



1 Introduction
Phonologists have long observed that phonological features tend to be evenly distributed across phonemes in phonemic inventories, a tendency that is referred to as symmetry (de Groot Reference de Groot1941; Martinet Reference Martinet1955). For example, in French, the feature [±voice] is spread across obstruents so that each obstruent specified as [−voice] has a [+voice] counterpart (Clements Reference Clements2003). Phonemic inventories that do not display this pattern are considered asymmetrical. In what is perhaps the most familiar case of consonant asymmetry, many languages with a [±voice] distinction in bilabial and coronal stops lack a corresponding voiced velar stop /ɡ/—a phenomenon known as the g-gap (Blevins Reference Blevins2004: 283).
In this paper, I present evidence for a rare asymmetry in the stop inventory of Witzapan Nawat, a critically endangered Uto-Aztecan language spoken in El Salvador. While other closely related Nahuan languages feature only a voiceless stop series /p t k kw/, I argue that the stop inventory of Witzapan Nawat is better analyzed as having voiceless stops /p t kw/ and a voiced stop /ɡ/ at the velar place of articulation. This asymmetry is unusual because it is not predicted by the main theories of phonemic inventory structure. For instance, proposals based on markedness posit that /ɡ/ is more marked than /b d/ due to aerodynamic factors (Gamkrelidze Reference Gamkrelidze1975). Under this framework, the prediction is that, if a language has a voiced stop in its inventory, it will be /b/ or /d/ rather than /ɡ/. On the other hand, theories based on feature economy predict that, if the feature [+voice] is present in one phoneme, it will also be present in others to maximize economy (Clements Reference Clements2003). This is not the case for Witzapan Nawat given that the [+voice] feature occurs only in /ɡ/ among all obstruents. In addition, I explain this asymmetrical phonemic inventory as a result of diachronic developments involving sound change and analogy, likely aided by frequency effects. This is consistent with Evolutionary Phonology (Blevins Reference Blevins2004), a framework in which asymmetrical phonemic inventories are predicted because sound and language change are not teleological, that is, they operate with no regard for symmetry.
Besides its theoretical goals, this paper is also meant as a contribution to the documentation of Witzapan Nawat phonology, which has only been briefly addressed in a few impressionistic works (e.g., Campbell Reference Campbell1985; Lemus Reference Lemus1997). This contribution is critical when considered in the context of the ongoing Nawat revitalization movement that is taking place in El Salvador (Lemus Reference Lemus, Hinton, Huss and Roche2018). Witzapan Nawat is the Nawat dialect with the highest number of speakers who learned it as a first language (L1) and has established itself as the standard that most second-language (L2) Nawat learners are acquiring all over the country. As such, a thorough understanding of Witzapan Nawat phonology/phonetics is required to effectively teach pronunciation to new L2 speakers.
This paper is structured as follows: Section 2 introduces Witzapan Nawat and the velar/labiovelar stops in Nahuan languages. The methods of this study are presented in Section 3, while the results are shown in Section 4. Section 5 deals with the discussion and Section 6 follows with the conclusions.
2 Witzapan Nawat and voicing of velar/labiovelar stops in Nahuan
The Nahuan languages form a distinct branch of the Uto-Aztecan language family and are divided into three subgroupings – Pochutec, Western Nahuan, and Eastern Nahuan (Canger Reference Canger1988; Pharao Hansen Reference Pharao Hansen2014). Nawat belongs to the Eastern Nahuan group and is closely related to varieties spoken along the Isthmus of Tehuantepec in Mexico. It is the only indigenous language still spoken in El Salvador, where less than 200 elders speak it as an L1 in a few towns in the western part of the country (Campbell Reference Campbell1985). Despite its high level of endangerment, the last twenty years have seen the emergence of an important Nawat revitalization movement led by L2 learners who do not identify as indigenous nor live in traditionally Nawat-speaking communities (Boitel Reference Boitel2018; Lemus Reference Lemus, Hinton, Huss and Roche2018). Owing to a strong social media presence, these activists have succeeded in bringing Nawat and its speakers to public awareness and, as a result, the language is now being learned as an L2 by hundreds of people all over El Salvador and even abroad.
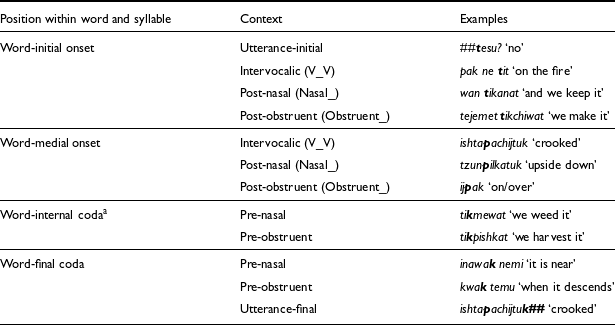
Nawat phonology has been described briefly in impressionistic works by Campbell (Reference Campbell1985), Lemus (Reference Lemus1997) and King (Reference King2014) without major discrepancies as to the phonemic inventory or the main phonological features of the language. Table 1 presents the Nawat phonemes according to Campbell (Reference Campbell1985) and King (Reference King2014) as well as their corresponding letters in the official Nawat alphabet in bold font.Footnote 1
Table 1. Nawat phonemic inventory, based on Campbell (Reference Campbell1985), Lemus (Reference Lemus1997), and King (Reference King2014). The corresponding letters in the official Nawat alphabet are in bold font

All Nawat non-initial syllables must have an onset and, barring a few exceptions, consonant clusters occur only word-internally when the consonants belong to different syllables, as in musta [ˈmus.ta] ‘tomorrow’. Stress is predictable in nearly all native words, falling on the penultimate syllable. The phonemic inventory of Nawat described by previous works is quite similar to that of most Nahuan languages of Mexico, such as Classical Nahuatl (Andrews Reference Andrews2003: 28), Mecayapan Nahuatl (Wolgemuth Reference Wolgemuth2002), Tetelcingo Nahuatl (Pittman Reference Pittman, Comas and Elson1961), and Milpa Alta Nahuatl (Whorf Reference Whorf and Osgood1946). Two features of the Nawat stop subsystem, also prevalent in Nahuan, are of special interest: Nawat distinguishes between a velar /k/ and a labiovelar stop /kw/ and has an inventory made of a single voiceless series /p t k kw/. However, descriptions of specific Nawat varieties document a number of voiced allophones of the velar stop /k/ in certain contexts. These are particularly frequent in Witzapan Nawat, the focus of this study (Campbell Reference Campbell1985; Lemus Reference Lemus1997).
Witzapan Nawat, spoken in the town of Witzapan – Santo Domingo de Guzmán in Spanish – is currently the Nawat variety with the highest number of L1 speakers (Campbell Reference Campbell1985; Lemus Reference Lemus2009).Footnote 2 This variety has established itself as the standard learned by most L2 Nawat speakers but there is very little work done on its phonology and phonetics. Nevertheless, all available descriptions of the language agree that the feature that sets Witzapan Nawat apart from all other Nawat varieties is found in the voicing and spirantization of the velar stop phoneme /k/ in different word positions and phonological contexts.
For instance, Campbell (Reference Campbell1985: 14) reports that the velar stop /k/ in Witzapan Nawat is categorically produced as [ɡ] in ‘initial position’ (without further definition of the term ‘initial’), intervocalically, and after a nasal. Likewise, Lemus (Reference Lemus1997: 16) and King et al. (Reference King, Hernández and Ramírez2003: 18) identify three allophonic variants of the velar stop phoneme: a voiced stop [ɡ] at the beginning of a word and after a voiced consonant, an approximant [ɣ̞] intervocalically, and a voiceless stop [k] in syllable-final position and after a voiceless consonant. Most recently, King (Reference King2014: 391) observes that ‘g-like sounds’ in Witzapan Nawat are found categorically at the beginning of a word, after ‘some consonants’ (which are not specified), and between vowels, adding that the velar stop is always voiceless [k] at the end of the syllable. In contrast to /k/, voiced allophones of the other stops, including the labiovelar /kw/, are quite rare and only sporadically documented in high frequency words such as the verb -ita [ˈi.da] ‘to see something’ (Campbell Reference Campbell1985: 56). The allophony of /k/ in Witzapan Nawat according to the previous literature is summarized as follows: [ɡ] at the beginning of a word or after a voiced consonant: kal [ˈɡal] ‘house’, anka [ˈaŋ.ɡa] ‘maybe’, kanka [ˈɡaŋ.ɡa] ‘to/from where?’. [ɣ̞] intervocalically: takat [ˈta.ɣ̞at] ‘man’, nikaki [ni.ˈɣ̞a.ɣ̞i], weyka [ˈwej.ɣ̞a] ‘body’. [k] in syllable-final position or after voiceless consonant: -ishka [ˈiʃ.ka] ‘to roast something’, tik [tik] ‘in, inside’, nikmatki [nik.ˈmat.ki] ‘I knew it’.
Voicing of the velar stop is not unique to Witzapan Nawat and is in fact found in other Nawat varieties of El Salvador, although to a lesser extent. For example, in Kwisnawat Nawat, /k/ is voiced in the 3rd person singular object prefix ki-, between two /a/, and between any two vowels provided that the first one is long, remaining [k] in all other contexts (Campbell Reference Campbell1985: 27). In Izalco Nawat, the velar is voiced only in /k/-initial unstressed particles in the intervocalic position, such as ka ‘that’ (Schultze-Jena Reference Schultze-Jena1935).Footnote 3
Voicing of /k/ and of the labiovelar /kw/ is a feature of various Nahuan languages of Mexico as well. As an illustration, in Chicontepec Nahuatl (Aguilar Reference Aguilar2020: 33), Sierra Norte de Puebla Nahuatl (Kakadelis Reference Kakadelis2018: 206), and varieties of the Alto Balsas region (Flores Farfán Reference Farfán and Antonio1992: 55), [ɡ] has been reported as a sporadic allophone of the velar phoneme /k/ in intervocalic contexts. Likewise, in varieties spoken in the Sierra de Zongolica (Monzón Reference Monzón1990: 31), the voiced allophone [ɡ] is found after a nasal while [ɡ] and [ɣ] can occur intervocalically. In some Nahuan languages, it is claimed that a phonemic distinction between /k/ and /ɡ/ has entered the stop subsystem, citing a small number of minimal pairs as evidence. For instance, in Pajapan Nahuat (García de León Reference García de León1976: 57), the velars are contrastive word-initially in katka ‘lark’ vs. gatka ‘it was’ and, in varieties of the Malinche Volcano region (Hill & Hill Reference Hill and Hill1986: 65) and the Sierra Zacapoaxtla (Key & Key Reference Key and Key1953: 53), they contrast intervocalically in -maga ‘to hit something’ vs. -maka ‘to give something to someone’.
