


1 Introduction
In the field of design and engineering, many existing tools support creativity during idea generation. These tools help designers generate solutions and explore a larger design space. This exploration is useful during conceptual design when divergent thinking can help avoid fixation (Jansson & Smith Reference Jansson and Smith1991; Purcell & Gero Reference Purcell and Gero1996) and dead-end branching (Shah et al. Reference Shah, Smith and Vargas-Hernandez2003), leading to more creative solutions (Siangliulue et al. Reference Siangliulue, Arnold, Gajos and Dow2015). But how should one go about this creative exploration? One option is to combine ideas from different sources.
Poincaré (Reference Poincaré1910) said ‘Among chosen combinations the most fertile will often be those formed of elements drawn from domains which are far apart…Most combinations so formed would be entirely sterile; but certain among them, very rare, are the most fruitful of all.’ Inspired by similar thinking, designers often connect seemingly unrelated information, for example, by using metaphors or analogy (Hey et al. Reference Hey, Linsey, Agogino and Wood2008). The entire field of biomimicry or biologically inspired design – finding designs in nature and adapting their principles to man-made artifacts – is just one link between different domains that designers have found fruitful. This paper presents computational techniques for finding other such bridges between domains – or bisociations (Koestler Reference Koestler1964) – given a set of design ideas.
Identifying good bisociations requires answering three technical questions: (1) What (specifically and computationally) does it mean to ‘bridge’ a domain? (2) Assuming that I find such bridges, which bridges are creative? and (3) Assuming I have found a creative bridge between domains, how do I represent that conceptual bridge to a designer such that they find it useful?
Researchers have heavily studied the first two questions. The remainder of the introduction reviews the past work and then focuses on the main theory that we leverage in this paper – bisociative networks – which builds a network (i.e., graph) and then uses properties of that network to find bridges between domains. However, the way standard bisociative networks represent ideas (i.e., using bridging words) causes problems for design exploration, both when forming the bisociative network and when using the output. This paper’s below methodology resolves these two problems. We use a randomized controlled experiment and qualitative comparisons of the output to demonstrate its efficacy with respect to standard baselines and existing state of the art.
1.1 Creativity and finding inspiration
Boden (Reference Boden1994) defines creativity as ‘the ability to come up with ideas or artifacts that are new, surprising and valuable.’ The first factor – newness or novelty – implies that an idea should not have existed previously, i.e., be original.
The second factor is the notion of surprise – an idea may be surprising because it may seem unlikely or unfamiliar (even if it is not, in and of itself, new). The third factor is the notion of value – a new concept must be valuable (not just new and surprising) to qualify as creative. However, an idea’s value depends on many scientific, social, economic, political, and other factors. Hence agreeing over the degree of creativity is difficult and context dependent.
Boden’s model of creativity also defines three roads to creativity: ‘combinatorial creativity which combines ideas within a domain, ‘exploratory creativity which finds new ideas across existing domains, and ‘transformational creativity which finds something new outside known domains. We focus on exploratory creativity – coming up with new and meaningful combinations. An example of such creative inspiration is the design of the Shinkansen high speed train in Japan, which was inspired by the beak of a kingfisher (DeYoung & Hobbs Reference DeYoung and Hobbs2009). Similarly, natural silk inspired the design of synthetic fibers, such as Nylon and Kevlar (Gosline et al. Reference Gosline, Guerette, Ortlepp and Savage1999).
To support exploratory creativity, researchers across many fields have developed different computational approaches under different names. In the engineering design domain, predictive models have been employed to characterize hidden patterns within existing datasets. For example, Benami & Jin (Reference Benami and Jin2002) investigated factors which stimulate creativity in conceptual design. Pahl, Newnes & McMahon (Reference Pahl, Newnes and McMahon2007) presented a generic model of the process leading to innovative design by comparing all the processes of creating outlined in the psychological literature. Their model defines and makes visible the path of generation and divergence of ideas, followed by a period of ‘editing’ and a final convergence into innovation. Zahner et al. (Reference Zahner, Nickerson, Tversky, Corter and Ma2010) provide two methods to reduce fixated thinking – abstracting and re-representing. They showed that abstractness promoted original ideas in the design of information systems. Similarly, the effect of different level of abstraction for textual representations in Gonçalves, Cardoso & Badke-Schaub (Reference Gonçalves, Cardoso and Badke-Schaub2012) showed the benefit of distant textual stimuli for generating original ideas. These models, while useful for single domain, are often limited in their ability to draw connections between seemingly unrelated domains. Sometimes, innovative design solutions across multiple, seemingly unrelated domains may be omitted entirely.
Generating original solutions by borrowing ideas from multiple domains has been a key challenge for designers. One of the widely used method to this problem is Design by analogy (DbA), which has been shown to be an effective method for inspiring innovative design solutions. It is a practice in which designers use solutions from other domains to gain inspiration. DbA supports designers in developing conceptual designs for new products by discovering new insights from multiple domains. Engineering designers have often used DbA for bio-inspired design too. It allows engineers to take ideas from nature and develop new design solutions for engineering problems by searching design analogies from biological domains. However, identifying useful solutions from outside domains using DbA is non-trivial. For example, Fu et al. (Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013) measured distances between patents using a hierarchical Bayesian model and showed that priming people with patents too ‘far’ (in terms of tree path length) from a target patent can be harmful to retrieving analogies, while likewise recommending patents too ‘near’ can result in design fixation. Likewise, Chan, Dow & Schunn (Reference Chan, Dow and Schunn2015) analyzed winning ideas submitted to the online design challenge website OpenIDEO and found, via each idea’s citations network, that the best design ideas often came from sources of inspiration which are not far away (in terms of path lengths in the citation graph).
Like these prior approaches, our method provides an automated computational tool to find abstract inspirations from unrelated domains by modeling a concept of ‘distance’ between ideas and domains. However, unlike past approaches, we do not assume that this distance metric is context independent (unlike, for example, tree hierarchy or citation graph paths). Our method differs from past studies, as it does not directly measure distances to identify ideas that are far-off or close by to a domain, but learns from the data to identify possible sources of inspiration. It does so by looking at ideas which are confused to belong to some other domain. Whereas past approaches find existing ideas as creative inspiration, we discover hidden concepts within ideas, which act as creative inspiration. Specifically, we focus on a prior line of work called bisociative creative information exploration which is inspired by Koestler’s model of creativity (Koestler Reference Koestler1964) proposed in the 1960s. His model centers around the concept of bisociation.
1.2 Koestler’s concept of bisociation
Bisociation, according to Koestler, means joining unrelated, often conflicting, information in a new way (Koestler Reference Koestler1964). He makes a clear distinction between habitual thinking (association) operating within a single plane of thought, and the more creative bisociative mode of thinking which connects independent planes of thought. Koestler conjectured that bisociation is a general mechanism for the creative act in the field of humor, science, engineering, and arts.
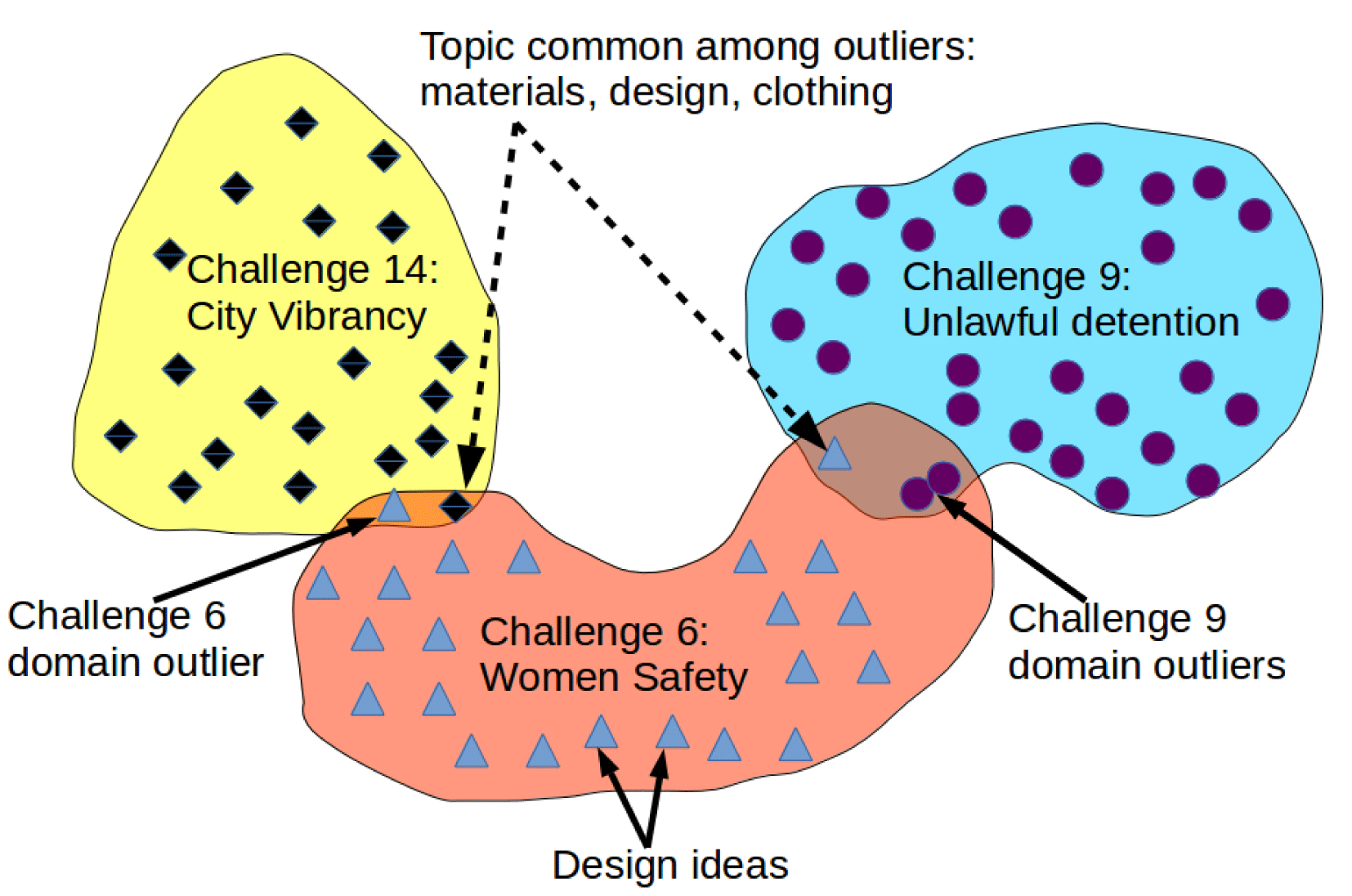
Figure 1. Three design domains and outlier ideas (ideas from these domains which are more similar to other domains). Topics common among outlier ideas but uncommon overall have high bisociation score. In this example, topic on using ‘clothing’ and ‘material’ is a b-topic. These ideas and challenge domains were sampled from the OpenIDEO dataset we introduce in the Results section.
Figure 1 provides a simple illustration to bisociation, by showing examples from a set of three OpenIDEO design challenges (or what we will call ‘domains’). Specifically, each of the three challenges – improving women’s safety in urban environments, reducing the risk of unlawful detection, and increasing vibrancy in cites facing economic decline – had several ideas (represented as markers in Figure 1) that users submitted in response to the challenge. Bisociations are indirect connections between ideas, which cross the border between (i.e., bridge) domains (or in this case, different challenges). On surface, these domains are quite dissimilar; however, one may discover an indirect concept, which is common to these domains. In Figure 1, for example, several ideas across all three challenges leverage the idea using wearable accessories to address the challenge problem. Koestler would call that concept – the use of wearable accessories – a bisociation, in that ideas from one challenge or domain might more easily transfer between domains that jointly share the concept. We show later in the paper how ideas from a design collection for these three domains were found to have this concept common among them. We also define precisely how to represent and compute bridging concepts in further sections.
Researchers have applied bisociation most readily to the discovery and exploration of research literature (i.e., academic papers). This work is typified by the work of Swanson (Reference Swanson1986) who introduces ‘Swanson linking’ to connect medical literature by assuming that new knowledge and insight arises when connecting knowledge sources which were thought to be unrelated. In his seminal paper, Swanson investigated connections between migraine and magnesium, based on published research papers. He found indirect relations via bridging terms (b-terms) – words that signaled possible connections between two domains – that suggested magnesium deficiency may cause migraines.
Several researchers have continued Swanson’s line of research, for example the RaJoLink method (Petriĕ et al. Reference Petriĕ, Urbanĕiĕ, Cestnik and Macedoni-Lukšiĕ2009) and the BISON project (Berthold Reference Berthold2012; Dubitzky et al. Reference Dubitzky, Kötter, Schmidt, Berthold and Berthold2012). These efforts pursued new algorithms to create, analyze, and explore domain-bridging words within text document collections. For example, Juršič et al. (Reference Juršič, Sluban, Cestnik, Grčar and Lavrač2012b ) select and rank keywords they claim highlight bridging words that help people discover cross-domain links that can lead to new ideas. They show that their methodology places a significantly higher number of bridging words toward the top of a ranked list compared to chance rankings. Kang (Reference Kang2016) and Kang & Tucker (Reference Kang and Tucker2017) applied bisociative design methodology to discover product attributes that correlate to an increase in enterprise profit. They do so by analyzing the associations between function attributes and 3D form attributes among different products. They use Latent Dirichlet Allocation (LDA) to extract the function attributes from the product descriptions and Reeb graphs to represent the form. Tucker & Kang (Reference Tucker and Kang2012) studied bisociations by decomposition of a design artifact by form, function, and behavior to quantify the level of similarity among items across domains. The authors demonstrated their method on marine and aviation domains. These bisociation studies are also supplemented by research on bisociative networks, predominantly used for creative exploration.
