



Policy Significance Statement
At a time when there is great interest on the part of research funders in the possible application of AI solutions to facilitate resource allocation and simplify administrative procedures in their evaluation pipelines, this study aims to demonstrate the potential and limitations of such an approach, discussing evidence-based, ethical, and legal implications. As a result of the activities presented, the funder in question has decided to systematically apply AI for the prescreening of research proposals, while introducing a number of relevant mitigating measures and exploring new ways to improve the accountability of the algorithms used, as well as redress mechanisms for the applicants who are removed from the selection process.
1. Introduction
1.1. Global context
The use of artificial intelligence (AI) has experienced significant growth in recent years, with the adoption of AI solutions by organizations more than doubling since 2017,Footnote 1 driven by swift advancements in algorithm performance—particularly the more recent breakthroughs in the field of natural language processing (NLP) (Radford et al., Reference Radford, Narasimhan, Salimans and Sutskever2018)—with models capable of carrying out increasingly complex tasks with very high levels of accuracy, in addition to, for example, the widespread availability of cloud-based high-performance computing resources at consumer-level costs (Aljamal et al., Reference Aljamal, El-Mousa and Jubair2019). These technologies permeate various industries, including healthcare, finance, and transportation (Jan et al., Reference Jan, Ahamed, Mayer, Patel, Grossmann, Stumptner and Kuusk2022), and have a significant influence on multiple aspects of everyday life, from voice assistants and facial recognition features in mobile phones to customer service chatbots or the recommender systems of streaming platforms (Dande and Pund, Reference Dande and Pund2023).
The pervasiveness of and increasing reliance on AI-powered solutions begets a series of ethical considerations about their impact and potential harm to citizens. Concerns include job displacement as a consequence of automation (Acemoglu and Restrepo, Reference Acemoglu and Restrepo2018; Eloundou et al., Reference Eloundou, Manning, Mishkin and Rock2023) or algorithmic bias and discrimination (O’neil, Reference O’neil2017), particularly in relation to decision-making in sensitive areas—for example, allocation of social benefits and predictive policing—in addition to the robustness and resilience of AI systems to malicious attacks—for example, in the case of autonomous vehicles (Eykholt et al., Reference Eykholt, Evtimov, Fernandes, Li, Rahmati, Xiao, Prakash, Kohno and Song2018) or the energy industry (Chen et al., Reference Chen, Tan and Zhang2019)—and the use of AI for purposes such as lethal autonomous weapon systems (Krishnan, Reference Krishnan2016).
In light of this, numerous calls have been made for the regulation of AI systems,Footnote 2 so that developers implementing them ensure that they are transparent, that their outcomes can be interpreted in human terms, and that their operation aligns with human values (Shahriari and Shahriari, Reference Shahriari and Shahriari2017). In the European context, this has resulted, notably, in the approval of the AI Act draft (European Commission, 2021), which aims to establish a harmonized framework for AI regulation within the EU and, despite its intended geographical scope, may have global implications (Siegmann and Anderljung, Reference Siegmann and Anderljung2022). It establishes different sets of rules for the different levels of risk associated with the use of AI systems, with an emphasis on unacceptable and high-risk applications, and special provisions for generative AI.Footnote 3
1.2. AI in research evaluation
Modern research peer review finds itself under considerable stress, with manuscript submissions increasing year by year, resulting in a significant workload for editors and reviewers alike—the former struggling to find reviewers, the latter receiving an increasing number of requests and lacking fair compensation (McCook, Reference McCook2006; Cheah and Piasecki, Reference Cheah and Piasecki2022)—in addition to being plagued by issues of bias and lack of transparency (Lee et al., Reference Lee, Sugimoto, Zhang and Cronin2013). It has been suggested that automation could play a role in the peer review pipeline (Shah, Reference Shah2022), both as a time-saving device for editors due to the sheer scale of submissions, and as a means of making the process more impartial and objective, mitigating sources of human bias, in addition to improving efficiency and cost savings helping redirect resources from research evaluation to the research funding itself—indeed, a recent estimation puts the time that researchers allocate to peer review, in terms of monetary value, at over 2 billion dollars per year for researchers based in the United States, United Kingdom, and China alone (Aczel et al., Reference Aczel, Szaszi and Holcombe2021).
Several studies have used algorithms to replicate reviewer scores assigned to submissions; however, they have been met with skepticism and criticism from the research community.Footnote 4 Notably, it has been suggested that a high level of correlation between the algorithm’s output and the actual reviews—that is, achieving human-level performance in the assessment—could be a sign that the algorithm is merely replicating biases already present in the historical human reviews (Checco et al., Reference Checco, Bracciale, Loreti, Pinfield and Bianchi2021)—for example, measures of readability (Crossley and McNamara, Reference Crossley and McNamara2011) could put texts submitted by non-English speakers at a disadvantage, since they are more likely to be perceived as “badly written” and rejected without an in-depth review—and therefore the exploration of these tools could be actually used not to substitute peer review, but to uncover existing biases in the process.
More fundamentally, it has been posited that large language models (LLMs) that have been trained on text form and structure have no way of learning meaning (Bender and Koller, Reference Bender and Koller2020). While this is the subject of an ongoing debate, and there exist arguments to the contrary—suggesting that LLMs may reach a sort of human-like understanding in an emergent fashion (Piantadosi and Hill, Reference Piantadosi and Hill2022; Mitchell and Krakauer, Reference Mitchell and Krakauer2023)—there is also evidence that, in terms of performance alone, their apparent success at tasks that, in principle, require understanding, their success may be due to the fact that they are leveraging artifacts present in the training data (Gururangan et al., Reference Gururangan, Swayamdipta, Levy, Schwartz, Bowman and Smith2018; McCoy et al., Reference McCoy, Pavlick and Linzen2019; Le Bras et al., Reference Le Bras, Swayamdipta, Bhagavatula, Zellers, Peters, Sabharwal and Choi2020). Therefore, an algorithm would be capable of evaluating text structure and complexity, identify typos, and potential plagiarism (Foltỳnek et al., Reference Foltỳnek, Meuschke and Gipp2019), but it would be still unable to assess the relevance, novelty, and/or impact of the research itself (Schulz et al., Reference Schulz, Barnett, Bernard, Brown, Byrne, Eckmann, Gazda, Kilicoglu, Prager, Salholz-Hillel, Ter Riet, Vines, Vorland, Zhuang, Bandrowski and Weissgerber2022).
