


Introduction
Dans cet articleFootnote 1 , nous présentons une classification sémantique à gros grain des noms du français, fondée sur des tests linguistiques. Les entreprises de classification comportent, comme on le sait, des limites, qui tiennent notamment à la nécessaire discrétisation de phénomènes distribués sur un continuum. La classification des faits en extension peut poser problème, car elle requiert souvent une représentation rigidifiée de certaines propriétés. Les classifications présentent néanmoins l’intérêt de proposer une grille d’analyse qui permet d’appréhender les éléments à classer et d’identifier leurs propriétés distinctives. In fine, le recours aux catégories, si celles-ci sont envisagées en tant que pôles de classification, apparaît plus éclairant que problématique théoriquement. De fait, les travaux en linguistique font régulièrement appel aux classifications sémantiques, que ce soit à finalité directe ou indirecte (s’agissant de rendre compte de faits connexes, tels que les restrictions de sélection pesant sur les arguments d’un prédicat ou les opérations sémantiques associées à la construction morphologique).
Il existe dans la littérature des propositions de classification sémantique des noms en français (Gross Reference Gross1996, Flaux et Van de Velde Reference Flaux and Van de Velde2000, Huyghe Reference Huyghe2015), et certaines classes ont fait l’objet de travaux spécifiques (Balibar-Mrabti Reference Balibar-Mrabti1995, Van de Velde Reference Van de Velde1995, Godard et Jayez Reference Godard and Jayez1996, Grossmann et Tutin Reference Grossmann and Tutin2005, Haas et al. Reference Haas, Huyghe, Marín, Durand, Habert and Laks2008, Goossens Reference Goossens2009, Flaux et Stosic Reference Flaux, Stosic, de Saussure and Rihs2012, entre autres). L’identification des catégories distinguées n’est cependant pas toujours étayée par le recours à des tests linguistiques systématisés. Par ailleurs, la classification des lexèmes dans les travaux théoriques est rarement envisagée en extension, avec pour objectif une couverture lexicale complète ni basée sur une méthodologie de classification. Inversement, les ressources lexicales ou lexicographiques existantes proposent des descriptions couvrantes, mais les critères de classification sont rarement explicités. La description sémantique des noms repose souvent sur la seule évaluation référentielle, et donne l’impression de s’apparenter à un classement des objets du monde plutôt qu’à l’identification de propriétés linguistiques distinctives (cf. par exemple WordNet pour l’anglais, Petrolito et Bond Reference Petrolito, Bond, Orav, Fellbaum and Vossen2014).
Nous adoptons ici une approche distributionnaliste, en présupposant que les propriétés sémantiques d’une unité lexicale déterminent son environnement linguistique et que celui-ci peut en retour nous renseigner sur le sens des unités lexicales (Harris Reference Harris1954). Il faut noter toutefois que, considérés individuellement, tous les contextes d’emploi d’un mot ne sont pas également distinctifs et caractéristiques de ses particularités sémantiques. Les tests proposés dans ce travail reposent précisément sur la compatibilité avec des constructions propres à certaines catégories sémantiques. Ils suggèrent une hiérarchisation des contextes d’emploi selon le degré de spécificité sémantique que ceux-ci peuvent révéler. Le recours aux tests distributionnels vise un certain contrôle de la catégorisation, même s’il comporte lui aussi des limites avérées. Les tests impliquent, sinon une certaine normativité, tout au moins une évaluation intuitive des tendances d’emploi des unités testées, dont la fiabilité peut être questionnée. La consultation des corpus ainsi que la co-annotation permettent de limiter ce problème, mais aucun système de tests n’évitera l’existence de cas douteux ou exceptionnels, difficiles à analyser selon les critères proposés. Il reste qu’en dépit de ces imperfections, les tests distributionnels garantissent une assise linguistique à la classification sémantique, et constituent un apport indéniable à l’évaluation purement référentialiste. Il ne s’agit pas ici de disqualifier les conceptions référentielles du sens nominal, mais de les mettre en regard d’une certaine matérialité linguistique, permettant de guider l’analyse sémantique, et d’éviter que celle-ci ne soit cantonnée à une réflexion sur la nature des référents plutôt que sur celle des motsFootnote 2 .
L’objectif spécifique de cet article est d’exposer une typologie sémantique des noms et de proposer une méthode permettant leur annotation sémantique aussi bien en langue qu’en discours. Les tests proposés se fondent sur les propriétés sémantiques identifiées dans la littérature et s’inspirent des tests existants, avec certains amendements, ajouts et propositions nouvelles. Le travail présenté est un état de notre réflexion après plusieurs campagnes d’annotation lexicale réalisées dans le cadre de différents projets et études, en particulier du projet Nomage (Balvet et al. Reference Balvet, Barque, Condette, Haas, Huyghe, Marín and Merlo2011), de l’étude des noms morphologiquement simples (Tribout et al. Reference Tribout, Barque, Haas, Huyghe, Neveu, Blumenthal, Hriba, Gerstenberg, Meinschaefer and Prévost2014), et du projet FR-SemCor (Barque et al. Reference Barque, Haas, Huyghe, Tribout, Candito, Crabbé, Segonne and Calzolari2020).
L’article est organisé comme suit : dans la première section, nous présentons les principes généraux de classification ; dans la deuxième section, nous présentons les 14 classes simples retenues dans notre étude, avec les tests associés ; la troisième section recense les 7 classes complexes qui regroupent des noms sémantiquement hybrides (i.e. relevant conjointement de plusieurs types sémantiques) et les tests de co-prédication associés ; enfin, la quatrième section expose la méthode de classification.
1. Principes de classification
Nous commençons par présenter quelques éléments nécessaires à la bonne compréhension de la méthode proposée. Ceux-ci concernent l’emploi des termes désignant les classes de noms (section 1.1), le fonctionnement général des tests (section 1.2) et le traitement des noms à sens multiples (section 1.3).
1.1. Métalangue et langue ordinaire
Les étiquettes employées pour nommer les classes sont des objets métalinguistiques qui ne présupposent pas de cohérence avec l’emploi standard des termes. Ainsi, on désigne par « noms d’événement », « noms d’animé », « noms d’objet naturel », etc. des noms qui possèdent une série de traits linguistiques qui les fait appartenir aux classes commodément appelées événement, animé, objet naturel. Par exemple, les noms d’événement appartiennent à cette classe en vertu de leurs propriétés sémantiques (ce sont des noms abstraits qui dénotent des situations d’aspect dynamique), repérables par leur comportement distributionnel qui leur permet de valider les tests afférents à cette classe, et non en vertu de l’adéquation référentielle avec ce que nous appelons un “événement” dans la vie quotidienne. Ainsi, selon les tests appliqués, un nom comme réparation sera classé parmi les noms d’événement, alors qu’on ne se représente pas nécessairement une réparation comme un “événement” dans le sens courant du terme. Corollairement, les propriétés des substantifs employés métalinguistiquement pour nommer les catégories sémantiques ne nous renseignent pas sur les propriétés des noms qui instancient ces catégories. Afin d’éviter toute ambiguïté entre langue ordinaire et métalangue, les noms choisis pour nommer les classes sémantiques apparaissent dans le texte en petites capitales.
1.2. Fonctionnement des tests
La classification sémantique que nous proposons s’appuie sur les propriétés distributionnelles des noms mises en évidence par les tests, avec l’idée (i) que les différentes constructions sont sémantiquement révélatrices, et (ii) que certaines constructions sont fortement discriminantesFootnote 3 . La personne qui applique un test prend position sur son applicabilité pour une acception donnée d’un nom. Afin de limiter le recours à l’intuition des annotateurs, il est nécessaire de consulter de vastes corpus du français pour déterminer l’acceptabilité des phrases résultant de l’application des tests. Pour réaliser le travail que nous présentons ici, nous avons eu recours aux corpus frCow (Schäfer et Bildhauer Reference Schäfer, Bildhauer and Calzolari2012, Schäfer Reference Schäfer, Banski, Biber, Breiteneder, Kupietz, Längen and Witt2015), frTenTen12 et frTenTen17 (Jakubicek et alii Reference Jakubicek, Kilgarriff, Kovar, Rychly and Suchomel2013) qui ont été interrogés avec les outils d’exploration « SketchEngine » et « NoSketchEngine ». Il s’agit de corpus constitués d’extractions du Web (2016 pour FrCow ; 2012 et 2017 pour les corpus frTenTen) qui offrent l’avantage d’être très vastes (entre 6 et 10 milliards de mots selon le corpus). Notons que le recours aux corpus pour déterminer les acceptabilités est à la fois qualitatif (à travers une évaluation des exemples attestés) et quantitatif (le nombre d’exemples recueillis attestant de la représentativité de la distribution observée).
Les réponses possibles aux tests sont “oui” (o) ou “non” (n). Les tests proposés sont tous complexes, en ce sens qu’ils ne se résument pas à une tournure unique à appliquer au nom. Différentes constructions sont proposées et selon les cas, celles-ci doivent être vérifiées de manière conjointe ou disjointe. Un test conjonctif (marqué “ET”) est positif si le N testé peut entrer dans l’ensemble des constructions distributionnelles proposées. La conjonction permet que le test ne soit pas trop permissif et n’accepte que les noms de la classe visée. Un test disjonctif (marqué “OU”) est positif si le N testé peut entrer dans au moins l’une des tournures proposées. La disjonction permet d’augmenter la couverture de la classe.
1.3. Traitement des noms à sens multiples
On sait que les noms, notamment les plus fréquents (cf. Zipf Reference Zipf1949), sont susceptibles d’avoir plusieurs sens Footnote 4 . À titre indicatif, 74% des 10 000 noms les plus employés dans frWaC, un large corpus du Web français (1,3 milliard de mots collectés dans le domaine .fr en 2010), reçoivent plusieurs définitions dans le Wiktionnaire Footnote 5 . Toute entreprise de classification sémantique doit donc prendre en compte ce phénomène massif.
Parmi les noms à sens multiples, il convient de distinguer ceux dont les sens sont exclusifs les uns des autres (en cas d’homonymie ou de polysémie) de ceux qui ont des sens multiples compatibles entre eux, et que nous appellerons ici les noms sémantiquement hybrides Footnote 6 . Pour savoir si des sens associés à une même forme sont ou non compatibles, on recourt traditionnellement au test de la co-prédication (Cruse Reference Cruse1986, Godard et Jayez Reference Godard and Jayez1996, Asher et Pustejovsky Reference Asher and Pustejovsky2006, Asher Reference Asher2011, Murphy Reference Murphy2021, entre autres). Ce test consiste à appliquer à une même occurrence du nom testé deux prédicats ciblant chacun un sens différent. Si la co-prédication construite produit un effet zeugmatique, comme avec le nom bureau en (1c), alors les deux sens testés, celui de meuble en (1a) et celui de pièce de travail en (1b), sont incompatibles. Si au contraire la co-prédication est jugée naturelle, comme avec livre en (2c), c’est que les deux sens testés, celui de contenu informationnel en (2a) et de support physique en (2b), sont compatibles entre eux.

