



1. Introduction
Since Taylor introduced the notion of turbulent diffusion in the 1920s (Taylor Reference Taylor1922), a wide variety of stochastic models have been proposed to represent the dynamics of particles in turbulent flows (e.g. Thomson Reference Thomson1987; Rodean Reference Rodean1996; Majda & Kramer Reference Majda and Kramer1999; Berloff & McWilliams Reference Berloff and McWilliams2002). The Brownian dynamics used by Taylor models Lagrangian velocities as white noise processes and is a good approximation only on sufficiently long time scales. More complex models incorporate temporal and/or spatial correlation (e.g. Griffa Reference Griffa1996; Pasquero, Provenzale & Babiano Reference Pasquero, Provenzale and Babiano2001; Lilly et al. Reference Lilly, Sykulski, Early and Olhede2017). For example, Langevin dynamics incorporates autocorrelation in Lagrangian velocities by representing them as Ornstein–Uhlenbeck processes (Uhlenbeck & Ornstein Reference Uhlenbeck and Ornstein1930). It is in general unclear when such additional complexity leads to improved predictions rather than to overfitting. Given the increased difficulty and cost of implementing more complex models, a method for comparing the performance of competing stochastic models for particle dynamics is needed.
To this end, we propose a data-driven approach: we apply Bayesian model comparison (BMC) (Kass & Raftery Reference Kass and Raftery1995; Jaynes Reference Jaynes2003; MacKay Reference MacKay2003), which assigns probabilities to competing models based on their ability to explain observed data. We focus on the comparison between the Brownian and Langevin models for particles in two-dimensional homogeneous isotropic turbulence, with data that consist of sequences of particle positions obtained from simulated Lagrangian trajectories. While this set-up is highly idealised, the methodology developed is applicable to more complex flows and models of particle dynamics.
Model comparison is complicated by two issues: (i) proposed models typically contain a number of parameters whose values are uncertain, and (ii) a measure of model suitability is required, balancing accuracy and complexity. The natural language for this problem is then that of decision theory (see e.g. Bernardo & Smith (Reference Bernardo and Smith1994) and Robert (Reference Robert2007) for an overview of decision problems under uncertainty); however, several philosophical issues therein, such as the choice of utility function and its subjectivity, can be avoided by adopting the ready-made approach of BMC. BMC and the related technique Bayesian model averaging are gaining popularity in many applied fields (Min, Simonis & Hense Reference Min, Simonis and Hense2007; Mann Reference Mann2011; Carson et al. Reference Carson, Crucifix, Preston and Wilkinson2018; Mark et al. Reference Mark, Metzner, Lautscham, Strissel, Strick and Fabry2018). In this paper, we demonstrate the potential of BMC by comparing the Brownian and Langevin models of dispersion in two-dimensional turbulence. This provides a simple illustration of the BMC methodology while addressing a problem of interest: dispersion in two-dimensional turbulence has received much attention as a paradigm for transport and mixing in stratified, planetary-scale geophysical flows (Provenzale, Babiano & Villone Reference Provenzale, Babiano and Villone1995), and can be modelled with stochastic processes (e.g. Pasquero et al. Reference Pasquero, Provenzale and Babiano2001; Lilly et al. Reference Lilly, Sykulski, Early and Olhede2017).
The paper is structured as follows. We introduce the Brownian and Langevin models in § 2 and review the BMC method in § 3. In § 4 we show how this method can be applied to discrete particle trajectory data; we also show results of a test case, where the data are generated by the Langevin model itself. In § 5 we apply BMC to data from direct numerical simulations of two-dimensional turbulence. In § 6 we give our conclusions on the method.
2. Models and data
2.1. Brownian and Langevin models
The models of interest are the Brownian model, which for passive particles in homogeneous and isotropic turbulence is given by
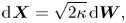 \begin{equation} \text{d}\kern0.06em \boldsymbol{X} = \sqrt{2\kappa}\,\text{d}\boldsymbol{W}, \end{equation}
\begin{equation} \text{d}\kern0.06em \boldsymbol{X} = \sqrt{2\kappa}\,\text{d}\boldsymbol{W}, \end{equation}
with 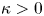 $\kappa >0$, and the Langevin model, which, under the same conditions, is given by
$\kappa >0$, and the Langevin model, which, under the same conditions, is given by
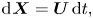 $$\begin{gather} \text{d}\kern0.06em \boldsymbol{X} = \boldsymbol{U}\,\text{d}t, \end{gather}$$
$$\begin{gather} \text{d}\kern0.06em \boldsymbol{X} = \boldsymbol{U}\,\text{d}t, \end{gather}$$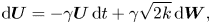 $$\begin{gather}\text{d}\boldsymbol{U} ={-}\gamma \boldsymbol{U}\, \text{d}t+\gamma\sqrt{2k}\,\text{d}\boldsymbol{W}, \end{gather}$$
$$\begin{gather}\text{d}\boldsymbol{U} ={-}\gamma \boldsymbol{U}\, \text{d}t+\gamma\sqrt{2k}\,\text{d}\boldsymbol{W}, \end{gather}$$
with 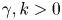 $\gamma, k > 0$, and where, in both cases,
$\gamma, k > 0$, and where, in both cases, 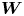 $\boldsymbol {W}$ is a vector composed of independent Brownian motions. We denote the models by
$\boldsymbol {W}$ is a vector composed of independent Brownian motions. We denote the models by 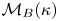 $\mathcal {M}_B(\kappa )$ and
$\mathcal {M}_B(\kappa )$ and 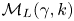 $\mathcal {M}_L(\gamma,k)$.
$\mathcal {M}_L(\gamma,k)$.
We note some important characteristics of the two models. The Brownian model involves particle position, 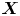 $\boldsymbol {X}$, as its only component, which evolves as a scaled
$\boldsymbol {X}$, as its only component, which evolves as a scaled 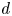 $d$-dimensional Brownian motion, where
$d$-dimensional Brownian motion, where 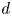 $d$ is the number of spatial dimensions. This implies that particle velocity evolves as a white noise process. The model has one parameter, the diffusivity
$d$ is the number of spatial dimensions. This implies that particle velocity evolves as a white noise process. The model has one parameter, the diffusivity 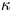 $\kappa$. The validity of (2.1) is typically justified by arguments involving strong assumptions of scale separation between mean flows and small-scale fluctuations which rarely hold in applications (Majda & Kramer Reference Majda and Kramer1999; Berloff & McWilliams Reference Berloff and McWilliams2002).
$\kappa$. The validity of (2.1) is typically justified by arguments involving strong assumptions of scale separation between mean flows and small-scale fluctuations which rarely hold in applications (Majda & Kramer Reference Majda and Kramer1999; Berloff & McWilliams Reference Berloff and McWilliams2002).
The Langevin model, by contrast, involves two components, particle position and particle velocity, 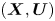 $(\boldsymbol {X},\boldsymbol {U})$. The velocity component evolves according to a mean-zero Ornstein–Uhlenbeck process, and position results from time integration of this velocity. The model has two parameters,
$(\boldsymbol {X},\boldsymbol {U})$. The velocity component evolves according to a mean-zero Ornstein–Uhlenbeck process, and position results from time integration of this velocity. The model has two parameters, 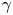 $\gamma$ and
$\gamma$ and 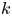 $k$, where
$k$, where 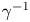 $\gamma ^{-1}$ is a Lagrangian velocity decorrelation time and
$\gamma ^{-1}$ is a Lagrangian velocity decorrelation time and 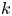 $k$ characterises the strength of Gaussian velocity fluctuations. The Brownian and Langevin models are the first two members of a hierarchy of Markovian models involving an increasing number of time derivatives of the position (Berloff & McWilliams Reference Berloff and McWilliams2002).
$k$ characterises the strength of Gaussian velocity fluctuations. The Brownian and Langevin models are the first two members of a hierarchy of Markovian models involving an increasing number of time derivatives of the position (Berloff & McWilliams Reference Berloff and McWilliams2002).
In practice, the Brownian model is favoured over the Langevin model for its simplicity as well as for the practical virtue of having a smaller, more easily explored, one-dimensional parameter space. Note that if these models are to be implemented in the limit of continuous concentrations of particles then it is their corresponding Fokker–Planck equations which must be solved – this means solving partial differential equations in 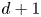 $d+1$ or
$d+1$ or 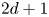 $2d+1$ dimensions, respectively.
$2d+1$ dimensions, respectively.
Both the Brownian and Langevin model can be extended to account for spatial anisotropy, inhomogeneity and the presence of a mean flow, at the cost of increasing the dimension of their parameter spaces; full details are given in Berloff & McWilliams (Reference Berloff and McWilliams2002). Brownian and Langevin dynamics underlie the so-called random displacement and random flight models used for dispersion in the atmospheric boundary layer (Esler & Ramli Reference Esler and Ramli2017), and have been applied to the simulation of ocean transport, as models of mixing in the horizontal (Berloff & McWilliams Reference Berloff and McWilliams2002), vertical (Onink, van Sebille & Laufkötter Reference Onink, van Sebille and Laufkötter2022) and on neutral surfaces (Reijnders, Deleersnijder & van Sebille Reference Reijnders, Deleersnijder and van Sebille2022). Ying, Maddison & Vanneste (Reference Ying, Maddison and Vanneste2019) showed how Bayesian parameter inference can be applied to the Brownian model in the inhomogeneous setting using Lagrangian trajectory data. We restrict attention to isotropic turbulence in this work for simplicity, noting that the methods demonstrated below are equally applicable in the more general case.
2.2. Data
For our comparison we consider trajectory data of the form
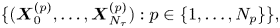 \begin{equation}
\{(\boldsymbol{X}^{(p)}_0, \ldots,
\boldsymbol{X}^{(p)}_{N_{\tau}}):
p\in\{1,\ldots, N_p\}\},
\end{equation}
\begin{equation}
\{(\boldsymbol{X}^{(p)}_0, \ldots,
\boldsymbol{X}^{(p)}_{N_{\tau}}):
p\in\{1,\ldots, N_p\}\},
\end{equation}
where 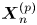 $\boldsymbol {X}^{(p)}_n$ is the position of particle
$\boldsymbol {X}^{(p)}_n$ is the position of particle 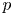 $p$ at time
$p$ at time 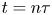 $t=n\tau$. In words, we observe the positions of a set of
$t=n\tau$. In words, we observe the positions of a set of 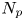 $N_p$ particles at discrete time intervals of length
$N_p$ particles at discrete time intervals of length 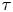 $\tau$, which we refer to as the sampling time. The performance of the models depends crucially on
$\tau$, which we refer to as the sampling time. The performance of the models depends crucially on 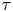 $\tau$. Since both models are homogeneous in space, we can rewrite the observations as the set of displacements
$\tau$. Since both models are homogeneous in space, we can rewrite the observations as the set of displacements
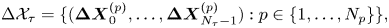 \begin{equation}
\Delta\mathcal{X}_{\tau} =\{(\boldsymbol{\Delta}
\boldsymbol{X}^{(p)}_0, \ldots, \boldsymbol{\Delta}
\boldsymbol{X}^{(p)}_{N_{\tau}-1}):
p\in\{1,\ldots, N_p\}\},
\end{equation}
\begin{equation}
\Delta\mathcal{X}_{\tau} =\{(\boldsymbol{\Delta}
\boldsymbol{X}^{(p)}_0, \ldots, \boldsymbol{\Delta}
\boldsymbol{X}^{(p)}_{N_{\tau}-1}):
p\in\{1,\ldots, N_p\}\},
\end{equation}
where 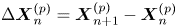 $\Delta \boldsymbol {X}^{(p)}_n = \boldsymbol {X}^{(p)}_{n+1} - \boldsymbol {X}^{(p)}_n$.
$\Delta \boldsymbol {X}^{(p)}_n = \boldsymbol {X}^{(p)}_{n+1} - \boldsymbol {X}^{(p)}_n$.
In § 4 we consider the case that the trajectory data are generated by Langevin dynamics, while in § 5 we compare the Brownian and Langevin models given data from direct numerical simulations of a forced–dissipative model of stationary, isotropic two-dimensional turbulence.
3. Methods
In this work we appeal to the Bayesian interpretation of probability and statistics. This means that probabilities reflect levels of plausibility in light of all available information. In particular, we deal with uncertainty in both the parameters of each model and the models themselves by assigning probabilities to them. We outline this procedure in §§ 3.1 and 3.2.
3.1. Parameter inference
The goal of parameter inference is to infer the values of the parameters 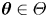 $\boldsymbol {\theta }\in \varTheta$ of a statistical model, say
$\boldsymbol {\theta }\in \varTheta$ of a statistical model, say 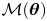 $\mathcal {M}(\boldsymbol {\theta })$, given observational data
$\mathcal {M}(\boldsymbol {\theta })$, given observational data 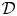 $\mathcal {D}$. A model is characterised completely by its likelihood function
$\mathcal {D}$. A model is characterised completely by its likelihood function 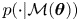 $p({\cdot }|\mathcal {M}(\boldsymbol {\theta }))$, which denotes the probability (density) of observations under
$p({\cdot }|\mathcal {M}(\boldsymbol {\theta }))$, which denotes the probability (density) of observations under 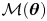 $\mathcal {M}(\boldsymbol {\theta })$. Bayesian inference requires the specification of one's belief prior to observations through a prior distribution
$\mathcal {M}(\boldsymbol {\theta })$. Bayesian inference requires the specification of one's belief prior to observations through a prior distribution 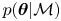 $p(\boldsymbol {\theta }|\mathcal {M})$. One can then invoke Bayes’ theorem, (3.1), to update this belief in light of the observations. This results in a posterior distribution
$p(\boldsymbol {\theta }|\mathcal {M})$. One can then invoke Bayes’ theorem, (3.1), to update this belief in light of the observations. This results in a posterior distribution
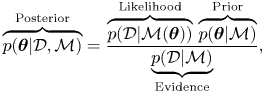 \begin{equation} \overbrace{p(\boldsymbol{\theta}|\mathcal{D},\mathcal{M})}^{\text{Posterior}} = \frac{\overbrace{p(\mathcal{D}|\mathcal{M}(\boldsymbol{\theta}))}^{\text{Likelihood}}\, \overbrace{p(\boldsymbol{\theta}|\mathcal{M})}^{\text{Prior}}}{\underbrace{p(\mathcal{D}|\mathcal{M})}_{\text{Evidence}}}, \end{equation}
\begin{equation} \overbrace{p(\boldsymbol{\theta}|\mathcal{D},\mathcal{M})}^{\text{Posterior}} = \frac{\overbrace{p(\mathcal{D}|\mathcal{M}(\boldsymbol{\theta}))}^{\text{Likelihood}}\, \overbrace{p(\boldsymbol{\theta}|\mathcal{M})}^{\text{Prior}}}{\underbrace{p(\mathcal{D}|\mathcal{M})}_{\text{Evidence}}}, \end{equation}
which denotes the probability (density) of each 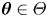 $\boldsymbol {\theta }\in \varTheta$ given observations and prior knowledge (Jeffreys Reference Jeffreys1983). The posterior fully describes the uncertainty in the inferred parameters, in our case
$\boldsymbol {\theta }\in \varTheta$ given observations and prior knowledge (Jeffreys Reference Jeffreys1983). The posterior fully describes the uncertainty in the inferred parameters, in our case  $\boldsymbol {\theta }= \kappa$ or
$\boldsymbol {\theta }= \kappa$ or 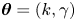 $\boldsymbol {\theta }=(k,\gamma )$. In applications where point estimates of the parameters are required, these can be taken as e.g. the mean or mode of the posterior.
$\boldsymbol {\theta }=(k,\gamma )$. In applications where point estimates of the parameters are required, these can be taken as e.g. the mean or mode of the posterior.
