



1 Introduction
Unstressed vowels are known to be prone to reduction of phonetic qualities (Lindblom Reference Lindblom1963, Mooshammer & Geng Reference Mooshammer and Geng2008) and to be affected by neutralisation of phonemic contrasts (Crosswhite 2004, Padgett & Tabain Reference Padgett and Tabain2005). While previous research has addressed neutralisation of vowel monophthongs in unstressed syllable positions, the nature of neutralisation processes in the context of a consonant vocalisation – such as coda-/r/ vocalisation (Dittrich & Reibisch Reference Dittrich and Reibisch2006) – is still poorly understood. Recently, neutralisation has been documented in pre-rhotic contexts due to the type of /r/ that follows the vowel (Lawson, Scobbie & Stuart-Smith Reference Lawson, Scobbie and Stuart-Smith2013). The neutralisation process affects three originally distinct checked vowels of Scottish English and is likely to have been triggered by coarticulation with the following bunched /r/ that exerts a stronger coarticulatory force over the preceding vowel than a front-tongue raised /r/. In contrast, speakers with the front-tongue raised /r/ often derhoticise, most likely due to delayed anterior tongue gestures (Lawson, Stuart-Smith & Scobbie Reference Lawson, Stuart-Smith and Scobbie2018).
The phonetics of rhotics in the languages of the world varies substantially (Ladefoged & Maddieson Reference Ladefoged and Maddieson1996: Chapter 7) and can be socially stratified (Lawson et al. Reference Lawson, Scobbie and Stuart-Smith2013, Reference Lawson, Stuart-Smith and Scobbie2018). This is also true for German where the variation is primarily constrained by dialectal, stylistic and allophonic factors and includes taps and trills in different places of articulation [ɾ]/[r]/[ʀ], the uvular fricative [ʁ] and the uvular approximant [ʁ̞] (Kohler 1977/Reference Kohler1995). Phonologically, German rhotics are treated as [+sonorant] because of their phonotactic behaviour (see Hall Reference Hall1993 and Wiese Reference Wiese2003 for discussion). Since uvular [ʁ] and [ʁ̞] are the most widespread variants in Standard German (Kohler 1977/Reference Kohler1995, Wiese Reference Wiese2003), an adequate representation of the Standard German rhotic is arguably /ʁ/.Footnote 1 Vocalised variants of /ʁ/ are widespread in post-vocalic coda positions of Standard German (e.g. Ulbrich Reference Ulbrich1973, Kohler 1977/Reference Kohler1995, Barry Reference Barry1995, Meinhold Reference Meinhold and Slembek1989, Simpson Reference Simpson1998). The process of /ʁ/-vocalisation gives rise to many lowering diphthongs in German (e.g. in hier [hiːɐ] ‘here’, Herr [hɛɐ] ‘Mister’, etc.) and also results in an additional central vowel which is known as the ‘Lehrer’-schwa or the ‘dark’ schwa (Barry Reference Barry1995, Reference Barry1997). According to existing accounts of German, the unstressed word-final vowels in words like Opa ‘grandpa’ and Oper ‘opera’ are traditionally transcribed with two different IPA symbols, [a] and [ɐ] (Kohler 1977/Reference Kohler1995, Reference Kohler1990). This representation implies a perceivable difference in quality between the two unstressed vowels. However, it is not clear if this contrast is indeed produced and perceived by native speakers of German. For example, a common mistake made by children acquiring Standard German orthography is the spelling of <a> for word-final <er>. This misspelling is very frequent (Schmidlin Reference Schmidlin, Tophinke and Röber-Siekmeyer2002) and considered as one of the typical, phonetically motivated mistakes (Fay Reference Fay2010).
The aim of the present study is to investigate whether or not speakers of Standard (Northern) German – a variety that displays the post-vocalic /ʁ/-vocalisation (Kohler 1977/Reference Kohler1995) – have a systematic acoustic difference when producing the unstressed word-final /a/ and [ɐ],Footnote 2 and if this vowel contrast can also be reliably identified by native adult listeners of Standard German. In the following, we will discuss the phonological background and the phonetic underpinnings of this vowel distinction. We further consider how a potential vowel merger might be influenced by sentence-level prosody or orthography, and outline the open questions that our study aims to answer.
1.1 Schwa sounds in Standard German
The status of [ɐ] in the phonology of German is considered marginal, despite the existence of surface minimal pairs like bitte [bɪtə] ‘please’ vs. bitter [bɪtɐ] ‘bitter’ and Weite [vaɪtə] ‘width’ vs. weiter [vaɪtɐ] ‘further’. In phonological descriptions, the dark schwa [ɐ] is often discussed as the surface representation of the rhotic phoneme /ʁ/ or of the phoneme sequence /əʁ/, derived through a post-lexical vocalisation rule (see e.g. ʀ-coalescence in Hall Reference Hall1992: 58). Consequently, [ɐ] and [ʁ] are not considered as two separate phonemes, but two allophones of one phoneme in complementary distribution: [ʁ] appears in the onset of a syllable, [ɐ] in all other positions. According to Meinhold (Reference Meinhold and Slembek1989), the dark schwa can surface (i) as a postvocalic /ʁ/-allophone in a stressed syllable (e.g. in hört [hØːɐt] ‘(s/he) hears’), (ii) as a realisation of the (unstressed) prefixes <er>, <ver>, <zer> (e.g. in verbringen ‘to spend’, with both [fɛɐˈbʁɪŊən] and [fɐˈbʁɪŊən] being possible surface variants), and (iii) as a realisation of the (unstressed) <er> suffix (e.g. in weiter [ˈvaɪ̯tɐ] ‘further’).
The status of [ɐ] in the phonology of German is considered marginal, despite the existence of surface minimal pairs like bitte [bɪtə] ‘please’ vs. bitter [bɪtɐ] ‘bitter’ and Weite [vaɪtə] ‘width’ vs. weiter [vaɪtɐ] ‘further’. In phonological descriptions, the dark schwa [ɐ] is often discussed as the surface representation of the rhotic phoneme /ʁ/ or of the phoneme sequence /əʁ/, derived through a post-lexical vocalisation rule (see e.g. ʀ-coalescence in Hall Reference Hall1992: 58). Consequently, [ɐ] and [ʁ] are not considered as two separate phonemes, but two allophones of one phoneme in complementary distribution: [ʁ] appears in the onset of a syllable, [ɐ] in all other positions. According to Meinhold (Reference Meinhold and Slembek1989), the dark schwa can surface (i) as a postvocalic /ʁ/-allophone in a stressed syllable (e.g. in hört [hØːɐt] ‘(s/he) hears’), (ii) as a realisation of the (unstressed) prefixes <er>, <ver>, <zer> (e.g. in verbringen ‘to spend’, with both [fɛɐˈbʁɪŊən] and [fɐˈbʁɪŊən] being possible surface variants), and (iii) as a realisation of the (unstressed) <er> suffix (e.g. in weiter [ˈvaɪ̯tɐ] ‘further’).
As exemplified in (i) and (ii) above, /ʁ/-vocalisation can lead to a surface diphthong. Such diphthongal realisations seem to be optional in unstressed syllables and in coda positions of stressed syllables that contain an open vowel. A study by Dittrich & Reibisch (Reference Dittrich and Reibisch2006) compared formant trajectories of F1, F2 and F3 across several vowels followed by /ʁ/, and provided evidence against a postvocalic diphthongisation after /aː/ (e.g. in words like Paar [paː] ‘a pair’) and argued against the existence of the [aːɐ] diphthong in Standard German. Although most phonologists agree on the phonetic quality and use the symbol [ɐ] for (iii), Hall (Reference Hall1993) assumes [ʌ] instead of [ɐ] in his description of German phonology. The argument for this deviation is, however, purely phonological, related to the succinctness of the derivational rule /ʁ/ → [ʌ] that requires a change in only one feature ([consonantal]) instead of two ([consonantal] and [back]).
