





Impact Statement
We applied explainable machine learning to predict cirrus clouds and improve process understanding. The results can validate and improve cirrus cloud parameterizations in global climate models, essential for climate change projections and support assessing cirrus-based climate engineering methods.
1. Introduction
Cirrus clouds consist of ice crystals and occur at temperatures below −38°C in the upper troposphere (Sassen et al., Reference Sassen, Wang and Liu2008). Like all other clouds, they influence the Earth’s radiative budget via the reflection of solar radiation and absorption and emission of terrestrial infrared radiation into space (Liou, Reference Liou1986). Depending on the cloud microphysical properties (CMPs), namely ice water content
 $ \mathrm{IWC} $
and ice crystal number concentration
$ \mathrm{IWC} $
and ice crystal number concentration
 $ {N}_i $
, the cloud radiative effect of cirrus varies significantly and ranges from a cooling effect at lower altitudes for optically thick cirrus to a warming effect at high altitudes for optically thin cirrus (Heymsfield et al., Reference Heymsfield, Krämer, Luebke, Brown, Cziczo, Franklin, Lawson, Lohmann, McFarquhar, Ulanowski and Van Tricht2017). However, due to the high spatiotemporal variability of cirrus, different formation pathways, and the nonlinear dependence on environmental conditions and aerosols, constraining CMP and hence the cloud radiative effect remains an active field of study (Gasparini et al., Reference Gasparini, Meyer, Neubauer, Münch and Lohmann2018; Gryspeerdt et al., Reference Gryspeerdt, Sourdeval, Quaas, Delanoë, Krämer and Kühne2018; Krämer et al., Reference Krämer, Rolf, Spelten, Afchine, Fahey, Jensen, Khaykin, Kuhn, Lawson, Lykov, Pan, Riese, Rollins, Stroh, Thornberry, Wolf, Woods, Spichtinger, Quaas and Sourdeval2020). An improved process understanding of cirrus CMP will help to reduce uncertainties in global climate models and climate change projections and assess climate intervention methods targeted at cirrus clouds. This study aims to quantify the impacts of individual cirrus drivers on the CMP. We approach this task with a two-stage process. First, we train a black-box machine learning (ML) model to predict
$ {N}_i $
, the cloud radiative effect of cirrus varies significantly and ranges from a cooling effect at lower altitudes for optically thick cirrus to a warming effect at high altitudes for optically thin cirrus (Heymsfield et al., Reference Heymsfield, Krämer, Luebke, Brown, Cziczo, Franklin, Lawson, Lohmann, McFarquhar, Ulanowski and Van Tricht2017). However, due to the high spatiotemporal variability of cirrus, different formation pathways, and the nonlinear dependence on environmental conditions and aerosols, constraining CMP and hence the cloud radiative effect remains an active field of study (Gasparini et al., Reference Gasparini, Meyer, Neubauer, Münch and Lohmann2018; Gryspeerdt et al., Reference Gryspeerdt, Sourdeval, Quaas, Delanoë, Krämer and Kühne2018; Krämer et al., Reference Krämer, Rolf, Spelten, Afchine, Fahey, Jensen, Khaykin, Kuhn, Lawson, Lykov, Pan, Riese, Rollins, Stroh, Thornberry, Wolf, Woods, Spichtinger, Quaas and Sourdeval2020). An improved process understanding of cirrus CMP will help to reduce uncertainties in global climate models and climate change projections and assess climate intervention methods targeted at cirrus clouds. This study aims to quantify the impacts of individual cirrus drivers on the CMP. We approach this task with a two-stage process. First, we train a black-box machine learning (ML) model to predict
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
, given the input of meteorological variables and aerosol concentrations. Next, we calculate the individual contributions to the predictions for each input feature using post hoc feature attribution methods from the emerging field of eXplainable AI (XAI) (Belle and Papantonis, Reference Belle and Papantonis2020). Using XAI methods to understand and discover new physical laws via ML has been discussed in recent publications and is increasingly adopted in the atmospheric science community (McGovern et al., Reference McGovern, Lagerquist, Gagne, Jergensen, Elmore, Homeyer and Smith2019; Ebert-Uphoff and Hilburn, Reference Ebert-Uphoff and Hilburn2020). We train and explain a gradient-boosted regression tree on instantaneous data and a long short-term memory (LSTM) network (Hochreiter and Schmidhuber, Reference Hochreiter and Schmidhuber1997) with an attention layer on time-resolved data. The former is aimed to yield better interpretability, while the latter incorporates temporal information of the predictors. The remainder of this paper is structured as follows: A brief background about cirrus drivers is presented in Section 2, followed by a description of the data set, ML models, and feature attribution methods in Section 3. Section 4 presents the prediction performance of the ML models and the corresponding feature attributions. Finally, the results are summarized and discussed in Section 5.
$ {N}_i $
, given the input of meteorological variables and aerosol concentrations. Next, we calculate the individual contributions to the predictions for each input feature using post hoc feature attribution methods from the emerging field of eXplainable AI (XAI) (Belle and Papantonis, Reference Belle and Papantonis2020). Using XAI methods to understand and discover new physical laws via ML has been discussed in recent publications and is increasingly adopted in the atmospheric science community (McGovern et al., Reference McGovern, Lagerquist, Gagne, Jergensen, Elmore, Homeyer and Smith2019; Ebert-Uphoff and Hilburn, Reference Ebert-Uphoff and Hilburn2020). We train and explain a gradient-boosted regression tree on instantaneous data and a long short-term memory (LSTM) network (Hochreiter and Schmidhuber, Reference Hochreiter and Schmidhuber1997) with an attention layer on time-resolved data. The former is aimed to yield better interpretability, while the latter incorporates temporal information of the predictors. The remainder of this paper is structured as follows: A brief background about cirrus drivers is presented in Section 2, followed by a description of the data set, ML models, and feature attribution methods in Section 3. Section 4 presents the prediction performance of the ML models and the corresponding feature attributions. Finally, the results are summarized and discussed in Section 5.
