



Background
In the past 5 years a number of high-quality meta-analyses have examined the statistical strength of various types of suicide prediction. Franklin et alReference Franklin, Ribeiro, Fox, Bentley, Kleiman and Huang1 and Ribeiro et alReference Ribeiro, Franklin, Fox, Bentley, Kleiman and Chang2 conducted meta-analytic reviews of longitudinal studies that reported the predictive strength of a broad spectrum of suicide risk factors including suicidal ideation and suicidal behavior. After reviewing 50 years of research they concluded that even the most well-established suicide risk factors ‘only provide a marginal improvement in diagnostic accuracy above chance’.Reference Ribeiro, Franklin, Fox, Bentley, Kleiman and Chang2 Other authors have used meta-analysis to examine the predictive strength of validated suicide risk scales concluding that ‘the scales lack sufficient evidence to support their use’,Reference Chan, Bhatti, Meader, Stockton, Evans and O'Connor3 ‘are not clinically useful’,Reference Carter, Milner, McGill, Pirkis, Kapur and Spittal4 and ‘do not fulfil requirements for diagnostic accuracy’.Reference Runeson, Odeberg, Pettersson, Edbom, Jildevik Adamsson and Waern5 More recently Belsher et al synthesised 17 suicide prediction models that were developed using both training (exploratory) and testing (validation) stages and concluded that they ‘produce accurate overall classification models, but their accuracy of predicting a future suicide event is near zero’.Reference Belsher, Smolenski, Pruitt, Bush, Beech and Workman6
A 2016 meta-analysis of longitudinal studies examined the predictive properties of 29 exploratory studies that retrospectively fitted two or more non-demographic suicide risk factors to suicide mortality and 24 validation studies of suicide risk scales.Reference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7 Although the modest pooled odds ratio (OR) of 4.8 across the exploratory and validation studies was consistent with the disappointing results of later meta-analyses,Reference Chan, Bhatti, Meader, Stockton, Evans and O'Connor3–Reference Belsher, Smolenski, Pruitt, Bush, Beech and Workman6 the authors emphasised the extent of the between-study heterogeneity in ORs and tested possible moderators including the year of publication and different study methods. They hypothesised that prediction models that included more suicide risk factors would have better predictive strengthReference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7 but instead found that that the number of included suicide risk factors did not explain between-study heterogeneity in ORs.Reference Large, Galletly, Myles, Ryan and Myles8 However, the inclusion of both exploratory and validation studies might have obfuscated this anticipated association given that exploratory and validation methods have quite different ways of determining the number of included risk suicide factors. An unrelated limitation of the 2016 study was a lack of studies examining predictions made using clinical judgement or machine learning.Reference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7
Potential role for machine learning
Machine learning is a subset of artificial intelligence research employing computer algorithms that improve automatically through experience. Machine leaning has been touted as a method to revolutionise and personalise medicine across the spectrum of healthcare.Reference Wilkinson, Arnold, Murray, van Smeden, Carr and Sippy9 Given the difficulty in translating the large volume of research about suicide risk factors into clinically useful suicide prediction models, there is hope that machine learning may provide a solution to the intractable problem of suicide prediction.Reference McHugh and Large10
Aims
In this meta-analysis we expand research into suicide prediction models by examining a large and representative sample of exploratory suicide prediction models derived from cohort and controlled studies conducted in population, primary care and specialist care settings. We examined the effect size, expressed as the OR of the highest risk and lower-risk groups, according to the different types of suicide prediction models (including experimental scales, machine learning and clinical judgement) and the number of suicide risk factors included in the prediction models. We also examined other possible moderators of the ORs according to different diagnostic groups, different study settings and measures of study reporting strength. Finally, we identified the suicide risk factors that were most commonly included in the suicide prediction models. In accordance with the unanswered questions posed by the 2016 meta-analysisReference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7 we hypothesised that the use of machine learning and a larger number of included suicide risk factors would both be associated with statically stronger suicide predictions.