Phonologically, the two schwas of German – [ɐ] and [ə] – differ in their underlying representation which might lead to different articulatory specifications and the corresponding phonetic realisations. Kohler (1977/Reference Kohler1995, Reference Kohler1990) whose account of German is adopted in the present paper, acknowledges the phonological status of /ə/ in contrast to the derived surface character of [ɐ] that is phonologically /əʁ/. Phonetic differences between the two schwas have also been addressed in previous research (e.g. Meinhold Reference Meinhold and Slembek1989, Barry Reference Barry1995). For example, Meinhold (Reference Meinhold and Slembek1989) documented top–down effects in the perception of [ə] vs. [ɐ] (e.g. in Miete [miːtə] ‘rent’ vs. Mieter [miːtɐ] ‘tenant’) and showed that both schwas could only be correctly identified if listeners heard some lexico-syntactic context surrounding the target word with the schwa. If the context was missing and a word had to be judged in isolation, the correct identification of the target vowel declined and was replaced by a bias towards the perception of [ə]. Following the framework of Articulatory Phonology (Browman & Goldstein Reference Browman and Goldstein1992), Barry (Reference Barry1995) investigated the acoustic contrast between [ə] and [ɐ] in German, and focused primarily on the issue of the contextual influences on the realisation of the two schwas. According to Articulatory Phonology (e.g. Browman & Goldstein Reference Browman and Goldstein1992), a schwa is a targetless vowel whose production does not involve an active articulatory gesture (only a relaxation movement toward a neutral tongue position) and is therefore highly prone to coarticulatory influences from the neighbouring segments. Given that there are two schwas in German, neither [ə] nor [ɐ] can be completely targetless, though they might still be more variable than the other vowels of the system. Similarly, Moisik (Reference Moisik2006) argued that the presence of [ɐ] may lead to a slight displacement of the schwa in the vowel space, as compared to the schwa in English (see Figure 1).
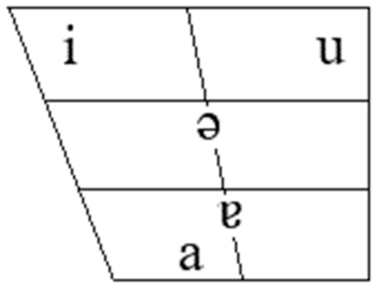
Figure 1 The relative location of [ɐ], /ə/ and /a/ in the German vowel space (after Moisik Reference Moisik2006: 26). Note that German /a/ is a central vowel, though traditionally represented by the front vowel IPA symbol (see Mooshammer & Geng Reference Mooshammer and Geng2008).
Barry’s (Reference Barry1995) results showed more contextually induced variability in the production of [ə] than in the production of [ɐ], supporting the idea of a distinction between a functionally defined target of [ɐ] on the one hand, and a hypothetical relaxation target of [ə] on the other. A longer duration found for [ɐ] was interpreted in support of its phonological interpretation as bi-segmental – i.e. consisting of /ə/ and /ʁ/ – in contrast to the phonologically uni-segmental /ə/. However, the durational difference observed in the data may also be interpreted as a reflex of the different degrees of jaw opening. The articulation of the more open vowel [ɐ] can be expected to take more time to be executed (see Solé & Ohala Reference Solé, Ohala, Fougeron, Kühnert, D’Imperio and Vallée2010 for a review on causes of intrinsic vowel duration). A comparison with /a/ is therefore required to shed light on the issue, given that [ɐ] and /a/ can contrast in unstressed word-final positions and produce minimal pairs like Opa ‘grandpa’ and Oper ‘opera’.
The IPA symbols used for the (broad) transcription of the two German central open vowels in unstressed positions – /a/ and [ɐ] (Kohler 1975/Reference Kohler1995, Reference Kohler1990) – imply a quality difference in vowel height. Note that a narrow transcription of the open stressed vowel is rather [a̠] since its quality is not as front as the traditional use of the symbol suggests (see Heike Reference Heike1972).
Acoustically, this difference is expected to surface primarily in the frequency of the first formant, with /a/ showing a higher F1 than [ɐ]. However, given that both vowels occur in lexically unstressed positions, the phonetic difference between them can also be expected to be minimised due to an articulatory target undershoot, with /a/ becoming less peripheral (Lindblom Reference Lindblom, Hardcastle and Marchal1990). The system of German full (i.e. stressable) vowels is known for more centralised vowel qualities and more closed tongue configurations in unstressed positions (Mooshammer & Geng Reference Mooshammer and Geng2008). Acoustically, centralisation affects particularly the first formant, with an unstressed /a/ measuring a lower F1 frequency as compared to a stressed /a/ (Mooshammer & Geng Reference Mooshammer and Geng2008). As a consequence, such target undershoot is likely to result in vowel neutralisation of the unstressed /a/ and [ɐ]. If this is the case, the two vowels might still differ with regard to their F2 frequency that has been previously found to distinguish between (stressed) /aː/ and /aːʁ/ (Dittrich & Reibisch Reference Dittrich and Reibisch2006). The trajectory of F2 is also likely be involved if /əʁ/ has a diphthongal quality (Meinhold Reference Meinhold and Slembek1989, Dittrich & Reibisch Reference Dittrich and Reibisch2006).
Apart from a difference in vowel quality, durational differences could also exist. Wiese (Reference Wiese2000: 255) argues against an individual sound-level distinction between /a/ and [ɐ] because of their similarity. Since it is, however, possible to distinguish them, he suggests that /a/ and the non-syllabic [ɐ̯] (as in Bier [biːɐ̯] ‘beer’ are separated on the syllabic tier of their representation by association with V and C, respectively. He further assumes that the unstressed vowel /a/ should be ‘long, or at least longer’ than a vocalic [ɐ] (in e.g. Oper ‘opera’ because the former is underlyingly tense. Since he does not account for short tense vowels in unstressed position and length in phonological representations is conceptualised as binary, it is unclear how the difference could be represented.
1.2 Influences of the orthography
Previous research has suggested that orthography might play a role in preventing vowel mergers specifically (Faber & Di Paolo Reference Faber and Di Paolo1995) or sound neutralisations more generally (e.g. Warner et al. Reference Warner, Jongman, Sereno and Kemps2004, Ernestus & Baayen Reference Ernestus, Baayen, Goldstein, Whalen and Best2006). In case of the two vowels in question here, the spelling differs systematically: while the unstressed /a/ is regularly spelled as <a>, the word-final [ɐ] is consistently represented by the digraph <er>. This spelling difference might potentially lead to different pronunciations of word pairs like Oper ‘opera’ and Opa ‘grandpa’, primarily with respect to their duration. Among many reasons that can affect duration of phonological homophones like the English time vs. thyme, Gahl (Reference Gahl2008) discusses the effects of orthography, which are two-fold. First, words with more letters could lead to a longer word duration. Indeed, this explanation has been corroborated by independent evidence provided by Nimz, Immel & Koop (Reference Nimz, Immel and Koop2016) for German phonological homophones like Wahl ‘choice’ and Wal ‘whale’ which show durational patterns as predicted by Gahl (Reference Gahl2008). With respect to our research question, the orthography account would predict that words containing [ɐ] (like Oper ‘opera’ should be longer than words with the unstressed /a/ (like Opa ‘grandpa’. Second, the regularity of grapheme-to-phoneme correspondences might also influence the word duration (Gahl Reference Gahl2008). If the phonemic representation of a word is well reflected in its spelling, the word is likely to be shorter than a word with a more complex orthographic representation of its phonemes (e.g. fin vs. thin in English or Wale ‘whales’ vs. Schale ‘bowl’ in German). Although German has a relatively unambiguous grapheme-to-phoneme mapping (e.g. Katz & Frost Reference Katz, Frost, Frost and Katz1992), and the <er> spelling of all word-final [ɐ] is very regular, we can still predict a shorter duration for words containing an unstressed /a/ due to its one-to-one phoneme-to-grapheme correspondence.
Duration sometimes plays a disambiguating role in spectral mergers. For example, durational differences among merged vowels have repeatedly been reported for stressed vowels (e.g. Labov & Baranowski Reference Labov and Baranowski2006, Fridland, Kendall & Farrington Reference Fridland, Kendall and Farrington2014, Wade Reference Wade2017). It is unclear if such phonetic cue can also apply to unstressed vowel mergers, though it lends some preliminary support to the prediction of the orthographically driven account and reinforces the idea that duration might distinguish between /a/ and [ɐ] in case of a spectral merger.
