


Malagasy is the westernmost Austronesian language and belongs to the South East Barito subgroup of the Western Malayo-Polynesian subfamily (Dahl Reference Dahl1988, Rasoloson & Rubino Reference Rasoloson2005). Dahl (Reference Dahl1951) presents widely-accepted evidence that Malagasy is most closely related to the Indonesian language Ma’anyan of Kalimantan (South Borneo). The term Malagasy refers to a macrolanguage (Lewis, Simons & Fennig Reference Lewis, Paul, Simons and Fennig2014), with many regional dialects distributed throughout the island of Madagascar, which lies off the east African coast across from Mozambique (see Figure 1) and has a population of over 22 million (INSTAT 2018). The central area of the country, or the ‘Central Highlands’, is a plateau of up to 5000 feet and includes the capital city of Antananarivo, with a metropolitan population of about four million. The dialect historically spoken in and around Antananarivo is called Merina, and it served as the primary basis for development of the standardized, institutional language referred to as Malagasy Ofisialy ‘Official Malagasy’ (OM).

Figure 1 Location of the island of Madagascar off the east coast of mainland Africa. Reproduced from www.mapsopensource.com.
Knowledge of the linguistic relationships among dialects of Malagasy has been hampered by the influence of political interests. Ethnopolitical divisions imposed under colonial rule came to be understood as representing both ethnoracial and linguistic reality. However, as various authors have pointed out and as the speakers themselves note, these labels do not constitute linguistically accurate dialect descriptions. Both Raharinjanahary (Reference Raharinjanahary2004) and Adelaar (Reference Adelaar2013) mention that in some cases, multiple distinct dialects exist within a single named region, and that the differences may be extreme; varieties under a single label may actually belong to different linguistically-defined major dialect groups (Adelaar Reference Adelaar2013).
Following Malagasy independence in 1960, rigorous research of dialect differences and genetic classifications has been limited until more recently, in part due to political efforts to promote Malagasy cultural pride and national unity by downplaying dialect differences (O’Neill Reference O’Neill2015, Paul Reference Paul2015). Adelaar (Reference Adelaar2013) discusses linguistic evidence for genetic sub-groupings of Malagasy dialects and concludes that the balance of the evidence indicates a basic division between a Southwestern and Western dialect grouping and a grouping of the Central, Northern and Eastern dialects (regions delineated in Figure 2). He further presents phonological evidence of a Central subgroup and indicates various ways in which the Merina dialect is particularly innovative. The Central group identified by Adelaar and discussed herein includes the Merina, Betsileo, Sihanaka, Tanala, Tambahoaka, Eastern Bara, and Bezanozano dialects. Within this group there is still variation in the phonetic realization of some phonemes; this is indicated and exemplified in the discussion where the data are available.Footnote 1
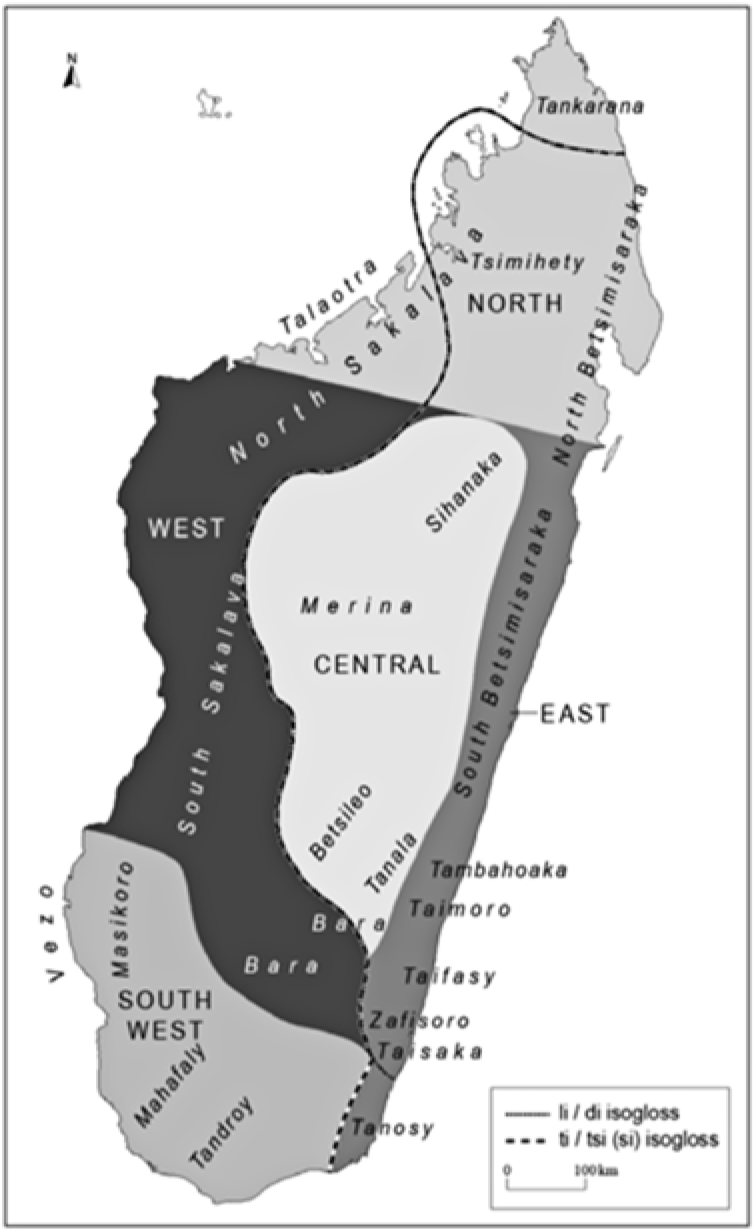
Figure 2 Boundaries of dialect subgroupings. Reproduced from Adelaar (Reference Adelaar2013: Map 1).
The recordings and experimental data for this study were collected by the author beginning in 2012, and the majority of the analysis is based on Howe (Reference Howe2017), which analyzed recordings of 61 speakers from the Central region. Recordings were of lists of lexical items embedded in a carrier phrase in a position of phrasal prominence, as well as sociolinguistic interviews with some participants. Where initials are used to identify speakers in the current work, they correspond to those found in Howe (Reference Howe2017) (except speaker WR, recorded in 2018 and 2019). The formant data are based on wordlist recordings of 15 out of the 61 speakers. The transcription of ‘The North Wind and the Sun’ is from a recording of male Betsileo speaker WR made in 2018 in Antananarivo.
Consonants
The consonant phonemes of the Central dialects are presented in the table below. Segments which are phonemic only in certain dialects within the Central region are enclosed in parentheses. An example for each segment with associated orthography is given below the table.
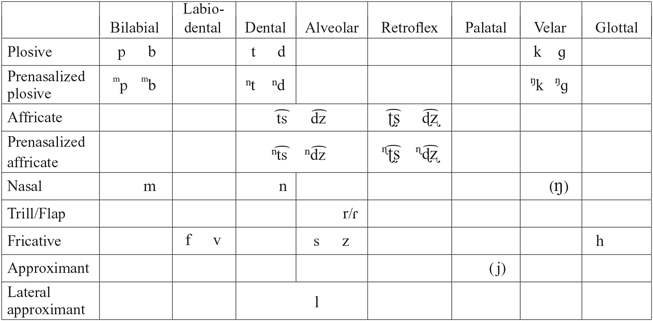

The chart above follows the orthography and traditional descriptions of OM and many individual dialects (e.g. Dahl Reference Dahl1952, Dez Reference Dez1963, Rakotofiringa Reference Rakotofiringa1982, Poirot Reference Poirot2011, O’Neill Reference O’Neill2015) in indicating a phonemic voicing distinction at every place of articulation for all obstruents except the glottal fricative. These earlier descriptions, however, already recognized variability in the use of modal voicing on obstruents of both voicing classes due to phonetic context and stress patterns; some also noted the presence of secondary phonetic cues to the phonemic distinction, including differences in fundamental frequency (f0) contours on following vowels (Dahl Reference Dahl1952, Rakotofiringa Reference Rakotofiringa1982). More recently, Howe (Reference Howe2017) provided extensive evidence from both production and perception that, at least in the oral obstruent series, this voicing distinction is now significantly reduced in the Central dialects, and f0 has replaced modal voicing as the primary acoustic cue to these contrasts. The former obstruent voicing contrasts are therefore better described as phonological tone contrasts following voiceless obstruents. This is exemplified in more detail in the sub-sections below for each consonant type and in the section ‘Tone’.
Plosives
Plosives occur in three places of articulation, as shown above. Previous descriptions disagree concerning the precise place characteristics of the coronal plosives (Thomas-Fattier Reference Thomas-Fattier1982, O’Neill Reference O’Neill2015), which are variably described as dental (Dez Reference Dez1963, Rasoloson & Rubino Reference Rasoloson2005), denti-alveolar (Dahl Reference Dahl1952), or alveolar (Rakotofiringa Reference Rakotofiringa1982). Without performing focused articulatory experimentation, the current dataset and the author’s experience listening to and speaking the language suggest that they are best described as dental in Central Malagasy.
Whereas previous works describe a primary phonological voicing distinction at each place, with the voiced series often displaying negative voice onset time (‘negative VOT’, i.e. voicing initiated before the release burst) or long voicing ‘bleed’ into the closure (i.e. voicing from a preceding vowel continuing through a large portion of the closure), the analysis presented in Howe (Reference Howe2017) indicates that for the Central dialects, the voicing distinction is minimal. Both plosive series display positive VOT values, typically ranging between 15 ms and 50 ms and generally greater when preceding high vowels and in velars. While /p t k/ are more likely than /b d g/ to include slight aspiration, the difference in VOT between minimal pairs is typically on the order of only 10–20 ms and is not consistent across lexical items and speakers. The difference in duration of voicing bleed before /p t k/ as opposed to /b d g/ is also much less than that observed in languages with a true voicing contrast (Davidson Reference Davidson2016, Howe Reference Howe2017). The more striking difference between the two plosive series is found in the f0 contours of the following vowels, where high f0 consistently follows /p t k/ and low f0 follows /b d g/. The minimal and near-minimal pairs in (1a–c) are produced by an older Merina speaker (ER) who exhibits the combination of VOT and f0 distinctions described above. The pair in (1d), from Merina speaker TR3, illustrates the increase in VOT preceding high vowels and following velars:
(1)


In (2) and (3), examples are presented from speakers of the Betsileo (MAIA) and Tanala (LAA2) dialects, respectively. These two speakers make no VOT duration distinction between plosives sharing the same place of articulation, and aspiration intensity is only marginally greater if at all for the /p t k/ series.
(2)
(3)


Lenition of the /p t k/ series is also common, particularly in unstressed syllables. Voicing bleed from a previous vowel may persist through the entire closure, with little or no release burst evident. This can be seen in the /t/ in mikatona [miˈkʰát̬ʊ́nǝ] ‘be closed’, produced by Merina speaker KA, and in the /p/ and /k/ in tapaka [ˈtáp̬ák̬ә] ‘cut off’, produced by Tanala speaker LAA2. Spectrograms are provided in Figure 3, where slight voicing is evident throughout the closure periods.
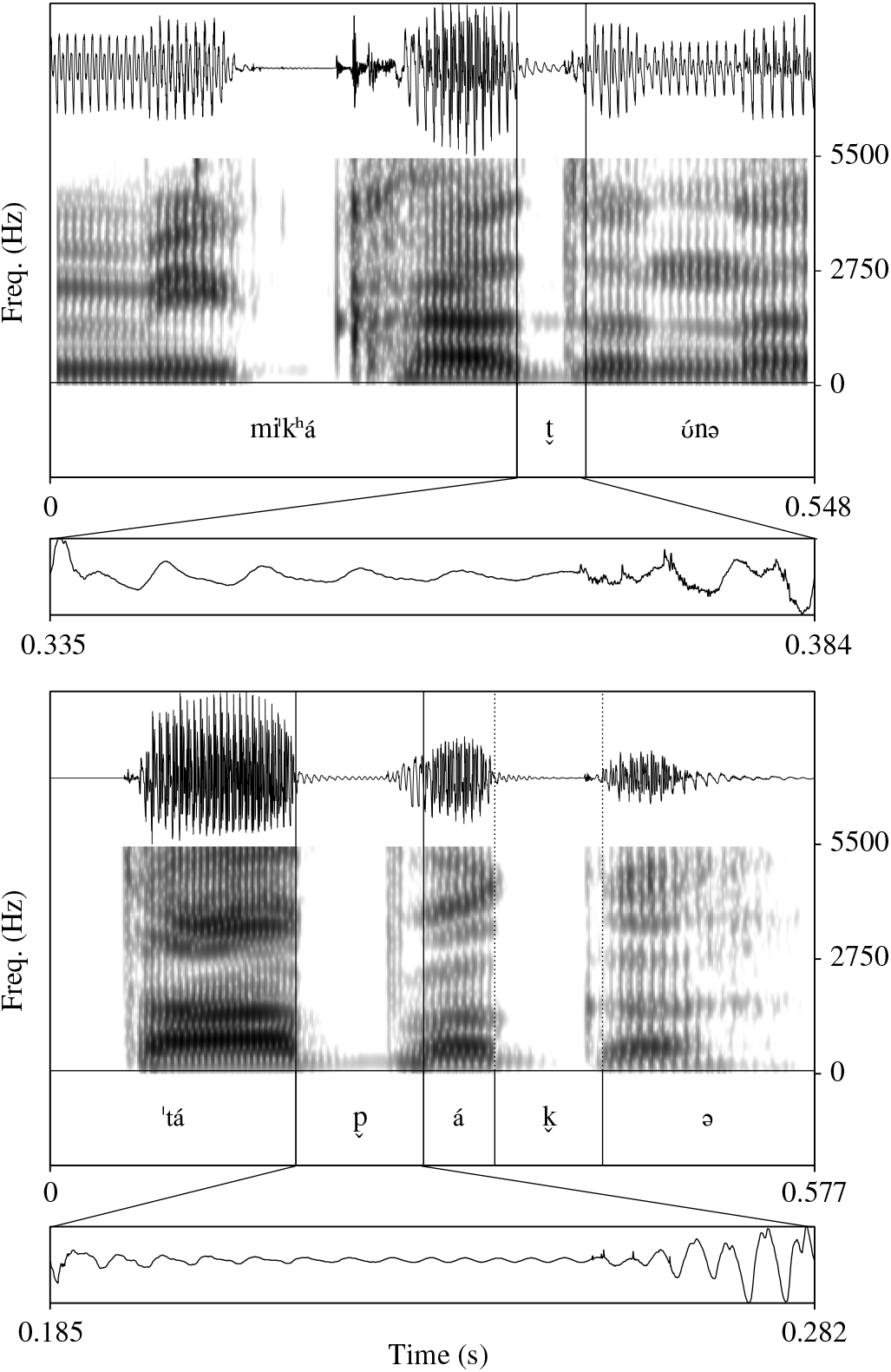
Figure 3 Spectrograms and waveforms of mikatona [miˈkʰát̬ʊ́nǝ] ‘be closed’ and tapaka [ˈtáp̬ák̬ə] ‘cut off’, where unstressed phonologically voiceless plosives are phonetically voiced.
