



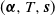
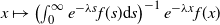
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Cheung, Eric C.K.
Peralta, Oscar
and
Woo, Jae-Kyung
2022.
Multivariate matrix-exponential affine mixtures and their applications in risk theory.
Insurance: Mathematics and Economics,
Vol. 106,
Issue. ,
p.
364.