3.2. Model inference
Beyond parameter inference we can also make inferences when the model itself, 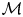 $\mathcal {M}$, is considered unknown. However, in order to meaningfully assign probabilities to models we must assume that the set of models under consideration,
$\mathcal {M}$, is considered unknown. However, in order to meaningfully assign probabilities to models we must assume that the set of models under consideration, 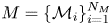 $M=\{\mathcal {M}_i\}_{i=1}^{N_M}$, includes all plausibly true models. That is, for any
$M=\{\mathcal {M}_i\}_{i=1}^{N_M}$, includes all plausibly true models. That is, for any 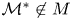 $\mathcal {M}^*\not \in M$,
$\mathcal {M}^*\not \in M$, 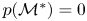 $p(\mathcal {M}^*)=0$. This is known as the
$p(\mathcal {M}^*)=0$. This is known as the 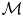 $\mathcal {M}$-closed regime (see chapter 6 of Bernardo & Smith (Reference Bernardo and Smith1994) or Clyde & Iversen Reference Clyde and Iversen2013). In situations where all models under consideration are known to be false this assumption appears dubious; however, we note that the same fallacy is committed in Bayesian parameter inference when we assign probabilities to the parameters of a parametric model which we know is imperfect, i.e. false. In the
$\mathcal {M}$-closed regime (see chapter 6 of Bernardo & Smith (Reference Bernardo and Smith1994) or Clyde & Iversen Reference Clyde and Iversen2013). In situations where all models under consideration are known to be false this assumption appears dubious; however, we note that the same fallacy is committed in Bayesian parameter inference when we assign probabilities to the parameters of a parametric model which we know is imperfect, i.e. false. In the 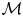 $\mathcal {M}$-closed regime one assigns prior probabilities to models such that
$\mathcal {M}$-closed regime one assigns prior probabilities to models such that 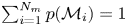 $\sum _{i=1}^{N_m}p(\mathcal {M}_i) = 1$. This allows us to again invoke Bayes’ theorem in the form
$\sum _{i=1}^{N_m}p(\mathcal {M}_i) = 1$. This allows us to again invoke Bayes’ theorem in the form
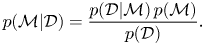 \begin{equation} p(\mathcal{M}|\mathcal{D}) = \frac{p(\mathcal{D}|\mathcal{M})\,p(\mathcal{M})}{p(\mathcal{D})}. \end{equation}
\begin{equation} p(\mathcal{M}|\mathcal{D}) = \frac{p(\mathcal{D}|\mathcal{M})\,p(\mathcal{M})}{p(\mathcal{D})}. \end{equation}
If 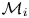 $\mathcal {M}_i$ is parametric with parameters
$\mathcal {M}_i$ is parametric with parameters 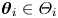 $\boldsymbol {\theta }_i\in \varTheta _i$,
$\boldsymbol {\theta }_i\in \varTheta _i$, 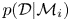 $p(\mathcal {D}|\mathcal {M}_i)$ is given by
$p(\mathcal {D}|\mathcal {M}_i)$ is given by
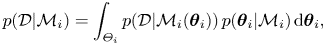 \begin{equation} p(\mathcal{D}|\mathcal{M}_i) = \int_{\varTheta_i} p(\mathcal{D}|\mathcal{M}_i(\boldsymbol{\theta}_i))\, p(\boldsymbol{\theta}_i|\mathcal{M}_i)\, \text{d}\boldsymbol{\theta}_i, \end{equation}
\begin{equation} p(\mathcal{D}|\mathcal{M}_i) = \int_{\varTheta_i} p(\mathcal{D}|\mathcal{M}_i(\boldsymbol{\theta}_i))\, p(\boldsymbol{\theta}_i|\mathcal{M}_i)\, \text{d}\boldsymbol{\theta}_i, \end{equation}
which is known as the model evidence (or marginal likelihood, or model likelihood) of 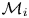 $\mathcal {M}_i$.
$\mathcal {M}_i$.
An important property of the evidence is that it accounts for parameter uncertainty. Considering the likelihood as a score of model performance given some fixed parameter values, the evidence can be viewed as an expectation of that score with respect to the prior measure on parameters. In this way the evidence favours models where observations are highly probable for the range of parameter values considered plausible a priori. In particular, this means that a model with many parameters which achieves a very high value of the likelihood only for a narrow range of parameter values which could not be predicted a priori is not likely to attain a higher value of the evidence than a model with fewer parameters whose values are better constrained by prior information. This apparent penalty is usually quantified by the so-called Occam (or Ockham) factor, named in reference to Occam's razor,
 \begin{equation} \mathrm{Occam}_i = p(\mathcal{D}|\mathcal{M}_i) / p(\mathcal{D}|\mathcal{M}_i(\boldsymbol{\theta}_i^*)) \in [0,1], \end{equation}
\begin{equation} \mathrm{Occam}_i = p(\mathcal{D}|\mathcal{M}_i) / p(\mathcal{D}|\mathcal{M}_i(\boldsymbol{\theta}_i^*)) \in [0,1], \end{equation}
where 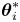 $\boldsymbol {\theta }_i^*$ is the posterior mode of
$\boldsymbol {\theta }_i^*$ is the posterior mode of 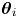 $\boldsymbol {\theta }_i$ (Jaynes Reference Jaynes2003; MacKay Reference MacKay2003).
$\boldsymbol {\theta }_i$ (Jaynes Reference Jaynes2003; MacKay Reference MacKay2003).
Given two models, 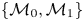 $\{\mathcal {M}_0,\mathcal {M}_1\}$, a test statistic for the hypotheses
$\{\mathcal {M}_0,\mathcal {M}_1\}$, a test statistic for the hypotheses
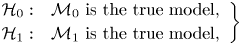 \begin{equation}
\left.\begin{array}{@{}ll} \mathcal{H}_0: &
\mathcal{M}_0\text{ is the true model},\\ \mathcal{H}_1: &
\mathcal{M}_1\text{ is the true model}, \end{array} \right\}
\end{equation}
\begin{equation}
\left.\begin{array}{@{}ll} \mathcal{H}_0: &
\mathcal{M}_0\text{ is the true model},\\ \mathcal{H}_1: &
\mathcal{M}_1\text{ is the true model}, \end{array} \right\}
\end{equation}
is given by the Bayes factor (Kass & Raftery Reference Kass and Raftery1995),
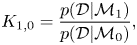 \begin{equation} K_{1,0} = \frac{p(\mathcal{D}|\mathcal{M}_1)}{p(\mathcal{D}|\mathcal{M}_0)}, \end{equation}
\begin{equation} K_{1,0} = \frac{p(\mathcal{D}|\mathcal{M}_1)}{p(\mathcal{D}|\mathcal{M}_0)}, \end{equation}
where a large value of 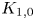 $K_{1,0}$ represents statistical evidence against
$K_{1,0}$ represents statistical evidence against 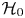 $\mathcal {H}_0$.
$\mathcal {H}_0$.
The log evidence is exactly equal to the log score (Gneiting & Raftery Reference Gneiting and Raftery2007), also known as the ignorance score (Bernardo Reference Bernardo1979; Bröcker & Smith Reference Bröcker and Smith2007), for probabilistic forecasts. Therefore, the log Bayes factor can be understood as a difference of scores for probabilistic models. Merits of the log score have been appreciated since at least the 1950s (Good Reference Good1952), including its intimate connection with information theory (Roulston & Smith Reference Roulston and Smith2002; Du Reference Du2021). This interpretation of the Bayes factor does not rely on the assumption of the 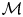 $\mathcal {M}$-closed regime. In what follows we use the Bayes factor to compare the Brownian and Langevin models.
$\mathcal {M}$-closed regime. In what follows we use the Bayes factor to compare the Brownian and Langevin models.
A useful approximation for the evidence (3.3) is given by Laplace's method: a Gaussian approximation of the unnormalised posterior, 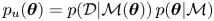 $p_u(\boldsymbol {\theta })=p(\mathcal {D}|\mathcal {M}(\boldsymbol {\theta }))\, p(\boldsymbol {\theta }|\mathcal {M})$, is obtained from a quadratic expansion of
$p_u(\boldsymbol {\theta })=p(\mathcal {D}|\mathcal {M}(\boldsymbol {\theta }))\, p(\boldsymbol {\theta }|\mathcal {M})$, is obtained from a quadratic expansion of 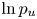 $\ln p_u$ about the posterior mode
$\ln p_u$ about the posterior mode  $\boldsymbol {\theta }^*$,
$\boldsymbol {\theta }^*$,
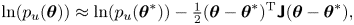 \begin{equation}
\ln(p_u(\boldsymbol{\theta})) \approx
\ln(p_u(\boldsymbol{\theta}^*)) -
\tfrac{1}{2}(\boldsymbol{\theta}-\boldsymbol{\theta}^*)^{\mathrm{T}}
\boldsymbol{\mathsf{J}}
(\boldsymbol{\theta}-\boldsymbol{\theta}^*),
\end{equation}
\begin{equation}
\ln(p_u(\boldsymbol{\theta})) \approx
\ln(p_u(\boldsymbol{\theta}^*)) -
\tfrac{1}{2}(\boldsymbol{\theta}-\boldsymbol{\theta}^*)^{\mathrm{T}}
\boldsymbol{\mathsf{J}}
(\boldsymbol{\theta}-\boldsymbol{\theta}^*),
\end{equation}
where
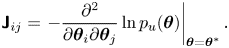 \begin{equation} \boldsymbol{\mathsf{J}}_{ij} = \left.-\frac{\partial^2}{\partial \boldsymbol{\theta}_i\partial \boldsymbol{\theta}_j}\ln p_u(\boldsymbol{\theta})\right\vert_{\boldsymbol{\theta}=\boldsymbol{\theta}^*}. \end{equation}
\begin{equation} \boldsymbol{\mathsf{J}}_{ij} = \left.-\frac{\partial^2}{\partial \boldsymbol{\theta}_i\partial \boldsymbol{\theta}_j}\ln p_u(\boldsymbol{\theta})\right\vert_{\boldsymbol{\theta}=\boldsymbol{\theta}^*}. \end{equation}
Taking an exponential of (3.7) we recognise that we have approximated 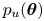 $p_u(\boldsymbol {\theta })$ with the probability density function (up to a known normalisation) of a Gaussian random variable with mean
$p_u(\boldsymbol {\theta })$ with the probability density function (up to a known normalisation) of a Gaussian random variable with mean  $\boldsymbol {\theta }^*$ and covariance
$\boldsymbol {\theta }^*$ and covariance 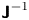 $\boldsymbol{\mathsf{J}}^{-1}$, so (3.3) becomes
$\boldsymbol{\mathsf{J}}^{-1}$, so (3.3) becomes
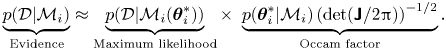 \begin{equation} \underbrace{p(\mathcal{D}|\mathcal{M}_i)}_{\text{Evidence}} \approx \underbrace{p(\mathcal{D}|\mathcal{M}_i(\boldsymbol{\theta}_i^*))}_{\text{Maximum likelihood}} \times\ \underbrace{p(\boldsymbol{\theta}_i^*| \mathcal{M}_i)\left(\text{det}(\boldsymbol{\mathsf{J}}/2{\rm \pi})\right)^{-{1}/{2}}}_{\text{Occam factor}}. \end{equation}
\begin{equation} \underbrace{p(\mathcal{D}|\mathcal{M}_i)}_{\text{Evidence}} \approx \underbrace{p(\mathcal{D}|\mathcal{M}_i(\boldsymbol{\theta}_i^*))}_{\text{Maximum likelihood}} \times\ \underbrace{p(\boldsymbol{\theta}_i^*| \mathcal{M}_i)\left(\text{det}(\boldsymbol{\mathsf{J}}/2{\rm \pi})\right)^{-{1}/{2}}}_{\text{Occam factor}}. \end{equation}
This approximation is accurate for a large number of data points 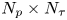 $N_p \times N_\tau$ where a Bernstein–von Mises theorem can be shown to hold, guaranteeing asymptotic normality of the posterior measure (van der Vaart Reference van der Vaart1998).
$N_p \times N_\tau$ where a Bernstein–von Mises theorem can be shown to hold, guaranteeing asymptotic normality of the posterior measure (van der Vaart Reference van der Vaart1998).
We highlight that a model's evidence is sensitive to the prior distribution on the parameters, 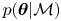 $p(\boldsymbol {\theta }|\mathcal {M})$. This is entirely in the spirit of Bayesian statistics in that a parametric model accompanied by the prior uncertainty on its parameters constitutes a single, complete hypothesis for explaining observations. The evidence for a model is less when the mass of prior probability on parameters is less concentrated on those values for which the likelihood is largest.
$p(\boldsymbol {\theta }|\mathcal {M})$. This is entirely in the spirit of Bayesian statistics in that a parametric model accompanied by the prior uncertainty on its parameters constitutes a single, complete hypothesis for explaining observations. The evidence for a model is less when the mass of prior probability on parameters is less concentrated on those values for which the likelihood is largest.
4. Results
In this section we provide details on how BMC can be performed for the Brownian and Langevin model and consider data generated by the Langevin model. We derive the likelihood function for each model, discuss prior distributions for parameters and the practicalities of inference calculations.
Before we compute the Bayes factor for the Langevin and Brownian models 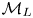 $\mathcal {M}_L$ and
$\mathcal {M}_L$ and 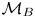 $\mathcal {M}_B$, we infer the parameters of both models using a range of datasets with varying sampling time,
$\mathcal {M}_B$, we infer the parameters of both models using a range of datasets with varying sampling time, 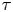 $\tau$, to establish when each model is sampling-time consistent – we say a model is sampling-time consistent when inferred parameter values are stable over a range of
$\tau$, to establish when each model is sampling-time consistent – we say a model is sampling-time consistent when inferred parameter values are stable over a range of 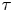 $\tau$. We emphasise that sampling-time consistency does not imply a model is good, but is certainly a desirable property when one wishes to use a model for extrapolation, e.g. for unobserved values of
$\tau$. We emphasise that sampling-time consistency does not imply a model is good, but is certainly a desirable property when one wishes to use a model for extrapolation, e.g. for unobserved values of 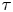 $\tau$.
$\tau$.
Justifications for the Brownian model apply formally only in the large-time limit; we are, therefore, interested in establishing a minimum time scale for the sampling-time consistency of the Brownian model, and further establishing whether the Langevin model, given that it includes time correlation, is sampling-time consistent on shorter time scales.
Note that in the large-time limit, that is, for 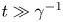 $t \gg \gamma ^{-1}$, the Langevin dynamics is asymptotically diffusive: for
$t \gg \gamma ^{-1}$, the Langevin dynamics is asymptotically diffusive: for 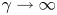 $\gamma \to \infty$, the Langevin equations (2.2) reduce to (Pavliotis Reference Pavliotis2014)
$\gamma \to \infty$, the Langevin equations (2.2) reduce to (Pavliotis Reference Pavliotis2014)
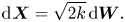 \begin{equation} \text{d}\kern0.06em \boldsymbol{X} = \sqrt{2k}\, \text{d}\boldsymbol{W}. \end{equation}
\begin{equation} \text{d}\kern0.06em \boldsymbol{X} = \sqrt{2k}\, \text{d}\boldsymbol{W}. \end{equation}This fact is important when comparing the models, and we return to it later.