En termes de classification, les noms comme bureau relèveront d’autant de classes qu’ils ont de sens distincts et incompatibles entre eux, tandis que les noms hybrides comme livre relèveront de classes complexes, dont les plus fréquentes seront présentées en détail dans la section 3.
Soulignons enfin que le traitement des sens multiples dépend de la granularité de la classification. Plus les classes sont générales, plus le nombre de sens distincts par nom considéré diminue. Le nom domino, par exemple, peut dénoter une pièce d’un jeu (le joueur qui a le domino double le plus fort commence) ou une pièce utilisée en électricité (changer un domino sur une applique). Dans une classification purement ontologique et qui n’identifie qu’une seule classe générale pour les noms d’artefact, cette polysémie du nom domino n’apparaîtra pas. La classification que nous présentons ici s’appuie en effet sur des classes générales et laisse donc dans l’ombre des distinctions de sens qui peuvent être plus ou moins importantes, selon la visée de chaque étude. Ce choix est essentiellement guidé par des contraintes d’ordre pratique : l’objectif étant ici de pouvoir appliquer la classification à l’ensemble du lexique nominal du français, nous ne pouvons envisager un grain sémantique plus fin sans considérablement alourdir la description sémantique. Il est néanmoins possible d’appliquer dans un second temps la même méthodologie aux noms des classes générales, une fois identifiés les tests permettant d’en distinguer des sous-classes.
2. Définition des classes simples
Cette section est consacrée à la présentation des 14 classes simples de notre typologie. Les classes considérées sont logiquement complémentaires, c’est-à-dire qu’elles sont appréhendées selon un même principe de catégorisation. En l’occurrence, la classification que nous présentons est de type ontologique, et non relationnel, c’est-à-dire qu’elle repose sur une partition du réel de référence, et non sur la description des relations sémantiques impliquées par les noms. Les catégories envisagées sont par exemple celles de nom d’animé, nom d’artefact ou nom d’événement, et non celles de nom collectif, nom partitif ou nom relationnel, qui sont logiquement compatibles avec les premières, et qui doivent faire l’objet d’une identification et d’une typologie indépendantes (Huyghe Reference Huyghe2015).
Nous présenterons tout d’abord les classes de noms ayant en commun de dénoter des entités concrètes pourvues d’une étendue dans l’espace, à savoir les noms d’animé, d’artefact et d’objet naturel (section 2.1). Viendront ensuite les noms dénotant des situations, parmi lesquelles on distingue les situations dynamiques, regroupant les noms d’événement et ceux de domaine, des situations statives, regroupant les noms de propriété et ceux d’état (section 2.2). Nous listerons enfin les classes que l’on peut considérer comme secondaires en ce qu’elles constituent des cas intermédiaires vis-à-vis des classes fondamentales et/ou dont l’extension est plus restreinte : noms d’institution, de phénomène, d’objet cognitif, d’objet financier, de temps, de quantité et de maladie (section 2.3).
2.1. Les noms dénotant des entités
Linguistiquement, une première ligne de partage se fait entre les N d’entité et les autres types de N selon les critères conjoints de localisation et d’étendue spatiales, ce qui correspond à l’opposition concret vs abstrait, dans une conception possible de cette distinction (cf. Kleiber et Vuillaume Reference Kleiber and Vuillaume2011). En effet, les noms se répartissent entre ceux qui peuvent dénoter des entités localisables dans l’espace, ce qui se manifeste par la compatibilité avec les compléments de dimension et de mesure (cf. tests T1a et T1b), et ceux qui ne le peuvent pas. Les noms d’entité dénotent toutes sortes d’objets et d’êtres vivants et l’on trouve des tests linguistiques pour les discriminer dans Dowty (Reference Dowty1991), Godard et Jayez (Reference Godard and Jayez1996), Flaux et Van de Velde (Reference Flaux and Van de Velde2000), Huyghe (Reference Huyghe2009), Kleiber et al. (Reference Kleiber, Benninger, Biermann-Fischer, Gerhard-Krait, Lammert, Theissen and Vassiliadou2012), entre autres.
Afin de discriminer les noms d’entité des autres types de noms, il convient d’appliquer en premier lieu le test conjonctif T1 présenté ci-dessous. Il faut d’une part que le N entre dans la tournure T1a et, d’autre part, qu’il entre dans celle de T1b. On note que pour T1b, trois formulations sont proposées (b1, b2 ou b3). Elles ne correspondent pas à un choix ni à une disjonction, mais répondent à des besoins de formulation différents selon que le N à classer est comptable [T1-b1], massif [T1-b2] ou collectif [T1-b3] — concernant les N collectifs (Ncoll), nous retenons la définition qu’en donne Lammert : est dit collectif « un nom qui, au singulier, dénote une entité composée d’un regroupement d’éléments » (Lammert Reference Lammert2010 : 66–70).

