



The term “ecological validity” (EV) has been defined variably across years and disciplines. It was originally coined in the 1940s by Egon Brunswik, pertaining to the degree to which a percept provides information about the actual properties of perceived stimulus (Brunswik, Reference Brunswik1956). In the 1960s and 1970s, experimental psychologists began to use EV to reflect the degree to which an experimental manipulation paralleled real-world cause-and-effect relationships (Anisfeld, Reference Anisfeld1968; Dudycha et al., Reference Dudycha, Dumoff and Dudycha1973; Jennings & Keefer, Reference Jennings and Keefer1969); and by the 1980s, clinical and developmental psychologists began to apply EV to intelligence testing, questioning whether IQ scores alone could explain real-world functioning (Gaylord-Ross, Reference Gaylord-Ross1979; Latham, Reference Latham1978; Wiedl & Herrig, Reference Wiedl and Herrig1978). On the heels of these developments, the emerging field of clinical neuropsychology began to question its own assessment methods (Newcombe, Reference Newcombe, Levin, Grafman and Eisenberg1987), leading to a flurry of ecologically-themed publications in the early 1990s (Farmer & Eakman, Reference Farmer and Eakman1995; Gass et al., Reference Gass, Russell and Hamilton1990; Johnson, Reference Johnson1994; Wilson, Reference Wilson1993), and culminating with the publication of a prominent edited textbook fully devoted to EV of neuropsychological assessment (Sbordone & Long, Reference Long, Sbordone and Long1996). As seen in Figure 1, following the publication of Sbordone’s and Long’s (Reference Long, Sbordone and Long1996) book, the term EV took a firm hold in the neuropsychological literature, and has since eclipsed the usage of other well-established validity terms, including predictive, concurrent, or criterion validity.
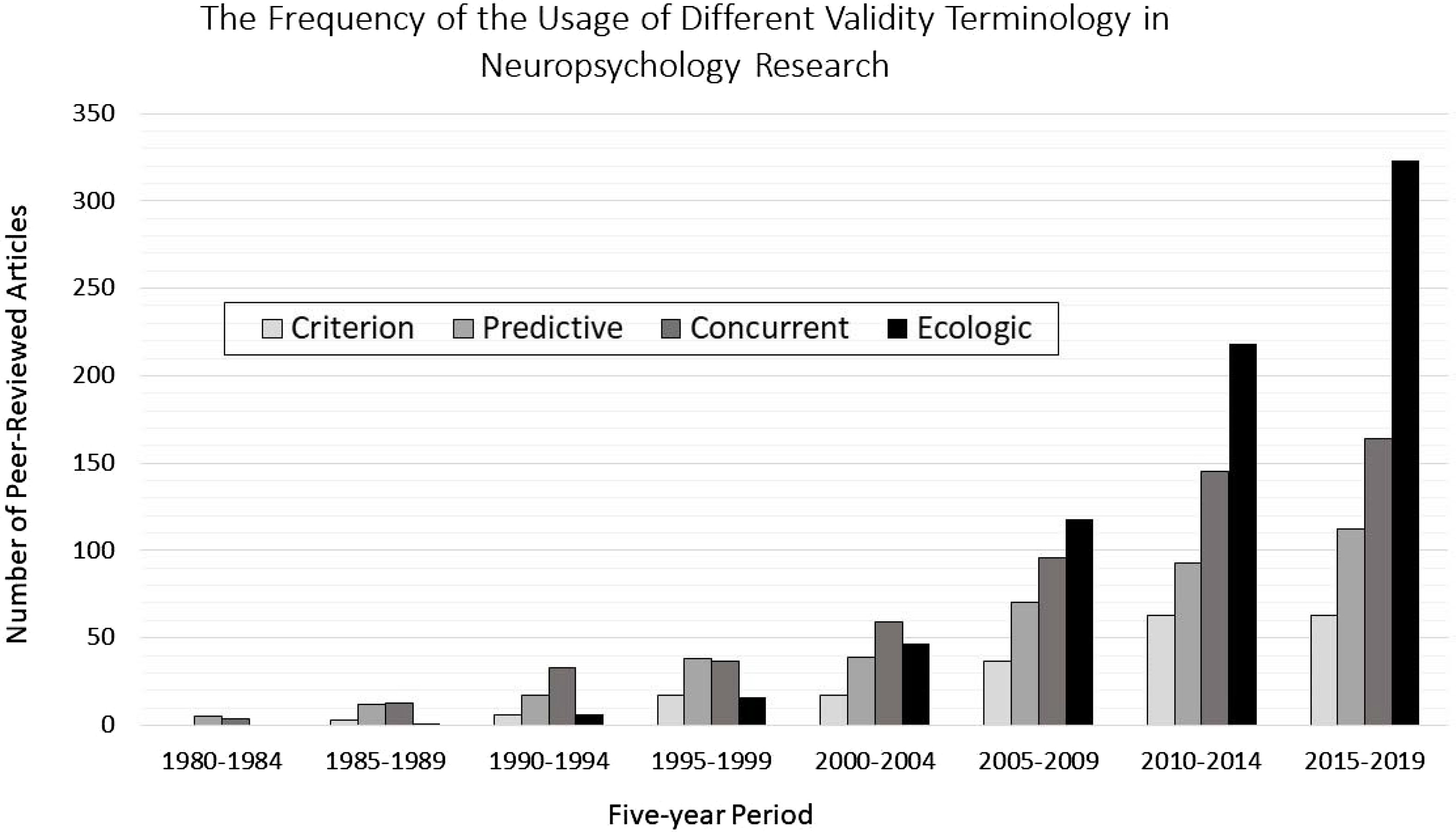
Figure 1. The figure illustrates the increase of the usage of the term “ecological validity” in peer-reviewed articles pertaining to neuropsychological assessment.
Given the proliferation of literature that examines, criticizes, or otherwise discusses EV of neuropsychological instruments, one would expect the term to be well understood and used consistently across studies. However, even a casual perusal of the literature reveals considerable inconsistencies. On the one hand, in their 1996 textbook, Sbordone (Reference Sbordone, Sbordone and Long1996, p. 16) defined EV as “the functional and predictive relationship between the patient’s performance … and the patient’s behavior in a variety of real-world settings” (i.e., the ability to predict real-world outcomes), which Long (Reference Long, Sbordone and Long1996) echoed. On the other hand, in the same text, Franzen & Wilhelm (Reference Franzen, Wilhelm, Sbordone and Long1996) proposed a two-pronged conceptualization of EV, stating that ecological validation involves “investigations of both verisimilitude and veridicality” (p. 96, italics added), wherein “verisimilitude” refers to “the similarity of the data collection method to tasks and skills required in the free and open environment” (p. 93) and “veridicality” refers to the test’s ability to “predict phenomena in the … ‘real world’” (p. 93)Footnote 1 . However, this conceptualization appears to have morphed over the years to confound EV with face validity. For example, Burgess and colleagues stated plainly in one of their publications that tests that are a “formalized version of real-world activity” are “inherently ecologically valid” (Burgess et al., Reference Burgess, Alderman, Evans, Emslie and Wilson1998, p. 547), and later publications (Alderman et al., Reference Alderman, Burgess, Knight and Henman2003; Zartman et al., Reference Zartman, Hilsabeck, Guarnaccia and Houtz2013) echoed this sentiment, suggesting that empirical examination of highly face-valid tests’ associations with functional outcomes is not necessary.
In light of the growing number of studies that use the term EV (see Fig. 1), along with different authors using EV to refer to different concepts, it is critical for our field to gain improved insight into existing conceptualizations of EV in neuropsychological research. This line of inquiry is not new within the broader field of psychology (Araújo et al., Reference Araújo, Davids and Passos2007; Dunlosky et al., Reference Dunlosky, Bottiroli, Hartwig, Hacker, Dunlosky and Graesser2009; Schmuckler, Reference Schmuckler2001). Indeed, Holleman et al. (Reference Holleman, Hooge, Kemner and Hessels2020) described the term EV as being “shrouded in both conceptual and methodological confusion.” To address the need for a better understanding of EV, Pinto et al. (Reference Pinto, Dores, Peixoto and Barbosa2023) conducted a literature review with the stated goal of examining how the term EV is defined in articles on neuropsychological assessment. While the authors confirmed that the two most-commonly used concepts in defining EV are verisimilitude and veridicality (referred to by the authors as representativeness and generalizability, respectively)Footnote 2 , this work had several limitations. First, the authors did not characterize the degree of agreement or disagreement among reviewed articles, or the presence of any potential misconceptions about EV, leaving the question about inconsistency among definitions unanswered. Relatedly, from among the 83 reviewed articles, only 50 were cited in the portion of results that pertained to the definition of EV, leaving unclear how EV was defined or conceptualized among reviewed articles that were not cited in this section (i.e., the remaining 33 articles). Consequently, no conclusions can be drawn from Pinto et al. (Reference Pinto, Dores, Peixoto and Barbosa2023) review about the relative frequency of different conceptualizations of EV within the literature. Second, the Pinto et al. (Reference Pinto, Dores, Peixoto and Barbosa2023) review only included publications that used the term EV in their title, thereby excluding many relevant articles. And third, the scope of included articles was very broad, with some falling well outside of neuropsychology in general and neuropsychological assessment in particular, making it difficult to determine how the results pertained to any one conceptually homogeneous research area.
To address these limitations, we conducted a systematic review of studies that used the term EV specifically as pertaining to neuropsychological assessment. Given that, within neuropsychology, EV is most often discussed in the context of assessment of executive functionsFootnote 3 (EFs; e.g, Barkley, Reference Barkley2012; Chaytor et al., Reference Chaytor, Schmitter-Edgecombe and Burr2006; Cripe, Reference Cripe1996; Manchester et al., Reference Manchester, Priestley and Jackson2004; Salimpoor & Desrocher, Reference Salimpoor and Desrocher2006; Wood & Bigler, Reference Wood, Bigler, McMillan and Wood2017), we focused our review on articles that used the term EV in conjunction with tests of EF, excluding articles pertaining to other neurocognitive domainsFootnote 4 . This allowed us to keep the cognitive construct of interest constant, thus affording greater consistency across methodologies and operationalizations pertaining to EV. Lastly, given that the term EV is heavily intertwined with the development of novel, more face-valid or naturalistic tests, we limited our review to articles that examined EV of such tests. By doing so, we were also able to examine how EV is conceptualized when pertaining to tests that are potentially characterized by both veridicality (i.e., association with real-world functioning) and verisimilitude (i.e., similarity to the real world), that is, the two characteristics formally proposed as defining EV (Franzen & Wilhelm, Reference Franzen, Wilhelm, Sbordone and Long1996; Pinto et al., Reference Pinto, Dores, Peixoto and Barbosa2023).
Across reviewed articles, we aimed to examine the following questions: (1) whether the term EV was defined, and, if so, what the components of such a definition were (i.e., verisimilitude only, veridicality only, both verisimilitude and veridicality, or other notions); (2) if the term was not defined, whether there was an implied conceptualization that could be gleaned from the study design, interpretation, or justification for referring to a test as being ecologically valid; and (3) whether the usage of the term EV varied by publication year, journal’s aims and scope, test type, and study purpose.
Method
This systematic review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (Page et al., Reference Page, McKenzie, Bossuyt, Boutron, Hoffmann, Mulrow, Shamseer, Tetzlaff, Akl, Brennan, Chou, Glanville, Grimshaw, Hróbjartsson, Lalu, Li, Loder, Mayo-Wilson, McDonald, McGuinness, Stewart, Thomas, Tricco, Welch, Whiting and Moher2021). No human data were used in preparation of this article, making the article exempt from review by University of Utah Institutional Board, and in compliance with the Helsinki Declaration.