1.3 Segment–prosody interaction
In terms of their prosodic characteristics, /a/ and [ɐ] are known to belong to two different vowel sets: while /a/ is a full vowel of German and can occur in stressed positions and carry a pitch accent, [ɐ] is a reduced vowel and is typically unstressed (Vennemann Reference Vennemann, Bertinetto, Kenstowicz and Loporcaro1991). According to Vennemann’s (Reference Vennemann, Bertinetto, Kenstowicz and Loporcaro1991) account of German phonology, unstressed /a/ and reduced [ɐ] are subject to different vowel prosodies which have unique phonological characteristics and can therefore be expected to show phonetic differences regardless of the presence of accentuation. For example, in English articulatory gestures are known to show larger amplitude and velocity differences between unstressed and stressed unaccented syllables than between stressed unaccented and accented syllables (Beckman & Edwards Reference Beckman, Edwards and Patricia1994). In general, stress and accentuation tend to lead to acoustically more peripheral vowel qualities and larger articulatory movements in German as well as other languages (de Jong, Beckman & Edwards Reference Jong, Beckman and Edwards1993, Hoole & Mooshammer Reference Hoole, Mooshammer, Auer, Gilles and Spiekermann2002, Mooshammer & Fuchs Reference Mooshammer and Fuchs2002, Mooshammer & Geng Reference Mooshammer and Geng2008). The amount of coarticulation found in accented words is also much reduced in comparison to unaccented words (de Jong et al. Reference Jong, Beckman and Edwards1993, Harrington, Fletcher & Roberts Reference Harrington, Fletcher and Roberts1995, Lindblom et al. Reference Lindblom, Agwuele, Sussman and Cortes2007). We thus can expect the difference between the two vowels to become more salient under accentuation and to be minimised when words are unaccented.
Positions within a prosodic phrase might also condition the variation between the two vowels. Within the  $\boldsymbol{\pi}$ (prosodic) gesture framework (Byrd & Saltzman Reference Byrd and Saltzman1998, Reference Byrd and Saltzman2003; Byrd et al. Reference Byrd, Kaun, Narayanan, Saltzman, Broe and Pierrehumbert2000, Reference Byrd, Lee, Riggs and Adams2005), articulatory gestures at phrasal edges are timed further apart as compared to phrase-medial position – a timing property that results in a smaller gestural overlap and could therefore lead to more hyperarticulated and less neutralised phonemic contrasts. To this end, Piroth & Janker (Reference Piroth and Janker2004) demonstrated that a complete neutralisation of a word-final voicing contrast in German obstruents was revoked in phrase-final positions resulting in subtle durational differences to preserve the underlying contrast, though the finding applied only in southern varieties of German. In contrast, phrase-medial positions tend to increase coarticulatory effects (see e.g. de Jong et al. Reference Jong, Beckman and Edwards1993, Cho Reference Cho2004). We can thus assume the distinction between unaccented /a/ and [ɐ] to diminish in phrase-medial positions and to potentially become manifest in phrase-final positions.
$\boldsymbol{\pi}$ (prosodic) gesture framework (Byrd & Saltzman Reference Byrd and Saltzman1998, Reference Byrd and Saltzman2003; Byrd et al. Reference Byrd, Kaun, Narayanan, Saltzman, Broe and Pierrehumbert2000, Reference Byrd, Lee, Riggs and Adams2005), articulatory gestures at phrasal edges are timed further apart as compared to phrase-medial position – a timing property that results in a smaller gestural overlap and could therefore lead to more hyperarticulated and less neutralised phonemic contrasts. To this end, Piroth & Janker (Reference Piroth and Janker2004) demonstrated that a complete neutralisation of a word-final voicing contrast in German obstruents was revoked in phrase-final positions resulting in subtle durational differences to preserve the underlying contrast, though the finding applied only in southern varieties of German. In contrast, phrase-medial positions tend to increase coarticulatory effects (see e.g. de Jong et al. Reference Jong, Beckman and Edwards1993, Cho Reference Cho2004). We can thus assume the distinction between unaccented /a/ and [ɐ] to diminish in phrase-medial positions and to potentially become manifest in phrase-final positions.
1.4 Perceptual evidence
A disparity of production and perception of a contrast has been previously observed in the context of (near-)mergers (Nycz Reference Nycz2013). Such disparity can go in both directions, i.e. a contrast being perceived but not produced (e.g. Hay, Warren & Drager Reference Hay, Warren and Drager2006, Hay, Drager & Thomas Reference Hay, Drager and Thomas2013) or produced but not perceived (Labov, Yaeger & Steiner Reference Labov, Yaeger and Steiner1972). Once spectral cues to a vowel distinction are lost, duration has been frequently shown to play an important role for a perceptual disambiguation (e.g. Labov & Baranowski Reference Labov and Baranowski2006, Wade Reference Wade2017). Little is known about the use of duration to distinguish between unstressed /a/ and [ɐ]. We argue that it is a likely cue to the vowel contrast in question (see Section 1.2). However, previous work (Dittrich & Reibisch Reference Dittrich and Reibisch2006) did not show a significant effect of duration in the production of vowels with and without a postvocalic /ʁ/, like Saar (a German river) vs. sah (past tense of the verb ‘to see’). There exists very limited perceptual evidence for a correct identification of [ɐ], as opposed to [ə]. Meinhold (Reference Meinhold and Slembek1989) showed that the correct perceptual identification was only possible if the target word containing either schwa was presented with some surrounding lexico-syntactic context – that is, the schwa perception seems to rely on a top–down rather than bottom–up processing. In the absence of the relevant context, vowel perception displayed a clear bias towards [ə] (Meinhold Reference Meinhold and Slembek1989).
1.5 Aims and hypotheses
The present study aims to investigate whether or not the contrast between the two unstressed open vowels of German – /a/ and [ɐ] – is maintained in production and perception by speakers of Standard (Northern) German. Following previous research, we hypothesised that the contrast will be enhanced in prosodically strong positions (i.e. under accentuation and phrase-finally) and reduced elsewhere (see de Jong et al. Reference Jong, Beckman and Edwards1993, Harrington et al. Reference Harrington, Fletcher and Roberts1995, Hoole & Mooshammer Reference Hoole, Mooshammer, Auer, Gilles and Spiekermann2002, Mooshammer & Fuchs Reference Mooshammer and Fuchs2002, Lindblom et al. Reference Lindblom, Agwuele, Sussman and Cortes2007, Mooshammer & Geng Reference Mooshammer and Geng2008).
If the maintenance of this contrast is driven primarily by the underlying phonological representations or orthography, we expected to find durational (maybe in conjunction with spectral) cues that differentiate between the two vowels. To this end, two competing predictions can be put forward: (i) given that [ɐ] is consistently represented by two (in contrast to just one) letters or phonemes, i.e. <er> in orthography and /əʁ/ in phonology, we could predict [ɐ] to be produced as a longer vowel and thus perceived as a distinct vowel, versus (ii) under the phonological assumption of a general prosodic difference between the full and the reduced vowel set (following Vennemann Reference Vennemann, Bertinetto, Kenstowicz and Loporcaro1991), longer durations could be expected in realisations of the full vowel /a/ that has the potential of carrying lexical stress within the German vowel system. Furthermore, since schwa vowels are also said to be targetless and therefore more variable (Browman & Goldstein Reference Browman and Goldstein1992, Barry Reference Barry1995), larger dispersions in the F1/F2 space are predicted for [ɐ] than for /a/.
In contrast, if the difference between the two vowels is primarily phonetic as many accounts of German suggest (Hall Reference Hall1993; Kohler 1975/Reference Kohler1995, Reference Kohler1990; Meinhold Reference Meinhold and Slembek1989), a difference in F1 would be the main acoustic feature to differentiate between the vowels (with a lower frequency for [ɐ]). Formant trajectories might also be expected to carry information about the two vowels, with more diphthongal spectral properties for [ɐ] due to a spelling pronunciation of <er> and the underlying bisegmental representation as /əʁ/ (Dittrich & Reibisch Reference Dittrich and Reibisch2006).
Accordingly, we analysed vowel duration, formant frequencies and trajectories in productions of (pseudo)minimal pairs contrasting /a/ and [ɐ] in the word-final position (Experiment 1). We included F3 in the formant analyses, given that F3 is one of the main acoustic correlates of rhoticity in varieties of English (Espy-Wilson et al. Reference Espy-Wilson, Boyce, Jackson, Narayanan and Alwan2000, Harrington Reference Harrington, Hardcastle, Laver and Gibbon2010) though to date, there are no reports that F3 might be of relevance in the German vowel system. Minimal pairs recorded in Experiment 1 were subsequently extracted from the context and tested in a forced-choice identification study (Experiment 2).