1.3 BisoNets: bisociative information networks
A bisociative information network (or BisoNet) is a method of practically computing Koestler’s bisociation. A BisoNet represents concepts as a network – a graph with vertices and edges – and then defines functions on that network that compute creative bisociations. This approach leads to two intimately coupled technical challenges. The first, which is common to all network modeling approaches, lies in how one constructs the network itself – e.g., what are the nodes and edges in the network, and how does that choice affect the outcome? The second, specific to bisociation, lies in how one computes which nodes ‘bridge’ domains in a creative way. We review the first challenge in this section, and address the second later in our methodology. In brief, the way that past work represented BisoNets (i.e., using specific bridging words), while effective for academic literature, does not perform well for design concepts. One of the contributions of this paper lies in defining a more appropriate network representation and subsequent function for computing bisociation under that new representation.
Specifically, a BisoNet is a weighted, undirected, k-partite graphFootnote 1 of concepts, such that similar concepts are connected by an edge – in essence, a similarity graph, but with a particular form of similarity called bisociation that we detail later in the paper. Vertices in BisoNets can represent any unit of analysis, such as words, documents, ideas, people, etc. Vertices of the same type are grouped into vertex partitions – for example, partitioning all words from a particular document together, or partitioning all articles from a given field together.
As with all network models, a key differentiator among past work lies in how they calculate the edge weight between the graph nodes. For example, finding relations between such nodes often focuses on discovering semantically related terms, frequently using lexical databases and ontologies. Edge weights can be calculated using measures like cosine similarity, normalized Google distance (NGD) measure (Cilibrasi & Vitanyi Reference Cilibrasi and Vitanyi2007), or similarity functions tailor-made for bisociation discovery, like Segond and Borgelt’s Bison measure (Segond & Borgelt Reference Segond and Borgelt2009).
Researchers have applied BisoNets to exploration of Biological and Financial Literature (Schmidt et al. Reference Schmidt, Kranjc, Mozetič, Thompson and Dubitzky2012) and Music Discovery (Stober et al. Reference Stober, Haun and Nürnberger2012), with unstructured text documents being one of the most widely used (and most challenging) applications. These past text-based approaches work well when there are specific, technical terms embedded in documents that are shared between domains. For example, in the autism–calcineurin benchmark dataset (Berthold Reference Berthold2012), standard BisoNet exploration tools identify individual scientific terms like ‘paroxysmal’ or ‘Bcl-2’ that discover links between two scientific domains (in that case, between autism and the human immune system). However, this example also highlights two key issues with past BisoNet approaches that make them ill-suited for creative design exploration.
First, past representations relied on identifying specific bridging words. As we demonstrate in our results, for design concepts this does not work well since design descriptions often rely on multiple words or ideas taken holistically together as a system – that is, there are no magic bridging words (like ‘Bcl-2’ in the autism example) but rather collections of words or phrases that, in aggregate, provide a new frame within which to view a design problem. Current approaches to bisociation do not handle such cases. This paper resolves the problem by introducing bridging topics – called b-topics, rather than bridging terms, to capture richer representations for bridges across domains.
Second, existing BisoNet approaches find bridging terms between only two, pre-identified domains (e.g., the autism–calcineurin or migraine–magnesium datasets). This assumes that one knows, a priori, which two domains will likely produce good bridging terms. While this pre-knowledge of domains may exist for certain design applications (e.g., in bio-inspired design), in general we largely do not know which combinations of two domains will be fruitful. This paper resolves this problem by generalizing existing bisociation techniques to exploration across multiple domains at once, not just between two. We demonstrate below that this leads to a much richer exploration of possible bridging concepts than if we were to pre-select two domains a priori.
Aside from bisociation, some researchers have approached the same problem from the perspective of serendipity (Roberts Reference Roberts1989; Kamahara et al. Reference Kamahara, Asakawa, Shimojo and Miyahara2005). Serendipitous discoveries overlap with bisociations since they often involve realizing a connection between dissimilar domains of knowledge. Serendipity has mainly been applied to recommender systems (Onuma, Tong & Faloutsos Reference Onuma, Tong and Faloutsos2009).
1.4 This paper’s contributions
Our work builds upon earlier BisoNet techniques (Schmidt et al. Reference Schmidt, Kranjc, Mozetič, Thompson and Dubitzky2012), but with three main differences. First, we apply bisociation principles to fourteen domains that are broader than analysis of scientific papers. Most of the previous techniques applied BisoNets to either a migraine and magnesium dataset or an autism–calcineurin domain. These datasets only have two domains and performance evaluation is straightforward due to the advantage of having gold-standard bridging terms. Second, by comparing with Cross Context Bisociation Explorer (CrossBee) tool – the existing state of the art in computational bisociation – we show that finding words as b-terms for unstructured text is not as useful for design concepts, thus small collections of words should be used instead. We propose using topic models for this purpose and re-define bisociation metrics such that they work for topics. Finally, we evaluate our method using human preferences elicited by crowd workers on Amazon Turk.
This paper’s key contributions are:
(1) The introduction of bridging topics – via Topic Models (Blei & Lafferty Reference Blei, Lafferty, Srivastava, Sahami and Kumar2009) – as a representation for computing bisociative links in the network.
(2) Introducing a new objective function for ranking topics by their bisociation potential.
(3) Generating a BisoNet from topic representations via identifying likely edges.
(4) Demonstrating that bisociation can be used in domains far broader than identifying bridging words within academic literature. Such bisociation produces new inspirational frames for design problems that, within our experiments, led humans to generate more creative solutions.
(5) Generalizing the principles of bisociation to simultaneously handle multiple domains, rather than just between two domains.
One major challenge compared to past BisoNet work is the lack of comprehensive benchmark datasets for multiple domains outside of scientific literature. One of this paper’s ancillary outcomes is to enable creation of such a dataset, so that others can study multi-domain bisociation in broad design domains. We have made data corresponding to our results available online Footnote 2 .
2 Methodology
Let us say that we are given ideas from
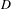 $D$
domains. Here, we propose a method, which finds a ranked list of concepts which indirectly connects these domains. Next, we also show how these concepts can be used to generate a BisoNet. Our approach to creative exploration consists of three main steps: (1) constructing the network nodes – that is, learning each idea’s topic representations, (2) finding likely bridging topics (or b-topics) and using those topics to create network edges that connect idea domains, and (3) constructing a BisoNet from highly probable bridging topics, so that users can explore and navigate a graph of cross-domain inspirations.
$D$
domains. Here, we propose a method, which finds a ranked list of concepts which indirectly connects these domains. Next, we also show how these concepts can be used to generate a BisoNet. Our approach to creative exploration consists of three main steps: (1) constructing the network nodes – that is, learning each idea’s topic representations, (2) finding likely bridging topics (or b-topics) and using those topics to create network edges that connect idea domains, and (3) constructing a BisoNet from highly probable bridging topics, so that users can explore and navigate a graph of cross-domain inspirations.
2.1 Representing ideas
The first step is to computationally represent an idea or design. In this research, we only consider text documents; however, the techniques we develop below for topic collections will transfer to other inputs or media (e.g., images). Traditionally, research on representing text documents largely used a vector space model where a document is expressed by a vector of keyword weights using the TF-IDF method (Salton & Buckley Reference Salton and Buckley1988). Researchers have since developed various other dimension reduction techniques to capture the hidden semantic structure in a document including probabilistic latent semantic analysis (pLSA) (Hofmann Reference Hofmann1999) and topic modeling (Blei & Lafferty Reference Blei, Lafferty, Srivastava, Sahami and Kumar2009). The ‘topics’ produced by topic modeling techniques are clusters of similar words. A topic model captures this intuition in a mathematical framework, which allows examining a set of documents and discovering, based on the statistics of the words in each, what the topics might be and what each document’s balance of topics is.
LDA (Blei, Ng & Jordan Reference Blei, Ng and Jordan2003) – is a widely used topic modeling method. In LDA, each document is described as a random mixture over a set of hidden topics and each topic is a discrete distribution over a text vocabulary – that is, words can belong to discrete clusters, and LDA learns from data how strongly any word should belong to any cluster. LDA has been applied to many areas (Rosen-Zvi et al. Reference Rosen-Zvi, Griffiths, Steyvers and Smyth2004; Wei & Croft Reference Wei and Croft2006; Krestel et al. Reference Krestel, Fankhauser and Nejdl2009) and several variants of LDA have also been proposed to tackle correlated (Blei & Lafferty Reference Blei and Lafferty2007) and network-based (Chang & Blei Reference Chang and Blei2009) structure between topics. In design, Chan, Schunn & Dow (Reference Chan, Schunn and Dow2014) used LDA to represent ideas on OpenIDEO and showed that concepts that cite sources had greater success than those that did not cite sources of inspiration. Chan & Schunn (Reference Chan and Schunn2015) also used LDA to represent ideas, where they hypothesized that iteration is necessary to convert far combinations into creative concepts.
The key insight from topic models relevant to our work is that, rather than using the specific bridging words from a document (as in standard BisoNet examples like ‘Bcl-2’ above), we can instead cluster words together into overall topics that contain sets of related words. For example, single bridging word like ‘care’ can be vague. It can refer to care in hospitals, care for the elderly, or health insurance care. However, the ambiguity is reduced for a semantically related collection of words like {‘care’, ‘health’, ‘patient’, ‘hospital’, ‘doctor’, ‘medical’, ‘center’}, as it provides clearer framing and context. Although, subjectivity of interpretation is a desirable property of our approach compared to showing existing ideas, it can often act as double edged sword in the design process. While showing existing ideas can often be too specific, showing single words can be too ambiguous. Under what conditions does including multiple words increase or decrease the clarity? One way to think about context clarity is whether a word (or set of words) collapses the conditional Shannon entropy of the topic posterior probability distribution in a topic model. When single words are used, the topic distribution generally has high entropy, implying that single word can come from many topics or contexts. When multiple related words from the same topic are used, the posterior probability distribution collapses to zero entropy (there is no topic uncertainty) and thus refers to only one topic. The above assumes that topics are a reasonable proxy for ‘context’ or ‘framing’ – an assumption we believe is reasonable, given that topic models are designed to capture document context. Hence, we claim that collections of relevant words (i.e., topics) can act as better bridges between design domains than individual terms used in current bisociative networks.
In this paper, we use LDA to capture the topic distribution of ideas; however, our contributions are independent of the specific topic model variant or implementation used. Specifically, we learn the topic distribution for each idea a corpus of designs – this means that we represent each design idea (text document, in this case) as a
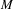 $M$
-dimensional vector of numbers between
$M$
-dimensional vector of numbers between
 $0$
and
$0$
and
 $1$
that corresponds to which topics are most prevalent in that idea. We use these vectors to identify edges and possible bridging topics.
$1$
that corresponds to which topics are most prevalent in that idea. We use these vectors to identify edges and possible bridging topics.
2.2 Bridging topic identification
Given sets of ideas and their topics proportions, our goal is to find, for a given domain or set of ideas, what topics might bridge across other domains. One naïve approach to finding bridging topics might be to simply look for topics that two or more domains have in common – after all, if a topic is highly represented within two domains, it seems sensible to expect that those topics would somehow bridge those two domains. The main problem with that approach is that the topics that are both representative of a particular domain and common across domains tend to be overly general topics that do not provide much creative insight – for example, common cross-domain topics might include topics such as {‘the’, ‘and’, ‘is’, ‘of’} or {‘man’, ‘woman’, ‘he’, ‘she’, ‘they’}, etc. While such topics certainly do bridge across domains, they are unlikely to meaningfully re-frame the problem in a creative way.
Instead, we are looking for a kind of ‘Goldilocks’ topic; topics that are uncommon enough to bring new insight to a problem, but common enough across domain outliers that the topic can be readily understood and adapted. This intuition – that we need to identify outliers within domains, but commonalities between domains – was the primary goal of previous research on bisociation; the central idea being to rank all bridging topics as a function of how rare they occur overall and how common they are among outliers within its own domain.
Specifically, we generalize the approach of Jurs̆ic̆ et al. (Reference Juršič, Cestnik, Urbančič and Lavrač2012a ) to collections of words (topics) rather than single words. Their essential approach was to train a machine classifier to distinguish domains from one another using individual words within documents, and then search for documents or terms that the classifier reliably misclassifies as a different domain. Why is that approach reasonable? The intuition is that documents that actually live within one domain – but are consistently classified as being in another (false negatives) – are more likely to ‘bridge’ domains. Jurs̆ic̆ et al. found this outlier-finding approach to be stable, even under minor modifications to the dataset, and that it consistently located the gold-standard bridging terms within the benchmark dataset.
To find bisociation scores for topics, we first find outlier ideas in every domain. Here, outlier ideas are false negatives in the multi-label classification – documents that have greater similarity to documents in some other domain than to those of their own domain. To find these outliers, we train a multi-class classifier and the documents wrongly classified by it (false negative) are marked as domain outliers. The input to the multi-class classifier is the vectorial representation for each document and the output labels are the domain index. Ground truth during training is the true label of the domain. If one uses a poor classifier with large number of false negatives (low recall), it would wrongly consider many ideas as outliers. Hence, the b-topic scoring will be erroneous and topics in such domains may get artificially high b-scores.