Data sources, search strategy, and inclusion/exclusion criteria
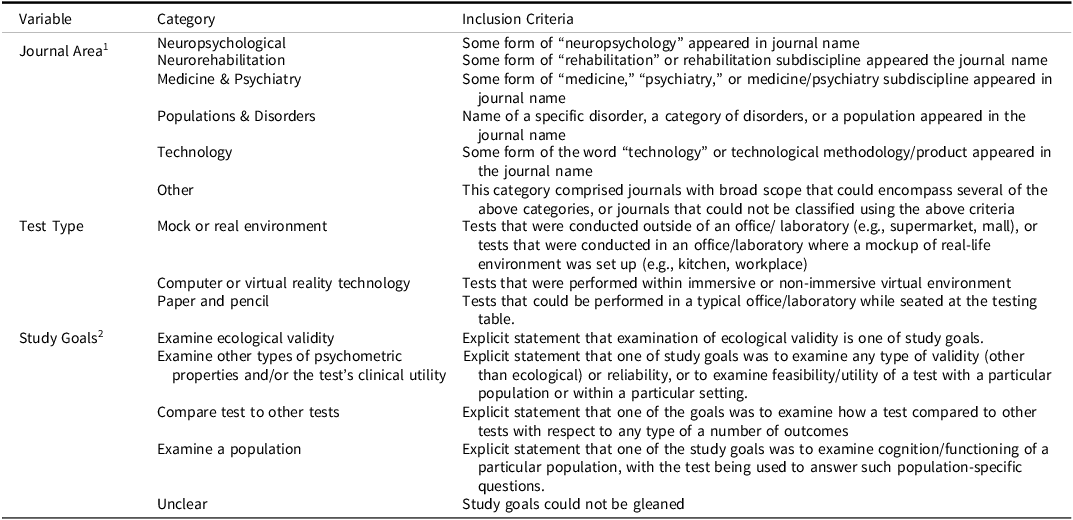
Comprehensive search was conducted on February 18, 2023, in MEDLINE and PsychINFO DatabasesFootnote 5 . No date limits were set on either end. Search terms were as follows: (TI ecologic* OR AB ecologic* or KW ecologic*)Footnote 6 AND neuropsychol* AND (executive functio* OR executive dysfunction OR executive abilit*). These terms were intended to target articles that used the term “ecological” (or some variant thereof) and that examined validity of face-valid and/or naturalistic tests of EF in the context of neuropsychological assessment. See Table 1 for inclusion and exclusion criteria.
Table 1. Inclusion and exclusion criteria
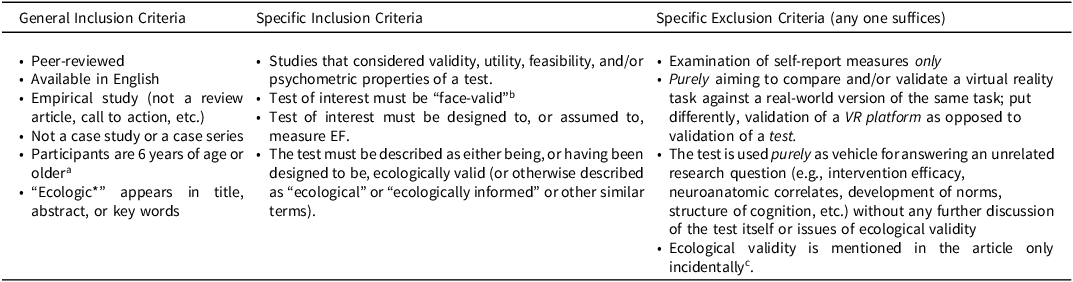
a Age limit was imposed since assessment of preschoolers, and methods and concepts surrounding such assessment, differ considerably from those associated with assessment of adults and school-age children.
b The term “face-valid” is taken to mean a test that was specifically designed to resemble tasks or demands encountered in people’s life outside of the laboratory. Such tests are also at times described as “naturalistic.”
c Incidental usage of the term EV refers to usage of the term outside of the goals/purposes of a given study, as adjudicated by agreement among authors.
Study selection
All retrieved article abstracts were first screened for general inclusion criteria and, when possible, specific inclusion and exclusion criteria (see Table 1) by the first author (YS). The remaining articles were retrieved and read by the first author (YS) and independently by at least one of four coauthors (LAD, MGM, SLB, MAN) to ascertain that inclusion and exclusion criteria listed in Table 1 were met. Whenever discrepancies occurred, these were adjudicated via discussion between the first author and at least one other coauthor.
Data extraction
Data were extracted by two authors (YS reviewed all studies, and MN, SLB, LAD, and MGM each independently reviewed a subset of studies). Discrepancies between authors were adjudicated via a discussion between the first author and at least one coauthor, such that either (a) a perfect agreement was reached, or (b) the datapoint was coded “unspecified.” We extracted two types of data: (1) Information pertaining to the conceptualization of the term EV, and (2) relevant correlates (i.e., publication year, journal type, test type, and study aims) of the conceptualization of EV.
Conceptualizations of the term EV
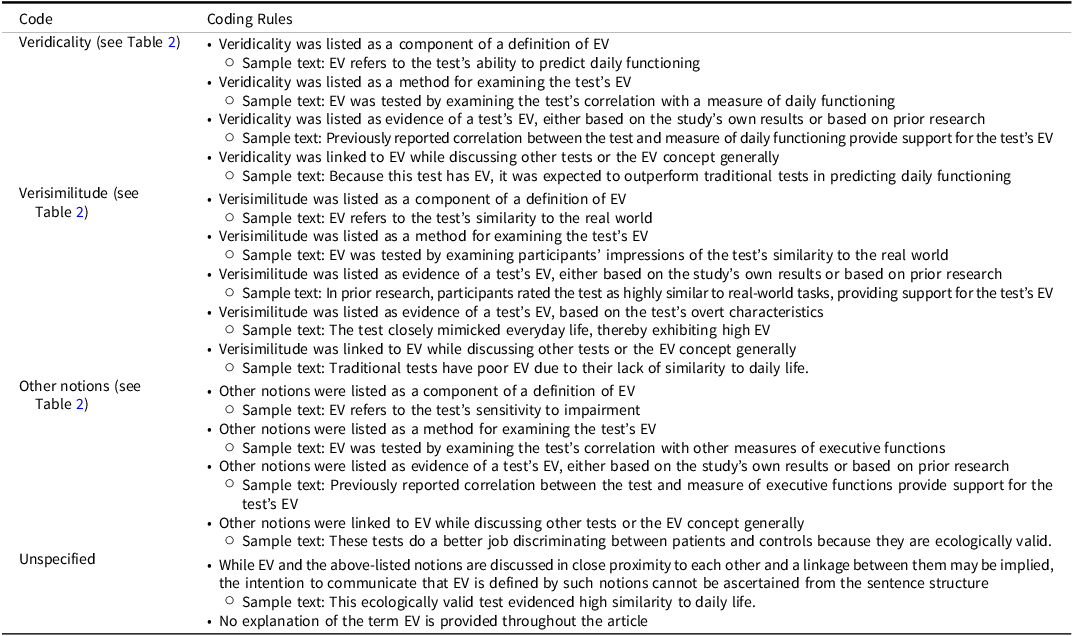
To code how EV was conceptualized, we conducted a deductive content analysis (using paragraphs as units of analysis). As a first step, we generated three categories, based on a recent literature review (Pinto et al., Reference Pinto, Dores, Peixoto and Barbosa2023): (1) veridicality, (2) verisimilitude, and (3) other notions (see Table 2 for descriptions). Next, each article was read by at least two authors and coded for presence of text reflecting any of the three categories. In the absence of text from any of the categories, or when agreement could not be reached among coders, the article was coded as “unspecified.” See Table 3 for coding rules. For transparency, representative examples of coded statements within each article were extracted and are provided in relevant tables offering an overview of all included articles.
Table 2. Definition and operationalization of veridicality, verisimilitude, and “other notions” as evidence of ecological validity
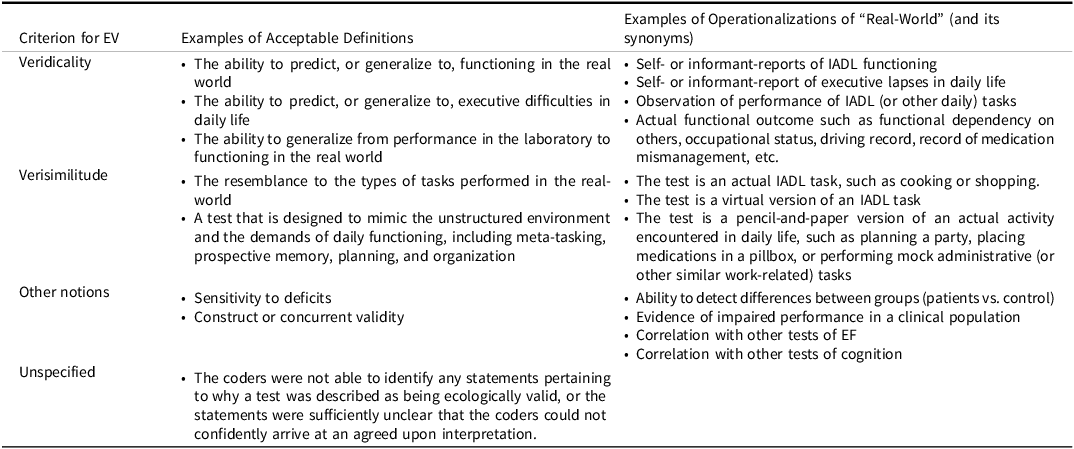
Table 3. Rules for coding conceptualization of ecological validity
Correlates of the conceptualizations of the term EV
To examine temporal trends of the usage of the term EV, we extracted the publication year. Years were clustered into five five-year blocks. To examine differences of usage based on journal type, test types, and study aims, we used coding rules outlined in Table 4.
Table 4. Rules for coding of correlates
1 Journal aims and scope were examined to ensure that the journal names corresponded to the primary areas of interest. If a discrepancy between journal name and aims and scope occurred, aims and scope was given precedence. For journal names that straddled two different categories, journal was classified based on aims and scope.
2 For the purpose of statistical analysis, studies were classified as though having only a single goal. Thus, if a study listed goals from multiple categories, the categories were ranked in the above-listed order and the highest-ranked category was used. This allowed us to categorize studies based on the degree to which ecological validity, or validity in general, was the focus of the study.
Results
Search results and general description of reviewed articles
Once duplicates were eliminated, the initial search yielded 514 articles. Screening of abstracts eliminated 406 articles based on criteria in Table 1. For the remaining 108 records, full articles were reviewed, resulting in the removal of an additional 18 articles (see Fig. 2), with 90 articles included in the reviewFootnote 7 . Figure 3 illustrates that selected articles spanned 25 years from 1998 to 2022, came primarily from neuropsychology or neurorehabilitation journals, focused primarily on paper-and-pencil tests or tests that utilized computer or VR technology, and typically specified ecological or other validation as study purpose.
