



INTRODUCTION
Mild cognitive impairment (MCI) is a heterogeneous clinical syndrome, often considered a transitional stage between healthy cognitive aging and dementia (Petersen, Reference Petersen2004), and it is also associated with an increased risk of developing dementia later on (Roberts et al., Reference Roberts, Knopman, Mielke, Cha, Pankratz, Christianson and Petersen2014). Early recognition and timely diagnosis are crucial in MCI, because they can provide an opportunity to reduce the rate of cognitive decline (Hahn & Andel, Reference Hahn and Andel2011), while also offering a chance for the patients and their relatives to start planning for the future (Knopman & Petersen, Reference Knopman and Petersen2014). Considering the high prevalence of MCI (Roberts & Knopman, Reference Roberts and Knopman2013) and especially the constantly overburdened clinical settings, it would be beneficial to replace the current labor-intensive and time-consuming assessments of cognitive functioning with swift, low-cost, and preferably automated tools.
Verbal fluency tests are neuropsychological tests, extensively used both in research and in the clinical practice. In the standard versions of the fluency tests, participants are given 60 s to list as many words as they can, beginning with a given letter (phonemic fluency) (Borkowski, Benton, & Spreen, Reference Borkowski, Benton and Spreen1967) or belonging to a given semantic category (semantic fluency) (Newcomb, Reference Newcomb1969). There is an additional, third type of verbal fluency task: action fluency (or verb fluency), where the patients have to produce as many verbs (‘things that people do’) as they can (Piatt, Fields, Paolo, & Troster, Reference Piatt, Fields, Paolo and Tröster1999). However, in the current study, for the sake of simplicity, action fluency will be regarded as a semantic fluency task, because both semantic fluency and action fluency are content-oriented speech tasks (Östberg, Fernaeus, Hellstrom, Bogdanovic, & Wahlund, Reference Östberg, Fernaeus, Hellström, Bogdanović and Wahlund2005).
Both phonemic and semantic fluency tasks require rapid associative exploration; however, semantic fluency relies more on semantic associations and reflects more on the integrity of semantic memory. On the other hand, phonemic fluency depends more on search strategies based on lexical representation (Henry, Crawford, & Phillips, Reference Henry, Crawford and Phillips2004; Teng et al., Reference Teng, Leone-Friedman, Lee, Woo, Apostolova, Harrell and Lu2013). Executive control processes also play a major role in the execution of verbal fluency tests, because during the task, subjects not only need to remember the exact instruction and keep the already used responses in mind, but they must also repress the repetitions and other potentially incorrect or irrelevant responses (Shao, Janse, Visser, & Meyer, Reference Shao, Janse, Visser and Meyer2014). Fluency tests have been validated in the assessment of verbal and executive skills (Shao et al., Reference Shao, Janse, Visser and Meyer2014), and both of these abilities have been reported to deteriorate in dementia and in other forms of cognitive impairments. Therefore, fluency tests have a great potential as effective screening tools for MCI (García-Herranz, Diaz-Mardomingo, Venero, & Peraita, Reference García-Herranz, Díaz-Mardomingo, Venero and Peraita2020; McDonnell et al., Reference McDonnell, Dill, Panos, Amano, Brown, Giurgius and Miller2020).
The traditional, most common approach for the assessment of verbal fluency performance requires the clinician to count the number of unique and correct words, along with the number of errors and the number of repetitions produced by the participant. This analysis can be refined by scoring the number of correct words based on time intervals (e.g., 0–20, 21–40, 41–60 s) (Demetriou & Holtzer, Reference Demetriou and Holtzer2017; Jacobs, Mercuri, & Holtzer, Reference Jacobs, Mercuri and Holtzer2021). Moving beyond simple word counts, a more sophisticated, qualitative method can be applied, which is called clustering. In this method, consecutive words are clustered based on linguistic similarity or a shared category (e.g., rhyming words in the case of phonemic fluency tasks, or pets in the case of the animal fluency task). Thus, the average sizes of the clusters and the number of switches between these clusters can be examined (Troyer, Moscovitch, & Winocur, Reference Troyer, Moscovitch and Winocur1997). Even though this approach may provide more information about the underlying mental processes, it is also relatively time-consuming. Furthermore, compared to the most widespread, word count-based assessment, this method requires the manual coding and grouping of words, which may even raise reliability issues (Taler, Johns, & Johns, Reference Taler, Johns and Jones2020).
Recently, there have been multiple attempts with different approaches to overcome the disadvantages of the above-mentioned methods by introducing automated analyses. These approaches have the benefit of being objective, repeatable, and they also yield quick output (König et al., Reference König, Linz, Tröger, Wolters, Alexandersson and Robert2018). The majority of these methods focus on the computation and analysis of semantic clusters. Latent semantic analysis (LSA) can be applied to examine the strength of the semantic relationship of two consecutive words by constructing a co-occurrence matrix for all of the words found in a given corpus of text (Ledoux et al., Reference Ledoux, Vannorsdall, Pickett, Bosley, Gordon and Schretlen2014; Pakhomov & Hemmy, Reference Pakhomov and Hemmy2014). A more recent computational method, called explicit semantic analysis (ESA), examines Wikipedia entries for the quantification of relationships between words based on different types of similarities (e.g., taxonomic, geographic, or linguistic) (Woods, Wyma, Herron, & Yund, Reference Woods, Wyma, Herron and Yund2016). It is also possible to combine semantic measures with temporal information. In this approach, the recalled words are organized in clusters defined semantically and also in clusters based on the temporal proximity of the words (Tröger et al., Reference Tröger, Linz, König, Robert, Alexandersson, Peter and Kray2019). Verbal fluency tasks can also be analyzed by exploring certain speech features that can be automatically extracted from fluency voice recordings (Lopez-de-Ipina et al., Reference Lopez-de-Ipina, Martinez-de-Lizarduy, Barroso, Ecay-Torres, Martinez-Lage, Torres and Faundez-Zanuy2015).