Method
We conducted a registered meta-analysis (PROSPERO; CRD42017059665) according to Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) and Meta-analysis Of Observational Studies in Epidemiology (MOOSE) guidelines.Reference Liberati, Altman, Tetzlaff, Mulrow, Gøtzsche and Ioannidis11,Reference Stroup, Berlin, Morton, Olkin, Williamson and Rennie12
Search strategy
Preliminary searches of Medline, Embase and PsycINFO from inception to January 2019 using the word ‘suicide’ resulted in an impractical number of hits,Reference McHugh, Corderoy, Ryan, Hickie and Large13 while searches with limits using the terms ‘prediction’, ‘model’, or ‘stratification’, missed papers that were identified in earlier reviews.Reference Belsher, Smolenski, Pruitt, Bush, Beech and Workman6,Reference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7,Reference Large, Myles, Myles, Corderoy, Weiser and Davidson14 In contrast, searches of PubMed using variants of the word ‘suicide’ in the title reliably located papers identified in searches of multiple databases. Therefore, in order obtain a large and representative sample of relevant studies, English language papers with accompanying abstracts listed in PubMed from inception to 15 August 2020 were identified using title searches with the term suicid* (expanded to ‘suicida[ti] OR suicidaire[ti] OR suicidaires[ti] OR suicidal[ti] OR suicidal/death[ti] OR suicidality[ti] OR suicidally[ti] OR suicidarse[ti] OR suicide[ti] OR suicide/attempted[ti] OR suicide/self[ti] OR suicide/suicide[ti] OR suicide’[ti] OR suicide's[ti] OR suicidedagger[ti] OR suiciders[ti] OR suicides[ti] OR suicides’[ti] OR suicidiality[ti] OR suicidical[ti] OR suicidio[ti] OR suicidios[ti] OR suicidogenic[ti] OR suicidology[ti]’) (Fig. 1). Two authors (M.C. and M.L.) screened full-text publications for inclusion and exclusion criteria. Electronic searches were supplemented by hand searches of the reference lists of included studies and earlier relevant meta-analyses.Reference Franklin, Ribeiro, Fox, Bentley, Kleiman and Huang1,Reference Ribeiro, Franklin, Fox, Bentley, Kleiman and Chang2,Reference Belsher, Smolenski, Pruitt, Bush, Beech and Workman6,Reference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7

Fig. 1 Flow chart of searches for studies reporting exploratory suicide prediction models (SPM).
Inclusion and exclusion criteria
We included data from studies that:
(a) examined groups of people who died by suicide or survived;
(b) used cohort or case–control methods;
(c) reported on a type of exploratory suicide prediction model using two or more clinical suicide risk factors (other than age and gender) or clinical judgement (assuming that clinicians consider more than one risk factor in making a clinical suicide risk assessment); and
(d) reported sufficient data to calculate the OR (i.e. the number of higher- and lower-risk patients that survived or died by suicide, the sensitivity and specificity, or other effect-size data).
We excluded data from studies that:
(a) examined validated existing suicide risk scales (including validation stages of machine-learning studies);
(b) reported on suicide attempts or a combined outcome of suicide and suicide attempts;
(c) used psychological autopsy methods;
(d) reported a suicide prediction model based on a single suicide risk factor combined with age and/or gender;
(e) only examined biological markers; or
(f) reported insufficient effect-size data to include in the meta-analysis.
Validation studies of suicide risk scales were excluded because the number and nature of items in suicide risk scales are not empirically derived from the validation data-set.
Data extraction
Two authors (M.L. and M.C.) independently extracted the effect-size data that was then reconciled by a third author (S.X.). Differences in effect-size data were resolved further by examination and consensus by M.L. and M.C. Where possible the effect-size data recorded was in the form of counts of true positives and total positives, and false negatives and total negatives to allow a meta-analysis of sensitivity and specificity of the suicide prediction models. Most studies dichotomised the patients into higher and lower-risk groups but, when three or more risk strata were reported, the cut-off point associated with the highest OR was used. Two authors (M.L. and H.A.-S.) independently extracted the moderator data that was then reconciled by a third author (K.M.), with differences resolved by further examination by M.L., M.C. and K.M. and consensus. The list of suicide risk factors used in each suicide prediction model was recorded by M.L. and crosschecked by K.M. Suicide risk factors that were included in more than five suicide prediction models were considered to be replicated independent predictors of suicide.