2 Method
2.1 Experiment 1: Production
2.1.1 Speakers
We recorded six monolingual native speakers of Standard German from the North of Germany (three male). Four speakers of the sample came from Schleswig-Holstein (Trittau, Kiel, Flensburg, Lübeck), one speaker each from Hamburg and Niedersachsen (Wolfsburg). The mean age of the speakers was 24 years (SD = 3) at the time of the recording, and all of them were students at the Christian-Albrechts-Universität zu Kiel. None of the speakers reported any speech or hearing impairment. All speakers were naive as to the purpose of this experiment. They were recorded in the sound-proof booth at the Institute of Phonetics and Speech Processing in Kiel.
2.1.2 Materials and procedure
The following four minimal pairs contrasting word-final [a] and [ɐ] were chosen for this study:

Each word was embedded in meaningful utterances, designed to vary their prosody with respect to the target word’s (i) phrasal position (phrase-final vs. phrase-medial) and (ii) presence of accentuation (accented vs. unaccented). For the ease of segmentation, words following the target always started with an initial /z/. Appendix A presents a full list of the test utterances in the four prosodic contexts. The utterances were printed on paper cards, repeated three times, and their serial order was randomised. This results in a total of 48 target tokens per speaker (4 minimal pairs × 2 accent conditions × 2 phrase positions × 3 repetitions). The participants were instructed to read the utterances at their comfortable speech rate and in their most natural tone of voice.
2.1.3 Segmental annotation
Praat (Boersma & Weenick Reference Boersma and Weenink2016) was used to segment and annotate the target words. Five tiers were generated: Word, Accent, Position, Syllable and Segment. Using default settings of Praat spectrogram and waveform displays, the target words were visually inspected, and all segments of the target word as well as the initial segments of the following word were manually annotated. Vowel boundaries were determined through the presence of a visible second formant in the spectrogram. Audible strong glottalisation of the target vowel in phrase-final positions was annotated as part of the vowel. The following pause, if produced, was labelled between the offset of the final vowel and the visible frication noise of the following, frequently devoiced /z/.
Additionally, syllables of the target word were identified as STR (initial stressed syllables), FUL (unstressed syllables with the full vowel [a]) and RED (unstressed syllables with the reduced vowel [ɐ]).
2.1.4 Prosodic annotation
To check if the speakers produced the intended prosodic structure, all sentences were prosodically annotated following GToBI guidelines (Baumann, Grice & Benzmüller Reference Baumann, Grice, Benzmüller and Jun2005). All analyses below are based on the actual productions of prosodic phrasing and accentuation (which sometimes deviated from the intended prosodic environment as prompted by the sentence context). The intended phrasal emphasis was missing in 11 out of 288 accented target words, and 73 out of the 288 unaccented target words were produced with a pitch accent. One female speaker (F2) in particular showed a strong tendency to produce words with a pitch accent regardless of the context. Approximately  $24\%$ of all unintended prosodic realisations were attributable to this speaker. The large majority of all prosodic boundaries were produced as intended in the given context. Only two of the intended phrase-medial target words were produced phrase-finally, with an intermediate phrase boundary and a high boundary tone. These two cases were excluded from the subsequent analyses. All of the intended phrase-final positions were signalled by a low boundary tone and a pause.
$24\%$ of all unintended prosodic realisations were attributable to this speaker. The large majority of all prosodic boundaries were produced as intended in the given context. Only two of the intended phrase-medial target words were produced phrase-finally, with an intermediate phrase boundary and a high boundary tone. These two cases were excluded from the subsequent analyses. All of the intended phrase-final positions were signalled by a low boundary tone and a pause.
2.1.5 Measurements
For acoustic analyses, standard procedures of the EmuR library were used (Bombien et al. Reference Bombien, Cassidy, Harrington, John and Palethorpe2006, Winkelmann et al. Reference Winkelmann, Jänsch, Cassidy and Harrington2017). Calculations of formant estimates were carried out by using the procedure PraatToFormants2AsspDataObj that transforms Praat estimates into EmuR formats. Settings of the largest formant value for the fifth formant were set to 5000 Hz for male speakers and to 5500 Hz for female speakers. Formant frequencies of the first three formants were extracted for the whole duration of the final vowel (see Figure 3 in Section 3.1.1 below). The midpoint of these formant trajectories was taken as the measure of vowel quality in these vowels (see Figure 2 in Section 3.1.1). The values were checked for outliers and manually corrected if necessary. Durations of the target vowels and words were also measured using standard procedures of EmuR. Syllable durations were used in order to calculate the log transformed ratios between the initial stressed vowel and the final unstressed vowel (see Sluijter & van Heuven Reference Sluijter and van Heuven1996), using the equation: log duration ratio = log (duration σ 1/duration σ 2).
2.1.6 Statistical analyses
Statistical analyses were carried out using R 3.3.0 (R Core Team 2018) with the packages lme4 (Bates et al. Reference Bates, Mächler, Bolker and Walker2015) and lmerTest (Kuznetsova, Brockhoff & Christensen Reference Kuznetsova, Brockhoff and Christensen2017). We tested for the effect of vowel quality (VOW: [a] vs. [ɐ]), accentuation (ACC: accented vs. unaccented), phrasal position (PHR: medial vs. final) and SEX. For the model construction in the production part, we follow the recommendation by Harrison et al. (Reference Harrison, Donaldson, Correa, Evans, Fisher, Goodwin, Robinson, Hodgson and Inger2018) that fixed effects should be selected in a hypothesis-driven way, and retained in the final model.
While prosodic factors of accentuation and phrasal position cannot be expected to interact with the speaker sex, vowel quality might potentially enter the interaction, given that females are known to lead sound changes ‘from below’ (Labov Reference Labov2001). Therefore, the tested fixed effects model was specified as VOW, ACC, PHR and SEX as main effects and interactions of VOW with ACC, PHR and SEX (i.e. fixed effects structure in R as VOW*ACC + VOW*PHR + VOW*SEX). Speaker and token were fitted as random effects.
In order to avoid collinearity between factors and factor levels, the factors were coded and centered by subtracting the grand mean, following suggestions by Gelman & Hill (Reference Gelman and Hill2006). Centering and coding affects the fixed effects in the following way: the reported intercept does not correspond to a base factor level but to the grand mean of the data. For the individual factors, the β-estimate corresponds to the difference between the two factor levels. As a preliminary, log-likelihood comparisons were used to assess whether the model fit improved by including random slopes by speaker. Relevant models are presented in Appendix B. For significant interactions, the data set was split accordingly. Statistical significances of the fixed effects are presented by the corresponding estimates of the regression coefficients and their associated standard errors, with probabilities of their quotient (a t-test) based on the Satterthwaite approximation for denominator degrees of freedom. Dependent variables included F1, F2, F3, duration (raw and normalised, see Section 3.1.2 for detail).
2.2 Experiment 2: Perception
2.2.1 Stimuli
To test the perceptual identification of the two vowels, we selected one instance out of the three target word repetitions from each speaker’s production data. All of these tokens were spoken clearly, without errors, stutters or hesitation and could be easily extracted from the carrier sentence. Silences of 100 ms in duration were added before and after each word. A total of 384 experimental stimuli were tested, i.e. the four minimal pairs in two accentual and two phrasal positions (8 × 2 × 2 = 32) produced by the six speakers of Experiment 1 (32 × 6 = 192) and repeated twice (192 × 2 = 384). The experiment was set up using the speech analysis software Praat (Boersma & Weenink Reference Boersma and Weenink2016).
2.2.2 Listeners
The perception experiment took place at the Humboldt Universität zu Berlin. Forty-four native listeners of Standard German (mean age: 29 years, SD = 5, 19 male) participated in the experiment. None of them reported any hearing impairment or considered themselves bilingual. They came from different regions of Germany, most of them were local ( $54\%$ came from Berlin/Brandenburg).
$54\%$ came from Berlin/Brandenburg).
2.2.3 Procedure
Laptops running the experimental Praat script and a pair of good-quality headphones were used for perceptual testing. Before and after the presentation of an auditory stimulus, participants saw a blank screen for 100 ms. Following a stimulus presentation, they saw a choice of two buttons labelled with the words of the respective minimal pair, and had to answer the question ‘Which word did you hear?’ by selecting either button. After registering a choice, the experiment proceeded to the next stimulus. The stimuli were presented in a randomised order twice. The location of the correct button on the screen was counterbalanced across the two repetitions of the same stimulus. An experimental session lasted some 20–30 minutes. Individual data (age, gender, place of birth and residence, dialect/standard statement, foreign languages, bilingualism and hearing ability check) were collected at the end of each testing session.
