


No CrossRef data available.
Article contents
Embedding theorems for random graphs with specified degrees
Published online by Cambridge University Press: 16 October 2024
Abstract
Given an 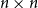 $n\times n$ symmetric matrix
$n\times n$ symmetric matrix 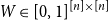 $W\in [0,1]^{[n]\times [n]}$, let
$W\in [0,1]^{[n]\times [n]}$, let 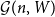 ${\mathcal G}(n,W)$ be the random graph obtained by independently including each edge
${\mathcal G}(n,W)$ be the random graph obtained by independently including each edge 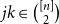 $jk\in \binom{[n]}{2}$ with probability
$jk\in \binom{[n]}{2}$ with probability 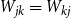 $W_{jk}=W_{kj}$. Given a degree sequence
$W_{jk}=W_{kj}$. Given a degree sequence 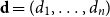 $\textbf{d}=(d_1,\ldots, d_n)$, let
$\textbf{d}=(d_1,\ldots, d_n)$, let 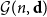 ${\mathcal G}(n,\textbf{d})$ denote a uniformly random graph with degree sequence
${\mathcal G}(n,\textbf{d})$ denote a uniformly random graph with degree sequence 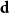 $\textbf{d}$. We couple
$\textbf{d}$. We couple 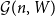 ${\mathcal G}(n,W)$ and
${\mathcal G}(n,W)$ and 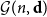 ${\mathcal G}(n,\textbf{d})$ together so that asymptotically almost surely
${\mathcal G}(n,\textbf{d})$ together so that asymptotically almost surely 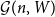 ${\mathcal G}(n,W)$ is a subgraph of
${\mathcal G}(n,W)$ is a subgraph of  ${\mathcal G}(n,\textbf{d})$, where
${\mathcal G}(n,\textbf{d})$, where 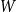 $W$ is some function of
$W$ is some function of 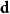 $\textbf{d}$. Let
$\textbf{d}$. Let  $\Delta (\textbf{d})$ denote the maximum degree in
$\Delta (\textbf{d})$ denote the maximum degree in 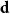 $\textbf{d}$. Our coupling result is optimal when
$\textbf{d}$. Our coupling result is optimal when 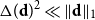 $\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$, that is,
$\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$, that is,  $W_{ij}$ is asymptotic to
$W_{ij}$ is asymptotic to  ${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for every
${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for every 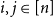 $i,j\in [n]$. We also have coupling results for
$i,j\in [n]$. We also have coupling results for 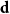 $\textbf{d}$ that are not constrained by the condition
$\textbf{d}$ that are not constrained by the condition  $\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$. For such
$\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$. For such  $\textbf{d}$ our coupling result is still close to optimal, in the sense that
$\textbf{d}$ our coupling result is still close to optimal, in the sense that 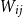 $W_{ij}$ is asymptotic to
$W_{ij}$ is asymptotic to 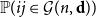 ${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for most pairs
${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for most pairs  $ij\in \binom{[n]}{2}$.
$ij\in \binom{[n]}{2}$.
Keywords
- Type
- Paper
- Information
- Copyright
- © The Author(s), 2024. Published by Cambridge University Press
References
Anastos, M., Frieze, A. and Gao, P. (2021) Hamiltonicity of random graphs in the stochastic block model. SIAM J. Discrete Math. 35 1854–1880.CrossRefGoogle Scholar
Barvinok, A. (2010) On the number of matrices and a random matrix with prescribed row and column sums and 0-1 entries. Adv. Math. 224 316–339.CrossRefGoogle Scholar
Barvinok, A. and Hartigan, J. A. (2013) The number of graphs and a random graph with a given degree sequence. Random Struct. Algor. 42 301–348.CrossRefGoogle Scholar
Bender, E. A. and Canfield, E. R. (1978) The asymptotic number of labeled graphs with given degree sequences. J. Combin. Theory, Ser. A. 24 296–307.CrossRefGoogle Scholar
Bohman, T. and Picollelli, M. (2012) Sir epidemics on random graphs with a fixed degree sequence. Random Struct. Algor. 41 179–214.CrossRefGoogle Scholar
Bollobás, B. (1980) A probabilistic proof of an asymptotic formula for the number of labelled regular graphs. Eur. J. Combin. 1 311–316.CrossRefGoogle Scholar
Chatterjee, S., Diaconis, P. and Sly, A. (2011) Random graphs with a given degree sequence. Ann. Appl. Probab. 21 1400–1435.CrossRefGoogle Scholar
Chung, F. and Lu, L. (2002) The average distances in random graphs with given expected degrees. Proc. Natl. Acad. Sci. 99 15879–15882.CrossRefGoogle ScholarPubMed