A smaller number of Nahuan languages of Mexico also feature voiced allophones of the labiovelar /kw/. In varieties of the Sierra de Zongolica (Monzón Reference Monzón1990: 38), [ɡw] is reported after a nasal while [ɣw] and [w] are found intervocalically. Moreover, a phonemic shift has taken place in some languages, where /kw/ is now /b/ in all contexts, as in /bawit/ ‘tree’ while most varieties have /kwawit/ (García de León Reference García de León1976: 41; Monzón & Roth-Seneff Reference Monzón and Roth-Seneff1984). Although more research is needed, it seems that no implicational hierarchy of velar stop voicing is at play – there are varieties that have voicing of /kw/, either at the allophonic or phonemic level, without voicing of /k/, as in Ixquihuacan Nahuatl (Sasaki Reference Sasaki2014: 145). Other languages, such as Chicontepec Nahuatl (Aguilar Reference Aguilar2020: 33), have allophonic or phonemic voicing of /k/ without voicing of /kw/, while varieties like Pajapan Nawat have voicing of both stops (García de León Reference García de León1976: 41).
The voicing of the velar and/or labiovelar stops in Nahuan languages is likely not due to the influence of Spanish, a language with phonemic /ɡ/ and /k/ that is dominant in most Nahuan-speaking communities. Evidence for this is the fact that /ɡ/ is the least common stop phoneme in Spanish, amounting to 1% of all phoneme occurrences according to various corpora (Pérez Reference Pérez2003), and it would be counterintuitive that Nahuan speakers acquire voicing in velars rather than in dental or bilabial stops when they rarely hear it or use it when they speak Spanish. Similarly, voicing of the velars cannot be linked to language attrition because it is present in Nahuan varieties that enjoy relative vitality, such as Chicontepec Nahuatl.
Regardless of its presence in numerous Nahuan languages, the phonetics of voicing in velars/labiovelars has yet to be addressed in detail (see Kakadelis Reference Kakadelis2018 for an exception), and little is known about the factors that condition it or that led to its development. For instance, previous descriptions of Witzapan Nawat find that voiced allophones of /k/ occur in ‘initial position’. However, it is unclear if that is the case when the word-initial /k/ is at the beginning of the utterance or following a voiceless obstruent, contexts that are crosslinguistically not conducive to voicing (Flege & Brown Reference Flege and Brown1982; Westbury & Keating Reference Westbury and Keating1986; Wetzels & Mascaro Reference Wetzels and Mascaro2001; Hayes Reference Hayes and McCarthy2004; Beckman et al. Reference Beckman, Jessen and Ringen2013). Also unresolved is whether spirantization affects word-initial /k/ across word boundaries and whether coda /k/ is subject to positional allophony the same way as onset /k/ is. By addressing these issues using original acoustic data from Witzapan Nawat speakers, this article hopes to contribute, not only to language documentation efforts, but to the literature on stop voicing and phonemic inventory structure in general.
3 Method
3.1 Participants and materials
One male and four female L1 Nawat speakers from the town of Witzapan participated in this study, recruited among personal acquaintances of the researcher. At the time of the recordings, the male participant (M1) was sixty years old and the female participants were respectively sixty-five (F1), fifty-seven (F2), sixty-three (F3) and sixty-three (F4) years old. All participants are balanced bilinguals, grew up speaking the Nawat variety of Witzapan in their household, and learned Spanish in their teenage years.
High-quality recordings of the L1 Nawat speakers were made in the field in 2018 and 2019 in quiet environments in the participants’ homes using a Plantronics USB head-mounted microphone connected to a laptop computer and using the Audacity (R) recording and editing software. Tokens were extracted from open-ended interviews dealing with Witzapan history as well as elicitation tasks dealing with spatial constructions, that is, goals unrelated to this project. All interviews, ranging in length from thirty to ninety minutes, were conducted in Nawat and transcribed.
3.2 Instrumental analysis
To have a comparative perspective of the phonetic properties of /k/ versus the other Witzapan Nawat stops, all the realizations of /k/ and /p t kw/ found within the first thirty minutes of each recording were segmented, manually extracted, and analyzed in Praat (Boersma Reference Boersma2001). Three acoustic correlates associated with voicing in oral stops and obstruents were measured: voice onset time (VOT; Lisker & Abramson Reference Lisker and Abramson1964), consonant duration (Ladefoged Reference Ladefoged2006; Johnson Reference Johnson2012), and percent voicing (Flege & Brown Reference Flege and Brown1982).
VOT is defined as the time from the stop release to the onset of voicing (Lisker & Abramson Reference Lisker and Abramson1964). Voicing was identified by the presence of periodic waves in the waveform and a voicing bar in the spectrogram. For voiced stops, VOT values are negative because voicing begins before the stop release. In contrast, in voiceless stops, voicing begins with the vowel following the stop release, which yields positive VOT values. Figure 1 shows the production of a word-initial onset /k/ in utterance-initial context. The presence of periodic waves in the waveform and a voicing bar in the spectrogram immediately before the stop release means that this realization has a negative VOT. In this case, the velar stop phoneme is produced as a voiced stop [ɡ] rather than voiceless stop [k]. VOT was not measured in unreleased stops and tokens produced as approximants given the absence of a visible stop release. Likewise, tokens of coda /k/ in the pre-obstruent context were not measured for VOT because there is no voicing after the release.

Figure 1. Production of utterance-initial /k/ in the word kuchiltik ‘color orange’ showing a negative VOT value. Production by speaker F3.
Consonant duration, measured as the time between the onset and the ending point of a consonant, is one of the strongest correlates of voicing in obstruents, as voiced obstruents have significantly shorter durations than their voiceless counterparts (Cooper et al. Reference Cooper, Borst and Gerstman1952). In this paper, the landmarks of duration depend on whether a stop phoneme is realized as a stop or an approximant, the latter being the most frequent production of /k/ in the intervocalic context (see Section 5.1). For stop realizations, the onset of the consonant was established at either the end of formant structure of a previous vowel, approximant, or nasal, the end of frication noise of a previous fricative or affricate, or after the release of a previous stop, while its ending point was placed before the release of the stop. Unreleased stops were not measured for duration because no landmark for the ending point of the stop can be located in these cases. In the case of approximant realizations, their duration was established following the procedures in Hualde et al. (Reference Hualde, Simonet and Nadeu2011): the onset of the consonant was located at the moment the previous vowel showed a decrease in intensity, as assessed in the waveform and spectrogram, and its ending point was set at the increase of intensity signaling the following vowel.
Finally, percent voicing is the ratio of voicing during the production of the consonant to the total consonant duration. Voicing was identified by the presence of periodic waves in the waveform and a voicing bar in the spectrogram during the production of the consonant. Figure 2 shows the landmarks of consonant duration for a stop production of /t/ as well as the period of voicing that is used for measuring the percent voicing.
Table 2. Positions within the word/syllable and phonological contexts used for coding tokens of /p t kw/ and /k/
a Only vowels can occur before a coda consonant in Witzapan Nawat, which is why the segment before the coda stop is not coded for.
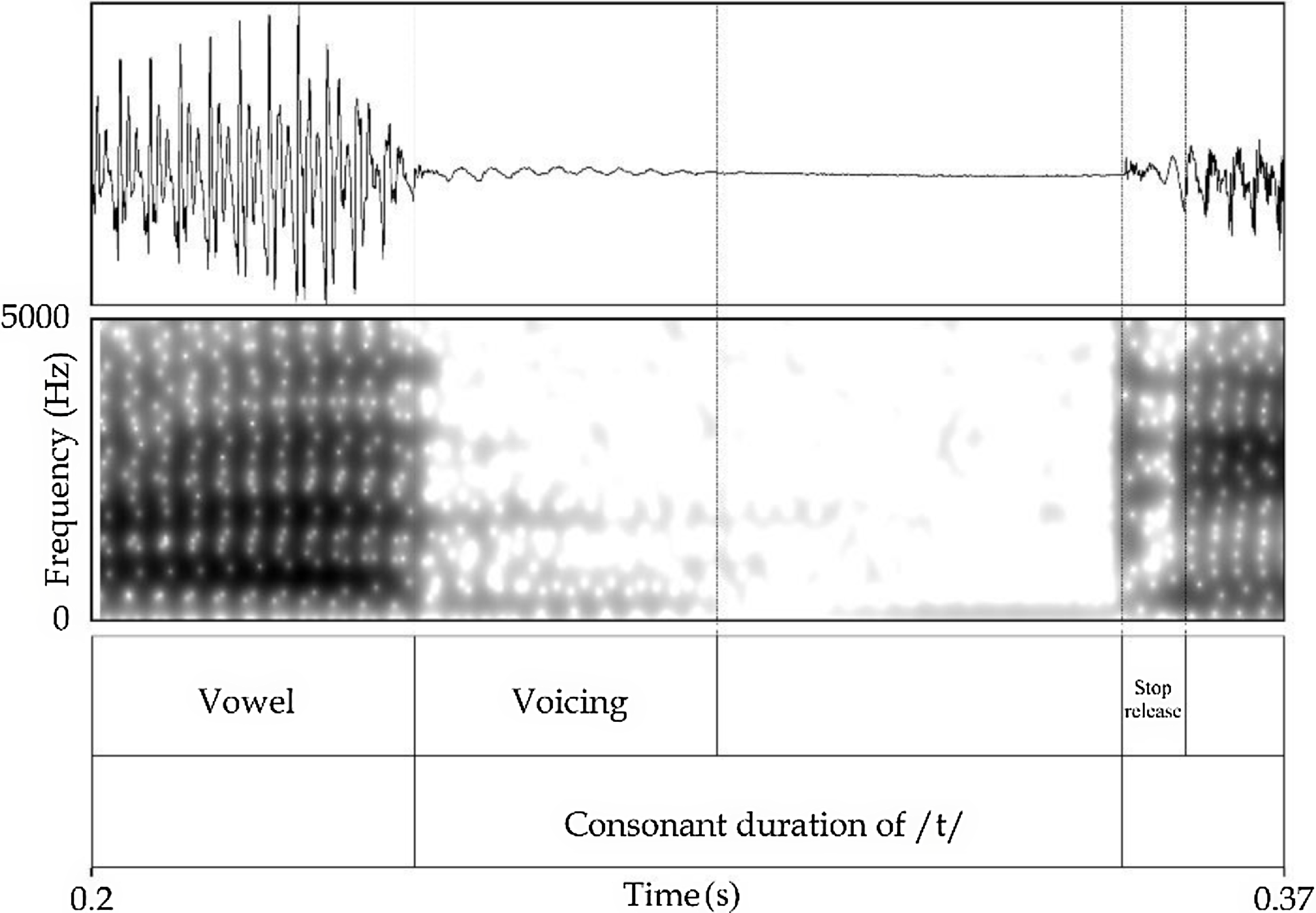
Figure 2. Production of word-initial intervocalic /t/ in the phrase taja tikwalani ‘you get mad’ (F2). The onset of the consonant is marked at the end of the formant structure of the previous vowel and its ending point is set before the stop release. This example shows a period of voicing in the consonant, used to calculate the percent voicing.