4.1. Likelihoods
We can derive explicit expressions for the probability of data of the form of 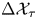 $\Delta \mathcal {X}_{\tau }$ under
$\Delta \mathcal {X}_{\tau }$ under 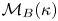 $\mathcal {M}_B(\kappa )$ and
$\mathcal {M}_B(\kappa )$ and 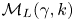 $\mathcal {M}_L(\gamma,k)$ by using their transition probabilities. The position increments for
$\mathcal {M}_L(\gamma,k)$ by using their transition probabilities. The position increments for 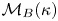 $\mathcal {M}_B(\kappa )$ satisfy
$\mathcal {M}_B(\kappa )$ satisfy
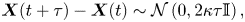 \begin{equation} \boldsymbol{X}(t+\tau)-\boldsymbol{X}(t)\sim \mathcal{N}\left(0,2\kappa\tau \mathbb{I}\right), \end{equation}
\begin{equation} \boldsymbol{X}(t+\tau)-\boldsymbol{X}(t)\sim \mathcal{N}\left(0,2\kappa\tau \mathbb{I}\right), \end{equation}
where 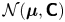 $\mathcal {N}(\boldsymbol {\mu },\boldsymbol{\mathsf{C}})$ is the
$\mathcal {N}(\boldsymbol {\mu },\boldsymbol{\mathsf{C}})$ is the 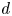 $d$-dimensional Gaussian distribution with mean
$d$-dimensional Gaussian distribution with mean 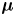 $\boldsymbol {\mu }$ and covariance matrix
$\boldsymbol {\mu }$ and covariance matrix 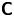 $\boldsymbol{\mathsf{C}}$, and
$\boldsymbol{\mathsf{C}}$, and 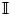 $\mathbb {I}$ is the
$\mathbb {I}$ is the 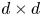 $d \times d$ identity matrix. Further, distinct increments are independent under
$d \times d$ identity matrix. Further, distinct increments are independent under 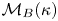 $\mathcal {M}_B(\kappa )$. Therefore, the desired probability is
$\mathcal {M}_B(\kappa )$. Therefore, the desired probability is
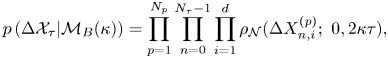 \begin{equation} p\left(\Delta \mathcal{X}_{\tau}|\mathcal{M}_B(\kappa)\right) = \prod_{p=1}^{N_p}\prod_{n=0}^{N_{\tau}-1}\prod_{i=1}^d\rho_{\mathcal{N}}(\Delta X^{(p)}_{n,i};\ 0, 2\kappa\tau), \end{equation}
\begin{equation} p\left(\Delta \mathcal{X}_{\tau}|\mathcal{M}_B(\kappa)\right) = \prod_{p=1}^{N_p}\prod_{n=0}^{N_{\tau}-1}\prod_{i=1}^d\rho_{\mathcal{N}}(\Delta X^{(p)}_{n,i};\ 0, 2\kappa\tau), \end{equation}
where 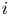 $i$ indexes spatial dimension and
$i$ indexes spatial dimension and 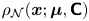 $\rho _{\mathcal {N}}(\boldsymbol {x};\boldsymbol {\mu },\boldsymbol{\mathsf{C}})$ is the probability density at
$\rho _{\mathcal {N}}(\boldsymbol {x};\boldsymbol {\mu },\boldsymbol{\mathsf{C}})$ is the probability density at 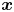 $\boldsymbol {x}$ of the Gaussian distribution
$\boldsymbol {x}$ of the Gaussian distribution 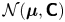 $\mathcal {N}(\boldsymbol {\mu }, \boldsymbol{\mathsf{C}})$.
$\mathcal {N}(\boldsymbol {\mu }, \boldsymbol{\mathsf{C}})$.
The corresponding likelihood for the Langevin model is shown in Appendix A to be
 \begin{equation} p(\Delta \mathcal{X}_{\tau}|\mathcal{M}_L(\gamma, k)) = \prod_{p=1}^{N_p}\prod_{i=1}^d \rho_{\mathcal{N}}((\Delta X_{0,i}^{(p)}, \ldots, \Delta X_{N_{\tau}-1,i}^{(p)})^{\mathrm{T}};\boldsymbol{0} ,\boldsymbol{\mathsf{S}}), \end{equation}
\begin{equation} p(\Delta \mathcal{X}_{\tau}|\mathcal{M}_L(\gamma, k)) = \prod_{p=1}^{N_p}\prod_{i=1}^d \rho_{\mathcal{N}}((\Delta X_{0,i}^{(p)}, \ldots, \Delta X_{N_{\tau}-1,i}^{(p)})^{\mathrm{T}};\boldsymbol{0} ,\boldsymbol{\mathsf{S}}), \end{equation}
where 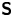 $\boldsymbol{\mathsf{S}}$ is the symmetric Toeplitz matrix with
$\boldsymbol{\mathsf{S}}$ is the symmetric Toeplitz matrix with
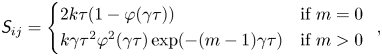 $$\begin{gather}
\textit{{S}}_{ij} = \left\{\begin{array}{@{}ll}
2k\tau(1-\varphi(\gamma \tau)) & \text{if $m=0$}\\
k\gamma\tau^2\varphi^2(\gamma\tau)\exp({-(m-1)\gamma\tau})
& \text{if $m>0$} \end{array}\right. ,
\end{gather}$$
$$\begin{gather}
\textit{{S}}_{ij} = \left\{\begin{array}{@{}ll}
2k\tau(1-\varphi(\gamma \tau)) & \text{if $m=0$}\\
k\gamma\tau^2\varphi^2(\gamma\tau)\exp({-(m-1)\gamma\tau})
& \text{if $m>0$} \end{array}\right. ,
\end{gather}$$
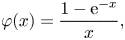 $$\begin{gather}\varphi(x) = \frac{1-\mathrm{e}^{{-}x}}{x}, \end{gather}$$
$$\begin{gather}\varphi(x) = \frac{1-\mathrm{e}^{{-}x}}{x}, \end{gather}$$
and 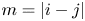 $m=|i-j|$.
$m=|i-j|$.
4.2. Prior distributions
It is necessary, both for parameter and model inference, to specify a prior distribution for each of the parameters, 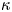 $\kappa$,
$\kappa$, 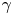 $\gamma$ and
$\gamma$ and 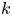 $k$. For a given flow we can appeal to scaling considerations to assign a prior mean to each parameter, derived from characteristic scales. Once such prior means are prescribed, the maximum entropy principle, along with positivity and independence of the parameters, motivates a choice of corresponding exponential distributions as priors (Jaynes Reference Jaynes2003; Cover & Thomas Reference Cover and Thomas2006). That is, for a parameter
$k$. For a given flow we can appeal to scaling considerations to assign a prior mean to each parameter, derived from characteristic scales. Once such prior means are prescribed, the maximum entropy principle, along with positivity and independence of the parameters, motivates a choice of corresponding exponential distributions as priors (Jaynes Reference Jaynes2003; Cover & Thomas Reference Cover and Thomas2006). That is, for a parameter 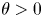 $\theta >0$ with prior mean
$\theta >0$ with prior mean 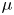 $\mu$, the distribution with maximum entropy is the exponential distribution
$\mu$, the distribution with maximum entropy is the exponential distribution 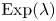 $\mathrm {Exp}(\lambda )$ with rate
$\mathrm {Exp}(\lambda )$ with rate 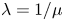 $\lambda =1/\mu$. We use this prescription for our choice of prior.
$\lambda =1/\mu$. We use this prescription for our choice of prior.
4.3. Inference numerics
The computations we perform for Bayesian parameter inference are: (i) an optimisation procedure to find the posterior mode,  $\boldsymbol {\theta }^*$, and (ii) a single evaluation of the Hessian of the log-posterior distribution at
$\boldsymbol {\theta }^*$, and (ii) a single evaluation of the Hessian of the log-posterior distribution at  $\boldsymbol {\theta }^*$,
$\boldsymbol {\theta }^*$, 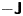 $-\boldsymbol{\mathsf{J}}$ in (3.8), which we can use to estimate the posterior variance by a Gaussian approximation as in (3.7). We have analytical expressions for the likelihood and prior for both models, so we can easily evaluate the negative log unnormalised posterior,
$-\boldsymbol{\mathsf{J}}$ in (3.8), which we can use to estimate the posterior variance by a Gaussian approximation as in (3.7). We have analytical expressions for the likelihood and prior for both models, so we can easily evaluate the negative log unnormalised posterior, 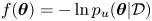 $f(\boldsymbol {\theta }) = -\ln p_u(\boldsymbol {\theta }|\mathcal {D})$, in each case; we find
$f(\boldsymbol {\theta }) = -\ln p_u(\boldsymbol {\theta }|\mathcal {D})$, in each case; we find  $\boldsymbol {\theta }^*$ by minimising
$\boldsymbol {\theta }^*$ by minimising 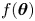 $f(\boldsymbol {\theta })$ using the SciPy function optimize.minimize().
$f(\boldsymbol {\theta })$ using the SciPy function optimize.minimize().
In the case of the Brownian model derivatives of 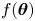 $f(\boldsymbol {\theta })$ are easily derived analytically, so we use the L-BFGS-B routine which exploits gradient information and allows for the specification of lower bound constraints to enforce positivity (Zhu et al. Reference Zhu, Byrd, Lu and Nocedal1997). In the case of the Langevin model calculation of derivatives of the posterior is non-trivial because the likelihood (4.4) is a complicated function. For this reason we use the gradient-free Nelder-Mead (Nelder & Mead Reference Nelder and Mead1965) routine rather than L-BFGS-B. We evaluate
$f(\boldsymbol {\theta })$ are easily derived analytically, so we use the L-BFGS-B routine which exploits gradient information and allows for the specification of lower bound constraints to enforce positivity (Zhu et al. Reference Zhu, Byrd, Lu and Nocedal1997). In the case of the Langevin model calculation of derivatives of the posterior is non-trivial because the likelihood (4.4) is a complicated function. For this reason we use the gradient-free Nelder-Mead (Nelder & Mead Reference Nelder and Mead1965) routine rather than L-BFGS-B. We evaluate 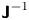 $\boldsymbol{\mathsf{J}}^{-1}$ approximately using a fourth-order central difference approximation for the log likelihood.
$\boldsymbol{\mathsf{J}}^{-1}$ approximately using a fourth-order central difference approximation for the log likelihood.
No further computations are required for BMC if the Laplace's method approximation for the evidence in (3.9) is used.
4.4. Test case: Langevin data
As a test case and to build intuition, we first consider trajectory data generated by the Langevin model with  $d=3$. In this case, one of the two candidate models is the true model. We generate the data by simulating the Langevin equation (2.2) exactly, drawing initial velocities from the stationary distribution
$d=3$. In this case, one of the two candidate models is the true model. We generate the data by simulating the Langevin equation (2.2) exactly, drawing initial velocities from the stationary distribution 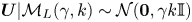 $\boldsymbol {U}|\mathcal {M}_L(\gamma, k)\sim \mathcal {N}(\boldsymbol {0},\gamma k\mathbb {I})$, and using the transition probabilities (A1); velocity data are discarded to construct the dataset of position increments
$\boldsymbol {U}|\mathcal {M}_L(\gamma, k)\sim \mathcal {N}(\boldsymbol {0},\gamma k\mathbb {I})$, and using the transition probabilities (A1); velocity data are discarded to construct the dataset of position increments 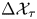 $\Delta \mathcal {X}_{\tau }$.
$\Delta \mathcal {X}_{\tau }$.
We set 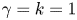 $\gamma = k = 1$, fix
$\gamma = k = 1$, fix 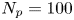 $N_p=100$ and
$N_p=100$ and 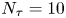 $N_{\tau }=10$ and perform Bayesian parameter inference and model comparison with a series of independently generated datasets with
$N_{\tau }=10$ and perform Bayesian parameter inference and model comparison with a series of independently generated datasets with 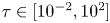 $\tau \in [10^{-2},10^2]$. We set fixed priors
$\tau \in [10^{-2},10^2]$. We set fixed priors 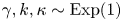 $\gamma,k,\kappa \sim \text {Exp}(1)$.
$\gamma,k,\kappa \sim \text {Exp}(1)$.
Figure 1 shows the results of the parameter inference. Note that both Langevin parameters are well identified until, at sufficiently large 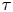 $\tau$, the error of the posterior mode estimate of
$\tau$, the error of the posterior mode estimate of 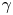 $\gamma$ grows along with the posterior standard deviation of
$\gamma$ grows along with the posterior standard deviation of 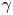 $\gamma$. This is a manifestation of the diffusive limit (4.1) of the Langevin dynamics, wherein
$\gamma$. This is a manifestation of the diffusive limit (4.1) of the Langevin dynamics, wherein 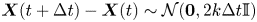 $\boldsymbol {X}(t+\Delta t)-\boldsymbol {X}(t)\sim \mathcal {N}(\boldsymbol {0}, 2k\Delta t\mathbb {I})$ is independent of
$\boldsymbol {X}(t+\Delta t)-\boldsymbol {X}(t)\sim \mathcal {N}(\boldsymbol {0}, 2k\Delta t\mathbb {I})$ is independent of 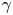 $\gamma$. Unsurprisingly, then,
$\gamma$. Unsurprisingly, then, 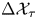 $\Delta \mathcal {X}_{\tau }$ is less informative about
$\Delta \mathcal {X}_{\tau }$ is less informative about 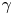 $\gamma$ when
$\gamma$ when 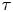 $\tau$ is large.
$\tau$ is large.
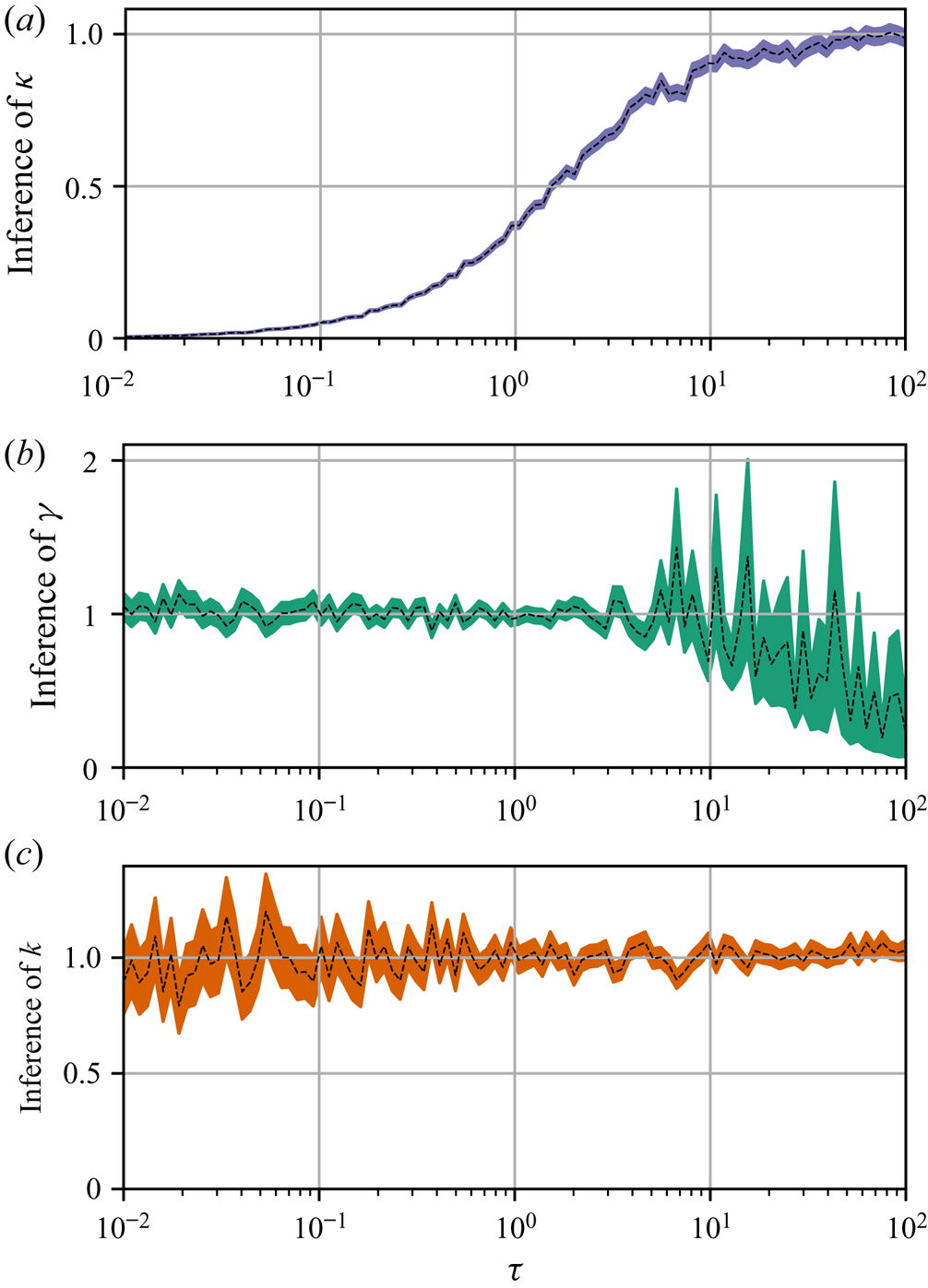
Figure 1. Parameter inference for the Brownian and Langevin models as a function of observation interval,  $\tau$, for data from the Langevin model in three spatial dimensions. Dashed lines indicate posterior mode estimates,
$\tau$, for data from the Langevin model in three spatial dimensions. Dashed lines indicate posterior mode estimates,  $\theta ^*=\kappa$ (a),
$\theta ^*=\kappa$ (a),  $\gamma ^*$ (b) and
$\gamma ^*$ (b) and  $k^*$ (c); shaded areas show
$k^*$ (c); shaded areas show 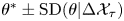 $\theta ^*\pm \text {SD}(\theta |\Delta \mathcal {X}_{\tau })$. Each inference is made with a fixed volume of data:
$\theta ^*\pm \text {SD}(\theta |\Delta \mathcal {X}_{\tau })$. Each inference is made with a fixed volume of data: 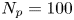 $N_p=100$ and
$N_p=100$ and 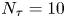 $N_{\tau }=10$.
