


“Crowdsourcing” samples have emerged as a fast, easy, and inexpensive source of subjects for experimental research. In particular, Amazon's Mechanical Turk has become a popular source for quickly and cheaply recruiting large numbers of respondents (Berinsky et al., Reference Berinsky, Huber and Lenz2012; Paolacci et al., Reference Paolacci, Chandler and Ipeirotis2010). “Turkers,” as they are known, are a ready alternative to undergraduates or professionally assembled samples, and offer two major benefits: their availability (Hitlin, Reference Hitlin2016; though also see Stewart et al., Reference Stewart, Ungemach, Harris, Bartels, Newll, Paolacci and Chandler2015) and their inexpensive cost, while still providing a diverse pool of subjects (Huff and Tingley, Reference Huff and Tingley2015; Ipeirotis, Reference Ipeirotis2010; Levay et al., Reference Levay, Freese and Druckman2016).
Determining what to pay subjects on Mechanical Turk can be challenging for two reasons that may risk the quality of the sample recruited. First, different pay rates may attract different participants. Turkers selectively choose which available HITs they will accept, making it possible that the selection process may introduce sample biases (Krupnikov and Levine, Reference Krupnikov and Levine2014). Higher pay rates may attract a different type of worker than lower pay rates, either demographically or along some other factor that might influence subject performance. Second, paying too little in compensation may lead to sub-par subject attention, as participants who decide they are not going to be sufficiently compensated alter their performance (Berinsky et al., Reference Berinsky, Margolis and Sances2016).
For simple tasks with “right” or “wrong” results that the Requester can evaluate, there is an easy mechanism for evaluating subject behavior – rewarding accurate behavior through payment and punishing inaccurate behavior by denying payment. The Requester simply checks on the work as it is returned to make sure that the Worker was indeed paying attention and performing adequately. Turkers know this, and behave accordingly.
As Ho, Slivkins, Suri, and Vaughan describe: “even when standard, unconditional payments are used and no explicit acceptance criteria is specified, workers may behave as if the payments are implicitly performance-based since they believe their work may be rejected if its quality is sufficiently low” (Ho et al., Reference Ho, Slivkins, Suri and Vaughan2015). In such scenarios, different pay rates have been demonstrated to motivate workers to do a greater quantity of work, but not at higher quality (Mason and Watts, Reference Mason and Watts2009). Similarly, several studies have shown that, when work is verifiable based upon accuracy or correctness, pay rates can influence worker behavior positively (Finnerty et al., Reference Finnerty, Kucherbaev, Tranquillini and Convertino2013; Horton and Chilton, Reference Horton and Chilton2010; Ho et al., Reference Ho, Slivkins, Suri and Vaughan2015; Ye et al., Reference Ye, You and Robert2017).
Social scientists should take pause at this, because all of these studies are conditional upon the ability to review subject performance using objective criteria. For example, determining if a subject correctly ordered images, or successfully identified words among a jumble of letters is relatively easy (Mason and Watts, Reference Mason and Watts2009). However, subject performance in social scientific studies tends to lack a strong evaluation component. That is, subjects are asked to behave “normally” and react to the information and stimuli they are provided as they would in the real-world, but without the ability of the experimenter to verify that they are indeed doing so. Behaving “normally” does not clearly indicate a “right” or “wrong” set of behaviors that can be observed. It is exceedingly difficult to determine if a subject is paying attention to an online study (Berinsky et al., Reference Berinsky, Huber and Lenz2012; Berinsky et al., Reference Berinsky, Margolis and Sances2016; Hauser and Schwarz, Reference Hauser and Schwarz2016, Paolacci et al., Reference Paolacci, Chandler and Ipeirotis2010), or answering honestly (Chandler et al., 2014; Rouse, Reference Rouse2015) or behaving as they normally would.
METHOD
We identified three areas where payment might affect subject behavior that could matter to a researcher: self-selection (who chooses to accept the HIT), engagement (how actively subjects paid attention to and interacted with the study), and performance (how those subjects reacted to what they saw in the study). Since, we can identify no correct form of behavior; we simply look to see if different pay rates produce different between-subject behavior across a range of measures. If pay rates do play an influence, we would expect to see either a linear relationship (where higher rates of pay lead to greater attention and performance), or a threshold effect (where performance shifts when an “acceptable rate” has been reached) on a consistent basis. Thus, we are not seeking a single significant finding, but are looking for emerging patterns of behavioral differences that emerge between pay groups.