Moderator variables
We classified the type of the suicide prediction models according to:
(a) clinical judgement (including both heuristic assessments of suicide risk recorded in medical records and risk categorisations by researchers who were masked to suicide outcomes);
(b) multi-item experimental scales with items selected after bivariate testing of suicide risk factors;
(c) multi-item experimental scales with items selected after multivariate testing of suicide risk factors;
(d) multivariate modelling other than machine learning (using statistically optimised risk models, for example classification plots generated by multiple regressions techniques); and
(e) machine learning (defined as any advanced experimental technique utilising computerised learning).
Where more than one type of suicide prediction model was described in a publication (as defined above) both suicide prediction models were included. When more than one suicide prediction model was reported using a single type of model (as defined above) only the model with the highest OR was used. When more than one population was reported in a single publication (such as men and women) both suicide prediction models were included.
Four continuous moderator variables were collected to investigate between-study heterogeneity in ORs:
(a) the number of included suicide risk factors in the suicide prediction models (because risk models that rely on more detailed information might be more accurate);
(b) the number of potential suicide risk factors (because studies considering more factors initially might then include more factors in the suicide prediction model);
(c) the mean length of follow-up (because studies with longer follow-up are less likely to misclassify eventual suicides); and
(d) publication year (because prediction might have improved over time with the introduction of more advanced types of suicide prediction model such as machine learning).
The number of potential suicide risk factors examined was often reported in the primary research paper or in an associated publication. Otherwise the number of potential risk factors was ascertained by counting all the independent variables listed in the paper. The number and nature of suicide risk factors included in the suicide prediction models was clearly documented in almost every study.
The study diagnostic group (schizophrenia spectrum, affective disorder, mixed diagnosis or other) and the research setting (general population/non-psychiatric care, after any form of self-harm or suicide attempt, specialist mental healthcare, discharged psychiatric in-patients, current psychiatric in-patients and in correctional settings) were collected as potential moderators of the strength of suicide prediction.
Assessment of strength of reporting in primary studies
The strength of reporting in the primary studies was assessed using a 0–6 point scale derived from the Newcastle-Ottawa scale for the assessment of reporting strength of non-randomised studiesReference Wells, Shea, O'Connnell, Peterson, Welch and Losos15 and adapted from a scale used in two earlier meta-analyses of suicide prediction models.Reference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7,Reference Large, Myles, Myles, Corderoy, Weiser and Davidson14 One point was assigned for each of the following items:
(a) cohort study (rather than a controlled study);
(b) gender-matched cohorts or controls;
(c) individuals recruited from a defined geographic area;
(d) suicide risk factors recorded prospectively (rather than by examination of medical records);
(e) suicides ascertained using an external mortality database (rather than suicide as determined by the researchers); and
(f) used ‘persons’ rather than clinical contacts as the denominator.
Studies with a score of 4 or more were considered to have stronger reporting and to be at lower risk of bias.
Data synthesis
A random-effects model was used to calculate the pooled effect size in the form of ORs using Comprehensive Meta-Analysis.Reference Borenstein, Hedges, Higgins and Rothstein16 Secondary outcomes included the sensitivity, specificity and positive predictive value. Between-study heterogeneity was examined using the I 2 and Q-value statistics. A meta-analytic estimate of the receiver operator curve and area under the curve was calculated using Meta-DiSc.Reference Zamora, Abraira, Muriel, Khan and Coomarasamy17 The possibility of publication bias was assessed using Egger's regressionReference Egger, Davey Smith, Schneider and Minder18 and was quantified using Duval and Tweedie's trim and fill method.Reference Duval and Tweedie19
The analysis was conducted at the level of suicide prediction model but a sensitivity analysis was conducted using publication as the unit of analysis. Between-group heterogeneity was examined using a mixed-effects model without assuming a common within-study variance and the significance of between-group heterogeneity was determined with Q-value statistics. Between-group analyses were performed to examine the moderation of OR according to: (a) the type of the suicide prediction model; (b) cohort versus control design; (c) diagnostic group; (d) research setting; and (e) strength of reporting items.