All tokens of /p t kw/ and /k/ were coded according to their place of articulation and their position within the word and syllable into four categories: word-initial onsets, word-medial onsets, word-internal codas, and word-final codas. They were also coded for their phonological contexts: onsets were classified as utterance-initial, intervocalic, post-nasal and post-obstruent. The only stop phoneme that occurred frequently in coda position was /k/. The contexts of coda /k/ were classified as pre-nasal, pre-obstruent and utterance-final. Examples of these categories are shown in Table 2, highlighting the relevant phoneme in bold. Notice that the intervocalic category includes tokens between vowels and glides /j w/. Phonemes classified as obstruents in the ‘post-obstruent’ and ‘pre-obstruent’ categories are /p t k kw t͡s t͡ʃ s ʃ h/. In all, 2,024 tokens were collected from the recordings of the five Witzapan Nawat speakers, corresponding to 293 tokens of /p/, 543 of /t/, 180 of /kw/ and 1,008 tokens of /k/. A total of twenty tokens were discarded for being unreleased stops or because of background noise. As seen in the following section, the descriptive statistics reveal categorical differences between /p t kw/ and /k/ in their VOT, duration, and percent voicing. For this reason, it was deemed that there was no need to perform further inferential analyses.
4 Results
4.1 VOT
Word-initial onset tokens of /p t kw/ and /k/ in the utterance-initial context lack acoustic cues to establish their duration and percent voicing. For this reason, VOT is the only correlate of voicing measured for utterance-initial tokens. A total of forty-three utterance-initial tokens of /p/, seventy-one of /t/, fifty-nine of /kw/ and 132 of /k/ were collected. Their VOT distribution is shown in Figure 3. Each box in the plot represents a stop phoneme, while the black horizontal lines within the boxes stand for the median VOT value. The height of the boxes represents the difference between the first and third quartile, known as the interquartile range. Whiskers stand for the extreme data points within 0.5 times the length of the box, large dots represent mean values, and the small black dots outside the boxes represent outliers. The horizontal dotted line at 0 ms separates positive from negative VOT values.
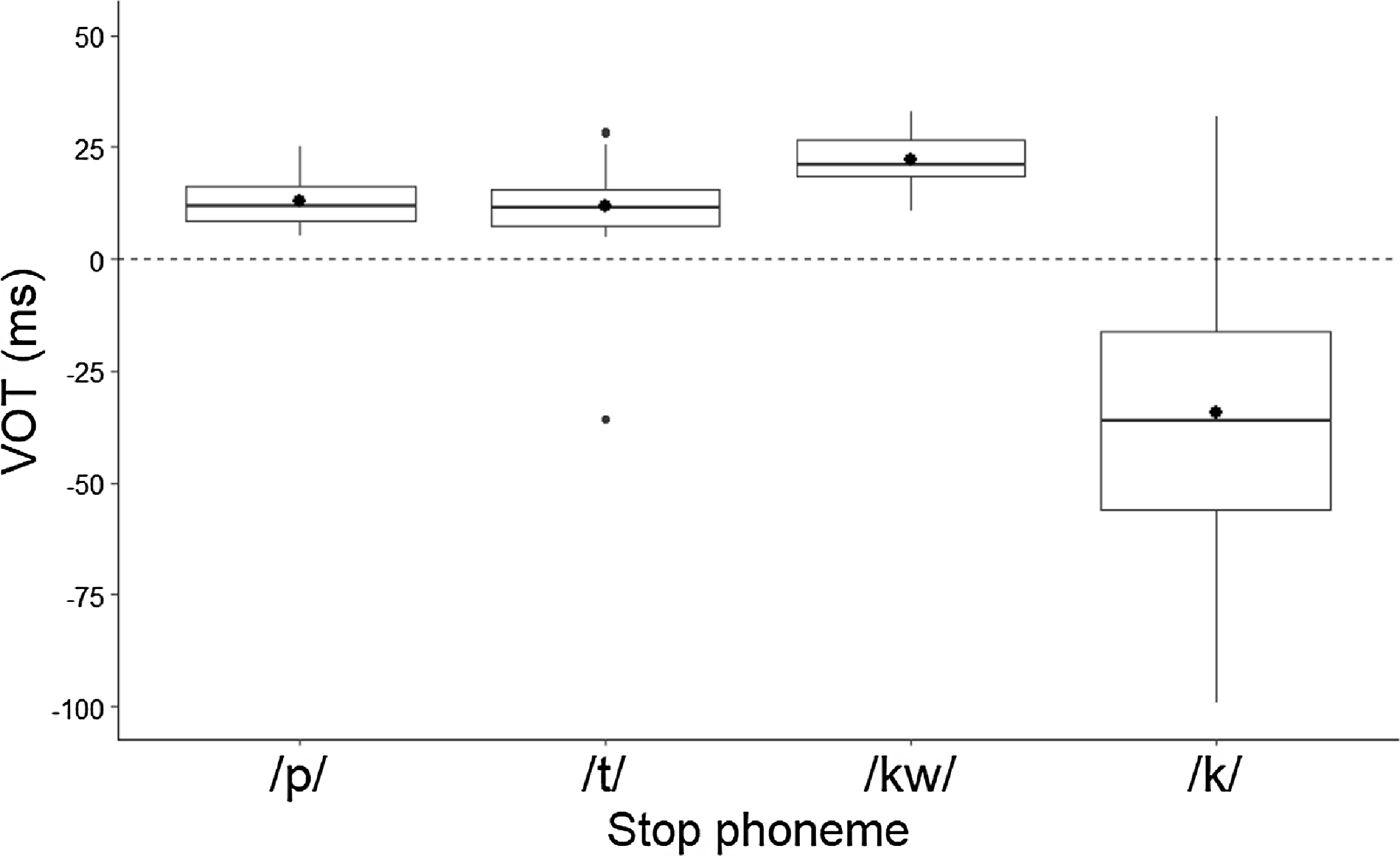
Figure 3. VOT of word-initial onset /p t kw/ and /k/ in the utterance-initial context.
A marked difference between /k/ and the other stop phonemes is patent in the utterance-initial context – while /p t kw/ have a mean VOT of around 13–24 ms, /k/ has a negative mean of −37 ms, which indicates the presence of voicing before the release of the consonant. A similar trend is presented in Figure 4, showing the VOT of sixty-seven word-initial onset tokens of /p/, 126 of /t/, seventy-nine of /kw/ and 188 of /k/ in the intervocalic, post-nasal and post-obstruent contexts. Word-initial /p t kw/ in these contexts have a mean VOT of around 11–26 ms. In stark contrast, word-initial onset tokens of /k/ after a nasal and after an obstruent have mean VOT values of around −25 ms and −23 ms.