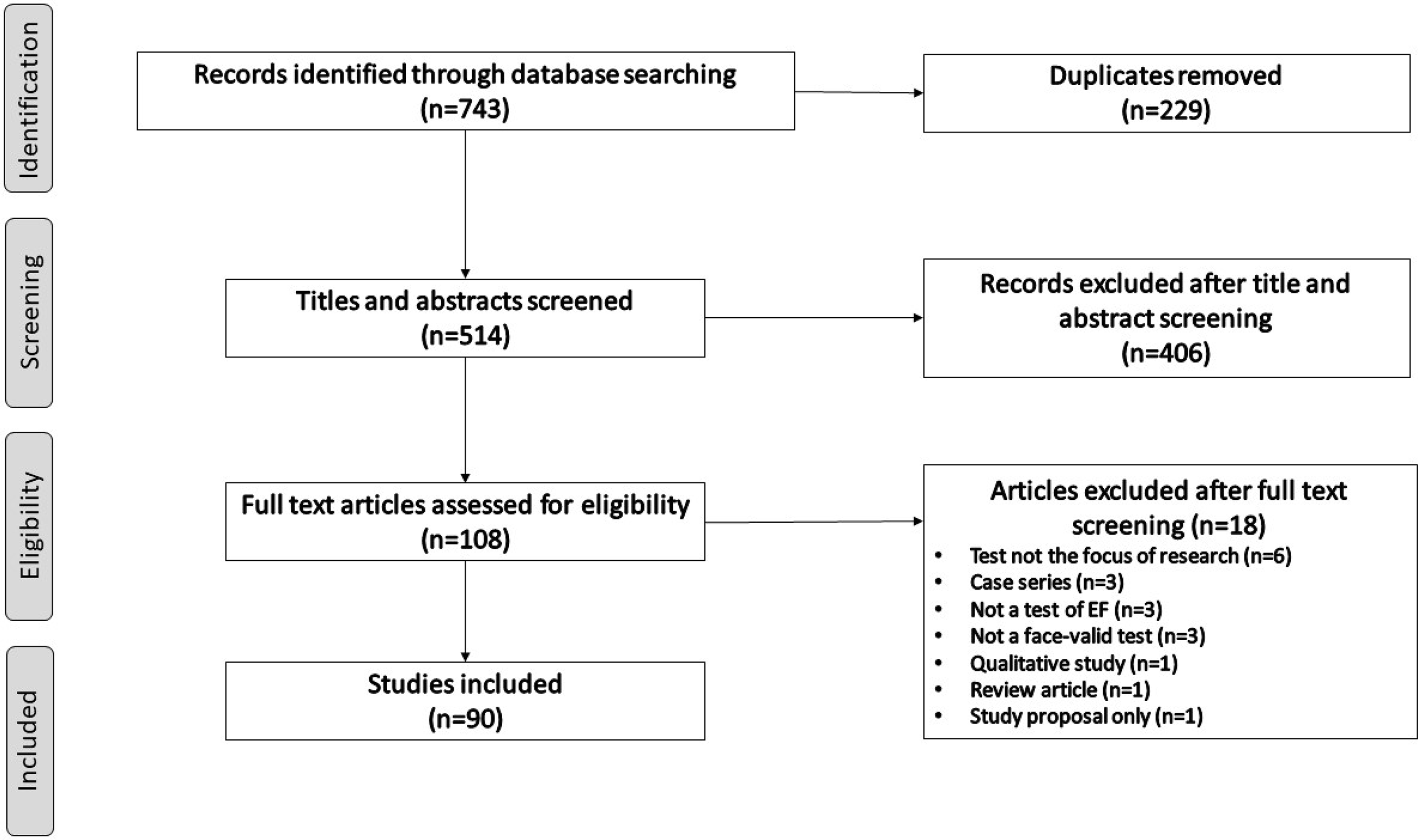
Figure 2. Article selection flowchart.
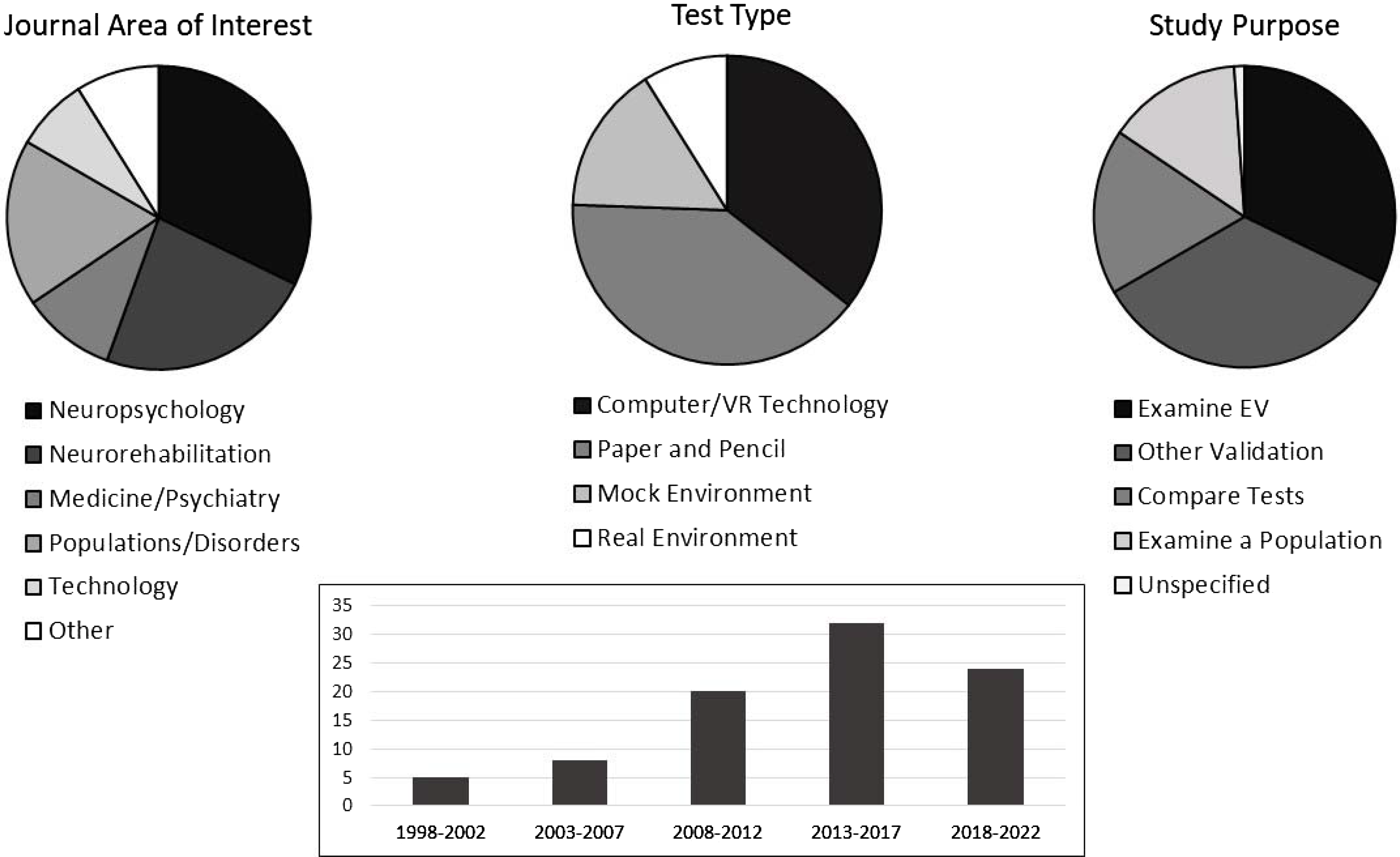
Figure 3. The figure provides an overview of the general characteristics of 90 articles included in the present systematic review.
Formal definitions
Only 28 articles (31%) provided a formal EV definitionFootnote 8 . Table 5 lists these 28 studies, and Table 6 lists the 28 definitions. As seen in Table 6, 14 of the 28 definitions (50%) subscribed to the two-pronged conceptualization of EV (i.e., requiring that a test have both veridicality and verisimilitude), 10 (36%) required only that a test predict real-world functioning (i.e., veridicality), and four (14%) required only that a test appear like the real world (i.e., verisimilitude). The one characteristic that was most prevalent among the definition (24 of 28, or 86%) was that the test be able to predict a real-world functional outcome (i.e., veridicality). Of the four articles that required only verisimilitude, one (Torralva et al., Reference Torralva, Strejilevich, Gleichgerrcht, Roca, Martino, Cetkovich and Manes2012) also noted the ability to discriminate between groups as an additional characteristic of EV, and one (Suchy et al., Reference Suchy, Lipio Brothers, DesRuisseaux, Gereau, Davis, Chilton and Schmitter-Edgecombe2022) implied that veridicality was another characteristic of EV but did not explicitly state so in the definition itself. Interestingly, provided definitions did not seem to serve as a conceptual framework for the study in all cases. Specifically, Chevignard et al. (Reference Chevignard, Servant, Mariller, Abada, Pradat-Diehl and Laurent-Vannier2009), whose explicit definition included the requirement to predict functional outcome, continued to refer to the test in question as ecologically valid despite having failed to find associations between the test and two different measures of daily functioning.
Table 5. Overview of studies that provided an explicit definition of the term EV

ABI = acquired brain injury, pABI = pediatric ABI, ADHD = Attention-Deficit/Hyperactivity Disorder, ASD = Autism Spectrum Disorder, AUD = Alcohol Used Disorder, BADS = Behavioral Assessment of Dysexecutive Syndrome, BADS-C = BADS for Children, MET = Multiple Errands Test, OCD = Obsessive Compulsive Disorder, ODD/CD = Oppositional Defiant Disorder/Conduct Disorder, JEF-C = Jansari assessment of Executive Functions for Children.
Codes for Journal and Test categories are presented in parentheses; journals codes: neuropsychological = 1, neurorehabilitation = 2, medicine & psychiatry = 3, populations/disorders = 4, technology = 5, and other = 6; Test type codes: mock or real environment = 1, computer or virtual environment = 2, and paper and pencil = 3.
Table 6. Definitions of ecological validity used in reviewed articles

A “definition” was defined as an explicit and direct explanation of the meaning or components of “ecological validity.” Indirect allusions or meaning that were only implied were not considered definitions.
a Phrasing of the definition appears to suggest that either veridicality or verisimilitude is sufficient.
b Article implies that verisimilitude is also a characteristic of EV, but this is not included in the definition as worded here.
c Definition suggests that sensitivity to brain damage is also needed in addition to verisimilitude.
Informal usage
We next examined how EV was conceptualized among the remaining 62 articles that did not provide a definition. Notably, six of these articles fairly consistently steered away from saying that tests in question were ecologically valid, describing them instead as “ecologically sensitive,” “ecologically informed,” or “ecologically relevant,” or as “ecological” tests, tasks, tools, measures, or assessments. While such phrasing is more circumspect by avoiding claims of “validity,” it is also open to interpretation; for example, the term could be used not to imply a psychometric property, but rather as a descriptor of an overt characteristic of the test or the environment in which it was performed. Thus, these articles were excluded from further examination of the informal usage of EV. See Table 7 for an overview of these articles. For the remaining articles, we examined the explicit or implied meaning of the term EV.
Table 7. Overview of studies that did not provide a definition and did not use the full term “ecological validity” when describing tests

ABI = acquired brain injury, AD = Alzheimer’s Disease, BADS (3)= Behavioral Assessment of Dysexecutive Syndrome, BD = bipolar disorder, MCI = mild cognitive impairment, pABI = pediatric acquired brain injury, TBI = traumatic brain injury.
Codes for Journal and Test categories are presented in parentheses; journals codes: neuropsychological = 1, neurorehabilitation = 2, medicine & psychiatry = 3, populations/disorders = 4, technology = 5, and other = 6; test type codes: mock or real environment = 1, computer or virtual environment = 2, and paper and pencil = 3.