However, there is a major obstacle in the application of the automatic analysis of fluency recordings that stems from the general characteristics of the responses produced by the participants: most voice recordings of fluency test performances contain more than just a sequence of task-relevant words. The recordings also contain speech segments irrelevant in terms of the task, including filler words or hesitations, irrelevant comments, questions directed at the examiner, or loud thinking. To be able to automatically analyze the task-relevant words, fluency recordings need to go through a time-consuming preparation process prior to the analysis: the words irrelevant to the task need to be removed from the recording or transcript, and some words need to be lemmatized (i.e., converted to their stem) (Chen et al., Reference Chen, Asgari, Gale, Wild, Dodge and Kaye2020; Holmlund, Cheng, Foltz, Cohen, & Elvevag, Reference Holmlund, Cheng, Foltz, Cohen and Elvevåg2019).
Given the substantial amount of task-irrelevant content in most fluency recordings, the question arises whether the analysis of these segments could provide valuable information regarding the overall verbal fluency performance of the patient. After manually annotating the recordings, we derived temporal parameters that, instead of targeting the task-relevant words, contained the silent segments, the hesitations, and the utterances irrelevant to the task. Therefore, the focus of this exploratory study was to move beyond the words recalled by the participants and explore the additional, previously unharvested information present in the fluency recordings. It should be noted that this approach, similarly to the previously summarized methods, required substantial manual work. However, in the future (depending on the characteristics of the given parameter) it could allow the development of automatic analysis.
Our main goal was: (1) to examine whether these parameters can differentiate between participants classified as healthy control (HC) and as MCI (temporal analysis method). Besides the temporal parameters, traditional fluency scores (number of correct words, errors, and repetitions) were also calculated for the same fluency recordings (traditional analysis method). We sought; (2) to compare the two methods of analysis regarding their ability to detect differences in the performance of the HC and MCI groups. The inclusion of both phonemic and semantic fluency tasks in the research protocol also allowed us; and (3) to compare the different types of fluency tasks to investigate their sensitivity to the presence of MCI.
METHODS
Participants
Participants (patients and their relatives, scheduled for consultations) were recruited at the Memory Clinic of the Department of Psychiatry, University of Szeged (Szeged, Hungary). Data collection was carried out between February 2018 and March 2020.
The required sample size for the study was assessed a priori using G * Power v.3.2.9.7. (Faul, Erdfelder, Lang, & Buchner, Reference Faul, Erdfelder, Lang and Buchner2007) with the settings of effect size d = 0.8; alpha error probability: 0.05, power (1-beta error probability): 0.8. Based on this, the optimal sample size was calculated as 52, which later (due to COVID-19 regulations halting data collection in clinical research) was limited to 50. Initially, a total of 79 individuals were recruited to take part in the study.
Inclusion criteria included at least 50 years of age, a minimum of 8 years of formal education, and Hungarian as a native language. Individuals were excluded if they had any past or present neuropsychological, psychotic or mood disorders, head injuries, stroke, substance abuse disorders, major (uncorrected) hearing loss, or language problems (e.g., stutter), based on patient history and medical records. Participants with MRI or CT records showing evidence of micro- or macrohemorrhages, lacunar or other infarctions, cerebral contusion, encephalomalacia, aneurysm, vascular malformation, or space-occupying lesions were also excluded.
In addition, the two main exclusion criteria were the presence of dementia or major cognitive deficits and depression. To rule out possible cases of dementia, the Mini-Mental State Examination (MMSE) (Folstein, Folstein, & Mchugh, Reference Folstein, Folstein and Mchugh1975) was applied as a screening tool: participants with a score of 24 or below were excluded from the study. The possibility of depression was assessed using the 15-item version of the Geriatric Depression Scale (GDS-15) (Yesavage & Sheikh, Reference Yesavage and Sheikh1986): participants scoring 7 or above on the test were excluded. After reviewing and evaluating the criteria, 50 subjects were considered eligible for inclusion in the study (Figure 1).
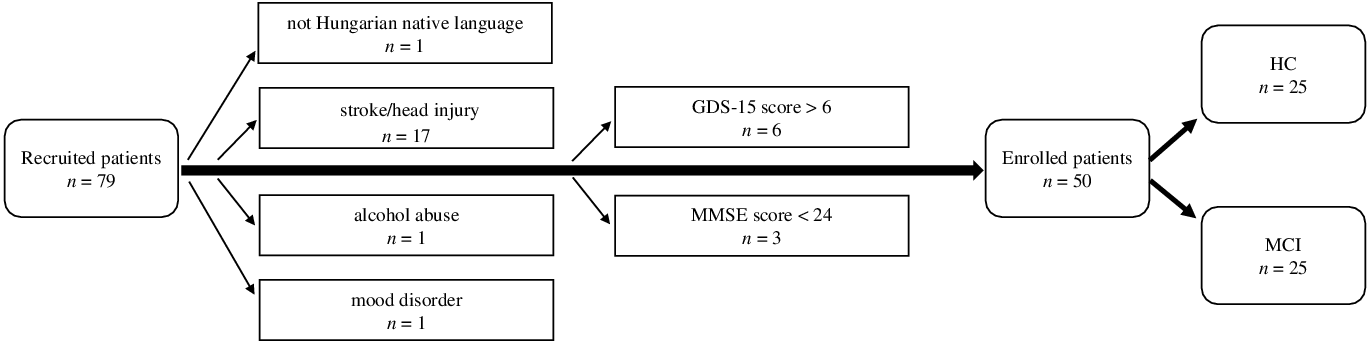
Fig. 1. Flowchart of the participant exclusion process. (GDS-15:15-item Geriatric Depression Scale; MMSE: Mini-Mental State Examination; HC: healthy control; MCI: mild cognitive impairment).