2.2.4 Analyses
To analyse perceptual patterns obtained from the listeners, the sensitivity index d-prime (d′) was calculated. As applied to our identification data, d′ reflects the listeners’ ability to correctly identify /a/ when presented with the words Clara, Opa, Dinah and Feta, and to correctly reject /a/ when presented with the words klarer, Oper, Diener and Väter. The score itself results from z-transformed hit and false-alarm rates calculated following the formula: d′ = z(hit) − z(false alarm) (e.g. Macmillan & Creelman Reference Macmillan and Creelman1991). The higher the resulting score, the better the perceptual separation between two categories, with scores close to 0 being indicative of a performance at chance level. The d′-data were then tested for significance using ANOVA, with stimulus speaker, accentuation and phrasal position (and the interaction of the two prosodic factors) as predictors. In addition, a mixed logistic regression was performed on the raw perception data, with the same fixed factors as above. Listener, item and order of presentation were fitted as random effects. Note that stimulus speaker was included as a predictor to test for a potential effect of the substantive inter-speaker variation that we found in the production data among the male speakers of the corpus (see Section 3.1).
3 Results
3.1 Acoustic analyses
3.1.1 Vowel quality
The formant frequencies of F1, F2 and F3 were considered, to measure a potential quality difference between the two vowels. A Lobanov vowel normalisation was applied to the formant data, in order to pool across male and female speakers (Adank, Smits & van Hout Reference Adank, Smits and van Hout2004). Subsequently, the data were rescaled back to Hertz by multiplying each Lobanov-transformed value by the group standard deviation and then adding the group mean (see Winkelmann et al. Reference Winkelmann, Jänsch, Cassidy and Harrington2017).
Figure 2 shows  $95\%$-dispersion ellipses of the Lobanov-normalised F1 and F2 frequencies measured at vowel midpoint, comparing reduced [ɐ] (in green, shown as 6), unstressed [a] (in brown) and stressed long [aː] (in black). The latter was extracted from the first syllable in Clara and klarer. Except for the speaker M2, all speakers show a considerable overlap between an unstressed [a] and a reduced [ɐ] whereas their stressed [aː] is distinct due to a higher F1 frequency, in comparison to the two unstressed vowels. Since F1 is known to inversely correlate with the degree of jaw opening and tongue lowering (e.g. Lindblom & Sundberg Reference Lindblom and Sundberg1971), this result suggests that both unstressed vowels were produced with a less open jaw and a higher tongue position than the stressed [aː].
$95\%$-dispersion ellipses of the Lobanov-normalised F1 and F2 frequencies measured at vowel midpoint, comparing reduced [ɐ] (in green, shown as 6), unstressed [a] (in brown) and stressed long [aː] (in black). The latter was extracted from the first syllable in Clara and klarer. Except for the speaker M2, all speakers show a considerable overlap between an unstressed [a] and a reduced [ɐ] whereas their stressed [aː] is distinct due to a higher F1 frequency, in comparison to the two unstressed vowels. Since F1 is known to inversely correlate with the degree of jaw opening and tongue lowering (e.g. Lindblom & Sundberg Reference Lindblom and Sundberg1971), this result suggests that both unstressed vowels were produced with a less open jaw and a higher tongue position than the stressed [aː].
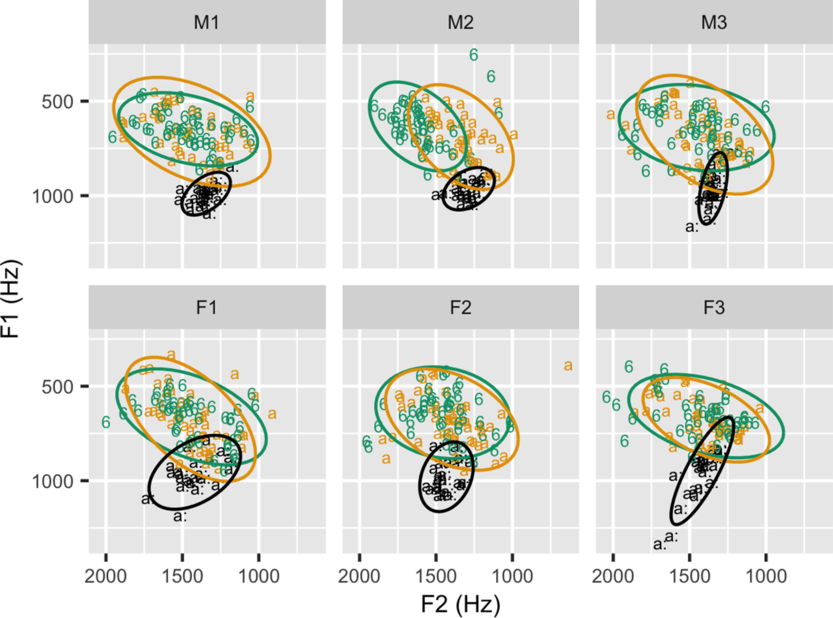
Figure 2 Dispersion ellipses of F1/F2 frequencies for [ɐ] (in green, annotated as 6, in line with the SAMPA notation of German, see Wells Reference Wells1996) and unstressed /a/ (in brown). F1/F2 of the stressed /aː/ (in black) is given for comparison (taken from the speakers’ productions of the target words Clara ([klaːʁa]) and klarer ([klaːʁɐ]). Male speaker data are plotted in the top panels, and female speaker data in the bottom panels.
Results from linear mixed-effects models are shown in Appendix B (see Table B1). They revealed no main effect of vowel quality ([a] vs. [ɐ]) for any of the three formants measured at vowel midpoint, and no interactions with either prosodic factor. In contrast, both accentuation (t = 6.3, p < .001) and phrasal position (t = 4.1, p < .01) showed an effect on F1, with higher F1frequencies measured under accentuation (an increase of 66 Hz) and in phrase-final positions (an increase of 98 Hz). Phrase-final positions led to a significant lowering of the higher formants, both F2 (by 187 Hz, t = 9.3, p < .001) and F3 (by 73 Hz, t = 2.5, p < .05). The frequencies of F3 further displayed a raising by 58 Hz under accentuation (t = 2.3, p < .05). For the frequencies of F2 and F3 there were also significant interactions between SEX and VOW that can be attributed to speaker M2 since the interaction lost significance once this speaker had been excluded from the dataset.

Figure 3 Time-normalised formant trajectories of unstressed /a/ (in brown) and [ɐ] (in green) averaged across accented and unaccented tokens produced by all female speakers (left panels), all male speakers (middle panels) versus speaker M2 only (right panels).
As hypothesised above, the dark schwa can be expected to be more variable in its target configuration than full vowels. Figure 2 indeed shows smaller dispersion ellipses for the stressed [aː] (they are, however, based on a smaller number of observations taken from two out of eight target words), though the dispersion of [ɐ] and unstressed [a] does not vary consistently.
Apart from the static differences in quality, we analysed formant trajectories of the two vowels, expecting a more diphthongal realisation for [ɐ]. For this, formant trajectories were extracted using EmuR library (Winkelmann et al. Reference Winkelmann, Jänsch, Cassidy and Harrington2017), displayed and checked visually. Figure 3 shows averaged and time-normalised formant trajectories of F1, F2, and F3 split by speaker sex and accentuation. The graph indicates no differences between the averaged trajectories that would be suggestive of a more diphthongal realisation of [ɐ] (displayed in green) as compared to [a] (displayed in brown). To represent a diphthongal pronunciation of [ɐ] as [əɐ], the F1 trajectory would be expected to display a lower F1 at the onset of the vowel and a slight rise towards the offset, which is not the case here. Moreover, M2 productions of [a] and [ɐ] (shown on the right) differ exclusively with respect to F2 height but not the predicted F1 dynamics. That is, the speaker does not display a tendency towards a diphthongal realisation of [əɐ].