The velar plosives /k/ and /g/ are often produced as palatalized variants [kJ] and [gJ] following the monophthong /i/ or the diphthong /ai/. The palatalization can occur whether or not the preceding /i/ is realized in full, unreduced form, and is most apparent in unstressed syllables occurring after the syllable with primary stress. This can be heard in the Merina speaker’s productions in (1a) above, and also in voapotsika [ˌv̥òˈpú͡tsʲkʲɛ] ‘mashed’, antsika [aˈn͡ʦikʲɛ́] ‘us (1pl, obj)’, and tsipika [ˈ͡ʦípʲkʲɛ] ‘line’ produced by Betsileo speaker HT. In stressed syllables, this palatalization may be much less prominent, as in the voiced example in (1c) above and in KA’s production of mikatona [miˈkʰát̬ʊ́nǝ] presented above. For some speakers, however, strong palatalization is also audible in this context (e.g. MAIA: migadogna [mʲˈɡ̥ʲàdʊ̀ŋa] ‘fall down’, mikatona [mʲˈkʲátʊ́na] ‘be closed’). Speakers of the Tanala dialect do not exhibit this palatalization process, as can be heard in example (3) above and in speaker LAA2’s productions of tsipika [sípʲka] ‘line’ and mikatona [miˈkátʊ́na] ‘be closed’ and speaker FZ’s productions of bika [ˈb̥ìká] ‘shape’ and antsika [ãsiká] ‘us (1pl, obj)’.
Fricatives
As described by Dahl (Reference Dahl1952) and Rakotofiringa (Reference Rakotofiringa1982), the fricatives /f/ and /v/ are labiodentals, articulated in the canonical place just behind the top of the lower lip. The fricative pair /s/−/z/ displays much more interdialectal and interspeaker variation in terms of place and manner of articulation, ranging from denti-alveolar to postalveolar and varying between apical and laminal productions. The aforementioned authors also note that /s/ and /z/ are often slightly palatalized in the Betsileo dialect and sometimes in the Merina dialect. However, the current dataset finds this palatalization primarily in the Betsileo and Tanala dialects rather than in Merina.Footnote 2 The examples in (4)–(7) demonstrate variation in the place of articulation of /s/ and /z/.
(4)
(5)
(6)
(7)
The Merina speaker (ER) in example (4) exhibits an anterior production, the Betsileo speaker (TAR2) in (5) exhibits a slightly retracted and more apical production, and the Tanala (LAA2) and Eastern Bara (EARD) speakers in (6) and (7) exhibit an even greater degree of palatalization.
As in the case of the plosives, athough they recognize the possibility of partial devoicing of /v/ and /z/, prior accounts describe the bilabial and alveolar fricative pairs as primarily distinguished by the presence or absence of modal voicing (Dahl Reference Dahl1952, Rakotofiringa Reference Rakotofiringa1982). The current data again show, however, that for many speakers, modal voicing distinctions are virtually absent, while contrasts in f0 contours are significant. Devoicing of /z/ is evident in examples (4) and (5) above, while examples (8)–(10) demonstrate devoicing of /v/.
(8) HLR (Betsileo)
(9) MVR (Merina)
(10) TAR2 (Betsileo)



Contrasts in f0 are most evident when comparing minimal pairs such as in (4), (8) and (9). On average for the entire group of Central dialect speakers, Howe (Reference Howe2017) found that intensity of frication noise was slightly greater for /s/ and /f/ than for /z/ and /v/. However, this is not true for all individual speakers, as can be seen in examples (4) and (8), where the two fricatives in each minimal pair have approximately the same intensity. Furthermore, in examples (9) and (10), the speakers’ stressed /v/ tokens have higher intensity than stressed /f/. Duration, on the other hand, does serve as a secondary acoustic distinction between fricative pairs (Howe Reference Howe2017). The ratio of consonant to vowel duration is greater in syllables with /f/ and /s/ than with /v/ and /z/; while differences in following vowel length make a larger contribution to the difference in this ratio, absolute durations of /f/ and /s/ are also slightly greater than those of /v/ and /z/. This is exemplified in (4), (5) and (8)–(10) above, where duration differences range from about 12–60 ms (or about 9–30% of the longer token).
The glottal fricative /h/ is also part of the Malagasy phoneme inventory, although as Dahl (Reference Dahl1952) notes, phonetic realization of /h/ is highly variable in terms of voicing and nasality, being strongly influenced by the surrounding segments. Rakotofiringa (Reference Rakotofiringa1982) notes that in the Merina dialect, /h/ is often elided completely. This is confirmed by the current dataset, which finds that /h/ elision is especially common in unstressed syllables for both Merina and urban Betsileo speakers. The examples in (11)–(12) are from a Merina speaker (SR), who sometimes produces an audible [h] when the syllable carries primary stress, as in (11), but often exhibits elision of /h/ in both stressed and unstressed syllables, as in (12a, b).
(11)
(12)

In example (13), Betsileo speaker (TAR2) also elides unstressed /h/.
(13)
Elision of /h/ often occurs even when it carries significant syntactic information in the future tense marker h- on verbs taking the patient focus prefix a-, resulting in homophony between the present and future forms (e.g. atao ‘do (pf, prs)’ vs. hatao ‘do (pf, fut)’, recordings not available). As observed for the alveolar fricatives, manner of production of /h/ is also subject to overt social commentary within the Central urban regions, with exaggerated enunciation of /h/ used to joke or to mimic speakers of some dialects, such as rural Betsileo speakers.
In Tanala and Bara, particularly among older speakers, /h/ is not elided. Tanala speaker FZ produces [h] in both stressed and unstressed syllables: hery [ˈheri] ‘strength’, fiarahana [ˌfíaˈraɦana] ‘companionship’, mahagaga [ˌmah̩ˈɡ̥àɡà] ‘cause surprise’. In the unstressed syllable in mahagaga, it is the vowel, rather than /h/, which is elided. This contrasts with the Merina speaker’s production of the same lexical item in (12), where the vowel of this syllable is produced despite elision of /h/, resulting in a surface form which contains a long vowel [aː].
Although Andrianasolo (Reference Andrianasolo1993: 171) suggests that this effective vowel lengthening is used regularly in /h/-eliding dialects to avoid collapse of meaning contrasts, it is in fact most likely confined to careful speech and citation forms. In many cases, /h/-elision can and does result in homophones, such as in the pairs produced by Betsileo speaker WR in (14).
(14)

When the vowel qualities differ between the preceding syllable and the syllable containing /h/, the result is vowel hiatus, as in matahotra [maˈtáʊʈ͡ʂə̥] ‘be afraid’ (ER, Merina) and mihasoa [ˌmiaˈsúǝ] ‘improve’ (TAR2, Betsileo). The length of these vowel hiatus sequences and the intensity curves differentiate them from diphthongs (see section ‘Vowels’ below).
Affricates
The affricate pair /t͡s/–/d͡z/ is apical, with place of articulation ranging from dental to alveolar. Previous works again describe a primary voicing distinction between these two phonemes (Dahl Reference Dahl1952, Rakotofiringa Reference Rakotofiringa1982); according to Dahl (Reference Dahl1952: 182), /d͡z/ is entirely voiced when in medial position, while voicing may begin shortly before the closure release in initial position. Frication intensity was also observed in these earlier studies to be stronger in /t͡s/ than in /d͡z/. In the current dataset, however, as described for the plosives and fricatives, voicing distinctions are minimal for most speakers, while f0 distinctions are large. The examples in (15) and (16) are from Merina speakers TR3 and NSA, respectively, who both exhibit little difference in frication intensity between the two sounds, strong f0 distinctions, and devoicing of /d͡z/ in both initial and medial positions (although there is slight voicing bleed into the initial closure in jipy).
(15)
(16)
Among Merina speakers, as in the preceding examples, there is typically a clear closure and a period of frication that is significantly shorter than in a simple fricative. However, in fast, connected speech, particularly in medial, unaccented syllables, the closure portion may be very reduced, as in speaker TR3’s production of betsaka [ˈb̥èt͡sákḁ] ‘many’, extracted from an interview recording.
In other Central dialects, such as Tanala and Betsileo, speakers may regularly omit the closure portion, producing these phonemes as simple fricatives, with duration of frication similar to that in /s/ and /z/. Devoicing of the voiced phoneme also occurs in these cases. This is illustrated for Tanala (FZ) in (17) and Betsileo (ANEJR) in (18).
(17)
(18)
As also reported by Dahl (Reference Dahl1952), realization of the alveolar affricates as fricatives does not entail a phonemic merger, as speakers who exhibit this pronunciation also tend to use a more retracted place of articulation for the fricative phonemes, so that place rather than manner becomes the main distinction between /s/–/z/ and /t͡s/–/d͡z/. Indeed, the speaker from (17) produces zaka [ˈʐ̥àká] ‘endured’, while the speaker from (18) produces misasa [m̩ʲˈʂáʂɘ̥] ‘wash oneself’.
The second affricate pair, /ʈ͡ʂ/–/ɖ͡ʐ/, also exhibits a good deal of variability in place and manner of articulation among speakers and dialects. These sounds are often retroflex, but may be produced with the top, tip, or bottom of the tongue depending on the speaker; some authors also describe these as post-alveolar affricates produced with the tongue blade (O’Neill Reference O’Neill2015, citing Rajaonarimanana Reference Rajaonarimanana1995). Compared with the denti-alveolar affricates, omission of the closure portion of these sounds is less common, although it may again be significantly lenited word-medially in fast speech (Dahl Reference Dahl1952, Rakotofiringa Reference Rakotofiringa1982). The frication portion is generally shorter than in the denti-alveolar pair. As for all other oral obstruent pairs, the Central dialects have shifted from a primary voicing distinction on these sounds (Dahl Reference Dahl1952) to a primary f0 distinction (Howe Reference Howe2017). The speakers in (19) and (20) exhibit differences in place/manner characteristics.
(19)
(20)
Merina speaker FTA in (19) produces a post-alveolar affricate with the tongue blade, with significant devoicing of /ɖ͡ʐ/ and no difference in frication duration between the two affricates. Tanala speaker FZ’s productions in (20) are more apical/retroflex, devoicing of /ɖ͡ʐ/ is less evident, and there is a slight distinction in frication duration. Betsileo speaker TAR2’s production of tratse [ˈʈ͡ʂát͡sɛ́] ‘chest’ clearly illustrates the difference in place of articulation between /ʈ͡ʂ/ and /t͡s/.
Some speakers, particularly of the Betsileo dialect, sometimes produce stop–trill articulations rather than affricates for the retroflex pair. This seems to occur primarily in unstressed syllables, as in JR4’s production of trotraka [ˈʈ͡ʂúʈ̬͡rə́ka̤] ‘exhausted’ (in which the unstressed consonant is also voiced). It may also be more common as a realization of /ɖ͡ʐ/ than of /ʈ͡ʂ/, though the current dataset cannot properly address this, as /ɖ͡ʐ/ is a relatively rare phoneme.
Prenasalized obstruents
There is some disagreement in the literature concerning the analysis of the prenasalized obstruents as single phonemes versus nasal–obstruent clusters arising from word-medial coda nasals (see O’Neill Reference O’Neill2015). It is not necessary to take a stance on this issue in order to describe their phonetic characteristics here; however, we note that the licensing of word-initial prenasalized sounds in a syllable structure that allows only simplex onsets (see section ‘Syllable and word structure’ below), the lack of word-final nasal codas, and speakers’ production when asked to syllabify words containing prenasalized sounds all lend support to the single-phoneme analysis.
As indicated in the consonant chart, the oral plosives and affricates all have prenasalized counterparts. The prenasalized and oral consonants have the same duration, averaging around 150 ms (Howe Reference Howe2017). As in the oral consonant series, the plosive and/or frication portions of these sounds are often devoiced in both members of the pair at each place of articulation; f0 distinctions on following vowels are only slightly smaller in magnitude than those observed for the oral consonants.Footnote 3 However, duration of voiced nasalization during the closure portion remains a major cue to the voicing distinction for these phoneme pairs. Nasalization persists through less than 50% of the closure in the voiceless sounds, but for the voiced sounds, it persists through significantly more than 50% of the closure, sometimes all the way through the release (Howe Reference Howe2017). Merina speaker FTA produces fully-voiced tokens of /nd/ and /mb/: andany [aˈndànɪ] ‘on the one hand’, an-tany [aˈntánɪ] ‘on earth’, ambaka [aˈmbàká] ‘inferior to’, ampaka [aˈmpáká] ‘marble game’. Betsileo speaker TAR2’s prenasalized affricates are both devoiced in the frication portion in amoron-drano [aˌmurʊˈɳɖ͡ʐ̥ànu] ‘water’s edge’ and iantrana [ˌiaˈɳʈ͡ʂánə] ‘be treated compassionately’, but again there is a significant difference in the duration of nasalization in the closure.