Participants were split into two groups based on their MMSE scores. MMSE cut-off scores were determined based on the results of previous studies conducted by our research group: in these works, the mean scores of MMSE emerged as 29.17 ± 0.71/29.24 ± 0.523 for the HC and 26.97 ± 0.96)/27.16 ± 0.898 for the MCI group (Gosztolya et al., Reference Gosztolya, Vincze, Tóth, Pákáski, Kálmán and Hoffmann2019; Toth et al., Reference Toth, Hoffmann, Gosztolya, Vincze, Szatloczki, Banreti and Kalman2018). Hence, participants achieving a score of 29 to 30 points were considered as healthy control (HC) subjects, while participants achieving a score of 25 to 28 points formed the MCI group. The subtypes of MCI (amnestic or non-amnestic) were not considered. The two groups showed no significant difference in gender and years of education. However, participants of the MCI group were significantly older than the participants enrolled in the HC group. No significant difference was found in the GDS-15 score between the two groups (Table 1).
Table 1. Descriptive and comparative statistics for the demographic characteristics and neuropsychological test scores of the study participants
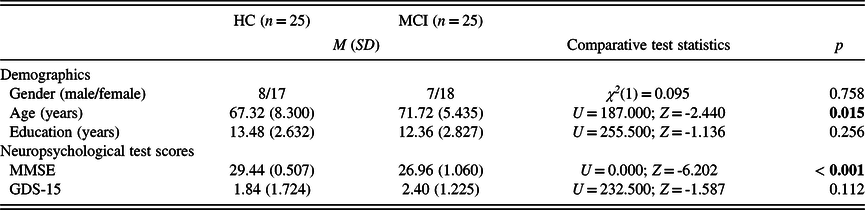
HC: healthy control; MCI: mild cognitive impairment; MMSE: Mini-Mental State Examination; GDS-15: 15-item Geriatric Depression Scale.
Significant p-values (p < 0.05) are in bold.
Study Protocol
Each participant performed a series of neuropsychological tests: six fluency tasks, the Digit Span Test – Forward and Backward (Wechsler, Reference Wechsler1981), the Non-Word Repetition Test (Gathercole, Willis, Baddeley, & Emslie, Reference Gathercole, Willis, Baddeley and Emslie1994), the Listening Span Test (Daneman & Carpenter, Reference Daneman and Carpenter1980), the Clock Drawing Test (Shulman, Shedletsky, & Silver, Reference Shulman, Shedletsky and Silver1986) and the Alzheimer’s Disease Assessment Scale – Cognitive Subscale (ADAS-Cog) (Rosen, Mohs, & Davis, Reference Rosen, Mohs and Davis1984). The fluency tasks were implemented in a fixed order, separated by the five shorter cognitive tests, while ADAS-Cog was administered at the very end of the study protocol to prevent fatigue. We also ensured that tasks assessing the same cognitive domain did not follow each other directly.
In the three phonemic fluency tasks, the participants were asked to list as many words as they can, starting with the letters ‘k’, ‘t’, and ‘a’, respectively, while avoiding proper nouns. For the semantic fluency tasks, participants had to name as many animals, food items, and actions (verbs – ‘things that people do’) as they could. The participants were instructed to avoid saying variations of the same word stem (e.g., horse, horses; go, goes). For all 6 verbal fluency tasks, participants had 1 min to perform the task. The 1-min interval began with the investigator saying: ‘Start.’ Every verbal fluency task was recorded using an Olympus Digital Voice Recorder (16 kHz sampling rate, 16-bit resolution). The recordings were also transcribed manually for the calculation of the traditional scores. Therefore, fluency performances were analyzed in two ways: by implementing the novel temporal parameters, and also by using the traditional method, based on word count.
Analysis Method Based on Temporal Parameters
Manual transcription process of the fluency recordings
Voice recordings of all fluency tasks were manually transcribed in Praat, a free language software enabling speech analysis (Boersma & Weenink, Reference Boersma and Weenink2020). The transcription process was supervised by a linguist specialized in language pathologies (I. H.), while quality control was ensured by an expert in the field of computational speech processing (G. G.). Due to the quality of their recordings, an HC participant’s animal category fluency task and an MCI participant’s ‘k’ letter fluency task were unsuitable for transcription; therefore, these recordings were not considered in the analysis of temporal parameters, but they were included in the traditional analysis.
Annotation of speech features in the verbal fluency recordings
The transcriptions of the fluency recordings contained not only the task-relevant answers of the participants (the recalled words – including correct, incorrect, and repeated words), but also silent pauses, hesitation sounds (filled pauses, like ‘hmm’ and ‘er’), and irrelevant utterances, such as comments or loud thinking said by the subjects (e.g., ‘did I say this before?’, ‘uh, it’s not an easy task, let me think…’). False starts (‘te-… tiger’), as well as laughing and coughing sounds were also annotated. The laughing, coughing, and false starts parameters were considered unintentional and were discarded from further analysis because we found that the number of these occurrences was negligible.