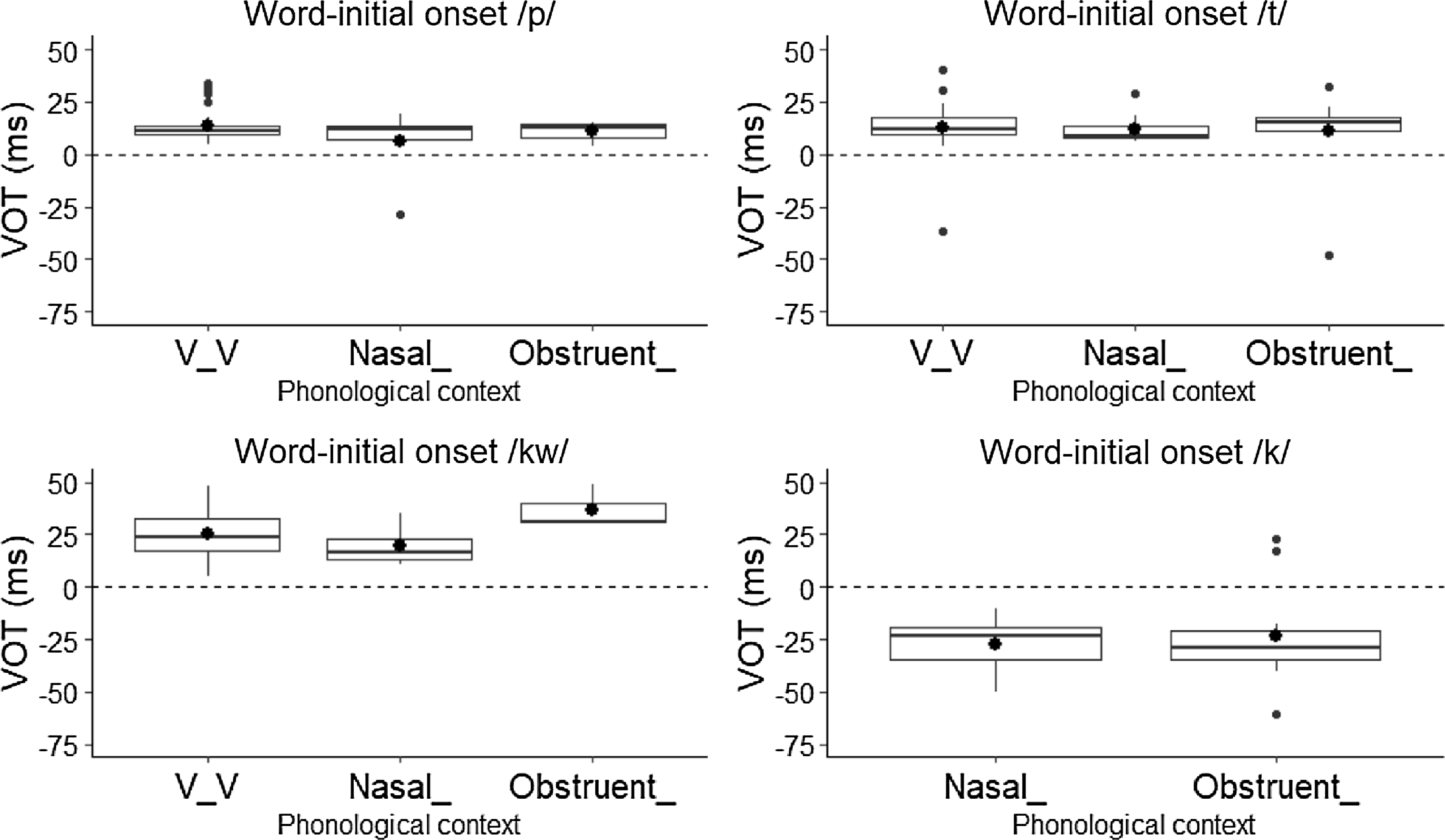
Figure 4. VOT of word-initial onset /p t kw/ and /k/ by phonological context.
VOT could not be measured for word-initial intervocalic /k/ because tokens were almost categorically produced as velar approximants [ɣ̞], which have no stop closure nor release. Only 10% (12/114) of tokens of word-initial, intervocalic /k/ showed other types of realization, either voiced stops or elisions. An approximant realization of word-initial, intervocalic /k/ is presented in Figure 5. The waveform and spectrogram corresponding to /k/ show decreased intensity, lack of a stop closure and release, and presence of voicing and formant structure throughout the consonant. These acoustic characteristics are consistent with approximants in languages such as Iwaidja (Shaw et al. Reference Shaw, Agostini, Mailhammer, Harvey and Derrick2020), Galician (Martínez Celdrán & Regueira Reference Martínez Celdrán and Regueira2008) and Spanish (Martínez Celdrán Reference Martínez Celdrán1991).
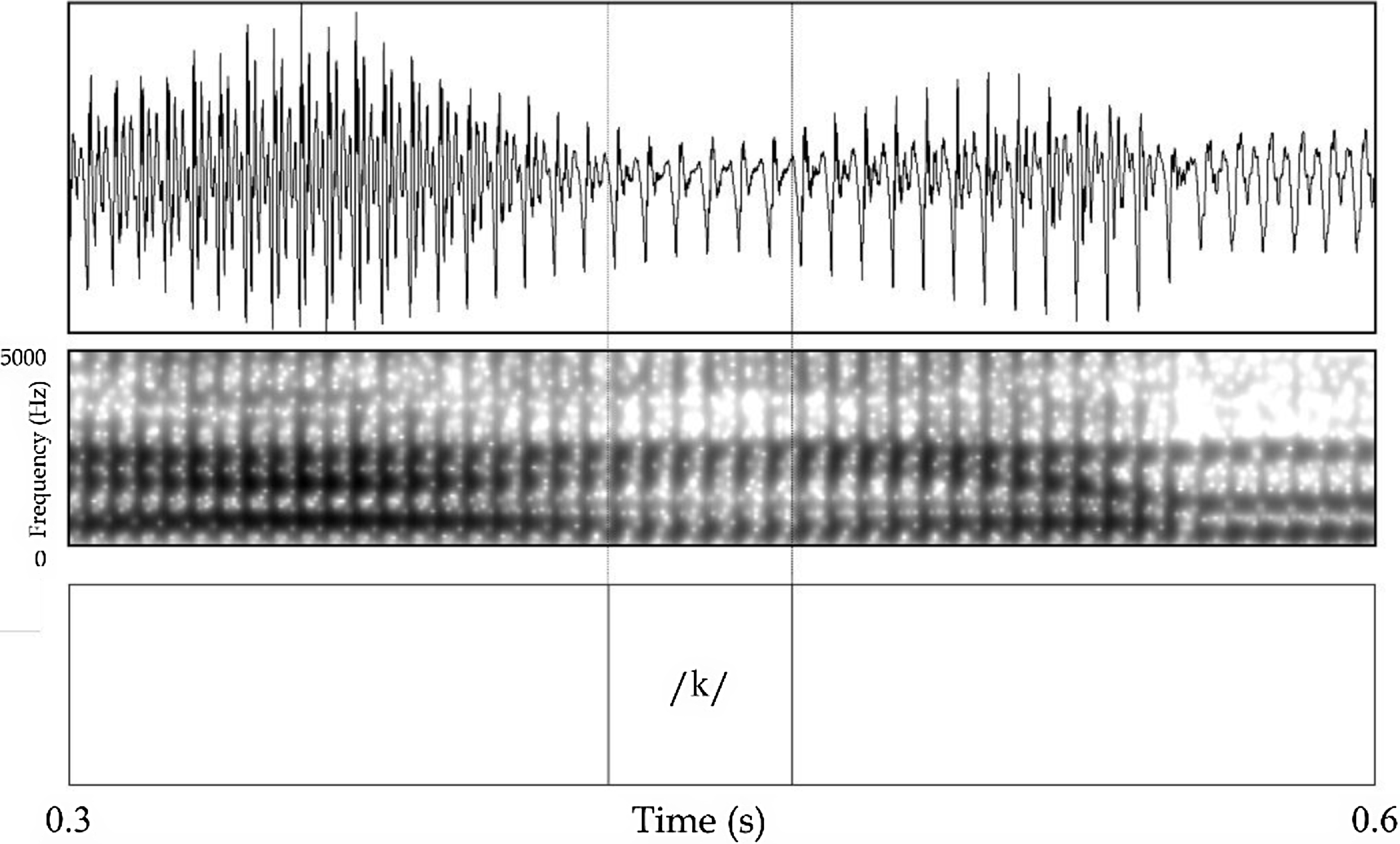
Figure 5. Production of word-initial intervocalic /k/ as an approximant in the phrase kenha keman pewa ‘it is the same when it begins’ (M1).
Following, Figure 6 presents the VOT of 183 word-medial onset tokens of /p/, 250 of /t/, 110 of /kw/, and 375 of /k/. Phonemes /p t/ display similar positive VOT between 12–13 ms in the three contexts considered. In contrast, word-medial /kw/ tokens show a mean VOT of 24 ms in the intervocalic and post-obstruent contexts and a negative mean of −27 ms post-nasally. Word-medial /k/ follows a similar trend, as post-nasal tokens have a negative mean of −25 ms while post-obstruent tokens show a positive VOT mean of 25 ms. As was the case with word-initial onsets, almost all intervocalic tokens of word-medial onset /k/ were produced as approximants and were not measured for VOT. Only 10% (23/213) of tokens of word-medial /k/ in intervocalic context were produced as either voiced stops, voiceless stops, or were deleted.