The rationale is that topics with high bisociation score are more common in outlier documents and less common overall. The outlier documents according to classification models should not belong to their domain and thus are likely to have borrowed concepts from other domains. Let
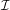 ${\mathcal{I}}$
be the set of all
${\mathcal{I}}$
be the set of all
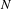 $N$
documents from
$N$
documents from
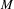 $M$
domains and
$M$
domains and
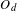 $O_{d}$
be the set of outliers for domain
$O_{d}$
be the set of outliers for domain
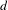 $d$
. Let
$d$
. Let
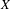 $X$
be the
$X$
be the
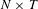 $N\times T$
document-topic matrix, where row
$N\times T$
document-topic matrix, where row
 $i$
represents
$i$
represents
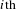 $i\text{th}$
document’s
$i\text{th}$
document’s
 $T$
dimensional topic proportion vector. For topic
$T$
dimensional topic proportion vector. For topic
 $t$
in domain
$t$
in domain
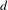 $d$
:
$d$
:
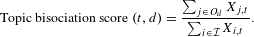 $$\begin{eqnarray}\text{Topic bisociation score }(t,d)=\frac{\mathop{\sum }_{j\in O_{d}}X_{j,t}}{\mathop{\sum }_{i\in {\mathcal{I}}}X_{i,t}}.\end{eqnarray}$$
$$\begin{eqnarray}\text{Topic bisociation score }(t,d)=\frac{\mathop{\sum }_{j\in O_{d}}X_{j,t}}{\mathop{\sum }_{i\in {\mathcal{I}}}X_{i,t}}.\end{eqnarray}$$
The above score is used to rank every topic by their potential to be a true bisociation candidate for a given domain (
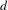 $d$
). For classification with multiple domains, we build a joint classification model to simultaneously classify all the documents. To make the outlier set more robust, the prediction scores for the three classifiers with highest accuracy are added to find the output domain in classification. Documents whose predicted challenge are different from true challenge are allotted to the outlier set. While we describe the exact classifiers we use in our results section, the specific choice of classifier is not central to the contributions of this paper; any ensemble that meaningfully reduces the classifier variance should suffice.
$d$
). For classification with multiple domains, we build a joint classification model to simultaneously classify all the documents. To make the outlier set more robust, the prediction scores for the three classifiers with highest accuracy are added to find the output domain in classification. Documents whose predicted challenge are different from true challenge are allotted to the outlier set. While we describe the exact classifiers we use in our results section, the specific choice of classifier is not central to the contributions of this paper; any ensemble that meaningfully reduces the classifier variance should suffice.

2.3 Generating the BisoNet
Lastly, we create a BisoNet where links between bridging nodes in different domains can be visualized and understood using graph exploration techniques. Essentially, we define a procedure for linking the bridging topics (b-topics) of a BisoNet by finding weights that indicate the association strength.
For BisoNets with words as nodes (rather than topics), Segond & Borgelt (Reference Segond and Borgelt2009) showed that keeping the edges between words that had the highest bisociation scores performed well at bisociative discovery – they referred to the ranking procedure as a Bison Measure. We modify their proposed Bison measure to use topic proportions instead of term frequencies, applying the same rationale for topics and define the Topic Bison Measure
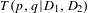 $T(p,q|D_{1},D_{2})$
between two topics
$T(p,q|D_{1},D_{2})$
between two topics
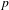 $p$
and
$p$
and
 $q$
as:
$q$
as:
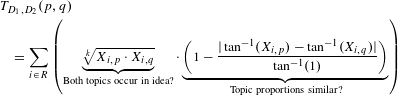 $$\begin{eqnarray}\displaystyle & & \displaystyle T_{D_{1},D_{2}}(p,q)\nonumber\\ \displaystyle & & \displaystyle \quad =\mathop{\sum }_{i\in R}\left(\underbrace{\sqrt[k]{X_{i,p}\cdot X_{i,q}}}_{\text{Both}\;\text{topics}\;\text{occur}\;\text{in}\;\text{idea}?}\cdot \underbrace{\bigg(1-\frac{|\tan ^{-1}(X_{i,p})-\tan ^{-1}(X_{i,q})|}{\tan ^{-1}(1)}\bigg)}_{\text{Topic}\;\text{proportions}\;\text{similar?}}\right)\quad\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle T_{D_{1},D_{2}}(p,q)\nonumber\\ \displaystyle & & \displaystyle \quad =\mathop{\sum }_{i\in R}\left(\underbrace{\sqrt[k]{X_{i,p}\cdot X_{i,q}}}_{\text{Both}\;\text{topics}\;\text{occur}\;\text{in}\;\text{idea}?}\cdot \underbrace{\bigg(1-\frac{|\tan ^{-1}(X_{i,p})-\tan ^{-1}(X_{i,q})|}{\tan ^{-1}(1)}\bigg)}_{\text{Topic}\;\text{proportions}\;\text{similar?}}\right)\quad\end{eqnarray}$$
where
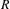 $R$
is the set of
$R$
is the set of
 $i$
ideas obtained by the union of domains
$i$
ideas obtained by the union of domains
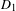 $D_{1}$
and
$D_{1}$
and
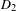 $D_{2}$
. In Eq. (2), the product term
$D_{2}$
. In Eq. (2), the product term
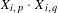 $X_{i,p}\cdot X_{i,q}$
implies that for two topics to be similar (have a high bison measure), they should both have large positive proportions in a document, as a vanishing topic proportion means that the two topics do not co-occur in the corresponding document. Secondly, they are more related if they have similar proportions. To further understand this, we have to keep in mind that having two topics, both of which have a topic proportion of 0.1, should be less important than having two topics with a topic proportion of 0.5. In the first case, the topics we are comparing appear only rarely in the considered document. On the other hand, in the latter case these topics appear very frequently in this document, which means that they are strongly linked according to this document.
$X_{i,p}\cdot X_{i,q}$
implies that for two topics to be similar (have a high bison measure), they should both have large positive proportions in a document, as a vanishing topic proportion means that the two topics do not co-occur in the corresponding document. Secondly, they are more related if they have similar proportions. To further understand this, we have to keep in mind that having two topics, both of which have a topic proportion of 0.1, should be less important than having two topics with a topic proportion of 0.5. In the first case, the topics we are comparing appear only rarely in the considered document. On the other hand, in the latter case these topics appear very frequently in this document, which means that they are strongly linked according to this document.
The arctan function normalizes the effects of comparing topic proportions of different magnitude. Parameter
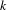 $k$
can be adjusted according to the importance one is willing to give to low topic proportion values. Hence, this form has the advantage that it takes into account that two topic proportion values for the same index have to be positive, similarity between topics is greater if the topic proportion values are large and the same difference between topic proportions has different impact according to the values of the topic proportions.
$k$
can be adjusted according to the importance one is willing to give to low topic proportion values. Hence, this form has the advantage that it takes into account that two topic proportion values for the same index have to be positive, similarity between topics is greater if the topic proportion values are large and the same difference between topic proportions has different impact according to the values of the topic proportions.
The procedure to obtain a BisoNet is described in Algorithm 2. To simplify the network for visualization purposes, one may threshold the bisociation score of topics to select a small percentage of the highest scoring topics as edges; these topics have high potential to be bisociative. After calculating the edge weights (the topic bison measure) between remaining topics, edge pruning can be done to retain only a small fraction of highest weight edges.

3 Results and discussion
To study our method’s effectiveness on a concrete example, we apply our technique to 14 OpenIDEO challenges to find interesting connections between domains. We then create a BisoNet for graph exploration and show meaningful themes discovered between different domains. Finally, we verify our results with different human experiments conducted with crowd workers.
3.1 Dataset
OpenIDEO is a successful online open innovation community centered around designing products, services, and experiences that promote social impact by building of ideas from distributed individuals (Fuge et al.
Reference Fuge, Tee, Agogino and Maton2014). Generally, challenges have various stages like: ‘Research, Ideas, Applause, Refinement, Evaluation, and Winners’ and address very different social issues. We focus on the ‘Ideas’ stage, where participants generate and view potential design ideas. In this stage, hundreds to thousands of ideas are submitted in a single challenge. Reading ideas posted in past challenges or even the same challenge to gain inspiration when developing their own ideas is challenging – for a single, medium-sized challenge (
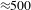 ${\approx}500$
ideas) it would take a person over 40 hours to read all idea entries. Because of this, participants often filter by date, the total number of comments, or just pick ideas randomly from the same challenge as inspiration. Once inspired, participants in a challenge may submit new ideas containing text and images, linking to existing ideas that inspired them. Over time, submitted ideas accrue views, applause, and comments as other participants provide feedback (Fuge & Agogino Reference Fuge and Agogino2014). Past work on helping filter ideas on OpenIDEO has investigated finding a small subset of diverse ideas (Ahmed, David Gorbunov & Fuge Reference Ahmed, David Gorbunov and Fuge2016) and ranking ideas by quality after training a classifier to identify winning ideas (Ahmed & Fuge Reference Ahmed and Fuge2017).
${\approx}500$
ideas) it would take a person over 40 hours to read all idea entries. Because of this, participants often filter by date, the total number of comments, or just pick ideas randomly from the same challenge as inspiration. Once inspired, participants in a challenge may submit new ideas containing text and images, linking to existing ideas that inspired them. Over time, submitted ideas accrue views, applause, and comments as other participants provide feedback (Fuge & Agogino Reference Fuge and Agogino2014). Past work on helping filter ideas on OpenIDEO has investigated finding a small subset of diverse ideas (Ahmed, David Gorbunov & Fuge Reference Ahmed, David Gorbunov and Fuge2016) and ranking ideas by quality after training a classifier to identify winning ideas (Ahmed & Fuge Reference Ahmed and Fuge2017).
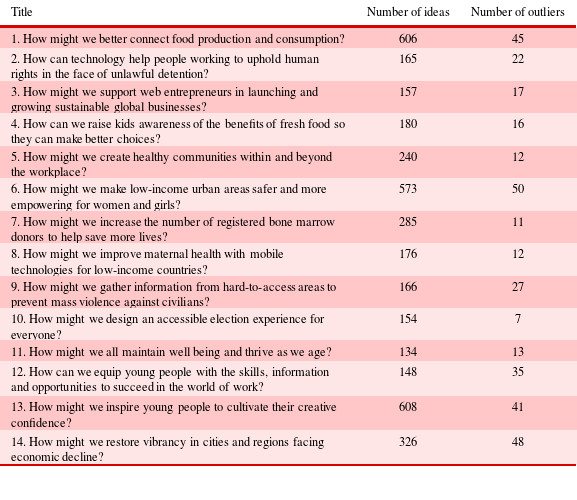
We ran our experiment on 14 different challenges (domains) with total 3918 ideas submitted to these challenges. The challenge titles are shown in Table 2. To gain some intuition about how similar or different these domains are, Figure 2 projects the topic vectors of all ideas into 2-D using t-distributed stochastic neighbor embedding (t-SNE) (Maaten & Hinton Reference Maaten and Hinton2008). t-SNE is a technique for dimensionality reduction that is particularly well suited for the visualization of high-dimensional datasets. The algorithm preferentially cares about preserving the local structure of the high-dimensional data. If two points are close in the original space, there is a strong attractive force between the points in the embedding, while if any two points are far apart in the original space, the algorithm is relatively free to place these points around.
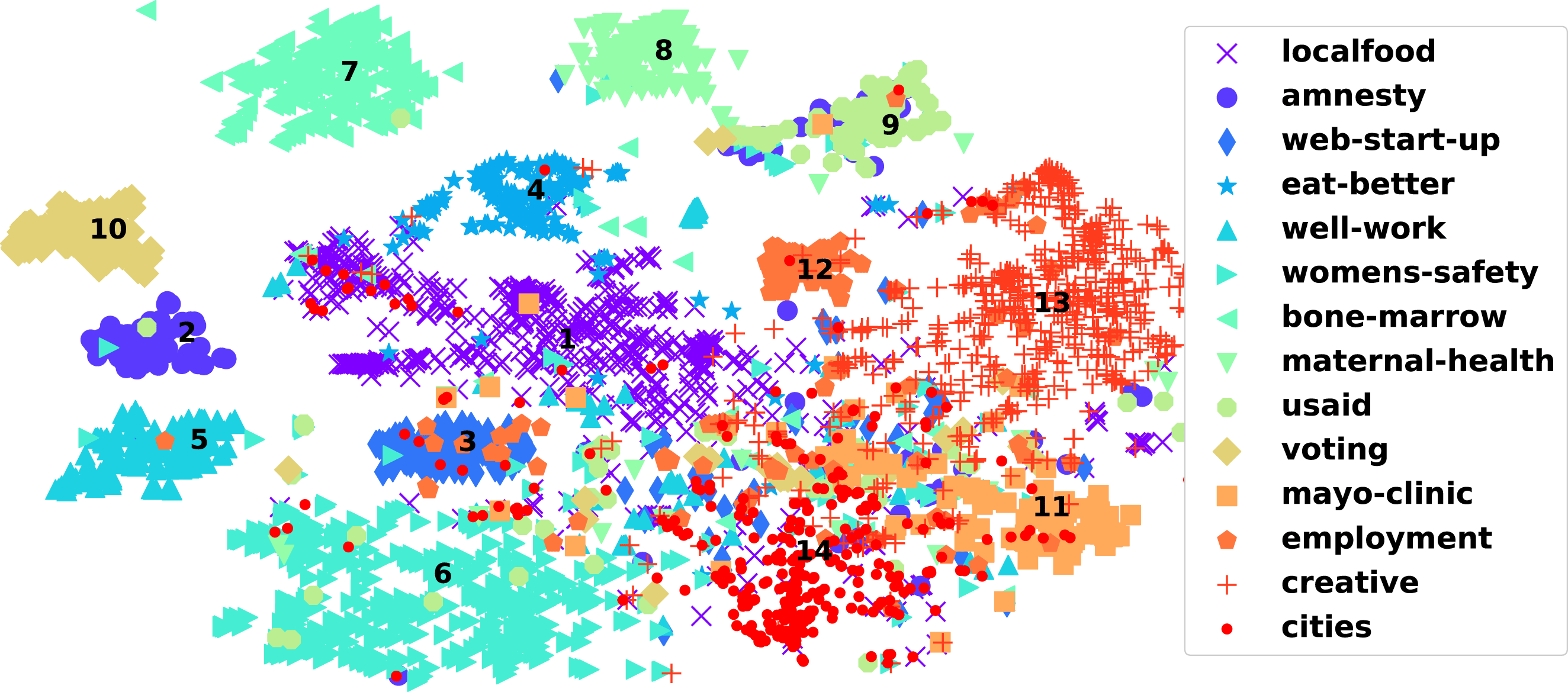
Figure 2. All ideas from 14 challenges projected on a 2-D plane using t-distributed stochastic neighbor embedding (t-SNE). Some challenges (e.g., the voting challenge #10), do not overlap many domains, while others (e.g., #14) may have significant overlap.