Dans T1 comme dans l’ensemble des autres tests proposés, sauf mention contraire, l’étiquette Dét renvoie à un déterminant singulier d’interprétation spécifique tiré de la liste suivante : ce / cet / cette, le / la, un / une, du / de la. Dét.card est à un déterminant cardinal nécessairement pluriel (deux, trois, quinze, deux cents, etc.). En T1a, on n’acceptera pas n’importe quel complément de localisation, mais uniquement ceux qui dénotent des lieux physiques, et que l’on piochera de préférence dans la liste (3). En T1b, l’élément “mesure” correspond à une forme composée d’un déterminant cardinal et d’un nom dénotant une unité de mesure. On s’inspirera des exemples proposés en (4a) pour les N comptables, en (4b) pour les N massifs et en (4c) pour les N collectifs.

Des noms comme table (5), farine (6) ou archipel (7) valident bien le test conjonctif T1a et T1b. Tel n’est pas le cas en revanche du nom idée car d’une part, le complément de localisation dans (8a) ne dénote pas un lieu physique, et d’autre part la seconde partie du test n’est pas validée (8b).

Les noms qui valident T1 dénotent des entités concrètes et se partagent entre trois classes : (i) animé (ex. cerf), (ii) artefact (ex. table) et (iii) objet-naturel (ex. lac), que nous présentons dans les trois sous-sections ci-après.
2.1.1. Les noms d’animé
Les noms d’animé dénotent des vivants doués d’intentionnalité. Les vivants non doués d’intentionnalité (ex. bactérie, virus, fleur) sont dénotés par des noms d’objet-naturel (cf. 2.1.3). Les noms d’animé se distinguent des autres N concrets par la validation de T2. Ils décrivent des entités dotées d’une étendue spatiale et localisables dans l’espace physique [T1a et b], volitionnelles [T2a et b] et capables de s’alimenter [T2c].

Le nom cerf valide bien chaque élément du test, comme le montre (9).

2.1.2. Les noms d’artefact
Parmi les noms qui sont positifs à T1 et négatifs à T2, c’est-à-dire parmi les noms qui dénotent des choses non animées, il est linguistiquement pertinent de distinguer ceux qui décrivent des artefacts de ceux qui décrivent des objets naturels. Parmi les premiers, on peut lister les noms d’objet, comme table ou robe (10), les noms de document, comme page de garde (10), les noms de construction, comme pont (11) ou encore les noms de mets, comme gâteau et glace (12). Tous ces noms valident le test disjonctif T3 présenté ci-dessous.

En T3b, le complément de matière correspond à un syntagme prépositionnel introduit par la préposition en suivie d’un nom dénotant une matière ou un matériau (ex. en bois, en plastique). En T3c, le complément d’arôme correspond à un syntagme prépositionnel introduit par la préposition à suivie d’un article défini et d’un nom dénotant un arôme ou un parfum (ex. à la vanille, au rhum).

2.1.3. Les noms d’objet-naturel
Parmi les N concrets, certains dénotent des objets naturels qui ne sont ni des artefacts (puisque non fabriqués par l’homme) ni des animés (puisque non doués d’intentionnalité). Ces noms d’objet-naturel (obj-nat) décrivent des substances naturelles (ex. neige, sang, graphite), des organismes vivants sans intentionnalité (ex. plante, fleur, bactérie), ou des lieux naturels (ex. mont, plaine, lac, glacier). Ces noms valident T1 (13a-b), mais rejettent T2 (13c-d) et T3 (13e-f).

2.2. Les noms dénotant des situations
Il existe plusieurs classes de noms renvoyant à des situationsFootnote 11 , qui peuvent être d’aspect dynamique ou statif, et que nous présentons dans cette sectionFootnote 12 . Pour distinguer les classes en question, nous utilisons et aménageons certains tests classiques proposés dans les travaux existants (cf. Gross Reference Gross1981, Gross et Vivès Reference Gross and Vivès1986, Balibar-Mrabti Reference Balibar-Mrabti1990, Gross et Kiefer Reference Gross and Kiefer1995, Van de Velde Reference Van de Velde1995, Godard et Jayez Reference Godard and Jayez1996, Kiefer Reference Kiefer1998, Daladier Reference Daladier1999, Gaatone Reference Gaatone2004, Tutin et alii Reference Tutin, Novakova, Grossman and Cavalla2006, Beauseroy Reference Beauseroy2009, Haas Reference Haas2009, Huyghe Reference Huyghe2014, entre autres).
2.2.1. Les noms d’événement
Une classe importante est celle qui regroupe les noms dénotant des situations dynamiques, c’est-à-dire des situations dans lesquelles il se passe quelque chose, soit qu’un événement survient, soit qu’une action est réalisée. Ces noms relèvent tous de la classe événement, étiquette métalinguistique qui ne s’oppose pas ici à “action”, mais qui l’englobe. Les noms entrant dans cette classe valident le test T4 présenté ci-dessous.


2.2.2. Les noms de domaine
Les noms de domaine regroupent des noms qui dénotent des activités (jardinage) et des champs de connaissance (histoire), en vertu du fait que ces deux types de dénotation sont souvent inextricablement liés. On associe un domaine d’expertise aux activités, et des activités (physiques ou intellectuelles) à de nombreux domaines d’expertise. A minima, les noms de domaine vérifient T5a ou T5b, mais de nombreux noms peuvent valider ces deux tests conjointement.