It has been suggested in other contexts that this kind of tools could be used to make evaluators aware of their own biases as well as help applicants prepare for evaluation.Footnote 5 The latter, in this particular case, could be realized as flagging areas of improvement to the authors themselves, allowing for subsequent resubmission of their article or proposal. Recent experiments with LLMs suggest that these models may indeed be able to construct feedback that can be helpful to authors and reviewers alike (Liang et al., Reference Liang, Zhang, Cao, Wang, Ding, Yang, Vodrahalli, He, Smith, Yin, McFarland and Zou2023; Robertson, Reference Robertson2023)—as a quick source of potential improvements during manuscript preparation, and as a supplement to their assessment of others’ research, respectively—but stress that their use should be limited to assisting human peer review, as they currently struggle to assess research quality even when immediately apparent to humans (Liu and Shah, Reference Liu and Shah2023).
While the issues highlighted above suggest that the peer review process is not susceptible to full automation, and requires human intervention, algorithms can be, and are, used in the editorial process to take on time-consuming tasks such as screenings for plagiarism, figure integrity, and statistical soundness (Nuijten and Polanin, Reference Nuijten and Polanin2020), among others. Another type of automation uses NLP techniques to assist the selection of reviewers, by comparing a given article or proposal to the current research landscape and finding the researchers whose output is most relevant to the focal text (Price et al., Reference Price, Flach and Spiegler2010). This is complemented by additional steps to ensure the integrity of the review process, taking care of, for example, conflicts of interest or fairly distributing reviewers across submissions (Leyton-Brown et al., Reference Leyton-Brown, Nandwani, Zarkoob, Cameron, Newman and Raghu2024).
Among the foremost examples of automation in the academic editorial process is Frontiers’ AIRA, a pre-peer review tool that assists editors in the assessment of language quality, the integrity of the figures, the detection of plagiarism, as well as identifying potential conflicts of interest, in addition to assisting the reviewer selection process.Footnote 6 Similar cases can be found in Aries Systems’ Editorial Manager, which offers a series of toolsFootnote 7 designed to screen for, for example, figure integrity and “research quality”—in practice, this amounts to checking whether a given article contains for example data availability or funding statementsFootnote 8—among others, as well as reviewer search and recommendation;Footnote 9 and Clarivate’s ScholarOne, which, in addition to using Clarivate’s own reviewer locator tool,Footnote 10 offers to detect anomalous behavior and reduce integrity-related retractions by uncovering issues before publication. Footnote 11
The use of AI in the research funding pipeline has received increasing levels of interest in recent years. Since these tools are sociotechnical systems, stakeholder perception and engagement are fundamental for their implementation and widespread adoption. Nonetheless, this reality is neither uniform nor static; it is context-dependent and continually redefined as the capabilities of the technology itself evolve. Recent surveys have found that researchers see great potential in the use of AI to accelerate the scientific process, including the automation of repetitive or administrative tasks, as well as fact checking, summarization, and translation, but with an emphasis on AI having a supporting role only (European Research Council (ERC), 2023; Noorden and Perkel, Reference Noorden and Perkel2023). From the perspective of funders, agencies such as the National Institutes of HealthFootnote 12 in the US and the Australian Research CouncilFootnote 13 have prohibited the use of generative AI tools to analyze and formulate peer reviews due to concerns about factual accuracy, breaches of confidentiality, and biases (Kaiser, Reference Kaiser2023). Aligned with this perspective, the UK’s Research Funders Policy Group agrees that generative AI should be excluded from the peer review process but considers its use in other cases, provided there is a clear acknowledgement.Footnote 14 Despite these concerns, some actors are actively engaging in the discussion around these technologies and responsible practices for their use. Examples include the GRAIL project,Footnote 15 of the Research on Research Institute, which explores good principles and practices for using AI and machine learning in the research funding ecosystem (Holm et al., Reference Holm, Waltman, Newman-Griffis and Wilsdon2022), and the European Association of Research Managers and Administrators’ AI Day,Footnote 16 focused on proposal evaluation, just to name a few.
From the implementation perspective, we find examples of automated systems already in place by the National Natural Science Foundation of China (Cyranoski, Reference Cyranoski2019), the Russian Science Foundation,Footnote 17 the Canadian Institutes of Health Research (Guthrie, Reference Guthrie2019), and the Research Council of Norway.Footnote 18 In all these cases, the goal is to assist with finding and assigning reviewers to the applications. This is not only geared toward saving time, but also includes navigating potential conflicts of interest between a given reviewer and the applicants, and avoiding cases when a single reviewer has to assess competing applications. Another justification for this choice, in the case of the NSFC, is the sheer scale of the process, since the agency receives hundreds of thousands of applications every year.Footnote 19
In all of the cases above, a strong emphasis is put on the fact that these systems correspond to AI-assisted peer review, as opposed to full automation, and that the actual decision as to whether to act on or ignore the outputs of the algorithm,Footnote 20 as well as about the scientific merit of an article or proposal, is made by a human being. However, if we imagine using AI-based solutions to help evaluate the research proposals themselves, what epistemological and ethical elements should be taken into account?
The “la Caixa” Foundation (LCF) has implemented the use of AI-based methods to support the prescreening of research proposals in the context of its “CaixaResearch Health” program. This article describes the experience of the Foundation and the epistemological considerations that can be drawn from it, and is organized as follows: Section 2 introduces the specific program and its features; Section 3 presents a series of relevant legal and ethical considerations that were part of the epistemological reflection in this specific case; the pilot project carried out by the Foundation and the implementation of the AI system are described in Section 4, followed by a discussion on the limitations of the approach and its next steps in Section 5, and the main conclusions and learning aspects in Section 6.
2. LCF’s CaixaResearch Health program
The LCF is one of the biggest charities in South Europe. It funds and promotes scientific research as part of its mission to build a better future for everyone. As a philanthropic organization, the LCF actively explores the improvement of research and innovation funding practices through evidence-based methods.
The “CaixaResearch Health” (HR) program is the flagship competitive funding program of LCF in biomedical research. Launched in 2017, it aims to promote excellent health research in Spain and Portugal in the fields of (a) Oncology, (b) Neuroscience, (c) Infectious Diseases, (d) Cardiovascular and related Metabolic Diseases, and (e) Enabling Technologies in any of these disorders. The program has progressively grown from 12 M€ to over 25 M€ in 2023. Individual grants are funded for 3 years up to €500,000 for single research organizations, or €1,000,000 for consortia of two to five organizations. The call is highly competitive, receiving 500–700 applications every year, with a very low success rate that has only recently surpassed 5% (reaching 6.7% in the latest edition).Footnote 21
The selection process represents costs equivalent to ca. 3% of the total funding of the program and comprises three main stages: (a) eligibility screening; (b) remote peer review process; (c) in-person interviews with preselected candidates. The remote peer review itself consists of around 200 reviewers who evaluate each proposal on the basis of the quality, methodology, and potential impact of the project itself, in addition to the capacities of the team involved, and give it a score ranging from 1 to 8. At the end of the remote evaluation, around 80 proposals are preselected for the final round of face-to-face interviews (12–17 by thematic area). It is important to note that, for example, the average shift in proposal rankings between the remote evaluation and the panels in the 2020 edition of the program, HR20,Footnote 22 was 3.79 positions out of a total of 12. In other words, for each subject area, the rank of the projects varied by 31.58% between the two phases; this highlights the relevance of the face-to-face stage of the process.