Random-effects meta-regression (method of moments) was used to examine whether continuous moderators were associated with between-study heterogeneity in ORs. Multiple meta-regression was used to assess the independence of the associations between the moderator of machine learning, the number of included suicide risk factors and the OR.
Ethical approval
No ethical approval was required.
Results
Searches and data extraction
The searches identified 86 studiesReference Ahmedani, Peterson, Hu, Lynch, Lu and Waitzfelder20–Reference Winkler, Mlada, Csemy, Nechanska and Hoschl105 reporting 102 samples of people who were categorised as being at high suicide risk using an exploratory suicide prediction model (see Supplementary Material Table S1: table of included studies reporting exploratory suicide prediction models; Supplementary Material Table S2: data used in the meta-analysis and ratings of strength of reporting in primary research; available at https://doi.org/10.1192/bjo.2020.162). There were four disagreements about the selection of studies that were resolved by consensus. An initial data extraction from a subset of studies resulted in disagreements in almost one-third of the effect-size data because of the selection of different cut-off points and different suicide prediction models. A second independent data extraction of the full data-set resulted in disagreements about effect-size data in 10 of the 102 (10%) suicide prediction models, all of which were resolved by further examination. Re-examination resolved 198 differences in 1428 (14%) moderator or reporting strength data points.
The included papers examined 20 210 411 people of whom 106 902 died by suicide. The earliest paper was published in 1966 and the median publication year was 2007. The total number of potential suicide risk factors examined was 12 242 (mean per model = 135, s.d. = 387) after excluding the samples that used clinical judgement (in which the number of potential and included suicide risk factors could not be ascertained) and a single machine-learning study that used 8071 predictor variables.Reference Kessler, Bauer, Bishop, Demler, Dobscha and Gildea62 The total number of included suicide risk factors in the suicide prediction models could not be ascertained exactly because some machine-learning studies did not clarify this precisely, but there were at least 777 (mean per model 8.7, s.d. = 9.9) of which 598 could be identified and tabulated (Supplementary Material Table S1, available at https://doi.org/10.1192/bjo.2020.162). The median reported OR was 8.0, the first quartile was 3.8, the third quartile was 19.2 and the range was 1.05–297.
Meta-analysis
The pooled OR of 102 suicide prediction models was 7.7 (95% CI 6.7–8.8; 95% prediction interval, 2.5–23.9) (Fig. 2) indicating a strong effect size.Reference Rosenthal106 There was very high between-study heterogeneity (I 2 = 99.5, Q-value 20 435, P < 0.001). An analysis using the 86 publications as the unit of analysis had a 2.5% lower OR of 7.5 (95% CI 6.5–8.7). There was some evidence of publication bias in favour of studies reporting a higher OR using Egger's test (intercept 2.94, t-value 1.99, two-tailed P = 0.05) (Fig. 3). Duval and Tweedie's trim and fill method identified 12 hypothetically missing studies with lower ORs and estimated an 11.5% lower OR of 6.8 (95% CI 6.0–7.8). The models achieved their ORs using differing trade-offs between sensitivity and specificity (Fig. 4). The pooled sensitivity of a high-risk prediction was 44% (n = 88 studies, 95% CI 37–50%, I 2 = 99.5) and the pooled specificity of a lower-risk prediction was 84% (n = 88 studies, 95% CI 79–88%, I 2 = 99.9). The pooled area under the curve was 0.79. The positive predictive value was 2.8% (95% CI 1.8–4.3%, I 2 = 98.8) among 36 cohort studies.