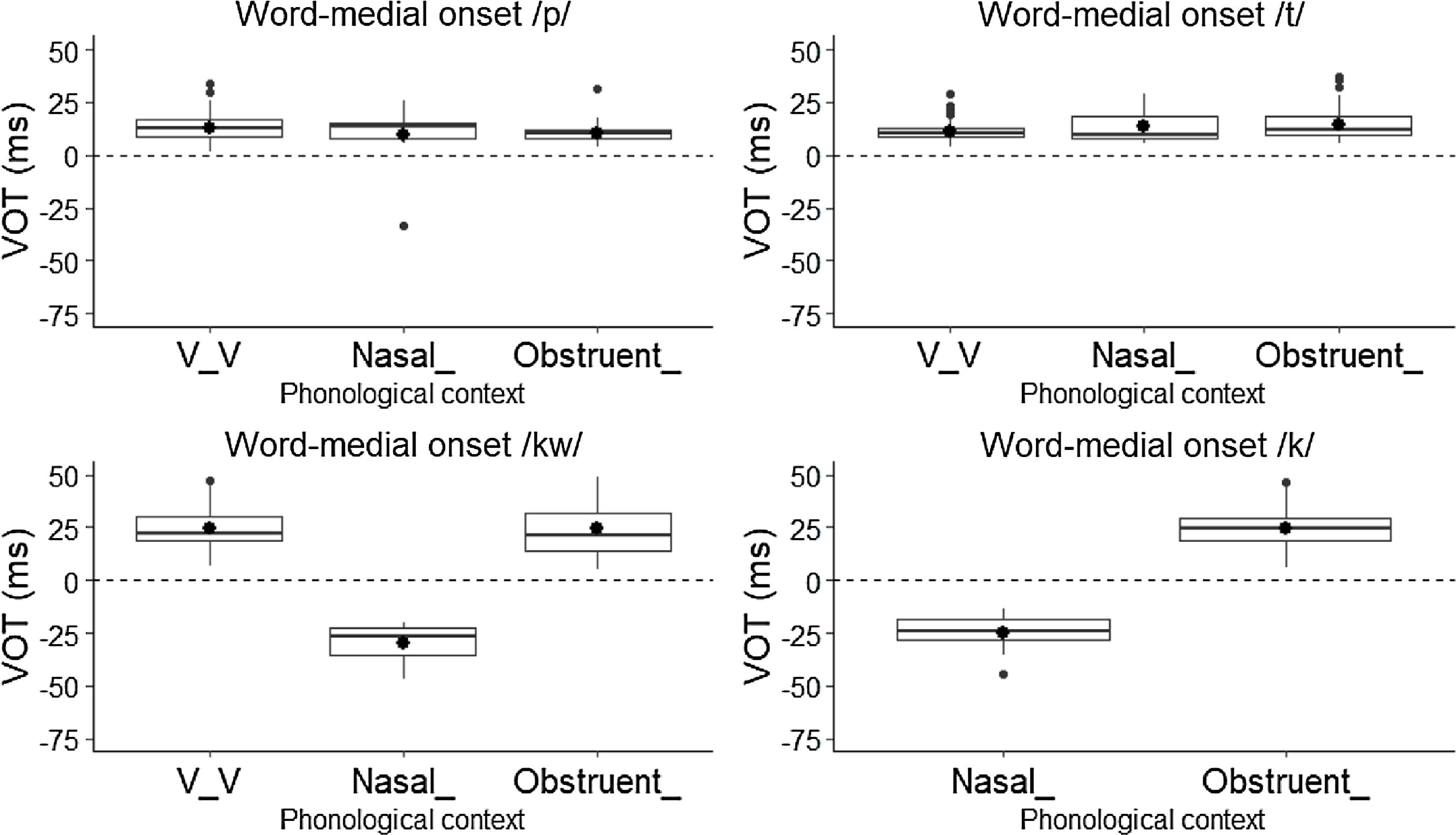
Figure 6. VOT of word-medial onset /p t kw/ and /k/ by phonological context.
In the case of codas, the only phoneme that occurs frequently in this position is /k/. However, since most collected coda tokens are followed by obstruents or pauses, the onset of voicing cannot be established and VOT could not be measured.
4.2 Consonant duration
The duration of word-initial onset tokens is shown in Figure 7, pointing again at important differences between /k/ and /p t kw/. While the mean duration of word-initial onset /p t kw/ in the considered contexts ranges between 89–103 ms, tokens of /k/ are more than half as long, showing a mean duration of 50 ms in the intervocalic context, 30 ms post-nasally and 48 ms after an obstruent.
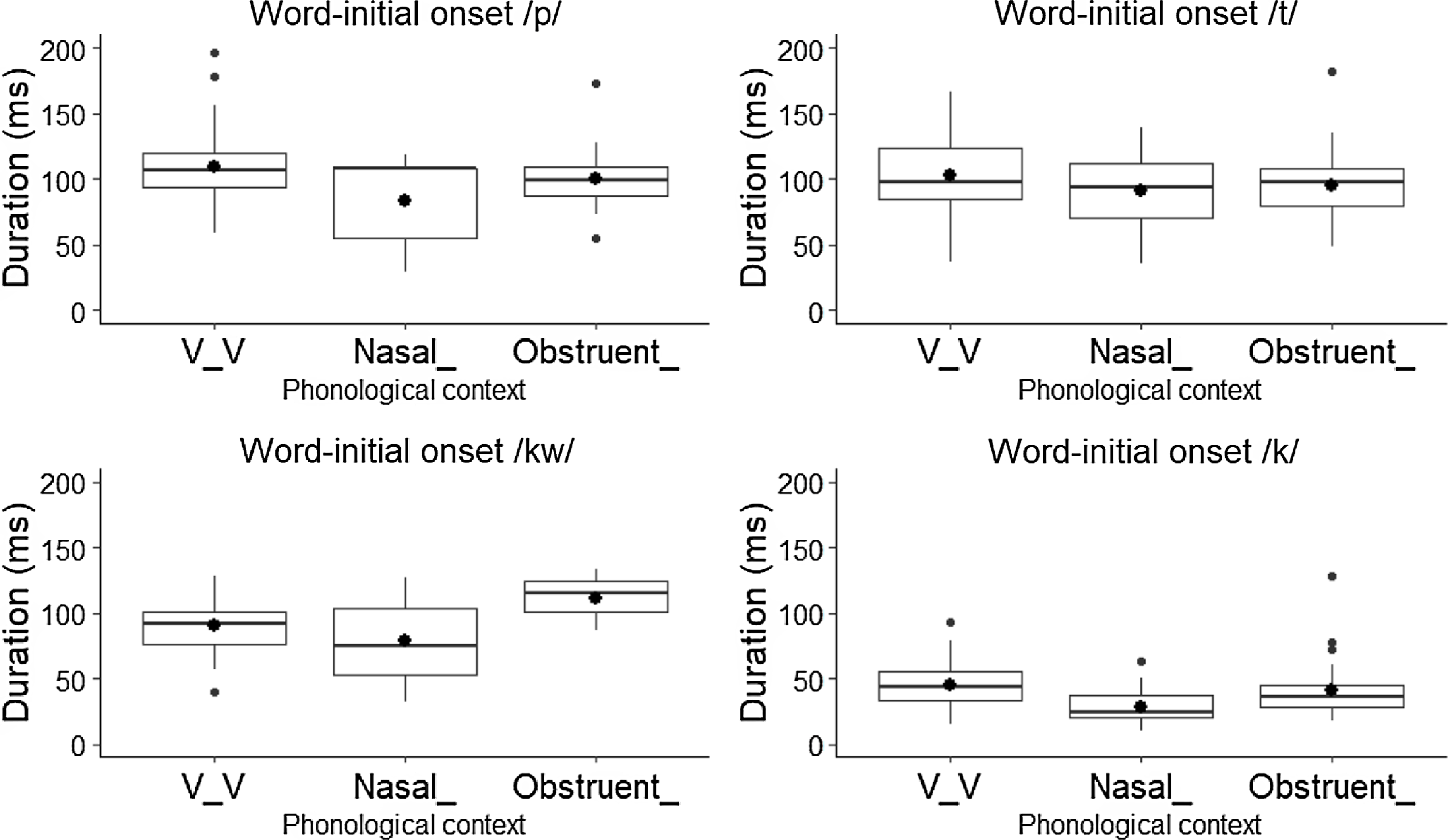
Figure 7. Duration of word-initial onset /p t kw/ and /k/ by phonological context.
Figure 8 presents the duration of the Witzapan Nawat stop phonemes in word-medial onset position. Again, tokens of /p t kw/ follow similar patterns – they have a mean duration closer to 100 ms in the intervocalic and post-obstruent contexts. After a nasal, /p t/ and specially /kw/ are considerably shorter, having a mean length of 57 ms, 59 ms and 30 ms respectively. In comparison, word-medial /k/ is considerably shorter than the other stops in the intervocalic and post-nasal contexts, reporting a mean duration of 47 ms and 29 ms. Tokens of word-medial onset /k/ are longest after an obstruent, in which case they have a mean duration of 90 ms, comparable to those of the other stop phonemes in the same context.
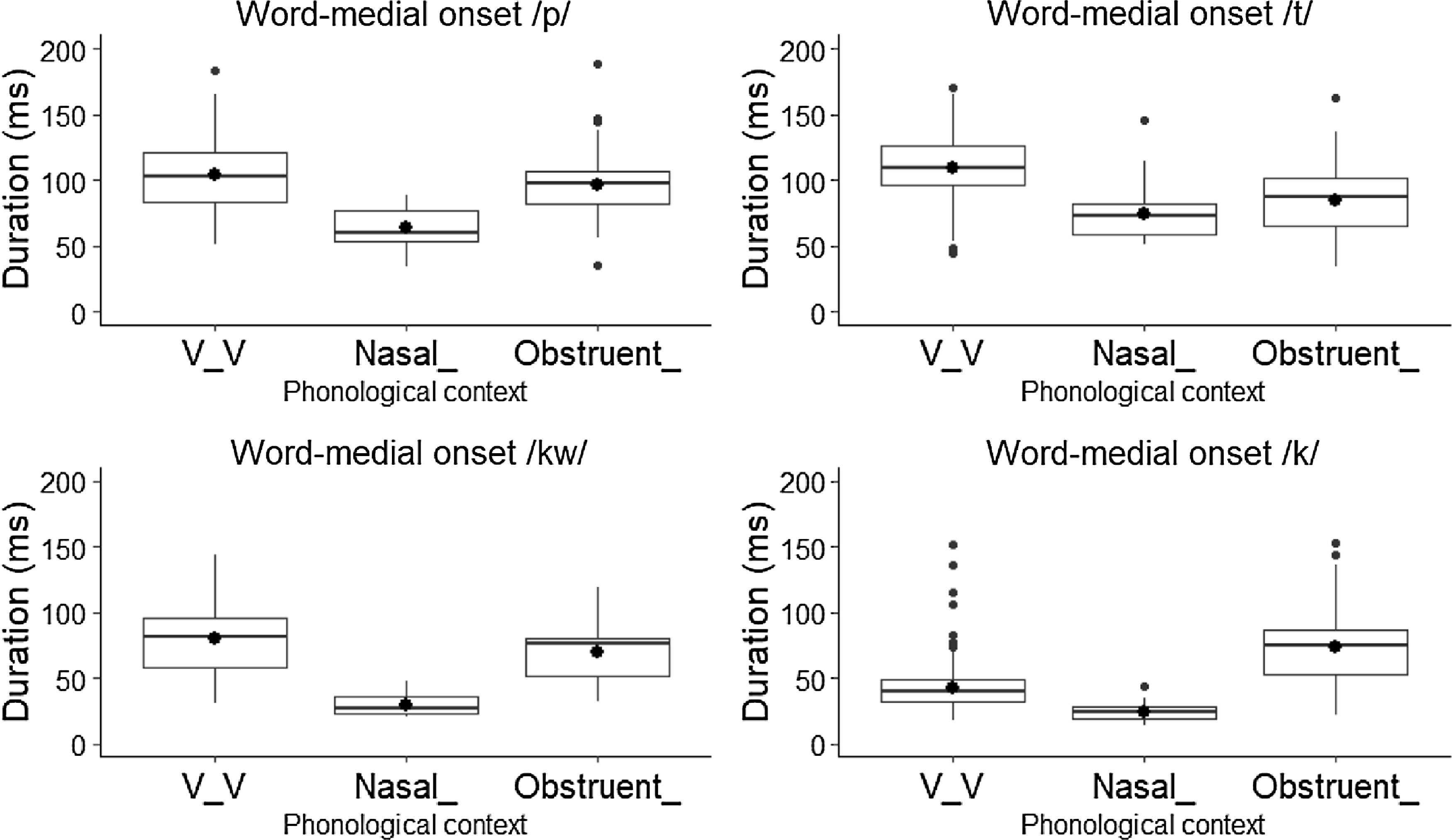
Figure 8. Duration of word-medial onset /p t kw/ and /k/ by phonological context.
