



Introduction
The fast global spread of the novel coronavirus is responsible for the current pandemic, known as coronavirus disease 2019 (Covid-19). Diagnostic tests for the novel coronavirus (nCov) are being employed worldwide. It is self-evident that increasing the number of diagnostic tests is important to combat the epidemic.
Widely used tests for Covid-19 detect the novel coronavirus RNA genome, using the real-time polymerase chain reaction method. The capacities for such tests, however, are limited by the used reactants, machine time, lab personnel time and overall logistics. Remarkably, testing capacities can be increased by a modification of the testing protocol.
Combining probes from several individuals and testing them together reduces the total amount of tests needed. This method, known as pooling or group testing, has been known for a long time [Reference Dorfman1]. The main idea is: when probes from several people are mixed together (pooled) and tested, the test will report negative when everyone is healthy and positive when at least one person is infected.
This study deals with Dorfman's classic two-stage protocol [Reference Dorfman1] (described below). More complicated procedures have been devised; however, we shall not consider them here.
The pooling method was validated for nCov tests by many laboratories [Reference Yelin2–Reference Gan15]. However, the following questions remained open, which we address in this paper. (1) What pool size should be used? (2) How are test errors affected by the procedure?
Results
The two-stage procedure is as follows [Reference Dorfman1]. We denote the number of people in one pool, i.e. the pool size, by M. Probes of M people are each split in two parts. One part is mixed together with the others, while the other part is kept for later. The mixture is tested for nCov. Upon a negative result, all the M people are declared healthy. When the result is positive, go to the second stage. In the second stage, each of the M people is tested individually using the probes that were put aside previously; the final test result is that of this second stage.
Pool size
Here we address the question: How many people should be pooled together?
We consider a ‘double-averaging’ model (see Methods), where the prevalence is estimated by a minimal and maximal value. Then, the results are only weakly dependent on the precise values, for reasonable values. Taking the prevalence to be between 0 and 30%, we have the result that a pool size of four is optimal; see Figure 1 for other ranges. Pool sizes of three and five give results which are close to optimal, see Figure 2 for a comparison.

Fig. 1. Optimal pool size (double-averging model), for different prevalence ranges.
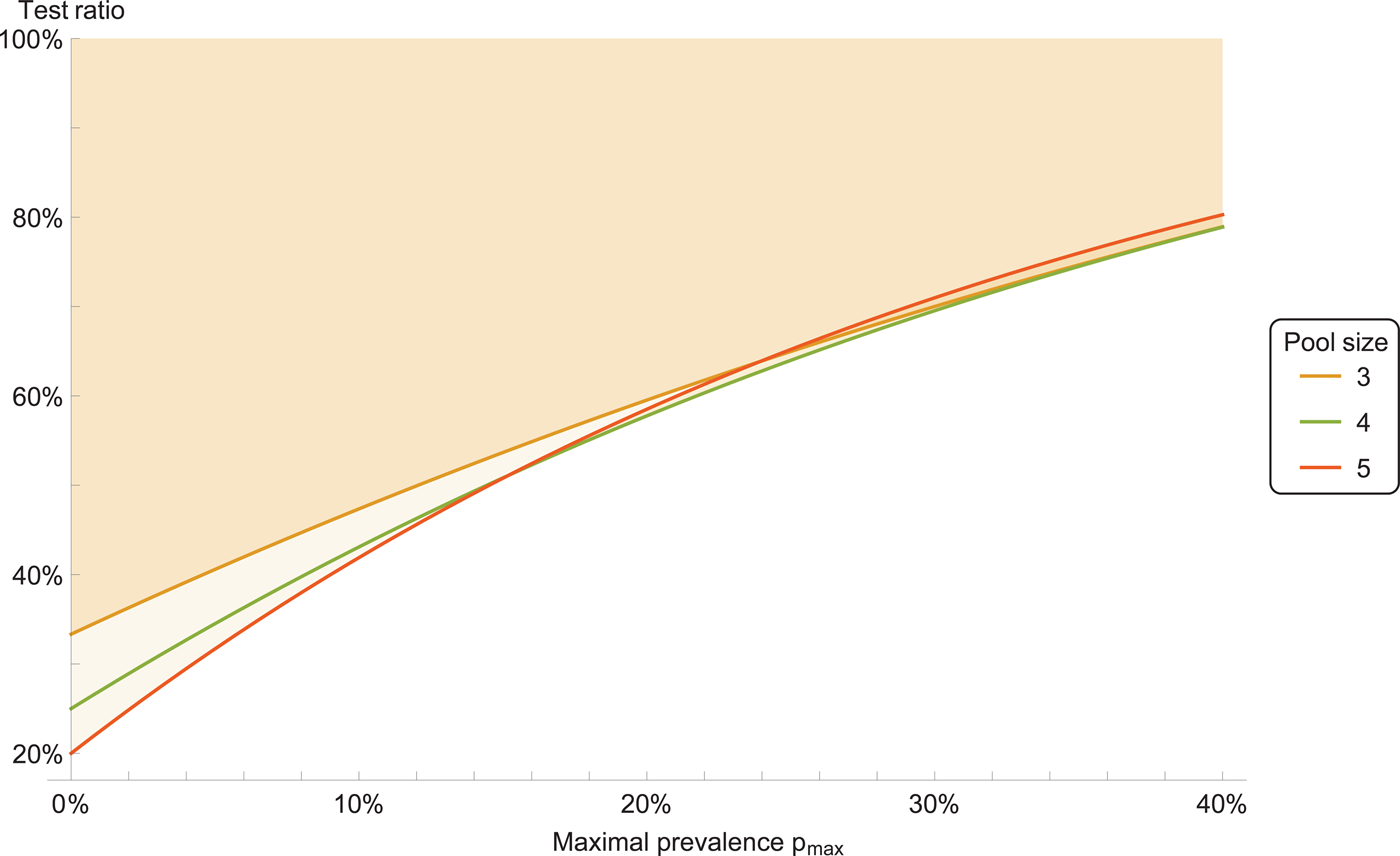
Fig. 2. Test ratio (number of tests with pooling divided by number of tests without pooling), for prevalence range between 0 and p max. The coloured area indicates improvement with respect to individual testing.
Therefore, we recommend a pool size of four. Pool sizes of three or five can be used as well, if that is more convenient for practical reasons.
Testing errors
Non-ideal tests produce erroneous results, which can be described by a false-negative rate and a false-positive rate, or equivalently, by giving the test sensitivity and specificity.
Two sources of errors arise in pooled tests. First, each test that is performed is inherently non-ideal and may give an error. These ‘single-test’ errors are described by single-test sensitivity and specificity. Second, an error may arise if several probes are mixed together, due to dilution of the material from each individual. Such ‘dilution errors’ are plausible for large pool sizes. We advocate small pool sizes (up to five), and at such small pool sizes no dilution errors have been found in lab studies [Reference Yelin2, Reference Abdalhamid4, Reference Schmidt11, Reference Hogan, Sahoo and Pinsky14, Reference Lohse16]. Thus, for our analysis we assume no dilution errors.
The two-stage testing protocol leads to a modification of the overall error rates. For the pooled sensitivity, one obtains that the sensitivity of the pooled test is equal to the square of sensitivity of a single test. This means that the pooled sensitivity is reduced, and the number of false negatives increased. The specificity of the pooled test, on the other hand, is increased compared with the single test. (See Methods for details.) This means that the number of false positives is reduced. The reason for this increase of specificity is, that probes tested positive in the first stage are tested again in the second stage, thus reducing false positives. Figure 3 shows, as an example, the improvement of the false-positive rate compared to single tests.