The remote evaluation phase represents a significant challenge due to the high number of proposals, the variety of topics, and the need for diversified experiences in assessing the proposals. For this reason, LCF has already implemented AI-based methods for the selection of reviewers. In an attempt to further improve the allocation of resources during the selection process, the Foundation has also implemented an AI solution with the objective of automating and enhancing the initial screening, identifying proposals that are unlikely to secure funding such that the number sent for review is reduced, thereby alleviating the workload of the experts. This application constitutes the primary focus of this article.
3. Legal and ethical considerations
The main questions we seek out to address are as follows: under which conditions is the automation of the evaluation of grant proposals (a) socially acceptable? (b) fair? and (c) reliable?
While the first, and to a lesser extent the second, of these points is inevitably conditioned by the perception of the applicants—and society at large—toward the use of AI in research evaluation, as seen above, we start by reiterating that the goal of this implementation is the automation of the initial screening—identifying proposals that are unlikely to succeed in securing funding—as opposed to the automation of the peer review itself—that is, of the identification of the proposals that are to advance to the face-to-face stage. It is however important to understand and mitigate the consequences of automatically filtering out potentially valuable research proposals.
We base ourselves on the ethics guidelines of the High-Level Expert Group on AI of the European Commission, published in 2019 (European Commission and Directorate-General for Communications Networks, Content and Technology, 2019), which state that, in order for AI to be trustworthy, it must be lawful, ethical, and robust, and list seven key requirements that AI systems should meet in this regard:
-
1. Human agency and oversight;
-
2. Technical robustness and safety;
-
3. Privacy and data governance;
-
4. Transparency;
-
5. Diversity, nondiscrimination, and fairness;
-
6. Societal and environmental well-being;
-
7. Accountability;
where we have highlighted, in bold, those we believe are the most relevant in this particular scenario due to the nature of the call and of the application, to which we explore their connection below.
3.1. Human agency and oversight
The first of these requirements implies that the operation of the AI system must be monitored, either in an overall manner or at every individual instance. We note that, due to the nature of this particular implementation, oversight would be required only in the cases the algorithm flags proposals for removal from the selection process, while the rest of the proposals will simply follow the normal course of the peer review.
Human oversight ensures that the system corresponds to an AI-assisted, rather than AI-powered, screening, in compliance with Art. 22 of the GDPR,Footnote 23 which enshrines the right of data subjects not to be subject to a decision based solely on automated processing. Furthermore, the flagging of proposals for removal should only be regarded as a recommendation, and should be able to be discretionarily ignored. This is echoed in Art. 14, paragraph 4(d) of the AI Act, stating that individuals overseeing the AI system should be able to decide, in any particular situation, not to use the high-risk AI system or otherwise disregard, override, or reverse the output of the high-risk AI system. Footnote 24
Therefore, a system must be set in place so that the research proposals flagged as candidates for removal are revised by human experts, who should have full autonomy to either ratify or revoke the initial “decision” of the algorithm.
3.2. Technical robustness and safety
AI systems must be engineered to prevent malicious use and minimize their vulnerability to attacks (Eykholt et al., Reference Eykholt, Evtimov, Fernandes, Li, Rahmati, Xiao, Prakash, Kohno and Song2018; Chen et al., Reference Chen, Tan and Zhang2019). While due to the nature of this application, we find a hacking scenario unlikely, in principle, efforts must be made to protect the data that is used in the pipeline, especially if this includes any personally identifiable information of the applicants. In terms of adversarial attacks affecting the outputs of the model, it might be possible to “game” the algorithm by crafting a nonsensical proposal that is able to circumvent the flagging. While this would not affect the final outcome of the selection process, since such a proposal would inevitably fail in the peer review stage, it does have a negative effect on resource allocation, however small, since it would need experts to review it.
It must also be ensured that AI systems provide accurate predictions—this is particularly relevant for sensitive applications (Olsson et al., Reference Olsson, Kartasalo, Mulliqi, Capuccini, Ruusuvuori, Samaratunga, Delahunt, Lindskog, Janssen, Blilie, Egevad, Spjuth and Eklund2022). For the scenario at hand, during the development phase, this is done by monitoring the performance of the algorithm when identifying the lowest-scoring proposals for a given call, based on data from previous years. As the system evolves, the nature of the problem shifts slightly: the definition of a proposal that is ineligible/unlikely to succeed would be based not only on the lowest-scoring proposals during the peer review phase but also on those that have been previously discarded in the AI-assisted step, since those will be representative of the bottom group despite having no score. The human experts overseeing the model are essential for the curation of these data.
Finally, care must be taken to guarantee that the model yields consistent and reproducible results; in other words that, presented with the same proposal a second time, it produces the same output.
3.3. Privacy and data governance
AI systems must ensure that the data collected and used from individuals is relevant to the application at hand, and guarantee that privacy is preserved through the entire lifecycle. This means, for example, that data about the applicants, including personal data, should be part of the pipeline only if strictly necessary for the correct operation of the system, and data access provisions should be put in place (Murdoch, Reference Murdoch2021; Khalid et al., Reference Khalid, Qayyum, Bilal, Al-Fuqaha and Qadir2023).
Additionally, the team in charge of the implementation must constantly monitor the quality and integrity of the data used to train the model, since any bias present in the data gathered from historical peer reviews—for example, gender, seniority—is very likely to be picked up and reproduced by the system, further amplifying it in subsequent iterations (Checco et al., Reference Checco, Bracciale, Loreti, Pinfield and Bianchi2021).
3.4. Transparency
The team should document all the process: the type of and which data are used, the model selected, the training parameters, as well as the test and validation mechanisms employed. In addition to this, all outputs from the model must be logged. In this case, the latter implies keeping track of all cases in which a given proposal has been flagged for removal, independent of the final decision made by the experts overseeing the system.
In addition to this, it should be possible to explain a given “decision” of the algorithm; that is, what makes it flag a proposal for removal from the selection process and, ideally, what could be changed in the text for the output to be reverted. When the accuracy level required by a given application is not very high—or in extremely sensitive cases (Rudin, Reference Rudin2019)—then simple, inherently explainable models—for example, logistic regression—are preferred, since their use makes the outputs of the system fully traceable. If a much higher accuracy is required for the operation of the AI system to be considered satisfactory, then black box models—for example, deep neural networks—may be needed. As the name suggests, these are not inherently interpretable; however, there exist a variety of algorithms that may be employed in an attempt to explain the outputs of black box algorithms, both from a global—what features influence the behavior of the model in general—and local—what determines an individual, specific prediction—perspective (Ribeiro et al., Reference Ribeiro, Singh and Guestrin2016; Lundberg and Lee, Reference Lundberg and Lee2017; Molnar, Reference Molnar2020).