Although some have claimed that voiceless prenasalized sounds are not allowed in initial position, arguing that the orthographic representation is purely a diachronic remnant and the synchronic realization is a simple oral consonant (see discussion in Rakotofiringa Reference Rakotofiringa1982), the current dataset includes several tokens in which these sounds are fully-realized in initial position, such as in Merina speaker ER2’s production of ntaolo [ˈntó.lʊ] ‘ancestors’. (Note, however, that Rasoloson & Rubino 2005 claimed that this particular lexical item is an exception to the prohibition.) In other cases, as also mentioned by Rakotofiringa (Reference Rakotofiringa1982), the nasal component of an initial prenasalized sound may be present, but devoiced, and thus difficult to detect. For example, there seems to be a short but audible voiceless nasal at the beginning of Betsileo speaker WR’s production of mpanjaka ‘sovereign’ (presented in the initial consonant chart above). Additionally, although no devoiced nasal is apparent prior to the release of the plosive, there is an impression of slight nasalization during the release and in the beginning of the following vowel in WR’s production of mpiasa [p̃ĩ́ˈasḁ] ‘worker’, when compared with a /p/-initial word such as patsa ‘small shrimp’ (exemplified above). Further study would be necessary to determine the extent and regularity of this nasalization across speakers and dialects.
This reduction in voiced nasalization on word-initial voiceless prenasalized consonants may also be part of a more general trend towards loss of voiced nasalization on these sounds in all positions in some Central dialects. Dahl (Reference Dahl1952) already commented on this loss of nasalization, stating that in Betsileo, the voiceless prenasalized segments are in the process of merging with their respective voiceless oral counterparts. The neighboring Bara dialect exhibits this reduction as a rule, indicating a possible areal feature (Adelaar, personal communication). Although no stance is taken here as to whether a true phonemic merger is taking place, in the current dataset there are indeed many word-medial tokens of both stressed and unstressed voiceless prenasalized consonants produced by Betsileo speakers in which the voiced nasalization seems to be absent or is realized as nasalization on the preceding vowel. For example, TAR2 produces antsasany [aˈt͡sásánɪ] ‘half of it’ and iantranao [iˌaʈ͡ʂáˈnaʊ] ‘you treat compassionately’ with no apparent nasalization. HJDR produces kintana [ˈkĩ́tána] ‘star’ and antsika [ãˈsíkʲá] ‘us (1pl, obj)’ with nasalization on the preceding vowel rather than during the consonant closure, which in the latter case is omitted (/t͡s/ realized as [s]). PR produces an-tagny [ãˈn̥táŋɪ] ‘on earth’ with very little voiced nasalization, and in mpampianatra [ˈm̥pám̥píˈanaʈ͡ʂə] ‘teacher’, the initial and medial tokens of /mp/ are nearly identical.
Although they are not lexically common, voiced prenasalized consonants are licensed in initial position, and the voiced prenasalization is typically realized. For example, Betsileo speaker WR produces mbizo [ˈmbìʐ̥u̥] ‘sweet potato’, ndao [ˈndàu] ‘let’s go’, ngeza [ˈŋɡèʐ̥ḁ] ‘great; very large’, and ndry [ˈŋɖ͡rì] ‘you (2sg, f, fam)’.
The palatalization process described for oral velar plosives following the vowels /i/ and /ai/ can also occur with the prenasalized velar plosives as in mihaingo [miˈhaiŋɡ̥ʲu̥] ‘decorate oneself’ produced by Betsileo speaker TMOCR. Some speakers also produce a trill rather than frication in the prenasalized retroflex affricates, as in andrefana [aˈɳɖ͡rèfə́nə] ‘west’ and an-drano [aˈɳɖ͡rànu] ‘at the water’ produced by Betsileo speaker JR4.
Sonorants
The nasals /m n ŋ/ are generally fully voiced, although assimilatory devoicing may occur when an unstressed vowel between a nasal and a voiceless obstruent is sufficiently reduced (Dahl Reference Dahl1952, Rakotofiringa Reference Rakotofiringa1982). Both anticipatory and perseverative nasalization of adjacent vowels are common.
Within the Central dialect group, and perhaps among all dialects of Malagasy (Dahl Reference Dahl1952 and Dez Reference Dez1963 disagree on this point), Merina is the only dialect which lacks phonemic /ŋ/, having merged it with /n/. O’Neill (Reference O’Neill2015) cites Deschamps (Reference Deschamps1936) as stating that only Merina spoken in the city lacks /ŋ/, whereas the Merina of the countryside maintains it. This apparent urban–rural distinction may also reflect a difference between the Merina dialect and OM, which are of course different, despite popular belief. The data from Merina speakers available for the current study do not indicate presence of phonemic /ŋ/. The sound [ŋ] does, however, appear in all dialects due to place-assimilation in both morphophonologically-introduced and lexeme-internal prenasalized velar plosives. Finally, as for the velar plosives, a preceding /i/ or /ai/ vowel can cause palatalization of the velar nasal /ŋ/, as in production of the word rindrigna ‘wall’ by Betsileo speakers HT [ˈriɳɖ͡ʐiŋʲa] and ANEJR [ˈriɳɖ͡ʐiŋʲḁ].
While most Central dialects have undergone the change *j > z, Adelaar & Kikusawa (Reference Adelaar2014: 488) and Adelaar (Reference Adelaar2018) indicate that /j/, a retention from Old Malagasy, remains phonemic in some lexemes in the Tanala dialect, as well as in some other non-Central dialects. The current dataset cannot offer significant further insight on this matter, although we note that the pronoun form iaho ‘1sg, nom’ exemplified above, which Adelaar cites for Tanala, is also common in Betsileo. In other Central dialects, this has become izaho [iˈz̥àu]. Similarly, aia [ˈai̯ja] ‘where?’ is common in Betsileo, while other Central dialects have aiza [ˈaizà] ‘where?’.
The phoneme /r/ may occur as a short alveolar trill in most dialects, including Merina, but is often reduced to an alveolar tap [R] in fast speech (O’Neill Reference O’Neill2015: 37, citing Albro Reference Albro2005). Although it has been claimed that realization of /r/ is contextual, with the trill occurring in initial position and the tap occurring elsewhere (O’Neill Reference O’Neill2015, citing Thomas-Fattier Reference Thomas-Fattier1982), speakers in the current dataset produce either allophone in either context. For example, Betsileo speaker JR4 produces trills initially and medially in the following: rano [ˈranu] ‘water’, atoraka [aˈtúrəka] ‘to be thrown’. Betsileo/Merina speaker HR2 produces an initial trill in ritsa [ˈrit͡sḁ] ‘evaporated’ and a devoiced medial trill in tery [ˈtér̥I̥] ‘narrow’, but a medial tap in orana [ˈuſana] ‘rain’. As mentioned above, speakers whose /r/ is prominently trilled sometimes, though not always, produce orthographic sequences dr and tr (and ndr and ntr) as stop–trill combinations rather than as affricates.
Whereas the trill variant is common in Betsileo, many bilingual speakers in Antananarivo use a more retracted, fricated variant for /r/; as suggested by Rakotofiringa (Reference Rakotofiringa1982: 544–545), this is due to influence from French. Rakotofiringa (Reference Rakotofiringa1982) indicated that these speakers use a voiced uvular trill [R] for this phoneme; I have observed use of the uvular fricatives [χ] and [ʁ], mirroring the French sound. For example, speaker ALJM uses uvular fricatives in the following: rano [ˈχanʊ] ‘water’, ritra [ˈχiʈ͡ʂá] ‘evaporated’, torana [ˈtúʁ”ana] ‘unconscious’.
The voiced lateral approximant /l/ varies between alveolar and denti-alveolar places of articulation and is generally produced using the top of the tongue tip (Dahl Reference Dahl1952, Rakotofiringa Reference Rakotofiringa1982). The following examples from speaker WR suggest that presence of a back vowel following /l/ favors the alveolar production: lavitra [ˈl̪av̥ʲʈ͡ʂa] ‘far’, leo [ˈl̪eu] ‘disgusted’, lalaovina [l̪aˈlovə̀na] ‘be played with’, loka [ˈluká] ‘a bet’.
Vowels
Monophthongs
Descriptions of OM and/or Merina typically identify only four phonemic monophthongs (see Rasoloson & Rubino Reference Rasoloson2005, O’Neill Reference O’Neill2015). However, because collapse of orthographic vowel sequences ao and oa from diphthongs or vowel hiatus pairs into a fifth monophthong, [o], is now so common in Merina and in other urban dialects in the Central region (e.g. in the Betsileo city of Fianarantsoa), all five are presented in the vowel chart below and in the formant plot in Figure 4 below. Examples of the vowels follow subsequently.
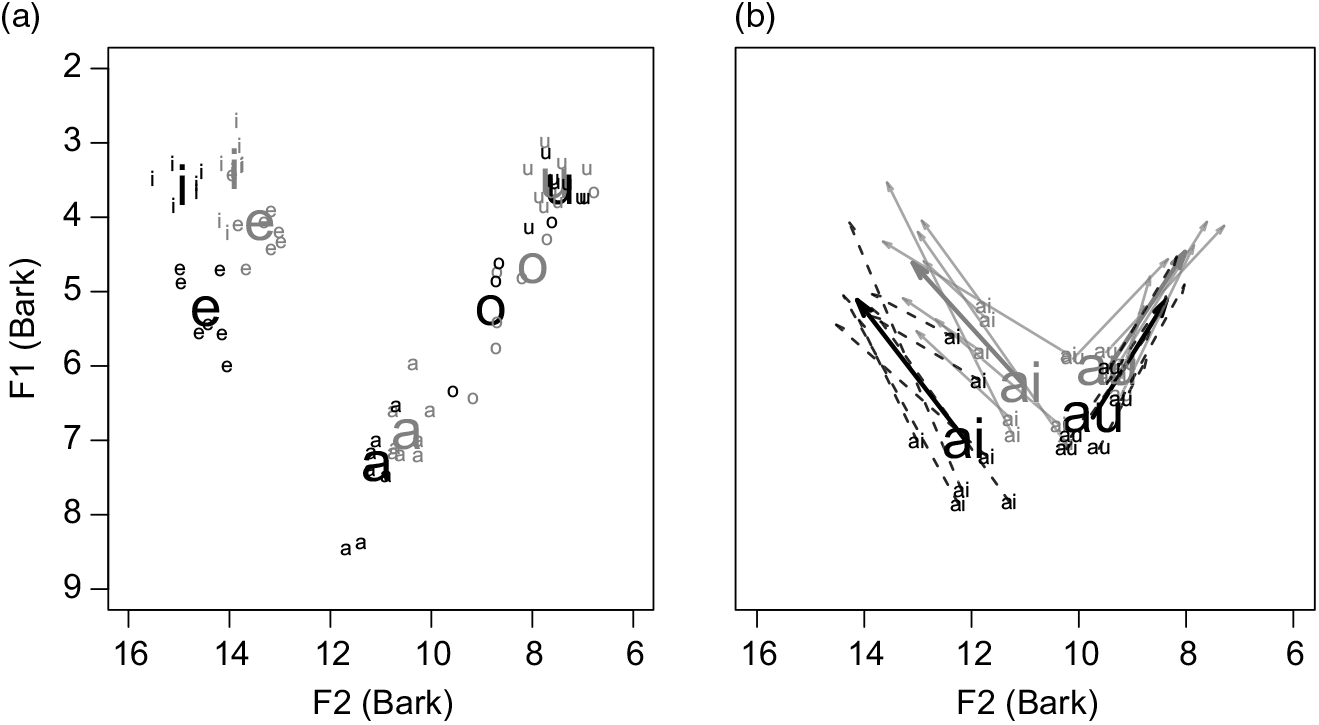
Figure 4 Vowel charts for (a) monophthongs and (b) diphthongs. Group averages (large) and individual speaker averages (small) for seven females (black) and eight males (gray).
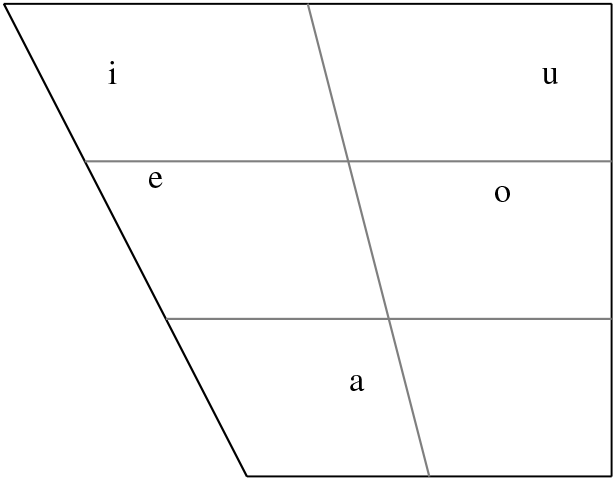

As seen in the above examples, orthographic a, e, and i correspond to their identical IPA symbols, while orthographic o represents /u/. Rakotofiringa (Reference Rakotofiringa1982) argued for the phonemic status of /o/ in Merina, a development which he viewed as phonetically expected given the imbalance in formant space inherent in the four-vowel system. To my knowledge, however, and as discussed by Rasoloson & Rubino (Reference Rasoloson2005) and O’Neill (Reference O’Neill2015), there are no minimal pairs in the Central dialects which distinguish a phoneme /o/ from the diphthong /au/ or the vowel hiatus sequence /ua/; rather, for some speakers, [o] is an allophone of both of these vowel sequences which occurs in complementary distribution, with the diphthongal or hiatus realization usually occurring word-finally and the monophthong elsewhere. Some very common lexical items, however, are exceptions to this rule, especially in the Merina dialect; for example, vao [vò] ‘just’ (see section (vi) of the transcribed passage below), izao [Iˈz̥ò] ‘now’, and atao [aˈtó] ‘be done’, among others. Orthographic convention uses the symbol ô for the sound [o] in non-Central dialects that have phonemic /o/, and sometimes this is also used by Central dialect speakers to replace oa or ao in informal written contexts.
In Merina and Betsileo, at least, /e/ is realized as the allophone [i] in syllables following the syllable bearing primary lexical stress (Dahl Reference Dahl1952: 154). The phonemic distinction between /e/ and /i/ in this position is evidenced by the appearance of the allophone [e] following a stress shift due to suffixation (see section ‘Stress’ below). For example, resy /ˈresi/ ‘defeated’ + /-ina/ ‘PF’ > resena /reˈsena/ ‘to be defeated’ (no recording available). Although many non-Central dialects allow [e] in all positions in the word, the current dataset does not contain any cases of post-stress [e] for the Central dialects.
The formant chart in Figure 4a shows F1 and F2 values for the four monophthongs and [o] measured as a mean over the window from 35% to 55% of vowel duration in stressed syllables produced by fifteen speakers in the Central region, seven female and eight male. Individual speaker means as well as the overall male and female means are plotted.