Calculation of temporal parameters based on the speech features
For each recording, task-relevant words, silent segments, hesitation sounds, and irrelevant utterances were annotated based on their boundaries (their exact start and end times), providing their duration measures. Based on this, the total number, the average length, and the total length of silent pauses; the total number, the average length, and the total length of hesitations; and the total number, the average length, and the total length of irrelevant utterances were calculated. Besides these parameters, the mean time between two consecutive task-relevant words (average word transition time) was also calculated based on the transcript. Not only correct words but also the errors and repetitions were considered task-relevant words. The average word transition time, irrelevant of its content, such as silent pause, hesitation, or irrelevant utterance, provided information about the average time the participant needed to produce a new task-relevant word, and because of this, it had a positive association with the average and total length of silent pauses, hesitations, and irrelevant utterances.
It is worth noting that because of the distinctive regular rhythm that is inherent in verbal fluency performances, each of the task-relevant words listed by the participants was separated by a silent pause (irrelevant of its length). Consequently, the number of silent pauses increased in parallel with the number of task-relevant words said by the participant. Therefore, analyzing the number of silent pauses can be viewed as the converse of the traditional approach of counting only the task-relevant words.
The parameters used in the study are listed and defined in Table 2; two waveform extracts from a fluency task performed by an HC and an MCI subject are shown in Figure 2.
Table 2. List and definitions of the temporal parameters

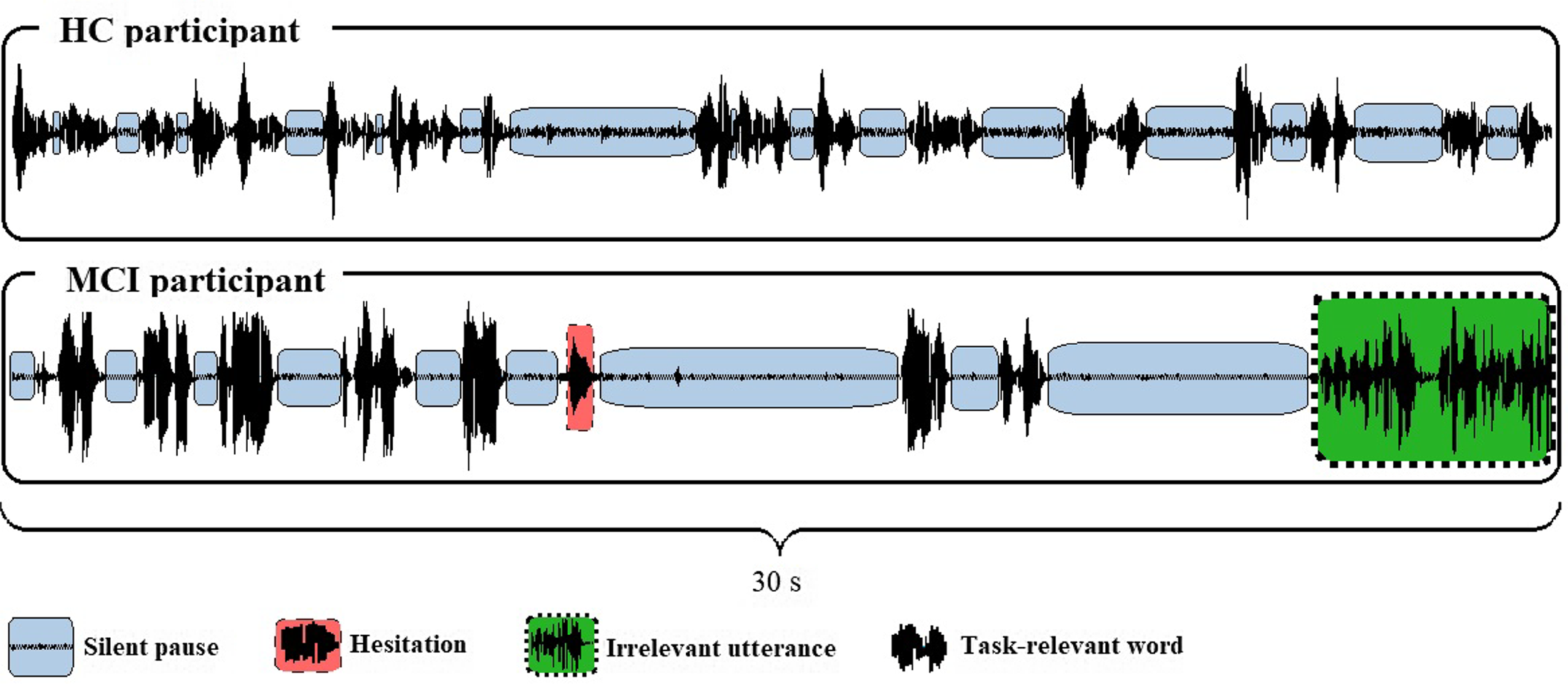
Fig. 2. Waveforms extracted from the food item fluency recordings of two participants. (Extracted from Praat. HC: healthy control; MCI: mild cognitive impairment).
Traditional Fluency Analysis Based on Word Count
In the traditional scoring method (Lezak, Reference Lezak2012), we calculated the number of correct words, the number of errors, and the number of repetitions or perseverations; the last two were considered as one variable. In the case of animal fluency, when a participant recalled synonymous words (e.g., cat and kitten), variations in gender (e.g., hen and rooster), or an animal and its offspring (e.g., horse and foal), words were only scored as one. The participants did not receive points for naming a subcategory if they also gave specific examples of it [e.g., in the case of food items: fruit (0 points), apple (1 point), pear (1 point)].