2. Cirrus Driver
Previous studies have found that cirrus CMP are mainly controlled by the ice crystal nucleation mode (Kärcher et al., Reference Kärcher, Hendricks and Lohmann2006), ice origin (Krämer et al., Reference Krämer, Rolf, Spelten, Afchine, Fahey, Jensen, Khaykin, Kuhn, Lawson, Lykov, Pan, Riese, Rollins, Stroh, Thornberry, Wolf, Woods, Spichtinger, Quaas and Sourdeval2020), meteorological variables such as temperature and updraft speeds, and aerosol environment (Gryspeerdt et al., Reference Gryspeerdt, Sourdeval, Quaas, Delanoë, Krämer and Kühne2018). There are two possible nucleation modes—homogeneous and heterogeneous nucleation. Homogeneous nucleation is the freezing of supercooled solution droplets below −38°C and high ice supersaturations (Koop et al., Reference Koop, Luo, Tsias and Peter2000). It strongly depends on updraft velocity, producing higher
 $ {N}_i $
with increasing updrafts (Jensen et al., Reference Jensen, Ueyama, Pfister, Bui, Lawson, Woods, Thornberry, Rollins, Diskin, DiGangi and Avery2016). Heterogeneous nucleation occurs via crystalline or solid aerosols acting as ice-nucleating particles that can significantly lower the energy barrier needed for ice nucleation (Kanji et al., Reference Kanji, Ladino, Wex, Boose, Burkert-Kohn, Cziczo and Krämer2017). Dust is considered the most important ice-nucleating particle (Kanji et al., Reference Kanji, Ladino, Wex, Boose, Burkert-Kohn, Cziczo and Krämer2017) and is hence often the only ice-nucleating particle considered in global climate models. The availability of ice-nucleating particles can lead to fewer but larger crystals by suppressing homogeneous nucleation (Kuebbeler et al., Reference Kuebbeler, Lohmann, Hendricks and Kärcher2014).
$ {N}_i $
with increasing updrafts (Jensen et al., Reference Jensen, Ueyama, Pfister, Bui, Lawson, Woods, Thornberry, Rollins, Diskin, DiGangi and Avery2016). Heterogeneous nucleation occurs via crystalline or solid aerosols acting as ice-nucleating particles that can significantly lower the energy barrier needed for ice nucleation (Kanji et al., Reference Kanji, Ladino, Wex, Boose, Burkert-Kohn, Cziczo and Krämer2017). Dust is considered the most important ice-nucleating particle (Kanji et al., Reference Kanji, Ladino, Wex, Boose, Burkert-Kohn, Cziczo and Krämer2017) and is hence often the only ice-nucleating particle considered in global climate models. The availability of ice-nucleating particles can lead to fewer but larger crystals by suppressing homogeneous nucleation (Kuebbeler et al., Reference Kuebbeler, Lohmann, Hendricks and Kärcher2014).
Wernli et al. (Reference Wernli, Boettcher, Joos, Miltenberger and Spichtinger2016) and Krämer et al. (Reference Krämer, Rolf, Spelten, Afchine, Fahey, Jensen, Khaykin, Kuhn, Lawson, Lykov, Pan, Riese, Rollins, Stroh, Thornberry, Wolf, Woods, Spichtinger, Quaas and Sourdeval2020) showed that the history of the air parcel leading up to a cloud significantly influences cirrus CMP. Two main categories with respect to the ice origin were identified: Liquid-origin cirrus form by freezing cloud droplets, that is, originating from mixed-phase clouds at temperatures above −38°C and leading to higher IWC, in situ cirrus form ice directly from the gas phase or freezing of solution droplets at temperatures below −38°C and lead to thinner cirrus with lower IWC. Besides the ice origin, the air parcel’s exposure to changing meteorological and aerosol conditions upstream of a cloud observation can impact the cirrus CMP. For instance, a high vertical velocity occurring prior to a cloud observation may increase
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
(Heymsfield et al., Reference Heymsfield, Krämer, Luebke, Brown, Cziczo, Franklin, Lawson, Lohmann, McFarquhar, Ulanowski and Van Tricht2017). In this study, we focus on the meteorological variables and aerosol environment as cirrus drivers. Nucleation mode and ice origin are classifications that are themselves controlled by the cirrus drivers.
$ {N}_i $
(Heymsfield et al., Reference Heymsfield, Krämer, Luebke, Brown, Cziczo, Franklin, Lawson, Lohmann, McFarquhar, Ulanowski and Van Tricht2017). In this study, we focus on the meteorological variables and aerosol environment as cirrus drivers. Nucleation mode and ice origin are classifications that are themselves controlled by the cirrus drivers.
3. Methods and Data
3.1. Data
This study combines satellite observations of cirrus clouds and reanalysis data of meteorology and aerosols to predict
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
. We use the DARDAR-Nice (Sourdeval et al., Reference Sourdeval, Gryspeerdt, Krämer, Goren, Delanoë, Afchine, Hemmer and Quaas2018) product for satellite-based cirrus retrievals. The DARDAR-Nice product combines measurements from CloudSat’s radar and CALIOP’s lidar to obtain vertically resolved retrievals for
$ {N}_i $
. We use the DARDAR-Nice (Sourdeval et al., Reference Sourdeval, Gryspeerdt, Krämer, Goren, Delanoë, Afchine, Hemmer and Quaas2018) product for satellite-based cirrus retrievals. The DARDAR-Nice product combines measurements from CloudSat’s radar and CALIOP’s lidar to obtain vertically resolved retrievals for
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
for ice crystals >5 μm in cirrus clouds. DARDAR-Nice also provides information about each layer’s distance to the cloud top. Additionally, we calculate a cloud thickness feature, which provides information about the vertical extent of a cloud. To represent cirrus cloud drivers, we use the ERA5 (Hersbach et al., Reference Hersbach, Bell, Berrisford, Horányi, Muñoz-Sabater, Nicolas, Peubey, Radu, Schepers, Simmons, Soci, Biavati, Dee and Thépaut2018) and MERRA2 (Global Modeling and Assimilation Office, 2015) reanalysis data sets for meteorological and aerosol drivers, respectively. All data sources are colocated on a 0.25°× 0.25°× 300 m spatial and hourly temporal resolution corresponding to the original ERA5 resolution. Due to the narrow swath of the satellite overpass (i.e., low spatial coverage) and long revisiting time (16 days), studies about the temporal development of cirrus clouds and their temporal dependencies on driver variables are not possible given only instantaneous DARDAR-Nice data colocated with driver variables.