As Figure 2 demonstrates, some challenges like challenge
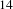 $14$
have many ideas which overlap with other challenges, while others like challenge
$14$
have many ideas which overlap with other challenges, while others like challenge
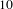 $10$
have a tight cluster whose ideas largely differ from other challenges. This disparity is expected; for example, challenge
$10$
have a tight cluster whose ideas largely differ from other challenges. This disparity is expected; for example, challenge
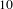 $10$
involves improving voting access during elections (a comparatively narrow and specific problem), while challenge
$10$
involves improving voting access during elections (a comparatively narrow and specific problem), while challenge
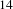 $14$
addresses improving vibrancy in cities facing economic decline (a comparatively broad and open-ended problem). Later we find that this observation is further supported when we perform outlier detection, with some challenges having fewer outliers. Topics in such challenges will not have high bisociation potential and are unlikely to be good bisociation candidates. This is because the bisociation score in Eq. (1) is proportional to the number of outliers. Intuitively, if a domain is very narrow and specific (like bone marrow or voting challenges), it is less likely to gain from indirect connections with other domains.
$14$
addresses improving vibrancy in cities facing economic decline (a comparatively broad and open-ended problem). Later we find that this observation is further supported when we perform outlier detection, with some challenges having fewer outliers. Topics in such challenges will not have high bisociation potential and are unlikely to be good bisociation candidates. This is because the bisociation score in Eq. (1) is proportional to the number of outliers. Intuitively, if a domain is very narrow and specific (like bone marrow or voting challenges), it is less likely to gain from indirect connections with other domains.
Before demonstrating our model, the next section summarizes how existing state of the art in BisoNet discovery – the ‘CrossBee’ toolFootnote 3 – performs on design examples to motivate the use of topics instead of words to bridge design domains. Thereafter, we discuss insights into the topic model and b-topics obtained using LDA. Then we run two experiments on Amazon’s Mechanical Turk platform to gather human evaluation data. In the first experiment, workers assess whether the b-topics themselves are creative (compared to non-b-topics). In the second experiment, we use the b-topics as inspiration in an idea generation task and ask workers to create or judge the generated ideas. Our experiments show that the above methodology is able to discover topics and produce ideas which people find creative.
3.2 CrossBee results: comparison to existing state of the art
The existing state-of-the-art bisociation tool is the CrossBee. It is an online tool to analyze text documents from two different domains. The tool finds and rank orders bridging terms (b-terms) but does not create a BisoNet. However, we demonstrate below that several issues arise when using words for design exploration rather than our proposed bridging topics. Since CrossBee can only handle two domains at once, we use it to find b-terms from Challenge
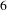 $6$
(women’s safety) and
$6$
(women’s safety) and
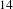 $14$
(city vibrancy) in our dataset as an illustrative and representative example. The full challenge topics are, respectively, ‘How might we make low-income urban areas safer and more empowering for women and girls?’Footnote
4
and ‘How might we restore vibrancy in cities and regions facing economic decline?’Footnote
5
$14$
(city vibrancy) in our dataset as an illustrative and representative example. The full challenge topics are, respectively, ‘How might we make low-income urban areas safer and more empowering for women and girls?’Footnote
4
and ‘How might we restore vibrancy in cities and regions facing economic decline?’Footnote
5
The top 10 b-terms obtained using CrossBee between the women safety and city vibrancy challenge were: ‘health, space, mobile, project, people, urban, community, city, program, area’. Without any gold-standard data for b-terms on this particular example, it is difficult to say which of these b-terms are actually bisociative. However, looking at each term individually, one realizes that it is difficult to discover connections between these non-scientific domains by just using individual words like ‘health’ or ‘space’. Individual words like ‘space’ can be ambiguous and may have different meanings depending on the context. Here ‘space’ may refer to the space occupied by a body or related to the physical universe. However, a collection of semantically related words like ‘space’, ‘outer’, ‘universe’, ‘earth’, ‘atmosphere’ reduces ambiguity. This is unlike b-terms in autism–calcineurin dataset, where individual terms like ‘paroxysmal’ or ‘Bcl-2’ can lead one to discover links between two specific, scientific concepts because they are quite domain specific. Next, we contrast this with our method that incorporate our proposed b-topics rather than standard b-terms.
3.3 Qualitative results: discovered B-Topics
We run LDA with
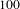 $100$
topics on all the
$100$
topics on all the
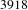 $3918$
documents from
$3918$
documents from
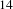 $14$
domains and set the hyper-parameters for topic distribution smoothness and topic word to values recommended in prior literature (Griffiths & Steyvers Reference Griffiths and Steyvers2004). The output of LDA is topic-word and document-topic distributions along with the topics. To gain some intuition about LDA’s output, we list the top seven words for some of the learned topics:
$14$
domains and set the hyper-parameters for topic distribution smoothness and topic word to values recommended in prior literature (Griffiths & Steyvers Reference Griffiths and Steyvers2004). The output of LDA is topic-word and document-topic distributions along with the topics. To gain some intuition about LDA’s output, we list the top seven words for some of the learned topics:
(i) food, cook, meal, recipe, restaurant, ingredient, eat
(ii) care, health, patient, hospital, doctor, medical, center
(iii) money, bank, saving, funding, pay, loan, financial
(iv) person, individual, need, van, match, contact, database.
These topics often (though not always, as shown by Topic 4) refer to some meaningful concept. Topic 1 above refers to food and restaurants, while Topic 2 refers to health care. Note that we have used LDA for topic analysis, but other topic model variants (Newman, Bonilla & Buntine Reference Newman, Bonilla and Buntine2011) can also be used.
To score these topics, we first find ideas that are outliers in a challenge. To train the classification model to classify ideas into challenges, the document-topic vectors were used as input. We trained multiple classification models to predict the domain, given vectors of ideas. For this dataset, three methods – linear discriminant, bagged trees, and subspace discriminant (MATLAB 2016) – had highest cross-validation accuracy of
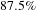 $87.5\%$
,
$87.5\%$
,
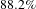 $88.2\%$
, and
$88.2\%$
, and
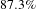 $87.3\%$
. The classification scores of these methods were added and the resultant method with
$87.3\%$
. The classification scores of these methods were added and the resultant method with
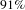 $91\%$
accuracy was used to allocate predicted domains to every idea. The average F-1 score is
$91\%$
accuracy was used to allocate predicted domains to every idea. The average F-1 score is
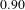 $0.90$
. Ideas assigned to domains different from their true domain (false negatives) were identified as outliers. The number of outliers in each challenge is shown in Table 2.
$0.90$
. Ideas assigned to domains different from their true domain (false negatives) were identified as outliers. The number of outliers in each challenge is shown in Table 2.
Next, Eq. (1) was used to find the topic bisociation score for every topic in every domain. To clarify and visualize our below explanations, we represent a topic by its top
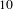 $10$
words; however, in reality each topic assigns a likelihood to every word and so other reasonable thresholding strategies could be used.
$10$
words; however, in reality each topic assigns a likelihood to every word and so other reasonable thresholding strategies could be used.
Let us take an example b-topic from challenge
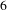 $6$
(the women’s safety challenge): ‘used, materials, design, clothing, wear, recycling, create, make, glass, shoe’. The idea with highest proportion of this b-topic is entitled ‘Red Chilli Powder Filled Glass Bangle for Women’s Self-defense.Footnote
6
’ It discusses how a hollow glass bangle filled with hot red chili powder or pepper spray can be used by women in self-defense. This idea combines wearable accessories with self-defense mechanisms for women safety. The same b-topic has also been used in other contexts for different domains. As one example, in challenge
$6$
(the women’s safety challenge): ‘used, materials, design, clothing, wear, recycling, create, make, glass, shoe’. The idea with highest proportion of this b-topic is entitled ‘Red Chilli Powder Filled Glass Bangle for Women’s Self-defense.Footnote
6
’ It discusses how a hollow glass bangle filled with hot red chili powder or pepper spray can be used by women in self-defense. This idea combines wearable accessories with self-defense mechanisms for women safety. The same b-topic has also been used in other contexts for different domains. As one example, in challenge
 $9$
(related to unlawful detention of human rights activists), an idea entitled ‘Emergency shoes’ proposes using special shoes with embedded wireless devices to help rights activists communicate their location to others in the event they are kidnapped or unlawfully detained. Multiple ideas across seemingly unrelated challenges – public safety, bone marrow registration, unlawful detention, among others – pursued a common theme of using clothing or wearable accessories as a possible solution. Surprisingly, this topic was the
$9$
(related to unlawful detention of human rights activists), an idea entitled ‘Emergency shoes’ proposes using special shoes with embedded wireless devices to help rights activists communicate their location to others in the event they are kidnapped or unlawfully detained. Multiple ideas across seemingly unrelated challenges – public safety, bone marrow registration, unlawful detention, among others – pursued a common theme of using clothing or wearable accessories as a possible solution. Surprisingly, this topic was the
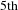 $5\text{th}$
least used topic among all existing ideas, making the concept quite rare. Such links may not be immediately obvious but once discovered can lead to different ideas than those that exist within the target domains.
$5\text{th}$
least used topic among all existing ideas, making the concept quite rare. Such links may not be immediately obvious but once discovered can lead to different ideas than those that exist within the target domains.
As a second example, a different b-topic for challenge
 $6$
(women’s safety) contains ‘street, neighborhoods, residence, community, walk, tour, owners, home, local, house’. The topic relates to walking in neighborhoods and is the
$6$
(women’s safety) contains ‘street, neighborhoods, residence, community, walk, tour, owners, home, local, house’. The topic relates to walking in neighborhoods and is the
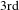 $3\text{rd}$
least used topic. A representative idea from the women safety challenge for this topic is ‘You’ll Never Walk AloneFootnote
7
’ which describes how women in low-income urban areas often share similar routes and could form walking groups by creating a group walking timetable between main points like bus stops. Likewise, in challenge 14 (city vibrancy) the idea entitled ‘Youth Led ToursFootnote
8
’ proposes using local youths to guide visitors on walking tours through their cities, showing visitors the city as the residents see it. The women safety challenge took place three years after the vibrant city challenge, and many participants could arguably have gained insight from studying this related concept of combining a walking activity with women’s safety. However, most users were unlikely to have looked three years back in an unrelated challenge to discover such a connection. Using our method to mine bisociative links between seemingly unrelated domains can inspire people to propose such creative cross-domain solutions.
$3\text{rd}$
least used topic. A representative idea from the women safety challenge for this topic is ‘You’ll Never Walk AloneFootnote
7
’ which describes how women in low-income urban areas often share similar routes and could form walking groups by creating a group walking timetable between main points like bus stops. Likewise, in challenge 14 (city vibrancy) the idea entitled ‘Youth Led ToursFootnote
8
’ proposes using local youths to guide visitors on walking tours through their cities, showing visitors the city as the residents see it. The women safety challenge took place three years after the vibrant city challenge, and many participants could arguably have gained insight from studying this related concept of combining a walking activity with women’s safety. However, most users were unlikely to have looked three years back in an unrelated challenge to discover such a connection. Using our method to mine bisociative links between seemingly unrelated domains can inspire people to propose such creative cross-domain solutions.
So far, we have discussed b-topics derived from domain outlier ideas, however, one can argue that creative links can also be found by using outlier topics directly, by identifying the most infrequently cited topics. However, we found this approach to be insufficient to identify bisociations, as these topics are often meaningless or completely unrelated to the problem in hand. For example, for challenge
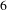 $6$
, we found the outlier topic to be: ‘donation, donor, marrow, bone, registration, aware, register, people, swab, spread’. This topic, predominantly used in bone marrow related challenge 7, is completely unrelated to women safety and has practically zero proportion in current domain. Hence, adding such topics as exemplars does not identify a meaningful link.
$6$
, we found the outlier topic to be: ‘donation, donor, marrow, bone, registration, aware, register, people, swab, spread’. This topic, predominantly used in bone marrow related challenge 7, is completely unrelated to women safety and has practically zero proportion in current domain. Hence, adding such topics as exemplars does not identify a meaningful link.
Although, we have not studied the distance between domains directly, as a consequence of finding the b-topics among domain outliers, we find that the discovered bisociations are also from nearby domains, that is not from domains which are too ‘far’ to share no outliers nor too ‘near’ to be within domain. In our analysis, the outliers are false negatives of the classification model, ideas which are far from their original domain, such that classifier confuses them to belong to another domain. The b-topics are topics which are common between outliers of two domains and uncommon overall. This generally means these topics are on concepts which are far from the mainstream concepts of the domain, but not very far from the domain to be absent from the outlier. As the bisociation score of a topic is proportional to the number of outliers (Eq. (1)), domains with more outliers (hence more nearby domains) have higher chances of discovering true bisociations. For example, the voting challenge has only seven outliers, hence topics get a low bisociation score in it, implying that it is unlikely to find an indirect connection from other domains. The challenge is narrow in scope and far away from all other domains (as visualized in Figure 2). Further research is needed to establish if discovering bisociations using outlier method supports previous research in Fu et al. (Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013), Chan et al. (Reference Chan, Dow and Schunn2015) showing that the ‘distance’ away from the design problem of the creativity stimulus has an influence on the quality of the new solution.