Précisons que le verbe faire utilisé en T5a ne doit avoir ni le sens de ‘fabriquer/confectionner’, ni celui de ‘avoir’. Ainsi, les noms purée (18) ou eczéma (19) ne sont pas des noms de domaine, mais respectivement un nom d’artefact (cf. supra section 2.1.2) et un nom de maladie (cf. infra section 2.3.7)
Si nous présentons les noms de domaine dans la partie consacrée aux situations, c’est d’une part parce que ces noms rejettent les tests propres aux N concrets (T1 à T3), tout comme ceux spécifiques des classes secondaires (cf. infra section 2.3), et d’autre part parce qu’une partie des noms de cette classe sont aspectuellement analysables comme dynamiques. Les noms tels que jardinage, natation, musculation, patinage peuvent être analysés comme relevant de la classe aspectuelle des « activités Footnote 13 » (cf. Van de Velde Reference Van de Velde1995, Haas et Huyghe Reference Haas and Huyghe2010). Ils sont dynamiques en vertu même de leur compatibilité avec T5a, faire du étant connue comme structure permettant de mettre en évidence le trait de dynamicité dans le domaine nominal (cf. Giry-Schneider Reference Giry-Schneider1978 et Reference Giry-Schneider1987, Van de Velde Reference Van de Velde1997, Vigier Reference Vigier2003, Heyd et Knittel Reference Heyd and Knittel2009). Ces noms étant fondamentalement massifs, ils valident T5a (20), mais ne vérifient pas les tests proposés pour la classe événement (21–22), qui conviennent strictement aux noms comptables (Huyghe Reference Huyghe2011).

Cela justifie l’existence de la classe des noms de domaine, distincte de celle des événement mais incluse dans les noms dénotant des situations.
2.2.3. Les noms de propriété
Parmi les situations statives, qui rejettent à la fois les tests de dynamicité T4 et T5a, on distingue la classe des N de propriété et celle des N d’état (cf. infra, section 2.2.4). Cette distinction s’apparente à l’opposition entre “individual-level predicate” (ILP) et “stage-level predicate” (SLP) (Carlson Reference Carlson1977) qui sépare les propriétés structurelles, considérées comme inhérentes et non soumises au temps, des propriétés transitoires, considérées comme contingentes et extrinsèquesFootnote 14 . Les noms de propriété, qui correspondent aux ILP et expriment des propriétés essentielles, sont identifiés par le test disjonctif T6 présenté ci-dessous.


Notons que T6a, si le sujet est un animé, doit être paraphrasable par « avoir du N », comme c’est le cas dans (27), ce qui permet d’exclure des noms comme famille ou aide. Ces derniers peuvent en effet être insérés dans la tournure T6a, mais les phrases résultantes ne sont pas synonymes de la construction en avoir (28).

2.2.4. Les noms d’état
Les noms d’état correspondent aux SLP, et vérifient le test disjonctif T7. Ces noms décrivent des situations transitoires (psychologiques ou matérielles) dans lesquelles peuvent se trouver des entités animées (29) ou non animées (30).
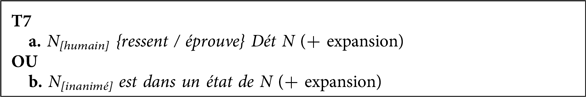
2.3. Les classes secondaires
Dans cette section, sont regroupées 7 classes de noms dont le comportement linguistique est original et suffisamment distinct de celui des classes principales (noms d’entité et noms de situation) pour constituer des classes sémantiques autonomes. Certaines de ces classes ont également une extension plus restreinte que celles dénotant des entités ou des situations. Ces classes, bien que relevant d’un grain sémantique plus fin que les classes précédentes, n’entretiennent pas avec elles de rapport hiérarchique inclusif et n’en constituent donc pas des sous-classes.
2.3.1. Les noms d’institution
Les noms d’institution, qui ont fait l’objet d’une attention particulière dans le cadre des études portant sur les entités nommées (Ehrmann Reference Ehrmann2008, Grouin et al. Reference Grouin, Rosset, Zweigenbaum, Fort, Galibert, Quintard, Ide, Meyers, Pradhan and Tomanek2011, entre autres), sont des noms dénotant des organismes, des commerces, des organisations politiques, administratives, scolaires, financières ou associatives. La validation du test disjonctif T8 permet de les identifier.

Les noms d’institution ont en commun avec les noms d’animé de valider les tests d’intentionnalité T2a et T2b (33). En revanche, ils ne valident pas T2c qui renvoie à la capacité de manducation propre aux animés (34).

2.3.2. Les noms de phénomène
Les noms de phénomène décrivent des référents accessibles aux sens, mais qui ne semblent se réduire ni à des objets ni à des événements. Ils dénotent plus précisément des odeurs (ex. fragrance), des sons (ex. cliquetis) ou des phénomènes lumineux (ex. lueur), et valident l’une des paires de tests présentées en T9a, T9b ou T9c.

Les noms de phénomène ne dénotent ni des entités matérielles, comme le montre le rejet de T1 en (35a), ni des situations dynamiques, comme le montre le rejet de T4 en (35b). Les phénomènes sonores valident T9a (36), les phénomènes lumineux valident T9b (37) et les phénomènes olfactifs valident T9c (38) Footnote 15 .

2.3.3. Les noms d’objet-cognitif
Les N d’objet-cognitif (obj-cog) dénotent des contenus informationnels (ex. idée, hypothèse). Ils sont aussi appelés “objets informationnels” (Godard et Jayez Reference Godard and Jayez1996), et correspondent à une partie de ce que Flaux et Stosic (Reference Flaux, Stosic, Goes, Lachet and Masset2014) appellent des “noms d’idéalités concrètes”. Les trois tournures proposées en T10 permettent, puisque leur emploi est disjonctif, de rassembler au sein de la classe des N d’objet-cognitif des noms couvrant un spectre sémantique varié, incluant notamment des noms en lien avec des V d’action (affirmer – affirmation, délirer – délire), des objets textuels (poème), culturels et artistiques (pièce de théâtre, chanson), des noms exprimant un jugement (évidence), etc.


Les N d’objet-cognitif ont un comportement particulier du point de vue de la localisation spatiale, ce qui est visible dans les exemples proposés par Godard et Jayez (Reference Godard and Jayez1996). Une phrase comme Cette idée se trouve déjà dans le Gorgias (Godard et Jayez Reference Godard and Jayez1996 : 44) indique certes la localisation d’un objet informationnel (idée), mais à l’aide d’un repère qui est lui-même un objet cognitif (le Gorgias), ce qui pose un problème de circularité. Le test de localisation T1 (cf. supra, section 2.1) évite cet écueil puisqu’il est très contraint et oblige à ce que le complément de localisation soit clairement physique.
2.3.4. Les noms d’objet-financier
Les noms d’objet-financier (obj-fin) regroupent des noms comme les noms de monnaie (ex. euro, dollar), mais aussi les noms dénotant des valeurs financières ou des sommes d’argent (ex. tarif, salaire). Les noms de cette classe valident le test disjonctif T11 (42)–(44).