$N_{\tau }=10$.
The diffusivity 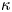 $\kappa$ of the Brownian model is sampling-time consistent only when
$\kappa$ of the Brownian model is sampling-time consistent only when 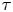 $\tau$ is sufficiently large, i.e. in the diffusive limit of the Langevin dynamics, when
$\tau$ is sufficiently large, i.e. in the diffusive limit of the Langevin dynamics, when 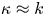 $\kappa \approx k$. The inaccuracy of posterior mode estimates of
$\kappa \approx k$. The inaccuracy of posterior mode estimates of 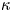 $\kappa$ at small
$\kappa$ at small 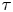 $\tau$ is expected as it is known that the inference of diffusivities from discrete trajectory data is sensitive to sampling time (Cotter & Pavliotis Reference Cotter and Pavliotis2009). We note that
$\tau$ is expected as it is known that the inference of diffusivities from discrete trajectory data is sensitive to sampling time (Cotter & Pavliotis Reference Cotter and Pavliotis2009). We note that 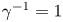 $\gamma ^{-1}=1$ is the decorrelation time for this data so that the time scales at which this limiting behaviour is observed,
$\gamma ^{-1}=1$ is the decorrelation time for this data so that the time scales at which this limiting behaviour is observed, 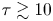 $\tau \gtrsim 10$, are indeed large.
$\tau \gtrsim 10$, are indeed large.
Note that the posterior mode estimates of 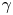 $\gamma$ eventually decay to zero as
$\gamma$ eventually decay to zero as 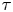 $\tau$ increases; since, as observed,
$\tau$ increases; since, as observed, 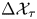 $\Delta \mathcal {X}_{\tau }$ becomes less informative about
$\Delta \mathcal {X}_{\tau }$ becomes less informative about 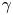 $\gamma$ with increasing
$\gamma$ with increasing 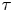 $\tau$, the contribution of the prior information to the posterior becomes dominant over the contribution from the likelihood – the consequence of this is that the posterior mode tends to the prior mode, which is zero since we take
$\tau$, the contribution of the prior information to the posterior becomes dominant over the contribution from the likelihood – the consequence of this is that the posterior mode tends to the prior mode, which is zero since we take 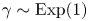 $\gamma \sim \text {Exp}(1)$.
$\gamma \sim \text {Exp}(1)$.
Figure 2 shows the log Bayes factors found using Laplace's method for the evidence. We see that, for a significant range of 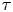 $\tau$, the Langevin model is preferred, indicated by large positive values of
$\tau$, the Langevin model is preferred, indicated by large positive values of 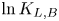 $\ln K_{L,B}$, but its dominance diminishes as
$\ln K_{L,B}$, but its dominance diminishes as 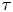 $\tau$ increases until the diffusive limit is reached, at which point values of
$\tau$ increases until the diffusive limit is reached, at which point values of 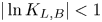 $|\ln K_{L,B}|< 1$ are typical, indicating insubstantial preference for either model.
$|\ln K_{L,B}|< 1$ are typical, indicating insubstantial preference for either model.
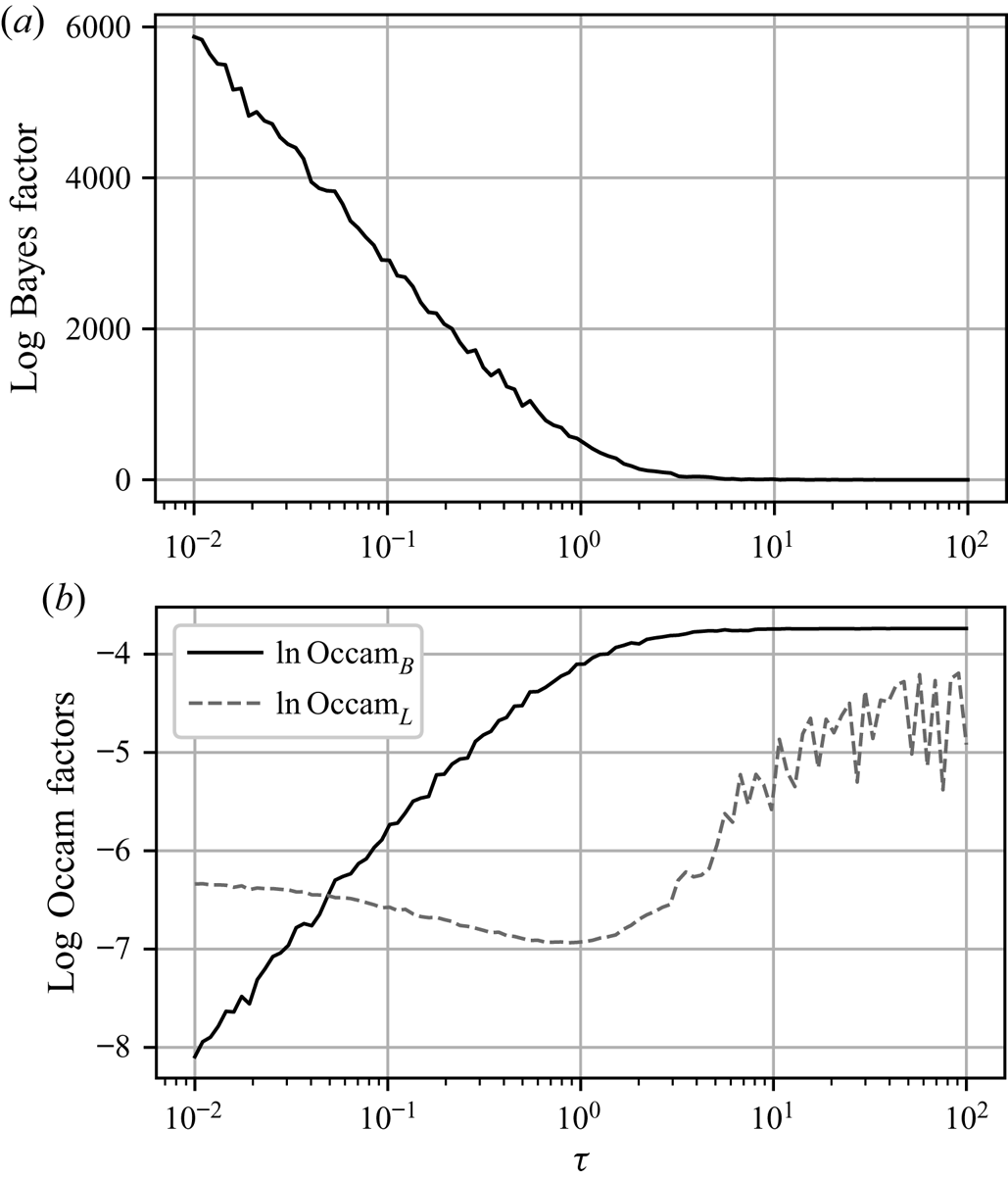
Figure 2. Log Bayes factors, 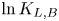 $\ln K_{L,B}$, and corresponding log Occam factors, as a function of
$\ln K_{L,B}$, and corresponding log Occam factors, as a function of 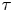 $\tau$, given the same data used for figure 1.
$\tau$, given the same data used for figure 1.
Also shown in figure 2 are the corresponding log Occam factors. Occam factors for the Brownian model are approximately constant once 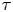 $\tau$ is sufficiently large, while the Occam factors for the Langevin model increase at large
$\tau$ is sufficiently large, while the Occam factors for the Langevin model increase at large 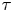 $\tau$, in line with a broadening posterior. This is indicative of decreased sensitivity to choice of parameters, specifically
$\tau$, in line with a broadening posterior. This is indicative of decreased sensitivity to choice of parameters, specifically 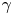 $\gamma$, whose value becomes less critical for explaining the dynamics on large time scales.
$\gamma$, whose value becomes less critical for explaining the dynamics on large time scales.
5. Application to two-dimensional turbulence
In this section we report an application of BMC to particle trajectories in a model of stationary, isotropic two-dimensional (2-D) turbulence.
5.1. Forced–dissipative model
We consider a forced–dissipative model of isotropic 2-D turbulence in an incompressible fluid governed by the vorticity equation (Vallis Reference Vallis2017)
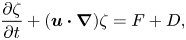 \begin{equation} \frac{\partial \zeta}{\partial t} + (\boldsymbol{u}\boldsymbol{\cdot}\boldsymbol{\nabla})\zeta = F + D, \end{equation}
\begin{equation} \frac{\partial \zeta}{\partial t} + (\boldsymbol{u}\boldsymbol{\cdot}\boldsymbol{\nabla})\zeta = F + D, \end{equation}
where 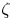 $\zeta$ is the vertical vorticity and
$\zeta$ is the vertical vorticity and 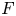 $F$ and
$F$ and 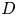 $D$ represent forcing and dissipation, respectively. The particular forcing used is an additive homogeneous and isotropic white Gaussian noise concentrated in a specified range of wavenumber centred about a forcing wavenumber,
$D$ represent forcing and dissipation, respectively. The particular forcing used is an additive homogeneous and isotropic white Gaussian noise concentrated in a specified range of wavenumber centred about a forcing wavenumber, 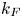 $k_F$. In particular, following Scott (Reference Scott2007), we have that, at each timestep, the Fourier transform of
$k_F$. In particular, following Scott (Reference Scott2007), we have that, at each timestep, the Fourier transform of 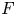 $F$ satisfies
$F$ satisfies
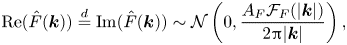 \begin{equation} \text{Re}(\hat{F}(\boldsymbol{k})) \stackrel{d}{=} \text{Im}(\hat{F}(\boldsymbol{k}))\sim \mathcal{N} \left(0, \frac{A_{F}\mathcal{F}_F(|\boldsymbol{k}|)}{2{\rm \pi}|\boldsymbol{k}|}\right), \end{equation}
\begin{equation} \text{Re}(\hat{F}(\boldsymbol{k})) \stackrel{d}{=} \text{Im}(\hat{F}(\boldsymbol{k}))\sim \mathcal{N} \left(0, \frac{A_{F}\mathcal{F}_F(|\boldsymbol{k}|)}{2{\rm \pi}|\boldsymbol{k}|}\right), \end{equation}
where 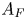 $A_F$ is the forcing amplitude, and
$A_F$ is the forcing amplitude, and 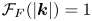 $\mathcal {F}_F(|\boldsymbol {k}|) = 1$ for
$\mathcal {F}_F(|\boldsymbol {k}|) = 1$ for 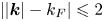 $||\boldsymbol {k}|-k_F|\leqslant 2$ and
$||\boldsymbol {k}|-k_F|\leqslant 2$ and 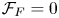 $\mathcal {F}_F= 0$ otherwise.
$\mathcal {F}_F= 0$ otherwise.
Two dissipation mechanisms are included: (i) small-scale dissipation implemented with a scale-selective exponential cutoff filter (see Arbic & Flierl (Reference Arbic and Flierl2003) for details and justification), and (ii) large-scale friction (aka hypodiffusion), so that total dissipation is given by
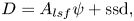 \begin{equation} D = A_{{lsf}}\psi + {\rm{ssd}}, \end{equation}
\begin{equation} D = A_{{lsf}}\psi + {\rm{ssd}}, \end{equation}where ssd denotes the small-scale dissipation.
Equation (5.1) is solved in a periodic domain, 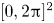 $[0,2{\rm \pi} ]^2$, using a standard pseudospectral solver, at a resolution of
$[0,2{\rm \pi} ]^2$, using a standard pseudospectral solver, at a resolution of 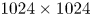 $1024\times 1024$ gridpoints, with the third-order Adams–Bashforth timestepping scheme. The complete set of flow configuration parameter values for our simulations are given in table 1.
$1024\times 1024$ gridpoints, with the third-order Adams–Bashforth timestepping scheme. The complete set of flow configuration parameter values for our simulations are given in table 1.
Table 1. Flow configuration parameter values for simulations of the 2-D turbulence model.
The model is initialised with a random Gaussian field with prescribed mean energy spectrum and is run until the total energy,
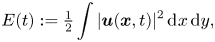 \begin{equation} E(t) := \tfrac{1}{2} \int |\boldsymbol{u}(\boldsymbol{x},t)|^2\, \text{d}\kern0.06em x\,\text{d}y, \end{equation}
\begin{equation} E(t) := \tfrac{1}{2} \int |\boldsymbol{u}(\boldsymbol{x},t)|^2\, \text{d}\kern0.06em x\,\text{d}y, \end{equation}
appears to reach a statistically stationary state; this amounted to a spin-up time of approximately 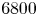 $6800$ eddy turnover times, where the eddy turnover time is estimated by
$6800$ eddy turnover times, where the eddy turnover time is estimated by
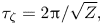 \begin{equation} \tau_{\zeta} = 2{\rm \pi}/\sqrt{Z}, \end{equation}
\begin{equation} \tau_{\zeta} = 2{\rm \pi}/\sqrt{Z}, \end{equation}
and 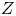 $Z$ is the total enstrophy,
$Z$ is the total enstrophy,
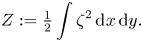 \begin{equation} Z := \tfrac{1}{2} \int \zeta^2\, \text{d}\kern0.06em x\,\text{d}y. \end{equation}
\begin{equation} Z := \tfrac{1}{2} \int \zeta^2\, \text{d}\kern0.06em x\,\text{d}y. \end{equation} Figure 3 shows a snapshot of the vorticity field at the end of the spin-up process. Enstrophy is concentrated in a population of coherent vortices whose scale is set by the forcing scale, 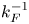 $k_F^{-1}$. Figure 4 shows the isotropic energy spectrum calculated at the same instant. A power law of approximately
$k_F^{-1}$. Figure 4 shows the isotropic energy spectrum calculated at the same instant. A power law of approximately 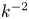 $k^{-2}$ is observed at wavenumbers between the peak wavenumber at
$k^{-2}$ is observed at wavenumbers between the peak wavenumber at 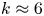 $k\approx 6$ and the forcing wavenumber at
$k\approx 6$ and the forcing wavenumber at 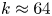 $k\approx 64$ (indicated with a vertical line). A second power law of approximately
$k\approx 64$ (indicated with a vertical line). A second power law of approximately 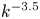 $k^{-3.5}$ is seen at wavenumbers between the forcing scale and the dissipation range. Large-scale friction prevents the indefinite accumulation of energy at the largest scales, while continued forcing prevents energy from concentrating exclusively around a peak wavenumber at late times, and, by inputting enstrophy at a moderate scale, sustains a lively population of vortices.
$k^{-3.5}$ is seen at wavenumbers between the forcing scale and the dissipation range. Large-scale friction prevents the indefinite accumulation of energy at the largest scales, while continued forcing prevents energy from concentrating exclusively around a peak wavenumber at late times, and, by inputting enstrophy at a moderate scale, sustains a lively population of vortices.