3.4 Qualitative results: Exploring the resulting BisoNet
So far, we discussed ranking topics by their bisociation potential. Next, we create a BisoNet across challenges to explore concepts which can be borrowed between challenges. Note that for 14 challenges, if existing word-based BisoNets without pruning are used with a global vocabulary size of
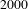 $2000$
, the number of nodes in the network will be
$2000$
, the number of nodes in the network will be
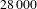 $28\,000$
. This will make graph exploration difficult, if not impossible. By using
$28\,000$
. This will make graph exploration difficult, if not impossible. By using
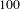 $100$
topics, we reduce the network size by
$100$
topics, we reduce the network size by
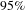 $95\%$
to
$95\%$
to
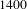 $1400$
nodes. However, to further help network exploration, one can optionally obtain further reduction by node removal and edge pruning methods.
$1400$
nodes. However, to further help network exploration, one can optionally obtain further reduction by node removal and edge pruning methods.
Formatting the full BisoNet of all
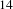 $14$
challenges legibly in this paper is difficult, so for clarity we discuss and visualize a smaller sample. Figure 3 shows a small subset of a full BisoNet by viewing the portion connecting challenges
$14$
challenges legibly in this paper is difficult, so for clarity we discuss and visualize a smaller sample. Figure 3 shows a small subset of a full BisoNet by viewing the portion connecting challenges
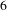 $6$
and
$6$
and
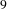 $9$
. Challenge
$9$
. Challenge
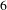 $6$
addresses women safety and empowerment while challenge
$6$
addresses women safety and empowerment while challenge
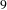 $9$
addresses gathering information from hard-to-access areas to prevent mass violence. To make network visualization easy, we only show the largest connected component of the graph after retaining the edges with the top
$9$
addresses gathering information from hard-to-access areas to prevent mass violence. To make network visualization easy, we only show the largest connected component of the graph after retaining the edges with the top
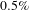 $0.5\%$
of edge weights and use parameter value
$0.5\%$
of edge weights and use parameter value
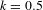 $k=0.5$
in Eq. (2). This BisoNet has
$k=0.5$
in Eq. (2). This BisoNet has
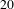 $20$
nodes, representing ten topics. Challenge
$20$
nodes, representing ten topics. Challenge
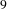 $9$
is shown by yellow squares, while challenge
$9$
is shown by yellow squares, while challenge
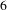 $6$
is shown by green circles. A larger edge weight (thicker line) between two different topics mean that topics may co-occur together in similar proportions in same ideas in these challenges. A larger edge weight between the same topic across two challenges illustrates that it has a high topic bisociation score (Eq. (2)).
$6$
is shown by green circles. A larger edge weight (thicker line) between two different topics mean that topics may co-occur together in similar proportions in same ideas in these challenges. A larger edge weight between the same topic across two challenges illustrates that it has a high topic bisociation score (Eq. (2)).
By inspecting the graph in Figure 3, we find topics that likely refer to a few broad themes that can apply to both domains. For example, the right side of the graph has topics on technology related solutions like network coverage or phone messaging with top words in topics being ‘device, use, technology, area, signal’ (Topic 22) and ‘phone, message, send, text, mobile’ (Topic 67). Within challenge 9, we find that the idea with highest proportion of latter topic is entitled ‘Balloon Communications’ – it proposes flying an iridium based sat-phone as a weather balloon payload over the affected area and receive/transmit text messages from local cell phones. Another idea in challenge
 $9$
proposed a text message based wristband that can send any number of predefined messages to a connector, network, or hub. Related to same topic in challenge
$9$
proposed a text message based wristband that can send any number of predefined messages to a connector, network, or hub. Related to same topic in challenge
 $6$
on women’s safety, we find linked ideas like creating a mobile application that can deter assault by automatically notifying your emergency contacts if the user does not travel from their stated start and end points safely or quickly. By using the proposed BisoNet to isolate these concepts that share b-topics across different challenges, we could promote more effective cross-pollination of ideas.
$6$
on women’s safety, we find linked ideas like creating a mobile application that can deter assault by automatically notifying your emergency contacts if the user does not travel from their stated start and end points safely or quickly. By using the proposed BisoNet to isolate these concepts that share b-topics across different challenges, we could promote more effective cross-pollination of ideas.
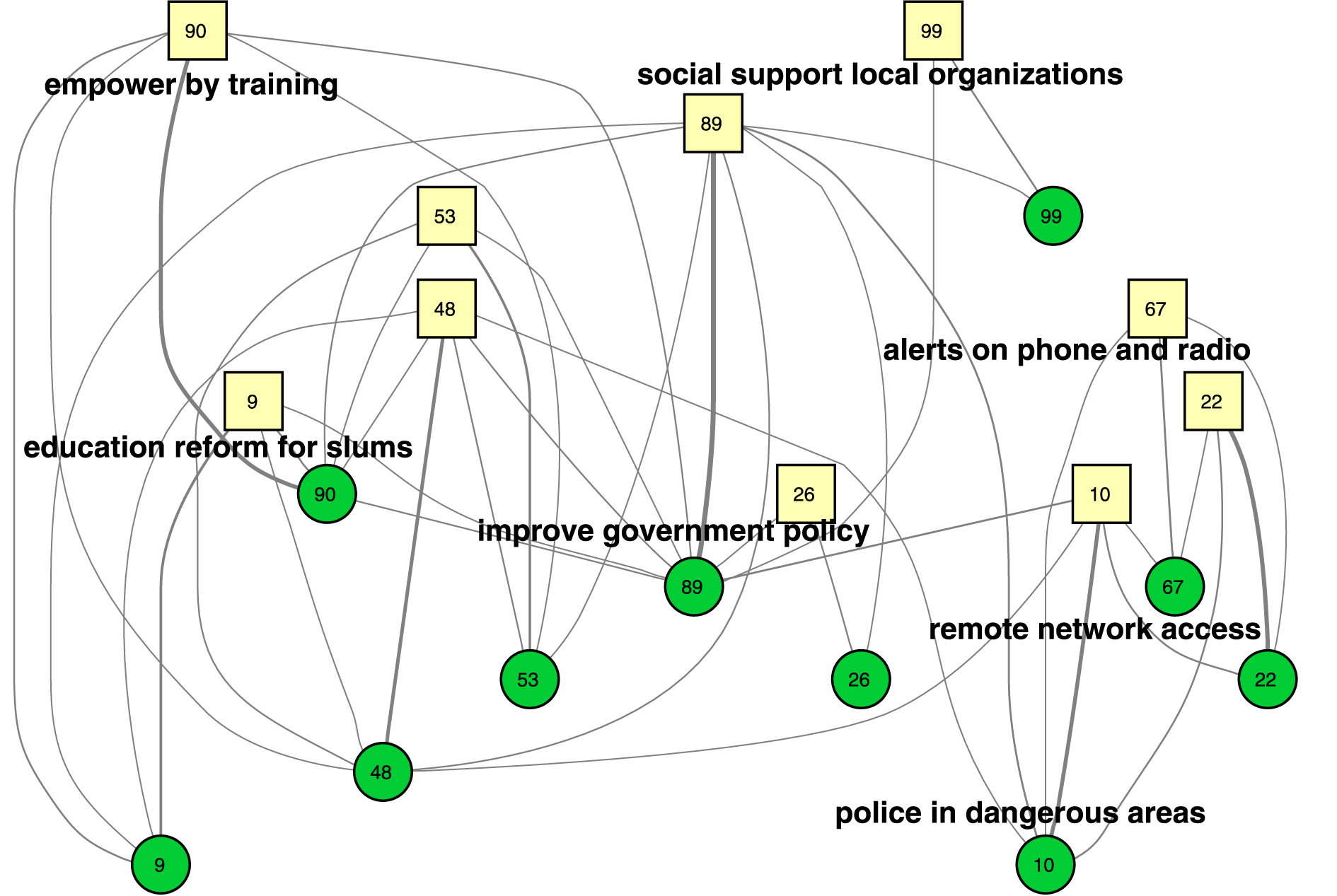
Figure 3. A snapshot of BisoNet showing links between topics between challenges
 $6$
and
$6$
and
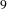 $9$
addressing, respectively, women’s safety and gathering information from hard-to-access areas. We only show largest connected component after thresholding to top
$9$
addressing, respectively, women’s safety and gathering information from hard-to-access areas. We only show largest connected component after thresholding to top
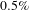 $0.5\%$
edges with highest bison similarity. Node with id
$0.5\%$
edges with highest bison similarity. Node with id
 $6\_9$
represents challenge
$6\_9$
represents challenge
 $6$
with topic id nine. Higher edge weights are shown with thicker lines. Major themes of the topics are captioned.
$6$
with topic id nine. Higher edge weights are shown with thicker lines. Major themes of the topics are captioned.
Similarly, in Figure 3 we find the left side topics are related to education and training (Topic 9 with words ‘girl, community, slums, schools’ and Topic 90 with words ‘woman, income, training, urban’). These are predominant in challenge 10 (women’s safety) and not heavily used in challenge 9. Uncovered themes include government policy improvements and community support. For example, within community support, a challenge 9 idea entitled ‘Reflexive distributive community warning system’ talks about organizing channels of communication and introducing universal codes that could increase speed of transmission and accuracy of information within a community. It mentions steps to design codes for danger, layout the location of each community in the area, and instructs each village with specific actions to undertake if they experience or witness atrocities. A similar concept of community preparation and action could likely also apply to safety in urban areas. Within the women’s safety challenge, one idea possessing this b-topic talks about establishing community-fitness centers to create a larger network of people who can recognize each other on the streets, commute together, and feel an overall sense of community. This idea discusses building a community, while the idea in challenge
 $9$
addresses action after the community is formed. Through the process of BisoNet graph exploration and use of b-topics to guide inspiration, our hypothesis is that ideas and concepts from other domains can help designer better explore, cross-pollinate, or gain inspiration within their own domain. As stated by Pioncaré above, while not all links may be useful, some may give valuable insights.
$9$
addresses action after the community is formed. Through the process of BisoNet graph exploration and use of b-topics to guide inspiration, our hypothesis is that ideas and concepts from other domains can help designer better explore, cross-pollinate, or gain inspiration within their own domain. As stated by Pioncaré above, while not all links may be useful, some may give valuable insights.
3.5 Quantitative results: Human evaluation
Our subjective analysis demonstrated a subset of useful b-topics and cross-domain links that the proposed BisoNet method identified. However, verifying BisoNet performance directly and objectively is difficult, as creative inspiration depends on human perception and there is no accepted gold-standard dataset within design (unlike those for existing word-based BisoNets using in academic literature search (Schmidt et al. Reference Schmidt, Kranjc, Mozetič, Thompson and Dubitzky2012)). Moreover, quantitatively comparing our topic based links with those of the word-based Crossbee b-terms would not represent a fair comparison, since our b-topics contain strictly more information compared to a single b-word.
One possible baseline against which to compare our method is to create topics using LDA, but, rather than going through the effort of finding b-topics, just show a designer a random topic from LDA as inspiration and compare the outcomes. However, this may be a comparatively weak baseline, as topics produced by LDA can vary in coherence and human interpretability. To create a stronger baseline, we calculate pointwise mutual information (PMI) for each topic and pick a random topic with similar PMI. Recent work (Newman et al. Reference Newman, Baldwin, Cavedon, Huang, Karimi, Martinez, Scholer and Zobel2010) has shown that PMI can be used to estimate human-judged topic coherence – hence the baseline random topic (r-topic) is similar in coherence to b-topic, resulting in a fairer comparison. To measure topic coherence, we use normalized PMI score, calculated over the entire Wikipedia corpus.
To compare the creativity of b-topics with an r-topic, we use crowd workers on Amazon’s Mechanical Turk platform. One naïve way to quantitatively compare b- and r-topics topic is to find existing ideas from the challenges with a high proportion of a b-topic versus r-topic and ask workers to rate the idea on quality and novelty. Although straightforward to implement, results from such an approach may be misleading. Two ideas on OpenIDEO may differ for multiple reasons – poor grammar, domain knowledge of author, etc. Thus, workers should ideally compare topics or ideas generated by the same author, where the only difference lies in the seed topic used for inspiration. To address this, we conducted two randomized experiments to answer two research questions:
(1) Are b-topics perceived as creative?
(2) Do b-topics, when used for creative inspiration, produce more creative ideas?
In both of our subsequent experiments, we use crowd-sourcing to both generate and evaluate the creativity of the generated ideas, building upon techniques used by researchers in both engineering and computer supported collaborative work (Green, Seepersad & Hölttä-Otto Reference Green, Seepersad and Hölttä-Otto2014; Kittur et al. Reference Kittur, Nickerson, Bernstein, Gerber, Shaw, Zimmerman, Lease and Horton2013; Kittur Reference Kittur2010).
