


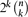 possible clauses over the variables
possible clauses over the variables Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Molloy, Michael
2012.
The freezing threshold for k-colourings of a random graph.
p.
921.
Sutton, Andrew M.
and
Neumann, Frank
2014.
Parallel Problem Solving from Nature – PPSN XIII.
Vol. 8672,
Issue. ,
p.
942.
Perkins, Will
2015.
Randomk‐SAT and the power of two choices.
Random Structures & Algorithms,
Vol. 47,
Issue. 1,
p.
163.
Molloy, Michael
2018.
The Freezing Threshold for
k
-Colourings of a Random Graph
.
Journal of the ACM,
Vol. 65,
Issue. 2,
p.
1.
Krivelevich, Michael
Kwan, Matthew
Loh, Po‐Shen
and
Sudakov, Benny
2018.
The random k‐matching‐free process.
Random Structures & Algorithms,
Vol. 53,
Issue. 4,
p.
692.
Kamčev, Nina
Krivelevich, Michael
Morrison, Natasha
and
Sudakov, Benny
2020.
The Kőnig graph process.
Random Structures & Algorithms,
Vol. 57,
Issue. 4,
p.
1272.
Kang, Mihyun
and
Missethan, Michael
2023.
The Early Evolution of the Random Graph Process in Planar Graphs and Related Classes.
SIAM Journal on Discrete Mathematics,
Vol. 37,
Issue. 1,
p.
146.