Furthermore, it should be communicated clearly and explicitly that the initial screening of proposals contains an automation step, in addition to the main features, capabilities and limitations of this tool—both to the applicants and to the human experts reviewing the outputs.
Both the ability to explain the recommendations of the model and the transparent communication of its use contribute to managing the expectations of the applicants with respect to the selection criteria of the program, and thus to the overall social acceptability of the system.
3.5. Diversity, nondiscrimination, and fairness
Developers must ensure that the outputs of the model do not discriminate against certain groups of people. As mentioned above, in this particular case, historical biases in the peer review process may put female or junior researchers at a disadvantage with respect to their peers, as a consequence of prestige bias (Lee et al., Reference Lee, Sugimoto, Zhang and Cronin2013; Murray et al., Reference Murray, Siler, Lariviere, Chan, Collings, Raymond and Sugimoto2018). It is therefore necessary to surveil the system’s operation at all stages of development and application in order to identify these patterns—for example, are the proposals flagged for removal disproportionately female-led compared to the ratio of female PIs in the entire pool of applicants?—and set up mechanisms to mitigate these unwanted outcomes.
3.6. Societal and environmental well-being
The computational resources required to train and fine-tune large-scale state-of-the-art models can result in a massive energy consumption (Strubell et al., Reference Strubell, Ganesh and McCallum2019). It is the responsibility of the developers to monitor the environmental cost of the solutions they implement, and to take measures to mitigate it—for example, by prioritizing the use of pretrained models or energy-efficient hardware.
3.7. Accountability
In conjunction with documenting and logging the AI system’s operating details and outcomes, facilitating its auditability, the appropriate mechanisms must be put in place so that the users of the system are able to report improper behavior. In this case, the “users” are the experts making the final decision on the algorithm’s recommendation, and they must be able to flag issues such as, for example, finding that they have to rescue a disproportionately high number of proposals initially flagged by the model.
At the same time, it must be ensured that researchers are able to contest the removal of their proposals from the pool of applications before peer review. The existence of this possibility must be clearly and openly communicated to the applicants. While this does not exist for the traditional peer review pipeline, nor for the eligibility screening, the fact that this process is a semiautomated enhancement of the latter changes the picture even though there are humans in the loop, because of the shallow evaluation they carry out and of their incentive to accept the algorithm’s recommendations, as discussed below.
Main questions to address and related requirements
Social acceptability
• Dependent on the attitude of researchers and general public toward the use of AI-assisted technologies.
• Requires managing the expectations of the applicants with respect to the selection criteria of the program.
• Transparency in the presentation of the rules and assurance of ethical practices are essential.
Fairness
• Compliance with the law.
• Sources of biases should be identified and constantly monitored.
• Final decisions should be made by a human being.
• Redress mechanisms should be put in place.
Reliability
• The outputs of the algorithm should be explainable in a manner that allows feedback to be given to the applicants.
• The model should be resilient and its predictions accurate and replicable.
4. LCF pilot
4.1. Methodological description and results
The implementation of the solution was carried out in two phases, with an initial trial run during the HR22 call and its actual operation in the HR23 call. A study was conducted prior to the trial to assess the feasibility of the application: in order to ensure data quality and reliability, the historical evaluations were analyzed to uncover biases in the selection process introduced by the human reviewers—for example, gender, geography; as a result, no evidence was found of systematic biases introduced during the selection process itself in the years since the program’s inception.
Human judgment is an integral part of the process. In the interest of fairness toward the applicants, LCF conducts a review with two human evaluators, or “eligibility reviewers,” for all the proposals filtered out by the model. If at least one of the two reviewers harbors a reasonable doubt regarding the prescreening, the proposal will be added back to the evaluation pool—that is, sent to peer review (see Figure 1). Eligibility reviewers are evaluators who have been part of previous selection committees in the call and are well aware of the type of projects commonly selected for funding.
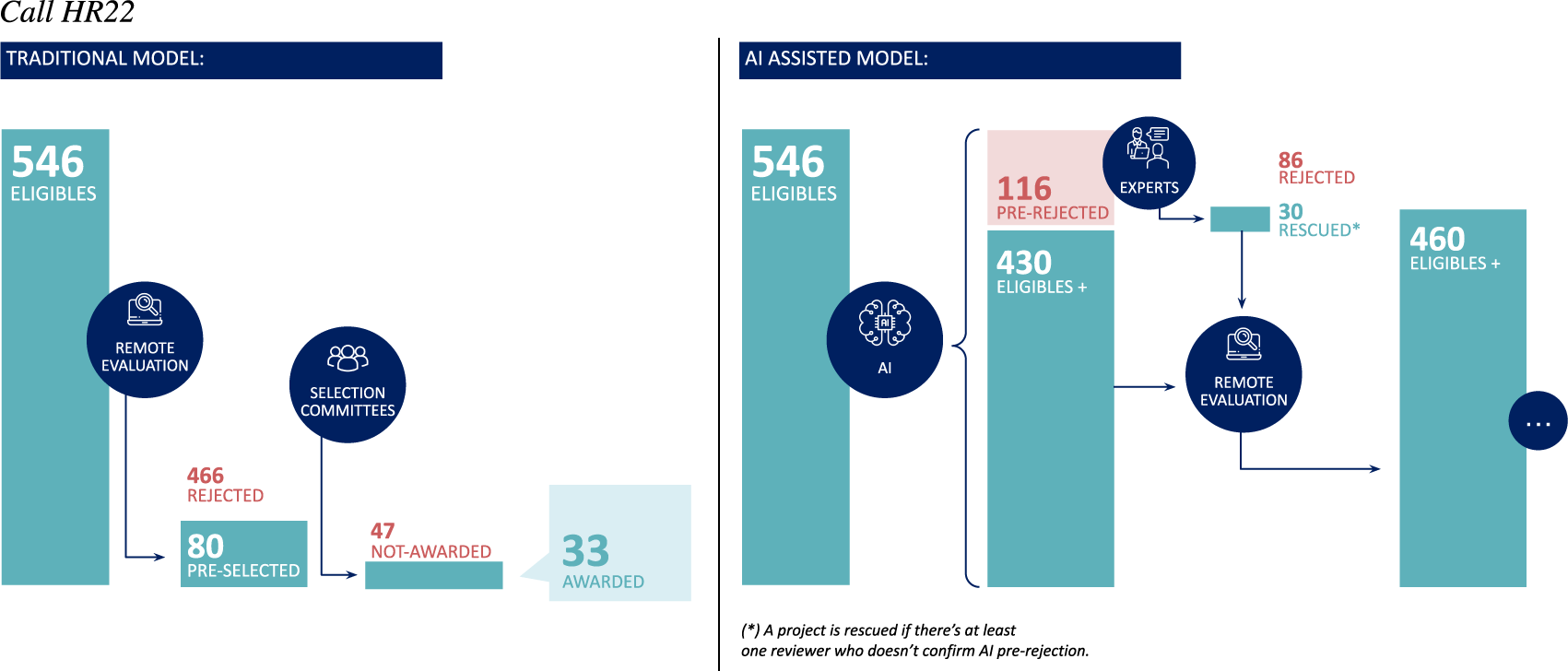
Figure 1. Traditional (left) versus AI-assisted (right) selection process, with numbers from the parallel evaluation conducted during the HR22 call: 546 proposals were deemed eligible for evaluation and sent to peer review in the traditional track; in the case of the AI-assisted track, 460 proposals would have been sent to peer review, after the algorithm flagged 116 for removal—that is, they were prescreened by all three models and flagged to be discarded from the process unanimously—30 of which were added back to the evaluation pool by the eligibility reviewers.