3.5.1 Quantitative experiment 1: Are b-topics perceived as creative?
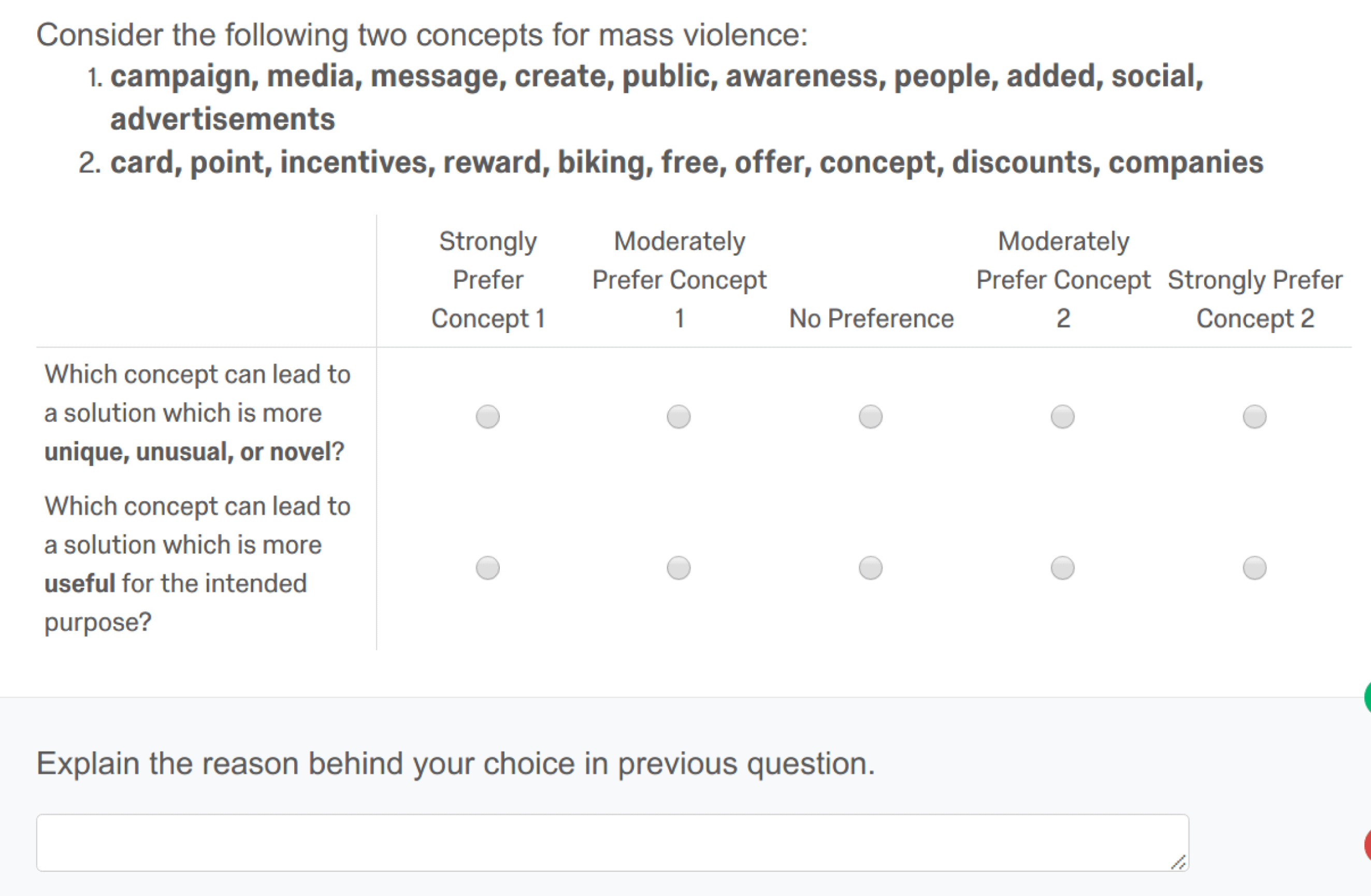
Figure 4. Objective survey example.
Here we consider the hypothesis that b-topics can find more creative links between design domains compared to baseline. To test this, we first showed both b-topics and baseline topics to online workers and asked them to rate the topics themselves. To design the survey, we selected four challenges and four topics in each challenge. Four b-topics were selected randomly from the top 10 topics with highest bisociation score for a challenge (total 16 b-topics for four challenges). While we chose the challenges randomly, we did not select a challenge with very few outliers, as all the topics in such challenges have low bisociation scores.
For the baseline, we found three random topics that had similar PMI scores to the b-topic and selected the one with the lowest bisociation score (the random baseline topic should not also be a b-topic). We showed the challenge brief to 30 Turkers for each pair of b-topic and r-topic. For novelty, the workers were asked ‘which topic can lead to a solution which is more unique’, while for quality, the workers were asked ‘which concept can lead to a solution which is more useful for the intended purpose’ as shown in Figure 4. These survey questions are based on Pang & Seepersad (Reference Pang and Seepersad2016), where novelty and quality questions were used to find concepts which are more creative. We ensured that the crowd-sourced responses were valid using a few quality checks. First, we allowed only those Turkers to participate, whose acceptance rate of past work was more than
 $95\%$
. Second, in every survey, we added one subjective question asking Turker to explain the rationale behind their choice. Some Turkers, who were only trying to maximize questions answered (and thus not meaningfully participating), often entered gibberish to this question and their responses were discarded. Finally, we also recorded time at task and number of clicks on page to filter out participants whose metrics were obvious outliers.
$95\%$
. Second, in every survey, we added one subjective question asking Turker to explain the rationale behind their choice. Some Turkers, who were only trying to maximize questions answered (and thus not meaningfully participating), often entered gibberish to this question and their responses were discarded. Finally, we also recorded time at task and number of clicks on page to filter out participants whose metrics were obvious outliers.
The survey results are shown in Figure 5 and Figure 6, where we notice that most workers preferred b-topics for both novelty and quality compared to other topics. We do not report statistical significant analyses for these experiments, as the Likert scales are ordinal and comparison for a particular domain are between different sets of topics with varying b-scores. In some assessments, the workers were asked to explain their choice, giving us useful insights into their thinking. For example, one user who strongly preferred concept 2 for novelty but prefers concept 1 for quality in Figure 4 quotes ‘I have never heard of discounts or offers or free things as a reward to help inform about mass violence. Advertisements, social interaction, campaigns and interacting with the public seem more useful, as many victims involved in areas where such crimes take place are not interested in discounts or free offers to stop violence. They just want the violence stopped’. While another user who supports the b-topic says ‘Concept 1 sounds like ‘getting the word out’ about atrocities and therefore hoping to prevent them. Concept 2 sounds like a tacky marketing ploy’.
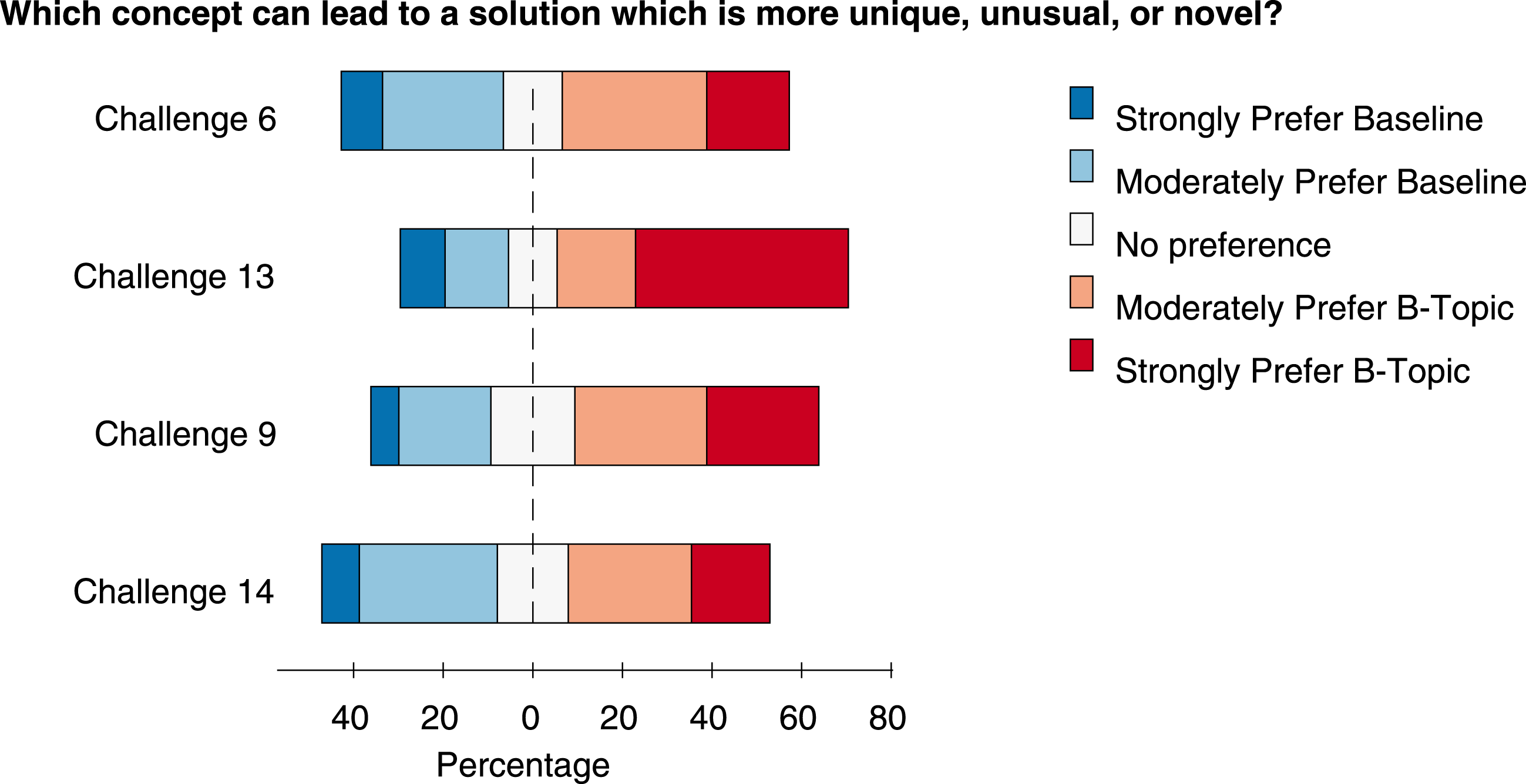
Figure 5. Novelty scores from objective assessment. Each challenge had four B-topic comparisons which were rated by 30 workers.
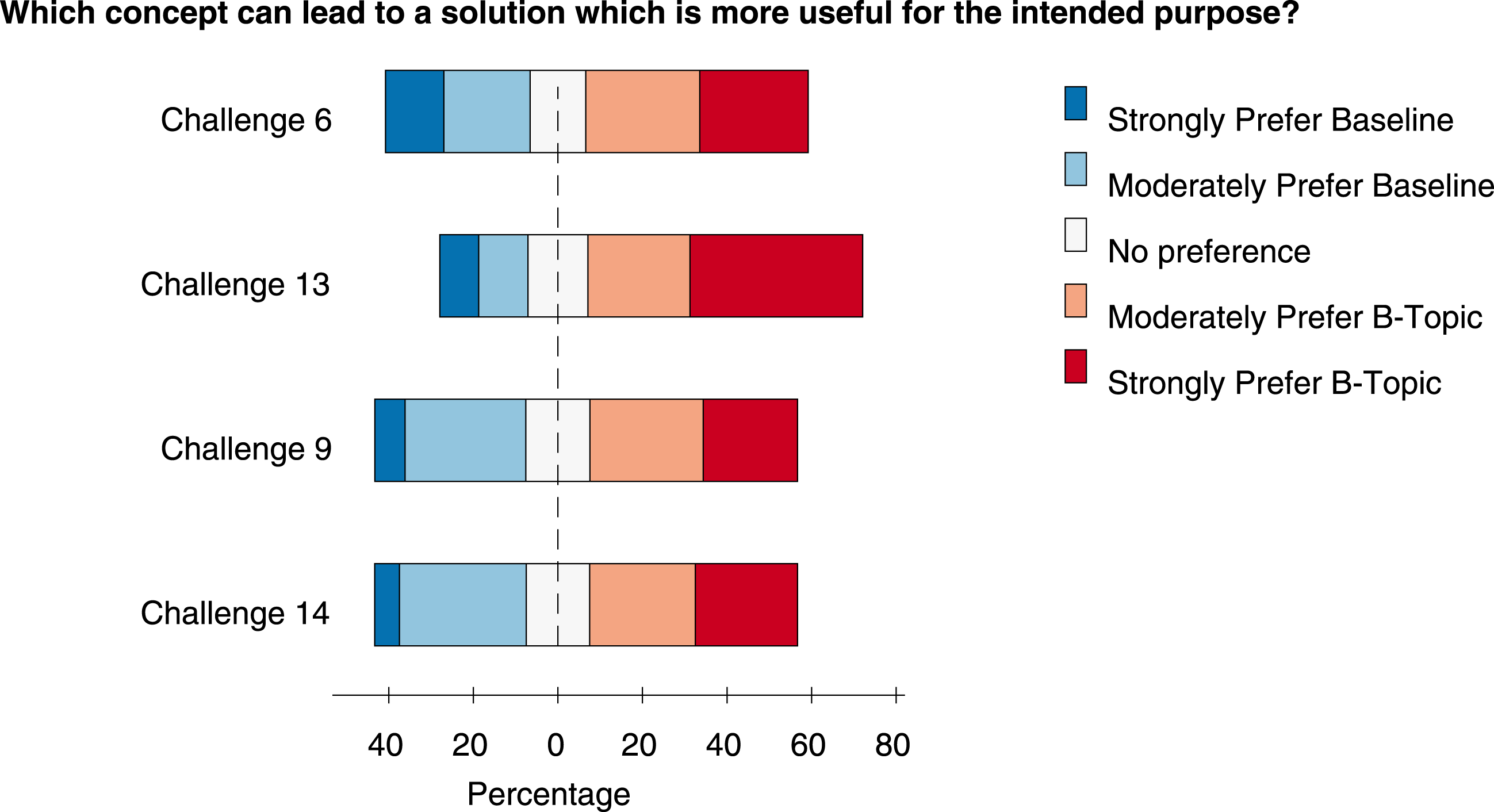
Figure 6. Quality scores from objective assessment. Each challenge had four B-topic comparisons which were rated by 30 workers.