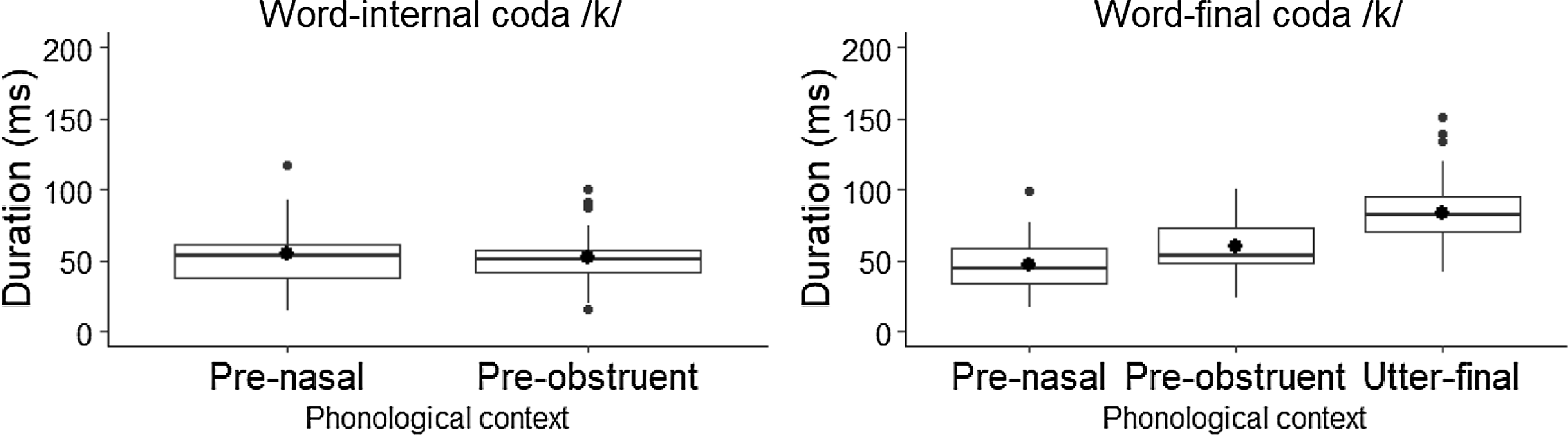
Figure 9. Duration of coda /k/ by phonological context.
A total of 109 tokens of coda /k/ in word-internal position and 203 in word-final position were collected. Their duration according to their phonological context – either pre-nasal, pre-obstruent or utterance-final – is shown in Figure 9. While the mean duration of coda /k/ in word-internal and word-final positions varies between 50–55 ms in the pre-nasal and pre-obstruent context, utterance-final /k/ shows a considerably longer mean duration of 90 ms.
4.3 Percent voicing
The percent voicing of stops in word-initial onset position is presented in Figure 10. Once again, /p t kw/ seem to pattern together, as they exhibit a mean percent voicing close to 27% or less in the considered contexts. In sharp contrast, tokens of word-initial onset /k/ in the intervocalic, post-nasal and post-obstruent contexts categorically show a mean percent voicing close to 100%, as represented by its median of 100% and lack of interquartile range.

Figure 10. Percent voicing of word-initial onset /p t kw/ and /k/ by phonological context.
The percent voicing of word-medial onset stops is shown in Figure 11. Stops /p t kw/ have a mean similar percent voicing of around 25% in the intervocalic context and, after an obstruent, their voicing is reduced to almost 0%. In the post-nasal context, /p t/ report similar mean percent voicing of 23% and 26%, but post-nasal /kw/ follows a clearly different trend in that its tokens have a mean percent voicing close to 100%. In contrast, tokens of word-medial onset /k/ are fully voiced intervocalically and after a nasal but, like the other stops, /k/ tokens show a mean percent voicing close to 0% when they occur after an obstruent.

Figure 11. Percent voicing of word-medial onset /p t kw/ and /k/ by phonological context.
The percent voicing of coda /k/ by position and phonological context is shown in Figure 12. In general, voicing of coda /k/ shows greater variation than onset /k/. The mean percent voicing of word-internal coda /k/ is 60% in the pre-nasal context and 45% in the pre-obstruent context. On the other hand, word-final coda /k/ shows mean percent voicing between 75% in the pre-nasal context and 45% when the following consonant is an obstruent. In the utterance-final context, coda /k/ has a considerably lower percent voicing averaging 17%.

Figure 12. Percent voicing of coda /k/ by position within word and phonological context.
To summarize, the descriptive statistics of VOT, consonant duration, and percent voicing evidences striking and categorical acoustic differences between /p t kw/ and /k/ in Witzapan Nawat. These differences and their implications for the analysis of the phonemic inventory of Witzapan Nawat will be discussed in the next session.
5 Discussion
In this section, based on the analyses of the acoustic data, I propose that the stop inventory of Witzapan Nawat is asymmetrical – it consists of voiceless stops /p t kw/ and the voiced velar stop /ɡ/. I show how this is an unusual asymmetry because it is not predicted by markedness or feature-economy theories of phonemic inventory structure. Finally, I propose a series of diachronic developments that led to the creation of this rare system in line with Evolutionary Phonology (Blevins Reference Blevins2004).
5.1 /ɡ/ as the velar stop phoneme in Witzapan Nawat
In word-initial onset position, /p t kw/ in the utterance-initial, intervocalic, post-nasal, and post-obstruent contexts categorically have positive VOT values. Their mean duration varies between 89–103 ms, and their mean percent voicing fluctuates between 0% in the post-obstruent context and 27% in the intervocalic and post-nasal contexts. As word-medial onsets, /p t/ tokens also display positive VOT values in all contexts, mean durations of around 100 ms, and percent voicing between 0–27%. On the other hand, word-medial onset /kw/ follows the pattern of /p t/ in the intervocalic and post-obstruent contexts, displaying positive VOT, a mean duration close to 100 ms, and a percent voicing between 0–27%, but shows negative VOT, a mean duration of 27 ms, and a mean percent voicing close to 100% in the post-nasal context. Thus, Witzapan Nawat /p t kw/ in almost all positions and contexts have acoustic characteristics – positive VOT, duration, and relatively low percent voicing – that are comparable to voiceless stops in other languages, that is stops specified as [−voice] (Lisker & Abramson Reference Lisker and Abramson1964). The only exception is /kw/, which shows characteristics of a voiced stop [ɡw] word-medially in the post-nasal context, as in kitankwa [ɡi.ˈtaŋ.ɡwa] ‘it (i.e., a coyote) bites it (a rabbit)’.
In stark contrast to the other stops, word-initial onset /k/ shows mean negative VOT in the utterance-initial, post-nasal and post-obstruent contexts. In the intervocalic context, it is produced categorically as an approximant. Duration-wise, word-initial /k/ is shorter than the other stops, averaging 38–50 ms in length, and its percent voicing is close to 100% in all contexts. As a word-medial onset, /k/ has negative VOT post-nasally but positive VOT in the post-obstruent context. Its mean duration and percent voicing is 29 ms and 100% in the post-nasal context and 90 ms and close to 0%in the post-obstruent context. As was the case with word-initial onset /k/, practically all intervocalic tokens of word-medial /k/ are produced as approximants.
As for coda /k/, it has a duration of 90 ms in the utterance-final context and is longer than in pre-nasal and pre-obstruent contexts, where it averages 50–55 ms. Likewise, utterance-final coda /k/ has an average percent voicing of 17%, which is lower than in pre-nasal and pre-obstruent contexts. On the other hand, percent voicing of coda /k/ is higher in the pre-nasal context, where it averages 55–75%, compared to the pre-obstruent context, where it averages 30%. Another important finding is that there is more variation in the percent voicing values of coda /k/ compared to onset /k/.
It is clear from the acoustic analyses that, unlike /p t kw/, there are three allophones of onset /k/ in Witzapan Nawat: voiceless stops, approximants and voiced stops. Notably, the only context in which onset /k/ consistently has the characteristics of a voiceless stop – positive VOT, longer duration, and relatively low percent voicing – is word-medially in the post-obstruent context. Conversely, in the intervocalic context, /k/ is produced as an approximant in word-initial and word-medial positions. In all other contexts and positions, onset /k/ shows negative VOT, shorter duration, and percent voicing close to 100%, features that are representative of voiced stops (Lisker & Abramson Reference Lisker and Abramson1964; Beckman et al. Reference Beckman, Jessen and Ringen2013).