$ {N}_i $
for ice crystals >5 μm in cirrus clouds. DARDAR-Nice also provides information about each layer’s distance to the cloud top. Additionally, we calculate a cloud thickness feature, which provides information about the vertical extent of a cloud. To represent cirrus cloud drivers, we use the ERA5 (Hersbach et al., Reference Hersbach, Bell, Berrisford, Horányi, Muñoz-Sabater, Nicolas, Peubey, Radu, Schepers, Simmons, Soci, Biavati, Dee and Thépaut2018) and MERRA2 (Global Modeling and Assimilation Office, 2015) reanalysis data sets for meteorological and aerosol drivers, respectively. All data sources are colocated on a 0.25°× 0.25°× 300 m spatial and hourly temporal resolution corresponding to the original ERA5 resolution. Due to the narrow swath of the satellite overpass (i.e., low spatial coverage) and long revisiting time (16 days), studies about the temporal development of cirrus clouds and their temporal dependencies on driver variables are not possible given only instantaneous DARDAR-Nice data colocated with driver variables.
CMPs are not only determined by their instantaneous environmental variables but undergo a temporal development in which they are exposed to changing atmospheric states such as shifts in temperature, updraft velocities, and aerosol environment. Thus, we add a temporal dimension to our data set by calculating 48 hr of Lagrangian backtrajectories for every cirrus cloud observation in the DARDAR-Nice data set with LAGRANTO (Sprenger and Wernli, Reference Sprenger and Wernli2015). An individual trajectory is calculated for every cirrus layer in an atmospheric column. For instance, for a 900 m thick cloud consisting of three 300 m layers, three individual trajectories are calculated and initialized simultaneously and identical latitude/longitude but at different height levels. LAGRANTO uses ERA5 wind fields for the trajectory calculation. All meteorological and aerosol variables are traced along the trajectory. These variables represent the changing meteorology and aerosol environment along the air parcel upstream of a cirrus observation in the satellite data. Figure 1 exemplarily displays the satellite overpass (gray), cirrus cloud observations (red), and the corresponding backtrajectories (blue).

Figure 1. Illustrative example of data for 1 hr. DARDAR-Nice satellite observations along the satellite overpass are displayed as gray dots. A vertical profile of 56 300 m thick vertical layers is available for each satellite observation. To keep the diagram uncluttered, only one vertical level is shown. Red crosses mark observations containing cirrus clouds. Blue dashes represent the corresponding 48 hr of backtrajectories calculated for each cirrus observation. Along each trajectory, meteorological and aerosol variables are traced.
To account for seasonal and regional covariations, we include categorical variables representing the different seasons (DJF, MMA, JJA, SON) and regions divided in 10° latitude bins into the data set. Additionally, the surface elevation of the ground below an air parcel is included to incorporate the influence of orographic lifting. Since an air parcel can travel through multiple 10° latitude bins in 48 hr and is exposed to varying topographies, both latitude bin and surface elevation are also traced along the trajectory. Finally, we use the land water mask provided by the DARDAR-Nice dataset. Please refer to Sourdeval et al. (Reference Sourdeval, Gryspeerdt, Krämer, Goren, Delanoë, Afchine, Hemmer and Quaas2018) for more information. All used data variables are specified in Table 1. The last column in the table indicates whether the variable is available along the backtrajectories or just at the time of the satellite observation. We chose to study a domain ranging from 140°W to 40°E and 25°N to 80°N. This study area covers a wide range of climate zones and topographies. In the vertical direction, we consider 56 vertical layers of 300 m thickness covering heights between 4,080 and 20,580 m. Since we only consider cirrus clouds in this study, all data above −38°C are omitted. The tropics are excluded from this study as convective regimes often drive liquid-origin cirrus clouds in this region, and convection is not well represented at this horizontal resolution. Due to gaps in the satellite data, we focus on the period between 2007 and 2009. Since sunlight can adversely affect the quality of satellite retrievals, we only consider nighttime observations.
Table 1. Summary of data used in this study.
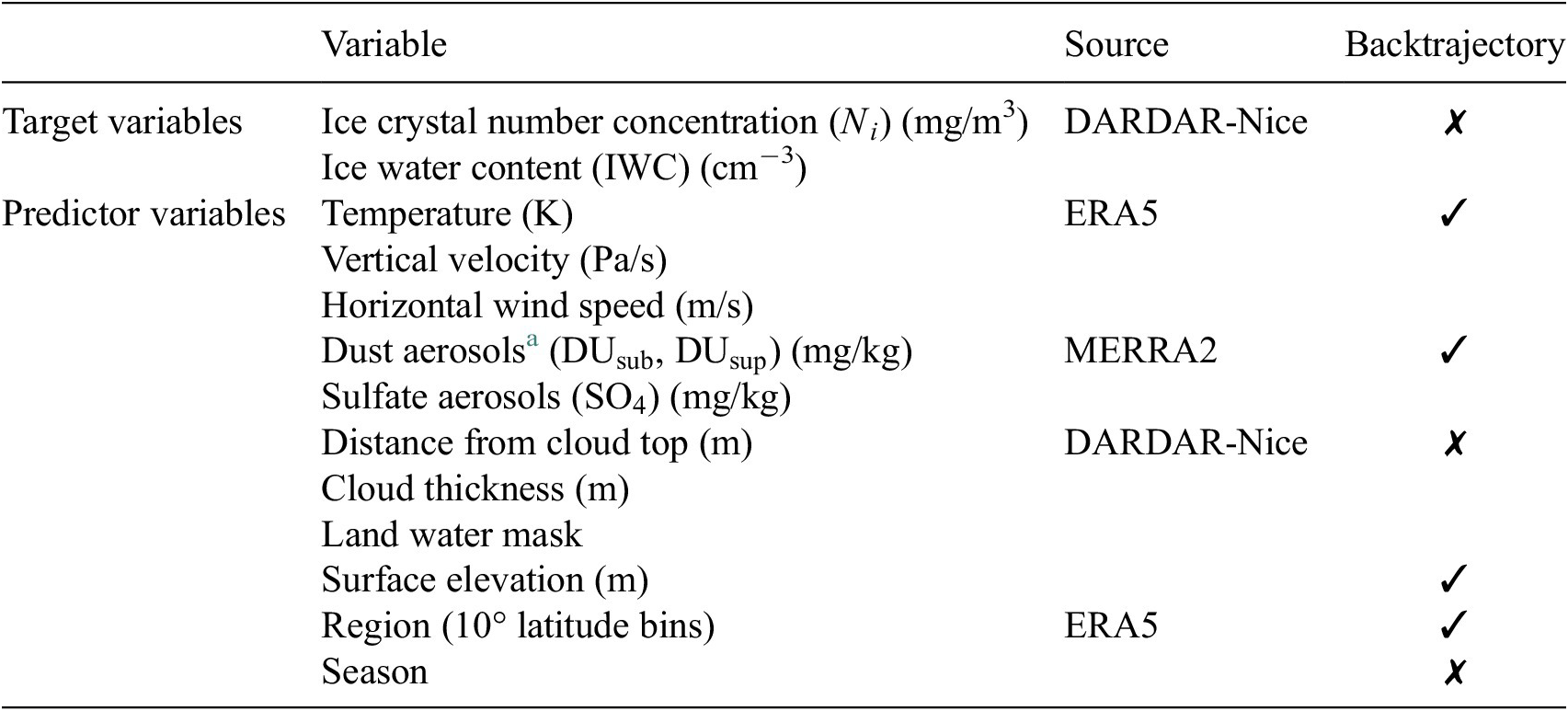
Note. Lagrangian backtrajectories were calculated 48 hr back in time for each cirrus observation. Variables with ✓ in the last column are available along backtrajectories (hourly data). Variables with ✗ are only available at the satellite overpass.