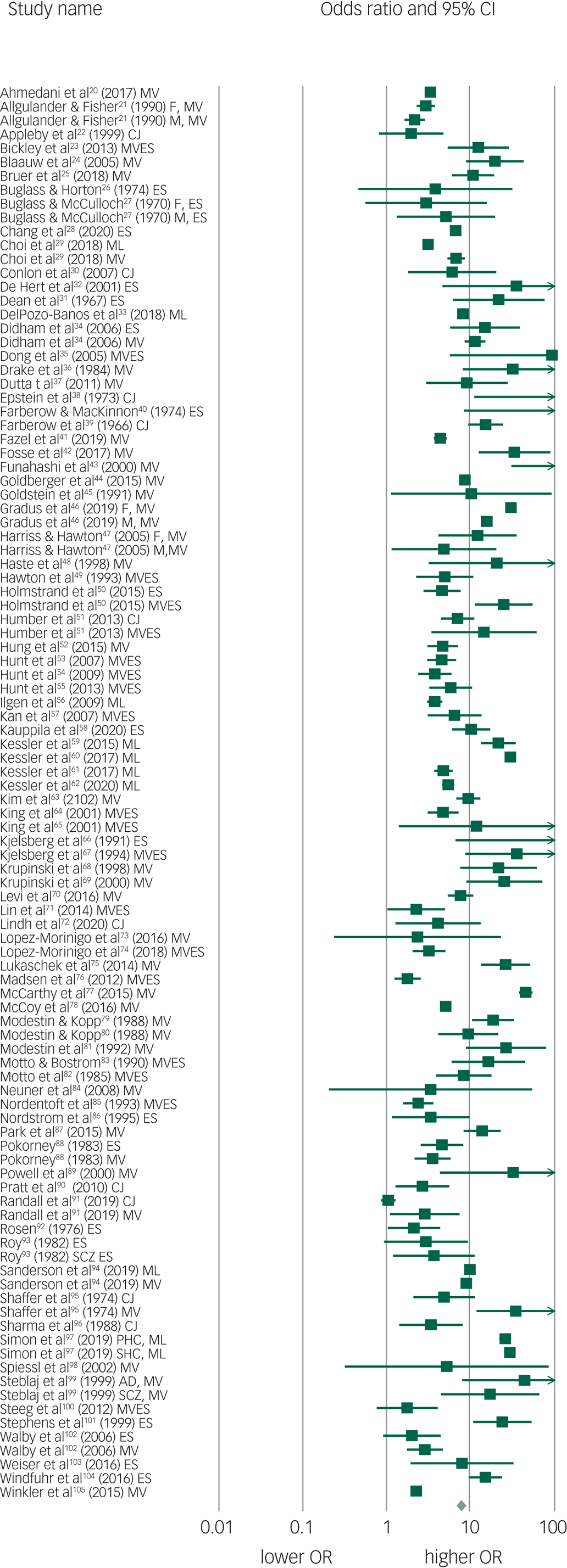
Fig. 2 Forest plot of suicide prediction models.
CJ, clinical judgement; MV, multivariate model; MVES, experimental scale based on multivariate analysis; ES, experimental scale based no bivariate analysis; ML, machine learning; M, male; F, female; AD, affective disorder; SCZ, schizophrenia spectrum; PHC, primary health care; SHC, secondary health care; OR, odds ratio.

Fig. 3 Funnel plot of standard error by log odds ratio of suicide prediction models.

Fig. 4 Receiver operating curve of exploratory suicide prediction models.
Suicide prediction models that used experimental scales derived from bivariate or multivariate testing performed better than clinical judgement. Multivariate modelling and machine learning achieved a higher OR than experimental scales. A seemingly large difference in ORs according to these types of suicide prediction model did not reach clinical significance (Table 1 and Fig. 5). The number of included suicide risk factors in the suicide prediction model (excluding ten clinical judgement samples and three models in which the number of included suicide risk variables was not reported) was significantly associated with the ORs, but this moderator was not significantly associated with the ORs among the 79 non-machine-learning, non-clinical judgement studies (Table 2). Machine-learning studies included a mean of 26 risk suicide factors whereas non-machine-learning studies (excluding clinical judgement studies that were not included in any analyses of the number of risk factors) incorporated a mean of 6.5 suicide risk factors. A multiple meta-regression found that neither machine learning (coefficient 0.21, 95% CI −0.50 to 0.91, Z-value = 0.57, P = 0.56) or the number of included suicide risk factors (coefficient 0.01, 95% CI −0.01 to 0.04, Z-value = 1.42, P = 0.15) made an independent contribution to heterogeneity in ORs and together explained about one tenth of the between-study heterogeneity (Q = 5.56, d.f. = 2, P = 0.06, R-square analogue 10.1%).