Coda /k/ follows different patterns from onset /k/. In the utterance-final context, coda /k/ shows duration and percent voicing comparable to voiceless stops. Nevertheless, pre-nasal and pre-obstruent coda /k/ is longer than onset /k/ in contexts where the latter is produced as a voiced stop but shorter than all other stops. Moreover, the percent voicing of coda /k/ shows more variability than onset /k/. In fact, even in the pre-nasal context, the mean percent voicing of coda /k/ is not 100%. This is evidence that pre-nasal and pre-obstruent coda /k/ shows acoustic characteristics intermediate between voiced and voiceless stops. Similar asymmetries between onset and coda segments are not uncommon and are often analyzed as instances of voice underspecification (Archangeli Reference Archangeli1988; Inkelas Reference Inkelas1994; Ernestus Reference Ernestus2000; Bale et al. Reference Bale, Papillon and Reiss2014). In this case, I suggest that coda /k/ in pre-nasal and pre-obstruent contexts is not specified for the [±voice] feature, and therefore does not display the percent voicing and duration of segments specified for [±voice].
To summarize, the allophones of /k/ and the positions and phonological contexts in which they are found are presented in Table 3, with the relevant segment highlighted in bold. Audio files of these words and phrases from the L1 Witzapan Nawat speakers are available as supplementary materials.
Table 3. Allophones of /k/ in Witzapan Nawat by word position and phonological context based on the analyses of correlates of voicing
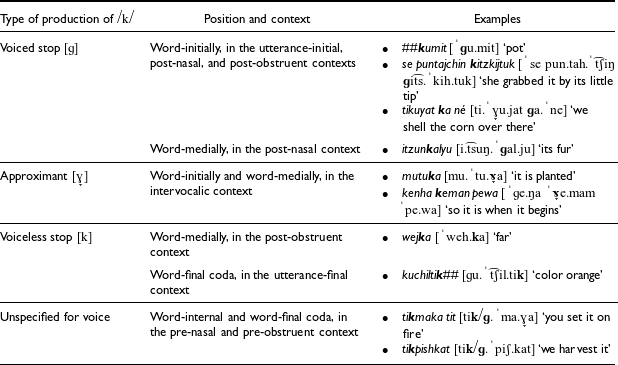
This allophonic distribution prompts the re-evaluation of /k/ as the velar stop phoneme in Witzapan Nawat for one main reason: if /k/ is underlying, it is difficult to account for the presence of the voiced allophone [ɡ] in contexts that are not conducive to voicing in obstruents. For instance, if /k/ is taken as the velar stop phoneme, the voiced allophone [ɡ] after nasals can be readily justified given the propensity of voiceless stops to gain the [+voice] feature in that context (Pater Reference Pater, Kager, van der Hulst and Zonneveld1999). However, the acoustic data show that [ɡ] also occurs when word-initial /k/ is in the utterance-initial and post-obstruent contexts, which crosslinguistically disfavor voicing in stops (Flege & Brown Reference Flege and Brown1982; Westbury & Keating Reference Westbury and Keating1986; Wetzels & Mascaro Reference Wetzels and Mascaro2001; Hayes Reference Hayes and McCarthy2004; Beckman et al. Reference Beckman, Jessen and Ringen2013). In order to account for the voicing of /k/ in these cases, it would be necessary to invoke ‘quirky’ rules or markedness constraints that give /k/ the [+voice] feature without any phonetic motivation.
Consequently, an interpretation that better accounts for the phonological facts is proposed, in which the velar stop phoneme is /ɡ/, a phoneme specified for [+voice].Footnote 4 This way, the allophones of the velar stop in different contexts can be readily explained by common phonological processes. More precisely, the voiceless stop allophone [k] that is found in the word-medial post-obstruent context, as in wej[k]a ‘far’ is accounted for as a case of progressive voicing assimilation, in which /ɡ/ acquires the [−voice] specification of the previous voiceless obstruent. As seen in Table 3, voicing assimilation to a previous obstruent is blocked when /ɡ/ is word-initial, as in tikuyat [ɡ]a né ‘we shell it over there’. This can be explained by appealing to the status of the beginning of a word as a phonologically strong position. Evidence from a variety of languages shows that segments in the word-initial position are resistant to assimilatory processes that affect the same segment elsewhere in the word, perhaps due to their psycholinguistic prominence (McCarthy & Prince Reference McCarthy, Prince, Beckman, Walsh-Dickey and Urbanczyk1995; Beckman Reference Beckman and McCarthy2004). Because of this, spreading of the [−voice] feature from a previous obstruent is blocked when /ɡ/ is in word-initial position.
Similarly, the velar approximant allophone [ɣ̞] found in the intervocalic position, as in mutu[ɣ̞]a ‘it is planted’, is the result of a process of spirantization of the voiced velar stop /ɡ/, which can be analyzed as the spreading of the [+continuant] feature from the adjacent vowels. Voiced stop/approximant alternations of this type are robustly documented in numerous languages (Kirchner Reference Kirchner, Hayes, Kirchner and Steriade2004; Martínez Celdrán & Regueira Reference Martínez Celdrán and Regueira2008). Finally, in all other contexts, including utterance-initially, onset /ɡ/ maintains its [+voice] and [−continuant] specifications and surfaces as a voiced stop. As for the velar stop in coda position, the acoustic analyses reveal that it displays characteristics that are intermediate between voiced and voiceless stops when it occurs in the pre-nasal and pre-obstruent context. For this reason, I propose that the velar stop is unspecified for [±voice] in these contexts. However, when a coda velar stop occurs in the utterance-final context, it consistently shows acoustic properties of voiceless stops, as in kuchilti[k]## ‘orange (color)’. To account for these systematic differences in behavior between utterance-final velars and coda velars in pre-nasal and pre-obstruent contexts, I propose that utterance-final velars acquire the feature [−voice] because this environment is not phonetically conducive to voicing – in anticipation of the end of the utterance, vocal folds begin to spread to reach their resting position. This inhibits voicing, especially in obstruents (Hock Reference Hock1991: 80; Blevins Reference Blevins2004: 104).
In contrast to /ɡ/, the Witzapan Nawat labiovelar stop is specified as [−voice]. The acoustic analysis revealed that this phoneme had a voiced stop allophone [ɡw] word-medially in the post-nasal context, as in kitankwa [ɡi.ˈtaŋ.ɡwa] ‘it bites it’. However, in this case, it cannot be claimed that the [+voice] feature is underlying for the labiovelar phoneme. Rather, it acquires this feature via spreading from the previous nasal. Further evidence of this comes from the fact that voiced allophones of the labiovelar do not occur when /kw/ is in word-initial position, even after a nasal, as in wan kwilin [ˈwaŋ ˈkwi.lin] ‘and worms’. This can be analyzed as another effect of the word-initial position, as described earlier. In the case of word-initial /kw/, voicing assimilation is blocked and the [−voice] specification of the stop is retained in the post-nasal context. Conversely, the same effect results in word-initial /ɡ/ maintaining its [+voice] specification after an obstruent.
To summarize, based on phonetic and phonological data, I propose that the stop inventory of Witzapan Nawat consists of voiceless /p t kw/ and voiced /ɡ/.Footnote 5 This inventory is asymmetrical because the feature [+voice] is present in only one of the members of the system. Moreover, it is an unusual inventory because it is not predicted by most theories of phonemic inventory structure. For instance, theories based on markedness posit that, due to their phonetic properties, some segments are more ‘marked’ than others (Gamkrelidze Reference Gamkrelidze1975). Consequently, asymmetries in phonemic inventories are caused by the absence of the most marked segments. As illustration, it is widely acknowledged that, in languages with a phonological voicing contrast in stops, the voiced velar stop /ɡ/ is more likely to be missing than stops at other points of articulation – the so-called ‘g-gap’. This is the case of Helong (Balle Reference Balle2017), Setswana (Boyer & Zsiga Reference Boyer, Zsiga, Orie and Sanders2013), some varieties of Galician (Martínez-Gil Reference Martínez-Gil, Auger, Clancy Clements and Vance2003), and Dutch (Booij Reference Booij1999), among many other languages. Under the markedness approach, the g-gap is explained by the fact that /ɡ/ is more marked than other voiced stops for aerodynamic reasons – the size of the supraglottal cavity is smaller in velar stops than in other points of articulation and this makes it more difficult to sustain the air pressure differential that is necessary for voicing in stops (Ohala Reference Ohala and MacNeilage1983: 40). For this reason, this model predicts that, if a language has a voiced stop, it will be unmarked /b d/ rather than marked /ɡ/, which is the opposite of what is observed in Witzapan Nawat.
On the other hand, feature-systemic models propose that phonemic inventories tend to maximize the number of segments that bear a feature that is already present in the system (Clements Reference Clements2003). Thus, the prediction is that, if a language has a stop with the [+voice] feature at a given place of articulation, it will also tend to have this feature in stops at other points of articulation to maximize feature economy. Nevertheless, in the case of Witzapan Nawat, the [+voice] feature in obstruents is only present in /ɡ/ and is not maximally or economically distributed across other manners and points of articulation.
A different approach to phonemic inventory structure is offered by Evolutionary Phonology (Blevins Reference Blevins2004). In this framework, synchronic sound patterns are understood attending to their diachronic origin. Departing from theories that see sound change as a symmetry-inducing factor in phonemic inventories, Evolutionary Phonology posits that, in fact, sound change leads to asymmetry just as often. To cite one example, the g-gap that many languages develop independently is an asymmetry that is introduced via phonetically motivated sound change. Accordingly, since sound change and language change in general do not necessarily lead to symmetry, the prediction is that asymmetrical phonemic inventories are a natural, and indeed common, consequence of diachrony. In the following subsection, I explain the Witzapan Nawat inventory as the result of a series of historical developments involving sound change and analogy in line with Evolutionary Phonology.