a Dust concentrations are divided in particles smaller than 1 μm (DUsub) and particles larger than 1 μm (DUsup).
3.2. Prediction models
We aim to predict
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
of cirrus clouds with meteorological and aerosol variables, a regression task from an ML perspective. By adding latitude bin, season, and surface elevation to the input features, we account for regional, seasonal, and topographic variability. We approach the regression task with (a) instantaneous and (b) time-resolved input data. The former has the advantage of training the ML model on a tabular data set that best suits the explainability methods described in the next section. The latter data set enables the model to incorporate the temporal dependencies of cirrus drivers on the cirrus CMP but is more difficult to interpret. Note that only the input data has a temporal dimension, namely the backtrajectories.
$ {N}_i $
of cirrus clouds with meteorological and aerosol variables, a regression task from an ML perspective. By adding latitude bin, season, and surface elevation to the input features, we account for regional, seasonal, and topographic variability. We approach the regression task with (a) instantaneous and (b) time-resolved input data. The former has the advantage of training the ML model on a tabular data set that best suits the explainability methods described in the next section. The latter data set enables the model to incorporate the temporal dependencies of cirrus drivers on the cirrus CMP but is more difficult to interpret. Note that only the input data has a temporal dimension, namely the backtrajectories.
3.2.1. Instantaneous prediction model
We train a gradient-boosted regression tree using the XGBoost algorithm (Chen and Guestrin, Reference Chen and Guestrin2016), which typically outperforms more complex deep-learning models on tabular data (Shwartz-Ziv and Armon, Reference Shwartz-Ziv and Armon2021). A separate XGBoost model is trained for each target variable.
3.2.2. Time-resolved prediction model
Given the temporally resolved backtrajectory data of cirrus drivers
 $ {x}_t $
with
$ {x}_t $
with
 $ t\in \left[-48,0\right] $
(sequential features) and static features
$ t\in \left[-48,0\right] $
(sequential features) and static features
 $ {x}_{\mathrm{static}} $
, like cloud thickness and distance to cloud top, we predict the target variables
$ {x}_{\mathrm{static}} $
, like cloud thickness and distance to cloud top, we predict the target variables
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
at
$ {N}_i $
at
 $ t=0 $
, that is, the time of the satellite observation, using a single multi-output LSTM architecture (Hochreiter and Schmidhuber, Reference Hochreiter and Schmidhuber1997). From an ML perspective, this is a many-to-one regression problem. LSTMs are neural networks that capitalize on temporal dependencies in the input data. The LSTM encodes the sequential features into a latent representation called hidden state
$ t=0 $
, that is, the time of the satellite observation, using a single multi-output LSTM architecture (Hochreiter and Schmidhuber, Reference Hochreiter and Schmidhuber1997). From an ML perspective, this is a many-to-one regression problem. LSTMs are neural networks that capitalize on temporal dependencies in the input data. The LSTM encodes the sequential features into a latent representation called hidden state
 $ {h}_t $
(1).
$ {h}_t $
(1).
 $$ {h}_t=\mathrm{LSTM}\left({x}_t\right),t\in \left[-48,0\right], $$
$$ {h}_t=\mathrm{LSTM}\left({x}_t\right),t\in \left[-48,0\right], $$
 $$ {u}_t=\tanh \left({Wh}_t+b\right), $$
$$ {u}_t=\tanh \left({Wh}_t+b\right), $$
 $$ {\alpha}_t=\frac{\exp \left({u}_tu\right)}{\sum_t\exp \left({u}_tu\right)}, $$
$$ {\alpha}_t=\frac{\exp \left({u}_tu\right)}{\sum_t\exp \left({u}_tu\right)}, $$
 $$ z=\sum \limits_t{\alpha}_t{h}_t. $$
$$ z=\sum \limits_t{\alpha}_t{h}_t. $$
Then, the output of the LSTM is fed to a simple attention mechanism that determines the relative importance of each timestep in the sequential input data for the final prediction. The attention mechanism provides a built-in approach to interpreting the ML model’s prediction for the temporal dimension. It comprises a single fully connected layer and a context vector
 $ u $
. First, a latent representation
$ u $
. First, a latent representation
 $ {u}_t $
of
$ {u}_t $
of
 $ {h}_t $
is created by passing
$ {h}_t $
is created by passing
 $ {h}_t $
through the attention layer (2), then the importance of each timestep
$ {h}_t $
through the attention layer (2), then the importance of each timestep
 $ {\alpha}_t $
is calculated by multiplying
$ {\alpha}_t $
is calculated by multiplying
 $ {u}_t $
with the context vector
$ {u}_t $
with the context vector
 $ u $
. We normalize the importance weights
$ u $
. We normalize the importance weights
 $ {\alpha}_t $
by applying the softmax function (3) so that all attention weights sum up to 1. Next, the weighted sum
$ {\alpha}_t $
by applying the softmax function (3) so that all attention weights sum up to 1. Next, the weighted sum
 $ z $
of the importance weights
$ z $
of the importance weights
 $ {\alpha}_t $
and the LSTM hidden state
$ {\alpha}_t $
and the LSTM hidden state
 $ {h}_t $
is calculated (4). The attention layer, as well as the context vector
$ {h}_t $
is calculated (4). The attention layer, as well as the context vector
 $ u $
, are randomly initialized and learned during the training through backpropagation together with the weights of the LSTM and other fully connected layers. To make the final prediction
$ u $
, are randomly initialized and learned during the training through backpropagation together with the weights of the LSTM and other fully connected layers. To make the final prediction
 $ y\in {\mathrm{\mathbb{R}}}_{+}^2 $
,
$ y\in {\mathrm{\mathbb{R}}}_{+}^2 $
,
 $ z $
is concatenated with the static input features
$ z $
is concatenated with the static input features
 $ {x}_{\mathrm{static}} $
and fed through a set of fully connected layers. Figure 2 visualizes the whole architecture consisting of LSTM, attention layer, fully connected layers, and finally, a linear layer.
