



No CrossRef data available.
Article contents
From reflected Lévy processes to stochastically monotone Markov processes via generalized inverses and supermodularity
Published online by Cambridge University Press: 19 September 2022
Abstract
It was recently proven that the correlation function of the stationary version of a reflected Lévy process is nonnegative, nonincreasing, and convex. In another branch of the literature it was established that the mean value of the reflected process starting from zero is nondecreasing and concave. In the present paper it is shown, by putting them in a common framework, that these results extend to substantially more general settings. Indeed, instead of reflected Lévy processes, we consider a class of more general stochastically monotone Markov processes. In this setup we show monotonicity results associated with a supermodular function of two coordinates of our Markov process, from which the above-mentioned monotonicity and convexity/concavity results directly follow, but now for the class of Markov processes considered rather than just reflected Lévy processes. In addition, various results for the transient case (when the Markov process is not in stationarity) are provided. The conditions imposed are natural, in that they are satisfied by various frequently used Markovian models, as illustrated by a series of examples.
Keywords
MSC classification
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2022. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Andersen, L. N. and Mandjes, M. (2009). Structural properties of reflected Lévy processes. Queueing Systems 63, 301–322.10.1007/s11134-009-9116-yCrossRefGoogle Scholar
Athreya, K. B. and Pantula, S. G. (1986). Mixing properties of Harris chains and autoregressive processes. J. Appl. Prob. 23, 880–892.CrossRefGoogle Scholar
Berkelmans, W., Cichocka, A. and Mandjes, M. (2019). The correlation function of a queue with Lévy and Markov additive input. Stoch. Process. Appl. 130, 1713–1734.CrossRefGoogle Scholar
Cambanis, S., Simons, G. and Stout, W. (1976). Inequalities for
 $\mathbb{E} k(X,Y)$
when the marginals are fixed. Z. Wahrscheinlichkeitsth. 36, 285–294.CrossRefGoogle Scholar
$\mathbb{E} k(X,Y)$
when the marginals are fixed. Z. Wahrscheinlichkeitsth. 36, 285–294.CrossRefGoogle Scholar
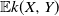 $\mathbb{E} k(X,Y)$
when the marginals are fixed. Z. Wahrscheinlichkeitsth. 36, 285–294.CrossRefGoogle Scholar
$\mathbb{E} k(X,Y)$
when the marginals are fixed. Z. Wahrscheinlichkeitsth. 36, 285–294.CrossRefGoogle ScholarÇinlar, E. and Pinsky, M. (1972). On dams with additive inputs and a general release rule. J. Appl. Prob. 9, 422–429.CrossRefGoogle Scholar
Daley, D. J. (1968). Stochastically monotone Markov chains. Z. Wahrscheinlichkeitsth. 10, 305–317.CrossRefGoogle Scholar
DĘbicki, K. and Mandjes, M. (2015). Queues and Lévy Fluctuation Theory. Springer, New York.CrossRefGoogle Scholar
Embrechts, P. and Hofert, M. (2013). A note on generalized inverses. Math. Meth. Operat. Res. 77, 423–432.CrossRefGoogle Scholar
Es-Saghouani, A. and Mandjes, M. (2008). On the correlation structure of a Lévy-driven queue. J. Appl. Prob. 45, 940–952.CrossRefGoogle Scholar
Glynn, P. and Mandjes, M. (2011). Simulation-based computation of the workload correlation function in a Lévy-driven queue. J. Appl. Prob. 48, 114–130.CrossRefGoogle Scholar
Kella, O. Concavity and reflected Lévy process. (1992). J. Appl. Prob. 29, 209–215.10.2307/3214806CrossRefGoogle Scholar
Kella, O. and Sverchkov, M. (1994). On concavity of the mean function and stochastic ordering for reflected processes with stationary increments. J. Appl. Prob. 31, 1140–1142.CrossRefGoogle Scholar
Kella, O. and Whitt, W. (1996). Stability and structural properties of stochastic storage networks. J. Appl. Prob. 33, 1169–1180.CrossRefGoogle Scholar
Keilson, J. and Kester, A. (1977). Monotone matrices and monotone Markov processes. Stoch. Process. Appl. 5, 231–241.10.1016/0304-4149(77)90033-3CrossRefGoogle Scholar
Kruk, L., Lehoczky, J., Ramanan, K. and Shreve, S. (2007). An explicit formula for the Skorokhod map on [0, a]. Ann. Prob. 35, 1740–1768.CrossRefGoogle Scholar
Kyprianou, A. (2006). Introductory Lectures on Fluctuations of Lévy Processes with Applications. Springer, New York.Google Scholar
Ott, T. (1977). The covariance function of the virtual waiting-time process in an M/G/1 queue. Adv. Appl. Prob. 9, 158–168.CrossRefGoogle Scholar
Puccetti, G. and Scarsini, M. (2010). Multivariate comonotonicity. J. Multivariate. Anal. 101, 291–304.10.1016/j.jmva.2009.08.003CrossRefGoogle Scholar
Puccetti, G. and Wang, R. (2015). Extremal dependence concepts. Statist. Sci. 30, 385–517.CrossRefGoogle Scholar
Rüschendorf, L. (2008). On a comparison result for Markov processes. J. Appl. Prob. 45, 279–286.CrossRefGoogle Scholar
Siegmund, D. (1976). The equivalence of absorbing and reflecting barrier problems for stochastically monotone Markov processes. Ann. Prob. 4, 914–924.CrossRefGoogle Scholar
Sierpinski, W. (1920). Sur les fonctions convexes mesurables. Fund. Math. 1, 125–129.10.4064/fm-1-1-125-128CrossRefGoogle Scholar