Les noms d’objet-financier ont en commun de référer à une valeur (soit ils sont porteurs d’une valeur, comme versement ou euro, soit ils fixent une valeur, comme tarif ou taux). Les noms de monnaie, inclus dans la classe des objets financiers en raison de leur sème ‘valeur’ sont à la fois des artefacts par métonymie (j’ai un euro dans ma poche) et des objets virtuels dotés d’une valeur (l’euro a encore perdu de sa valeur)Footnote 16 . Ils forment une classe restreinte, mais spécifique, qui valide la paire de tests T11c1-c2.
2.3.5. Les noms de temps
Les noms entrant dans cette classe ne sont pas tous ceux qui ont pu être repérés comme « noms de temps » dans la littérature (Berthonneau Reference Berthonneau1989), mais uniquement ceux dénotant des segments temporels (ponctuels ou duratifs), identifiables grâce au test T12. La description de l’étendue temporelle constitue dans le sémantisme de ces noms un trait central, voire unique, ce qui les distingue notamment des noms qui dénotent des événements duratifs (ex. promenade, réunion, concert).


2.3.6. Les noms de quantité
Les N de quantité dénotent des unités de mesure (ex. kilo), qui valident la paire de tests T13-a1 et T13-a2 (47). La classe contient également d’autres noms tels que les noms dénotant des quantités contenues dans des récipients (ex. bol (de riz), assiette (de soupe)), certains événements météorologiques employés métaphoriquement (ex. avalanche (de mails)), ou encore des noms collectifs (ex. forêt (de symboles), cf. Benninger Reference Benninger1999), qui ont tous en commun de permettre une quantification et qui valident T13-b (48).


2.3.7. Les noms de maladie
Les noms de maladie dénotent les maux que peuvent subir les animés (Labelle Reference Labelle1986). Ces noms ont un comportement linguistique singulier qui se manifeste dans leurs propriétés distributionnelles, et qui peuvent servir de test T14.


La conjonction des trois structures en T14 permet d’éviter l’extension de la classe des N de maladie que pourrait causer l’interprétation métaphorique de la tournure T14a, telle qu’en (50a). Le nom honte, qui valide apparemment T14a, mais en aucun cas T14b et T14c, ne sera pas classé parmi les noms de maladie, mais parmi les noms d’état (ressentir de la honte).

2.5. Récapitulatif pour l’identification des 14 classes simples
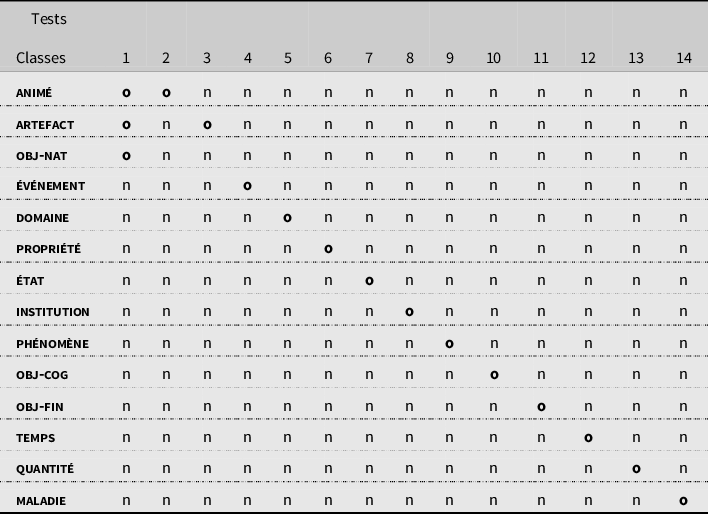
Dans le tableau 1 est récapitulé l’ensemble des 14 classes sémantiques simples présentées ci-dessus et des 14 tests permettant de les identifier. Pour des raisons de présentation, les tests ne sont évoqués que par leur numéro — à toutes fins pratiques, l’ensemble des tests est regroupé en annexe sous forme d’une liste. Nous rappelons que “valider un test” signifie bien entrer dans l’une des tournures proposées pour ledit test (test disjonctif) ou entrer dans l’ensemble des tournures requises (test conjonctif). Pour déterminer la classe simple d’un N, il convient que celui-ci valide le (ou les) tests propres à cette classe (marqués “o”), mais aussi qu’il rejette les tests marqués “n”. Si un N se comporte autrement, alors soit il est polysémique (et il convient de faire passer les tests aux différents sens discriminés en amont), soit il relève d’une classe complexe (cf. section suivante).
Tableau 1 : Classes sémantiques simples et tests identificatoires
3. Définition des classes complexes
Nous présentons dans cette section les sept classes complexes observées pour les noms hybrides du français Footnote 17 . Pour rappel, ces classes regroupent des noms qui ont la propriété d’avoir des sens distincts, mais compatibles (voir supra, section 1.3). Le nom télégramme, par exemple, relève de la classe complexe artefact*objet-cognitif, puisque ses deux sens de support physique (artefact) et de contenu (objet-cognitif) sont compatibles entre eux, comme l’indique une co-prédication telle que (51).
Notons que les tests proposés pour identifier les noms relevant d’une classe complexe sont plus souples que ceux permettant d’évaluer l’appartenance du nom testé à l’une et à l’autre des classes simples formant la classe complexe. On sait en effet que les propriétés de la co-prédication, notamment l’ordre et la nature des prédicats convoqués d’une part, et la nature et la relation entre les deux sens en jeu d’autre part, ont des effets sur le degré d’acceptabilité des phrases construites (Kleiber Reference Kleiber, Kleiber and Riegel1996, Cruse Reference Cruse2004, Gotham Reference Gotham2017, Asher Reference Asher2011, Ortega-Andrés et Vicente Reference Ortega-Andrés and Vicente2019, Murphy Reference Murphy2021, entre autres). Ces variations d’acceptabilité peuvent conduire, pour un même nom, à des analyses contradictoires selon la forme de co-prédication utilisée. Il suffira donc ici que le nom testé puisse entrer dans une occurrence au moins de co-prédication mettant en jeu un prédicat typique de la première classe et un prédicat typique de la seconde classe pour être analysé comme relevant de la classe complexe.
3.1. Les noms hybrides de la classe artefact*objet-cognitif
Les noms de cette classe, qui dénotent conjointement un contenu informationnel et son support physique, ont été largement décrits dans la littérature sur les types complexes (Cruse Reference Cruse, Dizier and Viegas1995 et Reference Cruse, Beckmann, König and Wolf2000, Ortega-Andrés et Vicente Reference Ortega-Andrés and Vicente2019, entre autres). Comme le nom livre, emblématique de cette classe, des noms comme tract, manuscrit et rapport peuvent entrer dans une co-prédication impliquant un prédicat typique de la facette artefact et un prédicat typique de la facette objet-cognitif (52).