We conducted two separate studies – one short and easy, the other long and difficult – in order to view the effects of different pay rates on performance in different styles of social science experiments. The first study was a short survey experiment designed in Qualtrics, involving one randomized image followed by 13 questions.Footnote 1 The second study was programmed in the Dynamic Process Tracing Environment (DPTE) and asked subjects to learn about and vote for political candidates.Footnote 2
If pay rates influence subject recruitment and participation, we anticipate subjects are likely to perform optimally when their compensation is highest (Hus et al., Reference Hus, Schmeiser, Haggerty and Nelson2017; Ye et al., Reference Ye, You and Robert2017). Subjects who feel they are being adequately compensated for their work are more likely to pay attention, to take seriously the task at hand, and to focus on the decisions they are asked to consider. Of course, as the studies progress and subjects spent greater time and effort in participating, their attitudes about “being adequately compensated” may change.
Thus, we further suspect that any differences in subject behavior are more likely to show up later in the study than earlier. Our first study, which took only about 4 min to complete, was unlikely to produce differences in behavior between the beginning and end of the survey. Our second study however, which could take 60 minutes to complete, we believe is more likely to produce effects toward the end of the study as subjects tired of participation and may have begun re-evaluating whether their payment was indeed adequate.
RESULTS
Our results from both studies were roughly identical, in that we found few reportable differences in our measures between the different pay rates.Footnote 3 For brevity, and to save space on reproducing dozens of null results, we only present our second study here, as it permits the more thorough look at Turker behavior. Matching results for the survey experiment can be found in the Online Appendix.
We first examine if our pay rates affected who we recruited to complete our study. We had no a priori assumptions about how pay rates might affect recruitment, so we relied on what we considered to be “conventional” demographic measures that we use in political science.
Table 1Footnote 4 shows that none of our eight categories (percentages of women, African-Americans, Hispanics, Democrats, Independents, or the mean age, political interest, or conservatism of our subjects) return significant results. Further, only one of our categories shows a consistent pattern in the results (a steady increase in Hispanic subjects as pay rates increased). With a relatively small sample size of 364 subjects, it is possible that a larger sample size might produce significant results, but looking at the substantive differences in results, it seems more likely that our demographic measures tended to show random fluctuation between the pay rates, rather than systematic differences in who chose to sign up for the study.
Table 1 Subject Demographics of the DPTE study, by Pay Rate

Our larger concern is for things that we were not able to measure, such as Turker experience. It is possible that more experienced Turkers may gravitate toward higher pay rates, or studies that they feel have a higher pay-to-effort ratio. This is, regrettably, something that we were not able to measure. However, since experimental samples do not tend to seek representative samples on Mechanical Turk, we feel that the risk of any demographic or background differences in who we recruit is that it could then lead to differences in behavior, either through attention to the study or in reaction to the various elements of the study. While we do not find observable demographic differences, we can continue on by examining how people performed within the study.
An advantage of using a DPTE experiment is that we have much greater ability to tease out how subjects performed across a range of measures. We first present the results of our attention checks, and then will move on to discuss engagement with the experiment and candidate evaluation.
Table 2 shows that the vast majority of all of our subjects passed our attention check tests, and there are again no significant differences between our pay rate groups.Footnote 5 There is an apparent pattern of subjects passing at higher rates when paid more however, which suggests that perhaps there may be an effect that our study was not large enough to fully capture. The lowest rates of passing the first two popups in the Primary are found in the $2 pay group (93.8% for both), and while subjects in the higher pay groups all passed the third and fourth popup at a 100% rate, subjects in our minimal $2 pay group passed this at the lowest rates we find in the study, below 90%. While not a significant finding, this suggests that perhaps subjects in this lowest pay group were not paying attention to the extent of the other pay groups.
Table 2 Subject Reaction to Attention Checks, by Pay Rate

If this is the case, however, further evidence should emerge elsewhere. We would expect that attention would get worse as the study carried on. However, it does not. These differences do not appear again in the General Election, when we expected effects to be the greatest. Overall, we find that our subjects generally responded well to our attention checks regardless of what they were being paid.