3.1.2 Durations of vowels, syllables and words
In terms of timing, both absolute and relative durations (calculated as ratios between the stressed and unstressed syllable duration in the same word) were considered. Figure 4 shows absolute durations of the two vowels in phrase-medial (on the left) and phrase-final (on the right) positions, in accented ([+acc]) and unaccented ([−acc]) words. Statistical results with inclusion of ACC slope for the random subject term are presented in Appendix B (see Table B2). All vowels were significantly longer in phrase-final as compared to phrase-medial positions (t = 23.91, p < .001). A visual inspection of the boxplots also suggested longer durations of [a] than [ɐ], but this numerical difference did not reach significance, either as a main effect or in interaction with accentuation.

Figure 4 Absolute durations in milliseconds of unstressed /a/ (in brown) and [ɐ] (in green) measured in different prosodic contexts: phrase-medially (on the left) and phrase-finally (on the right), under accentuation ([+acc]) and in unaccented positions ([−acc]). Straight lines across the boxplots indicate the median, diamonds indicate the mean.
In order to normalise for speech rate differences that might affect absolute durations, a syllable timing metric was calculated as the logarithm of the durational ratio between the stressed and the unstressed syllable (see Sluijter & van Heuven Reference Sluijter and van Heuven1996). This ratio indicates whether or not an unstressed [a] displays a larger effect of word stress (relative to the stressed syllable) than a reduced [ɐ], as predicted by Vennemann (Reference Vennemann, Bertinetto, Kenstowicz and Loporcaro1991) and Wiese (Reference Wiese2000). If the first syllable is longer than the second, the ratios take negative values. The resulting log ratios are shown in Figure 5, and are broken down by phrasal position and by word-pair.
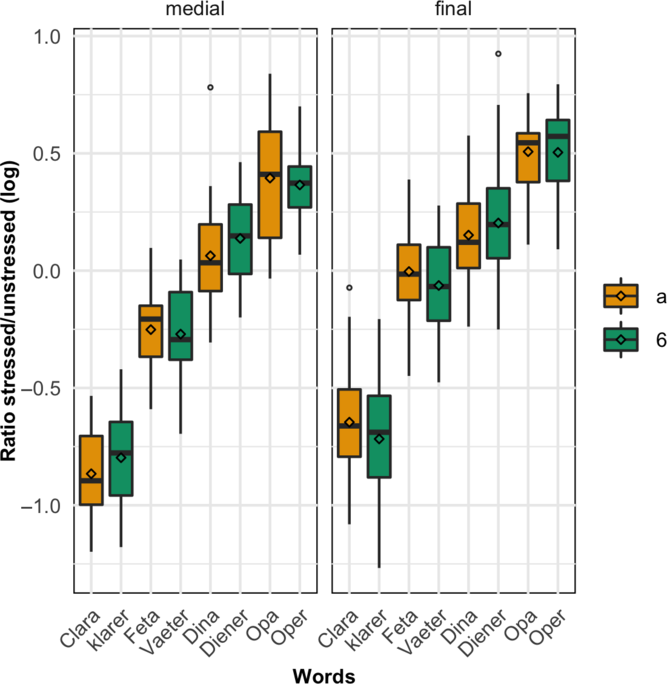
Figure 5 Normalised log-ratio durations of the stressed/unstressed syllables, displayed by target word pair and contrasting words with the full vowel /a/ (in brown) and words with the reduced vowel [ɐ] (annotated as 6, in green). Left: words in medial position; right: words in final position. 0 indicates that the stressed and the unstressed syllable are equal in duration; positive values indicate that the unstressed syllable containing /a/ or [ɐ] is longer. Straight lines across the boxplots indicate the median, diamonds indicate the mean.
As can be seen in Figure 5, the ratios are highly dependent on the word pair since the segmental composition of the first syllable varied from a very long duration (as in syllables with a consonant cluster and a long vowel, e.g. Clara/klarer) to a relatively short duration (as in syllables with a singleton or empty onsets and a long vowel, e.g. Opa/Oper). The difference between the two target vowels was thus tested for each word pair separately with speaker (but not token) as random effects. To avoid the type-1 error due to multiple pairwise comparisons, the alpha level was set to 0.0125 (deriving from 0.05/4). Phrasal position yielded significant main effects for all four word-pairs (see Appendix B, Table B3) whereas accentuation decreased the ratio only for the pair Feta/Väter. The word pair Clara/klarer showed a significant interaction between vowel quality and phrasal position which was lost once speaker M2 was excluded from the data set. For the word pair Dina/Diener, the interaction between vowel quality and accentuation was significant. After exclusion of M2, this interaction lost significance, though the model yielded a significant main effect of vowel quality, with larger ratios for Dina compared to Diener. One of the possible factors that might lead to a distinction between the two syllable durations in these words is the spelling difference. As was pointed out in the introduction, longer durations for the words ending in <er> could be expected because (i) there are more letters to represent one sound and (ii) the spelling is rather opaque with regards to its actual pronunciation.
So far, neither the raw vowel durations nor the ratios confirm these predictions for all word pairs. Since the differential spelling could also affect the duration of the whole word, Figure 6 presents these durations for medial and final positions. The effect of vowel identity was statistically tested for each word pair with the Bonferroni adjustment for multiple pairwise comparisons. All words lengthened significantly in phrasal position (see Appendix B, Table B4). Additionally, significant accentual lengthening was observed for word pairs Feta/Väter and Opa/Oper. The word pair that showed a significant effect of main interest here was Dina/Diener, with significantly shorter duration of the latter word. However, this finding is at odds with the hypothesis assuming a longer duration for a word with a higher number of graphemes. Given that the spelling of Diener has two letters more than the spelling of Dina (all other pairs differ in only one letter), the hypothesised effect is contrary to the present finding.
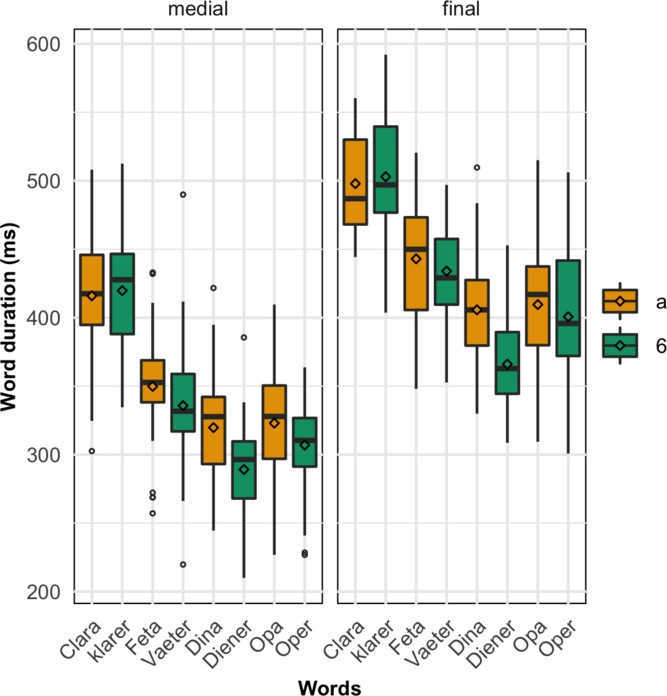
Figure 6 Word durations in milliseconds, displayed by target word pair and contrasting words with the full vowel /a/ (in brown) and words with the reduced vowel [ɐ] (annotated as 6, in green). Left: words in medial position; right: words in final position. Straight lines across the boxplots indicate the median, diamonds indicate the mean.
3.2 Perceptual identification
The sensitivity index d′ approached 0 across the overall dataset, though the subsequent analysis of variance showed a significant effect of stimulus speaker (F(1,5) = 2.8, p < .05). Figure 7 shows the percentage of correct responses broken down by speaker (Figure 7A) in comparison to accentuation (Figure 7B) and phrasal position (Figure 7C). For most speakers, the number of correct responses was close to chance (i.e.  $50\%$) while the perceptual identification of M2’s tokens at
$50\%$) while the perceptual identification of M2’s tokens at  $60\%$ was slightly (but significantly) better than chance. A by-item d′-analysis did not show any significant effects for any of the word pairs (see Figure 8).
$60\%$ was slightly (but significantly) better than chance. A by-item d′-analysis did not show any significant effects for any of the word pairs (see Figure 8).
