



1. Introduction
Online reviews have become a dominant force in the realm of e-commerce websites. Whether it’s purchasing products on platforms like Amazon and Myntra, exploring hotel options on TripAdvisor, checking out restaurant reviews on Yelp, or assessing services on Google, consumer/user reviews play a pivotal role in shaping the e-commerce landscape. Potential customers get attracted to these services and products, after checking the positive reviews of other people about that particular service or product. Hence, these reviews help in the consumer’s decision-making process. However, the presence of fake reviews creates a misleading environment that not only deceives but also misguides potential customers who rely on these reviews. The dissemination of false information, whether it be through news articles, reviews, or social media posts, has a disruptive effect on society and leads to social issues. For instance, the spread of inaccurate COVID-19-related news regarding vaccinations and lockdowns on social media resulted in widespread negative behaviour (Marco-Franco et al., Reference Marco-Franco, Pita-Barros, Vivas-Orts, González-de-Julián and Vivas-Consuelo2021).
Fake reviews manifest as either disinformation, where fraudulent reviews are intentionally generated to harm others, or misinformation, where false information is spread without malicious intent. Regardless of the intentions behind them, fake reviews pose a significant threat to consumer behaviour and fair business practices. The internet has facilitated the dissemination of false narratives and biased opinions that serve self-interests at the expense of others (Amos, Reference Amos2022). The inability to identify fake reviews poses significant disadvantages for all parties involved, including consumers, business service providers, and e-commerce platforms. Consumers must be protected against the influence of these deceptive reviews. Businesses and service providers need defence against artificially generated competition for the preservation of their reputation, as reviews directly impact product acceptability (He et al., Reference He, Hollenbeck and Prosperpio2022). E-commerce and online travel platforms have a responsibility to ensure fair review channels. Although industry giants like Google and Yelp have implemented fake review detection algorithms, these algorithms are not publicly accessible. Amazon, on the other hand, removes fake reviews over time, but there is typically a delay of around 100 days. However, by the time these reviews are deleted, a considerable number of consumers may have already been exposed to them, causing potential damage.
Genuine reviews provide valuable feedback to service providers and sellers, enabling them to enhance their products or services. Unfortunately, numerous brand marketers and service providers engage in unethical practices by purchasing fake positive reviews from both known and unknown reviewers. They resort to such tactics to give a boost to their new products or artificially enhance the popularity of their brand through inflated positive reviews. In some cases, they may even employ fake negative reviews to maliciously damage the reputation of their competitors. An alternative perspective could argue that choosing not to purchase fake reviews while competitors do, might result in the potential loss of customers. Hence, even ethical players in the industry may be tempted to resort to purchasing fake reviews as a desperate measure to stay competitive in a market. Through their research, He, Hollenbeck, and Prosperpio (He et al., Reference He, Hollenbeck and Prosperpio2022) have established a direct correlation between product reviews, average ratings, prices, and sales rank on Amazon.com, providing concrete evidence of the significant impact that buying fake reviews has on business outcomes. The widespread implementation of fake review detection (FRD) algorithms can bring about several benefits to society, encompassing three key aspects. Firstly, consumers will have access to authentic feedback, enabling them to make informed decisions and develop trust in the products or services they are considering. Secondly, businesses and service providers will be incentivized to improve their offerings to meet consumer expectations. Additionally, they will be deterred from engaging in the purchase of fake reviews, as it could hamper their reputation. Lastly, e-commerce websites that effectively tackle fake reviews will be regarded as trustworthy and fair, leading to increased user engagement and utilization of their platforms.
1.1. Contributions of this paper
Numerous studies have delved into the complex issue of detecting fake reviews, and this paper offers a survey and summary of these research endeavours. By exploring the application of machine learning, deep learning, and swarm intelligence techniques, researchers have aimed to identify the most effective methods for further investigation in fake review detection. However, the existing literature surveys did not encompass recent advancements in fake review detection utilizing new methodologies such as swarm intelligence and transformers, nor did they delve into the motivations behind the exponential growth of fake reviews. Furthermore, earlier surveys failed to provide a thorough examination of identifying features and used datasets. As a result, this paper incorporates relevant publications from esteemed journals and conferences between 2019 and 2023 to shed light on the challenges within this field. The contributions of this paper are as follows:
-
• This review paper provides an up-to-date analysis that encompasses the various state-of-the-art techniques employed in the realm of fake review detection.
-
• This paper conducts a comparative analysis of different methods used for fake review detection, evaluating their efficiency, and summarizing their respective strengths and weaknesses. By systematically comparing these methods, this paper aims to provide insights into their performance and help researchers and practitioners make informed decisions regarding the most effective approaches in this domain.
-
• This review also presents the various features extracted from the existing works and categorizes them as review-centric or reviewer-centric.
-
• This review paper summarizes the various datasets used in the existing research and discusses their limitations.
-
• Challenges and shortcomings in the current research are discovered and future research directions are introduced.
1.2. Methodology
The literature survey in this paper follows a stepwise methodology, as shown in Figure 1. These steps include planning, defining, searching keywords, selecting, and summarizing the results. The detailed explanation is given below:
-
• Planning: The planning phase involved outlining the objective and structure of the review paper. Inclusion and exclusion criteria were devised for selecting relevant studies.
-
• Defining: In this phase, the methodology for the review was clearly articulated. Criteria for selecting the research papers to be included in this study were defined. A timeline with milestones was also created to guide the progress of the review.
-
• Searching: For this research, various search terms such as ‘fake review detection’, ‘deceptive review detection’, and ‘fraudulent reviews’ were employed to gather material for this systematic literature review. The search was performed on Google Scholar, ResearchGate, and ScienceDirect. The search scope was from the year 2019 to 2023 and the primary sources consulted were scholarly journals and conference proceedings.
-
• Selection: A total of 98 papers were selected considering their relevance, novelty, and credibility based on indexing in academic databases. Of these 98, 71 reputed journal articles were identified with fake review text, 9 were old review papers, and 13 articles were from international Scopus-indexed conferences. The rest were articles that provided valuable insights for this review paper.
-
• Summarizing: After a thorough reading of these papers, the strengths and limitations of various techniques and features employed in FRD, were documented and various challenges were identified and listed in the paper.

Figure 1. Research methodology steps.
1.3. Comparison with previous literature surveys
Many literature surveys have been published in the past to comprehensively analyse the methodologies for fake review detection (FRD). But they suffer from one or more limitations. Table 1 concisely summarizes their strength and limitations.
Table 1. Summary of existing literature surveys in fake review detection
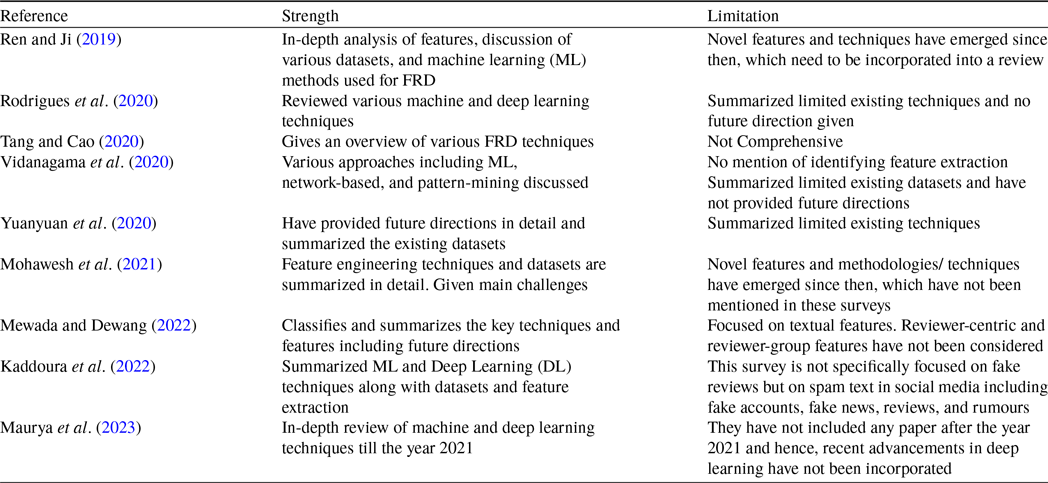
Review papers published between 2019 and 2023, specifically referenced as Ren and Ji (Reference Ren and Ji2019), Rodrigues et al. (Reference Rodrigues, Rodrigues, Gonsalves, Naik, Shetgaonkar and Aswale2020), Tang and Cao (Reference Tang and Cao2020), Wu et al. (Reference Wu, Ngai, Wu and Wu2020), Mohawesh et al. (Reference Mohawesh, Tran, Ollington and Xu2021) (in Table 1) have incorporated various machine learning and deep learning techniques. However, they are old according to the current context and hence these papers do not encompass novel techniques such as swarms or transformers. Vidanagama et al. (Reference Vidanagama, Silva and Karunananda2020), Mewada and Dewang (Reference Mewada and Dewang2022) have given limited emphasis on identifying all the features that are used for labelling a review as fake or real. Kaddoura et al. (Reference Kaddoura, Chandrasekaran, Popescu and Duraisamy2022) has encompassed a broader view of spam text with fake reviews being only a minor component. Hence it is not comprehensive. All of them have analysed the existing datasets. Maurya et al. (Reference Maurya, Singh and Maurya2023) is relatively new and has provided an in-depth analysis of nearly all the techniques including the BERT transformer. However, it still overlooks several recent advancements in the field. These advancements include techniques such as generative pre-trained transformers GPT-3 (Gambetti & Han, Reference Gambetti and Han2023; Shukla et al., Reference Shukla, Agarwal, Mein and Agarwal2023), GPT-4 (Shukla et al., Reference Shukla, Agarwal, Mein and Agarwal2023), opinion mining (Chopra & Dixit, Reference Chopra and Dixit2023), graph neural networks to find associations between reviews, users, and products (Ren et al., Reference Ren, Yuan and Huang2022), fitness-based grey wolf optimization (Shringi et al., Reference Shringi, Sharma and Suthar2022), artificial bee colony-based techniques (Jacob & Rajendran, Reference Jacob and Rajendran2022; Saini et al., Reference Saini, Shringi, Sharma and Sharma2021) and ensemble based on probability (Wu et al., Reference Wu, Liu, Wu and Tan2022). In addition, features such as discourse analysis (Alawadh et al., Reference Alawadh, Alabrah, Meraj and Rauf2023a, b), and the degree of suspicion (Wang et al., Reference Wang, Fong and Law2022) were introduced after the publication of the papers listed in Table 1. Furthermore, Shukla et al. (Reference Shukla, Agarwal, Mein and Agarwal2023) have created a novel labelled physician dataset for FRD. Consequently, our research work has more value when compared to its counterparts in presenting an extensive survey encompassing all current techniques for identifying fraudulent reviews.
