



No CrossRef data available.
Article contents
The ‘−1’ decay law for some small-scale quantities at large Péclet numbers and fixed Reynolds numbers
Published online by Cambridge University Press: 12 December 2023
Abstract
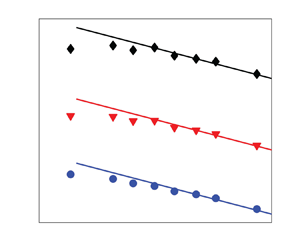
The effect of a uniform mean scalar gradient on the small scales of a passive scalar field in statistically stationary homogeneous isotropic turbulence is investigated through the transport equation for the scalar fluctuation. After some manipulation of the equation, it is shown that the effect can be recast in the form  $S_\theta ^* {{Pe^{-1}_{\lambda _\theta }}}$ (
$S_\theta ^* {{Pe^{-1}_{\lambda _\theta }}}$ ( $S_\theta ^*$ is the non-dimensional scalar gradient,
$S_\theta ^*$ is the non-dimensional scalar gradient,  ${{Pe_{\lambda _\theta }}}$ is the turbulent Péclet number). This effect gradually disappears as
${{Pe_{\lambda _\theta }}}$ is the turbulent Péclet number). This effect gradually disappears as  ${{Pe_{\lambda _\theta }}}$ becomes sufficiently large, implying a gradual approach towards local isotropy of the passive scalar. It is further argued that, for a given
${{Pe_{\lambda _\theta }}}$ becomes sufficiently large, implying a gradual approach towards local isotropy of the passive scalar. It is further argued that, for a given  $S_\theta ^*$, the normalized odd moments of the scalar derivative tend towards isotropy as
$S_\theta ^*$, the normalized odd moments of the scalar derivative tend towards isotropy as  ${{Pe^{-1}_{\lambda _\theta }}}$. This is supported by direct numerical simulations data for the normalized odd moments of the scalar derivative at large Péclet numbers. Further, the present derivation leads to the same prediction (
${{Pe^{-1}_{\lambda _\theta }}}$. This is supported by direct numerical simulations data for the normalized odd moments of the scalar derivative at large Péclet numbers. Further, the present derivation leads to the same prediction ( ${\sim }Sc^{-0.45}$ where Sc is the Schmidt number) as Buaria et al. (Phys. Rev. Lett., vol. 126, no. 3, 2021a, p. 034504) and complements the derivation by the latter authors, which is based on dimensional arguments and the introduction of a new diffusive length scale.
${\sim }Sc^{-0.45}$ where Sc is the Schmidt number) as Buaria et al. (Phys. Rev. Lett., vol. 126, no. 3, 2021a, p. 034504) and complements the derivation by the latter authors, which is based on dimensional arguments and the introduction of a new diffusive length scale.
JFM classification
- Type
- JFM Papers
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press
References
Abe, H., Antonia, R.A. & Kawamura, H. 2009 Correlation between small-scale velocity and scalar fluctuations in a turbulent channel flow. J. Fluid Mech. 627, 1–32.CrossRefGoogle Scholar
Antonia, R.A. & Browne, L.W.B. 1983 The destruction of temperature fluctuations in a turbulent plane jet. J. Fluid Mech. 134, 67–83.CrossRefGoogle Scholar
Antonia, R.A. & Orlandi, P. 2003 Effect of Schmidt number on small-scale passive scalar turbulence. Appl. Mech. Rev. 56 (6), 615–632.CrossRefGoogle Scholar
Brethouwer, G., Hunt, J.C.R. & Nieuwstadt, F.T.M. 2003 Micro-structure and Lagrangian statistics of the scalar field with a mean gradient in isotropic turbulence. J. Fluid Mech. 474, 193–225.CrossRefGoogle Scholar
Buaria, D., Clay, M.P., Sreenivasan, K.R. & Yeung, P.K. 2021 a Small-scale isotropy and ramp-cliff structures in scalar turbulence. Phys. Rev. Lett. 126 (3), 034504.CrossRefGoogle ScholarPubMed
Buaria, D., Clay, M.P., Sreenivasan, K.R. & Yeung, P.K. 2021 b Turbulence is an ineffective mixer when Schmidt numbers are large. Phys. Rev. Lett. 126 (7), 074501.CrossRefGoogle ScholarPubMed
Buaria, D. & Sreenivasan, K.R. 2023 Comparing velocity and passive scalar statistics in fluid turbulence at high Schmidt numbers and Reynolds numbers. arXiv:2302.05503.Google Scholar
Buaria, D., Yeung, P.K. & Sawford, B.L. 2016 A Lagrangian study of turbulent mixing: forward and backward dispersion of molecular trajectories in isotropic turbulence. J. Fluid Mech. 799, 352–382.CrossRefGoogle Scholar
Clay, M. 2017 Strained turbulence and low-diffusivity turbulent mixing using high performance computing. PhD thesis, Georgia Institute of Technology.Google Scholar
Corrsin, S. 1951 On the spectrum of isotropic temperature fluctuations in an isotropic turbulence. J. Appl. Phys. 22, 469–473.CrossRefGoogle Scholar