$ {x}_{\mathrm{static}} $
and fed through a set of fully connected layers. Figure 2 visualizes the whole architecture consisting of LSTM, attention layer, fully connected layers, and finally, a linear layer.
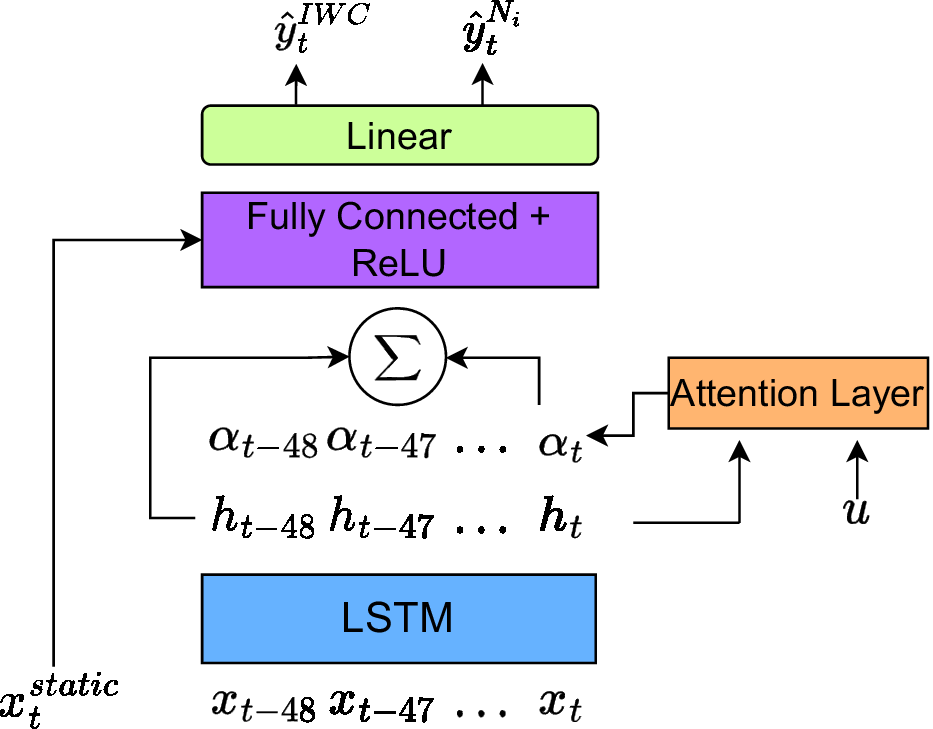
Figure 2. Architecture of the LSTM-based model with integrated attention method to predict
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
of cirrus clouds with the temporal data set. ReLU, rectified linear unit.
$ {N}_i $
of cirrus clouds with the temporal data set. ReLU, rectified linear unit.
3.2.3. Experimental setup
To train and evaluate the ML models, we split the data into 80% training, 10% validation, and 10% test data. Each cloud layer containing cirrus clouds is considered an individual sample, that is, a cloud consisting of 3300 m layers is considered as three different samples. To prevent overfitting due to spatiotemporally correlated samples in training and test sets, samples from the same month are put in the same split. In total, the data set consists of 6 million samples. Due to the large spread in scales, the target variables and aerosol concentrations are logarithmically transformed. The categorical features are one-hot encoded. For the XGBoost model, no further pre-processing is required. For the LSTM model, we standardize the continuous sequential and static features by removing the mean and dividing them by the standard deviation of the training samples. The hyperparameters of the models are tuned using Bayesian optimization. Fifty hyperparameter configurations are tested per model during the optimization. The final hyperparameters are displayed in Supplementary Appendix A.
3.3. Explainable AI
We apply post hoc feature attribution methods to the trained models. For each sample, the marginal contribution of each feature toward the prediction is calculated. By combining explanations for all samples, we can gain insight into the internal mechanics of the model and, eventually, an indication of the underlying physical processes. We focus on the instantaneous predictive model and only briefly interpret the temporal model by analyzing the attention weights. We use SHapley Additive exPlanations (SHAP) (Lundberg and Lee, Reference Lundberg and Lee2017) using the TreeSHAP (Lundberg et al., Reference Lundberg, Erion, Chen, DeGrave, Prutkin, Nair, Katz, Himmelfarb, Bansal and Lee2020) implementation to calculate feature attributions. SHAP is a widely applied XAI method based on game-theoretic Shapley values. For each feature, SHAP outputs the change in expected model prediction, that is, if a feature contributes to an increase or decrease in the prediction.