A “hidden” evaluation was conducted during HR22 to ascertain the performance and potential impact of the model, by running it in parallel to the call, yielding the projects that would have been pre-discarded. After the call concluded, the model’s predictions were compared against the final ranking of the traditional evaluation process in order to determine if any funded or panel projects had been filtered out in the parallel track. The eligibility reviewers screened both proposals flagged for deletion and a few that were not, and were made aware of this. In total, out of 546 proposals, the models unanimously recommended removing 116; 160 were flagged by the majority of the models; and 216 by at least one of them. All 216 proposals were sent to the reviewers, along with 13 that had not been flagged. They rescued 30 proposals, none of which advanced to the panel phase in the actual selection process. However, there were two cases in which 2 independent reviewers confirmed the proposals should be discarded, while in the traditional track, these ended up advancing to the panels and ultimately being funded: in the first case, the reviewers failed to spot one of the 13 proposals that were not flagged by the algorithm, while the second case corresponds to a flagged proposal. In both cases, the description of the projects turned out to be largely different from what is normally successful in the call, and in the latter case, in particular, the remote evaluators delivered mixed reviews due to concerns about the scope of the impact of the project, which was deemed too local.
The final implementation of the model within the call workflow took place during the HR23 call. In this edition, the model suggested screening out 98 proposals out of the 493 that were submitted. From these, 63 proposals were confirmed for removal from the process and 35 were rescued. Only one of the proposals in the latter group progressed to the panel phase, but did not secure funding. While it would be preferable to minimize any scenario in which a proposal flagged by the algorithm even makes it to the panel phase, this and the above examples highlight the importance of the role of the eligibility reviewers in rescuing incorrectly flagged proposals.
4.2. Model implementation
The prescreening comprises three NLP models working independently; these are BioLinkBERT-Base,Footnote 25 BioELECTRA-BaseFootnote 26 (raj Kanakarajan et al., Reference raj Kanakarajan, Kundumani and Sankarasubbu2021), and BioLinkBERT-Base incorporating Adapter (Houlsby et al., Reference Houlsby, Giurgiu, Jastrzebski, Morrone, De Laroussilhe, Gesmundo, Attariyan and Gelly2019). They are trained using the complete texts of the proposals from previous calls, plus their peer review scores. We note that this corresponds only to scientific data and does not include any personal or organizational information from the applicants. These proposals are categorized into three classes based on the scores, making it a classification problem rather than a regression problem. A proposal is filtered out if and only if all three models classify it as belonging to the bottom class independently. This approach attempts to minimize the possibility of unfair rejections, although the data from the pilot suggests that different criteria still yield reliable results.Footnote 27
The prescreening models are to be retrained annually by using the data already available and augmenting it with the data from the latest call. Additionally, the inclusion of new data requires a series of validations and tests to be conducted, making modifications to these datasets to determine which one yields optimal performance. The thresholds for the scores that define the classes may undergo subtle variations each year during retraining. For the HR23 call, the specific thresholds were as follows:
-
• Bottom class scores below 5.54
-
• Intermediate class: scores between 5.54 and 6.19
-
• Top class: scores above 6.19
4.2.1. Model explainability
In order to understand the sections of the proposals that are most influential on the model’s predictions, and to provide eligibility reviewers—and, ultimately, the applicants—with insights into their strengths and weaknesses, a post hoc explainability process was developed, computing multiple predictions according to the following scenarios:
-
• Global prediction: the actual prediction using the full text of the proposal.
-
• Local prediction by section: predictions generated for each single section of the proposal (e.g., abstract, methodology).
-
• Local predictions excluding sections: predictions generated using the full text excluding specific sections.
In an attempt to make these results more visually intuitive, the probability of a given proposal belonging to the bottom class is converted into a “quality score” and presented in a spider chart. Two visualizations of this type have been created: in Figure 2, the section-based strengths and weaknesses of a given proposal are highlighted in relation to the other proposals within the call; Figure 3, on the other hand, compares a proposal’s actual prediction to the hypothetical result of omitting individual sections of the text, in order to assess which contribute positively/negatively to its score.