3.2. Les noms hybrides de la classe artefact*institution
Les noms dénotant des institutions renvoient à des concepts plus ou moins complexes, qui incluent le plus souvent le bâtiment qui abrite l’institution (53a) et les différents groupes d’individus qui œuvrent en son sein (53b), parmi d’autres sens possibles selon le type d’institution en jeu (Arapinis et Vieu Reference Arapinis and Vieu2015, Ortega-Andrés et Vicente Reference Ortega-Andrés and Vicente2019). Le sens d’institution est compatible avec celui d’artefact, comme l’indique la co-prédication en (54). La compatibilité avec le sens d’animé collectif nous semblant plus sujette à caution (55), nous ne postulons pas ici de classe complexe animé*institution.

3.3. Les noms hybrides de la classe événement*état
Les noms de cette classe complexe dénotent un type d’action incluant une phase dynamique suivie d’un état résultant, ce qui correspond, d’un point de vue aspectuel, à des achèvements ou des accomplissements “gauches” (Piñón Reference Piñón, Lawson and Cho1997, Apothéloz Reference Apothéloz2008, Fradin Reference Fradin2011, Haas et Jugnet Reference Haas and Jugnet2013). Dans le test de co-prédication en (56a), la première prédication pointe la facette événement tandis que la facette état est identifiée par un prédicat de durée qui doit porter sur l’état résultant, et non sur l’événement (Piñón Reference Piñón, Bird, Carnie, Haugen and Norquest1999). Dans le cas de disparition en (56b), c’est bien l’absence de la personne qui dure deux semaines et non le passage de l’état présent à l’état absent. Il en va de même pour emprisonnement : les deux semaines ne s’appliquent pas à la durée de l’action d’emprisonner, mais bien à la durée de la détention.

3.4. Les noms hybrides de la classe événement*objet-cognitif
Les noms de cette classe dénotent conjointement un acte, souvent communicationnel, et le contenu informationnel associé à cet acte (Godard et Jayez Reference Godard and Jayez1996, Milicevic et Polguère Reference Milicevic, Polguère, Neveu, Muni Toke, Klingler, Durand, Mondada and Prévost2010). Le caractère hybride des noms comme déposition, témoignage ou traduction s’observe dans des structures co-prédicatives telles que celle présentée en (57), où le premier prédicat pointe la facette objet-cognitif et le second la facette événement.

3.5. Les noms hybrides de la classe événement*objet-financier
Les noms hybrides de cette classe complexe dénotent conjointement une action impliquant un transfert d’argent et la somme transférée. La co-prédication en (58a) indique que ces deux sens sont compatibles pour les noms testés en (58b).
3.6. Les noms hybrides de la classe événement*phénomène
On classe parmi les noms de phénomène les noms dénotant des odeurs (ex. parfum), des sons (ex. note) ou encore des éléments visuels (ex. lumière). À côté de cette classe de noms de phénomènes purs, il existe une classe de noms hybrides présentant une facette phénomène et une facette événement (Cance et Dubois Reference Cance and Dubois2005 : 22 ; David Reference David2000 : 65). La compatibilité des deux facettes est illustrée dans les co-prédications en (59).

3.7. Les noms hybrides de la classe événement*objet-naturel
On peut mentionner enfin la classe des noms hybrides dénotant conjointement un événement naturel et les conséquences physiques de cet événement, qui prennent la forme d’un objet naturel. Les co-prédications en (60) illustrent la facette dynamique et la facette d’entité concrète naturelle de noms comme lésion et éboulement.