Statistical Analysis
Descriptive statistical analysis was used to examine the demographic features, the neuropsychological test scores, and the fluency measures of the participants. The assumption of normality was not met according to the results of the Shapiro–Wilk test in more than two-thirds of the cases, therefore, in order to obtain comparable statistical measures, comparisons between the HC and the MCI groups were executed using the Mann–Whitney U test. Categorical variables were compared using the Chi-square test. Effect sizes were calculated using the Pearson correlation coefficient
 $(r={z\over{\sqrt N}})$
(Rosenthal, Reference Rosenthal1991).
$(r={z\over{\sqrt N}})$
(Rosenthal, Reference Rosenthal1991).
Receiver operating characteristic (ROC) analysis was applied to assess the classification abilities of the temporal parameters and the traditional scores. Sensitivity and specificity were calculated using threshold values that yielded the highest possible sensitivity (while keeping specificity at a minimum of 50%). For the comparison of classification abilities, the differences between the area under the curve variables (AUCs) were compared based on the method of DeLong, DeLong, and Clarke-Pearson (Reference DeLong, DeLong and Clarke-Pearson1988).
For all statistical comparisons, the level of significance was set at p < 0.05. All analyses were performed using SPSS v.24 (IBM SPSS Statistics for Windows, 2016), except for the comparison of AUCs, for which the MedCalc Statistical Software v.19.6. (MedCalc Software, 2020) was utilized.
RESULTS
Temporal Parameters of Verbal Fluency Performance
Considering the phonemic fluency tasks, in the ‘a’ fluency, the average length and the total length of irrelevant utterances were significantly higher in the MCI group, while none of the temporal parameters differed between the two groups in the case of the ‘k’ and ‘t’ phonemic fluencies (Table 3). Regarding the three semantic fluencies, the total number of silent pauses were significantly higher in the HC group in the animal and action fluency tasks, whereas the average length of silent pauses and the average word transition time were significantly higher in the MCI group throughout all of the three tasks (Table 4).
Table 3. Descriptive measures and statistical comparison of the temporal parameters in the phonemic fluency tasks
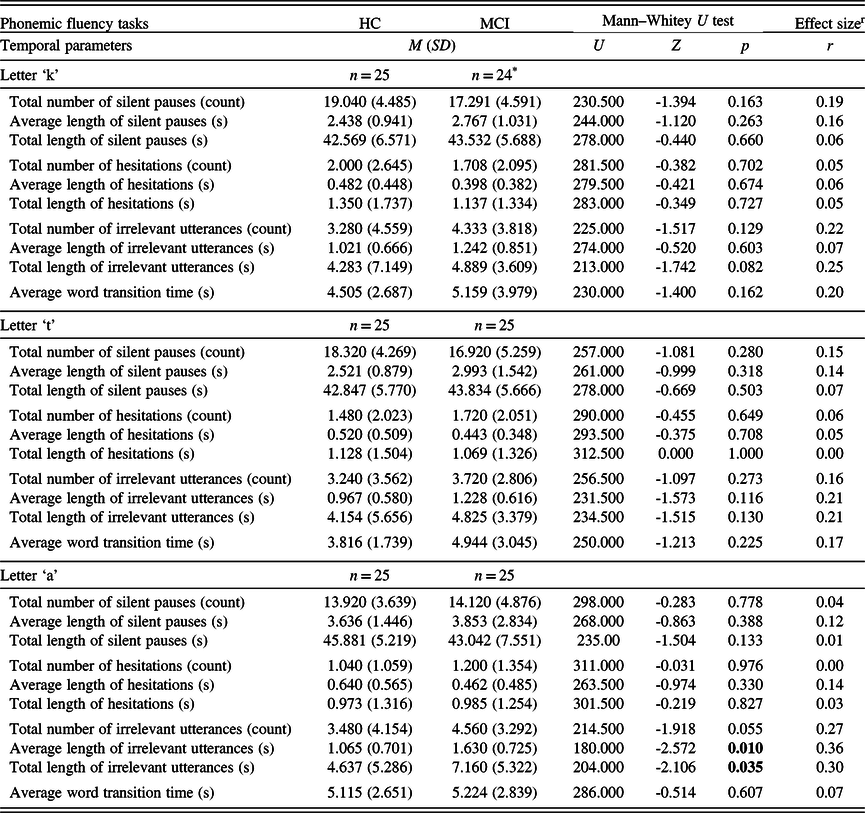
M: mean; SD: standard deviation; HC: healthy control; MCI: mild cognitive impairment.
Significant p-values (p < 0.05) are in bold.
* One fluency voice recording was unsuitable for transcription.
r Effect size is calculated as Pearson’s r, expressed in absolute value.
Strength of association: 0.1 to 0.3: small, 0.3 to 0.5: medium, 0.5 to 1.0: large (Cohen, Reference Cohen1988).
Table 4. Descriptive measures and statistical comparison of the temporal parameters in the semantic fluency tasks

M: mean; SD: standard deviation; HC: healthy control; MCI: mild cognitive impairment.
Significant p-values (p < 0.05) are in bold.
* One fluency voice recording was unsuitable for transcription.
r Effect size is calculated as Pearson’s r, expressed in absolute value.
Strength of association: 0.1 to 0.3: small, 0.3 to 0.5: medium, 0.5 to 1.0: large (Cohen, Reference Cohen1988).