5.2 The origin of an asymmetrical stop subsystem
Although numerous studies point at the incompatibility of velar stops and voicing due to aerodynamic reasons (Ohala Reference Ohala and MacNeilage1983; Maddieson Reference Maddieson, Hardcastle and Laver1999), there is also diachronic and synchronic evidence from several languages suggesting that /k/ and /kw/ are more likely to become voiced than other voiceless stops, especially in the intervocalic context. As illustration, in the development of several Romance languages, voicing of Latin /k/ to /ɡ/ was more frequent and occurred earlier than voicing of stops at other points of articulation (deGorog Reference deGorog1962; Recasens Reference Recasens2002). In fact, in modern Spanish, intervocalic /k/ is more likely to be fully voiced than /p t/ (Hualde et al. Reference Hualde, Simonet and Nadeu2011), a pattern that is particularly frequent in Chilean Spanish (Bolyanatz & Rogers Reference Bolyanatz, Rogers and Chappel2019). Preferential voicing of /k/ over other voiceless stops is also found in Basque (Hualde et al. Reference Hualde, Beristain, Icardo Isasa, Zhang, Sasha Calhoun, Tabain and Warren2019), the Papuan languages Kaeti and Wambon (Healey Reference Healey1970), Honduran Lenca (King Reference King2017), Ember Katío (Greenfield Vélez Reference Vélez and Teresa2012), and Q’anjob’al (Lichtman et al. Reference Lichtman, Chang and Cramer2010). Moreover, as seen in Section 2, some Nahuan languages of Mexico have reported a shift of /kw/>/b/ whereas all other stops remained voiceless. An identical change is reported in several Muskogean languages (Booker Reference Booker1993).
Previous studies have proposed that the crosslinguistic propensity for the voicing of velars in the intervocalic position is due to their articulatory characteristics (Hualde et al. Reference Hualde, Simonet and Nadeu2011: 326, f.n. 9; Recasens Reference Recasens2002; Shaw et al. Reference Shaw, Agostini, Mailhammer, Harvey and Derrick2020: 610). Unlike bilabial and coronal stops, voiceless velar stops and vowels share the tongue body as their active articulator. Thus, in the articulation of a Vowel+[k]+Vowel sequence, the tongue body must move quickly from the open gesture of the first vowel to the velar closure gesture of the stop and then to the open gesture of the following vowel. The opposing articulatory targets imposed to the tongue body by the velar stop and the surrounding vowels can result in a reduced duration of the closure gesture at the velum. In turn, shorter obstruent segments have been shown to have greater proportions of voicing and to be more likely to be perceived as voiced (Cole & Cooper Reference Cole and Cooper1975; Ohala & Riordan Reference Ohala and Riordan1979; Summerfield Reference Summerfield1981; Westbury & Keating Reference Westbury and Keating1986).
In support of this proposition, a number of languages report shorter duration of voiceless velar stops compared to other places of articulation, especially in the intervocalic context (Maddieson Reference Maddieson, Hardcastle and Laver1999). This is the case of /k/ in Spanish (Hualde et al. Reference Hualde, Simonet and Nadeu2011: 318), American English (Umeda Reference Umeda1977)Footnote 6 , Hungarian (Neuberger Reference Neuberger, Maria Wolters, Bernie Beattie, MacMahon, Stuart-Smith and Scobbie2015), and Oaxaca Chontal (Maddieson et al. Reference Maddieson, Avelino and O’Connor2009). In Sierra Norte de Puebla Nahuatl, a Nahuan language described with sporadic voicing of /k/, the velar stop in the intervocalic position is shorter than other stops (Kakadelis Reference Kakadelis2018: 215).
Considering these facts, I propose the following diachronic pathway that led to the asymmetrical phonemic inventory of modern Witzapan Nawat. Originally, the stop system of this variety consisted of /p t k kw/, like most Nahuan languages. However, at some point in time, a voiced stop allophone [ɡ] of the velar stop phoneme /k/ started to appear in the intervocalic context.Footnote 7 This scenario is further supported by the other Nahuan and Nawat varieties that have sporadic [ɡ] only in the intervocalic position, as seen in Section 2.Footnote 8 In a subsequent development, voiced allophones of /k/ spread to the post-nasal context, which is also conducive to voicing in stops (Pater Reference Pater, Kager, van der Hulst and Zonneveld1999). At this point, voicing spreading would operate regularly regardless of word position, affecting word-medial /k/, as in nikan [ˈni.ɡaŋ] ‘here’ and anka [ˈaŋ.ɡa] ‘maybe’, but also word-initial /k/, as in ne kal [ne ˈɡal] ‘the house’ and ipan kisa [ˈipaŋ ˈɡisa] ‘it leaves from behind’. Since the voiced stop allophone [ɡ] occurred only in contexts that favored /k/ voicing, the voiceless stop allophone [k] was produced in all other instances, such as in the post-obstruent context, as in wejka [ˈweh.ka]. Consequently, sometime in the history of Witzapan Nawat, there were synchronic allophonic alternations of word-initial /k/ – on the one hand, it was produced as [k] in the post-obstruent context, as in yejemet kisat [je.ˈhe.met ˈki.sat] ‘they leave’, and utterance-initially, as in ##kisa [ˈki.sa] ‘she leaves’. On the other hand, word-initial /k/ was produced as [ɡ] in the intervocalic context, as in ne kisa [ne ˈɡi.sa] ‘the one who leaves’, and after a nasal, as in ipan kisa [ˈipaŋ ˈɡisa] ‘it leaves from behind’.
It is likely that contexts in which word-initial /k/ was produced as [ɡ] were more frequent than contexts in which it was produced as [k]. Modern Witzapan Nawat offers evidence in favor of this scenario, since in the recordings of the Witzapan Nawat speakers, the most frequent contexts of the velar stop in word-initial position are those conducive to voicing – 156 tokens were collected in the intervocalic and twenty in the post-nasal context. In comparison, 132 tokens of the velar stop in word-initial position were found in the utterance-initial and twelve in the post-obstruent context, which do not favor voicing. If this same distribution is reflective of past stages of the language, when there was an alternation between voiceless and voiced stop allophones of the velar stop, that would mean that productions of the word-initial velar stop as [ɡ] were more frequent than [k]. Previous studies find that, in similar situations of allophonic alternation of word-initial segments, the most frequent variant tends to be generalized over the others (Raymond & Brown Reference Raymond, Brown, Thomas Gries and Divjak2012; Bybee Reference Bybee2017).
Given this scenario, I propose that, at some point in time, Witzapan Nawat speakers analogically generalized the voiced stop allophone [ɡ] of word-initial /k/ to all contexts, even to those that were not conducive to voicing, such as after an obstruent, as in yejemet kisat [je.ˈhe.met ˈɡi.sat] ‘they leave’, and utterance-initially, as in ##kisa [ˈɡi.sa] ‘she leaves’. In contrast, in the word-medial post-obstruent context and utterance-finally, in which there was never alternation between voiced and voiceless allophones, the velar stop remained being produced as [k], as in wejka [ˈweh.ka] ‘far’ and kuchiltik## [ɡu.ˈt͡ʃil.tik] ‘color orange’. Finally, at some later time, voiced stop allophones spirantized to velar approximants [ɣ̞] in the intervocalic context. This is the modern allophonic distribution of the velar stop phoneme in Witzapan Nawat, which is now better analyzed as a voiced velar stop /ɡ/, a segment specified as [+voice], rather than /k/.
This proposed diachrony of the phonemic inventory of Witzapan Nawat goes in line with the tenets of Evolutionary Phonology, according to which synchronic sound patterns are a reflection of their diachrony. As such, the prediction is that asymmetrical phonemic inventories are not only natural, but expected, because sound change, and language change in general, is not teleological – they operate with no regard for symmetry or articulatory/perceptual ease. Moreover, Evolutionary Phonology posits that common sound patterns are the result of common, phonetically motivated sound changes. On the other hand, rare sound patterns, including rare phonemic inventories, arise from the application of non-phonetic processes, such as analogy (Blevins Reference Blevins2004: 192).The diachrony of phonemic /ɡ/ that I advance is in agreement with this claim. In the development of the modern Witzapan Nawat phonemic inventory, an arguably common sound change led to the allophonic voicing of intervocalic and post-nasal /k/. However, it is only through the action of analogy, likely facilitated by frequency effects, that the shift /k/>/ɡ/ took place, leading to the creation of an asymmetrical and rare stop inventory – /p t ɡ kw/.
6 Conclusions
With this first instrumental study on the phonology/phonetics of Witzapan Nawat, I hope to contribute to the Nawat revitalization movement. This is because, in order to effectively teach the pronunciation of this language to L2 learners, a thorough understanding of its sound patterns is needed. This paper also leaves ample space for future research. For instance, it stresses the need for more research on Nahuan languages in which /k/ voicing has not advanced to the extent of Witzapan Nawat. Doing so will complete the picture of the origin of this phenomenon – whether it is common to all of Nahuan or an innovation of the Isthmus dialects that spread and whether /k/ voicing diffuses gradually through the lexicon from high-frequency words or morphemes. Moreover, it also brings out the need to assess the relationship between /k/ and /kw/ voicing in Nahuan to establish whether the /kw/>/b/ shift found in some Nahuan languages can be accounted for by the same diachronic mechanisms that I proposed for the /k/>/ɡ/ change in Witzapan Nawat. Finally, this study highlights yet again the need for the documentation of highly endangered languages, not only for the sake of linguistic sciences, but for its potential contributions to revitalization initiatives.
Acknowledgments
I am deeply grateful to Witzapan Nawat speakers Nantzin Antonia Ramírez, Nantzin Berfalia García, Nantzin Sixta Pérez, Nantzin Eugenia Torres and Tajtzin Juan Cruz for sharing their language and knowledge with me. Padiush ika annechpalewijket wey. I also thank Gary Ordóñez for his assistance in coordinating and transcribing interviews with Nawat speakers. An early version of this paper benefitted from the feedback provided by Rebeka Campos-Astorkiza, to whom I also express my gratitude. Lastly, I am thankful to two anonymous reviewers and JIPA associate editor Patrycja Strycharczuk for their thorough comments and suggestions.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0025100323000294.


















 Open access
Open access