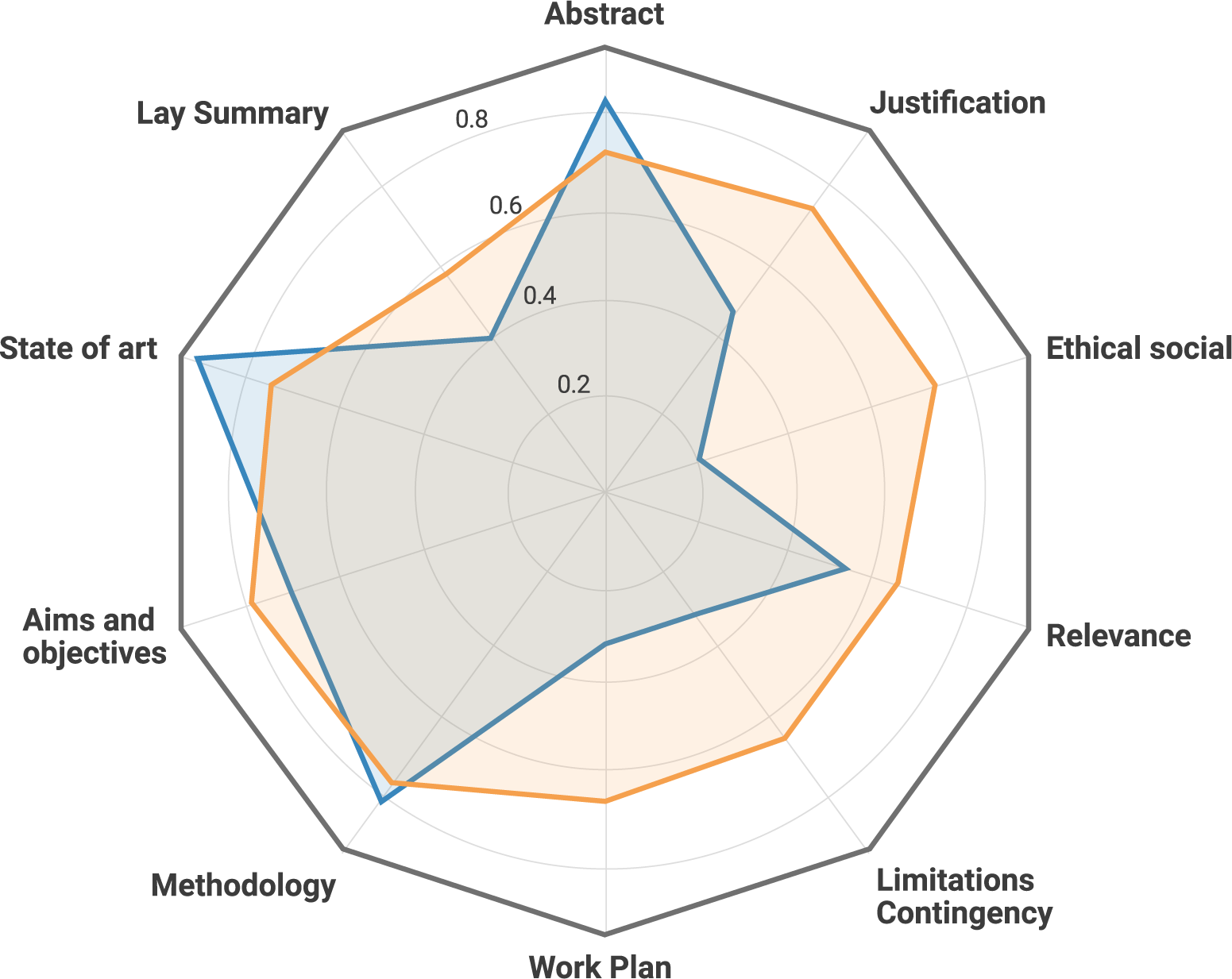
Figure 2. The local predictions for each section of a proposal (blue) are compared to the average of each section across the entire call (orange). This particular proposal’s strengths lie in its state of the art, abstract, and methodology, while its weak sections correspond to work plan, ethical and social, and limitations and contingency. Note that the score corresponds to 1 – P (bottom class).
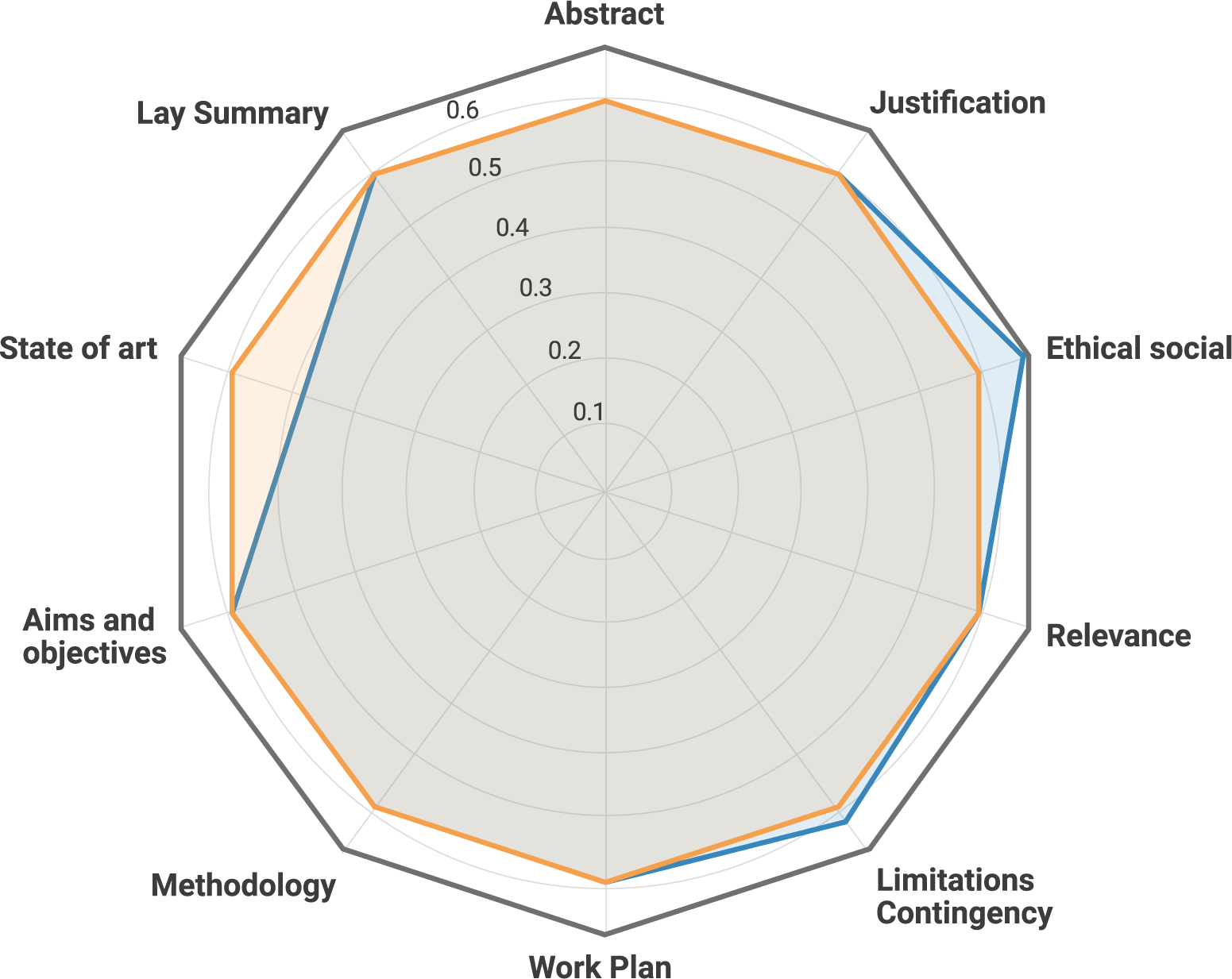
Figure 3. The local predictions excluding each one of the sections of a proposal (blue) are compared to the score obtained using the proposal’s full text (orange). In this case, the section contributing most positively to the proposal’s quality is the state of the art; conversely, the ethical and social section has a negative impact—the score increases when this section is omitted. Note that the score corresponds to 1 – P (bottom class).