The rest of the paper has been organized as follows—Section 2 is the overview of the problem that this paper addresses; including what are fake reviews, what is the need for their detection and how can this problem be solved. Section 3 is the literature review based on the various techniques, identifying features, and the datasets used by the current studies along with their shortcomings. Section 4 concludes this paper followed by the limitations of the existing work and identifying the future challenges in section 5.
2. Overview of the problem
This section focuses on what fake reviews are, the importance of fake review detection, and showcases how machine learning and deep learning techniques are employed to identify fraudulent reviews. The following subsections discuss the above-mentioned issues in order.
2.1. What are fake reviews?
Fake reviews can manifest in both positive and negative forms, with distinct motivations driving their creation. Numerous factors prompt individuals as well as businesses to participate in fake review creation.
Some of the motives for posting fake reviews are:
-
• Financial incentives: Positive fake reviews may be driven by monetary rewards or incentives (Zaman et al., Reference Zaman, Vo-Thanh, Nguyen, Hasan, Akter, Mariani and Hikkerova2023). Reviewers may receive direct payments, gift cards, free products, discounts, or other forms of compensation. Businesses may also employ individuals to post-fake positive reviews for their brand to boost their sales.
-
• Endorsement help: Positive fake reviews may also be posted for personal relationships, such as helping a friend or boosting self-esteem, without buying or using a product (Zaman et al., Reference Zaman, Vo-Thanh, Nguyen, Hasan, Akter, Mariani and Hikkerova2023; Thakur et al., Reference Thakur, Hale and Summey2018).
-
• Reputation management: Certain businesses may opt to create an abundance of positive reviews to counteract negative feedback and effectively oversee their online reputation (Barbado et al., Reference Barbado, Araque and Iglesias2019).
-
• Monetary compensation: On the other hand, posting negative fake reviews may be motivated by monetary compensation (Zaman et al., Reference Zaman, Vo-Thanh, Nguyen, Hasan, Akter, Mariani and Hikkerova2023) or for getting the product free. It might be possible that the brand may have the precedence of offering customers some discount for taking down the negative review.
-
• Means of seeking revenge: Upset customers or individuals who were once associated with a business may resort to posting negative fake reviews as a method of seeking vengeance (Thakur et al., Reference Thakur, Hale and Summey2018).
-
• Competitor sabotage: Competing businesses or individuals might write adverse reviews to tarnish the reputation of their rivals and secure a competitive edge (Barbado et al., Reference Barbado, Araque and Iglesias2019).
-
• Cold start of products or services: Fake reviews are created for a new product, service, or business, where there is little or no genuine user feedback available. The goal is to give the appearance of popularity and positive reception (Tang et al., Reference Tang, Qian and You2020).
-
• Competition: Even those with ethical standards in the industry might be enticed to buy fabricated reviews as a last-ditch effort to maintain competitiveness in the market.
The influx of negative reviews targeting a brand can result in unfair competition and adversely impact its ranking on prominent online platforms like Google, Amazon, and TripAdvisor (Salminen et al., Reference Salminen, Kandpal, Kamel, Jung and Jansen2022). However, the impact of fake reviews varies. Negative fake reviews targeting high-quality products can be particularly detrimental to businesses. Similarly, positive fake reviews associated with low-quality products are harmful to consumers. Moreover, competitors offering average or good quality products may suffer from the impact of fake positive reviews on poor quality products, especially if they lack a substantial number of reviews themselves.
In addition to fake positive and fake negative reviews, there are non-reviews known as disruptive spam reviews that offer no relevant opinions or insights regarding the product at hand (Mohawesh et al., Reference Mohawesh, Tran, Ollington and Xu2021). Jindal and Liu (Reference Jindal and Liu2007) were the first ones to identify fake reviews on Amazon and use a supervised learning technique. They categorized opinions into 3 types—type I as deceptive reviews, type II as brand-specific reviews, and type III as disruptive reviews or non-reviews which can be identified by humans easily. These non-reviews have no opinion. For example—‘Can anyone confirm this?’, ‘The other review is too funny’, ‘Go Eagles Go.’ etc. Hence, FRD systems need not bother with them, as they don’t misguide the consumer.
Yet another classification was done by Salminen et al. (Reference Salminen, Kandpal, Kamel, Jung and Jansen2022). According to them, reviews can be categorized into two types: original reviews (OR) and computer-generated (CG) reviews. This nomenclature is a part of the dataset created by Salminen and is available at https://osf.io/tyue9/. While original reviews have been the primary focus of discussion, computer-generated reviews created automatically by machines are consistently treated as fake. Table 2 shows some examples of OR and CG reviews on a product review dataset.
Table 2. Sample fake reviews from an annotated fake review dataset (weblink: https://osf.io/tyue9/) created by Salminen et al. (Reference Salminen, Kandpal, Kamel, Jung and Jansen2022). It contains 20K fake and 20K real product reviews. ‘OR’ stands for original reviews and ‘CG’ stands for computer-generated reviews

2.2. Why do we need fake review detection?
The problem of fake review detection involves classifying reviews as either genuine or fake. This problem can be addressed using natural language processing (NLP) techniques, employing machine learning (ML) algorithms or graph networks to ascertain the authenticity or falsehood of a given review. Numerous supervised, semi-supervised, and unsupervised algorithms have been utilized to assess the effectiveness of different models using datasets from platforms like Yelp, TripAdvisor, Amazon, and YouTube. However, fraudsters continuously adapt by incorporating new features into their reviews to evade detection by existing approaches (Wu et al., Reference Wu, Ngai, Wu and Wu2020; Wang & Wu, Reference Wang and Wu2020; Mattson et al., Reference Mattson, Bushardt and Artino2021).
Online reviews have become a vital resource for consumers, with a significant level of trust placed in them. According to a survey by Brightlocal in 2019, 76% of consumers trusted online reviews as much as personal recommendations from friends (Kumar & Saroj, Reference Kumar and Saroj2020). This percentage fell to a mere 46% in 2022 (Paget, Reference Paget2023). This shows how buyer confidence in the review system has eroded over the years. The reason is the exponential growth of fake reviews on online platforms.
Fake reviews hamper society in three ways. First, they mislead the consumer by providing inaccurate information about products or services. They undermine the credibility of genuine reviews, and erode their trustworthiness, meaning if fake reviews are in a large percentage, they would undermine the trustworthiness of genuine reviews by mitigating the impact of the genuine reviews on the decision-making process of the buyer. Secondly, they create unfair competition for businesses and decrease business reputation. Businesses that engage in writing or purchasing fake reviews gain an unfair advantage over competitors who rely on genuine feedback. They can tarnish a business’s reputation by providing false information about its products, services, or customer experiences. This can lead potential customers to form inaccurate perceptions, affecting the company’s image. Third, the presence of fake reviews also diminishes trust in e-commerce platforms that struggle to effectively detect and address false reviews. Users may be disappointed if they discover that the reviews on their favourite e-commerce platform are not genuine. The platform’s integrity and credibility suffer leading to a decline in user engagement and loyalty toward that platform.
Despite occasional warnings from government bodies and websites, it remains challenging for ordinary consumers to accurately identify fake reviews. Real-life examples from datasets, such as in Table 2, demonstrate this difficulty. In essence, humans struggle to find the authenticity of a review solely through reading it, necessitating the availability of additional features that can aid in making informed decisions (Filho et al., Reference Filho, Rafael, Barros and Mesquita2023). While studies, such as the analysis of Yelp reviews conducted by Kostromitina et al. (Reference Kostromitina, Keller, Cavusoglu and Beloin2021), shed light on the reasons behind extreme star ratings and customer preferences, they often overlook the presence of fake reviews. The emergence of computer-generated fake reviews further exemplifies the increasing sophistication of technology, making it increasingly difficult for humans to distinguish them from genuine reviews (Floridi & Chiriatti, Reference Floridi and Chiriatti2020). Companies like Amazon have witnessed sudden increases in unverified reviewers with 5-star ratings, which serves as an indicator of fake reviews (Abdulqader et al., Reference Abdulqader, Namoun and Alsaawy2022). Consequently, online platforms such as Amazon, Yelp, and Google must continually update their strategies for detecting and combating fake reviews (Salminen et al., Reference Salminen, Kandpal, Kamel, Jung and Jansen2022). The abundance of fake reviews significantly undermines the credibility of brands or products in the eyes of consumers (Ismagilova et al., Reference Ismagilova, Slade, Rana and Dwivedi2020). Figure 2 depicts the major contributors and effects of fake reviews.