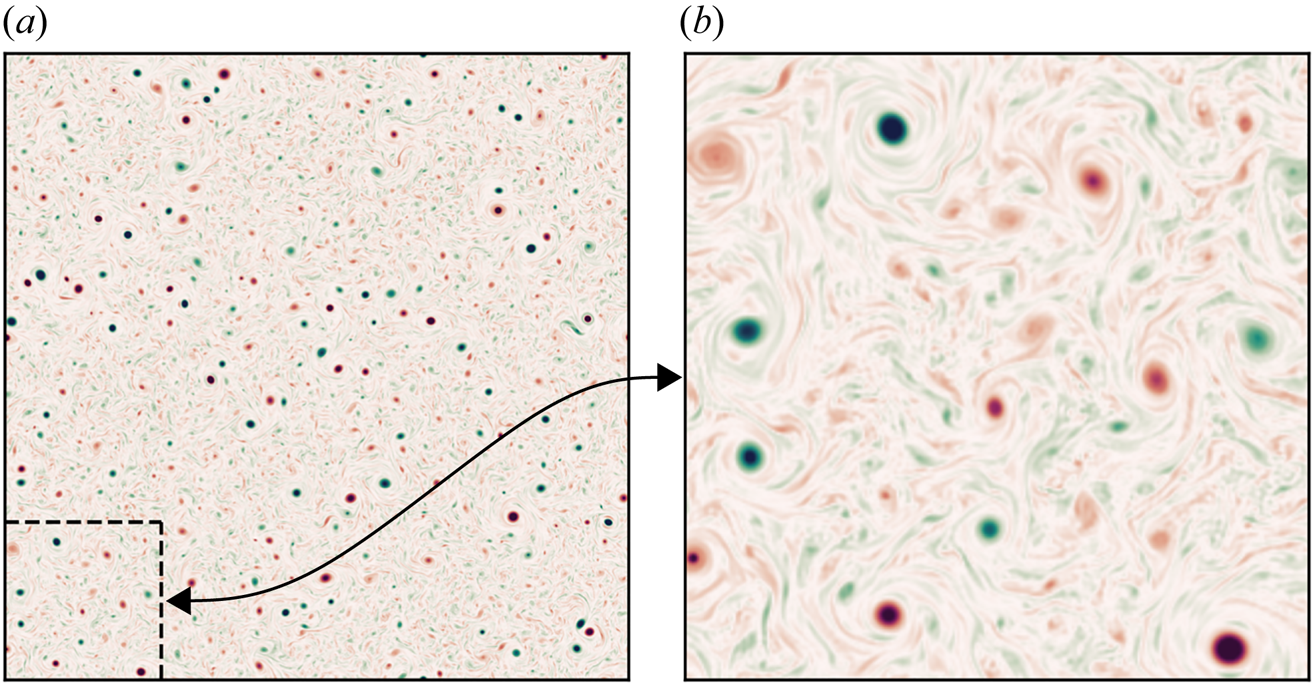
Figure 3. Snapshot of the vorticity field in the forced–dissipative model at stationarity showing 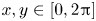 $x,y\in [0,2{\rm \pi} ]$ (a) and
$x,y\in [0,2{\rm \pi} ]$ (a) and 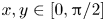 $x,y\in [0,{\rm \pi} /2]$ (b).
$x,y\in [0,{\rm \pi} /2]$ (b).
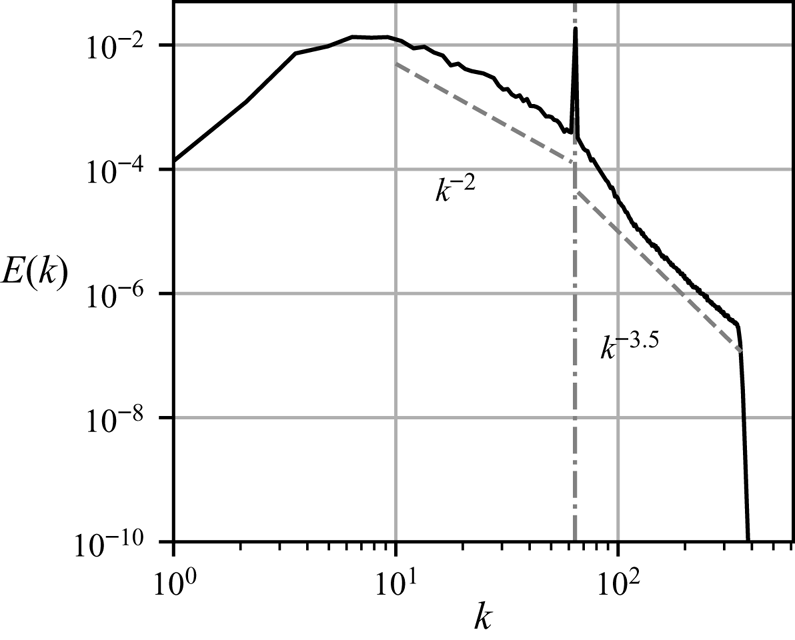
Figure 4. Snapshot of the isotropic energy spectrum in the forced–dissipative model at stationarity.
5.2. Particle numerics
After spin-up, a set of 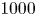 $1000$ passive tracer particles are evolved in the flow of the forced–dissipative model for approximately another
$1000$ passive tracer particles are evolved in the flow of the forced–dissipative model for approximately another 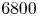 $6800$ eddy turnover times; this is done using bilinear interpolation of the velocity field and the fourth-order Runge–Kutta timestepping scheme. Particles are seeded at initial positions chosen uniformly at random in the domain. Figure 5 shows a subset of the trajectory data generated. Some particles follow highly oscillatory paths, while others do not, depending on whether they are seeded in the interior of a coherent vortex or in the background turbulence.
$6800$ eddy turnover times; this is done using bilinear interpolation of the velocity field and the fourth-order Runge–Kutta timestepping scheme. Particles are seeded at initial positions chosen uniformly at random in the domain. Figure 5 shows a subset of the trajectory data generated. Some particles follow highly oscillatory paths, while others do not, depending on whether they are seeded in the interior of a coherent vortex or in the background turbulence.
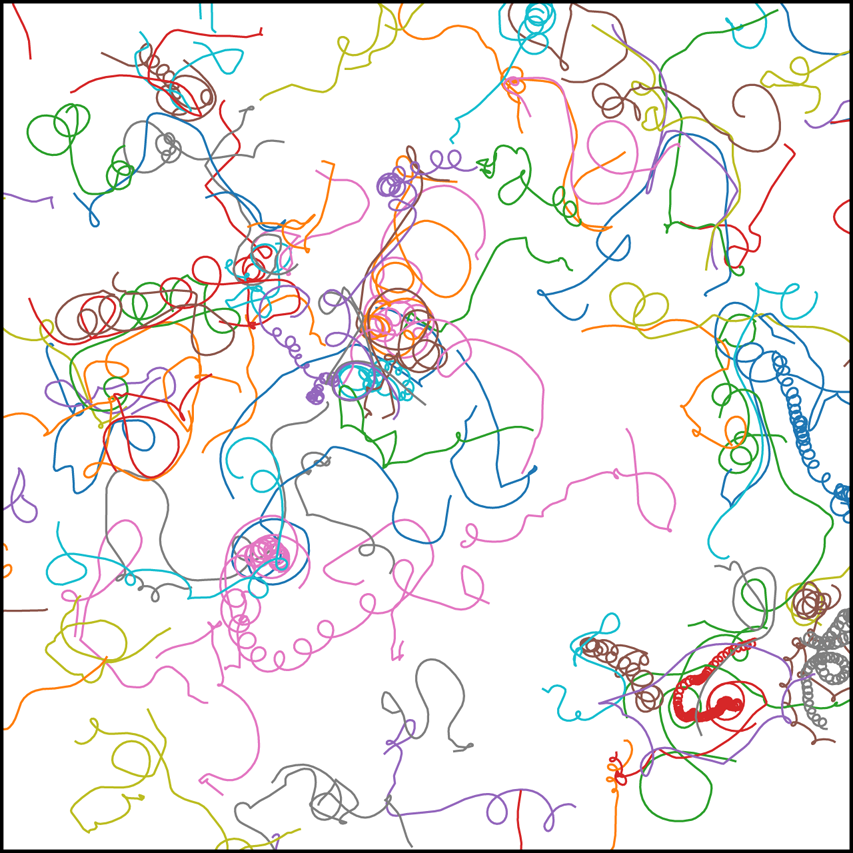
Figure 5. Trajectories of  $100$ passive particles advected in the forced–dissipative model, shown as recorded over a period of
$100$ passive particles advected in the forced–dissipative model, shown as recorded over a period of  $100\tau _{\zeta }$ with a different colour for each trajectory.
$100\tau _{\zeta }$ with a different colour for each trajectory.
5.3. Diagnostics
To illustrate the dynamics that we parameterise with the stochastic models we show two diagnostics commonly used in Lagrangian analyses (Pasquero et al. Reference Pasquero, Provenzale and Babiano2001; van Sebille et al. Reference van Sebille2018), namely, the Lagrangian velocity autocovariance function (LVAF), defined in the isotropic case as
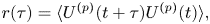 \begin{equation} r(\tau) = \langle U^{(p)}(t+\tau) U^{(p)}(t) \rangle, \end{equation}
\begin{equation} r(\tau) = \langle U^{(p)}(t+\tau) U^{(p)}(t) \rangle, \end{equation}
where the angled brackets denote the average over 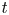 $t$ and particles
$t$ and particles 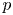 $p$, and the absolute diffusivity
$p$, and the absolute diffusivity
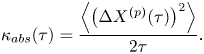 \begin{equation}
\kappa_{abs}(\tau) = \frac{\left\langle\left(\Delta X^{(p)}(\tau)\right)^2\right\rangle}{2\tau}.
\end{equation}
\begin{equation}
\kappa_{abs}(\tau) = \frac{\left\langle\left(\Delta X^{(p)}(\tau)\right)^2\right\rangle}{2\tau}.
\end{equation}
Figure 6 shows the LVAF as estimated from the simulated particle trajectory data. The corresponding LVAF of the Brownian model is a delta function at zero, since velocity is implicitly represented as a white noise process, while the LVAF of the Langevin model, which represents particle velocity as an Ornstein–Uhlenbeck process, is
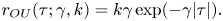 \begin{equation} r_{{OU}}(\tau; \gamma, k) = k\gamma\exp(-\gamma|\tau|). \end{equation}
\begin{equation} r_{{OU}}(\tau; \gamma, k) = k\gamma\exp(-\gamma|\tau|). \end{equation}In contrast, the estimated LVAF of the forced–dissipative model not only shows finite decorrelation time but is noticeably sub-exponential.
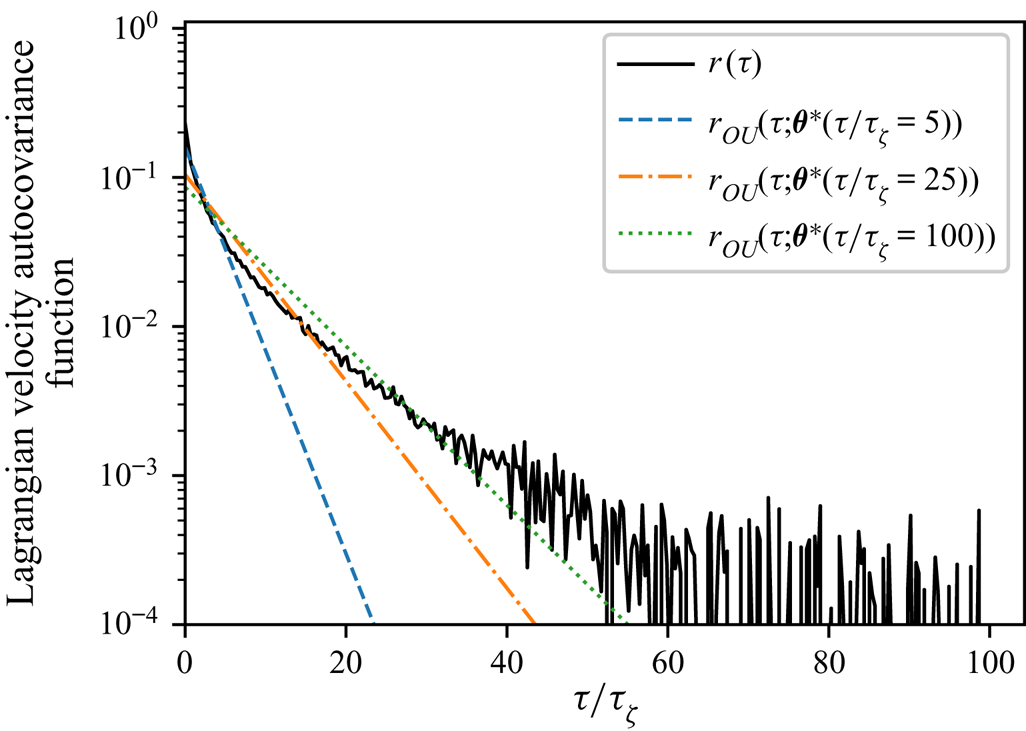
Figure 6. LVAF 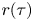 $r(\tau )$ for the forced–dissipative model, as estimated from the full set of
$r(\tau )$ for the forced–dissipative model, as estimated from the full set of 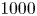 $1000$ simulated particle trajectories. The LVAF of the Langevin model
$1000$ simulated particle trajectories. The LVAF of the Langevin model 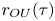 $r_{{OU}}(\tau )$ is also shown using posterior mode estimates (discussed below)
$r_{{OU}}(\tau )$ is also shown using posterior mode estimates (discussed below) 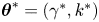 $\boldsymbol {\theta }^*=(\gamma ^*, k^*)$ derived from datasets with
$\boldsymbol {\theta }^*=(\gamma ^*, k^*)$ derived from datasets with 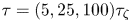 $\tau = (5, 25, 100) \tau _{\zeta }$, respectively (see figure 8).
$\tau = (5, 25, 100) \tau _{\zeta }$, respectively (see figure 8).
Figure 7 shows the estimated absolute diffusivity. In line with the asymptotic laws described in Taylor (Reference Taylor1922) the absolute diffusivity is linear at small 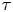 $\tau$ and constant at large
$\tau$ and constant at large 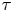 $\tau$, corresponding to the ballistic and diffusive regimes, respectively. The absolute diffusivity of the Brownian model is constant, while that of the Langevin model is
$\tau$, corresponding to the ballistic and diffusive regimes, respectively. The absolute diffusivity of the Brownian model is constant, while that of the Langevin model is
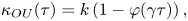 \begin{equation} \kappa_{{OU}}(\tau) = k\left(1-\varphi(\gamma\tau)\right), \end{equation}
\begin{equation} \kappa_{{OU}}(\tau) = k\left(1-\varphi(\gamma\tau)\right), \end{equation}
which is linear at small  $\tau$ and constant at large
$\tau$ and constant at large  $\tau$.
$\tau$.
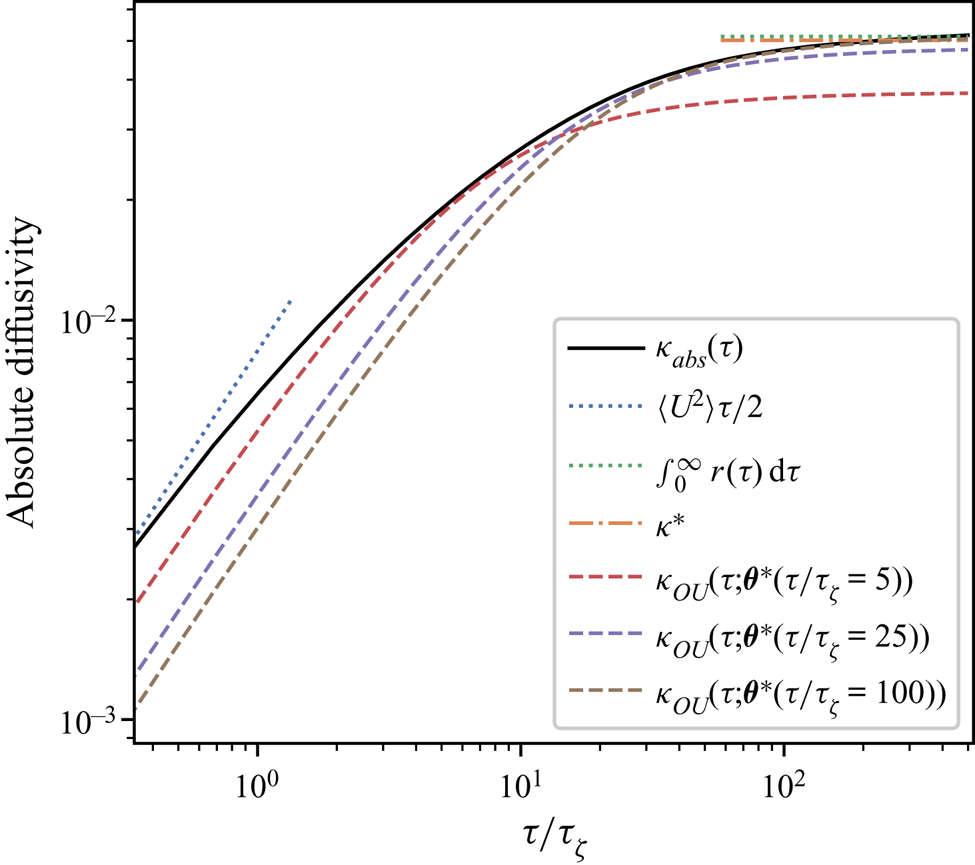
Figure 7. Absolute diffusivity, 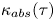 $\kappa _{{abs}}(\tau )$, for the forced–dissipative model, as estimated from the full set of
$\kappa _{{abs}}(\tau )$, for the forced–dissipative model, as estimated from the full set of 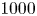 $1000$ simulated particle trajectories. A posterior mode estimate
$1000$ simulated particle trajectories. A posterior mode estimate 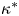 $\kappa ^*$ is shown, along with two asymptotic laws:
$\kappa ^*$ is shown, along with two asymptotic laws: 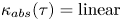 $\kappa _{{abs}}(\tau )= \mathrm {linear}$ (ballistic regime), and
$\kappa _{{abs}}(\tau )= \mathrm {linear}$ (ballistic regime), and 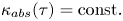 $\kappa _{{abs}}(\tau )= \mathrm {const.}$ (diffusive regime).