To evaluate the quality of black-box ML model explanations, it is customary to calculate faithfulness and stability metrics. The notion of faithfulness states how well a given explanation represents the actual behavior of the ML model (Alvarez Melis and Jaakkola, Reference Alvarez Melis and Jaakkola2018), and stability measures how robust an explanation is toward small changes in the input data (Alvarez Melis and Jaakkola, Reference Alvarez Melis and Jaakkola2018; Agarwal et al., Reference Agarwal, Johnson, Pawelczyk, Krishna, Saxena, Zitnik and Lakkaraju2022). In this study, we use Estimated Faithfulness (Alvarez Melis and Jaakkola, Reference Alvarez Melis and Jaakkola2018), which measures the correlation between the relative importance assigned to a feature by the explanation method and the effect of each feature on the performance of the prediction model. Higher importance should have a higher effect and vice versa. Explanation stability is evaluated using relative input stability (RIS) and relative output stability (ROS) (Agarwal et al., Reference Agarwal, Johnson, Pawelczyk, Krishna, Saxena, Zitnik and Lakkaraju2022). Implementation details of the XAI evaluation metrics are described in Supplementary Appendix B. To further validate our explanations, we compare them with LIME (Ribeiro et al., Reference Ribeiro, Singh and Guestrin2016) and baseline with randomly generated attributions. LIME is another popular XAI method that calculates feature attributions by fitting linear models in the neighborhood of a single sample.
4. Results
We first present the predictive performance of the XGBoost and LSTM-based models. The feature attributions of the XGBoost model are discussed. Finally, we analyze the weights of the attention layer in the LSTM-based model to understand which timesteps are important for the prediction tasks.
4.1. Cirrus cloud prediction performance
The prediction performance of the ML models and a linear baseline regression are displayed in Table 2. Both ML models outperform the baseline, and the LSTM-based model performs best overall with 0.49 (0.40)
 $ {R}^2 $
, and root mean squared error of 0.35 (0.33) for
$ {R}^2 $
, and root mean squared error of 0.35 (0.33) for
 $ \mathrm{IWC} $
(
$ \mathrm{IWC} $
(
 $ {N}_i $
). This shows that the backtrajectories contain useful information for cirrus cloud prediction. Like the LSTM-based model, the XGBoost model can capture nonlinear relationships in the data. Thus, it is fair to continue focusing on that model for model explainability.
$ {N}_i $
). This shows that the backtrajectories contain useful information for cirrus cloud prediction. Like the LSTM-based model, the XGBoost model can capture nonlinear relationships in the data. Thus, it is fair to continue focusing on that model for model explainability.
Table 2. Performance metrics evaluated on independent test data for the regression task of predicting cirrus CMP using meteorological and aerosol variables.
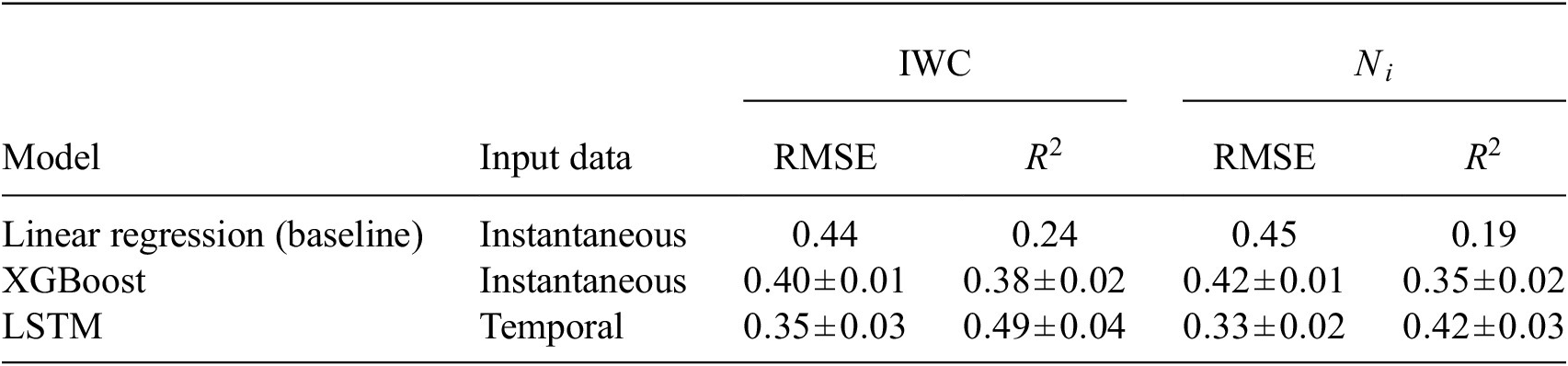
Note. Each model was trained 10 times; the values in the table represent the mean and standard deviation over the 10 model runs. Performance metrics are calculated on log-transformed values of target variables.
Abbreviations: CMP, cloud microphysical property; IWC, ice water content; LSTM, long short-term memory; R 2, coefficient of determination; RMSE, root mean squared error.
4.2. Feature attributions with SHAP
Figure 3 shows that SHAP explanations are more stable and have higher faithfulness than the other feature attribution methods and are thus best suited for our study. For each feature, the mean absolute SHAP value aggregated over all test samples is displayed in Figure 4 for
 $ \mathrm{IWC} $
(left) and
$ \mathrm{IWC} $
(left) and
 $ {N}_i $
(right). It can be seen that the vertical extent of the cloud and the position of the cloud layer within the cloud are important predictors for both CMP. As expected from theory, temperature, and vertical velocity are the main drivers for the prediction. Aerosol concentrations play only a minor role in the prediction.
$ {N}_i $
(right). It can be seen that the vertical extent of the cloud and the position of the cloud layer within the cloud are important predictors for both CMP. As expected from theory, temperature, and vertical velocity are the main drivers for the prediction. Aerosol concentrations play only a minor role in the prediction.