Figure 2. Fake review—motives and effects.
2.3. How is a fake review detected?
Detecting fake reviews using Artificial Intelligence (AI) involves training a model to analyse various features and patterns within reviews to distinguish between genuine and fake ones. Figure 3 depicts the steps of the fake review detection process which are enumerated below:

Figure 3. The process of Fake Review Detection (FRD).
1. Data Collection: A dataset is compiled containing a large number of reviews, including both genuine and fake ones. These reviews may be sourced from various platforms, such as e-commerce websites, social media, or review aggregation sites.
2. Feature Extraction: Relevant features are extracted from the reviews, which may include textual information like the review text, user profile details, timestamps, ratings, and other metadata associated with the review. Additional features can be derived, such as sentiment analysis, length of the review, or language patterns.
3. Data Preprocessing: The collected data is preprocessed to ensure consistency and improve the quality of input. This step involves removing noise, normalizing text (e.g. lowercasing, removing punctuation), handling missing data, and transforming features into a suitable format for AI algorithms.
4. Labelling the Data: Each review in the dataset needs to be labelled as either genuine or fake. This can be done manually by human reviewers who are familiar with fake review patterns or by using existing labelling techniques such as rule-based, algorithm-based filtering, and crowdsourced labelling (Mewada & Dewang, Reference Mewada and Dewang2022). It’s crucial to have a balanced dataset with representative samples of both genuine and fake reviews.
5. Model Training: A model is trained on the labelled dataset using various algorithms like logistic regression, decision trees, random forests, or more advanced techniques like support vector machines (SVMs) or deep learning models such as recurrent neural networks (RNNs) or convolutional neural networks (CNNs). The model learns to recognize patterns and relationships between the features and the review’s authenticity.
6. Model Evaluation: The trained model is evaluated using different evaluation metrics such as accuracy, precision, recall, and F1-score metrics. This step helps assess the model’s performance and determine if further adjustments or improvements are needed.
7. Model Deployment: Once the model demonstrates satisfactory performance, it can be deployed to detect fake reviews in real time. New reviews can be fed into the model, and it will predict authenticity based on the learned patterns from the training phase.
8. Continuous Learning: Fake review patterns can evolve, so it’s important to continuously monitor and update the model to adapt to emerging trends. Feedback from users and human reviewers can be incorporated to refine the model and improve its detection capabilities.
3. Literature review
Many researchers have tried to solve this problem of fake review detection using various artificial intelligence techniques. This section presents a comprehensive literature review of their work. We conducted three distinct types of reviews using the same set of research papers. The first one focused on the techniques utilized, the second examined the features employed, and the third analysed the datasets utilized. These three categorizations are illustrated in Figure 4 and discussed in Sections 3.1, 3.2, and 3.3 respectively. Section 3.1 classifies the studies based on the algorithms or techniques utilized, including machine learning, deep learning, transformers, and swarm intelligence. Section 3.2 analyses the linguistic and behavioural features used to distinguish between fake and genuine reviews. Further, Section 3.3 provides an overview of the datasets used or created in previous research endeavours. Figure 4 presents a diagrammatic representation of the three distinct types of reviews performed in this paper.

Figure 4. Structure of this literature review.
3.1. Review based on techniques
Several algorithms such as rule-based (using a set of rules to classify), graph-based (data representation as nodes and edges), machine learning (ML—learning from data and improving the performance) and deep learning (DL) have been employed to detect fake reviews. This section highlights the most recent algorithms used in this field of research. These algorithms are continually evolving as researchers strive to improve the accuracy and effectiveness of fake review detection techniques.
3.1.1. Machine learning techniques
Machine learning algorithms are computational models that learn patterns and relationships from data without being explicitly programmed. They use statistical techniques to automatically detect patterns, make predictions, or make decisions based on the input data. Some commonly used machine learning algorithms include Decision Trees, Random Forest (RF), Support Vector Machines (SVM), Naïve Bayes (NB), K-Nearest Neighbours (KNN), Logistic Regression (LR), etc. Researchers frequently employ these supervised, semi-supervised, and unsupervised machine learning techniques for fake review detection.
Supervised ML Algorithms
Supervised ML algorithms like SVM, KNN, and LR are among the most commonly used methods in the field. These ML algorithms have been used by Tufail et al. (Reference Tufail, Ashraf, Alsubhi and Aljahdali2022) to detect fake reviews on the Yelp hotel review dataset. Their model proved to be a robust one, but it only focused on supervised models. Similarly, Kumaran et al. (Reference Kumaran, Chowdhary and Sreekavya2021) have used naïve Bayes, Eristic regression, and SVM for detecting fake reviews in a dictionary based on social media keywords and online reviews. Their model uses a very limited feature set of uni-, bigrams, and length of review. Poonguzhali et al. (Reference Poonguzhali, Sowmiya, Surendar and Vasikaran2022) have implemented SVM for fake review detection by creating an online e-commerce interface. Fake reviews are predicted in this system and are not used in the database while recommending a product on this interface. But their method can’t upload more than one review by one user. So, their prevention method is not feasible in large databases.
Along similar lines, Hussain et al. (Reference Hussain, Mirza, Hussain, Iqbal and Memon2020) have given some important behavioural and linguistic pointers to identify fake reviews. For example, the absence of profile data of the reviewer, posting duplicate reviews, short and often grammatically erroneous reviews, groups of reviews with the same timestamp, and excessive use of positive or negative words. However, they have studied the behavioural model and linguistic model separately. The chances of reviews being classified accurately decrease when only one model is used. Hence, Alsubari et al. (Reference Alsubari, Deshmukh, Alqarni, Alsharif, Aldhyani, Alsaade and Khalaf2022) have extracted features such as sentiment score, four grams, number of verbs, nouns, and strong positive or negative words to identify fake reviews. Then they applied four different supervised classifiers—SVM, Naïve Bayes, Random Forest, and Adaptive Boost and compared their accuracy for fraudulent reviews detection. The limitation of this study was fewer extracted features and, their dataset was limited to the hotel domain. According to the findings of Abdulqader et al. (Reference Abdulqader, Namoun and Alsaawy2022), non-verbal features carry greater significance than verbal features, and their combination can enhance the accuracy of detection. However, they have only given a pure theory-based model, which may or may not apply to datasets other than the one used here. Alawadh et al. (Reference Alawadh, Alabrah, Meraj and Rauf2023a) experimented with a benchmark, balanced hotel review dataset and proved that real-time application of deep learning-based, semantically aware text features on web portals can effectively detect fraudulent reviews. However, they have only used a small dataset which doesn’t fully utilize the neural network advantage. A novel ML framework based on M-SMOTE has been created by Kumar et al. (Reference Kumar, Gopal, Shankar and Tan2022) to address the class imbalance problem. The study’s results confirm that combining reviewer-centric features with review-centric features significantly improves the performance of FRD models. A major limitation of this study is that the features extracted from the datasets used in this study, may not be present in other domains. Theuerkauf and Peters (Reference Theuerkauf and Peters2023) employ labelled reviews sourced from the iOS App Store and combine them with two statistical approaches. The simultaneous utilization of multiple feature sets is demonstrated to enhance the detection of fraudulent reviews, but undetected false positives might affect the evaluation metrics.
Semi-supervised ML Algorithms
The supervised machine algorithms use extensive labelling, which is laborious as well as subjective. Hence, the semi-supervised approach uses a pre-defined set of features to train classifiers. In their research, Jing-Yu et al. (Reference Jing-Yu and Ya-Jun2022) employed a semi-supervised approach called AspamGAN (Generative Adversarial Network), which utilizes an attention mechanism in the classifier to detect fake reviews. They have used the data from the TripAdvisor dataset. But, if the data generated by their model is insufficient, it may result in poor accuracy. The earlier version of this method spamGAN given by Stanton and Irissappane (Reference Stanton and Irissappane2020) was a powerful tool that used a simple classifier. But it has the disadvantage that it may lose important information such as context, the focus of the sentence, etc., and thus won’t be able to detect fake information with high probability. AspamGAN has the advantage that it has better performance with limited label data, than SpamGAN.
The semi-supervised approach relies on a pre-defined set of features to train classifiers. Due to the laborious labelling task of the fake review datasets, researchers such as Ligthart et al. (Reference Ligthart, Catal and Tekinerdogan2021) used four semi-supervised techniques in their study. This consisted of self-training (training on the labelled portion of the data), co-training (utilizing additional perspectives of data), Transductive SVM (variation of traditional SVM used in a semi-supervised setting), and label propagation plus spreading (again used for semi-supervised training). They train on one dataset and perform experiments on two more datasets from Yelp. Although their effort alleviates the labelling task, they have not considered metadata or reviewer-based features. In contrast, Wu et al. (Reference Wu, Liu, Wu and Tan2022) implement a semi-supervised probabilistic ensemble that collectively captures the individual behavioural characteristics of reviewers as well as the reviewer network. They use ten behavioural features such as the number of reviews in a day, burstiness, popularity of product that the user has reviewed, average distance between a user and other users, etc. They assume that the reviewer network presents homophily.