Articles that linked the results to conclusions about a test’s EVFootnote 9
Table 8 provides an overview of 30 articles that did not provide a definition, but that explicitly linked conclusions about the test’s EV to the study results, thereby offering direct evidence about how EV was operationalized. From these, 18 (60%) cited prediction of functional outcome (i.e., veridicality) alone as evidence of the test’s EV, and an additional five (17%) cited prediction of functional outcome in combination with the test’s appearance (i.e., verisimilitude; Allain et al., Reference Allain, Foloppe, Besnard, Yamaguchi, Etcharry-Bouyx, Le Gall, Nolin and Richard2014; Burgess et al., Reference Burgess, Alderman, Evans, Emslie and Wilson1998; Gilboa et al., Reference Gilboa, Jansari, Kerrouche, Uçak, Tiberghien, Benkhaled and Chevignard2019) or in combination with the test’s ability to discriminate between patients and controls (Kallweit et al., Reference Kallweit, Paucke, Strauß and Exner2020; Montgomery, Hatton, Fisk, Ogden, & Jansari, 2010). The remaining seven articles (23%) did not rely on the prediction of functional outcomes as evidence of EV. Instead, three (10%) relied on appearance (i.e., verisimilitude), either alone (Orkin Simon et al., Reference Orkin Simon, Jansari and Gilboa2022) or in combination with tests’ associations with other measures (Doherty et al., Reference Doherty, Barker, Denniss, Jalil and Beer2015; Jovanovski et al., Reference Jovanovski, Zakzanis, Campbell, Erb and Nussbaum2012); and four articles (13%) based their conclusions about EV on tests’ associations with other tests of EF (La Paglia et al., Reference La Paglia, La Cascia, Rizzo, Riva and La Barbera2012, Reference La Paglia, La Cascia, Rizzo, Cangialosi, Sanna, Riva and La Barbera2014; Raspelli et al., Reference Raspelli, Pallavicini, Carelli, Morganti, Poletti, Corra, Silani and Riva2011), or a correlation between the virtual and the real versions of the same test (Laloyaux et al., Reference Laloyaux, Van der Linden, Levaux, Mourad, Pirri, Bertrand, Domken, Adam and Larøi2014). Interestingly, three articles examined correlations between the test and functional outcome but did not link the results of these procedures to EV; instead, these articles used alternative “validity” terminology, referring to convergent (Gilboa et al., Reference Gilboa, Jansari, Kerrouche, Uçak, Tiberghien, Benkhaled and Chevignard2019; Kenworthy et al., Reference Kenworthy, Freeman, Ratto, Dudley, Powell, Pugliese and Anthony2020) and concurrent validity (Orkin Simon et al., Reference Orkin Simon, Jansari and Gilboa2022).
Table 8. Overview of studies that did not provide a definition but did link their results to conclusions about a test’s ecological validity
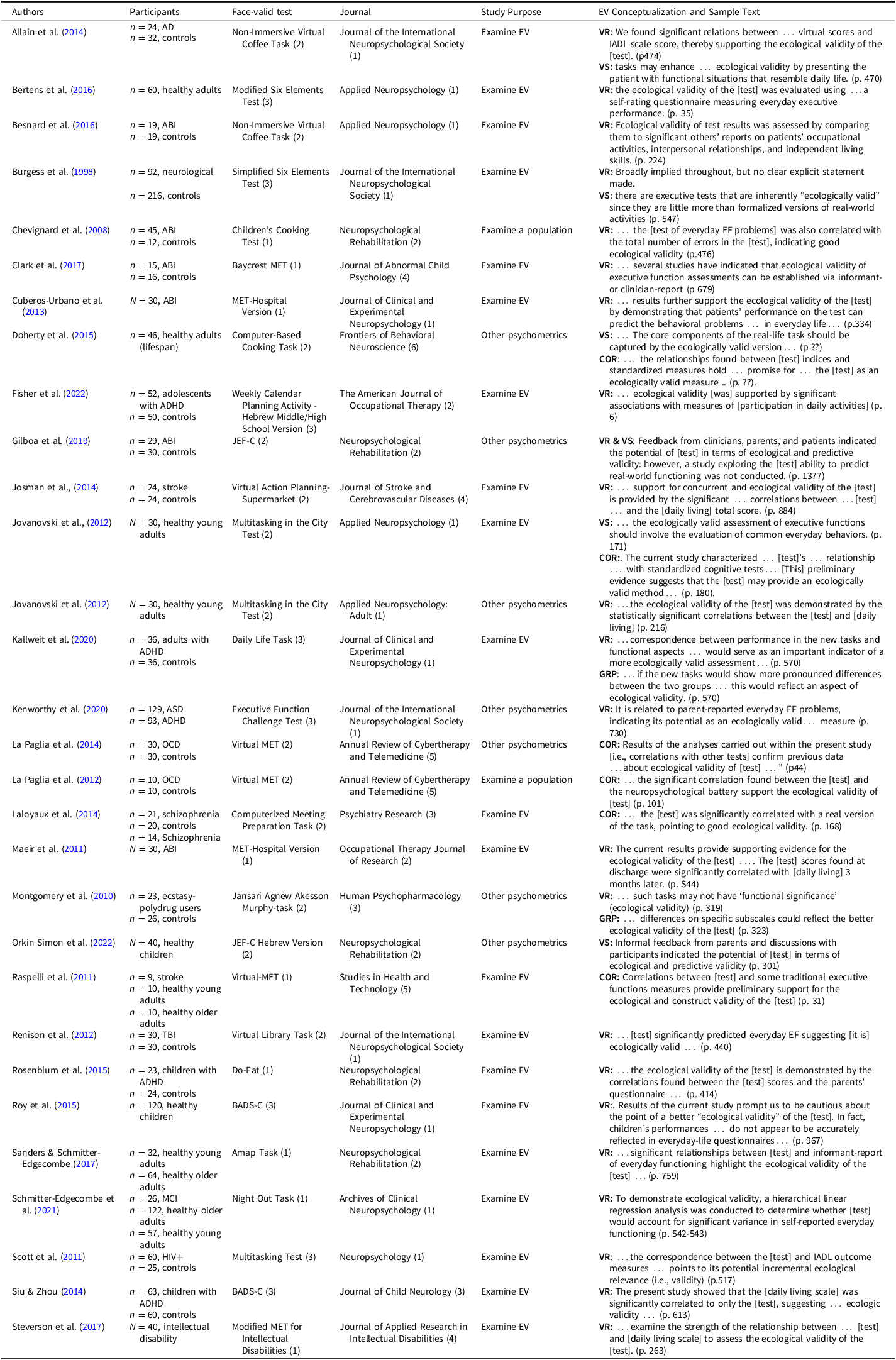
ABI = acquired brain injury, ADHD = Attention-Deficit/Hyperactivity Disorder, ASD = Autism Spectrum Disorder, BADS = Behavioral Assessment of Dysexecutive Syndrome, COR = correlation with other tests, GRP = examination of group differences, JEF-C = Jansari assessment of Executive Functions for Children, MET = Multiple Errands Test, OCD = Obsessive Compulsive Disorder, VR = Veridicality, VS = Verisimilitude.
Codes for Journal and Test categories are presented in parentheses; journals codes: neuropsychological = 1, neurorehabilitation = 2, medicine & psychiatry = 3, populations/disorders = 4, technology = 5, and other = 6; Test type codes: mock or real environment = 1, computer or virtual environment = 2, and paper and pencil = 3.
Articles that used the term EV without a definition or linkages to resultsFootnote 10
Lastly, we examined 26 remaining articles that described the tests of interest as ecologically valid but did not provide a definition or use their results as evidence of EV (see Table 9). Among these, seven articles (27%) seemed to judge EV based on test appearance (i.e., verisimilitude) alone, one (4%) relied on tests’ associations with functional outcomes (i.e., veridicality) alone, and six (23%) appeared to rely on both veridicality and verisimilitude. For the remaining 12 articles (46%), the presumed characteristics of EV could not be determined.
Table 9. Overview of studies that did not linked study findings to an instrument’s ecological validity
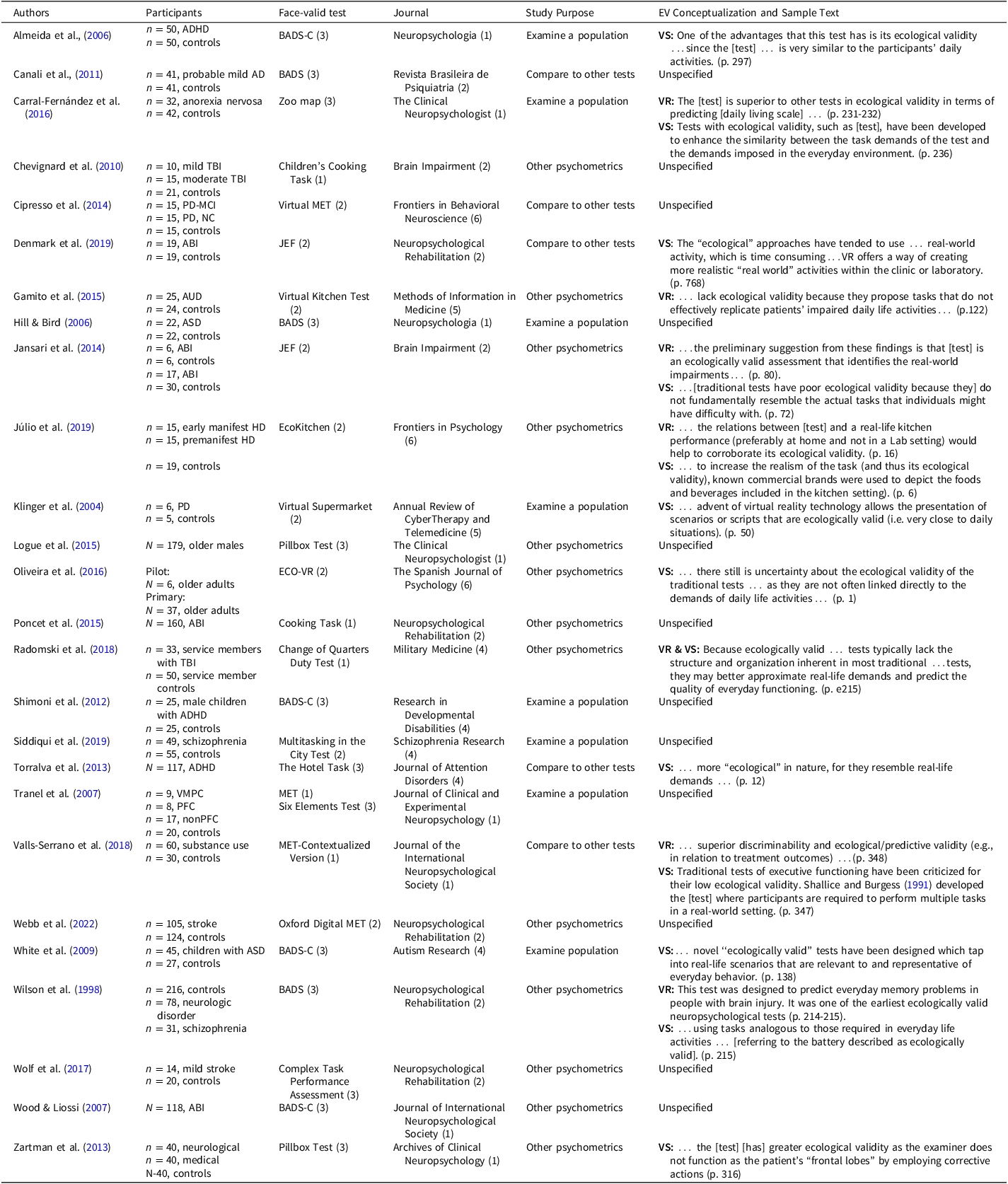
ABI = acquired brain injury, AD = Alzheimer’s Disease, ADHD = Attention-Deficit/Hyperactivity Disorder, ASD = Autism Spectrum Disorder, AUD = Alcohol Used Disorder, BADS = Behavioral Assessment of Dysexecutive Syndrome, BADS-C = Behavioral Assessment of Dysexecutive Syndrome- Children, COR = correlation with other tests, GRP = examination of group differences, HD = Huntington’s Disease, JEF = Jansari assessment of Executive Functions, MET = Multiple Errands Test, MCI = Mild Cognitive Impairment, PD = Parkinson’s Disease, PD-NC = Parkinson’s Disease-normal cognition, TBI = Traumatic Brain Injury, VR = Veridicality, VS = Verisimilitude.