Experiment 1 limitations:
This experiment was a more direct way of measuring perceived novelty and quality of generated b-topics. Although our results showed that b-topics are perceived to be more creative than the baseline, this observation should be taken with a grain of salt. First, we represent a topic by its top 10 words for sake of clarity. However, it is possible that discarding those lower-ranked words might subtly change the topic’s perceived meaning. Second, we presented the words in order of their proportion in the topic. It is possible that using a word cloud or a different ordering of the same words within the top 10 may alter a topic’s perception by the online workers.Footnote 9 Studying both effects would be an interesting area of future work but is not further addressed in this paper.
Another limitation of this experiment is that it is not straightforward to run direct tests of statistical significance to test whether or not b-topics are perceived as more creative than the baseline, in part because the differences in bisociation scores come from different populations and effect sizes, complicating traditional inference models. Despite these limitations, we studied within category (e.g., Prefer B-Topic, Neutral, etc.) trends for each challenge, as the difference in bisociation score between a random topic and b-topic increases. To do so, we noted differences in the b-scores between a b-topic and random topic with respect to the proportion of the response rate from the survey participants. Ideally, increasing difference in bisociation should lead to stronger relative preference for b-topics over random topics. We find that, for each challenge, a higher percentage of respondents preferred b-topics over the baseline and challenges 6, 9, and 14 mirror the slope behavior we would expect while challenge 13 does not. However, as the slope estimates are noisy and fairly small in magnitude, it is difficult to make strong statements about the effect. As such, our results should be interpreted with appropriate caution.
3.5.2 Quantitative experiment 2: Do b-topics produce more creative ideas?
Table 1. Sample ideas submitted by a crowd worker on two topics
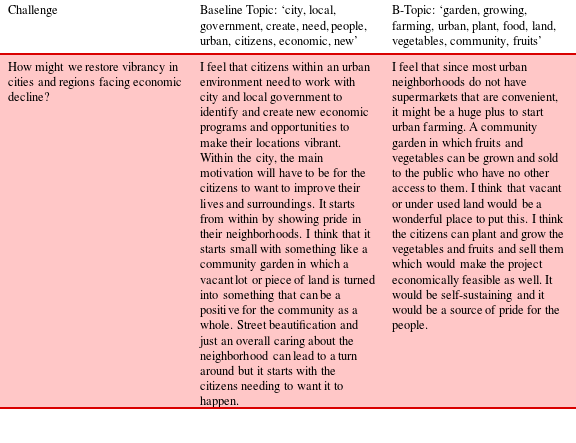
Table 2. 14 Challenges incorporated in dataset showing the size of the challenge and number of outliers
Next, we tested whether b-topics inspire more creative ideas by conducting a set of idea generation experiments and evaluations. First, we provided a few workers with the challenge brief and two topics. The workers were asked to write an original solution to the problem in more than 100 words. They were explicitly instructed to use the set of words from the provided topic (collection of 10 words) as inspirations to their idea.
Each worker was asked to perform this task twice, using two different topics: a b-topic and, as a baseline, the topic with highest proportion for the challenge prompt they received (most common topic). For a given pair of topics, we generate five pair of ideas from 5 workers. The workers are asked to self-assess their ideas on quality and novelty. Next, we judge the quality and novelty of these idea pairs (ideas generated by same worker) by asking another, independent set of 10 workers to compare these ideas on quality and novelty. The order of ideas is randomized and to remove possible bias on novelty, we do not repeat judges, hence using 50 unique workers. The experiment was done on Challenge
 $14$
on improving city vibrancy and the topics are shown in Table 1. Figures 7 and 8 show the quality and novelty results, respectively.
$14$
on improving city vibrancy and the topics are shown in Table 1. Figures 7 and 8 show the quality and novelty results, respectively.
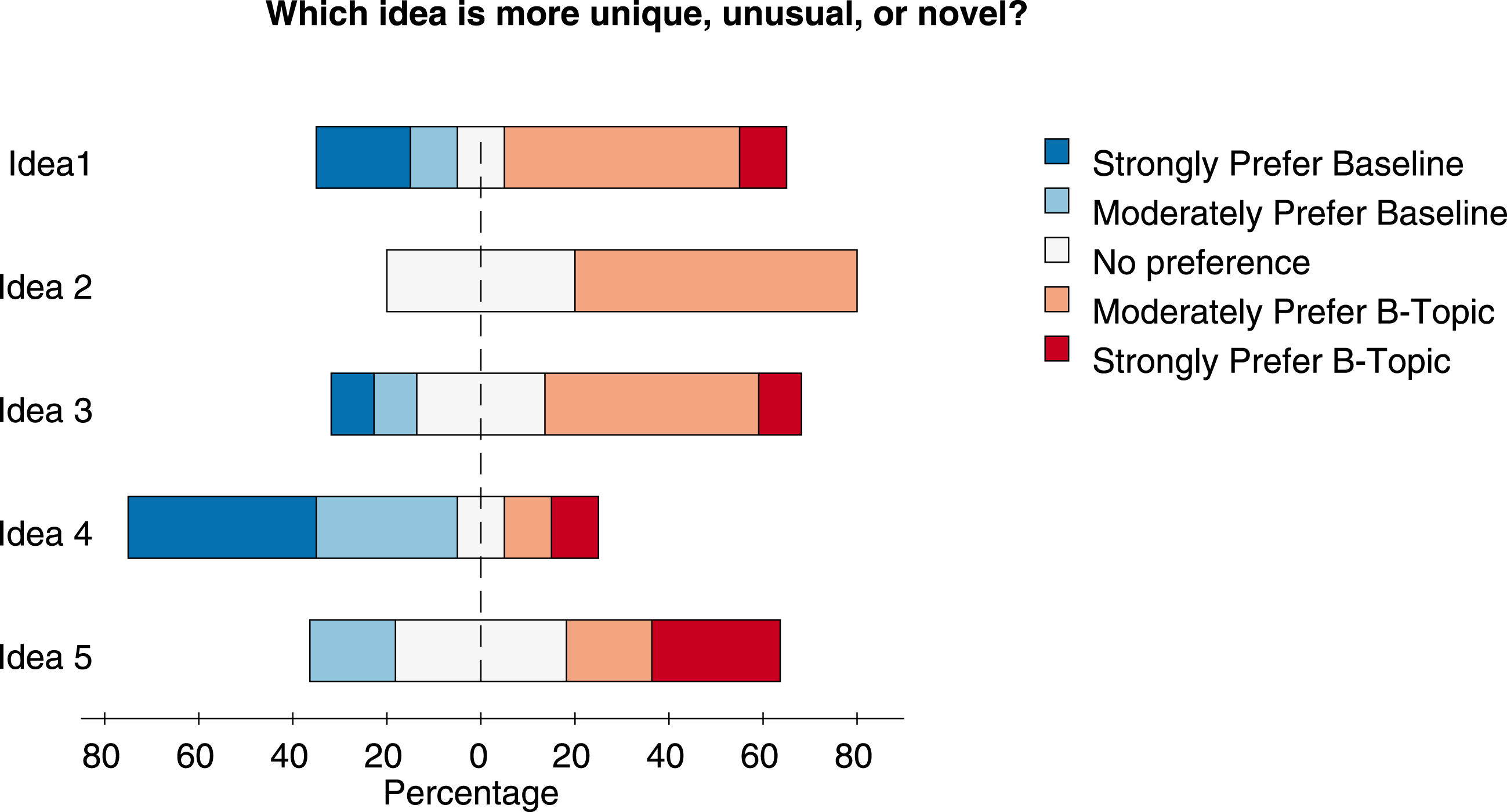
Figure 7. Novelty scores for ideas on topic ‘city, local, government, create, need, people, urban, citizens, economic, new’ versus ‘garden, growing, farming, urban, plant, food, land, vegetables, community, fruits’. Each idea pair is rated by 10 workers.
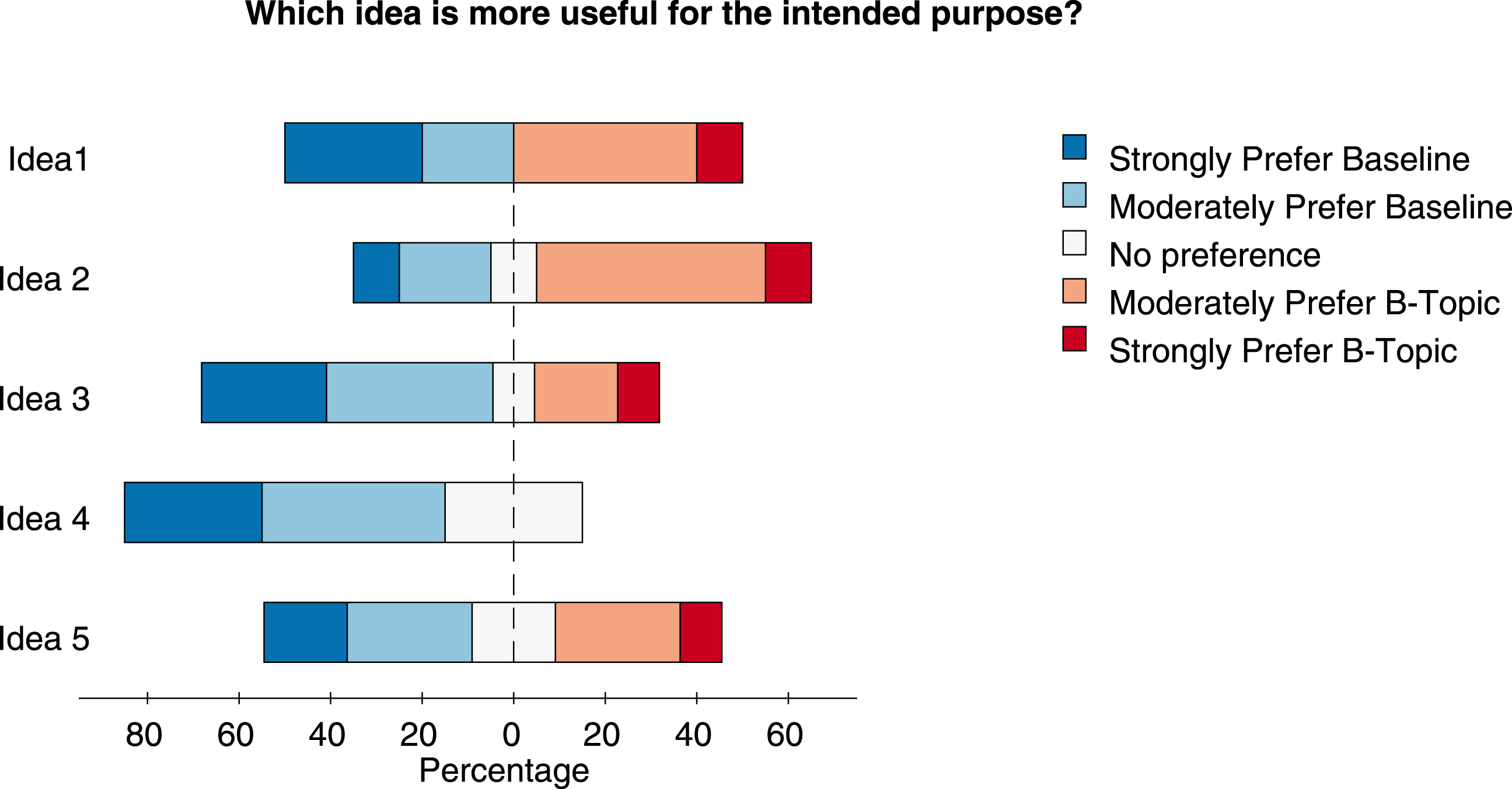
Figure 8. Quality scores for ideas on topic ‘city, local, government, create, need, people, urban, citizens, economic, new’ versus ‘garden, growing, farming, urban, plant, food, land, vegetables, community, fruits’. Each idea pair is rated by 10 workers.
Overall, we found that the workers judged ideas generated using the b-topic as more novel but not necessarily higher quality. When the writers of an idea were asked to rate their own ideas – i.e., the one generated with the b-topic prompt versus the baseline common topic – for novelty, three writers gave no preference while one strongly preferred the b-topic idea and one moderately preferred the b-topic idea. For quality, one strongly preferred the b-topic idea, two writers moderately preferred the b-topic idea, one gave no preference and one strongly preferred the baseline idea. Table 1 compares a sample idea pair. When the idea was evaluated by the independent raters, the b-topic idea received more favorable ratings for both novelty and quality, as shown in Figures 7 and 8.
We have two main observations. First, the idea writers were able to draw a connection between seemingly unrelated topic on ‘garden, growing, farming’ and propose novel ideas on city vibrancy. Secondly, the raters found the ideas prompted by b-topics more novel. Perhaps not surprisingly, the challenge topic was found to be more useful, compared to the b-topic, in part because it directly addressed the challenge issue.
To further test, how the results generalize to other challenges, we conducted the same experiment for Challenge
 $6$
on women safety. Here, the b-topic was ‘device, use, technology, area, signal, network, community, access, people, remote’ and the most common topic for this challenge was ‘woman, safety, safe, area, urban, community, low, city, ideas, income’. We found that the b-topic was rarely used in this challenge, with only eight ideas having it as the highest proportion topic. Figures 9 and 10 show the novelty and quality scores for set of five idea pairs generated by five Turkers and rated by another ten each. We find, that for this challenge too, b-topic was preferred for both novelty and quality.