Unsupervised ML Algorithms
As mentioned earlier, detecting fake reviews accurately is highly improbable by humans. Hence, the availability of labelled data is less. Unsupervised algorithms have a good scope here. The work done by Mothukuri et al. (Reference Mothukuri, Aasritha, Maramella, Pokala and Perumalla2022) creates clusters using the extracted features. They perform K-means clustering, GMM Full covariance clustering, and GMM Diagonal covariance unsupervised techniques to detect fake reviews taken from the café dataset of Yelp. They found that K-means shows the highest accuracy among the three. Many other unsupervised algorithms could have been explored in the aforementioned work, and different domains.
There is a major problem of concept drift (Mohawesh et al., Reference Mohawesh, Tran, Ollington and Xu2021; Tommasel & Godoy, Reference Tommasel and Godoy2019) while using machine learning techniques. Concept drift refers to the adaptation of fake reviewers over some time. They start writing in such a way that their writing skills are similar to real reviews and hence, can’t be detected by the detection algorithms in place. For this, Wang et al. (Reference Wang, Fong and Law2022) have incorporated the temporal patterns of reviews. They added a degree of suspicion for FRD by analysing 3D time series, the number of reviews, and the information entropy. Their framework seems comprehensive, but they have only used supervised algorithms. One major drawback of machine learning algorithms is that they require the extraction of features manually and a huge utilization of computational resources (Kaddoura et al., Reference Kaddoura, Chandrasekaran, Popescu and Duraisamy2022).
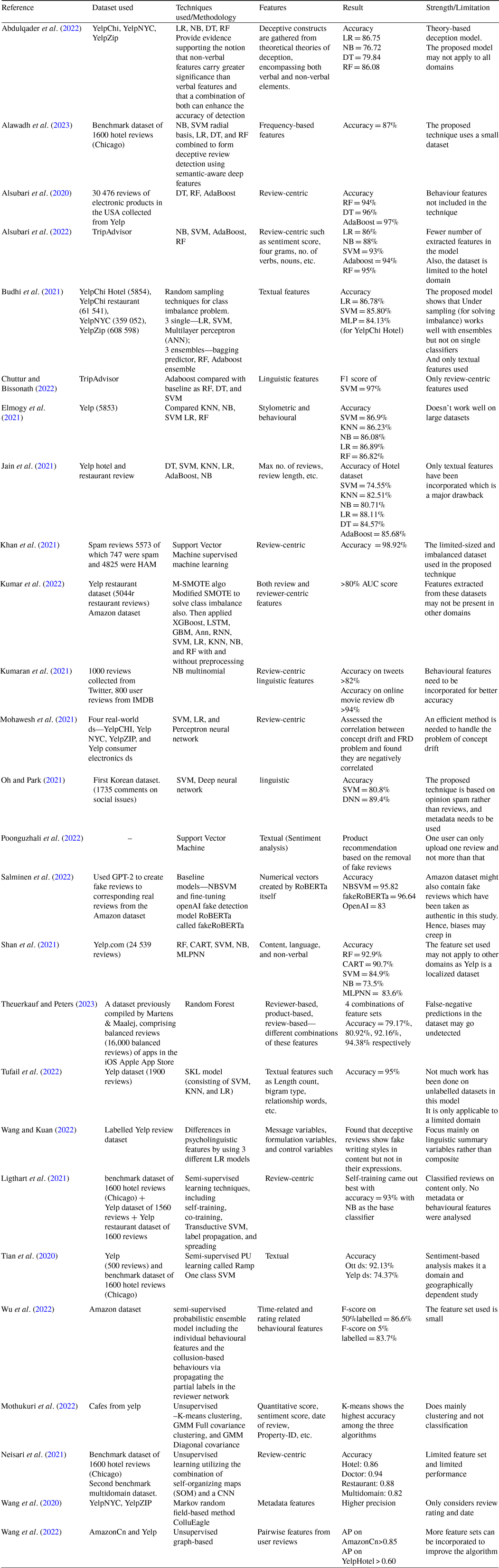
Many supervised, semi-supervised and unsupervised algorithms have been used to detect fake reviews, to date. These traditional machine learning algorithms perform adequately on small datasets and are highly valued by researchers. In addition to this, they are simpler to implement and computationally cheap but, their performance deteriorates on larger datasets as compared to deep learning models. Also, their solution doesn’t sustain over time and the problem of concept drift arises. In addition to the above shortcomings, they also require manual feature extraction and huge computational resources. Hence, deep learning algorithms were explored by researchers and their studies are discussed next. Table 3 is a summarized representation of the traditional machine learning algorithms used in FRD research work.
Table 3. Machine learning techniques used for FRD
3.1.2. Deep learning techniques
Several deep learning algorithms are suitable for fraudulent review identification. These algorithms leverage the power of deep neural networks to automatically learn features and structural patterns from review data. Some commonly used deep learning algorithms for FRD are Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Transformer-based Models, Deep Belief Networks (DBN) and Siamese Neural Networks. The researchers Alsubari et al. (Reference Alsubari, Deshmukh, Al-Adhaileh, Alsaade and Aldhyani2021) have used four datasets including hotels, restaurants, Yelp, and Amazon to perform convolutional and max-pooling layers of the CNN to reduce dimensions and extract features. They have done cross-domain analysis, but the performance of this model decreases on a single-domain dataset. Jing-Yu and Ya-Jun (Reference Jing-Yu and Ya-Jun2022) utilized a semi-supervised method called AspamGAN (Generative Adversarial Network) that incorporates an attention mechanism to detect fake reviews in their assembled, partially labelled dataset. Stanton and Irissappane (Reference Stanton and Irissappane2020) previously introduced the SpamGAN model, but AspamGAN addresses some of its limitations and performs better with limited labelled data.
The work done by Basyar et al. (Reference Basyar, Adiwijaya and Murdiyansah2020) built a Long-short-term memory (LSTM) model as well as a Gated Recurrent Unit (GRU) model to detect e-mail spam. The former outperformed the latter, but the result was not significant, and they only used a training dataset due to time constraints. The authors Liu et al. (Reference Liu, Wang, Shi and Li2022) give a layered attention network employing two stratums to capture semantic information. The authors then integrate a convolutional structure and Bi-LSTM to extract crucial semantics resulting in superior performance compared to other algorithms. Their limitation is the use of a supervised algorithm and a smaller number of extracted features. The work done by Crawford et al. (Reference Crawford, Khoshgoftaar, Prusa, Richter and Al Najada2021) uses inductive transfer learning to detect hotel review spam. However, they have limited their work to a single domain. As a different approach, Sadiq et al. (Reference Sadiq, Umer, Ullah, Mirjalili, Rupapara and Nappi2021) train deep learning algorithms to predict the star ratings that will match the review. But they don’t predict whether the review is fake or real. Salminen et al. (Reference Salminen, Kandpal, Kamel, Jung and Jansen2022) fine-tuned the RoBERTa model, which is an optimized model of the BERT transformer, and called it fakeRoBERTa. They also create a fake review dataset with the help language generation model GPT-2. They experiment with fakeRoBERTa on their created dataset and conclude that AI algorithms can outperform humans in detecting fake reviews. However, datasets and techniques need to keep evolving to outmanoeuvre the concept drift problem.
Recently, language generation models such as BERT, and GPT-3 have also been used for the classification of fake reviews. Gambetti and Qiwei (Gambetti & Han, Reference Gambetti and Han2023) used the OpenAI GPT-3 model to generate a fake review dataset and then fine-tuned a pre-trained GPT-Neo model for FRD. They have also correlated fake reviews of a restaurant with customer visits. Shukla et al. (Reference Shukla, Agarwal, Mein and Agarwal2023) have used the latest language transformer model GPT-3, on a novel, annotated dataset of physician reviews. Then they compare the results with LR, XG, RF, and SVM and find that GPT-3 is superior to all in terms of accuracy. However, the major disadvantage of using GPT-3 is that it can’t be fine-tuned to train datasets larger than 10 million characters, and the whole dataset can’t be tested at a go.
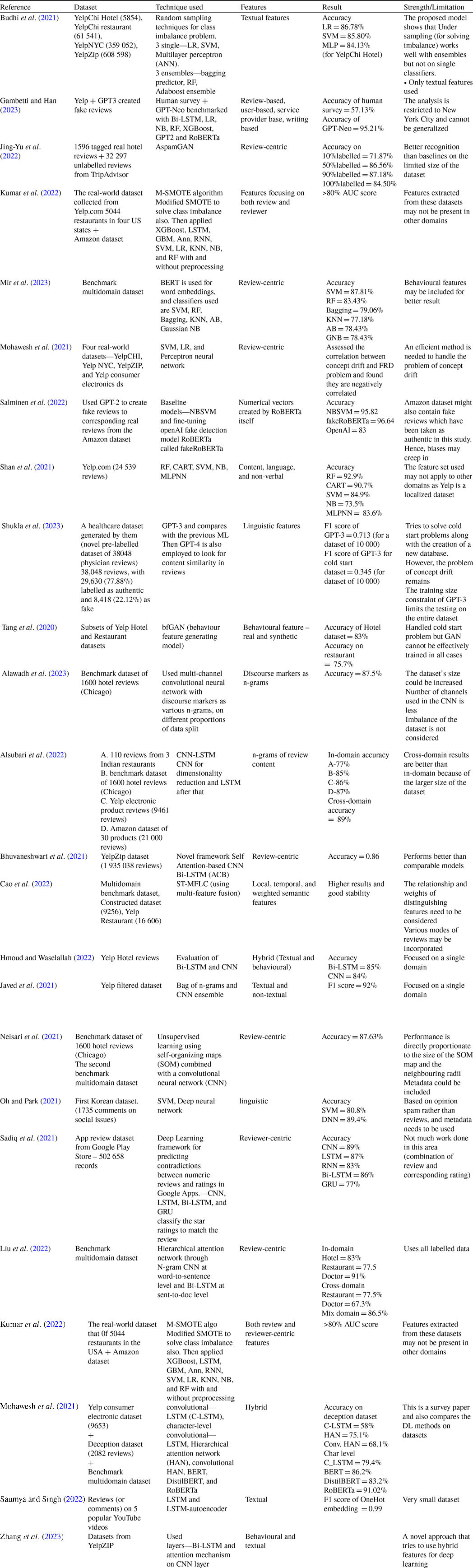
It is observed that deep learning algorithms outperform traditional machine learning models when applied to large-scale datasets. However deep learning models are computationally expensive. In addition to the above, deep learning models are susceptible to overfitting and thus, they can’t be used for smaller data. Some transformer-based models such as GPT-3 are uninterpretable. They operate as a black box and have higher computational requirements. Table 4 shows a summary of deep learning models used in FRD so far.