Fig. 3. False-positive ratio for pooled tests, for prevalence range between 0 and p max. The coloured area indicates improvement with respect to individual testing. Here the individual test s = 90% and specificity z = 99%. Pool size is 4.
Methods
When tests from M people are pooled, the pool infection rate p′ (i.e. the probability that a pool is infected) equals p′ = 1 − (1 − p)M, where p is the prevalence in the statistical population.
The number of tests performed during the two-stage pooling protocol (described above) will be denoted by T. Its expectation value for a statistical population of N individuals with prevalence p is E[T] = N/M + N − N(1 − p)M, while the variance is Var[T] = NM((1 − p)M − (1 − p)2M). It is convenient to present the results in terms of the test ratio t = T/N, which is the ratio of the number of tests performed with pooling to the number of tests without pooling. Smaller ratios indicate better performance of pooling. A plot of the test ratio as a function of the prevalence, with error bars due to the variance, is shown in Figure 4.

Fig. 4. Expected test ratio with pooling (black curve) as function of prevalence, for pool size M = 4. The coloured areas indicate the standard error (1σ), for different number of samples N = 20, 40, 100, 500.
The optimal pool size has been studied before and the answer that has been given, e.g. [Reference Dorfman1, Reference Abdalhamid4], is strongly dependent on the prevalence. This, however, is of limited usefulness because (i) the prevalence is unknown and (ii) it is unknown which statistical population is being sampled. Instead we propose to consider the prevalence itself to be a random variable, drawn from a uniform distribution. This amounts to sampling first from a population, and then sampling from a population of populations. Such a model may be not too far from reality. Consider, for example, one day a lab testing for Covid-19 all people from one workplace, another day testing travellers returning from a town and so on. The choice of a uniform distribution for the prevalence suggests itself because nothing is known; such assumptions are known as the principle of indifference.
We average the expectation value of the test ratio t = 1/M + 1 − (1 − p)M with respect to p, when p is uniformly distributed between p 1 and p 2. The resulting test ratio is 〈t〉 = 1/M + 1 + [(1 − p 2)M+1 − (1 − p 1)M+1]/[(p 2 − p 1)(M + 1)]. The results in Figures 1 and 2 are calculated from this expression.
The test errors can be calculated based on standard formulas for binary classification tests. We assume no dilution errors (see above for explanation). This means, for example, that the probability of obtaining a positive test result for one infected person is the same as for a pool of M people where at least one person is infected, even though the pool may contain a different amount of viral material.
Consider single-test sensitivity s and specificity z. The sensitivity and specificity of the pooled test is denoted by s′, z′ respectively. Following the two-stage protocol (as described above), one obtains: s′ = s 2. For the specificity, one has the expression

here M ≥ 2 is the pool size and p is the prevalence. The specificity of the pooled test is increased compared to the single-test specificity, as the right-hand side of the expression is always positive.
According to the double-average model, the expression for z′ can be averaged over a uniform distribution of prevalences. This gives

A plot, for some example values, is shown in Figure 3.
Conclusions
Pooling of tests allows to increase the test capacity for Covid-19 testing. For the classic two-stage protocol, a pool size of four is recommended, based on our model. In the absence of dilution errors, testing errors reduce the sensitivity and increase the specificity compared to a test without pooling.
Acknowledgements
We thank Professor Nils Blüthgen for helpful correspondence.
Financial support
This research received no specific grant from any funding agency, commercial or not-for-profit sectors. We thank Wolfram Research for Covid-19-related access to their software technology.
Conflict of interest
None.





 Open access
Open access