In unstressed syllables, /i/ may back or lower towards [ɨ] or [I], /e/ lower towards [ε], /a/ raise to [ə], and /u/ lower to [ʊ]. For example, speaker WR produces firavaka [fíˈravàka] ‘jewelry’, fasana [ˈfásə́nə̤] ‘tomb’, and kokoa [kʊ́ˈkúə] ‘more’ (in section (ii) of the transcribed passage below), and speaker TMOCR produces petany [pέˈtánI] ‘wall’.
Unstressed vowels are also often devoiced both word-medially and word-finally. Thus, speaker WR produces vadiko [ˈv̥àdɪ̥k̥ʲu̥] ‘my spouse’, mipasoka [miˈpásʊ̥ka] ‘to iron’, masoandro [ˌmasúˈaɳɖ͡ʐu̥] ‘sun’ (in the transcribed passage, section (i)), and mitafy [miˈtáfʲ] ‘wear’ and mafana [məˈfánə̥] ‘hot’ (in the transcribed passage, section (iii)). When individual lexical items are produced in isolation or utterance-finally, this final vowel devoicing can sometimes give the aural impression of the presence of a word-final consonant. However, both acoustic and visual cues indicate that the airstream continues and the articulatory gestures of the vowel remain, despite the cessation of laryngeal vibration; for example, lip rounding can be clearly observed during devoiced /u/ and lip spreading during devoiced /i/, and aperiodic noise can often be seen in the spectrograms. In connected speech, many word-final vowels are produced with modal voicing.
When an unstressed word-final vowel has the same vowel quality as a following unstressed word-initial vowel, a single instance of the vowel is produced. For example, in section (vii) of the transcribed passage, the final and initial /a/ of rivotra and avaratra are produced as a single token of [ə] with a length of about 60 ms. In contrast, where the onset vowel of the second word has primary or secondary stress, a vowel hiatus sequence occurs even with vowels of the same quality. Thus, in the same section of the transcribed passage, the final and initial /a/ of fa and afa-nenina are produced as distinct tokens of [a], as evidenced by the presence of two separate intensity peaks and a total duration of about 120 ms.
There are no phonemic nasal vowels reported in any dialect of Malagasy, with vowel nasalization occurring purely as a phonetic consequence of assimilation with preceding or following nasal consonants. As mentioned above, however, devoicing of the nasal component of voiceless prenasalized consonants is common, particularly in the Betsileo dialect. In such cases (for example, tsentsina [ˈsɛ͂́síŋʲa] ‘obstructed’ from Betsileo speaker ANEJR), the preceding vowel retains its anticipatory nasalization, such that vowel nasalization could eventually become the distinguishing cue between minimal pairs which were previously distinguished by a prenasalized vs. oral consonant contrast.Footnote 4
Vowel length distinctions are also not recognized as phonemic. As mentioned in the ‘Consonants’ section above, Andrianasolo (Reference Andrianasolo1993) states that minimal pairs in vowel length arise as a means of maintaining contrast that could be lost due to /h/-elision in dialects such as Merina. However, as demonstrated in the examples above, this lengthening process does not occur consistently, particularly in connected speech.
Diphthongs
There is considerable disagreement among descriptions of Malagasy concerning which vowel sequences should properly be described as diphthongs rather than vowel hiatus (see Tsimilaza Reference Tsimilaza1981, Andrianasolo Reference Andrianasolo1993, O’Neill Reference O’Neill2015). The most commonly-occurring diphthongs which go undisputed in the literature are /ai/ and /au/. Dahl (Reference Dahl1952: 162) argues for one additional diphthong in the Central dialects, /ui/, on the basis that naïve native speakers treat these three sequences as single syllables when asked to syllabify words but treat all other vowel sequences as separate syllables. Andrianasolo (Reference Andrianasolo1993), on the other hand, argues for a more inclusive set of diphthongs based on observation of phonetic differences in vowel hiatus sequences across morpheme boundaries and a lack of phonetic criteria distinguishing /ai/ and /au/ from other vowel sequences morpheme-internally. Across morpheme boundaries, he notes distinct intensity peaks for each vowel in the sequence and longer duration for the full sequence, whereas morpheme-internally, he observes for all vowel sequences that there is no intensity hiatus and that durations fall midway between durations of monophthongs and those of cross-morpheme hiatus sequences. It is beyond the scope of this work to take a stance on this issue; the examples presented below simply reflect what is available in the current dataset.
Figure 4b shows F1 and F2 measured just after onset (mean over a window from 15% to 30% of vowel duration) and near offset (mean over a window from 65% to 80% of vowel duration) for tokens of the diphthongs /ai/ and /au/ from the same group of seven female and eight male speakers whose formants were measured for monophthongs. Formant transitions for other vowel sequences are not plotted due to low frequency of occurrence in the dataset. Examples of the uncontested diphthongs are presented in (21) from speaker WR and in (22) from speaker TAR2. Seven other vowel sequences produced by speaker WR are presented in (23).
(21)
(22)
(23)



The remaining three orthographic vowel sequences which can be formed by combining the four phonemic monophthongs – ea, ae, and ei – are either very uncommon or lexically unattested morpheme-internally in the Central dialects.
As mentioned above, in Merina and other Central dialects, the orthographic sequences ao and oa are often produced as [o], which sometimes causes loss of lexical contrasts (as in WR’s productions of mandraoka [maˈɳɖ͡ʐoka] ‘gather’ and mandroaka [maˈɳɖ͡ʐoka] ‘expel’). In addition, the sequences ai and ia are sometimes produced as [e]. For example, in an interview setting, speaker MLR produces ampiasaina [ˌãpeˈséna] ‘be used’, and in section (iv) of the transcribed passage below speaker WR produces izay [iˈzè] ‘which’ and holazaina [ˈulaˈz̥èn?] ‘say (fut, pf)’. When bearing primary stress, the sequence oa may also be produced as the monophthong [u] and ia as the monophthong [i] as in NR’s production in an interview setting of satria [səˈʈ͡ʂíː] ‘because’. The latter type of simplification may simply be the result of devoicing of the second vowel in the sequence, but see O’Neill (Reference O’Neill2015) for further discussion.
Syllable and word structure
There is also some debate in the literature concerning allowed syllable structures in Malagasy, primarily hinging on analysis of the complex nasal–obstruent sounds as either consonant clusters or as single complex consonants. This issue is described briefly here. O’Neill (Reference O’Neill2015) provides a more in-depth discussion.
Dahl (Reference Dahl1952), Rakotofiringa (Reference Rakotofiringa1982), and O’Neill (Reference O’Neill2015) argue for treatment of the nasal– obstruent sounds as single complex consonants. Under this interpretation, the Central dialects of Malagasy allow only open (C)V syllables, with optional simplex onsets, no consonant clusters, and frequent vowel hiatus. Others argue that the nasal–obstruent sequences are actually clusters, with the nasal in coda position and the following oral consonant in onset position. Under this analysis, allowed syllable structures are (C)V(N). The existence of prenasalized consonants in word onset position, however, poses a difficulty for this interpretation. As discussed in the ‘Prenasalized obstruents’ section above, the nasal portion of a prenasalized voiceless consonant is often produced voicelessly so may go unnoticed by the listener word-initially; this has led some authors to argue that word-initial prenasalized sounds are disallowed. However, voiced prenasalized consonants occur in initial position in some common lexical items and are clearly articulated, as seen in the examples given above. In addition, there is a prohibition on all word-final codas in the Central dialects, including nasal codas. Historical analysis covering many Malagasy dialects shows that open syllable structure was imposed either by deletion of final consonants from cognates or by vowel paragoge. While one could thus argue that nasal codas are allowed only word-internally, this fact further complicates the nasal–obstruent cluster analysis. The view taken here, then, is that the Central Malagasy dialects allow only (C)V syllables.
Most Malagasy roots are di- or trisyllabic, although some are monosyllabic and a few have four or more syllables. Primary lexical stress can in general occur in final, penultimate, or antepenultimate position (see ‘Intonation and stress’ section below). All roots with antepenultimate stress as well as some disyllables end in one of the so-called ‘weak final syllables’ and exhibit different behavior from other lexical items when undergoing morphological processes. In Merina and OM, a weak final syllable can have the orthographic form -na, -ka, or -tra, as in namana [ˈnamanḁ] ‘friend’, setroka [ˈséʈ͡ʂʷkə̥] ‘smoke’, tolotra [ˈtúlʊ̥ʈ͡ʂa] ‘an offering’ (speaker ER). In Betsileo and other dialects, the morphological behavior is the same but the phonological makeup of the weak final syllables can vary. Thus, speaker HR2 produces fasagna [ˈfásáŋḁ] ‘tomb’ and mavesatsa [maˈv̥èát͡sə̥] ‘heavy’. Final syllables with these phonological forms are not predictably weak; that is, some lexical items contain one of these final syllables but carry penultimate stress and follow regular morphological processes.
Tone
As mentioned above, Howe (Reference Howe2017) presents extensive production and perception data supporting the claim that Central Malagasy dialects have developed phonological tone in the obstruent consonant classes, replacing a former voicing class distinction which is still reflected in the orthography. She shows that high tone follows ‘voiceless’ consonants, and low tone follows ‘voiced’ consonants, and the formerly ‘voiced’ consonants are frequently entirely devoiced; furthermore, perception of tone is at least quasi-categorical for Central dialect speakers but non-categorical for speakers of other dialects. Figure 5 illustrates the tone minimal pair folo [ˈfólo̥] ‘ten’ – volo [ˈv̥ólo̥] ‘hair’ produced by Merina speaker OHR, in which the /v/ is entirely devoiced and an f0 difference of about 25–30 Hz persists throughout the vowel.
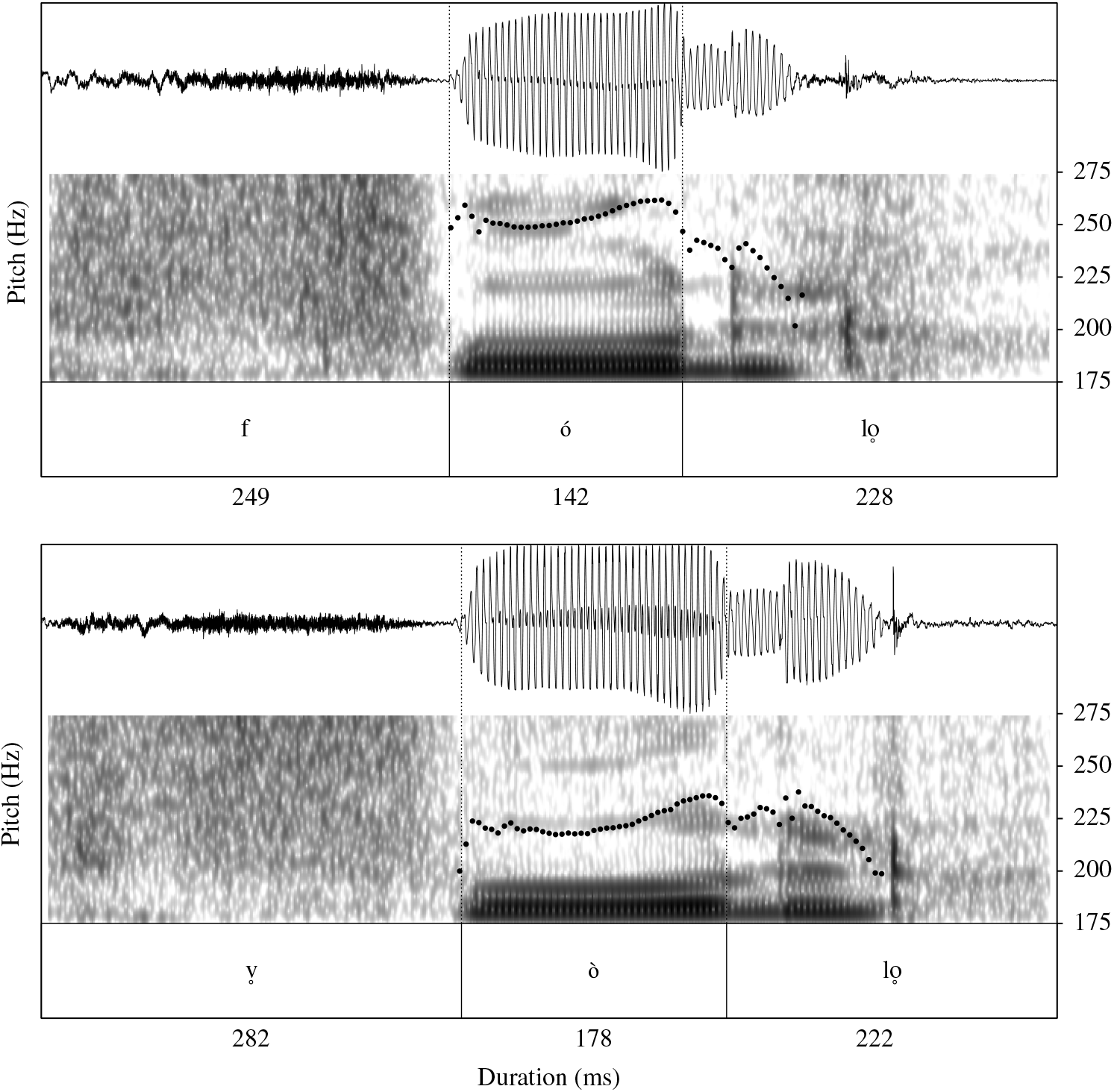
Figure 5 Tone minimal pair folo ‘ten’ – volo ‘hair’ as produced by Merina speaker OHR.
Tone minimal and near-minimal pairs for each oral consonant manner and place of articulation are provided in the respective consonant sections above. Although tone is not carried on the weak final syllables, it is otherwise distinctive on both stressed and unstressed syllables, as demonstrated by minimal triads such as the set shown in Figure 6 from Merina speaker AR3: kaka [ˈkákǝ́] ‘a wedge’, gaka [ˈɡ̥àkǝ́] ‘quack’, gaga [ˈɡ̥àɡ̥ǝ́] ‘shocked’.