Codes for Journal and Test categories are presented in parentheses; journals codes: neuropsychological = 1, neurorehabilitation = 2, medicine & psychiatry = 3, populations/disorders = 4, technology = 5, and other = 6; test type codes: mock or real environment = 1, computer or virtual environment = 2, and paper and pencil = 3.
Summary of conceptualization of EV
The pie chart in Figure 4 provides a summary of conceptualizations across all studies, illustrating that about two-thirds of the articles subscribed to one of the two “classic” conceptualizations of EV (i.e., either veridicality alone, or veridicality together with verisimilitude). This also means that for about one-third of the studies, the definition was comprised either of verisimilitude alone, or some combination of other notions (e.g., associations with other tests or ability to discriminate between diagnostic groups), or the meaning was unclear. The bar graph in Figure 4 illustrates that the conceptualization of EV differed dramatically [Likelihood Ratio (8) = 71.63, p < .001, Cramer’s V = .62] based on whether (a) an article provided a definition of EV and (b) if not providing a definition, whether it attempted to draw linkages between the results of the study and the test’s EV. Specifically, the overwhelming majority of articles that provided a definition conceptualized EV as a test’s ability to predict functional outcomes, either by this notion alone or in conjunction with tests’ appearance. This was also the case (although to a lesser extent) for articles that, without providing a definition, drew some linkages between their results and the test’s EV. However, about a quarter of these articles also seemed to confound EV with other notions, such as sensitivity to group differences or associations with other tests. For studies that described the tests in question as ecologically valid without providing a definition and without drawing linkages between the study results and tests’ EV, the EV conceptualization was unclear in nearly half the cases. The remainder was about evenly split between relying purely on test appearance, or test appearance in conjunction with prediction of functional outcome.
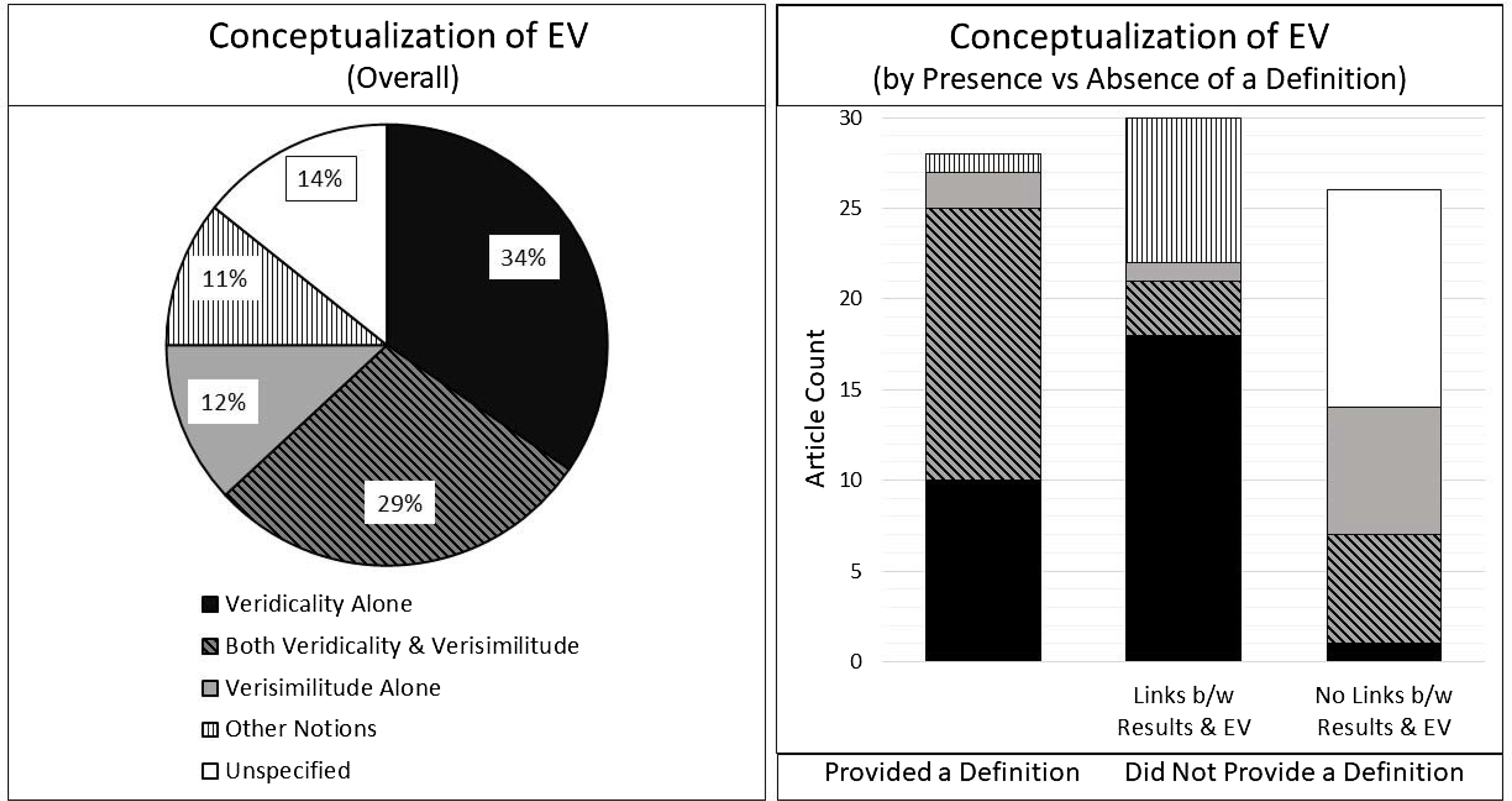
Figure 4. The figure provides an overall summary of the conceptualization of the term ecological validity (EV) across 84 articles that used the full term “ecological validity” as pertaining to a test of interest. Of note, six articles are excluded, due to reliance on less explicity terminology (e.g., “ecological relevance” or “ecological tests”).
Correlates of usage of the term EV
As seen in Figure 5, both the usage of a definition and the conceptualization of EV varied based on study purpose [Likelihood Ratio (3) = 11.85, p = .008, Cramer’s V = .36, and Likelihood Ratio (12) = 34.92, p < .001, Cramer’s V = .37, respectively]. Specifically, studies that focused on comparison to other tests were more likely to use a definition. Additionally, studies that explicitly aimed to examine a measure’s EV overwhelmingly viewed prediction of functional outcome (i.e., veridicality) as evidence of EV, whereas studies that focused on examining a population were most likely to rely on test appearance (i.e., verisimilitude) alone. Conceptualization further varied by publication year [Likelihood Ratio (16) = 28.25, p = .030, Cramer’s V = .29] and test type [Likelihood Ratio (8) = 18.65, p = .017, Cramer’s V = .30]. Specifically, as seen in Figure 6, in the first five years of the study of EV, prediction of functional outcome was invariably viewed as an aspect of EV, typically in combination with test appearance, which became less common in later years. Additionally, VR and computer tests were the most likely to rely on nontraditional definitions of EV.
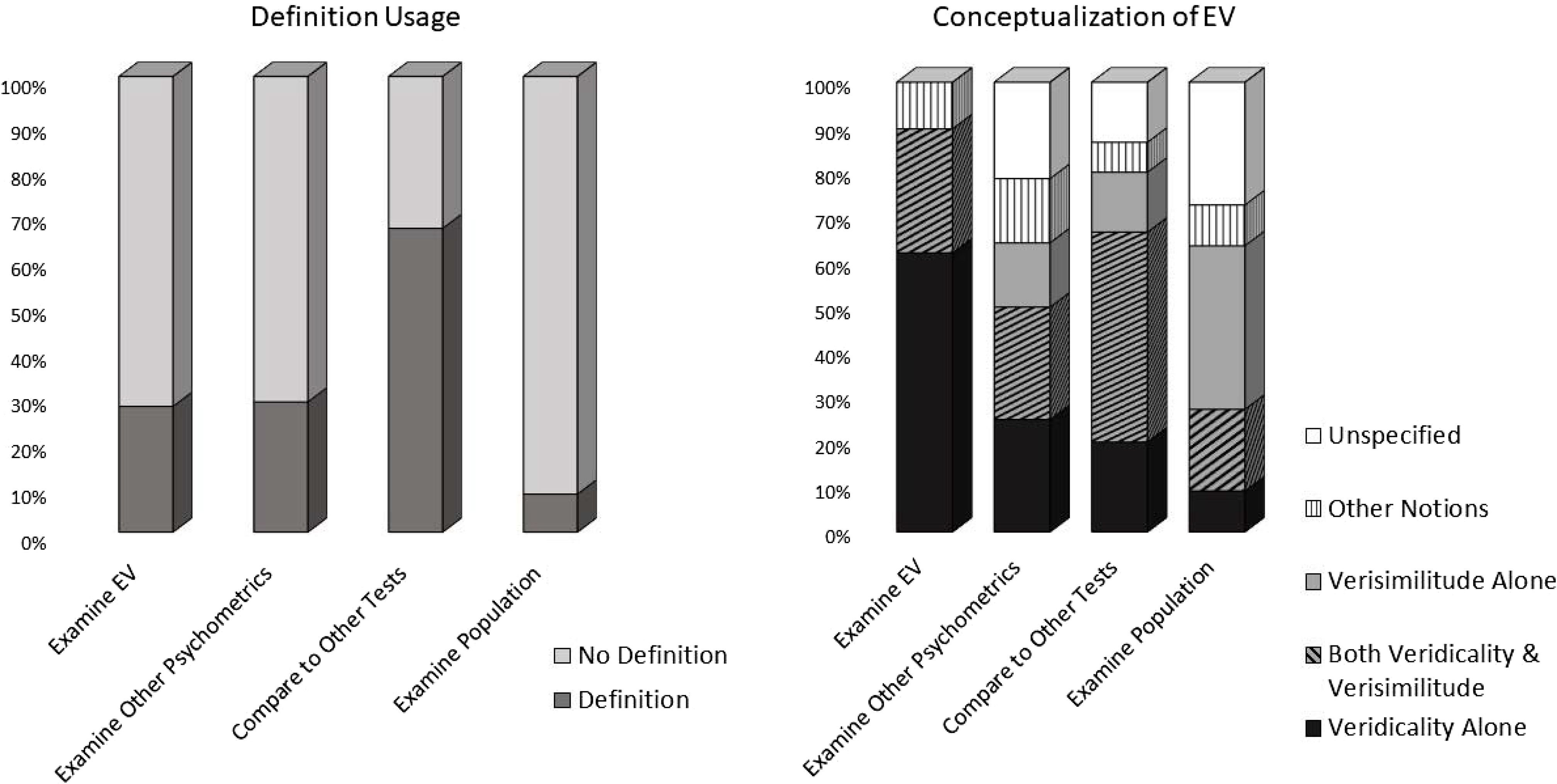
Figure 5. The figure illustrates how how the explicitly stated purposes of individual studies related to whether an rticle provided a definition of ecological validity (EV), and to how the term EV was conceptualized. “Definition” graph is based on all 90 articles reviewed for this study. Conceptualization graph is based on 84 articles that used the full term “ecological validity.”.