Logistic mixed-effects models fit by maximum likelihood revealed a significant effect of phrasal position (df = 1, LRT = 7.2, p < .01) and stimulus speaker (df = 5, LRT = 53.7, p < .001). The effect of phrasal position indicated that tokens extracted from phrase-final positions were more often correctly identified than tokens taken from phrase-medial positions (see Figure 7C). The speaker effect was driven exclusively by the male speaker M2 whose stimuli were recognised correctly more often than tokens produced by any other speakers (see Figure 7A). Once the data from speaker M2 were excluded from the set, none of the tested factors reached significance. For the remaining speakers, there was a trend toward significance for accentuation (df = 1, LRT = 2.8, p = .0950), indicating that accented tokens were slightly more often correctly identified than the unaccented ones.

Figure 7 Proportion of correct answers for six stimulus speakers (A), two accentuation levels (B: unaccented, accented) and two phrasal positions (C: medial, final). The chance level is  $50\%$. Straight lines across the boxplots indicate the median, diamonds indicate the mean.
$50\%$. Straight lines across the boxplots indicate the median, diamonds indicate the mean.
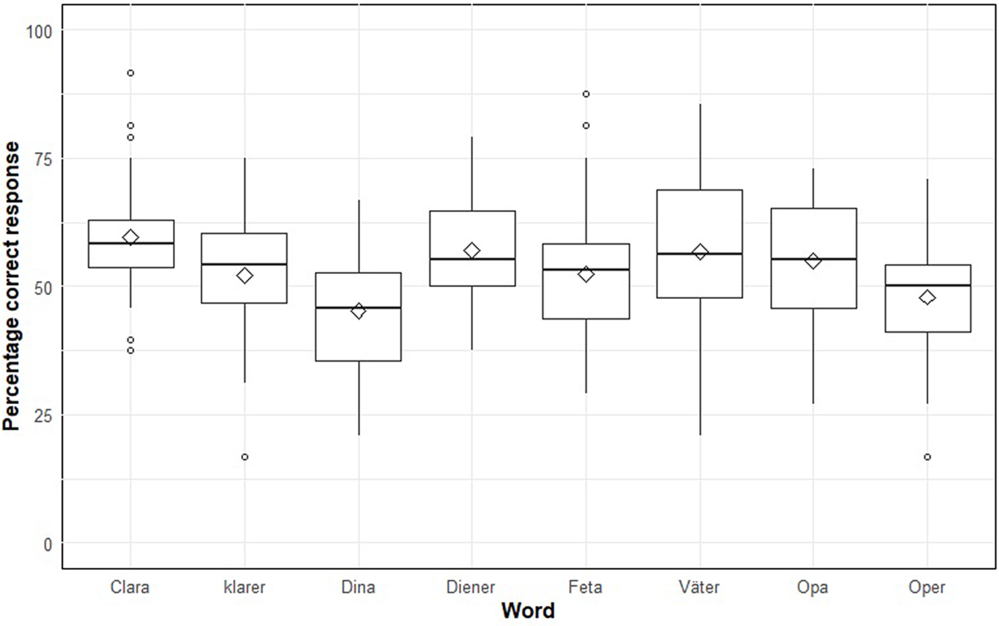
Figure 8 Proportion of correct answers for the eight target words of the study. The chance level is  $50\%$. Straight lines across the boxplots indicate the median, diamonds indicate the mean.
$50\%$. Straight lines across the boxplots indicate the median, diamonds indicate the mean.
4 Discussion and conclusion
4.1 Neutralisation of unstressed vowels
The results of both production and perception experiments presented here go hand in hand. While our acoustic analyses of the production data in Section 2.1 above show little difference between temporal measures, dynamic and static formant values of [a] versus [ɐ], results from the perception test with around  $53.5\%$ correct identification rates also suggest that the difference between [a] and [ɐ] is very subtle and therefore difficult to detect. Accentuation slightly enhanced the listener ability to distinguish between the two vowels, but the dataset did not provide the necessary statistical support for the associated hypothesis. Contrary to our hypothesis, identification scores were not consistently improved in phrase-final positions. Phrasal position had an effect on the perception of tokens produced by the outlier speaker though. M2’s vowels [a] and [ɐ] could be significantly better distinguished in phrase-final than in phrase-medial positions, as predicted (de Jong et al. Reference Jong, Beckman and Edwards1993, Piroth & Janker Reference Piroth and Janker2004, Cho Reference Cho2004; see Section 1.3 above). Speaker M2 was the only speaker out of the six speakers of the present corpus who produced consistently different vowel qualities as measured by F2 and F3, although no difference in F1 could be measured even in this speaker’s data. Given existing impressionistic descriptions of German (e.g. Hall Reference Hall1993; Kohler Reference Kohler1990, 1975/Reference Kohler1995; Meinhold Reference Meinhold and Slembek1989), a lower F1 for unstressed /a/ was expected. Thus, the difference between unstressed /a/ and [ɐ] is subtle, if at all present, in these speakers’ productions.
$53.5\%$ correct identification rates also suggest that the difference between [a] and [ɐ] is very subtle and therefore difficult to detect. Accentuation slightly enhanced the listener ability to distinguish between the two vowels, but the dataset did not provide the necessary statistical support for the associated hypothesis. Contrary to our hypothesis, identification scores were not consistently improved in phrase-final positions. Phrasal position had an effect on the perception of tokens produced by the outlier speaker though. M2’s vowels [a] and [ɐ] could be significantly better distinguished in phrase-final than in phrase-medial positions, as predicted (de Jong et al. Reference Jong, Beckman and Edwards1993, Piroth & Janker Reference Piroth and Janker2004, Cho Reference Cho2004; see Section 1.3 above). Speaker M2 was the only speaker out of the six speakers of the present corpus who produced consistently different vowel qualities as measured by F2 and F3, although no difference in F1 could be measured even in this speaker’s data. Given existing impressionistic descriptions of German (e.g. Hall Reference Hall1993; Kohler Reference Kohler1990, 1975/Reference Kohler1995; Meinhold Reference Meinhold and Slembek1989), a lower F1 for unstressed /a/ was expected. Thus, the difference between unstressed /a/ and [ɐ] is subtle, if at all present, in these speakers’ productions.
The finding that the vowels were not distinguished by duration is somewhat surprising, given how frequently this acoustic feature is exploited for a distinction in spectral vowel mergers (Labov & Baranowski Reference Labov and Baranowski2006, Fridland et al. Reference Fridland, Kendall and Farrington2014, Wade Reference Wade2017). Duration also plays a role in distinguishing between /a/ and vocalised /aʁ/ in stressed syllables that do not show any spectral differences due to /ʁ/-vocalisation (Ulbrich & Ulbrich Reference Ulbrich and Ulbrich2007). Neither the phonological nor the orthographic accounts helped to adequately predict vowel duration patterns in these data. This finding suggests that in the context of a merger, the systems of stressed versus unstressed vowels obey different principles. While non-spectral cues like duration are often exploited in stressed vowel mergers, unstressed vowels with their shorter durations do not seem to benefit from trading cue relations in a comparable way. Indeed, neutralisation of unstressed vowel contrasts has often been attributed to their short duration given that articulatory targets are more likely to be undershot if the articulators have insufficient time to execute the required movements, with open vowels being particularly affected (e.g. Lindblom Reference Lindblom1963, Flemming Reference Flemming2004). Vowel mergers in unstressed syllables are quite common in the languages of the world (for an overview see Crosswhite Reference Crosswhite2004), though short duration cannot be assumed to be the sole factor driving such effects (see Mooshammer & Geng Reference Mooshammer and Geng2008).
The results presented here generally showed a high level of agreement between the acoustic patterns found in the production data and their perception by a group of native German listeners, though there was also a discrepancy. More specifically, phrase-final tokens of the less-neutralising speaker M2 were better distinguished by the listeners than his phrase-medial realisations of the two vowels, though F2/F3 differed only slightly in his production of the two vowels across all prosodic contexts. While such discrepancies are not unprecedented in the context of ongoing mergers (Hay et al. Reference Hay, Warren and Drager2006), our study pointed out how such discrepancies may be moderated by prosody. The effect might be, at least partly, attributable to longer durations of target words due to the finality. Given that the vowel quality differences of the speaker’s productions were rather subtle across the board, and increase only slightly under accentuation, his phrase-final, longer vowels could be more salient in perception than his phrase-medial, shorter vowels. Moreover, phrase-final positions evoke less coarticulation than phrase-medial positions (see e.g. de Jong et al. Reference Jong, Beckman and Edwards1993, Byrd & Saltzman Reference Byrd and Saltzman2003, Cho Reference Cho2004) and can thus lead to less centralised vowel qualities.