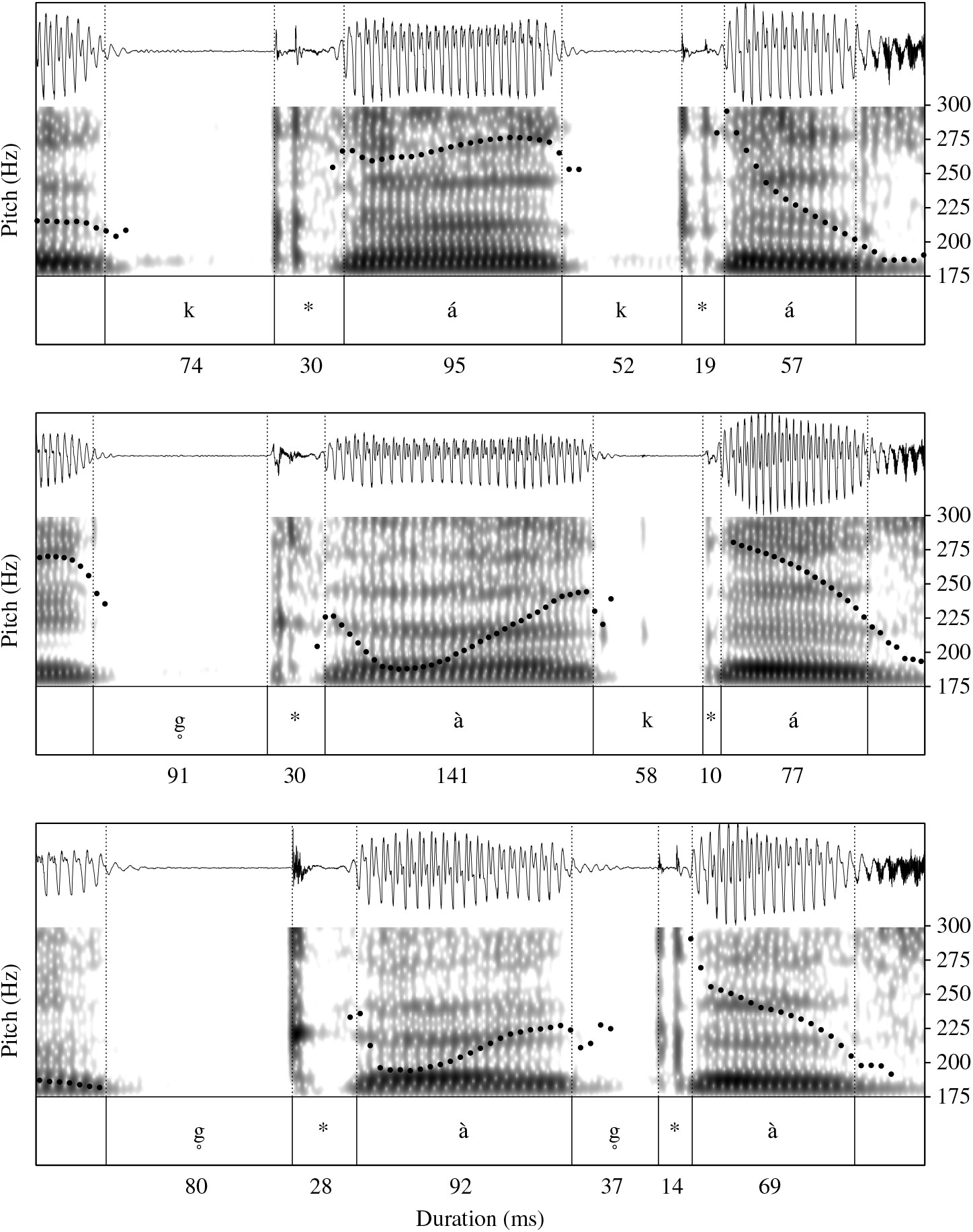
Figure 6 Tone minimal triad kaka ‘a wedge’, gaka ‘quack’, gaga ‘shocked’ produced by Merina speaker AR3. Asterisks in TextGrid mark stop bursts. After Howe (Reference Howe2017: Figure 6.1).
Both tones are phonologically level, but their phonetic shape in stressed syllables is modulated by phrase-level intonation, or ‘pitch accent’ (see section ‘Intonation and stress’ below). On syllables not bearing pitch accent, f0 falls gradually throughout the vowel for high and low tones in both stressed and unstressed syllables. In stressed syllables only, in lexical items bearing pitch accent, high tones are phonetically high and level or slightly rising, while low tones are typically low–rising. Figure 7 shows tone contours for high and low tones in stressed and unstressed syllables in lexical items bearing pitch accent. Data are averaged from 61 (26 male, 35 female) Central dialect speakers producing a word list in a carrier phrase. Time has been normalized as percent of duration through the vowel and f0 as deviation in semitones from each individual speaker’s mean. On average, the low tone is significantly longer than the high tone (Howe Reference Howe2017), as expected cross-linguistically for low or low–rising tones (Yip Reference Yip2002, Thurgood Reference Thurgood, Harris, Burusphat and Harris2007) and as seen in a single instance in the minimal pair in Figure 5 above.

Figure 7 Tone tracks in (a) stressed and (b) unstressed syllables in lexical items bearing pitch accent following phonologically voiceless (VL) and voiced (VD) oral obstruents. Pitch tracks following sonorants (SON) are provided for comparison. Legend gives total number of tokens measured for each syllable type. Data are from 61 Central dialect speakers, 26 male and 35 female. Time is normalized as percent of duration through the vowel and f0 as deviation in semitones from each individual speaker’s mean. Pitch tracks in both stressed and unstressed syllables in lexical items not bearing pitch accent are similar to those shown in (b) (see Howe 2017 and discussion in text).
Intonation and stress
Intonation
Much work remains to be done concerning intonation in Malagasy, particularly regarding dialectal variation and intonation patterns other than those in declarative statements. It is beyond the scope of the current work to address these gaps, but this section presents some important observations which are relevant in teasing apart the effects of tone, intonation, and stress.
Intonation has been claimed to serve primarily a demarcative function in the Merina dialect (Rafitoson Reference Rafitoson1980), with utterances divided into ‘accentual groups’Footnote 5 that align with syntactic constituents and with one major pitch accent occurring on the primary stressed syllable of the final lexical item in each accentual group. Raoniarisoa (Reference Raoniarisoa1990) argues against this strict syntactic basis for the placement of pitch accents; however, it is at least true that in short utterances consisting of a predicate and a subject, each belongs to a separate accentual group (Dahl Reference Dahl1952, Raoniarisoa Reference Raoniarisoa1990, Frascarelli Reference Frascarelli2010, Aziz Reference Aziz2018). The shape of the identified pitch accent in terms of Autosegmental–Metrical (AM) theory (see Ladd Reference Ladd2008) has been variably described as L*+H (Frascarelli Reference Frascarelli2010, describing pitch accent in the accentual group of the predicate only) or L+H* (Aziz Reference Aziz2018, describing pitch accent in both predicate and subject accentual groups). Single-word utterances, or citation forms, also exhibit this same pitch accent (Raoniarisoa Reference Raoniarisoa1990: 224–225). In general, the pitch accent can be characterized as a sharp rise in f0 occurring in close alignment with the syllable bearing primary lexical stress. As mentioned in the section ‘Tone’ above, the lexical tones are identified as simply high and low level tones, while the characteristic shape of the f0 contours on stressed syllables bearing pitch accent (shown in Figure 7a) is due to their combination with this intonational feature. Tone contours on unstressed syllables and on all syllables in lexical items not carrying pitch accent are slightly falling, as in Figure 7b.
Disagreement about which tonal target of the pitch accent should be treated as central (i.e. starred) in terms of AM theory is likely due to variation caused by interaction with lexical tone, which previous accounts have not taken into consideration. While no solution will be proposed to the issue of L*+H vs. L+H* here, the following observations can be made. When the stressed syllable carries high lexical tone, the maximum peak of the intonation contour may sometimes align with the onset of the stressed vowel or the contour may be essentially high level through the vowel, thus favoring the L+H* analysis. It is common, however, as noted in the section ‘Tone’ above, that an f0 rise is seen even following onset of a high-tone vowel (as in Figures 5 and 6). Furthermore, when the stressed syllable carries low lexical tone, the f0 minimum aligns with onset of the stressed vowel followed by a rapid f0 increase, but the f0 maximum may sometimes occur on the following syllable; these facts may favor the L*+H analysis. Use of L+H* to label plots herein is arbitrary and does not reflect a theoretical claim.
The precise position of the f0 maximum may also depend on the lexical tone of the following syllable. This is illustrated in Figure 8 for examples taken from the ‘Consonants’ section above. In the near-minimal triad mirava ‘disperse’, misava ‘inspect’, mazava ‘clear’, in which the unstressed final syllable in each word carries low lexical tone, maximum f0 over the whole word aligns with the stressed syllable (Figure 8a). However, in the triad maka ‘take’, fako ‘trash’, vaky ‘broken’, in which the unstressed final syllable in each word carries high lexical tone, maximum f0 over the whole word occurs on the final syllable (Figure 8b). In the triad lany ‘used up’, trano ‘house’, gadrana ‘be imprisoned’, in which the final syllables do not carry lexical tone, high f0 also carries over into the final syllable (Figure 8c). It is also worth noting that in the case where the stressed syllable is unmarked for lexical tone (i.e. it is onset-less or has a sonorant onset), the pattern is similar to that in syllables carrying low lexical tone (although the f0 level of the L is slightly less low on average, as seen in Figure 7).
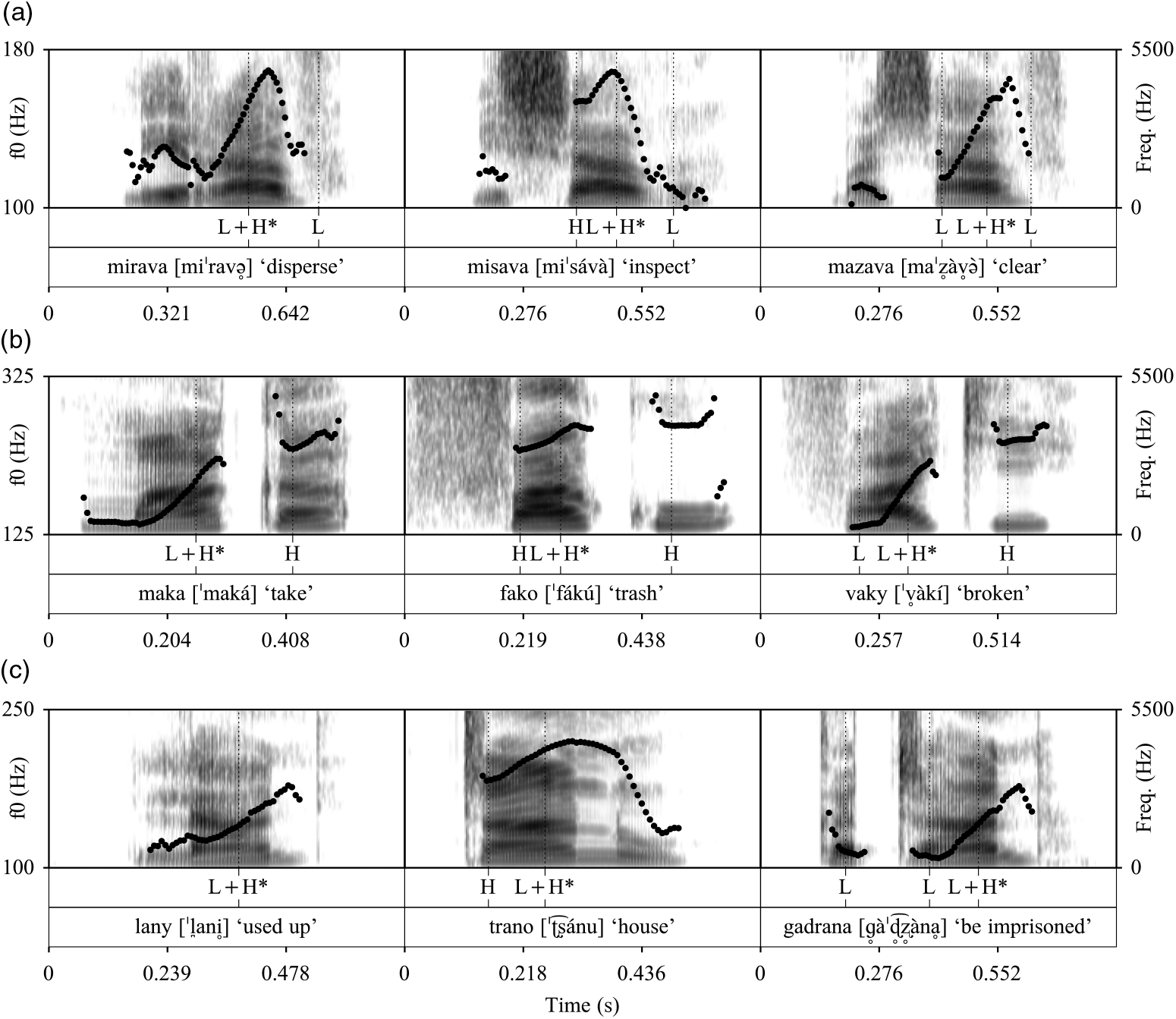
Figure 8 Near-minimal triads illustrating interaction between the pitch accent on the stressed syllable and lexical tones on both the stressed syllable and the following syllable, where the final syllable has (a) low lexical tone, (b) high lexical tone, and (c) unspecified lexical tone. L+H* indicates the pitch accent, while L and H indicate lexical tones.
Previous accounts also make some observations concerning edge tones. Discussion in Raoniarisoa (Reference Raoniarisoa1990: 128) suggests that intermediate phrases (‘continuation’) could be described in AM terms as marked by a final H phrase accent (see Ladd Reference Ladd2008: 88). In contrast, she notes that ‘finality’ (that is, the end of an intonation phrase, in AM terms), is marked by a low tone. Aziz (Reference Aziz2018) also identifies a L% boundary tone at the end of an intonation phrase following the final pitch accent but does not discuss phrase accents (the current discussion also will not address phrase accents in intonation phrases). These observations are supported by the current data, and interaction between pitch accent and edge tone provides further explanation for variability in the shape of the pitch accent contour. The following discussion uses examples from the transcribed passage to illustrate these patterns.