4. Méthode de classification
Nous présentons ici la méthode adoptée pour classer les noms du français dans une ou plusieurs des classes sémantiques simples ou complexes qui viennent d’être décrites. Cette méthode peut, rappelons-le, s’appliquer aussi bien en langue qu’en discours. Elle peut ainsi être utilisée pour classer les différents sens lexicalisés d’un nom ou pour classer des occurrences de ce nom en corpus. Dans les deux cas, il s’agit bien de classer des formes lexicales spécifiées sémantiquement, ce qui implique que l’identification du sens en jeu ait été opérée en amont.
4.1. Arbre de décision
La méthode de classification consiste à appliquer successivement à un nom, pris dans l’un de ses sens s’il en a plusieurs, les tests permettant d’identifier la classe sémantique à laquelle il appartientFootnote 18 . L’ordre dans lequel ces tests doivent être appliqués est représenté dans l’arbre de décision dans la figure 1 ci-après.
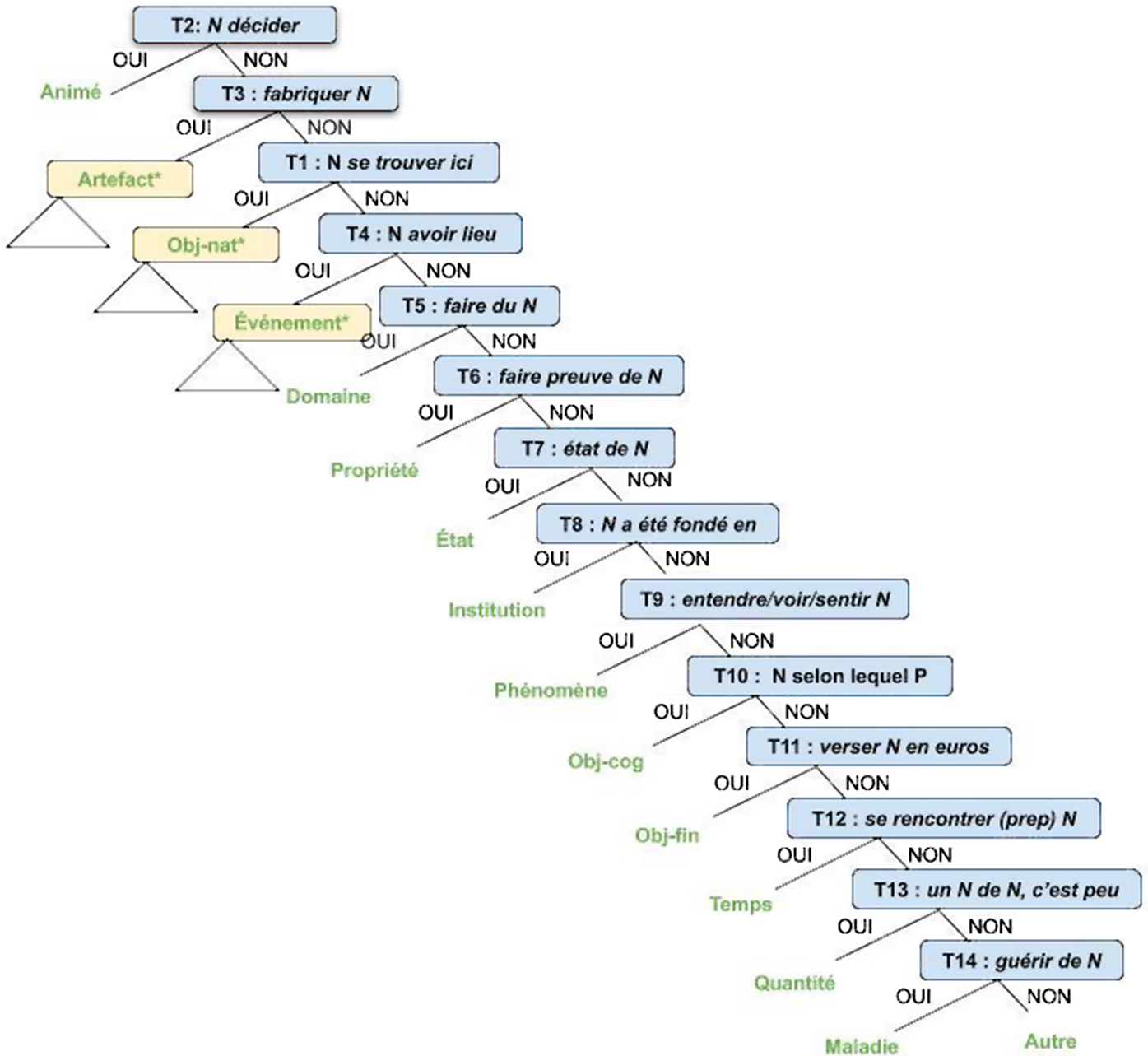
Figure 1: Arbre de décision pour la classification.
Les feuilles de l’arbre de décision correspondent aux différentes classes sémantiques retenues. Les nœuds, quant à eux, correspondent soit à l’application d’un test (nœuds bleus) soit à l’identification d’une classe pouvant entrer dans la composition d’une classe complexe (nœuds jaunes) et devant faire l’objet d’une étape d’analyse supplémentaire (cf. infra).
L’arbre est construit de manière à respecter l’ordre d’importance des classes (on teste en premier l’appartenance aux classes les plus fréquentes) et de manière à ce qu’à chaque nœud, la réponse “oui” au test conduise le plus directement possible à la classification du nom testé. C’est pourquoi le premier nœud de l’arbre ne correspond pas au test T1, commun aux trois classes animé, artefact et obj-naturel, mais au test T2, qui distingue uniquement la classe animé des autres classes.
La classification proposée a pour ambition de couvrir entièrement le lexique nominal français, cependant, il est inévitable que certains N, qui ne répondent positivement à aucun test, demeurent sans étiquette (cf. feuille “autre” en bas de l’arbre).
4.2. Classification des N relevant de classes complexes
En cas de réponse positive à un test, la classification du nom n’est directe que pour les classes qui ne sont pas suivies d’un astérisque. Celles qui le sont, artefact*, objet-naturel* et événement*, sont celles susceptibles d’entrer dans la composition d’une classe complexe (cf. supra, section 3). La figure 2 détaille les trois sous-arbres concernés.
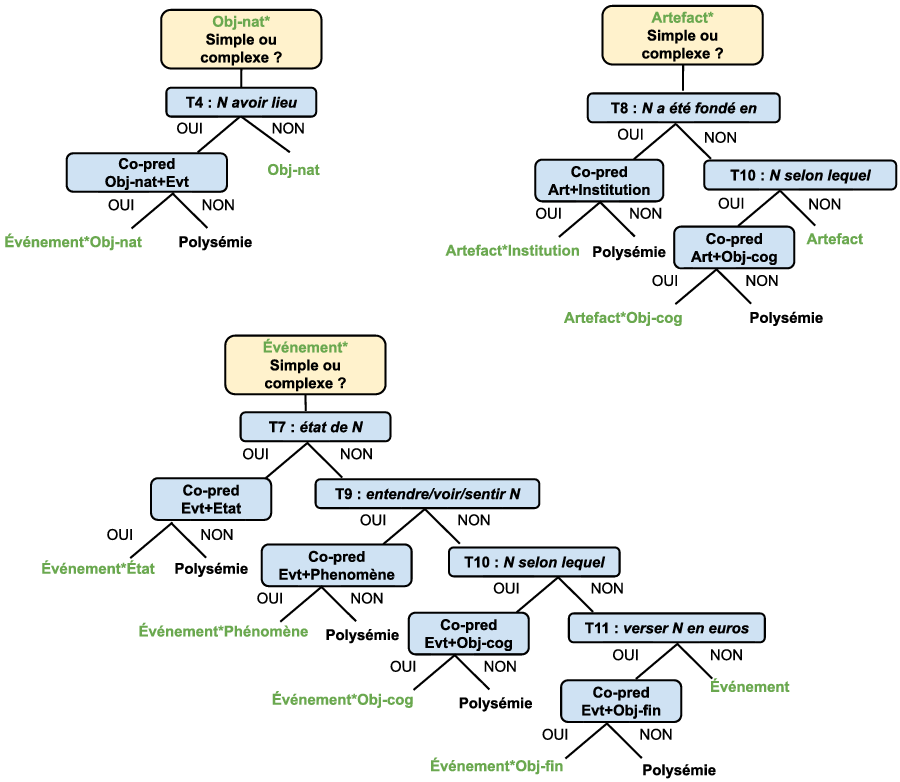
Figure 2: Sous-arbres pour l’identification des classes complexes.
La démarche, qui consiste à évaluer si le nom testé appartient à la classe simple ou à l’une des classes complexes associées, est la même dans les trois sous-arbres. On évalue tout d’abord si le nom valide le test révélant l’appartenance à l’autre classe constitutive de la classe complexe. Par exemple, dans le sous-arbre objet-naturel*, auquel on accède quand un nom a passé le test révélateur de la classe objet-naturel, on évalue au moyen de T4 si le nom en cours d’analyse est aussi de type événement, puisqu’il existe une classe complexe événement*objet-naturel (ex. éboulement). Le cas échéant, on construit une co-prédication pour déterminer si les deux sens sont compatibles ou non. Si le nom entre dans une co-prédication, il est rangé dans la classe complexe. Si au contraire, on ne trouve pas de co-prédication naturelle, on doit considérer que la forme testée est en fait polysémique, et prendre position sur le sens lexical en cours d’analyse. Enfin, si le nom ne passe aucun test révélateur de l’autre classe formant la classe complexe, il est rangé dans la classe simple.
4.3. Exemples d’application de la méthode de classification
Les principaux éléments de la méthode de classification ayant été exposés, prenons deux exemples d’application : les noms étoile et discussion considérés dans leurs emplois en (61).