Table 4. Summary of Deep Learning models used for FRD
3.1.3. Graph-based techniques
Graph-based techniques in machine learning refer to approaches that leverage graph structures or networks to represent and analyse data. In these techniques, data elements are represented as nodes, while relationships or connections between the elements are represented as edges or links in the graph. Graph Neural Networks (GNNs), Graph Convolutional Networks (GCNs), and Graph Embeddings such as node2vec, GraphSAGE, and DeepWalk are some commonly used graph-based techniques in machine learning. They can capture complex dependencies and make informed predictions.
The authors Ren et al. (Reference Ren, Yuan and Huang2022) use graph neural networks to find associations between reviews, users, and products. This is based on the premise that there is a dependency between the user and product, the reviewer and the time, ratings, etc. Then they introduce the idea of suspicious values based on the TrustRank (Gyongyi et al., Reference Gyongyi, Garcia-Molina and Pederson2004) method. Their model finds more fake reviews, but the accuracy has not increased significantly. Manaskasemsak et al. (Reference Manaskasemsak, Tantisuwankul and Rungsawang2023) have used two novel graph-partitioning algorithms BeGP and BeGPX for FRD. They use the snowball effect to capture all fraudulent users. In the extended version of BeGPX, they also capture the semantic and emotional content of text.
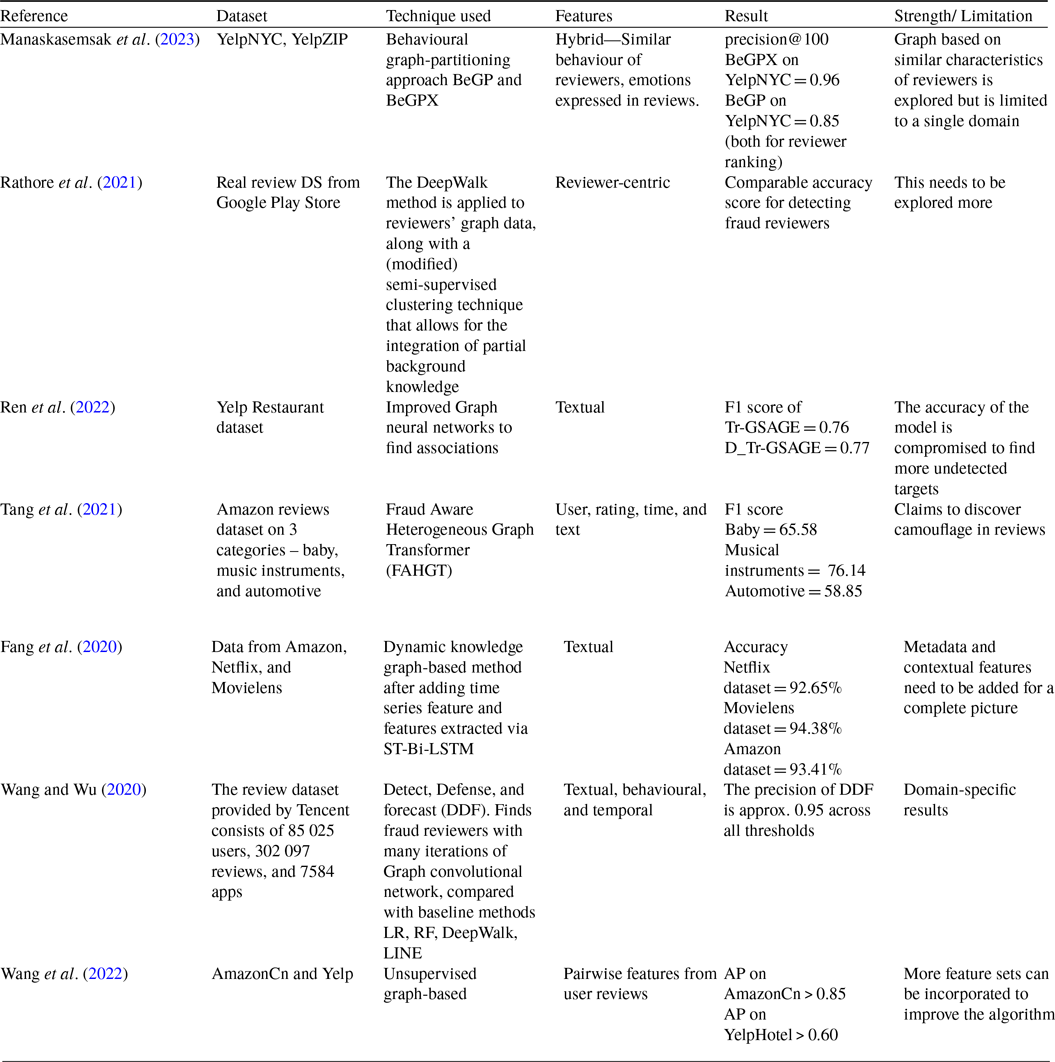
Although graph-based techniques have several advantages, they suffer from scalability and data sparsity issues. As the datasets grow, the size of the graph and in turn, computational complexity grows exponentially. If the labelled data is sparse, as is in the case of most fake review datasets, it can result in weaker signals in graphs. Further, interpreting the results of graph-based techniques is a challenge in itself. Table 5, given below, summarizes the graph-based models used for fake review detection in the recent past.
Table 5. Summary of graph-based techniques used for FR
3.1.4. Swarm intelligence techniques
Swarm techniques for fake review detection draw inspiration from the behaviour of swarms in nature, where collective intelligence emerges from the interactions of simple individuals. These techniques leverage swarm intelligence principles to detect fake reviews by considering the collective behaviour of reviewers or reviews within a dataset. Ant Colony Optimization (ACO), Particle Swarm Optimization (PSO), Bee Algorithm (BA), and Firefly Algorithm (FA) are a few examples of swarm techniques used in fake review detection. The work done by Shringi et al. (Reference Shringi, Sharma and Suthar2022) uses the Fitness-based Grey Wolf Optimization (FGWOK) technique and k-means clustering to classify fake and authentic reviews. The datasets used are synthetic spam review (from the Database and Information System Lab, University of Illinois, TripAdvisor dataset), movie review dataset from IMDB, and Yelp review dataset. After comparing their results with various metaheuristic clustering methods, such as genetic algorithm (GA), particle swarm optimization (PSO), cuckoo search (CS), and artificial bee colony clustering, they found that their algorithm performs better than the current ways. However, they have not considered the feature interactions and could have used better optimizers. Similarly, Jacob and Rajendran (Reference Jacob and Rajendran2022) give a Fuzzy Artificial Bee colony-based CNN-LSTM approach for fake review classification. After data preprocessing, they use the chi-squared technique for feature extraction and selection and CNN-LSTM-FABC is applied, which is found to outperform the earlier approaches. Here also, contextual features are not considered, which may give higher accuracy when combined with the extracted features. Previously, Saini et al. (Reference Saini, Shringi, Sharma and Sharma2021) used k-means artificial bee colony for feature selection after data preprocessing. Then they optimized clusters using ABC with k-means on three datasets namely Synthetic Spam (containing 478 total reviews), Yelp (containing 4952 reviews), and Movie (a subset of IMDB containing 8544 reviews). Earlier Pandey and Rajpoot (Reference Pandey and Rajpoot2019) used a combination of cuckoo search and Fermat spiral to identify spam reviews. It is compared to six metaheuristics clustering methods and was found to be better than these six. But still, the accuracy could have been improved further.
Thus, swarm intelligence approaches give an optimized result for the fake review detection problem, but this area has not been explored fully to date. Many bio-inspired techniques can be utilized and investigated. Table 6 summarizes the few swarm techniques employed for FRD so far.
Table 6. Summary of swarm techniques for FRD

3.1.5. Other techniques
In addition to machine learning techniques, several other approaches and techniques can be used for fake review detection. Some commonly used methods are linguistic analysis, metadata analysis, reviewer behaviour analysis, etc. These identifying features will be discussed in detail in Section 3.2. Hussain et al. (Reference Hussain, Mirza, Hussain, Iqbal and Memon2020) focused on identifying behavioural and linguistic indicators of fake reviews. Filho et al. (Reference Filho, Rafael, Barros and Mesquita2023) experimented on five theoretical studies.