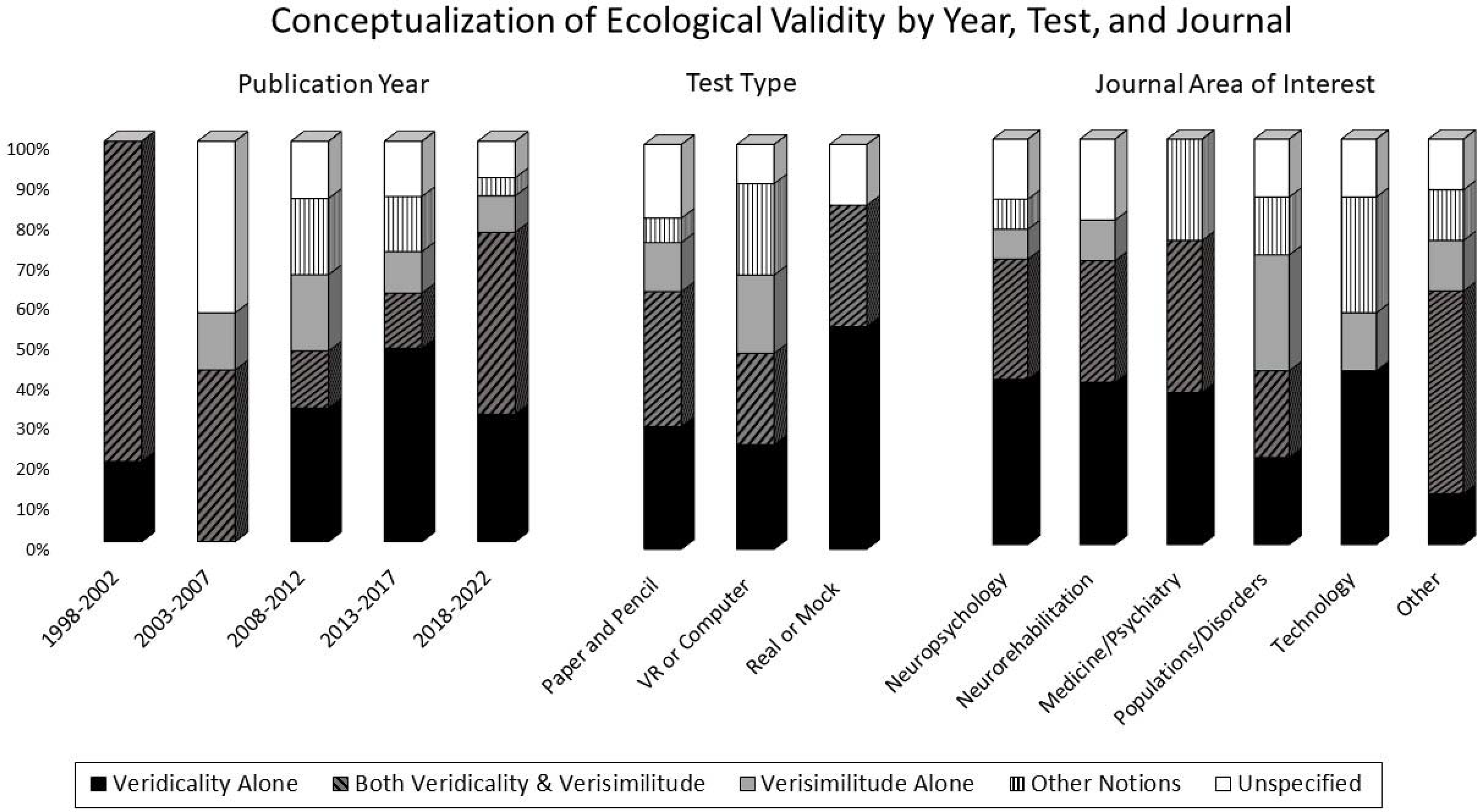
Figure 6. The figure illustrates the associations between how the term ecological validity was conceptualized and publication year, test type, and journal area. Differences were statistically significant for publication year and test type. Based on 84 articles that used the full term “ecological validity.” VR = virtual reality. “Real or mock”=real or mock up environments.
Discussion
Criticisms of inconsistent and confusing usage of the term EV in psychological research have been repeatedly raised (Araújo et al., Reference Araújo, Davids and Passos2007; Dunlosky et al., Reference Dunlosky, Bottiroli, Hartwig, Hacker, Dunlosky and Graesser2009; Holleman et al., Reference Holleman, Hooge, Kemner and Hessels2020; Schmuckler, Reference Schmuckler2001). The present review examined how the term EV is used specifically in the context of neuropsychological research of novel, face-valid tests of EF. The key findings are that (a) EV is infrequently defined and (b) both formal definitions and informal usage of EV vary considerably. These findings suggest that the literature on EV of face-valid EF tests is unclear and potentially highly misleading, consistent with similar concerns raised within the broader field of psychology (Araújo et al., Reference Araújo, Davids and Passos2007; Dunlosky et al., Reference Dunlosky, Bottiroli, Hartwig, Hacker, Dunlosky and Graesser2009; Holleman et al., Reference Holleman, Hooge, Kemner and Hessels2020; Schmuckler, Reference Schmuckler2001). Indeed, the present review reveals that a statement in a study’s abstract or conclusions section claiming that the results supported a test’s EV could be referring to different notions, including that the test: (a) predicted daily functioning, (b) differentiated clinical groups, (c) correlated with other cognitive measures, and/or (d) has face validity. This inconsistency in conceptualization, together with the frequent absence of a formal definition, is further compounded by the fact that readers themselves likely interpret statements about EV through the lens of their own understanding of what the term means, potentially drawing highly skewed conclusions about implications for clinical practice.
Trends over time, test types, journals, and study purpose
As illustrated in Figure 1, the usage of EV within neuropsychological publications has grown more than 20-fold over the past 25 years. With this increase in usage, there has been a drift in how the term is conceptualized. On the one hand, our results suggest that, initially, the term appeared to be exclusively taken to mean that a given test predicted functioning in daily life (i.e., veridicality), either alone or in conjunction with test appearance (i.e., verisimilitude). On the other hand, results suggest that in the past 20 years, in the literature on face-valid tests of EF, researchers have begun to rely on test appearance alone to claim EV. Additionally, wholly erroneous conceptualizations have also begun to emerge, conflating EV with sensitivity to brain injury (Torralva et al., Reference Torralva, Strejilevich, Gleichgerrcht, Roca, Martino, Cetkovich and Manes2012), tests’ ability to differentiate groups (Kallweit et al., Reference Kallweit, Paucke, Strauß and Exner2020; Montgomery et al., Reference Montgomery, Hatton, Fisk, Ogden and Jansari2010), or construct or concurrent validity evidenced by associations with other tests (Doherty et al., Reference Doherty, Barker, Denniss, Jalil and Beer2015; Jovanovski et al., Reference Jovanovski, Zakzanis, Ruttan, Campbell, Erb and Nussbaum2012; La Paglia et al., Reference La Paglia, La Cascia, Rizzo, Riva and La Barbera2012, Reference La Paglia, La Cascia, Rizzo, Cangialosi, Sanna, Riva and La Barbera2014; Laloyaux et al., Reference Laloyaux, Van der Linden, Levaux, Mourad, Pirri, Bertrand, Domken, Adam and Larøi2014; Raspelli et al., Reference Raspelli, Pallavicini, Carelli, Morganti, Poletti, Corra, Silani and Riva2011). Importantly, for some authors, EV appears to have become completely decoupled from prediction of functional outcome, as some studies that examined the association between the test and functional outcome failed to draw any connection between their results and EV (Alderman et al., Reference Alderman, Burgess, Knight and Henman2003; Chevignard et al., Reference Chevignard, Catroppa, Galvin and Anderson2010; Chicchi Giglioli et al., Reference Chicchi Giglioli, Pérez Gálvez, Gil Granados and Alcañiz Raya2021; Finnanger et al., Reference Finnanger, Andersson, Chevignard, Johansen, Brandt, Hypher, Risnes, Rø and Stubberud2022; Júlio et al., Reference Júlio, Ribeiro, Patrício, Malhão, Pedrosa, Gonçalves, Simões, van Asselen, Simões, Castelo-Branco and Januário2019; Laloyaux et al., Reference Laloyaux, Van der Linden, Levaux, Mourad, Pirri, Bertrand, Domken, Adam and Larøi2014; Longaud-Valès et al., Reference Longaud-Valès, Chevignard, Dufour, Grill, Puget, Sainte-Rose and Dellatolas2016; Moriyama et al., Reference Moriyama, Mimura, Kato, Yoshino, Hara, Kashima, Kato and Watanabe2002; O’Shea et al., Reference O’Shea, Poz, Michael, Berrios, Evans and Rubinsztein2010; Oliveira et al., Reference Oliveira, Lopes Filho, Jé, Sugarman, Esteves, Lima, Moret-Tatay, Irigaray and Argimon2016; Orkin Simon et al., Reference Orkin Simon, Jansari and Gilboa2022; Verdejo-García & Pérez-García, Reference Verdejo-García and Pérez-García2007; Zartman et al., Reference Zartman, Hilsabeck, Guarnaccia and Houtz2013). Notably, some authors even claimed evidence of EV in face of their own negative findings about veridicality (Chevignard et al., Reference Chevignard, Servant, Mariller, Abada, Pradat-Diehl and Laurent-Vannier2009; Clark et al., Reference Clark, Anderson, Nalder, Arshad and Dawson2017; Gilboa et al., Reference Gilboa, Jansari, Kerrouche, Uçak, Tiberghien, Benkhaled and Chevignard2019). Taken together, these results illustrate that the usage of the term EV has become increasingly inconsistent, departing further from original conceptualizations (Franzen & Wilhelm, Reference Franzen, Wilhelm, Sbordone and Long1996; Sbordone, Reference Sbordone, Sbordone and Long1996). That said, as seen in Figure 6, the past decade evidences an apparent trend toward returning to the original two-pronged conceptualization, perhaps as a function of emerging criticisms of confusing usage (Araújo et al., Reference Araújo, Davids and Passos2007; Dunlosky et al., Reference Dunlosky, Bottiroli, Hartwig, Hacker, Dunlosky and Graesser2009; Holleman et al., Reference Holleman, Hooge, Kemner and Hessels2020; Schmuckler, Reference Schmuckler2001).