Fig. 5 Clinical judgement, machine learning and the number of included risk variables in suicide prediction models.
Table 1 Meta-analysis of study methods suicide and the strength of prediction models

Table 2 Meta-regression of continuous moderator variables and the strength of prediction models

Cohort studies, those conducted in geographically defined catchment areas and studies that used external suicide mortality data had a lower pooled OR, respectively, than controlled studies, those that were based on a hospital or health service sample and those that assessed suicide mortality using local data (Table 1). Groups of studies that were matched for gender and those that collected research data prospectively had similar pooled ORs to those that were, respectively, not gender matched or that extracted the research data from medical records (Table 1).
The group of studies that examined suicides based on clinic contacts rather than individuals reported a higher pooled OR (Table 1). Suicide prediction models performed better among cohorts of people with schizophrenia, in primary health/general population samples and among psychiatric in-patients. Suicide prediction models performed less well among cohorts of patients who had presented with suicide attempts or self-harm (Table 3).
Table 3 Meta-analysis of diagnostic groups and research settings and the strength of prediction models
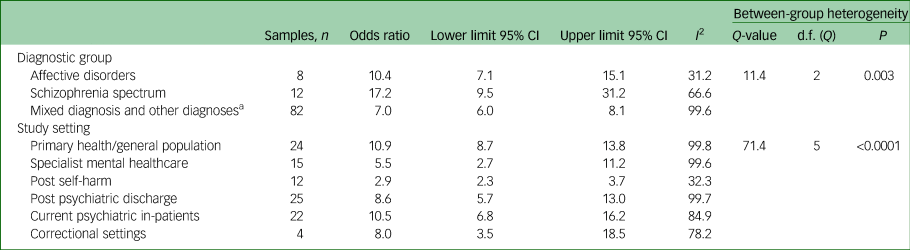
a. Includes one sample of patients with borderline personality disorder and one sample of people with epilepsy.
Meta-regression found no evidence that the year of publication or length of follow-up contributed to between-study heterogeneity (Table 2). The number of potential suicide risk factors did not contribute to between-sample heterogeneity (Table 2). Further, machine learning made no independent contribution to between-sample heterogeneity in various post hoc multiple meta-regression that included the methodological variable of whether the study used people or clinical contacts in the denominator and other indicators of reporting strength. (For the full data-set used in the study including effect-size data, moderators and strength of reporting data see Supplementary Material Table S2.)
Suicide risk factors in the suicide prediction models
A previous suicide attempt or any form of self-harm was the most common included suicide risk factor that was present in 68 of the 102 suicide prediction models. This was followed by depressive diagnosis or symptoms (n = 50), alcohol or substance use (n = 34), suicidal ideation (n = 31), previous psychiatric hospital admission (n = 24), male gender (n = 20), psychotropic medication (n = 20), physical comorbidity (n = 19), psychiatric diagnosis (n = 19), psychotic symptoms (n = 19), older age (n = 17), previous psychiatric care (n = 17), adverse life events (n = 12), family history of mental disorder or suicide (n = 12), childhood or developmental adversity (n = 11), ethnicity (n = 9), anxiety disorder (n = 8), forensic history (n = 7), housing problems (n = 7), bipolar disorder (n = 7), personality disorder (n = 7), schizophrenia spectrum disorder (n = 7), problems with psychiatric discharge (n = 6), longer psychiatric hospitalisation (n = 6), problems with rapport (n = 6), current financial stress (n = 5) and involuntary psychiatric treatment (n = 5). Some risk factors were included with opposing effect sizes, for example both employment and unemployment were included in (n = 4) suicide prediction models, and being divorced or not married (n = 6) and being married (n = 3) appeared in suicide prediction models.