Traditional Word Count Measures of Verbal Fluency Performance
In the three phonemic fluency tasks, no statistically significant difference was found between the groups regarding the number of correct words and the number of repetitions or perseverations. However, in the ‘a’ phonemic fluency task, participants from the MCI group produced more errors than participants from the HC group (Table 5). As for the semantic fluency tests, participants from the HC group had a significantly higher number of correct words in the case of all three (animals, food items, and actions) tasks. In the number of repetitions or perseverations, there was no statistically significant difference between the two study groups (Table 6).
Table 5. Descriptive measures and statistical comparison of the traditional fluency scores in the phonemic fluency tests
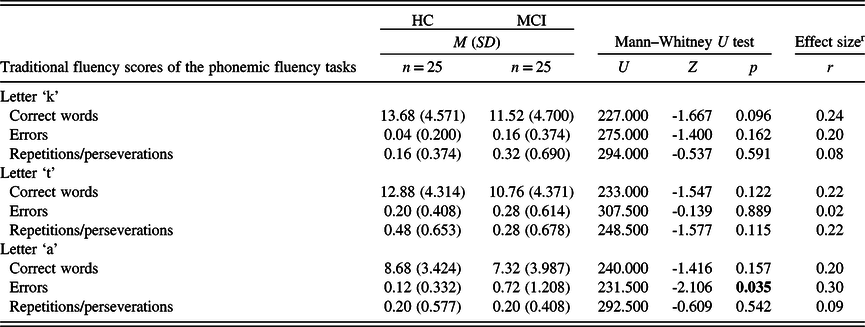
M: mean; SD: standard deviation; HC: healthy control; MCI: mild cognitive impairment).
Significant p-values (p < 0.05) are in bold.
r Effect size calculated as Pearson’s r, expressed in absolute value. Strength of association: 0.1 to 0.3: small, 0.3 to 0.5: medium, 0.5 to 1.0: large (Cohen, Reference Cohen1988).
Table 6. Descriptive measures and statistical comparison of the traditional fluency scores in the semantic fluency tests
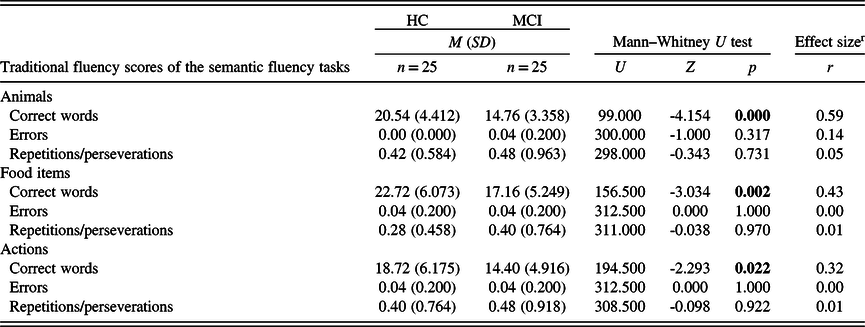
M: mean; SD: standard deviation; HC: healthy control; MCI: mild cognitive impairment.
Significant p-values (p < 0.05) are in bold.
r Effect size calculated as Pearson’s r, expressed in absolute value.
Strength of association: 0.1 to 0.3: small, 0.3 to 0.5: medium, 0.5 to 1.0: large (Cohen, Reference Cohen1988).
ROC Analysis of the Significant Temporal Parameters
ROC analysis of the temporal parameters was carried out in the case of the five parameters that, based on the previously conducted comparative tests, showed significant differences between the HC and MCI groups.
The analysis revealed that the average length and the total length of irrelevant utterances had a significant classification ability in the case of the ‘a’ phonemic fluency, with the same sensitivity (80%) and specificity (52%) for both parameters. In the semantic fluency tests, the number of silent pauses had significant classification ability in both the animal and action fluency tests, while the average length of silent pauses and the average word transition time was shown to be able to discriminate between the groups in the case of all three semantic fluency tests. Sensitivity was the highest in the case of the average word transition time in the animal fluency test (sensitivity: 96.0%; specificity: 62.5%). Accuracy measures of the temporal parameters that differed between the groups are given in Table 7. For every ROC analysis, sensitivity and specificity were determined using threshold values optimal for early screening, i.e., maximizing the sensitivity, while keeping specificity greater than or equal to 50%.
Table 7. Accuracy measures of those temporal parameters that significantly differed between the two groups based on the previous comparative statistic tests
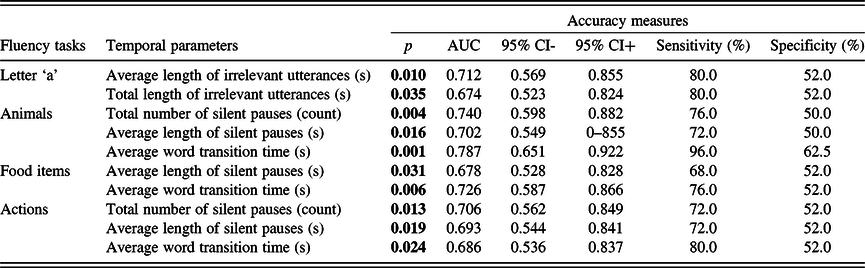
AUC: area under the curve; CI: confidence interval.
Significant p-values ( p < 0.05) indicate that the measure is significantly better than chance at discriminating individuals of the two groups.