Figure 9 presents an example of a predicate–subject intonation group with two pitch accents aligned with these two syntactic constituents from section (v) of the transcribed passage. High f0 near the beginning is due to high lexical tone (not marked in the figure); f0 then falls for the low lexical tone on izay and jumps up again for high tone on faran’ny. The first rising pitch accent occurs on the first syllable of heriny; overall maximum f0 occurs on the second syllable; and the intermediate phrase ends with a H phrase accent marking continuation. The second rising pitch accent occurs on avaratra, in which the stressed syllable has low lexical tone; a local maximum f0 occurs on the following syllable, but the expected L% fall is not observed. The inflection point in the f0 contour, however, indicates that f0 begins moving towards the low target for L%; that it does not finally arrive at this target can be attributed to the devoicing of the final vowel.
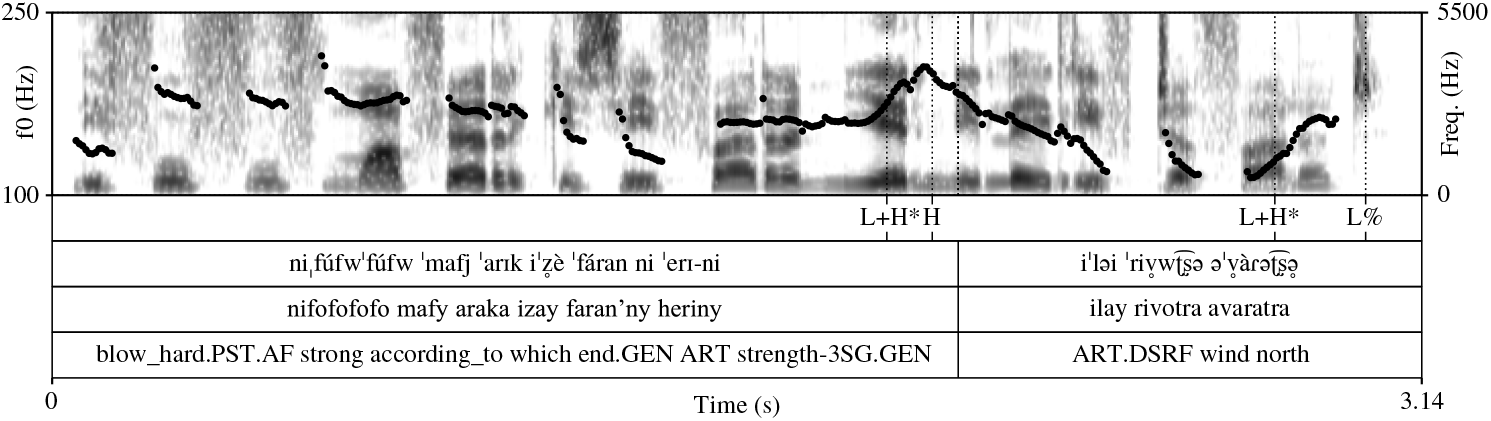
Figure 9 A relatively simple predicate–subject intonation group with two pitch accents from section (v) of the transcribed passage. Lexical tone is not marked in the intonation tier.
Figure 10 illustrates another case where the expected fall to the L% boundary tone is obscured. This example from section (iv) of the transcribed passage shows a series of several intermediate phrases at the end of an intonation group, thus including several pitch accents. The final pitch accent is much shallower than those in the intermediate phrases, and the f0 contour ends in a shallow low-rise rather than a fall. In this case, the last pitch accent occurs at the edge of the intonation phrase because the final lexical item has final syllable stress. Thus, the final shallow-rising f0 contour represents the interaction of the pitch accent and the boundary L%, which when realized together on a single syllable manifest as an f0 rise of decreased magnitude, with the subsequent fall left unrealized (Aziz Reference Aziz2018 describes this case as a H% allotone).
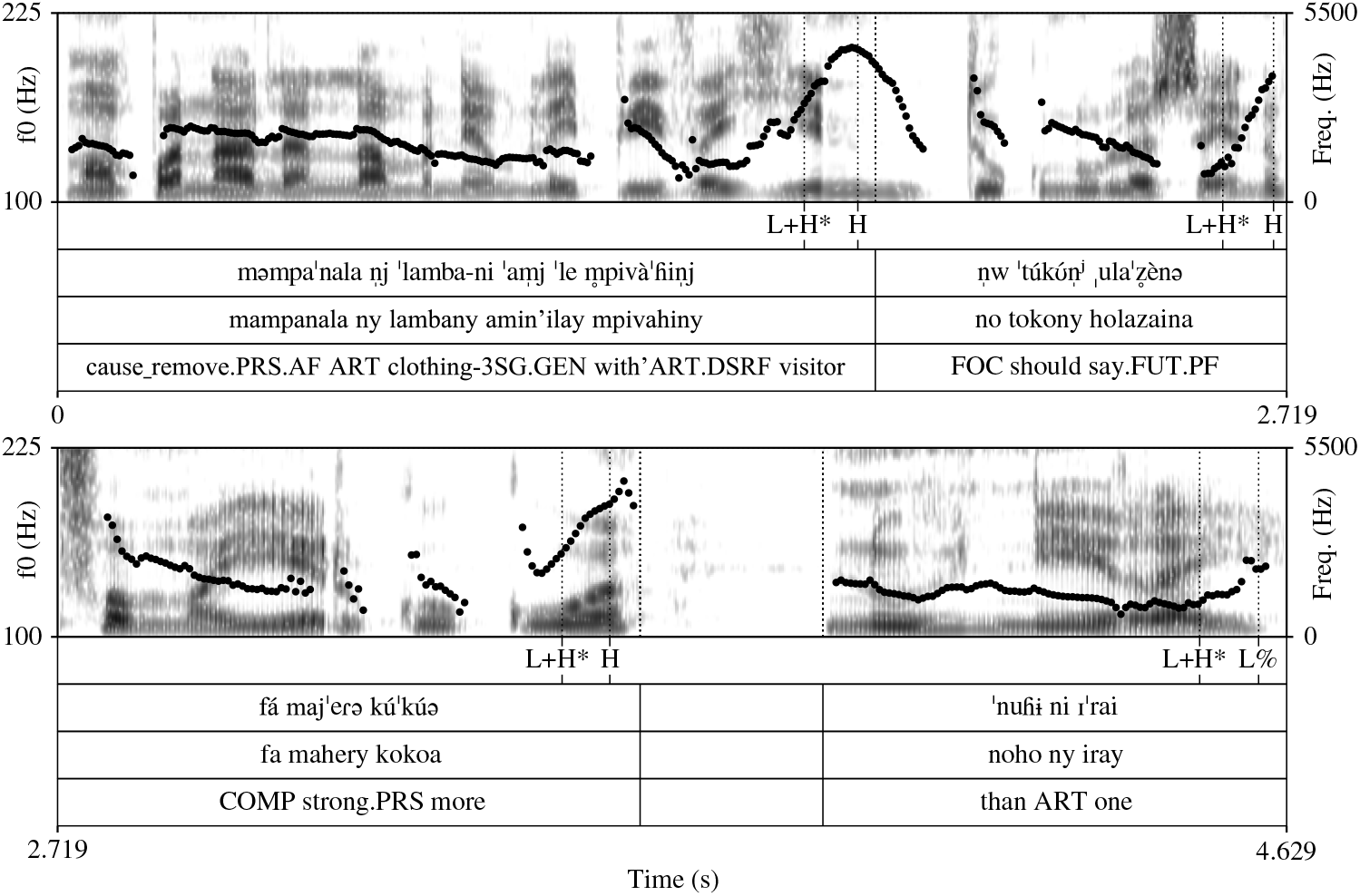
Figure 10 A series of intermediate phrases at the end of an intonation group from section (iv) of the transcribed passage. Final pitch accent and L% boundary tone co-occur on the final syllable, producing a shallow low-rising contour rather than a rise-fall. Downdrift of f0 peaks is not observed.
Raoniarisoa (Reference Raoniarisoa1990: 201–202) notes that the level of the maximum f0 in the pitch accents in a series of intermediate phrases may gradually decrease; this ‘downdrift’ is said to depend on the number of intervening syllables but does not occur as a strict rule. The series in Figure 10 does not display downdrift, but Figure 11 also shows a series of intermediate phrases at the end of an intonation group from section (vii) of the transcribed passage, and does display downdrift. Figure 11 also shows a case where the stressed syllable carrying the final pitch accent is antepenultimate, resulting in the expected rise–fall contour in combination with the final L% boundary tone (although utterance-final creak interferes with clear analysis of the pitch contour).
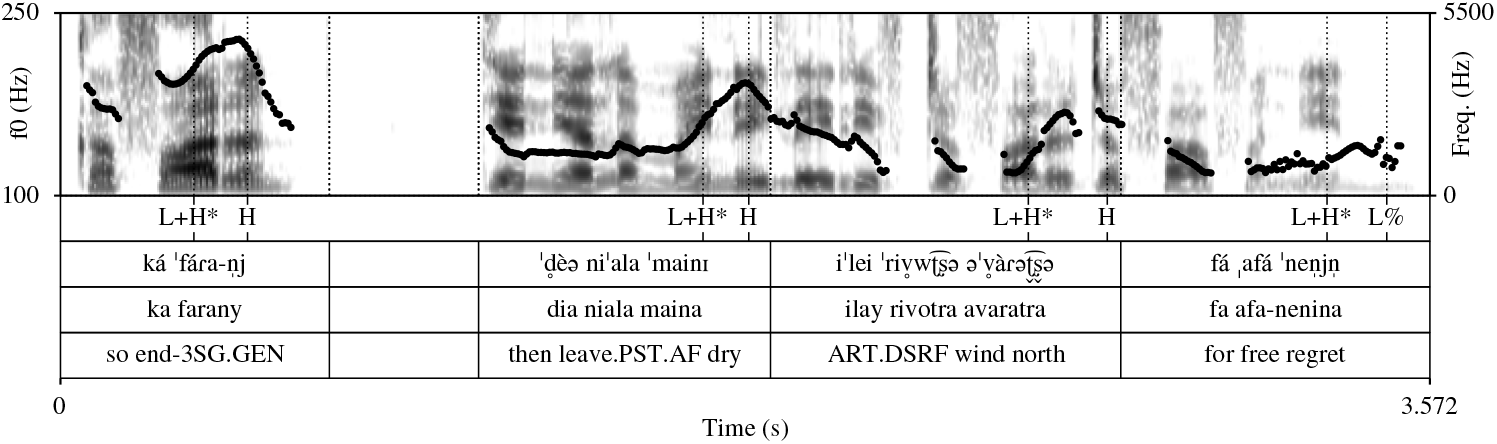
Figure 11 A series of intermediate phrases at the end of an intonation group from section (vii) of the transcribed passage, displaying downdrift of f0 peaks and a phonetically-realized L% boundary tone.
Stress
Blust (Reference Blust2013: 355) describes most Austronesian languages as ‘agglutinative-synthetic’. Some authors specifically describe Malagasy as agglutinative (Raoniarisoa Reference Raoniarisoa1990: 11; Ranaivoarison, Laporte & Ralalaoherivony Reference Ranaivoarison, Aina, Laporte and Ralalaoherivony.2013: 1). However, in comparison to other Austronesian languages, Malagasy has developed characteristics which distance it somewhat from the prototypical agglutinative language. Although the relation between morphemes and meanings in Malagasy is generally one-to-one, morphophonological processes of nasal substitution and fortition as well as various alternations and apocope relating to the weak final syllables can conspire to make morphological boundaries less than transparent and to make derived and inflected forms relatively unpredictable.Footnote 6 Malagasy can, on the other hand, comfortably be described as a synthetic language; in the Central dialects, there are many derivational and inflectional morphemes including prefixes, suffixes, and clitics; in addition, reduplication and compounding are common. In particular, this significant affixation can result in long words and can produce shifts in the location of primary stress.
Primary lexical stress usually occurs on the penultimate syllable, but it may also occur in final position or in antepenultimate position for lexical items with weak final syllables (see ‘Syllable and word structure’). Stress is not predictable and can be phonologically distinctive, as in àty ‘liver’ vs. atỳ ‘here’ and tànana ‘hand’ vs. tanàna ‘town’ (recordings not available in current dataset).Footnote 7 Erwin (Reference Erwin1996) posits an analysis in terms of metrical stress theory, arguing that stress occurs on the leftmost mora of the rightmost full foot, with the stipulations that paragogic vowels do not enter into metrical foot structure and that two morae within a single syllable must belong to the same foot. In words containing four or more morae, Erwin (Reference Erwin1996: 8) states that secondary stress is assigned to every second mora preceding the syllable bearing primary stress, as in traotraoka [ˌʈ͡ʂáuˈʈ͡ʂáukə̥] ‘Adam’s apple’ (speaker HT) and milalao [ˌmil̪aˈlau] ‘to play’ (speaker WR). It is easy to find exceptions to this stated rule; however, it is beyond the scope of this article to discuss the analysis of stress placement in depth, and the following discussion will focus largely on primary stress.