$\kappa _{{abs}}(\tau )= \mathrm {const.}$ (diffusive regime).
Qualitatively, from comparing these diagnostics with those of the stochastic models it is clear that, on sufficiently large times (in the diffusive regime), the Brownian model is valid; in particular, the LVAF is well approximated by a delta function at large times, and correspondingly, the absolute diffusivity is constant. On time scales shorter than the diffusive regime the LVAF of the observed trajectories may be better approximated by that of the Langevin model; however, the quality of this approximation is in general unclear a priori. It could be tempting to estimate 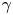 $\gamma$ by fitting the LVAF, using e.g. a least-squares method, but this approach would not correctly deal with uncertainty in parameters.
$\gamma$ by fitting the LVAF, using e.g. a least-squares method, but this approach would not correctly deal with uncertainty in parameters.
5.4. Parameter inference and BMC
We now apply the parameter inference and BMC procedures demonstrated in the test case of § 4.4. By subsampling the results of our particle simulations we generate datasets with 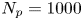 $N_p=1000$,
$N_p=1000$, 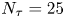 $N_{\tau }=25$, and a set of sampling times
$N_{\tau }=25$, and a set of sampling times 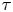 $\tau$ in the range
$\tau$ in the range 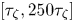 $[\tau _{\zeta }, 250\tau _{\zeta }]$.
$[\tau _{\zeta }, 250\tau _{\zeta }]$.
Prior means for the parameters are derived from 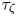 $\tau _{\zeta }$ and the root-mean-square velocity
$\tau _{\zeta }$ and the root-mean-square velocity 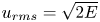 $u_{{rms}}=\sqrt {2E}$, where
$u_{{rms}}=\sqrt {2E}$, where  $E$ is the mean energy: as discussed in § 4.2 we take
$E$ is the mean energy: as discussed in § 4.2 we take
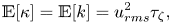 $$\begin{gather} \mathbb{E}[\kappa] = \mathbb{E}[k] = u_{{rms}}^2 \tau_{\zeta}, \end{gather}$$
$$\begin{gather} \mathbb{E}[\kappa] = \mathbb{E}[k] = u_{{rms}}^2 \tau_{\zeta}, \end{gather}$$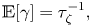 $$\begin{gather}\mathbb{E}[\gamma] = \tau_{\zeta}^{{-}1}, \end{gather}$$
$$\begin{gather}\mathbb{E}[\gamma] = \tau_{\zeta}^{{-}1}, \end{gather}$$and use the corresponding exponential distributions as priors.
The results of the parameter inference are shown in figure 8. The Brownian model is sampling-time consistent for 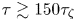 $\tau \gtrsim 150 \tau _{\zeta }$, with a posterior mode that differs by
$\tau \gtrsim 150 \tau _{\zeta }$, with a posterior mode that differs by 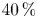 $40\,\%$ from the scaling estimate used as prior mean. The long time required for sampling-time consistency is in line with the expected validity of the Brownian model in the long-time limit. In this limit
$40\,\%$ from the scaling estimate used as prior mean. The long time required for sampling-time consistency is in line with the expected validity of the Brownian model in the long-time limit. In this limit 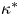 $\kappa ^*$ agrees very well with Reference TaylorTaylor's (Reference Taylor1922) theoretical prediction,
$\kappa ^*$ agrees very well with Reference TaylorTaylor's (Reference Taylor1922) theoretical prediction, 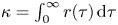 $\kappa =\int _0^\infty r(\tau )\,\text {d}\tau$ (see figure 7).
$\kappa =\int _0^\infty r(\tau )\,\text {d}\tau$ (see figure 7).
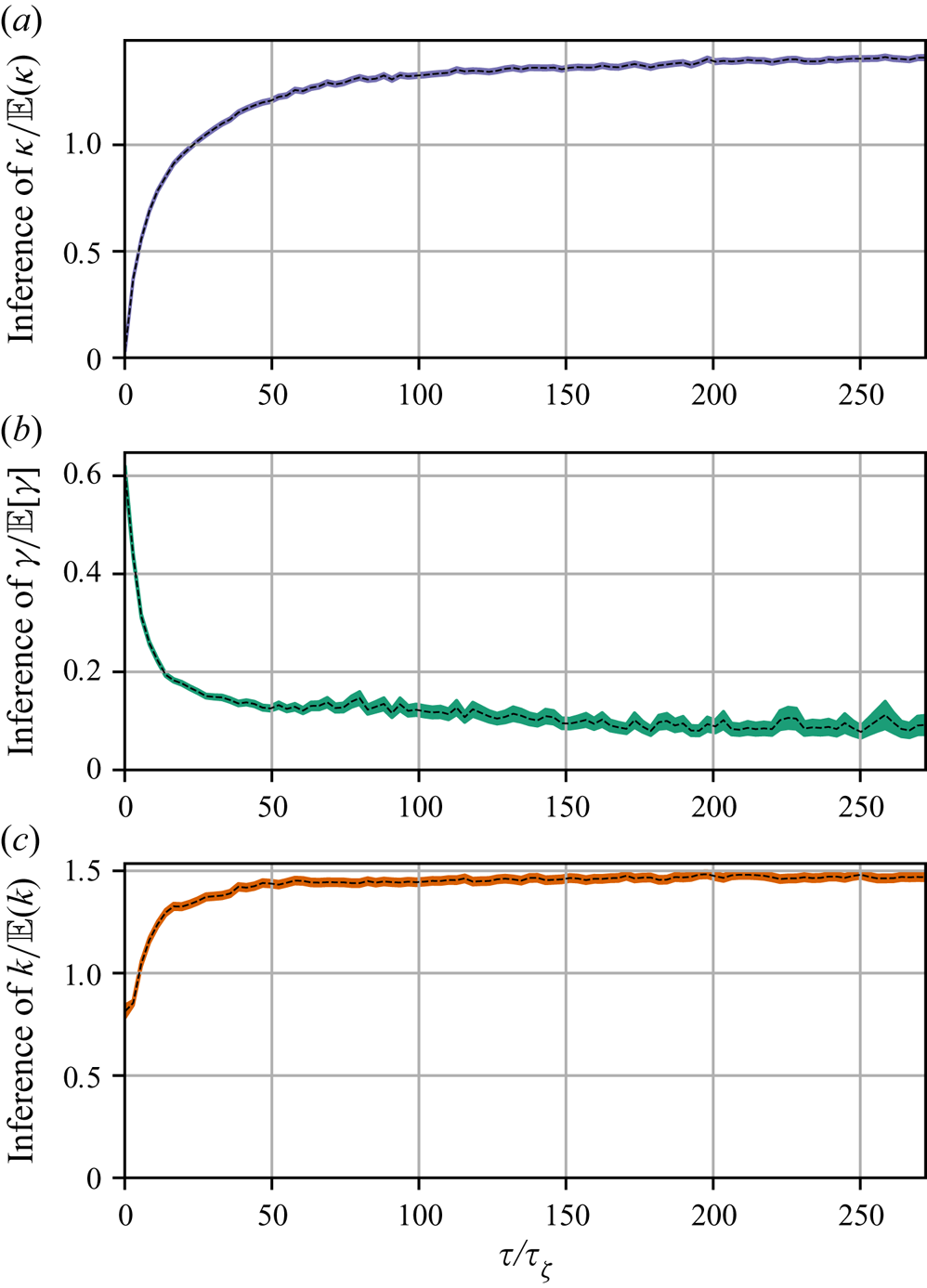
Figure 8. Parameter inference for the Brownian and Langevin models as a function of observation interval, 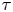 $\tau$, for data from the two-dimensional turbulence model. Dashed lines indicate posterior mode estimates,
$\tau$, for data from the two-dimensional turbulence model. Dashed lines indicate posterior mode estimates, 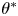 $\theta ^*$, normalised with respect to prior means, and shaded areas are
$\theta ^*$, normalised with respect to prior means, and shaded areas are 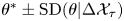 $\theta ^*\pm \text {SD}(\theta |\Delta \mathcal {X}_{\tau })$. Each inference is made with a fixed volume of data:
$\theta ^*\pm \text {SD}(\theta |\Delta \mathcal {X}_{\tau })$. Each inference is made with a fixed volume of data: 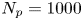 $N_p=1000$ and
$N_p=1000$ and 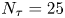 $N_{\tau }=25$.
$N_{\tau }=25$.
The Langevin model is roughly sampling-time consistent from much smaller values of 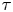 $\tau$, say
$\tau$, say 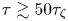 $\tau \gtrsim 50\tau _{\zeta }$. This suggests that there is a range of sampling times, roughly
$\tau \gtrsim 50\tau _{\zeta }$. This suggests that there is a range of sampling times, roughly 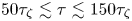 $50 \tau _{\zeta } \lesssim \tau \lesssim 150 \tau _{\zeta }$, where the Langevin model is potentially useful but the Brownian model is not. The BMC analysis below sheds further light on this. However, there is noticeable decay in the posterior mode estimates of
$50 \tau _{\zeta } \lesssim \tau \lesssim 150 \tau _{\zeta }$, where the Langevin model is potentially useful but the Brownian model is not. The BMC analysis below sheds further light on this. However, there is noticeable decay in the posterior mode estimates of 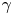 $\gamma$ with increasing
$\gamma$ with increasing 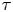 $\tau$ – this is likely a reflection of the sub-exponential nature of the true LVAF. In figure 6 we plot the Langevin LVAF given parameters inferred with data of various
$\tau$ – this is likely a reflection of the sub-exponential nature of the true LVAF. In figure 6 we plot the Langevin LVAF given parameters inferred with data of various 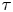 $\tau$, where the decay in estimates of
$\tau$, where the decay in estimates of 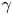 $\gamma$ corresponds to a shallowing of the Langevin LVAF. In figure 7 we plot the absolute diffusivity of the Langevin model
$\gamma$ corresponds to a shallowing of the Langevin LVAF. In figure 7 we plot the absolute diffusivity of the Langevin model 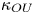 $\kappa _{{OU}}$ using the same parameter estimates as in figure 6. The absolute diffusivity is best approximated at a time scale matching the sampling time of the data. The posterior mode of
$\kappa _{{OU}}$ using the same parameter estimates as in figure 6. The absolute diffusivity is best approximated at a time scale matching the sampling time of the data. The posterior mode of 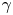 $\gamma$, when roughly stable, is almost an order of magnitude smaller than the scaling estimate in (5.11), indicating that particle dynamics decorrelate slower than might be predicted by a naive dimensional analysis based on the enstrophy alone. In particular, the inferred value of
$\gamma$, when roughly stable, is almost an order of magnitude smaller than the scaling estimate in (5.11), indicating that particle dynamics decorrelate slower than might be predicted by a naive dimensional analysis based on the enstrophy alone. In particular, the inferred value of 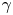 $\gamma$ corresponds to a decorrelation time of approximately
$\gamma$ corresponds to a decorrelation time of approximately 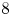 $8$ eddy turnover times. As in the test case of § 4.4 the posterior standard deviation of
$8$ eddy turnover times. As in the test case of § 4.4 the posterior standard deviation of 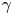 $\gamma$ grows with
$\gamma$ grows with 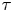 $\tau$ as the diffusive limit is reached and the particle dynamics becomes insensitive to
$\tau$ as the diffusive limit is reached and the particle dynamics becomes insensitive to 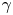 $\gamma$. It is interesting to note that the Langevin diffusivity
$\gamma$. It is interesting to note that the Langevin diffusivity 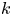 $k$ is estimated consistently for sampling times much shorter than those required to estimate the Brownian diffusivity
$k$ is estimated consistently for sampling times much shorter than those required to estimate the Brownian diffusivity 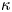 $\kappa$ even though their values are identical when the Brownian model represents the dispersion well. This suggests that carrying out Bayesian inference of the Langevin model might provide a means to estimate the Brownian diffusivity when data are not available over the long, diffusive time scales that are required a priori. This may generalise to other flows only when the Langevin model is a reasonable approximation – inference of
$\kappa$ even though their values are identical when the Brownian model represents the dispersion well. This suggests that carrying out Bayesian inference of the Langevin model might provide a means to estimate the Brownian diffusivity when data are not available over the long, diffusive time scales that are required a priori. This may generalise to other flows only when the Langevin model is a reasonable approximation – inference of 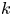 $k$ is unlikely to be sampling-time consistent if inference of
$k$ is unlikely to be sampling-time consistent if inference of 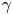 $\gamma$ is not, for example, due to the LVAF of the flow of interest being very far from exponential. We emphasise that the inference results just described are largely insensitive to specification of the prior.
$\gamma$ is not, for example, due to the LVAF of the flow of interest being very far from exponential. We emphasise that the inference results just described are largely insensitive to specification of the prior.
The results of the BMC for the turbulence model data are shown in figure 9. The picture is similar to that in the test case of § 4.4, in that the Bayes factor favours the Langevin model for shorter time scales, but with diminishing strength as 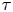 $\tau$ is increased, until, at time scales corresponding to convergence of the Brownian diffusivity, the value of the log Bayes factor becomes small enough that the two models cannot be meaningfully discriminated.
$\tau$ is increased, until, at time scales corresponding to convergence of the Brownian diffusivity, the value of the log Bayes factor becomes small enough that the two models cannot be meaningfully discriminated.