Interestingly, usage also varied by study purpose. First, studies that focused primarily on comparisons of the utility of various tests were more likely to provide a formal definition of EV (Figure 5), likely because the comparisons were typically made between tests that were presumed to be ecologically valid and those that were notFootnote 11 . Thus, provision of a definition was necessary to justify grouping of tests into ecological vs. non-ecological categories. Additionally, studies that set out to empirically examine tests’ EV were most likely to associate EV with predictions of functional outcomes, likely because examination of EV necessitated explicit operationalization of the term and explicit hypotheses. In contrast, studies that focused on particular disorders or populations tended to rely on test appearance (i.e., verisimilitude) as evidence of EV. This may be explained by the fact that articles that focus on a given population may not necessarily be interested in prediction of outcomes, but rather may be more focused on characterizing patients’ functioning. In this type of research, naturalistic tests of EF may then be assumed to provide an insight into patients’ daily lives, thereby representing an outcome rather than a predictor. Thus, it is understandable that high verisimilitude represents the most salient and valued aspect of EV in this line of research.
Additionally, considerable differences in conceptualization of EV were also evident by test type. Specifically, research on paper-and-pencil tests and tests administered in real or mock environments linked EV primarily to prediction of functional outcomes (either alone or in conjunction with test appearance), whereas research on tests performed in virtual or computer environments tended to equate EV with test appearance or with other nontraditional notions. It is likely that the latter is related to the fact that developers of computer-based naturalistic environments focus primarily on ensuring that such tests sufficiently approximate the natural environment, and in the process perhaps lose sight of the principal reason for test development, that is, the test’s eventual clinical utility.
Pitfalls associated with the term ecological validity
Clinical misconceptions
As the present review shows, there is no clear consensus about the meaning of the term EV, resulting in considerably inconsistent use across studies. This, in and of itself, is not all that unusual. Other terms used in neuropsychological literature are similarly plagued by the lack of a universally-accepted definition, with the neurocognitive domain of EF representing a salient example (Suchy, Reference Suchy2015). However, there is a critical difference between the problems with conceptualization of EF and conceptualization of EV. Specifically, inconsistencies in EF conceptualization pertain to certain discrete disagreements, such as whether the term is unitary or multidimensional, or how broad the umbrella of EF should be. Aside from these differences of opinion, there are core EF abilities that are fairly universally agreed upon, and differences in definitions are not likely to have a meaningful impact on how study results are interpreted or applied in clinical practice. In contrast, despite some overlap in definitions and usage of the term EV, differences in definitions appear to lead to diametrically opposed and mutually inconsistent interpretations and conclusions, with potentially clinically meaningful ramifications.
A clear example of diametrically opposed conclusions can be gleaned from studies that apply the term EV to traditional measures of EF. Specifically, consistent with the veridicality interpretation of EV, a number of studies that have found association between traditional EF tests (i.e., tests with low verisimilitude) and functional outcomes have explicitly concluded that, based on their findings, such test are ecologically valid (e.g., Chiu et al., Reference Chiu, Wu, Hung and Tseng2018; García-Molina et al., Reference García-Molina, Tormos, Bernabeu, Junqué and Roig-Rovira2012; Hoskin et al., Reference Hoskin, Jackson and Crowe2005; Kibby et al., Reference Kibby, Schmitter-Edgecombe and Long1998; Lea et al., Reference Lea, Benge, Adler, Beach, Belden, Zhang, Shill, Driver-Dunckley, Mehta and Atri2021; Mitchell & Miller, Reference Mitchell and Miller2008; Odhuba et al., Reference Odhuba, Broek and Johns2005; Possin et al., Reference Possin, LaMarre, Wood, Mungas and Kramer2014; Reynolds et al., Reference Reynolds, Basso, Miller, Whiteside and Combs2019; Silverberg et al., Reference Silverberg, Hanks and McKay2007; Sudo et al., Reference Sudo, Alves, Ericeira-Valente, Alves, Tiel, Moreira, Laks and Engelhardt2015; Van der Elst et al., Reference Van der Elst, Van Boxtel, Van Breukelen and Jolles2008; Ware et al., Reference Ware, Crocker, O’Brien, Deweese, Roesch, Coles, Kable, May, Kalberg, Sowell, Jones, Riley and Mattson2012). Yet, it is fairly common for articles that focus on novel face-valid tests to claim, as a matter of unequivocal fact, that traditional EF tests lack ecological validity (e.g., Allain et al., Reference Allain, Foloppe, Besnard, Yamaguchi, Etcharry-Bouyx, Le Gall, Nolin and Richard2014; Chevignard et al., Reference Chevignard, Taillefer, Picq, Poncet, Noulhiane and Pradat-Diehl2008; Jovanovski et al., Reference Jovanovski, Zakzanis, Ruttan, Campbell, Erb and Nussbaum2012; La Paglia et al., Reference La Paglia, La Cascia, Rizzo, Riva and La Barbera2012; Longaud-Valès et al., Reference Longaud-Valès, Chevignard, Dufour, Grill, Puget, Sainte-Rose and Dellatolas2016; Renison et al., Reference Renison, Ponsford, Testa, Richardson and Brownfield2012; Rosetti et al., Reference Rosetti, Ulloa, Reyes-Zamorano, Palacios-Cruz, de la Peña and Hudson2018; Shimoni et al., Reference Shimoni, Engel-Yeger and Tirosh2012; Torralva et al., Reference Torralva, Strejilevich, Gleichgerrcht, Roca, Martino, Cetkovich and Manes2012; Valls-Serrano et al., Reference Valls-Serrano, Verdejo-García, Noël and Caracuel2018; Verdejo-García & Pérez-García, Reference Verdejo-García and Pérez-García2007; Werner et al., Reference Werner, Rabinowitz, Klinger, Korczyn and Josman2009). While these latter statements are sometimes meant to simply communicate the tests’ lack of face validity (or, potentially, a failure to tap into all cognitive domains needed for daily functioning), they often also communicate (explicitly or implicitly) that these tests are not able to predict functional outcomes. Indeed, even if the authors do not purposely intend to comment on the test’s ability to predict outcomes, such conclusions may be drawn by readers, based on their own idiosyncratic ways of conceptualizing EV. Figure 7 illustrates how the slippage between the veridicality and verisimilitude notions of EV leads to a deductive fallacy with erroneous conclusions that contradict research findings and potentially impact clinical practice. Indeed, clinicians may favor tests with greater face validity over traditional measures, regardless of the strength of empirical evidence (or lack thereof) about such novel tests’ ability to predict functional outcomes.
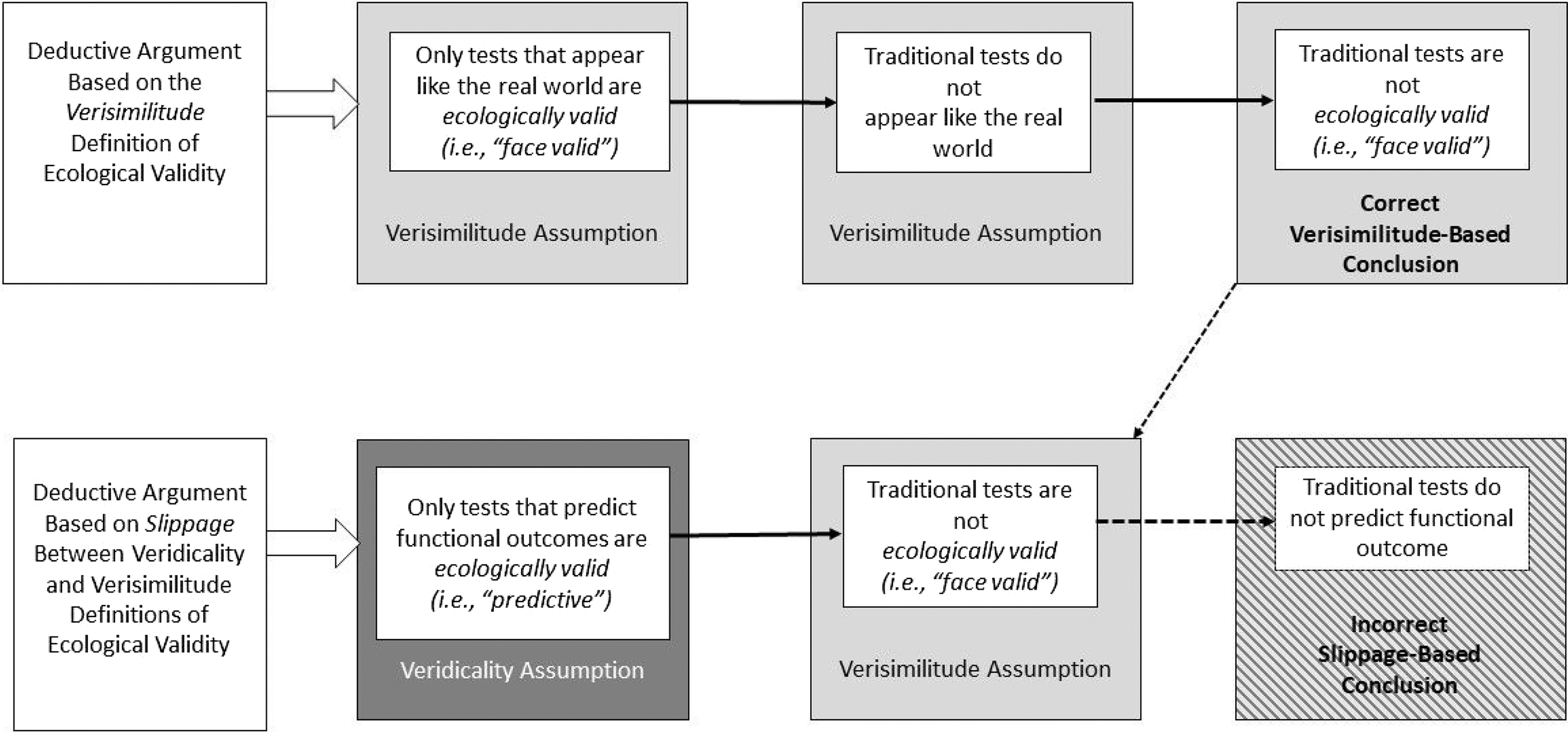
Figure 7. The figure illustrates how the slippage between the veridicality and verisimilitude conceptualizations of ecological validity can lead to logically-flawed conclusions, specifically, that traditional tests of executive functioning cannot predict functional outcomes due to their lack of verisimilitude. Extensive literature shows that this conclusion is incorrect.
Psychometric misconceptions
Interestingly, in the present review, even among the articles that did examine associations between a measure and a functional outcome as evidence of EV, some nevertheless strongly implied that the test characteristics were sufficient to describe the test as ecologically valid. For example, Alderman et al. (Reference Alderman, Burgess, Knight and Henman2003) stated that a test is “inherently ecologically valid” if it resembles real-world tasks (p. 37); and Zartman et al. (Reference Zartman, Hilsabeck, Guarnaccia and Houtz2013) followed suit, stating that the typical criticism of traditional tests’ ability to predict IADLs “does not apply” (p. 316) to their novel face-valid test, implying that such tests can be assumed to predict real-world functioning. From this perspective, EV (along with face validity) appears to carry a special status in that it is treated as though it is exempt from the requirement of empirical evidence. Such status, of course, contradicts the whole notion of test validation, wherein other types of validity (i.e., concurrent, predictive, construct, etc.) all require empirical confirmation. If treated in this manner, EV would then not reflect a test’s psychometric property (as other types of validity do), but rather a somewhat nebulous vernacular for readily apparent and potentially clinically irrelevant test characteristics. It is perhaps for these reasons that some authors opted to avoid linking together the words “ecological” and “validity,” describing their tests instead as “ecological assessments” or as “ecologically informed,” and other similar variations. Notably, we have repeatedly shown that naturalistic elements of a test do not necessarily improve upon prediction of objective real-world outcomes beyond measures with low face validity (Suchy et al., Reference Suchy, Lipio Brothers, DesRuisseaux, Gereau, Davis, Chilton and Schmitter-Edgecombe2022; Suchy et al., Reference Suchy, Gereau Mora, Lipio Brothers and DesRuisseauxin press; Ziemnik & Suchy, Reference Ziemnik and Suchy2019), demonstrating that predictive validity cannot be assumed based on test appearance alone.