Chung, F. and Lu, L. (2002) Connected components in random graphs with given expected degree sequences. Ann. Comb. 6 125–145.CrossRefGoogle Scholar
Chung, F. and Lu, L. (2006) The volume of the giant component of a random graph with given expected degrees. Siam. J. Discrete Math. 20 395–411.CrossRefGoogle Scholar
Chung, F., Lu, L. and Vu, V. (2004) The spectra of random graphs with given expected degrees. Internet Math. 1 257–275.CrossRefGoogle Scholar
Cooper, C., Frieze, A. and Reed, B. (2002) Random regular graphs of non-constant degree: connectivity and hamiltonicity. Combin. Probab. Comput. 11 249–261.CrossRefGoogle Scholar
Dudek, A., Frieze, A., Ruciński, A. and Šileikis, M. (2017) Embedding the Erdős–Rényi hypergraph into the random regular hypergraph and Hamiltonicity. J. Combin. Theory, Ser. B. 122 719–740.CrossRefGoogle Scholar
Fountoulakis, N., Kühn, D. and Osthus, D. (2008) The order of the largest complete minor in a random graph. Random Struct. Algor. 33 127–141.CrossRefGoogle Scholar
Frankston, K., Kahn, J., Narayanan, B. and Park, J. (2021) Thresholds versus fractional expectation-thresholds. Ann. Math. 194 475–495.CrossRefGoogle Scholar
Gao, P., Isaev, M. and McKay, B. D. (2020) Sandwiching random regular graphs between binomial random graphs. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SIAM. pp. 690–701.CrossRefGoogle Scholar
Gao, P., Isaev, M. and McKay, B. D. (2022) Sandwiching dense random regular graphs between binomial random graphs. Probab. Theory Rel. 184 115–158.CrossRefGoogle Scholar
Gao, P., Isaev, M. and McKay, B. D. (2023), Kim-vu’s sandwich conjecture is true for all
 $ d\ge \log ^4 n$
, arXiv preprint arXiv:2011.09449.Google Scholar
$ d\ge \log ^4 n$
, arXiv preprint arXiv:2011.09449.Google Scholar
 $ d\ge \log ^4 n$
, arXiv preprint arXiv:2011.09449.Google Scholar
$ d\ge \log ^4 n$
, arXiv preprint arXiv:2011.09449.Google ScholarGao, P. and Ohapkin, Y. (2023) Subgraph probability of random graphs with specified degrees and applications to chromatic number and connectivity. Random Struct. Algor. 62 911–934.CrossRefGoogle Scholar
Gao, P. and Wormald, N. (2016) Enumeration of graphs with a heavy-tailed degree sequence. Adv. Math. 287 412–450.CrossRefGoogle Scholar
Gao, Z. and Wormald, N. C. (2008) Distribution of subgraphs of random regular graphs. Random Struct. Algor. 32 38–48.CrossRefGoogle Scholar
Holland, P. W., Laskey, K. B. and Leinhardt, S. (1983) Stochastic blockmodels: first steps. Soc. Networks. 5 109–137.CrossRefGoogle Scholar
Isaev, M. and McKay, B. D. (2018) Complex martingales and asymptotic enumeration. Random Struct. Algor. 52 617–661.CrossRefGoogle Scholar
Kim, J. H. and Vu, V. H. (2004) Sandwiching random graphs: universality between random graph models. Adv. Math. 188 444–469.CrossRefGoogle Scholar
Klimošová, T., Reiher, C., Ruciński, A. and Šileikis, M. (2023) Sandwiching biregular random graphs. Combin. Probab. Comput. 32 1–44.CrossRefGoogle Scholar
Krivelevich, M., Sudakov, B., Vu, V. H. and Wormald, N. C. (2001) Random regular graphs of high degree. Random Struct. Algor. 18 346–363.CrossRefGoogle Scholar
Liebenau, A. and Wormald, N. (2017) Asymptotic enumeration of graphs by degree sequence, and the degree sequence of a random graph, arXiv preprint arXiv: 1702.08373.Google Scholar
Lusher, D., Koskinen, J. and Robins, G. (2013) Exponential random graph models for social networks: theory, methods, and applications. Cambridge University Press.Google Scholar
McKay, B. D. (1985) Asymptotics for symmetric 0-1 matrices with prescribed row sums. Ars. Combin. 19 15–25.Google Scholar
McKay, BD. and Wormald, N. C. (1990) Asymptotic enumeration by degree sequence of graphs of high degree. Eur. J. Combin. 11 565–580.CrossRefGoogle Scholar
McKay, B. D. and Wormald, N. C. (1991) Asymptotic enumeration by degree sequence of graphs with degrees
$o(n^{1/2})$
. Combinatorica. 11 369–382.CrossRefGoogle Scholar
 $o(n^{1/2})$
. Combinatorica. 11 369–382.CrossRefGoogle Scholar
$o(n^{1/2})$
. Combinatorica. 11 369–382.CrossRefGoogle ScholarMorris, J. F., O’Neal, J. W. and Deckro, R. F. (2014) A random graph generation algorithm for the analysis of social networks. J. Def. Model. Simul. 11 265–276.CrossRefGoogle Scholar
Newman, M. E. J., Strogatz, S. H. and Watts, D. J. (2001) Random graphs with arbitrary degree distributions and their applications. Phys. Rev. E. 64 026118.CrossRefGoogle ScholarPubMed
Van Der Hofstad, R. (2024) Random graphs and complex networks. Cambridge University Press.CrossRefGoogle Scholar
Wormald, N. C., et al. (1999) Models of random regular graphs, London mathematical society lecture note series, 239–298.CrossRefGoogle Scholar