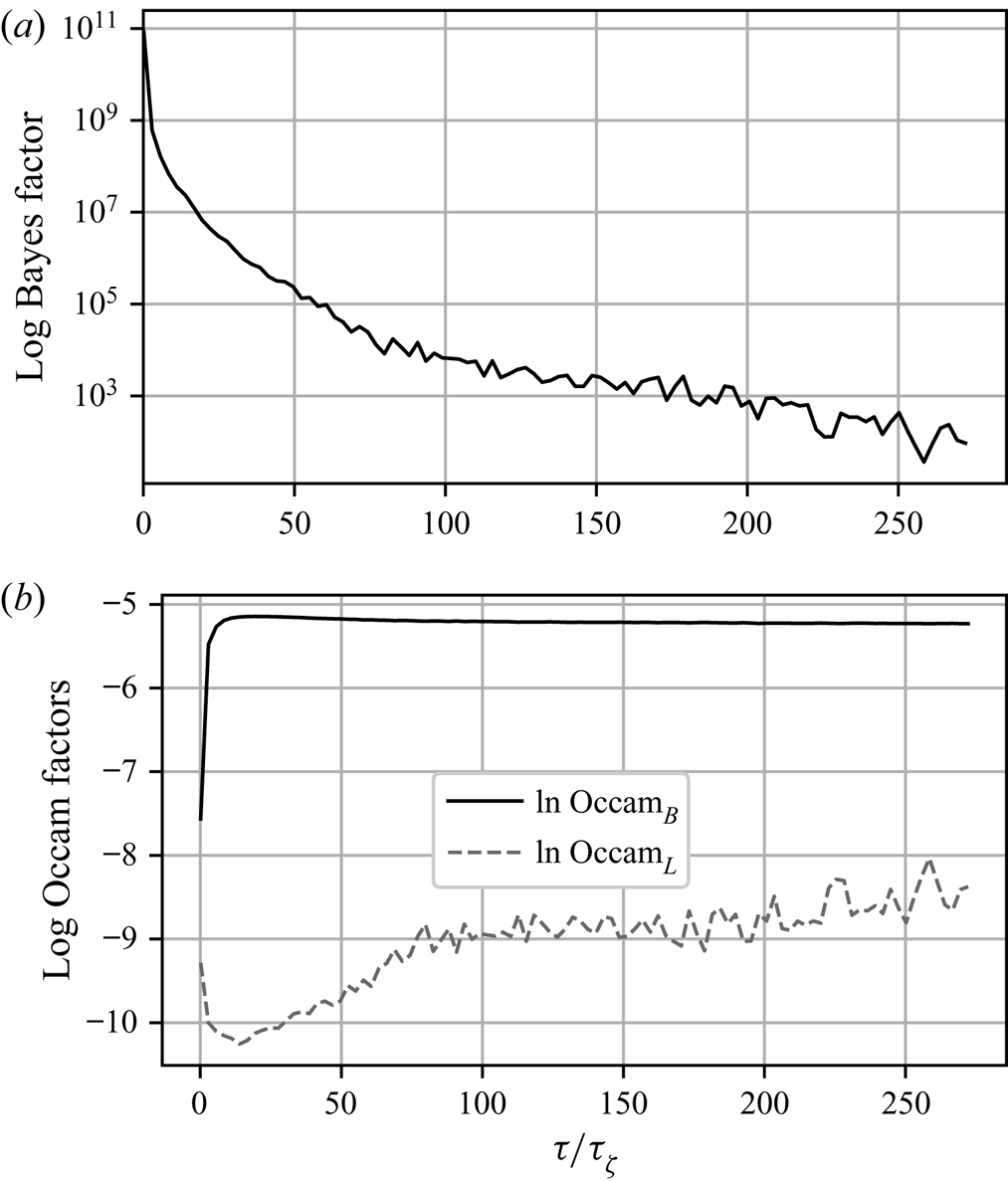
Figure 9. Log Bayes factors, 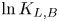 $\ln K_{L,B}$, and corresponding log Occam factors, as a function of
$\ln K_{L,B}$, and corresponding log Occam factors, as a function of 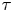 $\tau$, given the same data used for figure 8.
$\tau$, given the same data used for figure 8.
Also shown in figure 9 are the corresponding log Occam factors. For 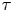 $\tau$ large enough that the Brownian model is sampling-time consistent, its Occam factor is approximately constant and larger than that of the Langevin model. As in the test case in § 4.4, the Occam factor for the Langevin model increases towards that of the Brownian model at large
$\tau$ large enough that the Brownian model is sampling-time consistent, its Occam factor is approximately constant and larger than that of the Langevin model. As in the test case in § 4.4, the Occam factor for the Langevin model increases towards that of the Brownian model at large 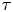 $\tau$ when the particle dynamics is sufficiently decorrelated that the likelihood is less sensitive to the value of
$\tau$ when the particle dynamics is sufficiently decorrelated that the likelihood is less sensitive to the value of 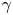 $\gamma$, albeit more slowly, owing to the more slowly decaying LVAF of the turbulent dynamics. The difference in log Occam factors is much smaller than the difference in the corresponding maximum log likelihoods for all but the largest values of
$\gamma$, albeit more slowly, owing to the more slowly decaying LVAF of the turbulent dynamics. The difference in log Occam factors is much smaller than the difference in the corresponding maximum log likelihoods for all but the largest values of 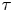 $\tau$, which explains why the Bayes factor mainly favours the Langevin model.
$\tau$, which explains why the Bayes factor mainly favours the Langevin model.
In summary, these results indicate that, while the Brownian model is adequate on sufficiently large time scales (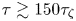 $\tau \gtrsim 150\tau _{\zeta }$), the Langevin model can explain better the dynamics of tracer particles in the turbulence model of § 5.1 on shorter time scales (
$\tau \gtrsim 150\tau _{\zeta }$), the Langevin model can explain better the dynamics of tracer particles in the turbulence model of § 5.1 on shorter time scales (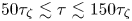 $50\tau _{\zeta }\lesssim \tau \lesssim 150\tau _{\zeta }$). On time scales
$50\tau _{\zeta }\lesssim \tau \lesssim 150\tau _{\zeta }$). On time scales 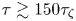 $\tau \gtrsim 150\tau _{\zeta }$ the two models are indistinguishable in their performance, so that in this regime the Brownian model should be favoured in practice as a more parsimonious description.
$\tau \gtrsim 150\tau _{\zeta }$ the two models are indistinguishable in their performance, so that in this regime the Brownian model should be favoured in practice as a more parsimonious description.
6. Conclusions
We have demonstrated the application of BMC to a problem of interest in fluid dynamics, and shown that we can compare the performance of competing stochastic models of particle dynamics given discrete trajectory data alone while accounting for parameter uncertainty. In particular, we found that the Langevin model is preferred over the Brownian model for describing the particle dynamics in a model of two-dimensional turbulence on a range of time scales, but that on sufficiently large time scales the two models perform equally well.
The broad conclusion of the BMC, then, is that the additional complexity of the Langevin model, associated with the presence of an additional parameter, is justified: its better capability to explain the data, as quantified by the maximum likelihood, overwhelms the penalty for complexity quantified by the Occam factor. We stress, however, that this conclusion does not take into account the computational cost involved if the models are used for predictions.
The application of the BMC method to other problems is limited by the feasibility of the calculation of the model evidence. Specifically, BMC inherits the usual challenges of Bayesian and likelihood-based inference procedures, namely that the likelihood can be intractable or expensive to compute for complex models – the Brownian and Langevin models considered here, as linear stochastic differential equations, are very simple examples whose likelihoods could be computed analytically – alternative models which are nonlinear, have higher dimension or have more complicated correlation structure will likely have intractable likelihoods. For example, for spatially inhomogeneous flows, such as in the atmosphere or oceans, nonlinear models arise with spatially varying (and hence high-dimensional) parameters. Fortunately, the collection of methods referred to as approximate Bayesian computation have been developed to deal with this problem. For example, Carson et al. (Reference Carson, Crucifix, Preston and Wilkinson2018) used the SMC $^2$ (‘sequential Monte Carlo squared’) algorithm to compare SDE models of glacial–interglacial cycles with intractable likelihoods.
$^2$ (‘sequential Monte Carlo squared’) algorithm to compare SDE models of glacial–interglacial cycles with intractable likelihoods.
There is the further issue of performing the integration required to obtain the evidence as in (3.3). When the posterior is sufficiently Gaussian like, i.e. peaked around a single mode, Laplace's method can be very accurate (Kass & Raftery Reference Kass and Raftery1995) as well as cheap, however, this requires (at least an approximation to) the Hessian of the log posterior at its mode. Aside from Laplace's method, Krog & Lomholt (Reference Krog and Lomholt2017) and Thapa et al. (Reference Thapa, Lomholt, Krog, Cherstvy and Metzler2018) have implemented the nested sampling algorithm of Skilling (Reference Skilling2004) to calculate the evidence in similar analyses, while the line of work by Hannart et al. (Reference Hannart, Carrassi, Bocquet, Ghil, Naveau, Pulido, Ruiz and Tandeo2016), Carrassi et al. (Reference Carrassi, Bocquet, Hannart and Ghil2017) and Metref et al. (Reference Metref, Hannart, Ruiz, Bocquet, Carrassi and Ghil2019) has sought to perform model evidence estimation using ensemble-based data assimilation methods originally designed for state estimation in the context of incomplete, noisy observations of high-dimensional dynamical systems.
While BMC inevitably comes with computational challenges in complex problems, there are many cases where it can feasibly be applied, and, where it cannot, it should serve as a useful theoretical starting point, with alternative methods measured by how well their conclusions agree with those of BMC.
Funding
M.B. was supported by the MAC-MIGS Centre for Doctoral Training under EPSRC grant EP/S023291/1. J.V. was supported by the EPSRC Programme Grant EP/R045046/1: Probing Multiscale Complex Multiphase Flows with Positrons for Engineering and Biomedical Applications (PI: Professor M. Barigou, University of Birmingham).
Declaration of interests
The authors report no conflict of interest.
Data availability statement
The code required to reproduce the results herein is available at doi.org/10.5281/zenodo.5820320 and the trajectory data generated with the 2-D turbulence model are available at doi.org/10.7488/ds/3267.
Appendix A. Langevin likelihood for position observations
To derive 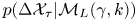 $p(\Delta \mathcal {X}_{\tau }|\mathcal {M}_L(\gamma, k))$ we simplify notation by recognising that all particles are independent under
$p(\Delta \mathcal {X}_{\tau }|\mathcal {M}_L(\gamma, k))$ we simplify notation by recognising that all particles are independent under 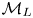 $\mathcal {M}_L$ and that the dynamics in each spatial dimension are independent. We therefore need only calculate
$\mathcal {M}_L$ and that the dynamics in each spatial dimension are independent. We therefore need only calculate 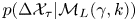 $p(\Delta \mathcal {X}_{\tau }|\mathcal {M}_L(\gamma, k))$ in the one-dimensional, single-particle case. We proceed by: (i) showing that the joint process of particle position and velocity is an order-one vector autoregressive process, or VAR(1) process, and hence, has a Gaussian likelihood, (ii) calculating the mean and covariance for a sequence of joint position–velocity observations and (iii) marginalising this likelihood to find
$p(\Delta \mathcal {X}_{\tau }|\mathcal {M}_L(\gamma, k))$ in the one-dimensional, single-particle case. We proceed by: (i) showing that the joint process of particle position and velocity is an order-one vector autoregressive process, or VAR(1) process, and hence, has a Gaussian likelihood, (ii) calculating the mean and covariance for a sequence of joint position–velocity observations and (iii) marginalising this likelihood to find 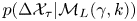 $p(\Delta \mathcal {X}_{\tau }|\mathcal {M}_L(\gamma, k))$.
$p(\Delta \mathcal {X}_{\tau }|\mathcal {M}_L(\gamma, k))$.
It can be shown that for the one-dimensional Langevin equation
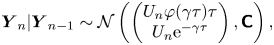 \begin{equation} \boldsymbol{Y}_n|\boldsymbol{Y}_{n-1} \sim \mathcal{N}\left( \begin{pmatrix} U_n\varphi(\gamma\tau)\tau \\ U_n \mathrm{e}^{-\gamma\tau} \end{pmatrix},\boldsymbol{\mathsf{C}} \right), \end{equation}
\begin{equation} \boldsymbol{Y}_n|\boldsymbol{Y}_{n-1} \sim \mathcal{N}\left( \begin{pmatrix} U_n\varphi(\gamma\tau)\tau \\ U_n \mathrm{e}^{-\gamma\tau} \end{pmatrix},\boldsymbol{\mathsf{C}} \right), \end{equation}
where 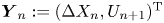 $\boldsymbol {Y}_n:=(\Delta X_n,U_{n+1})^{\mathrm {T}}$ and
$\boldsymbol {Y}_n:=(\Delta X_n,U_{n+1})^{\mathrm {T}}$ and
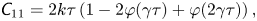 $$\begin{gather} \textit{{C}}_{11}= 2k\tau\left(1 - 2\varphi(\gamma\tau)+\varphi(2\gamma\tau)\right), \end{gather}$$
$$\begin{gather} \textit{{C}}_{11}= 2k\tau\left(1 - 2\varphi(\gamma\tau)+\varphi(2\gamma\tau)\right), \end{gather}$$ $$\begin{gather}\textit{{C}}_{12}=\textit{{C}}_{21}=k(\varphi(\gamma\tau)\gamma\tau)^2, \end{gather}$$
$$\begin{gather}\textit{{C}}_{12}=\textit{{C}}_{21}=k(\varphi(\gamma\tau)\gamma\tau)^2, \end{gather}$$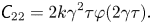 $$\begin{gather}\textit{{C}}_{22}= 2k\gamma^2\tau\varphi(2\gamma\tau). \end{gather}$$
$$\begin{gather}\textit{{C}}_{22}= 2k\gamma^2\tau\varphi(2\gamma\tau). \end{gather}$$This follows from the well-known solution of the Ornstein–Uhlenbeck process,
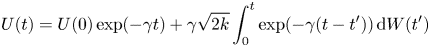 \begin{equation} U(t) = U(0)\exp({-\gamma t}) + \gamma\sqrt{2k}\int_0^t \exp({-\gamma(t-t')})\,\text{d}W(t') \end{equation}
\begin{equation} U(t) = U(0)\exp({-\gamma t}) + \gamma\sqrt{2k}\int_0^t \exp({-\gamma(t-t')})\,\text{d}W(t') \end{equation}and the corresponding solution for the position,
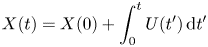 \begin{align} X(t) &= X(0) + \int_0^t U(t')\,\text{d}t' \end{align}
\begin{align} X(t) &= X(0) + \int_0^t U(t')\,\text{d}t' \end{align} \begin{align} &= X(0) + U(0)\varphi(\gamma t)t-\sqrt{2k}\int_0^t\exp({-\gamma(t-t')})\,\text{d}W(t')+\sqrt{2k}\,W(t). \end{align}
\begin{align} &= X(0) + U(0)\varphi(\gamma t)t-\sqrt{2k}\int_0^t\exp({-\gamma(t-t')})\,\text{d}W(t')+\sqrt{2k}\,W(t). \end{align}Therefore, we can write the Langevin model in the time-discretised form
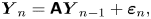 \begin{equation} \boldsymbol{Y}_n =\boldsymbol{\mathsf{A}} \boldsymbol{Y}_{n-1} + \boldsymbol{\varepsilon}_n, \end{equation}
\begin{equation} \boldsymbol{Y}_n =\boldsymbol{\mathsf{A}} \boldsymbol{Y}_{n-1} + \boldsymbol{\varepsilon}_n, \end{equation}where
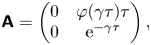 \begin{equation} \boldsymbol{\mathsf{A}} = \begin{pmatrix} 0 & \varphi(\gamma\tau)\tau \\ 0 & \mathrm{e}^{-\gamma\tau} \end{pmatrix}, \end{equation}
\begin{equation} \boldsymbol{\mathsf{A}} = \begin{pmatrix} 0 & \varphi(\gamma\tau)\tau \\ 0 & \mathrm{e}^{-\gamma\tau} \end{pmatrix}, \end{equation}
and 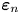 $\boldsymbol {\varepsilon }_n$ is a mean-zero white noise process with covariance matrix
$\boldsymbol {\varepsilon }_n$ is a mean-zero white noise process with covariance matrix 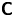 $\boldsymbol{\mathsf{C}}$.
$\boldsymbol{\mathsf{C}}$.