Overall, these results do not support the interpretation of Vennemann’s (Reference Vennemann, Bertinetto, Kenstowicz and Loporcaro1991) account of German phonology put forward in Section 1.5 above, according to which phonologically different ‘vowel prosodies’ of the unstressed, full vowel /a/ on the one hand and the derived, reduced [ɐ] on the other would lead to different surface realisations regardless of their accentuation. The same holds for Wiese’s (Reference Wiese2000: 255) assumption that an unstressed /a/ should be ‘long, or at least longer’ than [ɐ]. An expected durational contrast due to an underlying phonological difference in the vowels’ affiliation with the syllabic tier cannot be corroborated by the data, though the results support Wiese’s (Reference Wiese2000) featural specification of unstressed /a/ and [ɐ] that does not distinguish between the two vowels.
4.2 Implications for description of Standard (Northern) German
The results of this study indicate that the difference between unstressed /a/ and [ɐ] tends to be neutralised in speakers of Standard (Northern) German. Clear acoustic-phonetic differences between the two vowels are absent in productions of minimal pairs, and listeners are not able to reliably identify tokens containing /a/ versus [ɐ]. Accordingly, word pairs such as Oper ‘opera’ and Opa ‘grandpa’ can be considered homophones rather than minimal pairs. Following the principles of the IPA (first published in 1888), there should be a one-to-one correspondence between a sound and its symbol, i.e. only detectably different sounds are to be represented by different symbols. This implies that at least in Standard (Northern) German, one symbol should be used for both unstressed /a/ and [ɐ]. Based on the visual inspection of the formant charts and trajectories in Figures 2 and 3, the unstressed vowel [a] is produced with a lower F1 than its long, stressed counterpart [aː], indicating a more centralised and closed articulation in the unstressed vowel production. Given that the dispersion ellipses of the unstressed [a] and [ɐ] overlap almost completely, their location in the F1/F2 formant space suggests a slightly less open quality than that of a stressed [aː] in these data, the most likely candidate for this merged quality would be the symbol for the dark schwa [ɐ], leading to the transcription [ʔoːpʰɐ] for both, Opa ‘grandpa’ and Oper ‘opera’. The advantage of this transcription seems not only empirically valid but also quite obvious in the context of foreign language teaching where a phonological approach to the vowel representation might be particularly misleading.
There is, however, at least one argument against this recommendation, namely the fact that a vocalic merger of this kind stems from a general articulatory process of vowel reduction due to target undershoot that affects all German vowels in a similar way (see Mooshammer & Geng Reference Mooshammer and Geng2008). Moreover, vowels in many languages undergo such target undershoot in unstressed or unaccented positions (see e.g. Beckman, de Jong & Lee Reference Beckman, Kenneth, Jun and Lee1992, Crosswhite Reference Crosswhite2004). The undershoot in German does not depend on shorter vowel duration in the absence of stress or accent per se, but is caused by an increase in coarticulation with the neighbouring consonants (Mooshammer & Geng Reference Mooshammer and Geng2008). Traditionally, this kind of vowel reduction is not marked in broad transcriptions of German since it is a direct consequence of prosodically weak positions and can thus be derived by a rule. Therefore, it seems debatable whether unstressed /a/ should constitute an exception.
Moreover, the present findings are necessarily restricted to the Northern variety of Standard German and are unlikely to generalise to other dialects. The phonetic dispersion of possible cross-dialectal realisations of the dark schwa is shown in Figure 9 (after Kohler 1977/Reference Kohler1995), and can include [ə], [ɐ], [ɑ], [ɜ] (Russ Reference Russ1990). According to Ulbrich & Ulbrich (Reference Ulbrich and Ulbrich2007), /ʁ/-vocalisation is a relatively recent phenomenon in German. In the 1960s and the 1970s, postvocalic coda-/ʁ/ was still mostly produced as a trill or a fricative (at least after short vowels), while 1990s saw the rise of ‘rhotacised vowels’ in all postvocalic contexts (Ulbrich Reference Ulbrich2002). These predecessors of modern vocalised rhotics were first observed in the context of a preceding long vowel in the early 20th century (Viëtor Reference Viëtor1901). Work by Ulbrich & Ulbrich (Reference Ulbrich and Ulbrich2007) demonstrates that the process of /ʁ/-vocalisation applies across all dialectal areas of German-speaking Europe and has been spreading from the north to the south. Accordingly, we predict that vowel neutralisations due to /ʁ/-vocalisation might be particularly advanced in the variety studied here while other, especially southern, varieties are likely to show some phonetic differences between unstressed /a/ and /əʁ/ in the same linguistic materials as used here.
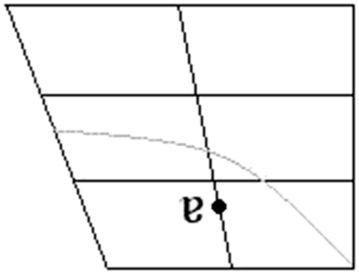
Figure 9 Cross-dialectal dispersion of [ɐ] in the vowel quadrilateral (after Kohler 1977/Reference Kohler1995: 165).
4.3 Conclusions and outlook
The present study found little evidence for a distinction between unstressed /a/ and [ɐ] in a small corpus of Standard Northern German, and we conclude that the vowel contrast is neutralised in this variety (see Ulbrich & Ulbrich Reference Ulbrich and Ulbrich2007). Our corpus included laboratory speech recordings rather than an unscripted speech database. If unstressed /a/ and [ɐ] were distinct vowel qualities, we would expect to find such different realisations primarily in the present type of data, but this was generally not the case. It is possible that we would find more hyperarticulated realisations of unstressed /a/ and [ɐ] under a corrective focus, e.g. in a “mishearing” scenario. Acoustic cues to a phonetic contrast in such explicit hyperarticulated contexts would benefit from further detailed analyses with respect to their spectral and durational cues. Additionally, the F0/F1 distance (see Traunmüller Reference Traunmüller1981) might be a promising phonetic cue to explore for these two vowels in different prosodic contexts. Moreover, the forced-choice identification task employed in the present study might have lacked the sensitivity that is required to tap into the perceptual processing of vowel neutralisations. More sophisticated online methods (such as e.g. eye tracking) might be more appropriate for observing the disambiguating effects of fine-phonetic detail in the acoustic signal of neutralised vowel contrasts.
The present study was based on a relatively small sample of six speakers and a geographically heterogenous group of listeners, and would benefit from a follow-up with larger, more homogenous groups of participants. Specifically, 44 listeners of our perception study came from diverse regional backgrounds, but were asked to respond to samples taken from the Standard Northern variety. We assumed that regional differences across German Standards would be negligible in read speech, though an effect of accent familiarity cannot be completely ruled out. However, such effects are known to affect online processing only temporarily (Floccia et al. Reference Floccia, Goslin, Girard and Konopczynski2006), and were accounted for in the statistical model of the perception data in the present study.
Acknowledgements
Parts of the data collection and preparation for analyses were carried out by Masters students at the Humboldt-Universität zu Berlin for course credit. We would like to thank all contributing students, with special thanks going to Johanna Bockelmann, Marie-Therese Ellert, Nico Friesenhan, Glen Generlich, Yelyzaveta Hiebert, Tatjana Malon, Friederike Naumann, Romy Sachs, Aleksandra Swiech, Monika Walak, Maria Yovcheva and Isabell Zander, and three anonymous reviewers whose comments helped us to improve the manuscript. We are further indebted to Raphael Winkelmann for his help with EmuR library.
Appendix A. Experimental materials (target words only)

Appendix B. Model summaries of the production data analyses
The factors included in the analyses and presented in Tables B1–B4 are as follows: VOW = vowel quality, ACCE = accentuation, PHR = phrase position, SEX = speaker sex, VOW*ACCE = interaction of vowel quality and accentuation, VOW*PHR = interaction of vowel quality and phrase position, VOW*SEX = interaction of vowel quality and speaker sex (see also Section 2.1.6 in the text).
Table B1 Results of linear mixed effects models for vowel quality (F1, F2 and F3).

Table B2 Results of linear mixed effects models for raw vowel duration (ms).

Table B3 Results of linear mixed effects models for vowel duration ratios comparing [a] and [ɐ] in each word pair separately.

Table B4 Results of linear mixed effects models for raw word duration comparing word pairs separately.

















 Open access
Open access