4.3. Workshop with the eligibility reviewers
During a workshop held after the HR22 call had ended, the eligibility reviewers from the trial run were presented with the full results of the parallel track, followed by a discussion during which several issues were raised by them; these are detailed below.
4.3.1. Patterns in the data
The evaluators inquired about the criteria used by the model in the classification, in addition to how specific sections of the proposals influence the decision.
It was made very clear that the model has no specific evaluation criteria, and only exploits statistical similarities between a given proposal and previous evaluations to determine which class it belongs to. Also, the evaluation is based on the full text; however, there is an ongoing effort to understand whether a particular section contributes to raising or lowering a proposal’s score.
Evaluators were made aware of the fact that proposals that are too special or innovative with respect to previous projects may be flagged by the algorithm despite not being of poor quality, and it is their responsibility to recognize their value. Faced with this scenario, they argued that the guidelines they receive about the review process by the Foundation should make a strong emphasis on this aspect. Additionally, they discussed the possibility of not being informed beforehand that the proposals they are reviewing are candidates for removal—see Section 4.3.2.
4.3.2. Sources of bias
Human bias in the training data
The evaluators worry that if the algorithm learns from prior evaluation processes, carried out by a limited number of people repeated every year, there exists a risk that the model will also acquire the intrinsic biases of this group. Even if the model does not have access to any personally identifiable information of the applicants, they wonder whether it is possible to be sure it does not discriminate on the basis of, for example, gender or mother tongue, if these features have influenced previous, human reviews.
The first issue could be tackled by varying the group of remote evaluators more frequently, or enlarging the pool of experts whence they are selected, or both, so that the scope of influence of each single evaluator is reduced—that is, the persons actually involved in the selection process are either more diverse or rotated more frequently, while maintaining the level of expertise required for the review. There are already efforts in place in this direction. However, it remains true that if prior human evaluations were affected by unconscious biases, these will creep into the model and, as mentioned above, algorithms commonly used in editorial processes tend to reproduce first impression biases. Despite the positive results obtained in the bias study prior to the trial, this is something to keep an eye out for, both in terms of the constant internal monitoring of the model by the technical team and of the task of the overseers who decide whether to reject the algorithm’s recommendations.
Incentive to accept the algorithm’s recommendation
The evaluators argue that the fact that they are informed that the proposals were pre-discarded by an algorithm may negatively influence them, so that they will not approach them in a neutral manner.
The pressure to standardize (Villani et al., Reference Villani, Bonnet, Schoenauer, Berthet, Levin, Cornut and Rondepierre2018), whereby the human in the loop has an incentive to agree with the algorithm’s recommendation, and thus avoid justifying their discretionary decisions, is indeed a real issue with these technologies. However, in this particular case, the “cost” associated with mistakenly ignoring the recommendations of the model—that is, sending a low-quality proposal to peer review—is much lower than that of mistakenly ratifying its “decision”—discarding a proposal of potential value—so that the experts are encouraged to do the former in case they have a reasonable doubt as to whether a given proposal should be sent to peer review. Furthermore, not informing the evaluators that they are looking at proposals flagged for removal from the selection process would defeat the purpose of an evaluation based on reasonable doubt only, and they would be subject to the same workload as a full revision would entail.
4.3.3. Accuracy
During the trial run, one of the proposals discarded by the algorithm ended up being successfully funded in the actual pipeline. The evaluators expressed concern about this type of mistake.
The algorithm may flag proposals that are too different with respect to previously high-scoring proposals. However, it is the task of the human experts to rescue them if they have any doubt as to whether they should be peer reviewed. In this case, after being pre-discarded, this proposal’s removal was ratified by two human experts. This may be the result of the aforementioned incentive to accept the algorithm’s recommendations. The Foundation has the responsibility to make the evaluators aware of the fact that the discretionary decision of ignoring the algorithm’s recommendations carries a lower “cost” than accepting them.
4.3.4. Cost effectiveness
Many evaluators disputed the usefulness of this type of process based on the scale of the program itself and the final number of discarded proposals, in terms of the resources of the Foundation. It was suggested that an even better approach would be to do a lottery among the proposals that pass the initial screening, which would not only be cost effective but also fair.
The main goal of the Foundation is to reduce the workload of the pool of remote evaluators and improve the quality of the proposals they receive; therefore, any reduction in the number of immature proposals sent to peer review, however small, represents a positive effect on the allocation of resources, since the evaluation of the first layer of experts, based only on reasonable doubt regarding the output of the algorithm, signifies a much lower amount of effort than a full review. Furthermore, the HR program has been used as a proof of concept, and the successful implementation of the AI-assisted screening may be exported to different programs and/or different research funding organizations, at a larger scale, where the effect of the advanced filtering of proposals may be more notorious.
With regard to the lottery, this indeed has been discussed internally in the Foundation. However, there exist fears that carrying this out directly after the initial screening may not be the best approach at the moment, since there are still immature proposals that reach the peer review stage, representing ca. 30% of the total, and the outstanding character of the final granted projects would not be guaranteed. As mentioned earlier, the face-to-face stage is considered to be fundamental in the evaluation pipeline of the program—with top-scoring preselected proposals failing to secure funding and vice versa—so that the Foundation also rules out the idea of a post-peer review lottery for the time being.
5. Discussion
5.1. Challenges, limitations, and next steps
At the technical level, the main challenges that have to be faced when carrying out this type of projects are data quantity and data quality. First and foremost, enough historical data are required to train the AI models and validate the results obtained, before implementation. This is, however, not sufficient: a homogeneous data structure is needed so that the model does not learn from obsolete criteria; in the context of this application, this means that projects must maintain a similar structure, and the evaluation criteria must be stable throughout the evolution of the program. We also note that keeping up with the evolution of the selection process itself and the shifting nature of the classification problem—because it is expected to have ever fewer proposals reaching the remote evaluation phase—represents another challenge for the development team.
The feasibility study carried out before the pilot was fundamental in assessing the data for the program according to the criteria above, and is behind the success of the current implementation. However, this was not the case for the innovation program of the Foundation, due to the lack of sufficient data and the heterogeneity of the proposal structure and evaluation criteria. If these issues could be overcome, would the same algorithms be a good option? Extending the use of the AI-assisted screening to this and other programs and exploring different models that may be more suitable for the task, represents an ongoing effort in the development and evolution of research evaluation pipelines within the Foundation.