At first, they implemented persuasion knowledge acquisition in which potential Customers can gain insights into the distinguishing features that set apart counterfeit reviews from authentic ones. Alternatively, in the second study, they are just told about which reviews are fake. Their research shows, that persons who know about the linguistic features of fake reviews are better able to detect them. But, due to the structure and vocabulary of fake and real reviews being very similar, their premise seems to fail in real life. The dichotomy of fake and real fails in real-life settings. Hlee et al. (2021) collected 4450 reviews from Yelp and showed that online reviews of new restaurants are manipulated. They elucidated the correlation between extreme ratings and counterfeit reviews. But again, they have just given a theoretical model. Li et al. (Reference Li, Wang, Zhang and Niu2021) use a reviewer grouping method. This is in the context of data mining; the objective is to categorize reviews from reviewers into distinct groups. These groups then contribute to the creation of innovative grouping models that can effectively identify both positive and negative deceptive reviews. In their study, Wang et al. (Reference Wang, Fong and Law2022) investigate the significance of emotional and cognitive cues in detecting Fake Review Deception. Upon experimentation, they found that fake reviews require deliberation at the writer’s end. Hence, emotional, and cognitive cues both play a significant role together. But writing real reviews is stress-free and hence cognitive cues are mostly absent there. However, their experiment is limited to the hospitality domain only and it is yet to be seen whether the results apply to other domains also. Table 7 shows theoretical models and other metadata-based techniques used for deceptive review identification.
Table 7. Summary of techniques used for FRD, other than ML, DL, Graph-based or bio-inspired
It is important to highlight that these techniques have the potential to be employed either individually or in conjunction with machine learning approaches, thereby enhancing the precision and dependability of fake review detection systems. Each technique has its strengths and limitations, and a holistic approach combining multiple methods often yields more robust results. Figure 5 depicts the number of publications year-wise, under various techniques. The analysis of this graph indicates that the trend in the number of publications employing purely traditional machine learning has seen a steep decline as compared to publications employing deep learning. The reason may be the advent of language generator transformers like BERT and GPT-3.

Figure 5. Distribution of various AI techniques for FRD. (The decline in the number for 2023 is because publications are taken only up to May 2023).
3.2. Review based on features
Up until now, the majority of the research has concentrated on either the textual attributes of the reviews or the behavioural characteristics of the reviewers. Hence, the former is known as the review-centric model and the latter is known as the reviewer-centric model. Jindal and Liu (Reference Jindal and Liu2007) categorized features based on information associated with a review: reviewer-centric, and review-centric. Wang et al. (Reference Wang, Fong and Law2022) have given a comprehensive fake review detection framework that combines both these models. They use Yelp and Amazon public datasets to find the effectiveness of their model. However, they have only used supervised learning algorithms. Earlier, Budhi et al. (Reference Budhi, Chiong, Wang and Dhakal2021) found 133 unique features that encompass a combination of textual and behavioural elements for detecting fake reviews through the utilization of ML techniques. Their approach was limited to balanced datasets only while in real life most of the datasets are imbalanced and the number of fake and real reviews is different. Furthermore, they employed two sampling methods to enhance the accuracy of balanced datasets.
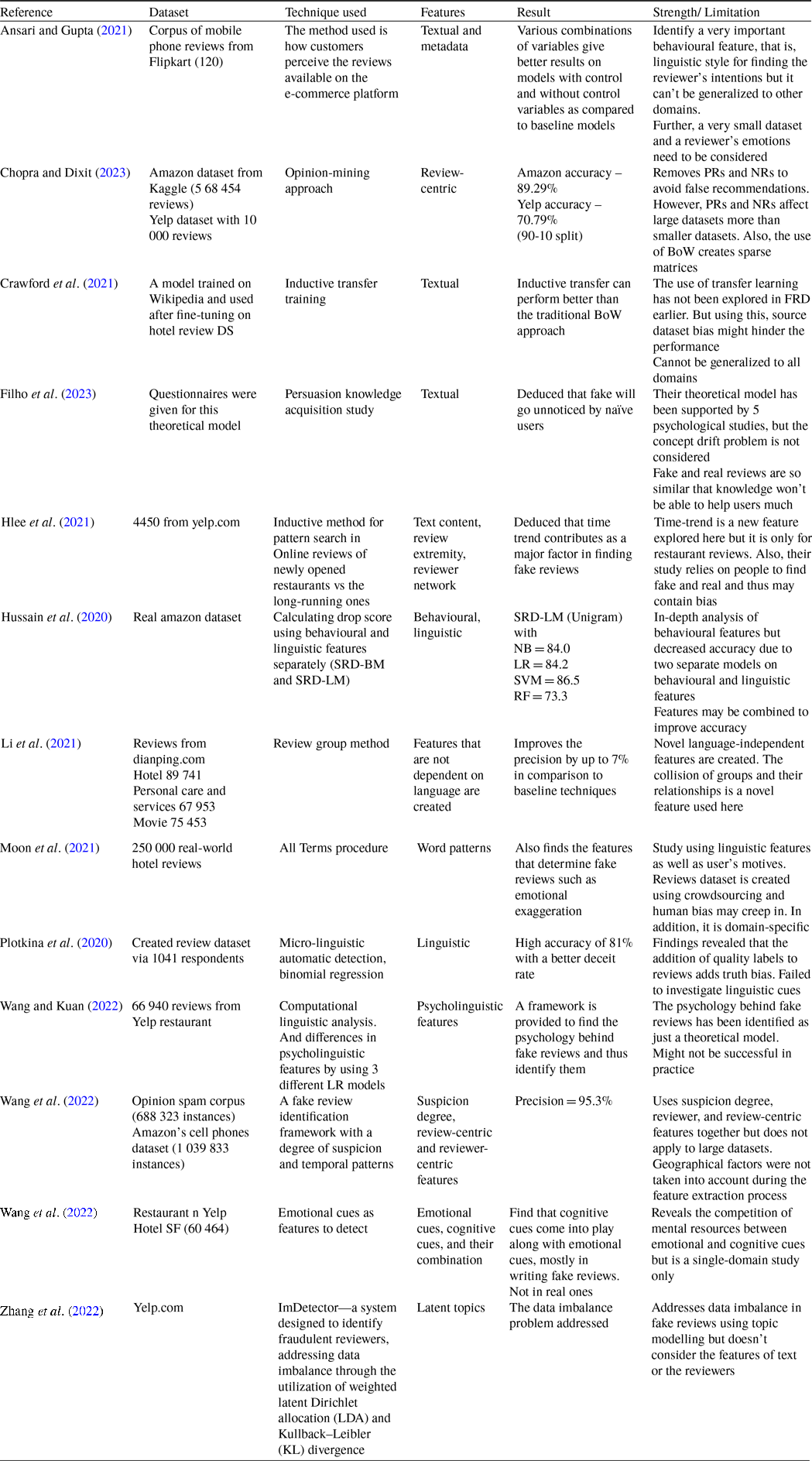
Mattson et al. (Reference Mattson, Bushardt and Artino2021) introduce a feature engineering approach known as the M-SMOTE (modified-synthetic minority over-sampling technique) model, which combines review- and reviewer-centric features for their analysis. In addition to incorporating the M-SMOTE model, they also aimed to address the issue of class imbalance in their study. They extract six reviewer-centric features namely rating entropy, review gap, review count, rating deviation, time of review, and user tenure. They also identified six review-centric features namely review length, word density, part-of-speech ratio, sentiment polarity ratio, SpamHitScore, and sentiment probability. A combination of both these models resulted in higher accuracy. However, their work is limited to the above-mentioned features only, which may not apply to other datasets. Alawadh et al. (Reference Alawadh, Alabrah, Meraj and Rauf2023a) perform discourse analysis on the reviews, based on the premise that factual reviews have strong coherence, whereas fraudulent reviews lack structure and semantics. However, their dataset is limited to a smaller review base as compared to the deep learning ones. In their other work, Alawadh et al. (Reference Alawadh, Alabarah, Meraj and Rauf2023b) have given a discourse analysis-based credibility check scheme, which gives higher performance. They have used the convolutional neural network with discourse markers as various n-grams, on different proportions of data split. However, they have used a small, balanced dataset, whose size could be increased to produce a scalable solution. Similarly, Chopra and Dixit (Reference Chopra and Dixit2023) investigate Push ratings (PRs) and nuke ratings (NRs) in fake reviews. Push ratings are higher ratings and nuke are lower ratings. They utilize opinion-mining techniques to determine the authenticity of the reviews. But they have used bag-of-words for preprocessing which results in a sparse matrix, which may lead to computational inefficiency. Tables 3, 4, 5 and 7 show the reviews used by the researchers in the past.
3.2.1. Reviewer-centric models
This model focuses on the atypical and suspicious behaviour of the reviewer as well as identifying the connections between a group of reviewers. These are non-linguistic characteristics of the reviews.
Tufail et al. (Reference Tufail, Ashraf, Alsubhi and Aljahdali2022) have extracted the behavioural features of the user. For example, review time, writing style, relationship words, grammatical errors, punctuation, etc. These features may contribute to the classification of the review. This robust model only uses supervised techniques which may not give apt results for big datasets. Alsubari et al. (Reference Alsubari, Deshmukh, Alqarni, Alsharif, Aldhyani, Alsaade and Khalaf2022) ponder upon the fact that 90% of genuine reviewers usually write one review a day, based on the product they bought or the service they used. But 70% of fraudsters may write up to 5 reviews a day. However, their dataset is limited to the hotel domain. Hence, the number of reviews per day is an important characteristic of detecting fake reviews (Heydari et al., Reference Heydari, Tavakoli, Salim and Heydari2015). However, the number of review features may not apply to other domains. According to Sadiq et al. (Reference Sadiq, Umer, Ullah, Mirjalili, Rupapara and Nappi2021), the reviewers tend to give a higher proportion of positive fake reviews compared to the proportion of negative fake reviews. But they also have limited their work to a single domain. The rating of the fake reviewer tends to be different from the ratings of the genuine reviewer. This can also help in identifying fraudsters (Ott et al., Reference Ott, Cardie and Hancock2013). The research conducted by Wang et al. (Reference Wang, Fong and Law2022) encompasses the analysis of the non-verbal behaviour of the reviewer. They say that usually, the fake reviewer attempts to mislead customers by posting reviews as early as possible. They either give maximum rating stars or minimum, depending upon the fake positive or negative review. This may be attributed to the algorithms of e-commerce engines that detect fake reviews after a certain period of days and then only remove them. But the damage has already been done till then. The reviewer’s credibility can also be assessed by determining the proportion of the reviewer’s friends and followers. In addition to these characteristics, users with longer profile timelines would be more authentic than the users who have recently created their profiles. Even with a limited number of non-verbal features employed, the computational cost is less as compared to review-centric feature selection. But theirs is a purely theoretical model and its practical implementation is yet to be seen.
