



No CrossRef data available.
Article contents
A transport process on graphs and its limiting distributions
Published online by Cambridge University Press: 10 October 2022
Abstract
Given a finite strongly connected directed graph
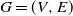 $G=(V, E)$
, we study a Markov chain taking values on the space of probability measures on V. The chain, motivated by biological applications in the context of stochastic population dynamics, is characterized by transitions between states that respect the structure superimposed by E: mass (probability) can only be moved between neighbors in G. We provide conditions for the ergodicity of the chain. In a simple, symmetric case, we fully characterize the invariant probability.
$G=(V, E)$
, we study a Markov chain taking values on the space of probability measures on V. The chain, motivated by biological applications in the context of stochastic population dynamics, is characterized by transitions between states that respect the structure superimposed by E: mass (probability) can only be moved between neighbors in G. We provide conditions for the ergodicity of the chain. In a simple, symmetric case, we fully characterize the invariant probability.
MSC classification
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2022. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Aldous, D. and Lanoue, D. (2012). A lecture on the averaging process. Prob. Surveys 9, 90–102.CrossRefGoogle Scholar
Bao, J., Mao, X., Yin, G. and Yuan, C. (2012). Competitive Lotka–Volterra population dynamics with jumps. Nonlinear Anal. 74, 6601–6616.CrossRefGoogle Scholar
Dunne, J. A., Maschner, H., Betts, M. W., Huntly, N., Russell, R., Williams, R. J. and Wood, S. A. (2016). The roles and impacts of human hunter-gatherers in North Pacific marine food webs. Scientific Reports 6, 21179.CrossRefGoogle ScholarPubMed
Ethier, S. and Kurtz, T. (1986). Markov Processes: Characterization and Convergence. John Wiley.CrossRefGoogle Scholar
Hairer, M. (2016) Convergence of Markov processes. Lecture notes, version of 13 January 2016. Available at http://www.hairer.org/notes/Convergence.pdf.Google Scholar
Hening, A. and Nguyen, D. H. (2018). Coexistence and extinction for stochastic Kolmogorov systems. Ann. Appl. Prob. 28, 1893–1942.CrossRefGoogle Scholar
Hening, A., Nguyen, D. H. and Schreiber, S. J. (2022). A classification of the dynamics of three-dimensional stochastic ecological systems. Ann. Appl. Prob. 32, 893–931.CrossRefGoogle Scholar
Holling, C. S. (1965). The functional response of predators to prey density and its role in mimicry and population regulation. Mem. Entomol. Soc. Can. 45, 1–60.Google Scholar
Liu, M. and Wang, K. (2014). Stochastic Lotka–Volterra systems with Lévy noise. J. Math. Anal. 410, 750–763.CrossRefGoogle Scholar
Murdoch, W. W. (1969). Switching in general predators: experiments on prey specificity and stability of prey populations. Ecol. Monog. 39, 335–354.CrossRefGoogle Scholar
Piltz, S., Porter, M. and Maini, P. (2014). Prey switching with a linear preference trade-off. SIAM J. Appl. Dynamical Systems 13, 658–682.CrossRefGoogle Scholar
Rosenthal, S. (2001). A review of asymptotic convergence for general state space Markov chains. Far East J. Theoret. Statist. 5, 37–50.Google Scholar
Smith, A. (2013). Analysis of convergence rates of some Gibbs samplers on continuous state spaces. Stoch. Process. Appl. 123, 3861–3876.CrossRefGoogle Scholar
Smith, A. (2014). A Gibbs sampler on the n-simplex. Ann. Appl. Prob. 24, 114–130.CrossRefGoogle Scholar
Teramoto, E., Kawasaki, K. and Shigesada, N. (1979). Switching effect of predation on competitive prey species. J. Theoret. Biol. 79, 303–315.CrossRefGoogle ScholarPubMed
Van Baalen, M., Křivan, V., van Rijn, P. and Sabelis, M. (2001). Alternative food, switching predators, and the persistence of predator–prey systems. Amer. Naturalist 157, 512–524.CrossRefGoogle ScholarPubMed
Videla, L. (2022) Strong stochastic persistence of some Lévy-driven Lotka–Volterra systems. J. Math. Biol. 84, 11.CrossRefGoogle ScholarPubMed