Another avenue of future work corresponds to improving the explainability of the current implementation, which we believe is its major limitation, by using local model-agnostic methods since clarifying individual predictions is crucial for establishing trust (Ribeiro et al., Reference Ribeiro, Singh and Guestrin2016). Additionally, attention- and gradient-based attribution techniques could be employed to provide deeper insights into which data segments are most influential in the model’s predictions (Zhao et al., Reference Zhao, Chen, Yang, Liu, Deng, Cai, Wang, Yin and Du2023). Finally, the development of comprehensive documentation to provide a clear view of the design and operation of the model is an ongoing effort.
5.2. The key requirements revisited
Going back to the main elements outlined in Section 3, the fundamental point is that of human oversight: the automation of the screening includes a layer of human evaluation, such that a group of experts carries out a revision of the proposals flagged for removal, and are able to rescue a given proposal if they are not sufficiently sure it is immature or of poor quality. The role of these experts is fundamental in the responsible implementation of the AI system. They must be made aware of the fact that the model can potentially flag proposals that do merit a full, traditional evaluation, but, for example, employ a language that differs from the standard found in previously successful projects. They must be given full autonomy and discretion to disregard the algorithm’s recommendations whenever suitable, and must comprehend that mistakenly following through with the recommendations carries a substantially larger cost than performing the opposite action and rescuing an immature proposal.
The implementation does not make use of any personally identifiable information about the applicants, and it is based only upon the texts of the proposals. Care must be taken, however, to ensure that the latter does not contain information that may be used to infer the identity of the applicants. In addition to this, it is paramount that the system is continuously monitored in order to identify and mitigate sources of historical bias in the selection process.
The main challenge at the moment corresponds to improving explainability. Currently, it is possible to see which sections of a given proposal are contributing positively/negatively to it being flagged for removal according to the algorithm; however, more efforts must be made in this direction in order to be able to provide meaningful feedback both to the eligibility reviewers about the algorithm’s recommendations, and to the applicants themselves—supplemented by the reviewers.
In addition to this, the major point of concern we find is that it is not currently possible to contest a negative decision, once ratified by the eligibility reviewers—who not only have an incentive to do so but also only carry out a superficial evaluation in the first place—nor to resubmit the proposal based on their feedback. We believe that such a mechanism must be put in place in order to ensure the transparency and fairness of the process.
All of the information about the workings of the AI system and the role of the eligibility reviewers must be public and clearly presented in the website of the program, as well as in the specification of the rules of the selection process. Moreover, it must be reiterated to the eligibility reviewers themselves at the moment they are recruited for the task.
Conditions for success
Based on the above, we believe that the main elements that are necessary to secure a successful, responsible implementation of an AI-assisted solution to the grant selection process can be summarized as follows.
Initial assessment and data selection
• Evaluate the availability of enough relevant data, in addition to its quality and regularity.
• Explore sources of structural human biases that may already be present in the selection process, and elaborate mitigation strategies accordingly.
• Avoid the use of personally identifiable information or any data representing characteristics of the applicants that are not relevant to the selection process.
Implementation
• Define the type of algorithm to be used and its suitability to the task—for example, its domain specificity and the potential need for further pretraining or fine-tuning.
• Define the evaluation objectives of the algorithm and the type of error, if any, to prioritize avoiding—for example, in this case, mistakenly flagging a proposal for removal is more negative than the opposite scenario.
• Carry out an extensive evaluation of algorithm performance on historical data.
• Implement a pilot study in a real-world scenario.
• Document all steps of the process.
Human agency
• Develop explainability measures that serve to make sense of the outputs of the system, both for the evaluators who are users of the tool and for the applicants who are subject to the decision.
• Elaborate clear and thorough guidelines for the users, emphasizing they have complete discretion over the decision-making process.
• Involve the users throughout the evaluation of the tool.
• Create an instance of appeal for applicants who wish to contest their removal from the selection process.
Communication
• Publish the details of the implementation along with the rules of the call.
• Be explicit about which stage or stages are automated, and emphasize the final human judgment.
• Include clear guidelines for redress.
As discussed in this article, most of these conditions are already met in the case study presented, and the Foundation is working toward addressing its current limitations.
6. Conclusion
The integration of human expertise and AI holds great potential to enhance decision-making processes such as research evaluation. While the latter allows for the timely processing of vast amounts of data, plus the capability of identifying hidden patterns and the potential to uncover cognitive biases, the experts bring years of experience, nuanced understanding, and the contextual insights that are required to make sense of the outcomes of the automated steps of the process. Effective and insightful decisions can only be the result of a responsible use of these tools that leverages the strengths of both AI and human expertise.
We have presented the implementation of an AI-assisted prescreening of research proposals carried out by LCF in the context of its flagship biomedical funding program, and analyzed it from the perspective of the conditions that such a system should fulfill in order to be deemed a responsible use of AI-assisted decision-making, as well as the reflections and attitude of the researchers involved in the evaluation process—a more detailed analysis of the technical aspects of the implementation itself will be presented elsewhere.
We have found that, while the current implementation considers the human role in the decision process and monitors biases in the data, more efforts must be made toward improving the explainability of the algorithms used and, more fundamentally, redress mechanisms must be put in place at the disposal of the applicants who are removed from the selection process before an in-depth peer review, in order to boost the transparency and auditability of the system.
We hope that these reflections constitute a positive contribution to the ongoing global debate surrounding the use of AI tools in the research evaluation pipeline.
Data availability statement
The research proposal texts cannot be made available. The pretrained models, in addition to all metrics and aggregated data on the results of the classification for the HR22 and HR23 calls are available upon request from LCF and IThinkUPC.
Author contribution
Conceptualization: C.C.C.; C.P.-R.; D.C.-M.; B.R.; I.L.-V. Methodology: C.C.C; C.P.-R.; A.P.-L.; R.F.-M.; D.C.-M. Investigation: C.C.C.; C.P.-R.; A.P.-L.; F.A.; S.V.-S.; R.F.-M.; B.R. Supervision: B.R.; I.L.-V. Writing—original draft: C.C.C.; C.P.-R.; A.P.-L.; S.V.-S.; R.F.-M. Writing—review and editing: C.C.C.; C.P.-R.; A.P.-L.; S.V.-S.; R.F.-M. All authors approved the final submitted draft.
Provenance
This article was submitted for consideration for the 2024 Data for Policy Conference to be published in Data & Policy on the strength of the Conference review process.
Funding statement
This project has been funded by “la Caixa” Foundation.
Competing interest
This article is authored by the key responsibles of the relevant area at LCF alongside its providers (SIRIS Academic and IThinkUPC). The authors believe they do not have competing interests.
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.




 Open access
Open access
Comments
No Comments have been published for this article.