Another view of the authors Sadiq et al. (Reference Sadiq, Umer, Ullah, Mirjalili, Rupapara and Nappi2021) says that the difference between the ratings given in a review and the emotional intensity of the review is also a giveaway. But they don’t predict whether the review is fake or real. Hlee et al. (2021) collected 4450 reviews from Yelp and showed that online reviews of new restaurants are manipulated. They elucidated the correlation between extreme ratings and fake reviews. But again, they have just given a theoretical model. Tang et al. (Reference Tang, Qian and You2020) used a generative adversarial network (GAN) trained model to identify six behaviour features including text, rating, and attribute features.
Thus, some of the important reviewer-centric features can be quantity, user profile, timespan, source credibility, non-immediacy, etc. The fake review detection algorithms show good performance with the incorporation of these non-textual features. This means analysing reviews using the behaviour of the review’s author or creator. But which behavioural features are to be selected for the detection problem, is a big task.
3.2.2. Review-centric model
This kind of fake review detection primarily centres on the textual content of the reviews. Research has indicated that there are substantial linguistic distinctions between authentic and fake reviews, which prove instrumental in their identification. These features may include micro-linguistic content or semantic content such as product characteristics.
Text features such as the count of nouns, verbs, and adjectives, along with the usage of strong positive and negative words in the review, have been recognized as potential indicators of a fake review (Jindal & Liu, Reference Jindal and Liu2007). The writing style of the reviewer can have lexical characters such as the number of characters and their proportion to uppercase letters, numeric characters, to the rate of spaces or tabs, called stylometric features can help in detecting fake reviews. However, they used the common features, and no new features were introduced for fake review detection. Jain et al. (Shan et al., Reference Shan, Zhou and Zhang2021), employed Linguistic Inquiry and Word Count (LIWC), which is considered a deep linguistic feature. Its output such as emotions, self-reference, social words, overall cognitive words, etc. can be incorporated to find the fake review. Moon et al. (Reference Moon, Kim and Lacobucci2021) obtain fake and authentic reviews of hotels via a survey and determine that features such as lack of details, temporal bias, and hyperbole are all part of fraudulent reviews. However, their work is based on surveys and is limited to just the hotel domain. Kumaran et al. (Reference Kumaran, Chowdhary and Sreekavya2021) have used language features like unigrams and their frequency, and bigrams and their frequency and length of reviews but conclude that behavioural features need to be added to accurately identify the reviews. However, their work focuses more on sentiment classification as positive or negative. The work done by Abdulqader et al. (Reference Abdulqader, Namoun and Alsaawy2022) finds that the short length of the online review, review replication, Term frequency-inverse document frequency (TF-IDF), cohesion and coherence measures, and stylometric features are some of the telltale signs of a spam reviewer. Along with these, LIWC such as less usage of personal pronouns (less use of ‘I’,, ‘we’ etc.), less information about time and location, and strong use of positive as well as negative words, all point to fake reviewers. However, their work is based on theory, which may or may not apply to other datasets. Text similarity is widely used as an indication of fake reviews because spammers tend to copy the reviews to save effort (Hussain et al., Reference Hussain, Mirza, Hussain, Iqbal and Memon2020). But their work has studied textual and behavioural models separately which decreases the accuracy of fake review detection. The authors Wang and Kuan (Reference Wang and Kuan2022) went a step further and divided the features into message level (review length and psychological cues), formulation level (readability and linguistic variables), and control level (rating extremity, review age, etc.). Although the dataset they used was Yelp (till 2012), their idea was to understand the process human brains undergo to formulate a message. Their limitation was that they focused on single domain and linguistic summary variables rather than composite variables.
Although review-centric features have been used extensively by researchers, it was found that they alone, or reviewer-centric features alone, are not sufficient to determine fake reviews accurately. Thus, a combination of important features of both should be incorporated to make any fake review detection algorithm outperform others. Table 8 shows some examples of the two types of identifying features used in the existing research. Figure 6 depicts the distribution of publications according to features. From the graph in this figure, it is observed that researchers have predominantly investigated the review-centric features over the reviewer-centric ones. This preference may stem from the fact that textual features are easier to identify as compared to behavioural or network-related ones. Additionally, hybrid (combination of review and reviewer-centric) and other features such as discourse and metadata (depicted in Table 8), are gaining popularity due to their enhanced performance in detecting fake reviews.
Table 8. Summary of identifying features in each publication

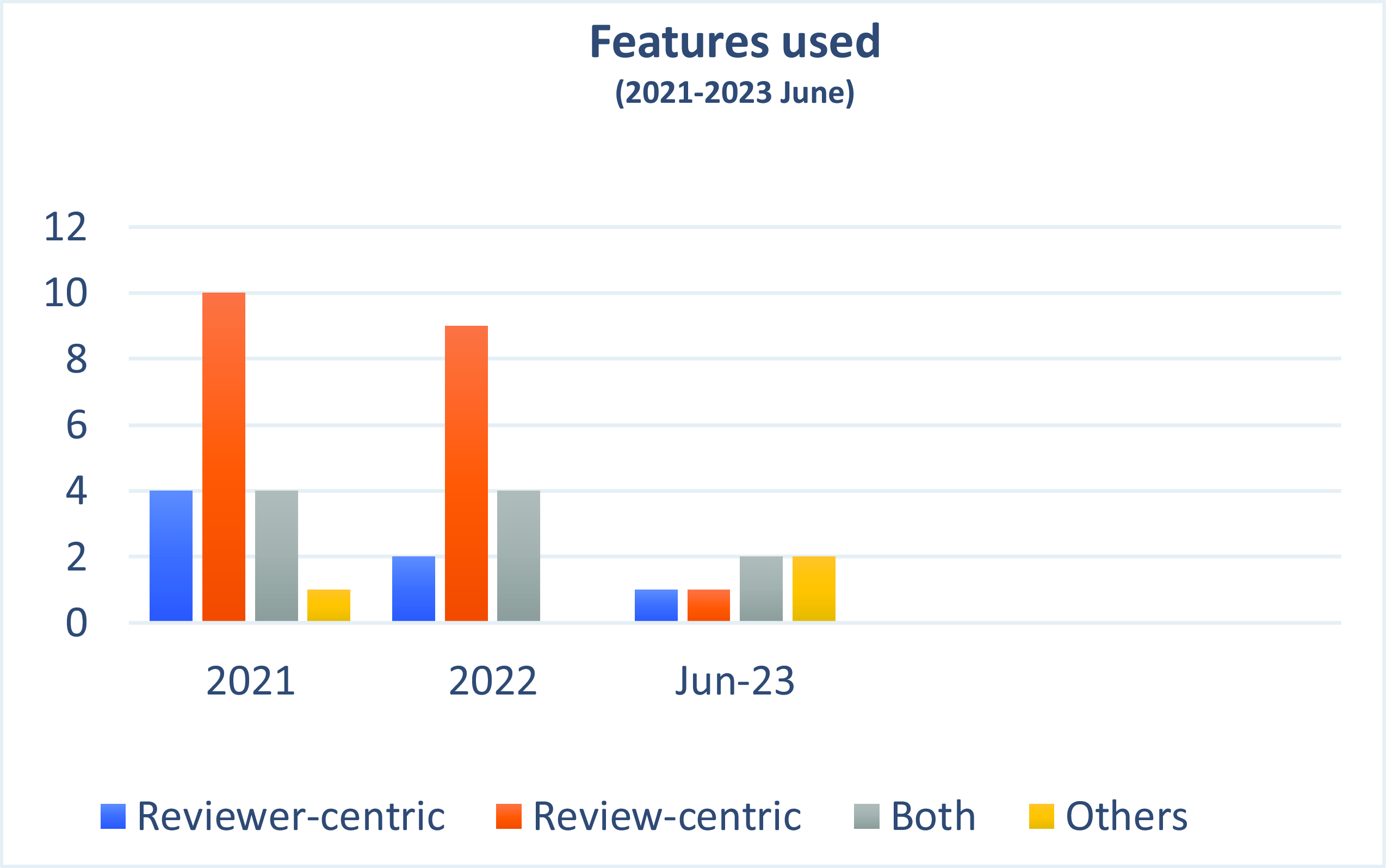
Figure 6. Number of publications in FRD according to features.
3.3. Review based on datasets
Fake review detection involves the use of various datasets to train and evaluate models. Here are some commonly used datasets in fake review detection research:
-
1. Yelp Dataset: The Yelp dataset contains a large collection of reviews from the Yelp platform, including both genuine and fake reviews. It is widely used for training and evaluating fake review detection models.