ROC Analysis of the Significant Traditional Measures
ROC analysis was also executed on the traditional measures that showed significant differences between the HC and MCI groups, to determine the classification ability of these measures. The analysis revealed that the number of errors in the ‘a’ phonemic fluency test had no significant classification ability. With respect to semantic fluency tests, the number of correct words showed significant classification abilities in the case of the animal, the food item, and the action fluencies. The animal naming fluency showed the highest sensitivity of 100% (specificity: 56%). Accuracy measures of the traditional fluency scores that showed significant differences between the groups are given in Table 8.
Table 8. Accuracy measures of those traditional fluency measures that significantly differed between the two groups based on the previous comparative statistic tests

AUC: area under the curve; CI: confidence interval.
Significant p-values ( p < 0.05) indicate that the measure is significantly better than chance at discriminating individuals of the two groups.
Comparison of the Temporal and Traditional Measures Regarding their Classification Ability
Pairwise comparisons of AUCs were executed to compare the classification ability of the three significant temporal parameters (total number of silent pauses, average length of silent pauses, average word transition time) and the significant traditional measure (number of correct words) in the semantic fluency tasks. In the animal category fluency, the results indicated no significant differences regarding AUCs between the number of correct words and the total number of silent pauses (Z = 1.433, p = 0.151) or the average word transition time (Z = 1.579, p = 0.114), however, the classification ability of the average length of silent pauses was smaller (Z = 2.043, p = 0.041) compared to the correct word count. In the case of the food item fluency, no difference was found between the AUCs of the number of correct words and the average length of silent pauses (Z = 0.978, p = 0.328), and the average word transition time (Z = 0.662, p = 0.508). Furthermore, in action fluency, the classification ability of correct word count did not differ from either the total number of silent pauses (Z = 0.267, p = 0.789), the average length of silent pauses (Z = 0.056, p = 0.954) or the average word transition time (Z = 0.046, p = 0.962).
DISCUSSION
Main Findings
This study presents a new practical framework for verbal fluency analysis. To the best of our knowledge, we are the first to report on verbal fluency performance beyond the recalled words, focusing on the pauses and task-irrelevant content of speech in the fluency recordings. We quantitatively analyzed a number of temporal parameters that were calculated based on silent pauses, hesitations, and irrelevant speech segments annotated in the recordings. Our main finding is that in the case of semantic fluency tests, some of the temporal parameters based on silent pauses can discriminate between individuals with cognitive impairment and individuals with healthy cognition. These results suggest that the analysis of these temporal parameters may complement or even substitute the widely applied, but more time-consuming and labor-intensive traditional word scoring method, while still providing comparable classification ability.
Three temporal parameters (total number of silent pauses, average length of silent pauses, and average word transition time) consistently differed between the HC and MCI groups in the case of the semantic (animal, food item, and action) fluency tests. In the phonemic fluency tests, differences could only be observed in the case of the ‘a’ phonemic fluency, where the average and total lengths of irrelevant utterances showed significant differences.
It should be noted that the direction of differences in the silence-based parameters might seem inconsistent: the average lengths of the silent pauses and the average word transition times were longer in the MCI group, whereas HC participants had a higher number of silent pauses in the case of the semantic tasks. Since silent pauses were defined as the absence of speech/sound regardless of length, every detectable silent segment found in the recordings was annotated as a silent pause, including even the brief transitions between words. Therefore, the number of silent pauses was increased by the number of words uttered by the participant. Since the HC group produced significantly more correct words in semantic fluency tasks, the number of silent pauses was also significantly higher in this group.
The average word transition time parameter also had a direct influence on the number of correct words. Since this parameter contains every task-irrelevant segment, the increase of the average word transition time by definition led to the decrease of the number of recalled words, therefore it could be viewed that these two parameters were somewhat inversely proportional. The average length of silent pauses parameter also affected the number of correctly recalled words. However, this is less of a general phenomenon, since the average length of silent pauses does not have a sole effect on the number of recalled words – it can be also significantly influenced by other task-irrelevant contents of speech (e.g., loud hesitations).
The importance of silent pauses has also been highlighted in the area of connected speech analysis: studies have shown that compared to HC subjects, participants with MCI produce more and longer silent pauses in their speech (Sluis et al., Reference Sluis, Angus, Wiles, Back, Gibson, Liddle and Angwin2020; Toth et al., Reference Toth, Hoffmann, Gosztolya, Vincze, Szatloczki, Banreti and Kalman2018). Even though spontaneous speech samples provide ecologically valid data, utilizing verbal fluency tests for the analysis of speech can be even more advantageous, as it can be combined with already standardized qualitative approaches. To be able to compare the results of these two types of study, it is important to note the difference between connected (spontaneous) speech and verbal fluency performances. Compared to connected speech, where pauses appear more randomly, in the fluency recordings silent pauses (with varying lengths) appear between every word, therefore producing a ‘word-pause-word-pause’-like sequence. Because of these distinct characteristics, the number of silent pauses needs to be interpreted based on the methodology of the specific study.
Most recent approaches to verbal fluency analysis usually focus on the semantic content when evaluating fluency performance (Tröger et al., Reference Tröger, Linz, König, Robert, Alexandersson, Peter and Kray2019; Woods et al., Reference Woods, Wyma, Herron and Yund2016). In contrast, this work focused on the examination of more easily quantifiable, objective variables; nevertheless, we were able to achieve classification abilities comparable to those reported in previous studies [AUC: 0.758 (König et al., Reference König, Linz, Tröger, Wolters, Alexandersson and Robert2018), AUC: 0.77 (Chen et al., Reference Chen, Asgari, Gale, Wild, Dodge and Kaye2020)]. The significant classification ability of the silent pause parameters in our study suggests that differentiation between HC and MCI patients’ semantic verbal fluency performance may be possible by examining only the silent pauses in their speech. This can be achieved, for example, by dividing the voice recordings into voiced and unvoiced segments (Lopez-de-Ipina et al., Reference Lopez-de-Ipina, Martinez-de-Lizarduy, Barroso, Ecay-Torres, Martinez-Lage, Torres and Faundez-Zanuy2015).