$6$
on women safety. Here, the b-topic was ‘device, use, technology, area, signal, network, community, access, people, remote’ and the most common topic for this challenge was ‘woman, safety, safe, area, urban, community, low, city, ideas, income’. We found that the b-topic was rarely used in this challenge, with only eight ideas having it as the highest proportion topic. Figures 9 and 10 show the novelty and quality scores for set of five idea pairs generated by five Turkers and rated by another ten each. We find, that for this challenge too, b-topic was preferred for both novelty and quality.
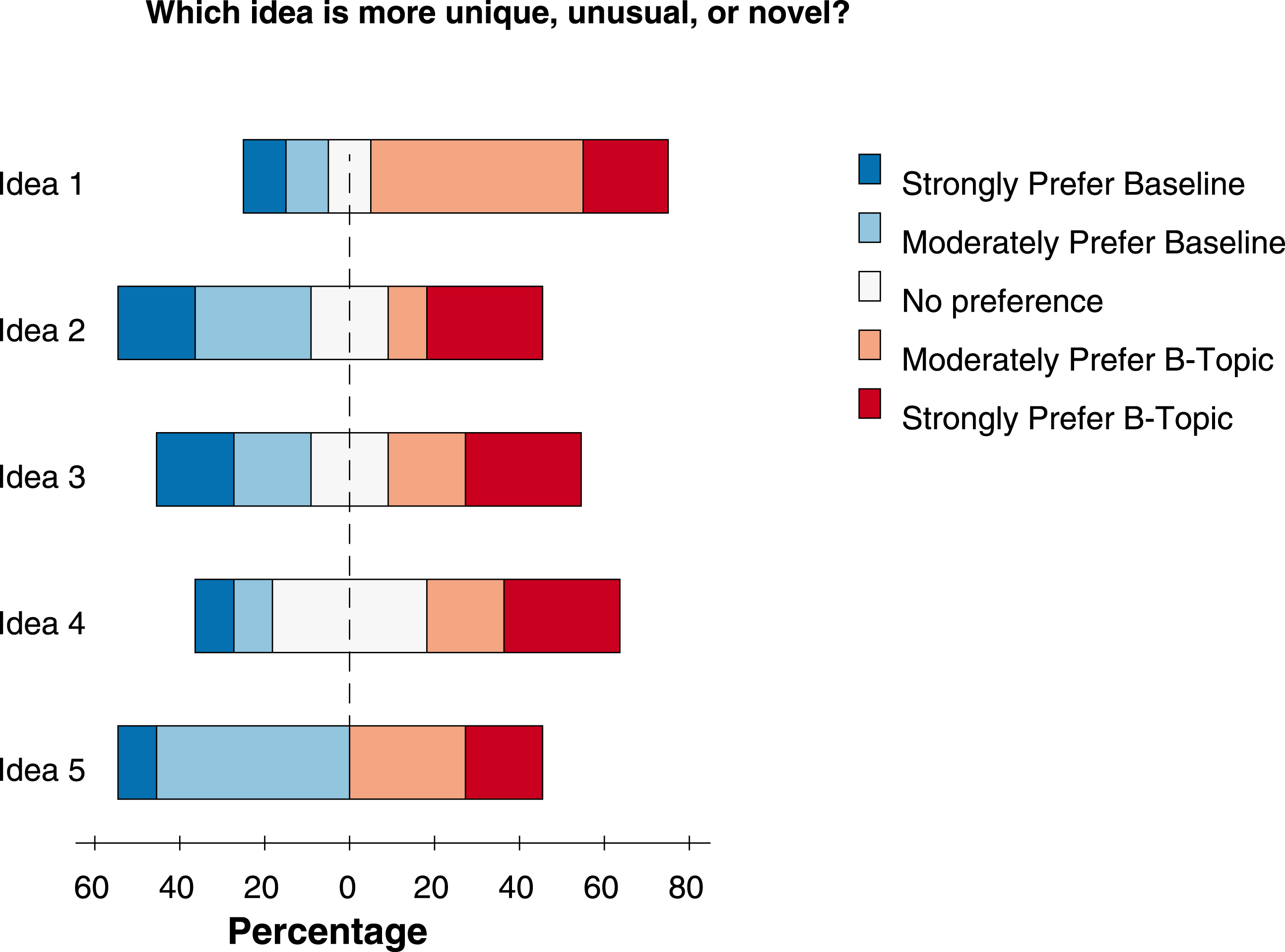
Figure 9. Novelty scores for ideas on topic ‘woman, safety, safe, areas, urban, community, low, city, ideas, income’ versus ‘device, use, technology, area, signal, network, community, access, people, remote’. Each idea pair is rated by 10 workers.
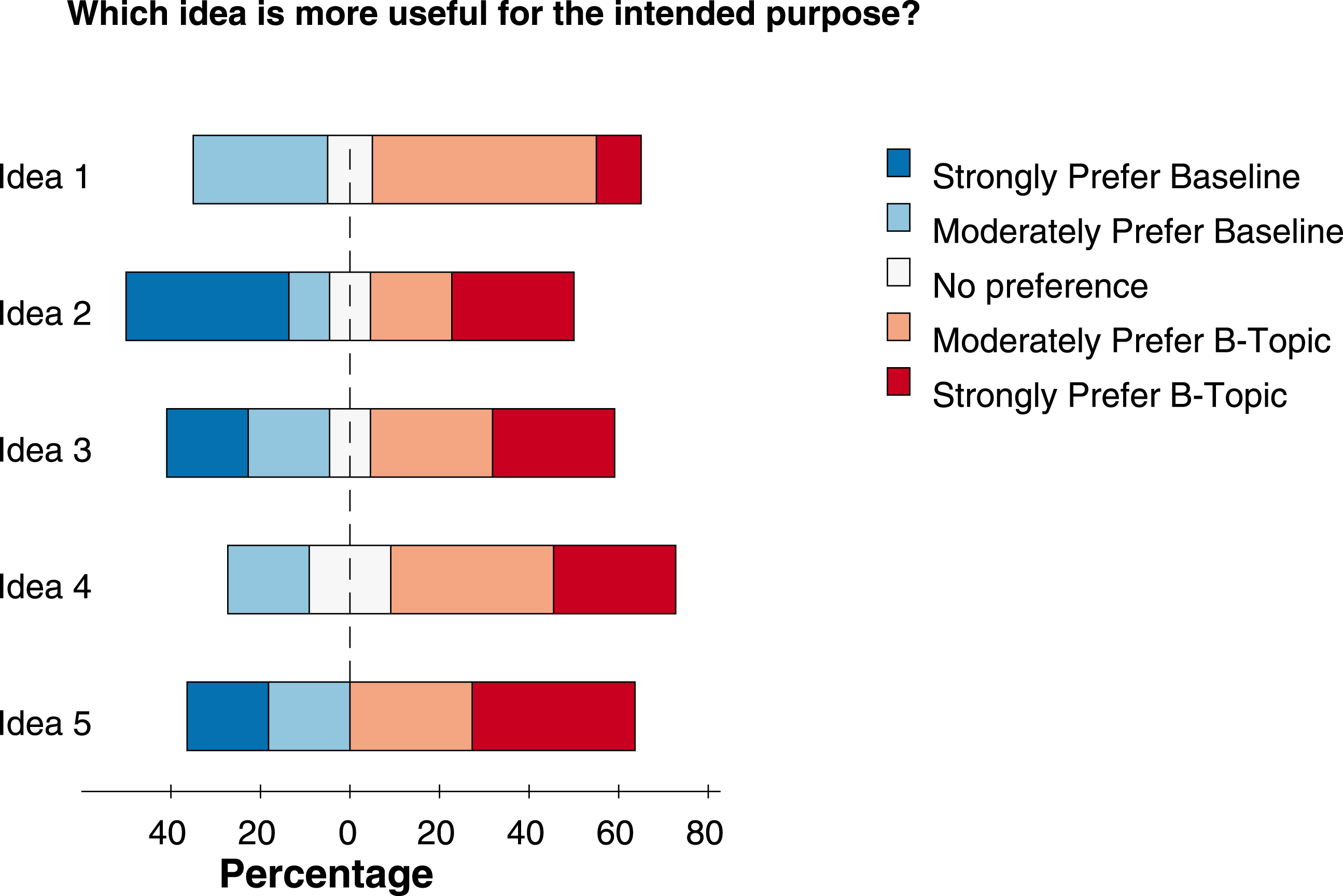
Figure 10. Quality scores for ideas on topic ‘woman, safety, safe, areas, urban, community, low, city, ideas, income’ versus ‘device, use, technology, area, signal, network, community, access, people, remote’. Each idea pair is rated by 10 workers.
Experiment 2 limitations:
While this experiment tested how useful b-topics were for inspiring creative ideas, it comes with a few caveats. First, it is difficult to guarantee how much of the idea was inspired by the novel connection provided by the topic; i.e., we could not force them to use the topic, though, anecdotally, by and large the ideas did appear to leverage the provided topic. In addition, there can be variations within the quality of work that the workers produce due to a writer’s past knowledge in a domain. Likewise, novice or non-imaginative writers may fail to see a relationship or connection between the challenge theme and b-topic, compared to the more obvious connections with the baseline common topic that is closer to the challenge domain. We also cannot isolate a particular topic; i.e., a generated idea may well use other concepts too, so the final ratings of an idea can depend on multiple factors beyond the chosen b-topic. Lastly, given that this experiment consists of 50 evaluations by raters from Amazon’s Mechanical Turk service, we should be careful when generalizing these results other domains and rater populations; replicating these results with additional experiments on alternative rater populations would provide useful comparisons. The monetary motivation and the time constraints for Turkers may also impact the experimental results. Lastly, as with experiment 1, it is not straightforward to run direct tests of statistical significance to test whether or not b-topics statistically more creative ideas than the baseline, again due to differences in bisociation scores from different populations with complicates traditional statistical inference models. As such, our results should be interpreted with appropriate caution.
4 Conclusions, limitations, and future work
This paper presented a method for exploring cross-domain design ideas through the use of bisociative information networks (BisoNets). Specifically, it introduced the use of bridging topics (b-topics) and generalized past results in BisoNets to allow simultaneous exploration of multiple domains. The paper demonstrated this capability on an example of design exploration and discovery using a dataset of thousands of ideas from OpenIDEO, an online collaborative community. In doing so, it answered the following two questions (1) Are b-topics perceived as creative? (2) Do b-topics, when used for creative inspiration, produce more creative ideas?
Our qualitative results demonstrated the limitations of existing BisoNet techniques when applied to non-specialist domains, along with the usefulness of representing conceptual bridges through collections of words (topics) rather than single terms. We also demonstrated the usefulness and efficiency of finding cross-domain inspiration from collections of thousands of ideas; such techniques have direct applications for both large-scale design ideation, in addition to traditional design search and retrieval for analysis of patents or other analogical stimuli. Our quantitative results demonstrated that b-topics, whether presented on their own or via ideas they inspired, were generally viewed as more novel, though not necessarily higher quality, compared to non-b-topic baselines. We also found that b-topics, when used for creative inspiration, helped produce more creative ideas compared to most common topic for a domain.
These findings show that bridging concepts can be found in outlier ideas which belong to one domain, but are confused to belong to another. Due to the rarity of these outlier ideas in the current domain, such links may not be immediately obvious, but once discovered they can lead to creative ideas. In contrast to past work, we show that representing the bridging concepts using latent topics is advantageous over single words. We also differ from past approaches which use distance metrics by using a classification model for outlier detection. This has the inherent advantage of finding bisociations depending on the distribution of ideas between domains and not distance between them. These outlier ideas help identify bisociations far from the mainstream concept, but not very far from the domain.
The main limitations of our proposed techniques are two-fold. First, our method relies on generating good topic distributions for each idea. With the available multitude of topic model variants, this is easier said than done. We used standard LDA to find collections of words organized in a fixed number of topics. In an unknown domain, it is difficult to know how many topics exist (though there are non-parametric, countably infinite dimensional LDA variants that can handle this (Teh et al. Reference Teh, Jordan, Beal and Blei2004)). As topic models themselves are not aware of existing bisociations; an interesting albeit challenging area of research would be to incorporate bisociation principles within the LDA update equations, so that topics found are more likely to be bisociative.
Second, even if the b-topics themselves are accurate, they still require some creative imagination on the part of the designer to connect the b-topic to the challenge at hand. While presenting collections of words or exemplar ideas are two straightforward mechanisms to help spark this inspiration, future research could address the open question as to what format or intervention would best help designers internalize or connect ideas across domains. It would also be interesting to study the effect of topics with similar bisociation score but varying in other attributes like the degree of abstraction and the type of words used. One of the directions of future work can be to study effectiveness of b-topic when it is dominated by certain type of words like functional words or behavior words.
Lastly, the use of topics or word collections as a vehicle to bridge two domains is a somewhat blunt (if effective) instrument, when compared to other more structured analogical reasoning approaches that require more detail about a design idea beyond just unstructured text – e.g., Gentner’s Structure-Mapping framework (Gentner Reference Gentner1983) or the use of Functional Basis Structures in biologically inspired design (Cheong et al. Reference Cheong, Chiu, Shu, Stone and McAdams2011). Merging bisociation with those more formal analogical structures could provide the best of both worlds.
Acknowledgments
This work was partially funded through a University of Maryland Minta Martin grant, as well as support from the Department of Mechanical Engineering. Partial funding for open access provided by the UMD Libraries’ Open Access Publishing Fund.
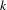
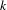













 Open access
Open access