Beyond merely paying attention to what was presented to them, this study also asked subjects to actively engage with the program, and actively learn about political candidates. This is another area where differential motivation based upon pay rates could influence behavior. Table 3 presents a series of one-way analysis-of-variance tests on measures of active engagement with the experiment. While the previous table measured how much attention subjects paid to the study, this table assesses how actively engaged Turkers were in interacting with the dynamic information boards by selecting information to view. If payments created different incentives to participate, this should be observable through the time subjects spent in the campaign scenarios, the number of items they chose to view, and how much time they devoted to the political aspects of the study relative to the more entertaining current event items.
Table 3 Subject Engagement with the Experiment, by Pay Rate
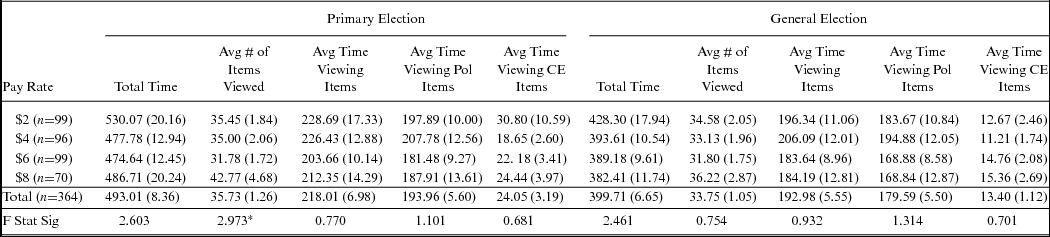
We find only one statistically significant result, and thus no consistent or clear evidence that pay rates influenced our subject behavior. The lone significant finding we have occurs for our measure of the number of information items subjects chose to open during the Primary Election. While significant, these results show that our highest paid group sought out the most information in the primary, while the second highest group sought out the least. This does not sensibly fit to our theory, and is not replicated along other measures. The lack of a clear pattern within the data again suggests that pay rates did not systematically influence subject performance, even in a long and taxing study.
A final way for us to consider how our subjects participated in the study is to evaluate their final decisions and evaluations of the candidates. It is possible that, while behavioral differences did not emerge, perhaps psychological appraisals of the subject matter were effected by anticipated rewards. We find, again, very little evidence that pay rates mattered. We asked our subjects who they voted for, how confident they were in their vote decision, how difficult that vote choice was, and how much they felt they knew about the candidates, for both the Executive and House race.
The only significant finding we have in Table 4 is for the confidence our subjects had in selecting the House candidate that they truly preferred. Here, we find a significant result and a pattern indicating that lower-paid subjects had greater confidence in their vote choice. This could lead us to assume that our rates of pay influenced how much consideration or psychological investment our subjects had in the study. However, this again appears to be an isolated finding. In all other measures, there are no significant differences or patterns in the data to find that pay rates played a role in how our subjects felt about the candidates or their vote decisions.
Table 4 Subject Evaluation of the Candidates, by Pay Rate

CONCLUSIONS
Our results are quite easy to summarize – pay rates did not seem to matter much to subject performance among Mechanical Turkers, at least not that we observed. While we only discuss our first study here, these results are replicated across another shorter study that collected a much larger sample and is presented in the Online Appendix. In both studies, no systematic patterns emerged that might suggest that pay rates significantly or substantively influenced subject behavior. This does not mean, of course, that pay rates produce no effects, but simply that we, using two very different social science studies, and observing numerous measures of behavior in each, were not able to identify any such effects. We do feel that have observed most, if not all, of the important characteristics of behavior likely to change.
Importantly, we report these results without correcting for multiple hypotheses testing, which would only further reduce the minimal effects we found. In each of our four areas, we analyze we have at least eight different measures, suggesting that by chance alone we should find some significant findings. Indeed, we do. However, these findings show no clear patterns of the influence of pay rates and it is in the absence of patterns that we feel safest in drawing our conclusions. Our clearest path is to conclude that pay rates largely do not influence subject participation and behavior on Mechanical Turk.
This is an important null finding for social scientists using online labor pools. However, we do not intend here to conclude fully that pay rates do not matter. Paying a fair wage for work done does still involve ethical standards (Zechmeister, Reference Zechmeister and Desposato2015). While our discipline as a whole has never established what ethical wages are for subjects, several suggestions both within the Turker community and academic literature have suggested a $6 per hour rate. This still makes crowdsourced samples considerably cheaper than professional alternatives, while also paying a fair rate to the people whose work we depend upon.
SUPPLEMENTARY MATERIAL
To view supplementary material for this article, please visit https://doi.org/10.1017/XPS.2018.7