The discrete process (A5) has the form of a VAR(1) process. Furthermore, 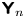 $\boldsymbol{\mathsf{Y}}_n$ is stationary with mean and stationary variance
$\boldsymbol{\mathsf{Y}}_n$ is stationary with mean and stationary variance
 \begin{equation} \boldsymbol{\mu} = \begin{pmatrix} 0\\ 0 \end{pmatrix},\quad \boldsymbol{\mathsf{V}}= \begin{pmatrix} 2k\tau(1-\varphi(\gamma \tau)) & k\varphi(\gamma\tau)\gamma\tau\\ k\varphi(\gamma\tau)\gamma\tau & k\gamma \end{pmatrix}. \end{equation}
\begin{equation} \boldsymbol{\mu} = \begin{pmatrix} 0\\ 0 \end{pmatrix},\quad \boldsymbol{\mathsf{V}}= \begin{pmatrix} 2k\tau(1-\varphi(\gamma \tau)) & k\varphi(\gamma\tau)\gamma\tau\\ k\varphi(\gamma\tau)\gamma\tau & k\gamma \end{pmatrix}. \end{equation}
To see this, note that the marginal distribution of 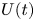 $U(t)$ at any time is given by the stationary distribution of the Ornstein–Uhlenbeck process,
$U(t)$ at any time is given by the stationary distribution of the Ornstein–Uhlenbeck process,
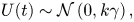 \begin{equation} U(t) \sim \mathcal{N} \left( 0, k\gamma \right), \end{equation}
\begin{equation} U(t) \sim \mathcal{N} \left( 0, k\gamma \right), \end{equation}
which gives 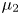 $\mu _2$ and
$\mu _2$ and 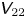 $\textit { {V}}_{22}$. Using (A1), (A8) and Lemma B.1 given in Appendix B yields
$\textit { {V}}_{22}$. Using (A1), (A8) and Lemma B.1 given in Appendix B yields 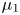 $\mu _1$ and
$\mu _1$ and 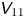 $\textit { {V}}_{11}$. Finally,
$\textit { {V}}_{11}$. Finally, 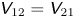 $\textit { {V}}_{12}=\textit { {V}}_{21}$ can be calculated using (A1) and the law of total covariance – specifically
$\textit { {V}}_{12}=\textit { {V}}_{21}$ can be calculated using (A1) and the law of total covariance – specifically
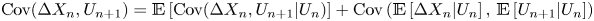 \begin{align} \text{Cov}(\Delta X_n, U_{n+1}) &= \mathbb{E}\left[\text{Cov}(\Delta X_n, U_{n+1}|U_n)\right] + \text{Cov}\left(\mathbb{E}\left[\Delta X_n|U_n\right], \,\mathbb{E}\left[U_{n+1}|U_n\right]\right) \end{align}
\begin{align} \text{Cov}(\Delta X_n, U_{n+1}) &= \mathbb{E}\left[\text{Cov}(\Delta X_n, U_{n+1}|U_n)\right] + \text{Cov}\left(\mathbb{E}\left[\Delta X_n|U_n\right], \,\mathbb{E}\left[U_{n+1}|U_n\right]\right) \end{align} \begin{align} &= \textit{{C}}_{12} + \text{Cov}\left(U_n\varphi(\gamma\tau)\tau,\, U_n \mathrm{e}^{-\gamma\tau}\right) \end{align}
\begin{align} &= \textit{{C}}_{12} + \text{Cov}\left(U_n\varphi(\gamma\tau)\tau,\, U_n \mathrm{e}^{-\gamma\tau}\right) \end{align}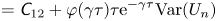 \begin{align} &= \textit{{C}}_{12} + \varphi(\gamma\tau)\tau\mathrm{e}^{-\gamma\tau}\text{Var}(U_n) \end{align}
\begin{align} &= \textit{{C}}_{12} + \varphi(\gamma\tau)\tau\mathrm{e}^{-\gamma\tau}\text{Var}(U_n) \end{align}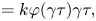 \begin{align} &= k\varphi(\gamma\tau)\gamma\tau, \end{align}
\begin{align} &= k\varphi(\gamma\tau)\gamma\tau, \end{align}
recalling that 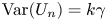 $\text {Var}(U_n)=k\gamma$.
$\text {Var}(U_n)=k\gamma$.
The autocovariance of 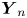 $\boldsymbol {Y}_n$ is defined as
$\boldsymbol {Y}_n$ is defined as
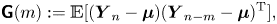 \begin{equation} \boldsymbol{\mathsf{G}}(m) := \mathbb{E}[(\boldsymbol{Y}_n-\boldsymbol{\mu})(\boldsymbol{Y}_{n-m}-\boldsymbol{\mu})^{\mathrm{T}}], \end{equation}
\begin{equation} \boldsymbol{\mathsf{G}}(m) := \mathbb{E}[(\boldsymbol{Y}_n-\boldsymbol{\mu})(\boldsymbol{Y}_{n-m}-\boldsymbol{\mu})^{\mathrm{T}}], \end{equation}
where 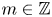 $m\in \mathbb {Z}$. Notice that
$m\in \mathbb {Z}$. Notice that 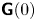 $\boldsymbol{\mathsf{G}}(0)$ is the stationary variance of
$\boldsymbol{\mathsf{G}}(0)$ is the stationary variance of 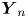 $\boldsymbol {Y}_n$. Postmultiplying (A5) by
$\boldsymbol {Y}_n$. Postmultiplying (A5) by 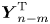 $\boldsymbol {Y}_{n-m}^{\mathrm {T}}$ and taking expectations gives
$\boldsymbol {Y}_{n-m}^{\mathrm {T}}$ and taking expectations gives
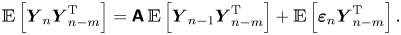 \begin{equation} \mathbb{E}\left[ \boldsymbol{Y}_n \boldsymbol{Y}_{n-m}^{\mathrm{T}} \right] = \boldsymbol{\mathsf{A}}\, \mathbb{E}\left[ \boldsymbol{Y}_{n-1} \boldsymbol{Y}_{n-m}^{\mathrm{T}} \right] + \mathbb{E}\left[ \boldsymbol{\varepsilon}_n \boldsymbol{Y}_{n-m}^{\mathrm{T}} \right]. \end{equation}
\begin{equation} \mathbb{E}\left[ \boldsymbol{Y}_n \boldsymbol{Y}_{n-m}^{\mathrm{T}} \right] = \boldsymbol{\mathsf{A}}\, \mathbb{E}\left[ \boldsymbol{Y}_{n-1} \boldsymbol{Y}_{n-m}^{\mathrm{T}} \right] + \mathbb{E}\left[ \boldsymbol{\varepsilon}_n \boldsymbol{Y}_{n-m}^{\mathrm{T}} \right]. \end{equation}
Thus, for 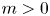 $m>0$, since
$m>0$, since 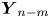 $\boldsymbol {Y}_{n-m}$ is independent of
$\boldsymbol {Y}_{n-m}$ is independent of 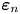 $\boldsymbol {\varepsilon }_n$,
$\boldsymbol {\varepsilon }_n$,
 \begin{equation} \boldsymbol{\mathsf{G}}(m) = \boldsymbol{\mathsf{AG}}(m-1). \end{equation}
\begin{equation} \boldsymbol{\mathsf{G}}(m) = \boldsymbol{\mathsf{AG}}(m-1). \end{equation}
Therefore, 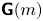 $\boldsymbol{\mathsf{G}}(m)$ can be calculated recursively for
$\boldsymbol{\mathsf{G}}(m)$ can be calculated recursively for 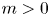 $m>0$ as
$m>0$ as
 \begin{align} \boldsymbol{\mathsf{G}}(m) &= \boldsymbol{\mathsf{A}}^m\, \boldsymbol{\mathsf{G}}(0) \end{align}
\begin{align} \boldsymbol{\mathsf{G}}(m) &= \boldsymbol{\mathsf{A}}^m\, \boldsymbol{\mathsf{G}}(0) \end{align}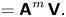 \begin{align} &= \boldsymbol{\mathsf{A}}^m\, \boldsymbol{\mathsf{V}}. \end{align}
\begin{align} &= \boldsymbol{\mathsf{A}}^m\, \boldsymbol{\mathsf{V}}. \end{align}Note that (A12) is an instance of a Yule–Walker equation (Lütkepohl Reference Lütkepohl2007, pp. 26–27).
Thus, the joint distribution of a sequence of observations 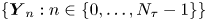 $\{\boldsymbol {Y}_n:n\in \{0, \ldots, N_{\tau } - 1\}\}$ is given by
$\{\boldsymbol {Y}_n:n\in \{0, \ldots, N_{\tau } - 1\}\}$ is given by
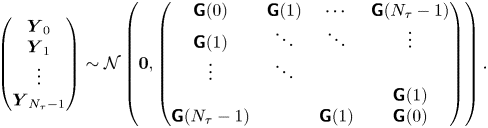 \begin{equation} \begin{pmatrix} \boldsymbol{Y}_0\\ \boldsymbol{Y}_1\\ \vdots\\ \boldsymbol{Y}_{N_{\tau}-1} \end{pmatrix} \sim\mathcal{N}\left(\boldsymbol{0}, \begin{pmatrix} \boldsymbol{\mathsf{G}}(0) & \boldsymbol{\mathsf{G}}(1) & \cdots & \boldsymbol{\mathsf{G}}(N_{\tau}-1)\\ \boldsymbol{\mathsf{G}}(1) & \ddots & \ddots & \vdots\\ \vdots & \ddots\\ & & & \boldsymbol{\mathsf{G}}(1)\\ \boldsymbol{\mathsf{G}}(N_{\tau}-1) & & \boldsymbol{\mathsf{G}}(1) & \boldsymbol{\mathsf{G}}(0) \end{pmatrix}\right). \end{equation}
\begin{equation} \begin{pmatrix} \boldsymbol{Y}_0\\ \boldsymbol{Y}_1\\ \vdots\\ \boldsymbol{Y}_{N_{\tau}-1} \end{pmatrix} \sim\mathcal{N}\left(\boldsymbol{0}, \begin{pmatrix} \boldsymbol{\mathsf{G}}(0) & \boldsymbol{\mathsf{G}}(1) & \cdots & \boldsymbol{\mathsf{G}}(N_{\tau}-1)\\ \boldsymbol{\mathsf{G}}(1) & \ddots & \ddots & \vdots\\ \vdots & \ddots\\ & & & \boldsymbol{\mathsf{G}}(1)\\ \boldsymbol{\mathsf{G}}(N_{\tau}-1) & & \boldsymbol{\mathsf{G}}(1) & \boldsymbol{\mathsf{G}}(0) \end{pmatrix}\right). \end{equation} Marginalising (A14) for the distribution of 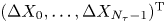 $(\Delta X_0, \ldots, \Delta X_{N_{\tau }-1})^{\mathrm {T}}$ we find
$(\Delta X_0, \ldots, \Delta X_{N_{\tau }-1})^{\mathrm {T}}$ we find
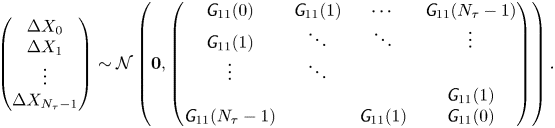 \begin{equation} \begin{pmatrix} \Delta X_0\\ \Delta X_1\\ \vdots\\ \Delta X_{N_{\tau}-1} \end{pmatrix} \sim\mathcal{N}\left(\boldsymbol{0}, \begin{pmatrix} \textit{{G}}_{11}(0) & \textit{{G}}_{11}(1) & \cdots & \textit{{G}}_{11}(N_{\tau}-1)\\ \textit{{G}}_{11}(1) & \ddots & \ddots & \vdots\\ \vdots & \ddots\\ & & & \textit{{G}}_{11}(1)\\ \textit{{G}}_{11}(N_{\tau}-1) & & \textit{{G}}_{11}(1) & \textit{{G}}_{11}(0) \end{pmatrix}\right). \end{equation}
\begin{equation} \begin{pmatrix} \Delta X_0\\ \Delta X_1\\ \vdots\\ \Delta X_{N_{\tau}-1} \end{pmatrix} \sim\mathcal{N}\left(\boldsymbol{0}, \begin{pmatrix} \textit{{G}}_{11}(0) & \textit{{G}}_{11}(1) & \cdots & \textit{{G}}_{11}(N_{\tau}-1)\\ \textit{{G}}_{11}(1) & \ddots & \ddots & \vdots\\ \vdots & \ddots\\ & & & \textit{{G}}_{11}(1)\\ \textit{{G}}_{11}(N_{\tau}-1) & & \textit{{G}}_{11}(1) & \textit{{G}}_{11}(0) \end{pmatrix}\right). \end{equation}
Using (A7a,b) and (A12) it is easy to see that for 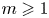 $m\geqslant 1$
$m\geqslant 1$
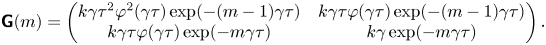 \begin{equation} \boldsymbol{\mathsf{G}}(m) = \begin{pmatrix} k\gamma\tau^2\varphi^2(\gamma\tau)\exp({-(m-1)\gamma\tau}) & k\gamma\tau\varphi(\gamma\tau)\exp({-(m-1)\gamma\tau})\\ k\gamma\tau\varphi(\gamma\tau)\exp({-m\gamma\tau}) & k\gamma \exp({-m\gamma\tau}) \end{pmatrix}. \end{equation}
\begin{equation} \boldsymbol{\mathsf{G}}(m) = \begin{pmatrix} k\gamma\tau^2\varphi^2(\gamma\tau)\exp({-(m-1)\gamma\tau}) & k\gamma\tau\varphi(\gamma\tau)\exp({-(m-1)\gamma\tau})\\ k\gamma\tau\varphi(\gamma\tau)\exp({-m\gamma\tau}) & k\gamma \exp({-m\gamma\tau}) \end{pmatrix}. \end{equation}Hence, in particular,
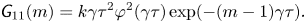 \begin{equation} \textit{{G}}_{11}(m) = k\gamma\tau^2\varphi^2(\gamma\tau)\exp({-(m-1)\gamma\tau}). \end{equation}
\begin{equation} \textit{{G}}_{11}(m) = k\gamma\tau^2\varphi^2(\gamma\tau)\exp({-(m-1)\gamma\tau}). \end{equation}
The likelihood 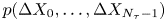 $p(\Delta X_0, \ldots, \Delta X_{N_{\tau }-1})$ is determined by (A15) and (A17).
$p(\Delta X_0, \ldots, \Delta X_{N_{\tau }-1})$ is determined by (A15) and (A17).
Appendix B
Lemma B.1 If 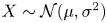 $X\sim \mathcal {N}(\mu,\sigma ^2)$ and
$X\sim \mathcal {N}(\mu,\sigma ^2)$ and  $Y|X\sim \mathcal {N}(aX,\tau ^2)$, then
$Y|X\sim \mathcal {N}(aX,\tau ^2)$, then 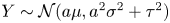 $Y\sim \mathcal {N}(a\mu,a^2\sigma ^2 +\tau ^2)$.
$Y\sim \mathcal {N}(a\mu,a^2\sigma ^2 +\tau ^2)$.
Proof. Consider the moment generating function of 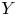 $Y$,
$Y$, 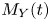 $M_Y(t)$. Recall that for a Gaussian random variable such as
$M_Y(t)$. Recall that for a Gaussian random variable such as 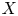 $X$ the moment generating function is
$X$ the moment generating function is
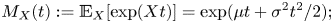 \begin{equation} M_X(t) := \mathbb{E}_X[\exp({Xt})] = \exp({\mu t+\sigma^2 t^2 / 2}); \end{equation}
\begin{equation} M_X(t) := \mathbb{E}_X[\exp({Xt})] = \exp({\mu t+\sigma^2 t^2 / 2}); \end{equation}
similarly, since 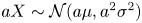 $aX\sim \mathcal {N}(a\mu,a^2\sigma ^2)$,
$aX\sim \mathcal {N}(a\mu,a^2\sigma ^2)$,
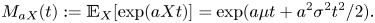 \begin{equation} M_{aX}(t) := \mathbb{E}_X[\exp({aXt})] = \exp({a\mu t+a^2\sigma^2 t^2 / 2}). \end{equation}
\begin{equation} M_{aX}(t) := \mathbb{E}_X[\exp({aXt})] = \exp({a\mu t+a^2\sigma^2 t^2 / 2}). \end{equation}Now,
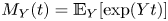 \begin{align} M_Y(t) &= \mathbb{E}_Y[\exp({Yt})] \end{align}
\begin{align} M_Y(t) &= \mathbb{E}_Y[\exp({Yt})] \end{align}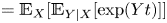 \begin{align} &= \mathbb{E}_X[\mathbb{E}_{Y|X}[\exp({Yt})]] \end{align}
\begin{align} &= \mathbb{E}_X[\mathbb{E}_{Y|X}[\exp({Yt})]] \end{align}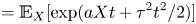 \begin{align} &= \mathbb{E}_X[\exp({aXt + \tau^2t^2/2})] \end{align}
\begin{align} &= \mathbb{E}_X[\exp({aXt + \tau^2t^2/2})] \end{align}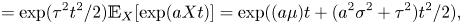 \begin{align} &= \exp({\tau^2t^2/2})\mathbb{E}_X[\exp({aXt})] = \exp({(a\mu) t+(a^2\sigma^2+\tau^2)t^2/2}), \end{align}
\begin{align} &= \exp({\tau^2t^2/2})\mathbb{E}_X[\exp({aXt})] = \exp({(a\mu) t+(a^2\sigma^2+\tau^2)t^2/2}), \end{align}
which we can recognise as the moment generating function of a Gaussian random variable with mean 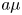 $a\mu$ and variance
$a\mu$ and variance 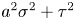 $a^2\sigma ^2+\tau ^2$.
$a^2\sigma ^2+\tau ^2$.
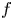









































 Open access
Open access