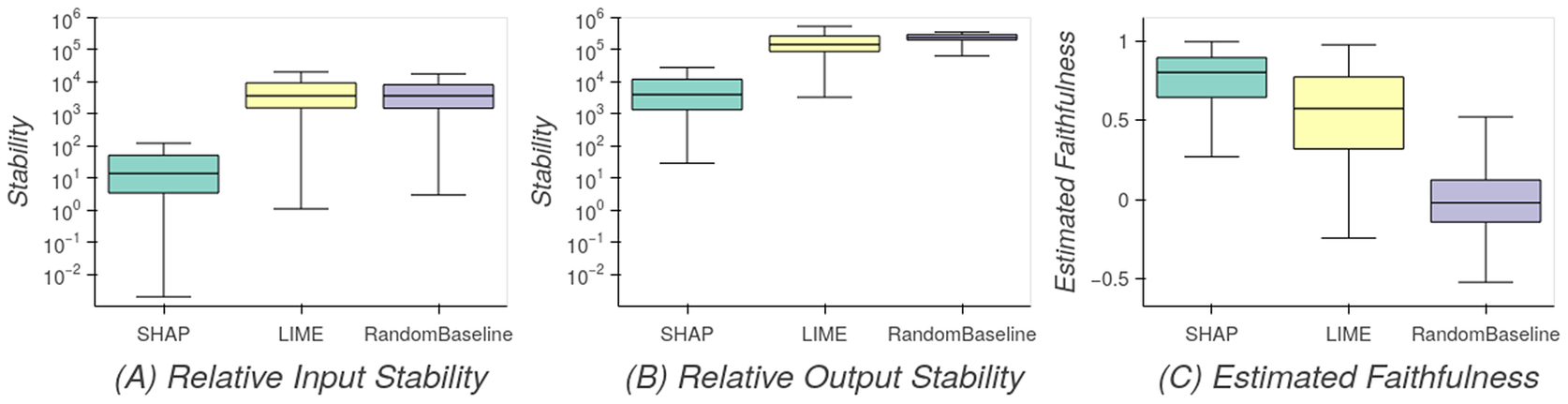
Figure 3. XAI evaluation metrics for SHAP, LIME, and a random baseline feature attribution of the XGBoost model. For the stability metrics RIS (a) and ROS (b), lower values indicate more stable explanations, that is, more robust toward small changes of the feature values. Estimated faithfulness (c) indicates whether features with high importance attributed by the feature attribution method are important for the prediction performance, where 1 denotes perfect estimated faithfulness.
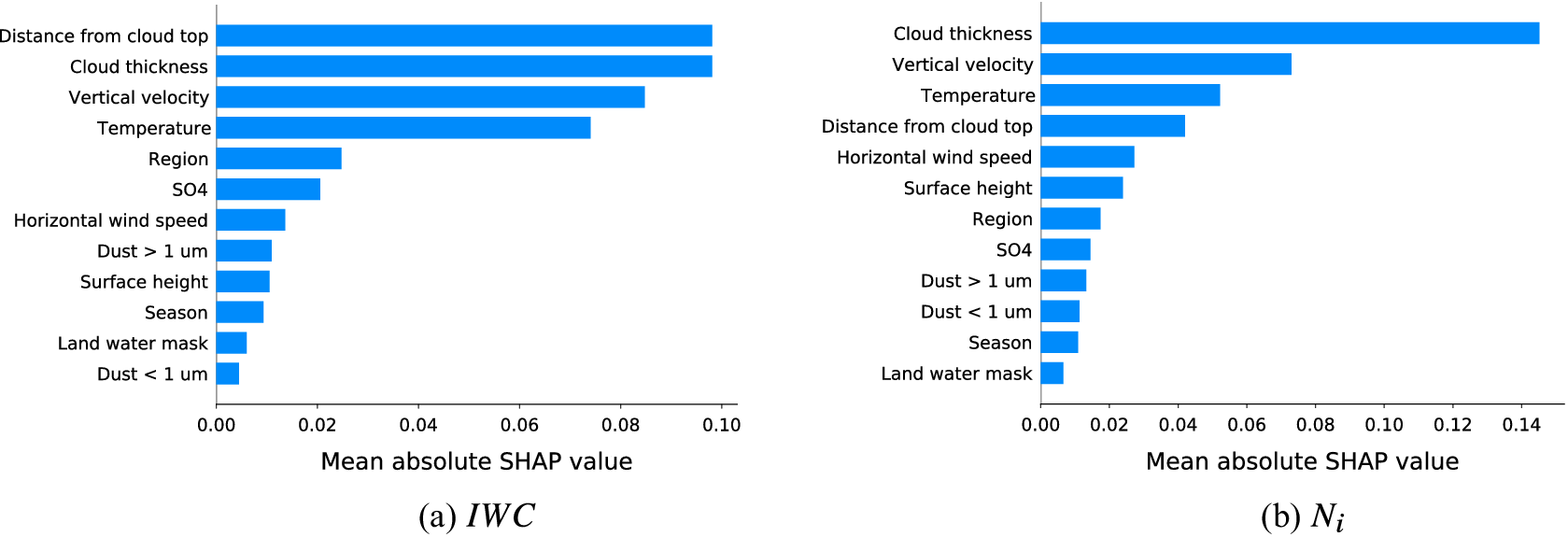
Figure 4. Mean absolute SHAP values of each feature for
 $ \mathrm{IWC} $
(a) and
$ \mathrm{IWC} $
(a) and
 $ {N}_i $
(b). The higher the value, the higher the contribution to the prediction, that is, the more important the feature.
$ {N}_i $
(b). The higher the value, the higher the contribution to the prediction, that is, the more important the feature.
Figure 5 allows a more detailed analysis of the SHAP values. Here, we aggregated the SHAP values for each feature along the range of occurring feature values. Increasing updrafts (i.e., negative vertical velocities (a)) are increasing the model predictions for
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
. Horizontal wind speed (e) has a near-linear contribution to the predictions with a positive impact for wind speeds exceeding 25/ms. Horizontal wind speed is not considered much in cirrus driver literature but could be a good indicator for dynamical systems such as warm conveyor belts. For temperature (b), a positive dependency is found for
$ {N}_i $
. Horizontal wind speed (e) has a near-linear contribution to the predictions with a positive impact for wind speeds exceeding 25/ms. Horizontal wind speed is not considered much in cirrus driver literature but could be a good indicator for dynamical systems such as warm conveyor belts. For temperature (b), a positive dependency is found for
 $ \mathrm{IWC} $
and a negative dependency for
$ \mathrm{IWC} $
and a negative dependency for
 $ {N}_i $
. At temperatures between 230 and 235 K, there is still a strong positive dependency for
$ {N}_i $
. At temperatures between 230 and 235 K, there is still a strong positive dependency for
 $ \mathrm{IWC} $
, while the curve for
$ \mathrm{IWC} $
, while the curve for
 $ {N}_i $
is flattening out. This could indicate that in this temperature range, keeping all other conditions the same, the main processes are growing or colliding ice crystals instead of the formation of new ice crystals. Looking at cloud thickness, it can be observed that vertically thicker clouds increase CMP regardless of where the cloud layer is positioned in the cloud. A strong decrease in CMP is visible for cloud layers at the top of the cloud, with a more pronounced effect for
$ {N}_i $
is flattening out. This could indicate that in this temperature range, keeping all other conditions the same, the main processes are growing or colliding ice crystals instead of the formation of new ice crystals. Looking at cloud thickness, it can be observed that vertically thicker clouds increase CMP regardless of where the cloud layer is positioned in the cloud. A strong decrease in CMP is visible for cloud layers at the top of the cloud, with a more pronounced effect for
 $ \mathrm{IWC} $
(d). This suggests that the entrainment of dry air at the cloud top is a dominant process for cirrus, causing the ice crystals to shrink and partially sublimate. Dust >1 μm slightly decreases the predictions when surpassing a concentration of
$ \mathrm{IWC} $
(d). This suggests that the entrainment of dry air at the cloud top is a dominant process for cirrus, causing the ice crystals to shrink and partially sublimate. Dust >1 μm slightly decreases the predictions when surpassing a concentration of
 $ 2\times {10}^{-4} $
mg/m3, with a stronger effect for
$ 2\times {10}^{-4} $
mg/m3, with a stronger effect for
 $ {N}_i $
. The physical effect acting here could be the suppression of homogeneous nucleation.