Prefixation does not alter the location of primary stress, but suffixation often causes a shift to the right, as in gadra /ˈɡaɖ͡ʐa/ [ˈɡàɖ̥͡ʐ̥ə] ‘fetters’, migadra ‘be in fetters’, /mi-ˈɡaɖ͡ʐa/ [m̩iʲˈɡ̥àɖ̥͡ʐ̥ə] gadrana /ˈɡaɖ͡ʐa-ana/ [ˈɡàɖ̥͡ʐ̥ànḁ] ‘be imprisoned’ (speaker WR, last example repeated from ‘Intonation’ section). Stress shift does not occur in disyllabic roots ending in a weak final syllable (e.g. mifona /mi-ˈfuna/ [miˈfuna] ‘(af, prs)-beg.pardon’ > ifonana /i-ˈfun-ana/[iˈfunana] ‘(prs, cf)-beg.pardon-(cf)’, Adelaar Reference Adelaar2012: 138, no recordings available) or when root stress is on the final syllable, as in the examples presented earlier in the text: milalao [ˌmil̪aˈlau] ‘to play’ vs. lalaovina [l̪aˈlovə̀na] ‘be played with’.Footnote 8 Figure 12 illustrates by means of the location of pitch accent the stress shift that occurs in gadrana but not in lalaovina. Adelaar (Reference Adelaar2012) offers a concise summary of the surface pattern, stating that in suffixed forms, primary stress appears on the syllable immediately before the suffix.Footnote 9
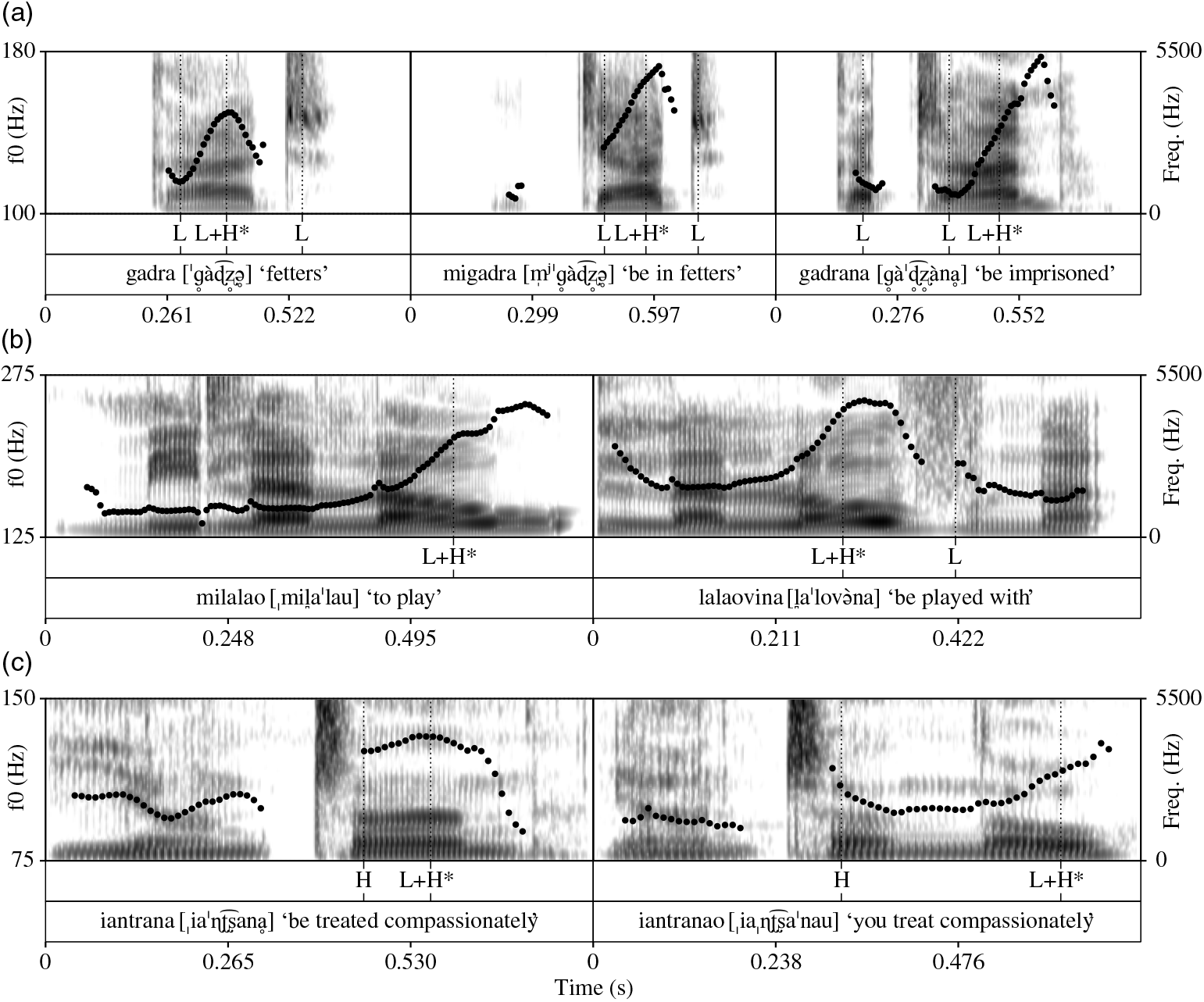
Figure 12 The primary stressed syllable can be identified by the location of the rising pitch accent. In (a), prefixation to the root gadra does not cause stress shift, but suffixation does. In (b), suffixation to the stress-final root lalao does not cause stress shift. In (c), the bimoraic enclitic =nao attracts primary stress and the root stress becomes secondary. See text for more discussion.
In contrast to suffixation, encliticization draws primary stress to the first mora of the clitic if the clitic is bimoraic; in such cases, stress in the cliticized root does not shift but is reduced to secondary prominence (speaker SR: iantrana i-ˈaɳʈ͡ʂa-ana/ [ˌiaˈɳʈ͡ʂanḁ] ‘be treated compassionately’ vs. iantranao i-ˈaɳʈ͡ʂa-ana = ˈnau/ [ˌiaˈɳʈ͡ʂaˈnau] ‘you treat compassionately’, see Figure 12). With monomoraic enclitics, no change in root stress occurs (speaker SR: tanako /ˈtanana = ku/ [ˈtánakʊ̥] ‘my hand’).
Reduplication in Malagasy confers continuous or habitual aspect or the cross-linguistically unusual diminutive meaning. The reduplicated material appears to the right of the original copied portion (Keenan & Polinsky Reference Keenan and Polinsky.1998: 571), and in most cases, reduplication adds a maximum of two syllables, which are usually identical to the syllable bearing primary stress and that immediately following (Martin Reference Martin2005). This pattern is seen in gegy /ˈgegi/ > gegigegy [ˌɡ̥èɡ̥ìˈɡ̥èɡ̥ɪ̥] ‘kind of furious’ (speaker JR4) and in additional examples (for which recordings are not available): akaiky /aˈkaiki/ ‘close’ > akaikikaiky [aˌkaikiˈkaiki] ‘fairly close’ and anarana /aˈnarana/ ‘name’ > anaranarana [aˌnaraˈnarana] ‘nickname’. The rightmost copy of the reduplicated material carries primary stress, while the stress in the root syllable that formerly carried primary stress is reduced to secondary.
In trisyllabic, VOWEL-initial roots with antepenultimate stress (and therefore with weak final syllables), the consonant of the final syllable is also included in the reduplicated material. Thus, araka /ˈaraka/ +redp +gen > arakaraky [ˌaɾaˈkárɪkí] ‘proportional (gen)’ in section (vi) of the transcribed passage (the change of the final vowel from [a] to [i] is due to the genitive morpheme). In trisyllabic, consonant-initial roots with antepenultimate stress, the initial consonant in the reduplicated material undergoes a regular morphophonological fortition process, but the consonant of the final syllable is only retained if it is a nasal. This results in forms such as fantatra /ˈfantaʈ͡şa/ ‘known’ > fantapantatra [ˌfantaˈpantaʈ͡şa], velona /ˈveluna/ ‘alive’ > velombelona [ˌveluˈmbeluna] (Keenan & Polinsky 1998: 572, no recordings available) and zendagna /ˈzendaŋa/ > zendanjendagna [ˌz̥èndaˈnd͡zèndaɳa] ‘a little astonished’ (speaker HT). Note that in all of these cases, reduplication adds only two syllables of material.
If the word is monosyllabic, disyllabic with final stress, or disyllabic with a weak final syllable, only the stressed syllable is reduplicated. Keenan & Polinsky (Reference Keenan and Polinsky.1998: 571) give the following examples of the first two cases: lo /ˈlu/ ‘rotten’ > lolo /ˌluˈlu/ and vovo /ˌvuˈvu/ ‘dog’s bark’ > vovovo /vuˌvuˈvu/.Footnote 10 The third case is exemplified in forms such as pika /ˈpika/ ‘click’ > pipika /piˈpika/ ‘repeating clicking sound’ and the frequently-used tsotsotra /ˌt͡suˈt͡suʈ͡şa/ ‘fairly simple’ from tsotra /ˈt͡suʈ͡şa/ ‘plain, simple’ (recordings not available).
According to Martin (Reference Martin2005), trisyllabic words with final stress exhibit reduplication of the foot carrying secondary stress rather than of the final syllable. Most such words are loanwords, as is his example [ˌsokoˈla] ‘chocolate’ (from French chocolat) > [ˌsokoˌsokoˈla]. Keenan & Polinsky (Reference Keenan and Polinsky.1998: 571), however, give the example lehibe /ˌlehiˈbe/ ‘big’ > lehibebe /ˌlehiˌbeˈbe/ ‘biggish’, in which the stressed syllable reduplicates rather than following Martin’s (Reference Martin2005) proposed pattern, which should produce /ˌlehiˌlehiˈbe/. My own consultant was reluctant to provide a reduplication of the latter word and could not give a firm preference for either form, on the grounds that this word would not normally be reduplicated.
Rasoloson & Rubino (Reference Rasoloson2005: 462) described Malagasy as employing ‘full root reduplication’ excluding the weak final syllables. This description fits some but not all of the examples given above, whereas the analysis of reduplication as targeting the primary stressed syllable and a maximum of one additional following syllable accommodates a greater range of cases, especially when taking into account that the consonants of the weak final syllables were historically syllable codas and thus would have fallen within the two syllable target window.Footnote 11
When a reduplicated base takes a verbal suffix, the primary stress on the reduplicated portion shifts to the right as described above, but the secondary stress on the original root remains fixed. For example, zarazara /ˌzaraˈzara/ > zarazaraina /ˌzarazaˈraina/ ‘to be shared around a little’ (Jedele & Randrianarivelo Reference Jedele, P. and Randrianarivelo.1998: XIII, recording not available).
In compounds, primary stress occurs on the original stressed mora of the rightmost component word, while the original stressed morae of other words in the compound present with secondary stress in the compounded form (Raoniarisoa Reference Raoniarisoa1990: 16); for example, amorondrano /a-ˈmuruna/ ‘loc-border’ + /ˈranu/ ‘water’ [aˌmurʊˈɳɖ͡ranʊ̥] ‘water’s edge’ (speaker JR4).
Acoustic correlates of stress and pitch accent
Although there is generally not disagreement among speakers of the language about the location of primary and secondary stress in any given Malagasy lexical item in citation form (Raoniarisoa Reference Raoniarisoa1990), previous reports have disagreed concerning the most important acoustic correlates of stress. This disagreement is largely attributable to the failure of some studies to properly differentiate between lexical stress and intonational pitch accent, or to recognize that f0 typically plays a minor role in stress marking cross-linguistically (see Beckman Reference Beckman1986; Ladd Reference Ladd2008: 44–54). Pitch, intensity, duration, and vowel quality have all been cited as primary markers of lexical stress in various Malagasy dialects. Rakotofiringa (Reference Rakotofiringa1982) concluded in his in-depth phonetic study, which included data from Central and non-Central dialects, that while all of these cues make some contribution, pitch is the most important factor. Raoniarisoa (Reference Raoniarisoa1990) recognized that the apparent relation between stress and f0 in the Merina dialect is in fact due to the expression of intonational pitch accent but did not investigate other acoustic cues to stress. Two more recent studies of other non-Central dialects, however, have suggested that duration is the most important factor (in North Betsimisaraka: O’Neill Reference O’Neill2015, in Vezo: Poirot Reference Poirot2011). This section summarizes the results of a preliminary study of the acoustic correlates of stress in Central dialects originally reported in Howe (Reference Howe2017).Footnote 12
Howe (Reference Howe2017) used mixed-effects logistic regression models to investigate the ability of phonetic cues including mean vowel f0, vowel f0 slope, syllable duration, consonant intensity, and proportion of modal voicing on the consonant to predict stress condition of a given syllable in the Central dialects of Malagasy.Footnote 13 Data came from word list and nonsense word recordings from 61 Central dialect speakers (26 male, 35 female), and from interviews with 10 speakers (7 male, 3 female). Results were examined separately for syllables with oral or prenasalized obstruent onsets and for lexical items that did and did not bear pitch accent.
Stressed syllables with oral obstruent onsets in words bearing pitch accent were marked by: increased mean f0, to a greater degree in initial syllables (f0: Est. = 0.62, SE = 0.043, p < .001; f0*initial: Est. = 0.31, SE = 0.053, p < .001); increased f0 slope (f0 slope: Est. = 1.86, SE = 0.12, p < .001); increased duration, to a lesser degree in initial syllables (duration: Est. = 0.044, SE = 0.0016, p < .001; duration*initial: Est. = −0.031, SE = 0.0016, p < .001); and DECREASED modal voicing, primarily in medial syllables. The modal voicing effect was much larger for ‘phonologically voiced’ (low tone) consonants (voicing: Est. = −2.02, SE = 0.42, p < .001; voicing*voiced: Est. = −2.22, SE = 0.43, p < .001; voicing*initial: Est. = 1.79, SE = 0.51, p < .001).Footnote 14 There was no significant effect of consonant intensity.
Stressed syllables with prenasalized obstruent onsets in word-medial positionFootnote 15 in words bearing pitch accent were also marked by raised f0, an increase in f0 slope, and an increase in duration (f0: Est. = 0.61, SE = 0.079, p < .001; f0 slope: Est. = 4.98, SE = 0.42, p < .001; duration: Est. = 0.047, SE = 0.0034, p < .001), but modal voicing was not significant (voicing: Est. = 0.58, SE = 0.67, p = .38).
In words NOT bearing pitch accent (data available for oral obstruents only), neither mean f0 nor f0 slope was significant (f0: Est. = 0.086, SE = 0.059, p = .15; f0 slope: Est. = 0.23, SE = 0.17, p = .18). Syllable duration was significant, although the effect was decreased in initial position (duration: Est. = 0.036, SE = 0.0063, p < .001; duration*initial: Est. = −0.026, SE = 0.0070, p < .001). Consonant intensity was not significant. Although the voicing cue did not reach significance at the p < .05 level, it showed the same trend as above of reduced voicing in stressed medial syllables (voicing: Est. = −1.37, SE = 0.72, p = .055; voicing*initial: Est. = 1.55, SE = 0.89, p = .081).