Discussion
This synthesis of a large and representative sample of exploratory suicide prediction models found a strong statistical association between being allocated to the highest suicide risk category and suicide. The meta-analyses of sensitivity and specificity suggests that under half of all suicides might be anticipated by suicide prediction models, with non-suicide being incorrectly predicted in more than one in ten cases. Meta-analyses of a subsample of cohort studies suggested that 34 in 35 suicide predictions are likely to be false positive predictions.
The first aim of our study was to assess whether machine-learning suicide prediction models had stronger prediction than studies using other types of suicide prediction. The second aim was to determine whether suicide prediction models with a larger number of included suicide risk factors had stronger prediction than suicide prediction models with fewer factors. While we had conceptualised these as separate questions, machine-learning studies included an average of four times the number of suicide risk factors than other types of suicide prediction model. When all the studies (except clinical judgement studies) were included, the number of included suicide risk factors was positively associated with the OR in line with our hypothesis. However, when machine-learning studies were excluded or when machine learning was used as a covariable in a multiple meta-regression, there was no association between the number of included suicide risk variables and the OR. This is in line with our findings in longitudinal suicide studiesReference Large, Kaneson, Myles, Myles, Gunaratne and Ryan7 and among samples of psychiatric in-patientsReference Large, Myles, Myles, Corderoy, Weiser and Davidson14 that models with more risk factors do not necessarily produce greater predictive strength.
This result is of interest because it challenges the traditional notion that considering more risk factors will necessarily improve suicide risk assessment. Further, the result is consistent with a key difference between machine learning and other types of suicide prediction model in that machine learning can potentially recognise the context of factors, such that factors with no overall association with suicide might be included if they confer risk in some contexts but are protective in others. Further research might show that machine learning can improve suicide risk prediction because it can recognise the context and non-linear relationships between risk factors.
However, in this data-set even though the effect size derived from machine learning was moderately stronger than other suicide prediction models, the P-value was below statistical significance. A future meta-analysis with more machine-learning studies may have a different result. Although this is encouraging for future machine-learning research, we urge some caution. In particular, the machine-learning studies we included had other study characteristics that might have inflated their results. In addition to examining a large number of potential suicide risk factors increasing the possibility of chance associations,Reference Gradus, Rosellini, Horvath-Puho, Street, Galatzer-Levy and Jiang46,Reference Kessler, Warner, Ivany, Petukhova, Rose and Bromet59,Reference Simon, Johnson, Lawrence, Rossom, Ahmedani and Lynch97 some machine-learning studies examined clinical contacts rather than people, resulting in possible oversampling of suicides if they were more frequent attenders.Reference Kessler, Hwang, Hoffmire, McCarthy, Petukhova and Rosellini60,Reference McCarthy, Bossarte, Katz, Thompson, Kemp and Hannemann77,Reference Simon, Johnson, Lawrence, Rossom, Ahmedani and Lynch97 Other machine-learning studies oversimplified the spectrum of non-suicide presentations by selective sampling and overweighting of a small proportion of controls.Reference Kessler, Hwang, Hoffmire, McCarthy, Petukhova and Rosellini60,Reference Kessler, Stein, Petukhova, Bliese, Bossarte and Bromet61 Still other machine-learning studies developed a large number of synthetic or compound potential suicide risk factors (for example alcohol use by various age and gender groups) increasing the risk of chance associations.Reference Gradus, Rosellini, Horvath-Puho, Street, Galatzer-Levy and Jiang46,Reference Simon, Johnson, Lawrence, Rossom, Ahmedani and Lynch97 We conclude that the case for machine learning as a statistically superior method of suicide prediction model is not yet conclusive.
Our findings also present an interesting conundrum for the clinician: although increasing the number of included risk factors will improve the strength of machine-learning programs, clinicians who use fewer risk factors to identify suicide risk are likely to do as well as those who use more complex risk models.