Communication breakdown and a call to action
Interestingly, as mentioned earlier, some studies that did find evidence for the test’s ability to predict functional outcome did not link their study results with the term EV, referring instead to convergent or concurrent validity (Chevignard et al., Reference Chevignard, Catroppa, Galvin and Anderson2010; Finnanger et al., Reference Finnanger, Andersson, Chevignard, Johansen, Brandt, Hypher, Risnes, Rø and Stubberud2022; Gilboa et al., Reference Gilboa, Jansari, Kerrouche, Uçak, Tiberghien, Benkhaled and Chevignard2019; Kenworthy et al., Reference Kenworthy, Freeman, Ratto, Dudley, Powell, Pugliese and Anthony2020; Oliveira et al., Reference Oliveira, Lopes Filho, Jé, Sugarman, Esteves, Lima, Moret-Tatay, Irigaray and Argimon2016; Orkin Simon et al., Reference Orkin Simon, Jansari and Gilboa2022; Pishdadian et al., Reference Pishdadian, Parlar, Heinrichs and McDermid Vaz2022; Zartman et al., Reference Zartman, Hilsabeck, Guarnaccia and Houtz2013). Yet, the methods and results of these articles could have legitimately warranted claims of EV (if relying on either of the two classical definitions of EV; Sbordone, Reference Sbordone, Sbordone and Long1996; Franzen & Wilhem, Reference Franzen, Wilhelm, Sbordone and Long1996), given that (a) the employed tests possessed face validity and (b) the tests showed the ability to predict functional outcomes. Conversely, some studies in the present review that failed to find any associations between the test and functional outcome nevertheless continued to describe their tests as ecologically valid (Chevignard et al., Reference Chevignard, Servant, Mariller, Abada, Pradat-Diehl and Laurent-Vannier2009; Clark et al., Reference Clark, Anderson, Nalder, Arshad and Dawson2017; Gilboa et al., Reference Gilboa, Jansari, Kerrouche, Uçak, Tiberghien, Benkhaled and Chevignard2019), contradicting the most prevalent conceptualizations of EV, at least as evidenced in the present review. It is our position that these and other grossly contradictory claims and interpretations (also see “clinical misconceptions” above) reported throughout this review represent a highly problematic breakdown in communication, rendering the term EV essentially meaningless and potentially harmful.
To address this breakdown in communication, Holleman et al. (Reference Holleman, Hooge, Kemner and Hessels2020) called upon reviewers and editors to “safeguard journals from publishing papers where terms such as ‘ecological validity’… are used without specification.” While we fully support this call, the present review suggests that provision of a definition may not be enough. For example, as noted earlier, Chevignard et al. (Reference Chevignard, Servant, Mariller, Abada, Pradat-Diehl and Laurent-Vannier2009) continued to describe the test in question as being ecologically valid, despite their own empirical findings that contradicted the definition provided by the authors themselves. Similarly, Alderman et al. (Reference Alderman, Burgess, Knight and Henman2003) claimed that their test was inherently ecologically valid due to its high face validity, despite having provided a definition that explicitly stated that EV is defined by the test’s ability to predict functional outcome. In other words, it appears that the term EV is implicitly linked not to empirical evidence of validity, but rather to subjective impressions about test appearance. Indeed, as reviewed above, the notion that highly naturalistic tests can be assumed to be ecologically valid has been repeatedly propagated in the literature (Burgess et al., Reference Burgess, Alderman, Evans, Emslie and Wilson1998; Zartman et al., Reference Zartman, Hilsabeck, Guarnaccia and Houtz2013).
We therefore call upon our profession to consider “retiring” the term EV, replacing it instead with concrete and readily interpretable terminology that well predates the usage of the term EV, specifically, criterion validity. Criterion validity (and its components, concurrent and predictive validity) is linked to clear empirical methodology, can be readily interpreted as the test’s association with a concrete external criterion, and has clear clinical implications. Indeed, Larrabee (Reference Larrabee2015) in his prominent article on the types of validity in clinical neuropsychology acknowledged that the term EV is sometimes used as a synonym for criterion validity. Reliance on more concrete terminology would not only improve communication but might also help address the unwarranted but widely held misgivings about the utility of traditional tests of EF. These misgivings emerged alongside the emergence of the term EV and appear to be based solely on the traditional tests’ lack of verisimilitude. In response to these misgivings, our field has been committing precious resources (financial, creative, scientific) to the development of novel “naturalistic” tests, with limited evidence that such tests will improve our clinical practice. Indeed, from among the 50+ novel tests developed with the goal of improving EV, only one instrument (Behavioral Assessment of Dysexecutive Syndrome; BADS; Wilson et al., Reference Wilson, Alderman, Burgess, Emslie and Evans1996) has thus far been translated into regular clinical practice (Rabin et al., Reference Rabin, Burton and Barr2007). Reclaiming traditional and more meaningful validation terminology would offer hope that both novel and traditional assessment approaches would focus on true empirical validation (i.e., criterion validity), in place of subjective and untested impressions about the importance of test appearance invoked by the term EV.
Limitations
The present review has several limitations. Perhaps the most salient is the fact that for some articles our interpretation of the conceptualization of EV was based on somewhat subjective impressions of what the authors intended to communicate. Specifically, although a number of articles provided explicit statements about how EV was conceptualized, many were much less explicit. For such articles, the interpretation of what the authors intended to communicate could potentially vary somewhat from one reader to the next. To assuage this problem, all articles were read independently by two raters, and disagreements among raters were adjudicated via a discussion between at least two coauthors. Ultimately, there were no instances where discrepancies could not be resolved. Importantly, the first author (YS) participated in all such adjudications, assuring that the same set of principles was applied evenly to all decisions. Additionally, to ensure that we did not over-interpret vague statements about the concept of EV, 12 articles were coded as “unspecified” about how EV was conceptualized. Relatedly, our deductive approach imposed the notions of verisimilitude and veridicality, thereby potentially overlooking subtle nuances within those concepts. That said, it is unlikely that such subtle nuances could have been reliably coded for each article, and, if they could be coded, the results would undoubtedly demonstrate an even greater divergence of opinions about the conceptualization of EV. In other words, by taking a more molar approach (i.e., collapsing across subtle differences in conceptualization of verisimilitude and veridicality), we employed fairly conservative criteria for divergence of conceptualizations. Thus, it is noteworthy that even with such conservative approach gross differences in conceptualization of EV emerged. Lastly, along the same lines, it is possible that a different group of authors would arrive at a different classification scheme for journal type, test type, and study purpose. While we acknowledge this possibility, the current scheme is a result of extensive thoughtful discussions among all authors and is clearly and transparently outlined and reported in tables.
Another potential limitation is that we only examined articles that used the term EV in the context of novel, face-valid tests of EF. This decision was made for two reasons. First, it is in this literature where the term EV is applied most frequently and where calls to action have been made for the development of new, more “ecological” tests of EF (e.g., Burgess et al., Reference Burgess, Alderman, Forbes, Costello, Coates, Dawson, Anderson, Gilbert, Dumontheil and Channon2006; Spooner & Pachana, Reference Spooner and Pachana2006). Second, it is in this literature that the term EV is most likely to be conflated with face validity. Specifically, studies that carry out empirical examinations of EV of traditional tests of EF overwhelmingly use the term EV to imply the ability to predict functional outcome. This is understandable, since the absence of face validity of traditional tests is self-evident; thus, if EV were conceptualized as reflecting face validity, empirical examination would be irrelevant. In other words, such studies cannot be conflating EV with face validity, potentially rendering a review unnecessary. That said, it is still possible that such studies might conflate the term EV with other test characteristics, such as the ability to differentiate among groups. The present study has not addressed potential variability in how EV is conceptualized in that literature. Nevertheless, it is highly likely that inclusion of such literature would increase the number of studies that conceptualize EV as veridicality (i.e., prediction of functional outcome) alone, altering the percentages presented in the present review.
Additionally, our literature search did not include all databases. Relatedly, our search terms may have missed some articles that would have been relevant. That said, our review was quite comprehensive and included many articles not covered by the Pinto et al. (Reference Pinto, Dores, Peixoto and Barbosa2023) review; indeed, from among the 90 articles included in our review, only nine were also included in the Pinto et al. (Reference Pinto, Dores, Peixoto and Barbosa2023) review. This discrepancy between the two reviews is most likely a reflection of the fact that Pinto et al. (Reference Pinto, Dores, Peixoto and Barbosa2023) only reviewed articles that included the term EV in the article title. Indeed, in the present review, the majority of reviewed articles referred to EV in the abstract, key words, and the body of the article, without mentioning it in the title. Nevertheless, a yet larger sample of articles would increase statistical power, thereby potentially affording a better insight into factors that are associated with various EV conceptualizations.
Lastly, we do not offer or recommend a particular definition or operationalization of EV, since extensive discussions of EV as a construct can be found in multiple chapters of the Sbordone and Long (Reference Sbordone and Long1996) book, as well as in many articles and reviews published since then (e.g., Burgess et al., Reference Burgess, Alderman, Forbes, Costello, Coates, Dawson, Anderson, Gilbert, Dumontheil and Channon2006, Chaytor et al., Reference Chaytor, Schmitter-Edgecombe and Burr2006; Spitoni et al., Reference Spitoni, Aragonaa, Bevacqua, Cotugno and Antonucci2018). Additionally, our review was not intended to provide guidance on how to conduct validation research, since methodology and scientific rigor of the reviewed articles were not examined here. However, a detailed review of typical methodological pitfalls associated with ecological validation is provided in our separate systematic review (Suchy et al., Reference Suchy, Gereau Mora, DesRuisseaux, Niermeyer and Lipio Brothersin press), in which we recommend (a) clearly defining all terminology and steering away from the term EV unless absolutely necessary, (b) seeking convergence across multiple outcome measures, (c) controlling for relevant confounds, and (d) examining incremental validity. The latter point is particularly important for the determination of clinical utility, given that veridicality occurs on a continuum. In other words, it is not the presence or absence of veridicality that determines clinical utility, but rather the degree to which test scores predict functional outcomes above and beyond performances on other available instruments.
Conclusions
The present systematic review provides compelling evidence that the term EV is conceptualized highly inconsistently, at least in the literature on novel, face-valid or naturalistic, tests of EF. This inconsistent use is likely contributing to misconceptions about the utility of both traditional and novel instruments, potentially harming clinical practice. Specifically, despite empirical evidence to the contrary, the permeability among different EV conceptualizations leads to the impressions that (a) novel EF tests that appear like the real world can automatically be assumed to predict daily functioning, and (b) traditional tests of EF cannot possibly predict daily functioning due to their low face validity. While we strongly support the call put forth by Holleman et al. (Reference Holleman, Hooge, Kemner and Hessels2020) that editors and reviewers ensure that the usage of the term EV in publications be accompanied by clear definitions and operationalizations, the present review suggests that provision of a definition may simply not be enough to remedy the pervasive breakdown in communication. Therefore, we call upon our field to consider retiring the term EV and replacing it with traditional terminology, namely criterion validity, which, at least according to some authors, refers to the same concept (e.g., Larrabee, Reference Larrabee2015).
Financial support
None.
Competing interests
None.

















 Open access
Open access