Therefore, the described method would not require additional time-consuming steps, such as the manual transcription and preparation of the answers, nor their identification as correct words, errors, repetitions, or clusters, as opposed to the majority of fluency analysis techniques. This could make the analysis procedure considerably faster and easier. However, since this method does not provide any semantic information, it can be viewed for example as an alternative, inverse approach of the traditional analyses based on word count, because instead of considering the number of recalled words, this method focuses on the silent pauses between the words.
Our results confirmed the advantage of semantic fluency in the detection of MCI. In all three semantic fluency tests (animal, food item, and action), the same three temporal parameters (number of silent pauses, average length of silent pauses, average word transition time), and one of the traditional measures (correct word count) showed differences between the two groups. In contrast, regarding the phonemic fluency tests, differences were only observed in the case of the ‘a’ phonemic fluency, where two temporal parameters (the average and total length of irrelevant utterances) and one of the traditional measures (incorrect words) showed significant difference. These results are consistent with those of earlier studies, confirming that semantic fluency tasks may be more appropriate for detecting the cognitive changes that occur in MCI (McDonnell et al., Reference McDonnell, Dill, Panos, Amano, Brown, Giurgius and Miller2020; Nikolai et al., Reference Nikolai, Bezdicek, Markova, Stepankova, Michalec, Kopecek and Vyhnalek2018). Furthermore, when compared to other subtypes of semantic fluency tests (plants, clothes, vehicles), the animal fluency test has previously shown the highest sensitivity (98.8%) in discriminating between HC and MCI participants (García-Herranz et al., Reference García-Herranz, Díaz-Mardomingo, Venero and Peraita2020). In agreement with the results of García-Herranz et al., animal fluency achieved the best accuracy scores in the present study as well, not only with the traditional scoring method but also when examining the temporal parameters.
Limitations
The significant age difference between the HC and MCI groups may be noted as a limitation of this study, although elderly age itself is a primary risk factor of MCI. However, it has been also suggested that age has a significant influence on verbal fluency abilities (Kempler, Teng, Dick, Taussig, & Davis, Reference Kempler, Teng, Dick, Taussig and Davis1998; Rodriguez-Aranda & Martinussen, Reference Rodriguez-Aranda and Martinussen2006). Thus, we cannot rule out the possibility that the age of the participants might have affected their verbal fluency performance regardless of their cognitive state. Nevertheless, this sample would closely represent the affected population in case of a potential real-life application.
When interpreting the results, it is important to take into consideration that because of the exploratory nature of this pilot study, corrections for multiple comparisons were not applied during the statistical analysis. As one of the main goals of this study was to investigate and identify all temporal fluency parameters that are able to differentiate between the groups, confirmatory studies are required to further attest the discriminatory ability and clinical utility of these significant temporal parameters.
This study established the main characteristics of a novel verbal fluency analysis, thus, further projects should be focused on the collection of more and higher quality data in order to define precise reference values for the amount of silent pauses associated with MCI. In the future, this would allow for the development of an automated tool for MCI screening, based on the analysis of temporal speech parameters. In addition, it remains to be determined whether combining this method of temporal parameter analysis with automated clustering analysis (reported earlier, e.g., König et al., Reference König, Linz, Tröger, Wolters, Alexandersson and Robert2018) could provide additional value with respect to classification.
CONCLUSION
In this study, we offered an alternative method of fluency analysis, and demonstrated the discriminatory ability of silent pause parameters in the case of semantic verbal fluency tests. Silence-related parameters can be extracted and calculated from fluency voice recordings using computerized methods. Therefore, this approach to fluency analysis seems to show promising potential, and, building on these results, the next step would be to construct an automated instrument capable of identifying MCI patients based on their speech/silence ratio. The development of remote, automated tools is especially important, seeing that the necessity and significance of medical consultations based on telemedicine are becoming common practice due to the current COVID-19 pandemic. Considering the high burden on the healthcare systems, an automated and cost-effective telemedical tool, based on the recognition of silent segments of speech, would be a valuable addition to practice, and it would likely improve the detection rates of MCI.
ACKNOWLEDGMENTS
The authors wish to thank all participants for their cooperation.
FINANCIAL SUPPORT
This work was supported by the Faculty of Medicine, University of Szeged (R.B. and I. N., grant number EFOP-3.6.3-VEKOP-16-2017-00009); the János Bolyai Research Scholarship of the Hungarian Academy of Sciences (G.G., grant number BO/00653/19); the Hungarian Ministry of Innovation and Technology (G.G., grant numbers ÚNKP-21-5, NKFIH-1279-2/2020); and the Ministry of Innovation and Technology NRDI Office (G.G., grant number NKFIH FK-124413) within the framework of the Artificial Intelligence National Laboratory Program (MILAB).
CONFLICTS OF INTEREST
The authors declare that there is no conflict of interest.
ETHICAL STANDARDS
Participation in the study was voluntary. All participants were informed about the aims of the study and gave their written consent. The experiment was conducted according to the ethical principles of the Declaration of Helsinki, and it was approved by the Regional Human Biomedical Research Ethics Committee of the University of Szeged (Reference No. 231/2017-SZTE).











 Open access
Open access