering demonstrated that the change could be attributed to systematic internal pressures, specifically following lateral environments. We argued that this promoted lower and backer realizations through a process of coarticulation. The younger speakers in our sample then extended this to the entire dress class. This is a different account of the change when compared to urban, middle-class communities. Thus, what on the surface looks like the same “product” is in fact the result of a very different “process.” Different dialects exhibit the same innovation, but they may take very different pathways to get there. We are still left with the question, however, of why Buckie is developing the particular context that allows dress-lowering, that is, /l/ allophony. This question forms the focus of future research where, in line with the present analysis, we will look at how this change sits within broader phonological developments, specifically the wider liquid system (cf. Carter & Local, Reference Carter and Local2007).
