Corrsin, S. 1952 Heat transfer in isotropic turbulence. J. Appl. Phys. 23 (1), 113–118.CrossRefGoogle Scholar
Corrsin, S. 1953 Remarks on turbulent heat transfer: an account of some features of the phenomenon in fully turbulent regions. In Proceedings of the first Iowa Thermodynamics Symposium, pp. 5–30. State University of Iowa.Google Scholar
Donzis, D.A., Sreenivasan, K.R. & Yeung, P.K. 2005 Scalar dissipation rate and dissipative anomaly in isotropic turbulence. J. Fluid Mech. 532, 199–216.CrossRefGoogle Scholar
Gibson, C.H., Friehe, C.A. & McConnell, S.O. 1977 Structure of sheared turbulent fields. Phys. Fluids 20, S156–S167.CrossRefGoogle Scholar
Holzer, M. & Siggia, E.D. 1994 Turbulent mixing of a passive scalar. Phys. Fluids 6 (5), 1820–1837.CrossRefGoogle Scholar
Mestayer, P.G., Gibson, C.H., Coantic, M.F. & Patel, A.S. 1976 Local anisotropy in heated and cooled turbulent boundary layers. Phys. Fluids 19, 1279–1287.CrossRefGoogle Scholar
Obukhov, A.M. 1949 Structure of the temperature field in turbulent flows. Izv. Akad. Nauk SSSR Geogr. Geofiz 13, 58–69.Google Scholar
Pumir, A. 1994 A numerical study of the mixing of a passive scalar in three dimensions in the presence of a mean gradient. Phys. Fluids 6 (6), 2118–2132.CrossRefGoogle Scholar
Schumacher, J. & Sreenivasan, K.R. 2003 Geometric features of the mixing of passive scalars at high Schmidt numbers. Phys. Rev. Lett. 91 (17), 174501.CrossRefGoogle ScholarPubMed
Shete, K.P., Boucher, D.J., Riley, J.J. & de Bruyn Kops, S.M. 2022 Effect of viscous-convective subrange on passive scalar statistics at high Reynolds number. Phys. Rev. Fluids 7 (2), 024601.CrossRefGoogle Scholar
Shraiman, B.I. & Siggia, E.D. 2000 Scalar turbulence. Nature 405 (6787), 639–646.CrossRefGoogle ScholarPubMed
Sreenivasan, K. 1991 On local isotropy of passive scalars in turbulent shear flows. Proc. R. Soc. Lond. A 434, 165–182.Google Scholar
Sreenivasan, K.R. 2019 Turbulent mixing: a perspective. Proc. Natl Acad. Sci. 116 (37), 18175–18183.CrossRefGoogle ScholarPubMed
Sreenivasan, K.R. & Antonia, R.A. 1977 Skewness of temperature derivatives in turbulent shear flows. Phys. Fluids 20 (12), 1986–1988.CrossRefGoogle Scholar
Sreenivasan, K. & Antonia, R.A. 1997 The phenomenology of small-scale turbulence. Annu. Rev. Fluid Mech. 29, 435–472.CrossRefGoogle Scholar
Sreenivasan, K.R., Antonia, R.A. & Britz, D. 1979 Local isotropy and large structures in a heated turbulent jet. J. Fluid Mech. 94 (4), 745–775.CrossRefGoogle Scholar
Sreenivasan, K.R. & Tavoularis, S. 1980 On the skewness of the temperature derivative in turbulent flows. J. Fluid Mech. 101 (4), 783–795.CrossRefGoogle Scholar
Subramanian, C.S. & Antonia, R.A. 1982 A model for the skewness of the temperature derivative in a turbulent boundary layer. Phys. Fluids 25, 957–958.CrossRefGoogle Scholar
Tong, C. & Warhaft, Z. 1994 On passive scalar derivative statistics in grid turbulence. Phys. Fluids 6 (6), 2165–2176.CrossRefGoogle Scholar
Warhaft, Z. 2000 Passive scalars in turbulent flows. Annu. Rev. Fluid Mech. 32, 203–240.CrossRefGoogle Scholar
Wyngaard, J.C. 1971 The effect of velocity sensitivity on temperature derivative statistics in isotropic turbulence. J. Fluid Mech. 48, 763–769.CrossRefGoogle Scholar
Yasuda, T., Gotoh, T., Watanabe, T. & Saito, I. 2020 Péclet-number dependence of small-scale anisotropy of passive scalar fluctuations under a uniform mean gradient in isotropic turbulence. J. Fluid Mech. 898, A4.CrossRefGoogle Scholar
Yeung, P.K., Donzis, D.A. & Sreenivasan, K.R. 2005 High-Reynolds-number simulation of turbulent mixing. Phys. Fluids 17, 081703.CrossRefGoogle Scholar
Yeung, P.K. & Sreenivasan, K.R. 2014 Direct numerical simulation of turbulent mixing at very low Schmidt number with a uniform mean gradient. Phys. Fluids 26 (1), 015107.CrossRefGoogle Scholar
Yeung, P.K., Xu, S., Donzis, D.A. & Sreenivasan, K.R. 2004 Simulations of three-dimensional turbulent mixing for Schmidt numbers of the order 1000. Flow Turbul. Combust. 72 (2), 333–347.CrossRefGoogle Scholar
Yeung, P.K., Xu, S. & Sreenivasan, K.R. 2002 Schmidt number effects on turbulent transport with uniform mean scalar gradient. Phys. Fluids 14 (12), 4178–4191.CrossRefGoogle Scholar
Yeung, P.K. & Zhou, Y. 1997 Universality of the Kolmogorov constant in numerical simulations of turbulence. Phys. Rev. E 56, 1746–1752.CrossRefGoogle Scholar