$ {N}_i $
. The physical effect acting here could be the suppression of homogeneous nucleation.

Figure 5. (a–f) Partial SHAP dependence plots for representative features showing the mean SHAP value per feature value for
 $ \mathrm{IWC} $
in blue color and
$ \mathrm{IWC} $
in blue color and
 $ {N}_i $
in red color as solid lines. The shaded area represents the standard deviation. Additionally, the marginal distribution of the feature is displayed in gray above each plot, and the marginal SHAP value distributions are displayed on the right of each plot. Note that the absolute SHAP values of
$ {N}_i $
in red color as solid lines. The shaded area represents the standard deviation. Additionally, the marginal distribution of the feature is displayed in gray above each plot, and the marginal SHAP value distributions are displayed on the right of each plot. Note that the absolute SHAP values of
 $ \mathrm{IWC} $
and
$ \mathrm{IWC} $
and
 $ {N}_i $
are not directly comparable as the SHAP value indicates the contribution of a feature to the prediction value, and the two variables have different yet similar distributions. The plots show only feature values with at least 5,000 occurrences in the test data set. (g) Mean of attention weight per timestep. Attention weights are learned during the training process of the LSTM model and represent the relative importance of the input data per timestep.
$ {N}_i $
are not directly comparable as the SHAP value indicates the contribution of a feature to the prediction value, and the two variables have different yet similar distributions. The plots show only feature values with at least 5,000 occurrences in the test data set. (g) Mean of attention weight per timestep. Attention weights are learned during the training process of the LSTM model and represent the relative importance of the input data per timestep.
4.3. Interpretation of attention weights
Figure 5g displays the mean attention weight per timestep of the attention layer of the LSTM model. Compared to the post hoc feature attribution with SHAP, the attention weights are learned during the training process in the attention layer. The weights indicate how important the model considers a given timestep for the prediction. Results suggest that all necessary information for cirrus prediction is encapsulated in the last 15 hr before the observations, with more information the closer the timestep to the observation.
5. Conclusion
This work shows that ML is well suited to capture the nonlinear dependencies between cirrus drivers and CMP. We applied a twofold approach by training an XGBoost model on instantaneous cirrus driver data and an LSTM model with an attention layer on temporally resolved cirrus driver data. The LSTM-based model yielded the best predictive performance, suggesting that the history of an air parcel leading up to a cirrus cloud observation contains useful information. By analyzing the weights of the attention layer, we can show that only the last 15 hr before the observation is of interest. Furthermore, we calculate post hoc feature attributions for the XGBoost model using SHAP values. The analysis of SHAP values enables us to quantify the impact of driver variables on the prediction of CMP. While the physical interdependencies are mostly already known and discussed in the literature, our study can convert qualitative estimates of the dependencies to quantitative ones, such as the slope of the temperature dependency or the dust aerosol concentration needed to see an impact on the CMP. We also demonstrate the importance of vertical cloud extent and cloud layer position to the CMP, apart from meteorological and aerosol variables. Our study is limited by the imperfect prediction of cirrus CMP, reducing the accuracy of the feature attributions. The authors assume that subgrid-scale processes in reanalysis data, like small-scale updrafts and satellite retrieval uncertainties, reduce predictive performance. In conclusion, ML algorithms can predict cirrus properties from reanalysis and macrophysical observational data. Model explainability methods, namely SHAP and attention mechanisms, are helpful tools in improving process understanding.
Acknowledgments
We are grateful for the funding from the European Union’s Horizon 2020 program. The authors would like to thank Heini Wernli, Hanin Binder, and Michael Sprenger for providing the backtrajectory data, Odran Sourdeval for helpful discussions on the DARDAR-Nice data set, and Miguel-Ángel Fernández-Torres for discussion on the ML implementation.
Author contribution
Conceptualization: K.J., U.L., D.N.; Data curation: K.J.; Data visualization: K.J.; Methodology: K.J, U.L., G.C.-V., D.N.; Writing—original draft: K.J. All authors approved the final submitted draft.
Competing interest
The authors declare no competing interests exist.
Data availability statement
The collocated data set and source code are available at https://doi.org/10.5281/zenodo.7590909 and https://doi.org/10.5281/zenodo.7988844, respectively. The original data sets are freely available online: DARDAR-Nice (https://doi.org/10.25326/09), ERA5 (Hersbach et al., Reference Hersbach, Bell, Berrisford, Horányi, Muñoz-Sabater, Nicolas, Peubey, Radu, Schepers, Simmons, Soci, Biavati, Dee and Thépaut2018), and MERRA2 (Global Modeling and Assimilation Office, 2015).
Ethics statement
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Funding statement
This research was supported by grants from the European Union’s Horizon 2020 research and innovation program iMIRACLI under Marie Skłodowska-Curie grant agreement No. 860100 and Swiss National Supercomputing Centre (Centro Svizzero di Calcolo Scientifico, CSCS; project ID s1144).
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/eds.2023.14.
Provenance statement
This article is part of the Climate Informatics 2023 proceedings and was accepted in Environmental Data Science on the basis of the Climate Informatics peer review process.

















 Open access
Open access