-
2. Amazon Product Reviews Dataset: This dataset comprises product reviews from the Amazon platform and is frequently utilized for fake review detection tasks. It covers diverse product categories and contains both authentic and deceptive reviews.
-
3. TripAdvisor Dataset: The TripAdvisor dataset consists of reviews from popular travel websites, encompassing different destinations, hotels, and attractions. It serves as a valuable resource for fake review detection research in the travel domain.
-
4. IMDB Movie Reviews Dataset: The IMDB dataset includes a vast collection of movie reviews. It has been used in fake review detection studies to identify deceptive or fraudulent reviews among the genuine ones.
-
5. Deceptive Opinion Spam Dataset: This dataset specifically focuses on deceptive opinion spam, which involves generating fake reviews to manipulate public perception. It contains hotel reviews labelled as either truthful or deceptive, making it suitable for studying fake review detection.
-
6. Yelp Challenge Dataset: The Yelp Challenge dataset is a subset of the Yelp dataset and was released as part of a research competition. It consists of reviews and associated metadata, providing researchers with a resource to explore fake review detection techniques.
These datasets serve as valuable resources for studying and developing fake review detection models. This facilitates researchers in training and evaluating their algorithms using a wide range of diverse and realistic data. A descriptive summary of the major datasets used in existing research is given in Table 9.
Table 9. Summary of existing datasets used by various research

This section examined multiple review datasets encompassing various domains such as products, stores, hotels, restaurants, and movies. This analysis is based on a thorough review of more than 80 research papers over a period spanning two and a half years. Figure 7 visualizes the distribution of datasets used across publications since 2021. These datasets vary in terms of size and composition. Figure 7 clearly shows the imbalance in the domains used for FRD. While the hospitality domain has been extensively utilized due to the availability of benchmark and labelled datasets, other domains such as healthcare and education have been largely overlooked. Annotated datasets in these domains are scarce, if not non-existent. For instance, the Gold standard dataset by Ott et al. (Reference Ott, Cardie and Hancock2013) consists of a collection of 400 genuine five-star reviews sourced from 20 hotels located in the Chicago area on TripAdvisor. Furthermore, the authors acquired 400 fabricated positive (deceptive) reviews for the identical set of 20 hotels from Amazon Mechanical Turk (AMT) to meet the requirements of their study.

Figure 7. Domain distribution in FRD.
By employing a word bag of features approach, they reported achieving an accuracy of 89.6% for their classification task. Mukherjee et al. (Reference Mukherjee, Venkataraman, Liu and Glance2013) conducted an analysis stating that reviews obtained from Amazon Mechanical Turk (AMT) are not truly fake as they lack adequate domain knowledge and do not exhibit a similar psychological mindset as expert authors who write genuine deceptive reviews. To address this issue, they utilized deceptive as well as truthful reviews from Yelp’s real-life data, specifically the YelpChi dataset, which consisted of reviews for well-known restaurants and hotels in the Chicago area. By employing n-gram features, they achieved an accuracy of 67.8%. To further enhance accuracy, they put forward a collection of behavioural features related to the users and their reviews. Li et al. (Reference Li, Chen, Liu, Wei and Shao2014) developed a benchmark dataset that spans multiple domains, including Restaurants, Hotel, and Doctors. This dataset encompasses three distinct types of opinions: authentic customer reviews (submitted by actual customers), domain-expert-generated fake opinion spam (fabricated by employees or experts), and crowdsourced fake reviews (produced by Turkers, i.e. workers on Amazon Mechanical Turk). Rayana and Akoglu (Reference Rayana and Akoglu2015) utilized three datasets, namely YelpChi, YelpNYC, and YelpZip, which were collected from Yelp.com. The YelpChi dataset consists of 67,395 reviews for 201 restaurants and hotels located in the Chicago area. The YelpNYC dataset contains 359 052 reviews for 923 restaurants situated in New York City. The YelpZip dataset comprises 608 598 reviews for 5044 restaurants located in various zip codes within the states of NY, NJ, VT, CT, and PA. To identify deceptive opinion spam and fraudulent reviewers, the researchers introduced a user-product bipartite graph model, specifically FraudEagle (unsupervised) and SpEagle (semi-supervised) approaches. These models leverage the graph structure to analyse patterns and detect potential instances of deceptive behaviour.
There are some limitations of these datasets. For instance, most of the datasets have been curated via crawling. Thus, they contain only limited features. Sometimes only review-centric features are there. This creates a big challenge for a benchmark dataset having multiple features. Secondly, Concept drift over time also poses a problem as the spam features also tend to drift with changes in fraud writings. Thirdly, there is a need for new datasets in languages other than English too. Korean, Arabic, and Chinese datasets have been created but they are small, and their labelling may be biased. Lastly, the problem of imbalance is a common issue with FRD. Class distribution is not uniform between fake and real. Thus, all researchers must put extra time into first balancing the dataset and then experimenting with it. Some work has been done by sampling techniques or ensembles in this area, but their performance is still not up to the mark.
4. Conclusion
The identification of deceptive reviews has emerged as a crucial concern for both researchers and unsuspecting consumers. To bridge the gap between earlier surveys and current research, this paper focuses on the research done between 2019 to 2023 and presents an updated overview of the various techniques, identifying features, and datasets employed in fake review detection. This paper conducted a comprehensive literature review in the field of Fake Review Detection (FRD) by examining three key aspects: the employed techniques, identifying features, and the datasets involved in the existing body of work.
In the first aspect, involving the FRD techniques, it was seen that the traditional machine learning methods depend on pre-defined features and require significant effort in feature engineering. Although these techniques are easy to implement and often perform well with small datasets, they face challenges when dealing with large datasets. Their effectiveness is limited due to a shortage of sufficient labelled data for input, which restricts the scope of their application. In contrast, deep learning models have the advantage of unsupervised learning of features from data, thus alleviating the need for manual feature engineering. While these models tend to perform better with large datasets, they may require more computational resources for training and can lead to overfitting on smaller datasets. Along with this, some language generation models used for classification, such as GPT-3, lack interpretability making it complex and difficult to comprehend how they arrive at their predictions. Further, it was found that swarm-based intelligence techniques yield optimized results, although these approaches have not been fully explored in the current research. In addition to the above, graph-based techniques in FRD leverage the relationships and structure within a graph representation to identify fake reviews as well as reviewers by detecting anomalies, identifying communities, or incorporating graph-based features into machine learning models.
The second categorization of this literature review focused on examining the identifying features. Analysis of these features reveals a decline in the popularity of review-centric features over time and hybrid features involving both textual and behavioural characteristics have emerged as efficient for FRD. However, the detection techniques need to be one step ahead of the fake reviews, necessitating the exploration of novel features. For instance, businesses may strategically promote positive fake reviews for their newly launched brand to give it a cold start. If these features can be scraped from their website, they can be used as a novel business-centric feature set, that can contribute to more effective FRD.
The final classification in this paper pertains to the use of various datasets in the current research. It has been noted that the datasets commonly employed in current studies are constructed through crowdsourced labelling and are prone to human perspective errors. Additionally, the findings reveal a predominant focus on the hospitality domain in the existing research, primarily due to the availability of labelled datasets. However, there is a need to gather and investigate data from domains such as education and the healthcare sector. This paper undertakes a comprehensive comparison and analysis of existing techniques to underscore the challenges within this field. This not only aids in identifying the most effective method but also facilitates further research on the intricate issue of detecting fake reviews.
5. Future directions
Most of the existing research primarily concentrates on training and testing models within a single domain. However, if a model can be trained in one domain and effectively applied to another, it can help address the scarcity of labelled datasets. This cross-domain classification will help a lot in areas where the availability of annotated datasets is much less. Another significant challenge in fake review detection is the problem of class imbalance, as most datasets have a substantial majority of reviews annotated as authentic rather than fake. Although some research has been done in this direction using sampling methods, the results have not been satisfactory. Hence, machine learning techniques like Siamese neural networks may be used for handling imbalances in datasets.
Another critical challenge is multilingual fake review detection, where research and data in languages other than English are severely lacking. Algorithms need to be trained to reflect global languages. Another demanding issue of fake review detection algorithms is the need to adapt and combat the problem of concept drift, ensuring they can identify fake reviews even as they evolve to resemble genuine ones. Classifiers need to be updated frequently to remain on top of the fake review detection. Moreover, existing feature extraction and selection methods exhibit various limitations, necessitating the exploration of novel feature sets. For instance, incorporating business-centric features such as fake reviews generated to boost sales of newly launched products could contribute to the development of a unique feature set.
Furthermore, the existing research has predominantly focused on employing machine learning, deep learning, and swarm intelligence techniques. The datasets used in these studies have primarily been obtained from platforms like Yelp and Amazon, but they are often outdated Many of these datasets are a result of web crawlers which causes many features to be left out or included unnecessarily. Consequently, the solutions developed on these datasets may or may not generalize well to newer datasets or different domains. Hence, there is a pressing need for a scalable, new benchmark dataset. In addition, previous research primarily focused on utilizing linguistic features for fraudulent review detection, neglecting the challenge of handling multimodal reviews that may include images, audio, video, metadata, etc. This is an emerging challenge as more and more reviews are described with the help of images and metadata.
Lastly, the FRD techniques employed by major companies like Google and Amazon are not publicly available. This highlights the need for a robust tool accessible to the public, accurately identifying fraudulent reviews and benefiting both consumers and e-commerce platforms.
Competing interests
On behalf of all authors, the corresponding author states that there is no conflict of interest.

















 Open access
Open access