Limitations to the generalisability of the pooled estimates
The very high between-study heterogeneity in effect size means that our pooled estimates may not be generalisable. Moreover, it is likely that the pooled effect size we report would not be as strong in replication/validation studies, given our results are based on exploratory studies in which the suicide prediction models were retro-fitted to suicide and survivor data.Reference Cohen107 The potential for chance findings in the primary research and therefore our pooled ORs is illustrated by the threshold P-value of 0.05 for the inclusion of a suicide risk factor and the large number of potential suicide risk factors examined. Of the over 12 000 potential suicide risk factors examined in the primary research, 1 in 20, or over 600 (77% of all the 777 included risk factors) might have been included by chance with a threshold of P = 0.05. This may not have had a great effect on the ultimate strength of the pooled effect size because the number of potential risk factors was not associated with the ultimate effect size and the number of included suicide risk factors (possibly including some chance associations) did not increase the strength of the predictions in non-machine-learning models. Notably, studies that used two or three included suicide risk factors performed just as well as studies that used more variables. Other cautions about the strength of the effect size reported flow from the statistical evidence of publication bias in favour of studies with a larger OR as well as the lower OR in cohort studies and those with generally stronger methods.
Other findings
We found evidence that suicide prediction models work better in the general community/non-mental health settings and in current in-patient settings. Although these finding were incidental and might not be replicated, it is possible that suicide risk factors are more meaningful in settings where the risk factors are less prevalent (such as a psychiatric diagnosis in the general community) and when more accurate and detailed risk profiles are available (such as in a hospital). Suicide prediction models seemed to perform less well after suicide attempts or self-harm. The most obvious reason for this is that suicide attempts or self-harm, which were the single most commonly included suicide risk factor, cannot be used in the suicide prediction model if both the suicides and survivors have this risk factor.
Implications
Machine learning makes it possible for vast amounts of information to be modelled to predict suicide risk, but to do this, much more information, including those for economic, social and network factors not traditionally examined in a clinical setting, might be needed. It is possible that machine learning will ultimately produce better suicide prediction models that are more clinically applicable, as well as better reflecting our intuitive knowledge about the complex social, cultural and personal factors that contribute to an individual's suicide. Alternatively, it might be that suicide is fundamentally unpredictable, with most of the uncertainty about suicide being aleatory rather than epistemic and therefore not very amenable to prediction.Reference Large, Galletly, Myles, Ryan and Myles8 In the meantime, we suggest that future machine-learning studies should focus on clinically relevant input variables, use people rather than clinical contacts as the denominator, and should examine ways of combining computational results with broader clinical considerations.
Although the potential of machine learning in suicide prediction remains uncertain, it should not be forgotten that the utility of any suicide prediction model depends on its clinical application and not its effect size or P-value. Even a suicide prediction model producing a strong statistical association may not be useful if there are no rational interventions that can be provided for people who are predicted to die by suicide, remembering the vast majority of predictions are false positives, or if there are no rational interventions that should be withheld from patients classified as lower risk, among whom many suicides might occur. Ultimately the utility of a suicide prediction model should not be evaluated by its statistical strength or perceived suitability to guide interventions, but should be judged by its contribution to a reduction in suicide mortality. Until such time as the use of any suicide prediction model has been shown to reliably reduce suicide, our clinical advice is to focus on understanding and caring for the person in front of us, including by treating any modifiable risk factors, irrespective of estimations of any overall suicide risk category.
Supplementary material
Supplementary material is available online at https://doi.org/10.1192/bjo.2020.162
Funding
None.
Acknowledgements
We would like to thank Roar Fosse, Navneet Kapur, Chian-Jue Kuo, and Fredrick Walby for correspondence about their studies and Dr Amy Corderoy for her assistance with the manuscript.
Data availability
All the data upon which the study is based has been submitted in the supplementary material.
Author contributions
M.C.: study conception, data acquisition and manuscript preparation. K.M.: data acquisition, data analysis and manuscript preparation. H.A.-S.: data acquisition, data analysis and manuscript preparation. S.X.: data acquisition and manuscript preparation. M.L.: study conception, overall supervision, data acquisition, data analysis and manuscript preparation.
Declaration of interest
M.L. provides expert opinion to courts on matters related to suicide. All other authors have no conflicts of interest.











 Open access
Open access
eLetters
No eLetters have been published for this article.