As illustrated clearly in Figure 13 and confirmed by the statistics, raised f0 and positive f0 slope play a major role in distinguishing stressed syllables only in the accented context, where the stressed syllable aligns with the intonational pitch accent. Mean f0 and f0 slope are the same in both stress conditions in unaccented words. This role of f0 in accented words corroborates the findings of Raoniarisoa (Reference Raoniarisoa1990) and contradicts Rakotofiringa’s (Reference Rakotofiringa1982) claim that pitch is the most consistent acoustic cue marking stress. This finding is not surprising given the observations already made concerning intonation in Central Malagasy and the cross-linguistic tendency for lexical stress to be marked primarily by cues other than f0 (Beckman Reference Beckman1986, Ladd Reference Ladd2008, Gordon & Nafi Reference Gordon2012, Silber-Varod, Sagi & Amir Reference Silber-Varod, Vered, Sagi and Amir.2016, among others). One possibility, however, which was not tested in this statistical model but which has been suggested by Hyslop (Reference Hyslop2018) for the language Kurtöp, is that enhancement of tonal f0 distinctions (i.e. in a two tone system, increased deviation of f0 from a speaker’s mean), rather than overall raised f0 or a specific f0 contour shape, could mark stress. Indeed, Howe (Reference Howe2017) reports that the difference in mean f0 over the first half of the vowel in the low vs. high tones in Central Malagasy is a full semitone greater in stressed syllables than in unstressed syllables. Further investigation is necessary in this area.
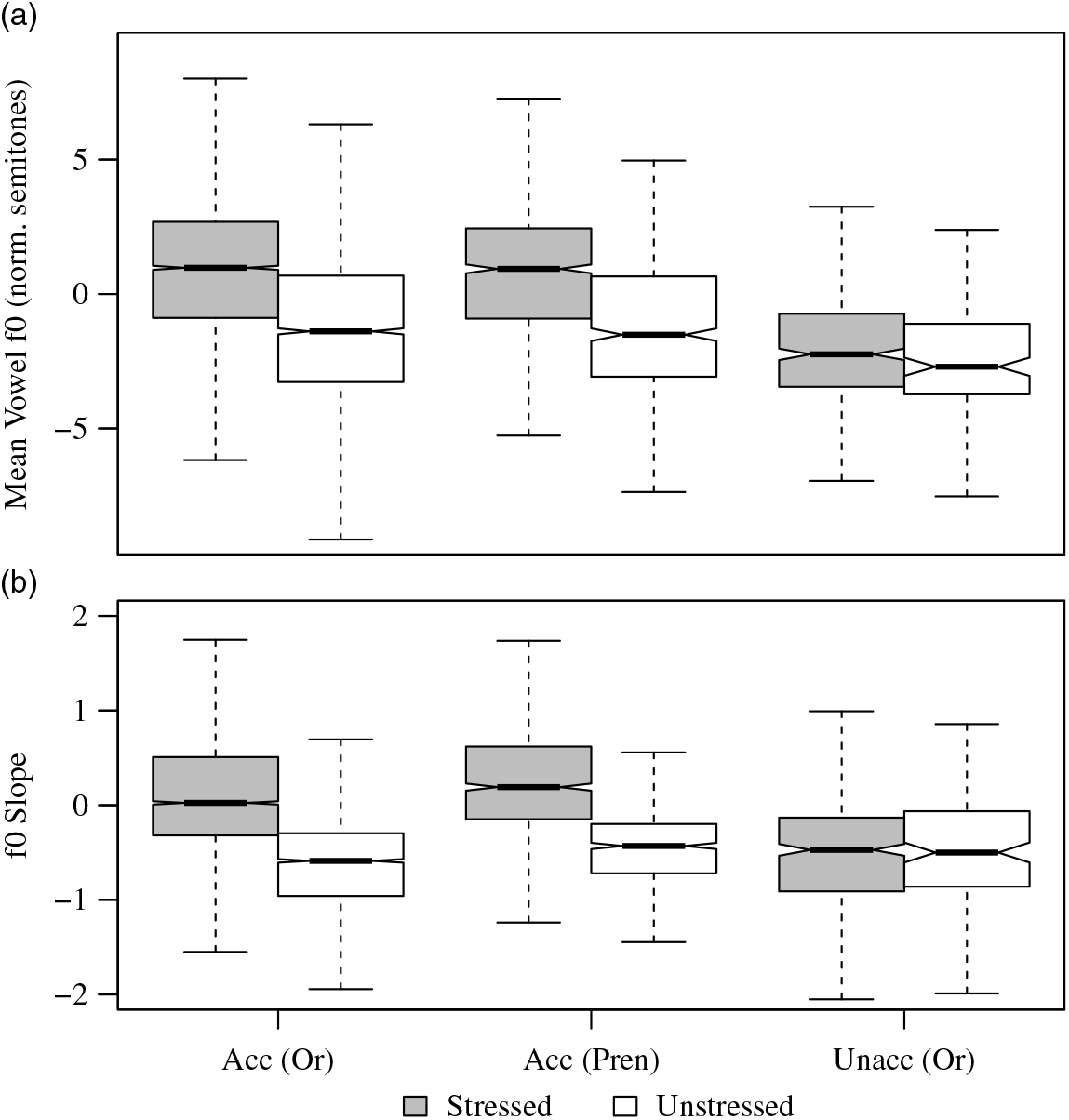
Figure 13 Box plot of (a) mean vowel f0 and (b) f0 slope for stressed and unstressed syllables in three syllable types: with oral obstruent onsets in lexical items bearing pitch accent, with prenasalized obstruent onsets in lexical items bearing pitch accent, and with oral obstruent onsets in lexical items not bearing pitch accent. In the latter case, neither cue is significant.
Independent of pitch accent, the results here indicate that duration is a major acoustic correlate of lexical stress in the Central Malagasy dialects. This aligns with the findings of O’Neill (Reference O’Neill2015) for the North Betsimisaraka dialect and Poirot (Reference Poirot2011) for the Vezo dialect. Figure 14 illustrates the clear duration difference between stressed and unstressed syllables in both accented and unaccented contexts. The greater magnitude duration distinction present in accented words suggests that duration is also a marker of intonational pitch accent.
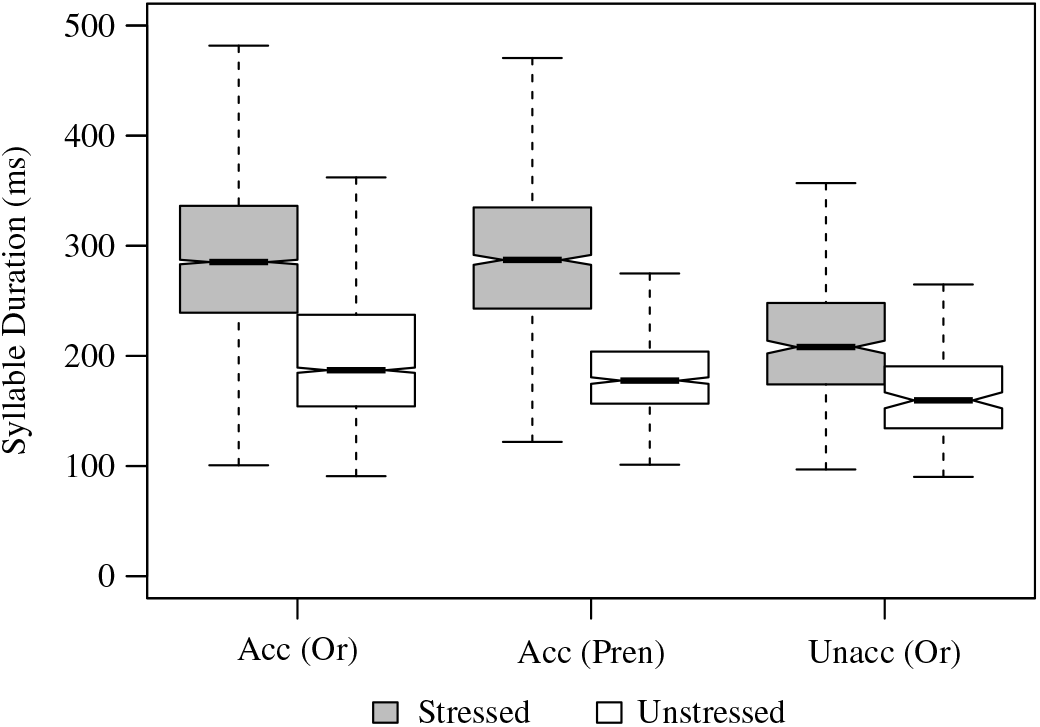
Figure 14 Box plot of syllable duration for stressed and unstressed syllables in three syllable types: with oral obstruent onsets in lexical items bearing pitch accent, with prenasalized obstruent onsets in lexical items bearing pitch accent, and with oral obstruent onsets in lexical items not bearing pitch accent. Duration is significant in all three cases.
Finally, one intriguing result is the apparent relationship between modal voicing and stress. Typical patterns of prosodically-driven reduction would predict that a language with a phonological voicing distinction would exhibit greater rates of devoicing in environments that favor reduction of articulatory and aerodynamic effort. For example, Smith (Reference Smith1997) found increased rates of fricative devoicing in English in unstressed syllables. For Central Malagasy speakers, however, the opposite pattern is observed in all syllable types investigated and reaches statistical significance in syllables with oral obstruent onsets in accented position: modal voicing rates increase in unstressed syllables. This is illustrated in Figure 15, which shows that modal voicing tends to increase in both ‘phonologically voiceless’ and ‘voiced’ consonants in unstressed syllables in both accented and unaccented lexical items (although the latter difference is not statistically significant, as reported above).
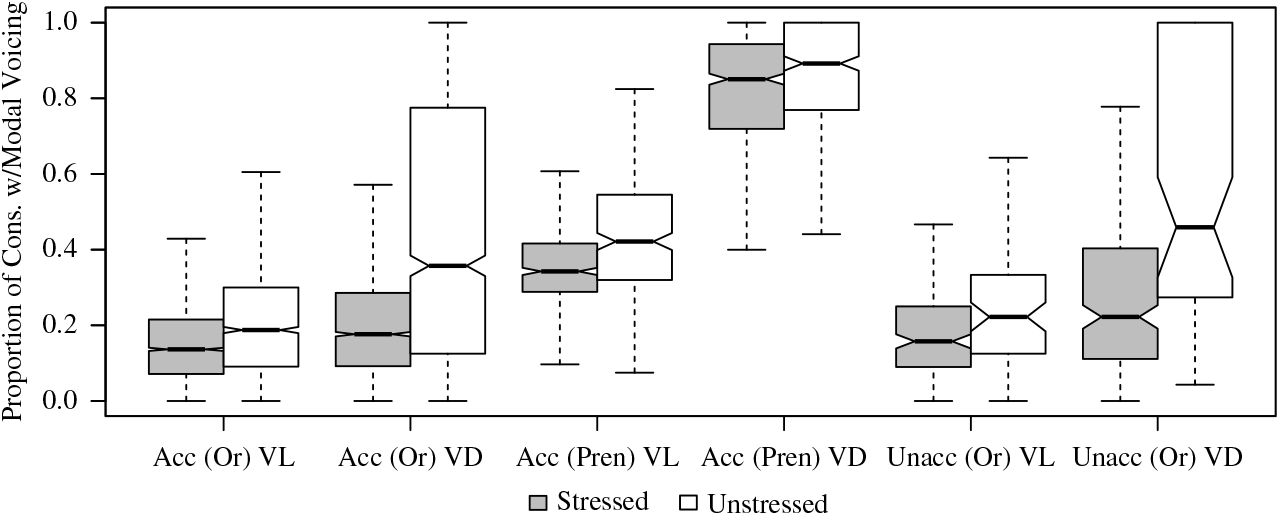
Figure 15 Box plot of proportion of consonant realized with modal voicing for stressed and unstressed syllables in three syllable types: with oral obstruent onsets in lexical items bearing pitch accent, with prenasalized obstruent onsets in lexical items bearing pitch accent, and with oral obstruent onsets in lexical items not bearing pitch accent. Tokens are further divided according to phonological voicing class of the onset consonant. In all syllable types, the tendency is for increased modal voicing in unstressed syllables, although this is only statistically significant for the Acc (Or) syllable type.
Howe (Reference Howe2017) argues based on these findings that Central Malagasy speakers’ reliance on f0 for marking lexical tonal distinctions may lead them to curtail general phonetic reduction processes in the prosodic contexts that might otherwise promote them and thus to avoid devoicing unstressed syllables (see Ladd Reference Ladd2008: 36). Instead, consonant voicing is reduced in long-duration stressed syllables, where tonal information can be reliably transmitted on the vowel, and consonant voicing is increased in unstressed syllables, where the shorter overall duration limits the vocalic material available for realizing lexical tone contrasts. This inversion of the usual correlation of modal voicing and stress (i.e. low prominence > devoicing) could indicate the start of a shift towards use of modal voicing as a cue to syllable stress category, a change reminiscent of one described by Ross (Reference Ross1993) in the Oceanic language Bukawa, in which all obstruents in strong syllables became voiceless and in weak syllables became voiced. This and other issues surrounding the interaction of tone, intonation, and stress remain interesting areas for future research.
Transcription of connected speech
The following is a transcription of ‘The North Wind and the Sun’, recorded by 34-year-old male Betsileo speaker WR living in Antananarivo in 2018. A narrow phonetic transcription is provided along with the standard orthography, interlinear gloss, and English translation.
(i)
(ii)
(iii)
(iv)
(v)
(vi)
(vii)
(viii)
(ix)
(x)
(xi)











Abbreviations
Abbreviations and symbols used in glosses in examples and the transcribed passage are as follows: 1, 2, 3 = first, second, third person; af = actor focus; art = article; cf = circumstantial focus; comp = complementizer; dist = distal; dsrf = discourse referential; f = feminine; fam = familiar; foc = focus; fut = future; gen = genitive; loc = locative; m = masculine; nmlz = nominalization; nom = nominative; obj = object; pf = patient focus; pl = plural; prox = proximal; prs = present; pst = past; quot = quotative; recp = reciprocal; redp = reduplication; sg = singular; , = continuing intonation; . = final intonation
Acknowledgements
Heartfelt thanks to the many Malagasy speakers who offered their assistance and participation. Field research was funded by the Rice University Wagoner Foreign Study Scholarship and by the Fulbright Scholar Program. Thanks are due also to the reviewers and editor, whose comments and suggestions greatly improved this work.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0025100319000100

