Le nom étoile est très polysémique (il peut dénoter, entre autres, un astre, une forme, une distinction, une personne), mais c’est dans son sens premier de corps céleste qu’il est employé en (61a) et c’est donc dans ce sens uniquement qu’il sera considéré ici. La réponse “non” au premier test appliqué (? L’étoile a décidé de se diriger vers le soleil) nous conduit à l’application du test suivant, qui donne lui aussi une réponse négative (? Il a fabriqué une étoile proche du soleil). Le test suivant, en revanche, s’applique bien au sens d’étoile considéré (L’étoile se trouve à plusieurs années-lumière du soleil et une étoile d’un million de kilomètres de diamètre), plaçant le nom dans la classe des noms d’objet-naturel.
Considérons maintenant le nom discussion en (61b). L’application des trois premiers tests (T2, puis T3, puis T1) conduit chaque fois à une réponse négative, indiquant que le nom ne dénote pas une entité concrète. Le nom répond en revanche positivement au test de dynamicité (la discussion a eu lieu dans son bureau), conduisant au nœud Événement * dans l’arbre. Il faut alors déterminer si discussion appartient à la classe simple des événement ou s’il appartient à une classe complexe impliquant le type événement (cf. supra figure 2). On applique successivement le test disjonctif de stativité (T7), que le nom testé ne valide pas (? Pierre ressent de la discussion ou ? Pierre est dans un état de discussion), puis T9, qui n’est pas valide non plus (? On a entendu une discussion tonitruante / Une discussion a retenti dans la cour), puis T10, qui indique que discussion dénote également un objet-cognitif (Il écoute les discussions décousues des convives). Le nom pouvant enfin entrer dans une co-prédication (il a écouté les discussions intéressantes qui ont eu lieu à l’issue de la rencontre), on considérera qu’il relève de la classe complexe événement*objet-cognitif.
Conclusion
Nous avons présenté dans cet article une typologie sémantique à gros grain, visant à couvrir l’ensemble des noms du français, et une méthode de classification de ces noms fondée sur l’application systématique de tests linguistiques. La typologie proposée est constituée de 14 classes simples et de 7 classes complexes, exclusives les unes des autres. La prise en compte des classes complexes, qui n’avait à notre connaissance pas fait jusqu’ici l’objet d’un recensement pour les noms du français, permet de distinguer clairement les différents cas de sens multiples dans le domaine nominal. Les noms homonymiques et polysémiques relèvent d’autant de classes qu’ils ont de sens en langue tandis que les noms hybrides, qui ont des sens distincts, mais compatibles, relèvent de classes complexes.
La méthode de classification proposée repose de manière cruciale sur l’utilisation de tests linguistiques. Inspirés pour la plupart de travaux existants, ils ont été repensés et amendés pour convenir à notre approche de classification générale des noms du français. Pour être révélateur d’une classe sémantique de noms et seulement d’elle, chaque test a été défini avec soin, illustré systématiquement et ses éventuelles contraintes d’utilisation (types de compléments à utiliser, types de déterminants, etc.) ont été explicitées chaque fois que nécessaire. Nous avons conscience du caractère potentiellement rigide de ces tests, qui peuvent laisser en dehors de l’analyse certains noms, notamment ceux apparaissant de manière plus naturelle avec des prédicats qui ne correspondent pas à ceux retenus pour les tests. Il est néanmoins possible, selon la visée de l’étude menée, de remodeler un test pour l’élargir ou au contraire le restreindre davantage, tout en gardant à l’esprit la nécessité d’évaluer dans de vastes corpus les implications de ces éventuels changements.
Nous espérons que le résultat de ce travail, issu de notre expérience acquise au fil de différentes campagnes d’annotation des noms du français, pourra s’avérer utile aux linguistes devant recourir à la classification sémantique pour toute étude ayant trait au lexique (sémantique, morphologie, micro-syntaxe)Footnote 19 . L’objectif essentiel était pour nous de proposer un mode de classification proprement linguistique, accessible aux non-spécialistes, et empiriquement exploitable à grande échelle.
Competing interests
The authors declare none.
Déclaration de conflit d’intérêts
Les auteur·es déclarent que cette étude a été menée indépendamment de toute relation commerciale ou financière qui pourrait constituer un potentiel conflit d’intérêts.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
ANNEXES : liste des tests
T1→ T1a ET T1b (sous la forme b1, b2 ou b3)
a. Dét N se trouve + complément de localisation spatiale
ET
b1. Dét N de + mesure [pour les N comptables]
b2. mesure + de N [pour les N massifs]
b3. Dét N de Dét.card N 2 [pour les N collectifs]
T2 → T2a ET T2b ET T2c
a. Dét N {décide / choisit} de SV
ET
b. Dét N + SV {volontairement / délibérément / consciemment}
ET
c. Dét N a beaucoup mangé
T3→ T3a OU T3b OU T3c
a N [humain] a {fabriqué / déchiré} Dét N {à tel endroit / à tel moment}
OU
b. N [humain] a construit Dét N + Compl de matière + Adj de couleur
OU
c. N [humain] a confectionné Dét N + Compl d’arôme
T4→ T4a OU T4b
a. Dét N {a eu lieu / s’est produit} {à tel moment / à tel endroit}
OU
b. N [humain] {a procédé à / a accompli / a effectué} Dét N (+ expansion facultative)
T5→ T5a OU T5b
a. N [humain] fait {du / de la} N
OU
b. N [humain] a reçu une formation dans le domaine {du / de la} N
T6 →T6a OU T6b OU T6c
a. N 0 est d’un(e) grand(e) N
OU
b. N [humain] a fait preuve {de N / d’un(e) N + expansion}
OU
c. Cela m’a altéré Dét N
T7→ T7a OU T7b
a. N [humain] {ressent / éprouve} Dét N (+expansion)
OU
b. N [inanimé] est dans un état de N (+expansion)
T8 → T8a OU T8b
a. Dét N a été fondé en telle année
OU
b. N [humain] a été nommé à la tête de (Dét) N
T9 → (T9-a1&a2) OU (T9-b1&b2) OU (T9-c1&c2)
a1. On a entendu un N (tonitruant / strident / mélodieux / aigu / grave)
& a2. Un N (a retenti / a résonné / s’est propagé) (au fond du couloir / dans la cour)
OU
b1. On a vu un N (aveuglant / éblouissant / blafard / pâle)
& b2. Det N (a resplendi / s’est propagé / a scintillé / a jailli) au fond du couloir
OU
c1. On a senti un N (nauséabond / âcre / enivrant / tenace / entêtant)
& c2. Det N (s’est répandu / persiste / embaume) (dans) la pièce
T10 → T10a OU T10b OU T10c
a. Dét N selon lequel P est difficile à admettre
OU
b. N [humain] écoute Dét [plur] N décousus de Vincent
OU
c. N [humain] a écrit Dét N {intéressant / pertinent}
T11 → T11a OU T11b OU (T11-b1 & T11-b2)
a. Il a versé Dét N en euros
OU
b. Il a obtenu Dét [indef, sing] N modique
OU
c1. Dét N est la monnaie de tel pays
& c2. Quel est le taux de change de Dét N ?
T12 → T12a OU T12b
a. Ils se sont rencontrés {N / courant N / Dét N / Dét.card N durant / à N}
OU
b. Attendez Dét [indef, sing] bref N
T13 → (T13-a1 & T13-a2) OU T13b
a1. Dét {courant / poids / lumière / intensité / tension / distance / période / vitesse} de Dét.card N, c’est {peu / beaucoup}
& a2. Dét N 0 {mesure / fait / pèse / dure} Dét.card N
OU
b. Dét N de N 2 , c’est (peu / beaucoup).
où N2 appartient à la liste : farine, huile, sable, messages, images, cheminées, projectiles, juristes
T14 → T14a ET T14b ET T14c
a. Dét N {est / n’est pas} une maladie contagieuse
ET
b. N [humain] a guéri de Dét N
ET
c. Le médecin m’a diagnostiqué Dét [indef, sing] N




 Open access
Open access